3. K-Means Clustering Algorithm
The k-means clustering algorithm is a method to carry out separations in data observations into
K exclusive groups to establish vector indices to show the
K cluster associated with each observation [
31,
32].
The k-means clustering algorithm takes each observation in the data as a point in a Euclidean space. A partition is determined considering that the objects within each group are close to each other, and far away from objects in other groups. Depending on the data type to group, clustering employs various measures to minimize the sum of the distances. In the partition, each cluster consists of the points and the center (centroid) [
31,
32].
Implementing the clustering includes the use of an iterative algorithm to reduce the sum of distances from each object to its own centroid group, regarding all groups until no further sums are possible to obtain the set of clusters [
31,
32].
Considering a set of observations , where each observation corresponds to a vector of d dimensions, the algorithm makes a partition of the observations into K sets , where . The steps of the k-means algorithm are as follows.
Establish a group of K centroids in the represented space.
Calculate the distance of each object with each of the centroids of K and assign it to the centroid for which its distance is the smallest.
When all objects are assigned, recalculate the position of the centroids.
Terminate the algorithm if the stop criterion is met; otherwise, return to step 2.
Equation (
4) shows a usual similarity measure based on the squared error, where
x is one of the elements and
the midpoint of the cluster
.
The first part of the algorithm includes using a statistical measure such as the mean or median to determine the initial value of the centroids. During the second step, any distance metric can be used, where each object is compared to all centroids, assigning the centroid with the smallest distance. In the third instance, some heuristics are usually used to modify the centroids; the mean or median position of the objects is usually employed to calculate the position of the new centroids. Lastly, under some conditions, the algorithm stops in the fourth step due to the number of iterations, or in cases when no variation is present in the sum of the shortest distances; otherwise, the algorithm returns to step 2.
4. C-Means Clustering Algorithm
The fuzzy c-means algorithm is a data clustering technique where each data point belongs to a group to a certain extent specified by a membership degree. This technique offers a method to group larger sets of data in multidimensional space into a specific number of distinct groups [
39,
40].
Using the groups generated by the fuzzy c-means algorithm, a fuzzy inference system can be built by creating membership functions to represent the linguistic labels of each group, employing the concept fuzzy partition.
A fuzzy partition characterizes the separation of each sample in all groups using membership functions that take values between zero and one, where, for each sample, the sum of the membership is one. In this way, it is possible to translate the fuzzy clustering problem to meet an optimal fuzzy partition [
29,
30,
40,
41].
Given that
a positive integer, and a subset
of dimension
d (in a Euclidean space), then a fuzzy partition of
X in
c groups is a list of
c membership functions
that accomplish Equations (
5)–(
7).
In this way, the fuzzy partitions are represented as
, where
i corresponds to the cluster and
k the data. Fuzzy c-means algorithms employ a clustering criterion given by an objective function that depends on the fuzzy partition. The procedure consists of iteratively minimizing this function until obtaining an optimal fuzzy partition [
29,
30,
40,
41].
Different clustering criteria can be used to determine the optimal fuzzy partition for
X; the most widely used is associated with the least squares error function given in Equation (
8).
The value
corresponds to the square distance between the elements of
X and the centers of the groups, given by Equation (
9), where
are the data,
is the center vector of the group
i, and finally
is the norm induced by
A that is a
positive definite weight matrix; when
A is the identity matrix, the square of the Euclidean distance is obtained.
Considering the
k-th data in the
i-th cluster, the factor
corresponds to the
m-th power of the respective membership value, where
controls the fuzzy overlap corresponding to the amount of data having significant membership in different clusters [
29,
30,
40,
41]. The general procedure of the fuzzy c-means algorithm is as follows.
Set c, m, A, and determine an initial matrix of fuzzy partitions.
Calculate the centers of the groups.
Update the fuzzy partition matrix.
Finish if stop criterion is met; otherwise, return to step 2.
The first part of the process is to set the parameters of the algorithm. The second part includes an approximation toward the center of the clusters to mark the average location of each group. Then, the fuzzy c-means algorithm for each group and datum assigns an associating degree of membership. Updating for each data point the cluster centers and membership degrees, the algorithm iteratively adjusts the cluster centers. This process is performed until a stop criterion is met [
29,
30,
40].
5. Test Functions Employed
Ideally, the test functions chosen to evaluate an MOEA should contain characteristics similar to the real-world problem to be solved [
1]. The specialized literature proposes to employ artificial functions to describe different levels of difficulty to test multi-objective evolutionary algorithms [
1].
Among different multi-objective test functions, the functions used were chosen considering the number of segments that compose the optimal Pareto front. In this way, different cases that arise when executing multi-objective optimization algorithms are considered, especially those functions that allow the observation of features to enhance the exploration of the optimization algorithms via the clustering process.
Figure 4 displays the Pareto fronts for the test functions considered, which are described below.
: Binh1
: Fonseca1
: Fonseca2
: Schaffer1
: Schaffer2
: Deb2
: Kursawe
: Poloni
Function selection is made to have different characteristics of the Pareto optimal fronts. Functions , , , and are characterized by presenting continuous POFs; it is expected that clustering algorithms perform an equal division of these POFs. Meanwhile, functions , , , and have non-continuous POFs, for which it is expected the formation of groups for each segment of the POF. As seen, there are 2, 3, and 6 segments.
With these test functions, the purpose is to observe if the clustering process allows the establishment of mechanisms to improve the exploration process of multi-objective optimization algorithms. Regarding some strategies, swarms can be formed considering the identified clusters, or the center of the cluster can be used to carry out a dispersion process that allows the determination of additional and more suitable solutions of the Pareto optimal front.
In
Figure 4,
,
,
, and
show continuous POFs; that is, they are not divided into segments, for which it is expected that the clustering algorithms perform a uniform segmentation of POFs. Moreover, in this figure, it seems that
,
,
, and
present discontinuous POFs, where there are different segments that do not have the same amount of data, for which it is expected that the algorithms will be able to make the groups for each segment.
The number of data used for each Pareto front shown in
Figure 4 is presented in
Table 1, where the largest amount of data is for
with 1100 points and the smallest for
,
and
with 200 points.
It should be noted that, in this work, no multi-objective optimization algorithm is employed to determine the Pareto front, for which Pareto front data reported in the literature as in [
42] are used.
6. Clustering Analysis
This section presents the results obtained first for the k-means algorithm and then for fuzzy c-means. It is noticeable that the clusters obtained their centers and the separation seeking to cover the data associated with the Pareto optimal front. Also presented is the processing time used in the clustering process for each optimal Pareto front.
Regarding implementation, the experiments were carried out with PC Intel i5-3230M 2.60 GHz and RAM of 6.00 GB using software MATLAB 2017a for the implementation of k-means [
43,
44] and fuzzy c-means [
45,
46].
The results using k-means can be seen in
Figure 5; the groups obtained for each Pareto front are shown taking
clusters. In the experiments, the maximum clusters taken are 6 since it is the maximum number of segments in the POFs (case of
).
Additionally, in
Table 2, one can see the sum of the total distances obtained (
distance) given in Equation (
10), where
is the
j-th data point (observation) and
is the
j-th centroid (a row vector). Each centroid corresponds to the median of the points in the respective cluster [
44,
47].
In order to show the results graphically, an array is made in
Figure 5, where the rows correspond to the POFs (from
to
), and the columns show the number of clusters used (from
to
). In this group of figures, the clusters are depicted using different colors and the center of each cluster with the symbol ◇. It is noteworthy that the first four rows correspond to continuous POFs while the last four rows to discontinuous POFs.
According to
Figure 5, for the continuous POFs, an adequate clustering distribution of the POF is observed, which can be used to improve the exploitation by improving each segment separately using a multi-objective optimization algorithm. On the other hand, for discontinuous POFs, it is sought that the number of segments be equal to the number of clusters. In the case of two segments, there is a correct segmentation of the POF; for three segments, it is not achieved correctly, and for six, it is achieved in most segments; however, there are three segments that share a few data in the clusters.
Based on
Table 2 for all cases, by increasing the number of clusters, an improvement in the objective function is obtained; however, for the case when the POFs are discontinuous, the best value is not obtained when the number of clusters coincides with the number of segments. This feature must be considered when including the clustering process in the optimization algorithm, since a procedure must be established to determine the appropriate number of clusters.
An interesting comparison can be made among test functions considering the performance index; nevertheless, the POFs do not have the same range values and the amount of data; for example, the POF for and has the same range values; however, the amount of data is different.
Observing
Table 3, the processing time tends to increase when increasing the number of clusters. However, there are a few cases where the processing time decreases. Considering the functions with continuous POF, for
, the shortest time is with
, for
with
, for
and
with
; meanwhile, taking the functions with continuous POFs,
,
,
, and
, the shortest time is obtained with
. It should also be noted that although the POF of
is the one with the most data, the processing time is not the longest found in the experiments carried out.
In addition, considering functions
and
with continuous POFs in the range
, where
has 200 points and
435 points, in
Table 3, it is observed that the shortest time is obtained for
with
.
On the other hand, the results using fuzzy c-means are depicted in
Figure 6; the groups for each Pareto front are obtained taking
clusters. Furthermore, in
Table 4, one can see the performance index used by the fuzzy c-means algorithm to establish the clusters. The objective function used is given by Equation (
11), where
represents the
i-th observation (data point),
corresponds to the
j-th cluster center,
D is the total number of data points, and
N is the amount of clusters; meanwhile,
is the fuzzy partition exponent employed for controlling the degree of fuzzy overlap; finally,
corresponds to the membership value of
in the respective
j-th cluster [
46,
48].
Figure 6 shows the clusters formed with the elements having the highest membership value associated with each cluster. In this figure, the results are organized in an array where functions
to
are found in the rows and number of clusters used from
to
in the columns. In these results, the symbol ◇ represents the center of each cluster depicted using different colors.
From
Figure 6, for the continuous POFs, an adequate distribution of the POF is observed since it tends to generate equitable groups in the Pareto optimal front. On the other hand, for discontinuous POFs, it is sought to have the number of POF segments equal to the number of clusters. For the case of two segments, there is a correct segmentation of the POF; for six segments, it is not achieved correctly, and for three, it is achieved in most segments.
Based on
Table 4, for all cases, by increasing the number of clusters, an improvement in the objective function is obtained; however, when the POFs are discontinuous, the best value is not obtained when the number of clusters coincides with the number of segments.
Considering
Table 5, it is observed that the processing time increases when increasing the number of clusters; nonetheless, there are a few cases where the processing time decreases. Considering the functions with continuous POF for
, the shortest time is with
, and for
,
, and
with
. Meanwhile, taking the functions with continuous POFs,
,
,
, and
, the shortest time is with
. It should also be noted that although the POF of
is the one with the most data, the processing time is not the longest obtained in the experiments carried out. In addition, considering
,
, and
that present 200 points in the POF, the shortest processing time is for
.
Regarding general observations of clustering analysis, as can be seen in
Table 2 and
Table 4, as the number of clusters increases, the performance index decreases for both k-means and fuzzy c-means. For continuous POF, it is sought that the clusters are well distributed along the POF, while, for discontinuous POFs, it is expected that the clusters will be generated for each segment of the POF.
For functions
,
,
, and
, the clustering algorithms perform a balanced segmentation of these POFs. Meanwhile, for discontinuous POFs using k-means and fuzzy c-means, a correct clustering for
and
is achieved; meanwhile, a suitable clustering for
is obtained using k-means, and for
using fuzzy c-means.
Figure 5 and
Figure 6 allow us to observe the cluster formation in a qualitative way.
Considering the above results, an important aspect when incorporating the clustering process into the multi-objective optimization algorithm is the mechanism to determine the appropriate number of clusters, which can be done iteratively; however, it also increases the computational time.
In addition, a combination of k-means and c-means allows an appropriate clustering of POFs; therefore, these clustering algorithms are suitable to use in the VMPSO algorithm. The clusters can be calculated after obtaining a certain number of solutions of the Pareto front. Then, with the clusters, the vortices of the VMPSO algorithm can be established to refine the solutions.
It should be noted that the performance index used for k-means is different from the one used with fuzzy c-means; therefore, a comparison of
Table 2 (for k-means) and
Table 4 (for fuzzy c-means) is not possible directly. Considering the above, the performance index
is calculated using the results of fuzzy c-means, obtaining
Table 6, observing that, in most cases, a better value is obtained with k-means since
is used as the performance index in k-means; however, a better value was obtained using fuzzy c-means for the cases of
with
, and also for
,
, and
with
, and finally for
with
.
Table 7 displays the difference in processing time between k-means and fuzzy c-means. In these results, the higher difference is for k-means (case
with 2 clusters); it is also observed that in 12 of the 40 implementations, the k-means algorithm required more time than fuzzy c-means; meanwhile, 28 implementations using fuzzy c-means required more time than k-means.
7. Discussion
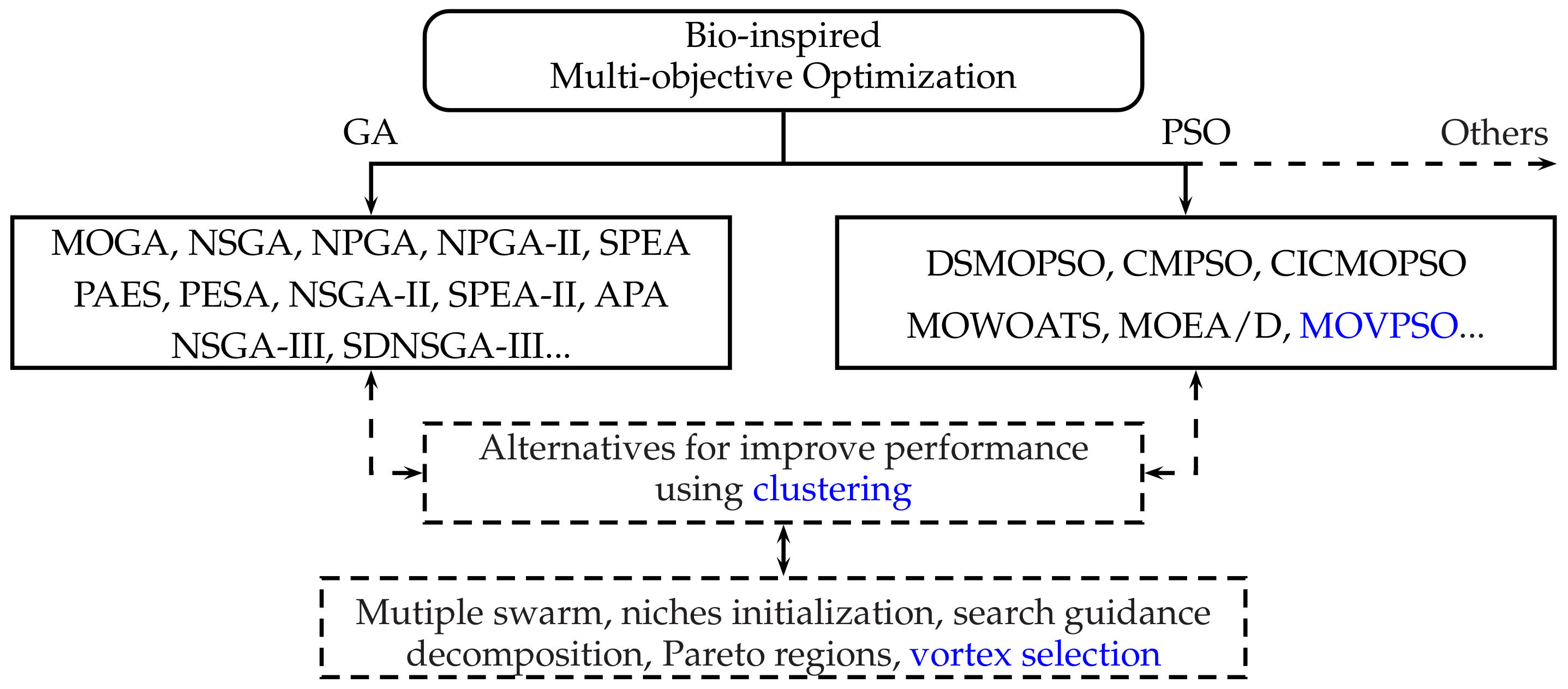
The present work is of an exploratory type to observe the characteristics that can be obtained with the clustering process to improve multi-objective optimization algorithms, particularly MOVPSO. A comparison with other proposals is expected to be made when the algorithm is implemented using clustering.
The originality is focused on establishing the characteristics that clustering has to improve in the multi-objective optimization algorithms, mainly observing the clusters for continuous and discontinuous Pareto optimal fronts. For continuous POFs, it is sought to have a suitable distribution of clusters, while for discontinuous POFs, it is necessary that the clusters coincide with the segments. As another important aspect, the processing time is also considered.
In this document, we present a clustering analysis that can be used to formulate alternatives to better explore the solutions of a Pareto front; however, it should be considered that this work presents the limitation of using the optimal points of the Pareto front. In the first place, it must be borne in mind that a multi-objective optimization algorithm constructs this front iteratively; therefore, it must be determined when to use the data obtained to establish the clusters. Second, from the perspective of the algorithm to improve the solutions, it must be locked with the decision variables, which is why it must be possible to establish the equivalent clusters in this domain.
For a multi-objective optimization algorithm that uses particle swarms, the found centers of each cluster can be used to create individual swarms. In particular, for the Multi-Objective Vortex Particle Swarm Optimization (MOVPSO) algorithm described in [
27,
28], where it is required to establish the vortex over which the particles will move, the center of each cluster can be used to determine the vortex point. In this way, it is sought to improve the solutions close to the established vortices.
Figure 7 displays the flow chart for MOVPSO, including the clustering process; it is observed that clustering is used in an iterative way after the algorithm performs a convergence or a dispersion process. In this order, the clustering is used to determine the vortex point where the swarm congregates in the convergence phase and then carries out the dispersion process.
Additionally, the computational complexity that the clustering technique adds to the optimization algorithm must be considered; for example, if the clustering technique is used in each iteration, it may increase the computation time. For the MOVPSO algorithm, the clustering process can be used when determining a set of solutions; then, the calculation required for the clustering technique is not extensive. When the total computational complexity of both the clustering and optimization processes is included together, the validity of the approach becomes meaningful in the context of performance and computational time. It is expected to evaluate this aspect when the optimization algorithm and the clustering processes will be implemented.
Moreover, when including clustering techniques in the multi-objective optimization algorithms, the mechanism to obtain the number of suitable clusters must be considered, which can influence the performance and computational complexity of the algorithm.
8. Conclusions
The k-means and fuzzy c-means algorithms achieve an adequate segmentation of the continuous POFs. In the case of discontinuous POFs, these algorithms can be complementary to find the appropriate groups for each POF segment.
Regarding the processing time, it is observed that the k-means algorithm has a lower processing time than fuzzy c-means. Time is a critical factor when using clustering algorithms in each iteration of the optimization algorithms; however, clustering algorithms can be used after having defined several solutions of the Pareto front.
The clustering analysis of the solutions from the Pareto optimal front presented in this paper can be used for the formulation of strategies to improve the quality of the solutions found. In this way, it is important to establish a mechanism to determine the suitable number of clusters.
A possible strategy to carry out considering the cluster analysis consists of the formation of multiple populations that improve the solutions associated with each group found. For MOVPSO, the clustering can be used for determining the vortex used in this algorithm.
The main disadvantage of including a clustering analysis in a multi-objective optimization algorithm is the additional calculations associated with the clustering algorithm used. Therefore, a strategy must also be implemented to determine the appropriate time to perform a clustering analysis during the execution of the multi-objective algorithm.
Including the clustering process in the multi-objective optimization algorithm can improve its performance; however, it can also significantly increase the computation time, which becomes relevant when researching the appropriate strategy to incorporate the clustering process.
Once the implementation of the clustering process is carried out in the optimization algorithm, it is expected to perform the comparison of results with other algorithms in further works.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}