Comparing the Robustness of Statistical Estimators of Proficiency Testing Schemes for a Limited Number of Participants

Abstract
:1. Introduction
2. Model Development
2.1. Kernel Density Plots and Initial Simulations
- (i)
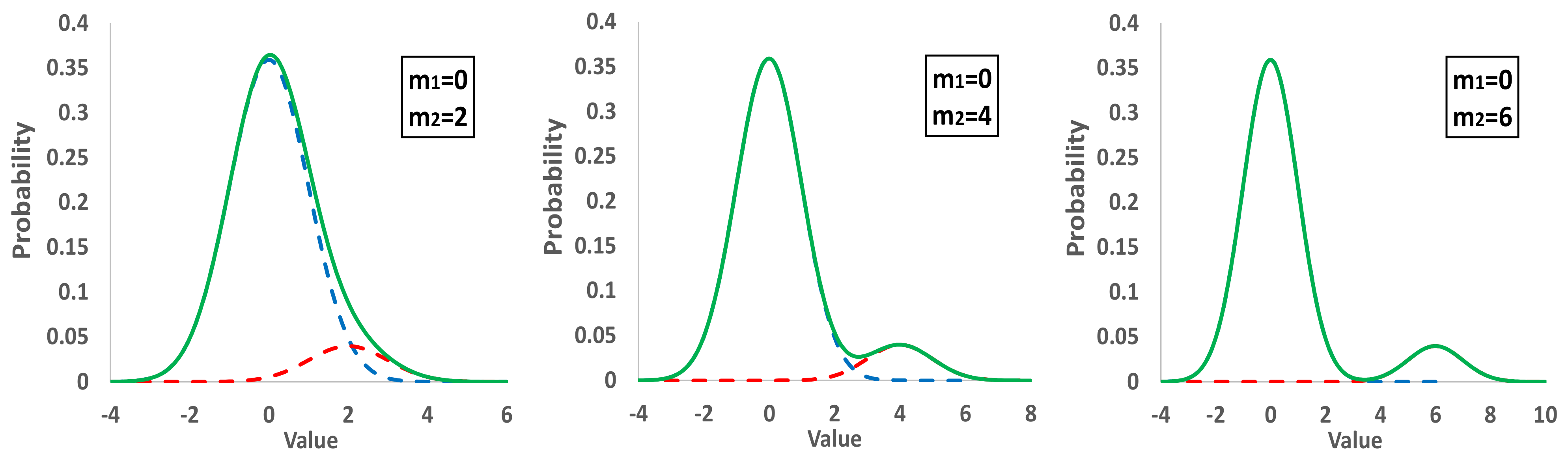
- The main normal distribution with m1 = 0 and s1 = 1 represents 90% of the population, while a secondary group representing the rest 10% has m2 = 2s1, 4s1, 6s1, and s2 = s1. The sum of the two populations results in a bimodal distribution.
- (ii)
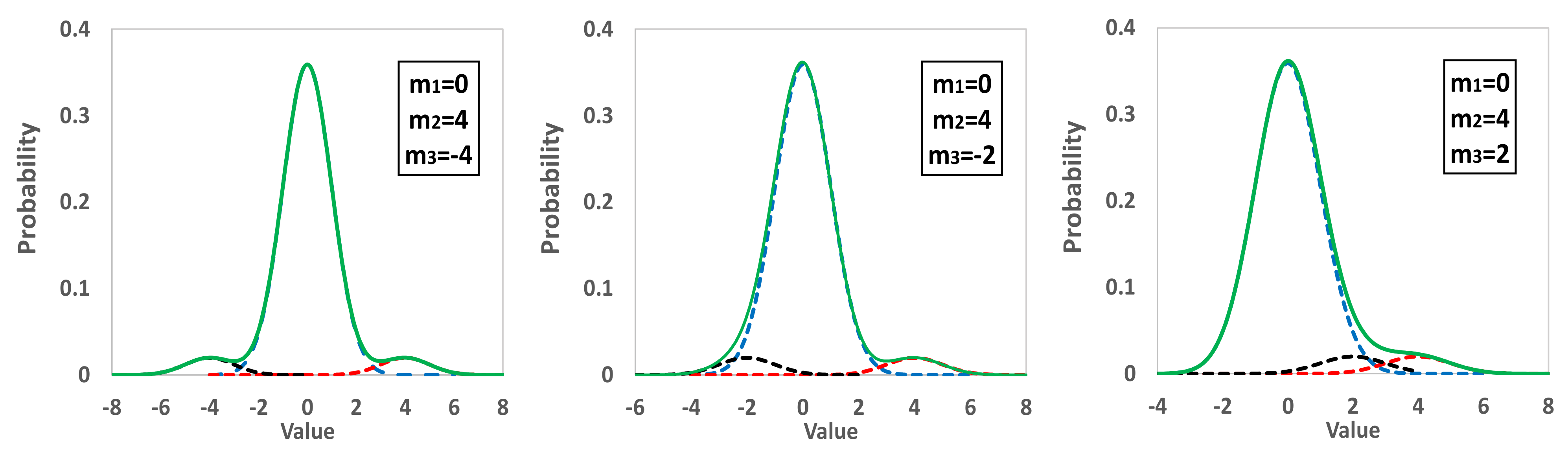
- The main distribution with m1 = 0 and s1 = 1 represents 90% of the population, a second one the 5% with m2 = 4s1, while a third distribution the rest 5% with m3 = −4s1, −2s1, 2s1. All the standard deviations are equal to one, and the derived distribution is trimodal.
- (iii)
2.2. Monte Carlo Simulations
- Number of participating laboratories, Nlab;
- Number of replicate analyses per laboratory, Nrep;
- Repeatability standard deviation, sr;
- Mean of the main normal distribution, m1;
- Standard deviation of the main normal distribution, s1;
- Mean and standard deviation of the second distribution, m2, s2;
- Population fraction of second distribution, fr2;
- Mean and standard deviation of the third distribution, m3, s3;
- Population fraction of third distribution, fr3;
- Number of iterations, Niter;
- Number of simulations, Ns;
- Number of buckets to create histograms, Nb.
3. Comparisons of Population Mean Values and Standard Deviations
3.1. Initial Implementation of Simulations
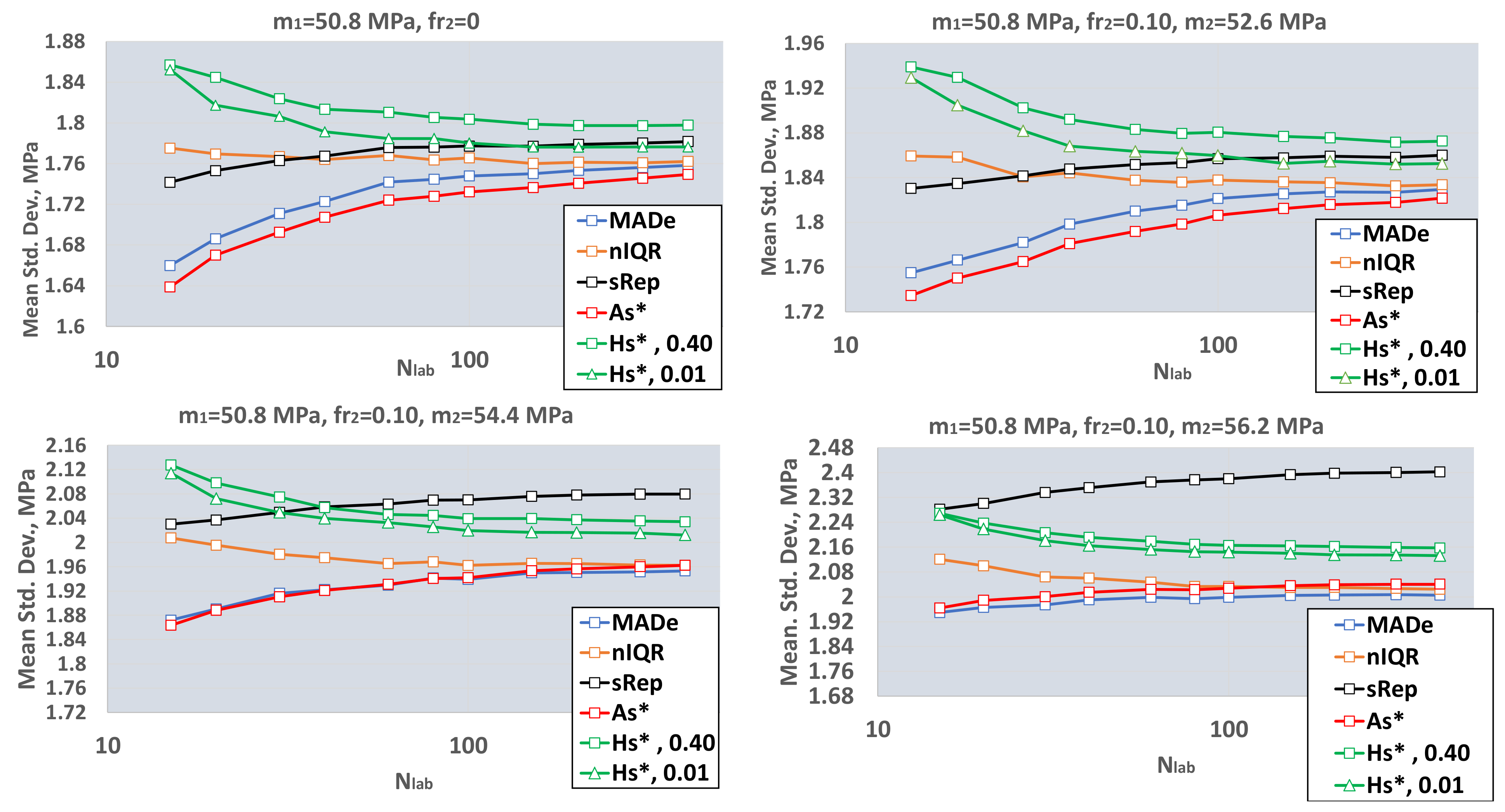
- (i)
- For a large number of laboratories, Nlab ≥ 200, the mean values of the estimators converge to different values. MADe, nIQR, and As* approach approximately the same value, while the convergence value of Hs* is higher for both repeatability values. The sRep is between these values for fr2 = 0 and m2 = m1 + s1 and becomes higher from both for m2 ≥ m1 + 2s1. The above proves that this estimator is not resistant to outliers. The high value of sRep for high m2 can underestimate the number of laboratories with |Z|>3.
- (ii)
- All functions between estimators and Nlab are monotonic. Those of MADe, sRep, and As* are increasing and those of nIQR and Hs* are decreasing. The MADe and As* low values for small Nlab may overestimate |Z| values. The current analysis shows MADe and As* are the lowest among robust estimators for small Nlab.
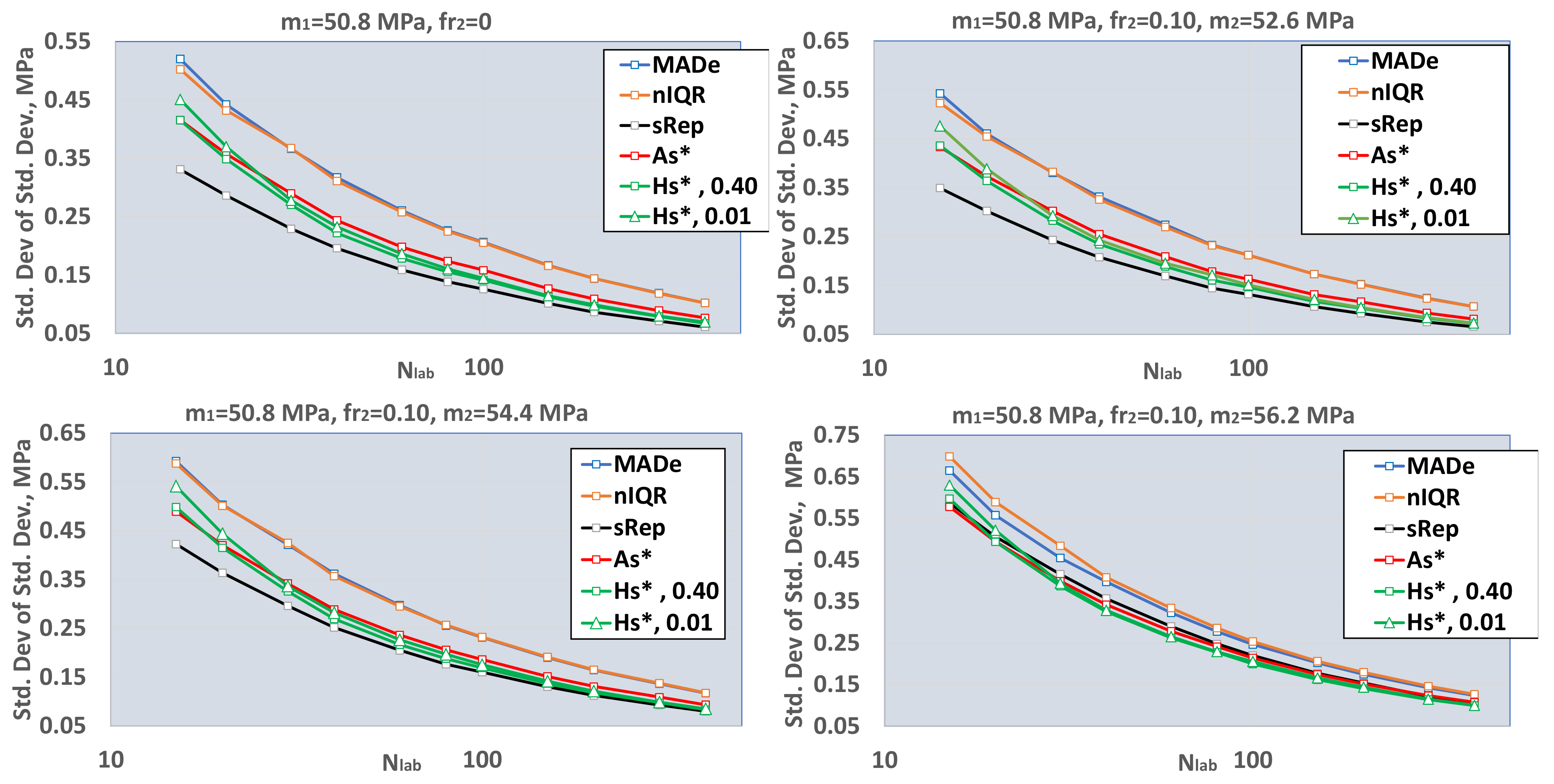
- (i)
- Increasing the m2 value, the average value and standard deviation of the population standard deviation also increase.
- (ii)
- The standard deviation of the population standard deviation of MADe and nIQR is continuously higher than the respecting values of the other three estimators. The above is in good agreement with paragraph 6.5.2 of ISO 13253:2015 [14] (p. 12), which further notes that more sophisticated robust estimators provide better performance for approximately normally distributed data, while retaining much of the resistance to outliers offered by MADe and nIQR.
- (iii)
- The average standard deviation of the Q method with sr = 0.40 is a little higher than that with negligible repeatability, sr = 0.01. Further simulations will utilize only sr = 0.01 for the Q method to be comparable with the other robust methods.
- (i)
- All distributions are approximately symmetric around their mean;
- (ii)
- The variance of MADe and nIQR is greater than that of other estimators, especially for lower values of m2.
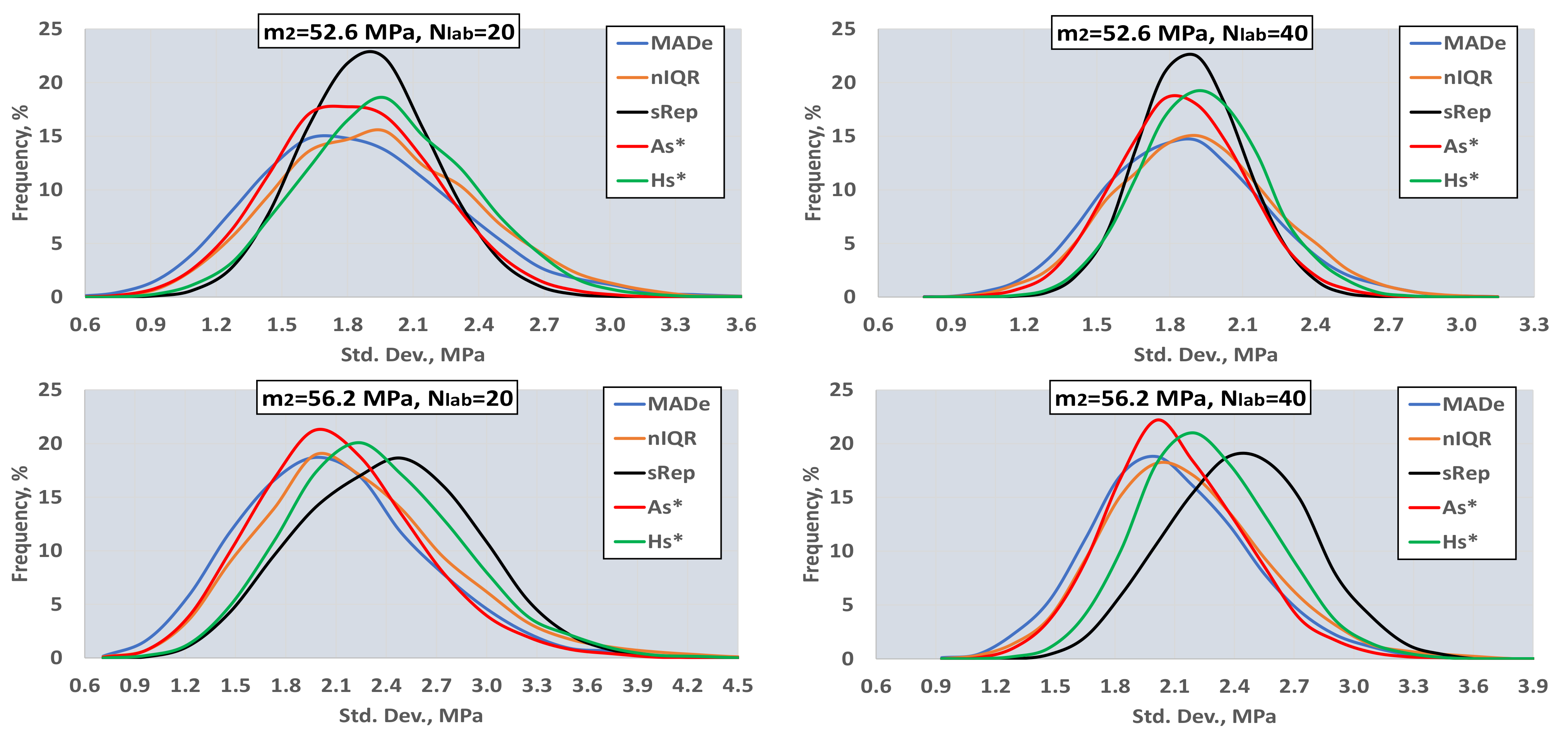
3.2. Determining the Best Estimators for a Small Number of Laboratories
- (i)
- It creates a main normal distribution D1 with mean value m1 and standard deviation s1 and two contaminating distributions D2, D3 with mean values m2, m3, and standard deviations s2 = s3 = s1.
- (ii)
- The fractions of the contaminating distributions are fr2 and fr3, and, depending on these two values, the total distribution can be unimodal, bimodal, or trimodal.
- (iii)
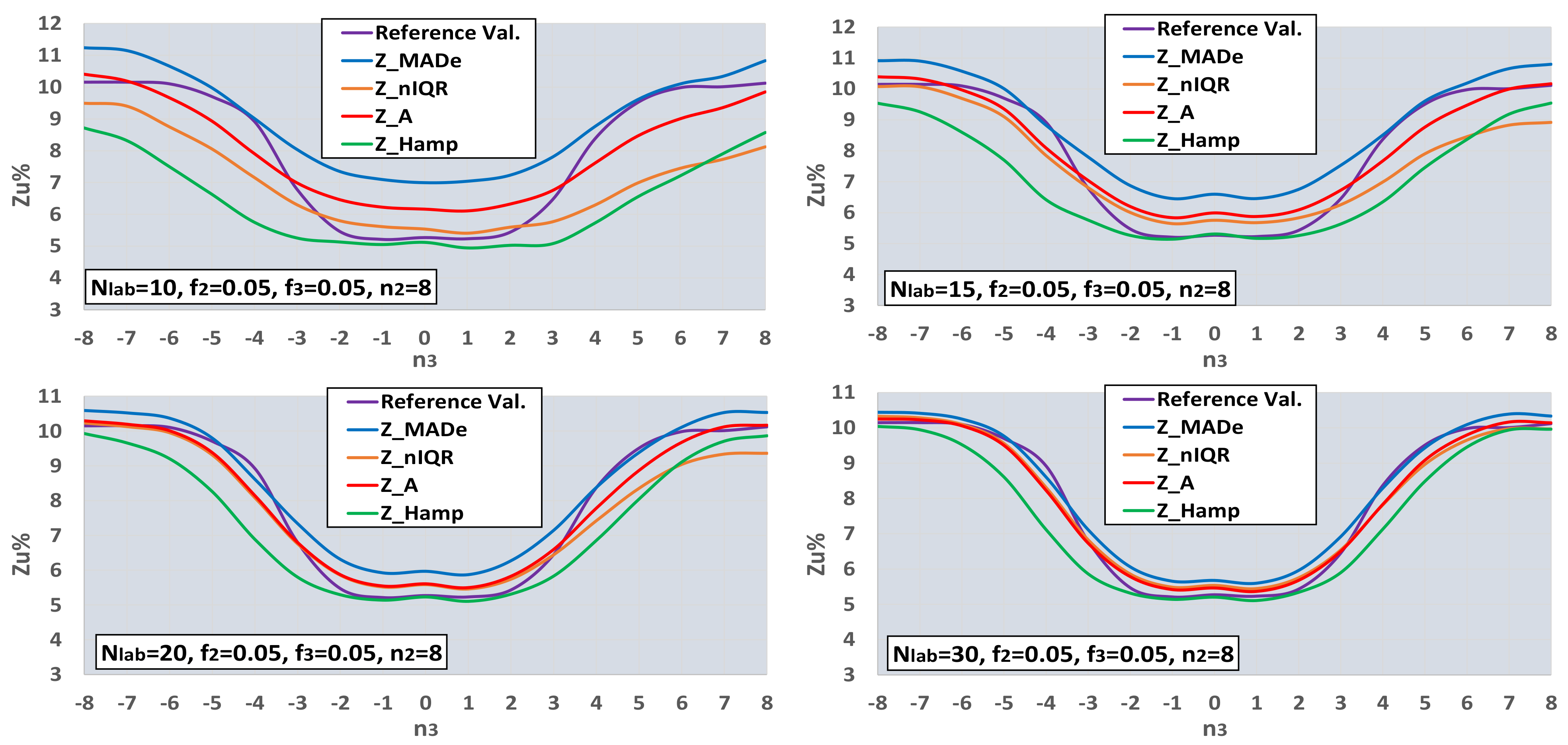
- The mean values m2 and m3 differ by an integer number of standard deviations s1 from m1, n2 and n3, shown in Equation (10). In the case of trimodal distribution, if n2·n3 > 0, then D2 and D3 are both to the same side of the D1. Otherwise, one is to the left and the other to the right of D1. Figure 4 of Section 2.1 depicts such distributions:
- (iv)
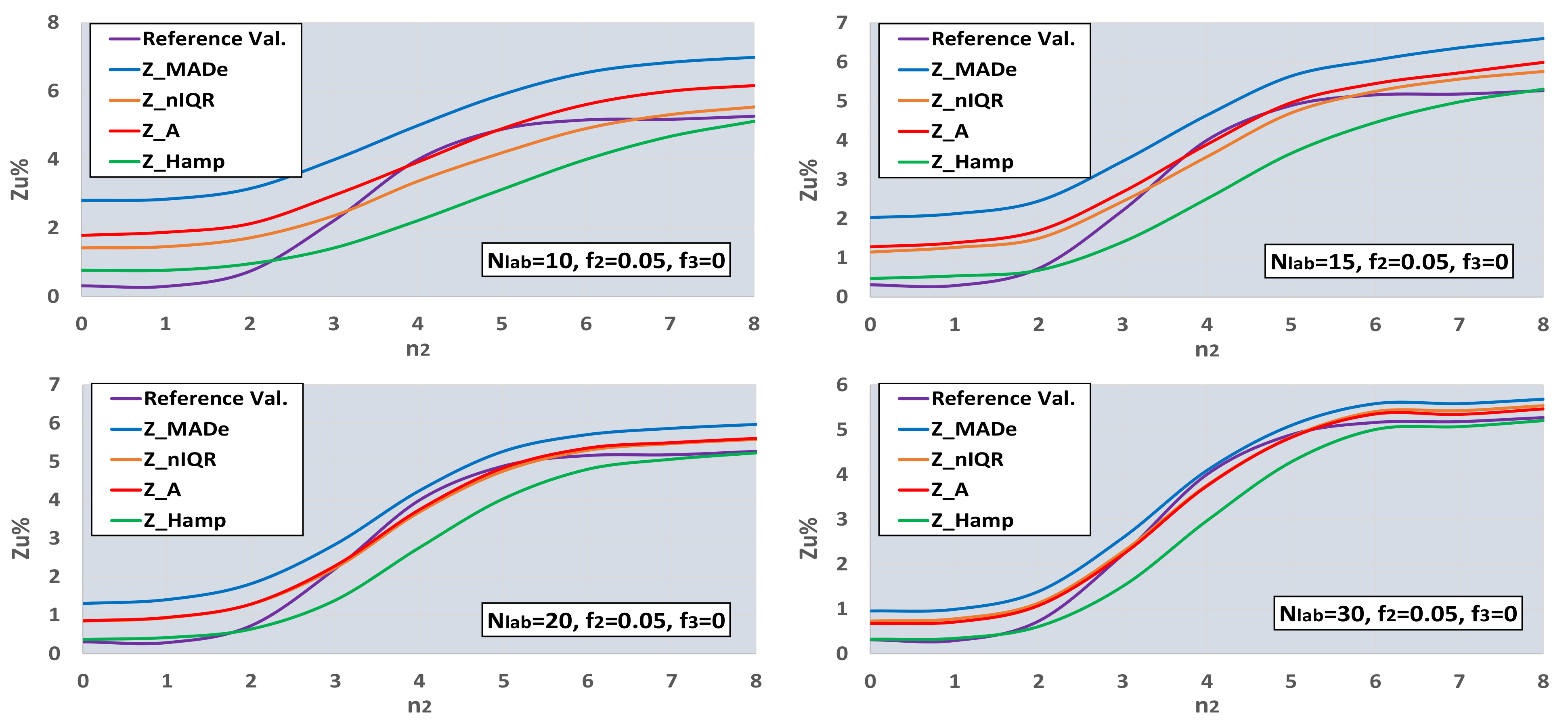
- According to the values of fr2, fr3, n2, and n3, the software calculates the values of Zu%, which are unsatisfactory, compared to the normal distribution function with mean and standard deviation m1 and s1, correspondingly. These values are the initial values. For example, if fr2 = 0.1, fr3 = 0, and n2 = 3, then Zu% = 0.24 (from D1) + 5.0 (from D2) = 5.24.
- (v)
- The algorithm calculates all the estimators for the mean and standard deviation shown in Table 1 and the Zu% for the absolute values of the five Z-factors presented in the same table using a Nlab = 400. Afterwards, it calculates the average of Zu% for Niter = 400 and Ns = 4. The other settings are the ones shown in Table 4. For this number of participants, all estimators converge to their final value. Figure 8 illustrates the procedure.
- (vi)
- The Zu% of each of the five Z-factors are compared with the initial results of step (iv). Those results closest to the initial ones are the reference values and represent the best estimation of the robust methods in approaching the unsatisfactory results calculated using the main distribution.
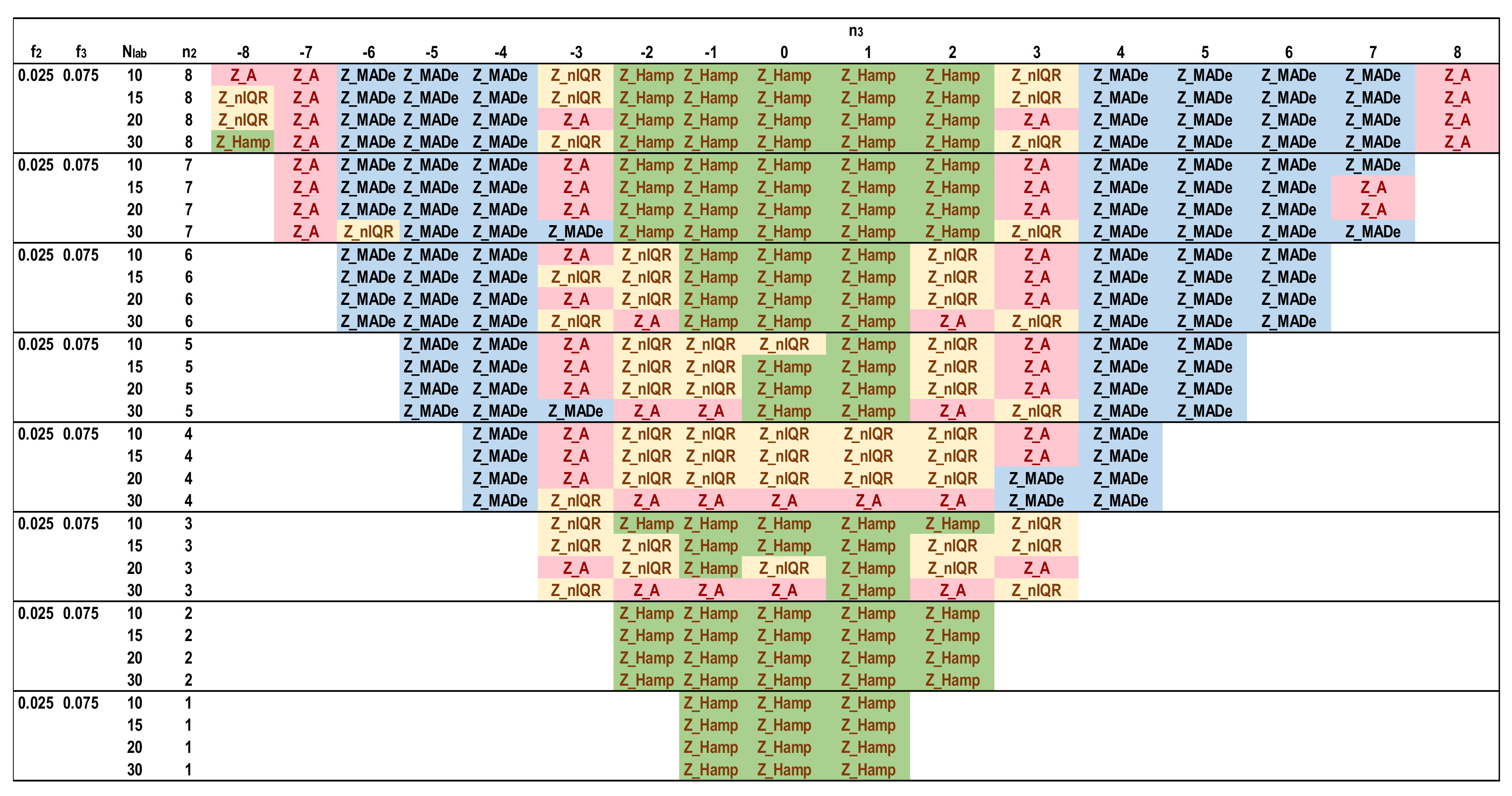
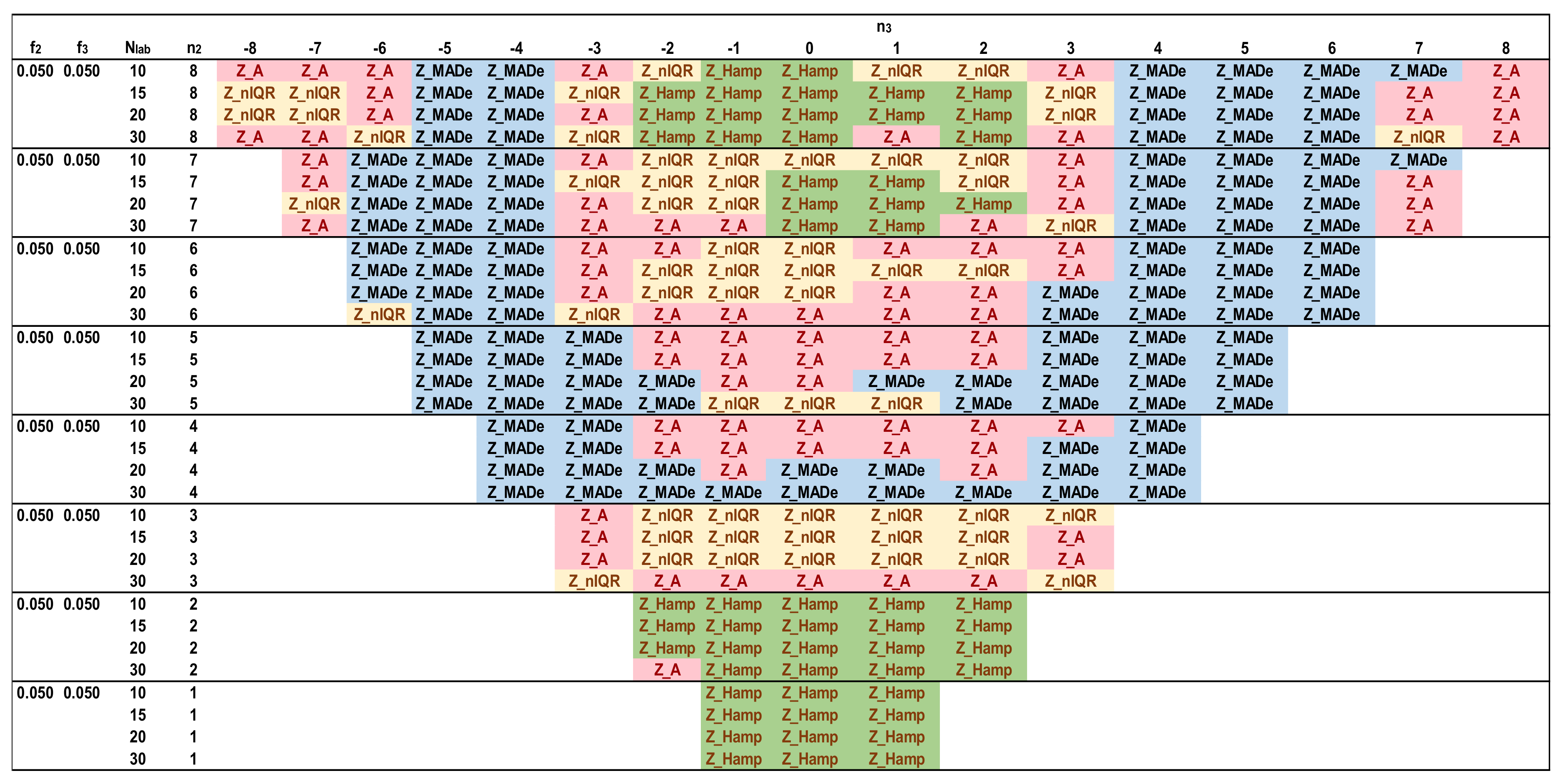
- (vii)
- The simulations implemented all the settings shown in Table 4 for participants up to 30. The populations correspond to unimodal, bimodal, and trimodal distributions with a maximum total fraction of secondary distributions up to 0.1. The coefficient of variation of the main distribution is 2% (=1/50 × 100).
- (viii)
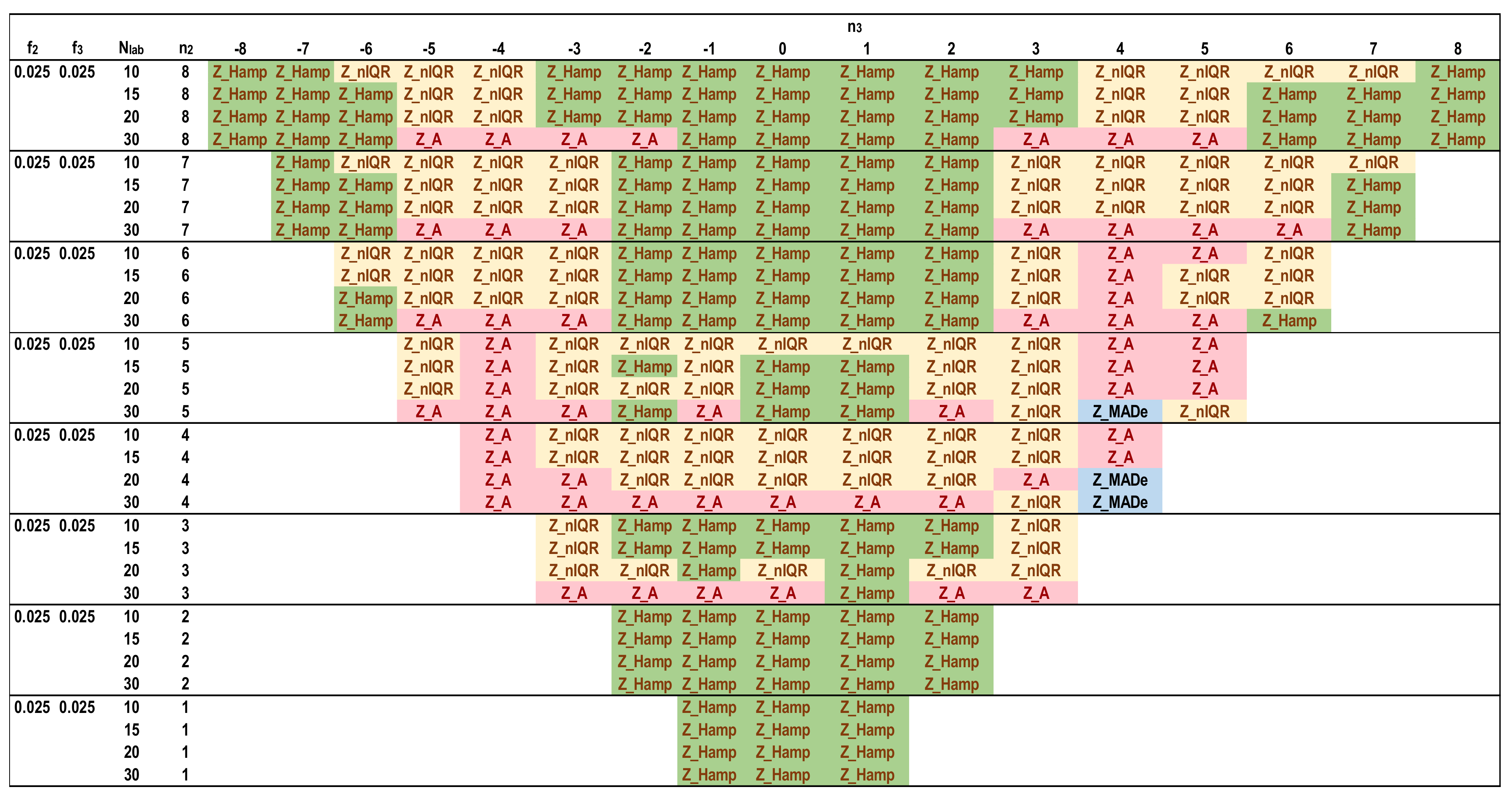
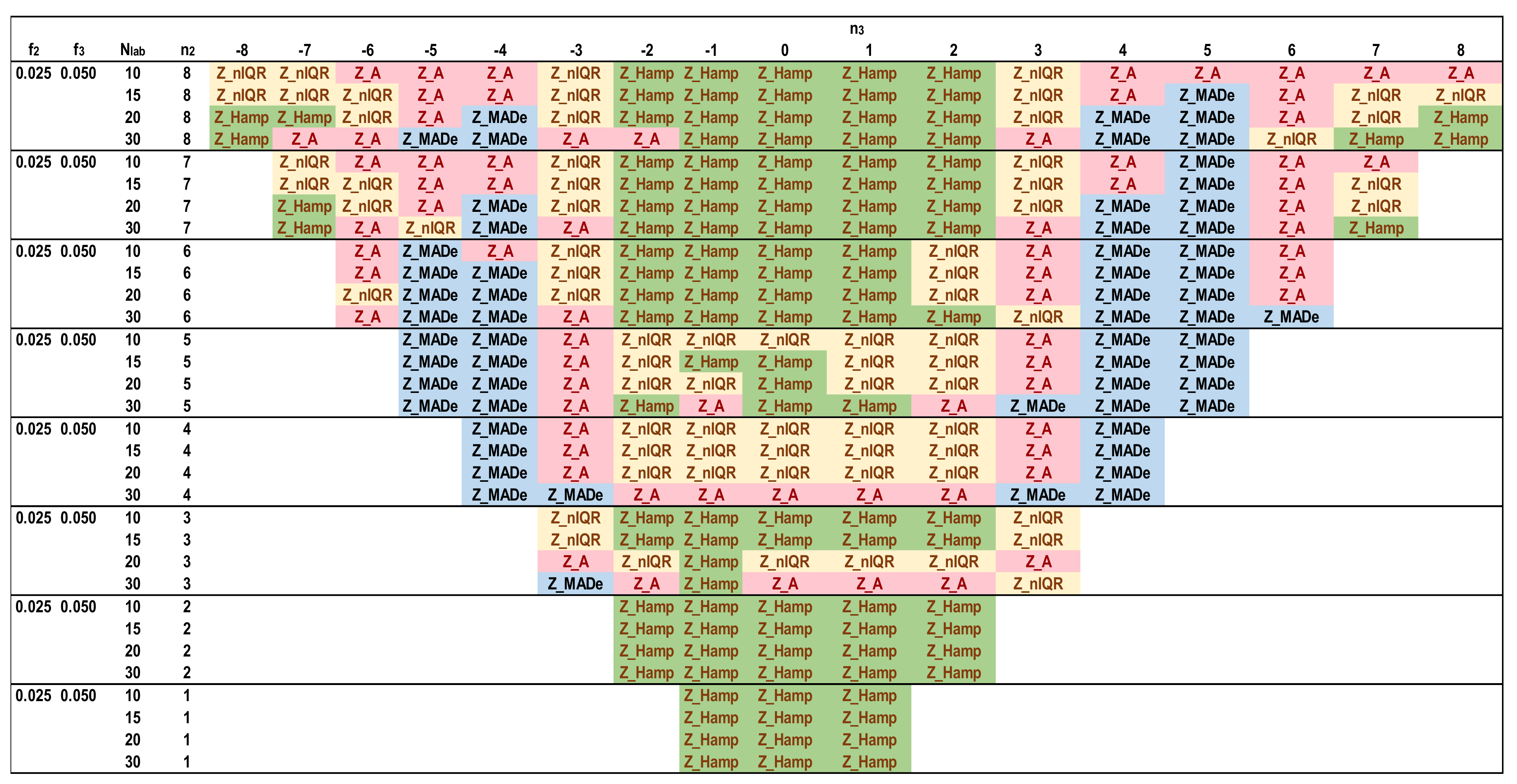
- The software performs Niter iterations and Ns simulations for each Nlab. For all these results, the average of each one of the five Zu% is calculated. These results are compared with each other and with reference values. The estimator providing the closest value to the reference value for each parameter set is optimal.
4. Optimal Robust Estimators for a Limited Number of Participants
4.1. Use of a Normal Distribution Mix
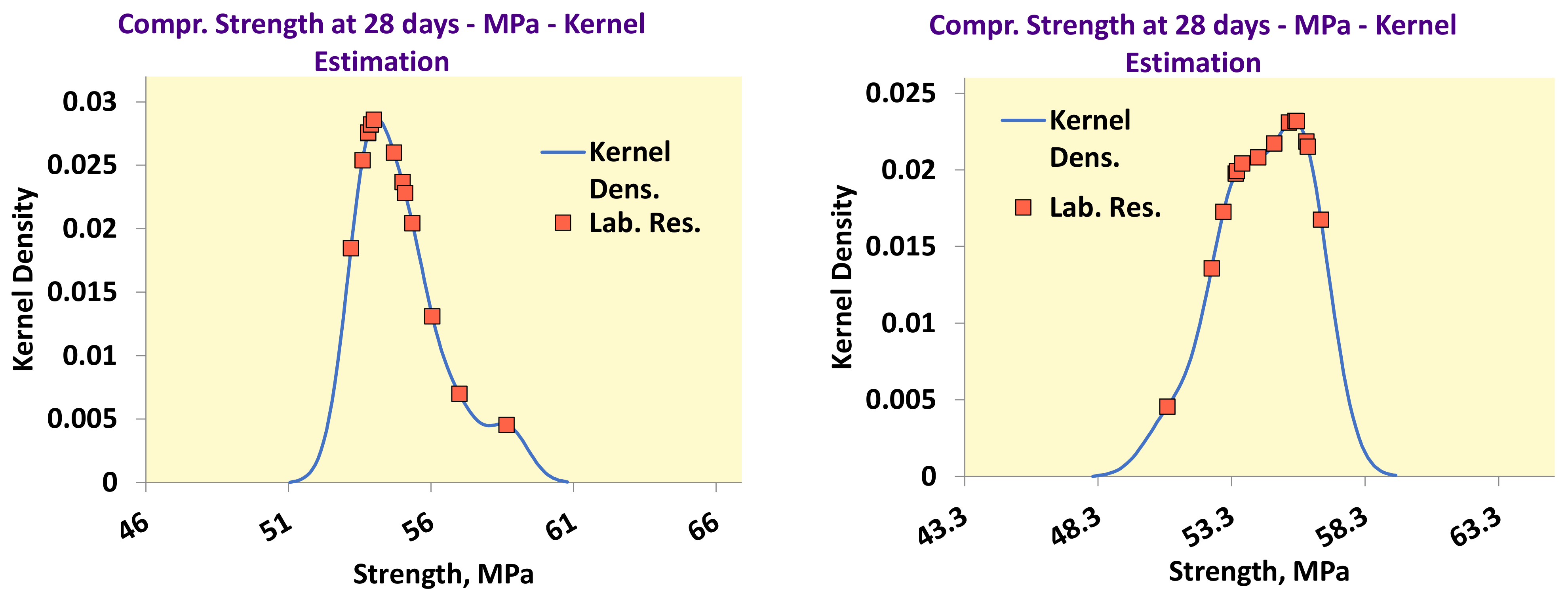
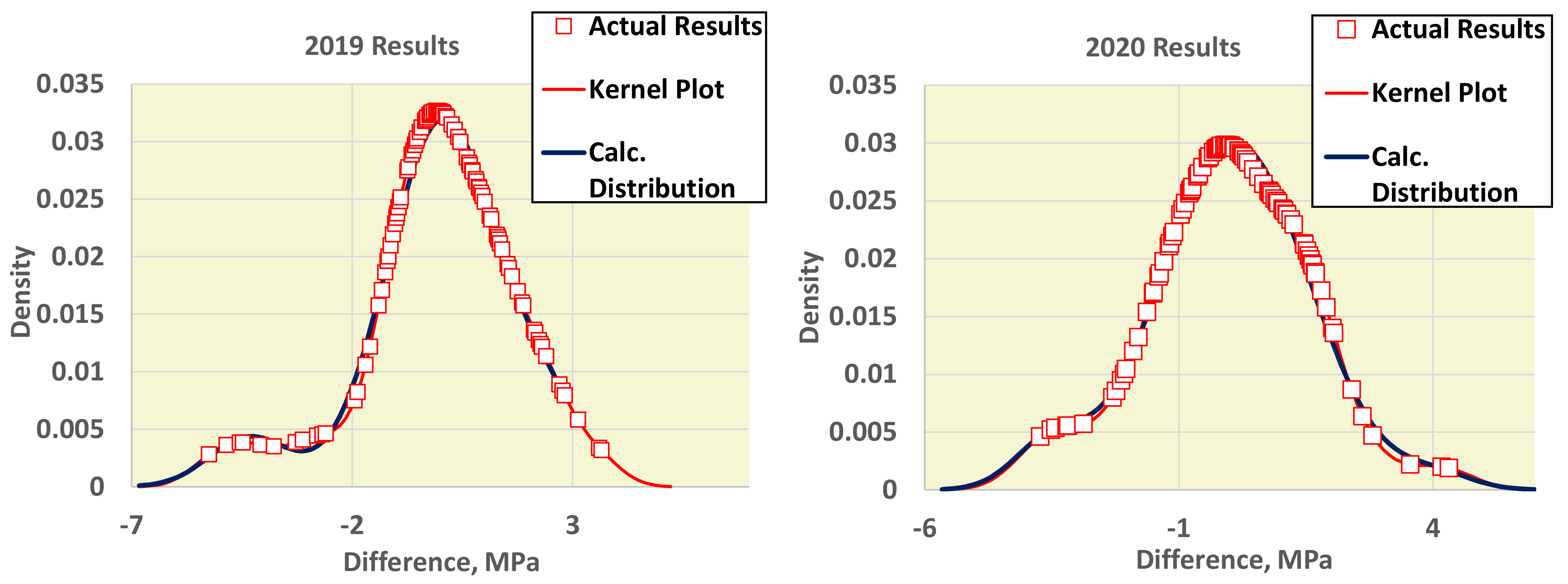
4.2. Use of Kernel Density Plots
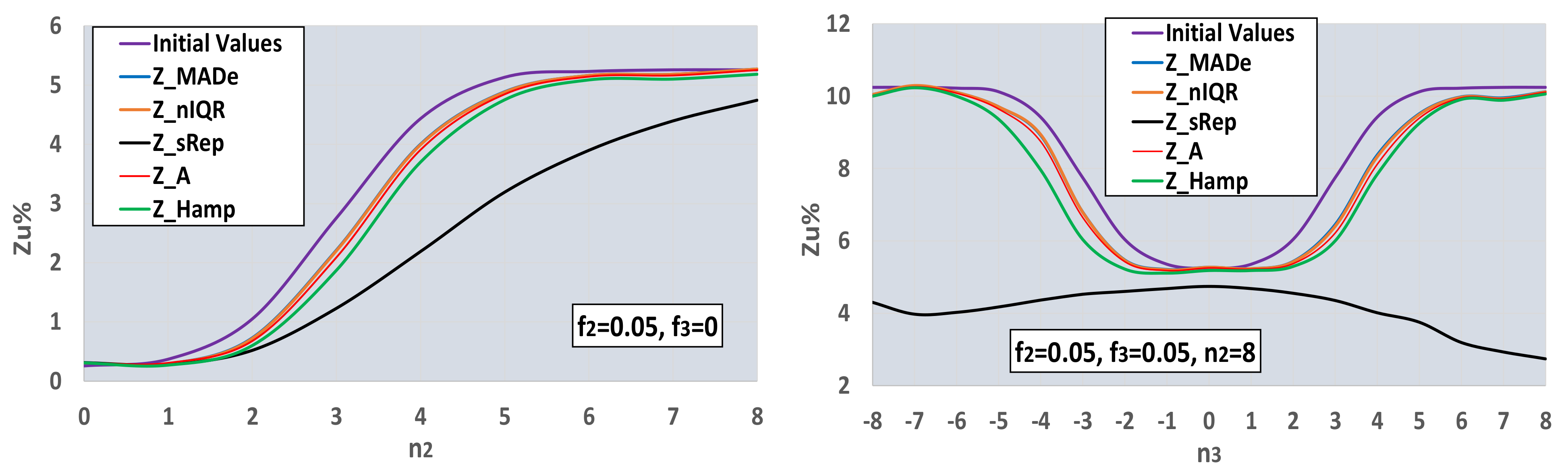
- The best estimator provided by the generalized algorithm depends on the distribution parameters.
- Z_sRep is always much lower than the reference values, Z_Ref, proving that it is not a robust estimator and verifying the findings of Section 3.2.
- For the given levels of Nlab and distribution parameters, Z_MADe is always much higher than Z_Ref and never optimum, verifying paragraph C. 2.3 of 13253:2015 [14] (p. 53). Z_A is closer to Z_Ref than Z_MADe but continuously overestimates Zu%.
- For the given range of m1, m2, m3, and s1, Z_nIQR and Z_Hamp are the best estimators: the first is 13 times, while the second is 8 times optimal. The results show that Z_Hamp is optimum for lower values of Zu% and Z_nIQR for higher Zu% values.
5. Conclusions
- ▪
- The impact of assigned value and standard deviation uncertainty on the Z-factors;
- ▪
- Type I and Type II errors of the estimators;
- ▪
- Comparison of the statistic estimators (a) for a medium and large number of participants; (b) for a range of variation coefficient of results’ distribution;
- ▪
- Direct use of the kernel density plots, by taking into account our generalized algorithm, in determining the best estimator;
- ▪
- Estimators’ comparisons for Z-factors of absolute value between two and three.
Funding
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- CEN. EN ISO/IEC 17043:2010 Conformity Assessment—General Requirements for Proficiency Testing; CEN Management Centre: Brussels, Belgium, 1994; pp. 2–3, 8–9, 30–33. [Google Scholar]
- ISO Committee on Conformity Assessment. ISO/IEC 17025:2017 General Requirements for the Competence of Testing and Calibration Laboratories, 3rd ed.; ISO: Geneva, Switzerland, 2017; p. 14. [Google Scholar]
- Rousseeuw, P.J.; Leroy, A.M. Robust Regression and Outlier Detection; John Wiley & Sons, Inc.: New York, NY, USA, 1987; pp. 9–18. [Google Scholar]
- Jurečková, J.; Picek, J.; Schindler, M. Robust Statistical Methods with R, 2nd ed.; CRC Press: New York, NY, USA, 2019. [Google Scholar]
- Wilcox, R.R. Introduction to Robust Estimation and Hypothesis Testing, 5th ed.; Academic Press: London, UK, 2021. [Google Scholar]
- Hampel, F.R.; Ronchetti, E.M.; Peter, J.; Rousseeuw, P.J.; Stahel, W.A. Robust Statistics: The Approach Based on Influence Functions; John Wiley & Sons, Inc.: New York, NY, USA, 1986. [Google Scholar]
- Huber, P.J.; Ronchetti, E.M. Robust Statistics, 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2009. [Google Scholar]
- Maronna, R.A.; Martin, R.D.; Yohai, V.J.; Salibián-Barrera, M. Robust Statistics: Theory and Methods (with R), 2nd ed.; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2018. [Google Scholar]
- Wang, H.; Mirota, D.; Hager, G.D. A Generalized Kernel Consensus-Based Robust Estimator. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 178–184. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vandermeulen, R.A.; Scott, C.D. Robust Kernel Density Estimation by Scaling and Projection in Hilbert Space. Available online: https://arxiv.org/pdf/1411.4378.pdf (accessed on 16 February 2022).
- Humbert, P.; Le Bars, B.; Minvielle, L.; Vayatis, N. Robust Kernel Density Estimation with Median-of-Means Principle. Available online: https://arxiv.org/pdf/2006.16590.pdf (accessed on 16 February 2022).
- Nazir, H.Z.; Schoonhoven, M.; Riaz, M.; Does, R.J. Quality quandaries: A stepwise approach for setting up a robust Shewhart location control chart. Qual. Eng. 2014, 26, 246–252. [Google Scholar] [CrossRef]
- Nazir, H.Z.; Riaz, M.; Does, R.J. Robust CUSUM control charting for process dispersion. Qual. Reliab. Eng. Int. 2015, 31, 369–379. [Google Scholar] [CrossRef]
- ISO/TC 69. ISO 13528:2015 Statistical Methods for Use in Proficiency Testing by Interlaboratory Comparison, 2nd ed.; ISO: Geneva, Switzerland, 2015; pp. 12, 32–33, 44–51, 52–62. [Google Scholar]
- ISO/TC 69. ISO 5725-2:1994 Accuracy (Trueness and Precision) of Measurement Methods and Results—Part 2: Basic Method for the Determination of Repeatability and Reproducibility of a Standard Measurement Method, 1st ed.; ISO: Geneva, Switzerland, 1994; pp. 10–14, 21–22. [Google Scholar]
- Rousseeuw, P.J.; Croux, C. Alternatives to the Median Absolute Deviation. J. Am. Stat. Assoc. 1993, 88, 1273–1283. [Google Scholar] [CrossRef]
- Filzmoser, P.; Maronna, R.; Werner, M. Outlier identification in high dimensions. Comput. Stat. Data Anal. 2008, 52, 1694–1711. [Google Scholar] [CrossRef]
- Kalina, J.; Schlenker, A. A Robust Supervised Variable Selection for Noisy High-Dimensional Data. Biomed. Res. Int. 2015, 320385. [Google Scholar] [CrossRef] [PubMed]
- Hubert, M.; Debruyne, M.; Rousseeuw, P.J. Minimum covariance determinant and extensions. Wiley Interdiscip. Rev. Comput. Stat. 2018, 10, e1421. [Google Scholar] [CrossRef] [Green Version]
- Ellison, S.L.R. Applications of Robust Estimators of Covariance in Examination of Inter-Laboratory Study Data. Available online: https://arxiv.org/abs/1810.02467 (accessed on 16 February 2022).
- Rosário, P.; Martínez, J.L.; Silván, J.M. Evaluation of Proficiency Test Data by Different Statistical Methods Comparison. In Proceedings of the First International Proficiency Testing Conference, Sinaia, Romania, 11–13 October 2007. [Google Scholar]
- Thompson, M.; Ellison, S.L.R. Fitness for purpose–the integrating theme of the revised harmonized protocol for proficiency testing in analytical chemistry laboratories. Accredit. Qual. Assur. 2006, 11, 467–471. [Google Scholar] [CrossRef]
- Srnková, J.; Zbíral, J. Comparison of different approaches to the statistical evaluation of proficiency tests. Accredit. Qual. Assur. 2009, 14, 373–378. [Google Scholar] [CrossRef]
- Tripathy, S.S.; Saxena, R.K.; Gupta, P.K. Comparison of Statistical Methods for Outlier Detection in Proficiency Testing Data on Analysis of Lead in Aqueous Solution. Am. J. Theor. Appl. Stat. 2013, 2, 233–242. [Google Scholar] [CrossRef]
- Daszykowski, M.; Kaczmarek, K.; Heyden, Y.V.; Walczaka, B. Robust statistics in data analysis—A review: Basic concepts. Chemom. Intell. Lab. Syst. 2007, 85, 203–219. [Google Scholar] [CrossRef]
- De Oliveira, C.C.; Tiglea, P.; Olivieri, J.C.; Carvalho, M.; Buzzo, M.L.; Sakuma, A.M.; Duran, M.C.; Caruso, M.; Granato, D. Comparison of Different Statistical Approaches Used to Evaluate the Performance of Participants in a Proficiency Testing Program. Available online: https://www.researchgate.net/publication/290293736_Comparison_of_different_statistical_approaches_used_to_evaluate_the_performance_of_participants_in_a_proficiency_testing_program (accessed on 12 February 2022).
- Kojima, I.; Kakita, K. Comparative Study of Robustness of Statistical Methods for Laboratory Proficiency Testing. Anal. Sci. 2014, 30, 1165–1168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Belli, M.; Ellison, S.; Fajgelj, A.; Kuselman, I.; Sansone, U.; Wegscheider, W. Implementation of proficiency testing schemes for a limited number of participants. Accredit. Qual. Assur. 2007, 12, 391–398. Available online: https://link.springer.com/article/10.1007/s00769-006-0247-0 (accessed on 16 February 2022). [CrossRef] [Green Version]
- Kuselman, I.; Belli, M.; Ellison, S.L.R.; Fajgelj, A.; Sansone, U.; Wegscheider, W. Comparability and compatibility of proficiency testing results in schemes with a limited number of participants. Accredit. Qual. Assur. 2007, 12, 563–567. Available online: https://link.springer.com/article/10.1007/s00769-007-0309-y (accessed on 16 February 2022). [CrossRef]
- Hund, E.; Massart, D.; Smeyers-Verbeke, J. Inter-laboratory studies in analytical chemistry. Anal. Chim. Acta 2000, 423, 145–165. [Google Scholar] [CrossRef]
- Working Group 1 of the Joint Committee for Guides in Metrology. ISO/IEC GUIDE 98-3/Suppl.1 Uncertainty of Measurement, Part 3: Guide to the Expression of Uncertainty in Measurement (GUM:1995), Supplement 1: Propagation of Distributions Using a Monte Carlo Method; ISO: Geneva, Switzerland, 2008. [Google Scholar]
- CEN/TC 51. EN 196-1:2005, Methods of Testing Cement–Part 1: Determination of Strength; CEN Management Centre: Brussels, Belgium, 2005. [Google Scholar]
- CEN/TC 51. EN 197-1:2011, Cement. Part 1: Composition, Specifications and Conformity Criteria for Common Cements; Management Centre: Brussels, Belgium, 2011. [Google Scholar]
- Simpson, D.G.; Yohai, V.J. Functional stability of one-step GM-estimators in approximately linear regression. Ann. Statist. 1998, 26, 1147–1169. [Google Scholar] [CrossRef]
- Cochran Variance Outlier Test. Available online: https://www.itl.nist.gov/div898/software/dataplot/refman1/auxillar/cochvari.htm (accessed on 5 January 2022).
- Grubbs’ Test for Outliers. Available online: https://www.itl.nist.gov/div898/handbook/eda/section3/eda35h1.htm (accessed on 5 January 2022).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | 2019 | 2020 |
|---|---|---|
| Main distribution mean value, m1, MPa | 0.00 | 0.04 |
| Main distribution standard deviation, s1, MPa | 1.24 | 1.46 |
| Second distribution mean value, m2, MPa | 2.51 | 4.00 |
| Second distribution standard deviation, s2, MPa | 0.90 | 0.70 |
| Third distribution mean value, m3, MPa | −4.30 | −3.60 |
| Third distribution standard deviation, s3, MPa | 0.90 | 0.70 |
| Fraction of the main distribution, fr1 | 0.812 | 0.925 |
| Fraction of the second distribution, fr2 | 0.107 | 0.019 |
| Fraction of the third distribution, fr3 | 0.081 | 0.057 |
| Distance of m1 and m2, |m2 − m1|/s1 | 2.0 | 2.7 |
| Distance of m1 and m3, |m3 − m1|/s1 | 3.5 | 2.5 |
| Statistic | Applied Standard | Variable Name |
|---|---|---|
| Mean values | ||
| General mean | ISO 5725-2:1994, 7.4 | GM1 |
| Median value | ISO 13528:2015, C. 2.1 | MED |
| Robust mean—Algorithm A with iterated scale | ISO 13528:2015, C. 3.1 | Ax* |
| Hampel estimator for mean | ISO 13528:2015, C. 5.3.2 | Hx* |
| Standard deviations | ||
| Scaled median absolute deviation | ISO 13528:2015, C. 2.2 | MADe |
| Normalized interquartile range | ISO 13528:2015, C. 2.3 | nIQR |
| Reproducibility standard deviation without outliers | ISO 5725-2:1994, 7.4 | sRep |
| Robust standard deviation—Algorithm A with iterated scale | ISO 13528:2015, C. 3.1 | As* |
| Robust standard deviation—Q method | ISO 13528:2015, C. 5.2.2 | Hs* |
| Absolute Z factors | ||
| Z using MED, MADe | 17043:2010. B3.1.3 | Z_MADe |
| Z using MED, nIQR | Z_nIQR | |
| Z using GM, sRep | Z_sRep | |
| Z using Ax*, As* | Z_A | |
| Z using Q/Hampel, Hx*, Hs* | Z_Hamp |
| GM | MED | Ax* | Hx* | GM | MED | Ax* | Hx* | GM | MED | Ax* | Hx* | GM | MED | Ax* | Hx* | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Nlab | Mean values, mav | Standard deviations, sav | Mean values, mav | Standard deviations, sav | ||||||||||||
| m2 = 52.6 MPa, mtot = 50.98 MPa, fr2 = 0.10 | m2 = 54.4 MPa, mtot = 51.16 MPa, fr2 = 0.10 | |||||||||||||||
| 15 | 50.98 | 50.96 | 50.97 | 50.97 | 0.48 | 0.59 | 0.50 | 0.50 | 51.16 | 51.05 | 51.09 | 51.09 | 0.54 | 0.63 | 0.55 | 0.55 |
| 20 | 50.98 | 50.96 | 50.97 | 50.97 | 0.41 | 0.50 | 0.42 | 0.42 | 51.15 | 51.04 | 51.09 | 51.09 | 0.47 | 0.53 | 0.47 | 0.47 |
| 30 | 50.97 | 50.96 | 50.97 | 50.97 | 0.33 | 0.41 | 0.34 | 0.34 | 51.15 | 51.04 | 51.09 | 51.09 | 0.38 | 0.44 | 0.38 | 0.38 |
| 40 | 50.98 | 50.96 | 50.97 | 50.97 | 0.28 | 0.34 | 0.28 | 0.28 | 51.15 | 51.03 | 51.08 | 51.08 | 0.31 | 0.36 | 0.31 | 0.31 |
| 60 | 50.98 | 50.96 | 50.97 | 50.97 | 0.23 | 0.28 | 0.23 | 0.23 | 51.15 | 51.03 | 51.09 | 51.09 | 0.26 | 0.30 | 0.26 | 0.26 |
| 80 | 50.98 | 50.96 | 50.97 | 50.97 | 0.21 | 0.25 | 0.21 | 0.21 | 51.16 | 51.03 | 51.09 | 51.09 | 0.23 | 0.27 | 0.23 | 0.23 |
| 100 | 50.98 | 50.96 | 50.97 | 50.97 | 0.18 | 0.23 | 0.19 | 0.19 | 51.16 | 51.03 | 51.09 | 51.09 | 0.21 | 0.24 | 0.21 | 0.21 |
| 150 | 50.98 | 50.96 | 50.97 | 50.97 | 0.15 | 0.19 | 0.15 | 0.15 | 51.16 | 51.04 | 51.09 | 51.09 | 0.17 | 0.20 | 0.17 | 0.17 |
| 200 | 50.98 | 50.96 | 50.97 | 50.97 | 0.13 | 0.16 | 0.13 | 0.13 | 51.16 | 51.03 | 51.09 | 51.09 | 0.15 | 0.17 | 0.15 | 0.15 |
| 300 | 50.98 | 50.96 | 50.97 | 50.97 | 0.11 | 0.13 | 0.11 | 0.11 | 51.16 | 51.03 | 51.09 | 51.09 | 0.12 | 0.14 | 0.12 | 0.12 |
| 400 | 50.98 | 50.96 | 50.97 | 50.97 | 0.09 | 0.11 | 0.09 | 0.09 | 51.16 | 51.03 | 51.09 | 51.09 | 0.10 | 0.12 | 0.10 | 0.10 |
| m2 = 56.2 MPa, mtot = 51.34 MPa, fr2 = 0.10 | ||||||||||||||||
| 15 | 51.31 | 51.06 | 51.15 | 51.15 | 0.63 | 0.64 | 0.59 | 0.59 | ||||||||
| 20 | 51.31 | 51.06 | 51.16 | 51.15 | 0.55 | 0.54 | 0.51 | 0.51 | ||||||||
| 30 | 51.32 | 51.05 | 51.15 | 51.15 | 0.45 | 0.44 | 0.41 | 0.41 | ||||||||
| 40 | 51.32 | 51.05 | 51.15 | 51.15 | 0.38 | 0.37 | 0.34 | 0.34 | ||||||||
| 60 | 51.33 | 51.05 | 51.14 | 51.14 | 0.31 | 0.31 | 0.28 | 0.28 | ||||||||
| 80 | 51.33 | 51.05 | 51.14 | 51.14 | 0.27 | 0.27 | 0.25 | 0.25 | ||||||||
| 100 | 51.33 | 51.05 | 51.14 | 51.14 | 0.24 | 0.25 | 0.23 | 0.23 | ||||||||
| 150 | 51.33 | 51.05 | 51.14 | 51.14 | 0.20 | 0.20 | 0.18 | 0.18 | ||||||||
| 200 | 51.34 | 51.05 | 51.14 | 51.14 | 0.17 | 0.17 | 0.16 | 0.16 | ||||||||
| 300 | 51.34 | 51.05 | 51.14 | 51.14 | 0.14 | 0.14 | 0.13 | 0.13 | ||||||||
| 400 | 51.34 | 51.05 | 51.14 | 51.14 | 0.12 | 0.12 | 0.11 | 0.11 | ||||||||
| Setting | Value |
|---|---|
| Nlab | 10, 15, 20, 30 and 400 1 |
| Nrep | 2 |
| sr, MPa | 0.01 |
| m1, MPa | 50 |
| s1, MPa | 1 |
| m2, MPa | m2 = m1 + n2·s1, n2 = 1 to 8 and step 1 |
| fr2 | 0, 0.025, 0.05, 0.075, 0.1 2 |
| m3, MPa | m3 = m1 + n3·s1, n3 = −8 to 8 and step 1 |
| fr3 | 0, 0.025, 0.05 |
| s2, s3, MPa | 1 |
| Niter | 1000 |
| Ns | 25 |
| Code | |||||||||
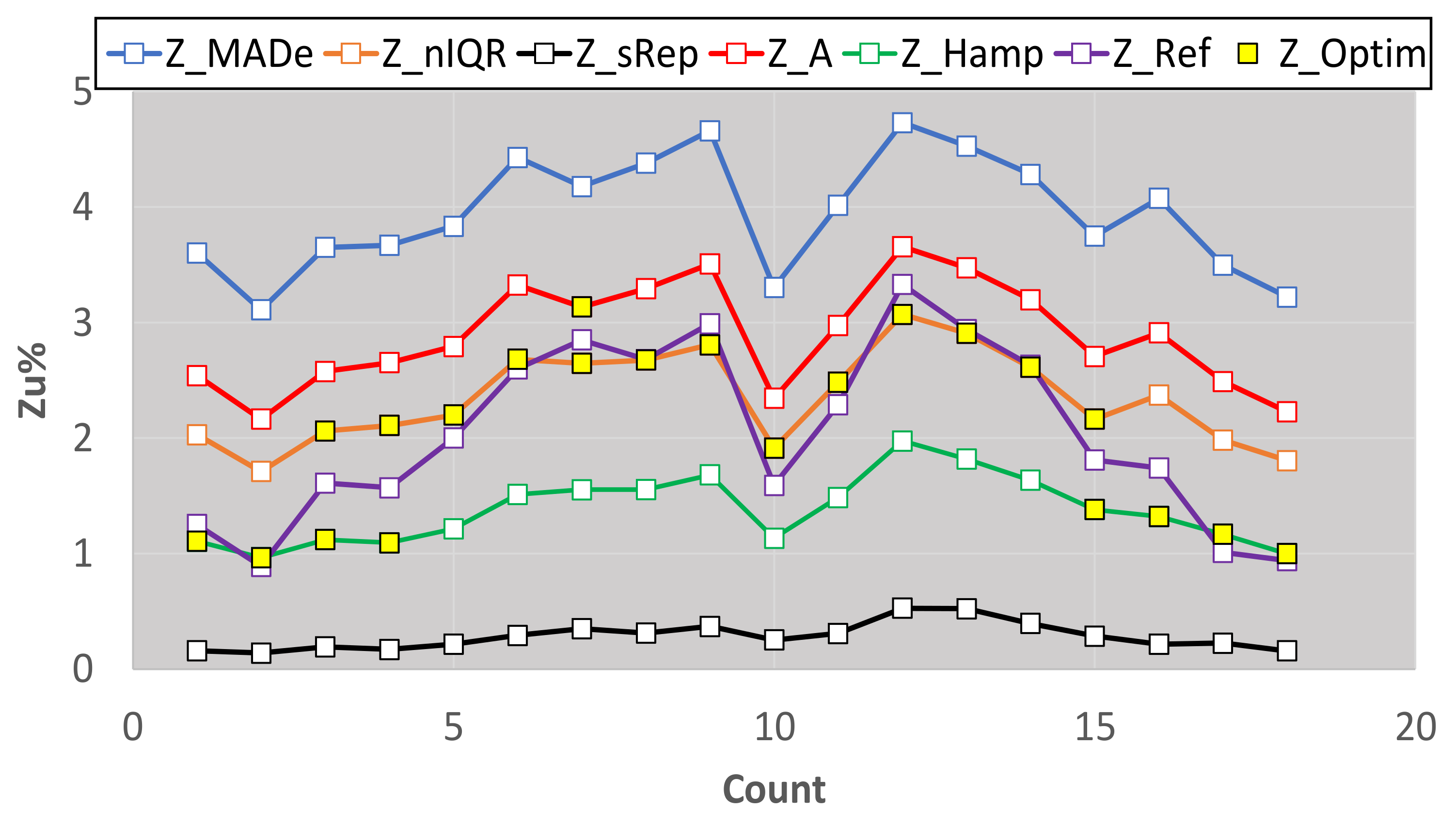
| 012019 | 022019 | 032019 | 042019 | 052019 | 062019 | 092019 | 102019 | 112019 | |
| Count | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| Nlab average | 12 | 12 | 13 | 13 | 13 | 13 | 12 | 13 | 13 |
| m1, MPa | 0.12 | 0.09 | 0.03 | 0.05 | 0.12 | 0.07 | 0.12 | 0.1 | -0.02 |
| s1, MPa | 1.48 | 1.56 | 1.59 | 1.64 | 1.51 | 1.37 | 1.46 | 1.48 | 1.23 |
| f2 | 0.024 | 0.015 | 0.019 | 0.017 | 0.015 | 0.036 | 0.015 | 0.033 | 0.105 |
| m2, MPa | 4.55 | 4.5 | 5.19 | 5.28 | 5.36 | 3.75 | 5.34 | 4 | 2.46 |
| s2, MPa | 0.67 | 0.82 | 0.74 | 0.63 | 0.52 | 1.45 | 0.49 | 1.36 | 0.85 |
| f3 | 0.101 | 0.08 | 0.044 | 0.053 | 0.08 | 0.074 | 0.06 | 0.056 | 0.081 |
| m3, MPa | −3.52 | −3.51 | −4.14 | −4.31 | −3.9 | −3.96 | −4.16 | −4.5 | −4.32 |
| s3, MPa | 1.15 | 1.13 | 0.8 | 0.88 | 1.01 | 0.93 | 0.96 | 0.88 | 0.99 |
| 2.99 | 2.83 | 3.25 | 3.19 | 3.47 | 2.69 | 3.58 | 2.64 | 2.02 | |
| −2.46 | −2.31 | −2.62 | −2.66 | −2.66 | −2.94 | −2.93 | −3.11 | −3.50 | |
| f2 + f3 | 0.125 | 0.095 | 0.063 | 0.070 | 0.095 | 0.110 | 0.075 | 0.089 | 0.186 |
| Optimal | Z_Hamp | Z_Hamp | Z_nIQR, Z_Hamp | Z_nIQR, Z_Hamp | Z_nIQR | Z_nIQR | Z_nIQR, Z_A | Z_nIQR | Z_nIQR |
| Status | N/A | OK | OK | OK | OK | OK | OK | OK | N/A |
| Figure | 14 | 13 | 13 | 14 | 14 | 13 | 13 | ||
| Nlab, n2, n3 | 10, −2, 3 | 15, −3, 3 | 15, −3, 3 | 15, −3, 3 | 15, −3, 3 | 10, −3, 4 | 15, −3, 3 | ||
| Code | |||||||||
| 012020 | 022020 | 032020 | 042020 | 052020 | 062020 | 092020 | 102020 | 112020 | |
| Count | 11 | 12 | 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| Nlab average | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 | 12 |
| m1, MPa | −0.14 | 0.43 | −0.28 | −0.3 | −0.37 | −0.41 | 0.08 | 0.16 | 0.04 |
| s1, MPa | 1.28 | 1.51 | 0.73 | 0.71 | 0.71 | 0.78 | 1.26 | 1.43 | 1.5 |
| f2 | 0.142 | 0.154 | 0.171 | 0.196 | 0.367 | 0.375 | 0.08 | 0.045 | 0.015 |
| m2, MPa | 2.31 | −0.58 | 1.47 | 1.42 | 1.25 | 1.34 | 2.94 | 1.43 | 4.7 |
| s2, MPa | 0.84 | 0.6 | 0.62 | 0.61 | 0.9 | 0.9 | 1.3 | 2.63 | 0.8 |
| f3 | 0.059 | 0.068 | 0.383 | 0.389 | 0.166 | 0.151 | 0.081 | 0.061 | 0.041 |
| m3, MPa | −4.27 | −4.04 | −0.16 | −0.23 | −2.63 | −3.03 | −3.54 | −3.61 | −3.69 |
| s3, MPa | 1.01 | 1.1 | 2.49 | 2.46 | 1.52 | 1.29 | 0.82 | 0.69 | 0.53 |
| 1.91 | −0.67 | 2.40 | 2.42 | 2.28 | 2.24 | 2.27 | 0.89 | 3.11 | |
| −3.23 | −2.96 | 0.16 | 0.10 | −3.18 | −3.36 | −2.87 | −2.64 | −2.49 | |
| f2 + f3 | 0.201 | 0.222 | 0.554 | 0.585 | 0.533 | 0.526 | 0.161 | 0.106 | 0.056 |
| Optimal | Z_nIQR | Z_nIQR | Z_nIQR | Z_nIQR | Z_nIQR | Z_nIQR, Z_Hamp | Z_Hamp | Z_Hamp | Z_Hamp |
| Status | N/A | N/A | N/A | N/A | N/A | N/A | N/A | Not OK | OK |
| Table | 13 | ||||||||
| Nlab, n2, n3 | 10, −2, 3 | ||||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsamatsoulis, D. Comparing the Robustness of Statistical Estimators of Proficiency Testing Schemes for a Limited Number of Participants. Computation 2022, 10, 44. https://doi.org/10.3390/computation10030044
Tsamatsoulis D. Comparing the Robustness of Statistical Estimators of Proficiency Testing Schemes for a Limited Number of Participants. Computation. 2022; 10(3):44. https://doi.org/10.3390/computation10030044
Chicago/Turabian StyleTsamatsoulis, Dimitris. 2022. "Comparing the Robustness of Statistical Estimators of Proficiency Testing Schemes for a Limited Number of Participants" Computation 10, no. 3: 44. https://doi.org/10.3390/computation10030044