1. Introduction
The COVID-19 virus was first reported in December 2019 [
1]. Chinese authorities told the World Health Organization (WHO) that a man died from a respiratory disease of unknown origin in Wuhan, Hubei province. In early January 2020, it was revealed that the genome of a new type of coronavirus is similar to the genome of the SARS virus that spread worldwide from China in 2002–2003 [
2]. Initially, the new coronavirus was treated by the world health system as an epidemic of a regional scale, affecting only China. Nevertheless, in the first month, the virus began to spread rapidly outside of China and threatened the health of the entire planet’s population [
3]. On 11 March 2020, the WHO declared a global pandemic of COVID-19.
The entire world community has directed efforts to prevent and combat the new coronavirus. The virus has spread across the globe through tourists and the availability of flights. In the spring of 2020, restrictive measures were introduced in most countries to contain the spread of COVID-19 [
4]. Among such activities were lockdowns, contact tracing with isolation of contact individuals, the introduction of a mask regime, social distancing, etc. As the epidemic was contained, the authorities of individual countries began to gradually ease lockdowns and other restrictive measures to minimize damage to the economy and prevent social problems [
5]. In the fall of 2020, the second and third waves of the epidemic began in many countries [
6]. New strains of the virus began to spread, characterized by increased virulence [
7].
A large-scale vaccination campaign, which was launched in a short time around the world, contributed significantly to the fight against COVID-19 [
8]. The development of vaccines against coronavirus diseases, such as SARS and MERS, which began even before the onset of the COVID-19 pandemic, made it possible to form knowledge about the structure and rules of the coronaviruses spread [
9]. Furthermore, it is this knowledge that has accelerated the development of various types of vaccines during the current pandemic. Many countries have introduced phased population vaccination plans, identifying groups at the highest risk of complications. Inactivated vaccines, live attenuated vaccines, vector non-replicating and vector replicating vaccines, vector inactivated, DNA and RNA vaccines, and recombinant protein vaccines have been developed. Some of them were used to combat the pandemic.
The unprecedented crisis caused by the global COVID-19 pandemic has demonstrated the significant role of digital technologies [
10]. Since the beginning of the pandemic, the world has seen an accelerated digitalization of many activities, such as the economy [
11], finance [
12], business [
13], transport [
14], education [
15], and many others. Digitalization has not bypassed the field of medicine with the improvement of diagnostic methods [
16], automated processing of medical data [
17], and storage of medical data [
18]. Models and methods for modeling epidemic morbidity received a new round.
This study aims to develop three models for predicting the dynamics of the COVID-19 epidemic process in specific areas using statistical machine learning methods and to study the results of the experiments of the constructed models.
To achieve this goal, the following tasks were formulated:
To analyze models and methods for modeling the epidemic process of COVID-19.
To analyze data on the incidence of COVID-19 in the selected territories.
To develop a model for predicting the dynamics of the COVID-19 epidemic process based on the K-Nearest Neighbors method.
To develop a model for predicting the dynamics of the COVID-19 epidemic process based on Gradient Boosting.
To develop a model for predicting the dynamics of the COVID-19 epidemic process based on the Random Forest method.
To evaluate the results of an experimental study using the developed models.
To analyze the developed models for accuracy and computational complexity.
The promising contribution of this study is two-stage. First, the development of models based on statistical machine learning methods will make it possible to assess the accuracy of forecasts of the dynamics of the COVID-19 epidemic process built using simple models. Secondly, a comparative study of three models of statistical machine learning will allow us to conclude which of them is more effective for studying the epidemic processes not only of COVID-19 but also of other infectious diseases.
The further
structure of the paper is the following:
Section 2, Current Research Analysis, provides an overview of models and methods of epidemic process simulation.
Section 3, Data on COVID-19 Morbidity Analysis, provides a brief description of the COVID-19 pandemic in countries investigated within the research: Germany, Japan, South Korea, and Ukraine.
Section 4, Model and Methods, describes three regression approaches to COVID-19 morbidity forecasting.
Section 4, Results, describes the results of models’ performance, estimation of developed models’ adequacy, and forecasting accuracy.
Section 5, Discussion, discusses the perspective use of models and their limitations. The conclusion describes the outcomes of the research.
Research is part of a complex intelligent information system for epidemiological diagnostics, the concept of which is discussed in [
19].
2. Current Research Analysis
The field of modeling epidemic processes originated at the beginning of the 20th century with the works of Ronald Ross [
20], William Hamer [
21], Anderson McKendrick, and William Kermack [
22]. The works of these scientists laid the mathematical foundations of epidemiology, proposing to describe the dynamics of morbidity using compartmental models [
23]. In such models, the population is divided into compartments depending on their belonging to a defined state. The epidemic process occurring in the population is described using systems of differential equations.
Compartment models are used to model and study many infectious diseases. The paper [
24] describes the application of compartmental models to study measles incidence. Double vaccination was considered, and the model was studied for balance and stability. The results show that the rate of transmission of infection has the most significant impact on the incidence of measles. In [
25], the incidence of influenza was considered, and the classical SIR model was studied. The application of the probabilistic approach in the transition between states is considered. It is concluded that the negative aspect of applying the compartmental approach to modeling influenza is the non-obviousness of the results concerning one or even several scenarios of the development of the epidemic. The compartmental approach to influenza modeling was used as early as the 1970s by Baroyan and Rvachev [
26]. The simulation results were used in the USSR to substantiate anti-epidemic measures aimed at combating the increase in the incidence of influenza.
Among intestinal infections, a compartmental approach is applied to modeling salmonellosis. The study [
27] considered non-infectious and endemic resistant states. The model itself is not accurate enough to conduct relevant experiments to study the dynamics of Salmonella bacterial infection. The model of the hepatitis A built-in [
28] aims to assess the impact of various vaccination strategies. The results show the importance of hepatitis A vaccination in early childhood.
In [
29], an air-borne infection diphtheria incidence model was constructed by extending the classical SIR model. The authors found a globally asymptotically stable equilibrium of infectious extinction. However, such results cannot be effectively interpreted in epidemiology and public health.
The compartmental approach also applies to infections with a contact route of transmission. The work [
30] is devoted to modeling HIV/AIDS with the possibility of treatment. The authors have proved that painless equilibrium is globally asymptotically stable when the base reproduction number is less than one. However, such a conclusion is a law of epidemiology and does not require analytical proof using modeling tools. The model of hepatitis B described in [
31] shows the importance of assessing population migration for the spread of the disease. The authors claim that it is possible to reduce the incidence of hepatitis B based on the model results. However, the main vectors of the infection are not taken into account when compiling compartments. The authors of [
32] describe a model of the epidemic process of hepatitis C. The emphasis is on people who inject drugs. The model is dynamic and interactively presented using a web application. The disadvantage of the model is that if there is a significant change in the rules of distribution, for example, the introduction of a policy to combat injecting drug users or the introduction of mass substitution therapy, all model parameters must be adjusted again.
A common disadvantage of the models described above is the impossibility of extending them to other objects. It is necessary to completely rebuild the model and find new coefficients related to a particular disease to model another disease.
With the onset of the global COVID-19 pandemic, compartmental models are actively used to model the epidemic process of a new coronavirus in various territories. Such territories can have different sizes, densities, and populations. Thus, in [
33], the territory of the college campus is considered, where complex public health protocols can be introduced. In [
34], the spread of COVID-19 in New York is modeled to determine the peak of the incidence wave. The work [
35] extends the territory of modeling to the state of New York. It examines strategies to manage the course of the epidemic based on control measures implemented in other states. In [
36,
37], the dynamics of COVID-19 are modeled on the island states, limited from the outside world of Sri Lanka and Cyprus. In the case of Sri Lanka, the emphasis is on the isolation of villages on the island and the absence of tourists. When modeling the epidemic situation in Cyprus, an arbitrary number of subgroups with different infection levels and testing were used. In [
38], an entire country was taken to model COVID-19: France. New cases, deaths, hospitalizations, intensive care unit admissions, hospital deaths, etc., are used. In [
39], several European countries are considered at once, and for each country, its transmission coefficients, recovery rates, etc., are calculated. Considering compartmental models for different areas, it should be noted that even when studying a single disease, such as COVID-19, the coefficients of the model should be found again for each area, and the system of differential equations should be rebuilt from the very beginning.
Compartmental approaches with different sets of states are also used to model COVID-19. The study [
40] uses the simplest SIR (susceptible—infected—recovered) model. The disadvantage of the model is the accuracy of forecasts, which is insufficient for decision-making, and the limitedness in population groups gives a very general understanding of the spread of the epidemic process. In [
41], the classical SIR model is extended by adding the exposed state. The model is used to find the peak of the disease, but the results have not materialized due to changes in the policy of control measures in the countries considered and the start of the vaccine campaign. The work [
42] extends the classical SIR model with the state Q—quarantined for isolated infected people. The model shows that the maximum number of infected in the real world is highly dependent on the speed with which quarantine restrictions are implemented. The authors of [
43] add the D-death state to the SEIR model for fatal cases. Modeling results show that unreported deaths from COVID-19 are significantly lower than unreported infections. In [
44], the authors extend the SEIR model with the state Q—quarantined. At the same time, the model does not consider isolation scenarios and social distancing. The study [
45] extends the SEIR model with states D—death and Q—quarantined. Moreover, the quarantined state means hospitalization since the authors hypothesize that hospitalization is similar to quarantine restrictions. In this case, the model considers the average behavior of the population, which leads to an underestimation of specific population groups. In [
46], the authors present a model consisting of seven compartments: susceptible (S), exposed (E), infectious (I), quarantined (Q), recovered (R), deaths (D), and vaccinated (V). The model can estimate predicted numbers of compartments, but only for a short time. Models with a much larger number of compartments are also known. However, a common disadvantage is that many states and subpopulations are needed to adequately describe a population, which makes models complex. The complexity of the models causes both difficulties with calculations and experimental studies and the impossibility of promptly making changes to the model when the behavior of the virus dynamics changes.
Models are also used for various tasks in the study of COVID-19. For example, work [
47] considers the effectiveness of vaccination distribution. The study [
48] looks at the transport effects of the COVID-19 pandemic. In [
49], the effectiveness of the introduction of lockdowns is estimated. Ref. [
50] explores the effects of social distancing. The authors of [
51] investigate the effectiveness of masks to combat the novel coronavirus pandemic. The study [
52] is devoted to assessing the economic aspects of applying control measures to combat the COVID-19 pandemic. Work [
53] uses compartmental models to investigate the transmission of the COVID-19 virus among medical personnel and methods for protecting healthcare workers from infection. Ref. [
54] uses modeling to estimate the medical throughput of hospitalization, including for intensive care units.
However, the compartmental approach to modeling infectious diseases, including COVID-19, has several disadvantages, among which are the following:
An accurate description of the population in which the epidemic process spreads requires considering the population’s heterogeneity, i.e., age, gender, behavior, physical interaction, etc. However, introducing all these characteristics into the compartmental model significantly complicates it and makes it unsuitable for practical use.
The apparatus of differential equations has high computational complexity with sufficiently detailed models.
Different diseases have different conditions and rules of infection transmission in different population groups, making it impossible to transfer an already ready model for one infectious disease to another disease. So, for each new disease, the model must be rebuilt.
The same model cannot be applied in different territories even for the same disease because transfer rules and control measures may differ depending on the location, climate, legal aspects, etc. For each new territory, the model needs to be built anew.
When the virulence of the disease changes, it is impossible to make changes to the model quickly, and all coefficients must be re-found experimentally. The rate at which model changes are made is especially critical when modeling COVID-19, as the virus mutates rapidly and new strains have different dynamics while circulating in the population along with known strains.
The non-adaptation of compartmental models to external factors makes it impossible to predict for medium and long-term periods. Sufficient accuracy for studying the epidemic process can be obtained only when calculating a short-term forecast.
Based on the analysis, we will use statistical machine learning models to eliminate the shortcomings of compartmental models. Such models are characterized by high predictive accuracy, adaptability, and the ability to overtrain models during a pandemic based on updated data, the ability to use a comprehensive set of population data to display more realistic behavior of the virus.
4. Models and Methods
As part of this study, three models for predicting new cases of COVID-19 were built based on regression methods. The models are based on the Random Forest, K-Nearest Neighbors regression, and Gradient Boosting methods.
Regression analysis is a set of statistical methods for assessing the relationship between variables [
76]. It can be used to model future relationships between variables, i.e., forecasting. Regression shows how changes in independent variables can be used to fix changes in dependent variables. In our case, the independent variables are the incidence of COVID-19, and the dependent variables are the predicted incidence.
4.1. Random Forest Model
A Random Forest is a machine learning algorithm that consists of many decision trees [
77]. It uses bootstrap and feature randomness to build each individual tree to create an uncorrelated forest that has a better prediction than any individual tree.
The algorithm for constructing a Random Forest consisting of N trees can be represented as follows:
For every n = 1, …, N:
Generate sample Xn using bootstrap.
Construct a decision tree bn by the sample Xn.
According to the given criterion, choose the best attribute, do a split in the tree according to it, and do it until the sample is exhausted.
The tree is built until there are no more than nmin objects in each leaf or until a certain height of the tree is reached.
For each partition, select m random features from n initial ones to find the optimal separation among them.
The final regression algorithm looks like this:
where
bi(
x) is a regression tree.
The recommended number of random features in regression tasks is m = n/3, where n is the number of initial features.
To improve the accuracy of forecasting by the Random Forest method, it is necessary to:
Have features that have some predictive power.
Uncorrelated forest tree predictions.
Correct choice of features and hyperparameters for constructing weak correlations.
The random subspace method reduces the correlation between trees and avoids overfitting. The basic algorithm is trained on various subsets of the feature description, which are selected randomly. The ensemble of models using the random subspace method has the following construction algorithm:
Let the number of objects for learning be N, and the number of features D.
Choosing the number of individual models L in the ensemble is necessary.
For each individual model l, it is necessary to choose dl (dl < D) as the number of features for l.
It is necessary for each individual model l to create a training sample by selecting dl features from D and to train the model.
It is necessary to combine the results of individual L models by combining the posterior probabilities.
4.2. K-Nearest Neighbors Model
The K-Nearest Neighbors method is a machine learning method based on finding the nearest objects with known target variable values [
78]. For the regression problem, the average method is usually used, and the forecasting result is the average value of the last K sample data.
To build a model, a training sample is required, on which the correspondence “group of objects”—“dependent variable” is set:
The distance function between objects must be uniquely specified on the set of objects. For a random object, the method determines the distance to objects of a particular class and arranges them in ascending order:
where
xi,u is the
i-th neighbor of object
u,
yi,u is the i-th neighbor for the dependent variable.
In general, the regression function looks like this:
where
K is selected by cross-validation, and the metric is selected based on the selected feature space.
In this case, the class boundaries will be very complex, which contradicts that the method has one parameter. However, the paradox is resolved by the fact that the objects of the training sample are also peculiar parameters of the method.
Cross-validation evaluates an analytical model and its behavior on independent data, using the available data as evenly as possible.
Advantages of the method:
Knowledge of features is optional, and only the proximity function is needed.
The method applies to objects of any complexity if the proximity function is specified.
Easy to implement.
Easy to interpret.
The disadvantage of the method is that the accuracy of the method deteriorates with increasing space dimension.
4.3. Gradient Boosting Model
Gradient Boosting is a machine learning technique for classification and regression problems that builds a prediction model in an ensemble of weak predictive models [
79]. In our case, Gradient Boosting is an ensemble of decision trees. The method is based on iterative learning of decision trees to minimize the loss function. Thanks to the features of decision trees, Gradient Boosting can work with categorical features and cope with nonlinearities. Boosting is a method of transforming poorly trained models into well-trained ones. In boosting, each new tree is trained on a modified version of the original dataset.
Let there be a set of pairs of features
x and target variables
y,{(
xi,
yi)}
i=1,…,n, on which it is necessary to restore the dependence of the form
y =
f(
x). It is necessary to minimize the loss function
L(
y,
f), which must be differentiable:
It is necessary to find approximations
in such a way as to minimize the loss function on the average on the available data. We restrict the search space to a parameterized family of functions
. Then the problem is reduced to the one solved by optimizing the parameter values:
Find the approximate value of the parameters iteratively.
where
is empirical loss function,
M is number of iterations.
To minimize using the gradient descent method. To do this, it is necessary to initialize the initial approximation of the parameters . For each iteration t = 1, …, M, the following steps must be performed:
To calculate the gradient of the loss function
at the current approximation
To set the current iterative approximation
based on the computed gradient.
To update parameter approximation
.
To save the final approximation
.
Advantages of the method:
The method is easy to implement.
Iteratively corrects weak classifier errors and improves accuracy by combining vulnerable learners.
Not prone to overtraining.
Disadvantages of the method:
4.4. Models Accuracy Estimation Methods
To assess the adequacy of the models we used the relative error [
80]. The relative error is the ratio of the absolute measurement error to the measurement performed.
In the case of evaluating models on different samples with different values, the relative error allows us to estimate the accuracy in relative terms.
For use in public health practice models, the mean absolute error was calculated [
81]. It is a measure of the error between the predicted and observed values.
where
yi is the predicted value,
xi is the observed value,
n is the number of observations.
5. Results
Models of the COVID-19 epidemic process were implemented using the Python programming language. An experimental study of the models was carried out on data on new cases of COVID-19 presented in the Coronavirus Resource Center of Johns Hopkins University and Medicine for Germany, Japan, South Korea, and Ukraine. The forecast is built for 3, 7, 10, 14, 21, and 30 days.
5.1. Forecasting Results
The forecast results show the retrospective dynamics of new cases of COVID-19 in the selected area.
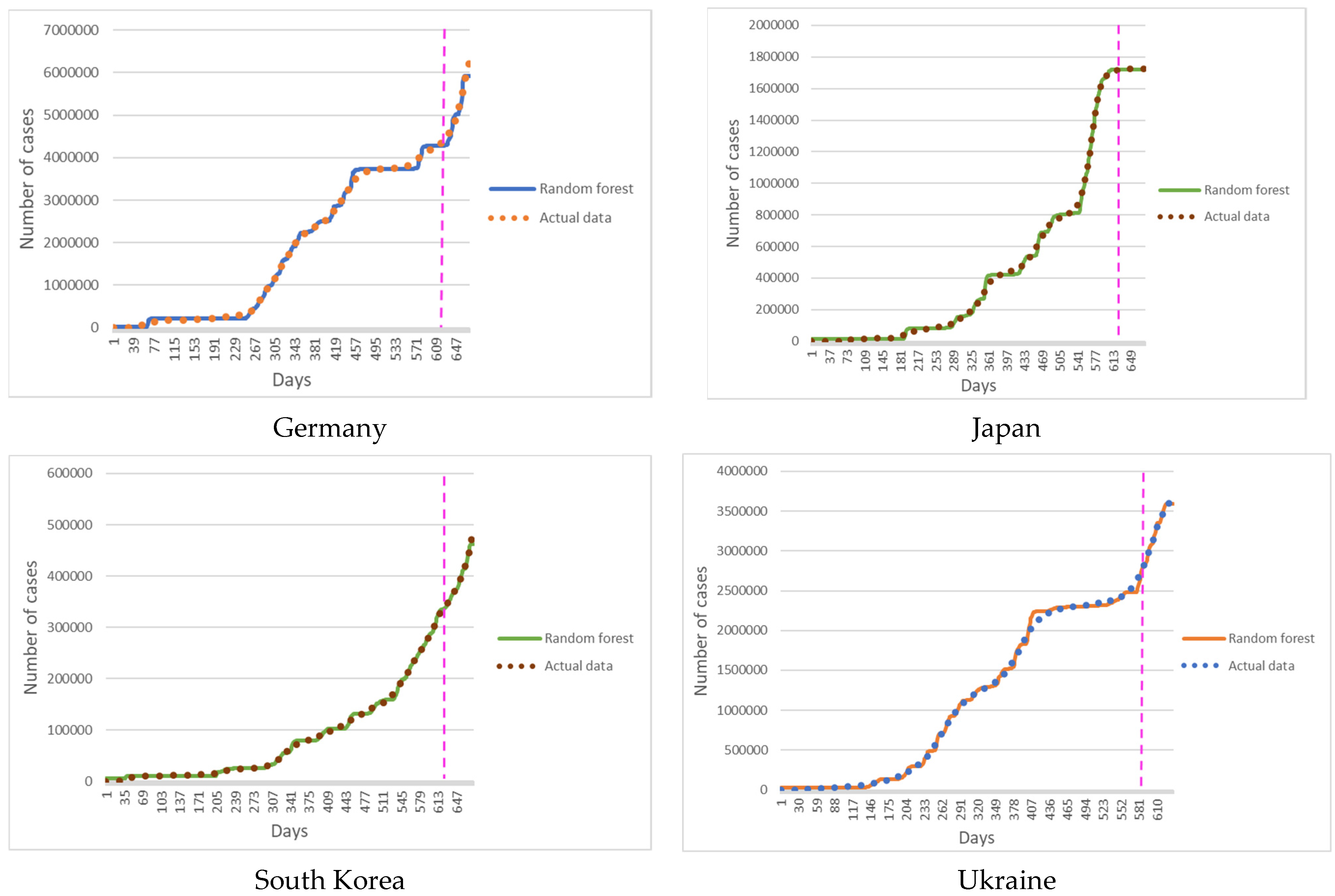
Figure 1 shows the results of predicting new cases of COVID-19 with a Random Forest model.
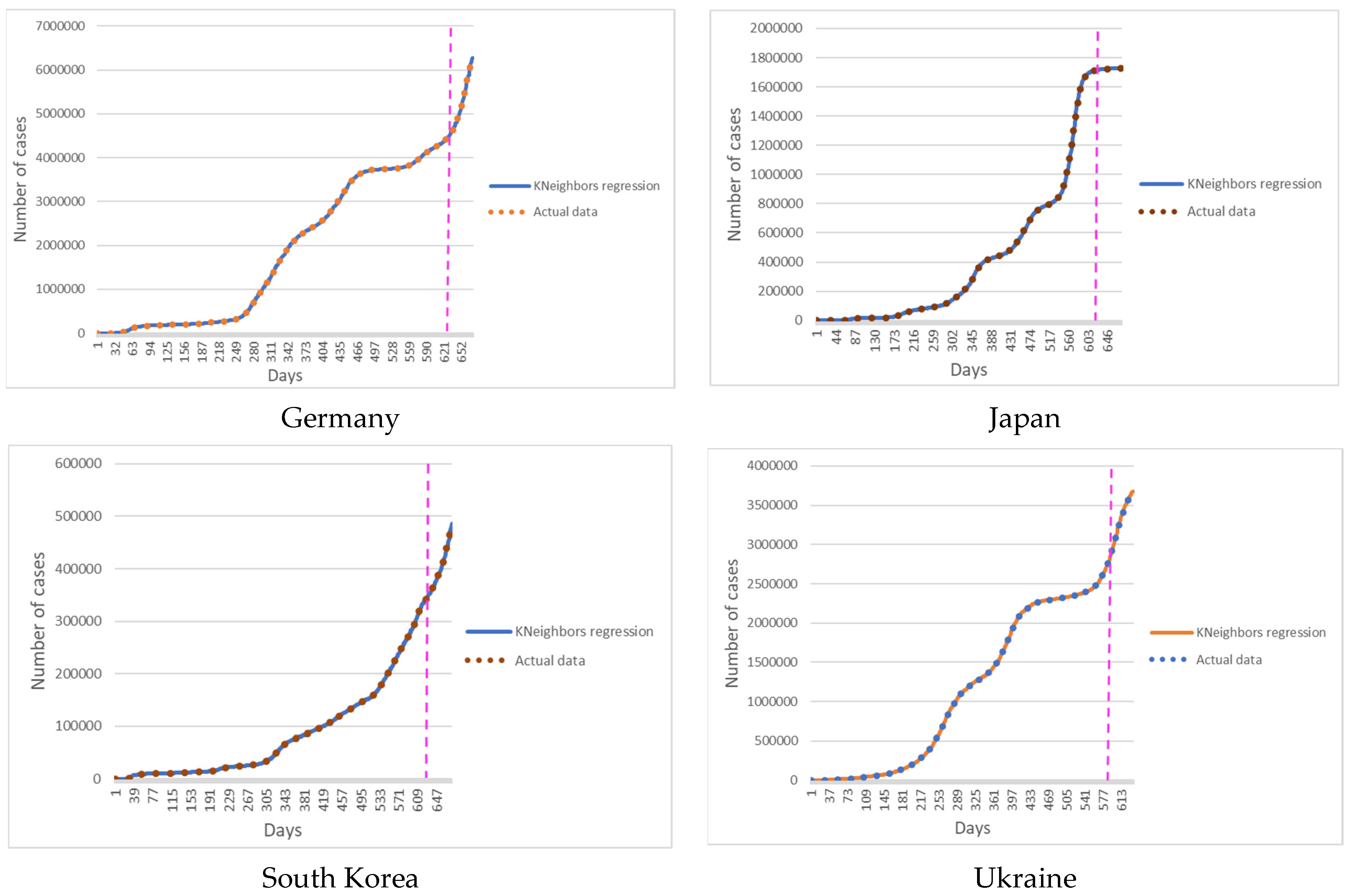
Figure 2 shows the results of predicting new cases of COVID-19 with a K-Nearest Neighbors model.
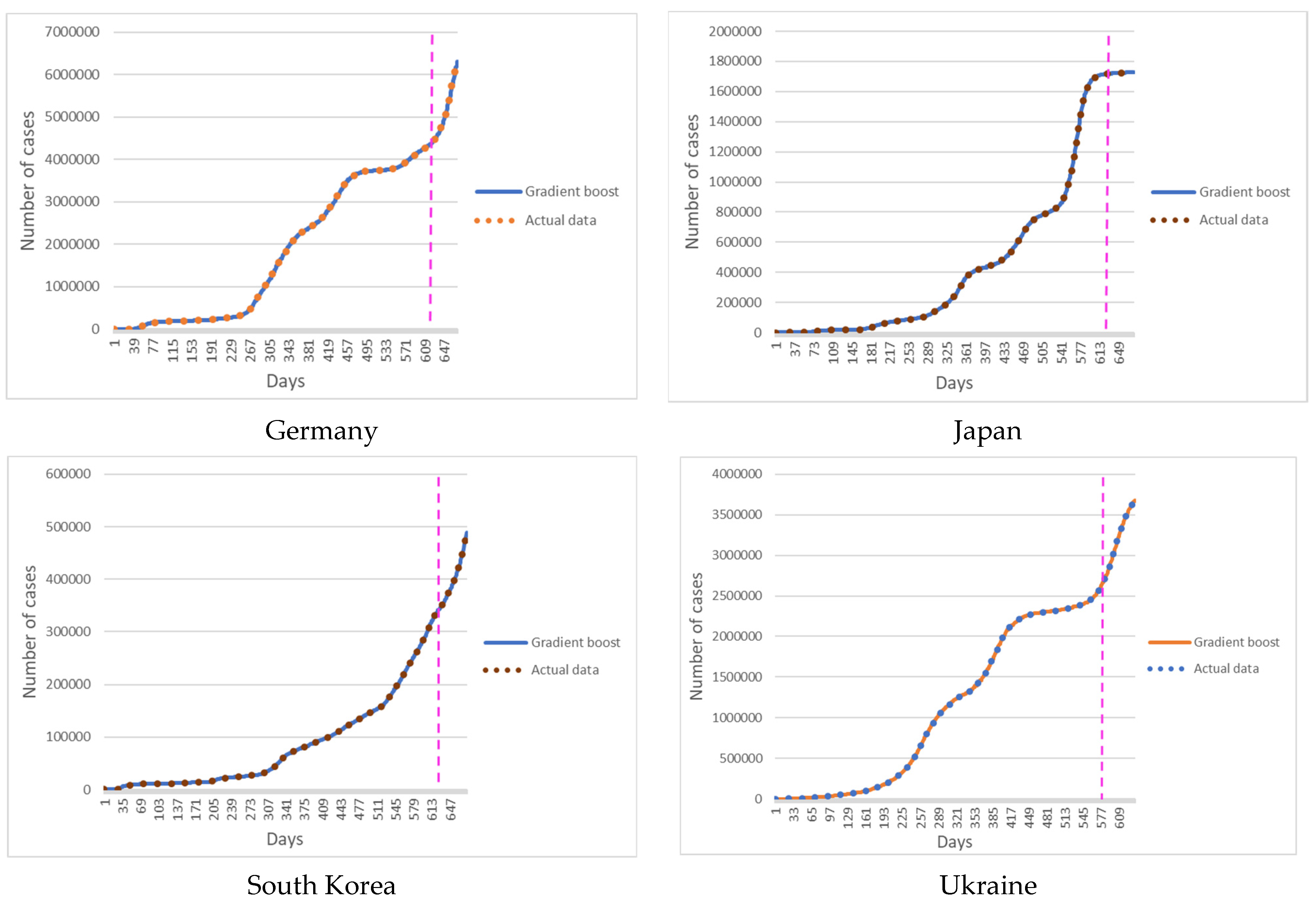
Figure 3 shows the results of predicting new cases of COVID-19 with a Gradient Boosting model.
Figure 1,
Figure 2 and
Figure 3 show the results of simulations for Germany, Japan, South Korea, and Ukraine.
5.2. Forecasting Accuracy Estimation
To assess the accuracy of the models, the relative error and the average absolute error were calculated for the retrospective forecast of the cumulative values of new cases of COVID-19 for the selected territories for 3, 7, 10, 14, 21, and 30 days. The relative error of training data shows the adequacy of the constructed model. The relative error of forecasted data shows the accuracy of the constructed model. However, the error in absolute incidence values is more informative for use in practice by epidemiologists and public health specialists. Absolute incidence rates make it possible to assess the future epidemic situation and take the necessary control measures to contain the epidemic.
Table 1 shows the relative error of developed models for predicting new cases of COVID-19 in Germany.
Table 2 shows the relative error of developed models for predicting new cases of COVID-19 in Japan.
Table 3 shows the relative error of developed models for predicting new cases of COVID-19 in South Korea.
Table 4 shows the relative error of developed models for predicting new cases of COVID-19 in Ukraine.
Table 5 shows the mean absolute error of developed models for predicting cumulative new cases of COVID-19 in Germany.
Table 6 shows the mean absolute error of developed models for predicting cumulative new cases of COVID-19 in Japan.
Table 7 shows the mean absolute error of developed models for predicting cumulative new cases of COVID-19 in South Korea.
Table 8 shows the mean absolute error of developed models for predicting cumulative new cases of COVID-19 in Ukraine.
5.3. Models Complexity Estimation
Let us estimate the computational complexity of the Random Forest model. When building a model, it has a large size. The complexity of the model is O (NK), where N is the number of trees.
The complexity of training the K-Nearest Neighbors model is O (1). O (n) is technically correct as well. It is needed to remember the training sample. Prediction complexity is O (n) for each feature. If it is required to predict k objects independently using a fixed training sample, then the complexity will be O (kn).
The complexity of the Gradient Boosting model is O (M n lognd), where M is the number of trees. In general, the model takes longer than a Random Forest because it builds the next tree based on the error or residual of the previous tree, so the process cannot be parallelized compared to a Random Forest.
6. Discussion
It should be noted that COVID-19 refers to infections with an easily possible aerosol transmission mechanism of the pathogen, the source of which is a sick person and a carrier, i.e., an asymptomatic person who sheds a pathogen into the environment and infects other susceptible people. The epidemic process of such infections is significantly influenced by social factors, such as crowding, physical distancing, mask regimen, vaccination coverage of the population, etc. [
82]. A step-by-step assessment of the predicted morbidity and its comparison with the registered one allows not only to correctly assess the epidemic situation, the manifestations of the epidemic process characteristic of specific conditions of space and time, but also to assess the quality, effectiveness, and correctness of the preventive and anti-epidemic measures taken, to choose the optimal ones on time and make adjustments as in regulatory documents, and in local preventive action plans.
New challenges for humanity associated with the COVID-19 pandemic forced specialists from various fields of science to mobilize their capabilities. The contribution of specialists in mathematical modeling can be essential for studying the dynamics and characteristics of the manifestations of the epidemic process of emergent infection, the behavior of the pathogen, and the patterns of the spread of the disease are studied simultaneously with the development of preventive and anti-epidemic measures [
83]. For a clearer understanding of the patterns of the spread of the COVID-19 pathogen and the choice of the most meaningful and rational measures, we propose evaluating the forecast results through different periods. This information will make it possible to understand the dynamics and features of the epidemic process characteristic of a specific time and a specific territory for which the forecast is made.
The first step is to estimate the expected incidence of COVID-19 after 3 days. The results obtained do not yet allow assessing the correctness of management decisions and the effectiveness of the measures that have been implemented. However, we can understand whether the intensity of the epidemic process has changed compared to the period for which case data were used to build a forecast. Lower rates of predicted morbidity than the actual ones indicate the intensification of the epidemic process and the need to strengthen control measures, which should be paid attention to by decision-makers. The disadvantage of this forecast is that if a period is taken that includes weekends and holidays, then the excess of the predicted incidence compared to the registered one will not reflect the effectiveness of the measures taken. The actual incidence may significantly exceed the registered one [
84].
The second step may be to assess the incidence after 7 days. The forecast results after this period allow us to give a preliminary assessment of the correctness of the adopted management decisions. Considering that the average incubation period of COVID-19 is 5–6 days [
85], the excess of the actual incidence data of the predicted incidence indicators will roughly give an idea of the need to strengthen control measures, draw the attention of decision-makers to the quality and correctness of the measures that have been developed. An approximate judgment can also be made about the amount of medical care needed for the population. The forecast after 7 days also allows to smooth out the error associated with holidays.
The third step compares the predicted and actual morbidity after 10 days, making it possible to assess the correctness of management decisions more accurately [
86]. Fluctuations in incidence associated with weekends and holidays will be leveled. Cases in which infection occurred when the modeling was carried out will be registered. The driving forces of the epidemic process that were in effect for that period (cases with an average incubation period) were taken into account, so those cases that arose after the time when the model was built. New factors could arise or become more active that affect the dynamics and intensity of the COVID-19 epidemic process.
The next step is to assess the incidence in two weeks. 14 days is the maximum incubation period [
87]. All cases of infection that occurred at the time of forecasting will already manifest as morbidity or carriage. Comparison of predicted and registered morbidity will allow assessing changes in the dynamics and intensity of the epidemic process, assessing the quality and effectiveness of the measures taken and the correctness of the managerial decisions made, and, if necessary, making adjustments to the volume and content of the control and preventive measures taken. In addition, in two weeks, it is possible to adjust the medical and laboratory network [
88]. Exceeding the predicted indicators after 14 days of those indicators registered on the modeling day is a signal for drawing up plans to deploy additional beds for patients, including beds equipped with oxygen, purchase the necessary diagnostic test systems, medicines, and train medical personnel. It is also a signal to strengthen the vaccination campaign in the territory [
89].
The next step is to evaluate the forecast data after 21 days. The results allow us to assess the epidemic situation and be a warning for time-taking measures to correct the situation, if necessary. Increasing rates of morbidity growth are a marker for the development of additional measures. You can also preliminarily estimate the required amount of resources—test systems for diagnostics, beds, oxygen stations, medicines, and medical personnel and understand whether the activities included in the plan at the previous stage were sufficient.
Furthermore, finally, the sixth step can be to assess the forecast of incidence in 30 days, which first of all, allows us to assess the burden on the healthcare system, institutions that provide medical care, the required amount of resources and personnel, and the damage from this disease [
90]. Estimating the predicted morbidity within this period allows for the taking of necessary advance measures to manage peaks or extreme indicators, such as providing institutions with the necessary resources, and conducting training and retraining of medical personnel, considering the current situation. Other possible strategies include developing the optimal logistics for medical support of both patients and healthy individuals to be vaccinated (organization of vaccination points, providing training of vaccination teams, development of routes, purchase of vaccines, etc.).
To choose a simulation method, one should also consider the possibility of retraining machine learning models. Retraining is characterized by a significant excess of the error value of the test sample of the value of the average error of the training sample. An analysis of the models built in the framework of this study showed that all models are not overfitted.
The minimum number of observations required for a correct result was also analyzed. For a model based on the Random Forest method, the minimum required number of observations is 40, for the Gradient Boosting model—25, for the K-Nearest Neighbors model—15.
7. Conclusions
The paper describes the results of experimental studies of three models based on statistical machine learning methods: Random Forest, K-Nearest Neighbors, and Gradient Boosting. The experiments were performed on new COVID-19 case data provided by the Coronavirus Resource Center of Johns Hopkins University and Medicine for Germany, Japan, South Korea, and Ukraine. These countries were selected because they have different dynamics of the epidemic process and different measures that health systems have implemented to control the pandemic.
All models showed sufficient accuracy in deciding to implement control measures to counter the COVID-19 pandemic. The tasks that can be solved with the help of models depending on the period of the constructed predictive incidence are described.
The prediction accuracy of the Random Forest model is from 94.83% to 99.65%, the K-Nearest Neighbors models are from 99.46% to 99.96%, and the Gradient Boosting models are from 99.97% to 99.99%.
An analysis of the change in the error depending on the forecasting period showed a high agreement between the registered and actual statistics on the incidence of COVID-19 in Japan and South Korea, a satisfactory agreement between the data in Germany, and a low agreement between the registered and actual incidence of COVID-19 in Ukraine. This is due to the completeness of population testing and the testing approaches those countries have implemented during the pandemic.
The scientific novelty of the study lies in the development and study of models of emerging infections using the example of COVID-19 based on simple methods of statistical machine learning. In contrast to other studies, the article analyzes various periods for constructing a forecast, which makes it possible to evaluate the effectiveness of its use for solving various problems of public health.
The practical novelty of the study lies in the implementation of an automated tool for assessing the dynamics of the COVID-19 epidemic process in various territories. It is shown what tasks of epidemiology can be solved when building forecasts for various periods. The accuracy of modeling depends on the completeness of the data of the recorded statistics. Another essential practical value is the ability of public health experts to make decisions based only on new cases of COVID-19. This is especially true for areas where collecting other patient data is not possible due to low funding for the healthcare system or force majeure. For example, in Russia’s war in Ukraine, it is impossible to collect complete data on COVID-19 cases, especially in the temporarily occupied territories and territories where active hostilities are taking place. Under such conditions, the proposed approach will be practical for the timely control of the COVID-19 epidemic process.
Future research development. Despite the high accuracy of the epidemic process models developed in the framework of this study based on statistical machine learning methods, such models do not allow us to identify the factors that affect the development of the epidemic process. It is the identification of factors and assessing their informativity that is an essential task of public health. Therefore, a further development of the study would combine the proposed machine learning models with multi-agent models of epidemic processes. On the one hand, multi-agent models will make it possible to identify and evaluate the factors influencing the dynamics of the epidemic process. On the other hand, machine learning models will improve the accuracy of the predictive incidence of multi-agent models. This will improve the adequacy of experimental studies and the effectiveness of decisions made based on simulation.


 ,
, 





{kind=link}
{kind=link}
{kind=link}