1. Introduction
The COVID-19 outbreak and its associated restrictions have created huge challenges for schools and higher education institutions, requiring urgent action to maintain the quality of teaching and student assessment.
The development of information technology, online learning and online exams are becoming more widespread. Distance learning and distance exams have facilitated the work of teachers and students to a certain extent, and at the same time, have balanced the gap in educational resources between regions. However, there are certain disadvantages in distance exams: the absence of observers makes it easy to cheat on the distance exam, which affects the fairness of the exam and the quality of education.
The use of information technology and the introduction of distance education in higher education requires the implementation of effective actions to control students. Proctoring performs the functions of recognition, tracking and evaluation during the execution of control, milestone and final work. This process can be live, automated and semi-automated, depending on the role of man and machines in it. Proctoring in higher education should be based on the theses of adaptation, standardization, information security, personalization and interactivity.
A number of educational institutions believe that proctoring technology is necessary to prevent fraud. A number of other educational institutions and students are concerned about the difficulties associated with this approach. Automated proctoring programs provide examiners with the tools to prevent fraud. These programs can collect system information, block network access, and parse keystrokes. They may also use computer cameras and microphones to record students and their surroundings.
Since the teacher does not have the opportunity to often memorize students, it becomes necessary to determine the examinees, as well as the normative support for the process of passing the exam. In the proctoring system, the trajectory detection and tracking technology based on face recognition uses the regional feature analysis algorithm, which integrates computer image processing technology and the principle of biostatistics. Mathematical model building has broad prospects for development.
Facial recognition falls under the category of artificial intelligence and uses computer optics, acoustics, physical sensors, biological statistical principles and advanced mathematical methods to create models that turn human physiological characteristics into identifiable ones. Face recognition can be widely used in many scenarios, such as airports, scenic spots, hotels, railway stations and other places.
With the rapid development of artificial intelligence technologies, facial recognition has become widely used in social work and life, while technologies such as face checking and door opening provide convenience, their own security issues have often led to the exposure of user security vulnerabilities, leading practitioners to realize the need to improve the facial recognition system. Face identification is a difficult problem in the field of image review and computer vision. Information security becomes a very significant and difficult task [
1,
2,
3,
4,
5,
6,
7,
8].
Most Kazakhstan’s universities have adapted to the situation with distance learning and are ready to organize intermediate and final attestation of students online. Evaluation of acquired knowledge is the most difficult stage of distance learning to implement. In the development of an automated proctoring system, an important role is played by the face recognition system. With a face recognition system, you can eliminate the influence of the human factor in proctoring by controlling all students equally. We explore the current topic of face recognition and our goal is to study the model of face recognition. We also apply the created face recognition system at our university.
2. Materials and Methods
The potential benefits of safeguards such as remote exam fraud research and remote verification and the methods used in education have been discussed in the works of many authors [
9,
10,
11,
12,
13,
14]. These articles raise current questions regarding cheating and other inappropriate test-taker behavior, how to deal with such behavior and whether remote proctoring provides an effective solution. Research in the field of pattern recognition has been confirmed by numerous works of scientists abroad [
15,
16,
17]. The specification of the direction by means and technologies of proctoring programs was published in the works of Kazakh researchers [
18,
19,
20].
A large number of works are devoted to the mathematical formulation of the problem of automatic pattern recognition. Explicitly or implicitly, questions of defining the initial concepts are intertwined in the circle of these questions. When discussing general issues of image recognition, geometric representations are widely used. Although it is clear that any kind of multidimensional, and even more so, infinite-dimensional constructions, have only an auxiliary character of explanation, the nature of methodological means are not intended for actual schematic implementation. The review will also use a geometric interpretation of the basic identification facts. A huge number of works are devoted to the mathematical formulation of the problem of automatic pattern recognition. When discussing general issues of pattern recognition, geometric representations are widely used [
21,
22,
23,
24,
25].
Formulation of the problem.
Within the framework of this work, the task is to study the parameters of face recognition algorithms. The research process can be divided into several tasks, namely:
- (1)
review methods and algorithms for face detection and recognition;
- (2)
describe mathematical models of face recognition;
- (3)
implementation of the face recognition algorithm;
- (4)
development of recommendations for improving the algorithm to obtain a given accuracy.
To test the influence of parameters on the accuracy of the results of the face recognition algorithms, we chose the Python programming language. The Python language supports the basic programming paradigms needed to get the job completed. Easy to manage with codes, a huge number of useful libraries (NumPy library, OpenCV, Dlib, OpenFace) were used. We used the Viola–Jones algorithm for face detection.
On the basis of proctoring, we used 400 pictures of students and 40 pictures of each student. Currently, there are different methods of face recognition. Here, we have used the libraries from OpenCv. To create a face detection instance model, we used cv2.face_recognition function of OpenCV API, then used the face_detector.py function.
We used photographs taken from different angles, and in the experiment, we used 400 photographs of 40 students. Students were asked to take pictures with different facial expressions. The Face Detection operation supports images that meet the following requirements: jpeg, png, gif (first frame) or bmp format; the file size is between 1 KB and 6 MB and the image size ranges from 36 × 36 pixels to 4096 × 4096 pixels. The following factors significantly influence the probability of correct image recognition: resolution (size)—the most stable (critical resolution) between the best resolution and the smallest resolution; brightness; lighting; grip angle.
There are various methods that allow you to determine the features of a person from a face image. The main criteria for evaluating methods are the computational difficulty of the algorithms and the probability of correct recognition. The choice of the pattern recognition method depends on the nature of the problem. Principal Component Analysis, Independent Component Analysis, Active Shape Model and Hidden Markov Model are some of the most important dimensionality reduction or early face detection algorithms. These methods have a wide range of applications in data compression to remove redundancy and eliminate noise in data. The advantages of these methods are that if emotions, lighting, etc. are present in the images, then additional components will appear; thus, it will be easy to save and search for images in large databases, and recreate images [
26,
27,
28]. The main difficulty of the methods is the high demand on images. Images must be obtained in low light conditions, at one angle, and high-quality pre-processing of images must be carried out, leading to standard conditions.
Support Vector Machines is a supervised learning method that can be widely used in statistical classification and regression analysis. Support vector machines are generalized linear classifiers. The characteristic of this family of classifiers is that they can minimize the empirical error and maximize the geometric edge area at the same time, which is why the support vector machine is also called the maximum edge area classifier. Neural Networks is a model for a specific classification task; the focus is on “learning” and the basis of machine learning is thinking. Neurons can work independently and process the information received, that is, the system can process input information in parallel, possessing the ability to self-organize and self-learn. The downside of Neural Networks is that the sample set has a lot of impact and requires a lot of computing power [
29,
30,
31]. A large amount of redundant data are generated, leading to low training efficiency, and a large number of false positive samples can appear in the classification. Different face recognition methods have different probabilities of correct recognition, and these methods are interdependent. It depends on the parameter of the recognized object (
Table 1).
Facial recognition is considered as a biometric authentication procedure in all automatic individual authentication systems [
33,
34,
35]. Many organizations and governments rely on this method to secure public places such as airports, bus stops, train stations, etc. Most current face recognition models require highly accurate machine learning to recognize labeled face datasets [
36,
37]. The most advanced face recognition models such as Facenet [
38,
39,
40] have shown recognition accuracy of 99% or better. Comprehensive experiments conducted with the Georgia Tech Face Dataset, the head pose image dataset and the Robotics Lab Face dataset showed that the proposed approach is superior to other modern mask recognition methods. As published in other review articles, invariant methods of face recognition [
41] or illumination [
42], dynamic face recognition from an image [
43,
44,
45,
46,
47], multimodal face recognition using 3D and infrared modalities [
48,
49,
50], attack detection methods (anti-counterfeiting) [
51].
Convolutional Neural Networks (CNNs) are the most commonly used type of deep learning method for face recognition. The main advantage of the deep learning method is that you can use a large amount of data for training to get a reliable idea of the changes that occur in the training data. This method does not require the development of specific characteristics that are robust to various types of class differences (such as lighting, posture, facial expression, age, etc.) but can be extracted from the training data. The main disadvantage of deep learning methods is that they need to use very large datasets to train, and these datasets must contain enough changes to be able to generalize to patterns that have never been seen before. Some large-scale face datasets containing images of natural faces have been made public and can be used to train CNN models. In addition to learning recognition features, neural networks can also reduce dimensionality and can be trained with classifiers or use metric learning methods. CNN is considered an end-to-end learning system and does not need to be combined with any other specific methods [
52,
53,
54].
A pattern recognition computer system basically consists of three interrelated but clearly differentiated processes; namely, data generation, pattern analysis and pattern classification. Data generation consists of converting the input template’s original information into a vector and giving it a form that is easy for a computer to process. Pattern analysis is the processing of data, including feature selection, feature extraction, data compression by size, and determination of possible categories. Image classification is the use of information obtained from image analysis to teach a computer to formulate recognition criteria in order to classify recognition images.
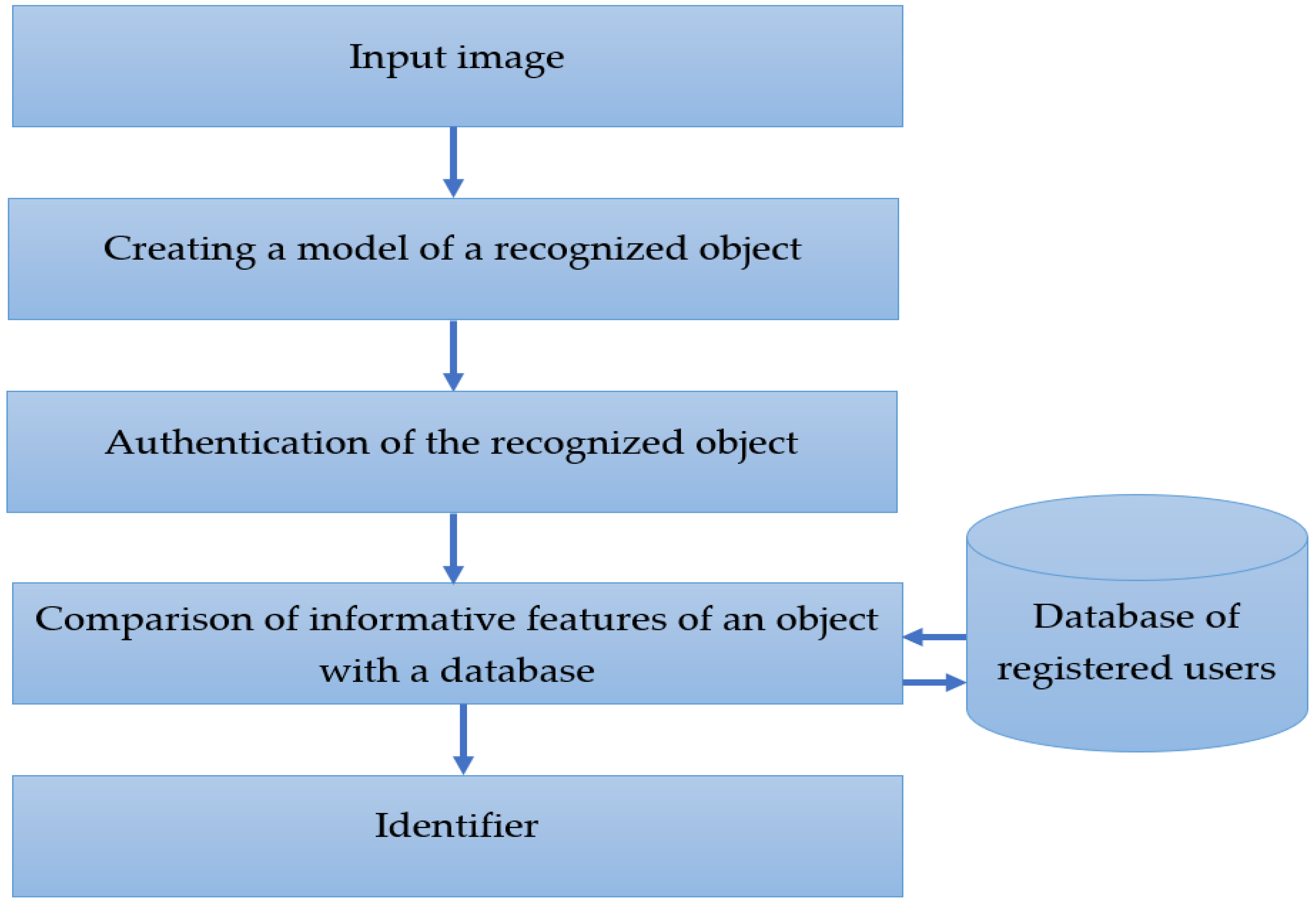
Face recognition system includes the following blocks (
Figure 1):
- -
a block for constructing an object recognition model (search for the coordinates of a person’s surface in a figure, determining the information zonal location, preprocessing and normalization;
- -
object recognition authentication block (authentication algorithms for an object to be identified by controlling access to the photo recognition system of a user registered in the database);
- -
a block for calculating information identification marks (convolutional neural networks, correlation indicators, Minkowski distance, etc.).
The mathematical model of face recognition is presented below. Let us define a set of face images in the database
The sets are divided into
L classes, where each class corresponds to a registered person [
55,
56,
57,
58]. For each image, we define a vector of
K values:
where
is the transpose operator. For each image (
1), we define the distance function. Distance functions
for the feature vector at the greatest distance
in the input form belongs to the class
,
For the distance function (
2), the class
must exceed a pre-computed threshold value
. The input to the face recognition algorithm is an image, and the output is a sequence of face frame coordinates (0 face frames or 1 face frame or multiple face frames). Typically, the output frame of face coordinates is an upward-facing square, but there are also some face detection technologies that output an upward-facing rectangle or a rectangle with a rotation direction. The conventional face detection algorithm is basically a “scanning” and “distinguishing” process, that is, the algorithm scans a range of images and then determines in turn whether a candidate area is a face. Therefore, the calculation speed of the face detection algorithm is related to the image size and image content. The input to the face registration algorithm is a “face image” plus a “frame of face coordinates”, and the output is a sequence of coordinates of the key points of the facial features. The number of facial feature keypoints is a predetermined fixed value that can be defined according to different semantics (typically 5 points, 68 points, 90 points, etc.).
Using a mathematical model to determine the integral image, you can find the coordinates of the face (Viola and Jones algorithm):
where
—the value of the
i-th element of the integral image with coordinates is the
—brightness of the pixel of the image under consideration with coordinates
. The integral image (
3) is calculated regardless of the size or location of the image and is used to quickly calculate the brightness of given parts of the image. Sign
—the sum of the brightness of the pixels lying in the white areas is subtracted from the sum of the intensities of the pixels lying in the black areas:
where
is the sum of the brightness of the pixels.
The Adaboost Method, directly determining the error rate of a simple classifier, avoids time-consuming processes such as iterative learning and statistical probability distribution. The closer (
4) is to 0, the lower the brightness; the closer the value is to 255, the higher the brightness. There are n training samples
where
corresponds to negative and positive sample samples. In the training set c, there are m samples of negative cases and l samples of positive cases. At the same time, there is a set of weights
corresponding to each sample.
The expression for this classifier with a threshold value
is:
The “best” strong classifier is calculated from a fixed number of weak classifiers. The expression for a strong classifier is shown:
where
is weak classifier;
are the weight coefficients of the weak classifier;
c is the number of the current weak classifier,
is the number of weak classifiers. An iterative algorithm that implements a “strong” classifier (
6) and (
7), which makes it possible to achieve classifiers based on “weak” (
5) compositions for learning arbitrary smaller errors. Images of the object before and after illumination can be described as follows:
where
j is the number of the current value of the sequence
—the brightness value of the pixel of the array
, corresponding to the image of the user’s face;
b is the identifier of the pixel array, indicating the backlight mode in which the array was prepared;
,
x and
y are the coordinates of the pixel in question;
W and
H are the number of pixels corresponding to the width and height array
.
The measure of dispersion of all values (
8) should be estimated. To describe the dispersion of the values of the numerical characteristic of the sample (
9), the total characteristic of the sample variance and the mathematical expectation (
10) for the mean value are introduced
. To assess the degree of dispersion relative to the average value (mathematical expectation), the dispersion is calculated:
where
is the mean value or mathematical expectation of a discrete random variable
which is calculated by the formula:
The above presentation of the identified problems can be found in many publications devoted to user identification by face images and modeling of information systems [
59,
60].
3. Results
The technology for recognizing users of proctoring systems uses the methods of searching for the coordinates of a face in an image, identifying an object from a face image, an algorithm for tracking a recognized object, and detecting a substitution of a recognized object for a photo, video recording or photo mask of a registered user’s face.
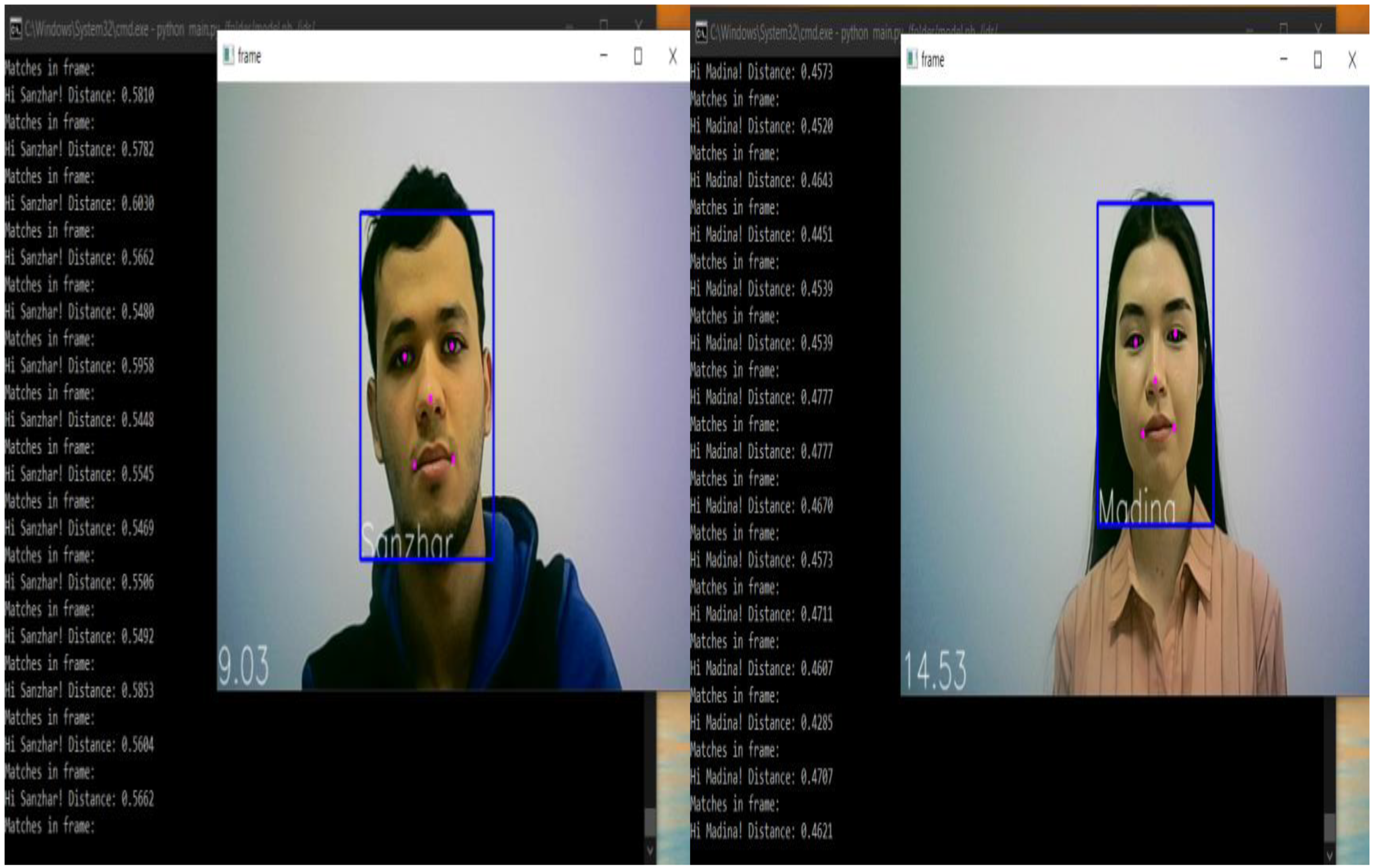
The advantages of OpenCV include: free open source library, fast and supported by most operating systems such as Windows, Linux and macOS. We have implemented face recognition using OpenCV and Python. To start, we used the OpenCV, dlib, face_recognition libraries and installed these libraries (
Table 2).
The following code algorithms (self, id_folder, mtcnn, sess, embeddings, images_placeholder, phase_train_placeholder, distance_treshold) check for folders with object names and determine how many images are found or defined in the folders content (Algorithm 1).
| Algorithm 1 Checking the presence of folders with object names |
- 1:
def_init_( ): - 2:
print(“Loading known identities: “, end = “”) - 3:
self.distance_treshold = distance_treshold - 4:
self.id_folder = id_folder - 5:
self.mtcnn = mtcnn - 6:
self.id_names = [] - 7:
self.embeddings = None - 8:
image_paths = [] - 9:
os.makedirs(id_folder, exist_ok = True) - 10:
ids = os.listdir(os.path.expanduser(id_folder)) - 11:
if not ids: - 12:
return - 13:
for id_name in ids: - 14:
id_dir = os.path.join(id_folder, id_name) - 15:
image_paths = image_paths + [os.path.join(id_dir, img) for img in os.listdir(id_dir)] - 16:
print(“Found %d images in id folder” % len(image_paths)) - 17:
aligned_images, id_image_paths = self.detect_id_faces(image_paths) - 18:
feed_dict = images_placeholder: aligned_images, phase_train_placeholder: False - 19:
self.embeddings = sess.run(embeddings, feed_dict = feed_dict)
|
These lines (Algorithm 2) show the distance between the object and the camera (Algorithm 2).
| Algorithm 2 Determining the distance between the object and the camera |
- 1:
def print_distance_table(self, id_image_paths): - 2:
“”“Prints distances between id embeddings”“” - 3:
distance_matrix = pairwise_distances(self.embeddings, self.embeddings) - 4:
image_names = [path.split(“/”)[-1] for path in id_image_paths] - 5:
print(“Distance matrix::20”.format(“”), end = “”) - 6:
[print(“:20”.format(name), end = “”) for name in image_names] - 7:
for path, distance_row in zip(image_names, distance_matrix): - 8:
print(“:20”.format(path), end = “”) - 9:
for distance in distance_row: - 10:
print(“:20”.format(“%0.3f” % distance), end = “”) - 11:
print()
|
These lines (Algorithm 3) load the neural network model that is used as the face recognition algorithm (Algorithm 3).
| Algorithm 3 Neural network model for face recognition |
- 1:
def load_model(model): - 2:
model_exp = os.path.expanduser(model) - 3:
if os.path.isfile(model_exp): - 4:
print(“Loading model filename: %s” % model_exp) - 5:
with gfile.FastGFile(model_exp, “rb”) as f: - 6:
graph_def = tf.GraphDef() - 7:
graph_def.ParseFromString(f.read()) - 8:
graph_def.ParseFromString(f.read()) - 9:
tf.import_graph_def(graph_def, name = “”) - 10:
else: - 11:
raise ValueError(“Specify model file, not directory!”)
|
These lines (Algorithm 4) allow the unknown object to be created as a new object and stored for further identification (Algorithm 4).
| Algorithm 4 Creating a new object |
- 1:
elif key = ord(“s”) and frame_detections is not None: - 2:
for emb, bb in zip(frame_detections[“embs”], frame_detections[“bbs”]): - 3:
patch = frame_detections[“frame”][bb[1] : bb[3], bb[0] : bb[2], :] - 4:
cv2.imshow(“frame”, patch) - 5:
cv2.waitKey(1) - 6:
new_id = easygui.enterbox(“Who’s in the image? Leave empty for non-valid”) - 7:
if len(new_id) > 0: - 8:
id_data.add_id(emb, new_id, patch) - 9:
cap.release() - 10:
cv2.destroyAllWindows()
|
These lines (Algorithm 5) identify the object if it was previously saved and its id, i.e., the name of the object (Algorithm 5).
| Algorithm 5 Object identification |
- 1:
def detect_id_faces(self, image_paths): - 2:
aligned_images = [] - 3:
id_image_paths = [] - 4:
for image_path in image_paths: - 5:
image = cv2.imread(os.path.expanduser(image_path), cv2.IMREAD_COLOR) - 6:
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB) - 7:
face_patches, _, _ = detect_and_align.detect_faces(image, self.mtcnn) - 8:
if len(face_patches) > 1: - 9:
print(“Warning: Found multiple faces in id image: %s” % image_path - 10:
+ “nMake sure to only have one face in the id images”. - 11:
+ “If that is the case then it’s a false positive detection and” - 12:
+ “you can solve it by increasing the thresholds of the cascade network”) - 13:
aligned_images = aligned_images + face_patches - 14:
id_image_paths += [image_path] * len(face_patches) - 15:
path = os.path.dirname(image_path) - 16:
self.id_names += [os.path.basename(path)] * len(face_patches) - 17:
return np.stack(aligned_images), id_image_paths
|
We determined the presence of folders using self, id_folder, mtcnn, sess, embeddings, images_placeholder, phase_train_placeholder, distance_treshold algorithms. We determined the distance between the object and the camera, and also identified the object using Algorithm 5.
We asked some students to look up and down to take 170 pictures. We also looked at five different facial expressions of students during a photo shoot in a video stream, eight tyies of accessories (five glasses and three caps) and ten lighting directions. In Front image (FI), the students looked directly at the camera. The database included images of students looking up, down, horizontally, and the direction of head rotation in these images was within
degrees (
Figure 7). The detection results are shown in
Table 3.
Table 3 shows that the system successfully identified 7898 facial features; out of 7898 images (only one person in each picture) there were only 74 false ones. Analyzing certain cases of errors, we can conclude that the accuracy decreases primarily due to images with noise and poor lighting quality.
The highest hit percentage is in the Front image (FI) dataset, as all faces are frontal. In Image looking down (ILD), Image looking up (ILU) and Image horizontally (IH), there are facial expressions, accessories and different lighting options. It is these changes that lead to more false alarms and fewer hits in the Front image (FI) dataset. It can be concluded that finding images that look down is somewhat more difficult for the system than images that look up.
The main idea is to take into account the statistical relationships between the location of the anthropometric points of the face. According to their relative position, faces are compared. The human eye system is mobile. The eyeballs make different movements when looking at different objects. When looking up, the apples of the eyes are open; when looking down, the apples of the eyes are half-closed or more. This affects the accuracy of face recognition in a certain way.
The accuracy of face detection depends on the variability of the training set. Most face orienting and alignment models work well when viewed from the front. Front view detection can approach 98.6% (CNN, CNN+Haar) accuracy at
. Accuracy drops more than 50% as you approach the corners (
=
and
=
). At angles above
,
, the accuracy of face detection is not determined (
Table 4). The source code created by our team still needs to be improved. The CNN + Haar method generally works better than traditional statistical methods. Detection accuracy depends on viewing angles. Increasing focal length generally improves landmark and alignment performance at the cost of less projection distortion. Based on experimental results, all methods perform best from frontal viewing angles, as expected. It is also interesting to note that the rolloff slope for performance degradation caused by shorter focal lengths (wider field of view) is smaller for CNN-based methods and the CCN + Haar, SupportVector approach. This is probably due to the fact that the CNN, SupportVector methods are based on image features, while the Haar method emphasizes local image features more specifically.
Due to the speed of image processing, ease of implementation and the minimum cost of the technical requirements for the system, we chose the Viola–Jones method and the CNN method. Using the CNN method with the Viola–Jones method allows you to choose algorithms and methods that provide high accuracy and minimize false positives when solving face recognition problems. Haar cascades in Open CV computer vision were used for face detection (cascadePath = “haarcascade_frontalface_default.xml”, faceCascade = cv2.CascadeClassifier(cascadePath). Local binary templates were used for recognition (recognizer = cv2.createLBPHFaceRecognizer(1,8,8,8,123)).
We used the ROC curve to evaluate the CNN, Haar-based, Support Vector, CNN + Haar methods. ROC analysis is a graphical method for assessing the performance of a binary classifier and selecting a discrimination threshold for class separation. The ROC curve shows the relationship between FPR false alarm probability and TPR true positive probability. With increasing sensitivity, the reliability of recognition of positive observations increases, but at the same time, the probability of false alarms increases.
The accuracy of verification on faces is calculated. The ROC results for the CNN, Haar-based, Support Vector, CNN + Haar methods are presented in
Table 5.
Figure 8 shows the results of the ROC curves for four methods trained by the described methods. It can be seen from the graph that the classifier trained according to the proposed CNN + Haar method outperforms the classifier trained in the classical way for all FPR values. At the same time, the TPR value increased by an average of 0.0078 in absolute value, or by 1.2% in relative terms. The maximum increase in TPR was 0.01 in absolute value, or 1.9%. Note that since only a sample containing singular point samples (left eye center, right eye center, nose tip, left mouth corner, right mouth corner) is used to train this classifier, the unification of background points does not affect the result. Therefore, only the classifier trained by the classical method and the classifier trained by unifying singular points participated in the comparison. The CNN algorithm can process up to 50 frames per second on the CPU (in a single thread) and more than 350 frames per second on the GPU, and thus, is one of the fastest face detection algorithms at the moment.
On average, the CNN + Haar and CNN algorithms provide an increase in TPR by 0.0190 and 0.0176, respectively, in absolute terms, or by 2.7 and 3.8% in relative terms. The maximum increase in TPR was 0.0418 and 0.0394, respectively, or 3.7 and 3.8%. Haar-based algorithms, on the contrary, showed a worse result by an average of 0.0086, or 1.1%, and a maximum of 0.0183, or 2.3%. When using new approaches to train the classifier, it is possible to achieve an improvement in the quality of segmentation by up to 4% according to the TPR metric, and a reduction in FPR classification errors by up to 10%. When comparing the ROC curves, it can be seen that the CNN + Haar classifier shows results that are noticeably superior to the results of the Support Vector classifier over the entire main operating range of FPR values. The share of correct answers of CNN algorithms is 0.9783, Support Vector is 0.9395, Haar-based is 0.7895 and CNN+Haar is 0.9895 (
Table 5).
The new method of training binary classifiers improves image quality by up to 4% by TPR (true positive bet result) and reduces segmentation errors by up to 10% by FPR (false positive) compared to the classical approach. The results of the proposed method and recommendations for its use can be formulated as follows:
- 1.
When comparing binary classifiers, training and testing should be carried out on the same training and test sets.
- 2.
The size of the test sample does not affect the test results.
- 3.
When regenerating samples, the results practically do not change.
- 4.
Test samples must be correctly composed so that the ROC curve does not contain duplicate points of the same class, as this leads to sharp jumps in TPR values.
4. Discussion
Recommendations are discussed for improving the algorithm to obtain a given accuracy. Since computer vision is a major research area, many researchers have invested a lot of energy in it, and hundreds of papers related to it are published every year. After analyzing the results of testing the algorithm, we can say that some of the errors occur due to noise in the image, which, when scaled, gives the effect of “blurring”. A more common reason is the incomplete invariance of the algorithm to the level of illumination. From the consideration of the value of the outputs of the first layer of neurons, it becomes clear that after training, a significant part of the neurons begins to respond only to illumination, clearly separating the background from the object.
The next group of errors occurs for images containing a face with a significant rotation or inclination (provided that there was no such image in the training sample for this class). To reduce the influence of noise and improve the overall accuracy at the preprocessing stage, the wavelet transform is proposed to use. To increase the stability of the algorithm to the quality of lighting, the normalization method is usually used. Its essence is to bring the statistical characteristics of the image (mathematical expectation and dispersion of pixel values) to fixed values.
Some problems of automated face recognition have not yet been fully resolved. In recent years, a number of different approaches to processing, localization and recognition of objects have been proposed, such as the principal component method, neural networks, evolutionary algorithms, the AdaBoost algorithm, the support vector machine, etc. However, these object recognition approaches lack accuracy, reliability and speed in a complex real-world environment characterized by the presence of noise in images and video sequences.
Difficulties arising in face recognition include overlapping faces, various head turns and tilts, variability of spectra, illumination intensities and angles, and facial expressions. Some of the errors occur due to the noise in the image, which, when scaled, gives the effect of “blurring”. A more common reason is the incomplete invariance of the algorithm to the level of illumination. A certain group of errors occurs for images containing a face with a significant rotation or inclination (provided that there was no such image in the training sample for this class). A certain group of errors occurs for images containing a face with a significant rotation or inclination (provided that there was no such image in the training sample for this class). The methods used to solve the problem of face and gesture recognition should provide acceptable recognition accuracy and high processing speed of video sequences. Thus, it is necessary to improve methods and algorithms for recognizing faces and gestures on static images and moving objects on video sequences in real time.
5. Conclusions
In the work provided, the main work of a neural network in Python using different face recognition algorithms is considered, the necessary approaches are implemented and an algorithm is selected. The algorithm can be widely used in the proctoring system and other automatic recognition systems. The article substantiates the rationality of using face detection technologies in order to increase the reliability of proctoring systems. The recognition system makes it possible to adjust the corresponding functions: managing the assignment of information from the camera, performing face detection in the frame, real-time shooting, where the object is located and real-time user recognition. In real life, facial recognition is widely used and has extremely wide prospects for development. While face recognition and face detection technologies are constantly evolving, the accuracy and amount of computation is constantly improving. Furthermore, the application or algorithms change frequently. The registration-based software for accessing a video stream analyzes its frames and offers the effects needed to detect a person in the video stream.
In this article, we reviewed mathematical models and face recognition algorithms. We compared existing methods such as Principal Component Analysis, Independent Component Analysis, Active Shape Model, Hidden Markov Model, Support Vector Machines and Neural Network Method. We identified the main disadvantages and advantages of these methods. We wrote a face recognition algorithm based on the CNN method and Viola–Jones and faced some problems related to photographs taken from different angles. Having examined the photographs taken at different angles, we found out that the accuracy of surface detection at angles above +750, −750 is not defined. It was found that the accuracy of face detection depends on the viewing angles.
The ROC curve was used to evaluate the CNN, Haar-based, Support Vector, CNN + Haar methods. When comparing the ROC curves, it can be seen that the CNN + Haar classifier shows results that are noticeably superior to the results of other classifiers over the entire main range of FPR values. The percentage of correct answers of the algorithms showed the following results: CNN—0.9783, Support Vector—0.9395, Haar-based—0.7895, CNN + Haar—0.9895. Human movement algorithms and eye movement algorithms can be complementary to detect some abnormalities in the testing process. In subsequent studies, we will consider algorithms for capturing human movements and eye movements or eye tracking models in video streams.
The results of the test program showed that the targeted use of the original algorithm makes it possible to effectively recognize surfaces in digital images and video streams. Human movement algorithms and eye movement algorithms can be complementary to detect some abnormalities in the testing process. In subsequent studies, we will consider algorithms for capturing human movements and eye movements or eye tracking models in video streams.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}