

Evaluation of the Effectiveness of Community Activities Restriction in Containing the Spread of COVID-19 in West Java, Indonesia Using Time-Series Clustering



Abstract
:1. Introduction
2. Overview
2.1. Coronavirus Disease 2019 (COVID-19)
2.2. Time-Series Clustering
3. Materials and Methods
3.1. Materials
3.2. Methods
3.2.1. Clustering Daily Positive Case Data Using K-Medoids with Cross-Correlation Based Distance
3.2.2. Calculating Cross-Correlation Based Distance
3.2.3. Determining the Number of Optimal Clusters with Elbow Methods
3.2.4. Clustering Daily Positive Case Data Using K-Medoids
- (a)
- Calculate the distance of each object using cross correlation-based distance with Equation (1).
- (b)
- Calculate for each object with
- (c)
- Sort from smallest to largest. Choose clusters that have the first smallest as the center (medoid).
- (d)
- Allocate non-medoid objects to the nearest medoid based on the cross correlation-based distance.
- (e)
- Calculate the total distance from the non-medoid cluster to the center.
- (f)
- Define a new medoid for each cluster which is an object that minimizes the total distance to other objects in the cluster. Update the existing medoid in each cluster by replacing it with a new medoid obtained from the existing cluster.
- (g)
- Allocate non-medoid objects to the nearest medoid based on the cross correlation-based distance.
- (h)
- Calculate the total distance from the non-medoid cluster to the center.
- (i)
- If the number of new centers differs from the total distance of the cluster centers in the first iteration, change the center (medoid). Otherwise, the iteration is stopped and the result becomes the final cluster.
3.3. Cluster Internal Validation
4. Results
- The first clustering period is 1 July 2021–30 September 2021.
- The second clustering period is 1 January 2022–31 May 2022.
4.1. Optimal Cluster Number Selection
4.2. Clusters Internal Validation
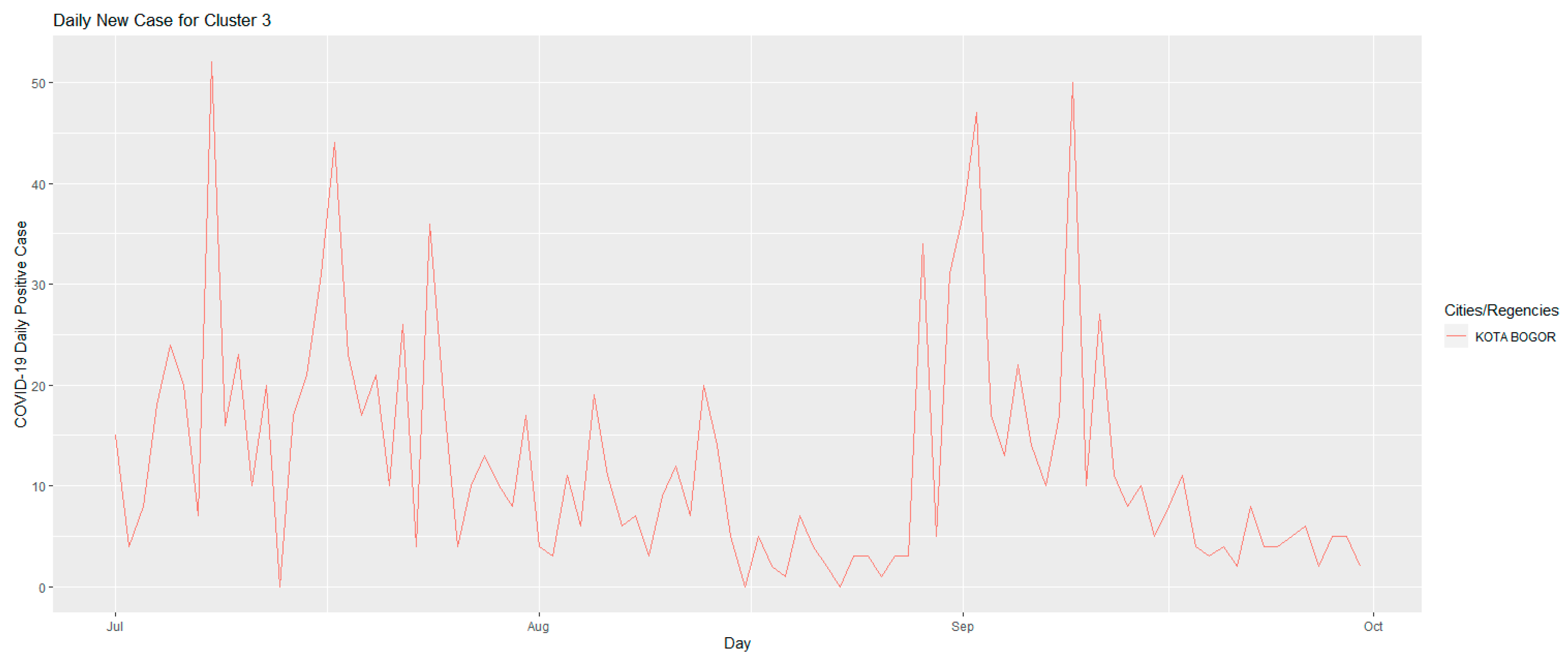
4.3. First Period (1 July 2021–30 September 2021) Clustering Results
4.4. Second Period (1 January 2022–31 May 2022) Clustering Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Nuraini, T.N. Kronologi Munculnya Covid-19 Di Indonesia Hingga Terbit Keppres Darurat Kesehatan. Available online: https://www.merdeka.com/trending/kronologi-munculnya-covid-19-di-indonesia-hingga-terbit-keppres-darurat-kesehatan-kln.html (accessed on 15 July 2022).
- COVID-19 Response Acceleration Task Force; Peta Sebaran. 2022. Available online: https://covid19.go.id/peta-sebaran (accessed on 15 July 2022).
- Worldometer; COVID-19 Cases by Country. 2022. Available online: https://www.worldometers.info/coronavirus/ (accessed on 15 July 2022).
- West Java Central Agency on Statistics (BPS). Hasil Sensus Penduduk 2020 Di Provinsi Jawa Barat; West Java Central Agency on Statistics (BPS): Bandung, Indonesia, 2020.
- Regional Government of West Java Province West Java Province COVID-19 Case Statistics Dashboard. Available online: https://dashboard.jabarprov.go.id/id/dashboard-pikobar/trace/statistik (accessed on 15 July 2022).
- Kompas Kebijakan Covid-19 Dari PSBB Hingga PPKM Empat Level. Kompaspedia 2021. Available online: https://kompaspedia.kompas.id/baca/infografik/kronologi/kebijakan-covid-19-dari-psbb-hingga-ppkm-empat-level (accessed on 15 July 2022).
- Wang, H.; Wang, W.; Yang, J.; Yu, P.S. Clustering by Pattern Similarity in Large Data Sets. Proc. ACM SIGMOD Int. Conf. Manag. Data 2002, 2, 394–405. [Google Scholar] [CrossRef]
- Das, G.; Lin, K.-I.; Mannila, H.; Renganathan, G.; Smyth, P. Rule Discovery from Time Series. KDD 1998, 1, 16–22. [Google Scholar]
- Fu, T.C.; Chung, F.L.; Ng, V.; Luk, R. Pattern Discovery from Stock Time Series Using Self-Organizing Maps. Work. Notes KDD2001 Work. Temporal Data Min. 2001, 1, 26–29. [Google Scholar]
- Keogh, E.; Lonardi, S.; Chiu, B.Y.C. Finding Surprising Patterns in a Time Series Database in Linear Time and Space. Proc. ACM SIGKDD Int. Conf. Knowl. Discov. Data Min. 2002, 550–556. [Google Scholar] [CrossRef]
- Zarikas, V.; Poulopoulos, S.G.; Gareiou, Z.; Zervas, E. Clustering Analysis of Countries Using the COVID-19 Cases Dataset. Data Br. 2020, 31, 105787. [Google Scholar] [CrossRef] [PubMed]
- Alvarez, E.; Brida, J.G.; Limas, E. Comparisons of COVID-19 Dynamics in the Different Countries of the World Using Time-Series Clustering. medRxiv 2020. [Google Scholar] [CrossRef]
- Abdullah, D.; Susilo, S.; Ahmar, A.S.; Rusli, R.; Hidayat, R. The Application of K-Means Clustering for Province Clustering in Indonesia of the Risk of the COVID-19 Pandemic Based on COVID-19 Data. Qual. Quant. 2022, 56, 1283–1291. [Google Scholar] [CrossRef] [PubMed]
- Elsi, Z.R.S.; Pratiwi, H.; Efendi, Y.; Rusdina, R.; Alfah, R.; Windarto, A.P.; Wiza, F. Utilization of Data Mining Techniques in National Food Security during the Covid-19 Pandemic in Indonesia. J. Phys. Conf. Ser. 2020, 1594, 012007. [Google Scholar] [CrossRef]
- World Health Organization. Coronavirus disease 2019 (COVID-19): Situation Report, 51. 2020. Available online: https://apps.who.int/iris/handle/10665/331475 (accessed on 14 June 2022).
- ECDC COVID-19 Situation Update for the EU/EEA and the UK. Available online: www.ecdc.europa.eu (accessed on 26 June 2022).
- CDC CDC FAQ on COVID-19. Available online: https://www.cdc.gov/coronavirus/2019ncov/faq.html#fSymptoms-&-Emergency-Warning-Signs (accessed on 14 June 2022).
- World Health Organization. Coronavirus Disease 2019 (COVID-19): Situation Report, 57. 2020. Available online: https://cdn.who.int/media/docs/default-source/searo/indonesia/covid19/external-situation-report-57_2-june-2021.pdf?sfvrsn=cb275259_5 (accessed on 14 June 2022).
- ECDC Q & A on COVID-19: Basic Facts. Available online: www.ecdc.europa.eu (accessed on 15 July 2022).
- Kaufman, L.; Rousseeuw, P.J. Finding Groups in Data: An Introduction to Cluster Analysis; John Wiley: New York, NY, USA, 1990. [Google Scholar]
- Omran, M.G.H.; Engelbrecht, A.P.; Salman, A. An Overview of Clustering Methods. Intell. Data Anal. 2007, 11, 583–605. [Google Scholar] [CrossRef]
- Shahnawaz, M.; Ranjan, A.; Danish, M. Temporal Data Mining: An Overview. Int. J. Eng. Adv. Technol. IJEAT Oct. 2011, 1, 2249–8958. [Google Scholar]
- Warren Liao, T. Clustering of Time Series Data—A Survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Lin, J.; Vlachos, M.; Keogh, E.; Gunopulos, D. Ierative Incremental Clustering of Time Series. Lect. Notes Comput. Sci. 2004, 2992, 106–122. [Google Scholar] [CrossRef]
- He, W.; Feng, G.; Wu, Q.; He, T.; Wan, S.; Chou, J. A New Method for Abrupt Dynamic Change Detection of Correlated Time Series. Int. J. Climatol. 2012, 32, 1604–1614. [Google Scholar] [CrossRef]
- Pavlidis, N.G.; Plagianakos, V.P.; Tasoulis, D.K.; Vrahatis, M.N. Financial Forecasting through Unsupervised Clustering and Neural Networks. Oper. Res. 2006, 6, 103–127. [Google Scholar] [CrossRef]
- Sfetsos, A.; Siriopoulos, C. Time Series Forecasting with a Hybrid Clustering Scheme and Pattern Recognition. IEEE Trans. Syst. Man Cybern. Part A Syst. Hum. 2004, 34, 399–405. [Google Scholar] [CrossRef]
- Mirri, S.; Delnevo, G.; Roccetti, M. Is a COVID-19 second wave possible in Emilia-Romagna (Italy)? Fore-casting a future outbreak with particulate pollution and machine learning. Computation 2020, 8, 74. [Google Scholar] [CrossRef]
- Huang, X.; Li, Z.; Lu, J.; Wang, S.; Wei, H.; Chen, B. Time-Series Clustering for Home Dwell Time during COVID-19: What Can We Learn from It? ISPRS Int. J. Geo-Inf. 2020, 9, 675. [Google Scholar] [CrossRef]
- Rojas-Valenzuela, I.; Valenzuela, O.; Delgado-Marquez, E.; Rojas, F. Estimation of COVID-19 Dynamics in the Different States of the United States during the First Months of the Pandemic. Eng. Proc. 2021, 3, 53. [Google Scholar] [CrossRef]
- Brida, J.G.; Alvarez, E.; Limas, E. Clustering of Time Series for the Analysis of the COVID-19 Pandemic Evolution. Econ. Bull. 2021, 41, 1082–1096. [Google Scholar]
- Pikobar Statistik Kasus COVID-19 Provinsi Jawa Barat. Available online: https://dashboard.jabarprov.go.id/id/dashboard-pikobar/trace/statistik (accessed on 16 June 2022).
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2021. [Google Scholar]
- Wickham, H. Ggplot2: Elegant Graphics for Data Analysis; Springer: New York, NY, USA, 2016; ISBN 978-3-319-24277-4. [Google Scholar]
- Wickham, H. Package ’Reshape’. 2015. Available online: https://cran.rproject.org/web/packages/reshape2/reshape2.pdf (accessed on 15 July 2022).
- Mori, U.; Mendiburu, A.; Lozano, J.A. Distance Measures for Time Series in r: The TSdist Package. R J. 2016, 8, 455–463. [Google Scholar] [CrossRef]
- Kassambara, A.; Mundt, F. Factoextra: Extract and Visualize the Results of Multivariate Data Analyses. 2020. Available online: https://CRAN.R-project.org/package=factoextra (accessed on 15 July 2022).
- Charrad, M.; Ghazzali, N.; Boiteau, V.; Niknafs, A. NbClust: An R Package for Determining the Relevant Number of Clusters in a Data Set. J. Stat. Softw. 2014, 61, 1–36. [Google Scholar] [CrossRef]
- Park, H.S.; Jun, C.H. A simple and fast algorithm for K-medoids clustering. Expert Syst. Appl. 2009, 36, 3336–3341. [Google Scholar] [CrossRef]
- Davis, R.A.; Matsui, M.; Mikosch, T.; Wan, P. Applications of distance correlation to time series. Bernoulli 2018, 24, 3087–3116. [Google Scholar] [CrossRef]
- Bholowalia, P.; Kumar, A. EBK-Means: A Clustering Technique Based on Elbow Method and K-Means in WSN. Int. J. Comput. Appl. 2014, 105, 975–8887. [Google Scholar]
- Thorndike, R.L. Who Belongs in the Family? Psychometrika 1953, 18, 267–276. [Google Scholar] [CrossRef]
- Kodinariya, T.M.; Makwana, P.R. Review on Determining of Cluster in K-Means. Int. J. Adv. Res. Comput. Sci. Manag. Stud. 2013, 1, 90–95. [Google Scholar]
- Brock, G.; Pihur, V.; Datta, S.; Datta, S. ClValid: An R Package for Cluster Validation. Solid State Commun. 2008, 25, 1–22. [Google Scholar] [CrossRef]
- Handl, J.; Knowles, J.; Kell, D.B. Computational Cluster Validation in Post-Genomic Data Analysis. Bioinformatics 2005, 21, 3201–3212. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A Graphical Aid to the Interpretation and Validation of Cluster Analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cluster | Periods | Cities/Districts |
|---|---|---|
| 1 | First Period | KAB. BANDUNG, KAB. BANDUNG BARAT, KAB. CIAMIS, KAB. CIANJUR, KAB. INDRAMAYU, KAB. KARAWANG, KAB. PANGANDARAN, KAB. SUBANG, KAB. SUKABUMI, KAB. TASIKMALAYA, KOTA BANDUNG, KOTA BANJAR, KOTA SUKABUMI, KOTA TASIKMALAYA |
| 2 | KAB. BEKASI, KAB. BOGOR, KAB. CIREBON, KAB. GARUT, KAB. KUNINGAN, KAB. MAJALENGKA, KAB. PURWAKARTA, KAB. SUMEDANG, KOTA BEKASI, KOTA CIMAHI, KOTA CIREBON | |
| 3 | KOTA BOGOR | |
| 4 | KOTA DEPOK | |
| 1 | Second Period | KAB. BANDUNG, KAB. BANDUNG BARAT, KAB. CIAMIS, KAB. CIANJUR, KAB. CIREBON, KAB. GARUT, KAB. INDRAMAYU, KAB. KARAWANG, KAB. KUNINGAN, KAB. MAJALENGKA, KAB. PANGANDARAN, KAB. PURWAKARTA, KAB. SUBANG, KAB. SUKABUMI, KAB. SUMEDANG, KAB. TASIKMALAYA, KOTA BANDUNG, KOTA BANJAR, KOTA CIMAHI, KOTA CIREBON, KOTA SUKABUMI, KOTA TASIKMALAYA |
| 2 | KAB. BEKASI, KAB. BOGOR, KOTA BEKASI, KOTA BOGOR, KOTA DEPOK |
| Number of Clusters | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|
| First Period | 0.2514 | 0.2605 | 0.2633 | 0.1952 | 0.1915 | 0.1720 | 0.1765 | 0.1247 | 0.1027 |
| Second Period | 0.6363 | 0.3056 | 0.3258 | 0.3339 | 0.3073 | 0.3154 | 0.3281 | 0.3016 | 0.2992 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pangestu, D.S.; Sukono; Anggriani, N. Evaluation of the Effectiveness of Community Activities Restriction in Containing the Spread of COVID-19 in West Java, Indonesia Using Time-Series Clustering. Computation 2022, 10, 153. https://doi.org/10.3390/computation10090153
Pangestu DS, Sukono, Anggriani N. Evaluation of the Effectiveness of Community Activities Restriction in Containing the Spread of COVID-19 in West Java, Indonesia Using Time-Series Clustering. Computation. 2022; 10(9):153. https://doi.org/10.3390/computation10090153
Chicago/Turabian StylePangestu, Dhika Surya, Sukono, and Nursanti Anggriani. 2022. "Evaluation of the Effectiveness of Community Activities Restriction in Containing the Spread of COVID-19 in West Java, Indonesia Using Time-Series Clustering" Computation 10, no. 9: 153. https://doi.org/10.3390/computation10090153
APA StylePangestu, D. S., Sukono, & Anggriani, N. (2022). Evaluation of the Effectiveness of Community Activities Restriction in Containing the Spread of COVID-19 in West Java, Indonesia Using Time-Series Clustering. Computation, 10(9), 153. https://doi.org/10.3390/computation10090153