

LSTM Reconstruction of Turbulent Pressure Fluctuation Signals

 ,
,  , ,
, , 
Abstract
1. Introduction
2. Data Curation
2.1. Governing Equations
2.2. Numerical Implementation
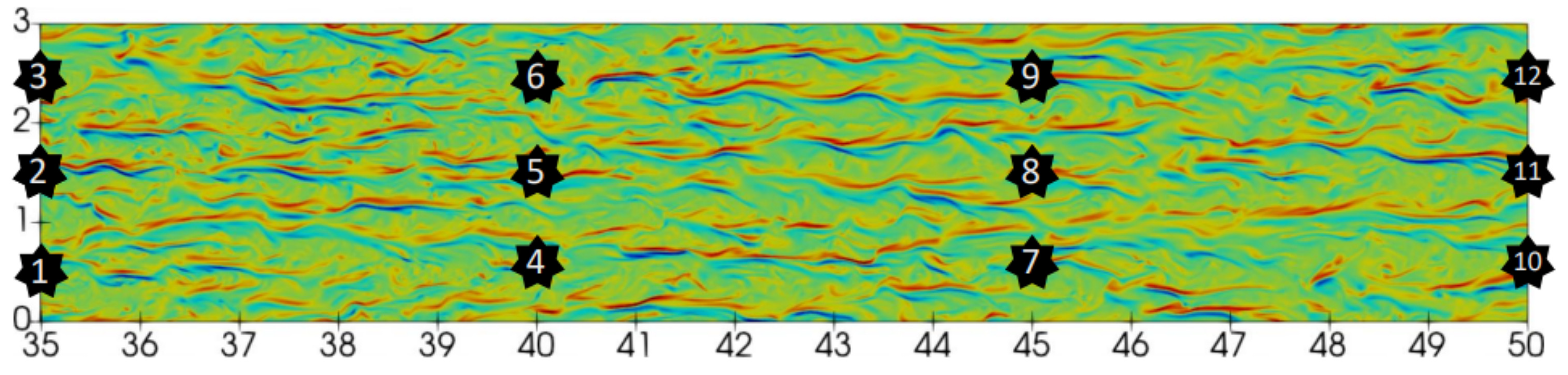
2.3. Pressure Signal Data
3. LSTM
Training and Model Hyperparameters
4. Results
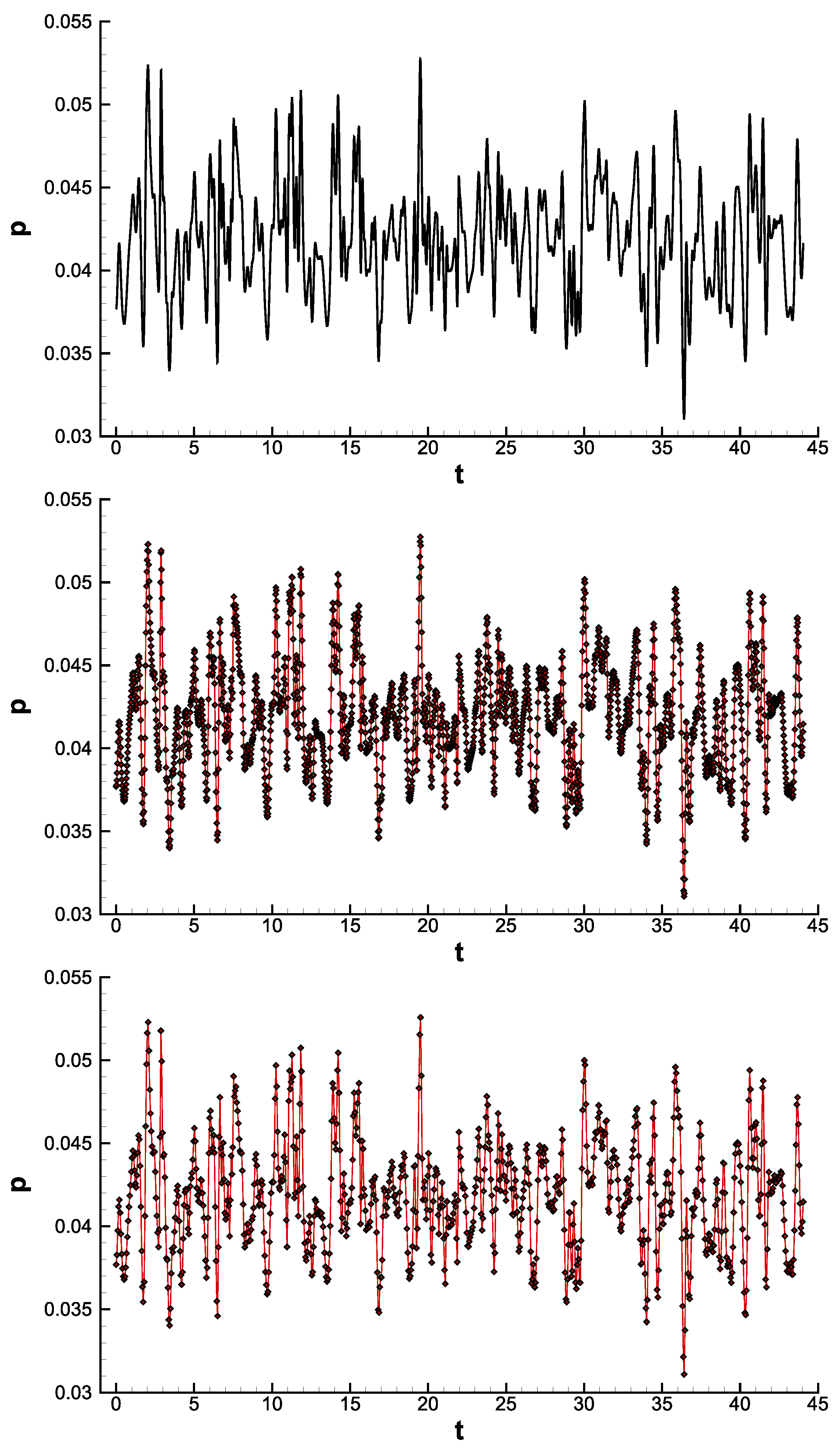
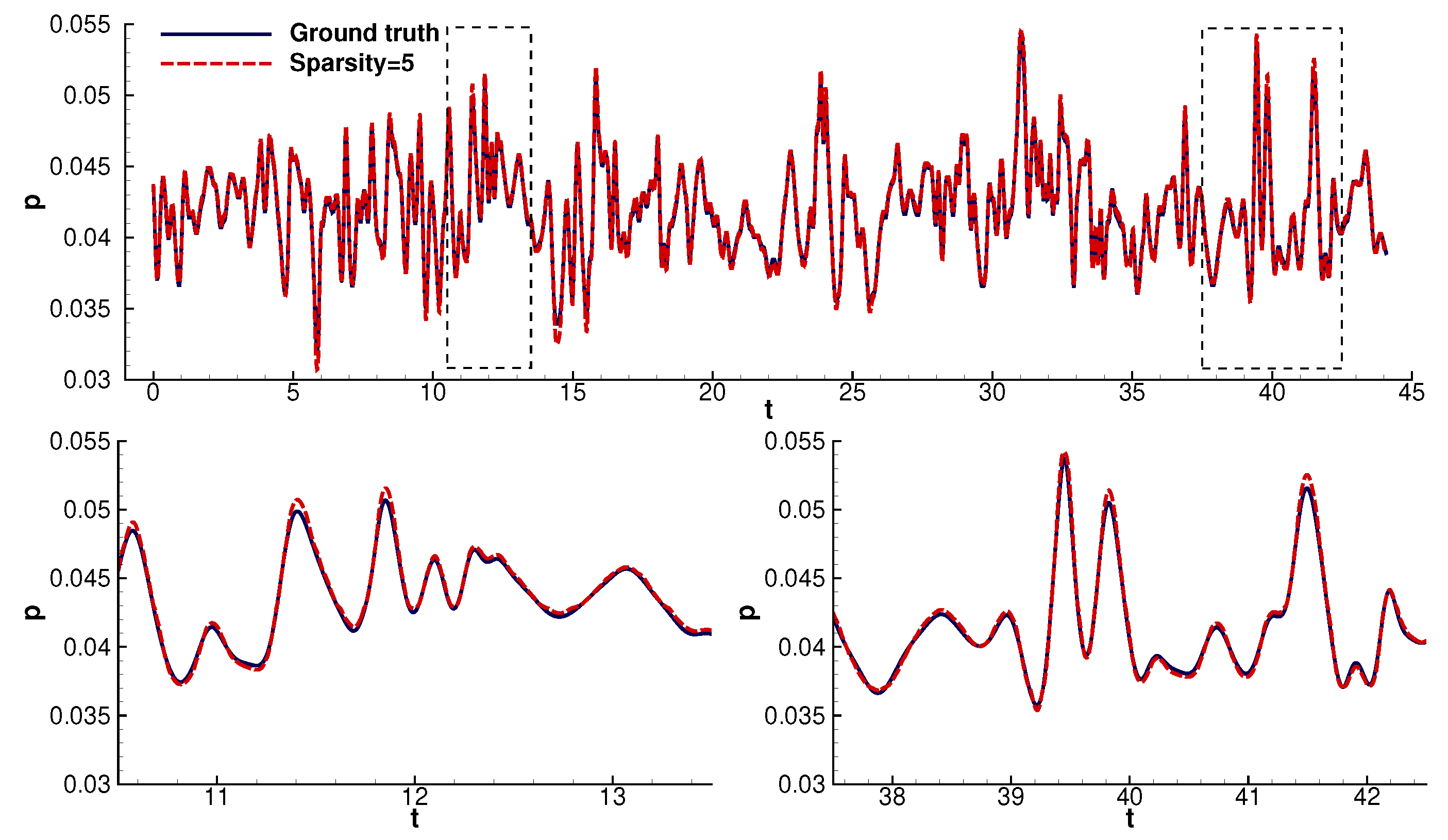
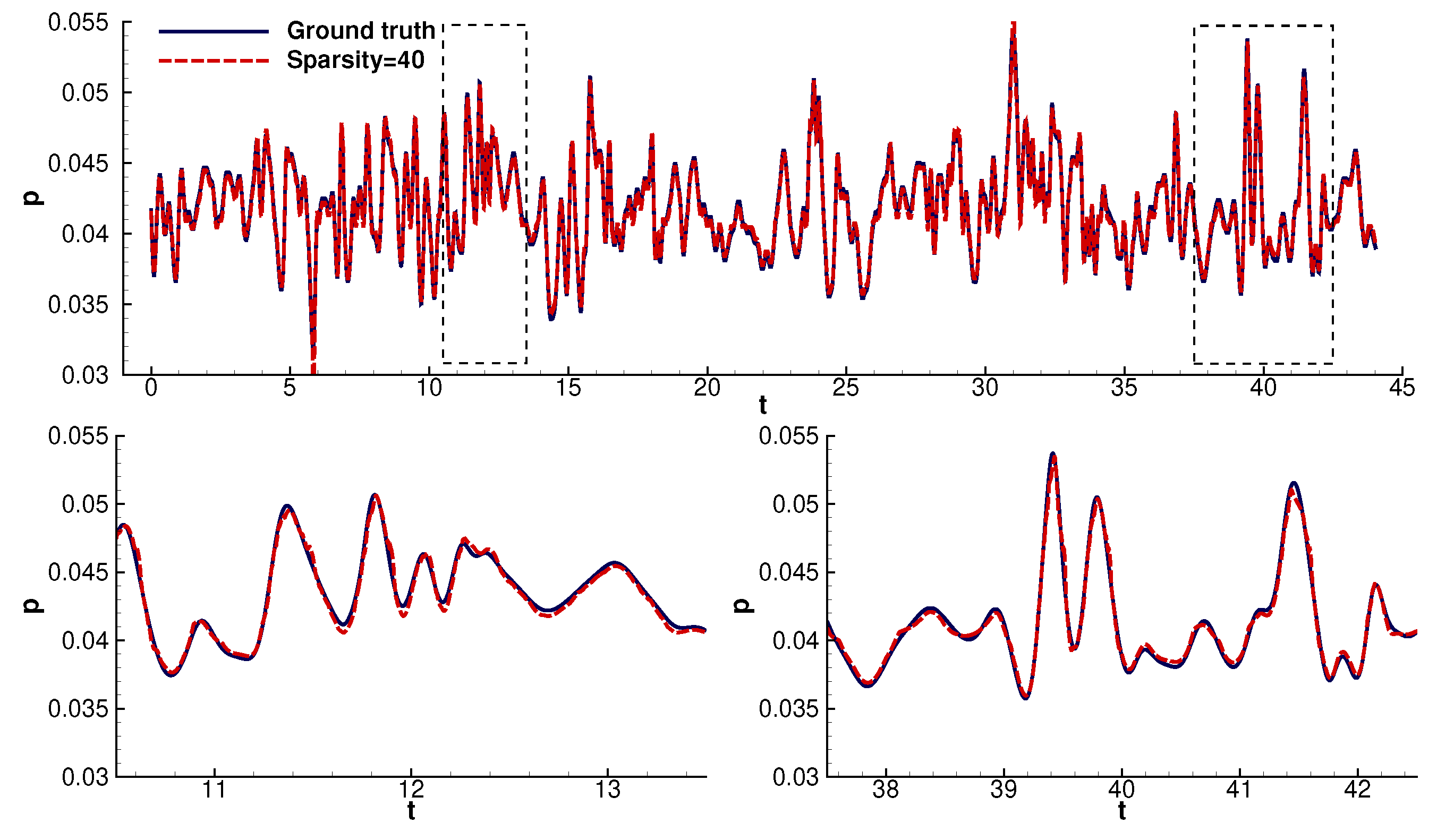
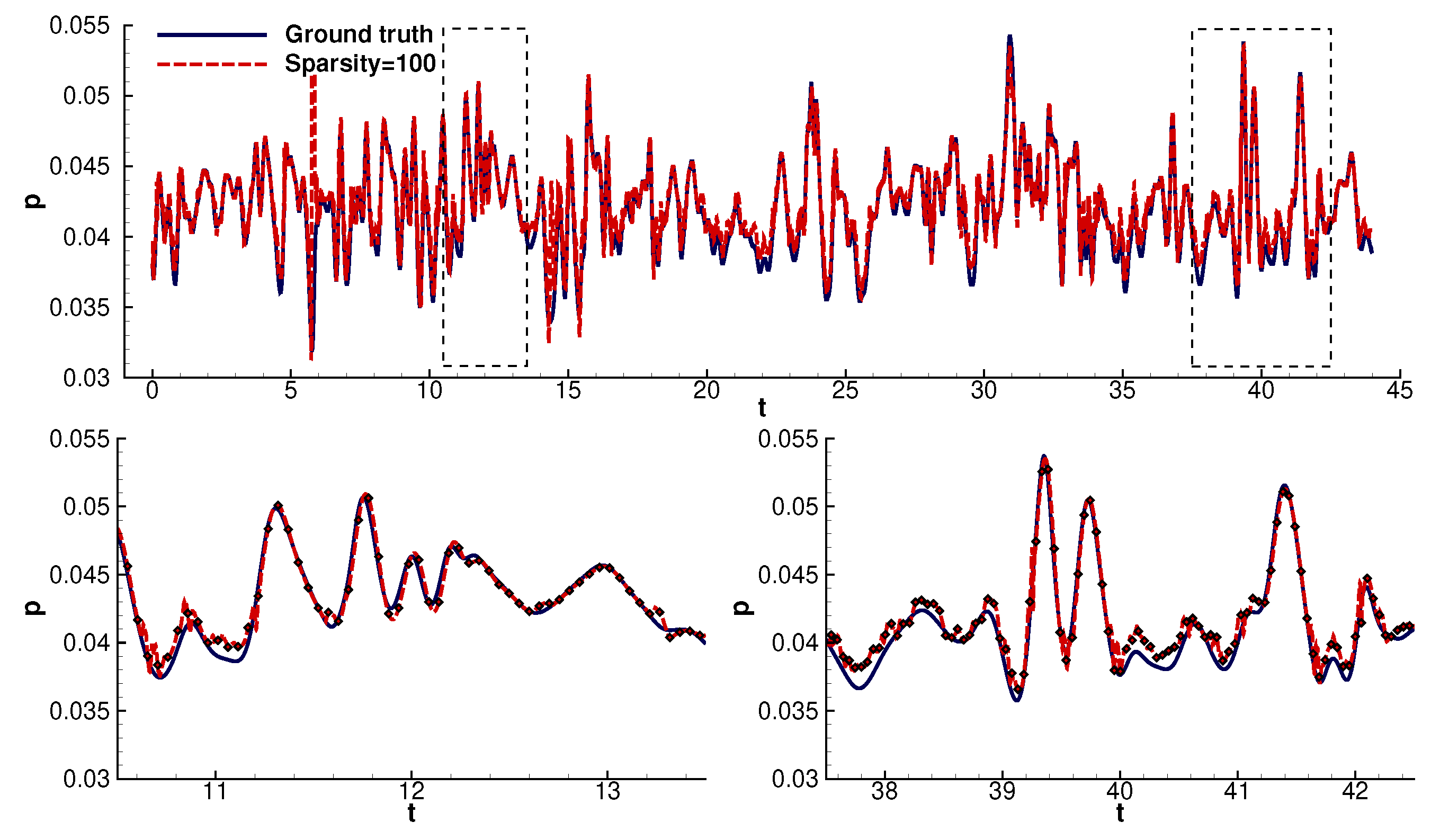
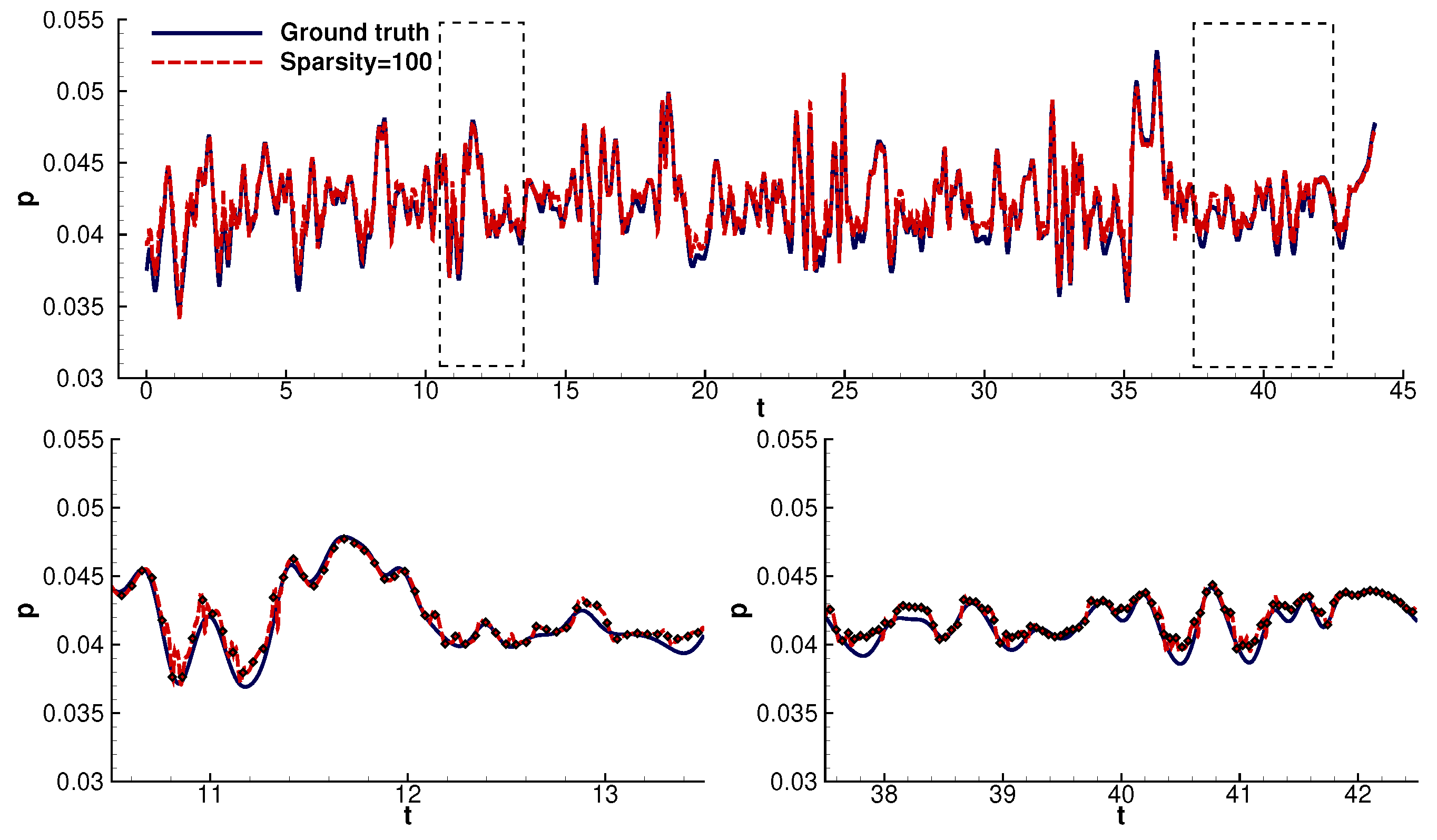
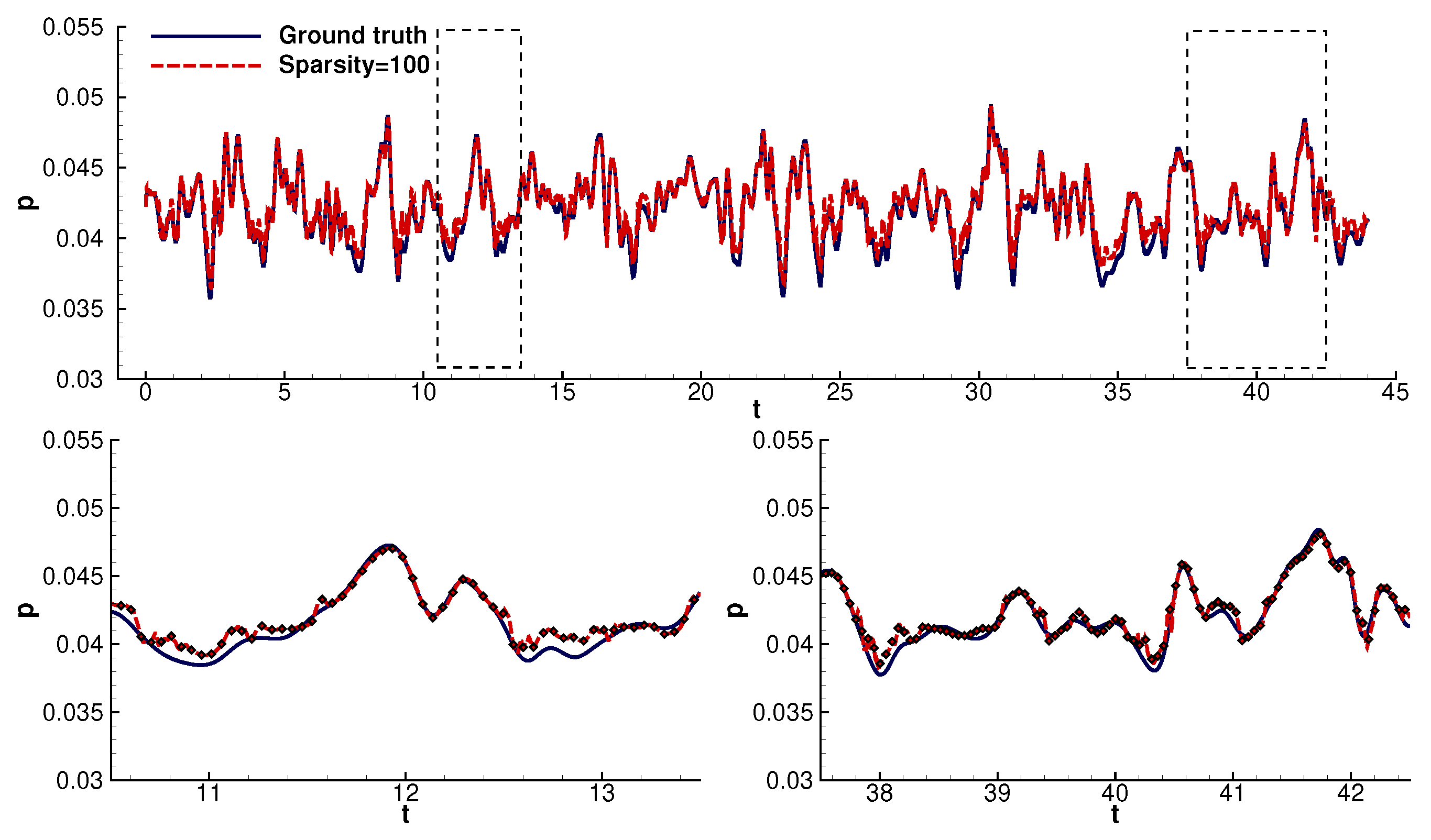
4.1. Time Domain Reconstruction
- The model, initially trained on probe 2, can be transferred to unseen signals with high accuracy.
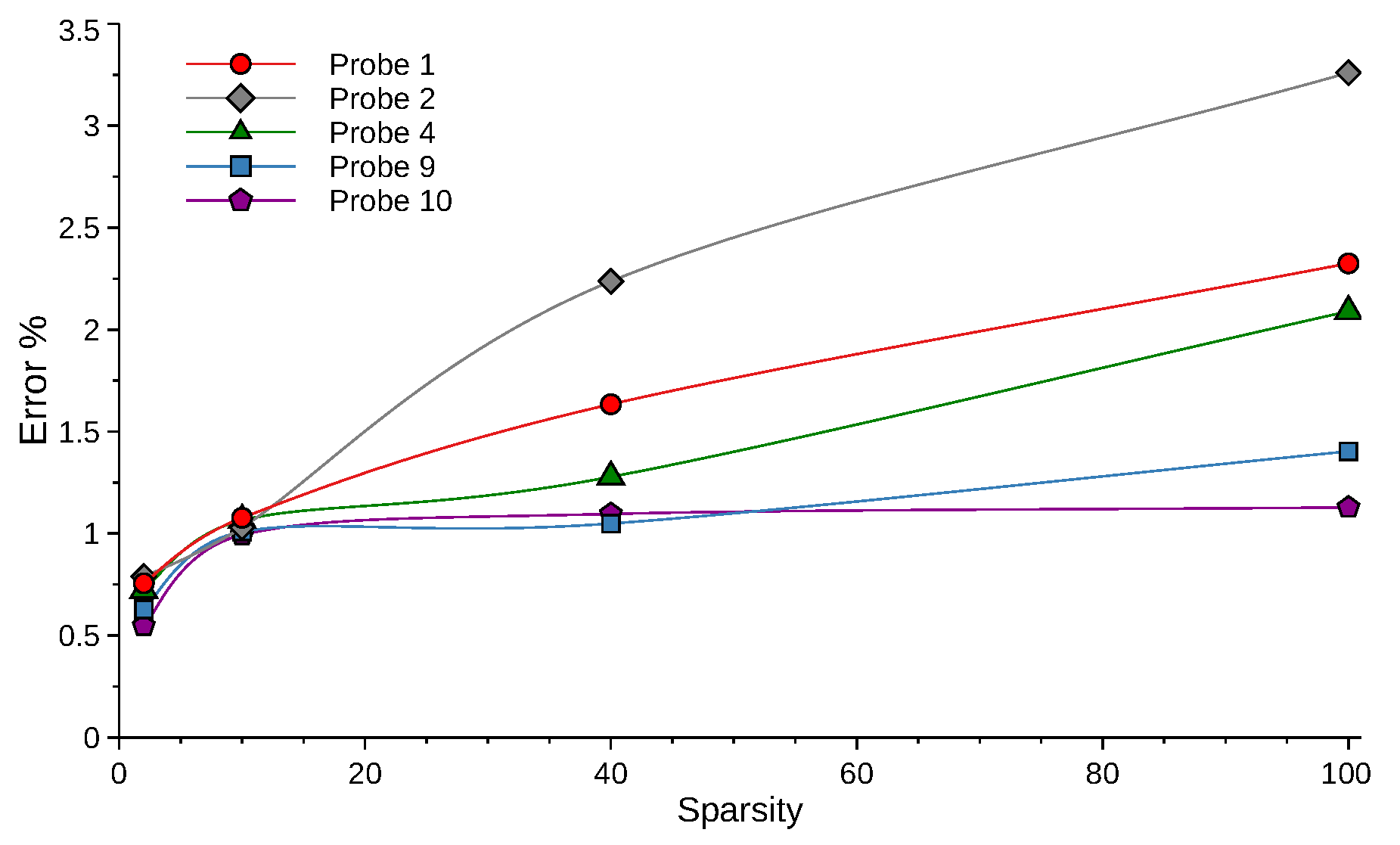
- Furthermore, the model can reconstruct the signals with less than 3% error even for an extremely high sparsity factor equal to 100. The reconstruction error remained well below 2% for sparsity factors <40 (Figure 10).
4.2. Power Spectrum Analysis
5. Conclusions
- We found through a series of numerical experiments that imputing missing intermediate values in the sampled sparse signals via cubic spline functions is effective.
- The normalized RMSE error shows that our model outperformed unseen signals compared with the training signal. This suggests that the model learned to follow a general behavior across all signals, avoiding overfitting.
- The normalized RMSE of reconstruction increased linearly up to a sparsity factor of 20. Then, the error’s rate of reduced, but the error variance between different probes increased.
- The reconstruction model could infer most values with high accuracy. The model lost accuracy in the areas of steep gradients. The model’s departure from the ground truth increased with increasing sparsity. Despite the above, the model could still follow the signal’s trend. In particular, even at high sparsities, the model consistently followed the linear parts of the signals.
- LSTM could predict the lower frequencies of the spectrum with high accuracy, including the cases of high sparsity. The accuracy of the model was restricted in those frequencies.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Frank, M.; Drikakis, D.; Charissis, V. Machine-Learning Methods for Computational Science and Engineering. Computation 2020, 8, 15. [Google Scholar] [CrossRef]
- Agliari, E.; Barra, A.; Barra, O.A.; Fachechi, A.; Franceschi Vento, L.; Moretti, L. Detecting cardiac pathologies via machine learning on heart-rate variability time series and related markers. Sci. Rep. 2020, 10, 8845. [Google Scholar] [CrossRef] [PubMed]
- Graves, A. Generating Sequences with Recurrent Neural Networks. arXiv 2014, arXiv:1308.0850. [Google Scholar] [CrossRef]
- Yadav, A.; Jha, C.K.; Sharan, A. Optimizing LSTM for time series prediction in Indian stock market. Procedia Comput. Sci. 2020, 167, 2091–2100. [Google Scholar] [CrossRef]
- Althelaya, K.A.; El-Alfy, E.S.M.; Mohammed, S. Evaluation of bidirectional LSTM for short-and long-term stock market prediction. In Proceedings of the 2018 9th International Conference on Information and Communication Systems (ICICS), Irbid, Jordan, 3–5 April 2018; pp. 151–156. [Google Scholar] [CrossRef]
- Muduli, P.R.; Gunukula, R.R.; Mukherjee, A. A deep learning approach to fetal-ECG signal reconstruction. In Proceedings of the 2016 Twenty Second National Conference on Communication (NCC), New Delhi, India, 4–6 March 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Yamamoto, K.; Hiromatsu, R.; Ohtsuki, T. ECG Signal Reconstruction via Doppler Sensor by Hybrid Deep Learning Model with CNN and LSTM. IEEE Access 2020, 8, 130551–130560. [Google Scholar] [CrossRef]
- Tong, W.; Li, L.; Zhou, X.; Hamilton, A.; Zhang, K. Deep learning PM2.5 concentrations with bidirectional LSTM RNN. Air Qual. Atmos. Health 2019, 12, 411–423. [Google Scholar] [CrossRef]
- Nakamura, T.; Fukami, K.; Hasegawa, K.; Nabae, Y.; Fukagata, K. Convolutional neural network and long short-term memory based reduced order surrogate for minimal turbulent channel flow. Phys. Fluids 2021, 33, 25116. [Google Scholar] [CrossRef]
- Fukami, K.; Fukagata, K.; Taira, K. Machine-learning-based spatio-temporal super resolution reconstruction of turbulent flows. J. Fluid Mech. 2021, 909, A9. [Google Scholar] [CrossRef]
- Liu, B.; Tang, J.; Huang, H.; Lu, X.Y. Deep learning methods for super-resolution reconstruction of turbulent flows. Phys. Fluids 2020, 32, 25105. [Google Scholar] [CrossRef]
- Chen, H.; Guo, M.; Tian, Y.; Le, J.; Zhang, H.; Zhong, F. Intelligent reconstruction of the flow field in a supersonic combustor based on deep learning. Phys. Fluids 2022, 34, 35128. [Google Scholar] [CrossRef]
- Fukami, K.; Fukagata, K.; Taira, K. Super-resolution reconstruction of turbulent flows with machine learning. J. Fluid Mech. 2019, 870, 106–120. [Google Scholar] [CrossRef]
- Spottswood, S.M.; Beberniss, T.J.; Eason, T.G.; Perez, R.A.; Donbar, J.M.; Ehrhardt, D.A.; Riley, Z.B. Exploring the response of a thin, flexible panel to shock-turbulent boundary-layer interactions. J. Sound Vib. 2019, 443, 74–89. [Google Scholar] [CrossRef]
- Brouwer, K.R.; Perez, R.A.; Beberniss, T.J.; Spottswood, S.M.; Ehrhardt, D.A. Experiments on a Thin Panel Excited by Turbulent Flow and Shock/Boundary-Layer Interactions. AIAA J. 2021, 59, 2737–2752. [Google Scholar] [CrossRef]
- Ritos, K.; Kokkinakis, I.W.; Drikakis, D. Physical insight into the accuracy of finely-resolved iLES in turbulent boundary layers. Comput. Fluids 2018, 169, 309–316. [Google Scholar] [CrossRef]
- Poulinakis, K.; Drikakis, D.; Kokkinakis, I.W.; Spottswood, S.M. Machine-Learning Methods on Noisy and Sparse Data. Mathematics 2023, 11, 236. [Google Scholar] [CrossRef]
- Poulinakis, K.; Drikakis, D.; Kokkinakis, I.W.; Spottswood, S.M. Deep learning reconstruction of pressure fluctuations in supersonic shock–boundary layer interaction. Phys. Fluids 2023, 35, 76117. [Google Scholar] [CrossRef]
- Song, W.; Gao, C.; Zhao, Y.; Zhao, Y. A Time Series Data Filling Method Based on LSTM—Taking the Stem Moisture as an Example. Sensors 2020, 20, 5045. [Google Scholar] [CrossRef]
- Mondal, D.; Percival, D. Wavelet variance analysis for gappy time series. Ann. Inst. Stat. Math. 2008, 62, 943–966. [Google Scholar] [CrossRef]
- Karaca, Y.; Zhang, Y.; Muhammad, K. A Novel Framework of Rescaled Range Fractal Analysis and Entropy-Based Indicators: Forecasting Modelling for Stock Market Indices. Expert Syst. Appl. 2019, 144, 113098. [Google Scholar] [CrossRef]
- Manousopoulos, P.; Drakopoulos, V.; Theoharis, T. Curve fitting by fractal interpolation. Trans. Comput. Sci. I 2008, 4750, 85–103. [Google Scholar]
- Raubitzek, S.; Neubauer, T. A fractal interpolation approach to improve neural network predictions for difficult time series data. Expert Syst. Appl. 2021, 169, 114474. [Google Scholar] [CrossRef]
- Ritos, K.; Drikakis, D.; Kokkinakis, I. Acoustic loading beneath hypersonic transitional and turbulent boundary layers. J. Sound Vib. 2019, 441, 50–62. [Google Scholar] [CrossRef]
- Drikakis, D.; Ritos, K.; Spottswood, S.M.; Riley, Z.B. Flow transition to turbulence and induced acoustics at Mach 6. Phys. Fluids 2021, 33, 76112. [Google Scholar] [CrossRef]
- Drikakis, D.; Hahn, M.; Mosedale, A.; Thornber, B. Large eddy simulation using high-resolution and high-order methods. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2009, 367, 2985–2997. [Google Scholar] [CrossRef] [PubMed]
- Kokkinakis, I.; Drikakis, D. Implicit Large Eddy Simulation of weakly-compressible turbulent channel flow. Comput. Methods Appl. Mech. Eng. 2015, 287, 229–261. [Google Scholar] [CrossRef]
- Kokkinakis, I.W.; Drikakis, D.; Ritos, K.; Spottswood, S.M. Direct numerical simulation of supersonic flow and acoustics over a compression ramp. Phys. Fluids 2020, 32, 66107. [Google Scholar] [CrossRef]
- Balsara, D.S.; Shu, C.W. Monotonicity Preserving Weighted Essentially Non-oscillatory Schemes with Increasingly High Order of Accuracy. J. Comput. Phys. 2000, 160, 405–452. [Google Scholar] [CrossRef]
- Toro, E.F.; Spruce, M.; Speares, W. Restoration of the contact surface in the HLL-Riemann solver. Shock Waves 1994, 4, 25–34. [Google Scholar] [CrossRef]
- Toro, E.F. Riemann Solvers and Numerical Methods for Fluid Dynamics, A Practical Introduction, 3rd ed.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Spiteri, R.; Ruuth, S. A New Class of Optimal High-Order Strong-Stability-Preserving Time Discretization Methods. SIAM J. Numer. Anal. 2002, 40, 469–491. [Google Scholar] [CrossRef]
- Yu, Y.; Si, X.; Hu, C.; Zhang, J. A review of recurrent neural networks: LSTM cells and network architectures. Neural Comput. 2019, 31, 1235–1270. [Google Scholar] [CrossRef]
- Ullah, M.; Ullah, H.; Khan, S.D.; Cheikh, F.A. Stacked LSTM network for human activity recognition using smartphone data. In Proceedings of the 2019 8th European Workshop on Visual Information Processing (EUVIP), Roma, Italy, 28–31 October 2019; pp. 175–180. [Google Scholar]
- Ghanbari, R.; Borna, K. Multivariate time-series prediction using LSTM neural networks. In Proceedings of the 2021 26th International Computer Conference, Computer Society of Iran (CSICC), Tehran, Iran, 3–4 March 2021; pp. 1–5. [Google Scholar]
- Deng, Z.; Chen, Y.; Liu, Y.; Kim, K.C. Time-resolved turbulent velocity field reconstruction using a long short-term memory (LSTM)-based artificial intelligence framework. Phys. Fluids 2019, 31, 75108. [Google Scholar] [CrossRef]
- Li, Y.; Chang, J.; Wang, Z.; Kong, C. An efficient deep learning framework to reconstruct the flow field sequences of the supersonic cascade channel. Phys. Fluids 2021, 33, 56106. [Google Scholar] [CrossRef]
- Lin, W.C.; Tsai, C.F. Missing value imputation: A review and analysis of the literature (2006–2017). Artif. Intell. Rev. 2020, 53, 1487–1509. [Google Scholar] [CrossRef]
- Beylkin, G. On the Fast Fourier Transform of Functions with Singularities. Appl. Comput. Harmon. Anal. 1995, 2, 363–381. [Google Scholar] [CrossRef]
- Carbone, M.; Bragg, A.D.; Iovieno, M. Multiscale fluid–particle thermal interaction in isotropic turbulence. J. Fluid Mech. 2019, 881, 679–721. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kandel, I.; Castelli, M. The effect of batch size on the generalizability of the convolutional neural networks on a histopathology dataset. ICT Express 2020, 6, 312–315. [Google Scholar] [CrossRef]
- Masters, D.; Luschi, C. Revisiting Small Batch Training for Deep Neural Networks. arXiv 2018, arXiv:1804.07612. [Google Scholar]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 7–19 June 2013; Volume 28. [Google Scholar]
- Ffowcs-Williams, J.E. Surface pressure fluctuations induced by boundary layer flow at finite Mach number. J. Fluid Mech. 1965, 22, 507–519. [Google Scholar] [CrossRef]
- Beresh, S.J.; Henfling, J.F.; Spillers, R.W.; Pruett, B.O.M. Fluctuating wall pressures measured beneath a supersonic turbulent boundary layer. Phys. Fluids 2011, 23, 75110. [Google Scholar] [CrossRef]
- Bernardini, M.; Pirozzoli, S.; Grasso, F. The wall pressure signature of transonic shock/boundary layer interaction. J. Fluid Mech. 2011, 671, 288–312. [Google Scholar] [CrossRef]
- Duan, L.; Choudhari, M.M.; Zhang, C. Pressure fluctuations induced by a hypersonic turbulent boundary layer. J. Fluid Mech. 2016, 804, 578–607. [Google Scholar] [CrossRef]
- Zhang, C.; Duan, L.; Choudhari, M.M. Effect of wall cooling on boundary-layer-induced pressure fluctuations at Mach 6. J. Fluid Mech. 2017, 822, 5–30. [Google Scholar] [CrossRef]
- Phillips, O.M. On the aerodynamic surface sound from a plane turbulent boundary layer. Proc. R. Soc. A 1956, 234, 327–335. [Google Scholar] [CrossRef]
- Bull, M.K. Wall-pressure fluctuations beneath turbulent boundary layers: Some reflections on forty years of research. J. Sound Vib. 1996, 190, 299–315. [Google Scholar] [CrossRef]
- Kraichnan, R.H. Pressure Fluctuations in Turbulent Flow over a Flat Plate. J. Acoust. Soc. Am. 2005, 28, 378–390. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (mm) | (m/s) | (K) | (kPa) | (kg/m3) | (K) | Tu (%) | |
|---|---|---|---|---|---|---|---|
| 2.0 | 1769.92 | 19.417 | 216.64 | 0.3124 | 1600 | 1.0 | 77,791 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Poulinakis, K.; Drikakis, D.; Kokkinakis, I.W.; Spottswood, S.M.; Dbouk, T. LSTM Reconstruction of Turbulent Pressure Fluctuation Signals. Computation 2024, 12, 4. https://doi.org/10.3390/computation12010004
Poulinakis K, Drikakis D, Kokkinakis IW, Spottswood SM, Dbouk T. LSTM Reconstruction of Turbulent Pressure Fluctuation Signals. Computation. 2024; 12(1):4. https://doi.org/10.3390/computation12010004
Chicago/Turabian StylePoulinakis, Konstantinos, Dimitris Drikakis, Ioannis W. Kokkinakis, S. Michael Spottswood, and Talib Dbouk. 2024. "LSTM Reconstruction of Turbulent Pressure Fluctuation Signals" Computation 12, no. 1: 4. https://doi.org/10.3390/computation12010004
APA StylePoulinakis, K., Drikakis, D., Kokkinakis, I. W., Spottswood, S. M., & Dbouk, T. (2024). LSTM Reconstruction of Turbulent Pressure Fluctuation Signals. Computation, 12(1), 4. https://doi.org/10.3390/computation12010004