
Modelling the Impact of Cloud Storage Heterogeneity on HPC Application Performance

Abstract
:1. Introduction
- We present an EVT-based model for characterising the performance of HPC applications that make use of heterogeneous storage technologies in cloud computing systems.
- We develop a method for predicting the performance of HPC applications based on return level analysis with different numbers of storage nodes, which can inform storage algorithms and hence improve the performance of applications.
- We evaluate the proposed model by using it to predict the performance of HPC applications running on heterogeneous cloud storage at large scales.
2. Background
2.1. Heterogeneous Storage Systems in Cloud Computing
2.2. Leveraging Heterogeneous Cloud Storage for HPC
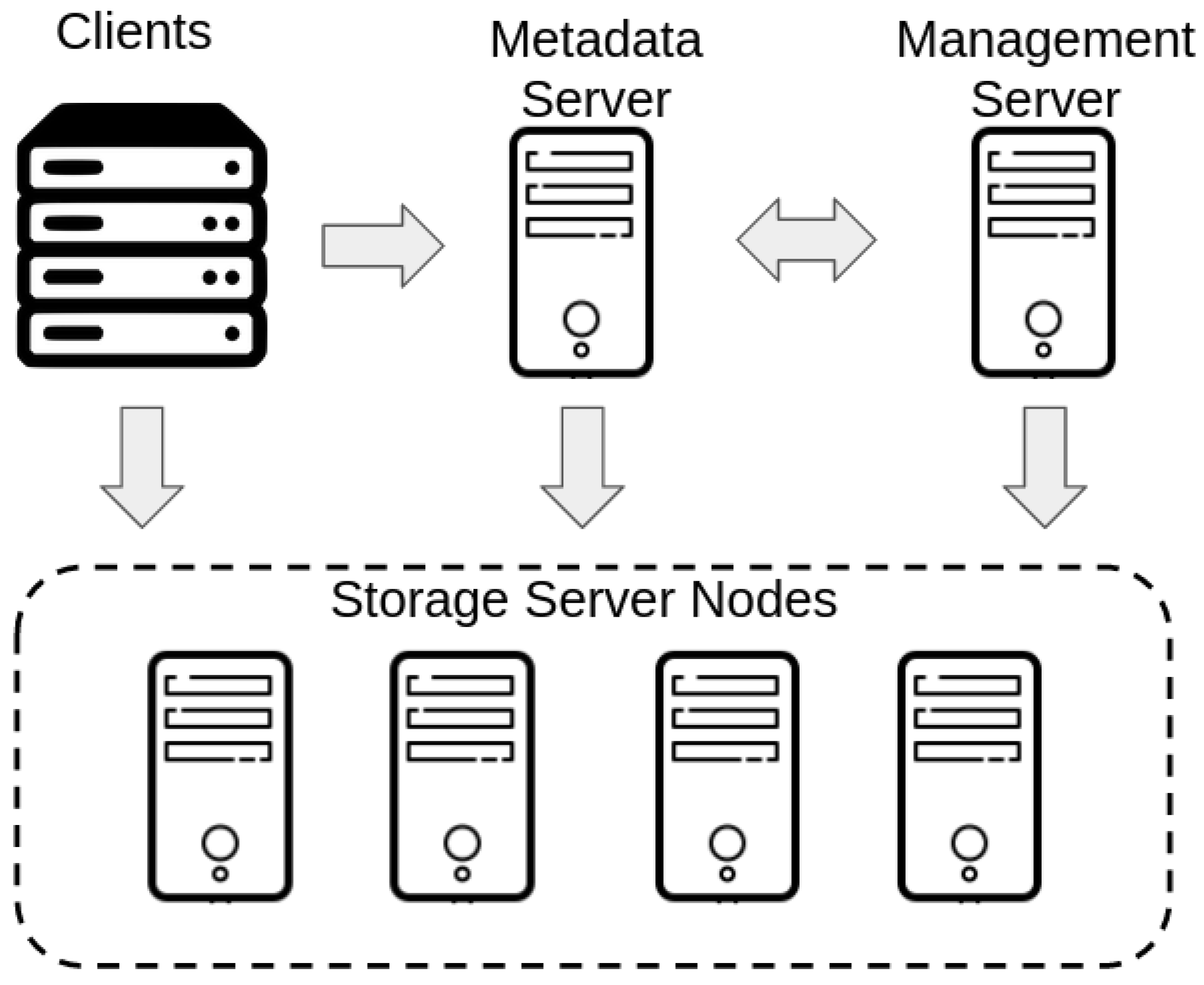
BeeGFS Parallel File System
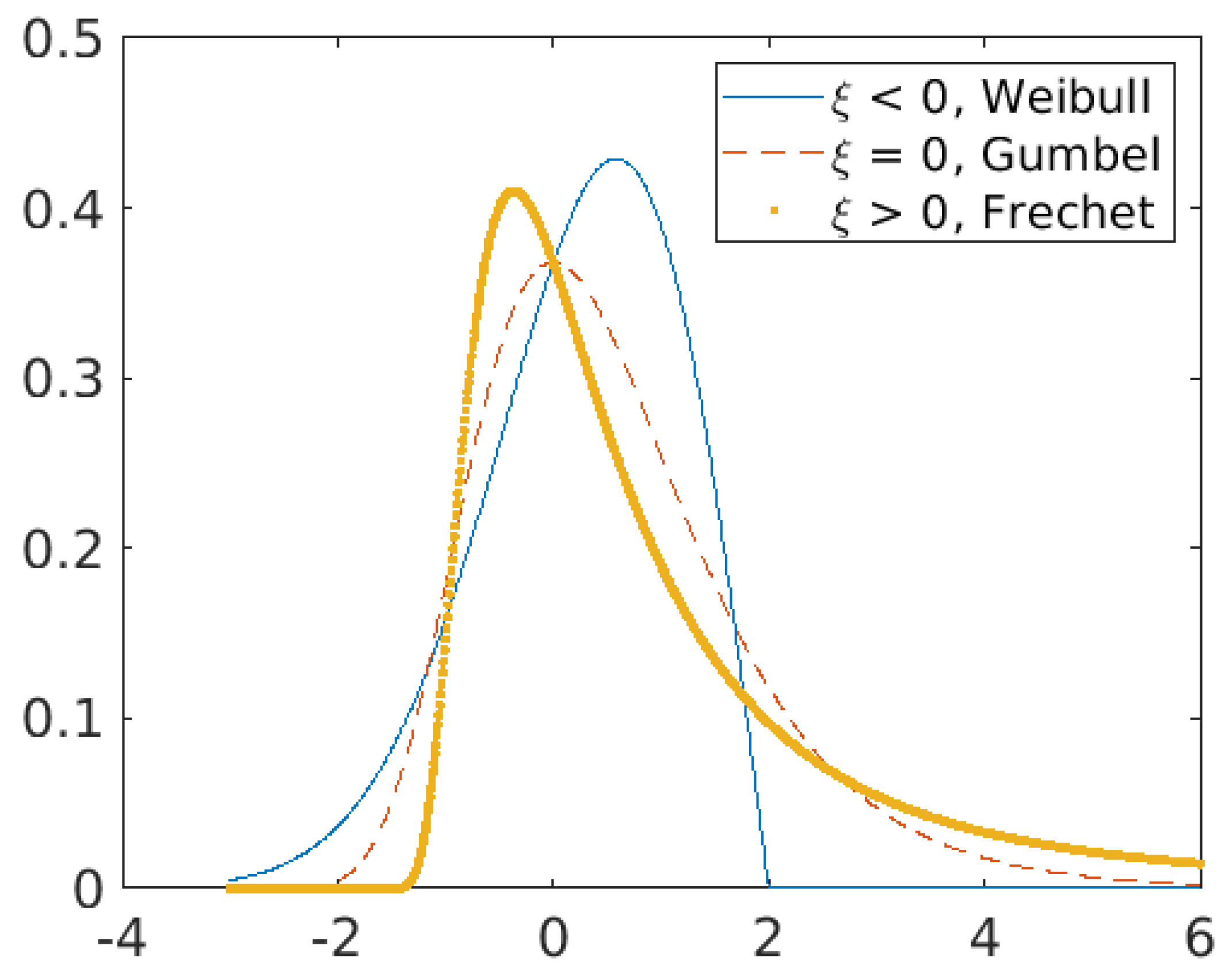
2.3. Modelling Extreme Values
3. Modelling Heterogeneous Cloud Storage Impact on HPC Application Performance
3.1. Modelling Approach
3.2. Estimating the Model Parameters
3.3. Predicting Performance on Heterogeneous Storage
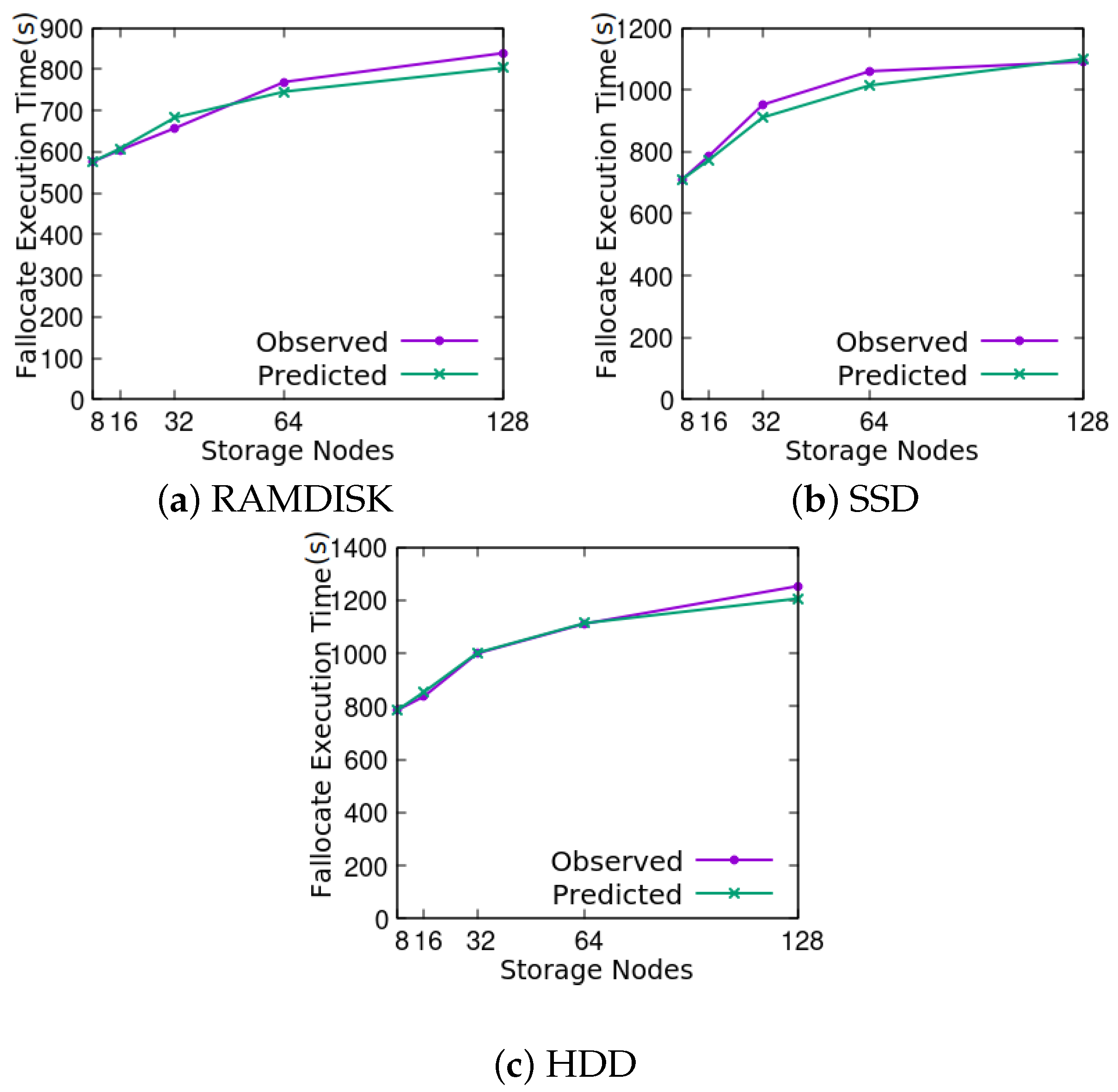
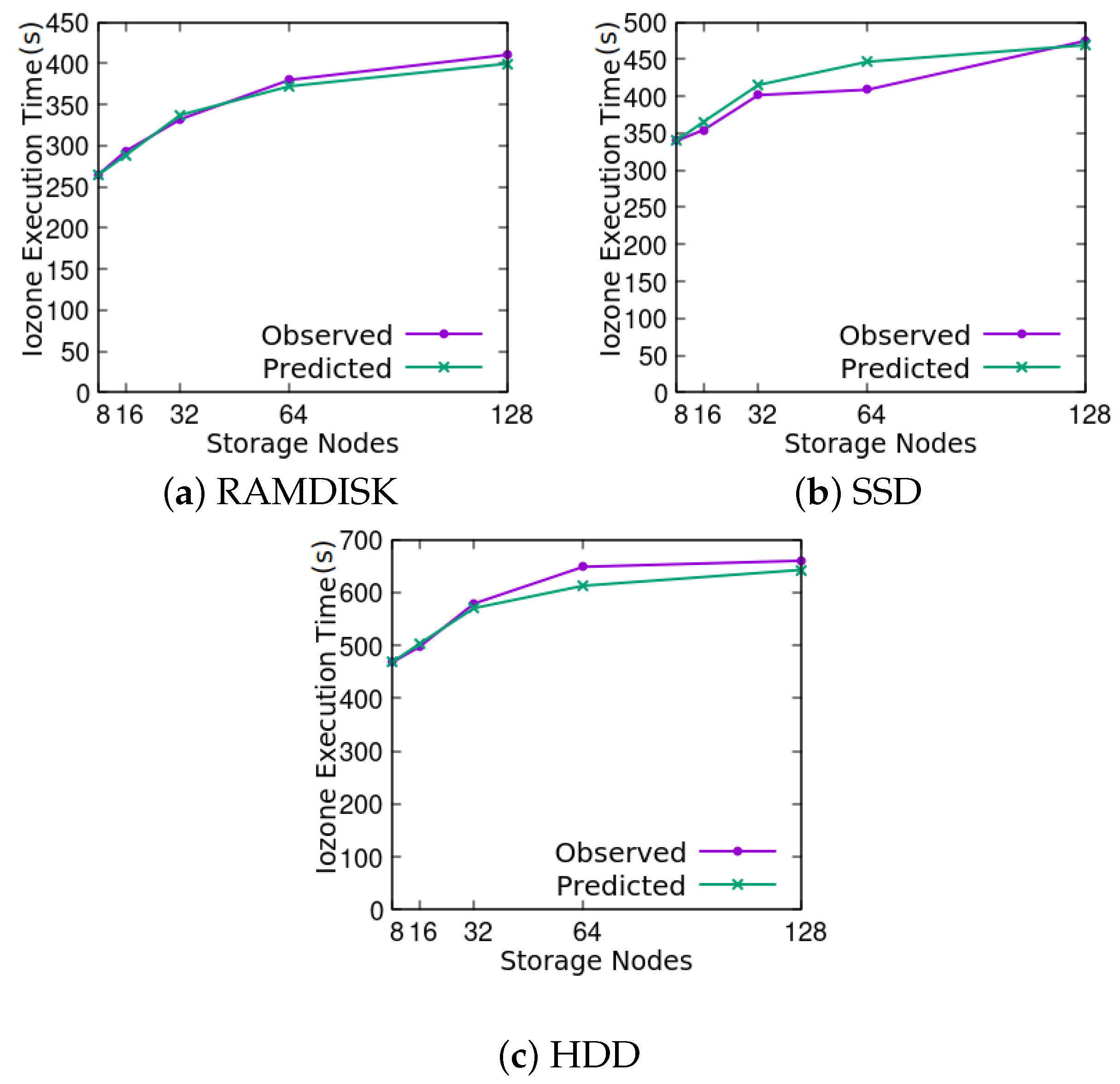
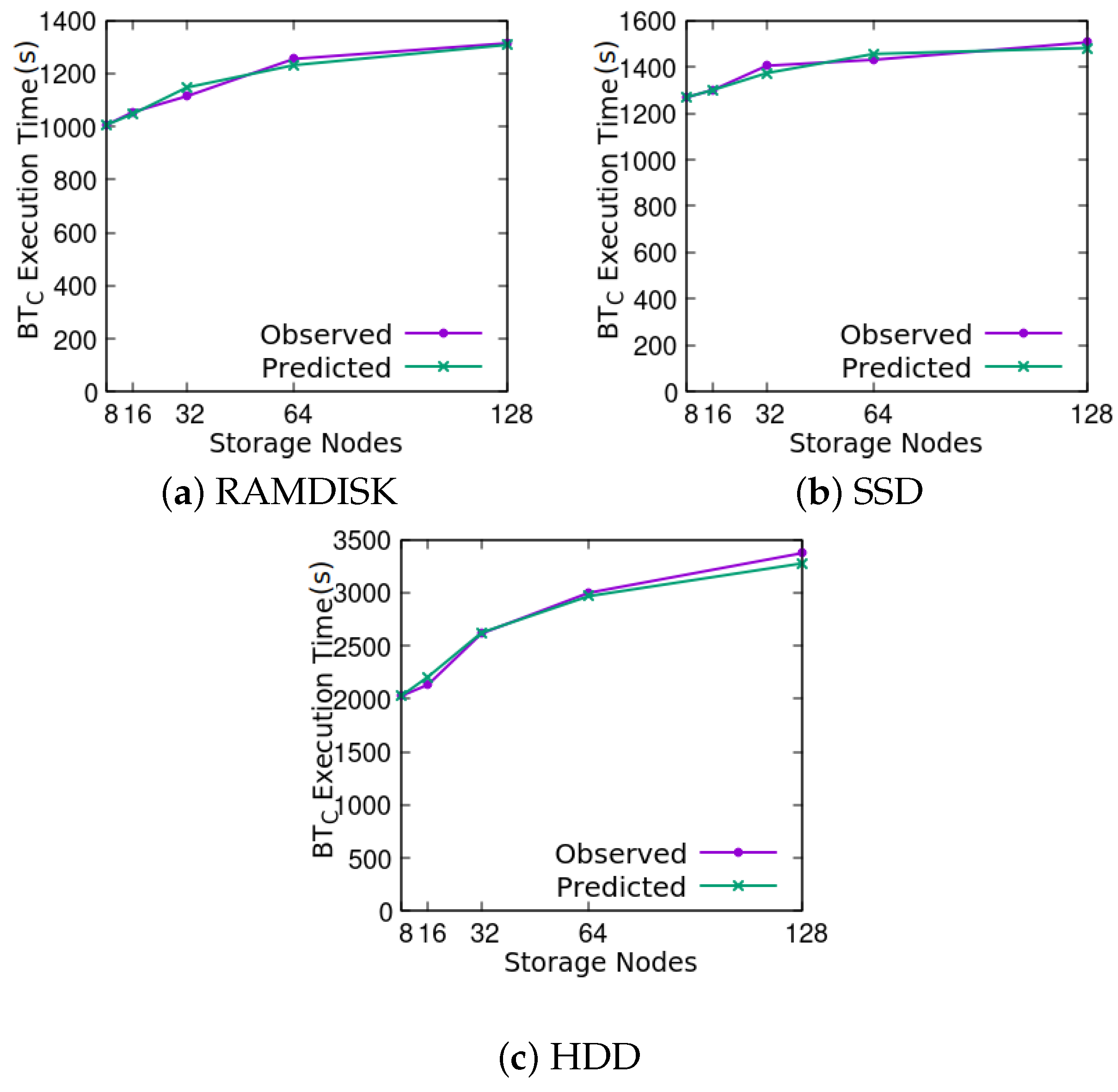
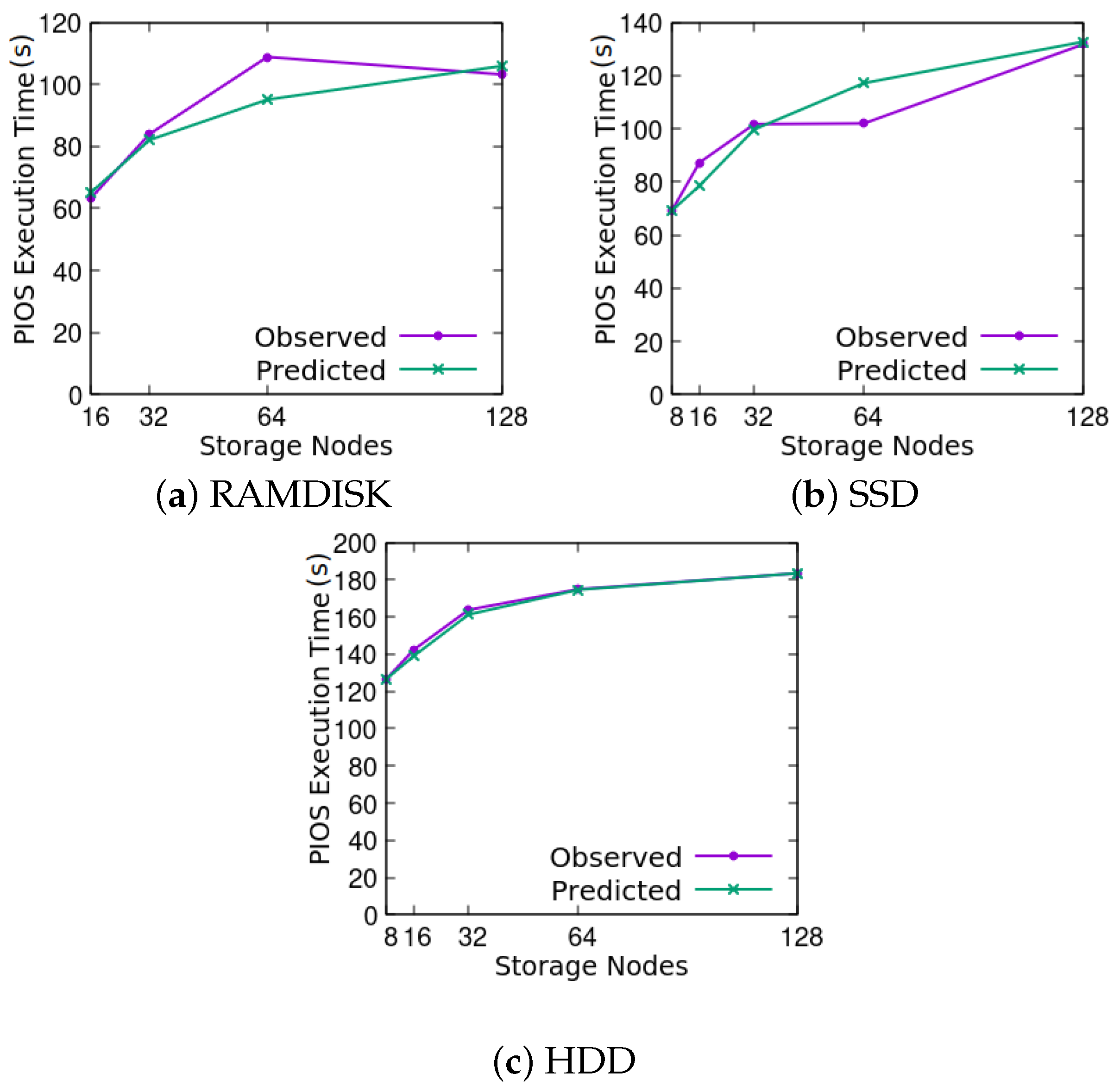
4. Validation of the Model
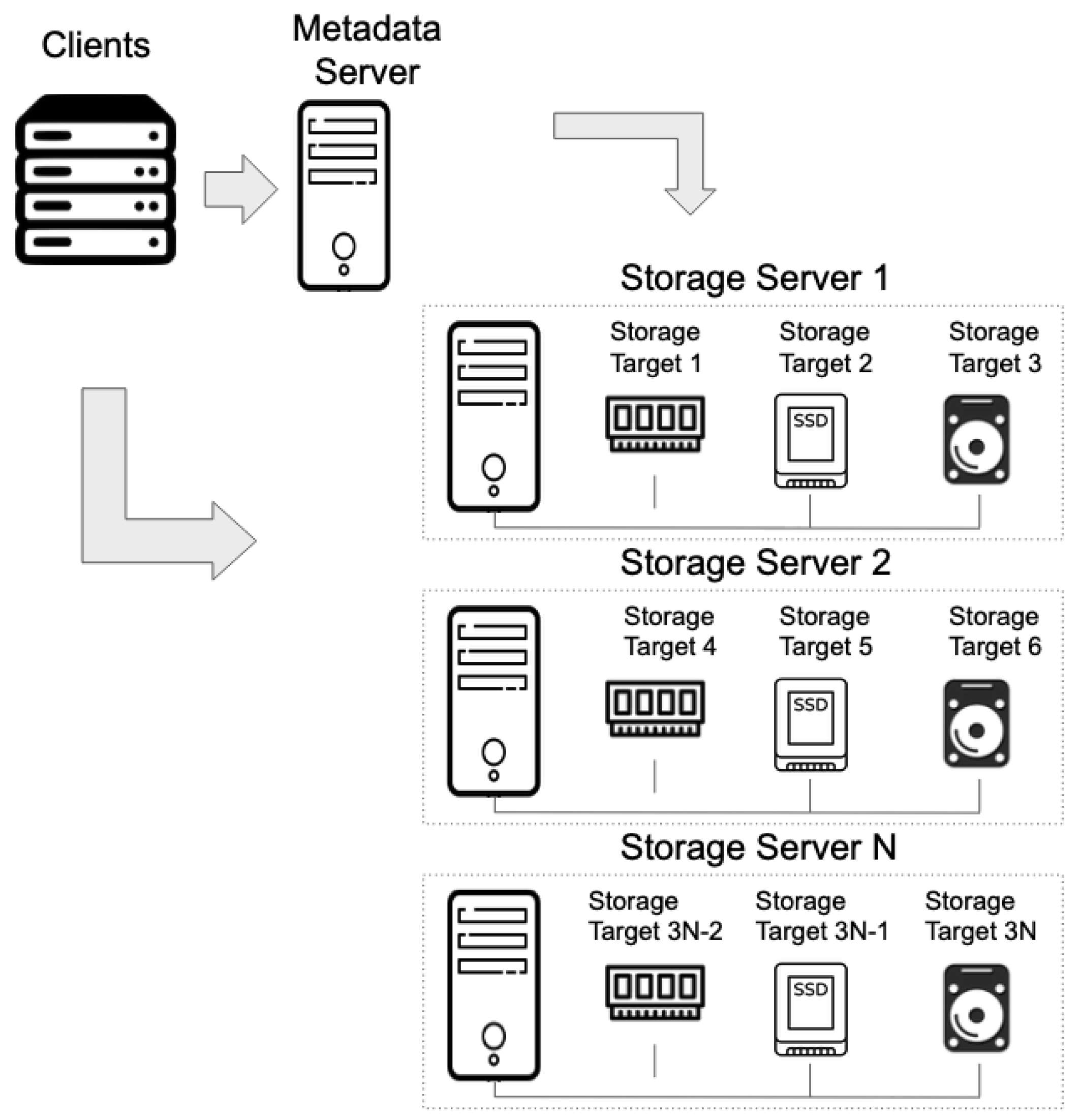
4.1. Experimental Setup
4.1.1. Benchmarks
- Iozone is a tool used for the analysis of file systems. It includes different operations such as write, read, re-write, and re-read, and allows for latency and bandwidth analysis. We use the write operation with a single stream measurement in order to allow BeeGFS to receive all the files as a single unit, and then split this over all the storage nodes.
- Fallocate is a Linux function that is widely used as a benchmark for file systems, as it can preallocate new spaces for files of a specific size. This tool first analyses whether the required space is sufficient for the file system, and then reserves that space for the file if required.
- BT was developed by NAS Parallel Benchmark (NPB) and is extensively used for testing HPC clusters. It solves a highly configurable block-tridiagonal (BT) problem using MPI.
- PIOS is a test tool created to work as an I/O simulator on file systems. This tool simulates a load from many clients that generate I/O in file systems. Due to its parallel nature, PIOS can write to the same or different files at the same time, but in this study it is used to write only to a single file.
4.1.2. Data Collection
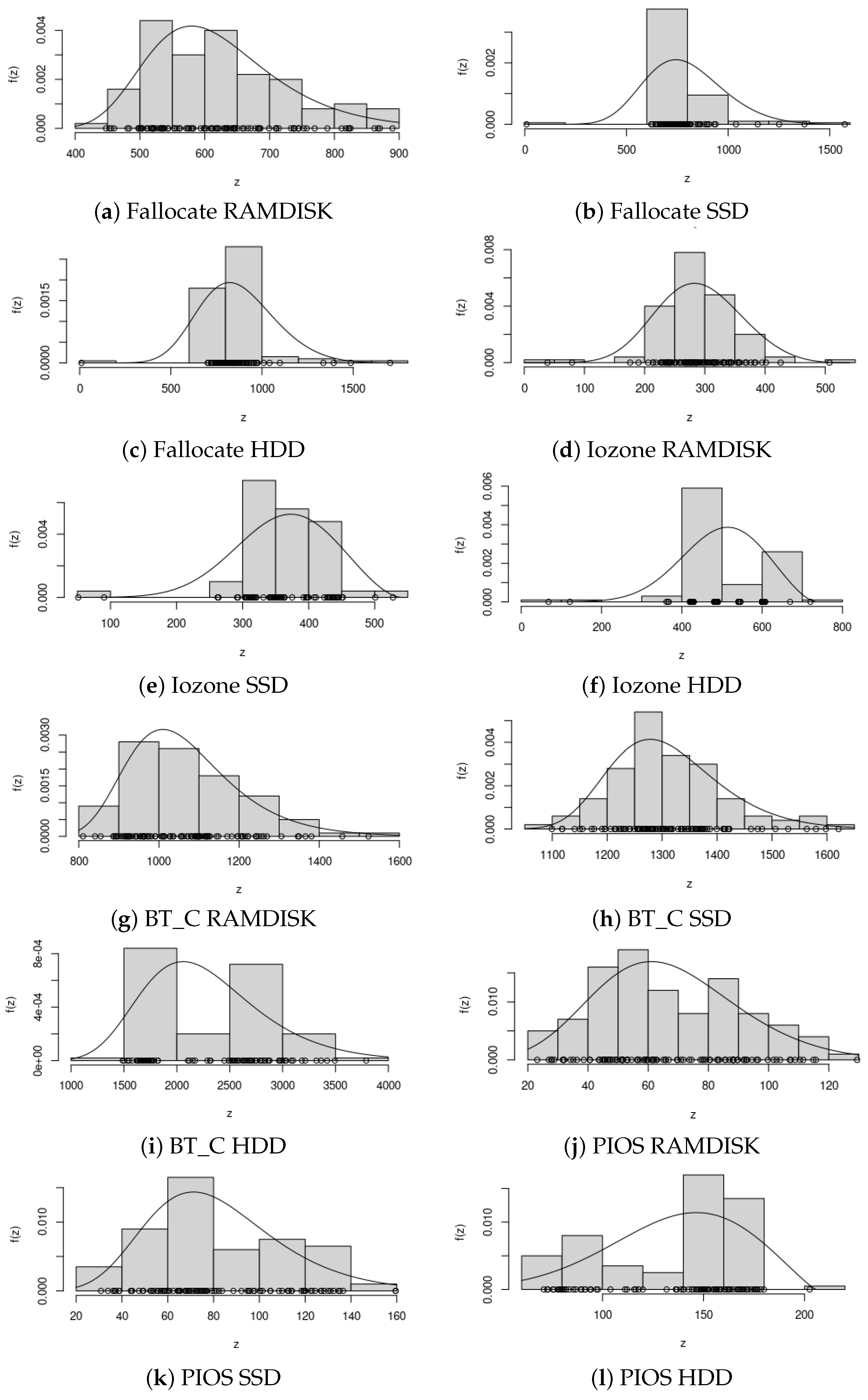
4.2. Estimation of GEV Parameters
4.3. Return Level Analysis
5. Related Work
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Neuwirth, S.; Paul, A.K. Parallel i/o evaluation techniques and emerging hpc workloads: A perspective. In Proceedings of the 2021 IEEE International Conference on Cluster Computing (CLUSTER), Portland, OR, USA, 7–10 September 2021; pp. 671–679. [Google Scholar]
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing; NIST: Boulder, CO, USA, 2011. [Google Scholar]
- Netto, M.A.S.; Calheiros, R.N.; Rodrigues, E.R.; Cunha, R.L.F.; Buyya, R. HPC Cloud for Scientific and Business Applications: Taxonomy, Vision, and Research Challenges. ACM Comput. Surv. 2018, 51, 1–29. [Google Scholar] [CrossRef]
- Borin, E.; Drummond, L.M.A.; Gaudiot, J.L.; Melo, A.; Alves, M.M.; Navaux, P.O.A. High Performance Computing in Clouds: Moving HPC Applications to a Scalable and Cost-Effective Environment; Springer Nature: Berlin/Heidelberg, Germany, 2023. [Google Scholar]
- Dancheva, T.; Alonso, U.; Barton, M. Cloud benchmarking and performance analysis of an HPC application in Amazon EC2. Clust. Comput. 2024, 27, 2273–2290. [Google Scholar] [CrossRef]
- Aithal, P. Information communication & computation technology (ICCT) as a strategic tool for industry sectors. Int. J. Appl. Eng. Manag. Lett. (IJAEML) 2019, 3, 65–80. [Google Scholar]
- dos Santos, M.A.; Cavalheiro, G.G.H. Cloud infrastructure for HPC investment analysis. Rev. Informática Teórica E Apl. 2020, 27, 45–62. [Google Scholar] [CrossRef]
- Cheriere, N.; Dorier, M.; Antoniu, G. How fast can one resize a distributed file system? J. Parallel Distrib. Comput. 2020, 140, 80–98. [Google Scholar] [CrossRef]
- Subramanyam, R. HDFS Heterogeneous Storage Resource Management Based on Data Temperature. In Proceedings of the 2015 International Conference on Cloud and Autonomic Computing, Boston, MA, USA, 21–25 September 2015; pp. 232–235. [Google Scholar] [CrossRef]
- Braam, P. The Lustre storage architecture. arXiv 2019, arXiv:1903.01955. [Google Scholar]
- Heichler, J. An introduction to BeeGFS. 2014. Available online: http://www.beegfs.de/docs/whitepapers/Introduction_to_BeeGFS_by_ThinkParQ.pdf (accessed on 1 April 2024).
- Souza Filho, P.; Felipe, L.; Aragäo, P.; Bejarano, L.; de Paula, D.T.; Sardinha, A.; Azambuja, A.; Sierra, F. Large Scale Seismic Processing in Public Cloud. In Proceedings of the 82nd EAGE Annual Conference & Exhibition, Amsterdam, The Netherlands, 8–11 June 2020; Volume 2020, pp. 1–5. [Google Scholar]
- Rao, M.V. Data duplication using Amazon Web Services cloud storage. In Data Deduplication Approaches: Concepts, Strategies, and Challenges; Academic Press: Cambridge, MA, USA, 2020; p. 319. [Google Scholar]
- Chakraborty, M.; Kundan, A.P. Grafana. In Monitoring Cloud-Native Applications: Lead Agile Operations Confidently Using Open Source Software; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Haan, L.; Ferreira, A. Extreme Value Theory: An Introduction; Springer: Berlin/Heidelberg, Germany, 2006; Volume 3. [Google Scholar]
- Reghenzani, F.; Massari, G.; Fornaciari, W. Probabilistic-WCET reliability: Statistical testing of EVT hypotheses. Microprocess. Microsyst. 2020, 77, 103135. [Google Scholar] [CrossRef]
- Omar, C.; Mundia, S.; Ngina, I. Forecasting value-at-risk of financial markets under the global pandemic of COVID-19 using conditional extreme value theory. J. Math. Financ. 2020, 10, 569–597. [Google Scholar] [CrossRef]
- Embrechts, P.; Klüppelberg, C.; Mikosch, T. Modelling Extremal Events: For Insurance and Finance; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013; Volume 33. [Google Scholar]
- Coles, S.; Bawa, J.; Trenner, L.; Dorazio, P. An Introduction to Statistical Modeling of Extreme Values; Springer: Berlin/Heidelberg, Germany, 2001; Volume 208. [Google Scholar]
- Wang, C.; Xu, C.; Xia, J.; Qian, Z.; Lu, L. A combined use of microscopic traffic simulation and extreme value methods for traffic safety evaluation. Transp. Res. Part C Emerg. Technol. 2018, 90, 281–291. [Google Scholar] [CrossRef]
- Beirlant, J.; Goegebeur, Y.; Segers, J.; Teugels, J.L. Statistics of Extremes: Theory and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Ouellette, P.; El-Jabi, N.; Rousselle, J. Application of extreme value theory to flood damage. J. Water Resour. Plan. Manag. 1985, 111, 467–477. [Google Scholar] [CrossRef]
- Merz, B.; Basso, S.; Fischer, S.; Lun, D.; Blöschl, G.; Merz, R.; Guse, B.; Viglione, A.; Vorogushyn, S.; Macdonald, E.; et al. Understanding heavy tails of flood peak distributions. Water Resour. Res. 2022, 58, e2021WR030506. [Google Scholar] [CrossRef]
- Tabari, H. Extreme value analysis dilemma for climate change impact assessment on global flood and extreme precipitation. J. Hydrol. 2021, 593, 125932. [Google Scholar] [CrossRef]
- Haskins, K.; Wofford, Q.; Bridges, P.G. Workflows for performance predictable and reproducible hpc applications. In Proceedings of the 2019 IEEE International Conference on Cluster Computing (CLUSTER), Albuquerque, NM, USA, 23–26 September 2019; pp. 1–2. [Google Scholar]
- Mondragon, O.H.; Bridges, P.G.; Levy, S.; Ferreira, K.B.; Widener, P. Understanding performance interference in next-generation HPC systems. In Proceedings of the SC’16: Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Salt Lake City, UT, USA, 13–18 November 2016; pp. 384–395. [Google Scholar]
- Seelam, S.; Fong, L.; Tantawi, A.; Lewars, J.; Divirgilio, J.; Gildea, K. Extreme scale computing: Modeling the impact of system noise in multicore clustered systems. In Proceedings of the 2010 IEEE International Symposium on Parallel & Distributed Processing (IPDPS), Atlanta, GA, USA, 19–23 April 2010; pp. 1–12. [Google Scholar]
- Fisher, R.A.; Tippett, L.H.C. Limiting forms of the frequency distribution of the largest or smallest member of a sample. In Proceedings of the Mathematical Proceedings of the Cambridge Philosophical Society; Cambridge University Press: Cambridge, UK, 1928; Volume 24, pp. 180–190. [Google Scholar]
- Gnedenko, B. Sur La Distribution Limite Du Terme Maximum D’Une Série Aléatoire. Ann. Math. 1943, 44, 423–453. [Google Scholar] [CrossRef]
- Jenkinson, A.F. The frequency distribution of the annual maximum (or minimum) values of meteorological elements. Q. J. R. Meteorol. Soc. 1955, 81, 158–171. [Google Scholar] [CrossRef]
- Markose, S.; Alentorn, A. The generalized extreme value distribution, implied tail index, and option pricing. J. Deriv. 2011, 18, 35–60. [Google Scholar] [CrossRef]
- Lu, L.H.; Stedinger, J.R. Variance of two-and three-parameter GEV/PWM quantile estimators: Formulae, confidence intervals, and a comparison. J. Hydrol. 1992, 138, 247–267. [Google Scholar] [CrossRef]
- Hirose, H. Maximum likelihood estimation in the 3-parameter Weibull distribution. A look through the generalized extreme-value distribution. IEEE Trans. Dielectr. Electr. Insul. 1996, 3, 43–55. [Google Scholar] [CrossRef]
- Hosking, J.R. L-moments: Analysis and estimation of distributions using linear combinations of order statistics. J. R. Stat. Soc. Ser. B (Methodol.) 1990, 52, 105–124. [Google Scholar] [CrossRef]
- Smith, R.L. Extreme value theory based on the r largest annual events. J. Hydrol. 1986, 86, 27–43. [Google Scholar] [CrossRef]
- McNeil, A.J. Calculating Quantile Risk Measures for Financial Return Series Using Extreme Value Theory; Technical Report; ETH Zurich: Zurich, Switzerland, 1998. [Google Scholar]
- Mehta, N.J.; Yang, F. Portfolio optimization for extreme risks with maximum diversification: An empirical analysis. Risks 2022, 10, 101. [Google Scholar] [CrossRef]
- Gu, X.; Ye, L.; Xin, Q.; Zhang, C.; Zeng, F.; Nerantzaki, S.D.; Papalexiou, S.M. Extreme precipitation in China: A review on statistical methods and applications. Adv. Water Resour. 2022, 163, 104144. [Google Scholar] [CrossRef]
- Beretta, S. More than 25 years of extreme value statistics for defects: Fundamentals, historical developments, recent applications. Int. J. Fatigue 2021, 151, 106407. [Google Scholar] [CrossRef]
- Cai, Y.; Hames, D. Minimum sample size determination for generalized extreme value distribution. Commun. Stat. Comput. 2010, 40, 87–98. [Google Scholar] [CrossRef]
- Henwood, R.; Watkins, N.W.; Chapman, S.C.; McLay, R. A parallel workload has extreme variability in a production environment. arXiv 2018, arXiv:1801.03898. [Google Scholar]
- Duplyakin, D.; Ricci, R.; Maricq, A.; Wong, G.; Duerig, J.; Eide, E.; Stoller, L.; Hibler, M.; Johnson, D.; Webb, K.; et al. The Design and Operation of CloudLab. In Proceedings of the 2019 USENIX Annual Technical Conference (ATC 2019), Renton, WA, USA, 10–12 July 2019; pp. 1–14. [Google Scholar]
- Fragalla, J. Configure, Tune, and Benchmark a Lustre FileSystem. In 2014 Oil & Gas HPC Workshop. 2014. Available online: http://rice2014oghpc.blogs.rice.edu/files/2014/03/Fragalla-Xyratex_Lustre_PerformanceTuning_Fragalla_0314.pdf (accessed on 1 April 2024).
- NORCOTT. Iozone Filesystem Benchmark. 2003. Available online: http://www.iozone.org/ (accessed on 1 April 2024).
- Conway, A.; Bakshi, A.; Jiao, Y.; Jannen, W.; Zhan, Y.; Yuan, J.; Bender, M.A.; Johnson, R.; Kuszmaul, B.C.; Porter, D.E.; et al. File systems fated for senescence? nonsense, says science! In Proceedings of the 15th USENIX Conference on File and Storage Technologies (FAST 17), Santa Clara, CA, USA, 27 February–2 March 2017; pp. 45–58. [Google Scholar]
- Yu, W.; Vetter, J.; Canon, R.S.; Jiang, S. Exploiting lustre file joining for effective collective io. In Proceedings of the Seventh IEEE International Symposium on Cluster Computing and the Grid (CCGrid’07), Rio de Janeiro, Brazil, 14–17 May 2007; pp. 267–274. [Google Scholar]
- Wong, P.; Der Wijngaart, R. NAS Parallel Benchmarks I/O; Version 2.4; Tech. Rep. NAS-03-002; NASA Ames Research Center: Moffet Field, CA, USA, 2003. [Google Scholar]
- Oracle. Lustre 1.6 Operations Manual. 2010. Available online: https://docs.oracle.com/cd/E19091-01/lustre.fs16/820-3681-11/820-3681-11.pdf (accessed on 6 April 2024).
- Amaral, J.N. About Computing Science Research Methodology. 2011. Available online: https://webdocs.cs.ualberta.ca/~amaral/courses/MetodosDePesquisa/papers/Amaral-research-methods.pdf (accessed on 2 April 2024).
- Huang, H.H.; Li, S.; Szalay, A.; Terzis, A. Performance modeling and analysis of flash-based storage devices. In Proceedings of the 2011 IEEE 27th Symposium on Mass Storage Systems and Technologies (MSST), Denver, CO, USA, 23–27 May 2011; pp. 1–11. [Google Scholar]
- Dominguez-Trujillo, J.; Haskins, K.; Khouzani, S.J.; Leap, C.; Tashakkori, S.; Wofford, Q.; Estrada, T.; Bridges, P.G.; Widener, P.M. Lightweight Measurement and Analysis of HPC Performance Variability. In Proceedings of the 2020 IEEE/ACM Performance Modeling, Benchmarking and Simulation of High Performance Computer Systems (PMBS); IEEE: New York, NY, USA, 2020; pp. 50–60. [Google Scholar]
- Lima, G.; Dias, D.; Barros, E. Extreme value theory for estimating task execution time bounds: A careful look. In Proceedings of the 2016 28th Euromicro Conference on Real-Time Systems (ECRTS), Toulouse, France, 5–8 July 2016; pp. 200–211. [Google Scholar]
- Berezovskyi, K.; Santinelli, L.; Bletsas, K.; Tovar, E. WCET measurement-based and extreme value theory characterisation of CUDA kernels. In Proceedings of the Proceedings of the 22nd International Conference on Real-Time Networks and Systems, Versailles, France, 8–10 October 2014; pp. 279–288. [Google Scholar]
- Castillo, J.D.; Padilla, M.; Abella, J.; Cazorla, F.J. Execution time distributions in embedded safety-critical systems using extreme value theory. Int. J. Data Anal. Tech. Strateg. 2017, 9, 348–361. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Cloud Platform | Disk Types | Storage Services/File Systems |
|---|---|---|
| Azure | Premium SSD Standard SSD Standard HDD Ultra Disk | Blob Storage Azure Files Queues Tables Disks |
| Amazon Web Services | SSD-io2-Provisioned IOPS SSD-io2 Block Express SSD-io1 SSD-gp3-General Purpose SSD-gp2 HDD-st1-Optimized Speed HDD-sc1-Cold | S3 Elastic Block Store Elastic File System Glacier Storage Gateway FSx Windows FSx Lustre |
| Google Cloud Platform | SSD-NVMe SSD HDD Zonal Persistent Disk Regional Persistent Disk Extreme Persistent Disk | Block Storage-Persistent disk Cloud Storage Standard storage Nearline storage Coldline storage Archive Filestore |
| Benchmark | Ref. |
|---|---|
| Iozone | [43,44] |
| Fallocate | [45] |
| BT-NPB | [46,47] |
| PIOS | [48] |
| Shape () | Scale () (s) | Location () (s) | |
|---|---|---|---|
| Fallocate RAMDISK | −0.16 | 154.47 | 566.95 |
| Fallocate SSD | −0.17 | 177.52 | 711.15 |
| Fallocate HDD | −0.17 | 192.99 | 785.41 |
| Iozone RAMDISK | −0.22 | 70.03 | 265.10 |
| Iozone SSD | −0.38 | 75.98 | 339.61 |
| Iozone HDD | −0.39 | 103.81 | 467.63 |
| BT_C RAMDISK | −0.05 | 116.63 | 1006.72 |
| BT_C SSD | −0.11 | 89.46 | 1268.03 |
| BT_C HDD | −0.07 | 498.15 | 2026.47 |
| PIOS RAMDISK | −0.17 | 21.99 | 57.42 |
| PIOS SSD | −0.08 | 25.67 | 69.20 |
| PIOS HDD | −0.46 | 36.71 | 126.54 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Marquez, J.; Mondragon, O.H. Modelling the Impact of Cloud Storage Heterogeneity on HPC Application Performance. Computation 2024, 12, 150. https://doi.org/10.3390/computation12070150
Marquez J, Mondragon OH. Modelling the Impact of Cloud Storage Heterogeneity on HPC Application Performance. Computation. 2024; 12(7):150. https://doi.org/10.3390/computation12070150
Chicago/Turabian StyleMarquez, Jack, and Oscar H. Mondragon. 2024. "Modelling the Impact of Cloud Storage Heterogeneity on HPC Application Performance" Computation 12, no. 7: 150. https://doi.org/10.3390/computation12070150