
Exploration of Sign Language Recognition Methods Based on Improved YOLOv5s


Abstract
:1. Introduction
2. Related Work
2.1. Overview of Object Detection Technology
2.2. Usage of Open Source Datasets for Gesture Recognition
3. Proposed Methods
3.1. Introduction of the YOLOv5 Algorithm
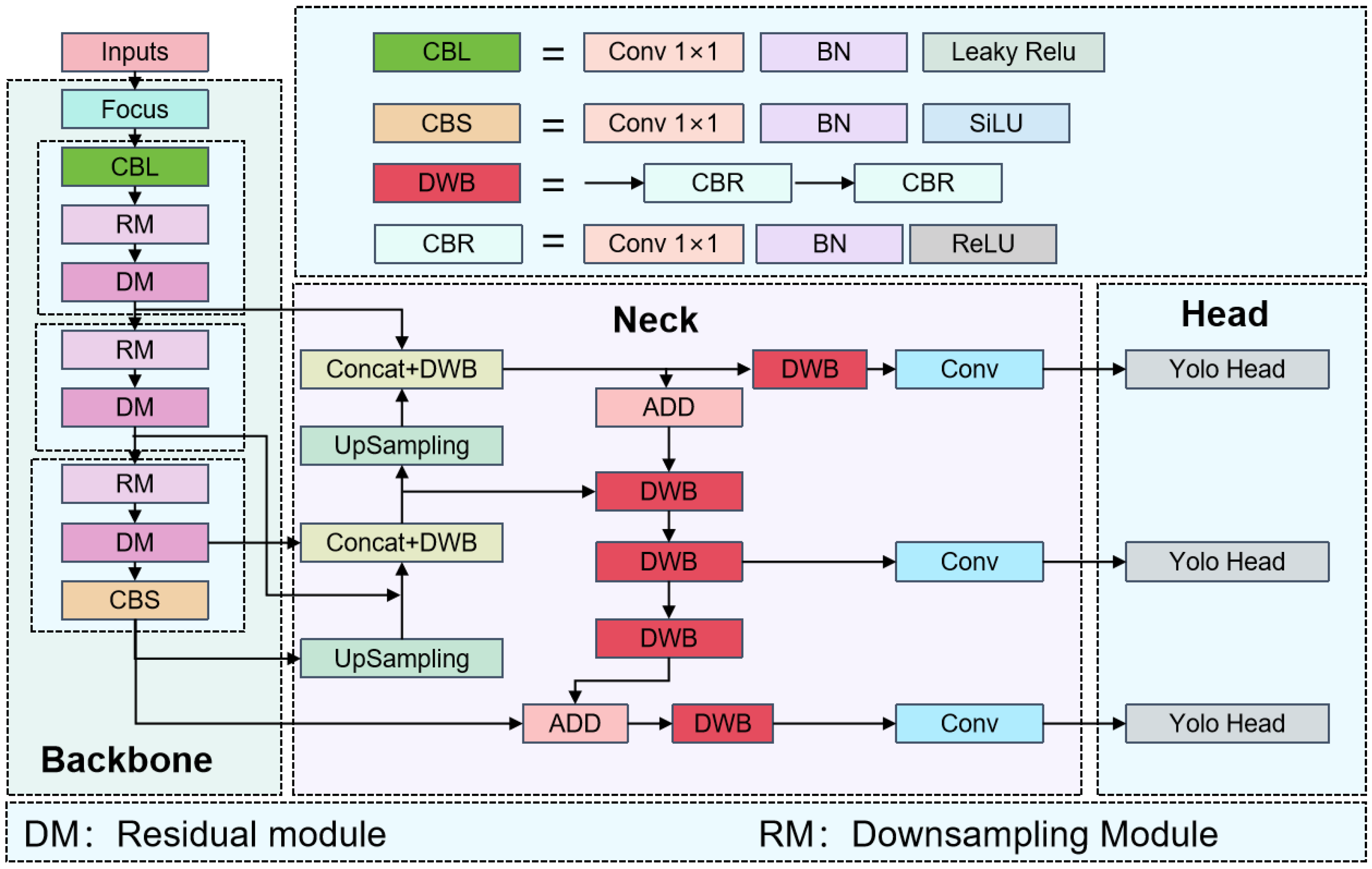
3.2. Improved YOLOv5-Lite Networking
3.2.1. Removal of the Focus Layer
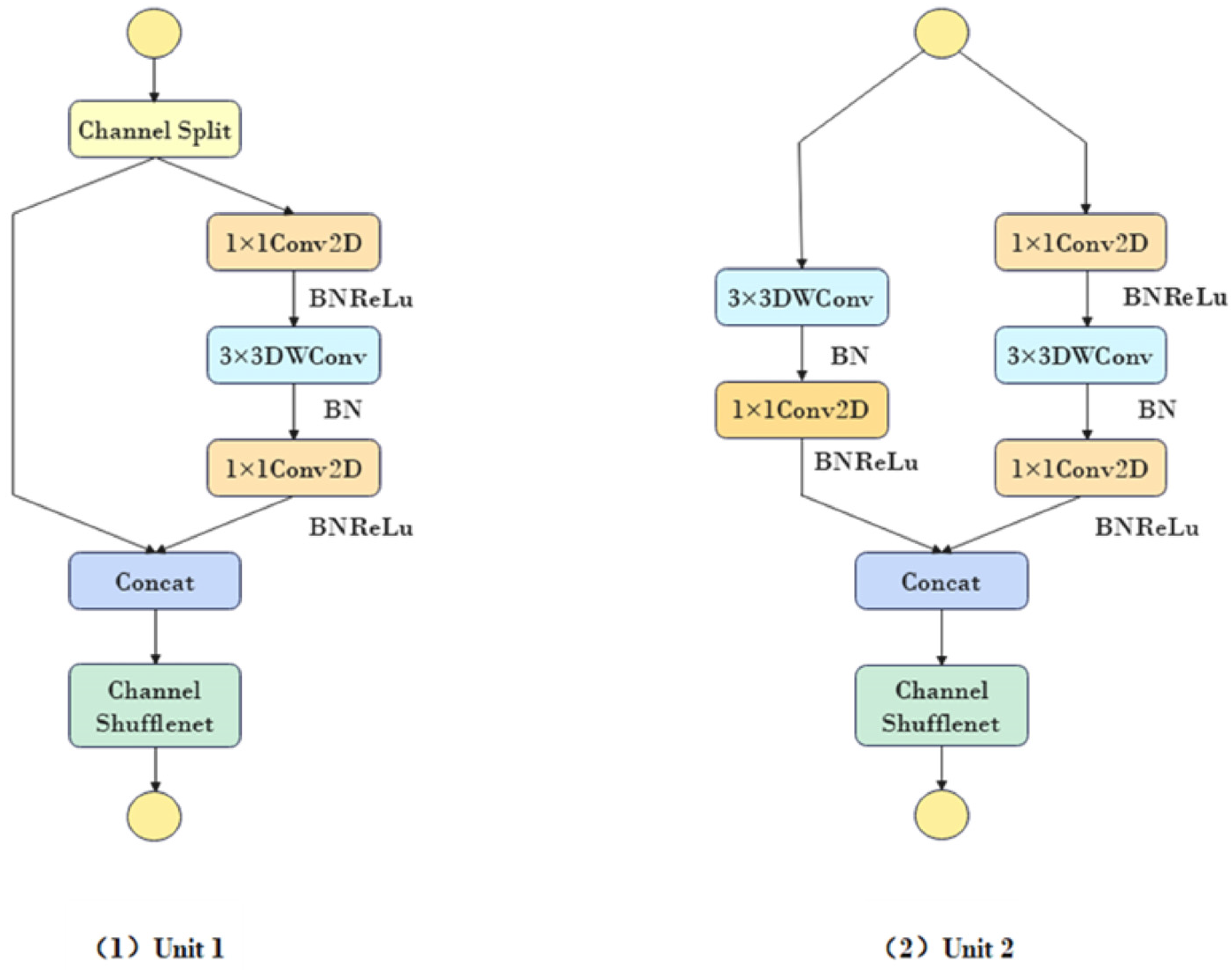
3.2.2. Using ShuffleNetv2
3.2.3. Pruning FPN + PAN
4. Experiment
4.1. Experimental Environment and Data Configuration
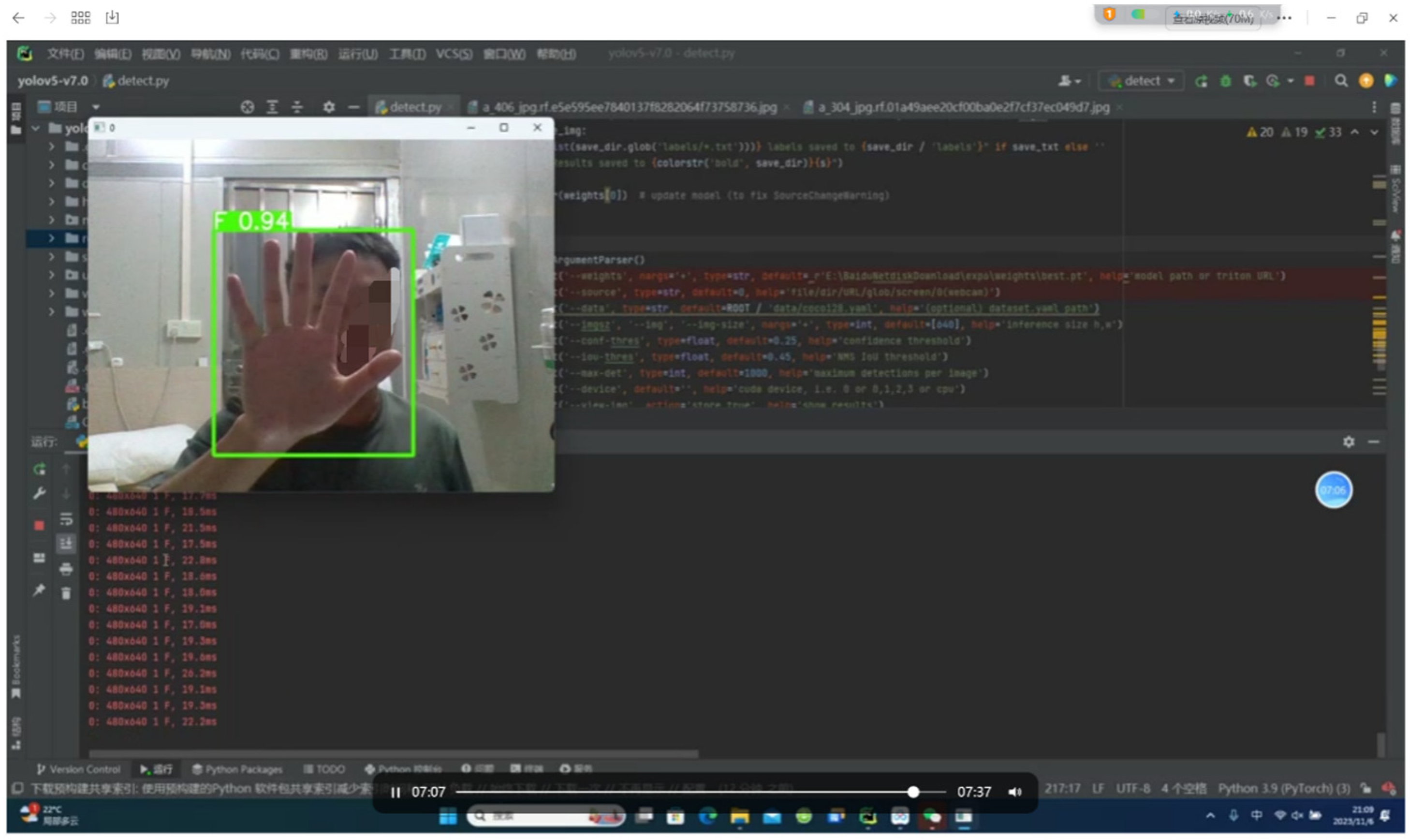
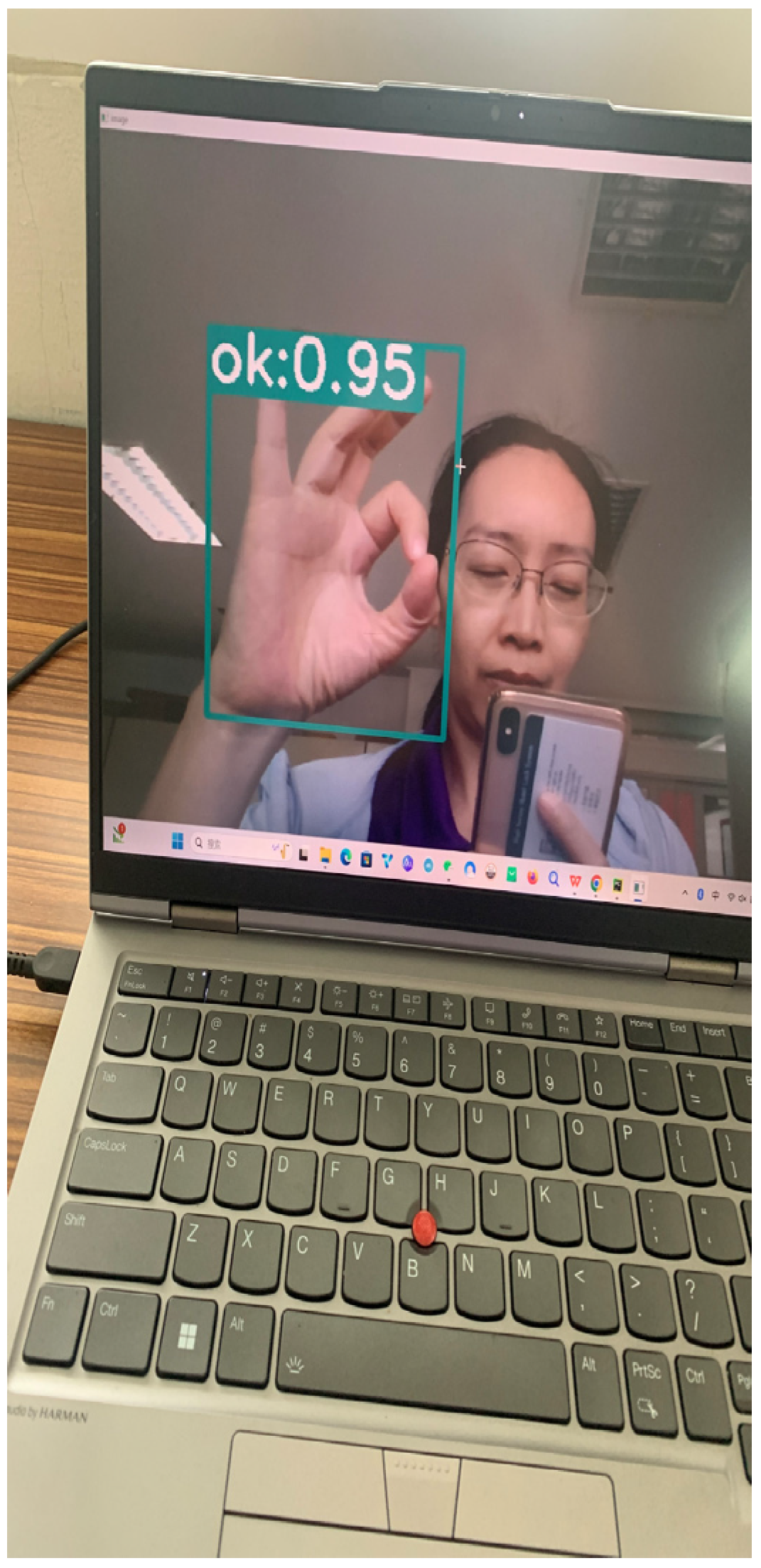
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, S.; Zhang, Q.; Li, H. Review of Sign Language Recognition Based on Deep Learning. J. Electron. Inf. Technol. 2020, 42, 1021–1032. [Google Scholar] [CrossRef]
- Elgendy, M. Deep Learning Computer Vision. Master’s Thesis, Tsinghua University Press, Beijing, China, 2022. [Google Scholar]
- Li, Y.; Cheng, R.; Zhang, C.; Chen, M.; Ma, J.; Shi, X. Sign language letters recognition model based on improved YOLOv5. In Proceedings of the 2022 9th International Conference on Digital Home (ICDH), Guangzhou, China, 28–30 October 2022; pp. 188–193. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Paipaixing. To What Extent Has Object Detection Developed|CVHub Takes You to Talk About the 22 Years of Development in Object Detection. 14 February 2023. Available online: https://www.tonguebusy.com/index.php?m=home&c=View&a=index&aid=3895 (accessed on 8 January 2023).
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:abs/1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- von Agris, U.; Zieren, J.; Canzler, U.; Bauer, B. Recent developments in visual sign language recognition. Univers. Access Inf. Soc. 2008, 6, 323–362. [Google Scholar] [CrossRef]
- Yuan, T.; Zhao, W.; Yang, X.; Hu, B. Establishment and Analysis of Large-Scale Continuous Chinese Sign Language Dataset. Comput. Eng. Appl. 2019, 55, 110–116. [Google Scholar]
- von Agris, U.; Kraiss, K.F. Signum database: Video corpus for signer-independent continuous sign language recognition. In Proceedings of the 4th Workshop on the Representation and Processing of Sign Languages: Corpora and Sign Language Technologies (LREC), Valletta, Malta, 22–23 May 2010; pp. 243–246. [Google Scholar]
- Neidle, C.; Thangalim, A.; Sclaroff, S. Challenges in development of the American Sign Language Lexicon Video Dataset (ASLLVD) corpus. In Proceedings of the 5th Workshop on the Representation and Processing of Sign Languages: Interactions Between Corpus and Lexicon, Istanbul, Turkey, 21–27 May 2012. [Google Scholar]
- Caselli, N.K.; Sehyr, Z.S.; Cohen-Goldberg, A.M.; Emmorey, K. ASL-LEX:a lexical database of American sign language. Behav. Res. Methods 2017, 49, 784–801. [Google Scholar] [CrossRef] [PubMed]
- Wan, J.; Zhao, Y.; Zhou, S.; Guyon, I.; Escalera, S.; Li, S.Z. ChaLearn looking at people RGB-D isolated and continuous datasets for gesture recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Chen, M.; Alregib, G.; Juang, B.H. 6DMG: A new 6D motion gesture database. In Proceedings of the Multimedia Systems Conference, Chapel Hill, NC, USA, 22–24 February 2012. [Google Scholar]
- Wang, H.; Chai, X.; Hong, X.; Zhao, G.; Chen, X. Isolated sign language recognition with grassmann covariance matrices. ACM Trans. Access. Comput. 2016, 8, 14–22. [Google Scholar] [CrossRef]
- Ma, N.; Zhang, X.; Zheng, H.T.; Sun, J. Shufflenet v2: Practical guidelines for efficient cnn architecture design. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 116–131. [Google Scholar]
- Kapitanov, A.; Kvanchiani, K.; Nagaev, A.; Kraynov, R.; Makhliarchuk, A. HaGRID—HAnd Gesture Recognition Image Dataset. In Proceedings of the 2024 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2024; pp. 4560–4569. [Google Scholar]
- Yan, S.; Xia, Y.; Smith, J.S.; Lu, W.; Zhang, B. Multiscale Convolutional Neural Networks for Hand Detection. Appl. Comput. Intell. Soft Comput. 2017, 2017, 9830641. [Google Scholar] [CrossRef]
- Ren, Z.; Yuan, J.; Meng, J.; Zhang, Z. Robust Part-Based Hand Gesture Recognition Using Kinect Sensor. IEEE Trans. Multimed. 2013, 15, 1110–1120. [Google Scholar] [CrossRef]
- Chen, L.; Fu, J.; Wu, Y.; Li, H.; Zheng, B. Hand Gesture Recognition Using Compact CNN via Surface Electromyography Signals. Sensors 2020, 20, 672. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm Type Contrast | R-CNN | SSD, YOLO |
|---|---|---|
| Types of detectors | Two-stage detector | Single-stage detector |
| velocity (FPS) | Generally lower than the single-stage detector | Generally higher than the two-stage detector |
| Average accuracy | Generally higher than the single-stage detector | Generally lower than the two-stage detector |
| Training Parameters | Parameter Values |
|---|---|
| Number of batch training samples | 8 |
| Number of iterations | 100 |
| Initial learning rate | 0.01 |
| Image size | 640 × 640 |
| Related Work | Methods of Work | Accuracy |
|---|---|---|
| Yan et al. [19] | Multiscale Convolutional Neural Networks | 85.5% |
| Ren et al. [20] | Kinect Sensor | 94.6% |
| Chen et al. [21] | Through electromyographic signals | 93.1% |
| Ours | Lightweight yolov5 | 99.5% |
| Model | Paramas/M | FLOP s/G | FPS/f·s-1 | Weight File/M |
|---|---|---|---|---|
| YOLOv5s | 7.04 | 15.8 | 227 | 14.0 |
| YOLOv3 | 103.67 | 282.3 | 36 | 202 |
| YOLOv6 | 4.23 | 11.8 | 222 | 8.4 |
| YOLOv8 | 3.01 | 8.1 | 238 | 6.1 |
| Ours | 0.72 | 2.6 | 416 | 1.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, X.; Jettanasen, C.; Chiradeja, P. Exploration of Sign Language Recognition Methods Based on Improved YOLOv5s. Computation 2025, 13, 59. https://doi.org/10.3390/computation13030059
Li X, Jettanasen C, Chiradeja P. Exploration of Sign Language Recognition Methods Based on Improved YOLOv5s. Computation. 2025; 13(3):59. https://doi.org/10.3390/computation13030059
Chicago/Turabian StyleLi, Xiaohua, Chaiyan Jettanasen, and Pathomthat Chiradeja. 2025. "Exploration of Sign Language Recognition Methods Based on Improved YOLOv5s" Computation 13, no. 3: 59. https://doi.org/10.3390/computation13030059
APA StyleLi, X., Jettanasen, C., & Chiradeja, P. (2025). Exploration of Sign Language Recognition Methods Based on Improved YOLOv5s. Computation, 13(3), 59. https://doi.org/10.3390/computation13030059