
Tree-Based Methods of Volatility Prediction for the S&P 500 Index
Abstract
1. Introduction
1.1. Overview
1.2. Literature Review
2. Materials and Methods
2.1. Preliminary Decisions
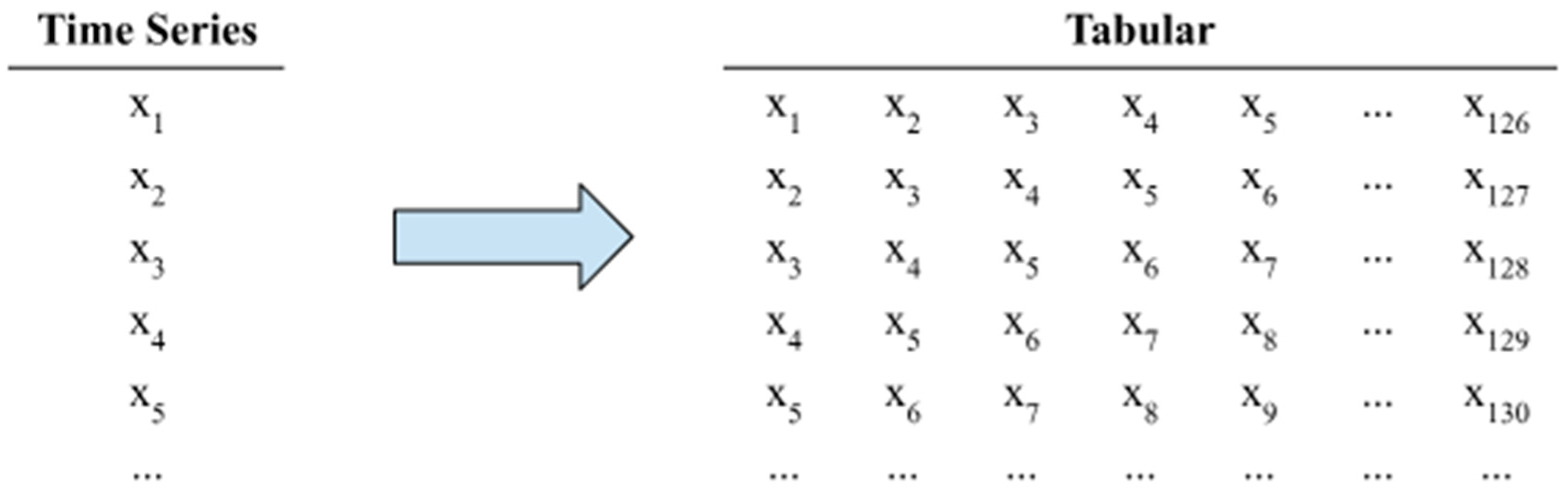
2.2. Data and Preprocessing
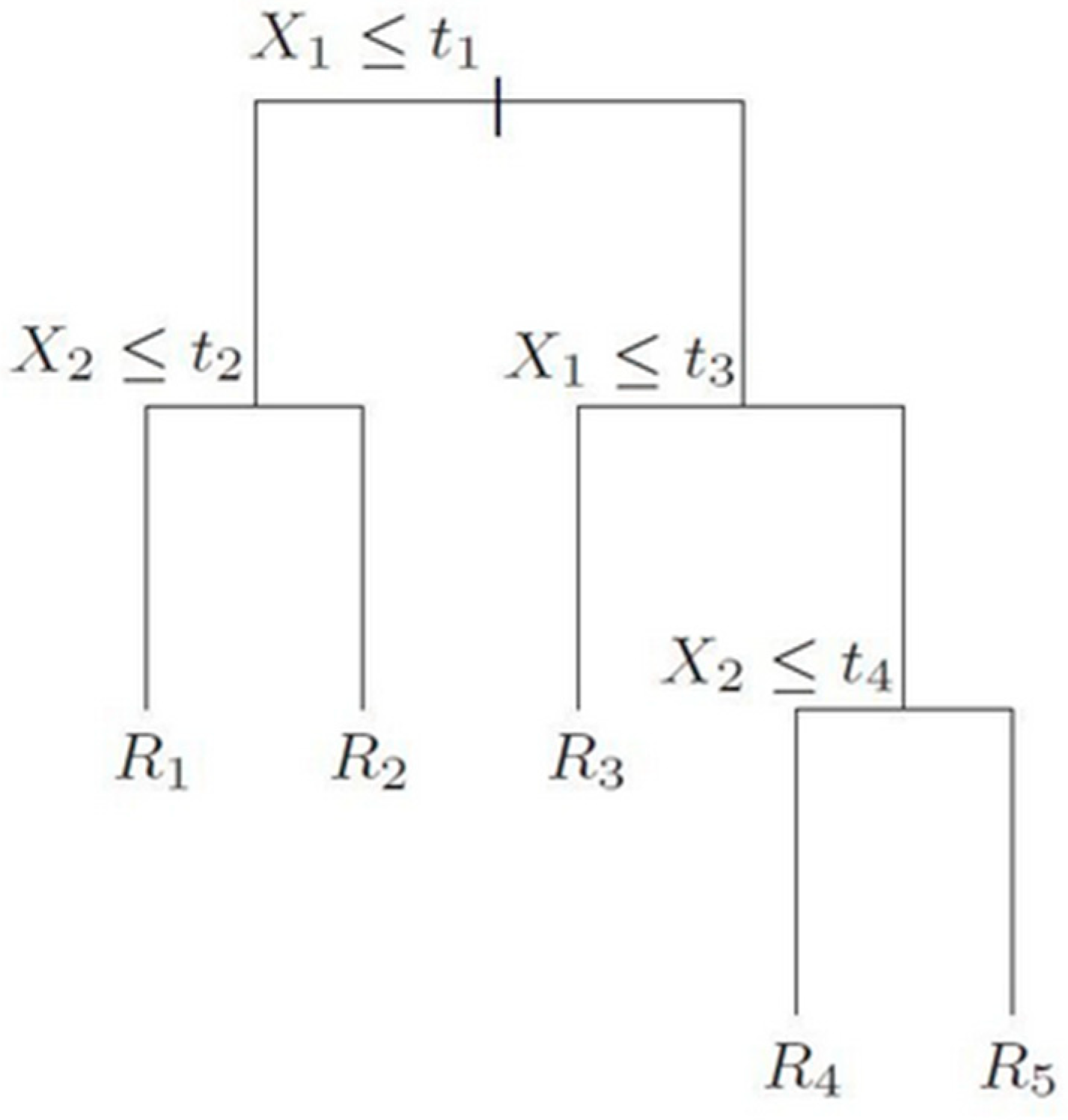
2.3. Prediction Methods
2.4. Evaluation Metrics
3. Results
3.1. Forecast Comparisons
3.2. Variable Importance
4. Discussion
Funding
Data Availability Statement
Conflicts of Interest
References
- Ang, A. Asset Management: A Systematic Approach to Factor Investing; Oxford University Press: New York, NY, USA, 2014; pp. 37–40. [Google Scholar]
- Cornuéjols, G.; Peña, J.; Tutuncu, R. Optimization Methods in Finance, 2nd ed.; Cambridge University Press: Cambridge, UK, 2018; pp. 90–95. [Google Scholar]
- Black, F.; Scholes, M. The pricing of options and corporate liabilities. J. Political Econ. 1973, 81, 637–654. [Google Scholar] [CrossRef]
- Mandelbrot, B. The variation of certain speculative prices. J. Bus. 1963, 36, 394. [Google Scholar] [CrossRef]
- Basak, S.; Kar, S.; Saha, S.; Khaidem, L.; Dey, S.R. Predicting the direction of stock market prices using tree-based classifiers. N. Am. J. Econ. Financ. 2019, 47, 552–567. [Google Scholar] [CrossRef]
- Sadorsky, P. Predicting gold and silver price direction using tree-based classifiers. J. Risk Financ. Manag. 2021, 14, 198. [Google Scholar] [CrossRef]
- Miller, M.B. Quantitative Financial Risk Management; John Wiley & Sons: Hoboken, NJ, USA, 2019; pp. 29–36. [Google Scholar]
- Engle, R.F. Autoregressive conditional heteroscedasticity with estimates of the variance of United Kingdom inflation. Econometrica 1982, 50, 987–1007. [Google Scholar] [CrossRef]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econ. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Lim, C.M.; Sek, S.K. Comparing the performances of GARCH-type models in capturing the stock market volatility in Malaysia. Procedia Econ. Financ. 2013, 5, 478–487. [Google Scholar] [CrossRef]
- Corsi, F. A simple approximate long-memory model of realized volatility. J. Financ. Econ. 2008, 7, 174–196. [Google Scholar] [CrossRef]
- Zeng, Q.; Lu, X.; Xu, J.; Lin, Y. Macro-driven stock market volatility prediction: Insights from a new hybrid machine learning approach. Int. Rev. Financ. Anal. 2024, 96, 103711. [Google Scholar] [CrossRef]
- Bucci, A. Realized volatility forecasting with neural networks. J. Financ. Econ. 2020, 18, 502–531. [Google Scholar] [CrossRef]
- Xiong, R.; Nichols, E.P.; Shen, Y. Deep Learning Stock Volatility with Google Domestic Trends. Working Paper. 2015. Available online: https://arxiv.org/abs/1512.04916 (accessed on 25 September 2024).
- Andersen, T.G.; Bollerslev, T.; Diebold, F.X.; Labys, P. Modeling and forecasting realized volatility. Econometrica 2003, 71, 579–625. [Google Scholar] [CrossRef]
- James, G.; Witten, D.; Hastie, T.; Tibshirani, R. An Introduction to Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2021; pp. 15–42. [Google Scholar]
- Breiman, L.; Friedman, J.; Olshen, R.A.; Stone, C.J. Classification and Regression Trees; Taylor & Francis Group: Boca Raton, FL, USA, 1984. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning, 2nd ed.; Springer: New York, NY, USA, 2009; pp. 305–316. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef]
- Friedman, J.H. Stochastic gradient boosting. Comput. Stat. Data Anal. 2002, 38, 367–378. [Google Scholar] [CrossRef]
- De Prado, M.L. Advances in Financial Machine Learning; John Wiley & Sons: Hoboken, NJ, USA, 2018; pp. 103–110. [Google Scholar]
- Ilmanen, A. Expected Returns; John Wiley & Sons Ltd.: Chichester, UK, 2011; pp. 307–319. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Hyperparameters | RMSE | MAE | MAPE |
|---|---|---|---|---|
| Simple Moving Average | Lookback = 21 days | 12.3% | 6.7% | 38.3% |
| EWMA | δ = 0.88 | 11.5% | 6.5% | 36.4% |
| GARCH | (p, q) = (1, 1) | 12.2% | 7.2% | 32.4% |
| VIX | 10.6% | 6.9% | 48.0% | |
| Random Forest | mtry = 30, trees = 500 | 9.9% | 5.2% | 31.5% |
| Gradient Boosting | eta = 0.1, trees = 450 | 9.6% | 5.3% | 31.1% |
| Gradient Boosting + VIX | eta = 0.1, trees = 250 | 9.5% | 5.0% | 29.0% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lolic, M. Tree-Based Methods of Volatility Prediction for the S&P 500 Index. Computation 2025, 13, 84. https://doi.org/10.3390/computation13040084
Lolic M. Tree-Based Methods of Volatility Prediction for the S&P 500 Index. Computation. 2025; 13(4):84. https://doi.org/10.3390/computation13040084
Chicago/Turabian StyleLolic, Marin. 2025. "Tree-Based Methods of Volatility Prediction for the S&P 500 Index" Computation 13, no. 4: 84. https://doi.org/10.3390/computation13040084
APA StyleLolic, M. (2025). Tree-Based Methods of Volatility Prediction for the S&P 500 Index. Computation, 13(4), 84. https://doi.org/10.3390/computation13040084