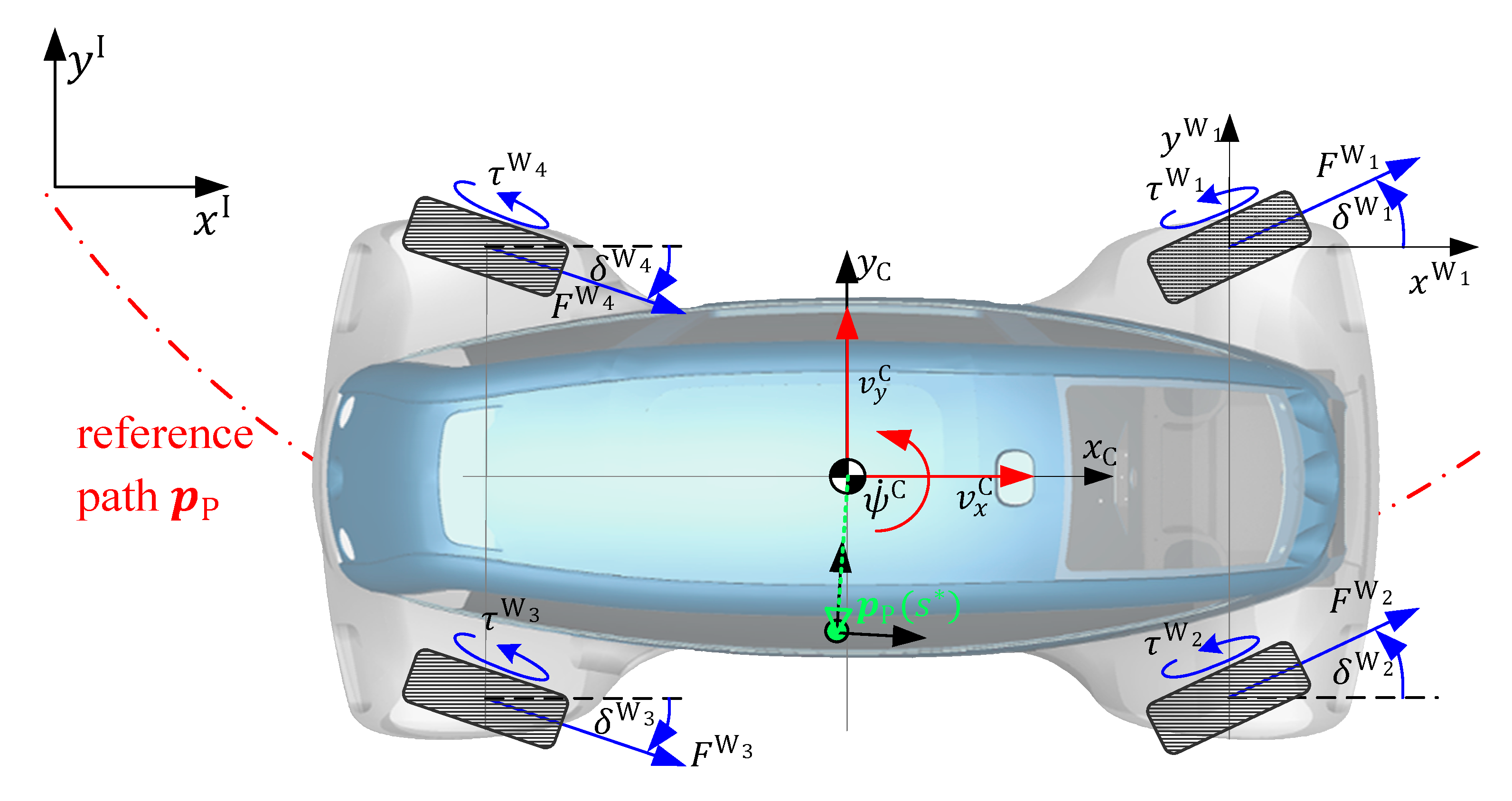
1. Introduction
Quadratic programming problems occur in various areas, for example in portfolio optimization where the risk-adjusted return shall be maximized [
1], in signal processing operations, in audio applications [
2], and in machine learning [
3]. The efficient and reliable solution of quadratic programming problems (QPs) is essential in the solution of many real-time control problems. Especially, the use on electronic control units and embedded platforms poses challenges, as described in [
1,
4]. To run on platforms with little memory space, the solver should consist of code with a small footprint that is self-contained and does not depend on external libraries. For the use in real-time applications, a solution must certainly be accomplished within the sampling time, which can be very short depending on the application. So, the solver needs to be reliable and provide a solution even in the case of poor quality data without causing a termination of the algorithm in which the solver is used. Furthermore, the solver needs to be provided in a programming language matching the requirements of safety-critical applications, such as C, which is widely used especially in the automotive sector. A new C-implemented QP solver is presented here. It is based on the dual method of Goldfarb and Idnani [
5]. Other solvers are based on the same method, such as the C++ libraries QuadProg++ [
6] and qpmad [
7] or a Matlab solver named QP [
8]. There also exists a Fortran implementation by Schittkowski named QL [
9] based on this dual method. Automatic conversion from Fortran to C is available with the f2c program [
10]. However, the C code generated in this way, is not appropriate for application on embedded systems, since it relies on external Fortran libraries and consists of many jump statements. Yet, simple control structures provide benefits for the use on embedded platforms since, e.g., loops with a fixed number of iterations and the avoidance of jump statements make it easier to analyze the overall execution of the code and to determine the real-time capability of the code. Moreover, code with simple control structures is easier to maintain if adaptations should be necessary. However, such manual modifications in the f2c-generated code are not advisable, since the converted code is confusing and not well readable. For these reasons, a handwritten well-readable and embedded system suitable C code implementation of the QL solver was developed. This new implementation is called EmbQP. Although the new solver is based on the same approach as the QL solver, it has been implemented completely new. The new solver follows the process of the QL solver [
9] only when handling non-positive definite matrices in the objective function of the QP problem. In contrast to [
9], the EmbQP solver can also be used to solve QP problems without any lower and/or upper bounds of the solution vector being given. As an application example for the use of QPs, the control allocation problem from [
11] is considered. It is included in the context of path following control for DLR’s ROboMObil (ROMO), a robotic full x-by-wire research vehicle [
12]. In [
11], the QL solver of Schittkowski was used to solve the QP problems. In the work presented here, the new EmbQP solver is used in this application example, and the simulation results of the two solvers are shown and compared.
The QL Fortran routine according to [
9] and the underlying algorithm of Goldfarb and Idnani are explained in
Section 2.
Section 3 details the implementation of the EmbQP solver. In
Section 4, the control allocation problem is described. The results of the simulations and the comparison between the QL solver and the new EmbQP solver are shown in
Section 5.
2. Description of the EmbQP Algorithm
The new C implemented QP solver follows the dual active set method of Goldfarb and Idnani [
5] with some additions from [
9]. The algorithm solves the following strictly convex quadratic programming problem:
with a symmetric and positive definite matrix
, vectors
and
, and a (
)-matrix
, together with
representing
linear constraints. Upper and lower bounds for the variable
are given by
and
, respectively. The number of all equality constraints is denoted as
.
In this implementation, the lower and upper bounds on are treated as additional inequality constraints by an appropriate expansion of and . Then, the number of constraints is adapted internally. However, it is optional to specify such limits, since the EmbQP solver can also handle QP problems without explicit declaration of lower and upper bounds on , where the constraints are thus only given by and . In contrast, the QL solver of Schittkowski always needs the input of such lower and upper bounds, and if a QP without such bounds is to be solved with it, sufficiently large values must be provided.
The QL routine of Schittkowski is based on the dual method of Goldfarb and Idnani, and the implementation of it goes back to Powell [
13]. Some important points of the method of Goldfarb and Idnani are described here, whereas a detailed description can be found in [
5]. A good summary of this method can also be found in [
14]. The method of Goldfarb and Idnani creates optimal approximate solutions, while the value of the objective function is monotonically increasing. The method uses a so-called active set of constraints
which is the empty set at the beginning. During the course of iterations, indices of the constraints are added to
so that
represents the set of constraints that are satisfied as equalities with the current solution. Indices of inequality constraints can also be removed from
if the corresponding constraint is no longer active. The minimum of the objective function subject to the current active set
is calculated at every iteration.
For an active set
, the subproblem
is defined to be the relaxed quadratic programming problem with the objective function of Equation (1) subject to the subset of constraints, which is given by the active set
. In every iteration of the algorithm,
and
are defined to be the solution pair
if the following conditions are fulfilled: the vectors
are linearly independent, the relaxed problem
is feasible,
minimizes the objective function
, and
satisfies all constraints in
with equality. With these definitions, the basic principle of the method of Goldfarb and Idnani can be described. It comprises the following steps in
Table 1.
Since the active set represents the empty set at the beginning of the algorithm, yields the minimum of the problem Equation (1) in the unconstrained case (), which is the minimum of the bare objective function. It serves as a starting point, and the first solution pair is given by . The iteratively calculated solution points are inadmissible except for the last one; therefore, there is no need to search for a feasible starting point with the dual method in contrast to other primal active set methods.
The algorithm terminates either after finding the optimal solution of the problem Equation (1) or after detecting that the problem is infeasible. The termination occurs after a finite number of steps, since the number of possible solution pairs is finite and since the return of the algorithm to a formerly computed solution pair is not possible, because the values of the objective function are monotonically increasing from one iteration to the next. The number of the solution pairs is limited by the number of possible subsets of , which is at the most. A reliable upper limit of iterations is particularly important for the use in hard real-time applications.
With a solution pair from the last iteration and a newly chosen violated constraint , two possible cases can occur. Either the vectors are linearly independent or is linearly dependent on . Based on these cases, the index can either be added directly to the active set or an element, which is no longer considered active, has to be removed from first before adding to it. The index is in any case added to .
A short summary of the algorithm of Goldfarb and Idnani is given in
Table 2 where, in comparison to the basic principle in
Table 1, particularly the computation of a new solution pair is described in more detail. The description of the algorithm is based on [
5,
14]. The notation
is used here to describe a reduced matrix composed only of the rows of
whose indices of the corresponding constraints are included in the current active set
.
The algorithm takes steps in the primal and dual space, which means in the primal and dual variables, so changes in
and/or in the Lagrange multipliers of the corresponding dual problem occur [
5]. The dual feasibility is always fulfilled, producing the primal optimality of the subproblems in each iteration. Primal feasibility, i.e., compliance with all constraints, applies only to the last, optimal solution point. A change in the active set and in the dual variables is possible without changing
; see step 6 in
Table 2.
The algorithm detects, on the basis of the step length, whether a new constraint can be added to the active set or whether an active constraint has to be removed first from the active set, i.e., whether a full step or a partial step is taken. If a step violates the dual feasibility, it has to be shortened. More details about the implementation of this method in the EmbQP algorithm are described in the next section.
3. EmbQP Implementation Details
Table 3 shows a summary of all inputs and outputs of the EmbQP solver. Further outputs are conceivable and easy to provide, such as the final active set
that includes the indices of all constraints satisfied with equality by the solution vector.
In comparison to
Table 2, the EmbQP solver implementation requires additional inputs that need to be specified in the calling function. These include Boolean parameters
and
that determine whether upper or lower bounds for the solution vector are provided or not. In contrast to the Fortran QL solver, the EmbQP solver also works if no upper or lower bounds or only either of them are given. Another additional input is the desired accuracy
. It is used for comparisons of variables with zero and should therefore be greater than the target machine precision. Furthermore, as it is the case with the Fortran QL solver, the integer input parameter
needs to be specified. It determines whether an initial Cholesky decomposition of
is already known from the start and can be provided by the calling function. If this is the case, the provided factorization is stored in the lower triangular part of
, and consequently, it is possible to save redundant Cholesky decomposition in the algorithm. When programming code for the use on embedded systems, dynamic memory allocation should be avoided. Wherever possible, the input arguments of a function are overwritten with internal calculations and output arguments to effectively use the available memory. Moreover, a function may need additional temporary memory for internal calculations. To overcome recurrent dynamic memory allocation, pointers to pre-allocated working arrays with an appropriate length and data type are passed to the function. The EmbQP code uses two working arrays, one for float-type data and one for integer-type data. Their size depends only on the dimensions
and
. The C code segment, where pointers to the integer working array are set, is shown in
Table A1. Turning to the outputs, the optimal solution
is returned as the main result. Moreover, the minimal objective function value
is provided and an integer
is returned. The latter reports whether the optimization was successful. This is the case if
and only then do the other outputs have reasonable values. The case
reveals an infeasible problem, and the case
occurs if the maximal number of iterations is exceeded. This last case may only arise due to rounding errors, since theoretically, with infinite precision, the algorithm will always find an optimal solution or detect the infeasibility of the problem. In the cases
or
, the EmbQP algorithm does not deliver meaningful values for
and
, but it ensures that the solution returned for
is within the bounds
and
.
Table A2 shows how this is done in the C code in the case of an unfeasible problem. So, at least these constraints are always fulfilled as long as they represent applicable boundaries. A C main function in
Table A3 shows data for an example QP problem and how the EmbQP solver is called with the above-mentioned inputs and outputs.
The matrix
in the objective function of Equation (1) needs to be symmetric and positive definite in the original algorithm. The routine of Schittkowski can also handle positive semidefinite matrices
that may occur as a consequence of rounding errors or other numerical deficiencies. This approach is also adopted in the EmbQP solver. At the beginning of the algorithm, a Cholesky decomposition of
is carried out (if not already provided), and during this factorization, a non-positive definite matrix can be identified. In this case, the identity matrix multiplied by a small factor
is added to the matrix
to increase its diagonal elements.
is increased iteratively until a positive definite matrix is obtained for which the Cholesky decomposition can be performed. In this situation, a quadratic programming problem with a slightly perturbed objective function with
instead of
is solved. Based on [
13], the value of
and the perturbed
are computed using the elements of the already calculated decomposition matrix as well as the pivotal element that caused the break of the decomposition. It is ensured that
is positive and increases its value in each step so that the procedure converges and provides a small value that gives positive definiteness.
Several options are possible for the choice of the violated constraint
to be added to the active set. The successful termination of the algorithm does not depend on this choice, so one has the freedom of choosing any violated constraint. However, by an adapted choice, the number of iterations may be reduced. A simple possibility with no additional computation is the choice of the violated constraint with the lowest index. An alternative that might be more effective is to choose the most severely violated constraint. Different strategies for this choice, for example the computation of euclidean distances, can be found in [
15]. In the implementation of the EmbQP solver, two possibilities were tested: in one case, the violated constraint with the lowest index was used, and in the other case, the most violated constraint was chosen. The latter one is the constraint for which the absolute value of the residual
is the greatest, with
a violated constraint from Equation (1). The results for both variants were equivalent in terms of
; however, the first variant required more iterations until the optimal solution was found, which led to a longer computing time. For this reason, the second option was used for the results presented in
Section 5. The corresponding segment of the EmbQP code selecting the violated constraint
is shown in
Table A4.
Table 4 shows a pseudo code of the EmbQP algorithm, using the method in
Table 2 and the input arguments of
Table 3.
Since the computation of the step sizes
and
and the dual variable
was taken from [
5,
14] and does not present any particular challenges for the implementation in C, it will not be addressed further here. However, the computation of the two matrices
and
, is an essential part of the algorithm and can be time-consuming if it is not done efficiently. It is explained in more detail in the following.
At every iteration of the algorithm, directions in the primal and dual space are computed by means of matrices
and
as specified in
Table 4 and step 3 of
Table 2. However, a direct evaluation of these matrices is not efficient. These matrices depend on the active set
, which differs only by one element from step to step because either an element is added to the active set or an element is removed from it. Taking advantage of this feature enables updating of the matrices
and
. Updating the appropriate decompositions of
and
reduces the effort for computing the step directions even more. The approach described in the following is based on [
5,
14]. At the beginning of the algorithm, the Cholesky decomposition of the objective function matrix
is carried out,
, and also the inverse of the lower triangular matrix
is computed:
For updating
and
, we assume that there exist matrices
and
with the following characteristics:
with
and an upper triangular matrix
, where
is the number of elements of the current active set
. The matrix
can be partitioned into two submatrices
where
comprises the first
columns of
and
comprises the last
columns. By exploiting this and substituting Equations (3) and (4) in the definition of the matrices
and
in step 3 of
Table 2, we obtain
Therefore, the matrices
and
can be expressed by means of the matrices
and
. By defining the vector
where
is the row of the matrix
with the index
, the vectors
and
can be expressed as
and
. Since
is an upper triangular matrix, the vector
can be easily calculated by backwards substitution. So, for computing the step directions, there is no need to determine the matrices
and
in every iteration. Updating
and
is sufficient and comprises all needed information. At the beginning of the algorithm, the active set
is empty and
. By choosing
with
from Equation (2), the prerequisites from Equation (3) are fulfilled in the first iteration of the algorithm. In the next steps, the updated matrix
is calculated by means of an orthogonal matrix
as
This approach can be used for both cases in the iteration, i.e., both when an element is added to
and when an element is removed from it. If an element
is added to
, the matrix
can be composed in this way:
The matrix
denotes the identity matrix in the
. With this approach, it follows with Equations (3) and (6):
Since the assumptions in Equation (3) must also be fulfilled in the next step, it follows that the matrix
must be chosen in a way that the product
is collinear with the first unit vector in the
. This can be achieved using Givens rotations. Thus, the matrix
is a product of
Givens rotations. They are successively multiplied with
and eliminate one component of the vector at a time, until
finally becomes collinear with the first unit vector. With
the matrix
needs to be successively multiplied with the Givens rotations. For
, it is:
where
denotes the first component of
. With (10) and (11), the matrices
and
can be updated by successively multiplying
and
with Givens rotations. These multiplications can be performed in one step in direct succession so that the Givens matrices do not have to be stored in each step, and the matrix
does not have to be calculated explicitly. In case an element is removed from the active set
, the same approach in Equation (7) can be used. We assume that the element
is removed, which is located at the position
of
. The operator
is defined to remove the row
of a matrix. With that, it is:
Using Equation (12) and the prerequisite from Equation (3), the following applies:
The operator
removes the
th column of
. The matrix
can be divided in submatrices:
with the upper triangular matrix
,
and
. Since
is an upper triangular matrix,
is an upper Hessenberg matrix. The matrix
is chosen as follows:
where
and
are identity matrices and
is an orthogonal matrix. Using Equations (15) and (14) in Equation (13) yields:
From that, it follows that
has to be chosen in a way that the product
becomes an upper triangular matrix. Again, Givens rotations are used. Therefore, the matrix
is a product of
Givens rotations, which are successively multiplied with
. Turning to the matrix
, we again use the partition from (4) and divide the matrix
into two further submatrices:
with
und
. With Equations (15) and (17), it is:
In
, only the columns
to
differ from
. The matrix
is multiplied with the same Givens rotations as
. This can again be carried out in parallel and without the need to explicitly determine the matrix
. With the described approach, the updating of the matrices
and
can be done efficiently, both when an element is added to the active set
and when an element is removed from it. All required algorithms for these computations, such as the Cholesky decomposition, Givens rotations, or backwards substitution, were implemented in C. The C function for computing plane Givens rotations used within the EmbQP solver is shown in
Table A5. As a consequence, the EmbQP algorithm is self-contained, and no external library is needed.
Furthermore, the C code was written in a way that adheres to the coding guidelines of Motor Industry Software Reliability Association (MISRA) [
16]. These guidelines aim at improving the quality of the C code by using only a subset of the C language with the objective of decreasing the incidence of undefined or unpredictable behaviors and of enhancing the reliability and maintainability of the code. In the automotive industry and safety-critical applications, the MISRA-C guidelines are established and typically required with the programming of embedded systems. One issue that comes up with the observance of the MISRA guidelines is the handling of input values from external sources. Their validity needs to be checked at the beginning of the algorithm. Another issue is the avoidance of dynamic memory allocation, which is resolved by the use of working arrays in the EmbQP code. Furthermore, the basic data types of C shall not be used directly. They are only allowed in type definitions. Thus, for each variable, the appropriate data type is defined according to its respective properties. Another example for the rules of the MISRA guidelines is the aspect that only one return or break statement is allowed to terminate an iteration. This was respected with the while loops in
Table 4 and implemented with additional if constructs. In summary, the EmbQP code was written in a way that respects the MISRA guidelines that are often required for safety-critical applications in the automotive sector.
5. Results of the Simulation
In this section, the EmbQP solver is assessed against the Fortran QL solver [
9] by means of comparative simulations of a path-following scenario with the ROMO. While using the Fortran QL solver, version 3.2, these simulations were already accomplished in [
11], which facilitates the comparison. The total simulation model comprising a complex vehicle dynamics model of the ROMO, the path-following control, and the control allocation-based motion control was established in [
11] using Modelica, an object-oriented modeling language for multiphysical systems, see [
21], and the software tool Dymola. Details about the modeling of the ROMO and the multiphysical Modelica components can be found in [
11].
For the comparison, the Fortran QL solver now only needed to be replaced by EmbQP, which is easy to accomplish, since both solvers can be interfaced into the Modelica environment using so-called external C functions. In the case of the Fortran QL solver, the Fortran code had been automatically converted from Fortran to C beforehand using f2c [
10]. The two solvers are compared with respect to the following criteria: the course of the solution vectors, the adherence to the constraints, the minimal objective function value, and the computing times.
The three matrices in the objective functions to be minimized in Equations (22)–(24), respectively, are chosen in a way that they are symmetric and either positive definite or positive semidefinite. In the latter case, a small multiple of the identity matrix is added to the positive semidefinite matrix during the optimization to obtain a positive definite one, as described in
Section 3.
The predefined path the vehicle should follow is specified by means of a look-up table used for interpolation. The simulation is performed for a path with a length of about 3083 m and with a sampling time of 0.004 s.
Figure 2 shows results of both the EmbQP solver and the QL solver for the QPs (23) and (24) for the fifth component of the eight-dimensional solution vector from (19), which is the drive torque for the front left wheel. In
Figure 2a, which shows the results for the entire path, there is hardly any difference to be observed between the two solutions.
Figure 2b shows a closer look at the first few steps of the simulation revealing discrepancies.
The differences are due to the fact that the two solvers do not solve the very same QPs in each time step. The EmbQP and the QL solver both are based on the same algorithm of Goldfarb and Idnani, but they represent different implementations in different programming languages. One difference is that the QL solver provides a separate handling of the lower and upper bounds [
9], while the EmbQP solver considers the bounds identical to the other linear constraints. Consequently, the two solvers provide slightly different results of the optimization. The two simulations, one with the QL solver and one with the EmbQP solver, have only in the first time step the same QP problem to be solved. The slightly varying results of the two solvers are used further and lead to a different position of the vehicle in the next time step and thus to different QPs that need to be optimized in the following time steps. Thus, slight differences in the solution of the solvers as in
Figure 2 are expected, since they solve different QPs, which impedes a comparison of the two solvers. Therefore, the comparison of the solvers has been carried out in a different manner for the following figures: both solvers solve the corresponding QPs in one time step, but only one solution is used for the next time step, and so on. To be more specific, in one simulation, the solution of the EmbQP solver is used for feedback in the next step of the motion control, while the QL solver also calculates solutions for the QPs, but these solutions are only used for comparison but are neglected for feedback. For a second simulation, it is done the other way round. With this proceeding, a better comparison of the two solvers is possible, because they solve QPs with the same input data in each time step.
First, the solution provided by the EmbQP solver is considered, while the QL solver runs simultaneously and solves the same QPs for a comparison.
Figure 3 shows the solutions of the two solvers obtained in this way for the QPs (23) and (24). The first and the fifth component of the solution vector from (19) are depicted. The results for the four steering angles and the four torques are similar, which is why only one component of each is shown here for better clarity.
Figure 3 also shows the lower and upper bounds for the respective component. It is noticeable that the solutions of both solvers remain within the limits and are very similar. Zooming in, as in
Figure 2b, does not result in both lines being visible separately, as they are close to each other. Therefore, the absolute difference is also plotted on a logarithmic scale. It is very slight and illustrates that both solvers find very similar solutions for these QPs.
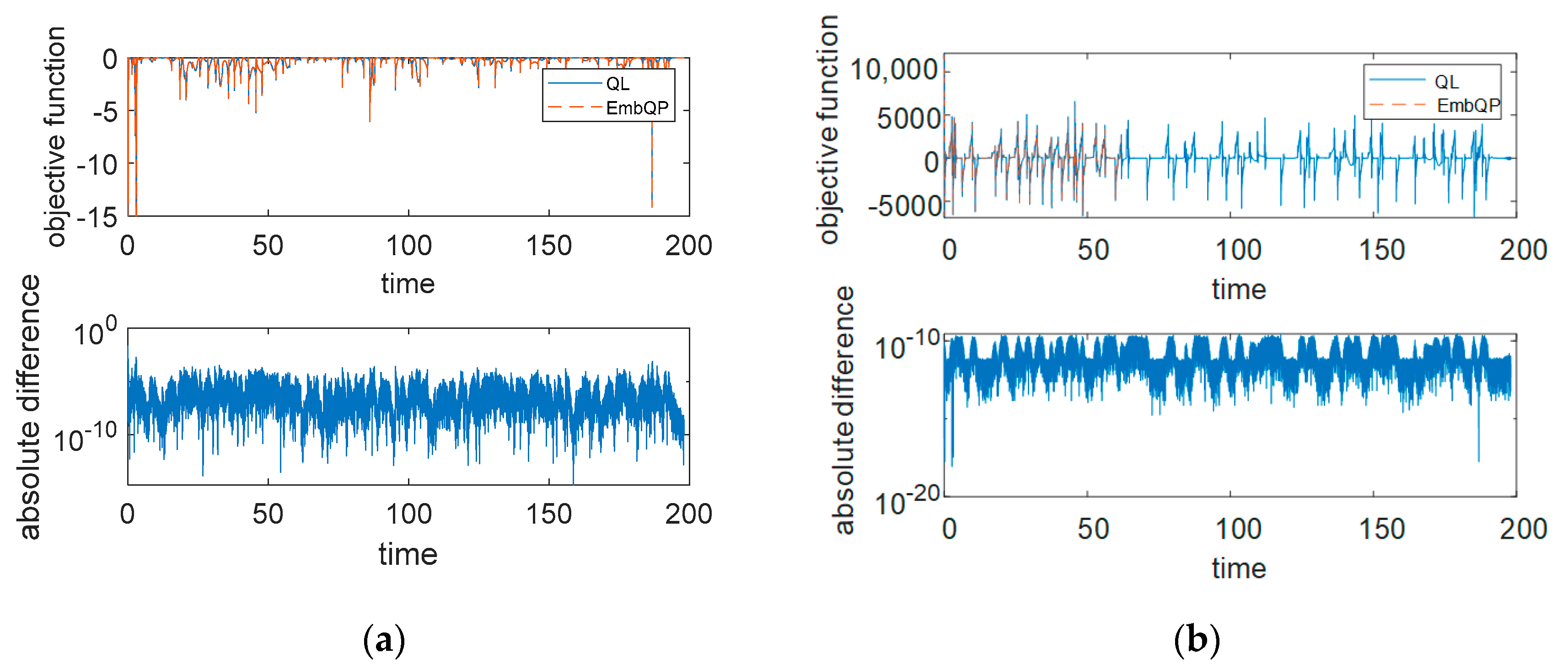
Figure 4 shows the optimal objective function value of the two solvers for the first QP (22) and the two QPs (23) and (24) as well as their respective absolute difference on a logarithmic scale. Since the solution vectors for QPs (23) and (24) are very similar, it is consequently also the objective function value. For QP (22), there are slightly larger differences.
The results mentioned above are obtained with the solution of the EmbQP solver, while the QL solver only runs in parallel and solves the same QPs in each time step. As a second simulation, the other way round is performed; that means the solution provided by the QL solver is considered, while the EmbQP solver runs simultaneously to solve the same problems and to enable a direct comparison. The solutions of the two solvers for the QPs (23) and (24) are very similar to the solutions in
Figure 3 and therefore are not shown here. Both solvers keep the limits, and again, the absolute differences between the two solvers are very small. The same holds for the objective function values corresponding to
Figure 4.
The C code was compiled using the Microsoft Visual C++ 2017 compiler. The test system on which the simulations were performed is a laptop with Intel i9-9980HK CPU @ 2.40GHz and 32GB RAM with Windows 10 (64 Bit) as operating system. The two solvers perform very similarly regarding the computing times. For this, the simulations have been carried out with only one of the solvers at a time. The simulation using the integration algorithm Dassl in Dymola yields an overall computing time of about 64 s for both solvers with a CPU time of about 1.3 ms for one grid interval of the simulation. Thus, the time for the simulation of one interval is considerably less than the sampling time of 4 ms. Since this simulation also includes the path-following controller and the vehicle model, the low computing time indicates the real-time capability of the solver.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




