
Intelligent Real-Time Deep System for Robust Objects Tracking in Low-Light Driving Scenario


Abstract
:1. Introduction
2. Related Work
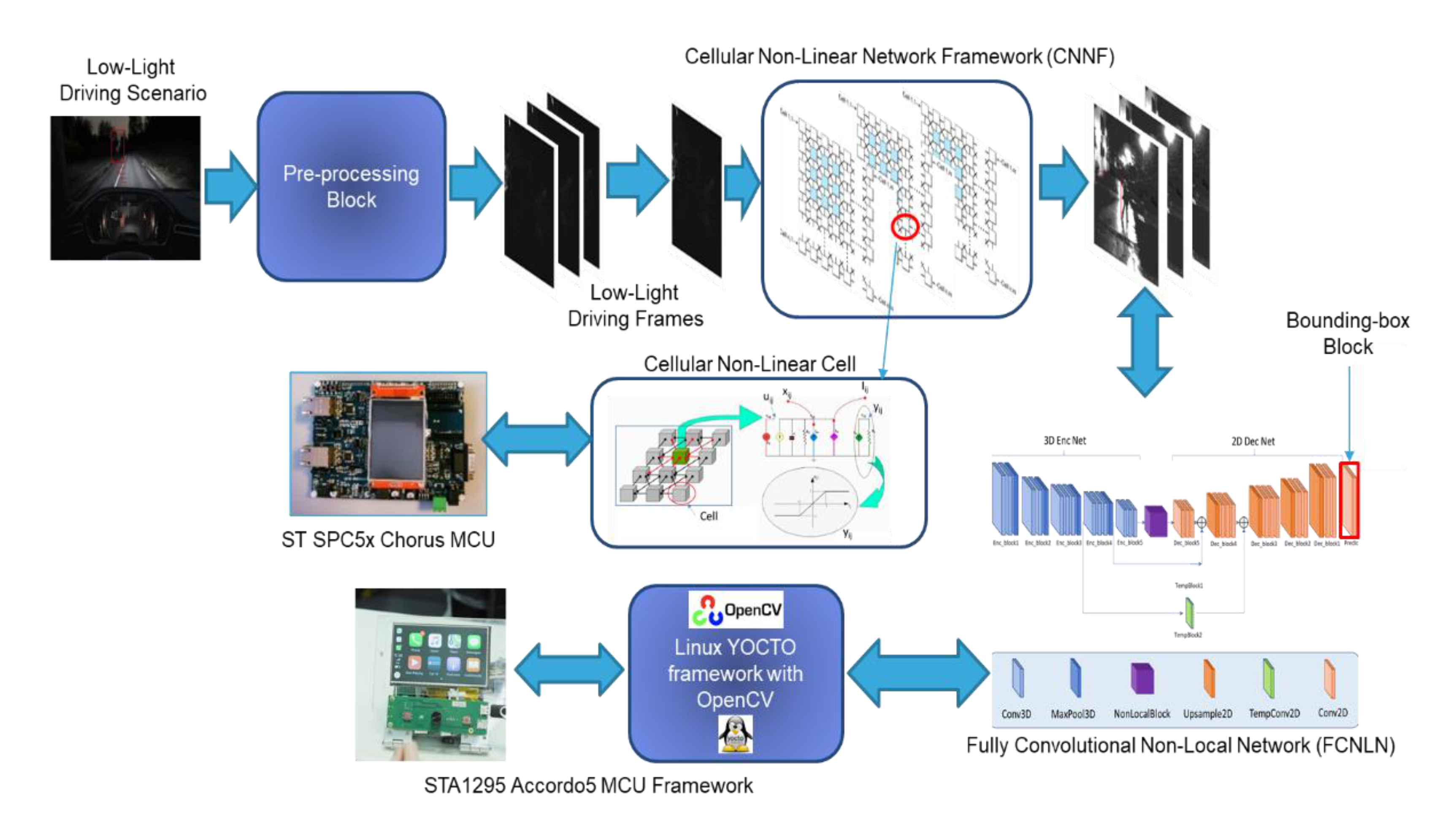
3. Materials and Methods
3.1. The Pre-Processing Block
3.2. The Cellular Non-Linear Network Framework
3.3. The Fully Convolutional Non-Local Network
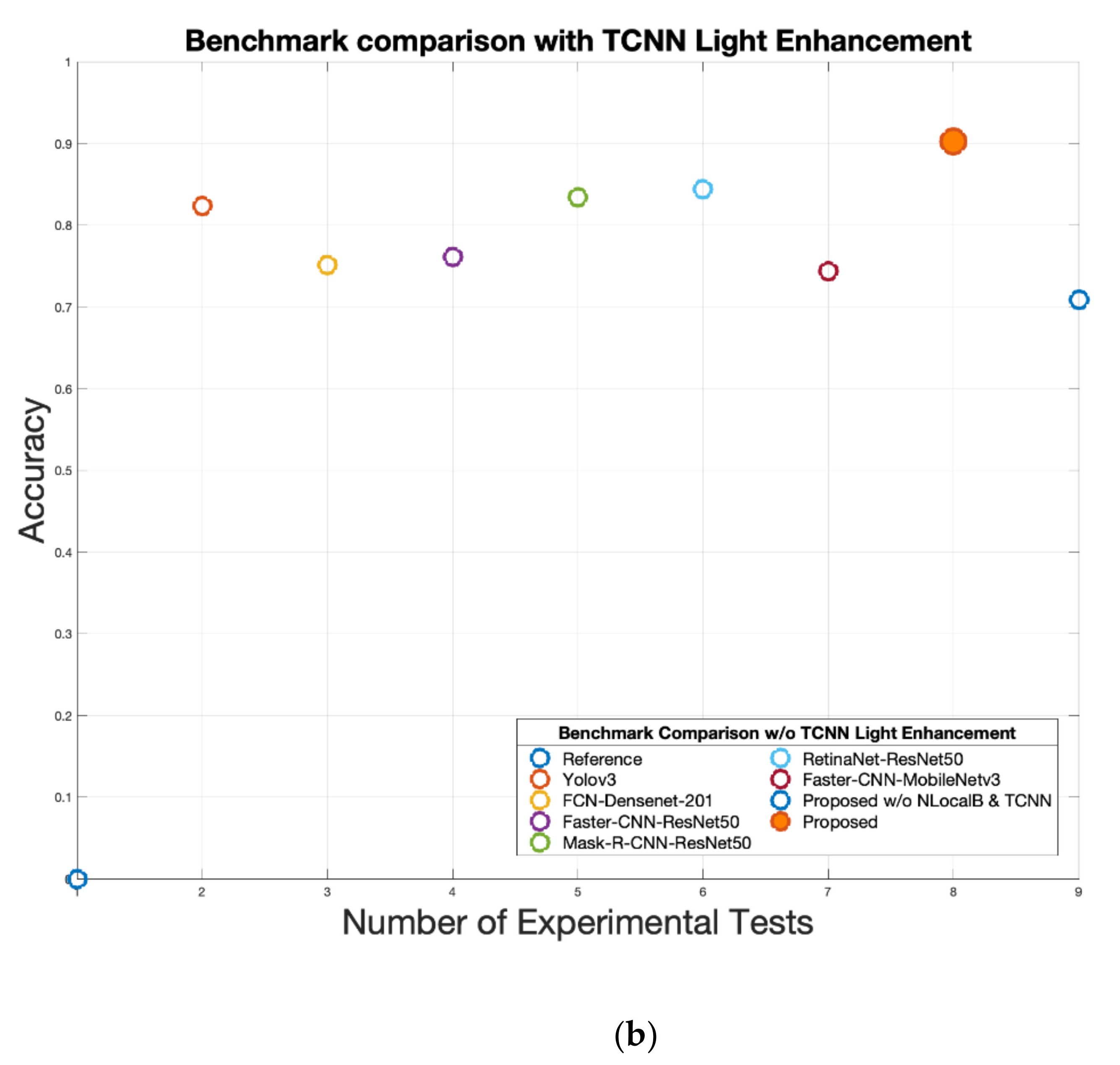
4. Experimental Results
5. Discussion and Conclusions
6. Patents
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Heimberger, M.; Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Computer vision in automated parking systems: Design, implementation and challenges. Image Vis. Comput. 2017, 68, 88–101. [Google Scholar] [CrossRef]
- Horgan, J.; Hughes, C.; McDonald, J.; Yogamani, S. Vision-Based Driver Assistance Systems: Survey, Taxonomy and Advances. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, New York, NY, USA, 15–18 September 2015; pp. 2032–2039. [Google Scholar]
- Pham, L.H.; Tran, D.N.-N.; Jeon, J.W. Low-Light Image Enhancement for Autonomous Driving Systems using DriveRetinex-Net. In Proceedings of the 2020 IEEE International Conference on Consumer Electronics-Asia (ICCE-Asia), Seoul, Korea, 1–3 November 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Rundo, F.; Conoci, S.; Spampinato, C.; Leotta, R.; Trenta, F.; Battiato, S. Deep Neuro-Vision Embedded Architecture for Safety Assessment in Perceptive Advanced Driver Assistance Systems: The Pedestrian Tracking System Use-Case. Front. Neuroinform. 2021, 15, 667008. [Google Scholar] [CrossRef] [PubMed]
- Rundo, F.; Petralia, S.; Fallica, G.; Conoci, S. A Nonlinear Pattern Recognition Pipeline for Ppg/Ecg Medical Assessments. In Convegno Nazionale Sensori; Sensors; Springer: Berlin/Heidelberg, Germany, 2018; pp. 473–480. [Google Scholar]
- Trenta, F.; Conoci, S.; Rundo, F.; Battiato, S. Advanced Motion-Tracking System with Multi-Layers Deep Learning Framework for Innovative Car-Driver Drowsiness Monitoring. In Proceedings of the 2019 14th IEEE International Conference on Automatic Face & Gesture Recognition (FG 2019), Lille, France, 14–18 May 2019; pp. 1–5. [Google Scholar]
- Rundo, F.; Rinella, S.; Massimino, S.; Coco, M.; Fallica, G.; Parenti, R.; Conoci, S.; Perciavalle, V. An innovative deep learning algorithm for drowsiness detection from eeg signal. Computation 2019, 7, 13. [Google Scholar] [CrossRef] [Green Version]
- Rundo, F.; Conoci, S.; Battiato, S.; Trenta, F.; Spampinato, C. Innovative Saliency Based Deep Driving Scene Understanding System for Automatic Safety Assessment in Next-Generation Cars. In Proceedings of the 2020 AEIT International Conference of Electrical and Electronic Technologies for Automotive (AEIT AUTOMOTIVE), Turin, Italy, 18–20 November 2020; pp. 1–6. [Google Scholar]
- Rundo, F.; Spampinato, C.; Battiato, S.; Trenta, F.; Conoci, S. Advanced 1D Temporal Deep Dilated Convolutional Embedded Perceptual System for Fast Car-Driver Drowsiness Monitoring. In Proceedings of the 2020 AEIT International Conference of Electrical and Electronic Technologies for Automotive (AEIT AUTOMOTIVE), Turin, Italy, 18–20 November 2020; pp. 1–6. [Google Scholar]
- Rundo, F.; Spampinato, C.; Conoci, S. Ad-hoc shallow neural network to learn hyper filtered photoplethysmographic (ppg) signal forefficient car-driver drowsiness monitoring. Electronics 2019, 8, 890. [Google Scholar] [CrossRef] [Green Version]
- Guo, Y.; Lu, Y.; Liu, R.W.; Yang, M.; Chui, K.T. Low-Light Image Enhancement with Regularized Illumination Optimization and Deep Noise Suppression. IEEE Access 2020, 8, 145297–145315. [Google Scholar] [CrossRef]
- Qu, Y.; Ou, Y.; Xiong, R. Low Illumination Enhancement for Object Detection In Self-Driving. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 1738–1743. [Google Scholar] [CrossRef]
- Chen, G.; Cao, H.; Conradt, J.; Tang, H.; Rohrbein, F.; Knoll, A. Event-Based Neuromorphic Vision for Autonomous Driving: A Paradigm Shift for Bio-Inspired Visual Sensing and Perception. IEEE Signal Process. Mag. 2020, 37, 34–49. [Google Scholar] [CrossRef]
- Rashed, H.; Ramzy, M.; Vaquero, V.; El Sallab, A.; Sistu, G.; Yogamani, S. FuseMODNet: Real-Time Camera and LiDAR Based Moving Object Detection for Robust Low-Light Autonomous Driving. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 2393–2402. [Google Scholar] [CrossRef] [Green Version]
- Deng, J.; Pang, G.; Wan, L.; Yu, Z. Low-light Image Enhancement based on Joint Decomposition and Denoising U-Net Network. In Proceedings of the 2020 IEEE Intl Conf on Parallel & Distributed Processing with Applications, Big Data & Cloud Computing, Sustainable Computing & Communications, Social Computing & Networking (ISPA/BDCloud/SocialCom/SustainCom), Exeter, UK, 17–19 December 2020; pp. 883–888. [Google Scholar] [CrossRef]
- Szankin, M.; Kwaśniewska, A.; Ruminski, J.; Nicolas, R. Road Condition Evaluation Using Fusion of Multiple Deep Models on Always-On Vision Processor. In Proceedings of the IECON 2018-44th Annual Conference of the IEEE Industrial Electronics Society, Washington, DC, USA, 21–23 October 2018; pp. 3273–3279. [Google Scholar] [CrossRef]
- Yang, W.; Wang, W.; Huang, H.; Wang, S.; Liu, J. Sparse Gradient Regularized Deep Retinex Network for Robust Low-Light Image Enhancement. IEEE Trans. Image Process. 2021, 30, 2072–2086. [Google Scholar] [CrossRef] [PubMed]
- Chua, L.O.; Yang, L. Cellular Neural Networks: Applications. IEEE Trans. Circuits Syst. 1988, 35, 1273–1290. [Google Scholar] [CrossRef]
- Chua, L.O.; Yang, L. Cellular Neural Networks: Theory. IEEE Trans. Circuits Syst. 1988, 35, 1257–1272. [Google Scholar] [CrossRef]
- Conoci, S.; Rundo, F.; Petralta, S.; Battiato, S. Advanced Skin Lesion Discrimination Pipeline for Early Melanoma Cancer Diagnosis towards PoC Devices. In Proceedings of the 2017 European Conference on Circuit Theory and Design (ECCTD), Catania, Italy, 4–6 September 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Mizutani, H. A New Learning Method for Multilayered Cellular Neural Networks. In Proceedings of the Third IEEE International Workshop on Cellular Neural Networks and their Applications (CNNA-94), Rome, Italy, 18–21 December 1994; pp. 195–200. [Google Scholar] [CrossRef]
- Cardarilli, G.C.; Lojacono, R.; Salerno, M.; Sargeni, F. VLSI Implementation of a Cellular Neural Network with Programmable Control Operator. In Proceedings of the 36th Midwest Symposium on Circuits and Systems, Detroit, MI, USA, 16–18 August 1993; Volume 2, pp. 1089–1092. [Google Scholar] [CrossRef]
- Roska, T.; Chua, L.O. Cellular Neural Networks with Nonlinear and Delay-Type Template Elements. In Proceedings of the IEEE International Workshop on Cellular Neural Networks and their Applications, Budapest, Hungary, 16–19 December 1990; pp. 12–25. [Google Scholar] [CrossRef]
- Arena, P.; Baglio, S.; Fortuna, L.; Manganaro, G. Dynamics of State Controlled CNNs. In Proceedings of the 1996 IEEE International Symposium on Circuits and Systems. Circuits and Systems Connecting the World. ISCAS 96, Atlanta, GA, USA, 12–15 May 1996; Volume 3, pp. 56–59. [Google Scholar] [CrossRef]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-Local Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7794–7803. [Google Scholar] [CrossRef] [Green Version]
- Rundo, F.; Banna, G.L.; Prezzavento, L.; Trenta, F.; Conoci, S.; Battiato, S. 3D Non-Local Neural Network: A Non-Invasive Biomarker for Immunotherapy Treatment Outcome Prediction. Case-Study: Metastatic Urothelial Carcinoma. J. Imaging 2020, 6, 133. [Google Scholar] [CrossRef] [PubMed]
- Min, K.; Corso, J.J. TASED-Net: Temporally-Aggregating Spatial Encoder-Decoder Network for Video Saliency Detection. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 2394–2403. [Google Scholar]
- STMicroelectronics ACCORDO 5 Automotive Microcontroller. Available online: https://www.st.com/en/automotive-infotainment-and-telematics/automotive-infotainment-socs.html?icmp=tt4379_gl_pron_nov2016 (accessed on 2 July 2019).
- Rundo, F.; Leotta, R.; Battiato, S. Real-Time Deep Neuro-Vision Embedded Processing System for Saliency-based Car Driving Safety Monitoring. In Proceedings of the 2021 4th International Conference on Circuits, Systems and Simulation (ICCSS), Kuala Lumpur, Malaysia, 26–28 May 2021; pp. 218–224. [Google Scholar] [CrossRef]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The oxford robotcar dataset. Int. J. Robot. Res. 2016, 36, 0278364916679498. [Google Scholar] [CrossRef]
- Loh, Y.P.; Chan, C.S. Getting to know low-light images with the Exclusively Dark dataset. Comput. Vis. Image Underst. 2019, 178, 30–42. [Google Scholar] [CrossRef] [Green Version]
- Jiao, L.; Zhang, F.; Liu, F.; Yang, S.; Li, L.; Feng, Z.; Qu, R. A Survey of Deep Learning-based Object Detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Jian, M.; Lam, K.; Dong, J.; Shen, L. Visual-Patch-Attention-Aware Saliency Detection. IEEE Trans. Cybern. 2015, 45, 1575–1586. [Google Scholar] [CrossRef] [PubMed]
- Jian, M.; Zhang, W.; Yu, H.; Cui, C.; Nie, X.; Zhang, H.; Yin, Y. Saliency detection based on directional patches extraction and principal local color contrast. J. Vis. Commun. Image Represent. 2018, 57, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Jian, M.; Wang, J.; Yu, H.; Wang, G.; Meng, X.; Yang, L.; Dong, J.; Yin, Y. Visual saliency detection by integrating spatial position prior of object with background cues. Expert Syst. Appl. 2021, 168, 114219. [Google Scholar] [CrossRef]
- Jian, M.; Qi, Q.; Dong, J.; Yin, Y.; Lam, K.-M. Integrating QDWD with pattern distinctness and local contrast for underwater saliency detection. J. Vis. Commun. Image Represent. 2018, 53, 31–41. [Google Scholar] [CrossRef]
- Rundo, F. Deep LSTM with Reinforcement Learning Layer for Financial Trend Prediction in FX High Frequency Trading Systems. Appl. Sci. 2019, 9, 4460. [Google Scholar] [CrossRef] [Green Version]
- Ortis, A.; Rundo, F.; Di Giore, G.; Battiato, S. Adaptive Compression of Stereoscopic Images. In Image Analysis and Processing–ICIAP 2013; Petrosino, A., Ed.; ICIAP 2013; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 8156. [Google Scholar] [CrossRef] [Green Version]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pipeline | Number of Detected Objects | Accuracy | NSS | CC |
|---|---|---|---|---|
| Ground Truth | 12,115 | / | / | / |
| Yolo V3 | 7878 | 0.650 | 1.552 | 0.331 |
| FCN DenseNet-201 backbone | 8321 | 0.686 | 1.654 | 0.340 |
| Faster-R-CNN ResNet-50 backbone | 8050 | 0.664 | 1.614 | 0.338 |
| Mask-R-CNN ResNet-50 backbone | 9765 | 0.806 | 2.003 | 0.377 |
| RetinaNet ResNet50 backbone | 9991 | 0.824 | 2.45 | 0.441 |
| Faster-CNN MobileNetv3 backbone | 7988 | 0.650 | 1.542 | 0.329 |
| Proposed | 10,937 | 0.902 | 2.654 | 0.488 |
| Proposed w/o Non-Local Blocks | 9.601 | 0.792 | 1.998 | 0.371 |
| Pipeline | Number of Detected Objects | Accuracy | NSS | CC |
|---|---|---|---|---|
| Ground Truth | 12,115 | / | / | / |
| Yolo V3 | 9980 | 0.823 | 2.425 | 0.441 |
| FCN DenseNet201 backbone | 9106 | 0.751 | 1.857 | 0.359 |
| Faster-R-CNN ResNet-50 backbone | 9230 | 0.761 | 1.899 | 0.362 |
| Mask-R-CNN ResNet-50 backbone | 10,115 | 0.834 | 2.502 | 0.461 |
| RetinaNet ResNet50 backbone | 10.227 | 0.844 | 2.539 | 0.469 |
| Faster CNN MobileNet v3 backbone | 9003 | 0.743 | 1.809 | 0.351 |
| Proposed | 10,937 | 0.902 | 2.654 | 0.488 |
| Proposed w/o NLocal Blocks & TCNN | 8.587 | 0.708 | 1.691 | 0.350 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rundo, F. Intelligent Real-Time Deep System for Robust Objects Tracking in Low-Light Driving Scenario. Computation 2021, 9, 117. https://doi.org/10.3390/computation9110117
Rundo F. Intelligent Real-Time Deep System for Robust Objects Tracking in Low-Light Driving Scenario. Computation. 2021; 9(11):117. https://doi.org/10.3390/computation9110117
Chicago/Turabian StyleRundo, Francesco. 2021. "Intelligent Real-Time Deep System for Robust Objects Tracking in Low-Light Driving Scenario" Computation 9, no. 11: 117. https://doi.org/10.3390/computation9110117
APA StyleRundo, F. (2021). Intelligent Real-Time Deep System for Robust Objects Tracking in Low-Light Driving Scenario. Computation, 9(11), 117. https://doi.org/10.3390/computation9110117