Technology Integration and Analysis Using Boosting and Ensemble


Abstract
1. Introduction
2. Machine Learning for Technology Analysis
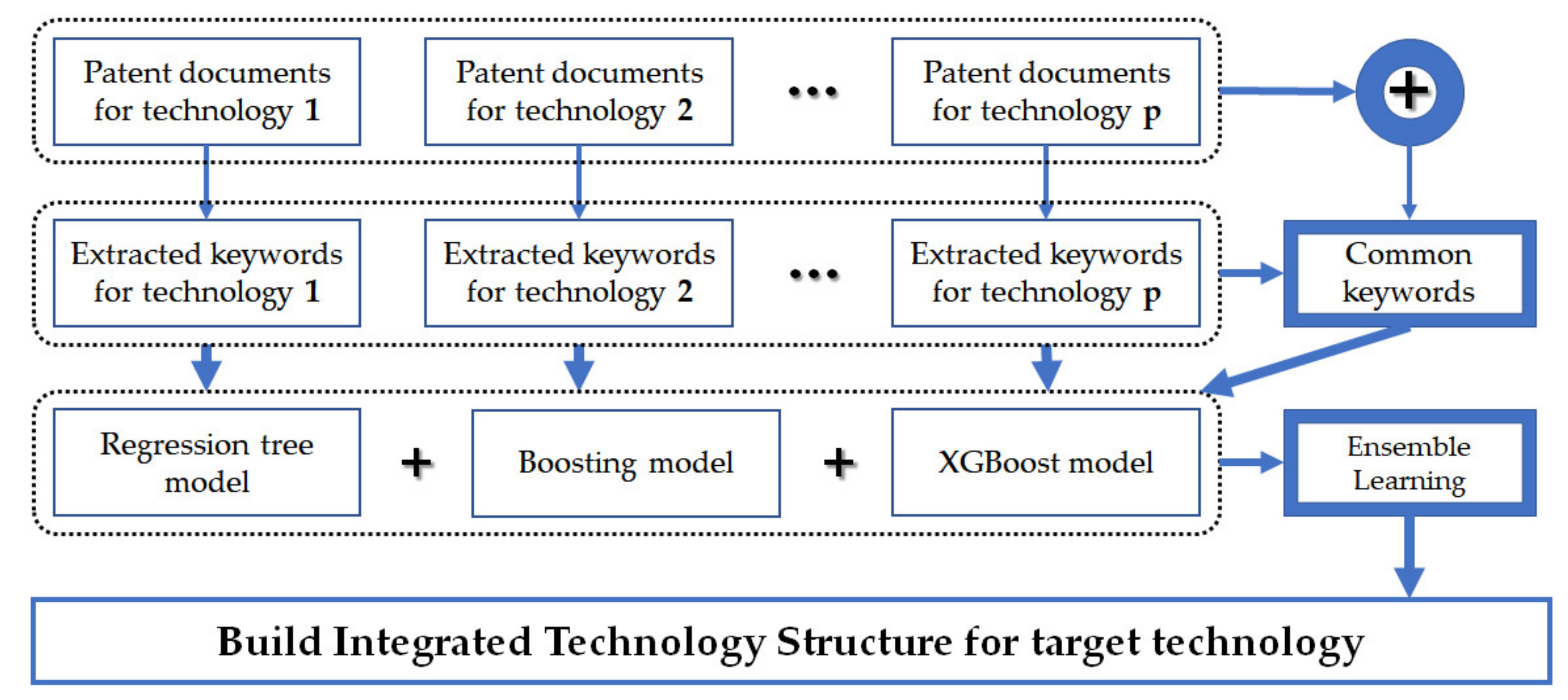
3. Boosting and Ensemble Models for Technology Integration and Analysis
- (Step 1)
- Given data (n: the number of data points, p: the number of variables)
- (1-1)
- Determine m (the number of sampled variables),
- (Step 2)
- Carry out bootstrap
- (2-1)
- Sample n data points with replacement
- (2-2)
- Sample m variables at random without replacement
- (Step 3)
- Apply tree splitting algorithm to p sampled variables
- (3-1)
- Given value t of X splitting node A into two sub nodes
- (3-2)
- as one partition (sub node) and as another partition (sub node)
- (3-3)
- Choose optimal t to minimize homogeneity within node
- (Step 4)
- Perform next split
- (4-1)
- Repeat (Step 2) and (Step 3) until the conditions for stopping tree growth are satisfied
- (Step 1)
- Initialize and K = the number of models
- (Step 2)
- Iterate k = 1, 2, …, K
- (2-1)
- Train a model minimizing weighted error using weights
- (2-2)
- Compute = sum of weights for misclassified observations
- (2-3)
- Compute
- (2-4)
- Add ensemble mode
- (2-5)
- Update increased in proportion to
- (Step 3)
- Repeat Step 2 until k = K
- (3-1)
- Estimate boosted model
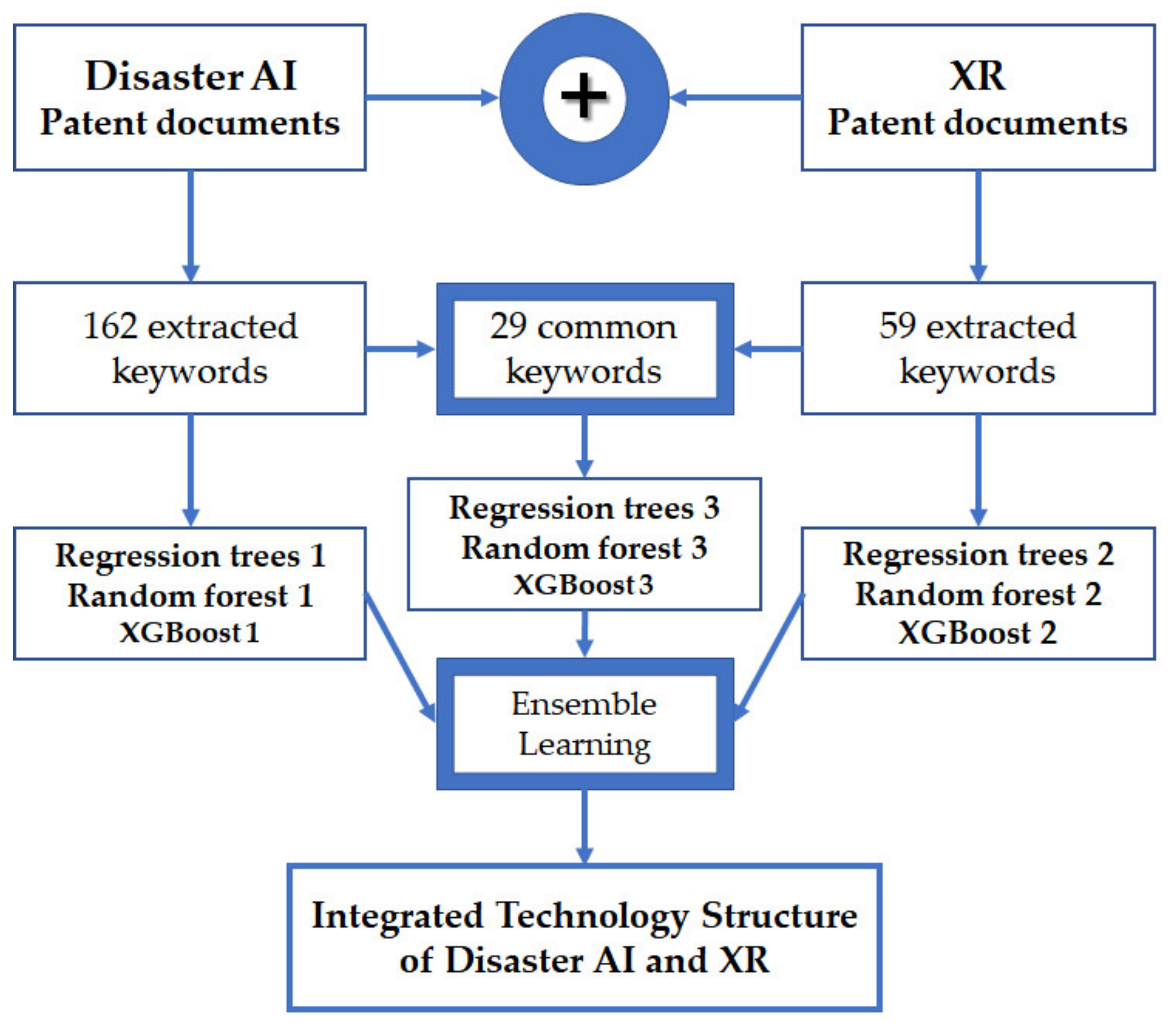
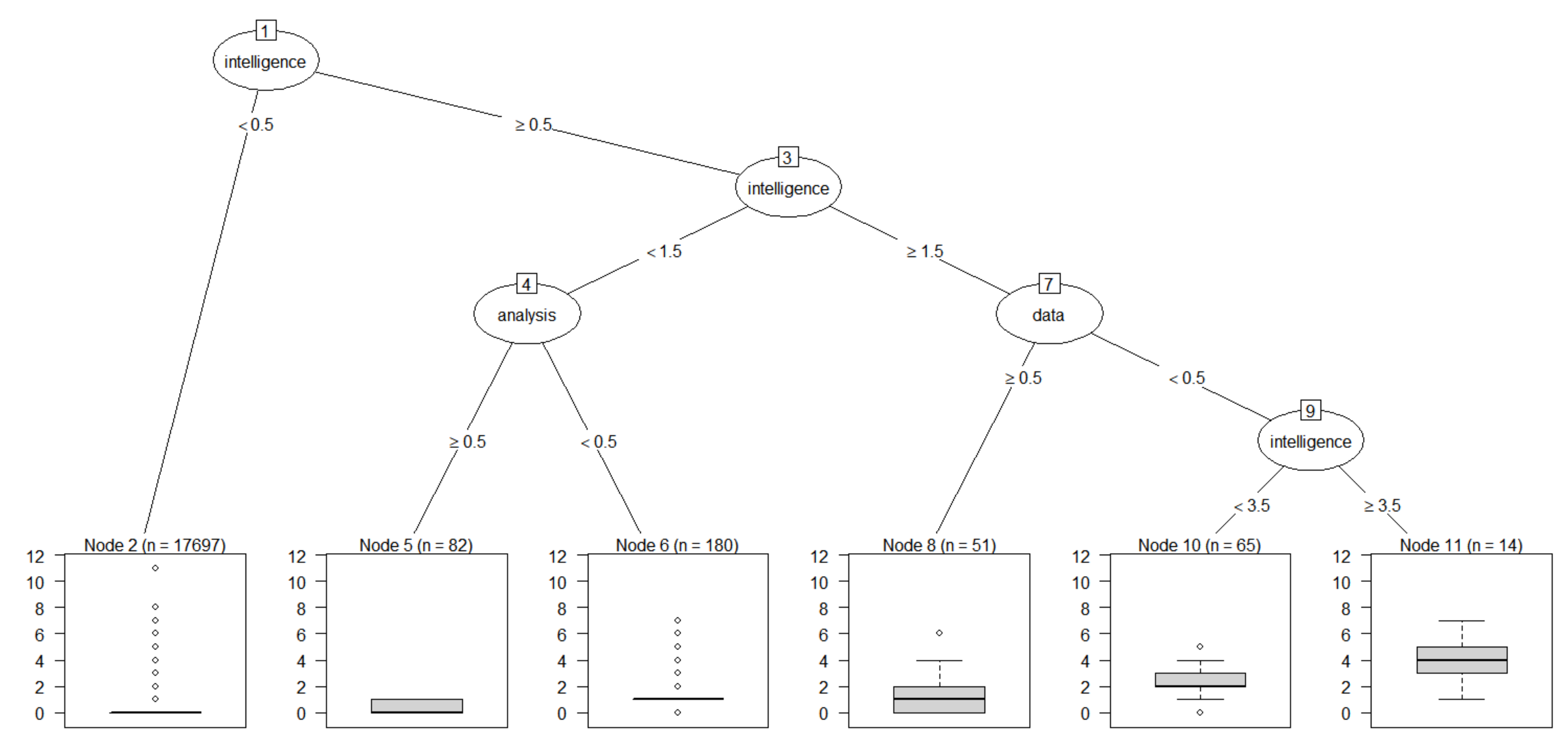
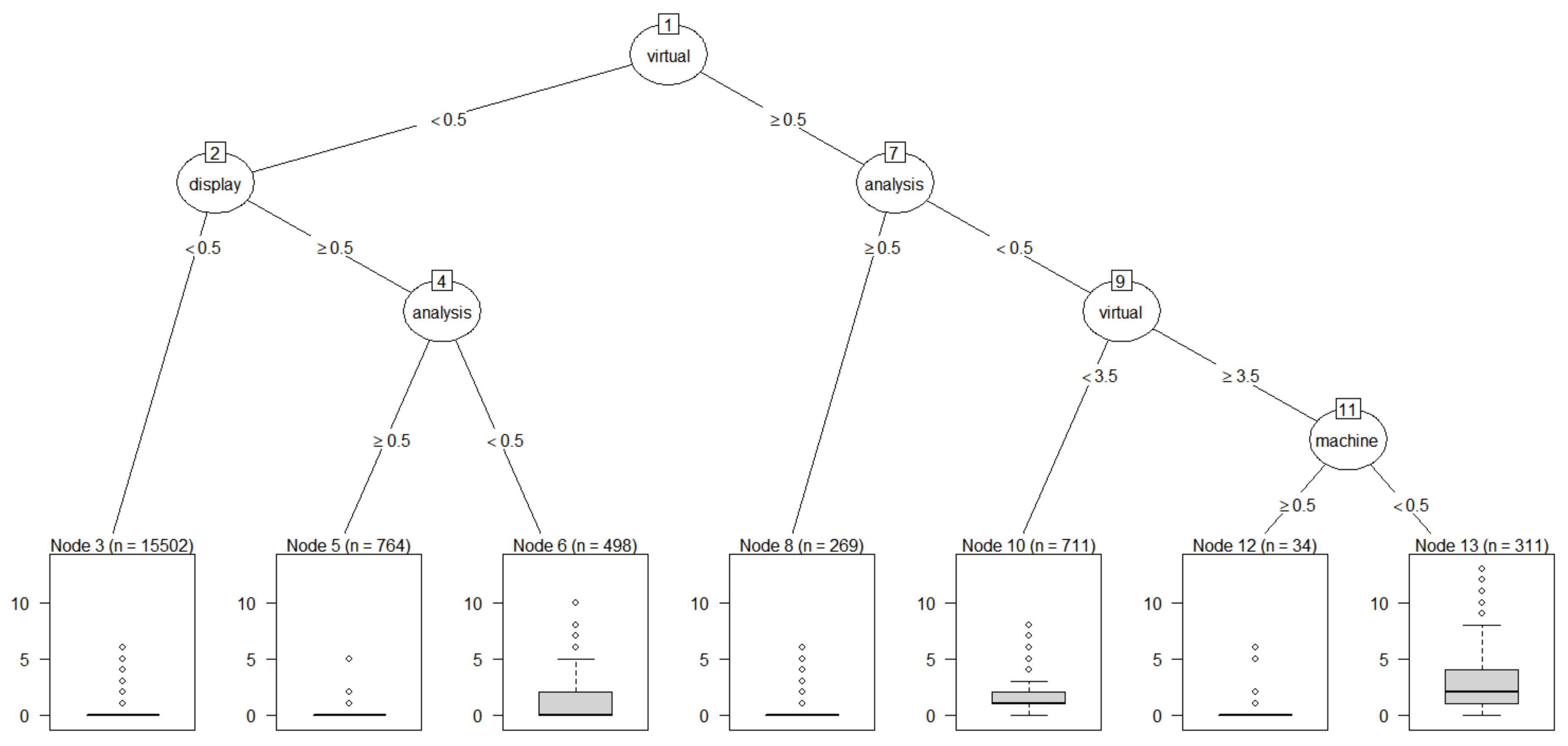
4. Case Study Using Disaster AI and Extended Reality Technologies
5. Discussion
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Roper, A.T.; Cunningham, S.W.; Porter, A.L.; Mason, T.W.; Rossini, F.A. Banks, Forecasting and Management of Technology; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Kim, J.; Jun, S.; Jang, D.; Park, S. Sustainable Technology Analysis of Artificial Intelligence Using Bayesian and Social Network Models. Sustainability 2018, 10, 115. [Google Scholar] [CrossRef]
- Lee, J.; Kang, J.; Jun, S.; Lim, H.; Jang, D.; Park, S. Ensemble Modeling for Sustainable Technology Transfer. Sustainability 2018, 10, 2278. [Google Scholar] [CrossRef]
- Park, S.; Jun, S. Statistical Technology Analysis for Competitive Sustainability of Three Dimensional Printing. Sustainability 2017, 9, 1142. [Google Scholar] [CrossRef]
- Wanga, L.; Jiang, S.; Zhang, S. Mapping technological trajectories and exploring knowledge sources: A case study of 3D printing technologies. Technol. Forecast. Soc. Chang. 2020, 161, 120251. [Google Scholar] [CrossRef]
- Park, S.; Jun, S. Patent Keyword Analysis of Disaster Artificial Intelligence Using Bayesian Network Modeling and Factor Analysis. Sustainability 2020, 12, 505. [Google Scholar] [CrossRef]
- Kim, J.; Jun, S. Integer-Valued GARCH Processes for Apple Technology Analysis. Ind. Manag. Data Syst. 2017, 117, 2381–2399. [Google Scholar] [CrossRef]
- Park, S.; Jun, S. Technology Analysis of Global Smart Light Emitting Diode (LED) Development Using Patent Data. Sustainability 2017, 9, 1363. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Theodoridis, S. Machine Learning: A Bayesian and Optimization Perspective; Elsevier: London, UK, 2015. [Google Scholar]
- Keller, J.; Gracht, H.A.V.D. The influence of information and communication technology (ICT) on future foresight processes—Results from a Delphi survey. Technol. Forecast. Soc. Chang. 2014, 85, 81–92. [Google Scholar] [CrossRef]
- Uhm, D.; Ryu, J.; Jun, S. Patent Data Analysis of Artificial Intelligence Using Bayesian Interval Estimation. Appl. Sci. 2020, 10, 570. [Google Scholar] [CrossRef]
- Kim, J.; Yoon, J.; Hwang, S.; Jun, S. Patent Keyword Analysis Using Time Series and Copula Models. Appl. Sci. 2019, 9, 4071. [Google Scholar] [CrossRef]
- Efron, B.; Hastie, T. Computer Age Statistical Inference; Cambridge University Press: New York, NY, USA, 2017. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A Scalable Tree Boosting System. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Chen, C.; Zhang, Q.; Yu, B.; Yu, Z.; Lawrence, P.J.; Ma, Q.; Zhange, Y. Improving protein-protein interactions prediction accuracy using XGBoost feature selection and stacked ensemble classifier. Comput. Biol. Med. 2020, 123, 103899. [Google Scholar] [CrossRef]
- Silge, J.; Robinson, D. Text mining with R.; O’Reilly: Sebastopol, CA, USA, 2017. [Google Scholar]
- Han, J.; Kamber, M.; Pei, J. Data Mining: Concepts and Techniques, 3rd ed.; Morgan Kaufmann: Waltham, MA, USA, 2012. [Google Scholar]
- Bruce, P.; Bruce, A.; Gedeck, P. Practical Statistics for Data Scientists; O’Reilly Media: Sebastopol, CA, USA, 2020. [Google Scholar]
- WIPSON. WIPS Corporation. Available online: http://global.wipscorp.com/main.do (accessed on 15 December 2019).
- USPTO. The United States Patent and Trademark Office. Available online: http://www.uspto.gov (accessed on 15 December 2019).
- KIPRIS. Korea Intellectual Property Rights Information Service. Available online: http://www.kipris.or.kr (accessed on 15 June 2020).
- Jeršov, S.; Tepljakov, A. Digital Twins in Extended Reality for Control System Applications. In Proceedings of the International Conference on Telecommunications and Signal Processing, Budapest, Hungary, 6–8 July 2020; pp. 274–279. [Google Scholar]
- Tromp, J.G.; Le, D.N.; Le, C.V. Emerging Extended Reality Technologies for Industry 4.0: Experiences with Conception, Design, Implementation, Evaluation and Deployment; Wiley: Hoboken, NJ, USA, 2020. [Google Scholar]
- Köse, A.; Tepljakov, A.; Petlenkov, E. Real Time Data Communication for Intelligent Extended Reality Applications. In Proceedings of the IEEE International Conference on Computational Intelligence and Virtual Environments for Measurement Systems and Applications, Tunis, Tunisia, 22–24 June 2020; pp. 1–6. [Google Scholar]
- Palmas, F.; Klinker, G. Defining Extended Reality Training: A Long-Term Definition for All Industries. In Proceedings of the IEEE 20th International Conference on Advanced Learning Technologies, Tartu, Estonia, 6–9 July 2020; pp. 322–324. [Google Scholar]
- Jun, S. Robust Generalized Linear Model for Sparse Text Data Analysis. J. Korean Inst. Intell. Syst. 2020, 30, 391–397. [Google Scholar] [CrossRef]
- R Development Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria. Available online: http://www.R-project.org (accessed on 15 July 2019).
- Feinerer, I.; Hornik, K. Package ‘tm’ Ver. 0.7-5, Text Mining Package, CRAN of R Project. Available online: https://cran.r-project.org/web/packages/tm/tm.pdf (accessed on 15 January 2020).
- Therneau, T.; Atkinson, B.; Ripley, B. Package ‘rpart’ Ver. 4.1-15, Recursive Partitioning and Regression Trees, CRAN of R Project. Available online: https://cran.r-project.org/web/packages/rpart/rpart.pdf (accessed on 1 January 2020).
- Breiman, L.; Cutler, A.; Liaw, A.; Wiener, M. Package ‘randomForest’ Ver. 4.6-14, Breiman and Cutler’s Random Forests for Classification and Regression, CRAN of R Project. Available online: https://cran.r-project.org/web/packages/randomForest/randomForest.pdf (accessed on 1 January 2020).
- Chen, T.; He, T.; Benesty, M.; Khotilovich, V.; Tang, Y.; Cho, H.; Chen, K.; Mitchell, R.; Cano, I.; Zhou, T.; et al. Package ‘xgboost’ Ver. 1.2.0.1, Extreme Gradient Boosting, CRAN of R Project. Available online: https://cran.r-project.org/web/packages/xgboost/xgboost.pdf (accessed on 1 January 2020).













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Technology | Keyword |
|---|---|
| Disaster AI | Abnormal, acoustic, air, alarm, amplitude, analysis, antenna, artificial, audio, automatic, band, battery, beam, big, cable, camera, car, channel, cloud, cluster, coal, communication, computing, cylinder, damage, data, database, deep, depth, detection, device, diagnosis, digital, disaster, display, earth, earthquake, echo, edge, electric, energy, engine, engineering, environment, estimation, fault, feedback, fire, flow, fluid, forecast, frame, fuzzy, gas, geological, grid, health, hole, human, image, information, intelligence, interaction, interface, land, language, laser, layer, learning, life, light, lightning, liquid, machine, magnetic, map, measurement, memory, metal, mobile, monitoring, natural, negative, network, neural, node, normal, oil, optical, parallel, patient, pattern, physical, picture, pipe, pipeline, pixel, plane, platform, power, prediction, pressure, probability, protection, protocol, pulse, pump, radar, radio, remote, risk, road, robot, rock, sampling, satellite, scale, scanning, sea, security, seismic, sensor, signal, software, soil, space, spatial, speed, stability, statistics, steel, stream, surface, switch, tank, temperature, time, transmission, tree, tunnel, turbine, ultrasonic, underground, user, valve, vehicle, velocity, video, virtual, visual, voice, voltage, warning, water, wave, waveform, wavelet, weather, web, wheel, wind, wire, and wireless. |
| XR | Configure, control, data, device, display, environment, extend, generate, image, object, position, reality, surface, system, user, virtual, association, augment, computing, connect, content, information, layer, light, optical, physical, present, receive, region, sensor, signal, space, structure, video, view, arrange, assemble, camera, capture, communication, component, contact, detect, edge, electric, eye, face, head, interaction, interface, map, mobile, move, render, rotate, scene, time, visual, wall |
| Disaster AI ∩ XR | Data, device, display, environment, image, surface, user, virtual, computing, information, layer, light, optical, physical, sensor, signal, space, video, camera, communication, detect, edge, electric, interaction, interface, map, mobile, time, visual |
| Target | Important Explanatory Keywords | Mean CP | Mean RE |
|---|---|---|---|
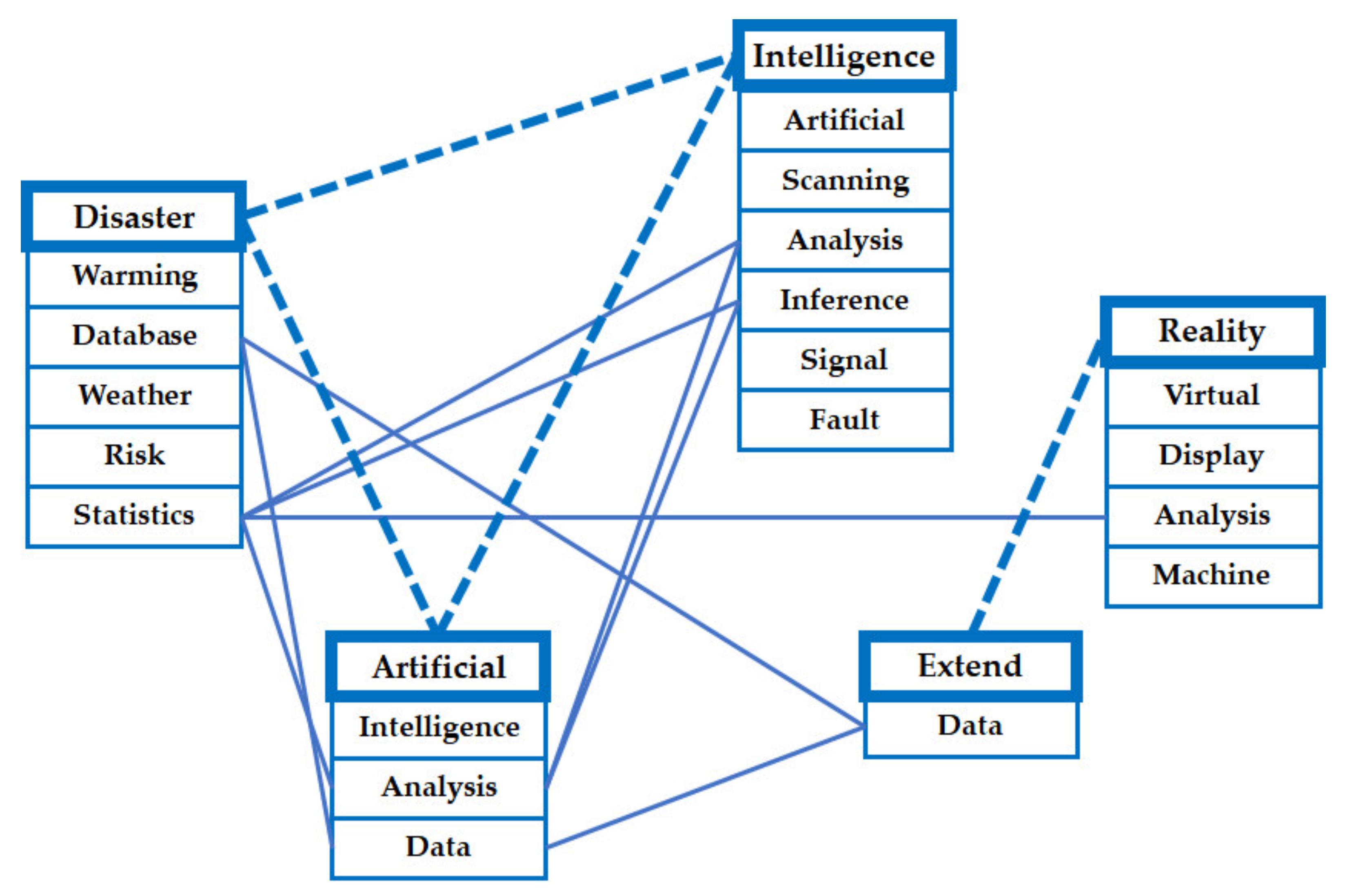
| Disaster | Warming, database, weather, risk, statistics | 0.0136 | 0.9572 |
| Artificial | Intelligence, analysis, data | 0.0481 | 0.7940 |
| Intelligence | Artificial, scanning, analysis, interface, signal, fault | 0.0500 | 0.7070 |
| Extend | Data | 0.0143 | 0.9907 |
| Reality | Virtual, display, analysis, machine | 0.0688 | 0.6971 |
| Importance Ranking | Target | ||||
|---|---|---|---|---|---|
| Disaster | Artificial | Intelligence | Extend | Reality | |
| 1 2 3 4 5 6 7 8 9 10 | Database Monitoring Depth Warming Risk Satellite Information Node Valve Air | Intelligence System Data User Signal Analysis Robot Information Environment Sensor | Artificial Fire User System Interface Environment Data Analysis Communication Memory | Device Present Wall Data Surface System Structure Layer Head Position | Virtual Display Analysis User View Content Data System Device Environment |
| Target | Features |
|---|---|
| Disaster | Extend, rotate, warning, arrange, present, move, assemble, configure, augment, generate |
| Artificial | Intelligence, extend, neural, configure, robot, augment, statistics, move, reality, natural |
| Intelligence | Artificial, extend, augment, move, arrange, statistics, rotate, robot, reality, generate |
| Extend | Arrange, statistics, present, generate, reality, augment, configure, artificial, tree, band |
| Reality | Augment, assemble, extend, render, configure, virtual, arrange, view, display, statistics |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jun, S. Technology Integration and Analysis Using Boosting and Ensemble. J. Open Innov. Technol. Mark. Complex. 2021, 7, 27. https://doi.org/10.3390/joitmc7010027
Jun S. Technology Integration and Analysis Using Boosting and Ensemble. Journal of Open Innovation: Technology, Market, and Complexity. 2021; 7(1):27. https://doi.org/10.3390/joitmc7010027
Chicago/Turabian StyleJun, Sunghae. 2021. "Technology Integration and Analysis Using Boosting and Ensemble" Journal of Open Innovation: Technology, Market, and Complexity 7, no. 1: 27. https://doi.org/10.3390/joitmc7010027
APA StyleJun, S. (2021). Technology Integration and Analysis Using Boosting and Ensemble. Journal of Open Innovation: Technology, Market, and Complexity, 7(1), 27. https://doi.org/10.3390/joitmc7010027