
An Overview of Knowledge Graph Reasoning: Key Technologies and Applications



 and
and 
Abstract
1. Introduction
2. Brief Introduction to Knowledge Graphs
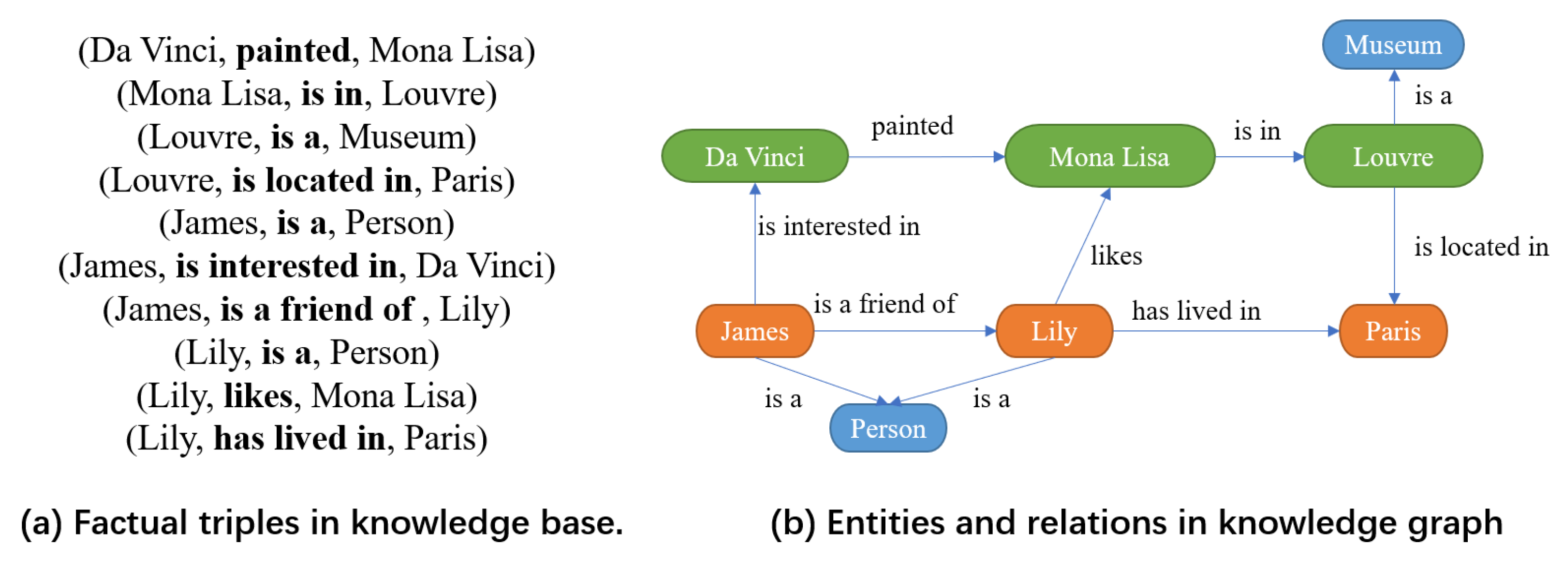
2.1. Knowledge Representation
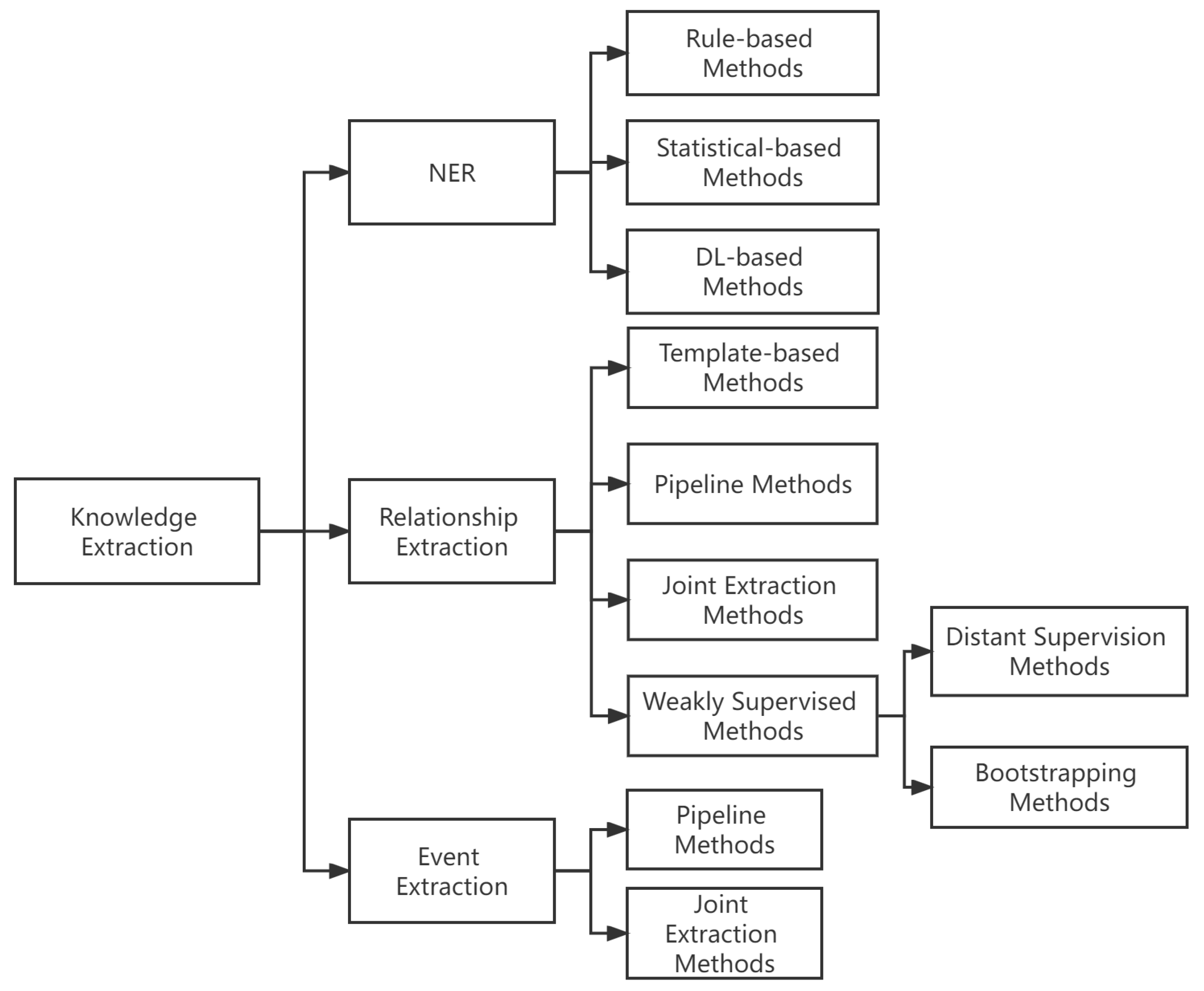
2.2. Knowledge Extraction
- Named entity recognition: the detection of named entities from text and classification of them into predefined categories, such as person, organization, place, time, etc. In general, named entity recognition is the basis of other knowledge extraction tasks.
- Relationship extraction: the identification and extraction of entities and relationships between entities from the text. For example, from the sentence “[Steve Jobs] is one of the founders of [Apple]”, the entities “[Steve Jobs]” and “[Apple]” are identified as having a “is-founder-of” relationship.
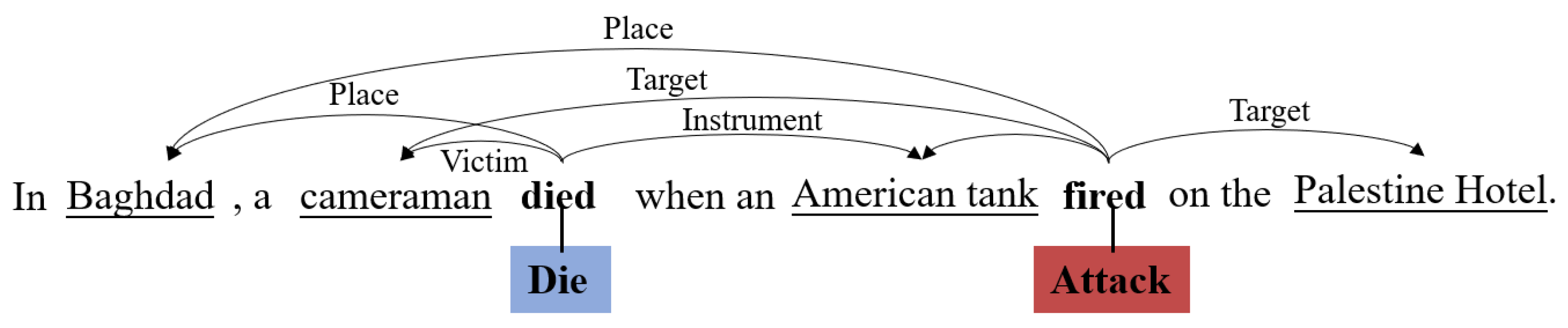
- Event extraction: the identification of the information about the event in the text and presentation of it in a structured form. For example, information such as location, time, target, and victim can be identified from news reports of terrorist attacks.
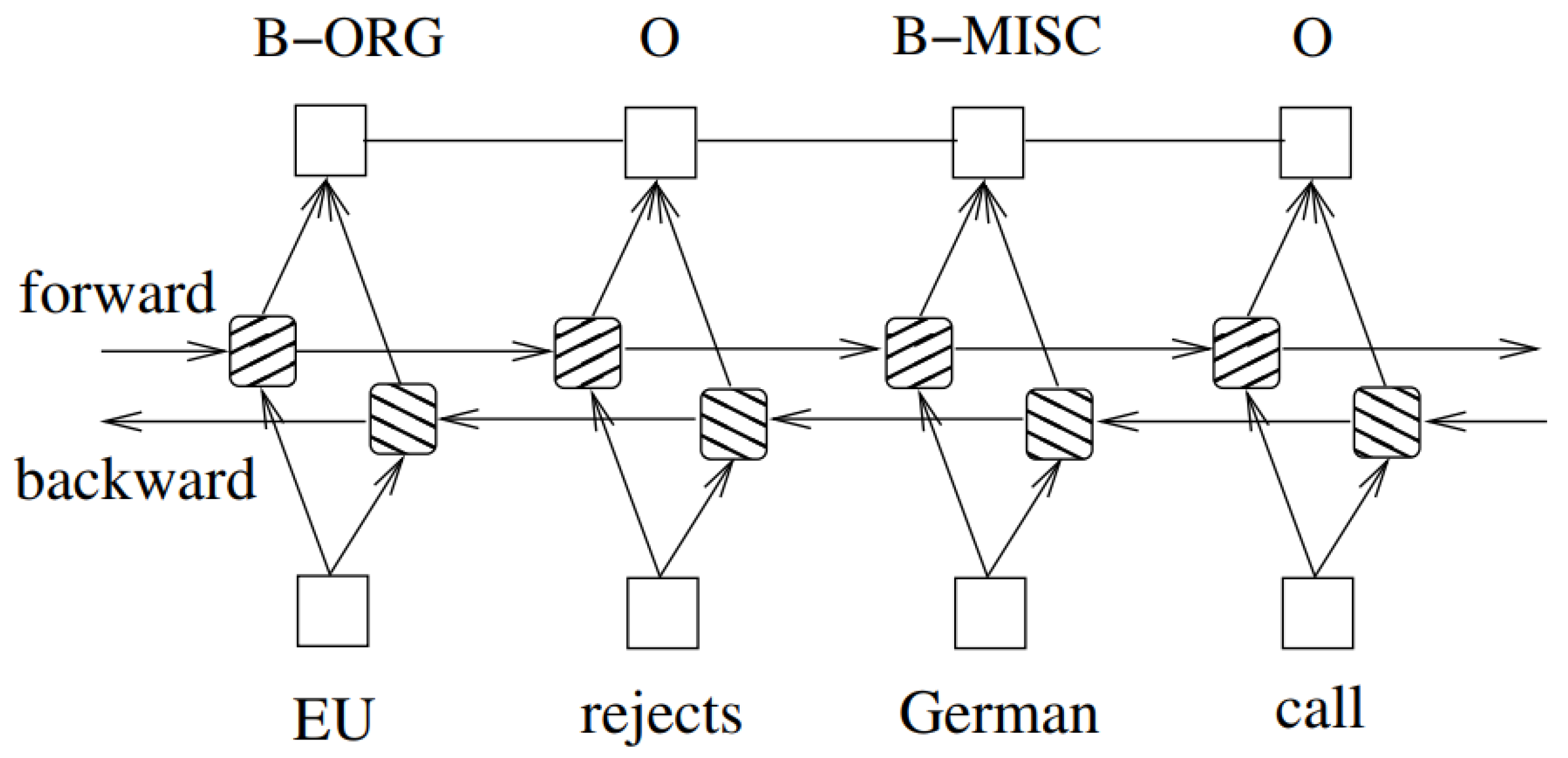
2.2.1. Named Entity Recognition
2.2.2. Relationship Extraction
2.2.3. Event Extraction
2.3. Knowledge Fusion
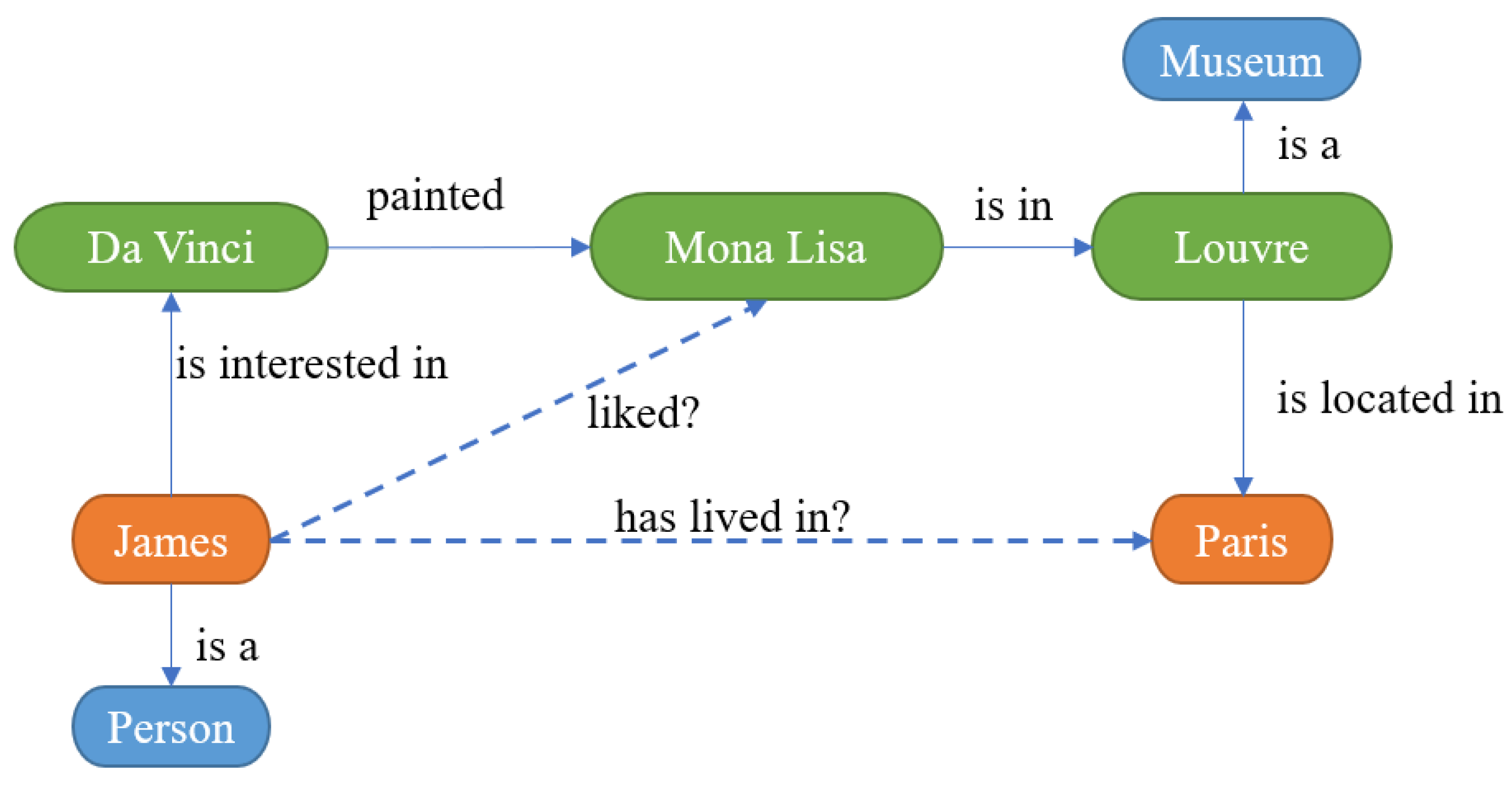
3. Knowledge Graph Reasoning
3.1. Introduction
3.2. Methods of Knowledge Graph Reasoning
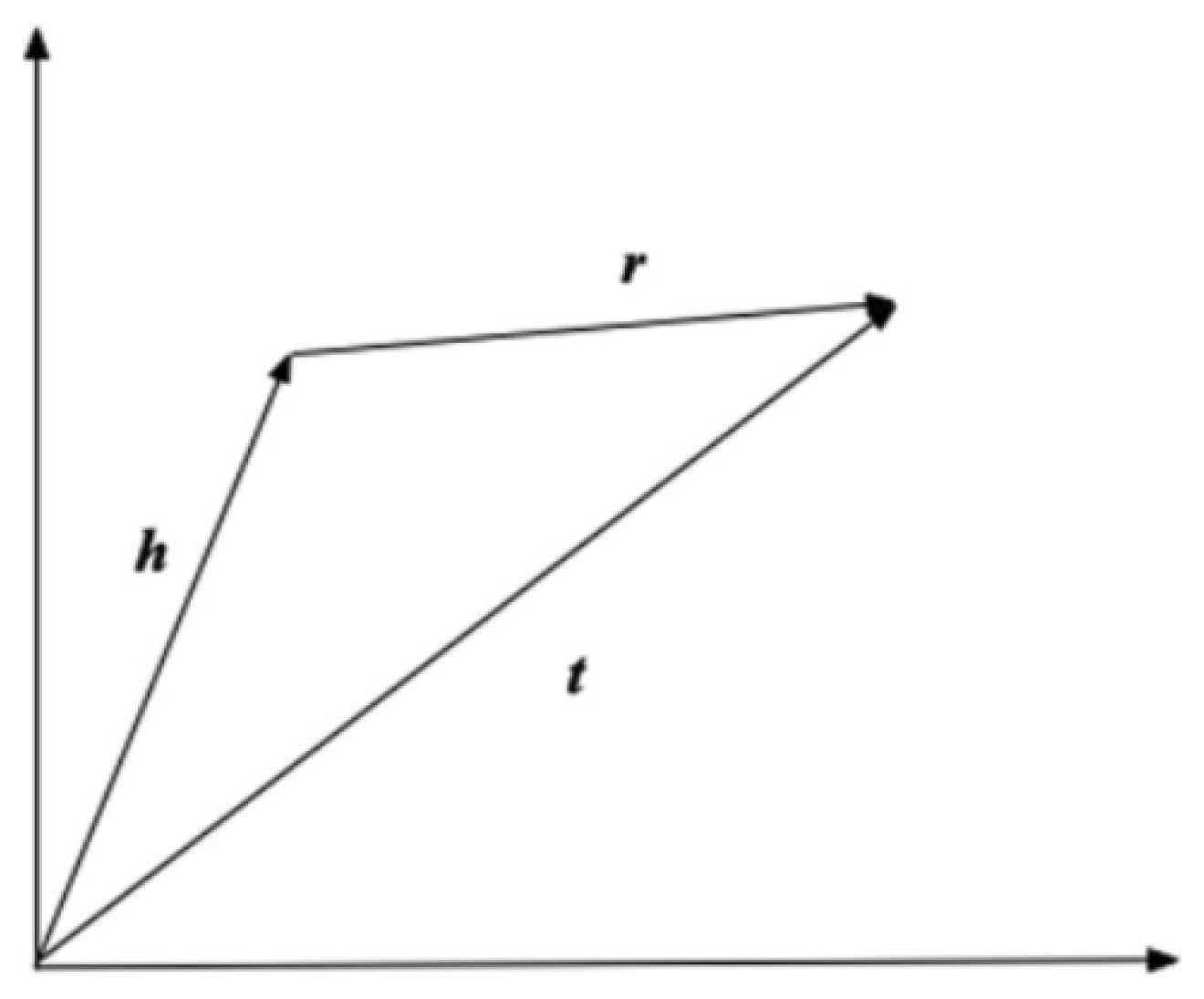
3.2.1. Embedding-Based Reasoning
3.2.2. Symbolic-Based Reasoning
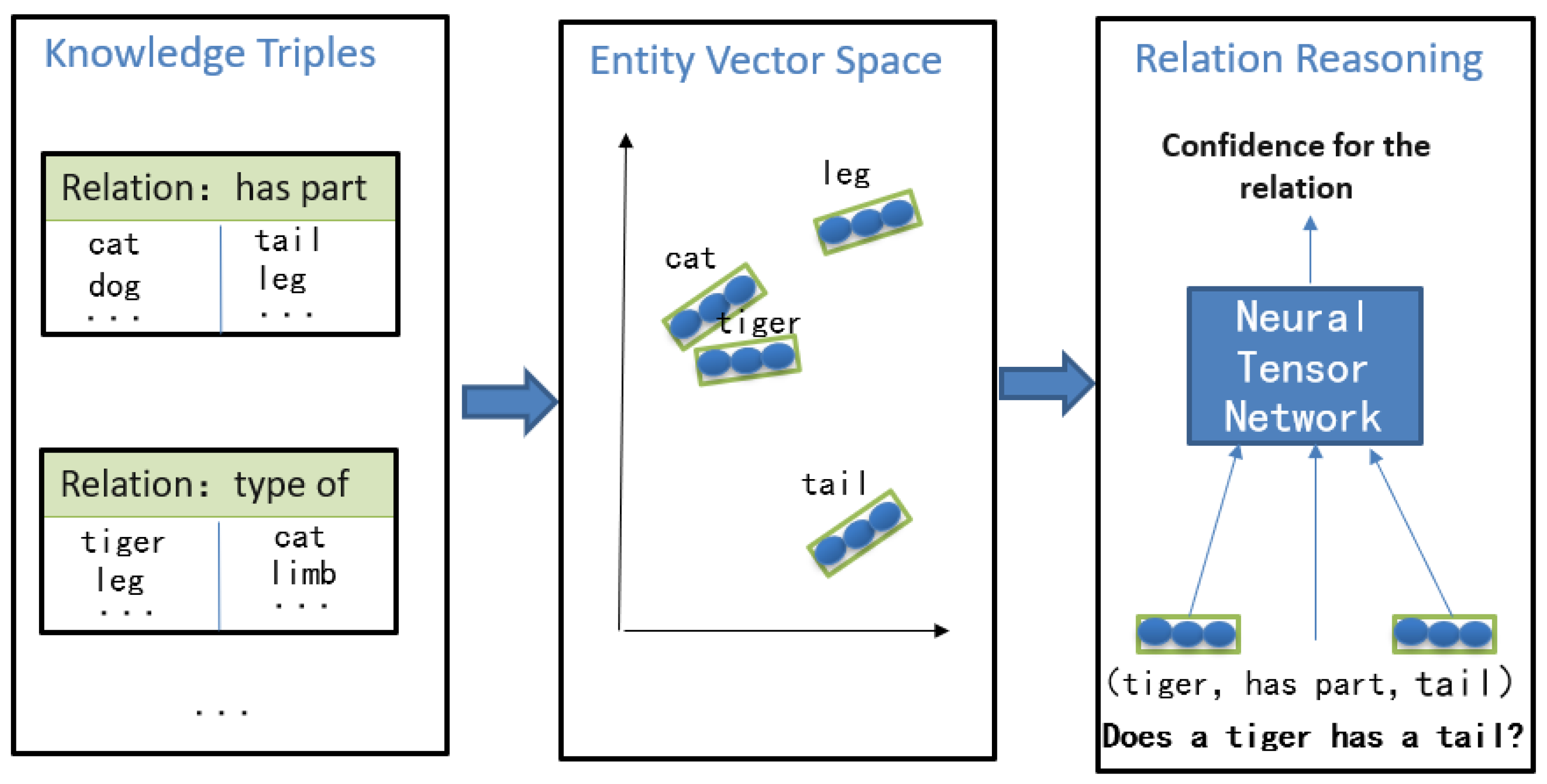
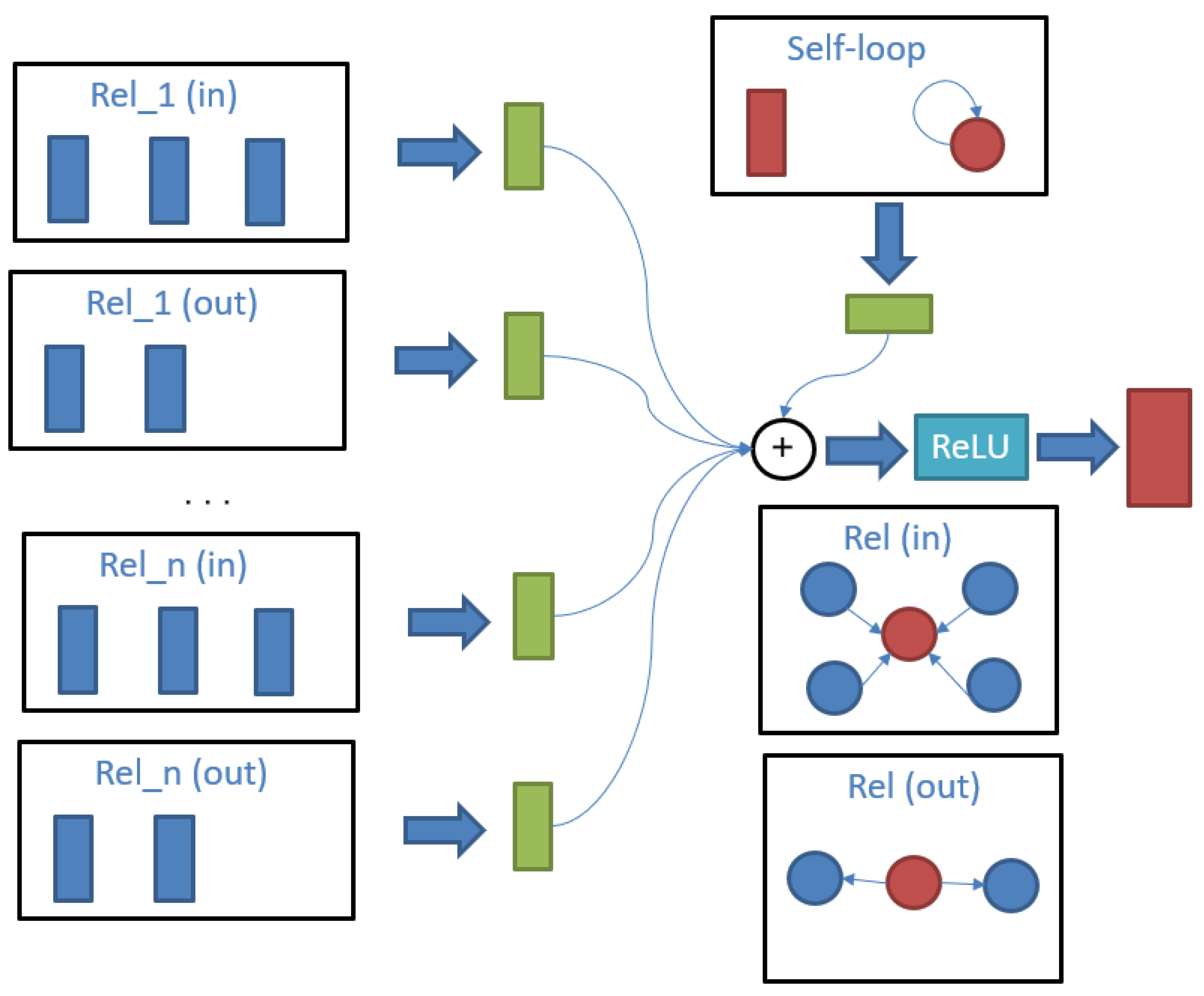
3.2.3. Neural Network-Based Reasoning
3.2.4. Mixed Reasoning
4. Comparisons and Analysis
- Knowledge graph embedding is usually embedded in Euclidean space. In recent years, MuRP, ATTH, and other models have explored the case of embedding in hyperbolic space and achieved very good results. However, in general, there are few studies on embedding knowledge graphs into hyperbolic space. Some models show that hyperbolic space and other non-Euclidean Spaces can better express knowledge graphs. The representation and reasoning of knowledge graph in non-Euclidean space is worth further exploration.
- Graph neural network natural matching knowledge graphs such as r-GCN and R GHAT models introduced in this paper are still early attempts and are far from perfect. The design of more sophisticated graph network structures to realize knowledge graph reasoning is a hot and promising direction.
- Transformer networks excel because of their strong expression ability and efficient parallel training ability in the field of natural language processing, and can be quickly migrated to computer vision, image processing, and speech recognition, in which the results are equally outstanding. It is believed that the converter network can also perform well in knowledge graphs and knowledge graph reasoning.
- Transfer learning based on the pre-training of models is widely used in natural language processing, image processing, and computer vision, but is rarely used in knowledge graph reasoning. It is worth exploring pre-training models in knowledge graphs and knowledge graph reasoning.
- Modern knowledge graph reasoning techniques also have great opportunities in data sets and corresponding contests and evaluations, especially in Chinese knowledge graph data sets.
5. Applications
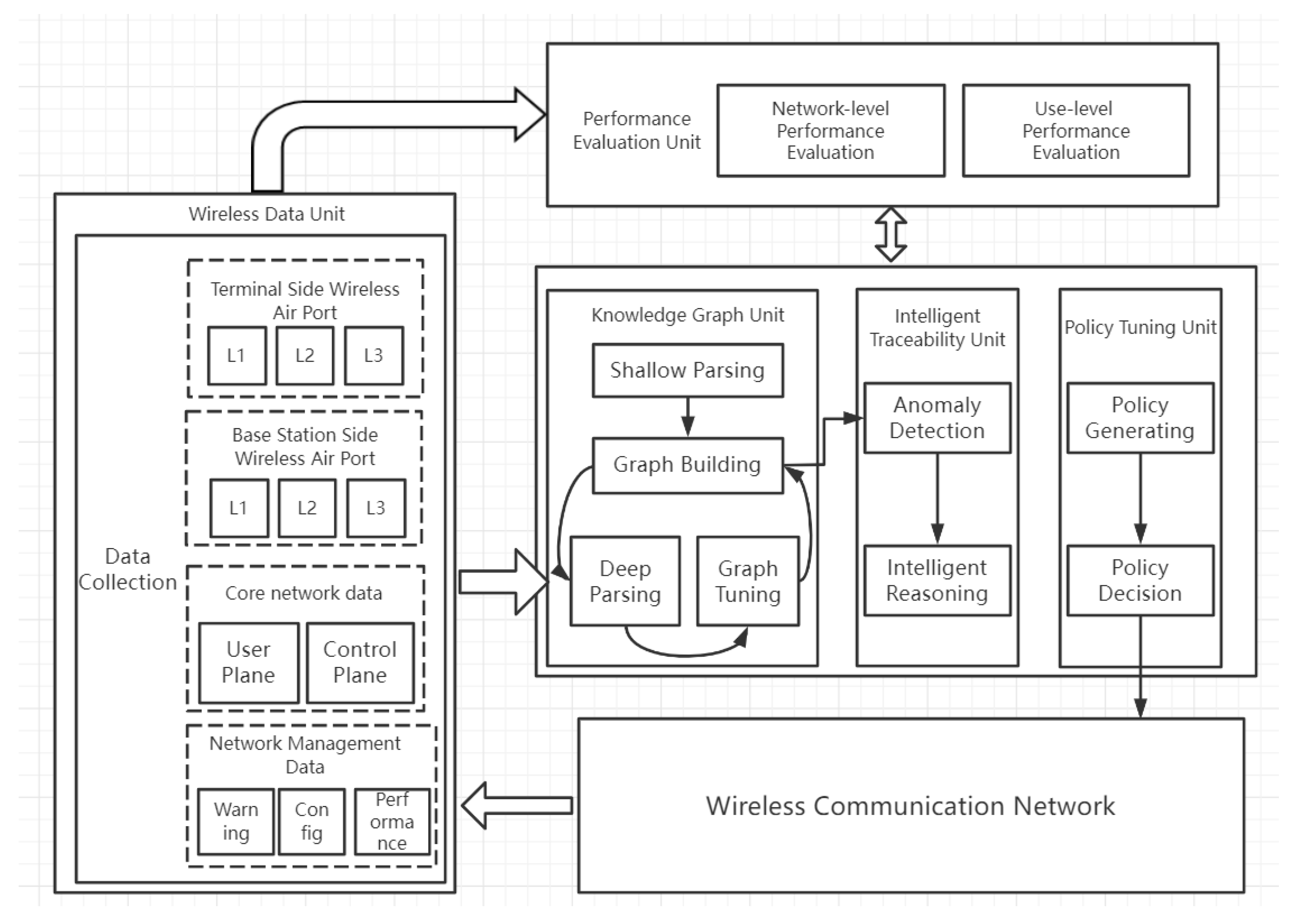
5.1. Wireless Communication Networks (WCN)
5.2. Question Answering (QA) Systems
5.3. Recommendation Systems
5.4. Personalized Search
6. Future Directions
7. Summary
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ren, H.; Dai, H.; Dai, B.; Chen, X.; Zhou, D.; Leskovec, J.; Schuurmans, D. SMORE: Knowledge Graph Completion and Multi-hop Reasoning in Massive Knowledge Graphs. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022. [Google Scholar]
- Ji, S.; Pan, S.; Cambria, E.; Marttinen, P.; Yu, P.S. A Survey on Knowledge Graphs: Representation, Acquisition, and Applications. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 494–514. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Ma, Y.; Wan, S. Multi-scale relation reasoning for multi-modal Visual Question Answering. Signal Process. Image Commun. 2021, 96, 116319. [Google Scholar] [CrossRef]
- Wu, Y.; Ji, X.; Ji, W.; Tian, Y.; Zhou, H. CASR: A context-aware residual network for single-image super-resolution. Neural Comput. Appl. 2020, 32, 14533–14548. [Google Scholar] [CrossRef]
- Li, G.; He, B.; Wang, Z.; Zhou, Y. A Data Agent Inspired by Interpersonal Interaction Behaviors for Wireless Sensor Networks. IEEE Internet Things J. 2022, 9, 8397–8411. [Google Scholar] [CrossRef]
- Xie, K.; Jia, Q.; Jing, M.; Yu, Q.; Yang, T.; Fan, R. Data Analysis Based on Knowledge Graph. In Proceedings of the 15th International Conference on Broad-Band and Wireless Computing, Communication and Applications, Yonago, Japan, 28–30 October 2020. [Google Scholar]
- Liu, W.; Yin, L.; Wang, C.; Liu, F.; Ni, Z. Medical Knowledge Graph in Chinese Using Deep Semantic Mobile Computation Based on IoT and WoT. Wirel. Commun. Mob. Comput. 2021, 2021, 5590754. [Google Scholar] [CrossRef]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z.G. DBpedia: A Nucleus for a Web of Open Data. In Proceedings of the 6th International Semantic Web Conference and 2nd Asian Semantic Web Conference, Busan, Korea, 11–15 November 2007; pp. 722–735. [Google Scholar]
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the Special Interest Group on Management Of Data, Vancouver, BC, Canada, 9–12 June 2008; pp. 1247–1250. [Google Scholar]
- Hoffart, J.; Suchanek, F.M.; Berberich, K.; Weikum, G. YAGO2: A spatially and temporally enhanced knowledge base from Wikipedia. Artif. Intell. 2013, 194, 28–61. [Google Scholar] [CrossRef]
- Dong, B.X.; Gabrilovich, E.; Heitz, G.; Horn, W.; Lao, N.; Murphy, K.; Strohmann, T.; Sun, S.; Zhang, W. Knowledge vault: A web-scale approach to probabilistic knowledge fusion. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; pp. 601–610. [Google Scholar]
- Wu, Q.; Zhang, H.; Gao, X.; He, P.; Weng, P.; Gao, H.; Chen, G. Dual graph attention networks for deep latent representation of multifaceted social effects in recommender systems. In Proceedings of the International World Wide Web Conference (WWW), San Francisco, CA, USA, 13–17 May 2019. [Google Scholar]
- Wang, H.; Zhang, F.; Xie, X.; Guo, M. Dkn: Deep knowledge-aware network for news recommendation. In Proceedings of the International World Wide Web Conference (WWW), Lyon, France, 23–27 April 2018. [Google Scholar]
- Wang, H.; Zhang, F.; Zhang, M.; Leskovec, J.; Zhao, M.; Li, W.; Wang, Z. Knowledge-aware graph neural networks with label smoothness regularization for recommender systems. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph convolutional neural networks for web-scale recommender systems. In Proceedings of the ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD), London, UK, 19–23 August 2018. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W.W. Open domain question answering using early fusion of knowledge bases and text. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W.W. Pullnet: Open domain question answering with iterative retrieval on knowledge bases and text. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Berant, J.; Chou, A.; Frostig, R.; Liang, P. Semantic parsing on freebase from question-answer pairs. In Proceedings of the Empirical Methods in Natural Language Processing the (EMNLP), Grand Hyatt Seattle, Seattle, DC, USA, 18–21 October 2013. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P. Improving multihop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the Annual Meeting of the Association for Computational Linguistics (ACL), Seattle, WA, USA, 5–10 July 2020. [Google Scholar]
- Ren, H.; Dai, H.; Dai, B.; Chen, X.; Yasunaga, M.; Sun, H.; Schuurmans, D.; Leskovec, J.; Zhou, D. Lego: Latent execution-guided reasoning for multi-hop question answering on knowledge graphs. In Proceedings of the International Conference on Machine Learning (ICML), Vienna, Austria, 18–24 July 2021. [Google Scholar]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. Kagnet: Knowledge-aware graph networks for commonsense reasoning. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, China, 3–7 November 2019. [Google Scholar]
- Feng, Y.; Chen, X.; Lin, B.Y.; Wang, P.; Yan, J.; Ren, X. Scalable multi-hop relational reasoning for knowledgeaware question answering. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Hong Kong, China, 3–7 November 2020. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. Qa-gnn: Reasoning with language models and knowledge graphs for question answering. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics (NAACL), Online, 6–11 June 2021. [Google Scholar]
- Lv, S.; Guo, D.; Xu, J.; Tang, D.; Duan, N.; Gong, M.; Shou, L.; Jiang, D.; Cao, G.; Hu, S. Graph-based reasoning over heterogeneous external knowledge for commonsense question answering. In Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), New York, NY, USA, 7–12 February 2020. [Google Scholar]
- Ruiz, C.; Zitnik, M.; Leskovec, J. Identification of disease treatment mechanisms through the multiscale interactome. Nat. Commun. 2021, 12, 1796. [Google Scholar] [CrossRef] [PubMed]
- Zitnik, M.; Agrawal, M.; Leskovec, J. Modeling polypharmacy side effects with graph convolutional networks. Bioinformatics 2018, 34, i457–i466. [Google Scholar] [CrossRef] [PubMed]
- Ioannidis, V.N.; Song, X.; Manchanda, S.; Li, M.; Pan, X.; Zheng, D.; Ning, X.; Zeng, X.; Karypis, G. Drkg—Drug Repurposing Knowledge Graph for COVID-19. 2020. Available online: https://github.com/gnn4dr/DRKG/ (accessed on 27 July 2022).
- Bordes, A.; Usunier, N.; García-Durán, A.; Weston, J.; Yakhnenko, O. Translating Embeddings for Modeling Multi-relational Data. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Nickel, M.; Tresp, V.; Kriegel, H.-P. A Three-Way Model for Collective Learning on Multi-Relational Data. In Proceedings of the 28th International Conference on Machine Learning, ICML 2011, Bellevue, WA, USA, 28 June–2 July 2011; pp. 809–816. [Google Scholar]
- Yang, B.; Yih, W.; He, X.; Gao, J.; Deng, L. Embedding Entities and Relations for Learning and reasoning in Knowledge Bases. In Proceedings of the International Conference on Machine Learning (ICLR) (Poster), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Galárraga, L.A.; Teflioudi, C.; Hose, K.; Suchanek, F.M. AMIE: Association rule mining under incomplete evidence in ontological knowledge bases. In Proceedings of the 22nd International World Wide Web Conference, WWW ’13, Rio de Janeiro, Brazil, 13–17 May 2013; pp. 413–422. [Google Scholar]
- Muggleton, S.H. Inductive Logic Programming. New Gener. Comput. 1991, 8, 295–318. [Google Scholar] [CrossRef]
- Socher, R.; Chen, D.; Manning, C.D.; Ng, A.Y. Reasoning With Neural Tensor Networks for Knowledge Base Completion. In Proceedings of the Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013. [Google Scholar]
- Schlichtkrull, M.S.; Kipf, T.N.; Bloem, P.; Berg, R.v.; Titov, I.; Welling, M. Modeling Relational Data with Graph Convolutional Networks. In Proceedings of the Extended Semantic Web Conference (ESWC), Heraklion,, Greece, 3–7 June 2018; pp. 593–607. [Google Scholar]
- Wang, P.-W.; Stepanova, D.; Domokos, C.; Kolter, J.Z. Differentiable learning of numerical rules in knowledge graphs. In Proceedings of the 8th International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Xiong, W.; Hoang, T.; Wang, W.Y. DeepPath: A Reinforcement Learning Method for Knowledge Graph Reasoning. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 9–11 September 2017; pp. 564–573. [Google Scholar]
- Das, R.; Dhuliawala, S.; Zaheer, M.; Vilnis, L.; Durugkar, I.; Krishnamurthy, A.; Smola, A.; McCallum, A. Go for a Walk and Arrive at the Answer: Reasoning Over Paths in Knowledge Bases using Reinforcement Learning. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Copenhagen, Denmark, 9–11 September 2018. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Knowledge Graph Embedding With Iterative Guidance From Soft Rules. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 4816–4823. [Google Scholar]
- Vrandecic, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2022, 57, 78–85. [Google Scholar] [CrossRef]
- Speer, R.; Havasi, C. ConceptNet5: A Large Semantic Network for Relational Knowledge. In The People’s Web Meets NLP, Collaboratively Constructed Language Resources; Springer: Berlin/Heidelberg, Germany, 2013; pp. 161–176. [Google Scholar]
- Lin, Y.; Liu, Z.; Luan, H.; Sun, M.; Rao, S.; Liu, S. Modeling Relation Paths for Representation Learning of Knowledge Bases. In Proceedings of the Empirical Methods in Natural Language Processing (EMNLP), Lisbon, Portugal, 17–21 September 2015; pp. 705–714. [Google Scholar]
- Zheng, S.; Wang, F.; Bao, H.; Hao, Y.; Zhou, P.; Xu, B. Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL), Vancouver, BC, Canada, 30 July–4 August 2017; Volume 1: Long Papers, pp. 1227–1236. [Google Scholar]
- Feng, J.; Huang, M.; Zhao, L.; Yang, Y.; Zhu, X. Reinforcement Learning for Relation Classification From Noisy Data. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 5779–5786. [Google Scholar]
- Morwal, S.; Jahan, N.; Chopra, D. Named Entity Recognition Using Hidden Markov Model(HMM). Int. J. Nat. Lang. Comput. (IJNLC) 2012, 1, 15–23. [Google Scholar] [CrossRef]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF Models for Sequence Tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL-HLT 2019, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8968–8975. [Google Scholar]
- Zheng, S.; Hao, Y.; Lu, D.; Bao, H.; Xu, J.; Hao, H.; Xu, B. Joint entity and relation extraction based on a hybrid neural network. Neurocomputing 2017, 257, 59–66. [Google Scholar] [CrossRef]
- Soares, L.B.; FitzGerald, N.; Ling, J.; Kwiatkowski, T. Matching the Blanks: Distributional Similarity for Relation Learning. In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Volume 1: Long Papers, pp. 2895–2905. [Google Scholar]
- Cai, R.; Zhang, X.; Wang, H. Bidirectional Recurrent Convolutional Neural Network for Relation Classification. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL, Berlin, Germany, 7–12 August 2016; 2016; Volume 1: Long Papers. [Google Scholar]
- Miwa, M.; Bansal, M. End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, ACL, Berlin, Germany, 7–12 August 2016; Volume 1: Long Papers. [Google Scholar]
- Wang, Y.; Sun, Y.; Liu, Z.; Sarma, S.E.; Bronstein, M.M.; Solomon, J.M. Dynamic Graph CNN for Learning on Point Clouds. ACM Trans. Graph. 2019, 38, 146:1–146:12. [Google Scholar] [CrossRef]
- Zeng, D.; Liu, K.; Chen, Y.; Zhao, J. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, EMNLP 2015, Lisbon, Portugal, 17–21 September 2015; pp. 1753–1762. [Google Scholar]
- Agichtein, E.; Gravano, L. Snowball: Extracting relations from large plain-text collections. In Proceedings of the Fifth ACM Conference on Digital Libraries, San Antonio, TX, USA, 2–7 June 2000; pp. 85–94. [Google Scholar]
- Carlson, A.; Betteridge, J.; Kisiel, B.; Settles, B.; Hruschka, E.R., Jr.; Mitchell, T.M. Toward an Architecture for Never-Ending Language Learning. In Proceedings of the Twenty-Fourth AAAI Conference on Artificial Intelligence, Atlanta, GA, USA, 11–15 July 2010. [Google Scholar]
- Wu, L.; Petroni, F.; Josifoski, M.; Riedel, S.; Zettlemoyer, L. Scalable Zero-shot Entity Linking with Dense Entity Retrieval. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 6397–6407. [Google Scholar]
- Li, C.; Cao, Y.; Hou, L.; Shi, J.; Li, J.; Chua, T.-S. Semi-supervised Entity Alignment via Joint Knowledge Embedding Model and Cross-graph Model. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; pp. 2723–2732. [Google Scholar]
- Zeng, W.; Zhao, X.; Tang, J.; Li, X.; Luo, M.; Zheng, Q. Towards Entity Alignment in the Open World: An Unsupervised Approach. In Proceedings of the Database Systems for Advanced Applications (DASFAA), Taipei, Taiwan, 11–14 April 2021; pp. 272–289. [Google Scholar]
- Zhu, H.; Xie, R.; Liu, Z.; Sun, M. Iterative Entity Alignment via Joint Knowledge Embeddings. In Proceedings of the Twenty-Sixth International Joint Conference on Artificial Intelligence, IJCAI 2017, Melbourne, Australia, 19–25 August 2017; pp. 4258–4264. [Google Scholar]
- Lin, Y.; Liu, Z.; Sun, M.; Liu, Y.; Zhu, X. Learning Entity and Relation Embeddings for Knowledge Graph Completion. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2181–2187. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, T.D.; Nguyen, D.Q.; Phung, D.Q. A Capsule Network-based Embedding Model for Knowledge Graph Completion and Search Personalization. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT), Minneapolis, MN, USA, 2–7 June 2019; pp. 2180–2189. [Google Scholar]
- Zhang, Z.; Zhuang, F.; Zhu, H.; Shi, Z.; Xiong, H.; He, Q. Relational Graph Neural Network with Hierarchical Attention for Knowledge Graph Completion. In Proceedings of the Thirty-Fourth AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 9612–9619. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed Representations of Words and Phrases and their Compositionality. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 3111–3119. [Google Scholar]
- Ji, G.; He, S.; Xu, L.; Liu, K.; Zhao, J. Knowledge Graph Embedding via Dynamic Mapping Matrix. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics (ACL), Beijing, China, 26–31 July 2015; pp. 687–696. [Google Scholar]
- Wang, Z.; Zhang, J.; Feng, J.; Chen, Z. Knowledge Graph Embedding by Translating on Hyperplanes. In Proceedings of the Twenty-Eighth AAAI Conference on Artificial Intelligence, Québec City, QC, Canada, 27–31 July 2014. [Google Scholar]
- Cohen, W.W. TensorLog: A Differentiable Deductive Database. arXiv 2016, arXiv:1605.06523. [Google Scholar]
- Wang, W.Y.; Mazaitis, K.; Cohen, W.W. Programming with personalized pagerank: A locally groundable first-order probabilistic logic. In Proceedings of the 22nd ACM International Conference on Information and Knowledge Management, CIKM’13, San Francisco, CA, USA, 27 October–1 November 2013; pp. 2129–2138. [Google Scholar]
- Wang, W.Y.; Mazaitis, K.; Lao, N.; Cohen, W.W. Efficient reasoning and learning in a large knowledge base—Reasoning with extracted information using a locally groundable first-order probabilistic logic. Mach. Learn. 2015, 100, 101–126. [Google Scholar] [CrossRef]
- Paulheim, H.; Bizer, C. Improving the Quality of Linked Data Using Statistical Distributions. Int. J. Semant. Web Inf. Syst. 2014, 10, 63–86. [Google Scholar] [CrossRef]
- Jang, S.; Megawati; Choi, J.; Yi, M.Y. Semi-Automatic Quality Assessment of Linked Data without Requiring Ontology. In Proceedings of the 14th International Semantic Web Conference (ISWC), Bethlehem, PA, USA, 11 October 2015; pp. 45–55. [Google Scholar]
- Shen, Y.; Huang, P.-S.; Chang, M.; Gao, J. Implicit ReasoNet: Modeling Large-Scale Structured Relationships with Shared Memory. arXiv 2016, arXiv:1611.04642v1. [Google Scholar]
- Shi, B.; Weninger, T. Open-World Knowledge Graph Completion. In Proceedings of the Thirty-Second AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; pp. 1957–1964. [Google Scholar]
- Wang, X.; He, X.; Cao, Y.; Liu, M.; Chua, T.-S. KGAT: Knowledge Graph Attention Network for Recommendation. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, KDD 2019, Anchorage, AK, USA, 4–8 August 2019. [Google Scholar]
- Guo, S.; Wang, Q.; Wang, L.; Wang, B.; Guo, L. Jointly embedding knowledge graphs and logical rules. In Proceedings of the Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–4 November 2016; pp. 1488–1498. [Google Scholar]
- Tay, Y.; Luu, A.T.; Hui, S.C. Non-Parametric estimation of multiple embeddings for link prediction on dynamic knowledge graphs. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 1243–1249. [Google Scholar]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Advantages | Disadvantages |
|---|---|---|
| TransE series (embedding-based reasoning) | Simple, fast speed. | Only suitable for one-to-one relationships. |
| AMIE (symbolic-based reasoning) | Interpretable; automatic discovery of rules. | With large search space and low coverage of generated rules, the prediction effect of the final model is also poor. |
| NTN (neural network-based reasoning) | More resilient against the sparsity problem. | High complexity; requires a large number of triples to be fully learned. |
| R-GCN (neural network-based reasoning) | The graph product network is introduced into knowledge reasoning domain for the first time. | Unstable; as the number of relationships increases, the number of parameters explodes, introducing too many relationship matrices. |
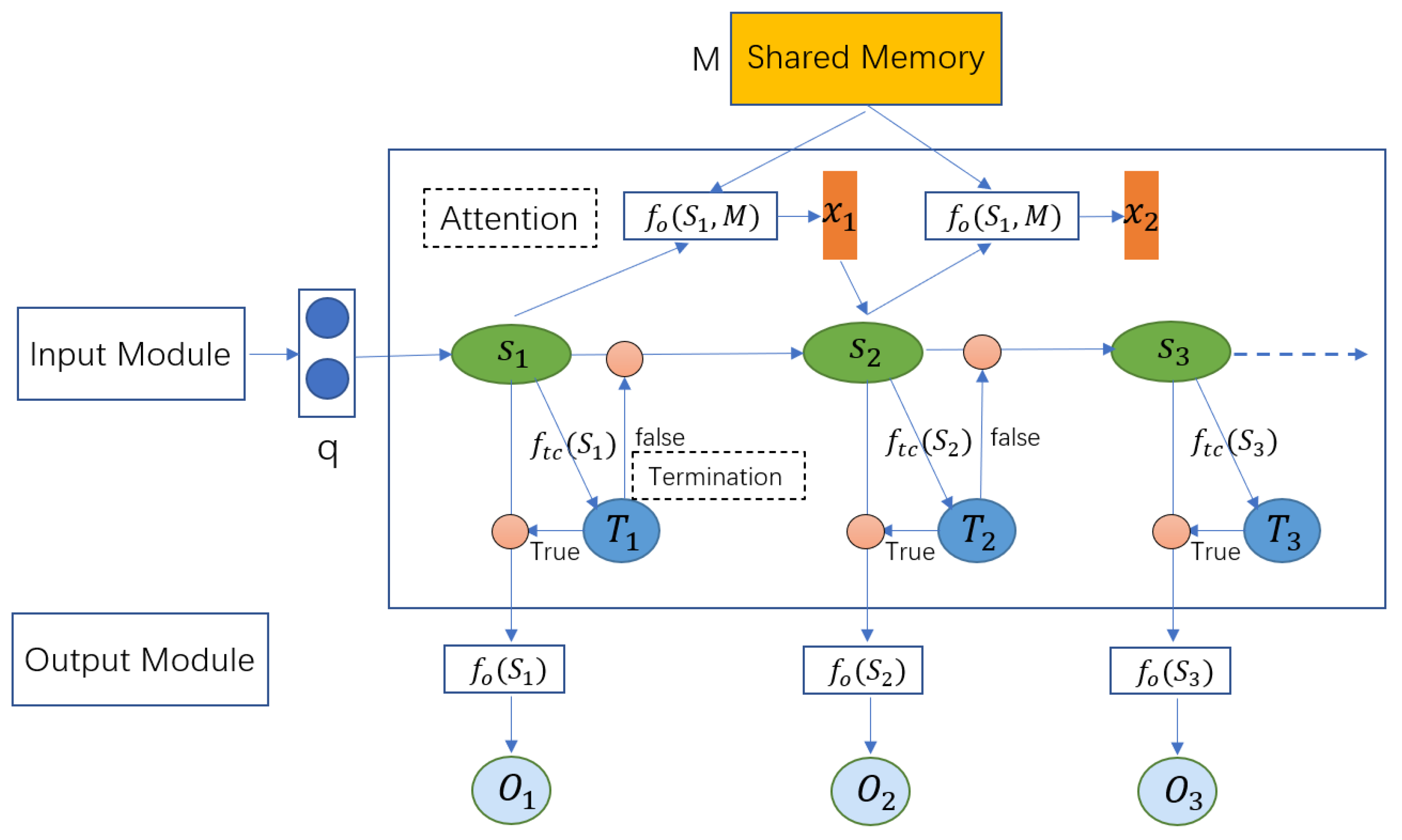
| IRN (neural network-based reasoning) | Stores knowledge through shared memory components. Can simulate the human brain to learn multi-step reasoning process. | Has difficulty with unstructured data and self-heating language query. |
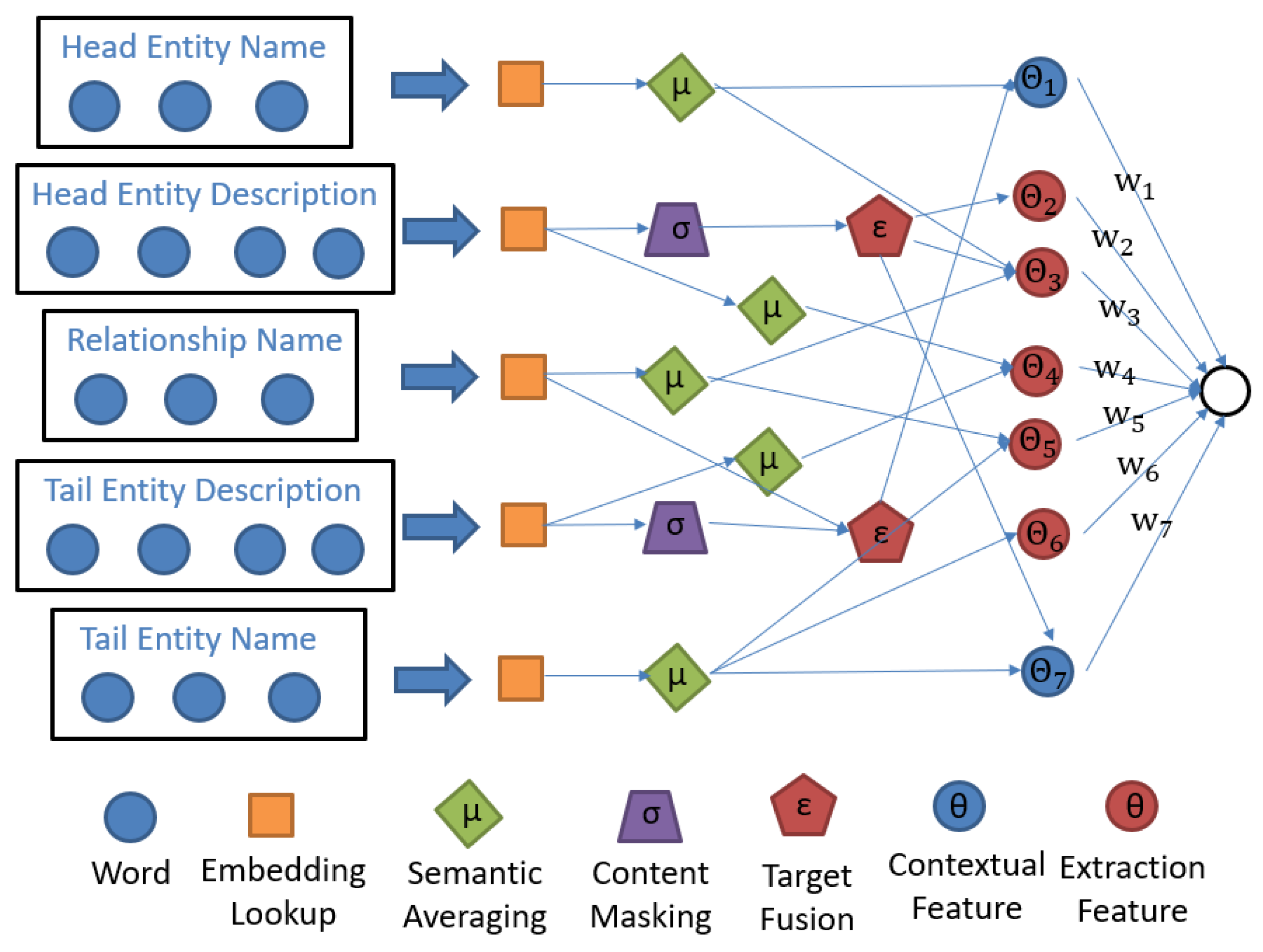
| ConMask (mixed reasoning) | Can add unknown new entities from outside the knowledge graph and link them to internal entity nodes. | When no text pair that can accurately describe entities or relations appears, the model cannot obtain enough reasoning basis, resulting in poor reasoning effect. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Li, H.; Li, H.; Liu, W.; Wu, Y.; Huang, Q.; Wan, S. An Overview of Knowledge Graph Reasoning: Key Technologies and Applications. J. Sens. Actuator Netw. 2022, 11, 78. https://doi.org/10.3390/jsan11040078
Chen Y, Li H, Li H, Liu W, Wu Y, Huang Q, Wan S. An Overview of Knowledge Graph Reasoning: Key Technologies and Applications. Journal of Sensor and Actuator Networks. 2022; 11(4):78. https://doi.org/10.3390/jsan11040078
Chicago/Turabian StyleChen, Yonghong, Hao Li, Han Li, Wenhao Liu, Yirui Wu, Qian Huang, and Shaohua Wan. 2022. "An Overview of Knowledge Graph Reasoning: Key Technologies and Applications" Journal of Sensor and Actuator Networks 11, no. 4: 78. https://doi.org/10.3390/jsan11040078
APA StyleChen, Y., Li, H., Li, H., Liu, W., Wu, Y., Huang, Q., & Wan, S. (2022). An Overview of Knowledge Graph Reasoning: Key Technologies and Applications. Journal of Sensor and Actuator Networks, 11(4), 78. https://doi.org/10.3390/jsan11040078