1. Introduction
In recent decades, the Internet of Things (IoT) concept has become widely popular with numerous fields and organizations implementing and investing in its use. IoT refers to the billions of devices that can connect to the internet, thus sharing and collecting vast amounts of data anywhere in the world. This ability of global devices coupled with communication technologies create a system that connects, exchanges, and analyzes data, resulting in faster and more efficient decision making. With the dawn of readily available inexpensive computer chips, and the omnipresence of wireless networks, it has become possible to transform anything into a part of the IoT [
1]. Hence, the number of IoT devices has skyrocketed over the past years. According to Statistica [
2], the global number of IoT devices has reached 16.4 billion, and by 2025, it is projected to reach more than 30 billion devices. However, with the rise in the wide use of IoT devices, vulnerabilities have arisen, leading to the breach of confidentiality and integrity of users and systems.
Most IoT devices perform operations on sensitive user data. Thus, various fundamental challenges in designing a secure IoT exist, such as privacy, access control, authentication, confidentiality, trust, etc. As discussed by Kolias et al. [
3], various malware botnets, such as Mirai, can take control and quickly spread, exploiting the vulnerabilities of IoT devices. This especially points out that insecure IoT devices can lead to direct risks to all the interconnecting devices in their network. Further, attackers often gain access to users’ data and may cause monetary losses and eavesdropping [
4,
5]. Particularly, IoT devices are prone to network attacks such as phishing attacks, data thefts, spoofing, and denial of service (DoS) attacks. These attacks can cause other cyber security threats, including serious data breaches and ransomware attacks that can cost organizations a lot of money and effort to recover from [
5].
Denial of service (DoS) attacks in such devices have also become pervasive, preventing access to services that the user has paid for [
6]. Moreover, DoS attacks can negatively affect the services of small networks such as homes, hospitals, educational institutions, etc. [
7,
8]. What is more is that such attacks quickly spread, leading to exploiting vulnerabilities of a plethora of IoT devices. In 2021, Forbes reported that the attacks on IoT devices skyrocketed and surpassed 300% [
9]. Thus, the need to have robust solutions to counter these attacks and prevent their expansion before it is too late is imminent.
The use of artificial intelligence (AI) techniques, mainly machine learning (ML), has become very useful due to their ability to learn from past experiences and prevent cyber-attacks before they spread and affect more and more devices [
10]. ML is a field in AI that uses data and algorithms to mimic how humans learn, improving over time with experience. Network security, particularly IoT security, is a very challenging field. Utilizing ML’s power can lead to more robust solutions to protect the confidentiality, integrity, and availability of IoT networks and users [
11,
12]. Thus, several research studies focus on attack detection in IoT environments using AI techniques. Accordingly, this research uses a recent dataset to apply ML techniques for detecting attacks in IoT environments.
The main contributions of this paper are as follows:
Study the effect of different sets of features on building ML models for detecting various IoT attacks and investigate the models’ performance using features selection techniques;
Perform a comparative analysis of binary and multiclass experiments on the dataset to detect and classify IoT attacks;
Achieve better benchmark results on the utilized IoT attacks dataset.
The paper is divided as follows:
Section 2 reviews related works in the field.
Section 3 outlines the research methodology, which describes the dataset used, the preprocessing steps carried out, the models applied, and the performance metrics utilized.
Section 4 discusses the experimental setup and the results obtained. Finally,
Section 5 presents the conclusion and future work.
2. Related Works
Many researchers worked on detecting cyberattacks in IoT networks as they aimed to offer more security to people and cities that use IoT systems. Most studies included in the literature review used the UNSW-NB15 [
13] dataset. Following this ideology, Verma et al. [
14] aimed to improve the security of IoT systems against DoS attacks by developing several ML models, namely, AdaBoost (AB), RF, a gradient boosting machine (GBM), extreme gradient boosting (XGB), classification and regression trees (CART), extremely randomized trees (ERT), and multi-layer perceptron (MLP). They used three datasets: CIDDS-001 [
15], UNSW-NB15 [
13], and NSL-KDD [
16]. The results showed that CART achieved the best performance with an accuracy level of 96.74%, while XGB resulted in the best performance at the AUC level of 98.77%. Additionally, Khatib et al. [
17] aimed to build an ML model for intrusion detection to enhance the accuracy of IoT networks against malicious attacks. For their experiments, the researchers used the UNSW-NB15 [
13] dataset, which consisted of 49 features and contained 2,540,044 samples, and applied seven ML classifiers, namely RF, decision trees (DT), AdaBoost, logistic regression (LR), linear discriminant analysis (LDA), a support vector machine (SVM), and Nystrom-SVM. In multiclass classification, SVM resulted in the best performance with an accuracy of 93%. While in binary classification, Nystrom-SVM, RF, and DT resulted in the best performance with an accuracy level of 95%.
In another study, Rashid et al. [
18] proposed ML models for anomaly detection to enhance the security of IoT in smart cities by using two UNSW-NB15 and CIC-IDS2017, having 175,341 and 190,774 instances, respectively. The study used an information gain ratio to select the best 25 features in each dataset for their experiments, and 10-fold cross-validation was used to train the models: LR, SVM, RF, DT, k-nearest neighbor (KNN), and artificial neural network (ANN). Ensemble techniques such as bagging, boosting, and stacking ensemble were also used. CIC-IDS2017 showed better performance among all the classifiers while stacking ensemble models resulted in the best performance with an accuracy level of 99.9%. Similarly, Alrashdi et al. [
19] proposed AD-IoT, an ML model for anomaly detection in IoT networks in smart cities using the UNSW-NB15 dataset, taking 699,934 instances for their experiments. For feature selection, the authors used the extra trees classifier to select the best features to train the ML model, and only 12 features were selected to train the model. An RF classifier was used to build the proposed model. The proposed model was developed for binary classification as normal and attack traffic, resulting in an accuracy of 99.34%.
On the other hand, some studies used different datasets for the same purpose as the previous studies. Gad et al. [
20] aimed to improve the security of vehicular ad hoc networks against DoS attacks by developing an ML model for intrusion detection using the used ToN-IoT [
21] dataset containing 44 features. Synthetic minority oversampling technique (SMOTE) was applied to handle the class imbalance, and the Chi2 algorithm was used for the features selection process resulting in the 20 best features. This study used five ML algorithms: LR, naive Bayes (NB), DT, SVM, KNN, RF, AB, and XGB. The XGB algorithm resulted in the best performance in accuracy levels of 99.1% and 98.3% in both binary and multiclass classification, respectively. In addition, Verma et al. [
22] proposed an ensemble ML model for anomaly detection to enhance the security of IoT networks by detecting zero-day attacks using the CSE-CIC-IDS2018-V2 [
23] dataset. The SMOTE oversampling technique was used to handle class imbalance. In addition, the authors used the random under-sampling technique to the benign class to reduce its number of instances, and the random search cross-validation algorithm was used to select the best features. To avoid overfitting, the authors split the dataset using a 70–30 train–test split and trained the proposed model 10 times using different instances in each set. This way combined both 10-fold cross-validation and the hold-out splitting method. The ensemble model presented in this study consisted of the RF and GBM classifiers and resulted in an accuracy level of 98.27%.
Similarly, to assess the systems that automate attack detection in industrial control systems (ICS), Arora et al. [
24] focused on evaluating different ML algorithms, namely, RF, SVM, DT, ANN, KNN, and NB. The dataset used in their experiment was the SCADA attacks dataset, containing seven features and the label classifying the data samples as normal or attack. Further, the dataset underwent an 80–20 train–test split, and the evaluation metrics utilized were accuracy, false alarm rate (FAR), UN-detection rate (UND), and the receiver operating characteristic (ROC) curve. The results showed that RF achieved the highest accuracy of 99.84% and the highest UND of 84.7%. In another study, Mothkuri et al. [
25] proposed a federated learning (FL)-based approach to anomaly detection to detect intrusions in IoT networks by employing decentralized on-device data. They used gated recurrent units (GRU) and kept the data intact on only the local IoT devices by sharing learned rates with the FL. Further, the ML model’s accuracy was optimized by aggregating updates from multiple sources. The Modbus-based network dataset [
26] was used for building and evaluating the results, and it contained several attack types such as man-in-the-middle, distributed denial of service (DDoS), synchronization DDoS, and query flood attacks. The experiment results demonstrated that the FL-based approach achieved a better performance average accuracy of 90.286% in successfully detecting attacks than the non-FL-based approach.
Table 1 Summarizes the reviewed papers.
Although many studies focused on detecting IoT attacks and achieved high performance, a gap and limitations still need to be resolved. From the literature, there is a need to explore new datasets that contain new attack types. Most of the reviewed papers used common datasets that contain old attacks, but many new attacks are being created in the IoT security field. Moreover, most of the datasets used targeted general network attacks. Using a dataset that targets IoT attacks may improve the detection of these attacks. Most reviewed studies used many features to train their models. Exploring feature selection and extracting the most important features will reduce the impact of cure of dimensionality and the time needed for attack detection.
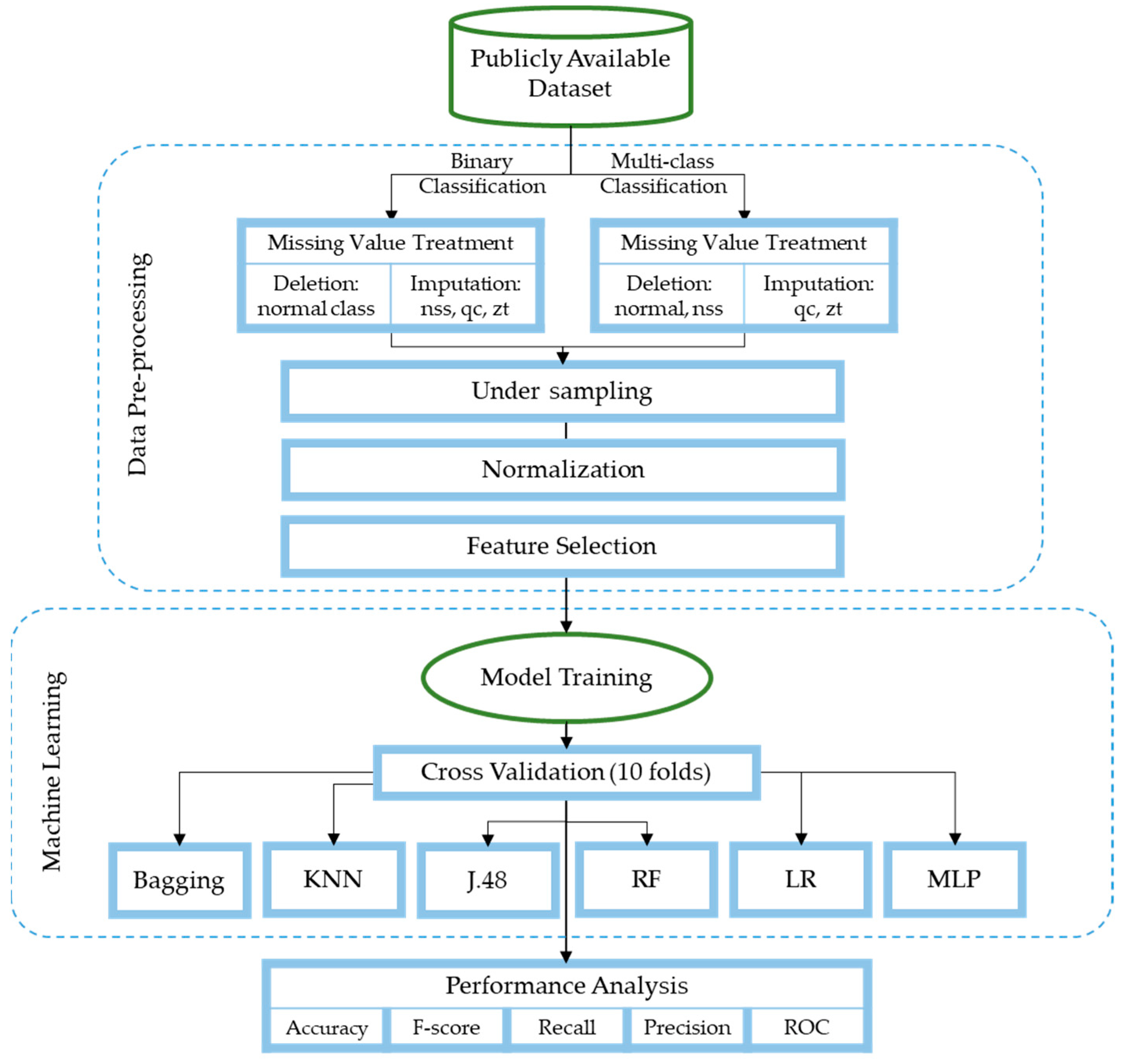
3. Methodology
The primary purpose of our study is to use ML algorithms to detect and classify IoT network security attacks. The models used include bagging, KNN, J48, RF, LR, and MLP. The models were trained using a publicly available dataset from Wheelus and Zhu [
27] to detect and categorize IoT network attacks. The dataset underwent several preprocessing steps to convert it into the most suitable format for training the models. Furthermore, we evaluated the performance of these models based on evaluation parameters, including classification accuracy, F-score, recall, precision, and ROC. Moreover, we implemented 10-fold cross-validation to build the models and performed two experiments for detection—binary classification to distinguish between normal and attack sessions—and two experiments for classification—multiclass classification to categorize normal sessions and three types of attack, namely, no shared secret (NSS), query cache (QC), and zone transfer (ZT). Furthermore, the experiments were conducted using a subset of the features to emphasize the significance of the features selection process while maintaining, if not increasing, the models’ performance.
Figure 1 demonstrates the research methodology steps.
3.1. Dataset Description
The dataset used in this study is a publicly available dataset released by Wheelus and Zhu [
27]. The dataset was collected for nine months, and the raw data underwent several preprocessing phases and organizing into sessions based on packet commonalities such as source and destination IP addresses and ports, as well as temporal characteristics. The set of features included in the dataset is depicted in
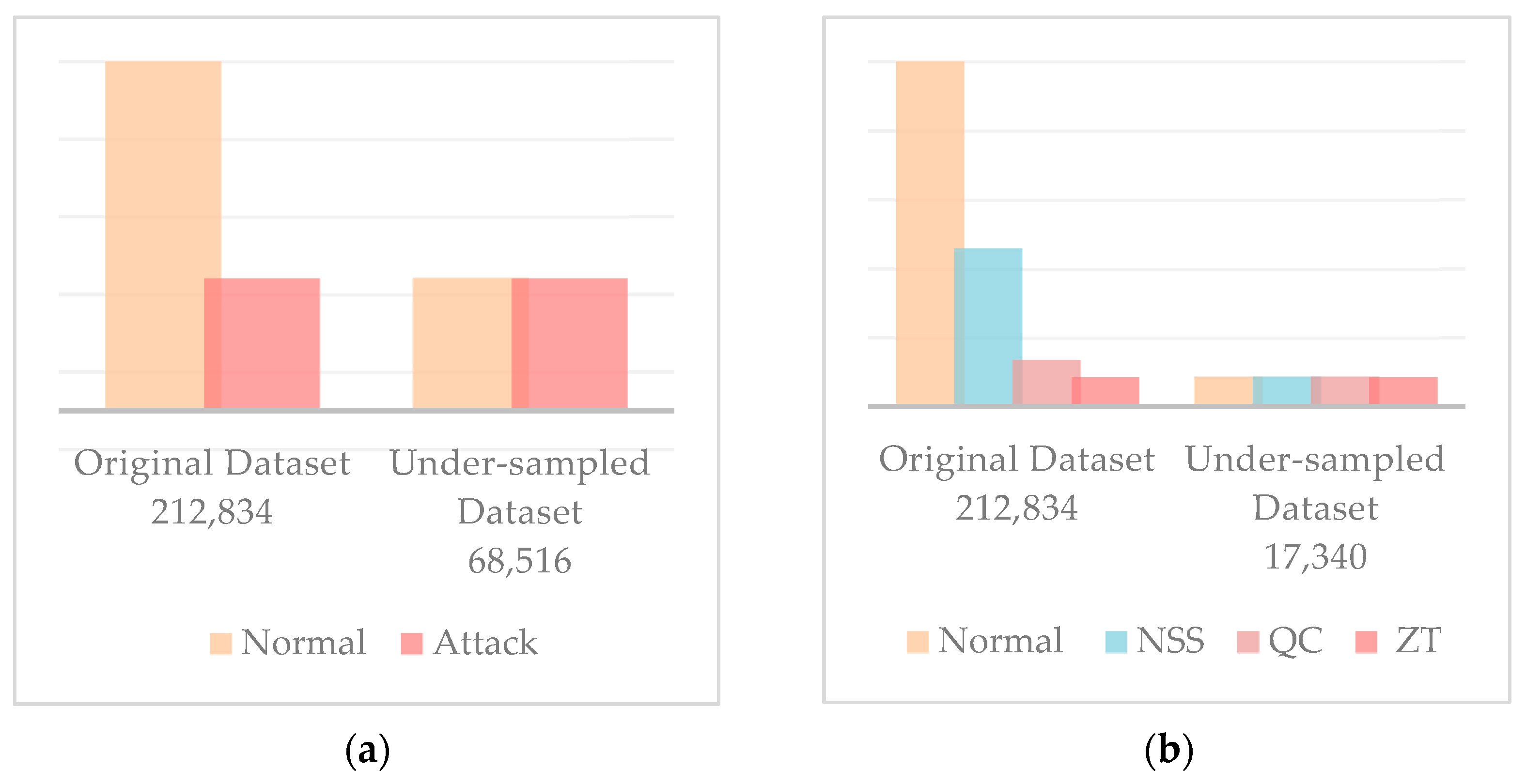
Table 2. For the binary case, the dataset aims to classify samples into attack or normal categories. For multiclass classification purposes, it aims to classify the sample into four categories of unauthorized attacks: normal, query cache (QC), zone transfer (ZT), and no shared secret (NSS). The QC error occurs when an unauthorized request for system data is evidenced by the incorrect sequence of requests made to the remote gate opener (RGO). In a ZT attack, a perpetrator tries to access domain name system (DNS) zone information to scan the IoT system’s components. The NSS attack happens when there is an unauthorized attempt to join the IoT network. This attempt is recognized when the shared secret, exchanged during authorization of RGO, is expired or invalid. The binary dataset consists of 212,834 samples, where 178,576 are normal and 34,258 are attacks. On the other hand, in the multiclass dataset, there are four classes: normal, NSS, QC, and ZT, where the number of examples that belong to each class are 178,576, 23,022, 6901, and 4335, respectively.
3.2. Preprocessing
Preprocessing is performed before using the dataset to ensure the data is in a format appropriate for training and testing the models. This step involves loading, cleaning, treating, and converting the data into a suitable format for the intended tasks. The dataset originally contains 212,834 instances, 178,576 of which represent normal traffic. This represents 83.9% of the dataset, indicating the imbalance in the data as this class is substantially higher than the others. Considering that the dataset suffers from imbalance and the presence of missing values in all classes, we worked on treating the missing values differently for each class depending on the best method for each. Because the normal class was significantly higher than the others, the method chosen to treat its missing values was deletion for both experiments. The missing values in the second class representing attacks were imputed using the mean for the binary classification experiments. This was possible as the features included missing values corresponding to variance values. Hence, using the mean was appropriate to impute those missing values. As for the multiclass experiments, the missing values in the NSS class were deleted as doing so would maintain the number of NSS attack instances to still be more than the lowest class. In other words, as illustrated in
Table 3, when the missing values of the NSS class are deleted, the number of instances becomes 5597, which is still more than the number of instances of the ZT class—4335. The missing values in the QC and ZT classes were treated by imputation using the mean because the number of instances was already low in those two classes.
Table 3 shows how the dataset appears after treating missing values. Moreover, under-sampling was performed due to the imbalance that remained. In addition, the dataset records were also normalized to the range of −1:1. How the final dataset instances appear after all these steps is visualized in
Figure 2 for the binary and multiclass classification experiments.
3.3. Feature Selection
The dataset included 20 features depicting relevant information about the traffic sessions. We performed four different experiments to obtain the highest performance. The class attribute takes the values of normal or attack in the case of the binary experiments, and in the case of multiclass classification, the attack values are further classified into three types of attacks: NSS, QC, and ZT. The same set of features is used for all four experiments.
Table 4 shows how the dataset appeared after feature selection. As shown in
Table 4, the correlation and information gain of all features were calculated. The top 30% of the features were selected. Therefore, the seven features with the highest correlations were selected, and another feature (duration) was added due to its high information gain value. Later, the correlation among the features was calculated, indicating that the riotb and riotp attributes had a 100% correlation. Only one was to be used; otherwise, we would have a redundant feature. According to the higher information gain value of the riotb feature, it was the one we kept. Hence, we had seven features to use in the four experiments.
3.4. Evaluation Metrics
The aforementioned model is evaluated in terms of accuracy, F1-score, recall, precision, and ROC. The following are the potential outcomes of attack prediction:
True positive (TP): TP refers to attack classes that were correctly predicted;
False positive (FP): FP signifies the normal classes that were incorrectly predicted as attack;
True negative (TN): TN reflects the normal classes that were correctly predicted;
False negative (FN): FN refers to attack classes that were incorrectly predicted as normal.
Accuracy indicates the overall rate of correctly identified instances in the test dataset compared with the total number of instances, defined as Equation (1):
F1 score measures both the precision and recall at the same time, calculated as Equation (2):
Recall indicates how correctly the model predicts the true positives, calculated as the ratio of the true positives detected to the total actual positive, shown in Equation (3):
Precision indicates the quality of prediction made, calculated as the ratio of true positives to the total positives (false and true), represented in Equation (4):
The ROC curve indicates the model’s performance at various classification thresholds. It plots two parameters: the true positive rate and false positive rate.
5. Conclusions
With the growing number of IoT devices, the number of cyber threats in IoT networks has drastically surged. This imminent situation requires instant action as most devices share and process sensitive data. Therefore, AI methods have been widely adopted to counter these threats due to their robustness and efficiency. Many researchers focused on detecting various attacks in IoT by building ML classifiers. In this study, we have focused on features engineering and building ML models using a new dataset as it is necessary to explore new cybersecurity datasets due to the changing nature of cyber threats.
We performed two classes of experiments: one for binary classification into normal and attack class, and another for multiclass classification into normal, QC (query cache), ZT (zone transfer), and NSS (no shared secret) classes. In both cases, the dataset underwent randomized under-sampling to obtain an equal number of classes, followed by normalization, and feature selection using correlation and information gain. Then, for each case, two sets of experiments were performed. One uses all the features, and another uses the best features only. The 10-fold cross-validation technique was applied to the dataset and the models applied were bagging, KNN, J48, RF, LR, and MLP. We evaluated their performance in terms of accuracy, F-score, recall, precision, and ROC. The results of the experiments showed that RF achieved the highest performance in all the experiment sets, obtaining a ROC of 99.9%. Furthermore, binary classification experiments gave better results than multiclass. Additionally, feature selection had little effect in both the experiment sets as most of the classifier performance remained the same except for the case of KNN, where its performance significantly increased. As for future work, we suggest building real-time models capable of identifying attacks in IoT devices and classifying them in real-time to stop malicious activity before it leaks or destroys sensitive data. Furthermore, this dataset can be used as an inspiration to build our dataset and generate more attack types to try our ML models on it.


 ,
, 



{kind=link}
{kind=link}