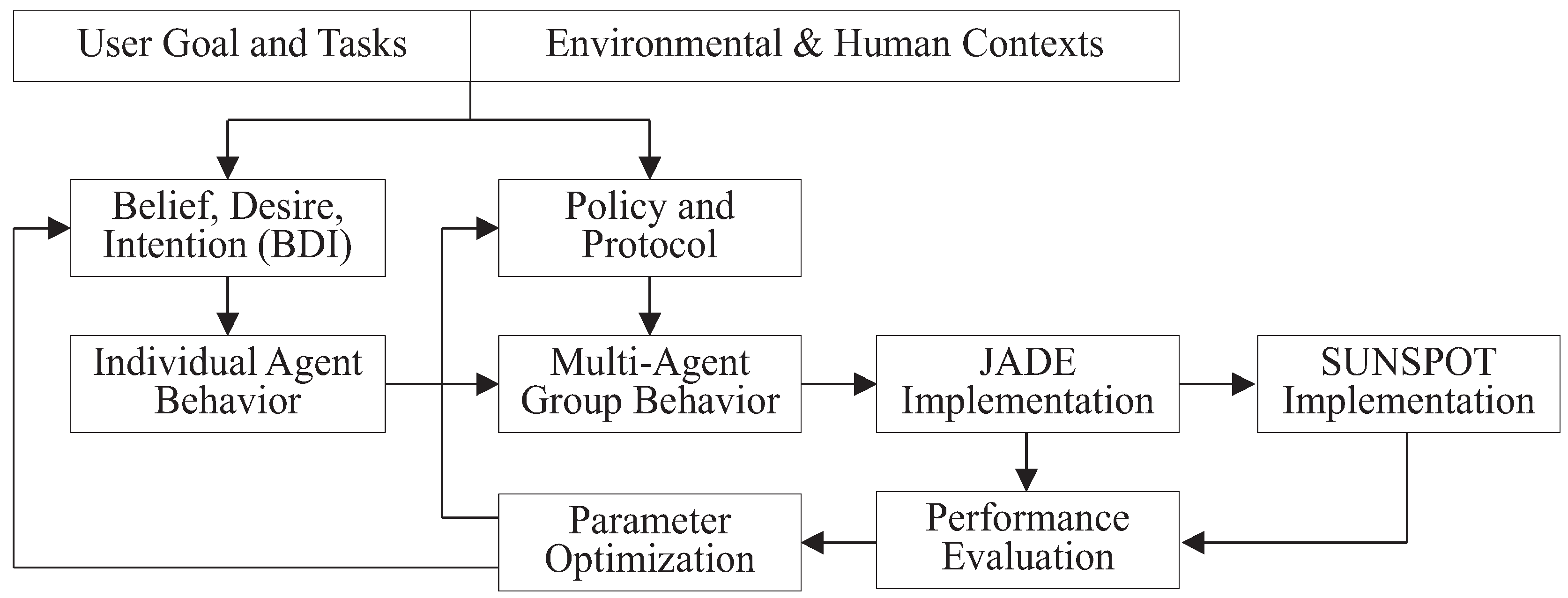
4.1. BDI Model-Based Individual Agent Behavior
An agent is a system that is situated in a changing environment and chooses autonomously among various options available. Each agent needs to have an appropriate behavior (
i.e., actions or procedures to execute in response to events) based on a belief, desire and intention (BDI) model.
Beliefs represent the information the agent has about itself, other agents and environments.
Desires store the information on the goals to be achieved, as well as properties and costs associated with each goal.
Intentions represent action plans to achieve certain desires.
Beliefs of an agent are derived from its perception of situations (i.e., the environment, itself and other agents). For example, an agent may have the following beliefs: (1) its own position, state, capability; (2) time, ambiance, temperature, location; (3) user’s activity disposition, preference; and (4) other agents’ state, conditions, capability. The desires of an agent are generated by user’s input and its own beliefs. Compared with the user’s goals, an agent’s desires are more practical and achievable. Intentions consist of feasible action plans. Each set of plans is formed from beliefs, desires and old plans. An intention depends on the current situation and updates events and user goals. Given an intention, the agent will choose a certain behavior model from a library.
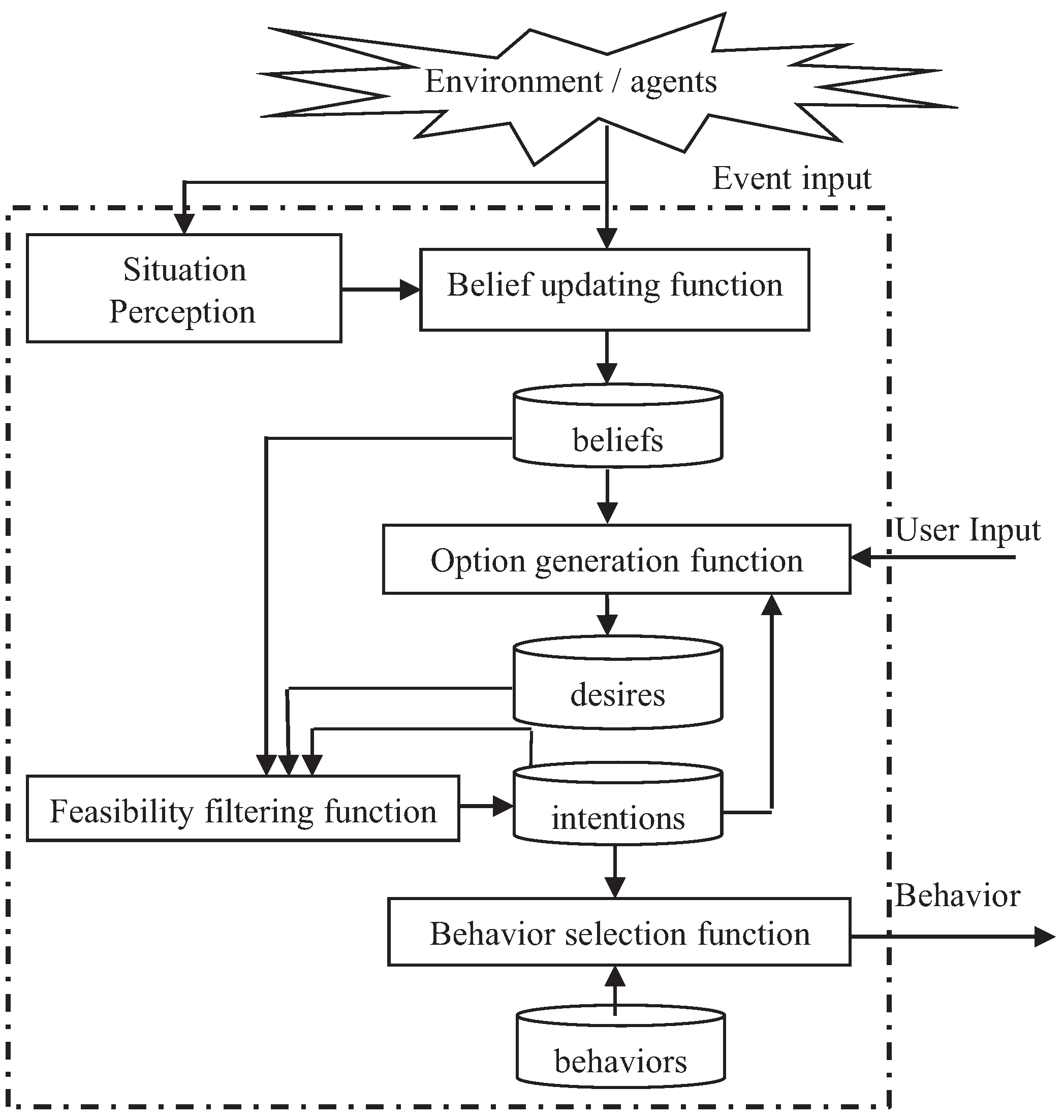
Figure 5 shows the generic BDI model for individual agent behavior design. The beliefs are modeled as a set of Bayesian networks to represent the relationships among random variables of the environment, user and agents. The belief updating function can recursively update the conditional probability functions of random variables according to up-to-date evidence. The option generation function can map the user’s goals to a set of feasible goals through existing beliefs. This is equivalent to adding constraints to a set of objective functions. The feasibility filtering function can generate an action sequence through dynamic programming of the constrained objective functions. Based on the possible action sequence, one of the behavior models from the behavior model library will be selected.
Figure 5.
BDI model based individual agent behavior design.
Figure 5.
BDI model based individual agent behavior design.
Table 2.
belief, desire and intention (BDI) model-based sensing agent individual behavior for lighting control.
Table 2.
belief, desire and intention (BDI) model-based sensing agent individual behavior for lighting control.
| User input | Illumination Control |
|---|
| Belief | location: living room |
| time: night |
| number of humans: two subjects |
| energy: moderate |
| Desire | Set up proper illumination conditions for each human activity |
| with the goal of reducing power consumption |
| Intention | (1) use thermal sensor to identify human activity |
| (2) use light sensor to detect the current illumination level |
| (3) adjust illumination conditions to a proper level for that activity |
| (4) choose the energy-efficient behavior mode |
| Behavior | (1) Sensor agent: (low resolution) sensing → (simple) processing → |
| (low data throughput) transmission → (parameter) configuration |
| (2) Action agent: (less frequent) communication → (parameter) configuration → |
| (less frequent) command |
Table 2 gives an example to illustrate the procedure of generating the behavior model. The user input is illumination control. The environmental beliefs include time, location, number of humans and energy conditions. Based on the beliefs, the desire is to setup proper illumination conditions with the goal of reducing power consumption. The intention plan includes four actions: (1) use thermal sensors to identify the subjects’ activities; (2) use light sensors to detect the current illumination conditions; (3) change the illumination conditions to accommodate the current activity; and (4) choose an agent behavior model that saves energy. As a result, energy-efficient behavior models for sensing and decision agents are selected to perform this illumination control task.
4.2. Regulation Policy-Based Multi-Agent Group Behavior
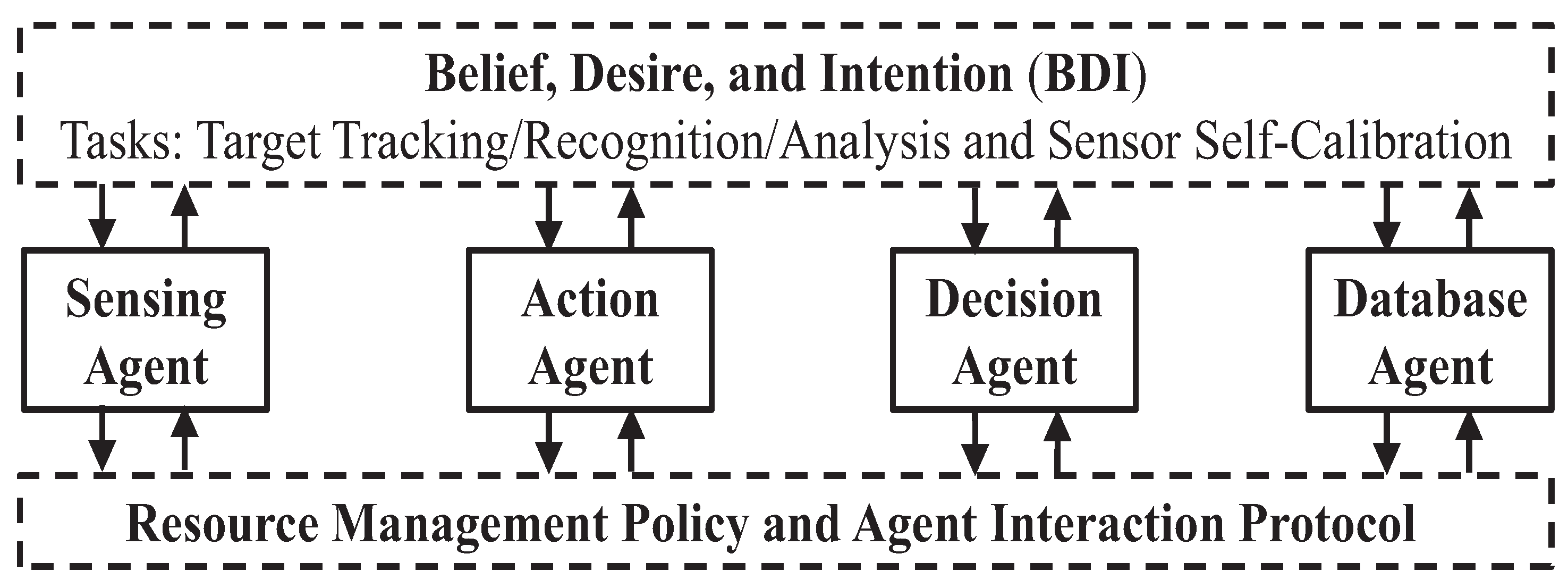
When a group of agents work together, three major issues need to be addressed: (1) communication protocol; (2) collaboration scheme; and (3) resource management. A group of collaborative agents exchange various types of information, including service requests, service reports and the states of each agent. Therefore, a communication protocol should be formulated to ensure high efficiency in information exchange among agents. The collaborative activities of a group of agents may result in conflicts on schedule, resource and causality. Deadlocks, oscillation, unreachable tasks should be avoided for group behaviors of agents.
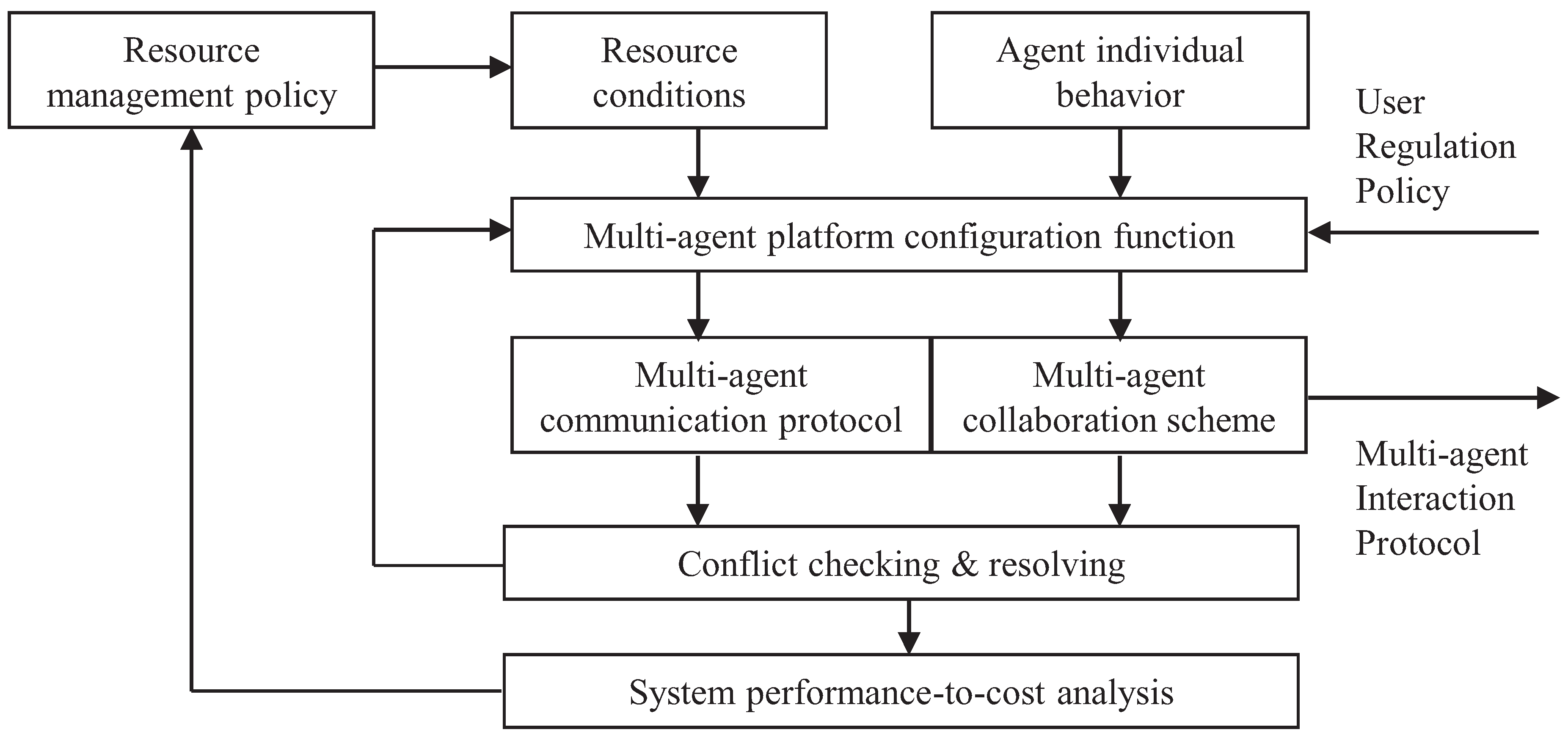
Figure 6 shows the process of generating a multi-agent interaction protocol. Each interaction protocol defines a group behavior. Given a user regulation policy, the multi-agent platform configuration function can generate a set of feasible communication protocols and collaboration schemes based on resource conditions and individual agent behavior models. Each regulation policy contains: (1) priority; (2) a task list; (3) a resource list; and (4) power consumption restrictions. Given a group behavior of multiple agents, possible conflicts can be checked and evaluated by using Petri-net methods. Among those protocols without any operational conflicts, the one with the highest perform-to-cost ratio will be chosen. A corresponding resource management policy will be adopted by the multi-agent platform.
Figure 6.
Regulation policy-based multi-agent group behavior design.
Figure 6.
Regulation policy-based multi-agent group behavior design.
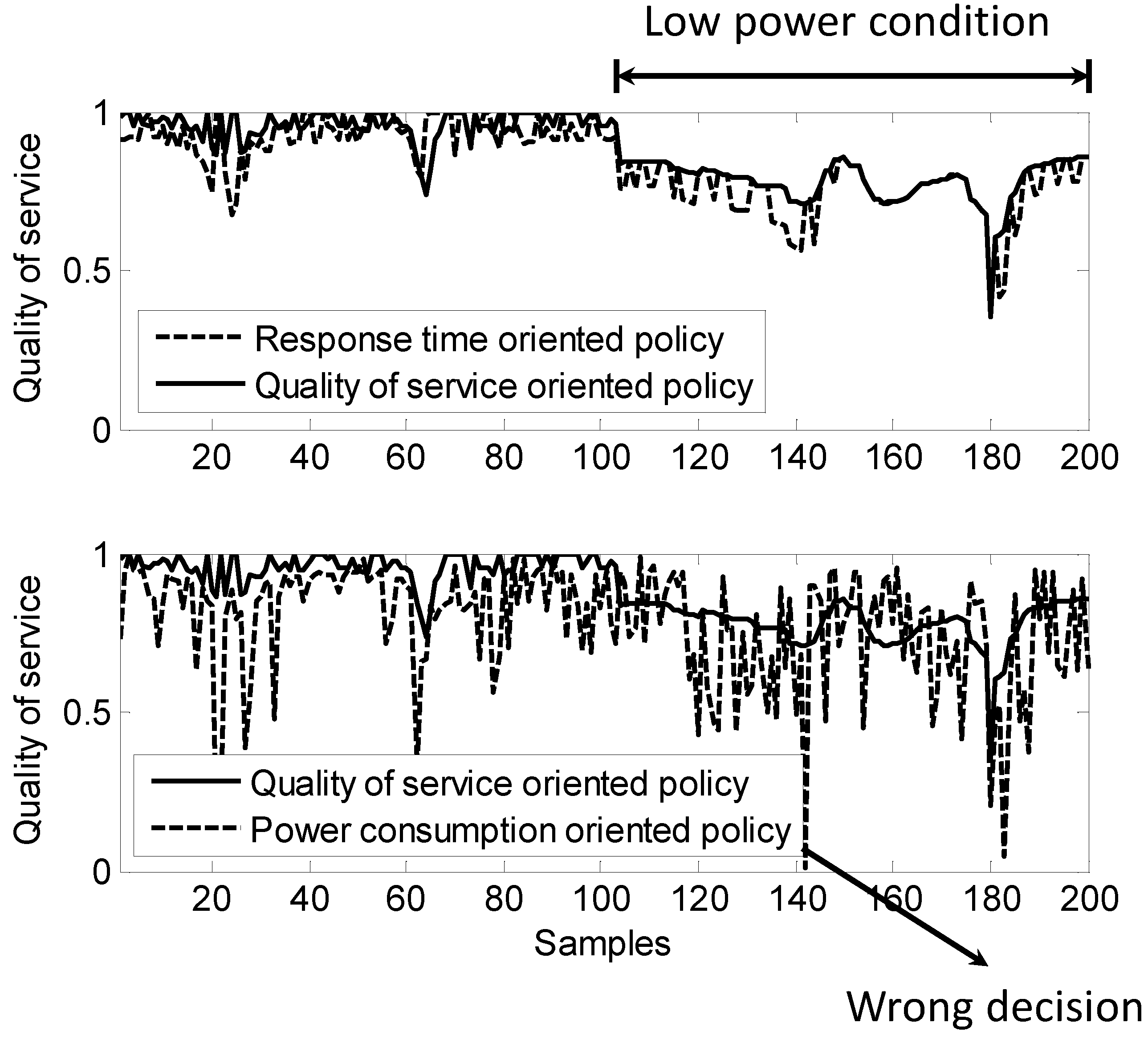
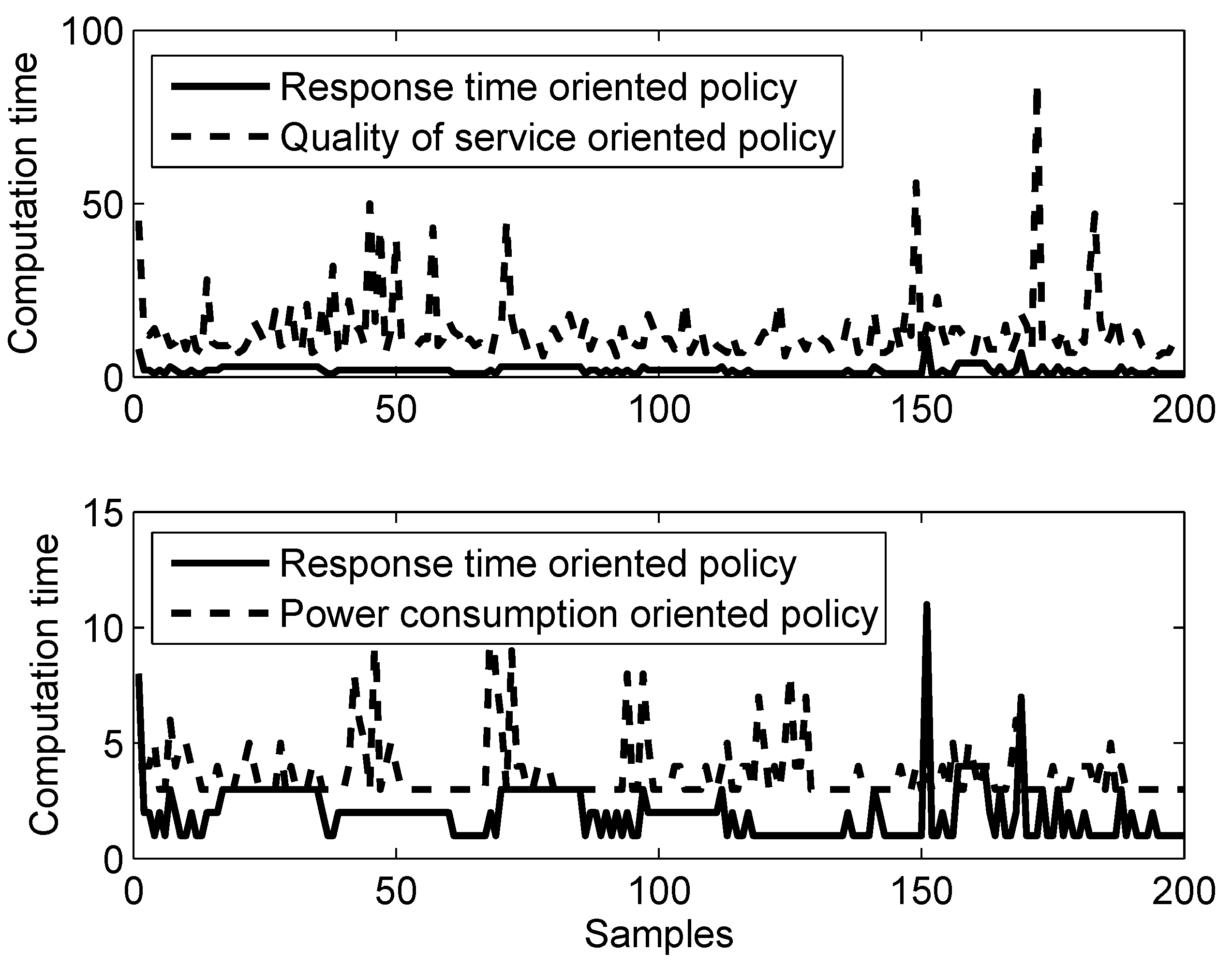
Table 3 shows three typical regulation policies with different priorities: (1) response time; (2) quality of service (QoS); and (3) energy efficiency. For response time-oriented regulation policies, fast sensing agents will be chosen, and no database agent will be used; decision agents will use simple algorithms to make fast decisions. For QoS-oriented regulation policies, high resolution sensing agents will be chosen, and a database agent will be used to enhance the situation/context awareness of the sensing process, which can improve the information fidelity; more complicated action planning will be used for action agents to achieve better control quality. For energy efficiency-oriented regulation policies, low resolution sensing agents will be chosen, and a database agent will be used to enrich the information content of the sparse measurements; more computations will be performed within each agent to reduce communication throughput; more planning activity within the decision agents will be performed to improve the efficiency of action agents.
Table 3.
Regulation policies and agent interaction protocol designs. QoS, quality of service.
Table 3.
Regulation policies and agent interaction protocol designs. QoS, quality of service.
| Regulation Policy Priority | Interaction Protocol |
|---|
| policy 1: response time | high-speed sensing → database agent → action agent |
| policy 2: QoS | high-resolution sensing → decision agent → database agent → decision agent → action agent |
| policy 3: energy efficiency | low-resolution sensing → decision agent → action agent |
4.3. Agent Behavior Model and Petri-Net-Based Analysis
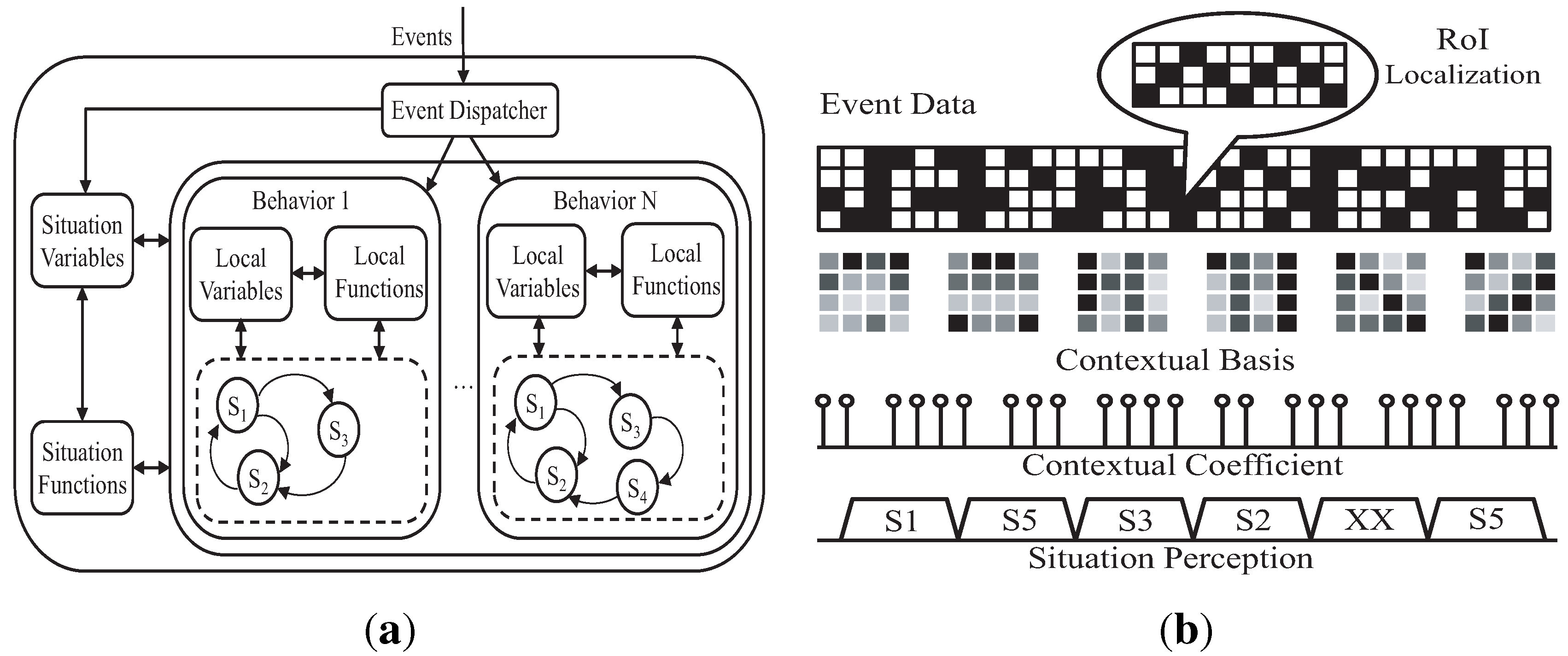
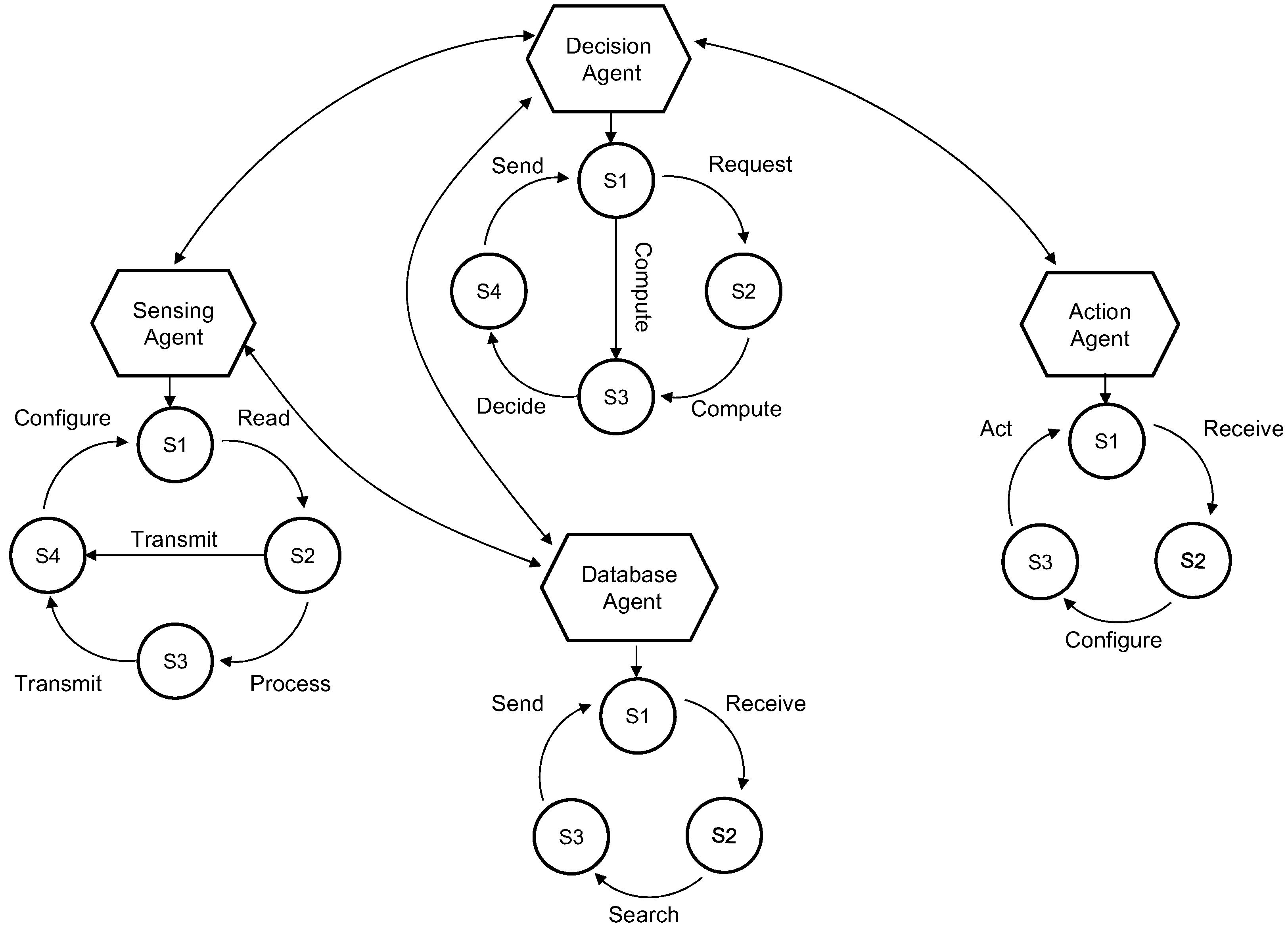
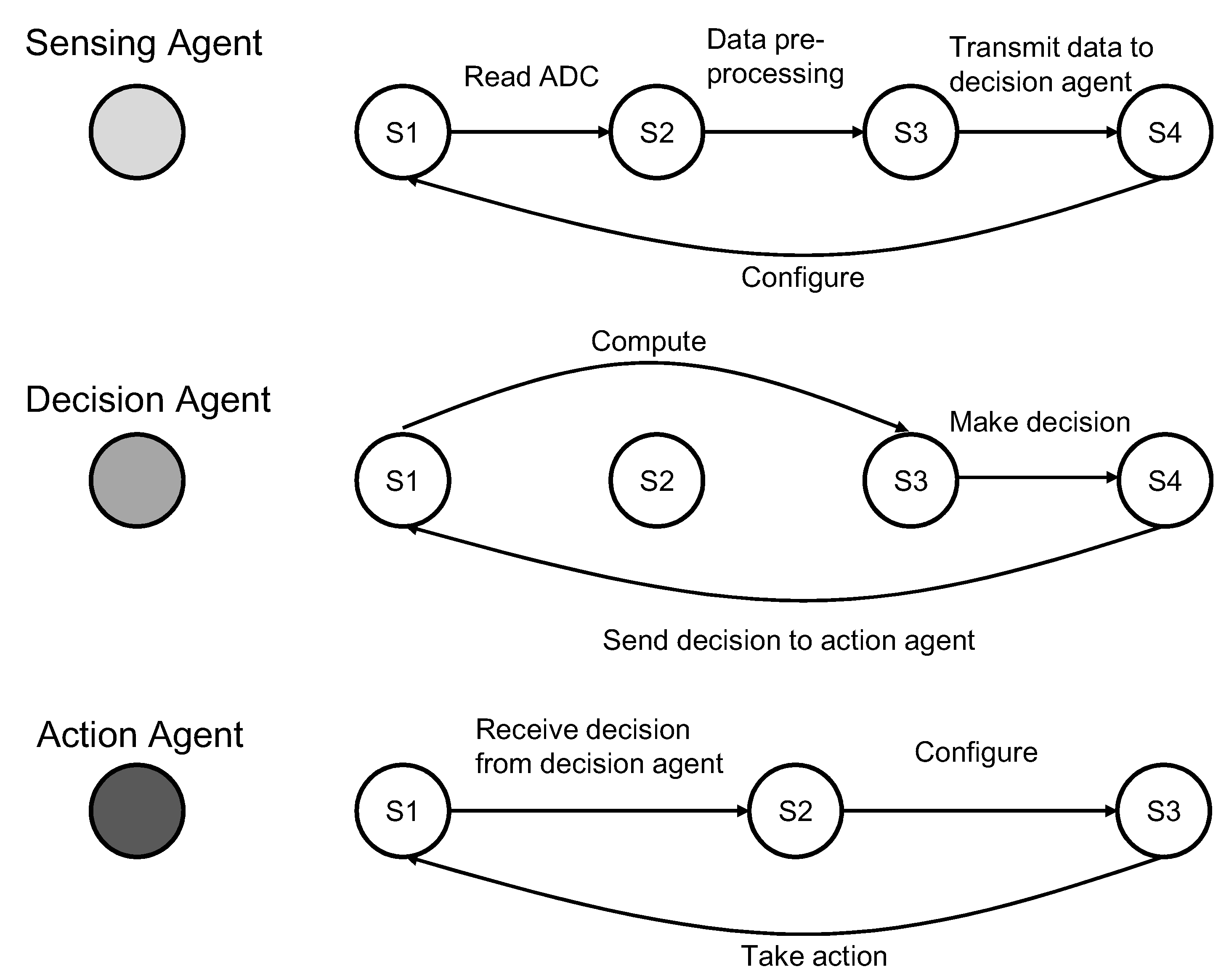
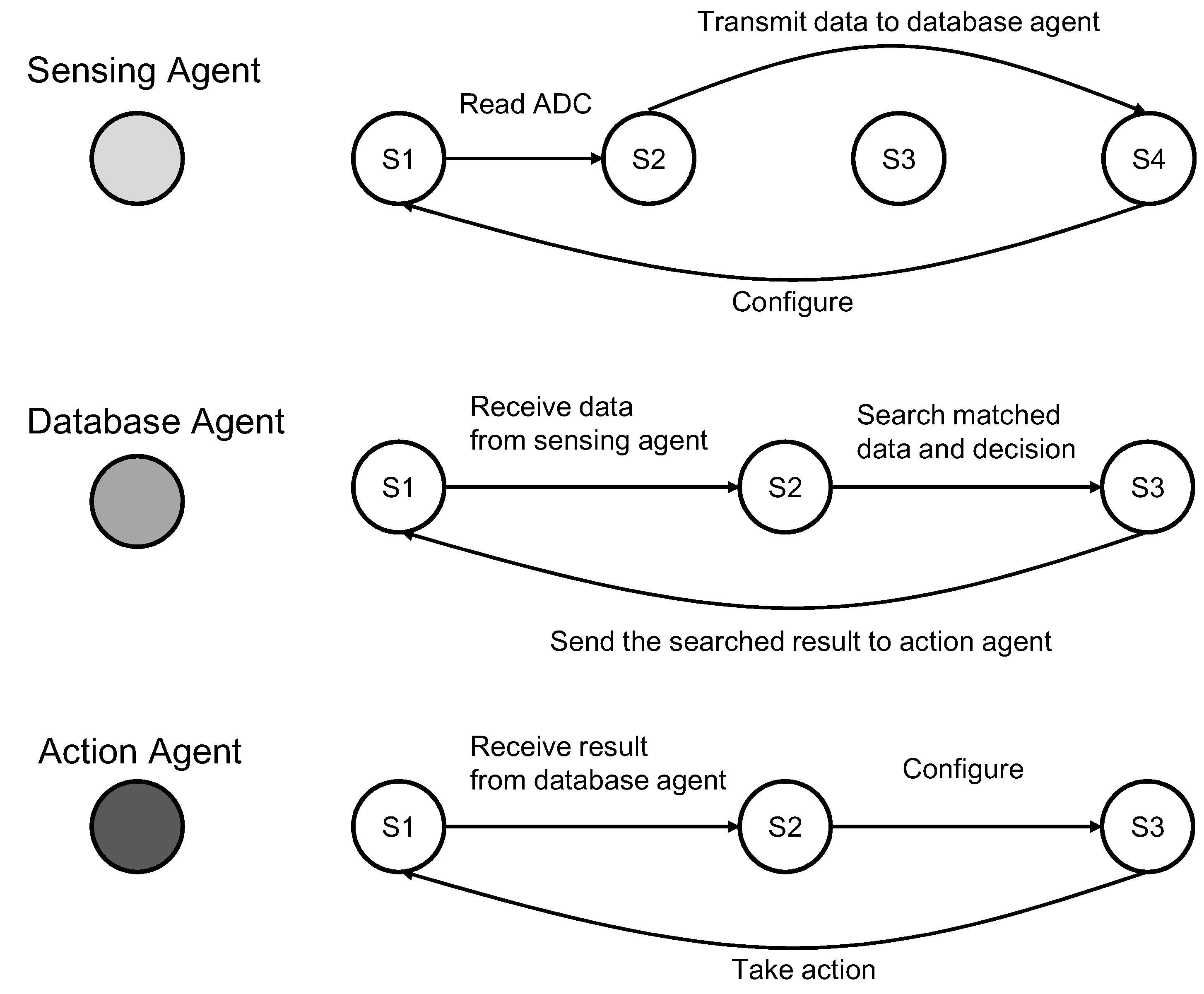
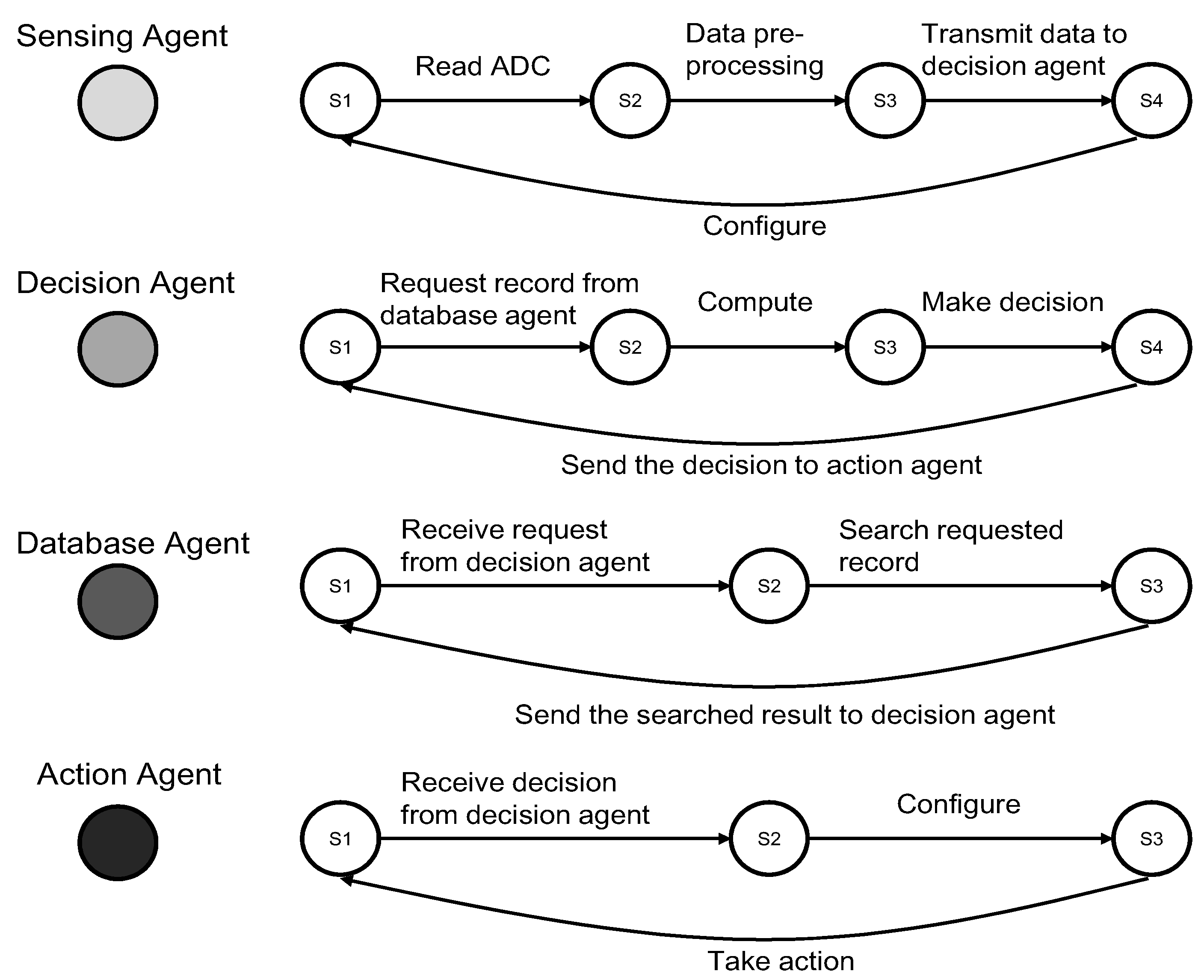
Both individual and group behaviors can be modeled as finite-state machines (FSM). A finite state machine consists of a number of states. For an agent, each state represents the status of an agent and is associated with certain functions. The transitions among states are also associated with certain operations. For example, as shown in
Figure 7, the database agent has three states: waiting, query, done. When the database agent receives a request from the decision agent, it will change from the first state to the second state, and after the query is done, it will change to the third state and send the result to the decision agent. At the same time, after the decision agent sent a request to the database agent, the decision agent will change to the waiting state. When the decision agent receives a reply from the database agent, it will change to the computing state. Once finished computing, it will change to another state for making the decision. The final decision will be sent to the action agent.
For a group of agents, each state represents the status of agent collaboration.
Figure 7 shows a composite FSM model of a multi-agent system consisting of four agents. The FSM models of multi-agent behaviors enable a mathematical analysis of their feasibility and stability. One reason is that FSM is a mathematical model of computation, and it can be used in distributed systems to implement system automation. The other reason is that we proposed to use Petri-net as the mathematical evaluation tool to analyze and test our multi-agent model. Moreover, the Petri-net is generated based on the FSM in our design.
The biggest challenge for agent collaboration is resolving possible conflicts in scheduling and resource allocation. Petri-net (PN) models have emerged as very promising performance modeling tools for systems that exhibit concurrency, synchronization and randomness. Petri-nets have been used as one of the mathematical models to describe the execution process of distributed systems. In this work, we utilize Petri-net approaches to study the reachability, consistency of the multi-agent system and evaluate its group behavior.
Figure 7.
The architecture of a multi-agent system and the finite states of each agent.
Figure 7.
The architecture of a multi-agent system and the finite states of each agent.
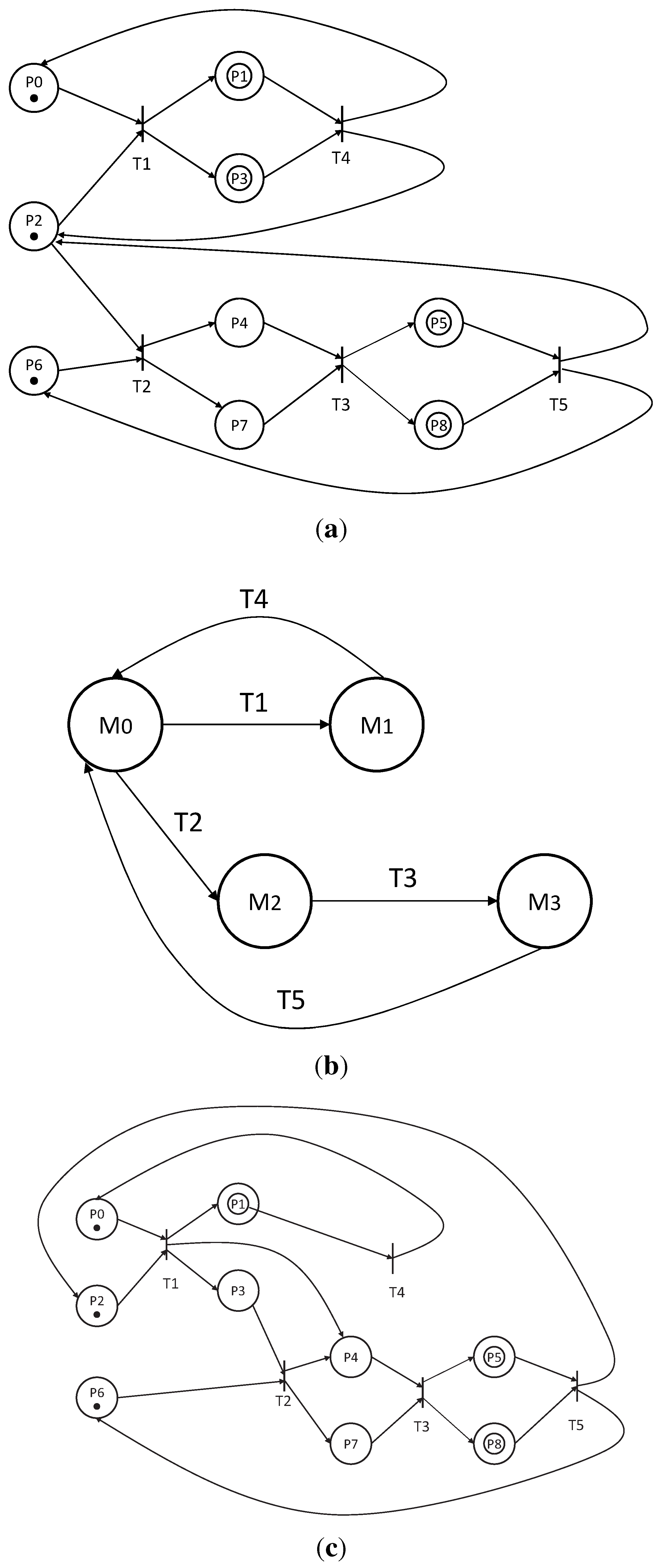
Figure 8 shows Petri-net graphs of three collaborative agents. Each PN consists of positions, transitions and input and output functions. A PN is said to be safe for an initial state if all states are reachable.
Figure 8a shows a reachable PN model. The states of a PN evolve by the firing of transitions. A transition is alive for an initial state if there exists a firing sequence for that initial state to reach the next state.
Figure 8b shows a state reachability graph of the valid model in (a). When certain transitions are no longer available or when all or part of the PN no longer functions, there will be mistakes in the system design.
Figure 8c shows an unreachable PN model. A PN is alive for an initial state if all transitions are live for that initial state. A deadlock is a state in which no transition can be fired. Liveness of a PN implies the degree of absence of potential deadlock states. Based on these concepts, the feasibility and performance of multi-agent collaboration can be evaluated [
34].
To check the security and reachability of a multi-agent collaboration scheme using Petri-net methods, we define a PN as a four-tuple combination,
, where:
is a set of states, and:
is a set of transitions subject to:
Figure 8.
Collaboration scheme design using a Petri-net (PN) graph for three agents. (a) a reachable PN model; (b) the state reachability graph of a valid collaboration model; (c) an unreachable PN model.
Figure 8.
Collaboration scheme design using a Petri-net (PN) graph for three agents. (a) a reachable PN model; (b) the state reachability graph of a valid collaboration model; (c) an unreachable PN model.
Assume is an input function that defines directed arcs from states to transitions, and is an output function that defines directed arcs from transitions to states. The process of testing security and reachability of our proposed collaboration model is demonstrated by the following algorithm:
| Algorithm 1: Security and reachability test algorithm. |
| Input: positions: P, transitions: T, position to transition function: , transition to position |
| function: |
| Output: state transition matrix: M |
| 1
; |
| 2 ; |
| 3 ; |
| 4 ; |
| 5 while do |
| 6 ; |
| 7 ; |
| 8 if the value of each element in is not larger than 1 then |
| 9 ; |
| 10 ; |
| 11 else |
| 12 ; |
| 13 ; |
| 14 end |
| 15 end |
| 16 return M |
Example I: We use an example to verify the safety and reachability of multi-agent collaboration schemes. For the model shown in
Figure 8a, the input function is given by:
The output function is given by:
According to the definition, an incidence matrix is given by:
We then obtain:
The incidence matrix is used to find out the changes in a Petri-net upon firing a given transition. The characteristic equation of a state transition is given by:
where
is the initial state of the state transition equation.
For this collaboration model, the initial state,
, should be:
The points in
are tokens, which represent the current state of the agent. We choose to fire transition 1; we can get the result of the next state:
We then continue to trigger all the transitions along the path shown in
Figure 8. The transition matrix is obtained as:
The complete state transition matrix will be:
It can be seen that in the state transition matrix, the number of tokens in any state is not larger than one. This means that there are no conflicts. In other words, the proposed collaboration model is safe and reachable. The state reachability graph is shown in
Figure 8b.
Example II: In contrast, for the PN model shown in
Figure 8c, the incidence matrix,
W, is:
The transition matrix,
T, is the same, and the state matrix is:
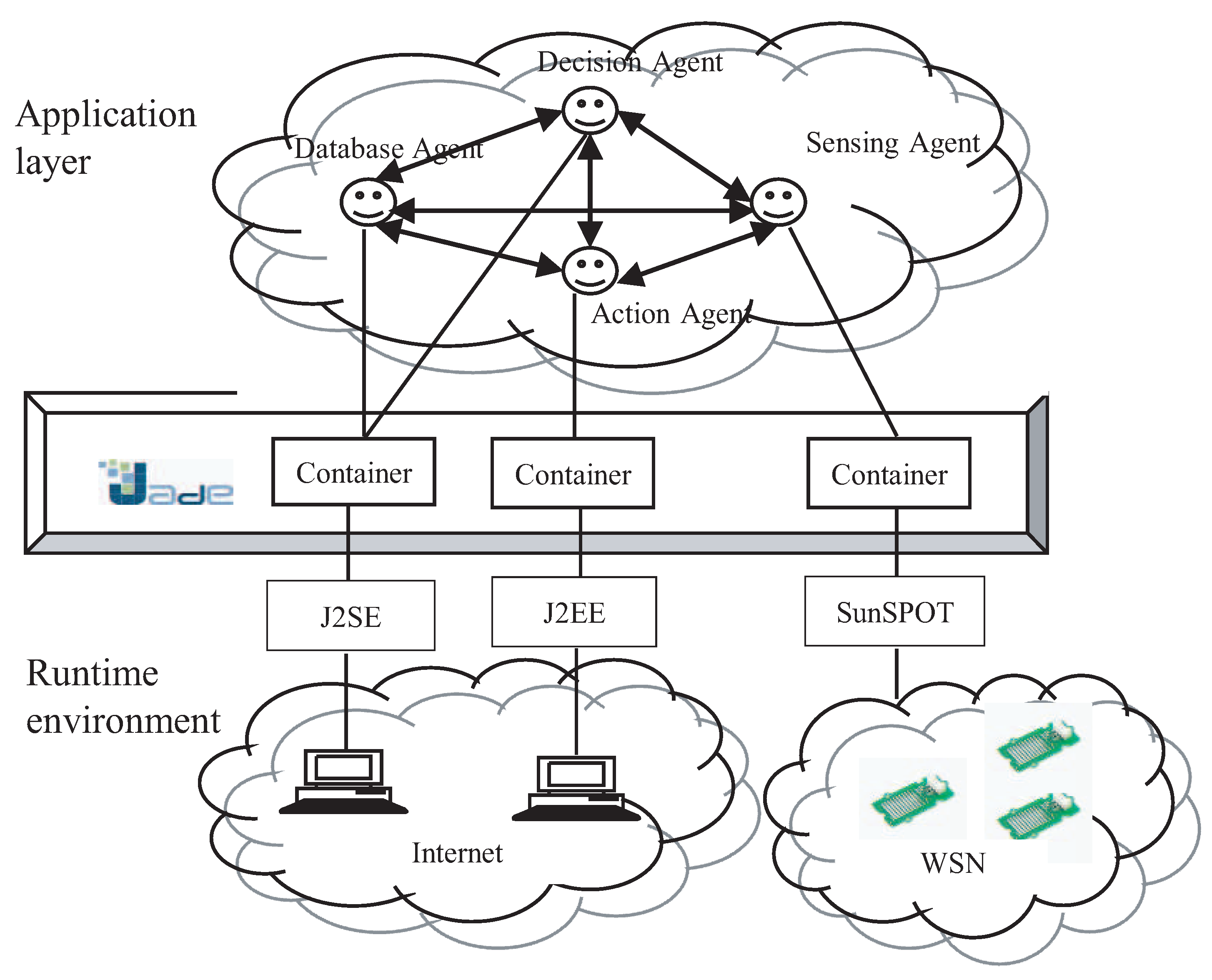
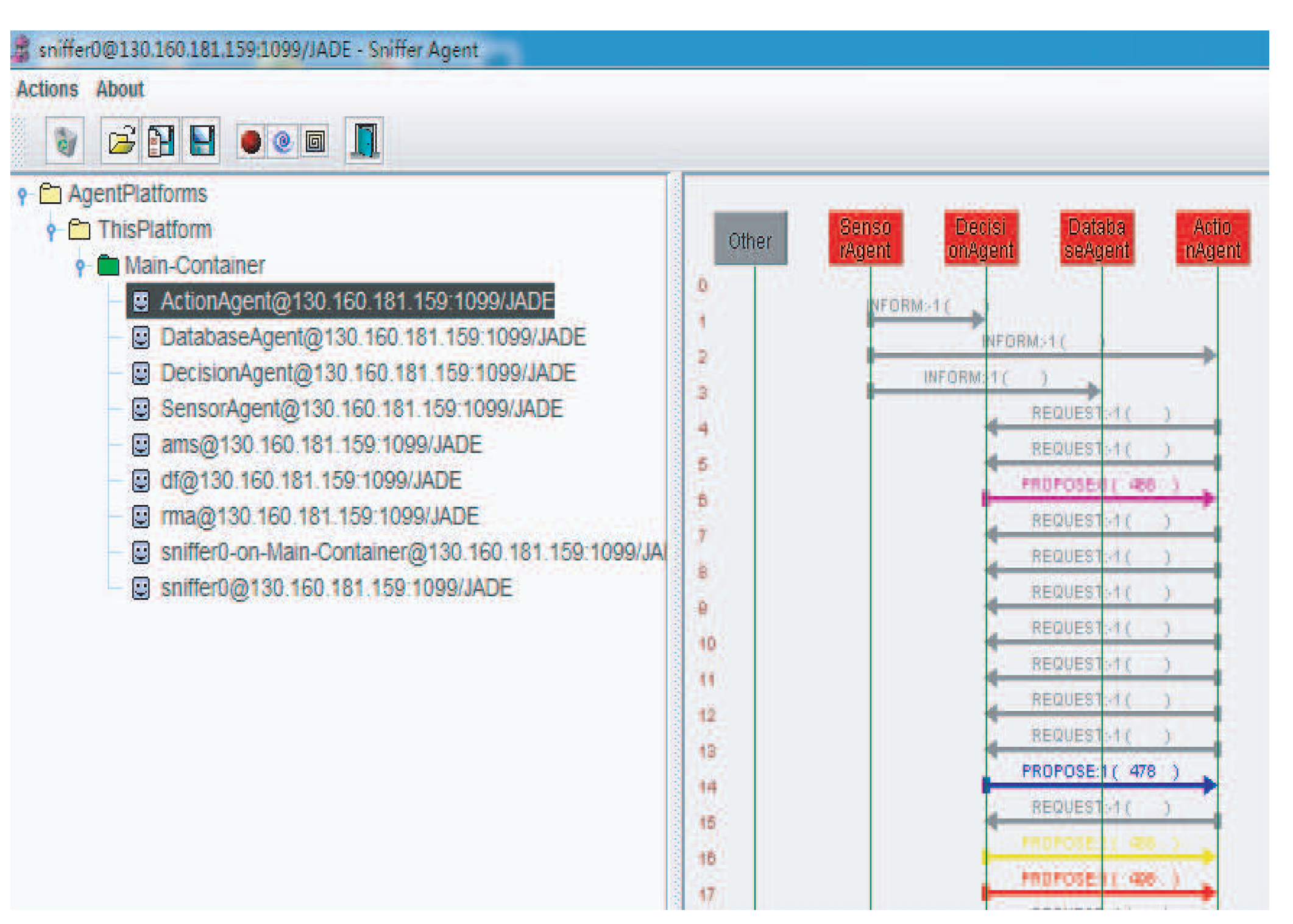
Figure 9.
Java Agent Development Environment (JADE) multi-agent implementation.
Figure 9.
Java Agent Development Environment (JADE) multi-agent implementation.
The Petri-net analysis method is based on the FSM model. In an FSM, any agent only can stay in one state at each moment. When the state transition matrix of
Figure 8c has a value of two, this means that at a certain moment, an agent needs to stay in two states. Obviously, such a status is hardly reachable during a collaboration. According to [
35], such a state transition matrix does not satisfy the safeness metric. Therefore, there is a conflict in the collaboration design shown in
Figure 8c, that is, such a collaboration is neither safe nor reachable.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}


























