The daily realized variance data of the period January 3, 2000, to May 22, 2012, was obtained from the Oxford-Man Institute of Quantitative Finance website
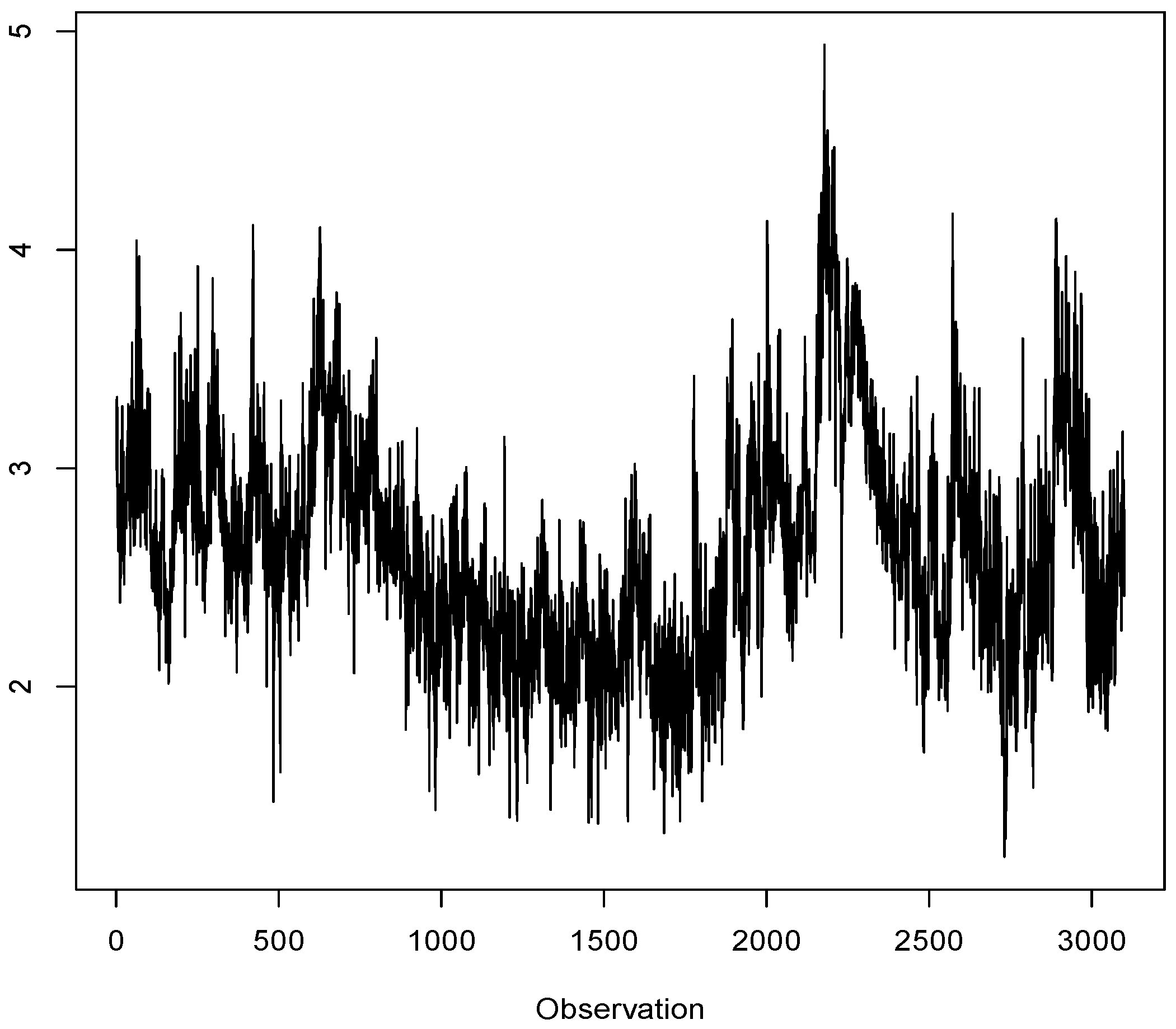
5 by taking the first series in this dataset (5-min realized variance of S&P 500 (live) index). It was transformed to the corresponding logarithm of the annualized realized volatility series
6 (see
Figure 7). The effective sample size was about 3,000 observations. It can be seen that the middle third of the period is relatively less volatile compared with the other two-thirds of the observations,
i.e., the periods with observations indexed by numbers 1–1,000 and 2,001–3,000. Hence, by looking at distinct periods, we can evaluate the behavior of the models in relatively calm and volatile periods.
Figure 7.
Logarithm of the annualized realized volatility of the S&P 500 (live) index (5-min).
Although the HAR-RV model is most widely used as an approximation of the underlying RV process, [
56] show, using a test proposed by [
57], that, for the realized volatility of S&P 500 returns, the restriction on parameters implied by the HAR-RV model is empirically inadequate. On the other hand, the restriction implied by the exponential Almon polynomial constraint cannot be rejected (see
ibidem). It should be pointed out that this constraint has already been used in modeling and forecasting the RV series also in the cases whenever there is only a single frequency,
i.e., where single step ahead forecasts are produced, leaning on the autoregressive terms (see, e.g., [
28,
55,
58]). The main aim here remains the same,
i.e., to reduce the number of parameters and the connected variability of the estimators using a certain, quite flexible restriction. In the sequel, we employ both competing restrictions.
The restrictions on the parameters in the HAR-RV model take the following form:
where the coefficients
and
correspond to the daily, weekly and monthly effects, respectively. It should be noted that Equation (
13) with restriction given by Equation (
14) represents the average of the logarithmically transformed data. In most applications of the HAR-RV model with a logarithmic transformation, the logarithms of the averages over five and 21 days of realized volatility are employed rather than the averages of the logarithms. In our study, the former approach was dominated in both the in-sample and the out-of-sample precision analysis by the model given by Equation (
13) with restriction as in Equation (
14). In the following, we shorten the notation of the HAR-RV model to HAR.
4.1. Significance of the MQ Terms
To test for the significance of the MQs, we need the (maximum) lag order
k. In the case of the HAR model, we fix it at 20 lags. Although [
59] found that the most informative maximum lag of aggregation could vary from 13 to 250 lags for different stocks, the normal maximum number of lags used in the HAR models is between 20 and 22, which correspond to the number of working days in a month. In our analysis, the difference between any of these three numbers was negligible. For example, the out-of-sample precision figures were unchanged when they were rounded to three digits (the precision level used to represent the relative out-of-sample forecast performance in
Table 4). Furthermore, our analysis of an informative moving window, which is used to calculate the MQs, also signified 20 lags (as discussed later). Hence, to avoid an uninformative and heavy presentation of many, very similar models with virtually the same properties, we also fix the number of lags for the HAR model at 20 periods.
In addition, in unrestricted Equation (
13) or the MIDAS-type models, the lag order is usually selected based on some information criteria. In our case, for both the unrestricted and the ALMON models,
is selected based on the usual criteria,
i.e., Akaike’s information criterion (AIC) and the Bayesian information criterion (BIC), where the maximum lag order considered is set to
. Consequently, in the following analysis, we use two potential maximum lag orders
, which correspond to the lag suggested by the information criteria and that are connected to the HAR lag order, respectively. Note that the window length used to define the MQs might not coincide with the maximum lag order of the linear autoregression
7. Hence, we describe several possible combinations. The names of each model used in the sequel indicate explicitly the maximum lag order of the linear autoregressive terms and the window size used to calculate the values of the MQs. For instance, ALMON(12)-MQ(20) corresponds to the case where there are 12 linear autoregressive terms and a window size of 20 is used to calculate the MQs (starting from the first lagged observation).
Table 2 shows the empirical significance of the tests of the absence of MQ effects in the linear model in Equation (
1) without and with the HAR and exponential Almon lag polynomial restrictions. Since the errors of realized volatility models are often found to be conditionally heteroscedastic (see, e.g., [
60]), we report also the testing results, which count on the heteroscedasticity consistent estimator of the asymptotic covariance matrix (see the
p-values in parentheses in
Table 2). Namely, we rely on the [
61] approach, which was shown by [
62] to perform well in small samples relative to other estimators.
The testing results have several dimensions. First, they are provided separately for each combination of orders of linear autoregression and MQs. Next, several quantile structures are considered to check the sensitivity of the results: the minimum-median-maximum, quartiles, quintiles and deciles.
Table 2.
p-values of the test for the absence of moving quantile (MQ) effects (estimation sample: 1–2,000). HAR, heterogeneous autoregression model.
Table 2.
p-values of the test for the absence of moving quantile (MQ) effects (estimation sample: 1–2,000). HAR, heterogeneous autoregression model.
| Models | MQ Window | Quantile Structures: |
|---|
| Min-Med-Max | Quartiles | Quintiles | Deciles |
|---|
| AR(12) | 12 | | | | |
| 20 | | | | |
| AR(20) | 12 | | | | |
| 20 | | | | |
| HAR | 12 | | | | |
| 20 | | | | |
| ALMON(12) | 12 | | | | |
| 20 | | | | |
| ALMON(20) | 12 | | | | |
| 20 | | | | |
In most of the situations considered, the MQ terms are significant at the usual significance levels, although there is a tendency of a decreasing significance with the usage of a more fine grid of quantiles. The constrained cases with HAR and ALMON restrictions imposed on parameters appear to favor the MQs quite strongly (although less so whenever accounting for the potential conditional heteroscedasticity). If the constraints are consistent with the underlying data generation process
8, this effect is expected to be present, because the restrictions reduce the variability in the estimator and increase the power of the test, as revealed in the previous section. Similarly, the usage of an excessively dense grid of deciles leads to a potential loss of power, which was one of our motivations for introducing and considering the MQs instead of looking directly at all of the order statistics.
In general, we can conclude that the nonlinear effects under consideration are quite likely to be present in the data. The min-med-max quantiles appear to be most significant, but our further study suggests that the moving median is the key variable favored by the information criteria. Hence, any of the quantile structures considered above would lead to the same result in practice.
4.2. In-Sample Performance and Forecasting Precision
Using the data characterized above, we perform a pseudo out-of-sample exercise using the fixed, recursive and rolling approaches for out-of-sample forecasting. The parameters of the models of a sub-sample are re-estimated during each update under the recursive and rolling types of forecast with all of the data up to the latest observation in the sub-sample and a fixed number of data (a rolling window), respectively. An initial model estimation period comprises the first 2,000 observations. In an additional sensitivity analysis, we also provide the results for the case where the initial model estimation period is reduced to the first 1,000 observations only.
The set of models considered comprises the unrestricted linear AR models, as in Equation (
13) (with different
k), as well as the HAR and ALMON models with and without the MQs.
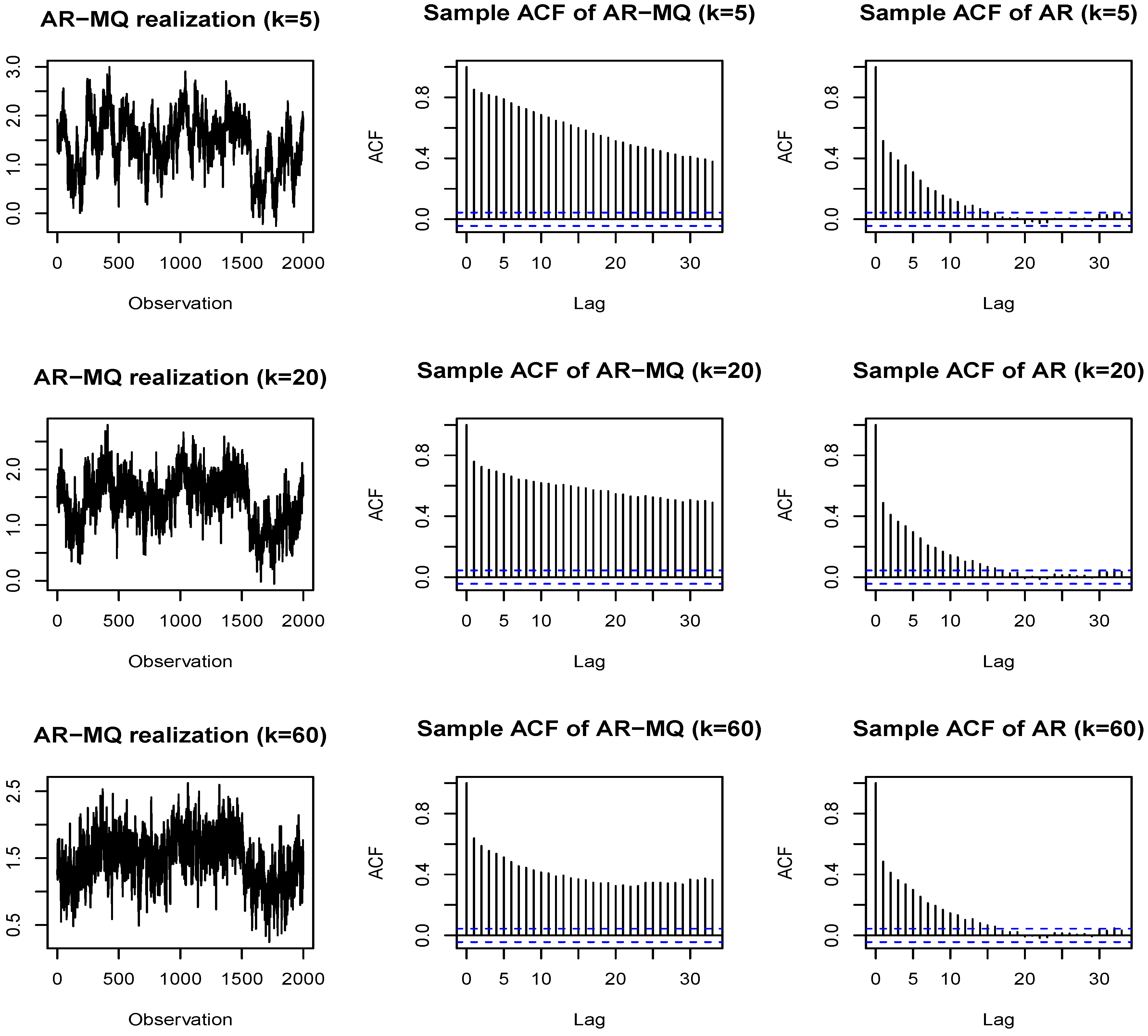
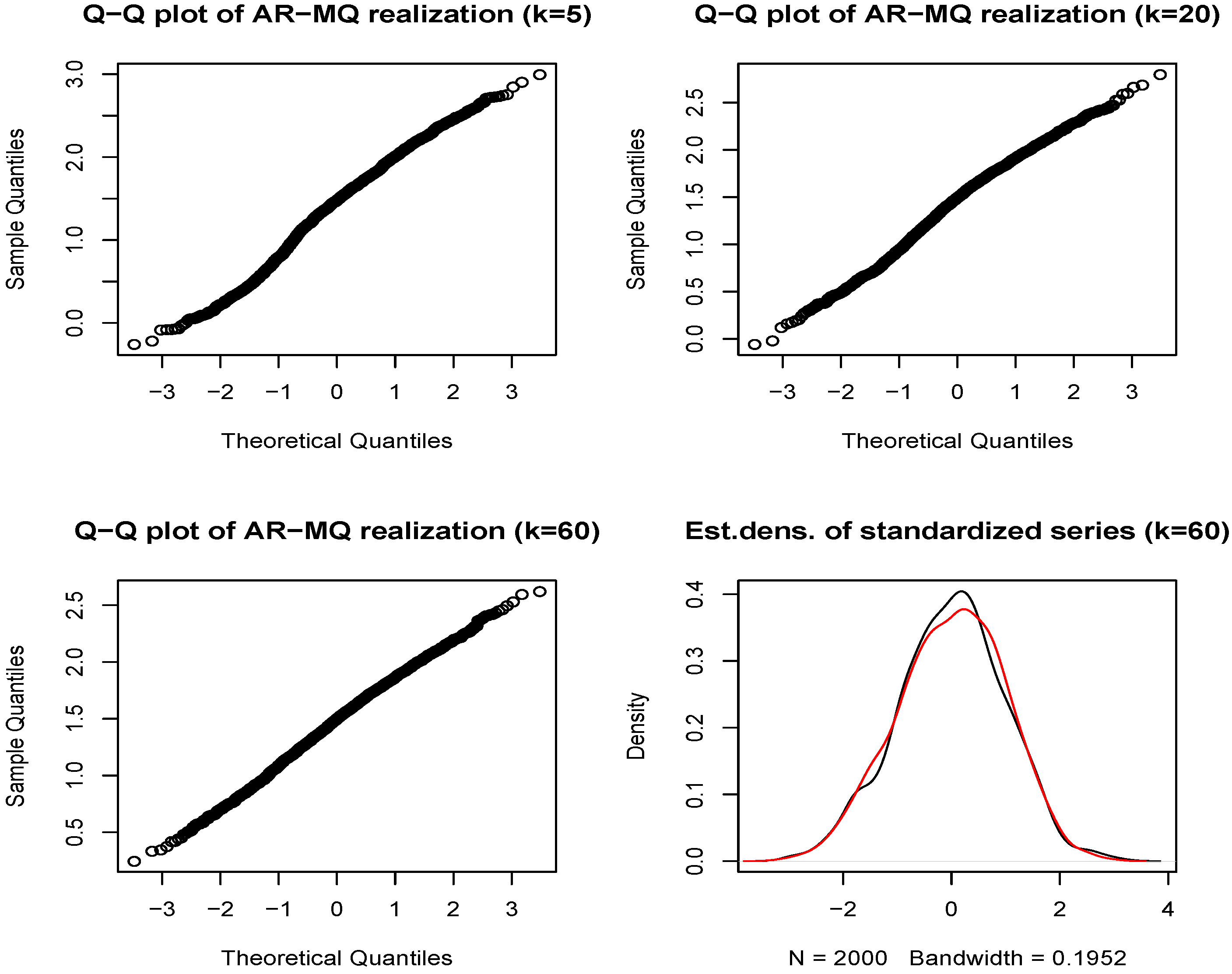
We use the AIC and BIC to select the relevant MQ terms, which mainly select the median as the relevant variable in most of the situations under consideration. Thus, we augment the linear models described above with a single term that corresponds to a moving median. Examples of estimated models and the corresponding auto-correlograms of the residuals are presented in
Appendix C. In particular, the results for the estimated HAR, HAR-MQ(20), ALMON(12) and ALMON(12)-MQ(20) models are presented. The ordinary and nonlinear least squares estimators are used where appropriate to estimate the parameters. It should be noted that any configuration of the ALMON-MQ model always satisfies the sufficient stability condition defined in Proposition 1, whereas the results for other models vary (see
Table C2 in
Appendix C).
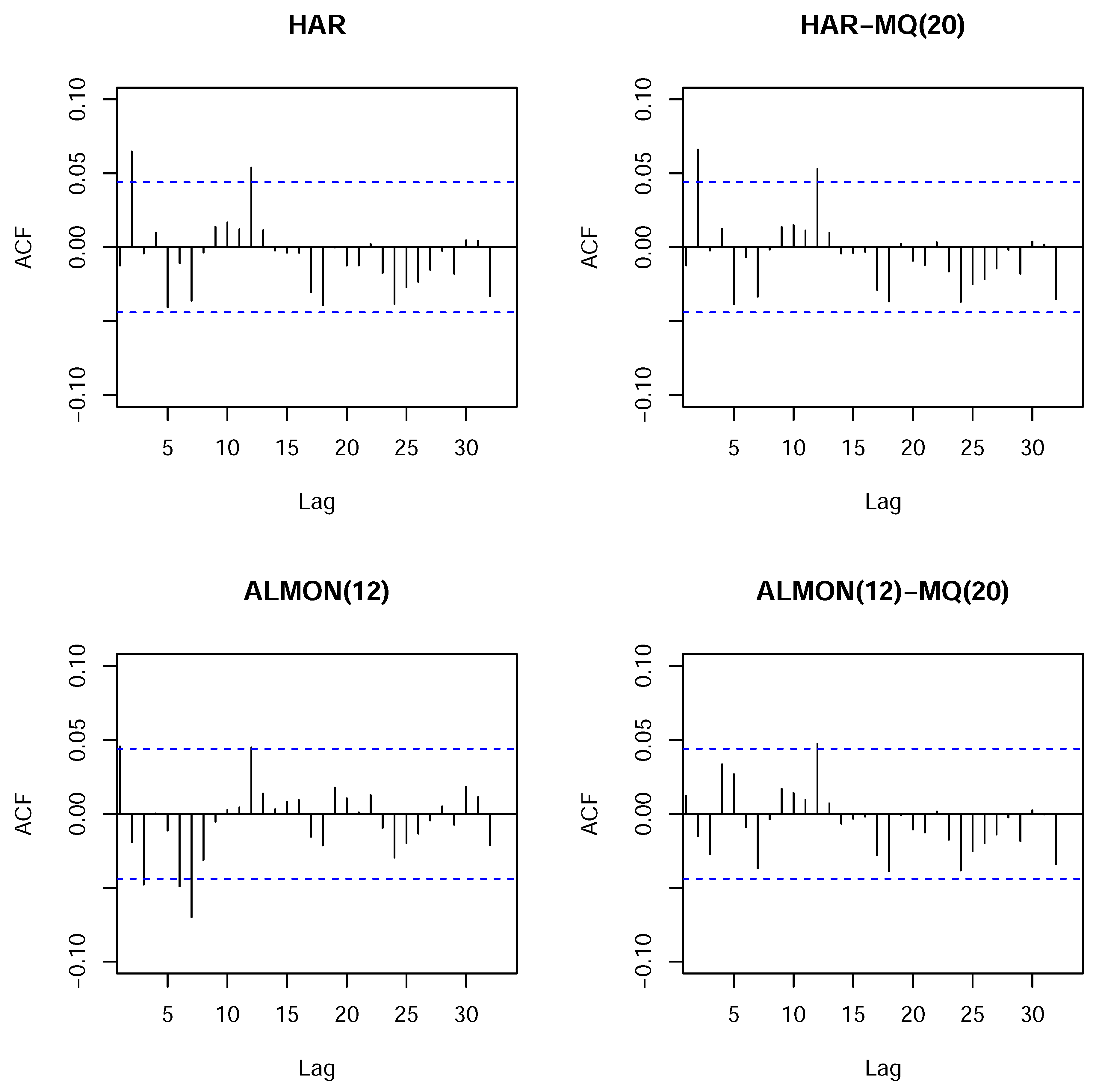
It can be seen from the results provided in
Appendix C, for the models with the MQ term, that the moving median is always significant, whereas the third HAR term, which is connected with the monthly aggregate component, becomes insignificant whenever the moving median is added, as in the HAR-MQ(20) model. Furthermore, by considering the plots of the autocorrelation functions of the residuals in
Figure C1 (see
Appendix C), we can see that the presence of the moving median in the ALMON(12)-MQ(20) model removes a number of the spikes observed in the autocorrelation function of the residuals of the ALMON(12) model. However, in the case of the HAR model, the moving median is not able to remove the observed spikes of the autocorrelations at Lags 2 and 12. The same also holds for the HAR-MQ(12) model (unreported). These results are presented for samples 1–2,000. The results for samples that only comprised the first 1,000 observations and the whole dataset are not reported, but they are very similar and, correspondingly, have a bit less (or more) pronounced features discussed previously when the first 1,000 observations (or the whole dataset) is used.
It is relevant to recall that two lag orders can be selected in the models with MQs: the number of linear autoregressive terms and the number of periods used to calculate the MQs (window size). In general, the window size used for the MQ calculations might not coincide with the number of linear autoregressive terms. However, as noted in
Section 2, MQs entail a representation with a certain linear part. As a result, unless the maximum lag of the MQ window is quite large, which would have the consequence of nearly negligible linear terms, we can expect to detect the required size of the moving window using the standard lag selection procedure based on a linear model. Indeed, whenever we used the information criteria to select the sub-sample window size from which the MQs are calculated, the criteria also indicate the 12 or 20 period window sizes for MQs in most situations,
i.e., combinations of models, various MQ terms, maximum number of lags and different samples.
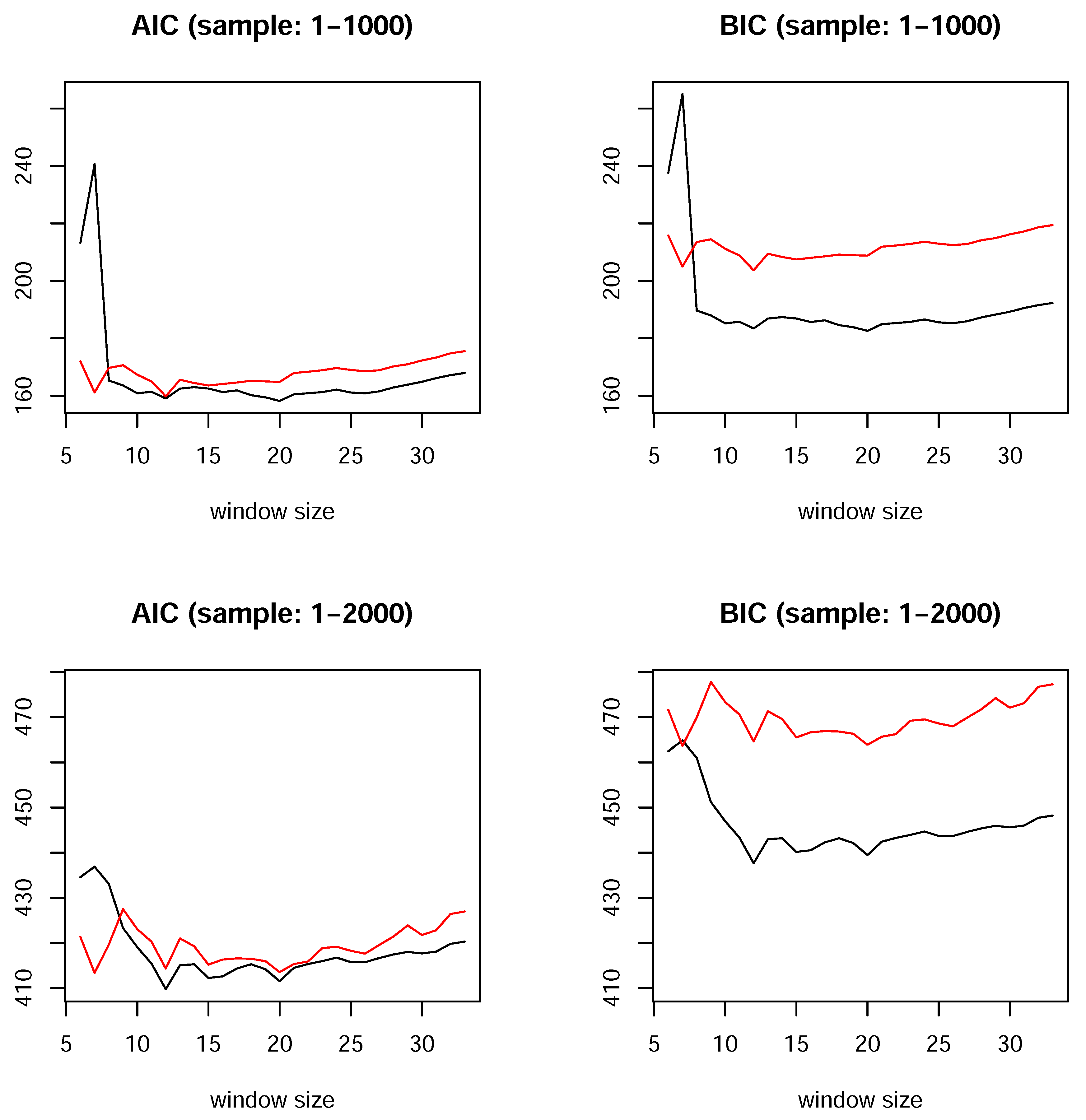
Figure 8 plots the AIC and BIC values for the ALMON model with a fixed number (twelve
9) of autoregressive terms, but a changing window size is used to calculate the MQs. The results are similar for the other models. The range of lags considered is 6–33, where the maximum is bounded by
. The results are presented for sample sizes 1–1,000 and 1-2,000, and the two cases of MQs: (1) with all of the MQs present in the model (red line); and (2) only including the moving median (black line).
Figure 8.
Effect of the moving window size, which is used to calculate the MQs, on the values of the information criteria for the ALMON(12) model with all MQs (red line) and only including the moving median (black line).
Figure 8.
Effect of the moving window size, which is used to calculate the MQs, on the values of the information criteria for the ALMON(12) model with all MQs (red line) and only including the moving median (black line).
The information criteria are basically in agreement. First, the lowest value is obtained when only the moving median is used in all cases. Furthermore, they select 20 as the most informative window size for the moving median when the sample comprises the first 1,000 observations, whereas the criteria select 12 periods for the window size of the moving median when the sample comprises the first 2,000 observations. It is important to note that the dips in the values of the criteria at window sizes of 12 and 20 are observed with all samples.
Next, it is interesting to note that for both of the samples, the AIC and BIC figures show that the model with all of the MQs has a dip at a window size of seven. With this window size, the moving median is quite uninformative (the information criteria have large values), which may suggest that considering some other quantiles in addition to this window size could improve the model further. This was not attempted in the present study in order to keep the presentation compact and because the BIC strongly favors the case that includes a single moving median. Hence, we use it in the sequel as the most informative MQ to augment the linear autoregressive models.
All of the results described above are obtained using only the in-sample data without observations 2,001–3,000.
Table 3 characterizes the in-sample model selection results,
i.e., the models among those considered that are suggested for use based on the information criteria. In each category, the numbers of the three most informative models are shown in bold, while the best in each category are underlined.
Table 3.
Values of the information criteria based on the in-sample evaluation of models.
Table 3.
Values of the information criteria based on the in-sample evaluation of models.
| Sample: | 1–1,000 | 1–2,000 |
|---|
| Criterion: | AIC | BIC | AIC | BIC |
|---|
| HAR | 161.1 | 185.5 | 422.7 | 450.6 |
| AR(12) | 167.2 | 235.8 | 423.2 | 501.5 |
| AR(20) | 175.7 | 283.2 | 432.0 | 555.0 |
| ALMON(12) | 167.2 | 186.8 | 435.8 | 458.2 |
| ALMON(20) | 162.8 | 182.4 | 429.9 | 452.3 |
| HAR-MQ(12) | 158.8 | 188.2 | 414.6 | 448.2 |
| HAR-MQ(20) | 162.3 | 191.7 | 418.7 | 452.3 |
| AR(12)-MQ(12) | 167.5 | 240.9 | 416.2 | 500.2 |
| AR(12)-MQ(20) | 164.2 | 237.6 | 417.8 | 501.7 |
| AR(20)-MQ(12) | 176.2 | 288.6 | 425.5 | 554.1 |
| AR(20)-MQ(20) | 177.1 | 289.5 | 429.2 | 557.8 |
| ALMON(12)-MQ(12) | 183.2 | 207.7 | 466.1 | 494.1 |
| ALMON(20)-MQ(12) | 179.3 | 203.7 | 461.9 | 489.8 |
| ALMON(12)-MQ(20) | 158.1 | 182.5 | 411.3 | 439.2 |
| ALMON(20)-MQ(20) | 212.0 | 236.4 | 522.3 | 550.3 |
The HAR model performs well, and it is among the best three models in three out of four cases. However, the ALMON(12)-MQ(20) model is not only among the best three models, but also the best in three out of four cases. Furthermore, in the case where it performs second best, the BIC value differs only marginally from that of the best model. Thus, the ALMON(12)-MQ(20) model appears to have a good chance of being selected a priori (using the in-sample data) as a suitable candidate for further usage/forecasting.
Let us consider the out-of-sample forecasting evaluation of the models. The maximum lag order does not vary in the HAR,
i.e., it is fixed at 20; thus, we set the HAR model precision as a benchmark in the relative forecasting performance evaluation.
Table 4 shows the relative out-of-sample mean squared forecasting errors for the models characterized above.
Table D1 and
Table D2 in
Appendix D also contain analogous results for the mean absolute percentage error (MAPE) and the mean absolute scaled error (MASE) criterion, which is favored by [
63]. The qualitative results are unchanged.
Table 4.
Relative out-of-sample forecasting precision (the benchmark is the mean squared forecasting error of the HAR model in each case). Index: S&P 500 (live). Initial series: realized variance (RV). Transformation: . Forecasting horizon: one day.
Table 4.
Relative out-of-sample forecasting precision (the benchmark is the mean squared forecasting error of the HAR model in each case). Index: S&P 500 (live). Initial series: realized variance (RV). Transformation: . Forecasting horizon: one day.
| Initial Estimation Sample: | 1–1,000 | 1–1,000 | 1–2,000 |
|---|
| Initial Forecast Sample: | 1,001–2,000 | 1,001–3,000 | 2,001–3,000 |
|---|
| Type of Forecast: | Fixed | Recursive | Rolling | Fixed | Recursive | Rolling | Fixed | Recursive | Rolling |
|---|
| HAR | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| AR(12) | 1.002 | 1.001 | 1.001 | 0.999 | 0.995 | 0.996 | 0.993 | 0.990 * | 0.989 * |
| AR(20) | 1.008 | 1.007 | 1.012 | 1.002 | 0.998 | 1.003 | 0.990 * | 0.990 | 0.993 |
| ALMON(12) | 1.018 | 1.006 | 0.999 | 1.001 | 0.995 | 0.993 | 0.987 * | 0.986 * | 0.986 * |
| ALMON(20) | 1.014 | 1.005 | 0.998 | 0.999 | 0.994 | 0.992 * | 0.987 * | 0.986 * | 0.986 * |
| HAR-MQ(12) | 0.996 | 0.995 | 0.996 | 1.002 | 1.001 | 1.001 | 1.009 | 1.005 | 1.005 |
| HAR-MQ(20) | 0.996 ** | 0.996 * | 0.995 | 0.997 ** | 0.999 | 0.999 | 1.001 | 1.001 | 1.002 |
| AR(12)-MQ(12) | 0.995 | 0.995 | 0.995 | 0.999 | 0.995 | 0.998 | 1.003 | 0.995 | 0.995 |
| AR(12)-MQ(20) | 0.998 | 0.999 | 0.999 | 0.997 | 0.993 * | 0.995 | 0.992 | 0.989 * | 0.988 * |
| AR(20)-MQ(12) | 1.003 | 1.001 | 1.007 | 1.002 | 0.998 | 1.005 | 1.000 | 0.996 | 0.999 |
| AR(20)-MQ(20) | 1.004 | 1.004 | 1.009 | 1.000 | 0.997 | 1.003 | 0.991 | 0.991 | 0.995 |
| ALMON(12)-MQ(12) | 0.994 | 0.990 | 0.987 ** | 0.994 | 0.991 * | 0.988 ** | 0.996 | 0.991 | 0.989 |
| ALMON(20)-MQ(12) | 0.993 | 0.990 | 0.987 ** | 0.993 | 0.990 * | 0.987 ** | 0.996 | 0.991 | 0.990 |
| ALMON(12)-MQ(20) | 0.992 | 0.992 | 0.988 ** | 0.987 *** | 0.987 *** | 0.985 *** | 0.985 ** | 0.983 ** | 0.983 ** |
| ALMON(20)-MQ(20) | 0.992 | 0.992 | 0.988 ** | 0.987 *** | 0.987 *** | 0.984 *** | 0.985 ** | 0.983 ** | 0.983 ** |
Let us take a look at the results presented in
Table 4. The numbers greater than one show that a model under consideration is inferior to the HAR in terms of the forecasting precision. The numbers shown in bold indicate the two models that perform best in each category in terms of the precision. In addition, the cases are indicated where the hypothesis of equal performance, in comparison with the HAR model, is rejected significantly using the [
64] test
10, such that the forecast precision of a model under consideration is not equivalent to the HAR model (in favor of the alternative that the mean squared forecasting error of a model under consideration is less than that of the HAR forecast).
It can be seen that the relative performance of the unrestricted linear and ALMON models is mixed compared with the HAR model. When the initial estimation sample size is 1,000, they are outperformed by the HAR model in most cases, but for a larger sample size of 2,000 observations, the unconstrained autoregressions and the ALMON model yield better (and sometimes significantly better) precision, which is consistent with the findings in [
56].
When the ALMON model is augmented with the moving median term, it outperforms all of the models under consideration, and in many cases, it also leads to the rejection of the hypothesis that its forecasting performance is equal to that of the HAR model. The moving median window of size of 20 appears to produce the best (or very close to the best) performance in all cases. However, even using a window size of 12, which equals the number of terms favored by the information criteria in the ALMON and unconstrained linear autoregression models (without MQs), produces a very similar performance. It should be noted that these models belong to a set of five models (underlined in
Table 4) that consistently outperform the HAR model in all of the situations considered (samples and types of forecasting).
We recall that the ALMON(12)-MQ(20) model was favored by the information criteria in the in-sample analysis. Hence, this precision would have been realized in practice if the standard model selection procedures were employed as described previously. Thus, we can conclude that MQs were not only significant in the in-sample analysis, but that they also were relevant for the improvement of the out-of-sample forecasting precision.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







