
Bayesian Treatments for Panel Data Stochastic Frontier Models with Time Varying Heterogeneity

Abstract
:1. Introduction
2. Model 1: A Panel Data Model with Nonparametric Time Effects
3. Model 2: A Panel Data Model with Factors
4. Monte Carlo Simulations
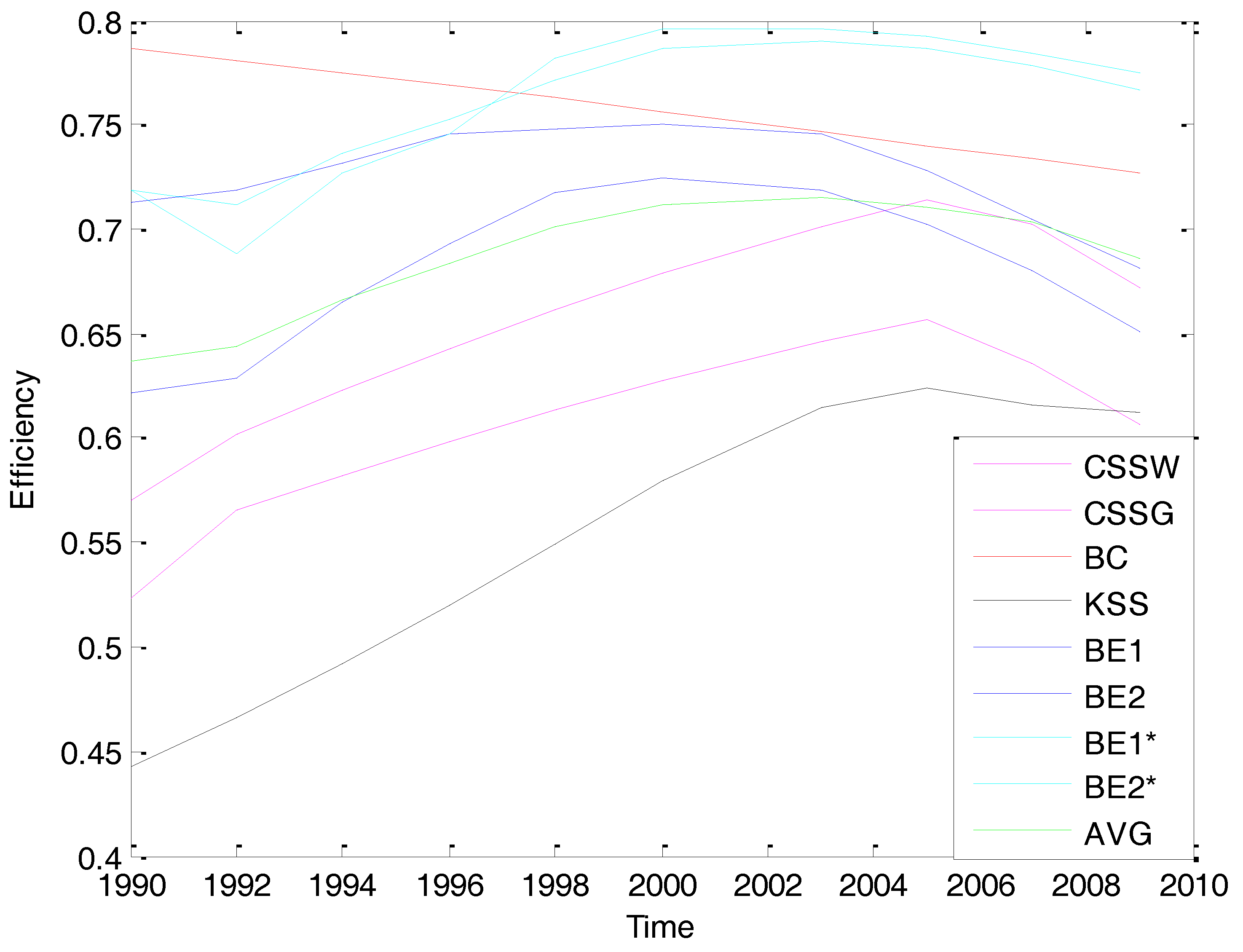
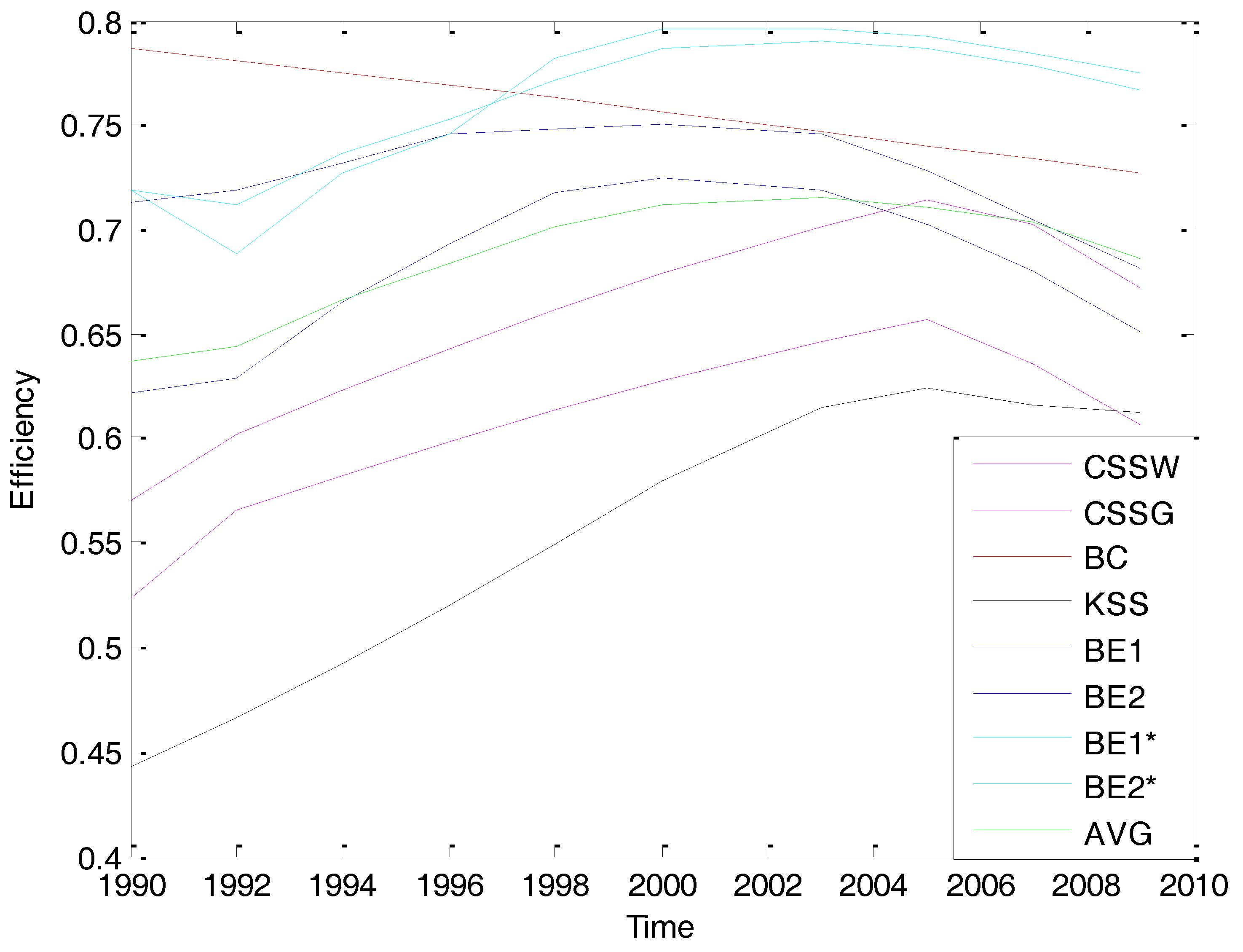
5. Empirical Application: Efficiency Analysis of the U.S. Banking Industry
5.1. Empirical Models
5.2. Data
5.3. Empirical Results
6. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A
A.1. Detailed Derivation of the Conditional Posterior Distribution of
A.2. Derivations of the Posterior Distribution of the Smoothing Parameter ω

{kind=link}
| Model | BC | CSSW | CSSG | KSS | BE1 | BE2 | BC | CSSW | CSSG | KSS | BE1 | BE2 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| CIL | 0.267394 | 0.211625 | 0.205296 | 0.320024 | 0.229974 | 0.262958 | PF*CD | −0.028282 | −0.023417 | −0.023420 | −0.024378 | −0.011996 | −0.012073 |
| (0.015604) | (0.014842) | (0.004009) | (0.016490) | (0.014168) | (0.013784) | (0.018853) | (0.011323) | (0.007121) | (0.009834) | (0.011182) | (0.019844) | ||
| CL | 0.102395 | 0.161658 | 0.169303 | 0.133170 | 0.151814 | 0.127101 | PF*DD | −0.114018 | −0.017305 | −0.024098 | −0.004148 | −0.015062 | −0.101234 |
| (0.012878) | (0.012244) | (0.003398) | (0.011736) | (0.010868) | (0.010493) | (0.015688) | (0.009595) | (0.006507) | (0.008484) | (0.008648) | (0.017367) | ||
| PFA | −0.126714 | −0.106713 | −0.124307 | −0.044849 | −0.122111 | −0.050466 | SA*CD | −0.141683 | −0.033535 | −0.059756 | −0.067716 | −0.055219 | −0.167241 |
| (0.031169) | (0.026743) | (0.008180) | (0.023470) | (0.024393) | (0.027912) | (0.031271) | (0.021438) | (0.012105) | (0.019169) | (0.019877) | (0.033330) | ||
| NOE | −0.151782 | −0.274994 | −0.273066 | −0.219497 | −0.152019 | −0.066570 | SA*DD | −0.006703 | 0.053747 | 0.061960 | 0.074933 | 0.036716 | 0.001257 |
| (0.035151) | (0.035071) | (0.009826) | (0.030924) | (0.028075) | (0.030319) | (0.030736) | (0.021559) | (0.011642) | (0.019549) | (0.019763) | (0.032234) | ||
| PF | −0.108846 | −0.057149 | −0.062796 | −0.067891 | −0.057049 | −0.138704 | CD*DD | −0.097991 | −0.105554 | −0.098626 | −0.057446 | −0.092207 | −0.119194 |
| (0.010370) | (0.006407) | (0.003582) | (0.007493) | (0.005713) | (0.010614) | (0.033377) | (0.020702) | (0.013151) | (0.017910) | (0.018797) | (0.036201) | ||
| SA | −0.305845 | −0.102552 | −0.141275 | −0.128912 | −0.170044 | −0.304152 | CIL*CIL | 0.239373 | 0.197944 | 0.207341 | 0.189705 | 0.227465 | 0.287373 |
| (0.023115) | (0.017762) | (0.005433) | (0.022026) | (0.014980) | (0.016878) | (0.024646) | (0.018416) | (0.006345) | (0.015932) | (0.017940) | (0.019379) | ||
| CD | −0.293822 | −0.242206 | −0.249235 | −0.152578 | −0.236288 | −0.286715 | CL*CL | 0.113335 | 0.045183 | 0.052787 | 0.016882 | 0.042151 | 0.084385 |
| (0.019988) | (0.013899) | (0.007184) | (0.014208) | (0.013410) | (0.020398) | (0.013263) | (0.010120) | (0.004141) | (0.009309) | (0.008506) | (0.012036) | ||
| DD | −0.029454 | −0.005520 | −0.029726 | −0.032132 | −0.025869 | −0.063642 | CIL*CL | −0.065016 | −0.045951 | −0.048370 | −0.040675 | −0.032145 | −0.058542 |
| (0.018062) | (0.014840) | (0.005759) | (0.014345) | (0.013910) | (0.016542) | (0.014523) | (0.011902) | (0.004307) | (0.010305) | (0.010754) | (0.012337) | ||
| PFA*PFA | −0.058407 | −0.076124 | −0.064595 | −0.027170 | 0.054452 | −0.116818 | CIL*PFA | −0.030027 | −0.040296 | −0.030441 | −0.048343 | −0.000616 | −0.046465 |
| (0.105551) | (0.081836) | (0.035034) | (0.067810) | (0.079399) | (0.097951) | (0.040094) | (0.029056) | (0.012041) | (0.025079) | (0.030007) | (0.036245) | ||
| NOE*NOE | −0.350934 | −0.263410 | −0.254762 | −0.194616 | −0.317941 | −0.647887 | CIL*NOE | 0.227956 | 0.032956 | 0.037051 | 0.068312 | 0.008093 | 0.245908 |
| (0.175695) | (0.111222) | (0.049618) | (0.096139) | (0.103994) | (0.170920) | (0.043142) | (0.032479) | (0.016995) | (0.028018) | (0.031391) | (0.046998) | ||
| PF*PF | −0.030317 | −0.017777 | −0.021905 | −0.019072 | −0.028032 | −0.050570 | CIL*PF | 0.036991 | 0.066231 | 0.066914 | 0.042524 | 0.044617 | 0.053115 |
| (0.009275) | (0.005224) | (0.003626) | (0.004633) | (0.004308) | (0.009989) | (0.011928) | (0.007423) | (0.004722) | (0.006691) | (0.007033) | (0.013064) | ||
| SA*SA | 0.057266 | 0.111105 | 0.088612 | 0.116956 | 0.037492 | 0.051178 | CIL*SA | −0.197701 | −0.045638 | −0.058945 | −0.056339 | −0.043310 | −0.213425 |
| (0.039891) | (0.031775) | (0.015405) | (0.030207) | (0.026234) | (0.043752) | (0.021737) | (0.015992) | (0.007671) | (0.014339) | (0.016593) | (0.020533) | ||
| CD*CD | 0.018957 | 0.063958 | 0.076793 | 0.104556 | 0.065066 | 0.034873 | CIL*CD | 0.033169 | 0.040877 | 0.040902 | 0.019851 | 0.036181 | 0.021669 |
| (0.054680) | (0.033776) | (0.020720) | (0.028297) | (0.027536) | (0.057257) | (0.022888) | (0.013701) | (0.009409) | (0.011750) | (0.012349) | (0.025882) | ||
| DD*DD | 0.008094 | 0.002895 | −0.012089 | −0.012085 | −0.001555 | −0.083644 | CIL*DD | −0.106948 | −0.048120 | −0.056765 | −0.016793 | −0.042321 | −0.137545 |
| (0.039544) | (0.025435) | (0.014893) | (0.021706) | (0.020225) | (0.043597) | (0.022452) | (0.016474) | (0.008142) | (0.014246) | (0.014006) | (0.021770) | ||
| PFA*NOE | −0.112425 | 0.086399 | 0.043034 | 0.070533 | 0.000583 | 0.082582 | CL*PFA | 0.048747 | 0.037970 | 0.032106 | 0.039504 | 0.007060 | 0.066231 |
| (0.102859) | (0.079549) | (0.036284) | (0.066471) | (0.071651) | (0.102329) | (0.027867) | (0.020247) | (0.010162) | (0.017601) | (0.021441) | (0.028297) | ||
| PFA*PF | −0.023871 | 0.001925 | 0.005802 | 0.014807 | 0.032413 | 0.004723 | CL*NOE | −0.134762 | −0.080639 | −0.079836 | −0.073912 | −0.026040 | −0.121342 |
| (0.024511) | (0.014311) | (0.009119) | (0.012065) | (0.012272) | (0.025037) | (0.033544) | (0.023290) | (0.012057) | (0.020149) | (0.026992) | (0.034329) | ||
| PFA*SA | 0.181100 | 0.065775 | 0.079467 | 0.056101 | 0.069803 | 0.194046 | CL*PF | 0.024490 | −0.023625 | −0.022260 | −0.016442 | −0.018719 | −0.002387 |
| (0.043433) | (0.033537) | (0.015360) | (0.029335) | (0.032844) | (0.043665) | (0.009238) | (0.005687) | (0.003329) | (0.004883) | (0.005182) | (0.009809) | ||
| PFA*CD | −0.191012 | −0.036207 | −0.035895 | −0.098737 | −0.156555 | −0.235290 | CL*SA | 0.052008 | 0.062364 | 0.064640 | 0.063839 | 0.044966 | 0.064692 |
| (0.053517) | (0.035121) | (0.020674) | (0.029706) | (0.032240) | (0.055515) | (0.014866) | (0.011813) | (0.005851) | (0.010214) | (0.010948) | (0.015289) | ||
| PFA*DD | 0.079834 | −0.017070 | −0.019489 | −0.060602 | −0.022135 | 0.000665 | CL*CD | 0.014655 | 0.001993 | 0.006427 | 0.000114 | 0.006044 | −0.007961 |
| (0.048869) | (0.030405) | (0.016956) | (0.026224) | (0.027307) | (0.049371) | (0.017719) | (0.011504) | (0.006786) | (0.009937) | (0.011207) | (0.017886) | ||
| NOE*PF | 0.137728 | 0.098342 | 0.099405 | 0.059733 | 0.049369 | 0.116370 | CL*DD | −0.057972 | 0.025662 | 0.021266 | 0.027790 | −0.001980 | −0.044490 |
| (0.031395) | (0.019230) | (0.012957) | (0.016994) | (0.016952) | (0.035380) | (0.015838) | (0.011538) | (0.005404) | (0.009853) | (0.008936) | (0.016080) | ||
| NOE*SA | −0.121524 | −0.118107 | −0.112644 | −0.115822 | −0.068949 | −0.119951 | CR | 0.217115 | 0.697573 | 0.622777 | 0.661193 | 0.650641 | 0.273590 |
| (0.065179) | (0.049241) | (0.024082) | (0.042867) | (0.042545) | (0.067800) | (0.207247) | (0.113233) | (0.089828) | (0.096325) | (0.074863) | (0.232643) | ||
| NOE*CD | 0.417943 | 0.145744 | 0.148929 | 0.183621 | 0.245112 | 0.478729 | LR | 1.103688 | 0.272672 | 0.303568 | 0.359501 | 0.601731 | 1.185407 |
| (0.083620) | (0.050044) | (0.029691) | (0.042715) | (0.045040) | (0.084171) | (0.174812) | (0.176180) | (0.057171) | (0.158809) | (0.152083) | (0.191323) | ||
| NOE*DD | 0.179106 | 0.083529 | 0.084223 | 0.057347 | 0.098175 | 0.329448 | MR | −0.002988 | −0.001070 | −0.000878 | −0.000466 | 0.000008 | −0.004905 |
| (0.064194) | (0.037821) | (0.022992) | (0.032270) | (0.031018) | (0.067150) | (0.002167) | (0.001070) | (0.000974) | (0.000906) | (0.000728) | (0.002496) | ||
| PF*SA | 0.031111 | −0.034051 | −0.028221 | −0.022330 | −0.012928 | 0.021033 | |||||||
| (0.016180) | (0.010140) | (0.006517) | (0.008749) | (0.009524) | (0.017828) |
References
- Ackerberg, Daniel A., Kevin Caves, and Garth Frazer. 2015. Identication properties of recent production function estimators. Econometrica 83: 2411–51. [Google Scholar] [CrossRef]
- Ahn, Seung C., Young H. Lee, and Peter Schmidt. 2013. Panel data models with multiple time-varying individual effects. Journal of Econometrics 174: 1–14. [Google Scholar] [CrossRef]
- Amsler, Christine, Artem Prokhorov, and Peter Schmidt. 2016. Endogeneity in stochastic frontier models. Journal of Econometrics 190: 280–88. [Google Scholar] [CrossRef]
- Bada, Oualid, and Dominik Liebl. 2014. Phtt: Panel data analysis with heterogeneous time trends in R. Journal of Statistical Software 59: 1–33. [Google Scholar] [CrossRef]
- Bai, Jushan. 2009. Panel data models with interactive fixed effects. Econometrica 77: 1229–79. [Google Scholar]
- Bai, Jushan. 2013. Fixed-effects dynamic panel models, a factor analytical method. Econometrica 81: 285–314. [Google Scholar]
- Bai, Jushan, and Josep Lluís Carrion-i-Silverstre. 2013. Testing panel cointegration with dynamic common factors that are correlated with the regressors. Econometric Journal 16: 222–49. [Google Scholar] [CrossRef] [Green Version]
- Bai, Jushan, and Serena Ng. 2007. Determining the number of primitive shocks in factor models. Journal of Business and Economic Statistics 25: 52–60. [Google Scholar] [CrossRef]
- Battese, G.E., and T.J. Coelli. 1992. Frontier production functions, technical efficiency and panel data: With application to paddy farmers in India. Journal of Productivity Analysis 3: 153–69. [Google Scholar] [CrossRef]
- Caves, Douglas W., Laurits R. Christensen, and W. Erwin Diewert. 1982. The economic theory of index numbers and the measurement of input, output, and productivity. Econometrica 50: 1393–414. [Google Scholar] [CrossRef]
- Cornwell, Christopher, Peter Schmidt, and Robin C. Sickles. 1990. Production frontiers with cross-sectional and time-series variation in efficiency levels. Journal of Econometrics 46: 185–200. [Google Scholar] [CrossRef]
- Fried, Harold O., C. A. Knox Lovell, and Shelton S. Schmidt. 2008. The Measurement of Productive Efficiency and Productivity Growth. New York: Oxford University Press. [Google Scholar]
- Gelfand, Alan E., and Adrian F.M. Smith. 1990. Sampling-based approaches to calculating marginal densities. Journal of the American Statistical Association 85: 398–409. [Google Scholar] [CrossRef]
- Gelman, Andrew, John B. Carlin, Hal S. Stern, David B. Rubin, Aki Vehtari, and Donald B. Rubin. 2003. Bayesian Data Analysis. Boca Raton: Chapman & Hall/CRC. [Google Scholar]
- Geweke, John. 1993. Bayesian treatment of the independent student-t linear model. Journal of Applied Econometrics 8: S19–S40. [Google Scholar] [CrossRef]
- Glass, Anthony J., Karligash Kenjegalieva, and Robin C. Sickles. 2016. Spatial autoregressive and spatial Durbin stochastic frontier models for panel data. Journal of Econometrics 190: 289–300. [Google Scholar] [CrossRef] [Green Version]
- Inanoglu, Hulusi, Michael Jacobs Jr., Junrong Liu, and Robin C. Sickles. 2015. Analyzing bank efficiency: Are "too-big-to-fail" banks efficient? In Handbook of Post-Crisis Financial Modeling. Edited by Emmanuel Haven, Philip Molyneux, John O. S. Wilson, Sergei Fedotov and Meryem Duygun. London: Palgrave MacMillan Handbook, pp. 110–46. [Google Scholar]
- Kim, Yangseon, and Peter Schmidt. 2000. A review and empirical comparison of Bayesian and classical approaches to inference on efficiency levels in stochastic frontier models with panel data. Journal of Productivity Analysis 14: 91–8. [Google Scholar] [CrossRef]
- Kim, Kyoo il, Amil Petrin, and Suyong Song. 2016. Estimating production functions with control functions when capital is measured with error. Journal of Econometrics 190: 267–79. [Google Scholar] [CrossRef]
- Kneip, Alois, Robin C. Sickles, and Wonho Song. 2012. A new panel data treatment for heterogeneity in time trends. Econometric Theory 28: 590–628. [Google Scholar] [CrossRef]
- Koop, Gary, Jacek Osiewalski, and Mark F.J. Steel. 1997. Bayesian efficiency analysis through individual effects: Hospital cost frontiers. Journal of Econometrics 76: 77–105. [Google Scholar] [CrossRef]
- Koop, Gary, and Dale J. Poirier. 2004. Bayesian variants of some classical semiparametric regression techniques. Journal of Econometrics 123: 259–82. [Google Scholar] [CrossRef] [Green Version]
- Kumbhakar, Subal C., and C. A. Knox Lovell. 2000. Stochastic Frontier Analysis. New York: Cambridge University Press. [Google Scholar]
- Levinsohn, James, and Amil Petrin. 2003. Estimating production functions using inputs to control for unobservables. The Review of Economic Studies 70: 317–41. [Google Scholar] [CrossRef]
- Li, Degui, Jia Chen, and Jiti Gao. 2011. Non-parametric time-varying coefficient panel data models with fixed effects. Econometrics Journal 14: 387–408. [Google Scholar] [CrossRef]
- Olley, G. Steven, and Ariel Pakes. 1996. The dynamics of productivity in the telecommunications equipment industry. Econometrica 64: 1263–97. [Google Scholar] [CrossRef]
- Onatski, Alexei. 2009. Testing hypotheses about the number of factors in large factor models. Econometrica 77: 1447–79. [Google Scholar]
- Osiewalski, Jacek, and Mark F.J. Steel. 1998. Numerical tools for the Bayesian analysis of stochastic frontier models. Journal of Productivity Analysis 10: 103–17. [Google Scholar] [CrossRef]
- Perrakis, Konstantinos, Ioannis Ntzoufras, and Efthymios G. Tsionas. 2014. On the use of marginal posteriors in marginal likelihood estimation via importance-sampling. Computational Statistics and Data Analysis 77: 54–69. [Google Scholar] [CrossRef]
- Pitt, Mark M., and Lung-Fei Lee. 1981. The measurement and sources of technical inefficiency in Indonesian weaving industry. Journal of Development Economics 9: 43–64. [Google Scholar] [CrossRef]
- Schmidt, Peter, and Robin C. Sickles. 1984. Production frontiers and panel data. Journal of Business and Economic Statistics 2: 367–74. [Google Scholar] [CrossRef]
- Tsionas, Efthymios G. 2006. Inference in dynamic stochastic frontier models. Journal of Applied Econometrics 21: 669–76. [Google Scholar] [CrossRef]
- Van den Broeck, Julien, Gary Koop, Jacek Osiewalski, and Mark F.J. Steel. 1994. Stochastic frontier models: A Bayesian perspective. Journal of Econometrics 61: 273–303. [Google Scholar] [CrossRef]
| 1 | Prior model probabilities are assumed to be equal so that the Bayes factor is equal to the posterior odds ratio. As pointed out by an anonymous referee, one could consider how prior model probabilities may favor a small g, and we find this issue an interesting question to study in future work. An exponential prior can be used, for example, with p(g) proportional to exp(-ag) for a = 1. |
| 2 | The estimation results for all first-order and second-order terms are displayed in Table A1 in Appendix A. Since our dataset is geometric mean corrected (each of the data points have been divided by their geometric sample mean), the second-order term in the elasticities expressed in (37) and (38) will diminish to zero when evaluated at the geometric mean of the sample. |
| Mean Squared Error for the Individual Effects | |||||||||||||||
| n | T | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||||||
| 50 | 20 | 0.7284 | 0.0012 | 0.0012 | 0.0039 | 0.0053 | 0.0671 | ||||||||
| 50 | 0.9371 | 0.0005 | 0.0005 | 0.1255 | 0.0021 | 0.0323 | |||||||||
| 100 | 20 | 0.8222 | 0.0008 | 0.0008 | 0.0033 | 0.0031 | 0.0183 | ||||||||
| 50 | 0.8245 | 0.0003 | 0.0003 | 0.0220 | 0.0018 | 0.0115 | |||||||||
| 200 | 20 | 0.8451 | 0.0008 | 0.0008 | 0.0023 | 0.0027 | 0.0101 | ||||||||
| 50 | 0.8823 | 0.0003 | 0.0003 | 0.0021 | 0.0011 | 0.0083 | |||||||||
| Estimate and Standard Error for the Slope Coefficients | |||||||||||||||
| T = 20 | T = 50 | ||||||||||||||
| BC | CSSW | CSSG | KSS | BE1 | BE2 | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||
| n = 50 | |||||||||||||||
| EST1 | 0.5250 | 0.4961 | 0.4965 | 0.4954 | 0.4981 | 0.5017 | 0.5105 | 0.4991 | 0.4992 | 0.4999 | 0.5013 | 0.4998 | |||
| SE1 | 0.0130 | 0.0033 | 0.0032 | 0.0029 | 0.0057 | 0.0042 | 0.0073 | 0.0021 | 0.0020 | 0.0019 | 0.0035 | 0.0027 | |||
| EST2 | 0.4856 | 0.4949 | 0.4948 | 0.4919 | 0.4985 | 0.5020 | 0.4969 | 0.5048 | 0.5047 | 0.5053 | 0.5001 | 0.5002 | |||
| SE2 | 0.0139 | 0.0035 | 0.0033 | 0.0031 | 0.0055 | 0.0041 | 0.0073 | 0.0020 | 0.0020 | 0.0018 | 0.0032 | 0.0024 | |||
| n = 100 | |||||||||||||||
| EST1 | 0.4973 | 0.5018 | 0.5013 | 0.5045 | 0.5023 | 0.5002 | 0.4843 | 0.4999 | 0.4998 | 0.4991 | 0.4999 | 0.5001 | |||
| STD1 | 0.0099 | 0.0023 | 0.0022 | 0.0021 | 0.0032 | 0.0027 | 0.0066 | 0.0014 | 0.0014 | 0.0014 | 0.0023 | 0.0018 | |||
| EST2 | 0.5047 | 0.5009 | 0.5012 | 0.5022 | 0.5016 | 0.5001 | 0.4995 | 0.5001 | 0.5000 | 0.4990 | 0.5003 | 0.5001 | |||
| STD2 | 0.0098 | 0.0022 | 0.0022 | 0.0020 | 0.0032 | 0.0028 | 0.0066 | 0.0014 | 0.0014 | 0.0013 | 0.0022 | 0.0017 | |||
| n = 200 | |||||||||||||||
| EST1 | 0.4936 | 0.5013 | 0.5015 | 0.5009 | 0.5000 | 0.4981 | 0.5000 | 0.5007 | 0.5007 | 0.5000 | 0.5012 | 0.5001 | |||
| STD1 | 0.0071 | 0.0016 | 0.0016 | 0.0016 | 0.0027 | 0.0022 | 0.0042 | 0.0010 | 0.0010 | 0.0010 | 0.0019 | 0.0015 | |||
| EST2 | 0.4983 | 0.5016 | 0.5020 | 0.5019 | 0.5002 | 0.4993 | 0.5027 | 0.4972 | 0.4972 | 0.4969 | 0.5003 | 0.5004 | |||
| STD2 | 0.0071 | 0.0016 | 0.0016 | 0.0016 | 0.0027 | 0.0022 | 0.0042 | 0.0010 | 0.0010 | 0.0010 | 0.0018 | 0.0014 | |||
| Mean Squared Error for the Individual Effects | |||||||||||||||
| n | T | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||||||
| 50 | 20 | 0.9202 | 0.1266 | 0.1266 | 0.0182 | 0.0071 | 0.0048 | ||||||||
| 50 | 0.9052 | 0.2996 | 0.2996 | 0.0238 | 0.0053 | 0.0025 | |||||||||
| 100 | 20 | 0.8588 | 0.4553 | 0.4553 | 0.0531 | 0.0040 | 0.0037 | ||||||||
| 50 | 0.9884 | 0.1065 | 0.1065 | 0.0046 | 0.0028 | 0.0013 | |||||||||
| 200 | 20 | 0.9183 | 0.6376 | 0.6375 | 0.0706 | 0.0022 | 0.0027 | ||||||||
| 50 | 0.9526 | 0.0616 | 0.0616 | 0.0028 | 0.0009 | 0.0008 | |||||||||
| Estimate and Standard Error for the Slope Coefficients | |||||||||||||||
| T = 20 | T = 50 | ||||||||||||||
| BC | CSSW | CSSG | KSS | BE1 | BE2 | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||
| n = 50 | |||||||||||||||
| EST1 | 0.4786 | 0.4857 | 0.4904 | 0.5059 | 0.5010 | 0.4993 | 0.4820 | 0.4811 | 0.4938 | 0.4972 | 0.5052 | 0.4983 | |||
| SE1 | 0.0460 | 0.0308 | 0.0298 | 0.0136 | 0.0262 | 0.0037 | 0.0243 | 0.0230 | 0.0227 | 0.0059 | 0.0177 | 0.0029 | |||
| EST2 | 0.4664 | 0.4414 | 0.4854 | 0.4599 | 0.5031 | 0.4992 | 0.4840 | 0.4660 | 0.4848 | 0.4988 | 0.5001 | 0.4999 | |||
| SE2 | 0.0491 | 0.0326 | 0.0314 | 0.0146 | 0.0261 | 0.0035 | 0.0241 | 0.0226 | 0.0225 | 0.0059 | 0.0174 | 0.0028 | |||
| n = 100 | |||||||||||||||
| EST1 | 0.4854 | 0.4818 | 0.4898 | 0.5065 | 0.4997 | 0.5002 | 0.5137 | 0.5360 | 0.5089 | 0.4950 | 0.5101 | 0.4987 | |||
| STD1 | 0.0200 | 0.0195 | 0.0188 | 0.0075 | 0.0163 | 0.0028 | 0.0415 | 0.0257 | 0.0254 | 0.0055 | 0.0128 | 0.0018 | |||
| EST2 | 0.5005 | 0.4996 | 0.5115 | 0.5101 | 0.4993 | 0.5001 | 0.4482 | 0.5283 | 0.5143 | 0.5127 | 0.5002 | 0.4992 | |||
| STD2 | 0.0198 | 0.0189 | 0.0186 | 0.0073 | 0.0164 | 0.0029 | 0.0415 | 0.0256 | 0.0254 | 0.0055 | 0.0130 | 0.0018 | |||
| n = 200 | |||||||||||||||
| EST1 | 0.5051 | 0.4995 | 0.5015 | 0.4864 | 0.4927 | 0.5013 | 0.4274 | 0.5097 | 0.4968 | 0.5018 | 0.5032 | 0.5011 | |||
| STD1 | 0.0169 | 0.0175 | 0.0171 | 0.0067 | 0.0120 | 0.0021 | 0.0527 | 0.0202 | 0.0200 | 0.0032 | 0.0078 | 0.0013 | |||
| EST2 | 0.4895 | 0.4898 | 0.5147 | 0.4951 | 0.4901 | 0.5020 | 0.3996 | 0.4930 | 0.5015 | 0.5042 | 0.5021 | 0.5031 | |||
| STD2 | 0.0170 | 0.0175 | 0.0171 | 0.0067 | 0.0121 | 0.0020 | 0.0531 | 0.0204 | 0.0202 | 0.0033 | 0.0077 | 0.0014 | |||
| Mean Squared Error for the Individual Effects | |||||||||||||||
| n | T | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||||||
| 50 | 20 | 3.3477 | 0.8816 | 0.8816 | 0.0130 | 0.0244 | 0.0356 | ||||||||
| 50 | 3.3639 | 0.8469 | 0.8468 | 0.0082 | 0.0134 | 0.0152 | |||||||||
| 100 | 20 | 3.5102 | 0.8309 | 0.8303 | 0.0123 | 0.0116 | 0.0282 | ||||||||
| 50 | 3.7625 | 0.8357 | 0.8356 | 0.0072 | 0.0028 | 0.0053 | |||||||||
| 200 | 20 | 3.8433 | 0.8335 | 0.8333 | 0.0121 | 0.0083 | 0.0116 | ||||||||
| 50 | 3.8513 | 0.8393 | 0.8392 | 0.0063 | 0.0014 | 0.0019 | |||||||||
| Estimate and Standard Error for the Slope Coefficients | |||||||||||||||
| T = 20 | T = 50 | ||||||||||||||
| BC | CSSW | CSSG | KSS | BE1 | BE2 | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||
| n = 50 | |||||||||||||||
| EST1 | 0.5277 | 0.5250 | 0.4994 | 0.4989 | 0.5012 | 0.5002 | 0.4868 | 0.4871 | 0.4976 | 0.5005 | 0.4991 | 0.5001 | |||
| SE1 | 0.0188 | 0.0203 | 0.0197 | 0.0029 | 0.0081 | 0.0038 | 0.0122 | 0.0122 | 0.0120 | 0.0018 | 0.0041 | 0.0025 | |||
| EST2 | 0.4905 | 0.4998 | 0.5062 | 0.4930 | 0.4981 | 0.4997 | 0.5259 | 0.5255 | 0.5207 | 0.5052 | 0.4994 | 0.5003 | |||
| SE2 | 0.0198 | 0.0215 | 0.0207 | 0.0031 | 0.0078 | 0.0035 | 0.0121 | 0.0120 | 0.0119 | 0.0018 | 0.0042 | 0.0023 | |||
| n = 100 | |||||||||||||||
| EST1 | 0.4816 | 0.4768 | 0.4998 | 0.5030 | 0.4961 | 0.4992 | 0.4877 | 0.4863 | 0.4972 | 0.4986 | 0.4995 | 0.5002 | |||
| STD1 | 0.0132 | 0.0139 | 0.0134 | 0.0021 | 0.0058 | 0.0025 | 0.0076 | 0.0077 | 0.0076 | 0.0013 | 0.0022 | 0.0017 | |||
| EST2 | 0.4907 | 0.4816 | 0.5088 | 0.5028 | 0.4971 | 0.4985 | 0.5024 | 0.5118 | 0.5089 | 0.4993 | 0.4990 | 0.5004 | |||
| STD2 | 0.0131 | 0.0135 | 0.0133 | 0.0021 | 0.0057 | 0.0024 | 0.0076 | 0.0077 | 0.0076 | 0.0013 | 0.0023 | 0.0018 | |||
| n = 200 | |||||||||||||||
| EST1 | 0.5120 | 0.5103 | 0.5110 | 0.5016 | 0.5012 | 0.5011 | 0.4976 | 0.5012 | 0.4962 | 0.4999 | 0.4981 | 0.5052 | |||
| STD1 | 0.0088 | 0.0091 | 0.0089 | 0.0016 | 0.0042 | 0.0013 | 0.0055 | 0.0054 | 0.0054 | 0.0010 | 0.0015 | 0.0011 | |||
| EST2 | 0.4885 | 0.4892 | 0.5019 | 0.5029 | 0.5015 | 0.5014 | 0.4874 | 0.4883 | 0.4957 | 0.4973 | 0.4992 | 0.4994 | |||
| STD2 | 0.0088 | 0.0091 | 0.0089 | 0.0016 | 0.0041 | 0.0012 | 0.0055 | 0.0055 | 0.0054 | 0.0010 | 0.0016 | 0.0012 | |||
| Mean Squared Error for the Individual Effects | |||||||||||||||
| n | T | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||||||
| 50 | 20 | 0.8042 | 0.2161 | 0.2161 | 0.0030 | 0.0130 | 0.0445 | ||||||||
| 50 | 0.9478 | 0.2056 | 0.2056 | 0.0890 | 0.0045 | 0.0141 | |||||||||
| 100 | 20 | 0.8770 | 0.1382 | 0.1382 | 0.0026 | 0.0112 | 0.0291 | ||||||||
| 50 | 0.8626 | 0.1337 | 0.1337 | 0.0193 | 0.0028 | 0.0055 | |||||||||
| 200 | 20 | 0.8764 | 0.1301 | 0.1301 | 0.0020 | 0.0098 | 0.0108 | ||||||||
| 50 | 0.9111 | 0.1445 | 0.1445 | 0.0015 | 0.0015 | 0.0021 | |||||||||
| Estimate and Standard Error for the Slope Coefficients | |||||||||||||||
| T = 20 | T = 50 | ||||||||||||||
| BC | CSSW | CSSG | KSS | BE1 | BE2 | BC | CSSW | CSSG | KSS | BE1 | BE2 | ||||
| n =50 | |||||||||||||||
| EST1 | 0.5521 | 0.5250 | 0.5329 | 0.4995 | 0.4922 | 0.4951 | 0.5031 | 0.4871 | 0.4901 | 0.4999 | 0.5051 | 0.5010 | |||
| SE1 | 0.0233 | 0.0203 | 0.0197 | 0.0030 | 0.0039 | 0.0031 | 0.0148 | 0.0122 | 0.0120 | 0.0019 | 0.0032 | 0.0025 | |||
| EST2 | 0.4788 | 0.4998 | 0.5014 | 0.4907 | 0.5011 | 0.4977 | 0.5201 | 0.5255 | 0.5246 | 0.5053 | 0.5001 | 0.5003 | |||
| SE2 | 0.0248 | 0.0215 | 0.0207 | 0.0031 | 0.0036 | 0.0032 | 0.0147 | 0.0120 | 0.0119 | 0.0018 | 0.0031 | 0.0028 | |||
| n = 100 | |||||||||||||||
| EST1 | 0.4732 | 0.4768 | 0.4713 | 0.5017 | 0.5001 | 0.5052 | 0.4720 | 0.4863 | 0.4867 | 0.4985 | 0.5003 | 0.5001 | |||
| STD1 | 0.0169 | 0.0139 | 0.0134 | 0.0022 | 0.0031 | 0.0027 | 0.0103 | 0.0077 | 0.0076 | 0.0014 | 0.0021 | 0.0017 | |||
| EST2 | 0.4880 | 0.4816 | 0.4836 | 0.5018 | 0.5000 | 0.5041 | 0.5077 | 0.5118 | 0.5117 | 0.4998 | 0.5002 | 0.5003 | |||
| STD2 | 0.0167 | 0.0135 | 0.0133 | 0.0021 | 0.0032 | 0.0025 | 0.0103 | 0.0077 | 0.0076 | 0.0014 | 0.0020 | 0.0015 | |||
| n = 200 | |||||||||||||||
| EST1 | 0.5029 | 0.5103 | 0.5112 | 0.5011 | 0.5032 | 0.5001 | 0.4891 | 0.5012 | 0.5012 | 0.5003 | 0.4991 | 0.5002 | |||
| STD1 | 0.0116 | 0.0091 | 0.0089 | 0.0016 | 0.0028 | 0.0020 | 0.0069 | 0.0054 | 0.0054 | 0.0010 | 0.0018 | 0.0014 | |||
| EST2 | 0.4892 | 0.4892 | 0.4934 | 0.5021 | 0.5013 | 0.5020 | 0.4940 | 0.4883 | 0.4886 | 0.4970 | 0.4987 | 0.5013 | |||
| STD2 | 0.0116 | 0.0091 | 0.0089 | 0.0016 | 0.0025 | 0.0022 | 0.0070 | 0.0055 | 0.0054 | 0.0010 | 0.0017 | 0.0013 | |||
| Model | BC | CSSW | CSSG | KSS | BE1 | BE2 | BE1* | BE2* |
|---|---|---|---|---|---|---|---|---|
| PFA | −0.1267 | −0.1067 | −0.1243 | −0.0448 | −0.1221 | −0.0505 | −0.0972 | −0.0555 |
| NOE | −0.1518 | −0.2750 | −0.2731 | −0.2195 | −0.1520 | −0.0666 | −0.1145 | −0.0424 |
| PF | −0.1088 | −0.0571 | −0.0628 | −0.0679 | −0.0570 | −0.1387 | −0.0930 | −0.1003 |
| SA | −0.3058 | −0.1026 | −0.1413 | −0.1289 | −0.1700 | −0.3042 | −0.1030 | −0.2542 |
| CD | −0.2938 | −0.2422 | −0.2492 | −0.1526 | −0.2363 | −0.2867 | −0.1541 | −0.2012 |
| DD | −0.0295 | −0.0055 | −0.0297 | −0.0321 | −0.0259 | −0.0636 | −0.0715 | −0.0335 |
| REL | 0.6302 | 0.6267 | 0.6254 | 0.5468 | 0.6182 | 0.6099 | 0.4103 | 0.4242 |
| CIL | 0.2674 | 0.2116 | 0.2053 | 0.3200 | 0.2300 | 0.2630 | 0.2415 | 0.2208 |
| CL | 0.1024 | 0.1617 | 0.1693 | 0.1332 | 0.1518 | 0.1271 | 0.1013 | 0.1212 |
| RTS | 1.0165 | 0.7891 | 0.8804 | 0.6459 | 0.7634 | 0.9102 | 0.6333 | 0.6871 |
| Avg.TE | 0.7576 | 0.6094 | 0.6608 | 0.5552 | 0.4584 | 0.6937 | 0.7944 | 0.7889 |
| Without Endogeneity | With Endogeneity | BF† | |||
|---|---|---|---|---|---|
| BE1 | BE2 | BE1* | BE2* | ||
| 1990 | 0.6216 | 0.7125 | 0.7189 | 0.7192 | 3.672 |
| 1992 | 0.5915 | 0.7317 | 0.6179 | 0.7003 | 3.855 |
| 1994 | 0.6718 | 0.7106 | 0.7283 | 0.7146 | 3.781 |
| 1996 | 0.7103 | 0.7325 | 0.7781 | 0.7613 | 4.038 |
| 1998 | 0.7317 | 0.7716 | 0.7925 | 0.7845 | 4.129 |
| 2000 | 0.7612 | 0.7815 | 0.8105 | 0.8006 | 4.217 |
| 2003 | 0.7120 | 0.7451 | 0.8023 | 0.7942 | 5.333 |
| 2005 | 0.7101 | 0.7222 | 0.7945 | 0.7943 | 5.885 |
| 2007 | 0.6787 | 0.7104 | 0.7824 | 0.7745 | 6.452 |
| 2009 | 0.6513 | 0.6817 | 0.7748 | 0.7663 | 6.812 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Sickles, R.C.; Tsionas, E.G. Bayesian Treatments for Panel Data Stochastic Frontier Models with Time Varying Heterogeneity. Econometrics 2017, 5, 33. https://doi.org/10.3390/econometrics5030033
Liu J, Sickles RC, Tsionas EG. Bayesian Treatments for Panel Data Stochastic Frontier Models with Time Varying Heterogeneity. Econometrics. 2017; 5(3):33. https://doi.org/10.3390/econometrics5030033
Chicago/Turabian StyleLiu, Junrong, Robin C. Sickles, and E. G. Tsionas. 2017. "Bayesian Treatments for Panel Data Stochastic Frontier Models with Time Varying Heterogeneity" Econometrics 5, no. 3: 33. https://doi.org/10.3390/econometrics5030033
APA StyleLiu, J., Sickles, R. C., & Tsionas, E. G. (2017). Bayesian Treatments for Panel Data Stochastic Frontier Models with Time Varying Heterogeneity. Econometrics, 5(3), 33. https://doi.org/10.3390/econometrics5030033