1. Introduction and Summary
This paper is inspired by a study on long-run causality, see
Hoover et al. (
2014). Causality is usually studied for a sequence of multivariate i.i.d. variables using conditional independence, see
Spirtes et al. (
2000) or
Pearl (
2009). For stationary autoregressive processes, causality is discussed in terms of the variance of the shocks, that is, the variance of the i.i.d. error term. For nonstationary cointegrated variables, the common trends play an important role for long-run causality. In
Hoover et al. (
2014), the concept is formulated in terms of independent common trends and their causal impact coefficients on the nonstationary observations. Thus, the emphasis is on independent trends, and how they enter the observation equations, rather than on the variance of the measurement errors.
The trend is modelled as an
dimensional Gaussian random walk, starting at
,
where
are i.i.d.
, that is, Gaussian in
m dimensions with mean zero and
variance
. This trend has an impact on future values of the
dimensional observation
modelled by
where
are i.i.d.
and
. It is also assumed that the
and
are independent for all
s and
t. In the following the joint distribution of
conditional on a given value of
is considered.
The observations are collected in the matrices
,
, and
,
, which are defined as
The processes
and
are obviously nonstationary, but the conditional distribution of
given
is well defined. We define
Then the density of
conditional on
is given by the prediction error decomposition
where
given
is
p dimensional Gaussian with mean and variance
In this model it is clear that
and
cointegrate, that is,
is stationary, and the same holds for
and the extracted trend
. Note that in the statistical model defined by (
1) and (
2) with parameters
, and
, only the matrices
and
are identified because for any
matrix
of full rank,
and
give the same likelihood, by redefining the trend as
.
Let be an estimator of . The paper investigates whether there is cointegration between and given two different estimation methods: A simple cointegrating regression and the maximum likelihood estimator in an autoregressive representation of the state space model.
Section 2, on the probability analysis of the data generating process, formulates the model as a common trend state space model, and summarizes some results in three Lemmas. Lemma 1 contains the Kalman filter equations and the convergence of
, see
Durbin and Koopman (
2012), and shows how its limit can be calculated by solving an eigenvalue problem. Lemma 1 also shows how
can be represented in terms of its prediction errors
,
. This result is used in Lemma 2 to represent
in steady state as an infinite order cointegrated vector autoregressive model, see (
Harvey 2006, p. 373).
Section 3 discusses the statistical analysis of the data and the identification of the trends and their loadings. Two examples are discussed. In the first example, only
B is restricted and the trends are allowed to be correlated. In the second example,
B is restricted but the trends are uncorrelated, so that also the variance matrix is restricted. Lemma 3 analyses the data from (
1) and (
2) using a simple cointegrating regression, see
Harvey and Koopman (
1997), and shows that the estimator of the coefficient
B suitably normalized is
n-consistent.
Section 4 shows in Theorem 1 that the spread between
and its estimator
is asymptotically stationary irrespective of the identification of
B and
. Then Theorem 2 shows that the spread between
and its estimator
is asymptotically stationary if and only if
B has been identified so that the estimator of
B is superconsistent, that is, consistent at a rate faster than
.
The findings are illustrated with a small simulation study in
Section 5. Data are generated from (
1) and (
2) with
, and the observations are analysed using the cointegrating regression discussed in Lemma 3. If the trends and their coefficients are identified by the trends being independent, the trend extracted by the state space model does not cointegrate with its estimator. If, however, the trends are identified by restrictions on the coefficients alone, they do cointegrate.
3. Statistical Analysis of the Data
In this section it is shown how the parameters of (
7) can be estimated from the CVAR (
18) using results of
Saikkonen (
1992) and
Saikkonen and Lutkepohl (
1996), or using a simple cointegrating regression, see (
Harvey and Koopman 1997, p. 276) as discussed in Lemma 3. For both the state space model (
1)–(
2) and for the CVAR in (
18) there is an identification problem between
and its coefficient
B, or between
and
, because for any
matrix
of full rank, one can use
as parameter and
as trend and
as variance, and similarly for
and
. In order to estimate
B,
T, and
, it is therefore necessary to impose identifying restrictions. Examples of such identification are given next.
Identification 1. Because
B has rank
m, the rows can be permuted such that
, where
is
and has full rank. Then the parameters and trend are redefined as
Note that
and
. This parametrization is the simplest which separates parameters that are
n-consistently estimated,
, from those that are
-consistently estimated,
, see Lemma 3. Note that the (correlated) trends are redefined by choosing
as the trend in
, then
as the trend in
, as in Example 1.
A more general parametrization, which also gives
n-consistency, is defined, as in simultaneous equations, by imposing linear restrictions on each of the
m columns and require the identification condition to hold, see
Fisher (
1966). ■
Identification 2. The normalization with diagonality of
is part of the next identification, because this is the assumption in the discussion of long-run causality. Let
be a Cholesky decomposition of
. That is,
is lower-triangular with one in the diagonal, corresponding to an ordering of the variables. Using this decomposition the new parameters and the trend are
such that
and
.
Identification of the trends is achieved in this case by defining the trends to be independent and constrain how they load into the observations. In Example 2, was defined as the trend in , and as the trend in , but orthogonalized on , such that the trend in is a combination of and . ■
3.1. The Vector Autoregressive Model
When the process is in steady state, the infinite order CVAR representation is given in (
18). The model is approximated by a sequence of finite lag models, depending on sample size
n,
where the lag length
is chosen to depend on
n such that
increases to infinity with
n, but so slowly that
converges to zero. Thus one can choose for instance
or
, for some
. With this choice of asymptotics, the parameters
,
,
,
, and the residuals,
, can be estimated consistently, see
Johansen and Juselius (
2014) for this application of the results of
Saikkonen and Lutkepohl (
1996).
This defines for each sample size consistent estimators
,
,
and
, as well residuals
. In particular the estimator of the common trend is
. Thus,
,
and
. If
is identified as
, then
. In steady state, the relations
hold, see (
11) and Lemma 2. It follows that
Finally, an estimator for
can be found as
Note that
is not a symmetric matrix in model (
18), but its estimator converges in probability towards the symmetric matrix
.
3.2. The State Space Model
The state space model is defined by (
1) and (
2). It can be analysed using the Kalman filter to calculate the diffuse likelihood function, see
Durbin and Koopman (
2012), and an optimizing algorithm can be used to find the maximum likelihood estimator for the parameters
,
, and
B, once
B is identified.
In this paper, an estimator is used which is simpler to analyse and which gives an
n-consistent estimator for
B suitably normalized, see (
Harvey and Koopman 1997, p. 276).
The estimators are functions of
and
, and therefore do not involve the initial value
. Irrespective of the identification, the relations
hold, and they gives rise to two moment estimators, which determine
and
, once
B has been identified and estimated.
Consider the identified parametrization (
19), where
, and take
. Then define
and
, such that
and
, that is,
This equation defines the regression estimator
:
To describe the asymptotic properties of
, two Brownian motions are introduced
Lemma 3. Let the data be generated by the state space model (1) and (2).
(a) From (21) and (22) it follows thatdefine -consistent asymptotically Gaussian estimators for
and ,
irrespective of the identification of B.
(b) If B and are identified as ,
,
and is adjusted accordingly, then in (24) is n-consistent with asymptotic Mixed Gaussian distribution (c) If B is identified as ,
,
and ,
then ,
but (27) still holds for ,
so that some linear combinations of are consistent.
Note that the parameters
,
, and
can be estimated consistently from (
24) and (
26) by
In the simulations of Examples 1 and 2 the initial value is , so the Kalman filter with is used to calculate the extracted trend using observations and known parameters. Similarly the estimator of the extracted trend is calculated using observations and estimated parameters based on Lemma 3. The next section investigates to what extent these estimated trends cointegrate with the extracted trends, and if they cointegrate with each other.
4. Cointegration between Trends and Their Estimators
This section gives the main results in two theorems with proofs in the
Appendix. In Theorem 1 it is shown, using the state space model to extract the trends and the estimator from Lemma 3, that
is asymptotically stationary. For the CVAR model it holds that
, such that this spread is asymptotically stationary. Finally, the estimated trends in the two models are compared, and it is shown that
is asymptotically stationary. The conclusion is that in terms of cointegration of the trends and their estimators, it does not matter which model is used to extract the trends, as long as the focus is on the identified trends
and
.
Theorem 1. Let and be generated by the DGP given in (1) and (2).
(a) If the state space model is used to extract the trends, and Lemma 3 is used for estimation, then is asymptotically stationary.
(b) If the vector autoregressive model is used to extract the trends and for estimation, then. .
(c) Under assumptions of (a) and (b), it holds that is asymptotically stationary.
In Theorem 2 a necessary and sufficient condition for asymptotic stationarity of , , and is given.
Theorem 2. In the notation of Theorem 1, any of the spreads , or is asymptotically stationary if and only if B and the trend are identified such that the corresponding estimator for B satisfies and .
The missing cointegration between
and
, say, can be explained in terms of the identity
Here the second term,
, is asymptotically stationary by Theorem 1
. But the first term,
, is not necessarily asymptotically stationary, because in general, that is, depending on the identification of the trend and
B, it holds that
and
, see (
16).
The parametrization
ensures
n-consistency of
, so there is asymptotic stationarity of
,
, and
in this case. This is not so surprising because
is stationary. Another situation where the estimator for
B is
n-consistent is if
satisfies linear restriction of the columns,
, or equivalently
for some
, and the condition for identification is satisfied
see
Fisher (
1966). For a just-identified system, one can still use
, and then solve for the identified parameters. For overidentified systems, the parameters can be estimated by a nonlinear regression of
on
reflecting the overidentified parametrization. In either case the estimator is
n-consistent such that
,
, and
are asymptotically stationary.
If the identification involves the variance , however, the estimator of B is only -consistent, and hence no cointegration is found between the trend and estimated trend.
The analogy with the results for the CVAR, where
and
need to be identified, is that if
is identified using linear restrictions (
29) then
is
n-consistent, whereas if
is identified by restrictions on
then
is
-consistent. An example of the latter is if
is identified as the first
m rows of the matrix
, corresponding to
, then
is
-consistent and asymptotically Gaussian, see (
Johansen 2010, Section 4.3).
5. A Small Simulation Study
The two examples introduced in
Section 2.1 are analysed by simulation. The equations are given in (
5) and (
3). Both examples have
and
. The parameters
B and
contain
parameters, but the
matrix
is of rank 2 and has only 5 estimable parameters. Thus, 4 restrictions must be imposed to identify the parameters. In both examples the Kalman filter with
is used to extract the trends, and the cointegrating regression in Lemma 3 is used to estimate the parameters.
Example 1 continued. The parameter
B is given in (
4), and the parameters are just-identified. Now
As
and
are the first two rows of
in (
30), they are both asymptotically stationary by Theorem 1(a).
To illustrate the results, data are simulated with
observations starting with
and parameter values
,
, and
, such that
The parameters are estimated by (
28) and the estimates become
,
,
,
, and
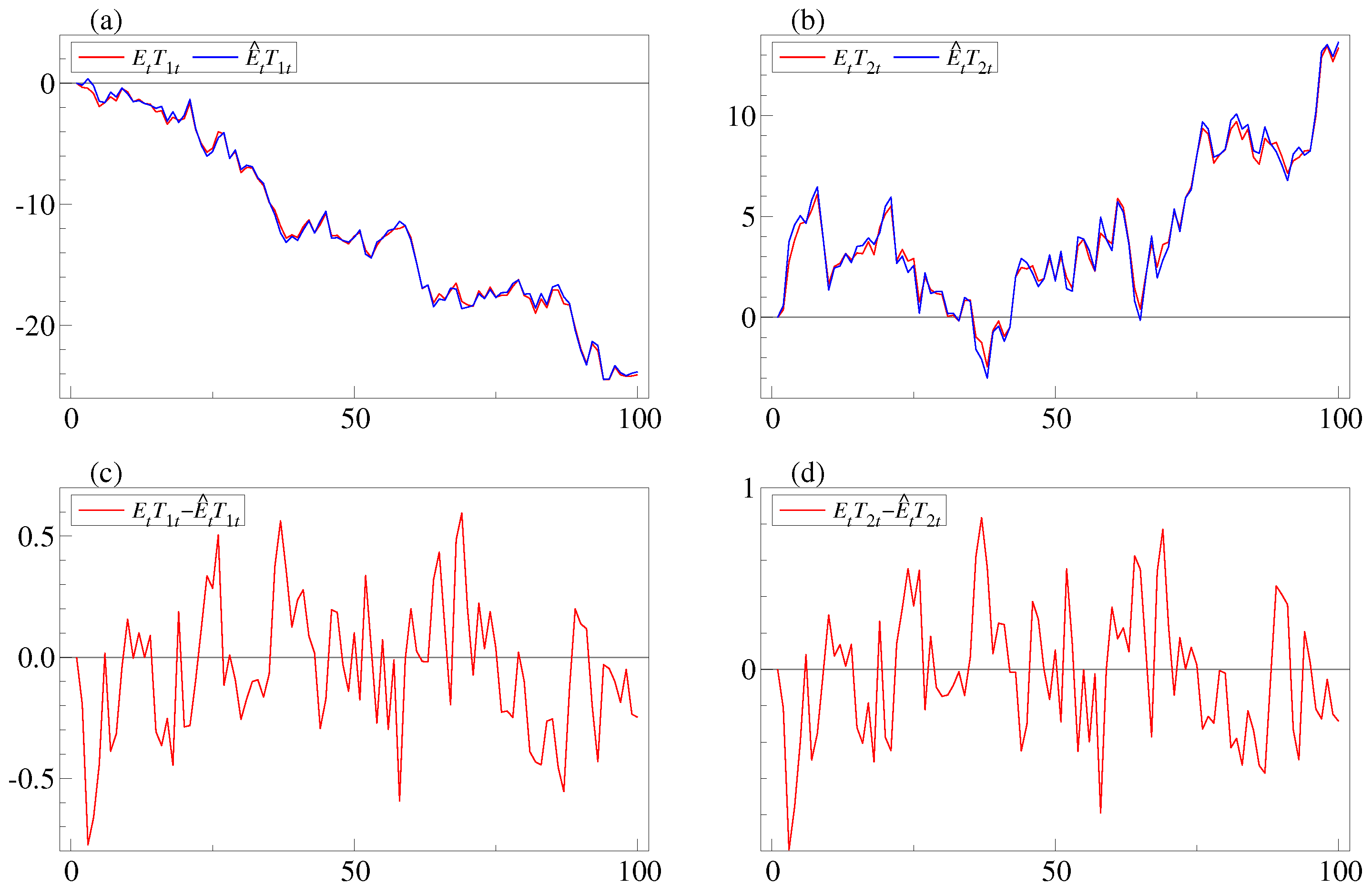
. The extracted and estimated trends are plotted in
Figure 1. Panels
a and
b show plots of
and
, respectively, and it is seen that they co-move. In panels
c and
d the differences
and
both appear to be stationary in this parametrization of the model. ■
Example 2 continued. The parameter
B in this example is given in (
6) such that
By the results in Theorem 1(a), all three rows are asymptotically stationary, in particular
. Moreover, the second row of (
32),
, is asymptotically stationary. Thus, asymptotic stationarity of
requires asymptotic stationary of the term
Here, the second term,
, is asymptotically stationary because
is. However, the first term,
, is not asymptotically stationary because
is
-consistent. In this case
, which has a Gaussian distribution, and
, where
is the Brownian motion generated by the sum of
It follows that their product
converges in distribution to the product of
Z and
,
, and this limit is nonstationary. It follows that
is not asymptotically stationary for the identification in this example. This argument is a special case of the proof of Theorem 2.
To illustrate the results, data are simulated from the model with
observations starting with
and parameter values
,
, and
, which is identical to (
31).
The model is written in the form (
19) with a transformed
B and
as
The parameters are estimed as in Example 1 and we find
,
,
,
, and
, which are solved for
,
,
,
, and
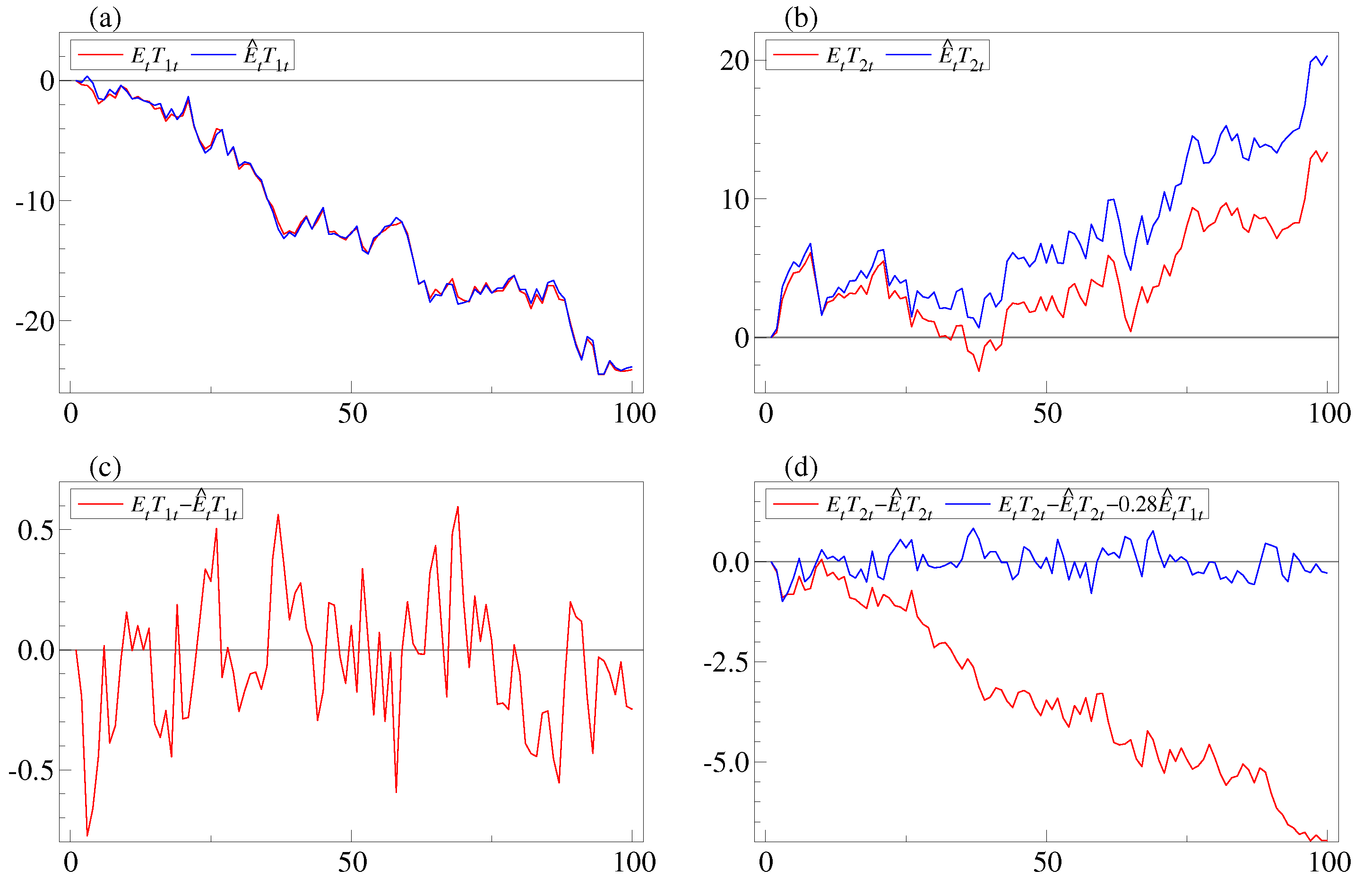
. The extracted and estimated trends are plotted in
Figure 2. The panels
a and
b show plots of
and
, respectively. It is seen that
and
co-move, whereas
and
do not co-move. In panels
c and
d, the differences
and
are plotted. Note that the first looks stationary, whereas the second is clearly nonstationary. When comparing with the plot of
in panel
a, it appears that the process
can explain the nonstationarity of
. This is consistent with Equation (
33) with
and
. In panel
d,
is plotted and it is indeed stationary. ■
6. Conclusions
The paper analyses a sample of n observations from a common trend model, where the state is an unobserved multivariate random walk and the observation is a linear combination of the lagged state variable and a noise term. For such a model, the trends and their coefficients in the observation equation need to be identified before they can be estimated separately. The model leads naturally to cointegration between observations, trends, and the extracted trends. Using simulations it was discovered, that the extracted trends do not necessarily cointegrate with their estimators. This problem is investigated, and it is found to be related to the identification of the trends and their coefficients in the observation equation. It is shown in Theorem 1, that provided only the linear combinations of the trends from the observation equation are considered, there is always cointegration between extracted trends and their estimators. If the trends and their coefficients are defined by identifying restrictions, the same result holds if and only if the estimated identified coefficients in the observation equation are consistent at a rate faster than . For the causality study mentioned in the introduction, where the components of the unobserved trend are assumed independent, the result has the following implication: For the individual extracted trends to cointegrate with their estimators, overidentifying restrictions must be imposed on the trend’s causal impact coefficients on the observations, such that the estimators of these become super-consistent.



{kind=link}
{kind=link}

