1. Introduction
Modeling asset prices with jumps has proven to be successful, both empirically and theoretically. Because of this a method to accurately and reliably estimate the timing and magnitude of jumps in asset pricing models would greatly aid the existing literature.
Since being introduced in
Mancini (
2001,
2004) and threshold-based methods have become popular ways to estimate the jumps in time series data. The essential idea of these methods is that if an observed return is sufficiently large in absolute value then it is likely that the interval in which that return was taken contained a jump. To think about such an idea consider a standard jump-diffusion process for a log-asset price:
where
is thought of as the drift of the process,
is a time-varying volatility process, and
is some finite activity jump process. (See
Section 2 for a more rigorous definition of the jump-diffusion processes we consider in this paper.) Defining the returns of the observed process
X as
where
is the sampling interval,
n is the number of high frequency increments per day, and
for the asymptotic approximations. Note that
is the geometric return in the asset price over the interval
. Given a sequence of thresholds,
, a threshold technique would label a return interval as containing a jump if
. While
Mancini (
2001) originally set
a common practice has emerged to use
where
and
are parameters selected by the researcher and
is the level of the local volatility around each return interval.
1 Typically, values are
or
and
is left as a tuning parameter.
If
or
the parameter
has a convenient interpretation. Since the diffusive moves in
are on the order
using
or
we see that the tuning parameter
has the interpretation of being essentially the number of local standard deviations of the process. A threshold-based jump selection scheme of this form then has the convenient interpretation of labeling returns as containing a jump (or multiple jumps) if the return is larger in absolute value than
local standard deviations. While this provides a nice interpretation of the method, unfortunately the literature leaves the choice
up to the researcher. The goal of the current paper is to provide a method for the selection of
. (We leave
or
since what is important in practice is the relative size of a ‘typical’ increment
and
. See
Jacod and Protter (
2012, p. 248) for a discussion.)
Our primary focus in this paper is effective jump detection for the jump regression context of
Li et al. (
2017a) and
Li et al. (
2017b) where
. We can think of such a setting as estimating
in the following model
where
are the
return intervals in
Z thought to contain a jump, where
is the total number of identified jumps. In finance applications,
Z is the log of a market index and
Y is the log of a stock price. The underlying theoretical model is
where
is the instantaneous jump operator (i.e.,
), and the orthogonality condition that identifies
is
.
2 Equation (
3) is the empirical counterpart of (
4).
Li et al. (
2017a) contains more explanation of the theoretical model and the identifying orthogonality condition.
With a truncation threshold of the form
we would estimate
as
Notice how crucially
and thereby the estimated
in (
3) depends on the choice of
. There are two types of jump classification errors that can be made: (i) incorrectly labeling a particular interval as containing a jump when it does not, and (ii) omitting an interval that actually contains a jump. If we set too low a threshold, we make type-(i) errors and include return intervals in
that do not actually contain jumps, and that could potentially badly bias the estimated ‘jump beta’.
To see why we do not want to set too high a threshold and make a type-(ii) errors, we need to think about the variance of our estimated jump beta. To do so consider a heuristic model where at the jumps times
we have
where the
are independent and identically distributed with common variances
. In addition, assume that the continuous returns are sufficiently small so that regardless of the truncation threshold used no continuous returns are included in the set of estimated jump returns. In this simplified setting
Notice that in this heuristic model that the variance of the estimated jump beta decreases as the number of jumps included in regression increases, i.e., as the set grows. If a truncation threshold of the form were used the variance of the estimator would be decreasing in .
Figure 1 illustrates these ideas using some empirical data. The left panel plots the jump beta for the jump regression of the SDPR S&P500 ETF (SPY) against the SDPR utilities ETF (XLU) for the years 2007 to 2014 using five-minute returns over a grid of
jump threshold parameters. Notice that going down from
to about
that the hypothesis of a constant jump beta might be supported, i.e., that
where
are the true jump times in
Z. The plotted jump beta is obviously noisy, but the estimated jump betas might very well be centered around a true and constant value. However after about
the estimated jump betas for this asset begin to rapidly decline. It is not hard to imagine that after about
the jump regressions became wildly corrupted by the addition of return intervals containing only diffusive moves. The right panel plots the reciprocal of the variance of the estimated jump betas along the same grid of
jump threshold parameters as the reciprocal of the variance of an estimator is often thought of as a measure of the ‘precision’ of the estimator. Notice how the precision increases as
decreases and we add return intervals to the jump regression. As in the left panel we plot a line at
. If after around
our jump regression begins to be rapidly corrupted by the addition of return intervals that only contain diffusive moves then, even though the precision of our estimator is increasing, our estimates of the jump beta are likely to be significantly biased. These panels illustrate the trade-off mentioned earlier in selecting a jump threshold. To decrease the variance of our estimated jump beta (or increase its precision) we would like a low jump threshold, but too low a jump threshold will likely bias our jump beta since we will likely include many returns that only contain diffusive moves.
In this paper, we develop a new method to balance the trade-off of setting too low a threshold and potentially including return intervals that only contain diffusive moves versus setting too high a threshold and potentially excluding return intervals that actually contain true jumps. The main idea is to find the value of for which the jump count function (defined below) ‘bends’ most sharply. Intuitively this could be thought of as the ‘take-off’ point of the jump count function. Selecting a threshold at this ‘take-off’ point should greatly reduce the number of misclassifications while maintaining many of the true jumps. We implement this idea by computing the point of maximum curvature to a smooth sieve-type estimator applied to the jump count function.
A related paper
Figueroa-López and Nisen (
2013) derives an optimal rate for the threshold in a threshold-based jump detection scheme with the goal of estimating the integrated variance. Using a loss function that equally penalizes jump misclassifications and missed jumps,
Figueroa-López and Nisen (
2013) find that the optimal threshold should be on the order of
similar to the threshold originally proposed in
Mancini (
2001). Since
is of order
this result does not provide any guidance on the scale of the threshold to choose. Any threshold of the form
for any
would be just as optimal in their setting. This presents a major challenge for practitioners. Because of this
Figueroa-López and Nisen (
2013) provide an iterative method for selecting the scale of the truncation threshold. This iterative method however is not motivated by a theory of the jumps or the returns and adds an additional estimation step for any researcher hoping to use their method.
While we could have used truncation thresholds of the form
for some
in our paper and investigated the choice of the scale of the threshold, i.e., the choice of
A we did not for two reasons. First, the difference in the relative convergence rates of
and
are tiny when
or
(see the discussion in
Jacod and Protter (
2012, p. 248)). Second, we feel using
provides a convenient interpretation for the tuning parameter
and therefore using
is preferable.
The rest of the paper is organized as follows.
Section 2 presents the setting. Our methodology and the main theory about its consistency are developed in
Section 3 and
Section 4.
Section 5 and
Section 6 present the results from a series of Monte Carlo studies and two empirical applications respectively. Finally,
Section 7 provides a conclusion. All proofs are in the
Appendix A.
2. The Setting
We start with introducing the formal setup for our analysis. The following notations are used throughout. We denote the transpose of a matrix A by . The adjoint matrix of a square matrix A is denoted . For two vectors a and b, we write if the inequality holds component-wise. The functions , and Tr denote matrix vectorization, determinant and trace, respectively. The Euclidean norm of a linear space is denoted . We use to denote the set of nonzero real numbers, that is, . The cardinality of a (possibly random) set is denoted . For any random variable , we use the standard shorthand notation satisfies some property} for { satisfies some property}. The largest smaller integer function is denoted by . For two sequences of positive real numbers and , we write if for some constant and all n. All limits are for . We use , and to denote convergence in probability, convergence in law, and stable convergence in law, respectively.
2.1. The Underlying Processes
The object of study of the paper is the optimal selecting of the cutoff level for a threshold-style jump detection scheme. Let X be the process under consideration and, for simplicity of exposition, assume that X is one-dimensional. (The results can be trivially generalized to settings where X is multidimensional, but doing so would unnecessarily burden the notation.)
We proceed with the formal setup. Let
X be defined on a filtered probability space represented as
. Throughout the paper, all processes are assumed to be càdlàg adapted. Our basic assumption is that
X is an Itô semimartingale (see, e.g.,
Jacod and Protter 2012, sct 2.1.4) with the form
where the drift
takes value in
; the volatility process
takes value in
, the set of positive real numbers;
W is a standard Brownian motion;
is a predictable function;
is a Poisson random measure on
with its compensator
for some measure
on
. The jump of
X at time
t is denoted by
, where
. Finally, the spot volatility of
X at time
t is denoted by
. Our basic regularity condition for
X is given by the following assumption.
Assumption 1. (a) The process b is locally bounded; (b) is nonsingular for ; (c) .
The only nontrivial restriction in Assumption 1 is the assumption of finite activity jumps in
X. This assumption is used mainly for simplicity as our focus in the paper are ‘big’ jumps, i.e., jumps that are not ‘sufficiently’ close to zero. Alternatively, we can drop Assumption 1(c) and focus on jumps with sizes bounded away from zero.
3Turning to the sampling scheme, we assume that X is observed at discrete times , for , within the fixed time interval . Following standard notation as discussed in the Introduction, the increments of X are denoted by Below, we consider an infill asymptotic setting, that is, as .
4. The Curvature Method
As briefly discussed above in the introduction, the selection of a jump threshold, i.e., the selection of
in Equation (
11), involves a trade off between setting too high a threshold and failing to include all of the jumps against setting too low a threshold and erroneously labeling diffusive moves as jumps. For example, setting
would correctly identify every jump but would also include every diffusive move. Similarly, setting
would guarantee that no diffusive moves were incorrectly labeled as jumps, but would fail to identify any of the jumps.
We can use the results of
Section 3 to guide the selection of a suitable
. Under the modeling assumptions of
Section 2, there are a finite (but random) number of jumps
on the interval
. From the theory (
Jacod and Protter 2012;
Li et al. 2017a) we know that for any fixed
the truncation scheme correctly classifies all
jumps when
n is sufficiently large. Thus, for any fixed
the jump count Function (
13) satisfies
almost surely. Furthermore, for a fixed
n and for higher values of
we should expect the jump count function to have a long flat region that is level at about
, but we should also expect the jump count function to rise sharply at lower values of
where many diffusive moves start getting erroneously classified as jumps. So the task is to determine from the jump count function that value of
where the jump count function starts to increase sharply as
declines. We think of this point as the point at which the jump count function begins to ‘take-off’. Our solution to find this ‘take-off’ point is to look for the value of
at which the jump count function
‘kinks’ or ‘bends’ most sharply.
The way to mathematically define a ‘kink’ or sharpest ‘bend’ in a smooth function is the point of maximum curvature. The curvature of a smooth function
is defined as
Intuitively, if we think of the function f as lying in a two-dimensional plane and representing the direction of travel of some object, the curvature of f represents the rate at which the direction of travel is changing. (Or more rigorously the magnitude of the rate of change of the unit tangent vector to the curve.) The point of maximum curvature then is the point at which the direction of travel changes the most.
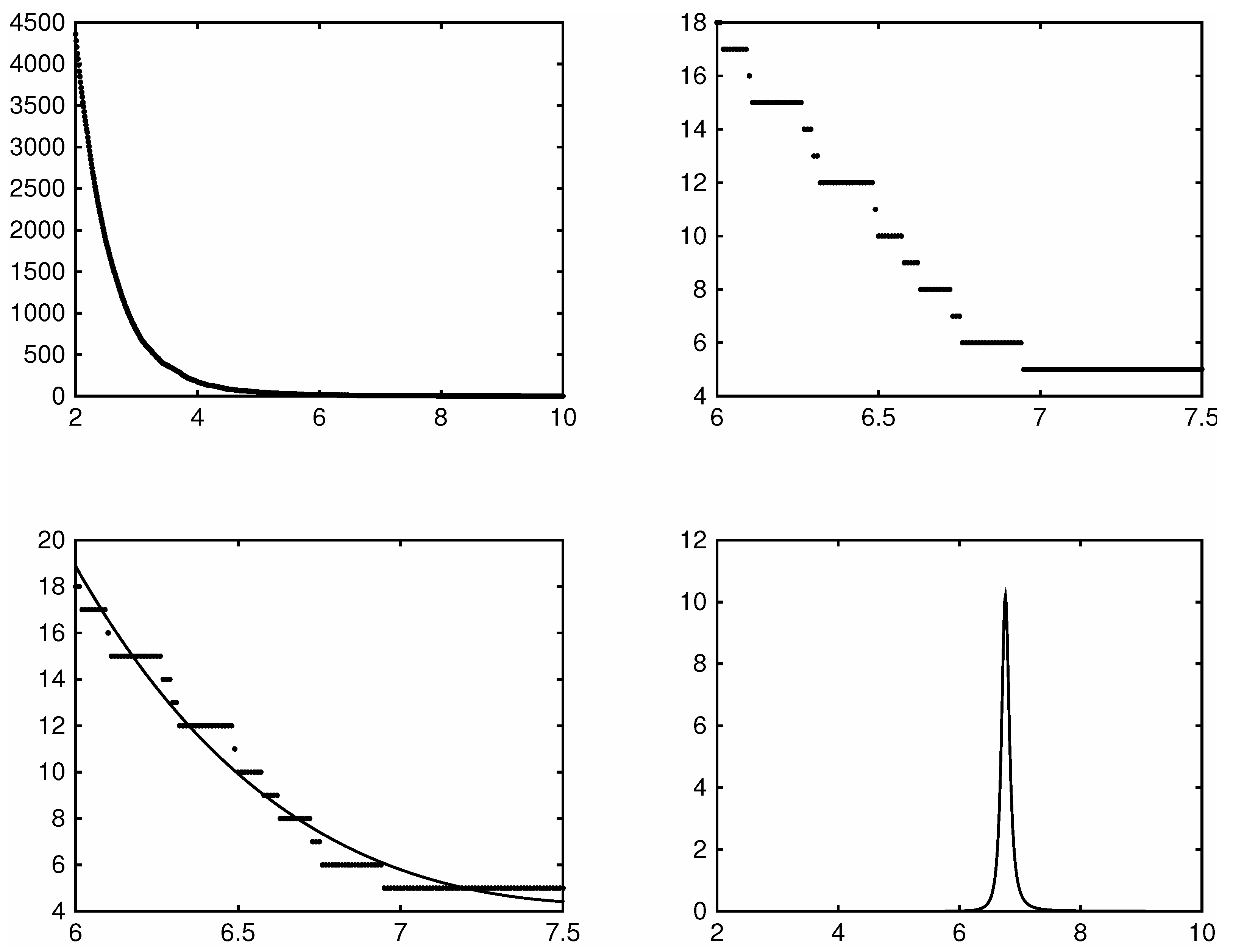
However, being piece-wise flat, the raw jump count function itself is ill-suited for this purpose, as evident in the top two panels of
Figure 2. These panels plot the jump count function for the five minute returns of the SDPR S&P500 ETF during the year 2014. In the top left panel the domain
is too wide making the steps barely noticeable. Zooming in however on the domain
the top right panel clearly shows the jump count function to be piece-wise flat.
Given this problem, we work with a smoother sieve estimator fitted to the jump count function. A natural choice might seem to be kernels or splines but these turn out to be ineffective due to the small wiggles and discontinuities that these functions have in their higher order derivatives. These wiggles and discontinuities in turn significantly affect the curvature of these functions making the point of maximum curvature often more dependent on the particular choice of which kernels or splines was chosen rather than the data. A far better approach is to do a least-squares projection of the observed jump count function onto a set of smooth basis functions. Given the shape of the jump count function, we use basis functions
where we need
for the point of maximum curvature to be well-defined. Using these basis functions we can define the projection of the jump count function onto
as
In practice we find that these basis functions result in projections with extremely tight
5 fits that have very high
s for low values of
or
. Because of this the projection itself amounts to a compact numerical representation of approximately the same information as in the raw jump count function itself.
With this idea in mind we select
as the value that maximizes the curvature of the appropriately smoothed jump count function, i.e.,
where
. We refer to such a selection method in what follows as the ‘curvature method’.
Setting the threshold right at this point of maximum curvature or ‘kink’ point then allows for a great many of the true jumps to be located, but guards against overly misclassify diffusive moves. Because of this, the procedure is evidently very conservative in that it lets through only a small number of diffusive moves. However, in a jump regression setting a very conservative jump selection procedure is to be preferred as the loss from including diffusive moves is very high because doing so potentially biases the estimates whereas incorrectly missing a true jump only entails a small loss of efficiency.
Though conservative, the curvature method is asymptotically accurate. We show this in Theorem 1 below. The theorem shows that in the limit the curvature method correctly identifies all of the jumps and excludes any returns that contain only diffusive moves. The theorem relies on the following definition for the convergence of random vectors with possibly different length: for a sequence of random integers and a sequence of random elements, we write if we have both and
Theorem 1. Under Assumptions 1 and 2 and with we have that
- (a)
, and
- (b)
.
The theorem above shows that as that the jump count function using our procedure will converge in probability to the true number of jumps and that the estimated index of the jumps over a region will converge in probability to the true index over that region.




{kind=link}
{kind=link}