Partial Cointegrated Vector Autoregressive Models with Structural Breaks in Deterministic Terms


Abstract
:1. Introduction
2. Models and Representations
2.1. Previous Models
2.2. The Partial Model with Structural Breaks
2.3. Representations
2.4. The Partial Model with Shifts in The Level
3. Testing for Cointegrating Rank in the Partial Models
3.1. Rank Test Statistic
3.2. Asymptotic Distribution of the Test Statistic
- (i)
- ;
- (ii)
- ;
- (iii)
- either of the following boundedness conditions
- (a)
- as ;
- (b)
- (i)
- , where Ω is positive definite;
- (ii)
- for some
3.3. Asymptotic Distribution for the Broken Constant Case
4. Approximations of the Asymptotic Distributions
4.1. Derivation of Response Surface
4.2. Implementation of Response Surface
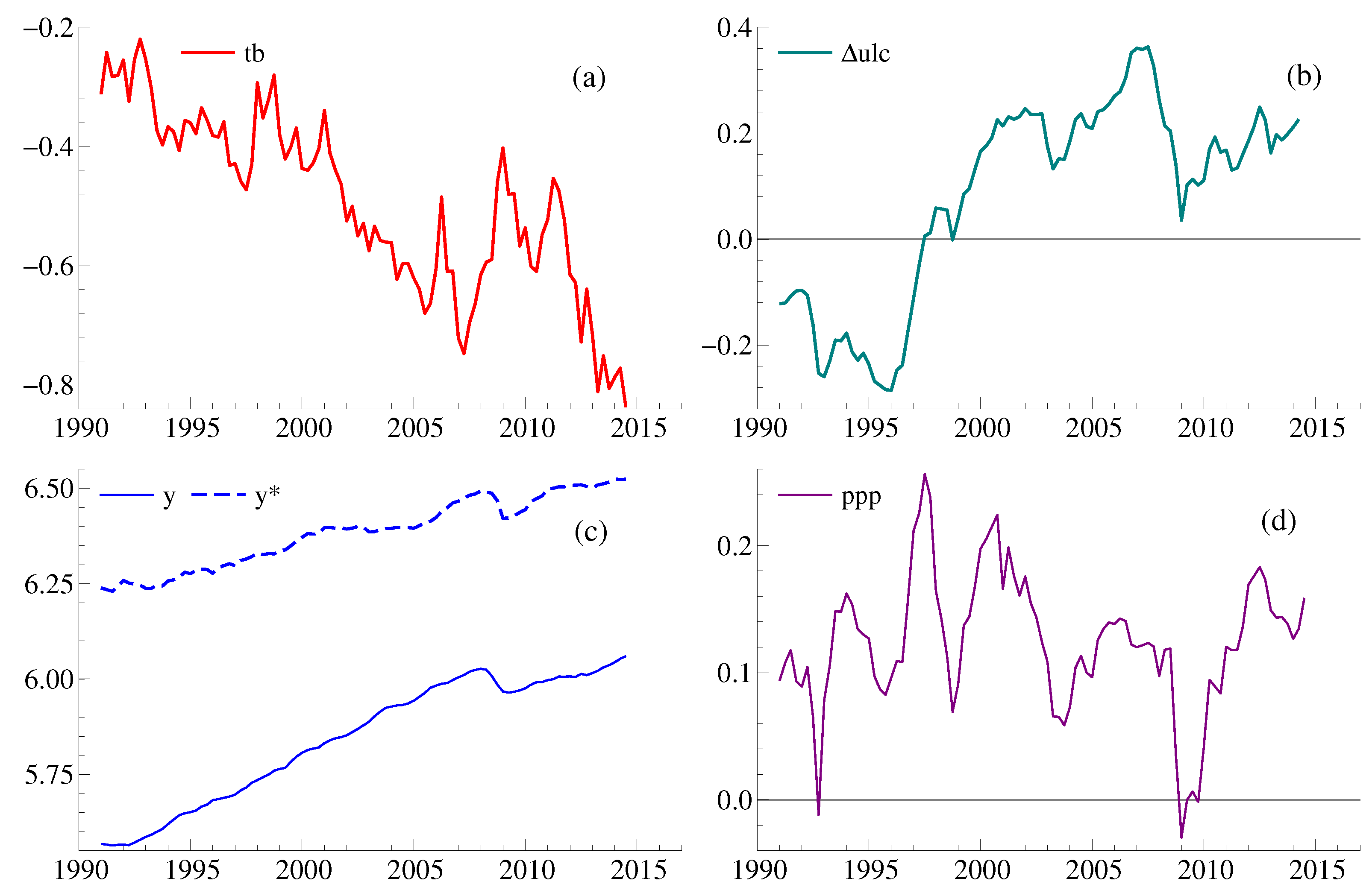
5. Empirical Illustration
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Tables for Response Surfaces

{kind=link}
| const. | 4.14 | const. | 0.5987 | const. | −1.298 |
| −6.301 | −0.0538 | 0.03616 | |||
| 5.8842 | a | −1.039 | −0.027 | ||
| −2.32576 | b | −0.39 | −2.022 | ||
| 0.17 | 0.00686 | a | −8.689 | ||
| a | 2.6165 | 5.547 | b | 2.225 | |
| b | 2.5245 | 2.331 | 59.77 | ||
| −0.0572 | 1.841 | 24.31 | |||
| −0.0971 | −0.00033 | −5.156 | |||
| −7.550 | −10.42 | −133.5 | |||
| −5.323 | −4.325 | −59.05 | |||
| −7.412 | −2.553 | −29.55 | |||
| −0.000124 | 9.905 | −66.58 | |||
| 0.161 | 1.862 | 255.3 | |||
| 0.179 | −61.09 | 280.5 | |||
| 10.40 | −17.09 | 155.3 | |||
| 6.096 | −11.48 | −240 | |||
| 5.851 | 117.68 | 21.32 | |||
| −8.860 | 35.19 | 71.68 | |||
| −4.948 | 18.6 | −305.7 | |||
| 46.15 | −8.836 | −321.1 | |||
| 31.85 | 1.033 | 332.1 | |||
| 26.12 | 66.94 | 0.038 | |||
| −86.58 | 10.84 | −0.184 | |||
| −50.50 | −140.88 | ||||
| −28.78 | −30.16 | ||||
| 5.296 | −10.05 | ||||
| 2.386 | 2.107 | ||||
| −29.03 | −1.029 | ||||
| −19.46 | −20.63 | ||||
| −13.42 | 3.511 | ||||
| 62.00 | 45.85 | ||||
| −5.880 | 4.267 | ||||
| 34.59 | 0.062 | ||||
| 15.93 |
| const. | 4.95486 | const. | 0.4472 | const. | −1.531 |
| −9.263 | 1.17564 | 0.9029 | |||
| 9.162 | −1.5294 | a | 4.164 | ||
| −3.662 | b | 0.8286 | 0.01579 | ||
| a | 3.05 | −0.0646 | 0.3388 | ||
| b | 0.3315 | 1.75 | −27.16 | ||
| 0.01738 | 0.04051 | −14.15 | |||
| −0.128 | −2.084 | −0.0013 | |||
| −14.61 | −3.698 | −0.0167 | |||
| −4.14 | −0.788 | −19.65 | |||
| −2.419 | −4.819 | 14.03 | |||
| −0.00084 | −3.897 | 42.2 | |||
| 0.3264 | 30.49 | 17.43 | |||
| 0.1302 | −5.108 | −77.72 | |||
| 0.0266 | 2.273 | −20.52 | |||
| 21.56 | −40.9 | 278.7 | |||
| 5.56 | 13.37 | 313.6 | |||
| 3.03 | 16 | 169.1 | |||
| −5.742 | 3.795 | −461.7 | |||
| 3.339 | −110.5 | −562.9 | |||
| 44.2 | 184.8 | −221.2 | |||
| 9.66 | −4.478 | 81.64 | |||
| −4.44 | 0.5014 | −315 | |||
| −81.67 | −9.833 | −384.8 | |||
| −15.2 | 73.02 | −114.6 | |||
| 2.41 | −5.835 | 804 | |||
| −3.44 | −130.2 | −290 | |||
| −24.23 | 4.743 | 860.7 | |||
| 9.6 | −0.2472 | 205.2 | |||
| 47.34 | 0.06919 | 0.18 | |||
| −7.22 | 3.765 | −0.00017 | |||
| −0.884 | 1.337 | ||||
| −14.06 | −0.0215 | ||||
| 1.944 | −0.408 |
Appendix B. Proof of the Granger–Johansen Representation
Appendix C. Proofs of Asymptotic Results
Appendix C.1. A High Level Assumption
- (a)
- ;
- (b)
- for all ;
- (c)
- for all ;
- (d)
Appendix C.2. Several Lemmas for the Partial Systems
Appendix C.3. Proofs of the Theorems in Section 3
References
- Anderson, Theodore W., and Naoto Kunitomo. 1992. Asymptotic distributions of regression and autoregression coefficients with martingale difference disturbances. Journal of Multivariate Analysis 40: 221–43. [Google Scholar] [CrossRef]
- Bårdsen, Gunnar, Øyvind Eitrheim, Eilev S. Jansen, and Ragnar Nymoen. 2005. The Econometrics of Macroeconomic Modelling. Oxford: Oxford University Press. [Google Scholar]
- Berenguer-Rico, Vanessa, and Bent Nielsen. 2017. Marked and Weighted Empirical Processes of Residuals with Applications to Robust Regressions. Discussion Paper 841. Oxford: Department of Economics, University of Oxford. [Google Scholar]
- Berenguer-Rico, Vanessa, and Ines Wilms. 2018. White Heteroscedasticity Testing in Robust Regressions. Discussion Paper 853. Oxford: University of Oxford, Department of Economics. [Google Scholar]
- Billingsley, Patrick. 1968. Convergence of Probability Measures. New York: John Wiley & Sons. [Google Scholar]
- Boswijk, H. Peter. 1992. Cointegration, Identification and Exogeneity, 3rd ed. Tinbergen Institute Research Series; Amsterdam: Thesis Publishers, volume 37. [Google Scholar]
- Boswijk, H. Peter. 1995. Efficient inference on cointegration parameters in structural error correction models. Journal of Econometrics 69: 133–58. [Google Scholar] [CrossRef]
- Boswijk, H. Peter, Giuseppe Cavaliere, Anders Rahbek, and A. M. Robert Taylor. 2016. Inference on co-integration parameters in heteroskedastic vector autoregressions. Journal of Econometrics 192: 64–85. [Google Scholar] [CrossRef]
- Boswijk, H. Peter, and Jurgen A. Doornik. 2005. Distribution approximations for cointegration tests with stationary exogenous regressors. Journal of Applied Econometrics 20: 797–810. [Google Scholar] [CrossRef] [Green Version]
- Brown, B. M. 1971. Martingale central limit theorems. Annals of Mathematical Statistics 42: 59–66. [Google Scholar] [CrossRef]
- Cavaliere, Giuseppe, Luca De Angelis, and Luca Fanelli. 2018. Co-integration rank determination in partial systems using information criteria. Oxford Bulletin of Economics and Statistics 80: 65–89. [Google Scholar] [CrossRef]
- Cavaliere, Giuseppe, Anders Rahbek, and A. M. Robert Taylor. 2010. Cointegration rank testing under conditional heteroskedasticity. Econometric Theory 26: 1719–60. [Google Scholar] [CrossRef]
- Cavaliere, Giuseppe, Anders Rahbek, and A. M. Robert Taylor. 2012. Bootstrap determination of the co-integration rank in vector autoregressive models. Econometrica 80: 1721–40. [Google Scholar]
- Chan, Ngai Hang, and Ching Zong Wei. 1988. Limiting distributions of least squares estimates of unstable autoregressive processes. Annals of Statistics 16: 367–401. [Google Scholar] [CrossRef]
- Doornik, Jurgen A. 1998. Approximations to the asymptotic distribution of cointegration tests. Journal of Economic Surveys 12: 573–93. [Google Scholar] [CrossRef]
- Doornik, Jurgen A. 2003. Asymptotic Tables for cointegration Tests Based on the GAmma-Distribution Approximation. Available online: www.doornik.com/research/coigamma_tables.pdf (accessed on 4 October 2019).
- Doornik, Jurgen A. 2013. An Object-Oriented Matrix Programming Language—OX7. London: Timberlake. [Google Scholar]
- Doornik, Jurgen A., and Henrik Hansen. 2008. An omnibus test for univariate and multivariate normality. Oxford Bulletin of Economics and Statistics 70: 927–39. [Google Scholar] [CrossRef]
- Doornik, Jurgen A., and David F. Hendry. 2013. PcGive 14. London: Timberlake, volume 2. [Google Scholar]
- Doornik, Jurgen A., David F. Hendry, and Bent Nielsen. 1998. Inference in cointegrating models: UK M1 revisited. Journal of Economic Surveys 12: 533–72. [Google Scholar] [CrossRef]
- Engle, Robert F. 1982. Autoregressive conditional heteroscedasticity with estimates of the variance of united kingdom inflation. Econometrica 50: 987–1108. [Google Scholar] [CrossRef]
- Engle, Robert F., David F. Hendry, and Jean-Francois Richard. 1983. Exogeneity. Econometrica 51: 277–304. [Google Scholar] [CrossRef]
- Ericsson, Neil R., and James G. MacKinnon. 2002. Distributions of error correction tests for cointegration. Econometrics Journal 5: 285–318. [Google Scholar] [CrossRef] [Green Version]
- Godfrey, Leslie G. 1978. Testing against general autoregressive and moving average error models when the regressors include lagged dependent variables. Econometrica 46: 1293–301. [Google Scholar] [CrossRef]
- Hall, P., and C. C. Heyde. 1980. Martingale Limit Theory and Its Applications. San Diego: Academic Press. [Google Scholar]
- Hannan, E. J., and C. C. Heyde. 1972. On limit theorems for quadratic functions of discrete time series. Annals of Mathematical Statistics 43: 2058–66. [Google Scholar] [CrossRef]
- Hansen, Bruce E. 1992. Convergence to stochastic integrals for dependent heterogeneous processes. Econometric Theory 8: 489–500. [Google Scholar] [CrossRef]
- Hansen, Peter Reinhard. 2005. Granger’s representation theorem: A closed-form expression for I(1) processes. Econometrics Journal 8: 23–38. [Google Scholar]
- Harbo, Ingrid, Søren Johansen, Bent Nielsen, and Anders Rahbek. 1998. Asymptotic inference on cointegrating rank in partial systems. Journal of Business and Economic Statistics 16: 388–99. [Google Scholar]
- Harvey, Andrew, and Stephen Thiele. 2017. Co-Integration and Control: Assessing the Impact of Events Using Time Series Data. Working Paper 1731. Cambridge: University of Cambridge, Faculty of Economics. [Google Scholar]
- Hendry, David F., and Michael Massmann. 2007. Co-breaking: Recent advances and a synopsis of the literature. Journal of Business & Economic Statistics 25: 33–51. [Google Scholar]
- Inoue, Atsushi. 1999. Tests of cointegrating rank with a trend-break. Journal of Econometrics 90: 215–37. [Google Scholar] [CrossRef]
- Jakubowski, Adam, Jean Ménin, and Gilles Pages. 1989. Convergence en loi des suites d’integrales stochastiques sur l’espace D1 de skorokhod. Probability Theory and Related Fields 81: 111–37. [Google Scholar] [CrossRef]
- Johansen, Søren. 1988. Statistical analysis of cointegration vectors. Journal of Economic Dynamics & Control 12: 231–54. [Google Scholar]
- Johansen, Søren. 1992a. Cointegration in partial systems and the efficiency of single-equation analysis. Journal of Econometrics 52: 389–402. [Google Scholar] [CrossRef]
- Johansen, Søren. 1992b. Testing weak exogeneity and the order of cointegration in the UK money demand data. Journal of Policy Modeling 14: 313–34. [Google Scholar] [CrossRef]
- Johansen, Søren. 1995. Likelihood Based Inference on Cointegration in the Vector Autoregressive Model. Oxford: Oxford University Press. [Google Scholar]
- Johansen, Søren, Rocco Mosconi, and Bent Nielsen. 2000. Cointegration analysis in the presence of structural breaks in the deterministic trend. Econometrics Journal 3: 216–49. [Google Scholar] [CrossRef]
- Juselius, Katarina. 2006. The Cointegrated VAR Model. Oxford: Oxford University Press. [Google Scholar]
- Kurita, Takamitsu. 2011. Local power of likelihood-based tests for cointegrating rank: Comparative analysis of full and partial systems. Journal of Time Series Analysis 32: 672–79. [Google Scholar] [CrossRef]
- Kurita, Takamitsu, and Bent Nielsen. 2009. Cointegrated vector autoregressive models with adjusted short-run dynamics. Quantitative and Qualitative Analysis in Social Sciences 3: 43–77. [Google Scholar]
- Kurita, Takamitsu, Heino Bohn Nielsen, and Anders Rahbek. 2011. An I(2) cointegration model with piecewise linear trends. Econometrics Journal 14: 131–55. [Google Scholar] [CrossRef]
- Kurtz, Thomas G., and Philip E. Protter. 1991. Weak limit theorems for stochastic integrals and stochastic differential equations. Annals of Probability 19: 1035–70. [Google Scholar] [CrossRef]
- Kurtz, Thomas G., and Philip E. Protter. 1996. Weak convergence of stochastic integrals and differential equations. In Probabilistic Models for Nonlinear Partial Differential Equations. Edited by Denis Talay and Luciano Tubaro. Lecture Notes in Mathematics; Berlin: Springer, volume 1627, pp. 197–285. [Google Scholar]
- Lai, Tze Leung, and Ching Zong Wei. 1982. Least squares estimates in stochastic regression models with applications to identification and control of dynamic systems. Annals of Statistics 10: 154–66. [Google Scholar] [CrossRef]
- Lai, T. L., and C. Z. Wei. 1985. Asymptotic properties of multivariate weighted sums with applications to stochastic regression in linear dynamic systems. In Multivariate Analysis—VI. Edited by P. R. Krishnaiah. Amsterdam: Elsevier, pp. 375–93. [Google Scholar]
- MacKinnon, James G., Alfred A. Haug, and Leo Michelis. 1999. Numerical distributions of likelihood ratio tests of cointegration. Journal of Applied Econometrics 14: 563–77. [Google Scholar] [CrossRef]
- Nielsen, B. 1997. Bartlett correction of the unit root test in autoregressive models. Biometrika 84: 500–4. [Google Scholar] [CrossRef]
- Nielsen, Bent. 2005. Strong consistency results for least squares estimators in general vector autoregressions with deterministic terms. Econometric Theory 21: 534–61. [Google Scholar] [CrossRef]
- Nielsen, Bent. 2006. Order determination in general vector autoregressions. In Time Series and Related Topics: In Memory of Ching-Zong Wei. Edited by Hwai-Chung Ho, Ching-Kang Ing and Tze Leung Lai. Lecture Notes–Monograph Series. Beachwood: Institute of Mathematical Statistics, vol. 52, pp. 93–112. [Google Scholar]
- Paruolo, Paolo. 1997. Asymptotic inference on the moving average impact matrix in cointegrated I(1) var systems. Econometric Theory 13: 79–118. [Google Scholar] [CrossRef]
- Paruolo, Paolo, and Anders Rahbek. 1999. Weak exogeneity in I(2) VAR systems. Journal of Econometrics 93: 281–308. [Google Scholar] [CrossRef]
- Perron, Pierre. 1989. The great crash, the oil price shock, and the unit root hypothesis. Econometrica 57: 1361–401, Erratum in volume 61, 248–49. [Google Scholar] [CrossRef]
- Pesaran, M. Hashem, Yongcheol Shin, and Richard J. Smith. 2000. Structural analysis of vector error correction models with exogenous I(1) variables. Journal of Econometrics 97: 293–343. [Google Scholar] [CrossRef] [Green Version]
- Rahbek, Anders, and Rocco Mosconi. 1999. Cointegration rank inference with stationary regressors in VAR models. Econometrics Journal 2: 76–91. [Google Scholar] [CrossRef]
- Schreiber, Vanessa. 2015. Cointegration Analysis of the Exchange Rate and Bilateral Trade between the United Kingdom and Germany. M.Phil. thesis, University of Oxford, Oxford, UK. [Google Scholar]
- Seo, Byeongseon. 1998. Statistical inference on cointegration rank in error correction models with stationary covariates. Journal of Econometrics 85: 339–85. [Google Scholar] [CrossRef]
- White, Halbert. 1980. A heteroskedasticity-consistent covariance matrix estimator and a direct test for heteroskedasticity. Econometrica 48: 817–38. [Google Scholar] [CrossRef]

| a | b | ||||||
|---|---|---|---|---|---|---|---|
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 7 | 4 | ||||||
| 7 | 4 | ||||||
| 7 | 4 | ||||||
| 7 | 4 | ||||||
| 7 | 4 |
| a | b | ||||||
|---|---|---|---|---|---|---|---|
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 2 | 1 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 4 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 5 | 3 | ||||||
| 7 | 4 | ||||||
| 7 | 4 | ||||||
| 7 | 4 | ||||||
| 7 | 4 | ||||||
| 7 | 4 |
| Single-Eq. Tests | Vector Tests | |||
|---|---|---|---|---|
| F(5,66) | F(20,120) | |||
| F(4,84) | F(93,162) | |||
| F(31,56) | (4) | |||
| (2) |
| 95% limit quantiles |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kurita, T.; Nielsen, B. Partial Cointegrated Vector Autoregressive Models with Structural Breaks in Deterministic Terms. Econometrics 2019, 7, 42. https://doi.org/10.3390/econometrics7040042
Kurita T, Nielsen B. Partial Cointegrated Vector Autoregressive Models with Structural Breaks in Deterministic Terms. Econometrics. 2019; 7(4):42. https://doi.org/10.3390/econometrics7040042
Chicago/Turabian StyleKurita, Takamitsu, and Bent Nielsen. 2019. "Partial Cointegrated Vector Autoregressive Models with Structural Breaks in Deterministic Terms" Econometrics 7, no. 4: 42. https://doi.org/10.3390/econometrics7040042
APA StyleKurita, T., & Nielsen, B. (2019). Partial Cointegrated Vector Autoregressive Models with Structural Breaks in Deterministic Terms. Econometrics, 7(4), 42. https://doi.org/10.3390/econometrics7040042