1. Introduction
Categorical time series data are collected in many fields of applications and the statistical research focusing on such data structures evolved considerably over the last years. As an important special case, binary time series that correspond to categorical data with two categories, occur in many different contexts. Often, binary time series are obtained from binarization of observed real-valued data. Such processes are considered, e.g., in
Kedem and Fokianos (
2002). In
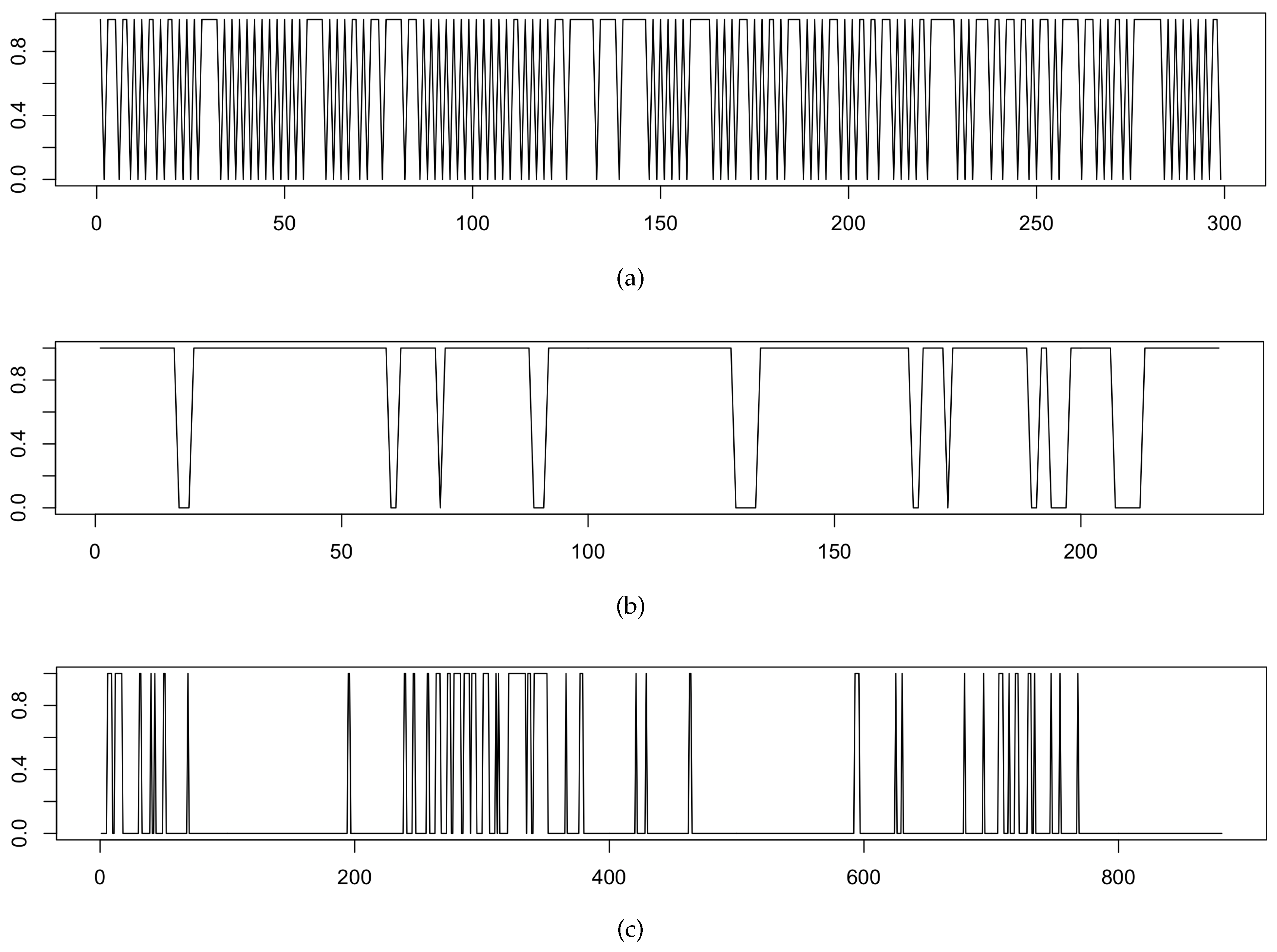
Figure 1, we show three real data examples of binary time series from different fields of research. For example, in
Figure 1a, the eruption duration of the Old Faithful Geyser in the Yellowstone National Park is binarized using a threshold. It is coded with a value of one if an eruption lasts for longer than three minutes and zero if it is shorter. In economics, the two states of recessions and economic growth are of interest, as discussed, e.g., in
Bellégo (
2009). One example of a recession/no-recession time series is shown in
Figure 1b, where for every quarter it is shown if Italy is in a recession, indicated by zero, or not, indicated by one. Recently, there is great interest in the air pollution in European cities, where an exceedance of the threshold of 50
g/m
PM
(fine dust) causes a fine dust alarm. The resulting sequence of states of no exceedance corresponding to zero and exceedance corresponding to one is shown in
Figure 1c. Further examples can be found, e.g., in geography, where sequences with the two states of dry and wet days are considered, e.g., in
Buishand (
1978). In biomedical studies, binary time series occur in the case, where the participants keep daily diaries of their disease. For example, in clinical trials, as in
Fitzmaurice et al. (
1995), the binary self assessment of participants of their arthritis is collected, where poor is indicated by zero and good by one. In natural language processing, the occurrence of vowels as a sequence can be of interest, as considered in
Weiß (
2009b), where a text is binarized by detecting a consonant or no consonant/vowel as the two states. The binarization of a time series by a threshold, as, e.g., in the PM
example, or by categorizing the time series into two states, as, e.g., in dry and wet days, indeed simplifies the real valued time series to a binary version. As mentioned in
Kedem (
1980), nevertheless, the transformation keeps the random mechanism from which the data are generated. For the example of PM
data, it might often be of more interest, whether a certain threshold is crossed (or not) instead of the actual amount. In general, the rhythm within the binarized time series contains a great amount of information of the original data.
As discussed in
Kedem (
1980), binary Markov chains are typically used for modelling the dependence structure due to their great flexibility. However, the number of parameters to estimate from the data grows exponentially with the order of the Markov model leading to over-parametrization (see, e.g.,
McKenzie (
2003)).
To avoid the estimation of a large number of parameters,
Jacobs and Lewis (
1983) proposed the class of (new) discrete autoregressive moving-average (NDARMA) models for categorical time series. More precisely, for processes with discrete and finite state space, a parsimonious model is suggested. The idea is to choose the current value for
randomly either from the past values of the time series
or from one of the innovations
with certain probabilities, respectively. This random selection mechanism is described by independent and identically distributed (i.i.d) random vectors
with
where
denotes the multinomial distribution with parameter 1 and probability vector
with
,
and
such that
. Then, the NDARMA(p,q) model equation is given by
where
is an i.i.d. process taking values in a discrete and finite state space
. Since for each time point
t only one entry in the random vector
is realized to be one while all others become zero, the value of
takes either one of the values of
for
or one of the error terms
for
. This sampling mechanism assures that the time series takes values in the state space
, such that, e.g., for a binary time series with
, the process stays binary. In contrast to the real-valued ARMA model, the lagged time series values and errors are not weighted according to the model coefficients and summed-up since only one of them is actually multiplied with one and all the others with zero based on the realization of
.
The model parameters are the probabilities of the multinomial distribution, summarized in the parameter vector
P, where all entries of
P lie in the unit interval and sum-up to one. In comparison to Markov Chains, NDARMA models maintain the nice interpretable ARMA-type structure and have a parsimonious parameterization. Furthermore, NDARMA models fulfill certain Yule–Walker-type equations, as shown in
Weiß and Göb (
2008).
In
Figure 2, one realization of an NDARMA(1,0) process, denoted by NDAR(1),
with binary state space is shown. NDAR(1) models are probably the simplest members of the NDARMA class, but
Figure 2 nicely illustrates the limited flexibility of the whole NDARMA class. The sampling mechanism of choosing the predecessor with some probability
tends to generate long runs of the same value in particular when the parameter
is large. A switching from one state to the other, e.g., from
to
, can only occur, e.g., if the error term
is selected (with probability
) and the error term takes the value
. Hence, the NDARMA class does not allow
systematically selecting the opposite value of
for
.
As for the NDARMA class all model parameters are restricted to be non-negative, which explains in particular why the NDARMA class can model exclusively non-negative autocorrelations in the data. For the example of a NDAR(1) process, the autocorrelation at lag one is equal to
, such that any alternating pattern that corresponds to negative model parameters as, e.g., observed in
Figure 1a, cannot be captured. For a more detailed discussion of the properties of NDARMA models, we refer also to
Jacobs and Lewis (
1983) or
Weiß (
2009a). To increase its flexibility,
Gouveia et al. (
2018) proposed an extension of the NDARMA model class by using a variation function, but the resulting models do also not allow for negative model parameters and, hence, no negative dependence structure. Hence, whenever negative dependence structure is present in binary time series data, the NDARMA model is not suitable. In fact, in all three data examples of
Figure 1, a straightforward estimation based on Yule–Walker estimators leads to at least some negative coefficients, such that NDAR models turn out to be not applicable.
To address this lacking flexibility of the NDARMA model class, we propose a simple and straightforward extension of the original idea of
Jacobs and Lewis (
1983) that allows also negative serial dependence. The resulting generalized binary ARMA (gbARMA) model class maintains the nicely interpretable model structure. Furthermore, no additional parameters are required to handle the negative dependence, preserving the parsimonious parameterization as well. In
Figure 3, a realization of a gbARMA(1,0) process, denoted as gbAR(1), is shown. As a straightforward extension of an NDAR(1) model in
Figure 2, gbAR(1) models allow for negative serial dependence. In fact, the range of the autocorrelation at lag one is extended from
for NDAR(1) to
for gbAR(1) models.
To allow for negative autocorrelation up to some limited extend,
Kanter (
1975) proposed the binary ARMA model class, where he applied the modulo 2 operator in an ARMA-type model equation. Using the modulo operation assures to stay in the binary state space, but the nice interpretability of the dependence structure in the model is lost since the past values of the time series are summed up prior to the modulo operation, see also
McKenzie (
1981). We follow a different path in this paper and propose a much simpler operation that enables modeling a systematic change of the state from one time point to the other.
The idea of allowing for negative serial dependence resulting in the gbARMA class is as follows: a negative model parameter
(and hence a negative autocorrelation
) in binary time series data corresponds to the time series
systematically changing from one state to the other over time. Hence, the natural idea to incorporate negative serial dependence in the
binary NDAR(1) Model (Equation (
2)) is to replace
by
as
holds. This leads to the model equation
This process has negative autocorrelation
at lag one. Note that, in comparison to Equation (
2), as
here, we have to use its absolute value
as the probability to select the
. Altogether, for
, we can define the generalized binary AR(1) (gbAR(1)) process by the model equation
Note that Equation (
4) extends the parameter space from
for NDAR(1) models to
for gbAR(1) models. Further, note that, for identification of the model, we have to assume
. Using indicator variables, Equation (
4) can be compactly written as
with
,
,
and
.
In
Figure 3, a realization of a gbAR(1) process with negative parameter
is shown, where the time series tends to take systematically the opposite state of the predecessor. The corresponding autocorrelation plot reflects the negative serial dependence leading to an alternating pattern. Runs of the same state can only occur, when the error term
is selected (with probability
) and the error term
takes the same value as
, that is,
. The empirical autocorrelations for the Old Faithful Geyser data can be found in
Figure 4a, where the pronounced alternating behavior clearly indicates negative linear dependence to be present in the data.
The idea of allowing for a negative model coefficient by replacing
by
in gbAR(1) processes (Equation (
5)) can be also employed for each parameter in
pth order gbAR processes, where each
,
may be replaced by
in the model equation.
The paper is organized as follows. In
Section 2, generalized binary AR processes of order
are defined, where we also give stationarity conditions and state the stationary solution. Further, stochastic properties are derived that include formulas for the transition probabilities, the marginal distribution, and Yule–Walker equations. As a real data example, we illustrate the applicability of our model class to the geyser eruption data in
Section 1. In
Section 3, we present several simulation experiments. First, in
Section 3.1, for the example of a gbAR(2) model, we illustrate the generality of the resulting gbAR model class in comparison to natural competitors including AR, NDAR, and Markov models of order two, respectively. In
Section 3.2, we examine the estimation performance of Yule–Walker estimators in the gbAR models in
Section 3.2.1. In
Section 3.2.2, we investigate the benefit of using the parsimonious gbAR models in comparison to Markov models and their robustness in cases where the model is mis-specified. By adding a moving-average part to gbAR models in
Section 4, ARMA-type extensions of gbAR models leading to gbARMA processes are discussed. We conclude in
Section 5. All proofs are deferred to
Appendix A.
4. Further Extension: The Generalized Binary ARMA Class
In this section, we extend the gbAR model class and give a definition of generalized binary ARMA (gbARMA) models that additionally contain a moving average part in their model equations. In the spirit of the gbAR model as an extension of the NDAR model class, we allow also for negative parameters in the moving-average part of the model.
First, we provide the definition of the gbARMA(p,q) model, derive its stationary solution, and state some basic properties of marginal, joint, and transition probabilities of gbARMA(p,q) processes. We conclude this section with an example of a gbARMA(1,1) process.
4.1. gbARMA Models
To be most flexible, the gbARMA model class allows additionally for negative parameters to capture negative dependence structure also in the moving average part. As before, we assume
for identification reasons. In the gbARMA(p,q) model class, the parameters
and
are allowed to be either positive or negative, e.g.,
for
and
. To modify the parameter vector
, again such that it contains the probabilities, we define
Definition 2 (Generalized binary ARMA processes)
. Let be a stationary process which takes values in . Let be a binary error process such that is independent of with mean and variance . Let be the parameter vector with as in Equation (21) such that . Further, letbe iid random vectors, which are independent of and . Then, the process is said to be a generalized binary ARMA(p,q) process, if it follows the recursionwith , and analogous definitions for and . The model parameters are contained in the vector P with entries for , and for . Note that, as holds, no random variable is contained in the model equation.
With probability , a predecessor is chosen, whereas, with probability , the process takes the value of an error term , where it follows that .
4.2. Stochastic Properties of gbARMA Models
When dealing with possibly negative parameters also in the moving-average part of gbARMA models, the idea of Equation (
4) is employed also for the lagged error terms. Hence, this allows modeling negative dependence in the moving average part as well. In the multinomial distribution, all values of the parameter vector
P have to be considered in absolute value, thus we have to use
as defined in Equation (
21). For the expectation of gbARMA processes, two additional sums show up in comparison to the NDARMA case. Precisely, we have
The construction of the stationary solution of the gbARMA time series is similar to the construction of the gbAR(p) process introduced in
Section 2.1 and (
Lütkepohl 2005, Chap. 11.3.2). The vector representation of the process
is equipped with a moving average part and thus the dimension of the corresponding random matrices becomes
. Precisely, the gbARMA(p,q) model can be written as a
-dimensional gbVAR(1) process
with the following matrices and vectors, such that the first entry of
is equal to the gbARMA(p,q) process. We define
To obtain a vector autoregressive representation for
, we define directly matrices that contain the random variables of the multinomial distribution. Precisely, for
, let
be
matrices, where
are
,
and
matrices, respectively, and
. Based on the notation introduced above, gbARMA(p,q) processes can be represented as a vector-valued gbAR model of first order (gbVAR(1)) as follows
with
being the one vector of length
.
To derive a suitable stationarity condition for the process, we know from
Lütkepohl (
2005) that it corresponds to the characteristic polynomial of the parameter matrix
.
From the block structure of
, the polynomial can be reduced to the determinant of the block matrices
and
. Hence, a gbARMA(p,q) process is stationary if the roots of the characteristic polynomial of the autoregressive part lie outside the unit circle, that is, if
holds. The assumption is fulfilled whenever an error term has a positive probability, such that there exists a
for some
. Therefore, the sum over all probabilities of choosing a predecessor fulfills
. Without any restriction, we assume that
is strictly positive for a stationary gbARMA process, i.e.,
.
For a stationary gbARMA(p,q) process, a moving average representation can be derived using the above defined vectors and matrices.
Theorem 3 (Moving Average representation of gbARMA processes)
. Let be a stationary gbARMA(p,q) process with gbVAR(1) representation (Equation (23) ). Then, it follows thatwhere in and is the first unit vector. The univariate moving average representation is obtained from the multivariate formula by multiplying it with the first unit vector because of .
Considering the autocorrelation structure,
Jacobs and Lewis (
1983) and
Weiß (
2011) showed that the NDARMA(p,q) model fulfils a set of Yule–Walker type equations which was also derived by
Möller and Weiß (
2018) for the GenDARMA class of categorical processes. The following result shows that this property is maintained for the gbARMA class.
Theorem 4 (Yule–Walker-type equations)
. Let be a stationary gbARMA(p,q) process. Set for . Define coefficients recursively byThen, the autocovariance function for lags is obtained by The autocovariances of the NDARMA and GenDARMA processes can only be positive, whereas the Yule–Walker type equations of gbARMA processes allow for possibly negative model parameters for and .
For the generalized binary ARMA model, formulas for the marginal, joint and transition probabilities can be calculated, extending the results from Lemma 1.
Lemma 2 (Marginal, joint, and transition probability of gbARMA processes). Let be a stationary gbARMA(p,q) process. Then, the following properties hold:
- (i)
- (ii)
Defining then it follows
- (iii)
- (iv)
The flexibility of gbARMA models obtained by allowing for negative parameters shows also in the transition probabilities and in the joint and marginal distributions. Hence, more complex structures can be captured since systematic changes in the error terms are allowed as well.
We conclude this section with an example of a gbARMA(1,1) model.
Example 3 (gbARMA(1,1) process)
. Let be a stationary gbARMA(1,1) process. Then, the process follows the recursionFour sign combinations of parameter pairs are possible and the corresponding model equations are given as follows:Whereas for identification purposes only takes positive values, the predecessors and are systematically switched if the corresponding model parameters are negative, respectively.For a stationary gbARMA(1,1) process, the moving average representation fulfills the following equation:From the stationarity assumption, we have , and . The moving average representation consists of three parts. There first is a sum over all terms for the potential case of . This part accounts for the choosing a predecessor and its switching. Since is strictly positive, the second is a sum over all error terms without any modification occurs. In the third sum, the random variable appears for controlling the case of .








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}