
A Hierarchical Machine Learning Method for Detection and Visualization of Network Intrusions from Big Data


Abstract
:1. Introduction
2. Background
2.1. Previous Resources
2.2. Big Data Processing in Network Anomaly Detection
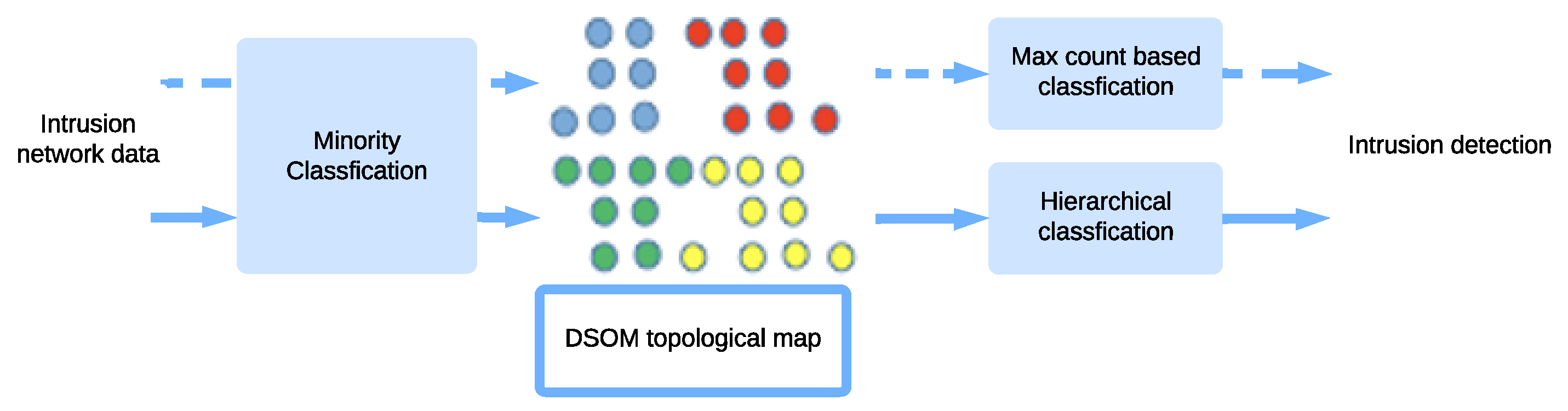
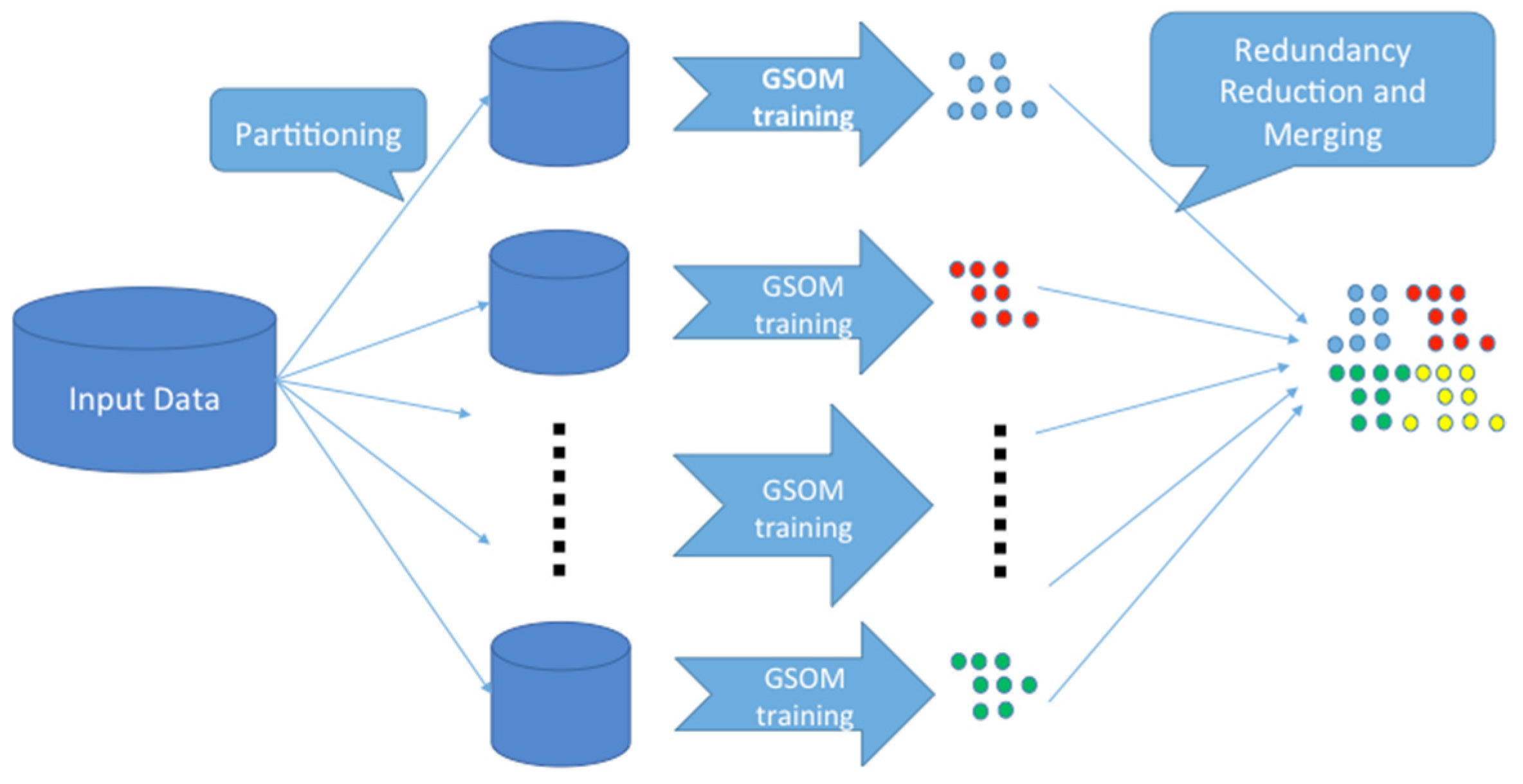
3. The Proposed Method
3.1. Self-Organization-Based Networking Data Processing
3.2. Distributed-GSOM-Based Parallel Processing for Big Data
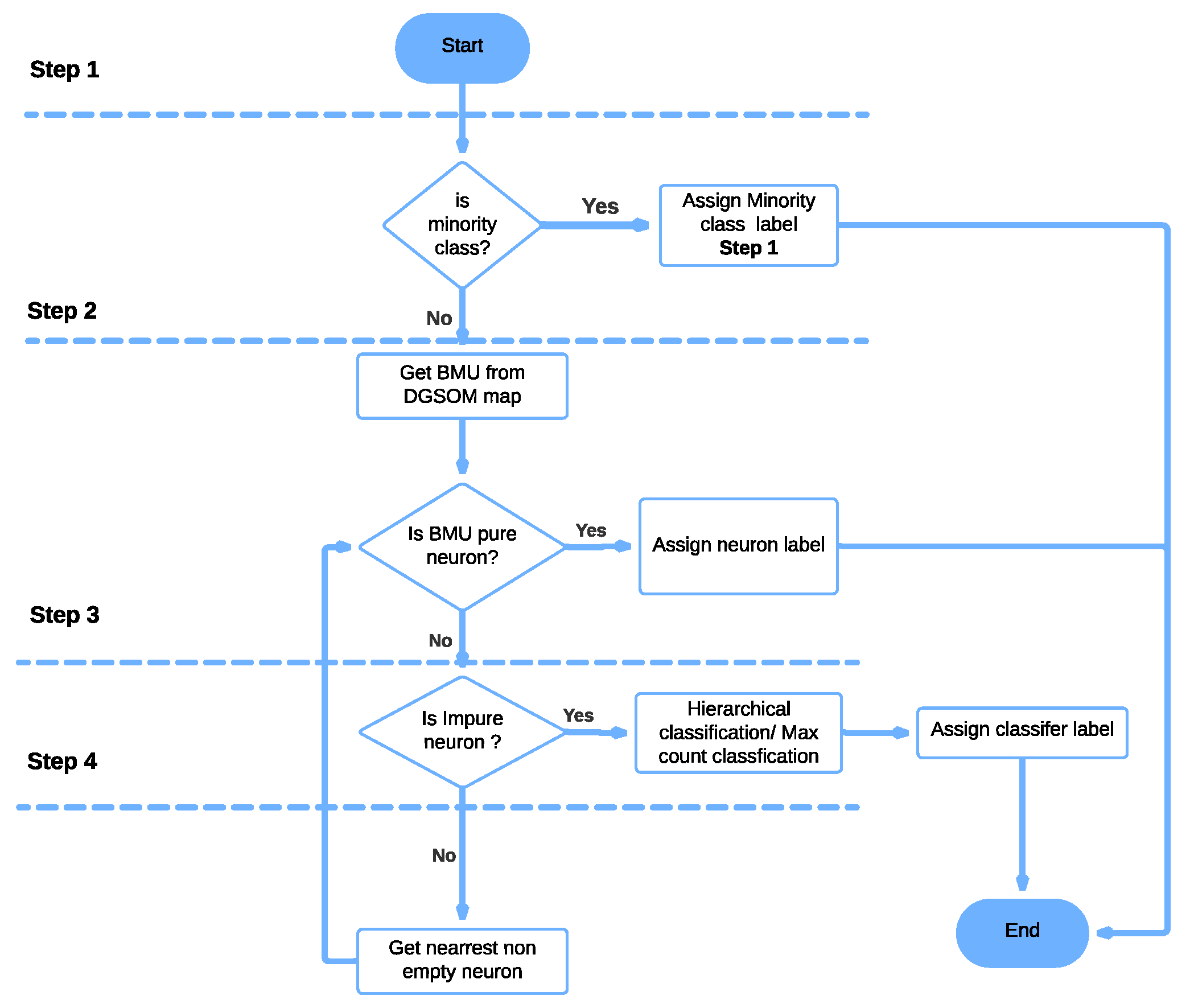
3.3. Hierarchical and Minority Classifiers Training
| Algorithm 1: Training Classifiers for Not-Pure Neurons for the Hierarchical Approach |
| Inputs: Matched training inputs for not-pure neurons |
| Return: Classifiers for not-pure neurons |
| Group neurons containing the same classes for each neuron group: Classifier training data fetch all the training inputs belonging to the neurons in this group Build a classifier for the training data Save the classifier |
| Algorithm 2: Training Classifiers to Identify Minority Class |
| Inputs: Matched training inputs for not-pure neurons; Threshold of dealing with minority label class |
| Return: Classifiers for not-pure neurons |
| for each label in classification labels: if percentage of data samples in a class < threshold: Resample the dataset and train a model to classify this class and the rest of the other classes |
3.4. GSOM-Based Anomaly Detection
| Algorithm 3: GSOM-based Classification |
| Inputs: Training inputs data; Test inputs data; Neurons in the training GSOM; Test inputs matched neurons; Flag of whether dealing with minority label class |
| Return: Predicted classification label for each testing input |
| for each neuron in the test inputs matched neurons: for each testing input in the neuron: if Flag of whether dealing with minority label class is True and testing input is predicted as a minority class label by minority classifiers defined in Algorithm 2 (only in hierarchical approach): update predicted classification label as the predicted label by the minority classifiers elif the neuron in training GSOM map is pure: update predicted classification label as the neuron representative class label elif the neuron is not pure: update predicted classification label for this test input based on a classification approach (Algorithms 4 and 5) else (the neuron is empty): search for the closest neuron (based on the latent space distance) which is not empty in the training map and update the predicted classification label for this test input based on a classification approach |
3.4.1. Max-Count-Based Approach
| Algorithm 4: Max Count Approach |
| Inputs: A test input ; Neurons in the training GSOM; Training inputs data |
| Return: Predicted class labels with a max frequency count for the test input, |
| neuron the matched neuron of test input in training GSOM map class label class label with max frequency count among the matched training inputs of the neuron class label |
3.4.2. Hierarchical Approach
| Algorithm 5: Hierarchical Approach |
| Inputs: A test input ; Neurons in the training GSOM; pre-trained classifiers |
| Return: Predicted class labels based on the classification result from classifier, |
| neuron the matched neuron of test input in training GSOM map classifier the classifier that neuron was assigned to among all pre-trained classifiers predicted class for based on classifier |
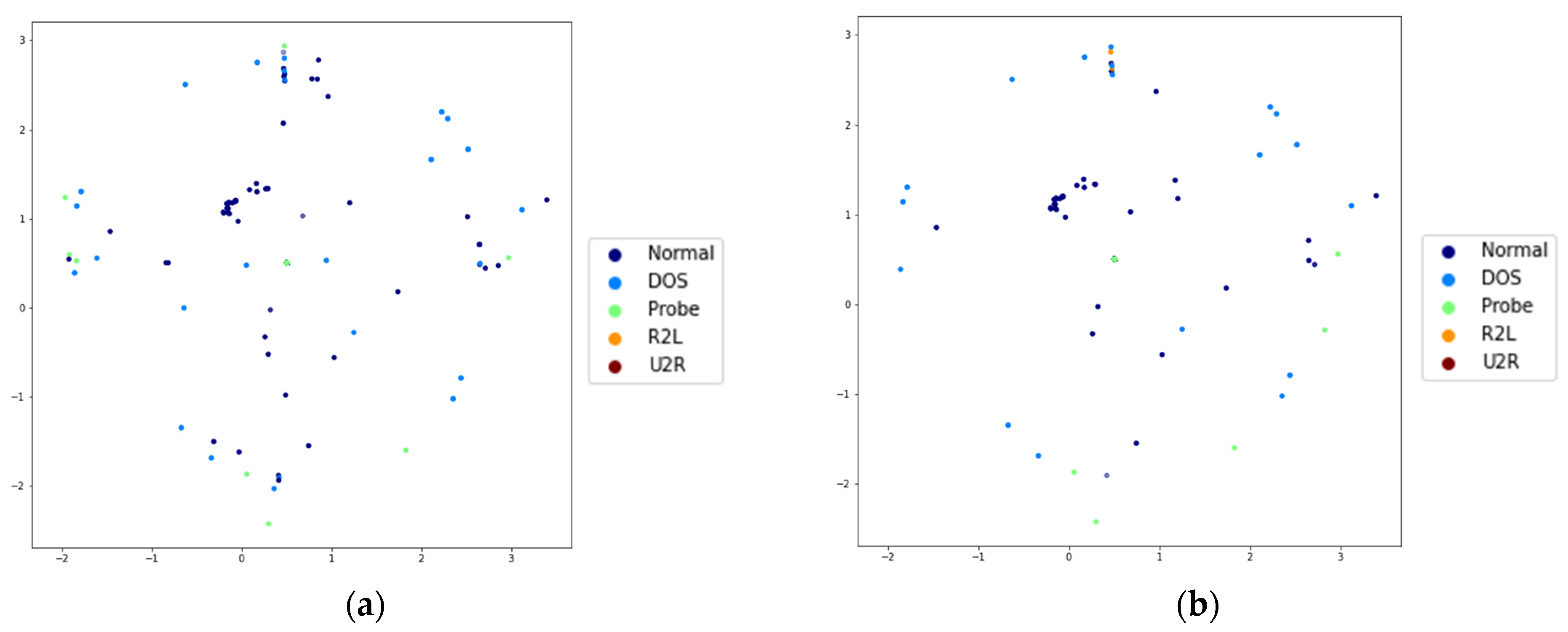
3.5. Explainability Through Visualization
4. Experiment and Results
4.1. The Dataset
4.1.1. KDD CUP 99 Dataset
4.1.2. NSL-KDD Dataset
4.2. Evaluation of Detection Performance
4.3. Configuration Settings
4.4. Results and Analysis
4.4.1. KDD CUP 99 Dataset
4.4.2. NSL-KDD Dataset
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Correction Statement
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Max Count Approach | Hierarchical Approach with Logistic Regression | Hierarchical Approach with Decision Tree | ||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Types | TP Rate (1) | TN Rate (2) | FP Rate (3) | FN Rate (4) | Precision | Accuracy | TP Rate (1) | TN Rate (2) | FP Rate (3) | FN Rate (4) | Precision | Accuracy | TP Rate (1) | TN Rate (2) | FP Rate (3) | FN Rate (4) | Precision | Accuracy |
| smurf | 0.9999 | 0.9997 | 0.0003 | 0.0001 | 0.9998 | 0.9998 | 0.9999 | 0.9998 | 0.0002 | 0.0001 | 0.9998 | 0.9998 | 0.9999 | 0.9992 | 0.0008 | 0.0001 | 0.9994 | 0.9996 |
| neptune | 0.9926 | 0.9864 | 0.0136 | 0.0074 | 0.9474 | 0.9876 | 0.9951 | 0.9999 | 0.0001 | 0.0049 | 0.9997 | 0.9990 | 0.9926 | 0.9999 | 0.0001 | 0.0074 | 0.9997 | 0.9985 |
| normal | 0.9954 | 0.9831 | 0.0169 | 0.0046 | 0.9392 | 0.9857 | 0.9844 | 0.9685 | 0.0315 | 0.0156 | 0.8909 | 0.9718 | 0.9478 | 0.9714 | 0.0286 | 0.0522 | 0.8967 | 0.9665 |
| satan | 0.8212 | 0.9996 | 0.0004 | 0.1788 | 0.9229 | 0.9986 | 0.8732 | 0.9973 | 0.0027 | 0.1268 | 0.6426 | 0.9966 | 0.8273 | 0.9973 | 0.0027 | 0.1727 | 0.6322 | 0.9963 |
| ipsweep | 0.9706 | 1.0 | 0.0 | 0.0294 | 0.9581 | 0.9999 | 0.9706 | 1.0 | 0.0 | 0.0294 | 0.9674 | 0.9999 | 0.9706 | 1.0 | 0.0 | 0.0294 | 0.9550 | 0.9999 |
| portsweep | 0.8927 | 0.9983 | 0.0017 | 0.1073 | 0.3940 | 0.9982 | 0.9492 | 0.9991 | 0.0009 | 0.0508 | 0.5619 | 0.9990 | 0.9463 | 0.9985 | 0.0015 | 0.0537 | 0.4278 | 0.9984 |
| Nmap | 1.0 | 1.0 | 0.0 | 0.0000 | 0.9767 | 1.0 | 1.0000 | 0.9997 | 0.0003 | 0.0000 | 0.5283 | 0.9997 | 1.0000 | 0.9998 | 0.0002 | 0.0000 | 0.6563 | 0.9998 |
| back | 0.3798 | 1.0 | 0.0 | 0.6202 | 0.9789 | 0.9976 | 0.0729 | 1.0000 | 0.0 | 0.9271 | 0.9302 | 0.9965 | 0.7359 | 0.9926 | 0.0074 | 0.2641 | 0.2722 | 0.9916 |
| teardrop | 0.6667 | 0.9999 | 0.0001 | 0.3333 | 0.2000 | 0.9999 | 0.6667 | 0.9999 | 0.0001 | 0.3333 | 0.2051 | 0.9999 | 0.8333 | 0.9999 | 0.0001 | 0.1667 | 0.2381 | 0.9999 |
| pod | 0.7471 | 1.0 | 0.0 | 0.2529 | 0.8553 | 0.9999 | 0.8851 | 0.9999 | 0.0001 | 0.1149 | 0.8370 | 0.9999 | 0.8966 | 0.9999 | 0.0001 | 0.1034 | 0.8298 | 0.9999 |
| guess_passwd | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9851 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9851 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9851 |
| buffer_overflow | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9999 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0 | 0.9999 | 0.0 | 1.0 | 0.0 | 1.0 | 0.0000 | 0.9999 |
| land | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| warezmaster | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9945 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9945 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9945 |
| imap | 0.0 | 1. | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| rootkit | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| loadmodule | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| ftp_write | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| multihop | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9999 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9999 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 0.9999 |
| phf | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| perl | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 | 0.0 | 1.0 | 0.0 | 1.0 | nan | 1.0 |
| Normal | DoS | Probe | R2L | U2R | ||
|---|---|---|---|---|---|---|
| Max Count Approach | True Positive Rate | 0.97 | 0.8 | 0.67 | 0.07 | 0 |
| True Negative Rate | 0.65 | 0.97 | 0.98 | 1 | 1 | |
| False Positive Rate | 0.35 | 0.03 | 0.02 | 0 | 0 | |
| False Negative Rate | 0.03 | 0.2 | 0.33 | 0.93 | 1 | |
| Precision | 0.68 | 0.93 | 0.83 | 0.93 | nan | |
| Accuracy | 0.79 | 0.91 | 0.95 | 0.88 | 1 | |
| Hierarchical Approach with Logistic Regression | True Positive Rate | 0.94 | 0.83 | 0.77 | 0.48 | 0.58 |
| True Negative Rate | 0.79 | 0.99 | 0.98 | 0.97 | 1 | |
| False Positive Rate | 0.21 | 0.01 | 0.02 | 0.03 | 0 | |
| False Negative Rate | 0.06 | 0.17 | 0.23 | 0.52 | 0.42 | |
| Precision | 0.77 | 0.97 | 0.86 | 0.69 | 0.27 | |
| Accuracy | 0.86 | 0.93 | 0.96 | 0.91 | 0.99 | |
| Hierarchical Approach with Decision Tree | True Positive Rate | 0.94 | 0.83 | 0.71 | 0.44 | 0.64 |
| True Negative Rate | 0.77 | 0.99 | 0.98 | 0.97 | 0.99 | |
| False Positive Rate | 0.23 | 0.01 | 0.02 | 0.03 | 0.01 | |
| False Negative Rate | 0.06 | 0.17 | 0.29 | 0.56 | 0.36 | |
| Precision | 0.76 | 0.97 | 0.84 | 0.72 | 0.21 | |
| Accuracy | 0.84 | 0.93 | 0.95 | 0.91 | 0.99 |
References
- Huang, M.Y.; Jasper, R.J.; Wicks, T.M. A Large Scale Distributed Intrusion Detection Framework Based on Attack Strategy Analysis. Comput. Netw. 1999, 31, 2465–2475. [Google Scholar] [CrossRef]
- Obeidat, I.M.; Hamadneh, N.; Alkasassbeh, M.; Almseidin, M.; AlZubi, M.I. Intensive Preprocessing of KDD Cup 99 for Network Intrusion Classification Using Machine Learning Techniques. Int. J. Interact. Mob. Technol. 2018, 13, 70–84. [Google Scholar] [CrossRef]
- Ortega-Fernandez, I.; Liberati, F. A Review of Denial of Service Attack and Mitigation in the Smart Grid Using Reinforcement Learning. Energies 2023, 16, 635. [Google Scholar] [CrossRef]
- Verwoerd, T.; Hunt, R. Intrusion Detection Techniques and Approaches. Comput. Commun. 2002, 25, 1356–1365. [Google Scholar] [CrossRef]
- Nabi, F.; Zhou, X. Enhancing Intrusion Detection Systems through Dimensionality Reduction: A Comparative Study of Machine Learning Techniques for Cyber Security. Cyber Secur. Appl. 2024, 2, 100033. [Google Scholar] [CrossRef]
- Pradhan, M.; Kumar Pradhan, S.; Sahu, S.K. Anomaly Detection Using Artificial Neural Network. Int. J. Eng. Sci. Emerg. Technol. 2012, 2, 29–36. [Google Scholar]
- Alkasassbeh, M.; Al-Naymat, G.; Hassanat, A.B.A.; Almseidin, M. Detecting Distributed Denial of Service Attacks Using Data Mining Techniques. IJACSA Int. J. Adv. Comput. Sci. Appl. 2016, 7, 1. [Google Scholar] [CrossRef]
- Ibrahim, L.M.; Taha, D.B.; Mahmod, M.S. A Comparison Study for Intrusion Database (KDD99, NSL-KDD) Based on Self Organization Map (SOM) Artificial Neural Network. J. Eng. Sci. Technol. 2013, 8, 107–119. [Google Scholar]
- Abdul, A.; Vermeulen, J.; Wang, D.; Lim, B.Y.; Kankanhalli, M. Trends and Trajectories for Explainable, Accountable and Intelligible Systems: An HCI Research Agenda. In Proceedings of the Conference on Human Factors in Computing Systems-Proceedings 2018, Montreal, QC, Canada, 21–26 April 2018. [Google Scholar] [CrossRef]
- Qu, X.; Yang, L.; Guo, K.; Ma, L.; Sun, M.; Ke, M.; Li, M. A Survey on the Development of Self-Organizing Maps for Unsupervised Intrusion Detection. Mob. Netw. Appl. 2021, 26, 808–829. [Google Scholar] [CrossRef]
- Choksi, K.; Shah, B.; Ompriya Kale, A.; Programme, M. Intrusion Detection System Using Self Organizing Map: A Survey. J. Eng. Res. Appl. 2014, 4, 11–16. [Google Scholar]
- Dlamini, G.; Fahim, M. DGM: A Data Generative Model to Improve Minority Class Presence in Anomaly Detection Domain. Neural Comput. Appl. 2021, 33, 13635–13646. [Google Scholar] [CrossRef]
- Tsai, C.F.; Hsu, Y.F.; Lin, C.Y.; Lin, W.Y. Intrusion Detection by Machine Learning: A Review. Expert Syst. Appl. 2009, 36, 11994–12000. [Google Scholar] [CrossRef]
- Tartakovsky, A.G.; Polunchenko, A.S.; Sokolov, G. Efficient Computer Network Anomaly Detection by Changepoint Detection Methods. IEEE J. Sel. Top. Signal Process. 2013, 7, 4–11. [Google Scholar] [CrossRef]
- Ahmed, M.; Naser Mahmood, A.; Hu, J. A Survey of Network Anomaly Detection Techniques. J. Netw. Comput. Appl. 2016, 60, 19–31. [Google Scholar] [CrossRef]
- Liao, H.J.; Richard Lin, C.H.; Lin, Y.C.; Tung, K.Y. Intrusion Detection System: A Comprehensive Review. J. Netw. Comput. Appl. 2013, 36, 16–24. [Google Scholar] [CrossRef]
- Maciej Serda; Becker, F.G.; Cleary, M.; Team, R.M.; Holtermann, H.; The, D.; Agenda, N.; Science, P.; Sk, S.K.; Hinnebusch, R.; et al. Shallow and Deep Networks Intrusion Detection System: A Taxonomy and Survey. Uniw. Śląski 2017, 7, 343–354. [Google Scholar]
- Maind, S.B.; Wankar, P. Research Paper on Basic of Artificial Neural Network. Int. J. Recent Innov. Trends Comput. Commun. 2014, 2, 96–100. [Google Scholar]
- Laskov, P.; Düssel, P.; Schäfer, C.; Rieck, K. Learning Intrusion Detection: Supervised or Unsupervised? Lect. Notes Comput. Sci. 2005, 3617, 50–57. [Google Scholar] [CrossRef]
- Stolfo, S.J.; Wei, F.; Lee, W.; Prodromidis, A.; Chan, P.K. Kdd Cup Knowledge Discovery and Data Mining Competition. Available online: http://kdd.ics.uci.edu/databases/kddcup99/kddcup99.html (accessed on 2 July 2024).
- Ravipati, R.D.; Abualkibash, M. Intrusion Detection System Classification Using Different Machine Learning Algorithms on KDD-99 and NSL-KDD Datasets—A Review Paper. Int. J. Comput. Sci. Inf. Technol. (IJCSIT) 2019, 11. [Google Scholar] [CrossRef]
- Sapre, S.; Ahmadi, P.; Islam, K. A Robust Comparison of the KDDCup99 and NSL-KDD IoT Network Intrusion Detection Datasets Through Various Machine Learning Algorithms. arXiv 2019, arXiv:1912.13204. [Google Scholar]
- Tavallaee, M.; Bagheri, E.; Lu, W.; Ghorbani, A.A. A Detailed Analysis of the KDD CUP 99 Data Set. In Proceedings of the IEEE Symposium on Computational Intelligence for Security and Defense Applications, CISDA 2009, Ottawa, ON, Canada, 8–10 July 2009. [Google Scholar] [CrossRef]
- Lane, T. A Decision-Theoritic, Semi-Supervised Model for Intrusion Detection. In Machine Learning and Data Mining for Computer Security; Springer: Berlin/Heidelberg, Germany, 2006; pp. 157–177. [Google Scholar] [CrossRef]
- Aslam, J.; Bratus, S.; Pavlu, V. Semi-Supervised Data Organization for Interactive Anomaly Analysis. In Proceedings of the Proceedings-5th International Conference on Machine Learning and Applications, ICMLA 2006, Orlando, FL, USA, 14–16 December 2006; pp. 55–62. [Google Scholar] [CrossRef]
- Chen, C.; Gong, Y.; Tian, Y. Semi-Supervised Learning Methods for Network Intrusion Detection. In Proceedings of the Conference Proceedings-IEEE International Conference on Systems, Man and Cybernetics, Singapore, 12–15 October 2008; pp. 2603–2608. [Google Scholar] [CrossRef]
- Vinutha, H.P.; Poornima, B. Analysis of NSL-KDD Dataset Using K-Means and Canopy Clustering Algorithms Based on Distance Metrics. Stud. Comput. Intell. 2019, 771, 193–200. [Google Scholar] [CrossRef]
- Tao, L.J.; Hong, L.Y.; Yan, H. The Improvement and Application of a K-Means Clustering Algorithm. In Proceedings of the 2016 IEEE International Conference on Cloud Computing and Big Data Analysis, ICCCBDA 2016, Chengdu, China, 5–7 July 2016; pp. 93–96. [Google Scholar] [CrossRef]
- Shyu, M.-L.; Chen, S.-C.; Sarinnapakorn, K.; LastName, L. A Novel Anomaly Detection Scheme Based on Principal Component Classifier. In Proceedings of the Proceeding of ICDM Foundation and New Direction of Data Mining Workshop, Melbourne, FL, USA, 19–22 November 2003. [Google Scholar]
- Zuech, R.; Khoshgoftaar, T.M.; Wald, R. Intrusion Detection and Big Heterogeneous Data: A Survey. J. Big Data 2015, 2, 1–41. [Google Scholar] [CrossRef]
- Ippoliti, D.; Zhou, X. A-GHSOM: An Adaptive Growing Hierarchical Self Organizing Map for Network Anomaly Detection. J. Parallel Distrib. Comput. 2012, 72, 1576–1590. [Google Scholar] [CrossRef]
- Ramadas, M.; Ostermann, S.; Tjaden, B. Detecting Anomalous Network Traffic with Self-Organizing Maps. Lect. Notes Comput. Sci. 2003, 2820, 36–54. [Google Scholar] [CrossRef]
- Sarasamma, S.T.; Zhu, Q.A.; Huff, J. Hierarchical Kohonenen Net for Anomaly Detection in Network Security. IEEE Trans. Syst. Man Cybern. Part B Cybern. 2005, 35, 302–312. [Google Scholar] [CrossRef]
- Gunes Kayacik, H.; Nur Zincir-Heywood, A.; Heywood, M.I. A Hierarchical SOM-Based Intrusion Detection System. Eng. Appl. Artif. Intell. 2007, 20, 439–451. [Google Scholar] [CrossRef]
- Tan, L.; Li, C.; Xia, J.; Cao, J. Application of Self-Organizing Feature Map Neural Network Based on K-Means Clustering in Network Intrusion Detection. Comput. Mater. Contin. 2019, 61, 275–288. [Google Scholar] [CrossRef]
- Amini, M.; Jalili, R.; Shahriari, H.R. RT-UNNID: A Practical Solution to Real-Time Network-Based Intrusion Detection Using Unsupervised Neural Networks. Comput. Secur. 2006, 25, 459–468. [Google Scholar] [CrossRef]
- Alahakoon, D.; Halgamuge, S.K.; Srinivasan, B. Dynamic Self-Organizing Maps with Controlled Growth for Knowledge Discovery. IEEE Trans. Neural Netw. 2000, 11, 601–614. [Google Scholar] [CrossRef]
- Apache Spark-Unified Engine for Large-Scale Data Analytics. Available online: https://spark.apache.org/ (accessed on 2 July 2024).
- Gupta, G.P.; Kulariya, M. A Framework for Fast and Efficient Cyber Security Network Intrusion Detection Using Apache Spark. Procedia Comput. Sci. 2016, 93, 824–831. [Google Scholar] [CrossRef]
- Jayaratne, M.; Alahakoon, D.; De Silva, D.; Yu, X. Apache Spark Based Distributed Self-Organizing Map Algorithm for Sensor Data Analysis. In Proceedings of the Proceedings IECON 2017-43rd Annual Conference of the IEEE Industrial Electronics Society 2017, Beijing, China, 29 October–1 November 2017; pp. 8343–8349. [Google Scholar] [CrossRef]
- Beyer, K.; Goldstein, J.; Ramakrishnan, R.; Shaft, U. When Is “Nearest Neighbor” Meaningful? In Proceedings of the Database Theory—ICDT’99: 7th International Conference Proceedings 7, Jerusalem, Israel, 10 January 1999; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1540, pp. 217–235. [Google Scholar]
- Zhang, T.; Wang, X.; Li, Z.; Guo, F.; Ma, Y.; Chen, W. A Survey of Network Anomaly Visualization. Sci. China Inf. Sci. 2017, 60, 1–17. [Google Scholar] [CrossRef]
- Kohonen, T. The Self-Organizing Map. Proc. IEEE 1990, 78, 1464–1480. [Google Scholar] [CrossRef]
- Jayaratne, K.M.C. Multimodal Perceptual Mechanisms for Unsupervised Self-Structuring Artificial Intelligence in Distributed Systems. Doctoral dissertation, La Trobe University, Melbourne, Australia, 2020. [Google Scholar]
- Banković, Z.; Moya, J.M.; Araujo, Á.; Fraga, D.; Vallejo, J.C.; De Goyeneche, J.M. Distributed Intrusion Detection System for Wireless Sensor Networks Based on a Reputation System Coupled with Kernel Self-Organizing Maps. Integr. Comput.-Aided Eng. 2010, 17, 87–102. [Google Scholar] [CrossRef]
- Sammon, J.W. A Nonlinear Mapping for Data Structure Analysis. IEEE Trans. Comput. 1969, C-18, 401–409. [Google Scholar] [CrossRef]
- Yin, S.; Li, H.; Sun, Y.; Ibrar, M.; Teng, L. Data Visualization Analysis Based on Explainable Artificial Intelligence: A Survey. IJLAI Trans. Sci. Eng. 2024, 2, 13–20. [Google Scholar]
- Chatti, M.A.; Guesmi, M.; Muslim, A. Visualization for Recommendation Explainability: A Survey and New Perspectives. ACM Trans. Interact. Intell. Syst. 2024, 14, 1–40. [Google Scholar] [CrossRef]
- Ables, J.; Kirby, T.; Anderson, W.; Mittal, S.; Rahimi, S.; Banicescu, I.; Seale, M. Creating an Explainable Intrusion Detection System Using Self Organizing Maps. In Proceedings of the 2022 IEEE Symposium Series on Computational Intelligence, SSCI 2022, Singapore, 4–7 December 2022; pp. 404–412. [Google Scholar] [CrossRef]
- Kirby, T.M.; Rahimi, S.; Mittal, S.; Banicescu, I.; Perkins, A.; Jankun-Kelly, T.J.; Keith, J.M. Pruning GHSOM to Create an Explainable Intrusion Detection System. Master Thesis, Mississippi State University, Starkville, MS, USA, 2023. [Google Scholar]
- Wickramasinghe, C.S.; Amarasinghe, K.; Marino, D.L.; Rieger, C.; Manic, M. Explainable Unsupervised Machine Learning for Cyber-Physical Systems. IEEE Access 2021, 9, 131824–131843. [Google Scholar] [CrossRef]
- Mahbooba, B.; Timilsina, M.; Sahal, R.; Serrano, M. Explainable Artificial Intelligence (XAI) to Enhance Trust Management in Intrusion Detection Systems Using Decision Tree Model. Complexity 2021, 2021, 6634811. [Google Scholar] [CrossRef]
- Lippmann, R.P.; Fried, D.J.; Graf, I.; Haines, J.W.; Kendall, K.R.; McClung, D.; Weber, D.; Webster, S.E.; Wyschogrod, D.; Cunningham, R.K.; et al. Evaluating Intrusion Detection Systems: The 1998 DARPA off-Line Intrusion Detection Evaluation. In Proceedings of the Proceedings-DARPA Information Survivability Conference and Exposition, DISCEX 2000, Hilton Head, SC, USA, 25–27 January 2000; Volume 2, pp. 12–26. [Google Scholar] [CrossRef]
- Ingre, B.; Yadav, A. Performance Analysis of NSL-KDD Dataset Using ANN. In Proceedings of the International Conference on Signal Processing and Communication Engineering Systems-Proceedings of SPACES 2015, in Association with IEEE, Guntur, India, 2–3 January 2015; pp. 92–96. [Google Scholar] [CrossRef]
- Özgür Corresp, A.; Erdem, H.; OzgürOzg, A. The Impact of Using Large Training Data Set KDD99 on Classification Accuracy. PeerJ Prepr. 2017, 5, e2838. [Google Scholar] [CrossRef]
- Bedi, P.; Gupta, N.; Jindal, V. Siam-IDS: Handling Class Imbalance Problem in Intrusion Detection Systems Using Siamese Neural Network. Procedia Comput. Sci. 2020, 171, 780–789. [Google Scholar] [CrossRef]
- Bedi, P.; Gupta, N.; Jindal, V. I-SiamIDS: An Improved Siam-IDS for Handling Class Imbalance in Network-Based Intrusion Detection Systems. Appl. Intell. 2021, 51, 1133–1151. [Google Scholar] [CrossRef]
- Su, T.; Sun, H.; Zhu, J.; Wang, S.; Li, Y. BAT: Deep Learning Methods on Network Intrusion Detection Using NSL-KDD Dataset. IEEE Access 2020, 8, 29575–29585. [Google Scholar] [CrossRef]
- Yin, C.; Zhu, Y.; Fei, J.; He, X. A Deep Learning Approach for Intrusion Detection Using Recurrent Neural Networks. IEEE Access 2017, 5, 21954–21961. [Google Scholar] [CrossRef]
- Ding, Y.; Zhai, Y. Intrusion Detection System for NSL-KDD Dataset Using Convolutional Neural Networks. ACM Int. Conf. Proceeding Ser. 2018, 2, 81–85. [Google Scholar] [CrossRef]
- Kempitiya, T.; Alahakoon, D.; Osipov, E.; Kahawala, S.; De Silva, D. A Two-Layer Self-Organizing Map with Vector Symbolic Architecture for Spatiotemporal Sequence Learning and Prediction. Biomimetics 2024, 9, 175. [Google Scholar] [CrossRef]
- Nallaperuma, D.; Nawaratne, R.; Bandaragoda, T.; Adikari, A.; Nguyen, S.; Kempitiya, T.; De Silva, D.; Alahakoon, D.; Pothuhera, D. Online Incremental Machine Learning Platform for Big Data-Driven Smart Traffic Management. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4679–4690. [Google Scholar] [CrossRef]


| Types | Training Dataset | Testing Dataset |
|---|---|---|
| smurf. | 2,807,886 | 164,091 |
| neptune. | 1,072,017 | 58,001 |
| normal. | 972,781 | 60,591 |
| satan. | 15,892 | 1633 |
| ipsweep. | 12,481 | 306 |
| portsweep. | 10,413 | 354 |
| Nmap. | 2316 | 84 |
| back. | 2203 | 1098 |
| Wareclient. | 1020 | 0 |
| teardrop. | 979 | 12 |
| pod. | 264 | 87 |
| guess_passwd. | 53 | 4367 |
| buffer_overflow. | 30 | 22 |
| land. | 21 | 9 |
| warezmaster. | 20 | 1602 |
| imap. | 12 | 1 |
| rootkit. | 10 | 13 |
| loadmodule. | 9 | 2 |
| ftp_write. | 8 | 3 |
| multihop. | 7 | 18 |
| phf. | 4 | 2 |
| perl. | 3 | 2 |
| spy | 2 | 0 |
| Max Count Approach | Hierarchical Approach with Logistic Regression | Hierarchical Approach with Decision Tree | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Types | Accuracy | False Positive Rate | Detection Rate | Accuracy | False Positive Rate | Detection Rate | Accuracy | False Positive Rate | Detection Rate |
| smurf | 0.9998 | 0.0003 | 0.9999 | 0.9998 | 0.0002 | 0.9999 | 0.9996 | 0.0008 | 0.9999 |
| neptune | 0.9876 | 0.0136 | 0.9926 | 0.9990 | 0.0001 | 0.9951 | 0.9985 | 0.0001 | 0.9926 |
| normal | 0.9857 | 0.0169 | 0.9954 | 0.9718 | 0.0315 | 0.9844 | 0.9665 | 0.0286 | 0.9478 |
| satan | 0.9986 | 0.0004 | 0.8212 | 0.9966 | 0.0027 | 0.8732 | 0.9963 | 0.0027 | 0.8273 |
| ipsweep | 0.9999 | 0.0000 | 0.9706 | 0.9999 | 0.0 | 0.9706 | 0.9999 | 0.0000 | 0.9706 |
| portsweep | 0.9982 | 0.0017 | 0.8927 | 0.9990 | 0.0009 | 0.9492 | 0.9984 | 0.0015 | 0.9463 |
| nmap | 1.0 | 0.0 | 1.0 | 0.9997 | 0.0003 | 1.0000 | 0.9998 | 0.0002 | 1.0000 |
| back | 0.9976 | 0.0 | 0.3798 | 0.9965 | 0.0 | 0.0729 | 0.9916 | 0.0074 | 0.7359 |
| teardrop | 0.9999 | 0.0001 | 0.6667 | 0.9999 | 0.0001 | 0.6667 | 0.9999 | 0.0001 | 0.8333 |
| pod | 0.9999 | 0.0 | 0.7471 | 0.9999 | 0.0001 | 0.8851 | 0.9999 | 0.0001 | 0.8966 |
| guess_passwd | 0.9851 | 0.0 | 0.0 | 0.9851 | 0.0 | 0.0 | 0.9851 | 0.0 | 0.0 |
| buffer_overflow | 0.9999 | 0.0 | 0.0 | 0.9999 | 0.0 | 0.0 | 0.9999 | 0.0 | 0.0 |
| land | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| warezmaster | 0.9945 | 0.0 | 0.0 | 0.9945 | 0.0 | 0.0 | 0.9945 | 0.0 | 0.0 |
| imap | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| rootkit | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| loadmodule | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| ftp_write | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| multihop | 0.9999 | 0.0 | 0.0 | 0.9999 | 0.0 | 0.0 | 0.9999 | 0.0 | 0.0 |
| phf | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| perl | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| Max Count Approach | Hierarchical Approach with Logistic Regression | Hierarchical Approach with Decision Tree | |
|---|---|---|---|
| Accuracy | 0.9733 | 0.9707 | 0.9654 |
| Normal | DoS | Probe | R2L | U2R | ||
|---|---|---|---|---|---|---|
| Max Count Approach | Detection Rate | 0.97 | 0.8 | 0.67 | 0.07 | 0 |
| False Positive Rate | 0.35 | 0.03 | 0.02 | 0 | 0 | |
| Accuracy | 0.79 | 0.91 | 0.95 | 0.88 | 1 | |
| Hierarchical Approach with Logistic Regression | Detection Rate | 0.94 | 0.83 | 0.71 | 0.44 | 0.64 |
| False Positive Rate | 0.23 | 0.01 | 0.02 | 0.03 | 0.01 | |
| Accuracy | 0.84 | 0.93 | 0.95 | 0.91 | 0.99 | |
| Hierarchical Approach with Decision Tree | Detection Rate | 0.94 | 0.83 | 0.77 | 0.48 | 0.58 |
| False Positive Rate | 0.21 | 0.01 | 0.02 | 0.03 | 0 | |
| Accuracy | 0.86 | 0.93 | 0.96 | 0.91 | 0.99 |
| Max Count Approach | Hierarchical Approach with Logistic Regression | Hierarchical Approach with Decision Tree | |
|---|---|---|---|
| Accuracy | 0.7638 | 0.8263 | 0.8154 |
| Normal | DoS | Probe | R2L | U2R | ||
|---|---|---|---|---|---|---|
| Our Max Count Approach | Detection rate | 0.97 | 0.8 | 0.67 | 0.07 | 0 |
| Our Hierarchical Approach with Logistic Regression | Detection rate | 0.94 | 0.83 | 0.71 | 0.44 | 0.64 |
| Our Hierarchical Approach with Decision Tree | Detection rate | 0.94 | 0.83 | 0.77 | 0.48 | 0.58 |
| BAT-MC [58] | Detection rate | 0.97. | 0.87 | 0.85 | 0.44 | 0.21 |
| DNN [57] | Detection rate | 0.97 | 0.76 | 0.62 | 0.04 | 0.25 |
| CNN [57] | Detection rate | 0.97 | 0.85 | 0.50 | 0.10 | 0.22 |
| XGBoost [57] | Detection rate | 0.97 | 0.84 | 0.51 | 0.09 | 0.02 |
| RNN [59] | Detection rate | 0.96 | 0.83 | 0.83 | 0.25 | 0.12 |
| LSTM [60] | Detection rate | 0.93 | 0.73 | 0.67 | 0.06 | 0 |
| SiamIDS [56] | Detection rate | 0.94 | 0.80 | 0.57 | 0.25 | 0.49 |
| I-SiamIDS [57] | Detection rate | 0.89 | 0.86 | 0.77 | 0.32 | 0.50 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Nguyen, S.; Kempitiya, T.; Alahakoon, D. A Hierarchical Machine Learning Method for Detection and Visualization of Network Intrusions from Big Data. Technologies 2024, 12, 204. https://doi.org/10.3390/technologies12100204
Wu J, Nguyen S, Kempitiya T, Alahakoon D. A Hierarchical Machine Learning Method for Detection and Visualization of Network Intrusions from Big Data. Technologies. 2024; 12(10):204. https://doi.org/10.3390/technologies12100204
Chicago/Turabian StyleWu, Jinrong, Su Nguyen, Thimal Kempitiya, and Damminda Alahakoon. 2024. "A Hierarchical Machine Learning Method for Detection and Visualization of Network Intrusions from Big Data" Technologies 12, no. 10: 204. https://doi.org/10.3390/technologies12100204
APA StyleWu, J., Nguyen, S., Kempitiya, T., & Alahakoon, D. (2024). A Hierarchical Machine Learning Method for Detection and Visualization of Network Intrusions from Big Data. Technologies, 12(10), 204. https://doi.org/10.3390/technologies12100204