
A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision





Abstract
1. Introduction
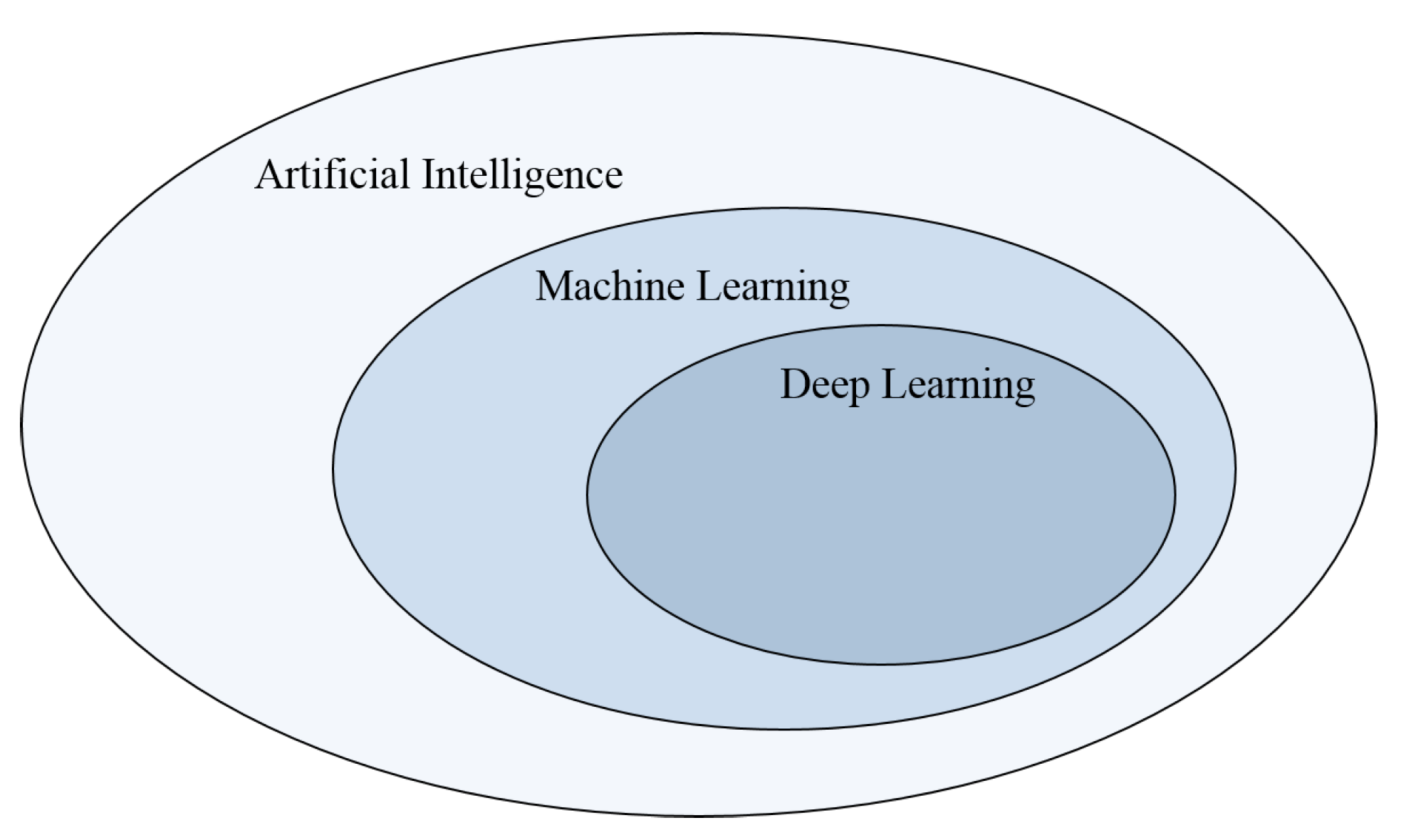
2. Machine Learning/Deep Learning Algorithms
2.1. Machine Learning
2.2. Deep Learning
2.3. Vision Applications Using Deep Learning Methods
- Image Recognition and Classification: Deep learning, especially convolutional neural networks (CNNs), excels in tasks like image classification, object recognition, facial recognition, and medical image analysis [4].
- Autonomous Vehicles: Deep learning, particularly CNNs, plays a crucial role in perception tasks for autonomous vehicles, enabling object detection, segmentation, and recognition [5].
- Medical Image Analysis: Deep learning, especially CNNs, is applied in tasks such as tumor detection, pathology recognition, and organ segmentation in medical image analysis [6].
- Generative Modeling: Generative models like GANs and VAEs are used for image synthesis, style transfer, and the generation of realistic data samples [7].
- Reinforcement Learning: Deep reinforcement learning successfully trains agents for game playing, robotic control, and optimizing complex systems through interaction with the environment [8].
- Human Activity Recognition: Deep learning models, especially RNNs and 3D CNNs, recognize and classify human activities from video or sensor data, with applications in healthcare, surveillance, and sports analytics [9].
3. Object Detection, Semantic Segmentation, and Human Action Recognition Methods
3.1. Image Preprocessing


3.2. Image Segmentation
3.2.1. Feature Extraction
3.2.2. Image Classification
- Naive Bayes classifier;
- Decision trees;
- Random forests;
- Neural networks;
- Nearest neighbor or k-means.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Mathematical Method | Application in Image Classification |
|---|---|
| Linear algebra [43] | Vectors and matrices: represent images and perform matrix operations for pixel manipulation. |
| Eigenvalue decomposition: dimensionality reduction (e.g., PCA, SVD). | |
| Statistics [44] | Probability and statistics: model feature distributions, probabilistic models (e.g., Naive Bayes, Gaussian Mixture Models). |
| Calculus [45] | Gradient descent: Optimization during machine learning model training. |
| Machine learning algorithms [46] | Support vector machine (SVM): Finds hyperplanes in feature space. |
| Decision trees and random forests: use mathematical decision rules for classification. | |
| Neural networks [47] | Backpropagation: updates weights during neural network training. |
| Activation functions: introduce non-linearity in neural networks. | |
| Signal processing [48] | Fourier transform: extracts features in the frequency domain. |
| Wavelet transform: captures high- and low-frequency components. | |
| Distance metrics [49] | Euclidean distance: measures similarity between feature vectors. |
| Mahalanobis distance: considers correlations between features. |
3.2.3. Object Detection
3.2.4. Object Tracking
3.3. Human Action Recognition
3.4. Semantic Segmentation
3.5. Automatic Feature Extraction
- Preprocessing:Image Enhancement.Methods like histogram equalization and noise reduction improve image quality, aiding neural networks in extracting meaningful features.
- Feature Extraction:
- Traditional Techniques: Edge and corner detection and texture analysis extract relevant features, capturing crucial visual information.
- Deep Learning-Based Techniques: Convolutional neural networks (CNNs) learn hierarchical features directly from raw pixel data, covering both low-level and high-level features.
- Data Augmentation: Automatic feature extraction is integrated into data augmentation, applying techniques like rotation and scaling to diversify the training dataset.
- Hybrid Models: Hybrid models combine traditional computer vision methods with neural networks, leveraging the strengths of both for feature extraction and classification.
- Transfer Learning: Pre-trained neural networks, especially in computer vision tasks, can be fine-tuned for specific robotic vision tasks, saving training time and resources.
- Object Detection and Recognition: Automatic feature extraction contributes to object detection, as seen in region-based CNNs (R-CNNs) using region proposal networks and subsequent feature extraction for classification.
- Semantic Segmentation: In tasks like semantic segmentation, automatic feature extraction aids the neural network in understanding context and spatial relationships within an image.
4. Robotic Vision Methods
4.1. Pattern Recognition—Object Classification
4.2. Mathematical Foundations of Deep Learning Methods in Robotic Vision
4.2.1. Convolutional Neural Networks (CNNs)
- Convolution Operation: The convolution operation in CNNs involves the element-wise multiplication of a filter (kernel) with a portion of the input image, followed by summing the results to produce an output feature map. Mathematically, it can be represented as:where I is the input image, K is the convolutional kernel, represents the spatial position in the output feature map, and iterates over the kernel dimensions.
- Activation Functions: Activation functions, such as the Rectified Linear Unit (ReLU), introduce non-linearity into the network. The ReLU function is defined as:and is applied to the output of the convolutional and fully connected layers.
- Pooling: Pooling layers reduce the spatial dimensions of feature maps. Max pooling, for example, retains the maximum value in a specified window. Mathematically, it can be represented as:where P is the pooled output and is the input.
- Fully Connected Layers: In the final layers of a CNN, fully connected layers perform traditional neural network operations. A fully connected layer computes the weighted sum of all inputs and passes it through an activation function, often a softmax, for classification tasks.
- Backpropagation: The training of CNNs relies on backpropagation, a mathematical process for adjusting network weights and biases to minimize a loss function. This process involves the chain rule to compute gradients and update model parameters.
4.2.2. Recurrent Neural Networks (RNNs)
4.2.3. Reinforcement Neural Networks (RNNs)
4.2.4. Generative Adversarial Networks (GANs)
4.2.5. Long Short-Term Memory (LSTM)
4.3. Combining Approaches for Robotic Vision
- Using CNNs for initial image feature extraction to identify objects and their positions.
- Integrating RNNs to process temporal data and track object movement and trajectories over time.
- Implementing GANs to generate synthetic data for training in various environments and conditions.
- Employing LSTMs to remember past states and recognize long-term patterns in robot actions and sensor data.
4.4. Big Data, Federated Learning, and Vision
4.4.1. Big Data
4.4.2. Federated Learning
5. Hubel and Wiesel’s Electrophysiological Insights, Van Essen’s Map of the Brain, and Their Impact on Robotic Vision
5.1. Hubel and Wiesel’s Contribution
5.2. Van Essen’s Functional Mapping of the Brain
6. Discussion
Challenges and Limitations
7. Conclusions
- Improved object detection: Overcoming challenges with small or occluded objects.
- Real-time 3D reconstruction: Creating 3D models of environments in real time.
- Automated image labeling: Automatically tagging images with descriptive and accurate labels.
- Visual reasoning and understanding: Developing algorithms that can reason and make decisions based on visual input.
- Robustness to adversarial attacks: Creating computer vision models that are robust to adversarial attacks, suitable for security applications, and capable of preventing image manipulation.
- Integration with other technologies: Finding new ways to integrate computer vision with other technologies, such as robotics, virtual reality, and augmented reality.
- Improved facial recognition: Developing more accurate and reliable methods for facial recognition that can be used in security and identification applications.
- More efficient deep learning models: Developing deep learning models that require less computation and can run faster on mobile devices.
- Enhanced video analysis: Improving the ability of computer vision to analyze video data, including object tracking and activity recognition.
- Expanding applications: Finding new and innovative ways to apply computer vision technology in fields such as healthcare, agriculture, and transportation.
- Detection of hidden/camouflaged objects, with applications in surveillance and biology.
- A challenging task will be the detection of objects that are intentionally designed to blend into their environments, like camouflaged ones [184]. This will be especially interesting in monitoring natural environments but also has potential in military applications.
- Finally, emergency rescue missions would be a highly impactful application to consider [188].
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
| Method | Performance and Advantages | Disadvantages and Limitations | Complexities |
|---|---|---|---|
| Deep learning (CNNs and RNNs) [9,61,62,63,64,65,66,67,68,69,70,71,72] | High accuracy in human action recognition. Comprehensive solution with spatial and temporal modeling. End-to-end learning enhances accuracy. Transfer learning improves performance. Robustness to variations. | Requires large labeled datasets. Computational complexity. “Black-box” nature. Prone to overfitting. Difficulty in capturing long-term dependencies. | Designing effective architectures. Hyperparameter tuning. Integration of modalities. Real-time processing. Adapting to dynamic environments. |
| Attention-based LSTM [73] | Selective feature attention. Enhanced discriminative power. Beneficial for sequential data. Multi-stream integration. Robust feature extraction. | Computational complexity. Limited generalization. Reduced interpretability. | Designing effective architectures. Hyperparameter tuning. Addressing convergence challenges. Integrating saliency information. Handling temporal misalignments. |
| Hybrid deep learning model [74] | Combined strengths for improved action recognition. Enhanced accuracy and generalization. Effective in capturing spatial and temporal features. Potential for end-to-end learning. | Complexity in architecture design. Increased computational requirements. Potential interpretability challenges. | Balancing architecture complexity. Hyperparameter tuning. Handling data variability. |
| Utilization of multiple models [75] | Captures global and local motion features. Improved accuracy through diversified learning. Potential for handling complex actions. | Increased computational demands. Model integration challenges. Complexity in handling diverse motion patterns. | Coordinating multiple models. Addressing computational efficiency. Handling variations in action patterns. |
| Utilization of RGB frames, Bi-LSTM, and CNN [76] | Leverages RGB frames for visual information. Bi-LSTM captures temporal dependencies. CNN extracts spatial features. Comprehensive approach for accurate action recognition. | Requires labeled RGB frame data. Challenges in handling long-term dependencies. Computational complexity with multiple components. | Integrating RGB frames, Bi-LSTM, and CNN. Optimal parameter tuning for each component. Addressing computational demands. |
| Novel hybrid architecture [77] | Combines knowledge from four pre-trained network models. Leverages pre-trained models for feature extraction. Potential for improved accuracy through model fusion. | Dependence on availability of pre-trained models. Challenges in model fusion and coordination. Interpretability may be compromised. | Integrating outputs from multiple pre-trained models. Handling domain shifts between pre-trained models. Addressing interpretability challenges. |
| Temporal-spatial mapping operation [78] | Utilizes temporal-spatial mapping for capturing intricate action patterns. Effective in handling spatial and temporal dynamics. Potential for improved accuracy in recognizing complex actions. | Computational demands for mapping operations. Models interpretability challenges. Dependence on effective mapping algorithms. | Designing and optimizing temporal-spatial mapping operations. Addressing computational complexity through efficient algorithms. Ensuring model interpretability through transparent mapping. |
| Image-based HAR through transfer learning [79] | Applies transfer learning for leveraging pre-existing image-based models. Reduces the need for extensive labeled data. Potential for improved accuracy through knowledge transfer. | Limited by the quality and diversity of pre-existing models. Challenges in transferring knowledge across different domains. May require additional adaptation for specific tasks. | Ensuring effective transfer of knowledge. Addressing domain-specific challenges in transfer learning. Fine-tuning for optimal performance in target tasks. |
| Cooperative approach for feature selection [80] | Cooperative approach for effective feature selection. Utilizes collaboration for identifying relevant features. Potential for enhanced accuracy through feature synergy. | Coordination challenges in cooperative feature selection. Dependence on effective collaboration mechanisms. May require additional computational resources. | Designing and implementing effective cooperative feature selection mechanisms. Addressing coordination challenges in a cooperative approach. Ensuring scalability and efficiency in the feature selection process. |
Appendix B
| Method | Performance and Advantages | Disadvantages/Limitations | Complexities |
|---|---|---|---|
| Identification of fundamental computer vision problems [12,81,82,83,84,85] | Establish a foundation for computer vision tasks. Address image classification, object detection, and segmentation. | Assume a clear understanding of the identified problems. May oversimplify the challenges faced by each problem. | Defining problem-specific criteria for identification. Ensuring a comprehensive understanding of each identified problem. |
| Semantic segmentation with CNNs [86,87,88,89,90,91,92] | Deep learning, particularly CNNs, significantly enhances semantic segmentation. Assign labels to every pixel in an image. | Require large labeled datasets for effective training. Computational complexity, especially with deep networks. | Leveraging pre-trained CNNs for transfer learning. Addressing challenges in dataset acquisition and annotation. |
| Semantic segmentation architectures [50,63,86,87,90,91,92,97,98,99,100,101,102,103,104,105,106,107] | Describe components of semantic segmentation architectures. Introduce three main approaches: region-based, FCN-based, and weakly supervised. | Variability in performance across different architectures. Difficulty in choosing the most suitable approach for a given task. | Understanding the components and trade-offs of each architecture. Task-specific evaluation to select the most appropriate approach. |
| Semantic segmentation in medical image analysis with DCNNs [108,109,110] | Focus on semantic segmentation in medical image analysis. Highlight the use of deep convolutional neural networks (DCNNs) in this context. | Limited availability of labeled medical imaging datasets. Ethical considerations and privacy concerns in medical data usage. | Developing strategies for obtaining or generating labeled medical datasets. Adhering to ethical guidelines and regulations in medical image analysis. |
Appendix C
| Method | Performance and Advantages | Disadvantages and Limitations | Complexities |
|---|---|---|---|
| Hubel and Wiesel’s electrophysiological studies [156,157,158,159] | Connect neuroscience, artificial neural networks (ANNs), and computer vision. | Limited to the understanding provided by electrophysiological studies. | Integrating findings from neuroscience into ANNs and computer vision. |
| Works building upon Hubel and Wiesel’s work [160,161,162,163] | Explore VLSI binocular vision systems, practical vergence eye control systems, hierarchical machine vision systems, and visual mechanisms. | Require expertise in various domains (VLSI design, eye control, machine vision). Practical implementation challenges in building complex systems. | Collaborating across multidisciplinary fields. Overcoming technical challenges in system design and integration. |
| Exploring cognitive neuroscience [164] | Merges psychology and neurobiology, with a focus on memory, perception, action, language, and awareness. | Complexity in studying and understanding cognitive processes. Interdisciplinary nature may result in varied perspectives. | Developing models that bridge psychological and neurobiological concepts. Ensuring a holistic understanding of cognitive processes. |
| Human visual cortex processing [165,166] | Explore how the human visual cortex processes complex stimuli. Reveal distinct regions for object recognition, letters, and face processing. Investigate challenges faced by individuals with autism in recognizing faces. | Limited to observational and correlational findings. Ethical considerations in studying neurological conditions. | Developing interventions based on understanding neural processing. Adhering to ethical guidelines in neuroscience research. |
| Machine learning methods for classifying autism [167,168,169,170,171,172,173,174,175,176,177,178,179] | Apply machine learning for classifying autism based on identified neural disruptions. | Rely on the availability of relevant and diverse datasets. Challenges in generalization to diverse populations. | Ensuring representative and unbiased datasets for training. Addressing the complexity of individual variations in autism. |
Appendix D
| Method | Performance and Advantages | Disadvantages and Limitations | Complexities |
|---|---|---|---|
| Cortical areas and connectivity patterns [180] | Outlines cortical areas tied to vision and other senses. Presents a database for connectivity patterns. | Limited to observational and correlational findings. The database may not capture dynamic changes over time. | Enhancing the database to incorporate temporal connectivity patterns. Ensuring accurate mapping of cortical areas for different sensory functions. |
| Surface-based visualization for functional specialization [181] | Explores surface-based visualization for mapping the cerebral cortex’s functional specialization. | Interpretation challenges in surface-based visualization. Limited to the visible cortex surface, potentially missing deeper structures. | Developing advanced visualization techniques for deeper structures. Validating functional specialization findings through complementary methods. |
| Brain activation–deactivation balance [182] | Reveals the brain’s activation–deactivation balance during tasks. Showcases ongoing brain organization and the impact of neural fluctuations on function. | Challenges in precisely quantifying activation–deactivation balance. Limited to the understanding provided by observational studies. | Developing quantitative measures for activation–deactivation balance. Integrating findings with computational models to understand neural dynamics. |
| Comprehensive map of human cerebral cortex [183] | Presents a comprehensive map of the human cerebral cortex’s divisions. Identifies new areas and develops a machine learning classifier for automated identification. | Limited by the quality and diversity of available datasets. Challenges in interpreting the functional significance of newly identified areas. | Ensuring diversity and representativeness in dataset collection. Collaborating with neuroscientists to validate functional roles of newly identified areas. |
References
- Bayoudh, K.; Knani, R.; Hamdaoui, F.; Mtibaa, A. A survey on deep multimodal learning for computer vision: Advances, trends, applications, and datasets. Vis. Comput. 2021, 38, 2939–2970. [Google Scholar] [CrossRef] [PubMed]
- Robinson, N.; Tidd, B.; Campbell, D.; Kulić, D.; Corke, P. Robotic Vision for Human-Robot Interaction and Collaboration: A Survey and Systematic Review. ACM Trans. Hum.-Robot. Interact. 2023, 12, 1–66. [Google Scholar] [CrossRef]
- Anthony, E.J.; Kusnadi, R.A. Computer Vision for Supporting Visually Impaired People: A Systematic Review. Eng. Math. Comput. Sci. (Emacs) J. 2021, 3, 65–71. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Anpalagan, A.; Guan, L.; Khwaja, A.S. Deep Learning for Object Detection and Scene Perception in Self-Driving Cars: Survey, Challenges, and Open Issues. Array 2021, 10, 100057. [Google Scholar] [CrossRef]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Sánchez, C.I. A Survey on Deep Learning in Medical Image Analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Huang, H.; Yu, P.S.; Wang, C. An Introduction to Image Synthesis with Generative Adversarial Nets. arXiv 2018, arXiv:1803.04469. [Google Scholar]
- Ibarz, J.; Tan, J.; Finn, C.; Kalakrishnan, M.; Pastor, P.; Levine, S. How to Train Your Robot with Deep Reinforcement Learning: Lessons We Have Learned. Int. J. Robot. Res. 2021, 40, 698–721. [Google Scholar] [CrossRef]
- Ganesh, D.; Teja, R.R.; Reddy, C.D.; Swathi, D. Human Action Recognition based on Depth maps, Skeleton and Sensor Images using Deep Learning. In Proceedings of the 2022 IEEE 3rd Global Conference for Advancement in Technology (GCAT), Bangalore, India, 7–9 October 2022. [Google Scholar] [CrossRef]
- Wu, D.; Sharma, N.; Blumenstein, M. Recent advances in video-based human action recognition using deep learning: A review. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 2865–2872. [Google Scholar]
- Chen, K.; Zhang, D.; Yao, L.; Guo, B.; Yu, Z.; Liu, Y. Deep learning for sensor-based human activity recognition: Overview, challenges, and opportunities. Acm Comput. Surv. (Csur) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. arXiv 2017, arXiv:1703.06870. [Google Scholar]
- Jin, L.; Zhu, Z.; Song, E.; Xu, X. An Effective Vector Filter for Impulse Noise Reduction Based on Adaptive Quaternion Color Distance Mechanism. Signal Process. 2019, 155, 334–345. [Google Scholar] [CrossRef]
- Chernov, V.; Alander, J.; Bochko, V. Integer-Based Accurate Conversion between RGB and HSV Color Spaces. Comput. Electr. Eng. 2015, 46, 328–337. [Google Scholar] [CrossRef]
- Tsapatsoulis, N. Digital Image Processing Lecture Notes. 2023. Available online: https://www.studocu.com/in/document/jawaharlal-nehru-technological-university-hyderabad/ece/digital-image-processing-lecture-notes-2022-2023/56139343 (accessed on 10 March 2023).
- Arunpandian, M.; Arunprasath, T.; Vishnuvarthanan, G.; Rajasekaran, M.P. Thresholding Based Soil Feature Extraction from Digital Image Samples–A Vision Towards Smarter Agrology. In Information and Communication Technology for Intelligent Systems (ICTIS 2017)-Volume 1; Springer: Berlin/Heidelberg, Germany, 2018; pp. 458–465. [Google Scholar]
- Kolkur, S.; Kalbande, D.; Shimpi, P.; Bapat, C.; Jatakia, J. Human Skin Detection Using RGB, HSV and YCbCr Color Models. arXiv 2017, arXiv:1708.02694. [Google Scholar]
- BlackIce. HSI Color Conversion—Imaging Toolkit Feature. 2023. Available online: https://www.blackice.com/colorspaceHSI.htm (accessed on 10 March 2023).
- Feng, X.; Jiang, Y.; Yang, X.; Du, M.; Li, X. Computer vision algorithms and hardware implementations: A survey. Integration 2019, 69, 309–320. [Google Scholar] [CrossRef]
- Boykov, Y.; Funka-Lea, G. Graph Cuts and Efficient ND Image Segmentation. Int. J. Comput. Vis. 2006, 70, 109–131. [Google Scholar] [CrossRef]
- Pizurica, A.; Philips, W.; Lemahieu, I.; Acheroy, M. A Joint Inter-and Intrascale Statistical Model for Bayesian Wavelet Based Image Denoising. IEEE Trans. Image Process. 2002, 11, 545–557. [Google Scholar] [CrossRef] [PubMed]
- Shi, X.; Li, Y.; Zhao, Q. Flexible Hierarchical Gaussian Mixture Model for High-Resolution Remote Sensing Image Segmentation. Remote Sens. 2020, 12, 1219. [Google Scholar] [CrossRef]
- Wang, X.F.; Huang, D.S.; Xu, H. An Efficient Local Chan–Vese Model for Image Segmentation. Pattern Recognit. 2010, 43, 603–618. [Google Scholar] [CrossRef]
- Bresson, X.; Esedoḡlu, S.; Vandergheynst, P.; Thiran, J.P.; Osher, S. Fast Global Minimization of the Active Contour/Snake Model. J. Math. Imaging Vis. 2007, 28, 151–167. [Google Scholar] [CrossRef]
- Aytaç, E. Unsupervised Learning Approach in Defining the Similarity of Catchments: Hydrological Response Unit Based k-Means Clustering, a Demonstration on Western Black Sea Region of Turkey. Int. Soil Water Conserv. Res. 2020, 8, 321–331. [Google Scholar] [CrossRef]
- Xu, K.; Qin, M.; Sun, F.; Wang, Y.; Chen, Y.K.; Ren, F. Learning in the Frequency Domain. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1740–1749. [Google Scholar]
- Dubes, R.C.; Jain, A.K.; Nadabar, S.G.; Chen, C.C. MRF Model-Based Algorithms for Image Segmentation. In Proceedings of the 10th International Conference on Pattern Recognition, Atlantic City, NJ, USA, 16–21 June 1990; Volume 1, pp. 808–814. [Google Scholar]
- Bleau, A.; Leon, L.J. Watershed-Based Segmentation and Region Merging. Comput. Vis. Image Underst. 2000, 77, 317–370. [Google Scholar] [CrossRef]
- Wu, Z.; Gao, Y.; Li, L.; Xue, J.; Li, Y. Semantic Segmentation of High-Resolution Remote Sensing Images Using Fully Convolutional Network with Adaptive Threshold. Connect. Sci. 2019, 31, 169–184. [Google Scholar] [CrossRef]
- Gout, C.; Le Guyader, C.; Vese, L. Segmentation under Geometrical Conditions Using Geodesic Active Contours and Interpolation Using Level Set Methods. Numer. Algorithms 2005, 39, 155–173. [Google Scholar] [CrossRef]
- Das, P.; Das, A. A Fast and Automated Segmentation Method for Detection of Masses Using Folded Kernel Based Fuzzy C-Means Clustering Algorithm. Appl. Soft Comput. 2019, 85, 105775. [Google Scholar] [CrossRef]
- Ziou, D.; Tabbone, S. Edge Detection Techniques-an Overview. Pattern Recognit. Image Anal. C/C Raspoznavaniye Obraz. Anal. Izobr. 1998, 8, 537–559. [Google Scholar]
- Kurak, C.W., Jr.; McHugh, J. A Cautionary Note on Image Downgrading. In Proceedings of the Annual Computer Security Applications Conference, San Antonio, TX, USA, 30 November–4 December 1992; pp. 153–159. [Google Scholar]
- Hussin, R.; Juhari, M.R.; Kang, N.W.; Ismail, R.C.; Kamarudin, A. Digital Image Processing Techniques for Object Detection from Complex Background Image. Procedia Eng. 2012, 41, 340–344. [Google Scholar] [CrossRef]
- Cruz, D.J.; Amaral, R.L.; Santos, A.D.; Tavares, J.M.R. Application of Digital Image Processing Techniques to Detect Through-Thickness Crack in Hole Expansion Test. Metals 2023, 13, 1197. [Google Scholar] [CrossRef]
- Wang, R.; Lei, T.; Cui, R.; Zhang, B.; Meng, H.; Nandi, A.K. Medical Image Segmentation Using Deep Learning: A Survey. Iet Image Process. 2022, 16, 1243–1267. [Google Scholar] [CrossRef]
- Yadav, S.S.; Jadhav, S.M. Deep Convolutional Neural Network Based Medical Image Classification for Disease Diagnosis. J. Big Data 2019, 6, 113. [Google Scholar] [CrossRef]
- Giuliani, D. Metaheuristic Algorithms Applied to Color Image Segmentation on HSV Space. J. Imaging 2022, 8, 6. [Google Scholar] [CrossRef]
- Mallick, S. Image Recognition and Object Detection: Part 1; Learn OpenCV. 2016. Available online: https://learnopencv.com/image-recognition-and-object-detection-part1/ (accessed on 9 March 2023).
- Xylourgos, N. Segmentation of Ultrasound Images for Finding Anatomical References. Bachelor’s Thesis, Technological Educational Institute of Crete, Heraklion, Greece, 2009. [Google Scholar]
- Nixon, M.; Aguado, A. Feature Extraction and Image Processing for Computer Vision; Academic Press: Cambridge, MA, USA, 2019. [Google Scholar]
- Wang, P.; Fan, E.; Wang, P. Comparative Analysis of Image Classification Algorithms Based on Traditional Machine Learning and Deep Learning. Pattern Recognit. Lett. 2021, 141, 61–67. [Google Scholar] [CrossRef]
- Uddin, M.P.; Mamun, M.A.; Hossain, M.A. PCA-based Feature Reduction for Hyperspectral Remote Sensing Image Classification. Iete Tech. Rev. 2021, 38, 377–396. [Google Scholar] [CrossRef]
- Wan, H.; Wang, H.; Scotney, B.; Liu, J. A Novel Gaussian Mixture Model for Classification. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 3298–3303. [Google Scholar]
- Haji, S.H.; Abdulazeez, A.M. Comparison of Optimization Techniques Based on Gradient Descent Algorithm: A Review. Palarch’s J. Archaeol. Egypt/Egyptol. 2021, 18, 2715–2743. [Google Scholar]
- Chandra, M.A.; Bedi, S.S. Survey on SVM and Their Application in Image Classification. Int. J. Inf. Technol. 2021, 13, 1–11. [Google Scholar] [CrossRef]
- Frenkel, C.; Lefebvre, M.; Bol, D. Learning without Feedback: Fixed Random Learning Signals Allow for Feedforward Training of Deep Neural Networks. Front. Neurosci. 2021, 15, 629892. [Google Scholar] [CrossRef] [PubMed]
- Zhao, X.; Huang, P.; Shu, X. Wavelet-Attention CNN for Image Classification. Multimed. Syst. 2022, 28, 915–924. [Google Scholar] [CrossRef]
- Venkataramanan, A.; Benbihi, A.; Laviale, M.; Pradalier, C. Gaussian Latent Representations for Uncertainty Estimation Using Mahalanobis Distance in Deep Classifiers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Waikoloa, HI, USA, 2–7 January 2023; pp. 4488–4497. [Google Scholar]
- Tong, K.; Wu, Y.; Zhou, F. Recent Advances in Small Object Detection Based on Deep Learning: A Review. Image Vis. Comput. 2020, 97, 103910. [Google Scholar] [CrossRef]
- Barazida, N. YOLOv6: Next Generation Object Detection—Review and Comparison. 2022. Available online: https://www.linkedin.com/posts/dagshub_yolov6-next-generation-object-detection-activity-6947577684583456768-06KJ?trk=public_profile_like_view (accessed on 9 March 2023).
- Zoph, B.; Cubuk, E.D.; Ghiasi, G.; Lin, T.Y.; Shlens, J.; Le, Q.V. Learning Data Augmentation Strategies for Object Detection. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12372, pp. 566–583. [Google Scholar] [CrossRef]
- Masita, K.L.; Hasan, A.N.; Shongwe, T. Deep Learning in Object Detection: A Review. In Proceedings of the 2020 International Conference on Artificial Intelligence, Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2020; pp. 1–11. [Google Scholar]
- Shepley, A.J.; Falzon, G.; Kwan, P.; Brankovic, L. Confluence: A Robust Non-IoU Alternative to Non-Maxima Suppression in Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 11561–11574. [Google Scholar] [CrossRef]
- Zhang, L.; Zhang, Y.; Zhang, Z.; Shen, J.; Wang, H. Real-Time Water Surface Object Detection Based on Improved Faster R-CNN. Sensors 2019, 19, 3523. [Google Scholar] [CrossRef]
- Zhong, F.; Quan, C. Stereo-Rectification and Homography-Transform-Based Stereo Matching Methods for Stereo Digital Image Correlation. Measurement 2021, 173, 108635. [Google Scholar] [CrossRef]
- Jin, S.; Liu, W.; Xie, E.; Wang, W.; Qian, C.; Ouyang, W.; Luo, P. Differentiable Hierarchical Graph Grouping for Multi-person Pose Estimation. In Computer Vision–ECCV 2020; Vedaldi, A., Bischof, H., Brox, T., Frahm, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2020; Volume 12352, pp. 718–734. [Google Scholar] [CrossRef]
- Min, K.; Lee, G.H.; Lee, S.W. Attentional Feature Pyramid Network for Small Object Detection. Neural Netw. 2022, 155, 439–450. [Google Scholar] [CrossRef] [PubMed]
- Ciaparrone, G.; Sánchez, F.L.; Tabik, S.; Troiano, L.; Tagliaferri, R.; Herrera, F. Deep Learning in Video Multi-Object Tracking: A Survey. Neurocomputing 2020, 381, 61–88. [Google Scholar] [CrossRef]
- Mehul. Object Tracking in Videos: Introduction and Common Techniques. 2020. Available online: https://aidetic.in/blog/2020/10/05/object-tracking-in-videos-introduction-and-common-techniques/ (accessed on 11 March 2023).
- Xia, L.; Chen, C.C.; Aggarwal, J.K. View invariant human action recognition using histograms of 3D joints. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Fathi, A.; Mori, G. Action recognition by learning mid-level motion features. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008. [Google Scholar] [CrossRef]
- Huang, C.P.; Hsieh, C.H.; Lai, K.T.; Huang, W.Y. Human Action Recognition Using Histogram of Oriented Gradient of Motion History Image. In Proceedings of the 2011 First International Conference on Instrumentation, Measurement, Computer, Communication and Control, Beijing, China, 21–23 October 2011. [Google Scholar] [CrossRef]
- Chun, S.; Lee, C. Human action recognition using histogram of motion intensity and direction from multiple views. Iet Comput. Vis. 2016, 10, 250–257. [Google Scholar] [CrossRef]
- Hassan, M.; Ahmad, T.; Farooq, A.; Ali, S.A.; hassan, S.R.; Liaqat, N. A Review on Human Actions Recognition Using Vision Based Techniques. J. Image Graph. 2014, 2, 28–32. [Google Scholar] [CrossRef]
- Al-Ali, S.; Milanova, M.; Al-Rizzo, H.; Fox, V.L. Human Action Recognition: Contour-Based and Silhouette-Based Approaches. In Computer Vision in Control Systems-2; Springer International Publishing: Cham, Switzerland, 2014; pp. 11–47. [Google Scholar] [CrossRef]
- Chang, M.J.; Hsieh, J.T.; Fang, C.Y.; Chen, S.W. A Vision-based Human Action Recognition System for Moving Cameras Through Deep Learning. In Proceedings of the 2019 2nd International Conference on Signal Processing and Machine Learning, New York, NY, USA, 27–29 November 2019. [Google Scholar] [CrossRef]
- Chiang, M.L.; Feng, J.K.; Zeng, W.L.; Fang, C.Y.; Chen, S.W. A Vision-Based Human Action Recognition System for Companion Robots and Human Interaction. In Proceedings of the 2018 IEEE 4th International Conference on Computer and Communications (ICCC), Chengdu, China, 7–10 December 2018. [Google Scholar] [CrossRef]
- Hoshino, S.; Niimura, K. Robot Vision System for Real-Time Human Detection and Action Recognition. In Intelligent Autonomous Systems 15; Springer International Publishing: Cham, Switzerland, 2018; pp. 507–519. [Google Scholar] [CrossRef]
- Hoshino, S.; Niimura, K. Robot Vision System for Human Detection and Action Recognition. J. Adv. Comput. Intell. Intell. Inform. 2020, 24, 346–356. [Google Scholar] [CrossRef]
- Chen, Q.; Tang, H.; Cai, J. Human Action Recognition Based on Vision Transformer and L2 Regularization. In Proceedings of the 2022 11th International Conference on Computing and Pattern Recognition, New York, NY, USA, 17–19 November 2022. [Google Scholar] [CrossRef]
- Majumder, S.; Kehtarnavaz, N. Vision and Inertial Sensing Fusion for Human Action Recognition: A Review. IEEE Sens. J. 2021, 21, 2454–2467. [Google Scholar] [CrossRef]
- Dai, C.; Liu, X.; Lai, J. Human Action Recognition Using Two-Stream Attention Based LSTM Networks. Appl. Soft Comput. 2020, 86, 105820. [Google Scholar] [CrossRef]
- Jaouedi, N.; Boujnah, N.; Bouhlel, M.S. A New Hybrid Deep Learning Model for Human Action Recognition. J. King Saud-Univ.-Comput. Inf. Sci. 2020, 32, 447–453. [Google Scholar] [CrossRef]
- Gu, Y.; Ye, X.; Sheng, W.; Ou, Y.; Li, Y. Multiple Stream Deep Learning Model for Human Action Recognition. Image Vis. Comput. 2020, 93, 103818. [Google Scholar] [CrossRef]
- Singh, T.; Vishwakarma, D.K. A Deeply Coupled ConvNet for Human Activity Recognition Using Dynamic and RGB Images. Neural Comput. Appl. 2021, 33, 469–485. [Google Scholar] [CrossRef]
- Yilmaz, A.A.; Guzel, M.S.; Bostanci, E.; Askerzade, I. A Novel Action Recognition Framework Based on Deep-Learning and Genetic Algorithms. IEEE Access 2020, 8, 100631–100644. [Google Scholar] [CrossRef]
- Song, X.; Lan, C.; Zeng, W.; Xing, J.; Sun, X.; Yang, J. Temporal–Spatial Mapping for Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2019, 30, 748–759. [Google Scholar] [CrossRef]
- Chakraborty, S.; Mondal, R.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. Transfer Learning with Fine Tuning for Human Action Recognition from Still Images. Multimed. Tools Appl. 2021, 80, 20547–20578. [Google Scholar] [CrossRef]
- Guha, R.; Khan, A.H.; Singh, P.K.; Sarkar, R.; Bhattacharjee, D. CGA: A New Feature Selection Model for Visual Human Action Recognition. Neural Comput. Appl. 2021, 33, 5267–5286. [Google Scholar] [CrossRef]
- Forch, V.; Hamker, F.H. Recurrent Spatial Attention for Facial Emotion Recognition. In Proceedings of the Workshop Localize IT, Chemnitz Linux-Tage, Chemnitz, Germany, 16–17 March 2019. [Google Scholar]
- Schröder, E.; Braun, S.; Mählisch, M.; Vitay, J.; Hamker, F. Feature Map Transformation for Multi-Sensor Fusion in Object Detection Networks for Autonomous Driving. In Proceedings of the Advances in Computer Vision: Proceedings of the 2019 Computer Vision Conference (CVC), Las Vegas, NV, USA, 25–26 April 2019; pp. 118–131. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on Imagenet Classification. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Region-Based Convolutional Networks for Accurate Object Detection and Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2016, 38, 142–158. [Google Scholar] [CrossRef] [PubMed]
- Lundgren, A.V.A.; dos Santos, M.A.O.; Bezerra, B.L.D.; Bastos-Filho, C.J.A. Systematic Review of Computer Vision Semantic Analysis in Socially Assistive Robotics. AI 2022, 3, 229–249. [Google Scholar] [CrossRef]
- Mo, Y.; Wu, Y.; Yang, X.; Liu, F.; Liao, Y. Review the State-of-the-Art Technologies of Semantic Segmentation Based on Deep Learning. Neurocomputing 2022, 493, 626–646. [Google Scholar] [CrossRef]
- Wei, Y.; Xiao, H.; Shi, H.; Jie, Z.; Feng, J.; Huang, T.S. Revisiting Dilated Convolution: A Simple Approach for Weakly-and Semi-Supervised Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7268–7277. [Google Scholar]
- Zhang, M.; Zhou, Y.; Zhao, J.; Man, Y.; Liu, B.; Yao, R. A Survey of Semi-and Weakly Supervised Semantic Segmentation of Images. Artif. Intell. Rev. 2020, 53, 4259–4288. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs. arXiv 2014, arXiv:1412.7062. [Google Scholar]
- Arbelaez, P.; Hariharan, B.; Gu, C.; Gupta, S.; Bourdev, L.; Malik, J. Semantic Segmentation Using Regions and Parts. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012. [Google Scholar] [CrossRef]
- Tighe, J.; Lazebnik, S. Finding Things: Image Parsing with Regions and Per-Exemplar Detectors. In Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition, Portland, OR, USA, 23–28 June 2013. [Google Scholar] [CrossRef]
- He, Y.; Chiu, W.C.; Keuper, M.; Fritz, M. STD2P: RGBD Semantic Segmentation Using Spatio-Temporal Data-Driven Pooling. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Adamek, T.; O’Connor, N.E.; Murphy, N. Region-Based Segmentation of Images Using Syntactic Visual Features. In Proceedings of the WIAMIS 2005—6th International Workshop on Image Analysis for Multimedia Interactive Services, Montreux, Switzerland, 13–15 April 2005. [Google Scholar]
- Ji, J.; Lu, X.; Luo, M.; Yin, M.; Miao, Q.; Liu, X. Parallel Fully Convolutional Network for Semantic Segmentation. IEEE Access Pract. Innov. Open Solut. 2021, 9, 673–682. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar] [CrossRef]
- Noh, H.; Hong, S.; Han, B. Learning Deconvolution Network for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Dai, J.; He, K.; Sun, J. BoxSup: Exploiting Bounding Boxes to Supervise Convolutional Networks for Semantic Segmentation. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar] [CrossRef]
- Chen, L.; Wu, W.; Fu, C.; Han, X.; Zhang, Y. Weakly Supervised Semantic Segmentation with Boundary Exploration. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 347–362. [Google Scholar]
- Kwak, S.; Hong, S.; Han, B. Weakly Supervised Semantic Segmentation Using Superpixel Pooling Network. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Ouassit, Y.; Ardchir, S.; Yassine El Ghoumari, M.; Azouazi, M. A Brief Survey on Weakly Supervised Semantic Segmentation. Int. J. Online Biomed. Eng. 2022, 18, 83–113. [Google Scholar] [CrossRef]
- Schmitt, M.; Prexl, J.; Ebel, P.; Liebel, L.; Zhu, X.X. Weakly Supervised Semantic Segmentation of Satellite Images for Land Cover Mapping–Challenges and Opportunities. arXiv 2020, arXiv:2002.08254. [Google Scholar] [CrossRef]
- Gama, P.H.T.; Oliveira, H.; dos Santos, J.A.; Cesar, R.M., Jr. An overview on Meta-learning approaches for Few-shot Weakly-supervised Segmentation. Comput. Graph. 2023, 113, 77–88. [Google Scholar] [CrossRef]
- Wang, J.; Ma, Y.; Zhang, L.; Gao, R.X.; Wu, D. Deep learning for smart manufacturing: Methods and applications. J. Manuf. Syst. 2018, 48, 144–156. [Google Scholar] [CrossRef]
- Zhang, D.; Han, J.; Cheng, G.; Yang, M.H. Weakly Supervised Object Localization and Detection: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5866–5885. [Google Scholar] [CrossRef] [PubMed]
- Azzi, Y.; Moussaoui, A.; Kechadi, M.T. Semantic Segmentation of Medical Images with Deep Learning: Overview. Med. Technol. J. 2020, 4, 568–575. [Google Scholar] [CrossRef]
- Singh, R.; Rani, R. Semantic Segmentation using Deep Convolutional Neural Network: A Review. Ssrn Electron. J. 2020, 1, 1–8. [Google Scholar] [CrossRef]
- Ding, H.; Jiang, X.; Shuai, B.; Liu, A.Q.; Wang, G. Semantic Segmentation With Context Encoding and Multi-Path Decoding. IEEE Trans. Image Process. 2020, 29, 3520–3533. [Google Scholar] [CrossRef]
- Miled, M.; Messaoud, M.A.B.; Bouzid, A. Lip reading of words with lip segmentation and deep learning. Multimed. Tools Appl. 2023, 82, 551–571. [Google Scholar] [CrossRef]
- Gianey, H.K.; Khandelwal, P.; Goel, P.; Maheshwari, R.; Galhotra, B.; Singh, D.P. Lip Reading Framework using Deep Learning. In Advances in Data Science and Analytics: Concepts and Paradigms; Scrivener Publishing LLC: Beverly, MA, USA, 2023; pp. 67–87. [Google Scholar]
- Wu, Y.; Wang, D.H.; Lu, X.T.; Yang, F.; Yao, M.; Dong, W.S.; Shi, J.B.; Li, G.Q. Efficient Visual Recognition: A Survey on Recent Advances and Brain-Inspired Methodologies. Mach. Intell. Res. 2022, 19, 366–411. [Google Scholar] [CrossRef]
- Santosh, K.; Hegadi, R. Recent Trends in Image Processing and Pattern Recognition. In Proceedings of the Second International Conference, RTIP2R 2018, Solapur, India, 21–22 December 2018. Revised Selected Papers, Part I; Communications in Computer and Information Science; Springer-Nature: Singapore, 2019. [Google Scholar]
- Liu, H.; Yin, J.; Luo, X.; Zhang, S. Foreword to the Special Issue on Recent Advances on Pattern Recognition and Artificial Intelligence. Neural Comput. Appl. 2018, 29, 1–2. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images; Technical Report; University of Toronto: Toronto, ON, Canada, 2009. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Wang, L.; Huynh, D.Q.; Koniusz, P. A Comparative Review of Recent Kinect-Based Action Recognition Algorithms. IEEE Trans. Image Process. 2019, 29, 15–28. [Google Scholar] [CrossRef] [PubMed]
- Al-Faris, M.; Chiverton, J.; Ndzi, D.; Ahmed, A.I. A Review on Computer Vision-Based Methods for Human Action Recognition. J. Imaging 2020, 6, 46. [Google Scholar] [CrossRef]
- Yu, H.; Yang, Z.; Tan, L.; Wang, Y.; Sun, W.; Sun, M.; Tang, Y. Methods and datasets on semantic segmentation: A review. Neurocomputing 2018, 304, 82–103. [Google Scholar] [CrossRef]
- Guo, Y.; Liu, Y.; Georgiou, T.; Lew, M.S. A review of semantic segmentation using deep neural networks. Int. J. Multimed. Inf. Retr. 2017, 7, 87–93. [Google Scholar] [CrossRef]
- Hao, S.; Zhou, Y.; Guo, Y. A Brief Survey on Semantic Segmentation with Deep Learning. Neurocomputing 2020, 406, 302–321. [Google Scholar] [CrossRef]
- Sanjaya, Y.C.; Gunawan, A.A.S.; Irwansyah, E. Semantic Segmentation for Aerial Images: A Literature Review. Eng. Math. Comput. Sci. (Emacs) J. 2020, 2, 133–139. [Google Scholar] [CrossRef]
- Chen, Y.L.; Cai, Y.R.; Cheng, M.Y. Vision-Based Robotic Object Grasping—A Deep Reinforcement Learning Approach. Machines 2023, 11, 275. [Google Scholar] [CrossRef]
- Yadav, S.P.; Nagar, R.; Shah, S.V. Learning Vision-based Robotic Manipulation Tasks Sequentially in Offline Reinforcement Learning Settings. arXiv 2023, arXiv:2301.13450. [Google Scholar]
- Vuletić, J.; Polić, M.; Orsag, M. Robotic Strawberry Flower Treatment Based on Deep-Learning Vision. In Human-Friendly Robotics 2022; Borja, P., Della Santina, C., Peternel, L., Torta, E., Eds.; Springer International Publishing: Cham, Switzerland, 2023; Volume 26, pp. 189–204. [Google Scholar] [CrossRef]
- Brogan, D.P.; DiFilippo, N.M.; Jouaneh, M.K. Deep Learning Computer Vision for Robotic Disassembly and Servicing Applications. Array 2021, 12, 100094. [Google Scholar] [CrossRef]
- Keerthikeshwar, M.; Anto, S. Deep Learning for Robot Vision. In Intelligent Manufacturing and Energy Sustainability; Reddy, A., Marla, D., Favorskaya, M.N., Satapathy, S.C., Eds.; Springer: Singapore, 2021; Volume 213, pp. 357–365. [Google Scholar] [CrossRef]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected Crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Sun, W.; Wang, R. Fully Convolutional Networks for Semantic Segmentation of Very High Resolution Remotely Sensed Images Combined With DSM. IEEE Geosci. Remote Sens. Lett. 2018, 15, 474–478. [Google Scholar] [CrossRef]
- Browne, M.; Ghidary, S.S. Convolutional Neural Networks for Image Processing: An Application in Robot Vision. In AI 2003: Advances in Artificial Intelligence; Goos, G., Hartmanis, J., Van Leeuwen, J., Gedeon, T.D., Fung, L.C.C., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; Volume 2903, pp. 641–652. [Google Scholar] [CrossRef]
- Ruiz-del-Solar, J.; Loncomilla, P.; Soto, N. A Survey on Deep Learning Methods for Robot Vision. arXiv 2018, arXiv:1803.10862. [Google Scholar]
- Bernstein, A.V.; Burnaev, E.V.; Kachan, O.N. Reinforcement Learning for Computer Vision and Robot Navigation. In Machine Learning and Data Mining in Pattern Recognition; Perner, P., Ed.; Springer International Publishing: Cham, Switzerland, 2018; Volume 10935, pp. 258–272. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Laraba, S.; Tilmanne, J.; Dutoit, T. Leveraging Pre-trained CNN Models for Skeleton-Based Action Recognition. In Computer Vision Systems; Tzovaras, D., Giakoumis, D., Vincze, M., Argyros, A., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11754, pp. 612–626. [Google Scholar] [CrossRef]
- Zhang, J. Multi-Source Remote Sensing Data Fusion: Status and Trends. Int. J. Image Data Fusion 2010, 1, 5–24. [Google Scholar] [CrossRef]
- Rajagopalan, S.S.; Morency, L.P.; Baltrušaitis, T.; Goecke, R. Extending Long Short-Term Memory for Multi-View Structured Learning. In Computer Vision – ECCV 2016; Leibe, B., Matas, J., Sebe, N., Welling, M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9911, pp. 338–353. [Google Scholar] [CrossRef]
- Li, T.; Hua, M.; Wu, X.U. A Hybrid CNN-LSTM Model for Forecasting Particulate Matter (PM2. 5). IEEE Access 2020, 8, 26933–26940. [Google Scholar] [CrossRef]
- Kollias, D.; Zafeiriou, S. A Multi-component CNN-RNN Approach for Dimensional Emotion Recognition in-the-Wild. arXiv 2019, arXiv:1805.01452. [Google Scholar]
- Rožanec, J.M.; Zajec, P.; Theodoropoulos, S.; Koehorst, E.; Fortuna, B.; Mladenić, D. Synthetic Data Augmentation Using GAN for Improved Automated Visual Inspection. Ifac-Papersonline 2023, 56, 11094–11099. [Google Scholar] [CrossRef]
- Tasdelen, A.; Sen, B. A Hybrid CNN-LSTM Model for Pre-miRNA Classification. Sci. Rep. 2021, 11, 14125. [Google Scholar] [CrossRef] [PubMed]
- Zieba, M.; Wang, L. Training Triplet Networks with GAN. arXiv 2017, arXiv:1704.02227. [Google Scholar]
- Sergiyenko, O.Y.; Tyrsa, V.V. 3D Optical Machine Vision Sensors with Intelligent Data Management for Robotic Swarm Navigation Improvement. IEEE Sens. J. 2020, 21, 11262–11274. [Google Scholar] [CrossRef]
- Jiang, H.; Peng, L.; Wang, X. Machine Vision and Big Data-Driven Sports Athletes Action Training Intervention Model. Sci. Program. 2021, 2021, 9956710. [Google Scholar] [CrossRef]
- Elfiky, N. Application of Analytics in Machine Vision Using Big Data. Asian J. Appl. Sci. 2019, 7, 376–385. [Google Scholar] [CrossRef]
- Popov, S.B. The Big Data Methodology in Computer Vision Systems. In Proceedings of the International Conference Information Technology and Nanotechnology (ITNT-2015), Samara, Russia, 29 June–1 July 2015; Volume 1490, pp. 420–425. [Google Scholar]
- Tuor, T.; Wang, S.; Ko, B.J.; Liu, C.; Leung, K.K. Overcoming Noisy and Irrelevant Data in Federated Learning. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 5020–5027. [Google Scholar]
- Zhang, H.; Bosch, J.; Olsson, H.H. Real-Time End-to-End Federated Learning: An Automotive Case Study. In Proceedings of the 2021 IEEE 45th Annual Computers, Software, and Applications Conference (COMPSAC), Madrid, Spain, 12–16 July 2021; pp. 459–468. [Google Scholar]
- Kairouz, P.; McMahan, H.B.; Avent, B.; Bellet, A.; Bennis, M.; Bhagoji, A.N.; Bonawitz, K.; Charles, Z.; Cormode, G.; Cummings, R. Advances and Open Problems in Federated Learning. In Foundations and Trends® in Machine Learning; Now Publishers Inc.: Boston, MA, USA, 2021; Volume 14, pp. 1–210. [Google Scholar]
- Caldas, S.; Duddu, S.M.K.; Wu, P.; Li, T.; Konečný, J.; McMahan, H.B.; Smith, V.; Talwalkar, A. LEAF: A Benchmark for Federated Settings. arXiv 2019, arXiv:1812.01097. [Google Scholar]
- Tyagi, S.; Rajput, I.S.; Pandey, R. Federated Learning: Applications, Security Hazards and Defense Measures. In Proceedings of the 2023 International Conference on Device Intelligence, Computing and Communication Technologies, (DICCT), Dehradun, India, 17–18 March 2023; pp. 477–482. [Google Scholar]
- Federated Learning: Collaborative Machine Learning without Centralized Training Data. 2017. Available online: https://blog.research.google/2017/04/federated-learning-collaborative.html (accessed on 9 March 2023).
- Kant, S.; da Silva, J.M.B.; Fodor, G.; Göransson, B.; Bengtsson, M.; Fischione, C. Federated Learning Using Three-Operator ADMM. IEEE J. Sel. Top. Signal Process. 2022, 17, 205–221. [Google Scholar] [CrossRef]
- Tao, J.; Gao, Z.; Guo, Z. Training Vision Transformers in Federated Learning with Limited Edge-Device Resources. Electronics 2022, 11, 2638. [Google Scholar] [CrossRef]
- Guo, T.; Guo, S.; Wang, J. pFedPrompt: Learning Personalized Prompt for Vision-Language Models in Federated Learning. In Proceedings of the ACM Web Conference 2023, Austin, TX, USA, 30 April–4 May 2023; pp. 1364–1374. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive Fields of Single Neurones in the Cat’s Striate Cortex. J. Physiol. 1959, 148, 574. [Google Scholar] [CrossRef]
- Hubel, D.H.; Wiesel, T.N. Receptive Fields, Binocular Interaction and Functional Architecture in the Cat’s Visual Cortex. J. Physiol. 1962, 160, 106. [Google Scholar] [CrossRef]
- Kandel, E.R. An Introduction to the Work of David Hubel and Torsten Wiesel. J. Physiol. 2009, 587, 2733. [Google Scholar] [CrossRef] [PubMed]
- Wurtz, R.H. Recounting the Impact of Hubel and Wiesel. J. Physiol. 2009, 587, 2817–2823. [Google Scholar] [CrossRef] [PubMed]
- Shimonomura, K.; Kushima, T.; Yagi, T. Binocular Robot Vision Emulating Disparity Computation in the Primary Visual Cortex. Neural Netw. 2008, 21, 331–340. [Google Scholar] [CrossRef] [PubMed]
- Shimonomura, K.; Yagi, T. Neuromorphic Vergence Eye Movement Control of Binocular Robot Vision. In Proceedings of the 2010 IEEE International Conference on Robotics and Biomimetics, Tianjin, China, 14–18 December 2010; pp. 1774–1779. [Google Scholar]
- Gochin, P.M.; Lubin, J.M. A Hierarchical Machine Vision System Based on a Model of the Primate Visual System. In Proceedings of the 5th IEEE International Symposium on Intelligent Control 1990, Philadelphia, PA, USA, 5–7 September 1990; pp. 61–65. [Google Scholar]
- Zeevi, Y.Y. Adaptive Machine Vision: What Can Be Learned from Biological Systems. In Intelligent Robots and Computer Vision VIII: Algorithms and Techniques; SPIE: Philadelphia, PA, USA, 1990; Volume 1192, pp. 560–568. [Google Scholar]
- Milner, B.; Squire, L.R.; Kandel, E.R. Cognitive Neuroscience and the Study of Memory. Neuron 1998, 20, 445–468. [Google Scholar] [CrossRef] [PubMed]
- Allison, T. Electrophysiological Studies of Human Face Perception. I: Potentials Generated in Occipitotemporal Cortex by Face and Non-face Stimuli. Cereb. Cortex 1999, 9, 415–430. [Google Scholar] [CrossRef] [PubMed]
- Dawson, G.; Webb, S.J.; McPartland, J. Understanding the Nature of Face Processing Impairment in Autism: Insights From Behavioral and Electrophysiological Studies. Dev. Neuropsychol. 2005, 27, 403–424. [Google Scholar] [CrossRef]
- Di Nuovo, A.; Conti, D.; Trubia, G.; Buono, S.; Di Nuovo, S. Deep Learning Systems for Estimating Visual Attention in Robot-Assisted Therapy of Children with Autism and Intellectual Disability. Robotics 2018, 7, 25. [Google Scholar] [CrossRef]
- El Arbaoui, F.E.Z.; El Hari, K.; Saidi, R. A Survey on the Application of the Internet of Things in the Diagnosis of Autism Spectrum Disorder. In Advanced Technologies for Humanity; Saidi, R., El Bhiri, B., Maleh, Y., Mosallam, A., Essaaidi, M., Eds.; Lecture Notes on Data Engineering and Communications Technologies; Springer: Cham, Switzerland, 2022; pp. 29–41. [Google Scholar] [CrossRef]
- Javed, H.; Park, C.H. Behavior-Based Risk Detection of Autism Spectrum Disorder Through Child-Robot Interaction. In Proceedings of the Hri’20: Companion of the 2020 Acm/Ieee International Conference on Human-Robot Interaction, New York, NY, USA, 23–26 March 2020; pp. 275–277. [Google Scholar] [CrossRef]
- Kollias, K.F.; Syriopoulou-Delli, C.K.; Sarigiannidis, P.; Fragulis, G.F. The Contribution of Machine Learning and Eye-tracking Technology in Autism Spectrum Disorder Research: A Review Study. In Proceedings of the 2021 10th International Conference on Modern Circuits and Systems Technologies (MOCAST), Thessaloniki, Greece, 5–7 July 2021; pp. 1–4. [Google Scholar]
- Kollias, K.F.; Syriopoulou-Delli, C.K.; Sarigiannidis, P.; Fragulis, G.F. The Contribution of Machine Learning and Eye-Tracking Technology in Autism Spectrum Disorder Research: A Systematic Review. Electronics 2021, 10, 2982. [Google Scholar] [CrossRef]
- Kollias, K.F.; Syriopoulou-Delli, C.K.; Sarigiannidis, P.; Fragulis, G.F. Autism Detection in High-Functioning Adults with the Application of Eye-Tracking Technology and Machine Learning. In Proceedings of the 2022 11th International Conference on Modern Circuits and Systems Technologies (MOCAST), Bremen, Germany, 8–10 June 2022; pp. 1–4. [Google Scholar]
- Kollias, K.F.; Maia Marques Torres E Silva, L.M.; Sarigiannidis, P.; Syriopoulou-Delli, C.K.; Fragulis, G.F. Implementation of Robots in Autism Spectrum Disorder Research: Diagnosis and Emotion Recognition and Expression. In Proceedings of the 2023 12th International Conference on Modern Circuits and Systems Technologies (MOCAST), Athens, Greece, 28–30 June 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Ramirez-Duque, A.A.; Frizera-Neto, A.; Bastos, T.F. Robot-Assisted Diagnosis for Children with Autism Spectrum Disorder Based on Automated Analysis of Nonverbal Cues. In Proceedings of the 2018 7th IEEE International Conference on Biomedical Robotics and Biomechatronics (Biorob), Enschede, The Netherlands, 26–29 August 2018; pp. 456–461. [Google Scholar] [CrossRef]
- Ramírez-Duque, A.A.; Frizera-Neto, A.; Bastos, T.F. Robot-Assisted Autism Spectrum Disorder Diagnostic Based on Artificial Reasoning. J. Intell. Robot. Syst. 2019, 96, 267–281. [Google Scholar] [CrossRef]
- Riva, G.; Riva, E. CARERAID: Controlled Autonomous Robot for Early Detection and Rehabilitation of Autism and Intellectual Disability. Cyberpsycho. Behav. Soc. Netw. 2019, 22, 747–748. [Google Scholar] [CrossRef]
- Romero-García, R.; Martínez-Tomás, R.; Pozo, P.; de la Paz, F.; Sarriá, E. Q-CHAT-NAO: A Robotic Approach to Autism Screening in Toddlers. J. Biomed. Inform. 2021, 118, 103797. [Google Scholar] [CrossRef]
- Shelke, N.A.; Rao, S.; Verma, A.K.; Kasana, S.S. Autism Spectrum Disorder Detection Using AI and IoT. In Proceedings of the 2022 Fourteenth International Conference on Contemporary Computing, Noida, India, 4–6 August 2022; pp. 213–219. [Google Scholar]
- Shushma, G.; Jacob, I.J. Autism Spectrum Disorder Detection Using AI Algorithm. In Proceedings of the 2022 Second International Conference on Artificial Intelligence and Smart Energy (ICAIS), Coimbatore, India, 23–25 February 2022; pp. 1–5. [Google Scholar]
- Felleman, D.J.; Van Essen, D.C. Distributed Hierarchical Processing in the Primate Cerebral Cortex. Cereb. Cortex 1991, 1, 1. [Google Scholar] [CrossRef] [PubMed]
- Van Essen, D.C.; Drury, H.A.; Joshi, S.; Miller, M.I. Functional and Structural Mapping of Human Cerebral Cortex: Solutions Are in the Surfaces. Proc. Natl. Acad. Sci. USA 1998, 95, 788–795. [Google Scholar] [CrossRef] [PubMed]
- Fox, M.D.; Snyder, A.Z.; Vincent, J.L.; Corbetta, M.; Van Essen, D.C.; Raichle, M.E. The Human Brain Is Intrinsically Organized into Dynamic, Anticorrelated Functional Networks. Proc. Natl. Acad. Sci. USA 2005, 102, 9673–9678. [Google Scholar] [CrossRef]
- Glasser, M.F.; Coalson, T.S.; Robinson, E.C.; Hacker, C.D.; Harwell, J.; Yacoub, E.; Ugurbil, K.; Andersson, J.; Beckmann, C.F.; Jenkinson, M.; et al. A Multi-Modal Parcellation of Human Cerebral Cortex. Nature 2016, 536, 171–178. [Google Scholar] [CrossRef] [PubMed]
- Tang, L.; Xiao, H.; Li, B. Can sam segment anything? when sam meets camouflaged object detection. arXiv 2023, arXiv:2304.04709. [Google Scholar]
- Wang, L.; Zhang, X.; Song, Z.; Bi, J.; Zhang, G.; Wei, H.; Tang, L.; Yang, L.; Li, J.; Jia, C.; et al. Multi-modal 3D Object Detection in Autonomous Driving: A Survey and Taxonomy. IEEE Trans. Intell. Veh. 2023, 8, 3781–3798. [Google Scholar] [CrossRef]
- Rajasegaran, J.; Pavlakos, G.; Kanazawa, A.; Feichtenhofer, C.; Malik, J. On the Benefits of 3D Pose and Tracking for Human Action Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, Canada, 18–22 June 2023; pp. 640–649. [Google Scholar]
- Zou, Z.; Chen, K.; Shi, Z.; Guo, Y.; Ye, J. Object detection in 20 years: A survey. Proc. IEEE 2023, 111, 257–276. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, Q.; Du, Z.; Wu, A. Human Action Recognition for Dynamic Scenes of Emergency Rescue Based on Spatial-Temporal Fusion Network. Electronics 2023, 12, 538. [Google Scholar] [CrossRef]







| Mathematical Method | Application in Image Segmentation |
|---|---|
| Graph Theory [20] | Graph cuts: partitions images into segments by minimizing an energy function. |
| Probability and statistics [21,22] | Bayesian methods: model pixel likelihood based on statistical properties. |
| Gaussian Mixture Models (GMMs): represent pixel intensity distribution. | |
| Partial Differential Equations (PDEs) [23,24] | Chan–Vese model: level-set method for segmentation, particularly for smooth object boundaries. |
| Active contour models (Snakes): PDE-based models that evolve contours for boundary identification. | |
| Clustering algorithms [25] | K-means clustering: unsupervised clustering for grouping pixels based on similarity. |
| Mean-shift clustering: adaptive clustering method for image segmentation. | |
| Fourier transform [26] | Frequency domain segmentation: transforms images for segmentation based on frequency characteristics. |
| Markov Random Fields (MRFs) [27] | MRF-based segmentation: models pixel dependencies for improved segmentation. |
| Distance metrics [28] | Watershed algorithm: segments images into regions based on distance metrics. |
| Convolutional neural networks (CNNs) [29] | Fully Convolutional Network (FCN): adapts CNNs for pixel-wise classification. |
| U-Net: specialized architecture for biomedical image segmentation. | |
| Level-set methods [30] | Geodesic active contour: combines level-set methods with geodesic active contours for accurate segmentation. |
| Fuzzy logic [31] | Fuzzy c-means clustering: fuzzy logic-based algorithm for uncertain boundary images. |
| Image Segmentation Algorithms | |
|---|---|
| Area Boundary Detection Algorithms | Algorithms Based on Regions |
| Edge detection [32] | Downgrading [33] |
| Detection of objects [34] | Expansion of areas [35] |
| Division and merging of areas [36] | |
| Segmentation based on Watershed [28] | |
| Mathematical Method | Application in Object Detection |
|---|---|
| Linear algebra [52] | Vectors and matrices: represent images and use linear algebra operations for processing. |
| Geometric transformations: perform translation, rotation, and scaling for object manipulation. | |
| Calculus [53] | Gradient descent: used for optimization during model training. |
| Partial derivatives: used for position determination in localization tasks. | |
| Statistics [54] | Probability and statistics: employ probabilistic models and statistical methods for feature analysis. |
| Non-maximum suppression: removes duplicate or low-confidence bounding boxes. | |
| Machine learning algorithms [55] | Region-based CNNs (R-CNNs): propose and classify bounding boxes. |
| Fast R-CNN, Faster R-CNN: enhance speed and accuracy. | |
| Geometry and trigonometry [56] | Trigonometric functions: use geometric calculations for object poses and orientations. |
| Homography: uses transformations for image rectification or feature matching. | |
| Optimization techniques [57] | Integer Linear Programming (ILP): refines bounding-box selection. |
| Deep learning architectures [58] | Feature Pyramid Networks (FPNs): capture features at multiple scales. |
| Single-Shot Multibox Detector (SSD), You Only Look Once (YOLO): efficiently detect objects in real time. |
| Method | References |
|---|---|
| Deep learning (CNNs and RNNs) addresses the critical task of human action recognition in computer vision, enhancing accuracy and optimizing performance. | [9,61,62,63,64,65,66,67,68,69,70,71,72] |
| Attention-based LSTM for feature distinctions, incorporating a spatiotemporal saliency-based multi-stream network. | [73] |
| A hybrid deep learning model for human action recognition. | [74] |
| Utilizes multiple models to capture global and local motion features for action recognition. | [75] |
| Uses RGB frames, Bi-LSTM, and a CNN for action recognition. | [76] |
| A novel hybrid architecture combining four pre-trained network models, predicting human actions. | [77] |
| Uses a temporal-spatial mapping operation for action recognition. | [78] |
| Use of image-based HAR through transfer learning. | [79] |
| A cooperative approach for feature selection. | [80] |
| Summary | References |
|---|---|
| Identify fundamental computer vision problems: image classification, object detection, and segmentation. | [12,81,82,83,84,85] |
| Semantic segmentation assigns labels to every pixel, significantly enhanced by deep learning, particularly CNNs. | [86,87,88,89,90,91,92] |
| Describe components of a semantic segmentation architecture and three main approaches: region-based, FCN-based, and weakly supervised. | [50,63,86,87,90,91,92,97,98,99,100,101,102,103,104,105,106,107] |
| Semantic segmentation, focusing on medical image analysis and DCNNs. | [108,109,110] |
| Method | Key Features |
|---|---|
| CNNs [131] | CNNs revolutionize robotic vision by automatically learning hierarchical features from raw pixel data. |
| RNNs [132] | RNNs are essential for temporal tasks like video analysis and gesture recognition. |
| RL [133] | RL uses neural networks to approximate mappings between states, actions, and rewards, improving robots’ understanding and navigation. |
| GANs [134] | GANs generate synthetic data and enhance data augmentation, especially beneficial for limited real-world data. |
| Transfer learning [135] | Transfer learning accelerates model convergence in robotic vision by leveraging pre-trained models. |
| Multi-modal fusion [136] | Multi-modal fusion combines information from various sensors through sensor fusion, including vision and LiDAR or radar data. |
| Neural Network | Details |
|---|---|
| Convolutional neural network (CNN) [87] | Mathematical model:
|
| Recurrent neural network (RNN) [81] | Mathematical model:
|
| Reinforcement learning (RL) [133] | Mathematical model:
|
| Generative Adversarial Network (GAN) [7] | Mathematical model:
|
| Long Short-Term Memory (LSTM) [138] | Mathematical model:
|
| Approach | Strategy | Benefits |
|---|---|---|
| CNN-RNN fusion [139] | Utilizes CNNs for initial image feature extraction and integrates RNNs to process temporal data. |
|
| GAN-based data augmentation [140] | Applies GANs to generate synthetic data, diversifying training datasets. |
|
| Hybrid CNN-LSTM models [141] | Combine CNNs for static feature extraction with LSTMs for sequential understanding. |
|
| Triplet network with GANs [142] | Implements GANs for generating realistic variations of images and uses a triplet network (embedding CNN) to enhance similarity comparisons. |
|
| Summary | References |
|---|---|
| Discuss Hubel and Wiesel’s electrophysiological studies connecting neuroscience, ANNs, and computer vision. | [156,157,158,159] |
| Build upon Hubel and Wiesel’s work, exploring VLSI binocular vision systems, practical vergence eye control systems, hierarchical machine vision systems, and visual mechanisms | [160,161,162,163] |
| Explores cognitive neuroscience by merging psychology and neurobiology, with a focus on memory, perception, action, language, and awareness. | [164] |
| Explore how the human visual cortex processes complex stimuli, revealing distinct regions for object and letter recognition and face processing. Individuals with autism face challenges in recognizing faces, with disruptions in neural systems linked to social issues. | [165,166] |
| Machine learning methods for classifying autism | [167,168,169,170,171,172,173,174,175,176,177,178,179] |
| Summary | Reference |
|---|---|
| Outlines cortical areas tied to vision and other senses and presents a database of connectivity patterns. | [180] |
| Explores surface-based visualization for mapping the cerebral cortex’s functional specialization. | [181] |
| Reveals the brain’s activation–deactivation balance during tasks, showcasing ongoing brain organization and supporting an understanding of neural fluctuations’ impact on function. | [182] |
| Presents a comprehensive map of the human cerebral cortex’s divisions, identifies new areas, and develops a machine learning classifier for automated identification. | [183] |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Manakitsa, N.; Maraslidis, G.S.; Moysis, L.; Fragulis, G.F. A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision. Technologies 2024, 12, 15. https://doi.org/10.3390/technologies12020015
Manakitsa N, Maraslidis GS, Moysis L, Fragulis GF. A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision. Technologies. 2024; 12(2):15. https://doi.org/10.3390/technologies12020015
Chicago/Turabian StyleManakitsa, Nikoleta, George S. Maraslidis, Lazaros Moysis, and George F. Fragulis. 2024. "A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision" Technologies 12, no. 2: 15. https://doi.org/10.3390/technologies12020015
APA StyleManakitsa, N., Maraslidis, G. S., Moysis, L., & Fragulis, G. F. (2024). A Review of Machine Learning and Deep Learning for Object Detection, Semantic Segmentation, and Human Action Recognition in Machine and Robotic Vision. Technologies, 12(2), 15. https://doi.org/10.3390/technologies12020015