Abstract
Computer Algebra Systems (CAS) currently lack an effective auditory representation, with most existing solutions relying on screen readers that provide limited functionality. This limitation prevents blind users from fully understanding and interpreting mathematical expressions, leading to confusion and self-doubt. This paper addresses the challenges blind individuals face when comprehending mathematical expressions within a CAS environment. We propose “Math for Everybody” (Math4e, version 1.0), a software module to reduce barriers for blind users in education. Math4e is a Sonification Module for CAS that generates a series of auditory tones, prosodic cues, and variations in audio parameters such as volume and speed. These resources are designed to eliminate ambiguity and facilitate the interpretation and understanding of mathematical expressions for blind users. To assess the effectiveness of Math4e, we conducted standardized tests employing the methodologies outlined in the Software Engineering Body of Knowledge (SWEBOK), International Software Testing Qualifications Board (ISTBQ), and ISO/IEC/IEEE 29119. The evaluation encompassed two scenarios: one involving simulated blind users and another with real blind users associated with the “Asociación de Invidentes Milton Vedado” foundation in Ecuador. Through the SAM methodology and verbal surveys (given the condition of the evaluated user), results are obtained, such as 90.56% for pleasure, 90.78% for arousal, and 91.56% for dominance, which demonstrates significant acceptance of the systems by the users. The outcomes underscored the users’ commendable ability to identify mathematical expressions accurately.
1. Introduction
The Pan American Health Organization (PAHO) estimates that, worldwide, 1.3 billion people have some form of visual impairment. Among this population, 14% have a moderate visual impairment, 16.7% have a moderately severe visual impairment, and 2.7% are classified as blind [1]. Unfortunately, a significant percentage of individuals with visual impairments abandon their studies, exacerbating the lack of educational opportunities for this minority. For example, in Spain, during the period from 2016 to 2017, only 650 students with visual disabilities completed secondary education, which accounts for a mere 0.032% of secondary education students. Furthermore, only 85 students attained a higher level of education, representing just 0.004% of high school students, during the same period [2].
In Ecuador, the country where the project associated with this work is carried out, the “National Council for Disability Equality” (Consejo Nacional para la Igualdad de Discapacidades, CONADIS) is a government institution responsible for promoting equal rights and opportunities for individuals with disabilities. According to a report by CONADIS, at the end of 2019 there were 54,397 people in Ecuador with a certain level of visual impairment. Out of this number, approximately 2625 individuals were enrolled in primary and secondary education, accounting for 4% of the total. Furthermore, only 1188 individuals had pursued higher education at universities, which represented 2.18% of the total population [3]. In this context, visually impaired individuals face significant challenges when pursuing higher education due to a substantial shortage of resources and guidance materials, which are frequently mandatory for technical courses. Consequently, gaining admission to and maintaining enrollment in higher education institutions become nearly insurmountable obstacles for this specific population group [4,5].
Numerous studies aim to enhance the quality of life for visually impaired individuals. Some of these studies explore the use of adaptive technology or video games to improve specific skills [6,7,8], wearable systems for face recognition [9], radar systems to facilitate the locomotion and navigation of visually impaired people [10,11], for enhancing accessibility to digital documents [12], or web applications [13]. However, few works focus on facilitating mathematics learning for visually impaired people.
In the field of engineering and exact sciences, Computerized Algebraic Systems (CAS) provide a range of powerful mathematical tools, including Gauss, version 1.0 [14], MAXIMA [15], Matlab [16], and Magma [17]. These platforms enable users to perform simple and complex calculations involving symbolic operations such as polynomials, equations, vectors, and matrices. Unfortunately, these software systems lack an inclusive user interface, making them inaccessible to individuals with visual disabilities [4,18]. While screen readers, such as NVDA, JAWS, and Talkback, can mitigate this limitation, they may struggle with the textual representation of visual elements, such as mathematical equations. As an example, Figure 1 demonstrates how a synthesized voice from a screen reader, linearly reading mathematical expressions, can generate confusion and ambiguity and hinder understanding for individuals with visual impairments.
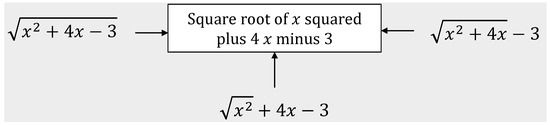
Figure 1.
Ambiguity reading on screen readers.
A well-designed and implemented tool to render different mathematical expressions generated by a CAS system via audio is crucial. The approach presented in this work facilitates the representation and elaboration of auditory resources, including synthesized voices with varying speed and volume, tonal and prosodic cues [4], and proper delimitation of expressions. This takes into account the importance of proper audio instructions in learning tools to guarantee an enhanced learning experience [19]. Consequently, visually impaired users are guided to comprehend and interpret the various components that form mathematical expressions without overwhelming their cognitive load [20].
The primary contribution of this study is the integration of a Sonification Module for algebraic-mathematical expressions into the IrisMath Web CAS system [21]. The module, Math for Everybody (Math4e), produces output compatible with the LaTeX language. Math4e allows for the representation and comprehension of equations through auditory cues. This enables users to identify the structure of a mathematical expression and differentiate the elements that make up each component, thus avoiding potential ambiguity. Notably, this work eliminates the need for external tools and equipment, such as braille screens.
It is crucial to emphasize that our module’s usability has been extensively validated through anonymous tests in collaboration with visually impaired users from the “Asociación de Invidentes Milton Vedado” Foundation in Quito, Ecuador. These tests have demonstrated that users comprehensively understand equation representation using Math4e. They could grasp the various elements that make up the structure of a mathematical expression without relying on external resources.
The subsequent sections of this paper are structured as follows. In Section 2, we provide an overview of the contributions made by related works. Section 3 delves into the platform’s development, encompassing baseline criteria and technical aspects while also elucidating the testing scenarios. Following that, Section 4 presents the findings and ensuing discussions. Lastly, Section 5 encapsulates the principal conclusions drawn from this study.
2. Related Work
This section presents an overview of previous works on the sonification of mathematical expressions in CAS. These works primarily focus on developing auditory systems and tools to assist individuals with visual disabilities in comprehending mathematical equations. They employ auditory resources that serve as descriptive guides to the components of the equation. It should be noted that this study focuses on sonifying equations rather than decomposing them. Similarly, subsequent projects, including this proposal, aim to enhance the understanding of equation structure through sonification.
Table 1 provides an example of the representation of a mathematical expression using various solutions proposed in the literature. The table also highlights certain details that may hinder the listening comprehension of the mathematical expressions, as mentioned in the observations column. Additionally, Table 2 summarizes different aspects of various sonification platforms, including Math4e, which is presented in this study. Based on this comparison, we can emphasize that our research introduces Math4e as a sonification module capable of representing all elements of a mathematical expression through detailed descriptions and a series of auditory cues. This approach ensures that the audio representation is easily understandable for visually impaired users, eliminating any potential ambiguity and providing clear and accurate descriptions that differentiate the different components of a mathematical expression.

Table 1.
Representations of mathematical expressions in diverse solutions as proposed in the literature.
Table 2.
Comparison of sonification features between different solutions proposed in the literature and Math4e, “✓” indicates that the software considers the feature in the first row of the table and “-” indicates that it does not consider that feature.
The MathSpeak solution, proposed in [22], utilizes Text-to-Speech (TTS) technology to represent equations. MathSpeak first converts the equation into a markup language, such as LaTeX, and then transforms it into a descriptive reading format. In sonification, a synthesized voice is employed to describe the boundaries of the different components that constitute the expression. This is achieved by using opening and closing parentheses for each element. For instance, if the denominator of a fraction consists of multiple components, an opening parenthesis is indicated, followed by a description of the argument. Finally, the closing parenthesis is indicated. However, it is important to note that the exclusive use of parentheses to represent compound expressions in MathSpeak can result in clutter and confusion, particularly when multiple parentheses are involved. The repetitive nature of the parentheses can make it challenging for users to fully comprehend the complete mathematical expression.
The Prototype for the Accessibility of Mathematical Expressions project, presented in [23], was developed at Universidad de Concepción de Chile. It introduces a web application that extracts the HTML code from an image of a mathematical expression and converts it into Content-MathML language. The expression is then transformed into a tree structure, allowing for the identification of the different components that form the expression. These components are represented in descriptive reading format and encoded into HTML for accessibility with screen readers. In terms of sonification, the mathematical equation is read linearly without the ability to control audio parameters such as playback speed, volume, or tone. Additionally, the delimitation of specific elements within the expression, such as, e.g., the beginning and end of a square root, is not provided. It is important to note that [23] encounters difficulties when dealing with mathematical expressions containing multiple parentheses. The sonification process does not properly identify nested arguments and instead represents them as silences or pauses, which can introduce ambiguities in understanding the expression.
In [24], the authors introduce Math Genie, a hearing equation browser that aims to represent mathematical expressions using a synthesized voice. This solution reads the elements of the expression one at a time, navigating within a hierarchical structure. While Math Genie provides detailed descriptions of mathematical expressions, it lacks hearing cues such as earcons or tones to guide the user through the different elements of the expression. The Web Sonification Sandbox system [28] represents mathematical expressions through graphs. Then, these graphs are mapped to determine different points in two dimensions (x-axis and y-axis), which are used to generate audio. Thus, the higher the point of the axis is, the sounds will be higher or lower (in pitch, not volume). Web Sonification Sandbox’s weakness is represented by not being able to identify the structure of an equation; it only gives sound to its resulting points.
Finally, Linear Access to Mathematics for Braille Device and Audio-synthesis (LAMBDA) [25] and L-MATH [26] focus on providing a linear description of equations using a synthesized voice with the Text-to-Speech (TTS) method. Similarly, CASVI [27,29] targets individuals with visual disabilities studying engineering and exact sciences. However, these solutions limit the sound process to a linear representation of the mathematical expression through a synthesized voice, lacking any hints about the elements that compose it. Unfortunately, there is limited technical information (programming languages, architecture, UML diagrams, and others) about these platforms, which restricts the analysis of their interaction with users (usability metrics).
3. Platform Development
In this section, we unveil the architecture of Math4e and expound upon key considerations pertinent to its development. Additionally, we elucidate aspects about the testing scenarios.
3.1. Baseline Criteria
Given the limitations observed in prior works, we identified a set of fundamental criteria that establish a foundation for developing Math4e. These criteria are pivotal in ensuring the proper functionality and effectiveness of Math4e. In the following, we offer a comprehensive description of these criteria and elaborate on their contributions to the overall functionality of Math4e in aiding visually impaired users in the interpretation and understanding of mathematical expressions:
- Hearing description of the components in a mathematical expression: Math4e is designed to generate a detailed auditory description of the various components within an expression. This includes operators, operands, variables, and functions. The generated description is structured to provide insightful information about the interrelationships among these components, enhancing the user’s comprehension.
- Math4e reproduces characteristic tones that enable users to identify the limits of mathematical operations, such as roots, fractions, and trigonometric functions. These tones serve as reference points for the most common components of an equation, indicating, e.g., the start and end of a mathematical expression and facilitating the user’s navigation and orientation within it. These tones should not overlap or be too long. Based on user experience, these tones do not exceed 0.3 s to enable users to assimilate and understand the information effectively without feeling overwhelmed or confused (more details are given in the Results section).
- Clear and consistent pronunciation: The synthesized voice employed by Math4e is required to maintain clear and consistent pronunciation, ensuring precise and confident differentiation among the various components of the mathematical expression. This practice is essential for mitigating ambiguities and minimizing the risk of misunderstandings, as emphasized by [30].
- Appropriate volume: The audio cues produced by Math4e should maintain a balance, avoiding excessive loudness or disturbance to preserve the user’s focus. Utilizing moderate volume levels, especially high-frequency sounds, is crucial for alerting users. This approach allows users to effectively associate these cues with distinct delimiters, ensuring their noticeability in the reproduced audio, as highlighted in [31].
- Timely processing: Math4e should efficiently process mathematical expressions with minimal latency to deliver a seamless and uninterrupted user experience. This commitment ensures that there are no substantial delays in reproducing the output.
- Cognitive load considerations: Math4e carefully considers working memory constraints to maintain a manageable cognitive load. According to the Center for Statistics and Evaluation of Education in Australia, the average person’s working memory typically retains around four pieces of information [20]. Consequently, Math4e is designed to employ a maximum of four distinct auditory cues, each representing essential categories of operations: fractions, roots and powers, parentheses, and trigonometric functions. These categories encompass the most frequently encountered mathematical expressions of moderate complexity. Recognizing that more intricate operators might exceed the user’s cognitive load and impede comprehension, as indicated in [20], the platform allows for an increased number of operators for users who have acquired advanced proficiency in its usage.
- Keyboard shortcut invocation: Math4e should be activated through an event triggered by a keyboard shortcut. This functionality offers users a convenient and efficient method to initiate the sonification process, as highlighted in [32].
- Testing period: An agreement has been signed between the PTT-21-02 Project from the Escuela Politécnica Nacional and The Milton Vedado Blind Association for performing the different tests carried out in several meetings with different types of users. The anonymous tests started on 16 December 2022 and finished on 3 February 2023. All surveys related to the perception aspects of the developed tool were carried out verbally to provide comfort and security to end users The agreement is available at the following link (in Spanish and translation to English): https://1drv.ms/b/s!AsRqANguaUiwhcp_lcIgYg84BC4ZUA?e=0n0vGh (accessed on 1 February 2024).
3.2. Operation and Technical Aspects
Math4e commences with the extraction of the structure of a mathematical expression in a markup language format such as LaTeX. This LaTeX format transforms into a descriptive reading format, elucidating the composition of the mathematical expression. Following this, the described sonification flow is implemented, where a synthesized voice audibly articulates the content in the descriptive reading format. This narration is complemented by a sequence of tones signifying the initiation and conclusion of operators and their internal structures (when applicable), along with sound effects acting as auditory cues. This workflow is depicted in Figure 2, outlining four distinct stages further described in the following.
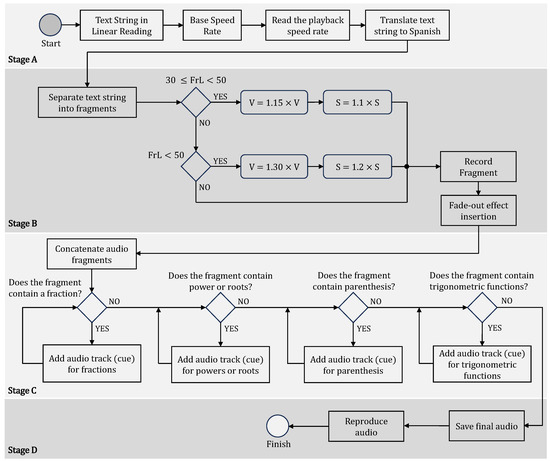
Figure 2.
Sonification workflow of Math4e.
The process commences in Stage A, with the input of a mathematical expression in a descriptive reading format that outlines its structure. This format aligns with the output of any CAS, which typically generates content in LaTeX format, serving as the required input for Math4e to initiate its process. To cater to diverse user preferences and hearing abilities, three speed levels—namely slow, medium, and fast—are provided, ensuring flexibility in accommodating varying levels of auditory comprehension. Including various speed levels empowers the module to tailor its performance to individual users’ unique skills and preferences. Research findings indicate that individuals blind from early life generally prefer higher speed levels compared to those who acquire blindness in adulthood [33]. In Section 4, we show the results of different tests with Math4e utilizing different speed levels to ascertain the most effective setting for ensuring a comprehensive understanding of the mathematical expression.
In this first version of our project, tailored for Latin American users, the auditory elements are translated into Spanish. To distinctly delineate the boundaries of specific structures defined by operators—namely (i) fractions, (ii) roots and powers, (iii) parentheses, and (iv) trigonometric functions—the translated description is segmented into fragments, each incorporating distinct auditory cues. Hence, in Stage B, the fragments undergo classification based on their length (FrL), specifically categorized as short, medium, or large, contingent on the number of characters they comprise. An incremental volume adjustment (in Figure 2, it is represented as V = V + 15% or V = V + 30%), coupled with speed configuration (in Figure 2, it is represented as S = S × 1.1 or S = S × 1.2), is applied to the reference level used by the blind user, ensuring sustained attentiveness during the auditory output. Volume and playback speed increases were established through various tests, as detailed later in Section 3.3. Thus, Stage B prevents extended fragments from generating monotonous audio, which could impede information retention in the memory of blind users. Subsequently, the text-to-speech (TTS) tool is employed, accompanied by the incorporation of a fade-out audio feature as a subtle cue denoting the conclusion of each fragment. The reference speeds and lengths of the text fragments, defining the corresponding adjustments in speed and volume during audio reproduction, were empirically established through a comprehensive analysis of diverse mathematical expressions. Additional details on this process are elaborated in Section 4.
During Stage C, each audio fragment is seamlessly concatenated with the preceding one, and a corresponding auditory cue is incorporated based on the delimiter operator associated with the fragment. In the concluding Stage D, after the integration of all fragments, the consolidated audio is saved and dispatched for playback on the user’s end.
Regarding these last stages, it is important to indicate that enhancing audio comprehension, particularly for expressions with fractions, necessitates a modification in the structure of the expression. For a better understanding, Figure 3 illustrates this process, commencing with the LaTeX output format from the Client-side CAS. The original LaTeX output employs the tag “\over” to represent a fraction (“{numerator} \over {denominator}”). However, this presents limitations when processed with Mathlive, the subsequent step in the sonification process. Specifically, this tag lacks clear delimitation for the fraction’s beginning and end. To address this challenge, we employ regular expressions and search patterns [34]. Furthermore, the structure “\over” is substituted with the “\frac” label, facilitating Mathlive in recognizing the numerator and denominator arguments within the fraction, i.e., \frac {numerator}{denominator}. This replacement guarantees precise interpretation and description of the fractions by the developed module in the mathematical expressions.
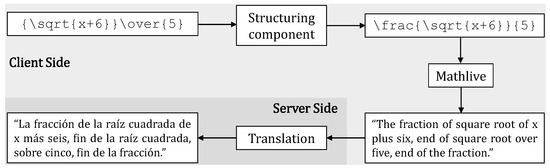
Figure 3.
LaTex structuring and processing to generate a descriptive reading format.
Subsequently, the Mathlive library transforms the LaTeX format into a text string using a descriptive reading format. As illustrated in Figure 3, the modification of the LaTeX structure, representing a fraction with a square root in the numerator and a number in the denominator, involves the transition from the “\over” tag to the “\frac” tag. The Mathlive library generates the expression description in the descriptive reading format, a step processed by Math4e on the server side. However, since the conversion to a descriptive reading format produces a text string in English, Math4e translates the string into Spanish using the Googletrans Library. Before initiating the translation process into Spanish, specific adjustments are applied to the text string to facilitate accurate translation. After conducting several tests, it was determined this process takes only 3 s, ensuring precise translations and minimizing delays while delivering fully descriptive audio for mathematical expressions. The audio reproduction occurs on the client side in the front end, whereas the processing is conducted by Math4e on the server side. In this case, communication occurs through an HTTP POST request, with the text string in a descriptive reading format.
Notably, the mathematical operators employed as delimiters for the fragments may encompass one or more elements within them. These elements encompass fractions, roots, parentheses, and trigonometric functions. Figure 4 visually demonstrates this concept, showcasing text string separations at the fraction and root’s commencement and conclusion. This strategic separation facilitates accurate recognition of the arguments within these operators.

Figure 4.
Transformation of a math expression description into fragments.
Upon generation of all fragments, each text fragment undergoes recording with a synthesized voice and is accompanied by a fade-out effect, signaling the conclusion of the fragment. Subsequently, the recorded fragments are combined with the corresponding tone, serving as an auditory cue to identify the mathematical operator acting as a delimiter. Ultimately, all the recorded fragments are amalgamated into a unified audio file, then dispatched to the client’s front end for playback. To mitigate potential disorientation when the user reproduces the output at the system interface, it is crucial to guarantee that the audio sequences do not overlap.
Considering that the processing within the CAS system occurs locally on the server side, we opted to utilize the pyttsx3 library. While the synthesized voice from this library may not match the naturalness of other libraries, its performance does not notably impact our proposed system. Importantly, it avoids the high latency often associated with online libraries, making it a suitable choice for efficient processing.
Throughout the development of Math4e, a range of libraries and resources were harnessed to facilitate audio output generation for representing mathematical expressions. A detailed overview of the libraries employed in the project is provided in Table 3.
Table 3.
Code libraries used in Math4e.
3.3. Alpha and Beta Testing Scenarios
This section presents the tests carried out to evaluate and verify the correct functioning of Math4e.
A dedicated computer laboratory was set up at the Escuela Politécnica Nacional in Ecuador to conduct the tests and serve as a controlled testing environment. The physical space was carefully managed, featuring closed blinds and artificial lighting to maintain low and consistent light levels, thereby preventing discomfort for visually impaired individuals sensitive to light. The laboratory was equipped with twelve computers, each with screens configured to a low brightness level and keyboards compatible with Spanish (ES), Latin American Spanish (LAA), and US English (EN) layouts. Access to the system was granted to voluntary participants, and the tests were carried out anonymously.
Two test scenarios were arranged (after a period of recruitment from 3 January 2023 to 14 January 2023):
- The first scenario (Alpha Test) involved seven sighted volunteers who were blindfolded during the test, creating a controlled environment with minimal light levels. The screens were set to a minimum brightness level (and the volunteer’s actions were monitored, such as reviewing if they were trying to force their view or turning off the screens randomly to see if they were only being guided by audio). This scenario will enable the definition of crucial values, such as those in Table 4, before conducting tests with blind individuals, corresponding to the second scenario.
Table 4. Fragment parameters based on their length.
- In the second scenario (Beta test), five visually impaired individuals with varying levels of blindness participated and used the developed Math4e module. These individuals were contacted through the “Asociación de Invidentes Milton Vedado” foundation in Quito, Ecuador. The research protocol for the Math4e experiments was submitted and approved by the foundation’s representatives through a cooperation agreement and a code of ethics signed by both parties (Refer to footnote).
In assistive technology, it is a well-established principle that sighted individuals should not be the sole evaluators of systems crafted for users with visual impairments [35]. Consequently, the first scenario is an Alpha Test featuring simulated blind users. This test serves the crucial purpose of establishing a baseline for minimum usability, enabling identifying and resolving potential issues with the tool. Following completion of the first scenario and resolving any deficiencies, the second scenario involving real blind users embodies the Beta Testing phase. During this stage, satisfaction levels and usability were systematically measured to validate the accurate functioning of the module.
The testing period lasted two months and included training and adaptation to the tool. During the Alpha Test, the participating users analyzed various parameters related to audio recording speed, reference volume, length of fragments, and tones. This preliminary stage allowed for the establishment of appropriate initial parameters for the tool’s operation. Based on this analysis, the audio tones for each type of component are determined after an initial set of tests: they must be tones that are sufficiently differentiated from each other, tones that are gentle to the human auditory perception, and tones that do not obscure the numerical focus of the end user. Furthermore, it was determined that high-frequency tones of short duration (not exceeding 0.3 s) were suitable as hearing cues for the different operators. Additionally, it was found that increasing the audio volume by 15% and 30%, and the speed by and for different fragments enables the understanding of larger fragments without losing the expression’s context. The number of characters in each fragment was considered to define the auditory characteristics of each fragment. Concretely, in this study, short fragments have fewer than 30 characters, medium fragments have no more than 50 characters, and long fragments have more than 50 characters. Table 4 summarizes each fragment type’s playback speed and volume increase.
The Beta tests adhered to well-established methodologies, incorporating ISO/IEC/IEEE 29119 [36] for the test environment’s design, configuration, and deployment. Additionally, the International Software Testing Qualifications Board (ISTQB) [37] was employed to delineate the actors, terms, and processes involved, while the Software Engineering Body of Knowledge (SWEBOK) [38] guided the definition of requirements, acceptance criteria, resources, and the time necessary for the successful execution of tests.
For the usability and complexity perception assessments, we used the Self-Assessment Manikin (SAM) methodology [39]. The test protocol for Math4e mirrored the one utilized in [27]. In both scenarios, verbal surveys were conducted separately to assess users’ (alpha or beta) comprehension of the proposed equations and their satisfaction level using the SAM scale, following a detailed protocol: (i) Each equation was reproduced using Math4e; (ii) Users were provided with at least two choices for the equation they heard; (iii) Users selected their preferred option; (iv) If needed, the audio was replayed. This comprehensive approach ensured a rigorous and systematic evaluation process for Math4e. The ensuing section presents the outcomes derived from the tests that were conducted.
4. Results and Discussion
The anonymous test participants comprised individuals aged between 18 and 59, exhibiting diverse levels of visual impairment ranging from 80% to 100%. One individual was blind from birth. All participants understood intermediate-level mathematical expressions, encompassing trigonometric functions, polynomials, and equations of the first and second degrees.
A diverse set of mathematical expressions was employed in the tests to ensure a comprehensive evaluation of the system’s performance. The selection encompassed both expressions, designed to verify an accurate understanding of their representation and those with similar auditory patterns to assess the system’s capability for correct differentiation. As a manifestation of potential ambiguity in linear readings, the four mathematical expressions presented in Table 5 were specifically used. Access to the audio recordings of these mathematical expressions, generated by Math4e, is available through the following link: https://1drv.ms/f/s!AsRqANguaUiwhcNOwA8kOZqsHYMEbQ?e=5deBDB (accessed on 1 February 2024).
Table 5.
Comparison of linear reading vs. Math4e reading.
The tests revealed that users encountering linear audio, lacking volume adjustments or audio cues, as seen in applications such as [24,25,26], experience difficulties in comprehending mathematical expressions. In contrast, the audio generated by Math4e significantly enhanced expression understanding, particularly in structure. Users successfully identified the commencement and conclusion of square roots and the numerators and denominators in fractions. Table 6 illustrates the average number of attempts users needed to fully grasp mathematical expressions when using Math4e. Notably, the Beta group required a maximum of two attempts. All these achievements, added with the satisfaction demonstrated by “alpha” users before, during, and after the audio tests (gathered through verbal surveys), provide compelling evidence that Math4e is an inclusive application for all users.
Table 6.
Mean number of attempts to completely understand a mathematical expression with Math4e.
In comparison to the MathSpeak [22] and Prototype for the Accessibility of Mathematical Expressions [23] projects, Math4e stands out with substantial enhancements. It replaces the conventional use of parentheses and pauses as expression delimiters with detailed descriptions that precisely indicate the initiation and conclusion of various elements within a mathematical expression. Additionally, unlike the LAMBDA [25], L-MATH [26], and Math Genie [24] systems, our module integrates hearing cues alongside synthesized voice descriptions, effectively eliminating ambiguity in the comprehension of mathematical expressions.
The evaluation of the average time required to obtain a representation of a mathematical expression was conducted at three different audio reproduction speeds generated by Math4e. Table 7 presents the results. As indicated in the table, an increase in speed results in a reduction in reproduction time. This is because shorter and faster audio representations are generally easier to process. In the results presented in Table 7, it is noteworthy that there was a negligible difference of 0.19 s between the execution times of sighted users (Alpha group) and blind users (Beta group).
Table 7.
Average time (in seconds) required for understanding a mathematical expression.
The SAM model facilitated the establishment of a numerical scale for assessing users’ satisfaction, emotion, and dominance levels while interacting with Math4e. Affective responses were considered, encompassing factors such as speed, tone, volume, and intelligibility of the audio generated from inputting algebraic expressions. Users’ emotions concerning the platform were gauged in pleasure, arousal, and dominance, utilizing a 9-point scale, where 1 represented the lowest rating and 9 denoted the highest. Evaluation criteria encompassed the level of interaction with Math4e, the playback of results obtained, and the comprehension of mathematical expressions at slow, medium, and fast audio reproduction speeds. These results are detailed in Table 8, along with the mean ratings for each category and the percentage values relative to the maximum rating of 9 (i.e., the normalized mean expressed as percentage). From these findings, it is noteworthy that individuals blind from birth exhibited greater acceptance and preference for fast audio reproduction. In contrast, those who acquired blindness preferred medium and slow speeds. The results showcase a 90.56% satisfaction rate for pleasure, 90.78% for arousal, and 91.56% for dominance, indicating a promising level of acceptance among users regarding the ease of use and understanding of the representation of mathematical expressions. In summary, the results point to high user satisfaction with our proposed module.
Table 8.
Evaluation of the user’s perception regarding the operation of Math4e in a 9-point scale for a population size of 12 participants.
5. Conclusions
The absence of inclusive interfaces and tools in the development of mathematical software has considerably impeded the capacity of blind individuals to comprehend and manipulate mathematical expressions. This issue is closely associated with a low enrollment rate of visually impaired individuals in university education, particularly in courses related to mathematical sciences, such as engineering. To overcome these challenges, we have developed Math4e, a sonification module employing synthesized voices, auditory cues, and operator delimiters to provide detailed and assisted descriptions of mathematical expressions within a CAS environment. Our module demonstrates substantial enhancements compared to earlier projects reliant on linear reading. Furthermore, it has been designed to operate independently without needing external hardware, such as braille outputs. This feature is particularly crucial in developing countries like Ecuador. In contrast to prior approaches employing parentheses or pauses to delineate expression boundaries, our solution effectively addresses this issue by adjusting playback volume and integrating audio cues. This proves particularly beneficial for lengthy and intricate mathematical expressions.
The conducted tests, encompassing two distinct scenarios and participants with various forms of blindness (acquired and congenital), have provided crucial insights for developing an effective sonification module. By identifying optimal elements and configurations for audio representation, we strive to make mathematical expressions comprehensible and interpretable, avoiding unnecessary information overload that might impede user concentration. Regarding the evaluation of user satisfaction, following the SAM methodology, the tests reveal a promising level of user acceptance, signifying not only the module’s user-friendly nature but also the satisfaction derived from understanding the representation of the mathematical expressions it offers.
While this proposal enhances the understanding of an equation, it currently focuses solely on reproducing it. There is considerable interest in decomposing the equation into its constituent elements and navigating between them. Therefore, this will be our primary focus for future work. Next, we envision integrating machine learning techniques into Math4e to facilitate automatic adaptation to the unique preferences of individual blind users. This adaptation might encompass personalized adjustments to playback speed and volume levels, and the incorporation of specific tones as auditory cues, among other customizable parameters. Furthermore, we are committed to exploring innovative approaches to improve table accessibility for visually impaired users by augmenting Math4e with spatial audio cues, complementing the auditory cues proposed in this study.
Author Contributions
Conceptualization, A.M.Z. and F.G.; methodology, M.N.S. and F.G.; software, M.N.S.; validation, M.N.S., A.M.Z., F.G., H.C.M. and N.O.G.; formal analysis, A.M.Z. and F.G.; investigation, M.N.S.; resources, A.M.Z.; data curation, A.M.Z., F.G., H.C.M. and N.O.G.; writing—original draft preparation, A.M.Z. and M.N.S.; writing—review and editing, A.M.Z., M.N.S., F.G., H.C.M. and N.O.G.; visualization, M.N.S., H.C.M. and N.O.G.; supervision, A.M.Z. and F.G.; project administration, A.M.Z.; funding acquisition, A.M.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was supported by the Escuela Politécnica Nacional through the Project: Sistema de Cálculo Numérico-Algebraico Virtual Interactivo Para Estudiantes de Ingeniería con Discapcidad Visual PTT-21-02.
Institutional Review Board Statement
Ethical review and approval were waived for this study due to the lack of the ethical committee of the Escuela Politécnica Nacional. The study was conducted following the agreement between the authors and the Milton Vedado Association of the Blind.
Informed Consent Statement
Informed consent was obtained from all subjects involved in the study.
Data Availability Statement
The original contributions presented in the study are included in the article.
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| PAHO | Pan American Health Organization |
| CAS | Computer Algebra System |
| CONADIS | Consejo Nacional para la Igualdad de Discapacidades |
| SAM | Self-Assessment Manikin |
| Math4e | Math for Everybody |
| TTS | Text to Speech |
| SWEBOK | Software Engineering Body of Knowledge |
References
- PAHO. Visual Health. 2019. Available online: https://www.paho.org/en/topics/visual-health (accessed on 1 February 2024).
- Ministerio de Educación y Formación de España. Estadística y Estudios del Ministerio de Educación y Formación Profesional, E. El Alumnado con Necesidad Específica de Apoyo Educativo; Technical report; Ministerio de Educación y Formación de España: Madrid, Spain, 2021. [Google Scholar]
- CONADIS. Disability Statistics. 2023. Available online: https://www.consejodiscapacidades.gob.ec/estadisticas-de-discapacidad/ (accessed on 1 February 2024).
- Mejía, P.; Martini, L.C.; Grijalva, F.; Larco, J.C.; Rodríguez, J.C. A survey on mathematical software tools for visually impaired persons: A practical perspective. IEEE Access 2021, 9, 66929–66947. [Google Scholar] [CrossRef]
- Zambrano, A.M.; Corrales, S.; Parra, C.; Grijalva, F.; Zambrano, J.A. A prototype software for grading management aimed at visually impaired teachers. In Proceedings of the IEEE Sixth Ecuador Technical Chapters Meeting (ETCM), Quito, Ecuador, 11–14 October 2022; pp. 1–6. [Google Scholar]
- Patel, K.K.; Vij, S. Spatial Learning Using Locomotion Interface to Virtual Environment. IEEE Trans. Learn. Technol. 2012, 5, 170–176. [Google Scholar] [CrossRef]
- Merabet, L.B.; Connors, E.C.; Halko, M.A.; Sánchez, J. Teaching the Blind to Find Their Way by Playing Video Games. PLoS ONE 2012, 9, e44958. [Google Scholar] [CrossRef] [PubMed]
- Legge, G.E.; Beckmann, P.J.; Tjan, B.S.; Havey, G.; Kramer, K.; Rolkosky, D.; Gage, R.; Chen, M.; Puchakayala, S.; Rangarajan, A. Indoor Navigation by People with Visual Impairment Using a Digital Sign System. PLoS ONE 2013, 8, e76783. [Google Scholar] [CrossRef] [PubMed]
- Neto, L.B.; Grijalva, F.; Maike, V.R.M.L.; Martini, L.C.; Florencio, D.; Baranauskas, M.C.C.; Rocha, A.; Goldenstein, S. A kinect-based wearable face recognition system to aid visually impaired users. IEEE Trans.-Hum.-Mach. Syst. 2016, 47, 52–64. [Google Scholar] [CrossRef]
- Ningbo, L.; Kaiwei, W.; Ruiqi, C.; Weijian, H.; Kailun, Y. Low power millimeter wave radar system for the visually impaired. J. Eng. 2019, 19, 6034–6038. [Google Scholar]
- Xuan, H.; Huailin, Z.; Chenxu, W.; Huaping, L. Knowledge driven indoor object-goal navigation aid for visually impaired people. Cogn. Comput. Syst. 2022, 4, 329–339. [Google Scholar]
- Acuña, B.; Martini, L.C.; Motta, L.L.; Larco, J.; Grijalva, F. Table detection for improving accessibility of digital documents using a deep learning approach. In Proceedings of the IEEE Latin American Conference on Computational Intelligence (LA-CCI), Guayaquil, Ecuador, 11–15 November 2019; pp. 1–6. [Google Scholar]
- Kingsley, O.; Hossein, J.; Abdel-Rahman H., T. Accessibility of dynamic web applications with emphasis on visually impaired users. J. Eng. 2014, 2014, 531–537. [Google Scholar]
- Sodhi, M.S.; Holl, W. Mathematical and Statistical System 5.0: Workhorse programming language proves a valuable tool for financial, econometric and statistical professionals and students, as well as operations researchers. OR/MS Today 2003, 30, 46–51. [Google Scholar]
- William, S. MAXIMA A Computer Algebra System. 2022. Available online: https://maxima.sourceforge.io/ (accessed on 1 July 2024).
- MathWorks. Matlab; MATLAB: Natick, MA, USA, 2023. [Google Scholar]
- Cannon, J.; Playoust, C. Using the Magma Computer Algebra System in Abstract Algebra Courses. J. Symb. Comput. 1997, 23, 459–484. [Google Scholar] [CrossRef][Green Version]
- Teixeira, C.S.C.; Moorkens, J.; Turner, D.; Vreeke, J.; Way, A. Creating a Multimodal Translation Tool and Testing Machine Translation Integration Using Touch and Voice. Informatics 2019, 6, 13. [Google Scholar] [CrossRef]
- Moloo, D.R.K. Audio Instructional Design Best Practices for an Enhanced Learning Experience. A Mixed Holistic-Systematic Mapping Study. IEEE Trans. Learn. Technol. 2023, 17, 725–740. [Google Scholar] [CrossRef]
- CESE-Australia. Cognitive Load Theory: Research That Teachers Really Need to Understand; Technical report; NSW Department of Education: Sydney, NSW, Australia, 2017. [Google Scholar]
- Zambrano, A.; Pilacuan, D.; Salvador, M.N.; Grijalva, F.; Garzón, N.O.; Mora, H.C. IrisMath: A Blind-friendly Web-based Computer Algebra System. IEEE Access 2023, 11, 71766–71776. [Google Scholar] [CrossRef]
- Nazemi, A.; Murray, I.; Mohammadi, N. Mathspeak: An Audio Method for Presenting Mathematical Formulae to Blind Students. In Proceedings of the 5th International Conference on Human System Interactions, Perth, WA, Australia, 6–8 June 2012; pp. 48–52. [Google Scholar]
- Fuentes, J.S. Accesibilidad en Expresiones Matematicas. Bachelor’s Thesis, Universidad de Concepción, Concepción, Chile, 2011. [Google Scholar]
- Barraza, P.; Gillan, D.J.; Karshmer, A.; Pazuchanics, S. A Cognitive Analysis of Equation Reading Applied to the Development of Assistive Technology for Visually-Impaired Students. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2004, 5, 922–926. [Google Scholar] [CrossRef]
- Schweikhardt, W.; Bernareggi, C.; Jessel, N.; Encelle, B.; Gut, M. LAMBDA: A European System to Access Mathematics with Braille and Audio Synthesis. In Proceedings of the 10th International Conference, ICCHP 2006, Linz, Austria, 11–13 July 2006; Volume 4061, pp. 1223–1230. [Google Scholar]
- Neeser, R. L-MATH: Linear Algebra for Geometric Applications. 2022. Available online: https://github.com/TheRiver/L-MATH (accessed on 1 July 2024).
- Mejía, P.; Martini, L.C.; Grijalva, F.; Zambrano, A.M. CASVI: Computer Algebra System Aimed at Visually Impaired People. Experiments. IEEE Access 2021, 9, 157021–157034. [Google Scholar] [CrossRef]
- Kondak, Z.; Liang, T.; Tomlinson, B.; Walker, B. Web Sonification Sandbox—an Easy-to-Use Web Application for Sonifying Data and Equations. In Proceedings of the 3rd Web Audio Conference, London, UK, 24 August 2017. [Google Scholar]
- Mejía, P.; César Martini, L.; Larco, J.; Grijalva, F. Casvi: A computer algebra system aimed at visually impaired people. In Computers Helping People with Special Needs, Proceedings of the 16th International Conference, ICCHP 2018, Linz, Austria, 11–13 July 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 573–578. [Google Scholar]
- Al-Jarf, R. Text-To-Speech Software for Promoting EFL Freshman Students’ Decoding Skills and Pronunciation Accuracy. J. Comput. Sci. Technol. Stud. 2022, 4, 19–30. [Google Scholar] [CrossRef]
- Woods, D.L.; Alain, C.; Diaz, R.; Rhodes, D.; Ogawa, K.H. Location and frequency cues in auditory selective attention. J. Exp. Psychol. Hum. Percept. Perform. 2001, 27, 65–74. [Google Scholar] [CrossRef]
- Bhore, N.; Mahala, S.; Acharekar, K.; Waghmare, M. Email System for Visually Impaired People. Int. J. Eng. Res. Technol. 2020, 9, 286–291. [Google Scholar]
- Bertonati, G.; Amadeo, M.B.; Campus, C.; Gori, M. Auditory speed processing in sighted and blind individuals. PLoS ONE 2021, 16, e0257676. [Google Scholar] [CrossRef]
- Gledec, G.; Horvat, M.; Mikuc, M.; Blašković, B. A Comprehensive Dataset of Spelling Errors and Users’ Corrections in Croatian Language. Data 2023, 8, 89. [Google Scholar] [CrossRef]
- Brulé, E.; Tomlinson, B.J.; Metatla, O.; Jouffrais, C.; Serrano, M. Review of Quantitative Empirical Evaluations of Technology for People with Visual Impairments. In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020. [Google Scholar]
- ISO/IEC/IEEE 29119; Software and Systems Engineering—Software Testing. ISO: Geneva, Switzerland, 2022.
- Board, I.S.T.Q. Software Testing Qualifications Board, y Hispanic America Software Testing Qualifications Board, “Probador Certificado del ISTQB”; CTFL-ISTQB: EEUU; International Software Testing Qualifications Board: Tampa, FL, USA, 2018. [Google Scholar]
- Bourque, P.; Fairley, R.E. Guide to the Software Engineering Body of KnowledgeVersion 3.0 SWEBOK; IEEE: Piscataway, NJ, USA, 2014. [Google Scholar]
- Bradley, M.M.; Lang, P.J. Measuring emotion: The self-assessment manikin and the semantic differential. J. Behav. Ther. Exp. Psychiatry 1994, 25, 49–59. [Google Scholar] [CrossRef] [PubMed]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).