


Deep Learning-Based Vision Systems for Robot Semantic Navigation: An Experimental Study
 and
and
Abstract
1. Introduction
- It reviews object detection algorithms that have been employed in robot semantic navigation systems.
- It discusses and analyzes existing vision datasets for indoor robot semantic navigation systems.
- It validates the efficiency of several object detection algorithms along with an object detection dataset through several experiments conducted in indoor environments.
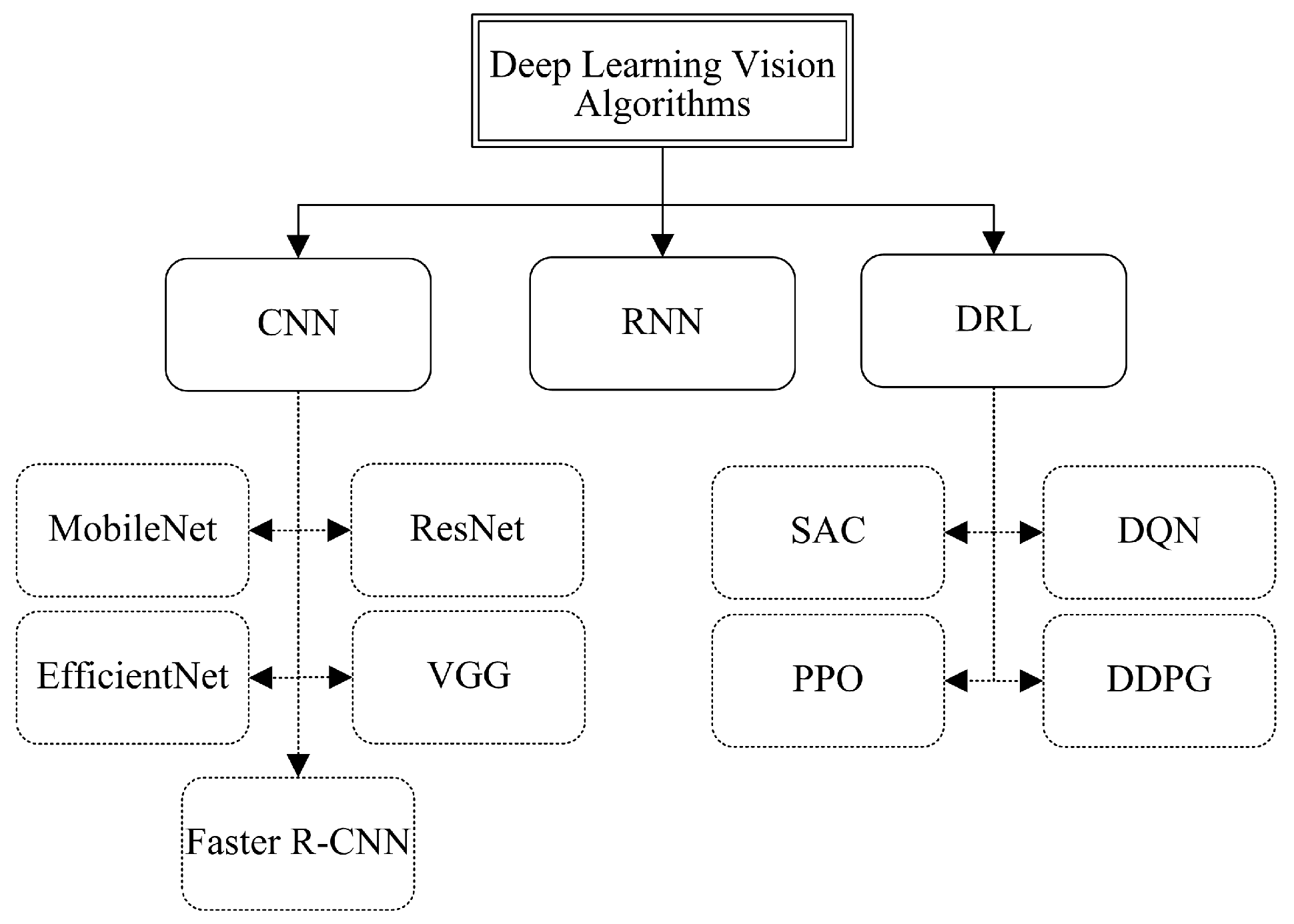
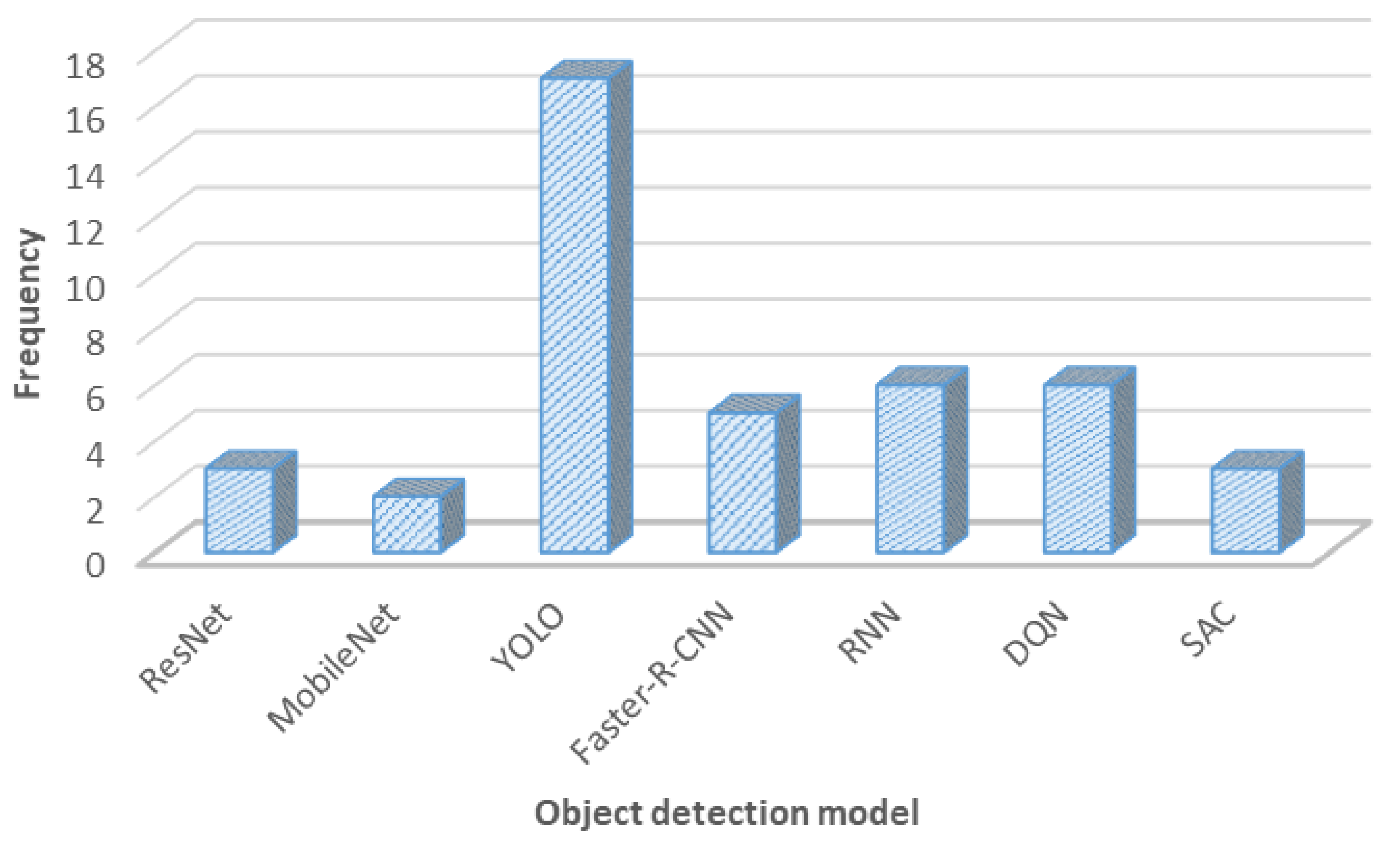
2. Object Detection Algorithms for Robot Semantic Navigation
- Indoor Robot Navigation: Object detection allows robots to perceive and recognize obstacles, furniture, or specific objects within indoor environments. This capability lets them plan optimal paths, avoid collisions, and safely navigate complex spaces [6].
- Manufacturing Quality Control: Object detection is essential in automated quality control systems within manufacturing settings. It helps identify defects, anomalies, or irregularities in products, ensuring consistent quality and minimizing errors during the production process [7].
- Autonomous Driving: Object detection is a fundamental component of autonomous driving systems. By detecting and tracking vehicles, pedestrians, traffic signs, and other objects in real-time, object detection enables self-driving cars to perceive their surroundings, make informed decisions, and respond to dynamic traffic situations [8].
2.1. Convolutional Neural Network (CNN) Object Detection Algorithms
2.1.1. Residual Network (ResNet)
2.1.2. Visual Geometry Group (VGG)
2.1.3. MobileNet
2.1.4. EfficientNet
2.1.5. YOLO
2.1.6. Faster R-CNN
2.2. Recurrent Neural Network (RNN) Object Detection Algorithms
2.3. Deep Reinforcement Learning (DRL) Object Detection Algorithms
2.3.1. Deep Q-Network (DQN)
2.3.2. Deep Deterministic Policy Gradient (DDPG)
2.3.3. Soft Actor-Critic (SAC)
2.3.4. Proximal Policy Optimization (PPO)
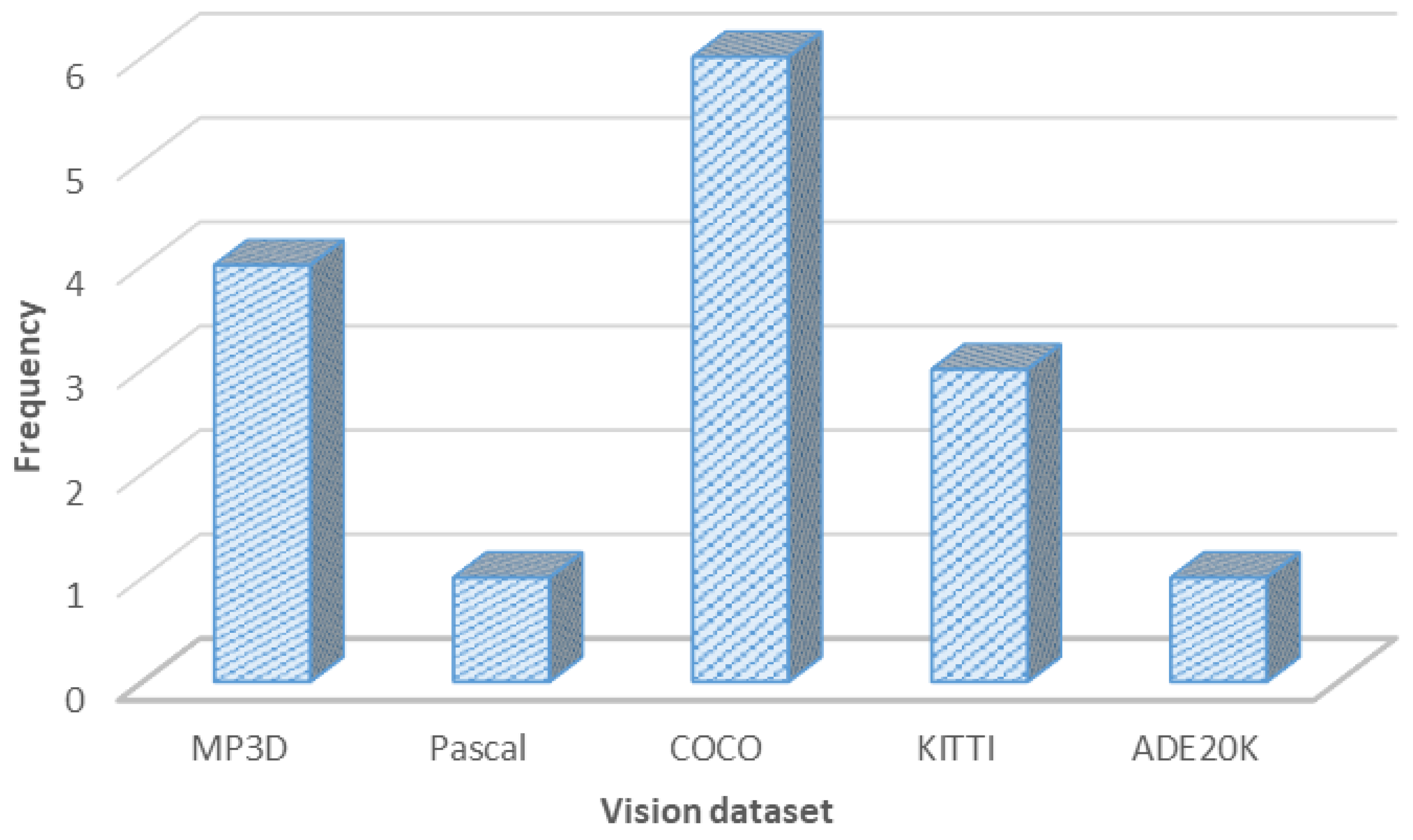
3. Vision Datasets for Robot Semantic Navigation
3.1. Microsoft Common Objects in Context Dataset (MS COCO)
3.2. Matterport 3D Dataset (MP3D)
3.3. Pascal VOC 2012 Dataset
3.4. KITTI Dataset
3.5. ADE20K Dataset
4. Experimental Study
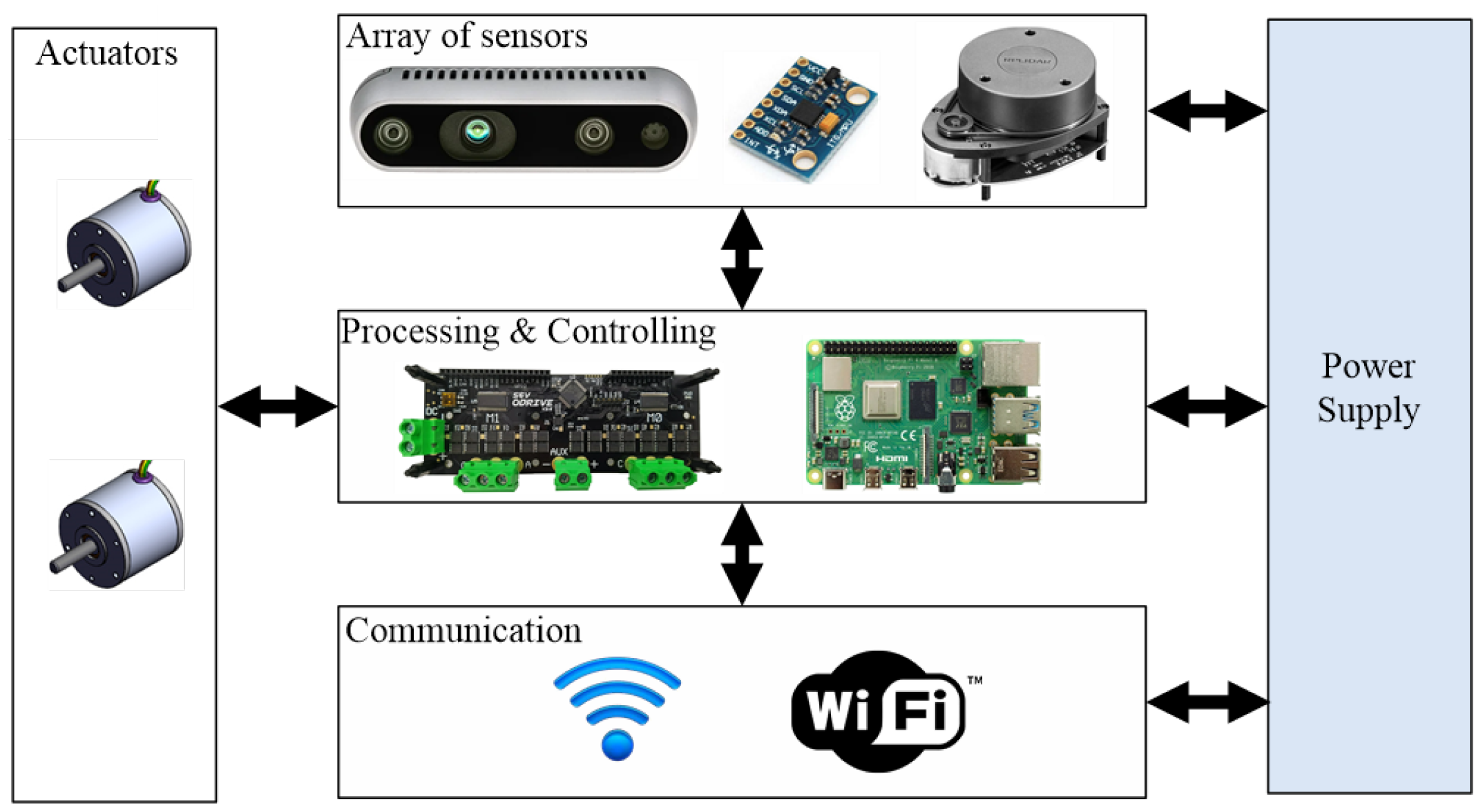
4.1. Environment Development
4.2. Experimental Results
- Object detection rate (ODR): This refers to the total number of objects that were successfully detected (true positive detections) using the employed object detection model, denoted as ‘’ in Equation (1), compared to the total number of existing objects in the environment, and referred to as ‘’ in the following equation:
- Object detection accuracy: This refers to the classification accuracy of the object detection model. In our study, we utilized the mean Average Precision metric to evaluate the model’s performance comprehensively. The aggregates precision scores across classes. Here is how it can be mathematically described.Let
- represent the Average Precision value for class i;
- N be the total number of classes.
The is calculated by averaging the across all classes, as follows:In this equation, the for each class is calculated individually, and then the mean of these values is calculated to obtain the score. To get to this point, we have to calculate the for class i, as shown in the following equation:where is the precision at recall level r, and is the change in recall from the previous recall level.The for a given class i is calculated by adding the precision values at various recall levels and weighting them by calculating the change in the recall. This technique aids in assessing how well the model detects objects of a certain class at varying confidence levels.The following is how to calculate both and in the average precision:- (a)
- Finding at a Specific Recall Level r:
- To calculate precision at a specific recall level r, we need to consider the precision value associated with the highest recall that is less than or equal to r, as follows:
- The precision at a specific recall level is the maximum precision value for all detections with a recall greater than or equal to that recall level.
- (b)
- Determining (change in the Recall):
- represents the change in recall from the previous recall level to the current recall level in the precision–recall curve, and it is calculated as follows:
- For each recall level, can be calculated as the difference between the current recall level and the previous recall level.
By computing precision at different recall levels and measuring the change in recall from one level to the next, we can effectively determine the precision–recall curve and subsequently calculate the for a specific class in object detection tasks.Finally, to determine the recall and precision for each class, we used the following equations:Precision:Recall:where- True Positives : Instances that the model correctly identifies as positive.
- False Positives : Instances that the model wrongly classifies as positive.
- False Negatives : Instances that the model wrongly classifies as negative but are positive.
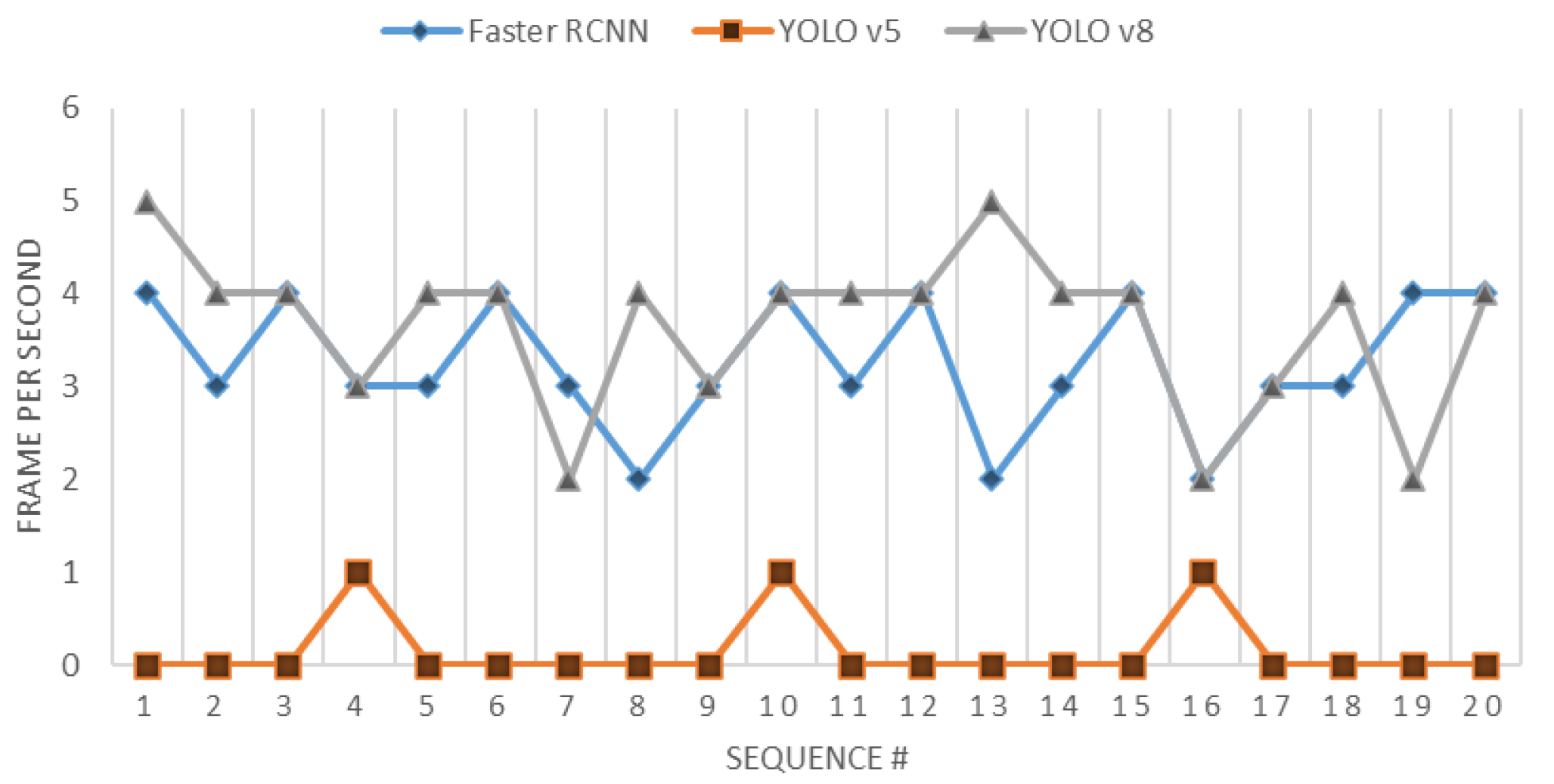
- Processing time for the object detection model: This refers to the total time required for the model to process the input frames obtained from the vision unit and perform the detection task. The processing time for the object detection model can be calculated as the difference between the end time and the start time of the processing task, formulated as follows:
5. Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alenzi, Z.; Alenzi, E.; Alqasir, M.; Alruwaili, M.; Alhmiedat, T.; Alia, O.M. A semantic classification approach for indoor robot navigation. Electronics 2022, 11, 2063. [Google Scholar] [CrossRef]
- Alhmiedat, T.; Marei, A.M.; Messoudi, W.; Albelwi, S.; Bushnag, A.; Bassfar, Z.; Alnajjar, F.; Elfaki, A.O. A SLAM-based localization and navigation system for social robots: The pepper robot case. Machines 2023, 11, 158. [Google Scholar] [CrossRef]
- Bhatt, D.; Patel, C.; Talsania, H.; Patel, J.; Vaghela, R.; Pandya, S.; Modi, K.; Ghayvat, H. CNN Variants for Computer Vision: History, Architecture, Application, Challenges and Future Scope. Electronics 2021, 10, 2470. [Google Scholar] [CrossRef]
- Alamri, S.; Alamri, H.; Alshehri, W.; Alshehri, S.; Alaklabi, A.; Alhmiedat, T. An autonomous maze-solving robotic system based on an enhanced wall-follower approach. Machines 2023, 11, 249. [Google Scholar] [CrossRef]
- Alqobali, R.; Alshmrani, M.; Alnasser, R.; Rashidi, A.; Alhmiedat, T.; Alia, O.M. A Survey on Robot Semantic Navigation Systems for Indoor Environments. Appl. Sci. 2023, 14, 89. [Google Scholar] [CrossRef]
- Uçar, A.; Demir, Y.; Güzeliş, C. Object recognition and detection with deep learning for autonomous driving applications. Simulation 2017, 93, 759–769. [Google Scholar] [CrossRef]
- Hernández, A.C.; Gómez, C.; Crespo, J.; Barber, R. Object Detection Applied to Indoor Environments for Mobile Robot Navigation. Sensors 2016, 16, 1180. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems 25, Lake Tahoe, NV, USA, 3–6 December 2012. [Google Scholar]
- Li, Z.; Liu, F.; Yang, W.; Peng, S.; Zhou, J. A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects. IEEE Trans. Neural Netw. Learn. Syst. 2022, 33, 6999–7019. [Google Scholar] [CrossRef] [PubMed]
- Ni, J.; Gong, T.; Gu, Y.; Zhu, J.; Fan, X. An improved deep residual network-based semantic simultaneous localization and mapping method for monocular vision robot. Comput. Intell. Neurosci. 2020, 2020, 7490840. [Google Scholar] [CrossRef]
- Mousavian, A.; Toshev, A.; Fišer, M.; Košecká, J.; Wahid, A.; Davidson, J. Visual representations for semantic target driven navigation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8846–8852. [Google Scholar]
- Teso-Fz-Betoño, D.; Zulueta, E.; Sánchez-Chica, A.; Fernandez-Gamiz, U.; Saenz-Aguirre, A. Semantic segmentation to develop an indoor navigation system for an autonomous mobile robot. Mathematics 2020, 8, 855. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Dang, T.V.; Bui, N.T. Multi-scale fully convolutional network-based semantic segmentation for mobile robot navigation. Electronics 2023, 12, 533. [Google Scholar] [CrossRef]
- Kim, W.; Seok, J. Indoor semantic segmentation for robot navigating on mobile. In Proceedings of the 2018 Tenth International Conference on Ubiquitous and Future Networks (ICUFN), Prague, Czech Republic, 3–6 July 2018; pp. 22–25. [Google Scholar]
- Dang, T.V.; Tran, D.M.C.; Tan, P.X. IRDC-Net: Lightweight Semantic Segmentation Network Based on Monocular Camera for Mobile Robot Navigation. Sensors 2023, 23, 6907. [Google Scholar] [CrossRef] [PubMed]
- Wei, Y.; Wei, W.; Zhang, Y. EfferDeepNet: An Efficient Semantic Segmentation Method for Outdoor Terrain. Machines 2023, 11, 256. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Lecture Notes in Computer Science; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Bersan, D.; Martins, R.; Campos, M.; Nascimento, E.R. Semantic map augmentation for robot navigation: A learning approach based on visual and depth data. In Proceedings of the 2018 Latin American Robotic Symposium, 2018 Brazilian Symposium on Robotics (SBR) and 2018 Workshop on Robotics in Education (WRE), João Pessoa, Brazil, 6–10 November 2018; pp. 45–50. [Google Scholar]
- Martins, R.; Bersan, D.; Campos, M.F.; Nascimento, E.R. Extending maps with semantic and contextual object information for robot navigation: A learning-based framework using visual and depth cues. J. Intell. Robot. Syst. 2020, 99, 555–569. [Google Scholar] [CrossRef]
- Dos Reis, D.H.; Welfer, D.; De Souza Leite Cuadros, M.A.; Gamarra, D.F.T. Mobile robot navigation using an object recognition software with RGBD images and the YOLO algorithm. Appl. Artif. Intell. 2019, 33, 1290–1305. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Sun, J.; Zhao, L.; Shi, H.; Seah, H.S.; Tandianus, B. Object-Aware Hybrid Map for Indoor Robot Visual Semantic Navigation. In Proceedings of the 2019 IEEE International Conference on Robotics and Biomimetics (ROBIO), Dali, China, 6–8 December 2019; pp. 1166–1172. [Google Scholar]
- Anebarassane, Y.; Kumar, D.; Chandru, A.; Adithya, P.; Sathiyamurthy, K. Enhancing ORB-SLAM3 with YOLO-based Semantic Segmentation in Robotic Navigation. In Proceedings of the 2023 IEEE World Conference on Applied Intelligence and Computing (AIC), Sonbhadra, India, 29–30 July 2023; pp. 874–879. [Google Scholar]
- Mengcong, X.; Li, M. Object semantic annotation based on visual SLAM. In Proceedings of the 2021 Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS), Shenyang, China, 22–24 January 2021; pp. 197–201. [Google Scholar]
- Miyamoto, R.; Adachi, M.; Nakamura, Y.; Nakajima, T.; Ishida, H.; Kobayashi, S. Accuracy improvement of semantic segmentation using appropriate datasets for robot navigation. In Proceedings of the 2019 6th International Conference on Control, Decision and Information Technologies (CoDIT), Paris, France, 23–26 April 2019; pp. 1610–1615. [Google Scholar]
- Henke dos Reis, D.; Welfer, D.; de Souza Leite Cuadros, M.A.; Tello Gamarra, D.F. Object Recognition Software Using RGBD Kinect Images and the YOLO Algorithm for Mobile Robot Navigation. In Intelligent Systems Design and Applications: 19th International Conference on Intelligent Systems Design and Applications (ISDA 2019) held December 3–5, 2019; Springer: Berlin/Heidelberg, Germany, 2021; pp. 255–263. [Google Scholar]
- Xia, X.; Zhang, P.; Sun, J. YOLO-Based Semantic Segmentation for Dynamic Removal in Visual-Inertial SLAM. In Proceedings of the 2023 Chinese Intelligent Systems Conference; Springer: Berlin/Heidelberg, Germany, 2023; pp. 377–389. [Google Scholar]
- Truong, P.H.; You, S.; Ji, S. Object detection-based semantic map building for a semantic visual SLAM system. In Proceedings of the 2020 20th International Conference on Control, Automation and Systems (ICCAS), Busan, Republic of Korea, 13–16 October 2020; pp. 1198–1201. [Google Scholar]
- Liu, X.; Muise, C. A Neural-Symbolic Approach for Object Navigation. In Proceedings of the 2nd Embodied AI Workshop (CVPR 2021), Virtual, 20 June 2021; pp. 19–25. [Google Scholar]
- Chaves, D.; Ruiz-Sarmiento, J.R.; Petkov, N.; Gonzalez-Jimenez, J. Integration of CNN into a robotic architecture to build semantic maps of indoor environments. In Advances in Computational Intelligence: 15th International Work-Conference on Artificial Neural Networks, IWANN 2019, Gran Canaria, Spain, June 12–14, 2019, Proceedings, Part II 15; Springer: Berlin/Heidelberg, Germany, 2019; pp. 313–324. [Google Scholar]
- Joo, S.H.; Manzoor, S.; Rocha, Y.G.; Bae, S.H.; Lee, K.H.; Kuc, T.Y.; Kim, M. Autonomous navigation framework for intelligent robots based on a semantic environment modeling. Appl. Sci. 2020, 10, 3219. [Google Scholar] [CrossRef]
- Qiu, H.; Lin, Z.; Li, J. Semantic Map Construction via Multi-sensor Fusion. In Proceedings of the 2021 36th Youth Academic Annual Conference of Chinese Association of Automation (YAC), Nanchang, China, 28–30 May 2021; pp. 495–500. [Google Scholar]
- Fernandes, J.C.d.C.S. Semantic Mapping with a Mobile Robot Using a RGB-D Camera. Master’s Thesis, Laboratório de Robótica Móvel, Instituto de Sistemas e Robótica-Universidade de Coimbra, Coimbra, Portugal, 2019. [Google Scholar]
- Xu, X.; Liu, L.I.; Xiong, R.; Jiang, L. Real-time instance-aware semantic mapping. J. Phys. Conf. Ser. 2020, 1507, 052013. [Google Scholar] [CrossRef]
- Liu, X.; Wen, S.; Pan, Z.; Xu, C.; Hu, J.; Meng, H. Vision-IMU multi-sensor fusion semantic topological map based on RatSLAM. Measurement 2023, 220, 113335. [Google Scholar] [CrossRef]
- Xie, Z.; Li, Z.; Zhang, Y.; Zhang, J.; Liu, F.; Chen, W. A multi-sensory guidance system for the visually impaired using YOLO and ORB-SLAM. Information 2022, 13, 343. [Google Scholar] [CrossRef]
- Qi, X.; Wang, W.; Liao, Z.; Zhang, X.; Yang, D.; Wei, R. Object semantic grid mapping with 2D LiDAR and RGB-D camera for domestic robot navigation. Appl. Sci. 2020, 10, 5782. [Google Scholar] [CrossRef]
- Sun, H.; Meng, Z.; Ang, M.H. Semantic mapping and semantics-boosted navigation with path creation on a mobile robot. In Proceedings of the 2017 IEEE International Conference on Cybernetics and Intelligent Systems (CIS) and IEEE Conference on Robotics, Automation and Mechatronics (RAM), Ningbo, China, 19–21 November 2017; pp. 207–212. [Google Scholar]
- Shao, C.; Zhang, L.; Pan, W. Faster R-CNN learning-based semantic filter for geometry estimation and its application in vSLAM systems. IEEE Trans. Intell. Transp. Syst. 2021, 23, 5257–5266. [Google Scholar] [CrossRef]
- Sevugan, A.; Karthikeyan, P.; Sarveshwaran, V.; Manoharan, R. Optimized navigation of mobile robots based on Faster R-CNN in wireless sensor network. Int. J. Sens. Wirel. Commun. Control 2022, 12, 440–448. [Google Scholar] [CrossRef]
- Sun, Y.; Su, T.; Tu, Z. Faster R-CNN based autonomous navigation for vehicles in warehouse. In Proceedings of the 2017 IEEE International Conference on Advanced Intelligent Mechatronics (AIM), Munich, Germany, 3–7 July 2017; pp. 1639–1644. [Google Scholar]
- Zhang, Z.; Zhang, J.; Tang, Q. Mask R-CNN based semantic RGB-D SLAM for dynamic scenes. In Proceedings of the 2019 IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Hong Kong, China, 8–12 July 2019; pp. 1151–1156. [Google Scholar]
- Sinha, R.K.; Pandey, R.; Pattnaik, R. Deep Learning For Computer Vision Tasks: A review. arXiv 2018, arXiv:1804.03928. [Google Scholar]
- Cheng, J.; Sun, Y.; Meng, M.Q.H. A dense semantic mapping system based on CRF-RNN network. In Proceedings of the 2017 18th International Conference on Advanced Robotics (ICAR), Hong Kong, China, 10–12 July 2017; pp. 589–594. [Google Scholar]
- Xiang, Y.; Fox, D. DA-RNN: Semantic mapping with data associated recurrent neural networks. arXiv 2017, arXiv:1703.03098. [Google Scholar]
- Zubair Irshad, M.; Chowdhury Mithun, N.; Seymour, Z.; Chiu, H.P.; Samarasekera, S.; Kumar, R. SASRA: Semantically-aware Spatio-temporal Reasoning Agent for Vision-and-Language Navigation in Continuous Environments. In Proceedings of the 2022 26th International Conference on Pattern Recognition (ICPR), Montreal, QC, Canada, 21–25 August 2022. [Google Scholar]
- Zhang, Y.; Feng, Z. Crowd-Aware Mobile Robot Navigation Based on Improved Decentralized Structured RNN via Deep Reinforcement Learning. Sensors 2023, 23, 1810. [Google Scholar] [CrossRef]
- Ondruska, P.; Dequaire, J.; Wang, D.Z.; Posner, I. End-to-end tracking and semantic segmentation using recurrent neural networks. arXiv 2016, arXiv:1604.05091. [Google Scholar]
- Le, N.; Rathour, V.S.; Yamazaki, K.; Luu, K.; Savvides, M. Deep Reinforcement Learning in Computer Vision: A Comprehensive Survey. arXiv 2021, arXiv:2108.11510. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, X.; Xu, Y.; Guo, J. A deep Q-network (DQN) based path planning method for mobile robots. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Wuyishan, China, 11–13 August 2018; pp. 366–371. [Google Scholar]
- Reddy, D.R.; Chella, C.; Teja, K.B.R.; Baby, H.R.; Kodali, P. Autonomous Vehicle Based on Deep Q-Learning and YOLOv3 with Data Augmentation. In Proceedings of the 2021 International Conference on Communication, Control and Information Sciences (ICCISc), Idukki, India, 16–18 June 2021; Volume 1, pp. 1–7. [Google Scholar]
- Zeng, F.; Wang, C.; Ge, S.S. A survey on visual navigation for artificial agents with deep reinforcement learning. IEEE Access 2020, 8, 135426–135442. [Google Scholar] [CrossRef]
- Dai, Y.; Yang, S.; Lee, K. Sensing and Navigation for Multiple Mobile Robots Based on Deep Q-Network. Remote Sens. 2023, 15, 4757. [Google Scholar] [CrossRef]
- Vuong, T.A.T.; Takada, S. Semantic Analysis for Deep Q-Network in Android GUI Testing. In Proceedings of the SEKE, Lisbon, Portugal, 10–12 July 2019; pp. 123–170. [Google Scholar]
- Kästner, L.; Marx, C.; Lambrecht, J. Deep-reinforcement-learning-based semantic navigation of mobile robots in dynamic environments. In Proceedings of the 2020 IEEE 16th International Conference on Automation Science and Engineering (CASE), Hong Kong, China, 20–21 August 2020; pp. 1110–1115. [Google Scholar]
- Xu, J.; Zhang, H.; Qiu, J. A deep deterministic policy gradient algorithm based on averaged state-action estimation. Comput. Electr. Eng. 2022, 101, 108015. [Google Scholar] [CrossRef]
- Zhu, K.; Zhang, T. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Sci. Technol. 2021, 26, 674–691. [Google Scholar] [CrossRef]
- Haarnoja, T.; Zhou, A.; Hartikainen, K.; Tucker, G.; Ha, S.; Tan, J.; Kumar, V.; Zhu, H.; Gupta, A.; Abbeel, P.; et al. Soft actor-critic algorithms and applications. arXiv 2018, arXiv:1812.05905. [Google Scholar]
- Sharma, S. SAC-RL: Continuous Control of Wheeled Mobile Robot for Navigation in a Dynamic Environment. Ph.D. Thesis, Indian Institute of Technology Patna, Patna, India, 2020. [Google Scholar]
- Wahid, A.; Stone, A.; Chen, K.; Ichter, B.; Toshev, A. Learning object-conditioned exploration using distributed soft actor critic. Proc. Conf. Robot. Learn. PMLR 2021, 155, 1684–1695. [Google Scholar]
- Schulman, J.; Wolski, F.; Dhariwal, P.; Radford, A.; Klimov, O. Proximal Policy Optimization Algorithms. arXiv 2017, arXiv:1707.06347. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; Ramanan, D.; Zitnick, C.L.; Dollár, P. Microsoft COCO: Common Objects in Context. arXiv 2015, arXiv:1405.0312. [Google Scholar]
- Pereira, R.; Gonçalves, N.; Garrote, L.; Barros, T.; Lopes, A.; Nunes, U.J. Deep-learning based global and semantic feature fusion for indoor scene classification. In Proceedings of the 2020 IEEE International Conference on Autonomous Robot Systems and Competitions (ICARSC), Ponta Delgada, Portugal, 15–17 April 2020; pp. 67–73. [Google Scholar]
- Georgakis, G.; Bucher, B.; Schmeckpeper, K.; Singh, S.; Daniilidis, K. Learning to map for active semantic goal navigation. arXiv 2021, arXiv:2106.15648. [Google Scholar]
- Yu, D.; Khatri, C.; Papangelis, A.; Namazifar, M.; Madotto, A.; Zheng, H.; Tur, G. Common sense and Semantic-Guided Navigation via Language in Embodied Environments. In Proceedings of the International Conference on Learning Representations ICLR 2020, Addis Ababa, Ethiopia, 30 April 2020. [Google Scholar]
- Krantz, J. Semantic Embodied Navigation: Developing Agents That Navigate from Language and Vision. Ph.D. Thesis, Oregon State University, Corvallis, OR, USA, 2023. [Google Scholar]
- Narasimhan, M.; Wijmans, E.; Chen, X.; Darrell, T.; Batra, D.; Parikh, D.; Singh, A. Seeing the un-scene: Learning amodal semantic maps for room navigation. In Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, August 23–28, 2020, Proceedings, Part XVIII 16; Springer: Berlin/Heidelberg, Germany, 2020; pp. 513–529. [Google Scholar]
- Vicente, S.; Carreira, J.; Agapito, L.; Batista, J. Reconstructing PASCAL VOC. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. Semantickitti: A dataset for semantic scene understanding of lidar sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9297–9307. [Google Scholar]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Gall, J.; Stachniss, C. Towards 3D LiDAR-based semantic scene understanding of 3D point cloud sequences: The SemanticKITTI Dataset. Int. J. Robot. Res. 2021, 40, 959–967. [Google Scholar] [CrossRef]
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Zhou, B.; Zhao, H.; Puig, X.; Fidler, S.; Barriuso, A.; Torralba, A. Scene Parsing through ADE20K Dataset. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5122–5130. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; Xue, B.; Zhuo, H.; Liao, L.; Yang, X.; Zhu, Z. Perceiving like a Bat: Hierarchical 3D Geometric and ndash;Semantic Scene Understanding Inspired by a Biomimetic Mechanism. Biomimetics 2023, 8, 436. [Google Scholar] [CrossRef] [PubMed]
- Raspberry Pi 4 2024. Available online: http://www.raspberrypi.com/products/raspberry-pi-4-model-b/ (accessed on 21 August 2024).
- RPLiDAR A1 2024. Available online: http://www.slamtec.ai/product/slamtec-rplidar-a1/ (accessed on 21 August 2024).
- Logitech Webcam 2024. Available online: https://www.logitech.com/en-sa/products/webcams/c920-pro-hd-webcam.960-001055.html (accessed on 21 August 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Application | Records | Classes | Size |
|---|---|---|---|---|
| COCO | Indoor | 330,000 | 80 | 25 GB |
| Matterport | Indoor | 10,800 | 40 | 176 GB |
| Cityscapes | Outdoor | 5000 | 30 | 11 GB |
| PASCAL | Outdoor | 11,530 | 20 | 2 GB |
| KITTI | Outdoor | 3978 | 11 | 5.27 GB |
| ADE20K | Hybrid | 20,210 | 150 | 4.38 GB |
| Specification | Value |
|---|---|
| Processor | Raspberry Pi 4—4 GB RAM |
| Driver control | O-drive |
| Ranger-finder | RPLiDAR A1 |
| Vision unit | 2MP Logitech Webcam |
| Robot dimension | 55 × 45 cm |
| Robot speed | 0.5 m/s |
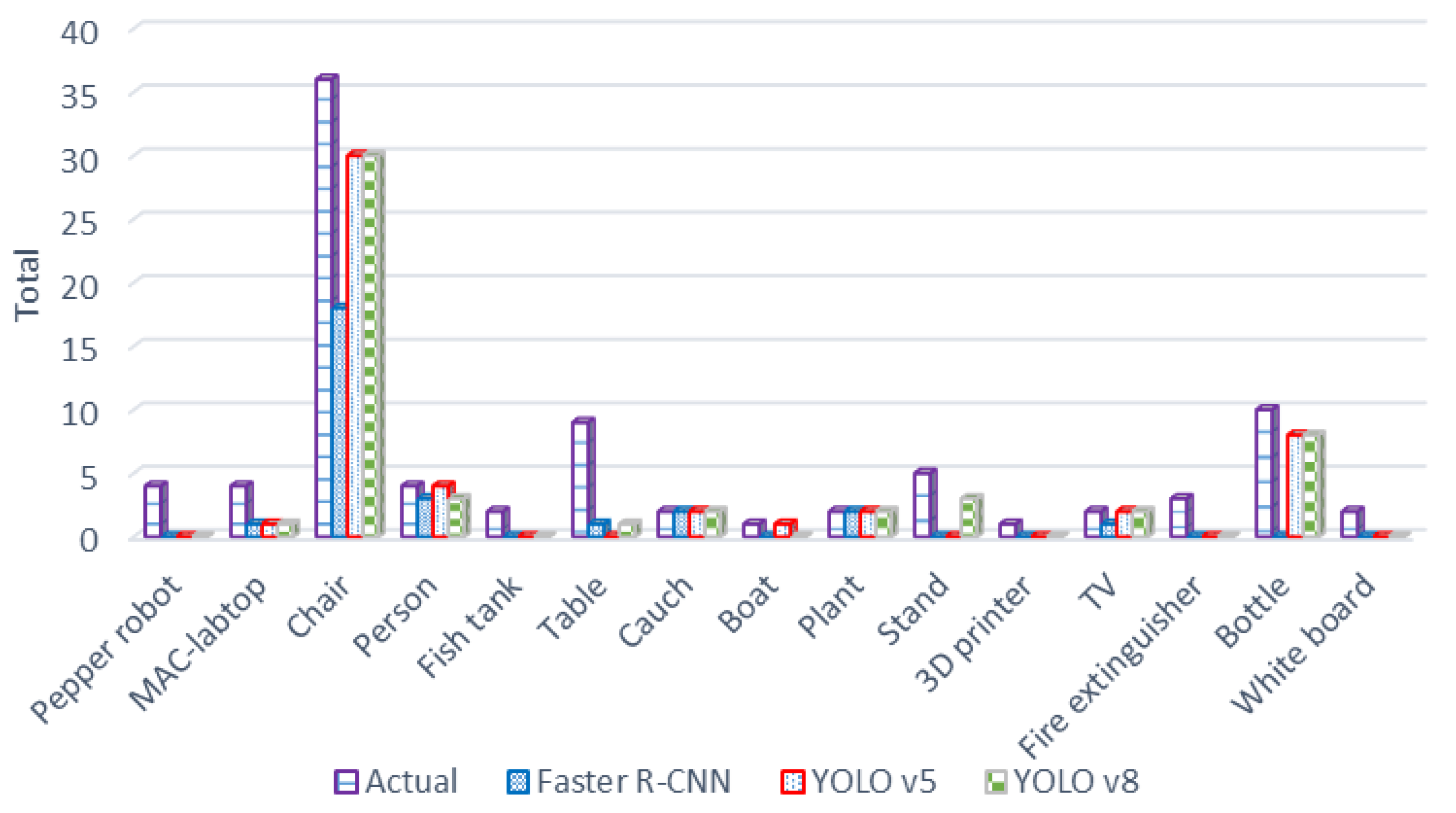
| Object | Total Exist | Faster R-CNN | YOLO v5 | YOLO v8 |
|---|---|---|---|---|
| Pepper robot | 4 | 0 | 0 | 0 |
| MAC-PC | 4 | 1 | 1 | 1 |
| Chair | 36 | 18 | 30 | 30 |
| Person | 4 | 3 | 4 | 3 |
| Fish tank | 2 | 0 | 0 | 0 |
| Table | 9 | 1 | 0 | 1 |
| Couch | 2 | 2 | 2 | 2 |
| Boat | 1 | 0 | 1 | 0 |
| Plant | 2 | 2 | 2 | 2 |
| Stand | 5 | 0 | 0 | 3 |
| 3D printer | 1 | 0 | 0 | 0 |
| TV | 2 | 1 | 2 | 2 |
| Fire extinguisher | 3 | 0 | 0 | 0 |
| Bottle | 10 | 0 | 8 | 8 |
| Whiteboard | 2 | 0 | 0 | 0 |
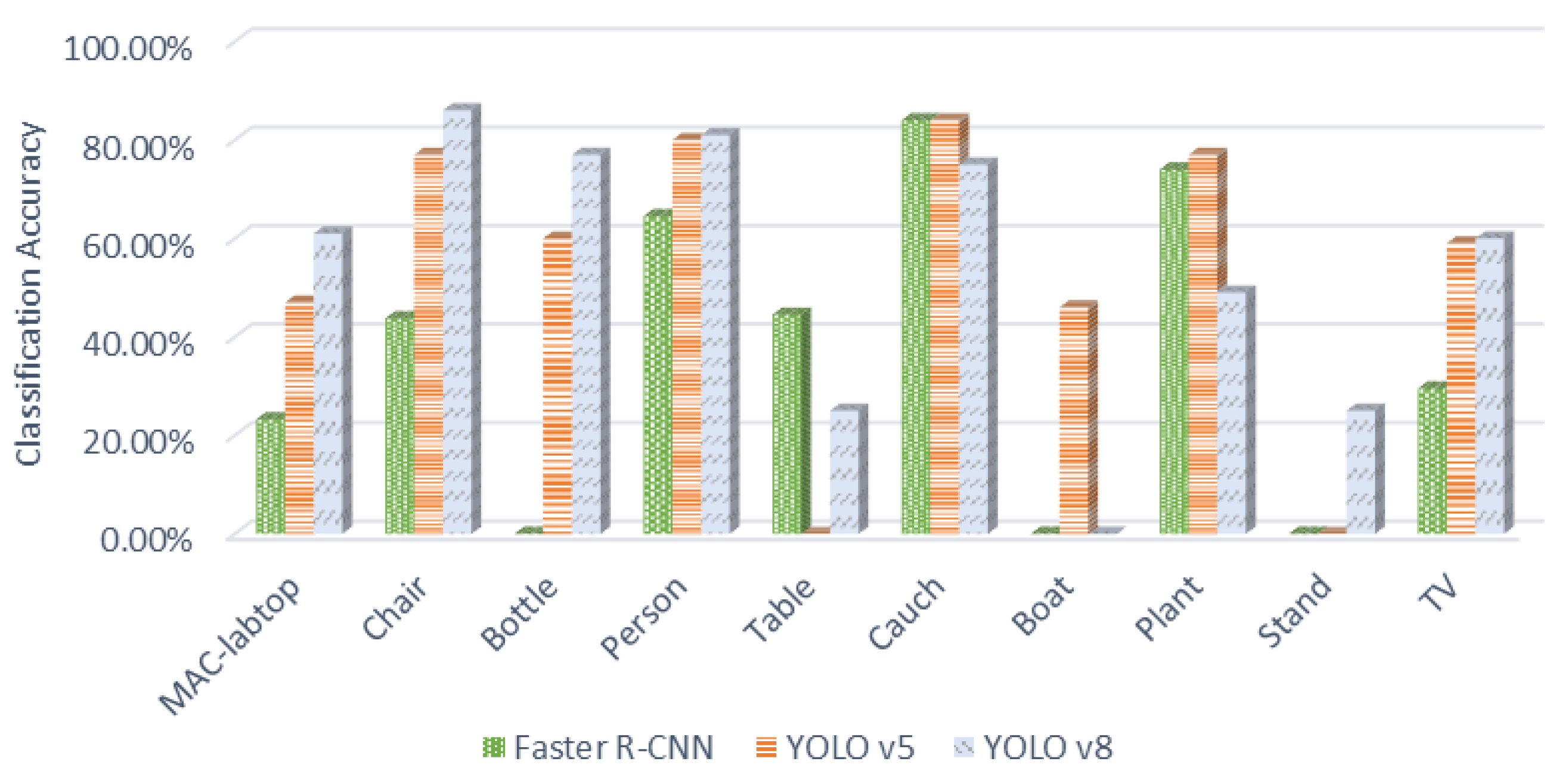
| Object | Faster R-CNN | YOLO v5 | YOLO v8 |
|---|---|---|---|
| MAC-PC | 23.25% | 47% | 61% |
| Chair | 43.75% | 77% | 86% |
| Person | 64.50% | 80% | 81% |
| Table | 44.50% | 0% | 25% |
| Couch | 84% | 84% | 75% |
| Boat | 0% | 46% | 0% |
| Plant | 74% | 77% | 49% |
| Stand | 0% | 0% | 25% |
| TV | 29.50% | 59% | 60% |
| Bottle | 0% | 60% | 77% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alotaibi, A.; Alatawi, H.; Binnouh, A.; Duwayriat, L.; Alhmiedat, T.; Alia, O.M. Deep Learning-Based Vision Systems for Robot Semantic Navigation: An Experimental Study. Technologies 2024, 12, 157. https://doi.org/10.3390/technologies12090157
Alotaibi A, Alatawi H, Binnouh A, Duwayriat L, Alhmiedat T, Alia OM. Deep Learning-Based Vision Systems for Robot Semantic Navigation: An Experimental Study. Technologies. 2024; 12(9):157. https://doi.org/10.3390/technologies12090157
Chicago/Turabian StyleAlotaibi, Albandari, Hanan Alatawi, Aseel Binnouh, Lamaa Duwayriat, Tareq Alhmiedat, and Osama Moh’d Alia. 2024. "Deep Learning-Based Vision Systems for Robot Semantic Navigation: An Experimental Study" Technologies 12, no. 9: 157. https://doi.org/10.3390/technologies12090157
APA StyleAlotaibi, A., Alatawi, H., Binnouh, A., Duwayriat, L., Alhmiedat, T., & Alia, O. M. (2024). Deep Learning-Based Vision Systems for Robot Semantic Navigation: An Experimental Study. Technologies, 12(9), 157. https://doi.org/10.3390/technologies12090157