
From Google Gemini to OpenAI Q* (Q-Star): A Survey on Reshaping the Generative Artificial Intelligence (AI) Research Landscape

 , ,
, ,  , , , and
, , , and
Abstract
1. Introduction
1.1. Changing AI Research Popularity
1.2. Objectives
1.3. Survey Methodology and Scope
- Relevance to Generative AI Topics: We included works that significantly discuss LLMs, MoE architectures, multimodal learning, or AGI-oriented methods.
- Peer-Reviewed or Preprint: Priority was given to journal and conference publications; however, we also considered selective preprints (e.g., arXiv) if they substantially contributed new findings.
- Domain Focus: Papers centered on purely sociological, philosophical, or economic aspects without explicit generative AI components were excluded.
- We organized papers by thematic clusters (e.g., Mixture-of-Experts Advances, Multimodal Extensions, or AGI Research Outlook).
- We cross-compared conflicting or convergent results to highlight consensus or outstanding debates.
- We derived a conceptual taxonomy to illustrate how new developments (e.g., Llama 2, Q-Star, etc.) potentially reshape the research landscape.
- Detailed examination of the evolving landscape in generative AI, emphasizing the advancements and innovations in their complex reasoning capabilities and their wide-ranging implications within the AI domain.
- Analysis of the transformative effect of advanced generative AI systems on academic research, exploring how these developments are altering research methodologies, setting new trends, and potentially leading to the obsolescence of traditional approaches.
- Thorough assessment of the ethical, societal, and technical challenges arising from the integration of generative AI in academia, underscoring the crucial need for aligning these technologies with ethical norms, ensuring data privacy, and developing comprehensive governance frameworks.
2. Background: Evolution of Generative AI
2.1. The Evolution of Language Models
2.1.1. Language Models as Precursors
2.1.2. Large Language Models: Technical Advancement and Commercial Success
2.1.3. Fine-Tuning, Hallucination Reduction, and Alignment in LLMs
2.1.4. Mixture of Experts: A Paradigm Shift
2.2. Multimodal AI and the Future of Interaction
2.3. Advancing Multimodal AI: A Comparative Perspective of Frontier LLMs
2.3.1. Gemini 2.0: Advancing Multimodal AI Capabilities
- Enhanced Multimodal Understanding: Gemini 2.0 exhibits improved capabilities in processing and reasoning across multiple modalities, allowing for more comprehensive and context-aware interactions.
- Native Image and Audio Generation: The model introduces native image generation and controllable text-to-speech functionalities, facilitating the creation of rich, multimodal content directly from textual inputs.
- Real-Time Multimodal Interactions: With the integration of the Multimodal Live API, Gemini 2.0 supports real-time audio and video streaming inputs, enabling dynamic and interactive AI experiences.
- Agentic Capabilities: Gemini 2.0 is designed for the agentic era, with the ability to plan, execute, and adapt actions autonomously, enhancing its utility in complex, real-world tasks.
2.3.2. Gemini: Redefining Benchmarks in Multimodality
- Breadth of Modalities: Unlike ChatGPT-4, which primarily focuses on text, documents, images, and code, Gemini handles a wider range of modalities, including audio and video. This extensive range allows Gemini to tackle complex tasks and understand real-world contexts more effectively.
- Performance: Gemini Ultra excels in key multimodality benchmarks, notably in massive multitask language understanding (MMLU) which encompasses a diverse array of domains like science, law, and medicine, outperforming ChatGPT-4.
- Scalability and Accessibility: Gemini is available in three tailored versions—Ultra, Pro, and Nano—catering to a range of applications from data centers to on-device tasks and featuring a level of flexibility not yet seen in ChatGPT-4.
- Code Generation: Gemini’s proficiency in understanding and generating code across various programming languages is more advanced, offering practical applications beyond ChatGPT-4’s capabilities.
- Transparency and Explainability: A focus on explainability sets Gemini apart, as it provides justifications for its outputs, enhancing user trust and understanding of the AI’s reasoning process.
2.3.3. Technical Challenges in Multimodal Systems
2.3.4. Multimodal AI: Beyond Text in Ethical and Social Contexts
2.3.5. Technical Challenges and Limitations of Current LLMs
2.4. Advances in Complex Reasoning and Emerging Trends
From AlphaGo’s Legacy to the Symbolism of Q*
2.5. Speculative Advances and Chronological Trends
2.5.1. From AlphaGo’s Groundtruth to Q-Star’s Exploration
2.5.2. Bridging Structured Learning with Creativity
3. The Current Generative AI Research Taxonomy
3.1. Model Architectures
- Transformer Models: Transformer models have significantly revolutionized the field of AI, especially in NLP, due to their higher efficiency and scalability [163,164,165]. They employ advanced attention mechanisms to achieve enhanced contextual processing, allowing for more subtle understanding and interaction [166,167,168]. These models have also made notable strides in computer vision, as evidenced by the development of vision transformers like EfficientViT [169,170] and YOLOv8 [171,172,173]. These innovations symbolize the extended capabilities of transformer models in areas such as object detection, offering not only improved performance but also increased computational efficiency.
- Recurrent Neural Networks (RNNs): RNNs excel in the realm of sequence modeling, making them particularly effective for tasks involving language and temporal data, as their architecture is specifically designed to process sequences of data, such as text, enabling them to capture the context and order of the input effectively [174,175,176,177,178]. This proficiency in handling sequential information renders them indispensable in applications that require a deep understanding of the temporal dynamics within data, such as natural language tasks and time series analysis [179,180]. RNNs’ ability to maintain a sense of continuity over sequences is a critical asset in the broader field of AI, especially in scenarios where context and historical data play crucial roles [181].
- MoE: MoE models can significantly enhance efficiency by deploying model parallelism across multiple specialized expert modules, which enables these models to leverage transformer-based modules for dynamic token routing and to scale to trillions of parameters, thereby reducing both memory footprint and computational costs [106,115,182,183,184,185]. MoE models stand out for their ability to divide computational loads among various experts, each specializing in different aspects of the data, which allows for handling vast scales of parameters more effectively, leading to a more efficient and specialized handling of complex tasks [106,186].
- Multimodal Models: Multimodal models, which integrate a variety of sensory inputs such as text, vision, and audio, are crucial in achieving a comprehensive understanding of complex datasets, making them particularly transformative in fields like medical imaging [8,134,136,187]. These models facilitate accurate and data-efficient analysis by employing multiview pipelines and cross-attention blocks [188,189]. This integration of diverse sensory inputs allows for a more nuanced and detailed interpretation of data, enhancing the model’s ability to accurately analyze and understand various types of information [190]. The combination of different data types, processed concurrently, enables these models to provide a holistic view, making them especially effective in applications that require a deep and multifaceted understanding of complex scenarios [134,190,191,192].
3.2. Training Techniques
- Supervised Learning: Supervised learning, a foundational approach in AI, uses labeled datasets to guide models towards accurate predictions, and it has been integral to various applications, including image recognition and NLP [193,194,195]. Recent advancements have focused on developing sophisticated loss functions and regularization techniques, aimed at enhancing the performance and generalization capabilities of supervised learning models, ensuring they remain robust and effective across a wide range of tasks and data types [196,197,198].
- Unsupervised Learning: Unsupervised learning is essential in AI for uncovering patterns within unlabeled data, which is a process central to tasks like feature learning and clustering [199,200]. This method has seen significant advancements with the introduction of autoencoders [201,202] and Generative Adversarial Networks (GANs) [203,204,205], which have notably expanded unsupervised learning’s applicability, enabling more sophisticated data generation and representation learning capabilities. Such innovations are crucial for understanding and leveraging the complex structures often inherent in unstructured datasets, highlighting the growing versatility and depth of unsupervised learning techniques.
- Reinforcement Learning: Reinforcement learning, characterized by its adaptability and optimization capabilities, has become increasingly vital in decision making and autonomous systems [206,207]. This training technique has undergone significant advancements, particularly with the development of Deep Q-Networks (DQNs) [208,209,210] and Proximal Policy Optimization (PPO) algorithms [211,212,213]. These enhancements have been crucial in improving the efficacy and applicability of reinforcement learning, especially in complex and dynamic environments. By optimizing decisions and policies through interactive feedback loops, reinforcement learning has established itself as a crucial tool for training AI systems in scenarios that demand a high degree of adaptability and precision in decision making [214,215].
- Transfer Learning: Transfer learning emphasizes versatility and efficiency in AI training, allowing models to apply knowledge acquired from one task to different yet related tasks, which significantly reduces the need for large labeled datasets [216,217]. Transfer learning, through the use of pretrained networks, streamlines the training process by allowing models to be efficiently fine-tuned for specific applications, thereby enhancing adaptability and performance across diverse tasks and proving particularly beneficial in scenarios where acquiring extensive labeled data is impractical or unfeasible [218,219].
3.3. Application Domains
- Natural Language Understanding (NLU): NLU is central to enhancing the comprehension and contextualization of human language in AI systems, and it involves key capabilities such as semantic analysis, named entity recognition, sentiment analysis, textual entailment, and machine reading comprehension [220,221,222,223]. Advances in NLU have been crucial in improving AI’s proficiency in interpreting and analyzing language across a spectrum of contexts, ranging from straightforward conversational exchanges to intricate textual data [220,222,223]. NLU is fundamental in applications like sentiment analysis, language translation, information extraction, and more [224,225]. Recent advancements have prominently featured large transformer-based models like BERT and GPT-3, which have significantly advanced the field by enabling a deeper and more complex understanding of language subtleties [226,227].
- Natural Language Generation (NLG): NLG emphasizes the training of models to generate coherent, contextually relevant, and creative text responses, which are critical components in chatbots, virtual assistants, and automated content creation tools [39,228,229,230]. NLG encompasses challenges such as topic modeling, discourse planning, concept-to-text generation, style transfer, and controllable text generation [39,231]. The recent surge in NLG capabilities, exemplified by advanced models like GPT-3, has significantly enhanced the sophistication and nuance of text generation, which enable AI systems to produce text that closely mirrors human writing styles, thereby broadening the scope and applicability of NLG in various interactive and creative contexts [57,61,232].
- Conversational AI: This subdomain is dedicated to developing AI systems capable of smooth, natural, and context-aware human–computer interactions by focusing on dialogue modeling, question answering, user intent recognition, and multiturn context tracking [233,234,235,236]. In finance and cybersecurity, AI’s predictive analytics have transformed risk assessment and fraud detection, leading to more secure and efficient operations [34,234]. The advancements in this area, demonstrated by large pretrained models like Meena (https://neptune.ai/blog/transformer-nlp-models-meena-lamda-chatbots; accessed on 10 January 2025) and BlenderBot (https://blenderbot.ai; accessed on 10 January 2025), have significantly enhanced the empathetic and responsive capabilities of AI interactions. These systems not only improve user engagement and satisfaction, but also maintain the flow of conversation over multiple turns, providing coherent, contextually relevant, and engaging experiences [237,238].
- Creative AI: This emerging subdomain spans across text, art, music, and more, pushing the boundaries of AI’s creative and innovative potential across various modalities including images, audio, and video by engaging in the generation of artistic content, encompassing applications in idea generation, storytelling, poetry, music composition, visual arts, and creative writing, which have resulted in commercial successes like MidJourney and DALL-E [239,240,241], as well as most recently with state-of-the-art video generation models, namely, OpenAI’s Sora [242] and Google’s Veo 2 [243]. The challenges in this field involve finding suitable data representations, algorithms, and evaluation metrics to effectively assess and foster creativity [241,244]. Creative AI serves not only as a tool for automating and enhancing artistic processes but also as a medium for exploring new forms of artistic expression, enabling the creation of novel and diverse creative outputs [241]. This domain represents a significant leap in AI’s capability to engage in and contribute to creative endeavors, redefining the intersection of technology and art, with Sora and Veo 2 representing significant breakthroughs in the field of high-definition video generation that convincingly simulates real-world physics.
3.4. Compliance and Ethical Considerations
- Bias Mitigation: Bias mitigation in AI systems is a critical endeavor to ensure fairness and representation, which involves not only balanced data collection to avoid skewed perspectives but also involves implementing algorithmic adjustments and regularization techniques to minimize biases [249,250]. Continuous monitoring and bias testing are essential to identify and address any biases that may emerge from AI’s predictive patterns [250,251]. A significant challenge in this area is dealing with intersectional biases [252,253,254] and understanding the causal interactions that may contribute to these biases [255,256,257,258].
- Data Security: In AI data security, key requirements and challenges include ensuring data confidentiality, adhering to consent norms, and safeguarding against vulnerabilities like membership inference attacks [259,260]. Compliance with stringent legal standards within applicable jurisdictions, such as the General Data Protection Regulation (GDPR) and California Consumer Privacy Act (CCPA), is essential, necessitating purpose limitation and data minimization [261,262,263,264]. Additionally, issues of data sovereignty and copyright emphasize the need for robust encryption, access control, and continuous security assessments [265,266]. These efforts are critical for maintaining the integrity of AI systems and protecting user privacy in an evolving digital landscape.
- AI Ethics: The field of AI ethics focuses on fairness, accountability, and societal impact; addresses the surge in ethical challenges posed by AI’s increasing complexity and potential misalignment with human values; and requires ethical governance frameworks, multidisciplinary collaborations, and technological solutions [28,245,267,268]. Furthermore, AI ethics involves ensuring traceability, auditability, and transparency throughout the model development lifecycle, as well as employing practices such as algorithmic auditing, establishing ethics boards, and adhering to documentation standards and model cards [268,269]. However, the adoption of these initiatives remains uneven, highlighting the ongoing need for comprehensive and consistent ethical practices in AI development and deployment [245].
- Privacy Preservation: This domain focuses on maintaining data confidentiality and integrity, as well as employing strategies like anonymization and federated learning to minimize direct data exposure, especially when the rise of generative AI poses risks of user profiling [270,271]. Despite these efforts, challenges such as achieving true anonymity against correlation attacks highlight the complexities in effectively protecting against intrusive surveillance [272,273]. Ensuring compliance with privacy laws and implementing secure data handling practices are crucial in this context, demonstrating the continuous need for robust privacy preservation mechanisms.
3.5. Advanced Learning
- Self-supervised Learning: This method emphasizes autonomous model training using unlabeled data, reducing manual labeling efforts and model biases [195,274,275]. It incorporates generative models like autoencoders and GANs for data distribution learning and original input reconstruction [276,277,278], as well as also includes contrastive methods such as SimCLR [279] and MoCo [280], which are designed to differentiate between positive and negative sample pairs. Further, it employs self-prediction strategies, inspired by NLP, using techniques like masking for input reconstruction, which are significantly enhanced by recent vision transformers developments [195,281,282]. This integration of varied methods highlights self-supervised learning’s role in advancing AI’s autonomous training capabilities.
- Meta-learning: Meta-learning, or ‘learning to learn’, centers on equipping AI models with the ability to rapidly adapt to new tasks and domains using limited data samples [283,284]. This technique involves mastering the optimization process and is critical in situations with limited data availability to ensure models can quickly adapt and perform across diverse tasks, which are essential capacities in the current data-driven landscape [285,286]. It focuses on few-shot generalization, enabling AI to handle a wide range of tasks with minimal data, underlining its importance in developing versatile and adaptable AI systems [286,287,288,289].
- Fine-tuning: This involves customizing pretrained models to specific domains or user preferences, enhancing accuracy and relevance for niche applications [71,290,291]. Its two primary approaches are end-to-end fine-tuning, which adjusts all weights of the encoder and classifier [292,293], and feature extraction fine-tuning, where the encoder weights are frozen to extract features for a downstream classifier [294,295,296]. This technique ensures that generative models are more effectively adapted to specific user needs or domain requirements, making them more versatile and applicable across various contexts.
- Human Value Alignment: This emerging aspect concentrates on harmonizing AI models with human ethics and values to ensure that their decisions and actions mirror societal norms and ethical standards, involving the integration of ethical decision-making processes and the adaptation of AI outputs to conform with human moral values [100,297,298]. This is increasingly important in scenarios where AI interacts closely with humans, such as in healthcare, finance, and using personal assistants, to ensure that AI systems make decisions that are not only technically sound, but also ethically and socially responsible, which means human value alignment is becoming crucial in developing AI systems that are trusted and accepted by society [100,104,299].
3.6. Emerging Trends
- Multimodal Learning: Multimodal learning in AI, a rapidly evolving subdomain, focuses on combining language understanding with computer vision and audio processing to achieve a richer, multisensory context awareness [135,300]. Recent developments like the Gemini model have set new benchmarks by demonstrating state-of-the-art performance in various multimodal tasks, including natural image, audio, and video understanding, as well as mathematical reasoning [8]. Gemini’s inherently multimodal design exemplifies the seamless integration and operation across different information types [8]. Despite the advancements, the field of multimodal learning still confronts ongoing challenges, such as refining the architectures to handle diverse data types more effectively [301,302], developing comprehensive datasets that accurately represent multifaceted information [301,303], and establishing benchmarks for evaluating the performance of these complex systems [13,304,305]. Omni-modal models represent a progression from multimodal systems, aiming to achieve universal sensory integration by enabling seamless processing across all conceivable modalities, including text, images, audio, video, and even tactile or environmental data. These models signify a shift toward unified architectures that transcend the limitations of modality-specific processing, enhancing generalizability and contextual reasoning by integrating diverse sensory inputs into a cohesive understanding. Recent research, such as OmniBench [306], has introduced benchmarks designed to evaluate models’ ability to interpret and reason across visual, acoustic, and textual inputs simultaneously. Studies [307] in this domain highlight the need for robust multimodal integration techniques and training strategies to enhance performance across diverse modalities, which address challenges in establishing holistic understanding and reasoning in real-world scenarios.
- Interactive and Cooperative AI: This subdomain aims to enhance the capabilities of AI models to collaborate effectively with humans in complex tasks [38,308]. This trend focuses on developing AI systems that can work alongside humans, thereby improving user experience and efficiency across various applications, including productivity and healthcare [309,310,311]. Core aspects of this subdomain involve advancing AI in areas such as explainability [312], understanding human intentions and behavior (theory of mind) [313,314], and scalable coordination between AI systems and humans, which involve a collaborative approach crucial in creating more intuitive and interactive AI systems capable of assisting and augmenting human capabilities in diverse contexts [38,315].
- AGI Development: AGI, representing the visionary goal of crafting AI systems that emulate the comprehensive and multifaceted aspects of human cognition, is a subdomain focused on developing AI with the capability for holistic understanding and complex reasoning that closely aligns with the depth and breadth of human cognitive abilities [67,316,317]. AGI is not just about replicating human intelligence but also involves crafting systems that can autonomously perform a variety of tasks, demonstrating adaptability and learning capabilities akin to those of humans [316,317]. The pursuit of AGI is a long-term aspiration, continually pushing the boundaries of AI research and development.
- AGI Containment: AGI safety and containment acknowledges the potential risks associated with highly advanced AI systems, focused on ensuring that these advanced systems are not only technically proficient but also ethically aligned with human values and societal norms [12,28,67]. As we progress towards developing superintelligent systems, it becomes crucial to establish rigorous safety protocols and control mechanisms [12]. Key areas of concern include mitigating representational biases, addressing distribution shifts, and correcting spurious correlations within AI models [12,318]. The objective is to prevent unintended societal consequences by aligning AI development with responsible and ethical standards.
- “Thinking” Models: Thinking models represent a transformative trend in generative AI, focusing on integrating test-time compute scaling that enables computational flexibility during inference. These approaches allow AI systems to dynamically allocate additional computational resources based on task complexity, enhancing reasoning capabilities for problems requiring step-by-step deliberation. By allocating extra computational resources for reasoning-intensive tasks, these models achieve greater adaptability and efficiency, bridging the gap between traditional static inference and the demands of real-time, complex decision making. The development of thinking models highlights the potential to create systems capable of iterative, context-aware reasoning, addressing limitations in single-pass architectures while paving the way for more robust AI applications.
- Agentic AI: Agentic AI represents a critical advancement in empowering AI systems with autonomy, enabling them to plan, execute, and adapt actions in dynamic, real-world environments [319]. These systems leverage advanced tooling capabilities, allowing direct interaction with external software and hardware to achieve predefined objectives. Agentic AI also incorporates decision making and actionability, where the AI autonomously determines the optimal sequence of steps to achieve a goal while adhering to constraints. The development of agentic AI aligns with human-centric design principles, ensuring these systems are ethically aligned and augment human capabilities in diverse fields ranging from healthcare to logistics. However, the rise of agentic AI necessitates addressing challenges such as value alignment, safety protocols, and mitigating unintended consequences in autonomous decision making [319].
- Test Time Optimization: The ability for LLMs to dynamically adjust model parameters at inference time is an important research direction for LLMs. Test Time Training (TTT) [320,321] addresses the limitations of static, pretrained models by enabling LLMs to update parameters for smaller models during inference, especially for task-specific requirements. This facilitates real-time learning, allowing models to refine their understanding of a task as new inputs are encountered. This shift toward more adaptable systems allows LLMs to learn from each unique context and improve responses dynamically while also addressing computational limitations associated with long sequences. Approaches like TTT also mitigate the problem of memorization by learning how to memorize, rather than simply memorizing training data, enhancing generalization. This adaptability is can be seen as being complemented by enhanced long-term neural memory [159], which stores and recalls past information, moving beyond the limitations of short context windows in standard attention. These solutions are composed of short-term memory (core attention), long-term memory that learns to memorize at test time, and persistent memory, which stores task-specific knowledge. These advancements are pivotalm as they enable more flexible, context-aware AI systems capable of improved accuracy, better generalization, and more dynamic reasoning in complex, real-world applications.
4. Innovative Horizon of MoE
4.1. Core Concept and Structure
- Sparse Routing: Because only a few experts are activated per token, the MoE scales model capacity significantly without linearly increasing compute. This “conditional computation” is particularly valuable for tasks where a large portion of the model parameters may be unnecessary for every input.
- Transformer Integration: Recent LLM research incorporates MoE layers interleaved with attention blocks to maintain the contextual strengths of transformers while boosting efficiency for large-scale training [186].
4.2. Training and Inference Efficiency
4.3. Load Balancing and Router Optimization
4.4. Parallelism and Serving Techniques
- DeepSpeed-MoE [322] introduces three main parallelism strategies—data parallelism, expert parallelism, and tensor slicing—to manage immense models (e.g., 1–2 trillion parameters) without exploding memory or latency.
- MoE Model Compression: Hybrid or partial expert load can further reduce runtime, enabling more cost-effective serving. This direction aligns with industry demands for on-device or edge-based LLM inference where VRAM is at a premium [325].
4.5. Future Directions and Applications
- Sparse Fine-Tuning and Instruction Tuning: Future research may explore gating-based fine-tuning that updates only a small subset of experts, enhancing computational and memory efficiency while retaining model quality. Instruction tuning can also be integrated, with specialized experts employed for each “instruction domain”.
- Multimodal Integration: The MoE can unify specialized experts for text, image, audio, and even 3D data, offering a flexible “mixture-of-modalities” approach. This is especially relevant for agentic AI systems requiring simultaneous processing of multiple data types.
- Adaptive Test-Time Compute: Research on on-demand expert activation—akin to recent “Thinking Model” frameworks—could allow LLMs to allocate more experts for complex tasks and fewer for simpler queries, optimizing both cost and performance.
- Calibration and Safety: Because experts can specialize in sensitive domains (e.g., healthcare, finance, etc.), robust mechanisms for bias mitigation and alignment with human values remain vital [80].
5. Capabilities of Q*-Enabled Models
5.1. Enhanced General Intelligence
- denotes a generalized intelligence operator integrating multiple modules;
- is a large-scale language model trained on broad corpora;
- stands for Chain-of-Thought prompting and reasoning [15];
- indicates retrieval modules for external knowledge (e.g., a vector database);
- ⊗ and ⊕ indicate functional integrations at different processing stages (e.g., fusing retrieval results with step-by-step reasoning).
5.2. Adaptive Self-Learning and Exploration
- is an adaptive self-learning and exploration operator;
- represents hierarchical reinforcement learning, splitting learning into high-level and low-level policies;
- is a policy neural network interfacing with the hierarchical controllers;
- denotes a knowledge buffer or episodic memory for iterative policy updates [335];
- implements reflection-based self-critique steps [334].
5.3. Multilayered Language Understanding and Reasoning
- denotes a multilayered language understanding operator;
- enumerates various modes of reasoning (expert logic, common sense, etc.);
- processes specialized or curated knowledge resources;
- is an alignment or value filter [80] ensuring compliance with domain or ethical constraints;
- ⊕ merges each reasoning layer’s output.
5.4. Context-Specific Common Sense and Tool Usage
- captures context-specific common sense and tool usage;
- is a core symbolic or Chain-of-Thought logic unit for everyday reasoning;
- encapsulates callable external utilities (e.g., search engines, calculators, code interpreters, etc.);
- is a dynamic knowledge base or curated fact store;
- ⊗ and ⊕ denote flexible chaining of these resources on demand.
5.5. Ethics, Verification, and Transparency
- stands for ethics, verification, and transparency;
- includes factual consistency or theorem-proving tools;
- produces Chain-of-Thought or post hoc rationales for interpretability;
- embeds societal or policy-based constraints.
6. Projected Capabilities of AGI
6.1. Revolution in Autonomous Learning
6.2. Broadening of Cognitive Abilities
6.3. Elevating Understanding and Interaction
6.4. Advanced Common Sense Reasoning
6.5. Holistic Integration of Knowledge
6.6. Challenges and Opportunities in AGI Development
7. Impact Analysis on Generative AI Research Taxonomy
7.1. Criteria for Impact Analysis

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Criteria | Score | Definition | Justification |
|---|---|---|---|---|
| ↗ | Emerging Direction | 5 | New research areas expected to arise as a direct consequence of AI advancements. | Emphasizes novel research domains emerging from AI breakthroughs [346,348]. |
| ↪ | Requiring Redirection | 4 | Areas that need to shift focus or methodology to stay relevant with new AI developments. | Technological shifts necessitate re-evaluation and redirection in AI research [346,347]. |
| ↔ | Still Relevant | 3 | Areas where the advancements have minimal or no impact, maintaining their current status and methodologies. | Observes the persistence of certain AI research areas despite technological advancements [347]. |
| ↘ | Likely to Become Redundant | 2 | Areas that may lose relevance or become obsolete with the advent of new AI technologies. | Discusses rapid obsolescence in AI methodologies due to new technologies [349]. |
| △ | Inherently Unresolvable | 1 | Challenges that may remain unresolved due to complexities like subjective human perspectives and diverse cultural values. | Inherent difficulties in issues such as aligning AI with diverse human values and ethics [350,351]. |
7.1.1. Emerging Direction (↗)
7.1.2. Requiring Redirection (↪)
7.1.3. Still Relevant (↔)
7.1.4. Likely to Become Redundant (↘)
7.1.5. Inherently Unresolvable (△)
7.2. Overview of Impact Analysis
7.2.1. Impact on Model Architecture
7.2.2. Impact on Training Techniques
7.2.3. Impact on Application Domains
7.2.4. Impact on Compliance and Ethical Considerations
7.2.5. Impact on Advanced Learning
7.2.6. Impact on Emerging Trends
- Thinking Models: Demand re-engineering of existing architectures, such as the MoE, to enable iterative solution-finding during inference. They also push multimodal and AGI work toward expanded context windows, hierarchical reasoning, and memory-augmented transformations.
- Agentic AI: Extends LLM capabilities by enabling them to plan actions, execute external commands, and adapt to real-time feedback. This raises new research questions about controllability, misalignment, and safety, linking to the emergent concept of test time optimization and dynamic resource allocation.
8. Emergent Research Priorities in Generative AI
8.1. Emergent Research Priorities in MoE
- (1)
- Advanced MoE Architectures for Multimodal Models in Model Architecture:
- (2)
- Synergy Between MoE and Multimodal Learning:
- (3)
- Investment Trends in MoE:
8.2. Emergent Research Priorities in Multimodality
- MoE-Driven Multimodal Pipelines: MoE models integrated within transformers can help manage complex data distributions by assigning modalities or subtasks to specialized experts [106]. This approach mitigates the computational overhead of large multimodal embeddings while preserving flexibility in learning.
- Transfer Learning for Cross-Modality: Transfer learning remains vital, enabling models to reuse representations from one modality to augment learning in another [87]. Emerging research focuses on bridging these modalities via universal encoders or decoders, which is in line with large LLM expansions into audio, vision, and beyond.
- Conversational and Creative AI Integration: With the advent of advanced generative models (e.g., ChatGPT, Sora, Gemini, etc.), multimodal AI increasingly supports natural interactions involving both text and visuals, further stimulating research on collaborative content generation and deeper user engagement.
- Self-Supervised Paradigms: Self-supervised learning plays a pivotal role in scaling to massive unlabeled multimodal datasets. Future work explores how gating or MoE logic can tailor representations to modality-specific nuances while still maintaining a shared latent space.
8.3. Emergent Research Priorities in AGI
- Reinforcement Learning for Agentic Reasoning: AGI aspirations hinge on adaptable models that learn from and respond to unstructured environments [352]. Combining MoE-based LLMs with reinforcement signals is emerging as a way to achieve both specialized skill (via experts) and generalizable decision making.
- Complex Application Domains: AGI extends beyond standard NLP tasks, targeting advanced medical diagnosis, scientific discovery, and highly creative endeavors. Natural Language Understanding (NLU), generative text, and multisensor integration underscore the potential for bridging multiple fields—while simultaneously raising new ethical and safety concerns [28].
- Bias Mitigation and Ethical Frameworks: As systems scale, so do risks of amplified biases, security loopholes, and accountability gaps. Aligning AI with fairness and transparency remains a priority, requiring cross-disciplinary collaboration [340].
- Meta-Learning and Emergent Trends: AGI solutions increasingly explore meta-learning, aiming to equip models with the capacity to rapidly adapt to new tasks or contexts [338]. Equally crucial is the integration of “AGI containment” or safety strategies, reflecting the need to manage advanced autonomous models responsibly.
9. Practical Implications and Limitations of Generative AI Technologies
9.1. Computational Complexity and Real-World Applications of Generative AI Technologies
9.1.1. Computational Complexity
- Processing Power Requirements: Advanced generative AI models, including MoE architectures and large-scale LLMs with multistep reasoning, typically demand substantial compute resources [353]. The need for efficient GPU/TPU provisioning grows more acute in scenarios involving multimodal data or test time scaling, potentially leading to significant infrastructure costs.
- Memory Usage in AI Modeling: A critical challenge in training and deploying large-scale AI models, particularly those with sparsely activated experts or multisensory inputs, lies in substantial GPU and VRAM requirements. Unlike main system memory, VRAM remains relatively constrained, posing a bottleneck for massive multimodal models or large MoE solutions. Novel methods that offload expert parameters or use dynamic expert loading can mitigate these challenges.
- Scalability and Efficiency: Addressing scalability in generative AI, especially in MoE-based and AGI contexts, involves optimizing load management and parallel processing [322]. Research on specialized routing, advanced pipeline parallelism, and memory-optimizing strategies is critical for real-world deployments in healthcare, finance, and education.
9.1.2. Real-World Application Examples of Generative AI Technologies
- Healthcare: Generative AI powers diagnostic imaging, personalized treatment recommendations, and disease forecasting [354]. However, reliance on large training corpora raises privacy questions and can demand specialized hardware for medical-grade model inference.
- Finance: AI-driven fraud detection and algorithmic trading illustrate high-impact, data-intensive applications [355]. At the same time, decision-making transparency and robust data governance become essential to counter possible biases or hidden vulnerabilities in generative pipelines.
- Education: Generative AI fosters adaptive learning, automated content creation, and personalized feedback loops. While these systems promise scalable tutoring and resource-saving benefits, ethical debates around academic integrity persist. Concerns arise regarding the potential of AI-generated content (AIGC) to displace educators or compromise academic authenticity.
9.2. Commercial Viability and Industry Solutions
9.2.1. Market Readiness
- Cost Analysis: Running large generative models—especially MoE or multimodal frameworks—can strain budgets due to hardware needs and specialized engineering talent.
- Accessibility and Deployment: Enterprise readiness varies. Some industries (e.g., tech, finance, etc.) rapidly embrace AI, while others face skill gaps and infrastructural barriers.
- User Adoption Trends: Public-facing generative AI tools, such as ChatGPT, show swift user adoption. However, domain-specific solutions require specialized training data, expansions in interpretability, and robust MLOps pipelines to gain user trust.
9.2.2. Existing Industry Solutions
- Sector-Wise Deployment: From content creation (marketing, design, etc.) to code generation and robotic process automation, generative AI demands re-evaluation of creative ownership and IP rights.
- Impact on Market Dynamics: Traditional players face competition from AI-native startups, while new business models, such as AI-as-a-Service (AIaaS), form around generative capabilities.
- Challenges and Constraints: Fundamental issues like scalability, data management complexity, and privacy concerns persist, underscoring the importance of robust governance, standard-setting bodies, and multistakeholder dialogues.
9.3. Limitations and Future Directions in Generative AI
9.3.1. Technical Limitations
- Contextual Understanding: Despite LLM breakthroughs, common sense reasoning and long-horizon context modeling remain weak points, spurring research into memory-augmented architectures.
- Handling Ambiguous Data: Real-world data often contain inconsistencies or missing attributes. Reliability in these conditions may demand robust inference techniques, e.g., Bayesian or reinforcement-based training, to handle uncertainty.
- Navigating Human Judgment: Even though generative AI can interpret policies and procedures, it falls short in reproducing nuanced human values or in assessing complex legal/political implications. Biased or manipulative usage of AI-generated content (AIGC) can lead to skewed decision making.
9.3.2. Future Research Directions
- Improved Contextual Understanding: Research on Chain-of-Thought prompting, hierarchical gating, and multihop inference can deepen AI’s ability to interpret extended or complex queries.
- Robust Handling of Ambiguity: Model architectures that incorporate reliability estimates or adversarial training may yield more stable performance under ambiguous data conditions.
- Ethical Integration of AIGC in Legal and Political Arenas: As generative models permeate high-stakes environments, developing frameworks that bolster transparency, mitigate bias, and validate correctness is imperative [356]. Researchers must also consider socio-technical complexities—such as corruption or manipulative usage—where advanced generative models could inadvertently amplify systemic inequities.
10. Impact of Generative AI on Preprints Across Disciplines
11. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AGI | Artificial General Intelligence |
| AI | Artificial Intelligence |
| AIGC | AI-generated content |
| BERT | Bidirectional Encoder Representations from Transformers |
| CCPA | California Consumer Privacy Act |
| DQN | Deep Q-Networks |
| EU | European Union |
| GAN | Generative Adversarial Network |
| GDPR | General Data Protection Regulation |
| GPT | Generative Pretrained Transformers |
| GPU | Graphics Processing Unit |
| LIDAR | Light Detection and Ranging |
| LLM | Large Language Model |
| LSTM | Long Short-Term Memory |
| MCTS | Monte Carlo Tree Search |
| ML | Machine Learning |
| MoE | Mixture of Experts |
| NLG | Natural Language Generation |
| NLP | Natural Language Processing |
| NLU | Natural Language Understanding |
| NN | Neural Network |
| PPO | Proximal Policy Optimization |
| RNNs | Recurrent Neural Networks |
| VNN | Value Neural Network |
| VRAM | Video Random Access Memory |
References
- Turing, A. Computing machinery and intelligence. Mind 1950, 59, 433. [Google Scholar] [CrossRef]
- McDermott, D. Artificial intelligence meets natural stupidity. Acm Sigart Bull. 1976, 57, 4–9. [Google Scholar] [CrossRef]
- Minsky, M. Steps toward artificial intelligence. Proc. IRE 1961, 49, 8–30. [Google Scholar] [CrossRef]
- Yann, L.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Minsky, M.; Papert, S. An introduction to computational geometry. Camb. Tiass. HIT 1969, 479, 104. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- OpenAI. OpenAI o3 Model Announcement. 2024. Available online: https://chatgpt.com (accessed on 13 January 2025).
- Gemini Team, Google. Gemini: A Family of Highly Capable Multimodal Models. 2023. Available online: https://gemini.google.com (accessed on 17 December 2023).
- Anthropic. Model Card and Evaluations for Claude Models. 2023. Available online: https://claude.ai (accessed on 13 January 2025).
- McIntosh, T.R.; Liu, T.; Susnjak, T.; Watters, P.; Ng, A.; Halgamuge, M.N. A Culturally Sensitive Test to Evaluate Nuanced GPT Hallucination. IEEE Trans. Artif. Intell. 2023, 5, 2739–2751. [Google Scholar] [CrossRef]
- Morris, M.R.; Sohl-dickstein, J.; Fiedel, N.; Warkentin, T.; Dafoe, A.; Faust, A.; Farabet, C.; Legg, S. Levels of AGI: Operationalizing Progress on the Path to AGI. arXiv 2023, arXiv:2311.02462. [Google Scholar]
- Schuett, J.; Dreksler, N.; Anderljung, M.; McCaffary, D.; Heim, L.; Bluemke, E.; Garfinkel, B. Towards best practices in AGI safety and governance: A survey of expert opinion. arXiv 2023, arXiv:2305.07153. [Google Scholar]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Halgamuge, M.N. Inadequacies of large language model benchmarks in the era of generative artificial intelligence. arXiv 2024, arXiv:2402.09880. [Google Scholar]
- Singh, A.; Ehtesham, A.; Kumar, S.; Khoei, T.T. Enhancing AI Systems with Agentic Workflows Patterns in Large Language Model. In Proceedings of the 2024 IEEE World AI IoT Congress (AIIoT), Seattle, WA, USA, 29–31 May 2024; pp. 527–532. [Google Scholar] [CrossRef]
- Wei, J.; Wang, X.; Schuurmans, D.; Bosma, M.; Ichter, B.; Xia, F.; Chi, E.; Le, Q.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar]
- Yao, S.; Yu, D.; Zhao, J.; Shafran, I.; Griffiths, T.L.; Cao, Y.; Narasimhan, K. Tree of Thoughts: Deliberate Problem Solving with Large Language Models. arXiv 2023, arXiv:2305.10601. [Google Scholar]
- Bi, Z.; Han, K.; Liu, C.; Tang, Y.; Wang, Y. Forest-of-Thought: Scaling Test-Time Compute for Enhancing LLM Reasoning. arXiv 2024, arXiv:2412.09078. [Google Scholar]
- Li, X.; Dong, G.; Jin, J.; Zhang, Y.; Zhou, Y.; Zhu, Y.; Zhang, P.; Dou, Z. Search-o1: Agentic Search-Enhanced Large Reasoning Models. arXiv 2025, arXiv:2501.05366. [Google Scholar]
- Chen, Z.; Deng, Y.; Wu, Y.; Gu, Q.; Li, Y. Towards Understanding the Mixture-of-Experts Layer in Deep Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 23049–23062. [Google Scholar]
- OpenAI. Learning to Reason with LLMs. 2024. Available online: https://openai.com/index/learning-to-reason-with-llms/ (accessed on 13 January 2025).
- DeepSeek-AI; Liu, A.; Feng, B.; Xue, B.; Wang, B.; Wu, B.; Lu, C.; Zhao, C.; Deng, C.; Zhang, C.; et al. DeepSeek-V3 Technical Report. arXiv 2024, arXiv:2412.19437. [Google Scholar]
- Zeng, Z.; Cheng, Q.; Yin, Z.; Wang, B.; Li, S.; Zhou, Y.; Guo, Q.; Huang, X.; Qiu, X. Scaling of Search and Learning: A Roadmap to Reproduce o1 from Reinforcement Learning Perspective. arXiv 2024, arXiv:2412.14135. [Google Scholar]
- Watch, R. Sleuths Spur Cleanup at Journal with Nearly 140 Retractions and Counting. 2024. Available online: https://retractionwatch.com/2024/08/22/sleuths-spur-cleanup-at-journal-with-nearly-140-retractions-and-counting/ (accessed on 13 January 2025).
- Watch, R. Springer Nature Journal Has Retracted over 200 Papers Since September. 2024. Available online: https://retractionwatch.com/2024/10/15/springer-nature-journal-has-retracted-over-200-papers-since-september/ (accessed on 13 January 2025).
- Watch, R. Signs of Undeclared ChatGPT Use in Papers Mounting. 2023. Available online: https://retractionwatch.com/2023/10/06/signs-of-undeclared-chatgpt-use-in-papers-mounting/ (accessed on 13 January 2025).
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 1–13. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving Language Understanding by Generative Pre-Training; OpenAI: San Francisco, CA, USA, 2018. [Google Scholar]
- Huang, C.; Zhang, Z.; Mao, B.; Yao, X. An overview of artificial intelligence ethics. IEEE Trans. Artif. Intell. 2022, 4, 799–819. [Google Scholar] [CrossRef]
- Besançon, L.; Peiffer-Smadja, N.; Segalas, C.; Jiang, H.; Masuzzo, P.; Smout, C.; Billy, E.; Deforet, M.; Leyrat, C. Open science saves lives: Lessons from the COVID-19 pandemic. BMC Med. Res. Methodol. 2021, 21, 177. [Google Scholar] [CrossRef] [PubMed]
- Triggle, C.R.; MacDonald, R.; Triggle, D.J.; Grierson, D. Requiem for impact factors and high publication charges. Account. Res. 2022, 29, 133–164. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y. A Path Towards Autonomous Machine Intelligence Version; 2022. Available online: https://openreview.net/pdf?id=BZ5a1r-kVsf (accessed on 13 January 2025).
- Kambhampati, S. Can large language models reason and plan? Ann. N. Y. Acad. Sci. 2024, 1534, 15–18. [Google Scholar] [CrossRef]
- McIntosh, T.; Kayes, A.; Chen, Y.P.P.; Ng, A.; Watters, P. Ransomware mitigation in the modern era: A comprehensive review, research challenges, and future directions. ACM Comput. Surv. (CSUR) 2021, 54, 197. [Google Scholar] [CrossRef]
- McIntosh, T.; Liu, T.; Susnjak, T.; Alavizadeh, H.; Ng, A.; Nowrozy, R.; Watters, P. Harnessing GPT-4 for generation of cybersecurity GRC policies: A focus on ransomware attack mitigation. Comput. Secur. 2023, 134, 103424. [Google Scholar] [CrossRef]
- Maddigan, P.; Susnjak, T. Chat2vis: Generating data visualisations via natural language using chatgpt, codex and gpt-3 large language models. IEEE Access 2023, 11, 45181–45193. [Google Scholar] [CrossRef]
- Dwivedi, Y.K.; Hughes, L.; Ismagilova, E.; Aarts, G.; Coombs, C.; Crick, T.; Duan, Y.; Dwivedi, R.; Edwards, J.; Eirug, A.; et al. Artificial Intelligence (AI): Multidisciplinary perspectives on emerging challenges, opportunities, and agenda for research, practice and policy. Int. J. Inf. Manag. 2021, 57, 101994. [Google Scholar] [CrossRef]
- Gabriel, I. Artificial intelligence, values, and alignment. Minds Mach. 2020, 30, 411–437. [Google Scholar] [CrossRef]
- Shaban-Nejad, A.; Michalowski, M.; Bianco, S.; Brownstein, J.S.; Buckeridge, D.L.; Davis, R.L. Applied artificial intelligence in healthcare: Listening to the winds of change in a post-COVID-19 world. Exp. Biol. Med. 2022, 247, 1969–1971. [Google Scholar] [CrossRef]
- Ji, Z.; Lee, N.; Frieske, R.; Yu, T.; Su, D.; Xu, Y.; Ishii, E.; Bang, Y.J.; Madotto, A.; Fung, P. Survey of hallucination in natural language generation. ACM Comput. Surv. 2023, 55, 1–38. [Google Scholar] [CrossRef]
- Min, B.; Ross, H.; Sulem, E.; Veyseh, A.P.B.; Nguyen, T.H.; Sainz, O.; Agirre, E.; Heintz, I.; Roth, D. Recent advances in natural language processing via large pre-trained language models: A survey. ACM Comput. Surv. 2023, 56, 1–40. [Google Scholar] [CrossRef]
- Li, J.; Cheng, X.; Zhao, W.X.; Nie, J.Y.; Wen, J.R. Halueval: A large-scale hallucination evaluation benchmark for large language models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–10 December 2023; pp. 6449–6464. [Google Scholar]
- Weidinger, L.; Mellor, J.; Rauh, M.; Griffin, C.; Uesato, J.; Huang, P.S.; Cheng, M.; Glaese, M.; Balle, B.; Kasirzadeh, A.; et al. Ethical and social risks of harm from language models. arXiv 2021, arXiv:2112.04359. [Google Scholar]
- Xi, Z.; Rui, Z.; Tao, G. Safety and ethical concerns of large language models. In Proceedings of the 22nd Chinese National Conference on Computational Linguistics (Volume 4: Tutorial Abstracts), Harbin, China, 3–5 August 2023; pp. 9–16. [Google Scholar]
- Mahmud, D.; Hajmohamed, H.; Almentheri, S.; Alqaydi, S.; Aldhaheri, L.; Khalil, R.A.; Saeed, N. Integrating LLMs with ITS: Recent Advances, Potentials, Challenges, and Future Directions. arXiv 2025, arXiv:2501.04437. [Google Scholar] [CrossRef]
- Sujan, M.; Slater, D.; Crumpton, E. How can large language models assist with a FRAM analysis? Saf. Sci. 2025, 181, 106695. [Google Scholar] [CrossRef]
- Brown, P.F.; Della Pietra, V.J.; Desouza, P.V.; Lai, J.C.; Mercer, R.L. Class-based n-gram models of natural language. Comput. Linguist. 1992, 18, 467–480. [Google Scholar]
- Katz, S. Estimation of probabilities from sparse data for the language model component of a speech recognizer. IEEE Trans. Acoust. Speech Signal Process. 1987, 35, 400–401. [Google Scholar] [CrossRef]
- Kneser, R.; Ney, H. Improved backing-off for m-gram language modeling. In Proceedings of the 1995 International Conference on Acoustics, Speech, And Signal Processing, Detroit, MI, USA, 9–12 May 1995; Volume 1, pp. 181–184. [Google Scholar]
- Kuhn, R.; De Mori, R. A cache-based natural language model for speech recognition. IEEE Trans. Pattern Anal. Mach. Intell. 1990, 12, 570–583. [Google Scholar] [CrossRef]
- Ney, H.; Essen, U.; Kneser, R. On structuring probabilistic dependences in stochastic language modelling. Comput. Speech Lang. 1994, 8, 1–38. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Nammous, M.K.; Saeed, K. Natural language processing: Speaker, language, and gender identification with LSTM. In Advanced Computing and Systems for Security; Springer: Singapore, 2019; Volume 883, pp. 143–156. [Google Scholar]
- Wei, D.; Wang, B.; Lin, G.; Liu, D.; Dong, Z.; Liu, H.; Liu, Y. Research on unstructured text data mining and fault classification based on RNN-LSTM with malfunction inspection report. Energies 2017, 10, 406. [Google Scholar] [CrossRef]
- Yao, L.; Guan, Y. An improved LSTM structure for natural language processing. In Proceedings of the 2018 IEEE International Conference of Safety Produce Informatization (IICSPI), Chongqing, China, 10–12 December 2018; pp. 565–569. [Google Scholar]
- Chen, M.; Tworek, J.; Jun, H.; Yuan, Q.; Pinto, H.P.d.O.; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst. 2022, 35, 27730–27744. [Google Scholar]
- Susnjak, T. Beyond Predictive Learning Analytics Modelling and onto Explainable Artificial Intelligence with Prescriptive Analytics and ChatGPT. Int. J. Artif. Intell. Educ. 2023, 34, 452–482. [Google Scholar] [CrossRef]
- Susnjak, T.; Griffin, E.; McCutcheon, M.; Potter, K. Towards Clinical Prediction with Transparency: An Explainable AI Approach to Survival Modelling in Residential Aged Care. arXiv 2023, arXiv:2312.00271. [Google Scholar]
- Yang, R.; Tan, T.F.; Lu, W.; Thirunavukarasu, A.J.; Ting, D.S.W.; Liu, N. Large language models in health care: Development, applications, and challenges. Health Care Sci. 2023, 2, 255–263. [Google Scholar] [CrossRef]
- Baidoo-Anu, D.; Ansah, L.O. Education in the era of generative artificial intelligence (AI): Understanding the potential benefits of ChatGPT in promoting teaching and learning. J. AI 2023, 7, 52–62. [Google Scholar] [CrossRef]
- Susnjak, T. ChatGPT: The end of online exam integrity? arXiv 2022, arXiv:2212.09292. [Google Scholar]
- Tlili, A.; Shehata, B.; Adarkwah, M.A.; Bozkurt, A.; Hickey, D.T.; Huang, R.; Agyemang, B. What if the devil is my guardian angel: ChatGPT as a case study of using chatbots in education. Smart Learn. Environ. 2023, 10, 15. [Google Scholar] [CrossRef]
- AlAfnan, M.A.; Dishari, S.; Jovic, M.; Lomidze, K. Chatgpt as an educational tool: Opportunities, challenges, and recommendations for communication, business writing, and composition courses. J. Artif. Intell. Technol. 2023, 3, 60–68. [Google Scholar] [CrossRef]
- George, A.S.; George, A.H. A review of ChatGPT AI’s impact on several business sectors. Partners Univers. Int. Innov. J. 2023, 1, 9–23. [Google Scholar]
- Hadfield, G.K.; Clark, J. Regulatory Markets: The Future of AI Governance. arXiv 2023, arXiv:2304.04914. [Google Scholar]
- LaGrandeur, K. How safe is our reliance on AI, and should we regulate it? AI Ethics 2021, 1, 93–99. [Google Scholar] [CrossRef]
- McLean, S.; Read, G.J.; Thompson, J.; Baber, C.; Stanton, N.A.; Salmon, P.M. The risks associated with Artificial General Intelligence: A systematic review. J. Exp. Theor. Artif. Intell. 2023, 35, 649–663. [Google Scholar] [CrossRef]
- Mitchell, M. AI’s challenge of understanding the world. Science 2023, 382, eadm8175. [Google Scholar] [CrossRef] [PubMed]
- Black, S.; Gao, L.; Wang, P.; Leahy, C.; Biderman, S. GPT-NeoX-20B: An Open-Source Autoregressive Language Model. 2022. Available online: https://github.com/EleutherAI/gpt-neox (accessed on 9 January 2025).
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]
- Bakker, M.; Chadwick, M.; Sheahan, H.; Tessler, M.; Campbell-Gillingham, L.; Balaguer, J.; McAleese, N.; Glaese, A.; Aslanides, J.; Botvinick, M.; et al. Fine-tuning language models to find agreement among humans with diverse preferences. Adv. Neural Inf. Process. Syst. 2022, 35, 38176–38189. [Google Scholar]
- Hu, Z.; Lan, Y.; Wang, L.; Xu, W.; Lim, E.P.; Lee, R.K.W.; Bing, L.; Poria, S. LLM-Adapters: An Adapter Family for Parameter-Efficient Fine-Tuning of Large Language Models. arXiv 2023, arXiv:2304.01933. [Google Scholar]
- Liu, H.; Tam, D.; Muqeeth, M.; Mohta, J.; Huang, T.; Bansal, M.; Raffel, C.A. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Adv. Neural Inf. Process. Syst. 2022, 35, 1950–1965. [Google Scholar]
- Zheng, H.; Shen, L.; Tang, A.; Luo, Y.; Hu, H.; Du, B.; Tao, D. Learn From Model Beyond Fine-Tuning: A Survey. arXiv 2023, arXiv:2310.08184. [Google Scholar]
- Manakul, P.; Liusie, A.; Gales, M.J. Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models. arXiv 2023, arXiv:2303.08896. [Google Scholar]
- Martino, A.; Iannelli, M.; Truong, C. Knowledge injection to counter large language model (llm) hallucination. In Proceedings of the European Semantic Web Conference, Hersonissos, Crete, Greece, 31 May 2023; pp. 182–185. [Google Scholar]
- Yao, J.Y.; Ning, K.P.; Liu, Z.H.; Ning, M.N.; Yuan, L. Llm lies: Hallucinations are not bugs, but features as adversarial examples. arXiv 2023, arXiv:2310.01469. [Google Scholar]
- Zhang, Y.; Li, Y.; Cui, L.; Cai, D.; Liu, L.; Fu, T.; Huang, X.; Zhao, E.; Zhang, Y.; Chen, Y.; et al. Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models. arXiv 2023, arXiv:2309.01219. [Google Scholar]
- Ji, J.; Liu, M.; Dai, J.; Pan, X.; Zhang, C.; Bian, C.; Sun, R.; Wang, Y.; Yang, Y. Beavertails: Towards improved safety alignment of llm via a human-preference dataset. arXiv 2023, arXiv:2307.04657. [Google Scholar]
- Liu, Y.; Yao, Y.; Ton, J.F.; Zhang, X.; Cheng, R.G.; Klochkov, Y.; Taufiq, M.F.; Li, H. Trustworthy LLMs: A Survey and Guideline for Evaluating Large Language Models’ Alignment. arXiv 2023, arXiv:2308.05374. [Google Scholar]
- Wang, Y.; Zhong, W.; Li, L.; Mi, F.; Zeng, X.; Huang, W.; Shang, L.; Jiang, X.; Liu, Q. Aligning large language models with human: A survey. arXiv 2023, arXiv:2307.12966. [Google Scholar]
- Sun, Z.; Shen, Y.; Zhou, Q.; Zhang, H.; Chen, Z.; Cox, D.; Yang, Y.; Gan, C. Principle-driven self-alignment of language models from scratch with minimal human supervision. arXiv 2023, arXiv:2305.03047. [Google Scholar]
- Wolf, Y.; Wies, N.; Levine, Y.; Shashua, A. Fundamental limitations of alignment in large language models. arXiv 2023, arXiv:2304.11082. [Google Scholar]
- Dang, H.; Mecke, L.; Lehmann, F.; Goller, S.; Buschek, D. How to prompt? Opportunities and challenges of zero-and few-shot learning for human-AI interaction in creative applications of generative models. arXiv 2022, arXiv:2209.01390. [Google Scholar]
- Ma, R.; Zhou, X.; Gui, T.; Tan, Y.; Li, L.; Zhang, Q.; Huang, X. Template-free prompt tuning for few-shot NER. arXiv 2021, arXiv:2109.13532. [Google Scholar]
- Qin, C.; Joty, S. LFPT5: A unified framework for lifelong few-shot language learning based on prompt tuning of t5. arXiv 2021, arXiv:2110.07298. [Google Scholar]
- Wang, S.; Tang, L.; Majety, A.; Rousseau, J.F.; Shih, G.; Ding, Y.; Peng, Y. Trustworthy assertion classification through prompting. J. Biomed. Inform. 2022, 132, 104139. [Google Scholar] [CrossRef] [PubMed]
- Fan, Y.; Jiang, F.; Li, P.; Li, H. GrammarGPT: Exploring Open-Source LLMs for Native Chinese Grammatical Error Correction with Supervised Fine-Tuning. In Proceedings of the CCF International Conference on Natural Language Processing and Chinese Computing, Foshan, China, 12–15 October 2023; pp. 69–80. [Google Scholar]
- Liga, D.; Robaldo, L. Fine-tuning GPT-3 for legal rule classification. Comput. Law Secur. Rev. 2023, 51, 105864. [Google Scholar] [CrossRef]
- Liu, Y.; Singh, A.; Freeman, C.D.; Co-Reyes, J.D.; Liu, P.J. Improving Large Language Model Fine-tuning for Solving Math Problems. arXiv 2023, arXiv:2310.10047. [Google Scholar]
- Talat, Z.; Névéol, A.; Biderman, S.; Clinciu, M.; Dey, M.; Longpre, S.; Luccioni, S.; Masoud, M.; Mitchell, M.; Radev, D.; et al. You reap what you sow: On the challenges of bias evaluation under multilingual settings. In Proceedings of the BigScience Episode# 5–Workshop on Challenges & Perspectives in Creating Large Language Models, Dublin, Ireland, 27 May 2022; pp. 26–41. [Google Scholar]
- Liu, Y.; Yu, S.; Lin, T. Hessian regularization of deep neural networks: A novel approach based on stochastic estimators of Hessian trace. Neurocomputing 2023, 536, 13–20. [Google Scholar] [CrossRef]
- Lu, Y.; Bo, Y.; He, W. Confidence adaptive regularization for deep learning with noisy labels. arXiv 2021, arXiv:2108.08212. [Google Scholar]
- Pereyra, G.; Tucker, G.; Chorowski, J.; Kaiser, Ł.; Hinton, G. Regularizing neural networks by penalizing confident output distributions. arXiv 2017, arXiv:1701.06548. [Google Scholar]
- Chen, E.; Hong, Z.W.; Pajarinen, J.; Agrawal, P. Redeeming intrinsic rewards via constrained optimization. Adv. Neural Inf. Process. Syst. 2022, 35, 4996–5008. [Google Scholar]
- Jiang, Y.; Li, Z.; Tan, M.; Wei, S.; Zhang, G.; Guan, Z.; Han, B. A stable block adjustment method without ground control points using bound constrained optimization. Int. J. Remote Sens. 2022, 43, 4708–4722. [Google Scholar] [CrossRef]
- Kachuee, M.; Lee, S. Constrained policy optimization for controlled self-learning in conversational AI systems. arXiv 2022, arXiv:2209.08429. [Google Scholar]
- Song, Z.; Wang, H.; Jin, Y. A Surrogate-Assisted Evolutionary Framework With Regions of Interests-Based Data Selection for Expensive Constrained Optimization. IEEE Trans. Syst. Man Cybern. Syst. 2023, 53, 6268–6280. [Google Scholar] [CrossRef]
- Yu, J.; Xu, T.; Rong, Y.; Huang, J.; He, R. Structure-aware conditional variational auto-encoder for constrained molecule optimization. Pattern Recognit. 2022, 126, 108581. [Google Scholar] [CrossRef]
- Butlin, P. AI alignment and human reward. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, Virtual, 19–21 May 2021; pp. 437–445. [Google Scholar]
- Faal, F.; Schmitt, K.; Yu, J.Y. Reward modeling for mitigating toxicity in transformer-based language models. Appl. Intell. 2023, 53, 8421–8435. [Google Scholar] [CrossRef]
- Leike, J.; Krueger, D.; Everitt, T.; Martic, M.; Maini, V.; Legg, S. Scalable agent alignment via reward modeling: A research direction. arXiv 2018, arXiv:1811.07871. [Google Scholar]
- Li, L.; Chai, Y.; Wang, S.; Sun, Y.; Tian, H.; Zhang, N.; Wu, H. Tool-Augmented Reward Modeling. arXiv 2023, arXiv:2310.01045. [Google Scholar]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Halgamuge, M.N. The Inadequacy of Reinforcement Learning from Human Feedback - Radicalizing Large Language Models via Semantic Vulnerabilities. IEEE Trans. Cogn. Dev. Syst. 2024, 16, 1561–1574. [Google Scholar] [CrossRef]
- Barreto, F.; Moharkar, L.; Shirodkar, M.; Sarode, V.; Gonsalves, S.; Johns, A. Generative Artificial Intelligence: Opportunities and Challenges of Large Language Models. In Proceedings of the International Conference on Intelligent Computing and Networking, Mumbai, India, 24–25 February 2023; pp. 545–553. [Google Scholar]
- Chen, Z.; Wang, Z.; Wang, Z.; Liu, H.; Yin, Z.; Liu, S.; Sheng, L.; Ouyang, W.; Qiao, Y.; Shao, J. Octavius: Mitigating Task Interference in MLLMs via MoE. arXiv 2023, arXiv:2311.02684. [Google Scholar]
- Dun, C.; Garcia, M.D.C.H.; Zheng, G.; Awadallah, A.H.; Kyrillidis, A.; Sim, R. Sweeping Heterogeneity with Smart MoPs: Mixture of Prompts for LLM Task Adaptation. arXiv 2023, arXiv:2310.02842. [Google Scholar]
- Naveed, H.; Khan, A.U.; Qiu, S.; Saqib, M.; Anwar, S.; Usman, M.; Barnes, N.; Mian, A. A comprehensive overview of large language models. arXiv 2023, arXiv:2307.06435. [Google Scholar]
- Xue, F.; Fu, Y.; Zhou, W.; Zheng, Z.; You, Y. To Repeat or Not To Repeat: Insights from Scaling LLM under Token-Crisis. arXiv 2023, arXiv:2305.13230. [Google Scholar]
- Vats, A.; Raja, R.; Jain, V.; Chadha, A. The Evolution of Mixture of Experts: A Survey from Basics to Breakthroughs. Preprints 2024, 2024080583. [Google Scholar]
- Lin, B.; Tang, Z.; Ye, Y.; Cui, J.; Zhu, B.; Jin, P.; Zhang, J.; Ning, M.; Yuan, L. Moe-llava: Mixture of experts for large vision-language models. arXiv 2024, arXiv:2401.15947. [Google Scholar]
- Tian, Y.; Xia, F.; Song, Y. Dialogue summarization with mixture of experts based on large language models. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2024; pp. 7143–7155. [Google Scholar]
- Li, Y.; Jiang, S.; Hu, B.; Wang, L.; Zhong, W.; Luo, W.; Ma, L.; Zhang, M. Uni-MoE: Scaling Unified Multimodal LLMs with Mixture of Experts. arXiv 2024, arXiv:2405.11273. [Google Scholar]
- Fedus, W.; Dean, J.; Zoph, B. A review of sparse expert models in deep learning. arXiv 2022, arXiv:2209.01667. [Google Scholar]
- Nowaz Rabbani Chowdhury, M.; Zhang, S.; Wang, M.; Liu, S.; Chen, P.Y. Patch-level Routing in Mixture-of-Experts is Provably Sample-efficient for Convolutional Neural Networks. arXiv 2023, arXiv:2306.04073. [Google Scholar]
- Santos, C.N.d.; Lee-Thorp, J.; Noble, I.; Chang, C.C.; Uthus, D. Memory Augmented Language Models through Mixture of Word Experts. arXiv 2023, arXiv:2311.10768. [Google Scholar]
- Wang, W.; Ma, G.; Li, Y.; Du, B. Language-Routing Mixture of Experts for Multilingual and Code-Switching Speech Recognition. arXiv 2023, arXiv:2307.05956. [Google Scholar]
- Zhao, X.; Chen, X.; Cheng, Y.; Chen, T. Sparse MoE with Language Guided Routing for Multilingual Machine Translation. In Proceedings of the Twelfth International Conference on Learning Representations, Vienna, Austria, 7–11 May 2024. [Google Scholar]
- Huang, W.; Zhang, H.; Peng, P.; Wang, H. Multi-gate Mixture-of-Expert Combined with Synthetic Minority Over-sampling Technique for Multimode Imbalanced Fault Diagnosis. In Proceedings of the 2023 26th International Conference on Computer Supported Cooperative Work in Design (CSCWD), Rio de Janeiro, Brazil, 24–26 May 2023; pp. 456–461. [Google Scholar]
- Liu, B.; Ding, L.; Shen, L.; Peng, K.; Cao, Y.; Cheng, D.; Tao, D. Diversifying the Mixture-of-Experts Representation for Language Models with Orthogonal Optimizer. arXiv 2023, arXiv:2310.09762. [Google Scholar]
- Wang, W.; Lai, Z.; Li, S.; Liu, W.; Ge, K.; Liu, Y.; Shen, A.; Li, D. Prophet: Fine-grained Load Balancing for Parallel Training of Large-scale MoE Models. In Proceedings of the 2023 IEEE International Conference on Cluster Computing (CLUSTER), Santa Fe, NM, USA, 31 October–3 November 2023; pp. 82–94. [Google Scholar]
- Yao, X.; Liang, S.; Han, S.; Huang, H. Enhancing Molecular Property Prediction via Mixture of Collaborative Experts. arXiv 2023, arXiv:2312.03292. [Google Scholar]
- Xiao, Z.; Jiang, Y.; Tang, G.; Liu, L.; Xu, S.; Xiao, Y.; Yan, W. Adversarial mixture of experts with category hierarchy soft constraint. In Proceedings of the 2021 IEEE 37th International Conference on Data Engineering (ICDE), Chania, Greece, 19–22 April 2021; pp. 2453–2463. [Google Scholar]
- Agbese, M.; Mohanani, R.; Khan, A.; Abrahamsson, P. Implementing AI Ethics: Making Sense of the Ethical Requirements. In Proceedings of the 27th International Conference on Evaluation and Assessment in Software Engineering, Oulu, Finland, 14–16 June 2023; pp. 62–71. [Google Scholar]
- Zhou, Y.; Lei, T.; Liu, H.; Du, N.; Huang, Y.; Zhao, V.; Dai, A.M.; Le, Q.V.; Laudon, J. Mixture-of-experts with expert choice routing. Adv. Neural Inf. Process. Syst. 2022, 35, 7103–7114. [Google Scholar]
- Guha, N.; Lawrence, C.; Gailmard, L.A.; Rodolfa, K.; Surani, F.; Bommasani, R.; Raji, I.; Cuéllar, M.F.; Honigsberg, C.; Liang, P.; et al. AI Regulation Has Its Own Alignment Problem: The Technical and Institutional Feasibility of Disclosure, Registration, Licensing, and Auditing. Georg. Wash. Law Rev. 2024, 92, 1473–1557. [Google Scholar]
- Team, G.; Georgiev, P.; Lei, V.I.; Burnell, R.; Bai, L.; Gulati, A.; Tanzer, G.; Vincent, D.; Pan, Z.; Wang, S. Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context. arXiv 2024, arXiv:2403.05530. [Google Scholar]
- Team, G.; Anil, R.; Borgeaud, S.; Alayrac, J.B.; Yu, J.; Soricut, R.; Schalkwyk, J.; Dai, A.M.; Hauth, A.; Millican, K. Gemini: A family of highly capable multimodal models. arXiv 2023, arXiv:2312.11805. [Google Scholar]
- Alsajri, A.; Salman, H.A.; Steiti, A. Generative Models in Natural Language Processing: A Comparative Study of ChatGPT and Gemini. Babylon. J. Artif. Intell. 2024, 2024, 134–145. [Google Scholar] [CrossRef]
- Yang, L.; Xu, S.; Sellergren, A.; Kohlberger, T.; Zhou, Y.; Ktena, I.; Kiraly, A.; Ahmed, F.; Hormozdiari, F.; Jaroensri, T. Advancing multimodal medical capabilities of Gemini. arXiv 2024, arXiv:2405.03162. [Google Scholar]
- Lewandowska-Tomaszczyk, B.; Liebeskind, C. Opinion events and stance types: Advances in LLM performance with ChatGPT and Gemini. Lodz Pap. Pragmat. 2024, 20, 413–432. [Google Scholar] [CrossRef]
- Google DeepMind. Introducing Gemini 2.0: Our New AI Model for the Agentic Era; Google: Mountain View, CA, USA, 2024. [Google Scholar]
- Akhtar, Z.B. From bard to Gemini: An investigative exploration journey through Google’s evolution in conversational AI and generative AI. Comput. Artif. Intell. 2024, 2, 1378. [Google Scholar] [CrossRef]
- Acosta, J.N.; Falcone, G.J.; Rajpurkar, P.; Topol, E.J. Multimodal biomedical AI. Nat. Med. 2022, 28, 1773–1784. [Google Scholar] [CrossRef]
- Qi, S.; Cao, Z.; Rao, J.; Wang, L.; Xiao, J.; Wang, X. What is the limitation of multimodal LLMs? A deeper look into multimodal LLMs through prompt probing. Inf. Process. Manag. 2023, 60, 103510. [Google Scholar] [CrossRef]
- Xu, B.; Kocyigit, D.; Grimm, R.; Griffin, B.P.; Cheng, F. Applications of artificial intelligence in multimodality cardiovascular imaging: A state-of-the-art review. Prog. Cardiovasc. Dis. 2020, 63, 367–376. [Google Scholar] [CrossRef] [PubMed]
- Birhane, A.; Prabhu, V.U.; Kahembwe, E. Multimodal datasets: Misogyny, pornography, and malignant stereotypes. arXiv 2021, arXiv:2110.01963. [Google Scholar]
- Li, Y.; Li, W.; Li, N.; Qiu, X.; Manokaran, K.B. Multimodal information interaction and fusion for the parallel computing system using AI techniques. Int. J. High Perform. Syst. Archit. 2021, 10, 185–196. [Google Scholar] [CrossRef]
- Zhang, C.; Yang, Z.; He, X.; Deng, L. Multimodal intelligence: Representation learning, information fusion, and applications. IEEE J. Sel. Top. Signal Process. 2020, 14, 478–493. [Google Scholar] [CrossRef]
- Qiao, H.; Liu, V.; Chilton, L. Initial images: Using image prompts to improve subject representation in multimodal ai generated art. In Proceedings of the 14th Conference on Creativity and Cognition, Venice, Italy, 20–23 June 2022; pp. 15–28. [Google Scholar]
- Stewart, A.E.; Keirn, Z.; D’Mello, S.K. Multimodal modeling of collaborative problem-solving facets in triads. User Model. User-Adapt. Interact. 2021, 34, 713–751. [Google Scholar] [CrossRef]
- Xue, L.; Yu, N.; Zhang, S.; Li, J.; Martín-Martín, R.; Wu, J.; Xiong, C.; Xu, R.; Niebles, J.C.; Savarese, S. ULIP-2: Towards Scalable Multimodal Pre-training For 3D Understanding. arXiv 2023, arXiv:2305.08275. [Google Scholar]
- Yan, L.; Zhao, L.; Gasevic, D.; Martinez-Maldonado, R. Scalability, sustainability, and ethicality of multimodal learning analytics. In Proceedings of the LAK22: 12th International Learning Analytics and Knowledge Conference, Online, 21–25 March 2022; pp. 13–23. [Google Scholar]
- Liu-Thompkins, Y.; Okazaki, S.; Li, H. Artificial empathy in marketing interactions: Bridging the human-AI gap in affective and social customer experience. J. Acad. Mark. Sci. 2022, 50, 1198–1218. [Google Scholar] [CrossRef]
- Rahman, M.S.; Bag, S.; Hossain, M.A.; Fattah, F.A.M.A.; Gani, M.O.; Rana, N.P. The new wave of AI-powered luxury brands online shopping experience: The role of digital multisensory cues and customers’ engagement. J. Retail. Consum. Serv. 2023, 72, 103273. [Google Scholar] [CrossRef]
- Sachdeva, E.; Agarwal, N.; Chundi, S.; Roelofs, S.; Li, J.; Dariush, B.; Choi, C.; Kochenderfer, M. Rank2tell: A multimodal driving dataset for joint importance ranking and reasoning. arXiv 2023, arXiv:2309.06597. [Google Scholar]
- Cui, C.; Ma, Y.; Cao, X.; Ye, W.; Zhou, Y.; Liang, K.; Chen, J.; Lu, J.; Yang, Z.; Liao, K.D.; et al. A survey on multimodal large language models for autonomous driving. arXiv 2023, arXiv:2311.12320. [Google Scholar]
- Temsamani, A.B.; Chavali, A.K.; Vervoort, W.; Tuytelaars, T.; Radevski, G.; Van Hamme, H.; Mets, K.; Hutsebaut-Buysse, M.; De Schepper, T.; Latré, S. A multimodal AI approach for intuitively instructable autonomous systems: A case study of an autonomous off-highway vehicle. In Proceedings of the Eighteenth International Conference on Autonomic and Autonomous Systems, ICAS 2022, Venice, Italy, 22–26 May 2022; pp. 31–39. [Google Scholar]
- Lee, J.; Shin, S.Y. Something that they never said: Multimodal disinformation and source vividness in understanding the power of AI-enabled deepfake news. Media Psychol. 2022, 25, 531–546. [Google Scholar] [CrossRef]
- Muppalla, S.; Jia, S.; Lyu, S. Integrating Audio-Visual Features for Multimodal Deepfake Detection. arXiv 2023, arXiv:2310.03827. [Google Scholar]
- Kumar, S.; Chaube, M.K.; Nenavath, S.N.; Gupta, S.K.; Tetarave, S.K. Privacy preservation and security challenges: A new frontier multimodal machine learning research. Int. J. Sens. Netw. 2022, 39, 227–245. [Google Scholar] [CrossRef]
- Marchang, J.; Di Nuovo, A. Assistive multimodal robotic system (AMRSys): Security and privacy issues, challenges, and possible solutions. Appl. Sci. 2022, 12, 2174. [Google Scholar] [CrossRef]
- Peña, A.; Serna, I.; Morales, A.; Fierrez, J.; Ortega, A.; Herrarte, A.; Alcantara, M.; Ortega-Garcia, J. Human-centric multimodal machine learning: Recent advances and testbed on AI-based recruitment. SN Comput. Sci. 2023, 4, 434. [Google Scholar] [CrossRef]
- Wolfe, R.; Caliskan, A. American==White in multimodal language-and-image ai. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, Oxford, UK, 1–3 August 2022; pp. 800–812. [Google Scholar]
- Wolfe, R.; Yang, Y.; Howe, B.; Caliskan, A. Contrastive language-vision ai models pretrained on web-scraped multimodal data exhibit sexual objectification bias. In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, Chicago, IL, USA, 12–15 June 2023; pp. 1174–1185. [Google Scholar]
- Afshar, M.; Sharma, B.; Dligach, D.; Oguss, M.; Brown, R.; Chhabra, N.; Thompson, H.M.; Markossian, T.; Joyce, C.; Churpek, M.M.; et al. Development and multimodal validation of a substance misuse algorithm for referral to treatment using artificial intelligence (SMART-AI): A retrospective deep learning study. Lancet Digit. Health 2022, 4, e426–e435. [Google Scholar] [CrossRef] [PubMed]
- Alwahaby, H.; Cukurova, M.; Papamitsiou, Z.; Giannakos, M. The evidence of impact and ethical considerations of Multimodal Learning Analytics: A Systematic Literature Review. In The Multimodal Learning Analytics Handbook; Springer: Cham, Switzerland, 2022; pp. 289–325. [Google Scholar]
- Wu, W.; Mao, S.; Zhang, Y.; Xia, Y.; Dong, L.; Cui, L.; Wei, F. Visualization-of-Thought Elicits Spatial Reasoning in Large Language Models. arXiv 2024, arXiv:2404.03622. [Google Scholar]
- Behrouz, A.; Zhong, P.; Mirrokni, V. Titans: Learning to Memorize at Test Time. arXiv 2024, arXiv:2501.00663. [Google Scholar]
- Mitchell, M. How do we know how smart AI systems are? Science 2023, 381, eadj5957. [Google Scholar] [CrossRef]
- Miao, Q.; Zheng, W.; Lv, Y.; Huang, M.; Ding, W.; Wang, F.Y. DAO to HANOI via DeSci: AI paradigm shifts from AlphaGo to ChatGPT. IEEE/CAA J. Autom. Sin. 2023, 10, 877–897. [Google Scholar] [CrossRef]
- Rong, Y. Roadmap of AlphaGo to AlphaStar: Problems and challenges. In Proceedings of the 2nd International Conference on Artificial Intelligence, Automation, and High-Performance Computing (AIAHPC 2022), Zhuhai, China, 25–27 February 2022; Volume 12348, pp. 904–914. [Google Scholar]
- Gao, Y.; Zhou, M.; Liu, D.; Yan, Z.; Zhang, S.; Metaxas, D.N. A data-scalable transformer for medical image segmentation: Architecture, model efficiency, and benchmark. arXiv 2022, arXiv:2203.00131. [Google Scholar]
- Peebles, W.; Xie, S. Scalable diffusion models with transformers. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 4195–4205. [Google Scholar]
- Pope, R.; Douglas, S.; Chowdhery, A.; Devlin, J.; Bradbury, J.; Heek, J.; Xiao, K.; Agrawal, S.; Dean, J. Efficiently scaling transformer inference. In Proceedings of the 6th Machine Learning and Systems, Miami, FL, USA, 4–8 June 2023. [Google Scholar]
- Ding, Y.; Jia, M. Convolutional transformer: An enhanced attention mechanism architecture for remaining useful life estimation of bearings. IEEE Trans. Instrum. Meas. 2022, 71, 3515010. [Google Scholar] [CrossRef]
- Ding, Y.; Jia, M.; Miao, Q.; Cao, Y. A novel time–frequency Transformer based on self–attention mechanism and its application in fault diagnosis of rolling bearings. Mech. Syst. Signal Process. 2022, 168, 108616. [Google Scholar] [CrossRef]
- Wang, G.; Zhao, Y.; Tang, C.; Luo, C.; Zeng, W. When shift operation meets vision transformer: An extremely simple alternative to attention mechanism. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 22 February–1 March 2022; Volume 36, pp. 2423–2430. [Google Scholar]
- Cai, H.; Li, J.; Hu, M.; Gan, C.; Han, S. EfficientViT: Lightweight Multi-Scale Attention for High-Resolution Dense Prediction. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 17302–17313. [Google Scholar]
- Liu, X.; Peng, H.; Zheng, N.; Yang, Y.; Hu, H.; Yuan, Y. EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 14420–14430. [Google Scholar]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Talaat, F.M.; ZainEldin, H. An improved fire detection approach based on YOLO-v8 for smart cities. Neural Comput. Appl. 2023, 35, 20939–20954. [Google Scholar] [CrossRef]
- Tamang, S.; Sen, B.; Pradhan, A.; Sharma, K.; Singh, V.K. Enhancing covid-19 safety: Exploring yolov8 object detection for accurate face mask classification. Int. J. Intell. Syst. Appl. Eng. 2023, 11, 892–897. [Google Scholar]
- Lu, J.; Xiong, R.; Tian, J.; Wang, C.; Hsu, C.W.; Tsou, N.T.; Sun, F.; Li, J. Battery degradation prediction against uncertain future conditions with recurrent neural network enabled deep learning. Energy Storage Mater. 2022, 50, 139–151. [Google Scholar] [CrossRef]
- Onan, A. Bidirectional convolutional recurrent neural network architecture with group-wise enhancement mechanism for text sentiment classification. J. King Saud-Univ.-Comput. Inf. Sci. 2022, 34, 2098–2117. [Google Scholar] [CrossRef]
- Shan, F.; He, X.; Armaghani, D.J.; Zhang, P.; Sheng, D. Success and challenges in predicting TBM penetration rate using recurrent neural networks. Tunn. Undergr. Space Technol. 2022, 130, 104728. [Google Scholar] [CrossRef]
- Sridhar, C.; Pareek, P.K.; Kalidoss, R.; Jamal, S.S.; Shukla, P.K.; Nuagah, S.J. Optimal medical image size reduction model creation using recurrent neural network and GenPSOWVQ. J. Healthc. Eng. 2022, 2022, 2354866. [Google Scholar] [CrossRef]
- Zhu, J.; Jiang, Q.; Shen, Y.; Qian, C.; Xu, F.; Zhu, Q. Application of recurrent neural network to mechanical fault diagnosis: A review. J. Mech. Sci. Technol. 2022, 36, 527–542. [Google Scholar] [CrossRef]
- Lin, S.; Lin, W.; Wu, W.; Zhao, F.; Mo, R.; Zhang, H. Segrnn: Segment recurrent neural network for long-term time series forecasting. arXiv 2023, arXiv:2308.11200. [Google Scholar]
- Wei, Z.; Zhang, X.; Sun, M. Extracting weighted finite automata from recurrent neural networks for natural languages. In Proceedings of the International Conference on Formal Engineering Methods, ICFEM 2022, Madrid, Spain, 24–27 October 2022; pp. 370–385. [Google Scholar]
- Bonassi, F.; Farina, M.; Xie, J.; Scattolini, R. On recurrent neural networks for learning-based control: Recent results and ideas for future developments. J. Process. Control 2022, 114, 92–104. [Google Scholar] [CrossRef]
- Büchel, J.; Vasilopoulos, A.; Simon, W.A.; Boybat, I.; Tsai, H.; Burr, G.W.; Castro, H.; Filipiak, B.; Le Gallo, M.; Rahimi, A. Efficient scaling of large language models with mixture of experts and 3D analog in-memory computing. Nat. Comput. Sci. 2025, 5, 13–26. [Google Scholar] [CrossRef]
- Liao, X.; Sun, Y.; Tian, H.; Wan, X.; Jin, Y.; Wang, Z.; Ren, Z.; Huang, X.; Li, W.; Tse, K.F. mFabric: An Efficient and Scalable Fabric for Mixture-of-Experts Training. arXiv 2025, arXiv:2501.03905. [Google Scholar]
- Park, B.; Go, H.; Kim, J.Y.; Woo, S.; Ham, S.; Kim, C. Switch Diffusion Transformer: Synergizing Denoising Tasks with Sparse Mixture-of-Experts; Springer: Cham, Switzerland, 2025; pp. 461–477. [Google Scholar]
- Di Sario, F.; Renzulli, R.; Tartaglione, E.; Grangetto, M. Boost Your NeRF: A Model-Agnostic Mixture of Experts Framework for High Quality and Efficient Rendering; Springer: Cham, Switzerland, 2025; pp. 176–192. [Google Scholar]
- Du, N.; Huang, Y.; Dai, A.M.; Tong, S.; Lepikhin, D.; Xu, Y.; Krikun, M.; Zhou, Y.; Yu, A.W.; Firat, O.; et al. Glam: Efficient scaling of language models with mixture-of-experts. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 5547–5569. [Google Scholar]
- Dhivya, K.; Kumar, S.N.; Victoria, D.R.S.; Sherly, S.I.; Durgadevi, G. Advanced Neural Networks for Multimodal Data Fusion in Interdisciplinary Research. In Advanced Interdisciplinary Applications of Deep Learning for Data Science; IGI Global Scientific Publishing: Hershey, PA, USA, 2025; pp. 201–232. [Google Scholar]
- Guo, Z.; Tang, Y.; Zhang, R.; Wang, D.; Wang, Z.; Zhao, B.; Li, X. Viewrefer: Grasp the multi-view knowledge for 3d visual grounding. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 2–6 October 2023; pp. 15372–15383. [Google Scholar]
- Pan, C.; He, Y.; Peng, J.; Zhang, Q.; Sui, W.; Zhang, Z. BAEFormer: Bi-Directional and Early Interaction Transformers for Bird’s Eye View Semantic Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 9590–9599. [Google Scholar]
- Xu, P.; Zhu, X.; Clifton, D.A. Multimodal learning with transformers: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 12113–12132. [Google Scholar] [CrossRef] [PubMed]
- Molenaar, I.; de Mooij, S.; Azevedo, R.; Bannert, M.; Järvelä, S.; Gašević, D. Measuring self-regulated learning and the role of AI: Five years of research using multimodal multichannel data. Comput. Hum. Behav. 2023, 139, 107540. [Google Scholar] [CrossRef]
- Steyaert, S.; Pizurica, M.; Nagaraj, D.; Khandelwal, P.; Hernandez-Boussard, T.; Gentles, A.J.; Gevaert, O. Multimodal data fusion for cancer biomarker discovery with deep learning. Nat. Mach. Intell. 2023, 5, 351–362. [Google Scholar] [CrossRef]
- Rani, V.; Nabi, S.T.; Kumar, M.; Mittal, A.; Kumar, K. Self-supervised learning: A succinct review. Arch. Comput. Methods Eng. 2023, 30, 2761–2775. [Google Scholar] [CrossRef] [PubMed]
- Schiappa, M.C.; Rawat, Y.S.; Shah, M. Self-supervised learning for videos: A survey. ACM Comput. Surv. 2023, 55, 228. [Google Scholar] [CrossRef]
- Yu, J.; Yin, H.; Xia, X.; Chen, T.; Li, J.; Huang, Z. Self-supervised learning for recommender systems: A survey. IEEE Trans. Knowl. Data Eng. 2023, 36, 335–355. [Google Scholar] [CrossRef]
- Bharti, V.; Kumar, A.; Purohit, V.; Singh, R.; Singh, A.K.; Singh, S.K. A Label Efficient Semi Self-Supervised Learning Framework for IoT Devices in Industrial Process. IEEE Trans. Ind. Inform. 2023, 20, 2253–2262. [Google Scholar] [CrossRef]
- Sam, D.; Kolter, J.Z. Losses over labels: Weakly supervised learning via direct loss construction. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 9695–9703. [Google Scholar]
- Wang, M.; Xie, P.; Du, Y.; Hu, X. T5-Based Model for Abstractive Summarization: A Semi-Supervised Learning Approach with Consistency Loss Functions. Appl. Sci. 2023, 13, 7111. [Google Scholar] [CrossRef]
- Li, Q.; Peng, X.; Qiao, Y.; Hao, Q. Unsupervised person re-identification with multi-label learning guided self-paced clustering. Pattern Recognit. 2022, 125, 108521. [Google Scholar] [CrossRef]
- Nancy, P.; Pallathadka, H.; Naved, M.; Kaliyaperumal, K.; Arumugam, K.; Garchar, V. Deep Learning and Machine Learning Based Efficient Framework for Image Based Plant Disease Classification and Detection. In Proceedings of the 2022 International Conference on Advanced Computing Technologies and Applications (ICACTA), Coimbatore, India, 4–5 March 2022; pp. 1–6. [Google Scholar]
- An, P.; Wang, Z.; Zhang, C. Ensemble unsupervised autoencoders and Gaussian mixture model for cyberattack detection. Inf. Process. Manag. 2022, 59, 102844. [Google Scholar] [CrossRef]
- Yan, S.; Shao, H.; Xiao, Y.; Liu, B.; Wan, J. Hybrid robust convolutional autoencoder for unsupervised anomaly detection of machine tools under noises. Robot. Comput.-Integr. Manuf. 2023, 79, 102441. [Google Scholar] [CrossRef]
- Ayanoglu, E.; Davaslioglu, K.; Sagduyu, Y.E. Machine learning in NextG networks via generative adversarial networks. IEEE Trans. Cogn. Commun. Netw. 2022, 8, 480–501. [Google Scholar] [CrossRef]
- Yan, K.; Chen, X.; Zhou, X.; Yan, Z.; Ma, J. Physical model informed fault detection and diagnosis of air handling units based on transformer generative adversarial network. IEEE Trans. Ind. Inform. 2022, 19, 2192–2199. [Google Scholar] [CrossRef]
- Zhou, N.R.; Zhang, T.F.; Xie, X.W.; Wu, J.Y. Hybrid quantum–classical generative adversarial networks for image generation via learning discrete distribution. Signal Process. Image Commun. 2023, 110, 116891. [Google Scholar] [CrossRef]
- Ladosz, P.; Weng, L.; Kim, M.; Oh, H. Exploration in deep reinforcement learning: A survey. Inf. Fusion 2022, 85, 1–22. [Google Scholar] [CrossRef]
- Matsuo, Y.; LeCun, Y.; Sahani, M.; Precup, D.; Silver, D.; Sugiyama, M.; Uchibe, E.; Morimoto, J. Deep learning, reinforcement learning, and world models. Neural Netw. 2022, 152, 267–275. [Google Scholar] [CrossRef] [PubMed]
- Bertoin, D.; Zouitine, A.; Zouitine, M.; Rachelson, E. Look where you look! Saliency-guided Q-networks for generalization in visual Reinforcement Learning. Adv. Neural Inf. Process. Syst. 2022, 35, 30693–30706. [Google Scholar]
- Hafiz, A. A Survey of Deep Q-Networks used for Reinforcement Learning: State of the Art. In Intelligent Communication Technologies and Virtual Mobile Networks, Proceedings of ICICV 2022, Tamil Nadu, India, 10–11 February 2022; Springer: Singapore, 2022; pp. 393–402. [Google Scholar]
- Hafiz, A.; Hassaballah, M.; Alqahtani, A.; Alsubai, S.; Hameed, M.A. Reinforcement Learning with an Ensemble of Binary Action Deep Q-Networks. Comput. Syst. Sci. Eng. 2023, 46, 2651–2666. [Google Scholar] [CrossRef]
- Alagha, A.; Singh, S.; Mizouni, R.; Bentahar, J.; Otrok, H. Target localization using multi-agent deep reinforcement learning with proximal policy optimization. Future Gener. Comput. Syst. 2022, 136, 342–357. [Google Scholar] [CrossRef]
- Hassan, S.S.; Park, Y.M.; Tun, Y.K.; Saad, W.; Han, Z.; Hong, C.S. 3TO: THz-enabled throughput and trajectory optimization of UAVs in 6G networks by proximal policy optimization deep reinforcement learning. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 5712–5718. [Google Scholar]
- Jayant, A.K.; Bhatnagar, S. Model-based safe deep reinforcement learning via a constrained proximal policy optimization algorithm. Adv. Neural Inf. Process. Syst. 2022, 35, 24432–24445. [Google Scholar]
- Lin, B. Reinforcement learning and bandits for speech and language processing: Tutorial, review and outlook. Expert Syst. Appl. 2023, 238, 122254. [Google Scholar] [CrossRef]
- Luo, B.; Wu, Z.; Zhou, F.; Wang, B.C. Human-in-the-loop reinforcement learning in continuous-action space. IEEE Trans. Neural Netw. Learn. Syst. 2023, 35, 15735–15744. [Google Scholar] [CrossRef]
- Raza, A.; Tran, K.P.; Koehl, L.; Li, S. Designing ecg monitoring healthcare system with federated transfer learning and explainable ai. Knowl.-Based Syst. 2022, 236, 107763. [Google Scholar] [CrossRef]
- Siahpour, S.; Li, X.; Lee, J. A novel transfer learning approach in remaining useful life prediction for incomplete dataset. IEEE Trans. Instrum. Meas. 2022, 71, 3509411. [Google Scholar] [CrossRef]
- Guo, Z.; Lin, K.; Chen, X.; Chit, C.Y. Transfer learning for angle of arrivals estimation in massive mimo system. In Proceedings of the 2022 IEEE/CIC International Conference on Communications in China (ICCC), Sanshui, Foshan, China, 11–13 August 2022; pp. 506–511. [Google Scholar]
- Liu, S.; Lu, Y.; Zheng, P.; Shen, H.; Bao, J. Adaptive reconstruction of digital twins for machining systems: A transfer learning approach. Robot. Comput.-Integr. Manuf. 2022, 78, 102390. [Google Scholar] [CrossRef]
- Liu, H.; Liu, J.; Cui, L.; Teng, Z.; Duan, N.; Zhou, M.; Zhang, Y. Logiqa 2.0—An improved dataset for logical reasoning in natural language understanding. IEEE/ACM Trans. Audio Speech Lang. Process. 2023, 31, 2947–2962. [Google Scholar] [CrossRef]
- Meng, Y.; Huang, J.; Zhang, Y.; Han, J. Generating training data with language models: Towards zero-shot language understanding. Adv. Neural Inf. Process. Syst. 2022, 35, 462–477. [Google Scholar]
- Samant, R.M.; Bachute, M.R.; Gite, S.; Kotecha, K. Framework for deep learning-based language models using multi-task learning in natural language understanding: A systematic literature review and future directions. IEEE Access 2022, 10, 17078–17097. [Google Scholar] [CrossRef]
- Weld, H.; Huang, X.; Long, S.; Poon, J.; Han, S.C. A survey of joint intent detection and slot filling models in natural language understanding. ACM Comput. Surv. 2022, 55, 156. [Google Scholar] [CrossRef]
- Ajmal, S.; Ahmed, A.A.I.; Jalota, C. Natural Language Processing in Improving Information Retrieval and Knowledge Discovery in Healthcare Conversational Agents. J. Artif. Intell. Mach. Learn. Manag. 2023, 7, 34–47. [Google Scholar]
- Montejo-Ráez, A.; Jiménez-Zafra, S.M. Current Approaches and Applications in Natural Language Processing. Appl. Sci. 2022, 12, 4859. [Google Scholar] [CrossRef]
- Manning, C.D. Human language understanding & reasoning. Daedalus 2022, 151, 127–138. [Google Scholar]
- Peng, W.; Xu, D.; Xu, T.; Zhang, J.; Chen, E. Are GPT Embeddings Useful for Ads and Recommendation? In Proceedings of the International Conference on Knowledge Science, Engineering and Management, KSEM 2023, Guangzhou, China, 16–18 August 2023; pp. 151–162. [Google Scholar]
- Erdem, E.; Kuyu, M.; Yagcioglu, S.; Frank, A.; Parcalabescu, L.; Plank, B.; Babii, A.; Turuta, O.; Erdem, A.; Calixto, I.; et al. Neural natural language generation: A survey on multilinguality, multimodality, controllability and learning. J. Artif. Intell. Res. 2022, 73, 1131–1207. [Google Scholar] [CrossRef]
- Qian, J.; Dong, L.; Shen, Y.; Wei, F.; Chen, W. Controllable natural language generation with contrastive prefixes. arXiv 2022, arXiv:2202.13257. [Google Scholar]
- Rashkin, H.; Nikolaev, V.; Lamm, M.; Aroyo, L.; Collins, M.; Das, D.; Petrov, S.; Tomar, G.S.; Turc, I.; Reitter, D. Measuring attribution in natural language generation models. Comput. Linguist. 2023, 49, 777–840. [Google Scholar] [CrossRef]
- Pandey, A.K.; Roy, S.S. Natural Language Generation Using Sequential Models: A Survey. Neural Process. Lett. 2023, 55, 7709–7742. [Google Scholar] [CrossRef]
- Khan, J.Y.; Uddin, G. Automatic code documentation generation using gpt-3. In Proceedings of the 37th IEEE/ACM International Conference on Automated Software Engineering, Rochester, MI, USA, 10–14 October 2022; pp. 1–6. [Google Scholar]
- Dwivedi, Y.K.; Kshetri, N.; Hughes, L.; Slade, E.L.; Jeyaraj, A.; Kar, A.K.; Baabdullah, A.M.; Koohang, A.; Raghavan, V.; Ahuja, M.; et al. “So what if ChatGPT wrote it?” Multidisciplinary perspectives on opportunities, challenges and implications of generative conversational AI for research, practice and policy. Int. J. Inf. Manag. 2023, 71, 102642. [Google Scholar] [CrossRef]
- Fu, T.; Gao, S.; Zhao, X.; Wen, J.r.; Yan, R. Learning towards conversational AI: A survey. AI Open 2022, 3, 14–28. [Google Scholar] [CrossRef]
- Ji, H.; Han, I.; Ko, Y. A systematic review of conversational AI in language education: Focusing on the collaboration with human teachers. J. Res. Technol. Educ. 2023, 55, 48–63. [Google Scholar] [CrossRef]
- Wan, Y.; Wang, W.; He, P.; Gu, J.; Bai, H.; Lyu, M.R. Biasasker: Measuring the bias in conversational ai system. In Proceedings of the 31st ACM Joint European Software Engineering Conference and Symposium on the Foundations of Software Engineering, San Francisco, CA, USA, 5–7 December 2023; pp. 515–527. [Google Scholar]
- Kusal, S.; Patil, S.; Choudrie, J.; Kotecha, K.; Mishra, S.; Abraham, A. AI-based conversational agents: A scoping review from technologies to future directions. IEEE Access 2022, 10, 92337–92356. [Google Scholar] [CrossRef]
- Xiao, Z. Seeing Us Through Machines: Designing and Building Conversational AI to Understand Humans. Ph.D. Thesis, University of Illinois at Urbana-Champaign, Champaign, IL, USA, 2023. [Google Scholar]
- Ko, H.K.; Park, G.; Jeon, H.; Jo, J.; Kim, J.; Seo, J. Large-scale text-to-image generation models for visual artists’ creative works. In Proceedings of the 28th International Conference on Intelligent User Interfaces, Sydney, NSW, Australia, 27–31 March 2023; pp. 919–933. [Google Scholar]
- Pearson, A. The rise of CreAltives: Using AI to enable and speed up the creative process. J. AI Robot. Workplace Autom. 2023, 2, 101–114. [Google Scholar] [CrossRef]
- Rezwana, J.; Maher, M.L. Designing creative AI partners with COFI: A framework for modeling interaction in human-AI co-creative systems. ACM Trans. Comput.-Hum. Interact. 2023, 30, 67. [Google Scholar] [CrossRef]
- Brooks, T.; Peebles, B.; Holmes, C.; DePue, W.; Guo, Y.; Jing, L.; Schnurr, D.; Taylor, J.; Luhman, T.; Luhman, E.; et al. Video Generation Models as World Simulators; OpenAI: San Francisco, CA, USA, 2024. [Google Scholar]
- Google DeepMind. Veo 2: Google’s Advanced Video Generation Model; Google: Mountain View, CA, USA, 2024. [Google Scholar]
- Sharma, S.; Bvuma, S. Generative Adversarial Networks (GANs) for Creative Applications: Exploring Art and Music Generation. Int. J. Multidiscip. Innov. Res. Methodol. 2023, 2, 29–33. [Google Scholar]
- Attard-Frost, B.; De los Ríos, A.; Walters, D.R. The ethics of AI business practices: A review of 47 AI ethics guidelines. AI Ethics 2023, 3, 389–406. [Google Scholar] [CrossRef]
- Gardner, A.; Smith, A.L.; Steventon, A.; Coughlan, E.; Oldfield, M. Ethical funding for trustworthy AI: Proposals to address the responsibilities of funders to ensure that projects adhere to trustworthy AI practice. AI Ethics 2022, 2, 277–291. [Google Scholar] [CrossRef]
- Schuett, J. Three lines of defense against risks from AI. AI Soc. 2023. [Google Scholar] [CrossRef]
- Sloane, M.; Zakrzewski, J. German AI Start-Ups and “AI Ethics”: Using A Social Practice Lens for Assessing and Implementing Socio-Technical Innovation. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 935–947. [Google Scholar]
- Vasconcelos, M.; Cardonha, C.; Gonçalves, B. Modeling epistemological principles for bias mitigation in AI systems: An illustration in hiring decisions. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 323–329. [Google Scholar]
- Yang, Y.; Gupta, A.; Feng, J.; Singhal, P.; Yadav, V.; Wu, Y.; Natarajan, P.; Hedau, V.; Joo, J. Enhancing fairness in face detection in computer vision systems by demographic bias mitigation. In Proceedings of the 2022 AAAI/ACM Conference on AI, Ethics, and Society, Oxford, UK, 1–3 August 2022; pp. 813–822. [Google Scholar]
- Schwartz, R.; Vassilev, A.; Greene, K.; Perine, L.; Burt, A.; Hall, P. Towards a Standard for Identifying and Managing Bias in Artificial Intelligence; NIST Special Publication; NIST: Gaithersburg, MD, USA, 2022; Volume 1270. [Google Scholar]
- Guo, W.; Caliskan, A. Detecting emergent intersectional biases: Contextualized word embeddings contain a distribution of human-like biases. In Proceedings of the 2021 AAAI/ACM Conference on AI, Ethics, and Society, Virtual, 19–21 May 2021; pp. 122–133. [Google Scholar]
- Kong, Y. Are “intersectionally fair” ai algorithms really fair to women of color? A philosophical analysis. In Proceedings of the 2022 ACM Conference on Fairness, Accountability, and Transparency, Seoul, Republic of Korea, 21–24 June 2022; pp. 485–494. [Google Scholar]
- Tan, Y.C.; Celis, L.E. Assessing social and intersectional biases in contextualized word representations. Adv. Neural Inf. Process. Syst. 2019, 32, 1–12. [Google Scholar]
- Cheng, L.; Mosallanezhad, A.; Sheth, P.; Liu, H. Causal learning for socially responsible AI. arXiv 2021, arXiv:2104.12278. [Google Scholar]
- Correa, J.D.; Tian, J.; Bareinboim, E. Identification of causal effects in the presence of selection bias. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 2744–2751. [Google Scholar]
- Ghai, B.; Mueller, K. D-BIAS: A causality-based human-in-the-loop system for tackling algorithmic bias. IEEE Trans. Vis. Comput. Graph. 2022, 29, 473–482. [Google Scholar] [CrossRef] [PubMed]
- Yan, J.N.; Gu, Z.; Lin, H.; Rzeszotarski, J.M. Silva: Interactively assessing machine learning fairness using causality. In Proceedings of the 2020 Chi Conference on Human Factors in Computing Systems, Honolulu, HI, USA, 25–30 April 2020; pp. 1–13. [Google Scholar]
- Bertino, E.; Kantarcioglu, M.; Akcora, C.G.; Samtani, S.; Mittal, S.; Gupta, M. AI for Security and Security for AI. In Proceedings of the Eleventh ACM Conference on Data and Application Security and Privacy, Virtual, 26–28 April 2021; pp. 333–334. [Google Scholar]
- Susanto, H.; Yie, L.F.; Rosiyadi, D.; Basuki, A.I.; Setiana, D. Data security for connected governments and organisations: Managing automation and artificial intelligence. In Web 2.0 and Cloud Technologies for Implementing Connected Government; IGI Global: Hershey, PA, USA, 2021; pp. 229–251. [Google Scholar]
- Dilmaghani, S.; Brust, M.R.; Danoy, G.; Cassagnes, N.; Pecero, J.; Bouvry, P. Privacy and security of big data in AI systems: A research and standards perspective. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 5737–5743. [Google Scholar]
- McIntosh, T. Intercepting Ransomware Attacks with Staged Event-Driven Access Control. Ph.D. Thesis, La Trobe University, Melbourne, VIC, Australia, 2022. [Google Scholar]
- McIntosh, T.; Kayes, A.; Chen, Y.P.P.; Ng, A.; Watters, P. Applying staged event-driven access control to combat ransomware. Comput. Secur. 2023, 128, 103160. [Google Scholar] [CrossRef]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Nowrozy, R.; Halgamuge, M.N. From COBIT to ISO 42001: Evaluating Cybersecurity Frameworks for Opportunities, Risks, and Regulatory Compliance in Commercializing Large Language Models. arXiv 2024, arXiv:2402.15770. [Google Scholar] [CrossRef]
- Hummel, P.; Braun, M.; Tretter, M.; Dabrock, P. Data sovereignty: A review. Big Data Soc. 2021, 8, 2053951720982012. [Google Scholar] [CrossRef]
- Lukings, M.; Habibi Lashkari, A. Data Sovereignty. In Understanding Cybersecurity Law in Data Sovereignty and Digital Governance: An Overview from a Legal Perspective; Springer: Cham, Switzerland, 2022; pp. 1–38. [Google Scholar]
- Hickok, M. Lessons learned from AI ethics principles for future actions. AI Ethics 2021, 1, 41–47. [Google Scholar] [CrossRef]
- Zhou, J.; Chen, F. AI ethics: From principles to practice. AI Soc. 2022. [Google Scholar] [CrossRef]
- Kroll, J.A. Outlining traceability: A principle for operationalizing accountability in computing systems. In Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency, Virtual, 3–10 March 2021; pp. 758–771. [Google Scholar]
- Oseni, A.; Moustafa, N.; Janicke, H.; Liu, P.; Tari, Z.; Vasilakos, A. Security and privacy for artificial intelligence: Opportunities and challenges. arXiv 2021, arXiv:2102.04661. [Google Scholar]
- Stahl, B.C.; Wright, D. Ethics and privacy in AI and big data: Implementing responsible research and innovation. IEEE Secur. Priv. 2018, 16, 26–33. [Google Scholar] [CrossRef]
- Ma, C.; Li, J.; Wei, K.; Liu, B.; Ding, M.; Yuan, L.; Han, Z.; Poor, H.V. Trusted ai in multiagent systems: An overview of privacy and security for distributed learning. Proc. IEEE 2023, 111, 1097–1132. [Google Scholar] [CrossRef]
- Song, M.; Wang, Z.; Zhang, Z.; Song, Y.; Wang, Q.; Ren, J.; Qi, H. Analyzing user-level privacy attack against federated learning. IEEE J. Sel. Areas Commun. 2020, 38, 2430–2444. [Google Scholar] [CrossRef]
- Misra, I.; Maaten, L.v.d. Self-supervised learning of pretext-invariant representations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 6707–6717. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar]
- Chen, T.; Zhai, X.; Ritter, M.; Lucic, M.; Houlsby, N. Self-supervised gans via auxiliary rotation loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 12154–12163. [Google Scholar]
- Jenni, S.; Favaro, P. Self-supervised feature learning by learning to spot artifacts. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2733–2742. [Google Scholar]
- Patel, P.; Kumari, N.; Singh, M.; Krishnamurthy, B. Lt-gan: Self-supervised gan with latent transformation detection. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 5–9 January 2021; pp. 3189–3198. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the International Conference on Machine Learning, Virtual, 12–18 July 2020; pp. 1597–1607. [Google Scholar]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 14–19 June 2020; pp. 9729–9738. [Google Scholar]
- Liu, A.T.; Li, S.W.; Lee, H.y. Tera: Self-supervised learning of transformer encoder representation for speech. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 2351–2366. [Google Scholar] [CrossRef]
- Pang, Y.; Wang, W.; Tay, F.E.; Liu, W.; Tian, Y.; Yuan, L. Masked autoencoders for point cloud self-supervised learning. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 604–621. [Google Scholar]
- Hospedales, T.; Antoniou, A.; Micaelli, P.; Storkey, A. Meta-learning in neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 5149–5169. [Google Scholar] [CrossRef]
- Vilalta, R.; Drissi, Y. A perspective view and survey of meta-learning. Artif. Intell. Rev. 2002, 18, 77–95. [Google Scholar] [CrossRef]
- Al-Shedivat, M.; Li, L.; Xing, E.; Talwalkar, A. On data efficiency of meta-learning. In Proceedings of the International Conference on Artificial Intelligence and Statistics, Virtual, 13–15 April 2021; pp. 1369–1377. [Google Scholar]
- Hu, Y.; Liu, R.; Li, X.; Chen, D.; Hu, Q. Task-sequencing meta learning for intelligent few-shot fault diagnosis with limited data. IEEE Trans. Ind. Inform. 2021, 18, 3894–3904. [Google Scholar] [CrossRef]
- Baik, S.; Choi, J.; Kim, H.; Cho, D.; Min, J.; Lee, K.M. Meta-learning with task-adaptive loss function for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, BC, Canada, 11–17 October 2021; pp. 9465–9474. [Google Scholar]
- Chen, Y.; Liu, Z.; Xu, H.; Darrell, T.; Wang, X. Meta-baseline: Exploring simple meta-learning for few-shot learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montréal, BC, Canada, 11–17 October 2021; pp. 9062–9071. [Google Scholar]
- Jamal, M.A.; Qi, G.J. Task agnostic meta-learning for few-shot learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 11719–11727. [Google Scholar]
- Behnia, R.; Ebrahimi, M.R.; Pacheco, J.; Padmanabhan, B. EW-Tune: A Framework for Privately Fine-Tuning Large Language Models with Differential Privacy. In Proceedings of the 2022 IEEE International Conference on Data Mining Workshops (ICDMW), Orlando, FL, USA, 28 November–1 December 2022; pp. 560–566. [Google Scholar]
- Wei, J.; Bosma, M.; Zhao, V.Y.; Guu, K.; Yu, A.W.; Lester, B.; Du, N.; Dai, A.M.; Le, Q.V. Finetuned language models are zero-shot learners. arXiv 2021, arXiv:2109.01652. [Google Scholar]
- Kuang, W.; Qian, B.; Li, Z.; Chen, D.; Gao, D.; Pan, X.; Xie, Y.; Li, Y.; Ding, B.; Zhou, J. Federatedscope-llm: A comprehensive package for fine-tuning large language models in federated learning. arXiv 2023, arXiv:2309.00363. [Google Scholar]
- Nguyen, M.; Kishan, K.; Nguyen, T.; Chadha, A.; Vu, T. Efficient Fine-Tuning Large Language Models for Knowledge-Aware Response Planning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Turin, Italy, 18–22 September 2023; pp. 593–611. [Google Scholar]
- Engelbach, M.; Klau, D.; Scheerer, F.; Drawehn, J.; Kintz, M. Fine-tuning and aligning question answering models for complex information extraction tasks. arXiv 2023, arXiv:2309.14805. [Google Scholar]
- Nguyen, T.T.; Wilson, C.; Dalins, J. Fine-tuning llama 2 large language models for detecting online sexual predatory chats and abusive texts. arXiv 2023, arXiv:2308.14683. [Google Scholar]
- Zhou, Q.; Yu, C.; Zhang, S.; Wu, S.; Wang, Z.; Wang, F. RegionBLIP: A Unified Multi-modal Pre-training Framework for Holistic and Regional Comprehension. arXiv 2023, arXiv:2308.02299. [Google Scholar]
- Arnold, T.; Kasenberg, D. Value Alignment or Misalignment—What Will Keep Systems Accountable? In Proceedings of the AAAI Workshop on AI, Ethics, and Society, San Francisco, CA, USA, 4 February 2017.
- Gabriel, I.; Ghazavi, V. The challenge of value alignment: From fairer algorithms to AI safety. arXiv 2021, arXiv:2101.06060. [Google Scholar]
- Nyholm, S. Responsibility gaps, value alignment, and meaningful human control over artificial intelligence. In Risk and Responsibility in Context; Routledge: Oxfordshire, UK, 2023; pp. 191–213. [Google Scholar]
- Wu, S.; Fei, H.; Qu, L.; Ji, W.; Chua, T.S. Next-gpt: Any-to-any multimodal llm. arXiv 2023, arXiv:2309.05519. [Google Scholar]
- Bayoudh, K.; Knani, R.; Hamdaoui, F.; Mtibaa, A. A survey on deep multimodal learning for computer vision: Advances, trends, applications, and datasets. Vis. Comput. 2021, 38, 2939–2970. [Google Scholar] [CrossRef] [PubMed]
- Hu, P.; Zhen, L.; Peng, D.; Liu, P. Scalable deep multimodal learning for cross-modal retrieval. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; pp. 635–644. [Google Scholar]
- Rahate, A.; Walambe, R.; Ramanna, S.; Kotecha, K. Multimodal co-learning: Challenges, applications with datasets, recent advances and future directions. Inf. Fusion 2022, 81, 203–239. [Google Scholar] [CrossRef]
- Che, L.; Wang, J.; Zhou, Y.; Ma, F. Multimodal federated learning: A survey. Sensors 2023, 23, 6986. [Google Scholar] [CrossRef]
- Liang, P.P.; Lyu, Y.; Fan, X.; Wu, Z.; Cheng, Y.; Wu, J.; Chen, L.; Wu, P.; Lee, M.A.; Zhu, Y.; et al. Multibench: Multiscale benchmarks for multimodal representation learning. arXiv 2021, arXiv:2107.07502. [Google Scholar]
- Li, Y.; Zhang, G.; Ma, Y.; Yuan, R.; Zhu, K.; Guo, H.; Liang, Y.; Liu, J.; Yang, J.; Wu, S.; et al. OmniBench: Towards The Future of Universal Omni-Language Models. arXiv 2024, arXiv:2409.15272. [Google Scholar]
- Chen, L.; Hu, H.; Zhang, M.; Chen, Y.; Wang, Z.; Li, Y.; Shyam, P.; Zhou, T.; Huang, H.; Yang, M.H.; et al. Omni×R: Evaluating Omni-modality Language Models on Reasoning across Modalities. arXiv 2024, arXiv:2410.12219. [Google Scholar]
- Ashktorab, Z.; Liao, Q.V.; Dugan, C.; Johnson, J.; Pan, Q.; Zhang, W.; Kumaravel, S.; Campbell, M. Human-ai collaboration in a cooperative game setting: Measuring social perception and outcomes. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–20. [Google Scholar] [CrossRef]
- Esmaeilzadeh, P.; Mirzaei, T.; Dharanikota, S. Patients’ perceptions toward human–artificial intelligence interaction in health care: Experimental study. J. Med. Internet Res. 2021, 23, e25856. [Google Scholar] [CrossRef]
- Nazar, M.; Alam, M.M.; Yafi, E.; Su’ud, M.M. A systematic review of human–computer interaction and explainable artificial intelligence in healthcare with artificial intelligence techniques. IEEE Access 2021, 9, 153316–153348. [Google Scholar] [CrossRef]
- Rajawat, A.S.; Rawat, R.; Barhanpurkar, K.; Shaw, R.N.; Ghosh, A. Robotic process automation with increasing productivity and improving product quality using artificial intelligence and machine learning. In Artificial Intelligence for Future Generation Robotics; Elsevier: Berlin/Heidelberg, Germany, 2021; pp. 1–13. [Google Scholar]
- Mohseni, S.; Zarei, N.; Ragan, E.D. A multidisciplinary survey and framework for design and evaluation of explainable AI systems. ACM Trans. Interact. Intell. Syst. (TiiS) 2021, 11, 1–45. [Google Scholar] [CrossRef]
- Buehler, M.C.; Weisswange, T.H. Theory of mind based communication for human agent cooperation. In Proceedings of the 2020 IEEE International Conference on Human-Machine Systems (ICHMS), Rome, Italy, 7–9 September 2020; pp. 1–6. [Google Scholar]
- Çelikok, M.M.; Peltola, T.; Daee, P.; Kaski, S. Interactive AI with a Theory of Mind. arXiv 2019, arXiv:1912.05284. [Google Scholar]
- Dafoe, A.; Hughes, E.; Bachrach, Y.; Collins, T.; McKee, K.R.; Leibo, J.Z.; Larson, K.; Graepel, T. Open problems in cooperative AI. arXiv 2020, arXiv:2012.08630. [Google Scholar]
- Bubeck, S.; Chandrasekaran, V.; Eldan, R.; Gehrke, J.; Horvitz, E.; Kamar, E.; Lee, P.; Lee, Y.T.; Li, Y.; Lundberg, S.; et al. Sparks of artificial general intelligence: Early experiments with gpt-4. arXiv 2023, arXiv:2303.12712. [Google Scholar]
- Fei, N.; Lu, Z.; Gao, Y.; Yang, G.; Huo, Y.; Wen, J.; Lu, H.; Song, R.; Gao, X.; Xiang, T.; et al. Towards artificial general intelligence via a multimodal foundation model. Nat. Commun. 2022, 13, 3094. [Google Scholar] [CrossRef] [PubMed]
- Williams, R.; Yampolskiy, R. Understanding and avoiding ai failures: A practical guide. Philosophies 2021, 6, 53. [Google Scholar] [CrossRef]
- Shavit, Y.; Agarwal, S.; Brundage, M.; Adler, S.; O’Keefe, C.; Campbell, R.; Lee, T.; Mishkin, P.; Eloundou, T.; Hickey, A.; et al. Practices for Governing Agentic AI Systems; OpenAI White Paper; OpenAI: San Francisco, CA, USA, 2023. [Google Scholar]
- Sun, Y.; Wang, X.; Liu, Z.; Miller, J.; Efros, A.; Hardt, M. Test-time training with self-supervision for generalization under distribution shifts. In Proceedings of the International Conference on Machine Learning, Virtual, 13–18 July 2020; pp. 9229–9248. [Google Scholar]
- Akyürek, E.; Damani, M.; Qiu, L.; Guo, H.; Kim, Y.; Andreas, J. The Surprising Effectiveness of Test-Time Training for Abstract Reasoning. arXiv 2024, arXiv:2411.07279. [Google Scholar]
- Rajbhandari, S.; Li, C.; Yao, Z.; Zhang, M.; Aminabadi, R.Y.; Awan, A.A.; Rasley, J.; He, Y. Deepspeed-moe: Advancing mixture-of-experts inference and training to power next-generation ai scale. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 18332–18346. [Google Scholar]
- Shen, L.; Wu, Z.; Gong, W.; Hao, H.; Bai, Y.; Wu, H.; Wu, X.; Bian, J.; Xiong, H.; Yu, D.; et al. Se-moe: A scalable and efficient mixture-of-experts distributed training and inference system. arXiv 2022, arXiv:2205.10034. [Google Scholar]
- Fedus, W.; Zoph, B.; Shazeer, N. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. J. Mach. Learn. Res. 2022, 23, 5232–5270. [Google Scholar]
- Hwang, C.; Cui, W.; Xiong, Y.; Yang, Z.; Liu, Z.; Hu, H.; Wang, Z.; Salas, R.; Jose, J.; Ram, P.; et al. Tutel: Adaptive mixture-of-experts at scale. In Proceedings of the 6th Machine Learning and Systems, Miami, FL, USA, 4–8 June 2023. [Google Scholar]
- Puigcerver, J.; Jenatton, R.; Riquelme, C.; Awasthi, P.; Bhojanapalli, S. On the adversarial robustness of mixture of experts. Adv. Neural Inf. Process. Syst. 2022, 35, 9660–9671. [Google Scholar]
- Li, J.; Jiang, Y.; Zhu, Y.; Wang, C.; Xu, H. Accelerating Distributed {MoE} Training and Inference with Lina. In Proceedings of the 2023 USENIX Annual Technical Conference (USENIX ATC 23), Boston, MA, USA, 10–12 July 2023; pp. 945–959. [Google Scholar]
- Wang, Y.; Mukherjee, S.; Liu, X.; Gao, J.; Awadallah, A.H.; Gao, J. Adamix: Mixture-of-adapter for parameter-efficient tuning of large language models. arXiv 2022, arXiv:2205.12410. [Google Scholar]
- Chi, Z.; Dong, L.; Huang, S.; Dai, D.; Ma, S.; Patra, B.; Singhal, S.; Bajaj, P.; Song, X.; Mao, X.L.; et al. On the representation collapse of sparse mixture of experts. Adv. Neural Inf. Process. Syst. 2022, 35, 34600–34613. [Google Scholar]
- Zoph, B.; Bello, I.; Kumar, S.; Du, N.; Huang, Y.; Dean, J.; Shazeer, N.; Fedus, W. Designing effective sparse expert models. arXiv 2022, arXiv:2202.08906. [Google Scholar]
- Fan, Z.; Sarkar, R.; Jiang, Z.; Chen, T.; Zou, K.; Cheng, Y.; Hao, C.; Wang, Z. M3vit: Mixture-of-experts vision transformer for efficient multi-task learning with model-accelerator co-design. Adv. Neural Inf. Process. Syst. 2022, 35, 28441–28457. [Google Scholar]
- Zadouri, T.; Üstün, A.; Ahmadian, A.; Ermiş, B.; Locatelli, A.; Hooker, S. Pushing mixture of experts to the limit: Extremely parameter efficient moe for instruction tuning. arXiv 2023, arXiv:2309.05444. [Google Scholar]
- Zhu, J.; Zhu, X.; Wang, W.; Wang, X.; Li, H.; Wang, X.; Dai, J. Uni-perceiver-moe: Learning sparse generalist models with conditional moes. Adv. Neural Inf. Process. Syst. 2022, 35, 2664–2678. [Google Scholar]
- Shinn, M.; Gu, S.S.; Bengio, Y. Reflexion: Language Agents with Verbal Reinforcement. arXiv 2023, arXiv:2303.11366. [Google Scholar]
- Mialon, T.; Denoyer, L.; Hoffmann, J.; Casanova, H.; Chalumeau, N.; Razdaibiedina, A.; Piantanida, P.; Caron, M.; Lhoest, Q.; de Vries, H.; et al. Augmented Language Models: A Survey. arXiv 2023, arXiv:2302.07842. [Google Scholar]
- Parisi, G.P.; Canton-Ferrer, C.; Palenicek, D.; Goodwin, R.; Gordon, J. TALM: Tool Augmented Language Models. In Proceedings of the 2022 EMNLP Workshop on Structured and Visually Grounded Supervision for Statistical Parsing of Scenes and Language (SV-PARSE), Abu Dhabi, United Arab Emirates, 7–8 December 2022. [Google Scholar]
- Weidinger, L.; Mellor, J.; Bentham, M.R.; Redkin, V.; Zain, G.; Taylor, R.; Chadwick, M.; Everitt, T.; Guardino, C.; Grünbaum, B.B.; et al. Ethical and Social Risks of Harm from Language Models. arXiv 2022, arXiv:2112.04359. [Google Scholar]
- Dou, F.; Ye, J.; Yuan, G.; Lu, Q.; Niu, W.; Sun, H.; Guan, L.; Lu, G.; Mai, G.; Liu, N.; et al. Towards artificial general intelligence (agi) in the internet of things (iot): Opportunities and challenges. arXiv 2023, arXiv:2309.07438. [Google Scholar]
- Jia, Z.; Li, X.; Ling, Z.; Liu, S.; Wu, Y.; Su, H. Improving policy optimization with generalist-specialist learning. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 10104–10119. [Google Scholar]
- Simeone, M. Unknown Future, Repeated Present: A Narrative-Centered Analysis of Long-Term AI Discourse. Hum. Stud. Digit. Age 2022, 7, 1–13. [Google Scholar] [CrossRef]
- Nair, A.; Banaei-Kashani, F. Bridging the Gap between Artificial Intelligence and Artificial General Intelligence: A Ten Commandment Framework for Human-Like Intelligence. arXiv 2022, arXiv:2210.09366. [Google Scholar]
- Jarrahi, M.H.; Askay, D.; Eshraghi, A.; Smith, P. Artificial intelligence and knowledge management: A partnership between human and AI. Bus. Horizons 2023, 66, 87–99. [Google Scholar] [CrossRef]
- Edwards, D.J.; McEnteggart, C.; Barnes-Holmes, Y. A functional contextual account of background knowledge in categorization: Implications for artificial general intelligence and cognitive accounts of general knowledge. Front. Psychol. 2022, 13, 745306. [Google Scholar] [CrossRef] [PubMed]
- McCarthy, J. Artificial Intelligence, Logic, and Formalising Common Sense. In Philosophical Logic and Artificial Intelligence; Springer: Dordrecht, The Netherlands, 2022; pp. 69–90. [Google Scholar]
- Friederich, S. Symbiosis, not alignment, as the goal for liberal democracies in the transition to artificial general intelligence. AI Ethics 2023, 4, 315–324. [Google Scholar] [CrossRef]
- Makridakis, S. The forthcoming Artificial Intelligence (AI) revolution: Its impact on society and firms. Futures 2017, 90, 46–60. [Google Scholar] [CrossRef]
- Verma, S.; Sharma, R.; Deb, S.; Maitra, D. Artificial intelligence in marketing: Systematic review and future research direction. Int. J. Inf. Manag. Data Insights 2021, 1, 100002. [Google Scholar] [CrossRef]
- Pal, S.; Kumari, K.; Kadam, S.; Saha, A. The AI Revolution; IARA Publication: Tiruchirappalli, India, 2023. [Google Scholar]
- Budhwar, P.; Chowdhury, S.; Wood, G.; Aguinis, H.; Bamber, G.J.; Beltran, J.R.; Boselie, P.; Lee Cooke, F.; Decker, S.; DeNisi, A.; et al. Human resource management in the age of generative artificial intelligence: Perspectives and research directions on ChatGPT. Hum. Resour. Manag. J. 2023, 33, 606–659. [Google Scholar] [CrossRef]
- Telkamp, J.B.; Anderson, M.H. The implications of diverse human moral foundations for assessing the ethicality of Artificial Intelligence. J. Bus. Ethics 2022, 178, 961–976. [Google Scholar] [CrossRef]
- Zhou, X.; Liu, C.; Zhai, L.; Jia, Z.; Guan, C.; Liu, Y. Interpretable and robust ai in eeg systems: A survey. arXiv 2023, arXiv:2304.10755. [Google Scholar]
- McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Ng, A.; Halgamuge, M.N. A game-theoretic approach to containing artificial general intelligence: Insights from highly autonomous aggressive malware. IEEE Trans. Artif. Intell. 2024, 5, 6290–6303. [Google Scholar] [CrossRef]
- Zhang, C.; Zhang, C.; Li, C.; Qiao, Y.; Zheng, S.; Dam, S.K.; Zhang, M.; Kim, J.U.; Kim, S.T.; Choi, J.; et al. One small step for generative ai, one giant leap for agi: A complete survey on chatgpt in aigc era. arXiv 2023, arXiv:2304.06488. [Google Scholar]
- Singhal, K.; Tu, T.; Gottweis, J.; Sayres, R.; Wulczyn, E.; Hou, L.; Clark, K.; Pfohl, S.; Cole-Lewis, H.; Neal, D.; et al. Towards expert-level medical question answering with large language models. arXiv 2023, arXiv:2305.09617. [Google Scholar] [CrossRef] [PubMed]
- Wu, S.; Irsoy, O.; Lu, S.; Dabravolski, V.; Dredze, M.; Gehrmann, S.; Kambadur, P.; Rosenberg, D.; Mann, G. Bloomberggpt: A large language model for finance. arXiv 2023, arXiv:2303.17564. [Google Scholar]
- Henderson, P.; Sinha, K.; Angelard-Gontier, N.; Ke, N.R.; Fried, G.; Lowe, R.; Pineau, J. Ethical challenges in data-driven dialogue systems. In Proceedings of the 2018 AAAI/ACM Conference on AI, Ethics, and Society, New Orleans, LA, USA, 2–3 February 2018; pp. 123–129. [Google Scholar]
- Bin-Nashwan, S.A.; Sadallah, M.; Bouteraa, M. Use of ChatGPT in academia: Academic integrity hangs in the balance. Technol. Soc. 2023, 75, 102370. [Google Scholar] [CrossRef]
- Liu, N.; Brown, A. AI Increases the Pressure to Overhaul the Scientific Peer Review Process. Comment on “Artificial Intelligence Can Generate Fraudulent but Authentic-Looking Scientific Medical Articles: Pandora’s Box Has Been Opened”. J. Med. Internet Res. 2023, 25, e50591. [Google Scholar] [CrossRef] [PubMed]
- Siddaway, A.P.; Wood, A.M.; Hedges, L.V. How to do a systematic review: A best practice guide for conducting and reporting narrative reviews, meta-analyses, and meta-syntheses. Annu. Rev. Psychol. 2019, 70, 747–770. [Google Scholar] [CrossRef]
- Landhuis, E. Scientific literature: Information overload. Nature 2016, 535, 457–458. [Google Scholar] [CrossRef] [PubMed]
- Chloros, G.D.; Giannoudis, V.P.; Giannoudis, P.V. Peer-reviewing in surgical journals: Revolutionize or perish? Ann. Surg. 2022, 275, e82–e90. [Google Scholar] [CrossRef] [PubMed]
- Allen, K.A.; Reardon, J.; Lu, Y.; Smith, D.V.; Rainsford, E.; Walsh, L. Towards improving peer review: Crowd-sourced insights from Twitter. J. Univ. Teach. Learn. Pract. 2022, 19, 2. [Google Scholar]
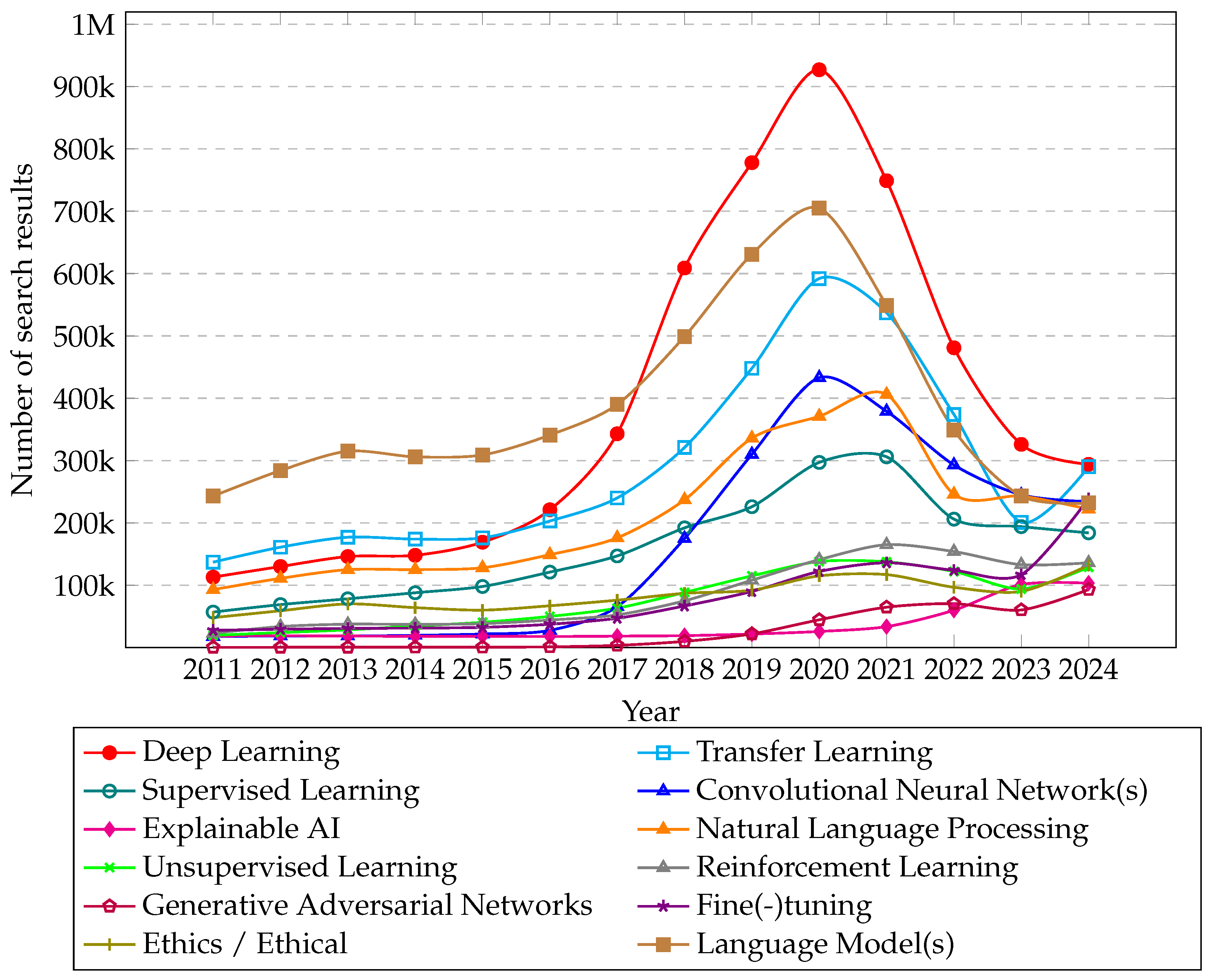



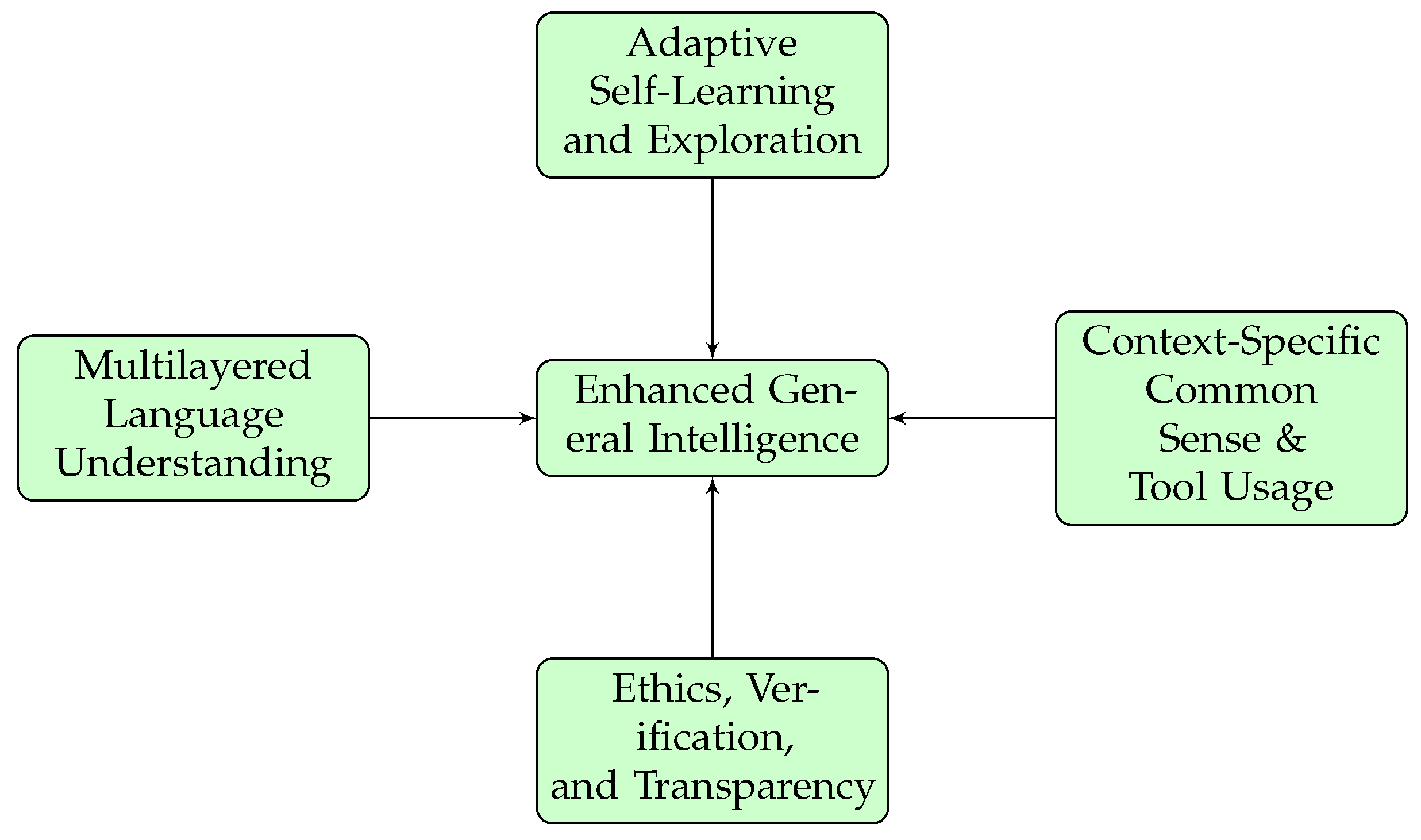
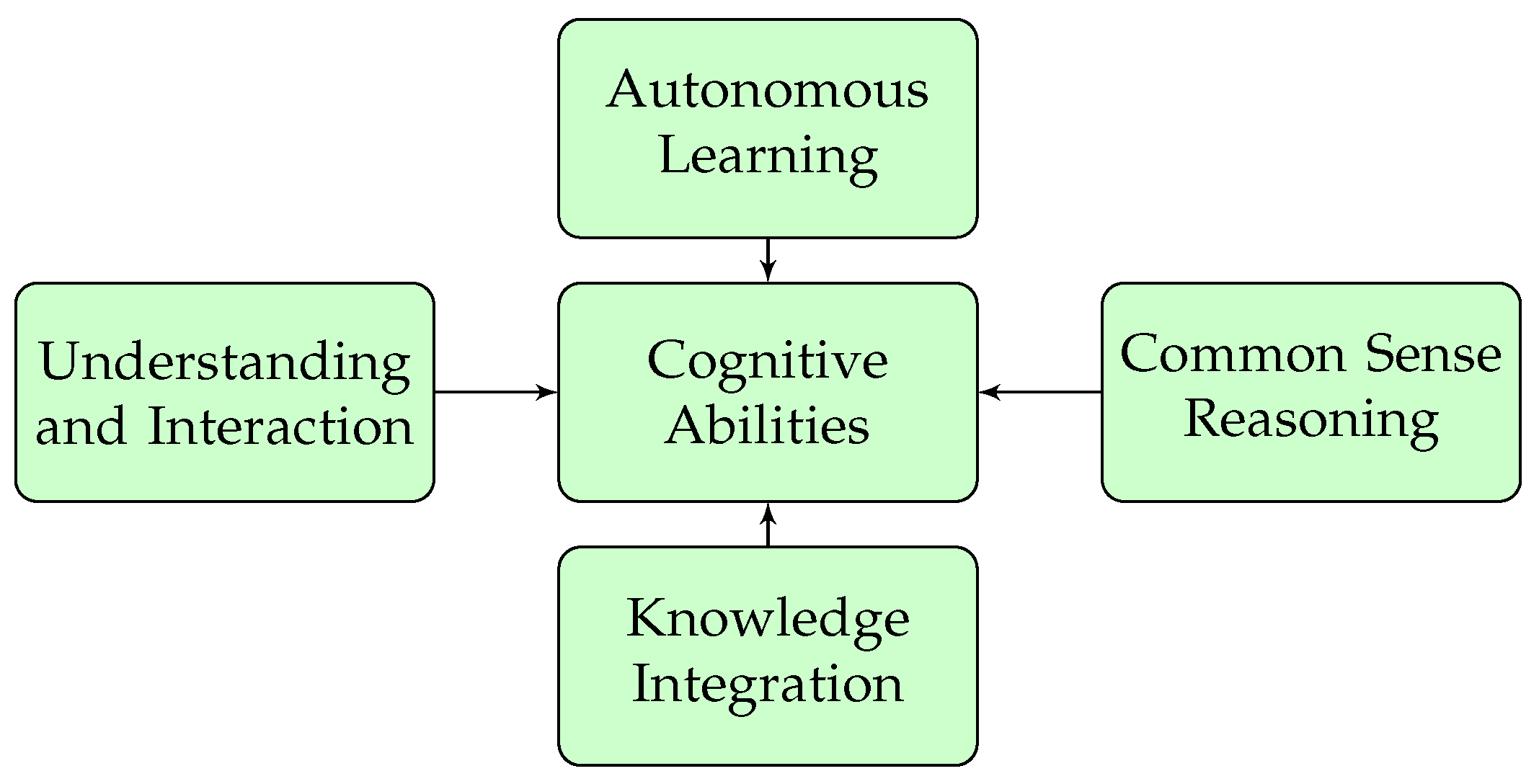


| Model | Type | Developer | Key Features/Remarks |
|---|---|---|---|
| GPT-4o | Proprietary | OpenAI | State-of-the-art performance but limited transparency and restricted model access. |
| Gemini | Proprietary | Multimodal focus, Agentic AI-capabilities; currently closed-source with advanced MMLU scores. | |
| Claude | Proprietary | Anthropic | Emphasizes AI safety and interpretability; closed-source but widely used in industry. |
| GPT-NeoX [69] | Open-Source | EleutherAI | Community-driven LLM with openly released weights and configurations. Encourages reproducibility. |
| Llama 3 [70] | Open-Source (restricted) | Meta | Large-scale model with partial open license, fosters academic innovation with direct model access. |
| DeepSeek [21] | Open-Source | DeepSeek-AI | Large-scale MoE model, with multimodal versions DeepSeek-VL and DeepSeek-VL2, which integrate vision and language understanding. |
| Domain | Subdomain | Key Focus | Description |
|---|---|---|---|
| Model Architecture | Transformer Models | Efficiency, Scalability | Optimizing network structures for faster processing and larger datasets. |
| Recurrent Neural Networks | Sequence Processing | Handling sequences of data, like text, for improved contextual understanding. | |
| MoE | Specialization, Efficiency | Leveraging multiple expert modules for enhanced efficiency and task-specific performance. | |
| Multimodal Models | Sensory Integration | Integrating text, vision, and audio inputs for comprehensive understanding. | |
| Training Techniques | Supervised Learning | Data Labeling, Accuracy | Using labeled datasets to train models for precise predictions. |
| Unsupervised Learning | Pattern Discovery | Finding patterns and structures from unlabeled data. | |
| Reinforcement Learning | Adaptability, Optimization | Training models through feedback mechanisms for optimal decision making. | |
| Transfer Learning | Versatility, Generalization | Applying knowledge gained in one task to different but related tasks. | |
| Application Domains | Natural Language Understanding | Comprehension, Contextualization | Enhancing the ability to understand and interpret human language in context. |
| Natural Language Generation | Creativity, Coherence | Generating coherent and contextually relevant text responses. | |
| Conversational AI | Interaction, Naturalness | Developing systems for natural and contextually relevant human–computer conversations. | |
| Creative AI | Innovation, Artistic Generation | Generating creative content, including text, art, and music. | |
| Compliance and Ethical Considerations | Bias Mitigation | Fairness, Representation | Addressing and reducing biases in AI outputs. |
| Data Security | Data Protection, Confidentiality | Ensuring data confidentiality, integrity, and availability security in AI models and outputs. | |
| AI Ethics | Fairness, Accountability | Addressing ethical issues such as bias, fairness, and accountability in AI systems. | |
| Privacy Preservation | Privacy Compliance, Anonymization | Protecting data privacy in model training and outputs. | |
| Advanced Learning | Self-supervised Learning | Autonomy, Efficiency | Utilizing unlabeled data for model training, enhancing learning efficiency. |
| Meta-learning | Rapid Adaptation | Enabling AI models to quickly adapt to new tasks with minimal data. | |
| Fine Tuning | Domain-Specific Tuning, Personalization | Adapting models to specific domains or user preferences for enhanced relevance and accuracy. | |
| Human Value Alignment | Ethical Integration, Societal Alignment | Aligning AI outputs with human ethics and societal norms, ensuring decisions are ethically and socially responsible. | |
| Emerging Trends | Multimodal Learning | Integration with Vision, Audio | Combining language models with other sensory data types for richer understanding, leading to fully omni-modal models. |
| Interactive and Cooperative AI | Collaboration, Human–AI Interaction | Enhancing AI’s ability to work alongside humans in collaborative tasks. | |
| AGI Development | Holistic Understanding | Pursuing the development of AI systems with comprehensive, human-like understanding. | |
| AGI Containment | Safety Protocols, Control Mechanisms | Developing methods to contain and control AGI systems to prevent unintended consequences. | |
| ’Thinking Models’ | Test-Time Compute, Inference Efficiency, Advanced Reinforcement Learning | Enabling AI systems to dynamically allocate computational resources during inference, enhancing flexibility and performance in complex reasoning tasks achieved by learned reasoning via reinforcement learning. | |
| Agentic AI | Autonomy, Task Execution | Empowering AI systems with the ability to autonomously plan, execute various tools, and adapt actions in real-world environments, aligning with human intentions and goals. | |
| Test Time Optimization | Adaptation, Memory | Adaptation at inference time via model updates and improved memory and ability to handle long dependencies. |
| Domain | Subdomain | MoE | Multimodality | AGI | Overall Score |
|---|---|---|---|---|---|
| Model Architecture | Transformer Models | ↪ (4) | ↔ (3) | ↪ (4) | 11 |
| Recurrent Neural Networks | ↘ (2) | ↔ (3) | ↘ (2) | 7 | |
| MoE | ↔ (3) | ↗ (5) | ↪ (4) | 12 | |
| Multimodal Models | ↗ (5) | ↔ (3) | ↗ (5) | 13 | |
| Training Techniques | Supervised Learning | ↪ (4) | ↔ (3) | ↘ (2) | 9 |
| Unsupervised Learning | ↪ (4) | ↔ (3) | ↪ (4) | 11 | |
| Reinforcement Learning | ↔ (3) | ↪ (4) | ↗ (5) | 12 | |
| Transfer Learning | ↔ (3) | ↗ (5) | ↪ (4) | 12 | |
| Application Domains | Natural Language Understanding | ↔ (3) | ↔ (3) | ↗ (5) | 11 |
| Natural Language Generation | ↔ (3) | ↪ (4) | ↗ (5) | 12 | |
| Conversational AI | ↪ (4) | ↗ (5) | ↗ (5) | 14 | |
| Creative AI | ↪ (4) | ↗ (5) | ↗ (5) | 14 | |
| Compliance and Ethical Considerations | Bias Mitigation | ↪ (4) | ↪ (4) | ↗ (5) | 13 |
| Data Security | ↔ (3) | ↔ (3) | ↔ (3) | 9 | |
| AI Ethics | ↪ (4) | ↪ (4) | △ (1) | 9 | |
| Privacy Preservation | ↪ (4) | ↪ (4) | ↪ (4) | 12 | |
| Advanced Learning | Self-supervised Learning | ↪ (4) | ↗ (5) | ↔ (3) | 12 |
| Meta-learning | ↔ (3) | ↔ (3) | ↗ (5) | 11 | |
| Fine-tuning | ↔ (3) | ↔ (3) | ↘ (2) | 8 | |
| Human Value Alignment | △ (1) | △ (1) | △ (1) | 3 | |
| Emerging Trends | Multimodal Learning | ↗ (5) | ↔ (3) | ↗ (5) | 13 |
| Interactive and Cooperative AI | ↪ (4) | ↔ (3) | ↗ (5) | 12 | |
| AGI Development | ↪ (4) | ↪ (4) | ↔ (3) | 11 | |
| AGI Containment | △ (1) | △ (1) | ↗ (5) | 7 | |
| Thinking Models | ↪ (4) | ↗ (5) | ↗ (5) | 14 | |
| Agentic AI | ↪ (4) | ↪ (4) | ↗ (5) | 13 | |
| Test Time Optimization | ↗ (5) | ↪ (4) | ↗ (5) | 14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
McIntosh, T.R.; Susnjak, T.; Liu, T.; Watters, P.; Xu, D.; Liu, D.; Halgamuge, M.N. From Google Gemini to OpenAI Q* (Q-Star): A Survey on Reshaping the Generative Artificial Intelligence (AI) Research Landscape. Technologies 2025, 13, 51. https://doi.org/10.3390/technologies13020051
McIntosh TR, Susnjak T, Liu T, Watters P, Xu D, Liu D, Halgamuge MN. From Google Gemini to OpenAI Q* (Q-Star): A Survey on Reshaping the Generative Artificial Intelligence (AI) Research Landscape. Technologies. 2025; 13(2):51. https://doi.org/10.3390/technologies13020051
Chicago/Turabian StyleMcIntosh, Timothy R., Teo Susnjak, Tong Liu, Paul Watters, Dan Xu, Dongwei Liu, and Malka N. Halgamuge. 2025. "From Google Gemini to OpenAI Q* (Q-Star): A Survey on Reshaping the Generative Artificial Intelligence (AI) Research Landscape" Technologies 13, no. 2: 51. https://doi.org/10.3390/technologies13020051
APA StyleMcIntosh, T. R., Susnjak, T., Liu, T., Watters, P., Xu, D., Liu, D., & Halgamuge, M. N. (2025). From Google Gemini to OpenAI Q* (Q-Star): A Survey on Reshaping the Generative Artificial Intelligence (AI) Research Landscape. Technologies, 13(2), 51. https://doi.org/10.3390/technologies13020051