
Disrupting Audio Event Detection Deep Neural Networks with White Noise


Abstract
:1. Introduction
2. Materials and Methods
2.1. CNN Models in Audio Detection Systems
- Convolutional layers: three convolutional blocks, each one with two convolutional 2D layers. These layers have 32, 64, 64, 64, 128 and 128 filters (total of 480) of size 3 by 3. Same padding is also applied to the first convolutional layer of each block.
- Pooling layers: three 2 by 2 max pooling layers, each coming right after the second convolutional layer of each convolutional block.
- Dense layers: two dense (also known as fully connected) layers come after the last convolutional block.
- Activation functions: these functions compute the weighted sum of inputs and biases, and as such, are responsible for the firing or no firing of neurons [35]. For the presented CNN, ReLU activation is applied after each convolutional layer as well as after the first fully connected layer, while Softmax activation is applied only once, after the second fully connected layer. In other words, ReLU is applied to all inner layers, while Softmax is applied to the most outer layer.
- Regularization: applied in the end of each convolutional block as well as after the first fully connected layer, with 25, 50, 50 and 50% respectively. Regularization, also known as dropout, per [36], addresses the overfitting problem, among other common neural network issues.The CNN uses sparse categorical cross entropy as a loss function and RMSprop as an optimizer. A visual representation of its architecture can be seen in Figure 2.
2.2. CRNN Models in Audio Detection Systems
- Convolutional layers: one convolutional block, with one convolutional layer. This block is made by 128 filters of size 32, ReLU activation and batch normalization, pooling layer of size of 40 and a dropout layer of 0.3.
- LSTM layer: one backwards LSTM layer with 128 units, followed by tanh activation and a new dropout of 0.3.
- Dense layers: two stacked dense layers, the first with 128 units and the second with two, each one followed by batch normalization and the first one followed by a ReLU activation and the last one by a Softmax activation.
2.3. Datasets
2.4. Spectrograms
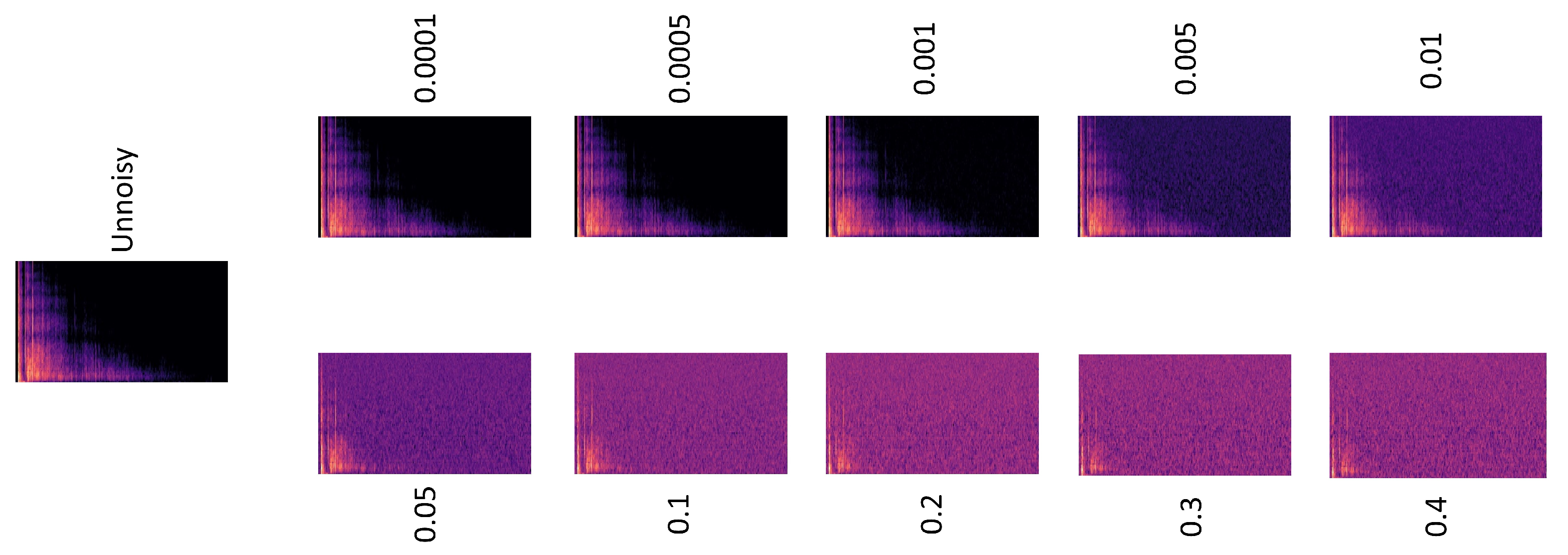
2.5. Attacks with Noise
2.6. Experiments
- Unnoisy experiments: Both AED classifiers exposed to digital gunshot sounds, without any disturbance.
- White noise experiments: Both AED classifiers exposed to digital gunshot sounds. The disturbances, made of white noise, are dynamic in nature, and after much experimentation, ten different noisy thresholds, namely 0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.2, 0.3 and 0.4. The process for generating the white noise infused samples can be seen in Algorithm 1.
| Algorithm 1: White Noise Generation Algorithm |
 |
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| AED | Audio Event Detection |
| SR | Speech Recognition |
| DL | Deep Learning |
| ML | Machine Learning |
References
- Wang, Z.; Song, H.; Watkins, D.; Ong, K.; Xue, P.; Yang, Q.; Shi, X. Cyber-physical systems for water sustainability: Challenges and opportunities. IEEE Commun. Mag. 2015, 53, 216–222. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Qiu, M.; Tsai, C.; Hassan, M.; Alamri, A. Health-CPS: Healthcare cyber-physical system assisted by cloud and big data. IEEE Syst. J. 2015, 11, 88–95. [Google Scholar] [CrossRef]
- Wang, L.; Onori, M. Current status and advancement of cyber-physical systems in manufacturing. J. Manuf. Syst. 2015, 37, 517–527. [Google Scholar] [CrossRef]
- Zander, J.; Mosterman, P.; Padir, T.; Wan, Y.; Fu, S.X. Cyber-physical systems can make emergency response smart. Procedia Eng. 2015, 107, 312–318. [Google Scholar] [CrossRef] [Green Version]
- Reddy, R.; Mamatha, C.; Reddy, R. A Review on Machine Learning Trends, Application and Challenges in Internet of Things. In Proceedings of the International Conference on Advances in Computing, Communications and Informatics (ICACCI), Bangalore, India, 19–22 September 2018. [Google Scholar]
- Chan, R. Internet of Things Business Models. J. Serv. Sci. Manag. 2015, 8, 552–568. [Google Scholar] [CrossRef] [Green Version]
- Venkatesh, J.; Aksanli, B.; Chan, C.; Akyurek, A.; Rosing, T. Scalable-Application Design for the IoT. IEEE Software 2017, 34, 62–70. [Google Scholar] [CrossRef]
- Carlini, N.; Wagner, D. Towards evaluating the robustness of neural networks. In Proceedings of the IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2017. [Google Scholar]
- Brown, T.; Mane, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Goodfellow, I.; Shlens, J.; Szegedy, C. Explaining and harnessing adversarial examples. arXiv 2014, arXiv:1412.6572. [Google Scholar]
- Akhtar, N.; Mian, A. Threat of adversarial attacks on deep learning in computer vision: A survey. IEEE Access 2018, 6, 14410–14430. [Google Scholar] [CrossRef]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. arXiv 2017, arXiv:1707.07397. [Google Scholar]
- Metzen, H.; Kumar, C.; Brox, T.; Fischer, V. Universal adversarial perturbations against semantic image segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017. [Google Scholar]
- Su, J.; Vargas, D.; Sakurai, K. One pixel attack for fooling deep neural networks. IEEE Trans. Evol. Comput. 2019, 23, 828–841. [Google Scholar] [CrossRef] [Green Version]
- Kurakin, A.; Goodfellow, I.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.; Fergus, R. Intriguing properties of neural networks. arXiv 2013, arXiv:1312.6199. [Google Scholar]
- Nguyen, A.; Yosinski, J.; Clune, J. Deep neural networks are easily fooled: High confidence predictions for unrecognizable images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Liu, Y.; Ma, S.; Aafer, Y.; Lee, W.; Zhai, J.; Wang, W.; Zhang, X. Trojaning attack on neural networks. In Proceedings of the Network and Distributed Systems Security (NDSS) Symposium, San Diego, CA, USA, 26 February–1 March 2017. [Google Scholar]
- Carlini, N.; Mishra, P.; Vaidya, T.; Zhang, Y.; Sherr, M.; Shields, C.; Zhou, W. Hidden Voice Commands. In Proceedings of the USENIX Security, Austin, TX, USA, 10–12 August 2016. [Google Scholar]
- Carlini, N.; Wagner, D. Audio adversarial examples: Targeted attacks on speech-to-text. In Proceedings of the IEEE Security and Privacy Workshops (SPW), San Francisco, CA, USA, 24 May 2018. [Google Scholar]
- Kwon, H.; Kim, Y.; Yoon, H.; Choi, D. Selective audio adversarial example in evasion attack on speech recognition system. IEEE Trans. Inf. Forensics Secur. 2019, 15, 526–538. [Google Scholar] [CrossRef]
- Hamid, A.; Mohamed, A.; Jiang, H.; Deng, L. Convolutional Neural Networks for Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1533–1545. [Google Scholar] [CrossRef] [Green Version]
- Bilen, Ç.; Ferroni, G.; Tuveri, F.; Azcarreta, J. A Framework for the Robust Evaluation of Sound Event Detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Cowling, M. Comparison of techniques for environmental sound recognition. Pattern Recognit. Lett. 2003, 10, 2895–2907. [Google Scholar] [CrossRef]
- Zhou, H.; Song, Y.; Shu, H. Using deep convolutional neural network to classify urban sounds. In Proceedings of the IEEE Region 10 Conference (TENCON), Penang, Malaysia, 5–8 November 2017. [Google Scholar]
- Lim, H.; Park, J.; Han, Y. Rare sound event detection using 1D convolutional recurrent neural networks. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2017 Workshop, Munich, Germany, 16–17 November 2017. [Google Scholar]
- Alraddadi, S.; Alqurashi, F.; Tsaramirsis, G.; Luhaybi, A.; Buhari, S. Aroma Release of Olfactory Displays Based on Audio-Visual Content. Appl. Sci. 2019, 9, 4866. [Google Scholar] [CrossRef] [Green Version]
- Boyat, A.; Joshi, B. A review paper: Noise models in digital image processing. arXiv 2015, arXiv:1505.03489. [Google Scholar] [CrossRef]
- The Free Firearm Library—Expanded Edition. Available online: airbornesound.com (accessed on 1 January 2021).
- Detection of Rare Sound Events. Available online: cs.tut.fi/sgn/arg/dcase2017/challenge/task-rare-sound-event-detection (accessed on 1 January 2021).
- A Dataset and Taxonomy for Urban Sound Research. Available online: justinsalamon.com (accessed on 1 January 2021).
- Khan, A.; Sohail, A.; Zahoora, U.; Qureshi, A. A survey of the recent architectures of deep convolutional neural networks. arXiv 2019, arXiv:1901.06032. [Google Scholar]
- Yamashita, R.; Nishio, M.; Do, R.; Togashi, K. Convolutional neural networks: An overview and application in radiology. Insights Imaging 2018, 9, 611–629. [Google Scholar] [CrossRef] [Green Version]
- Thakkar, V.; Tewary, S.; Chakraborty, C. Batch Normalization in Convolutional Neural Networks—A comparative study with CIFAR-10 data. In Proceedings of the Fifth International Conference on Emerging Applications of Information Technology (EAIT), Kolkata, India, 12–13 January 2018. [Google Scholar]
- Nwankpa, C.; Ijomah, W.; Gachagan, A.; Marshall, S. Activation Functions: Comparison of Trends in Practice and Research for Deep Learning. In Proceedings of the Machine Learning: Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1919–1958. [Google Scholar]
- Fu, X.; Ch’ng, E.; Aickelin, U.; See, S. CRNN a joint neural network for redundancy detection. In Proceedings of the IEEE International Conference on Smart Computing (SMARTCOMP), Hong Kong, China, 29–31 May 2017. [Google Scholar]
- Gao, S.; Lin, B.; Wang, C. Share price trend prediction using CRNN with LSTM structure. In Proceedings of the International Symposium on Computer, Consumer and Control (IS3C), Taichung, Taiwan, 6–8 December 2018. [Google Scholar]
- Sound Dataset for Malfunctioning Industrial Machine Investigation and Inspection. Available online: zenodo.org/ (accessed on 1 January 2021).
- ESC-50 Dataset for Environmental Sound Classification. Available online: github.com/karolpiczak/ESC-50 (accessed on 1 January 2021).
- Freesound. Available online: freesound.org/help/faq/ (accessed on 1 January 2021).
- Free Sound Effects & Royalty Free Music. Available online: www.zapsplat.com (accessed on 1 January 2021).
- Fesliyan Studios Royalty Free Music. Available online: fesliyanstudios.com/contact (accessed on 1 January 2021).
- What Is a Spectrogram. Available online: tomroelandts.com/articles/what-is-a-spectrogram (accessed on 1 January 2021).
- Dennis, J.; Tran, H.; Li, H. Spectrogram Image Feature for Sound Event Classification in Mismatched Conditions. IEEE Signal Process. Lett. 2011, 18, 130–133. [Google Scholar] [CrossRef]
- Prasadh, S.; Natrajan, S.; Kalaivani, S. Efficiency analysis of noise reduction algorithms: Analysis of the best algorithm of noise reduction from a set of algorithms. In Proceedings of the International Conference on Inventive Computing and Informatics (ICICI), Coimbatore, India, 23–24 November 2017. [Google Scholar]
- Edmonds, E. Abstraction and interaction: An art system for white noise. In Proceedings of the International Conference on Computer Graphics, Imaging and Visualisation (CGIV), Sydney, NSW, Australia, 26–28 July 2006. [Google Scholar]
- Dahlan, R. AdaBoost Noise Estimator for Subspace based Speech Enhancement. In Proceedings of the International Conference on Computer, Control, Informatics and its Applications (IC3INA), Tangerang, Indonesia, 1–2 November 2018. [Google Scholar]
- Vasuki, P.; Bhavana, C.; Mohamed, S.; Lakshmi, E. Automatic noise identification in images using moments and neural network. In Proceedings of the International Conference on Machine Vision and Image Processing (MVIP), Coimbatore, India, 14–15 December 2012. [Google Scholar]
- Montillet, J.; Tregoning, P.; McClusky, S.; Yu, K. Extracting White Noise Statistics in GPS Coordinate Time Series. IEEE Geosci. Remote Sens. Lett. 2013, 10, 563–567. [Google Scholar] [CrossRef]
- How to Set up Alexa Guard on an Amazon Echo. Available online: cnbc.com/2019/05/14/how-to-set-up-alexa-guard-on-an-amazon-echo.html (accessed on 1 January 2021).
- Nest Hub. Available online: store.google.com/us/product/google_nest_hubl (accessed on 1 January 2021).
- Nest Mini. Available online: store.google.com/product/google_nest_mini (accessed on 1 January 2021).
- See Sound. Available online: see-sound.com/devices/ (accessed on 1 January 2021).
- The Best Sound Machines on Amazon, According to Hyperenthusiastic Reviewers. Available online: nymag.com/strategist/article/best-sound-machines-noise-machines.html (accessed on 1 January 2021).
- So What Is This Secretive Chinese Sonic Weapon Exactly? Available online: popularmechanics.com/military/ (accessed on 1 January 2021).
- U.S. Military Is Developing a Sound Weapon that Sounds Like a Retro Modem. Available online: digitaltrends.com/cool-tech/military-sound-weapon-old-modem/ (accessed on 1 January 2021).
- Plug your Ears and Run’: NYPD’s Use of Sound Cannons Is Challenged in Federal Court. Available online: nbcnews.com/news/us-news/plug-your-ears-run-nypd-s-use-sound-cannons-challenged-n1008916 (accessed on 1 January 2021).
- Using Sound to Attack: The Diverse World of Acoustic Devices. Available online: cnn.com/2017/08/10/health/acoustic-weapons-explainer/index.html (accessed on 1 January 2021).
- A Man Stashed Guns in His Las Vegas Hotel Room. 3 Years Later, a Killer Did the Same. Available online: nytimes.com/2018/09/28/us/las-vegas-shooting-mgm-lawsuits.html (accessed on 1 January 2021).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
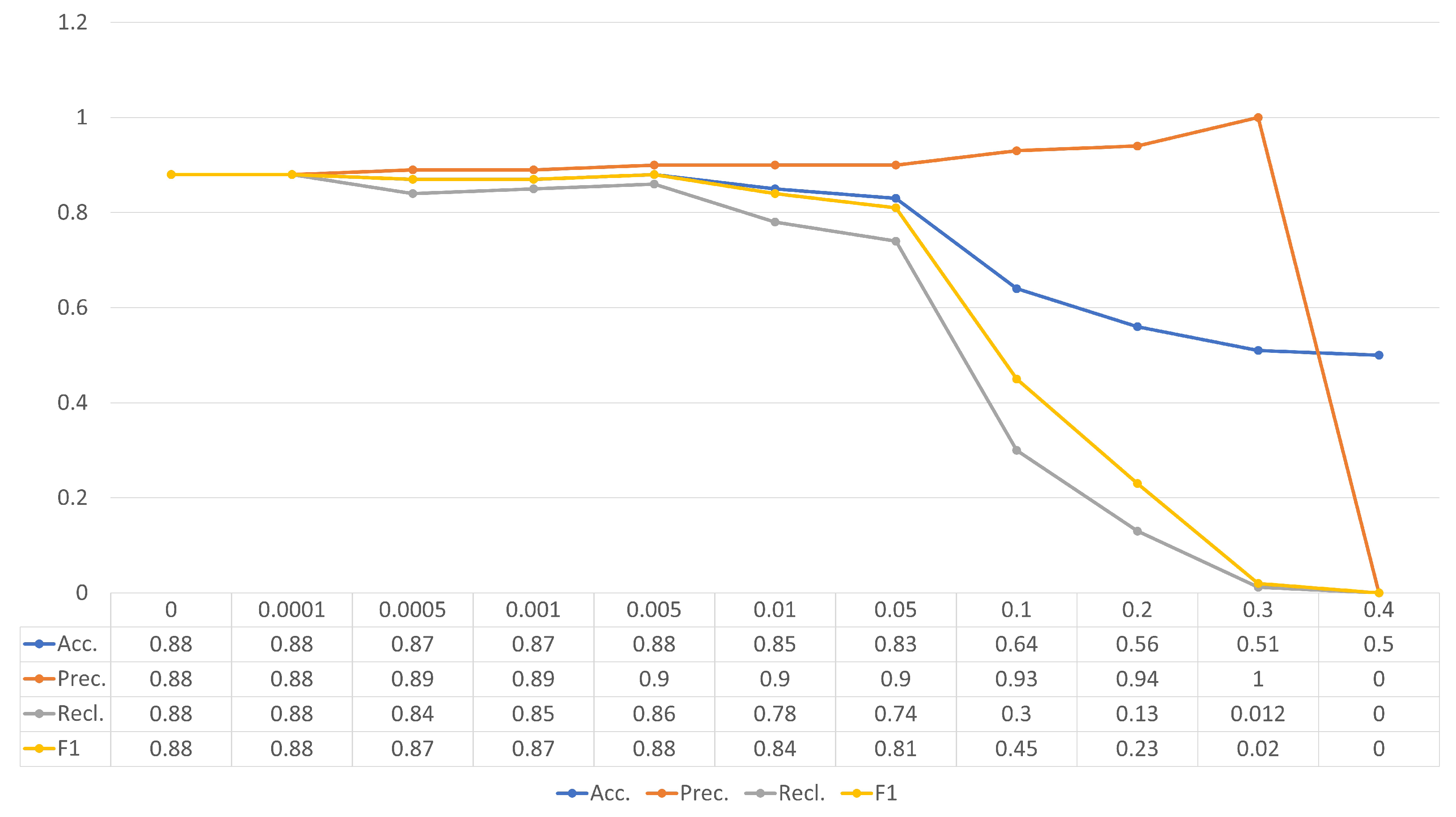
| CNN | CRNN | |||||||
|---|---|---|---|---|---|---|---|---|
| Condition | Acc. | Prec. | Rcl. | F1 | Acc. | Prec. | Rcl. | F1 |
| Unnoisy | 0.88 | 0.88 | 0.88 | 0.88 | 0.81 | 0.93 | 0.66 | 0.77 |
| 0.0001 | 0.88 | 0.88 | 0.88 | 0.88 | 0.81 | 0.93 | 0.66 | 0.78 |
| 0.0005 | 0.87 | 0.89 | 0.84 | 0.87 | 0.81 | 0.92 | 0.67 | 0.78 |
| 0.001 | 0.87 | 0.89 | 0.85 | 0.87 | 0.81 | 0.92 | 0.67 | 0.78 |
| 0.005 | 0.88 | 0.90 | 0.86 | 0.88 | 0.81 | 0.92 | 0.68 | 0.79 |
| 0.01 | 0.85 | 0.90 | 0.78 | 0.84 | 0.81 | 0.88 | 0.73 | 0.80 |
| 0.05 | 0.83 | 0.90 | 0.74 | 0.81 | 0.84 | 0.87 | 0.80 | 0.83 |
| 0.1 | 0.64 | 0.93 | 0.30 | 0.45 | 0.70 | 0.66 | 0.83 | 0.73 |
| 0.2 | 0.56 | 0.94 | 0.13 | 0.23 | 0.66 | 0.64 | 0.74 | 0.68 |
| 0.3 | 0.51 | 1 | 0.012 | 0.02 | 0.49 | 0.48 | 0.35 | 0.41 |
| 0.4 | 0.5 | 0 | 0 | 0 | 0.49 | 0.34 | 0.11 | 0.16 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
dos Santos, R.; Kassetty, A.; Nilizadeh, S. Disrupting Audio Event Detection Deep Neural Networks with White Noise. Technologies 2021, 9, 64. https://doi.org/10.3390/technologies9030064
dos Santos R, Kassetty A, Nilizadeh S. Disrupting Audio Event Detection Deep Neural Networks with White Noise. Technologies. 2021; 9(3):64. https://doi.org/10.3390/technologies9030064
Chicago/Turabian Styledos Santos, Rodrigo, Ashwitha Kassetty, and Shirin Nilizadeh. 2021. "Disrupting Audio Event Detection Deep Neural Networks with White Noise" Technologies 9, no. 3: 64. https://doi.org/10.3390/technologies9030064
APA Styledos Santos, R., Kassetty, A., & Nilizadeh, S. (2021). Disrupting Audio Event Detection Deep Neural Networks with White Noise. Technologies, 9(3), 64. https://doi.org/10.3390/technologies9030064