
Smartphone Handwritten Circuits Solver Using Augmented Reality and Capsule Deep Networks for Engineering Education




Abstract
1. Introduction
2. Literature Review
3. Materials and Methods
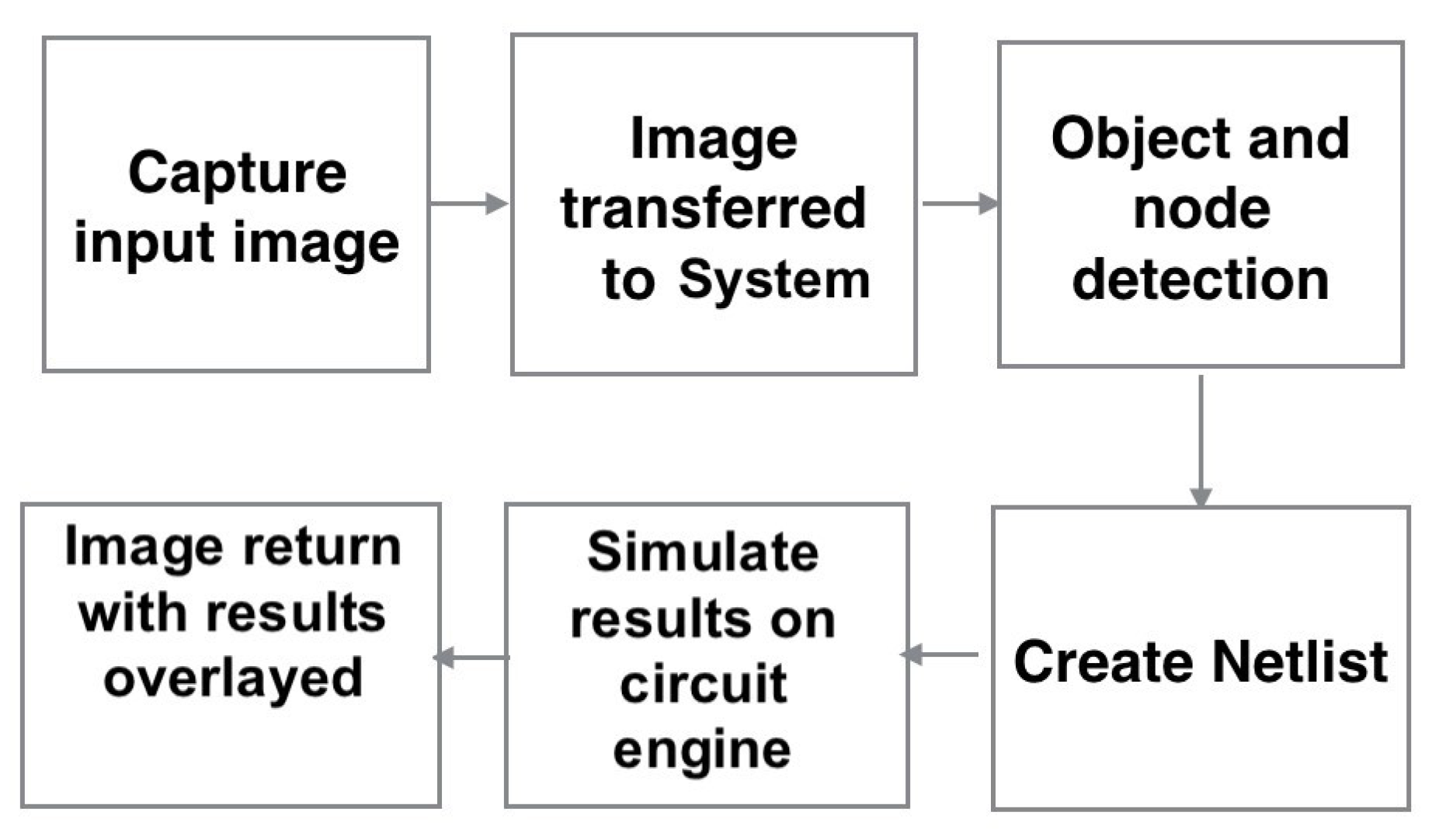
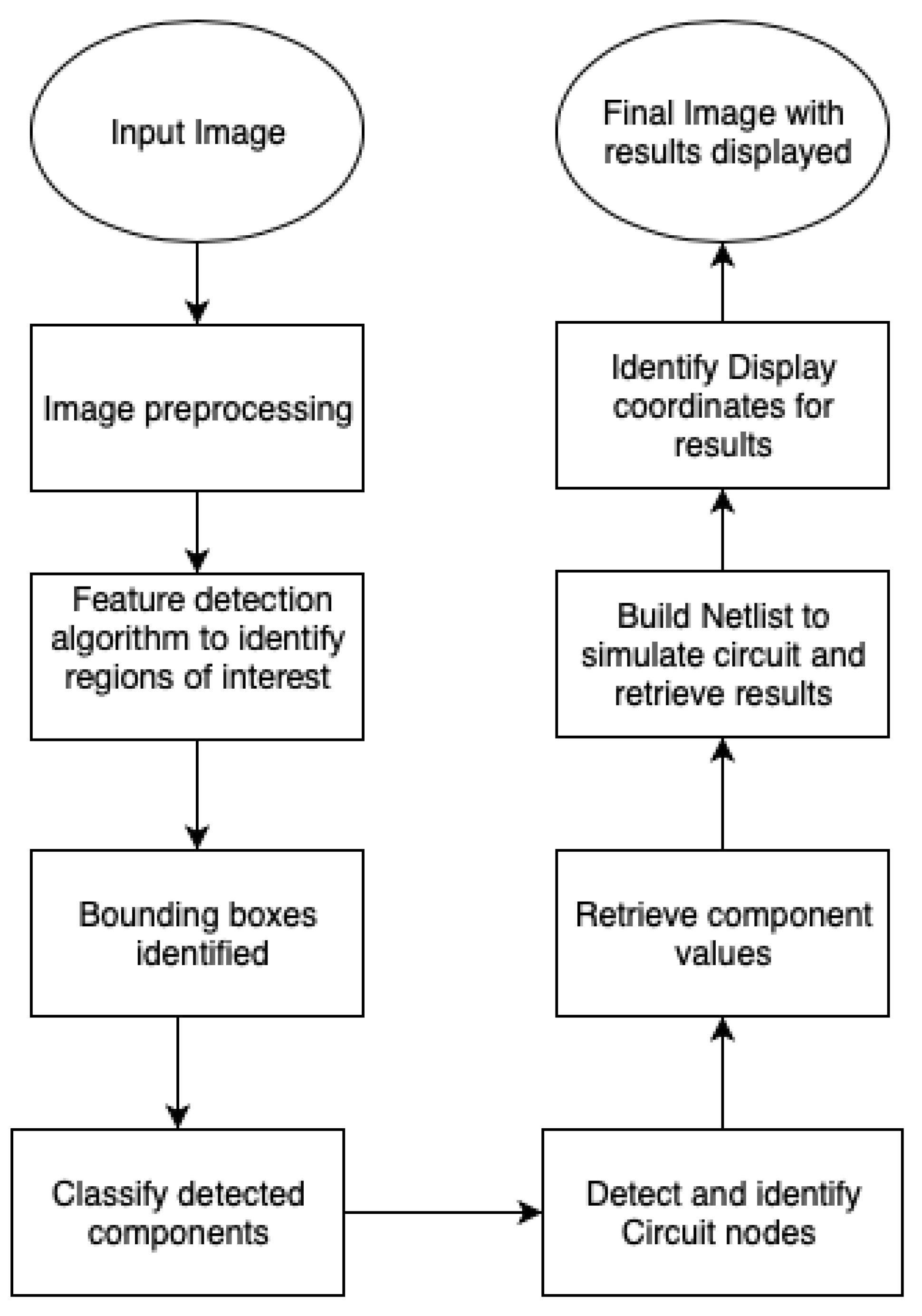
3.1. System Overview
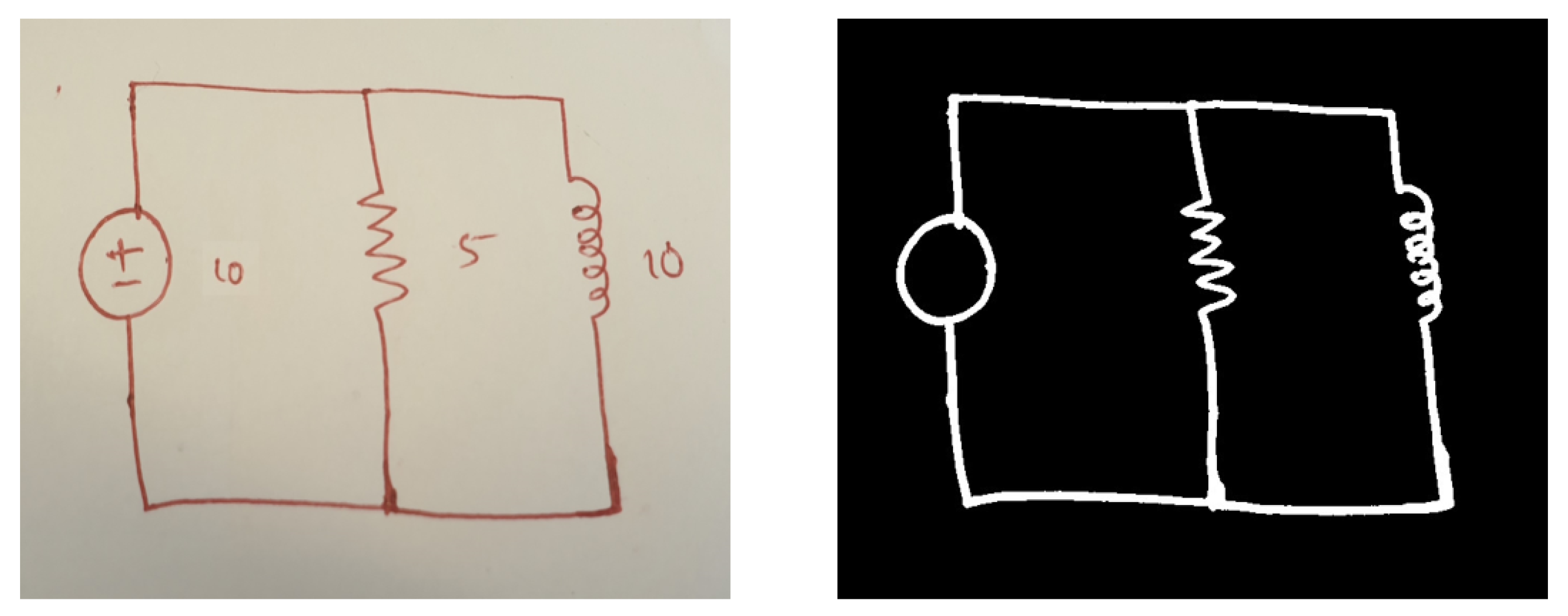
3.1.1. Data Collection
3.1.2. Preprocessing
3.1.3. Region Proposal Algorithm
- Preprocess the image before performing a feature analysis. We convert the image to binary, filter text and symbols from the image, and dilate it.
- Perform edge and corner detection using SURF, Eigen, and FAST methods to identify capacitor, inductor, and resistor. Circuit images consist of background with less noise enabling feature detection to identify components as a concentrated set of points.
- Dilate the detected feature points to create locations for the components and filter to remove relatively small regions. Bounding boxes are placed over the remaining detected regions.
- Detect circles using Hough transform to identify Voltage and Current sources. All circles with a radii range of 20 to 500 px are accepted. Next, we identify and remove overlapping circles. Given two circles with Center , radii , Center , and radii . The distance between the two circles is calculated by & . If Distance > Radius, then circles overlap and vice versa. We merge both circles into one to confirm the circular component is fully localized instead of partially.
- Any bounding box overlapping a circle is removed.
- Bounding boxes are created over circles and added to the existing list of bounding boxes, creating our final list of localized components.
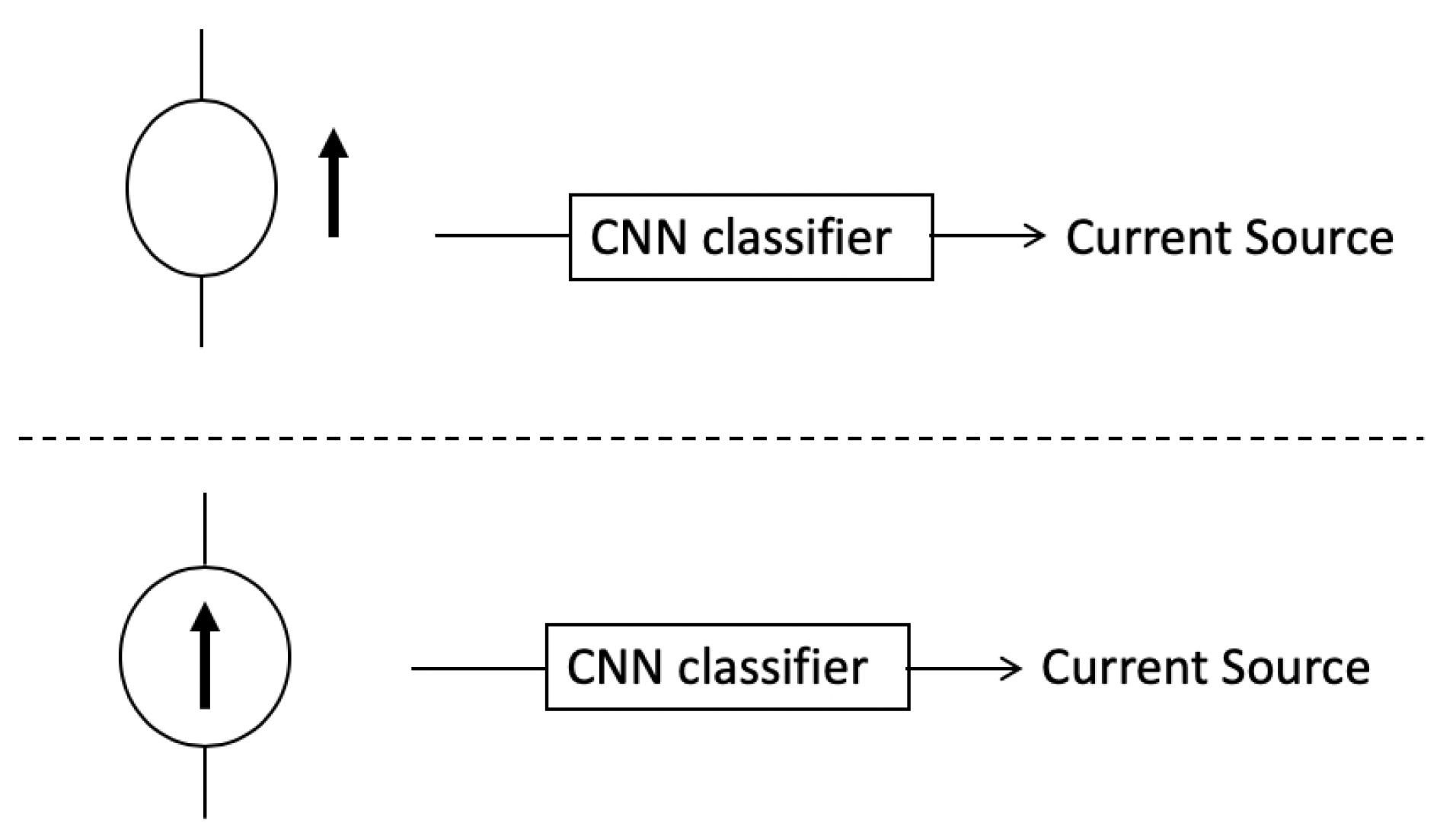
3.1.4. Object Classification
3.1.5. Identify Display Locations for Results
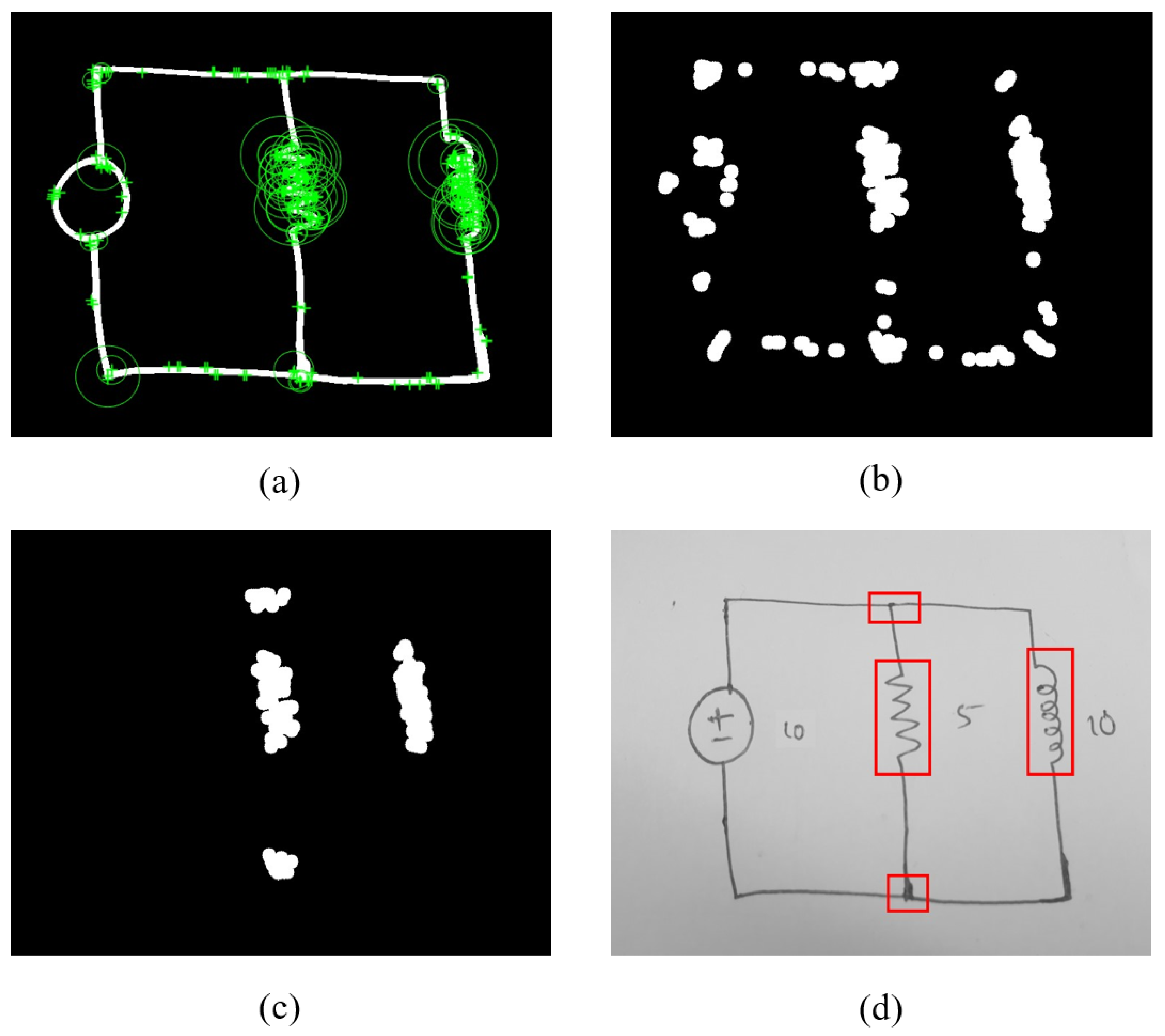
3.1.6. Node Detection
- 1
- We increase the bounding box of detected components by 2% around all four sides and get a list of all the region’s pixels.
- 2
- We remove the initially detected component, and we are left with the wires in the circuit. Each wire is counted as a node, and we retrieve all pixel locations in each wire after filtering any relatively small objects.
- 3
- We loop over all components to identify the nodes it belongs to by comparing the pixel information.
- 4
- Each component can only have two connecting points, and thus only two nodes.
- 5
- We will be requesting user input to get the component values.
3.1.7. Circuit Simulation Results
3.2. Convolutional Neural Networks
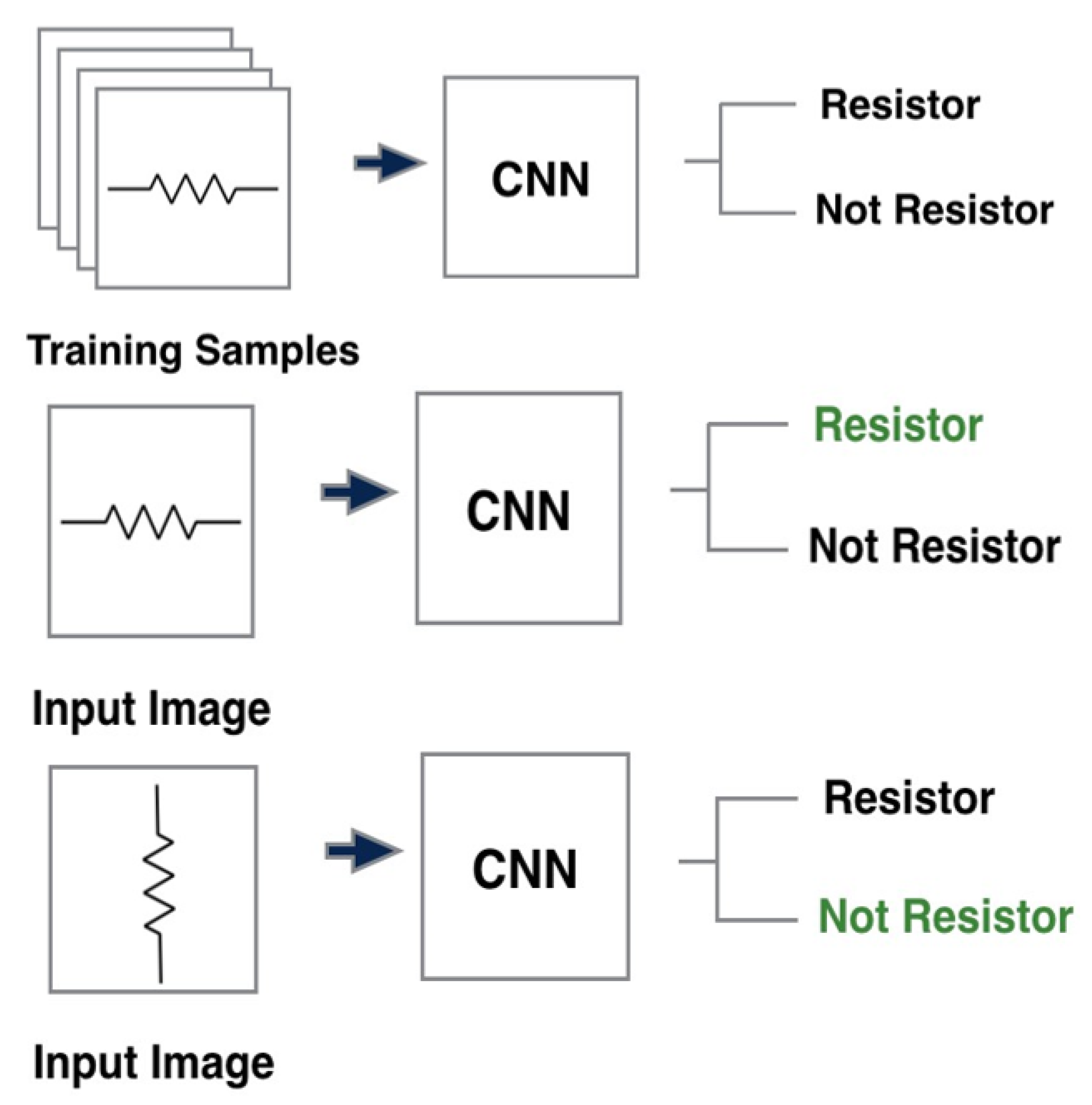
3.3. Challenges with CNN
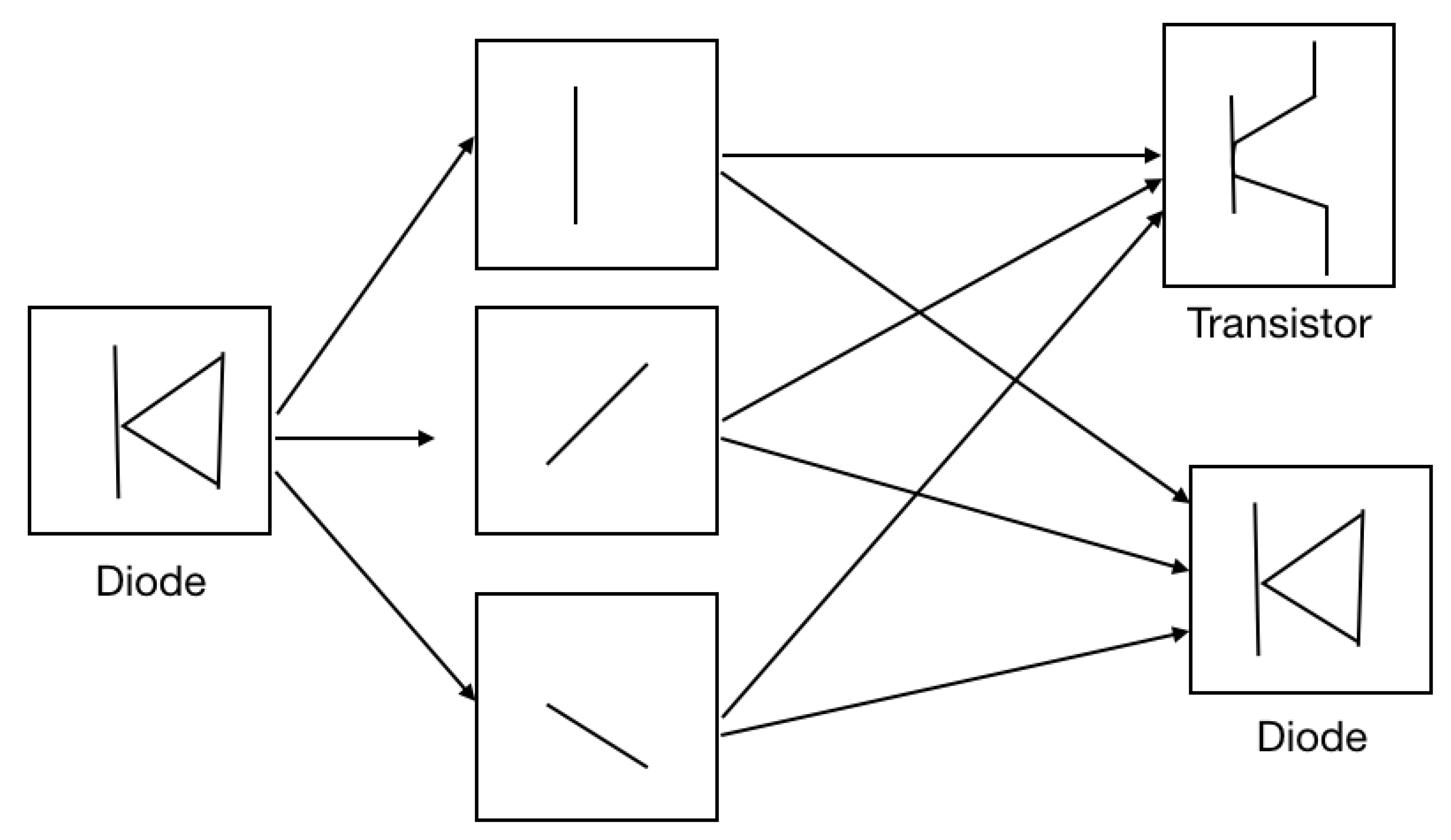
3.4. Capsule Network
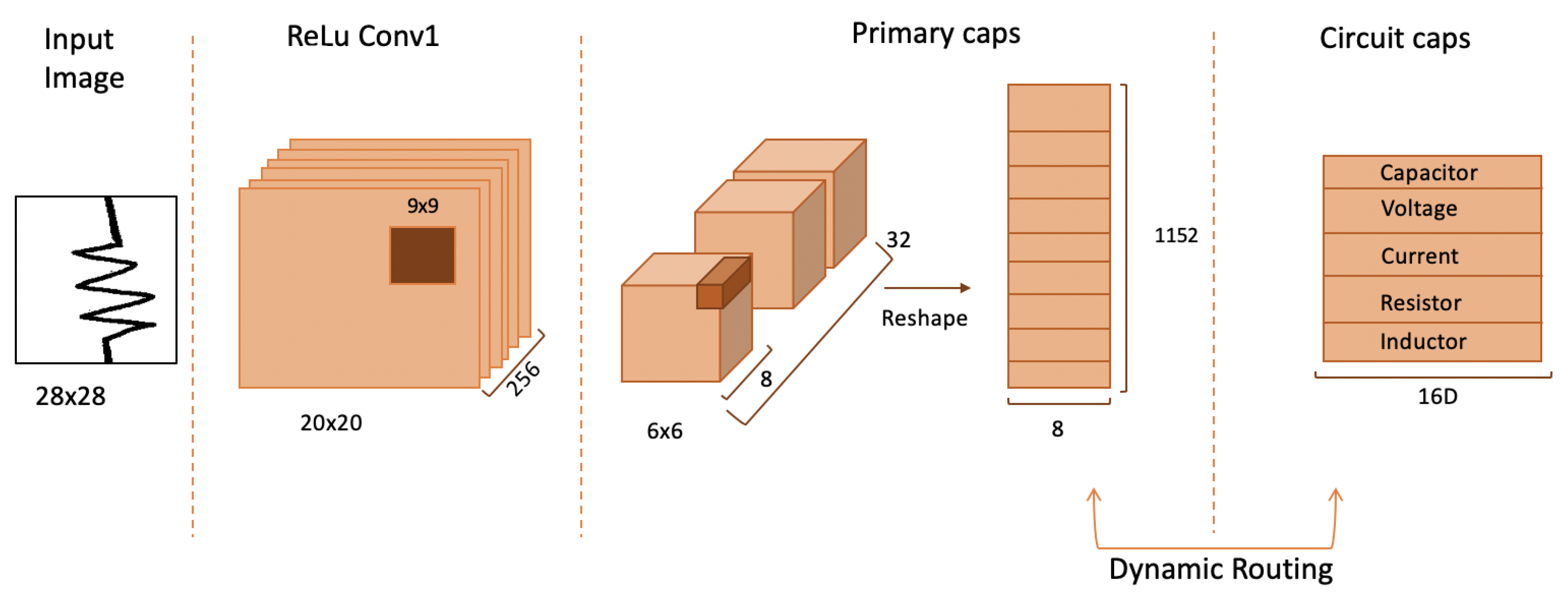
3.4.1. Capsule Network’s Architecture
- Convolution takes a image, which is convolved with a kernel and stride of 1. We convolve with 256 different feature maps. This layer will extract all the basic features from the input image, such as edges. This layer’s output, a image, is taken as input to the Primary capsule layer. ReLU nonlinear activation function was used where . Output image size changes from to based on the size calculation of:
- Layer 2 consists of a primary capsule network that implements convolution with a kernel and stride 2. We also rearrange the output to resemble a capsule network; the convolution results in a image. The 256 feature maps output is divided into 32 capsules sets with a dimension of 8. Therefore, each capsule has a dimension of 8. The output image size changes from to based on the size calculation given in Equation (2). The primary capsule has three functions, first is to detect higher-level features than edges and curves. Second, it reshapes the output of 32 blocks of eight dimensions into a flatted matrix of size capsules of 8 dimensions. Third, it predicts each capsule’s output, which is used to route the capsules to a higher capsule. The primary capsule is multiplied by the weight matrix to receive a prediction for the diode’s spatial location, as shown in Equation (3). If , the prediction vector turns out to be similar to the weight multiplication for other low-level features, then the probability of diode detected is higher. This is how dynamic routing is implemented in capsule networks.
- The third layer represents the circuit-caps layer, which takes the inputs specified by the dynamic routing algorithm and provides a classification along with instantiating parameters measuring 16 dimensions per class.
3.4.2. Dynamic Routing Algorithm
4. Results & Discussions
4.1. Circuit Recognition System
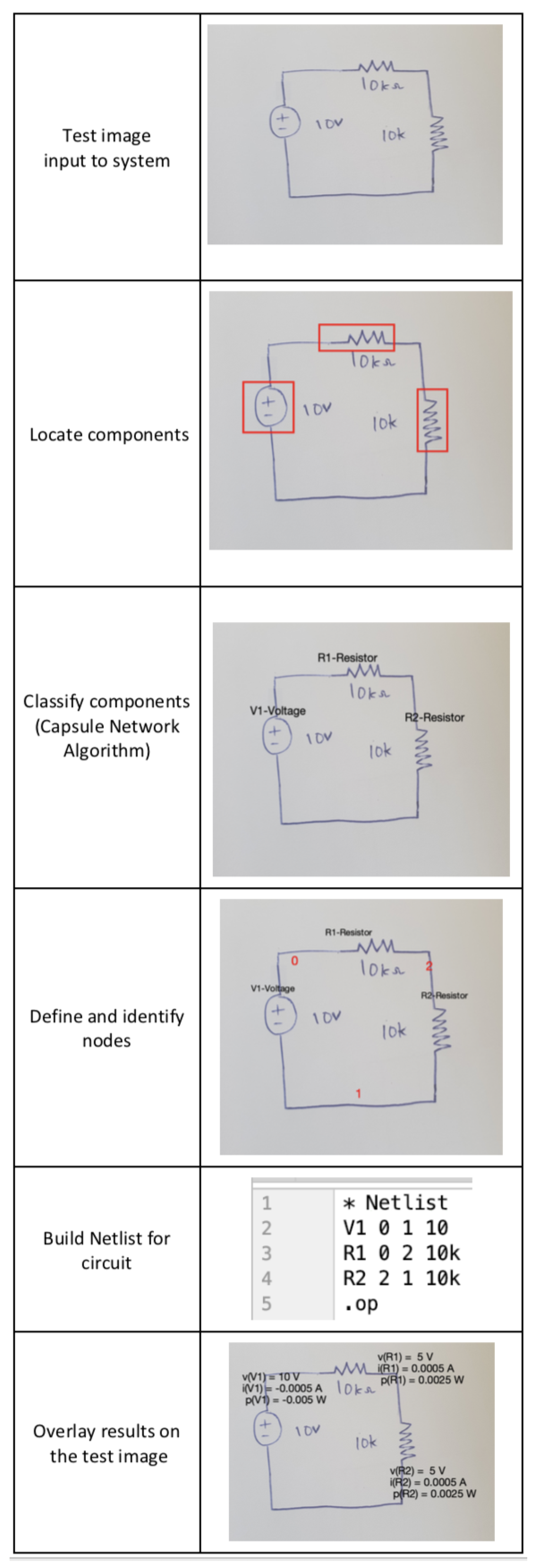
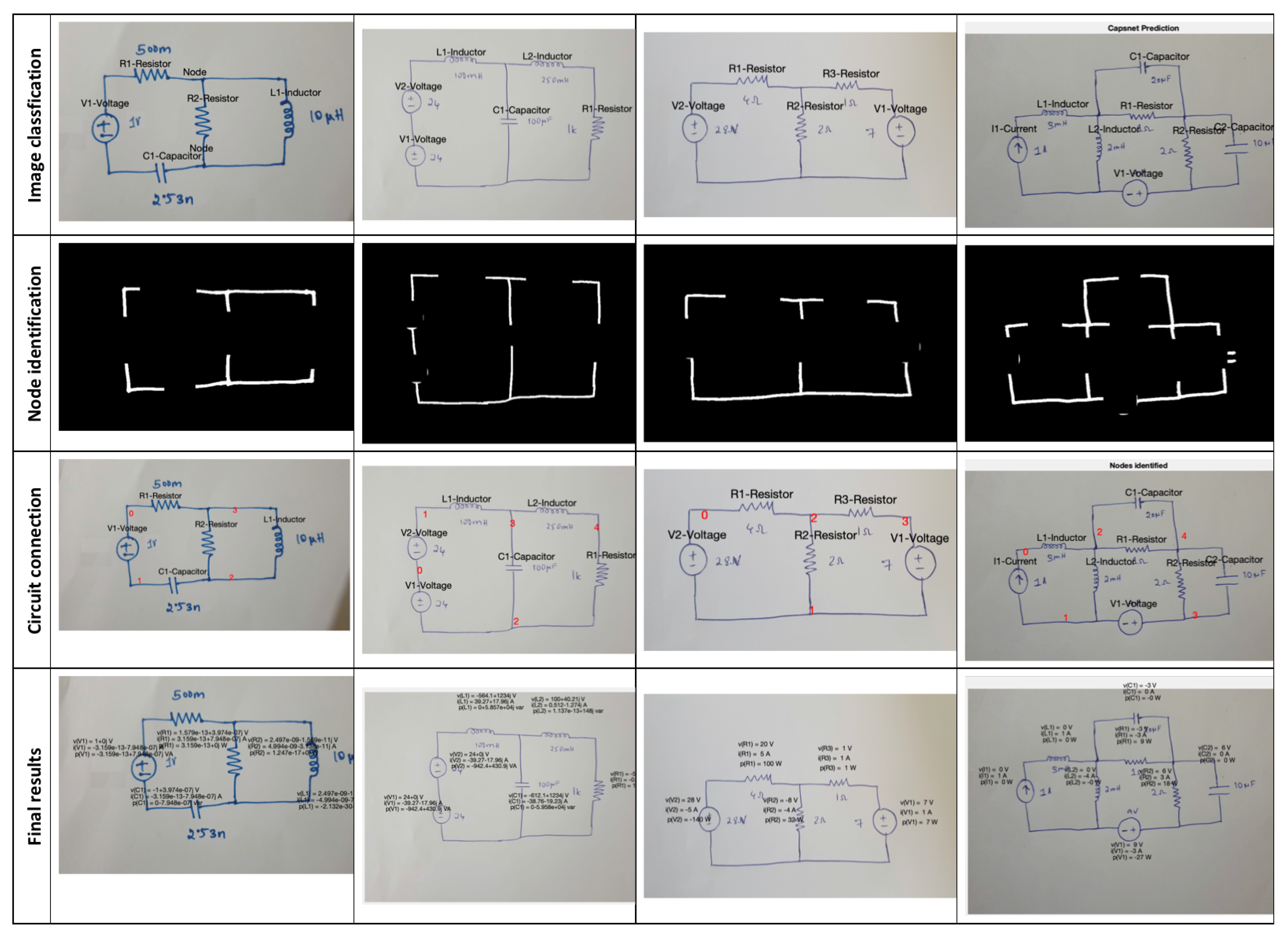
- Object classification using capsule network, as illustrated in Figure 12. An additional class called ‘Node’ was added to identify wrongly localized components, e.g., wires or corners that do not fall under the circuit component category.
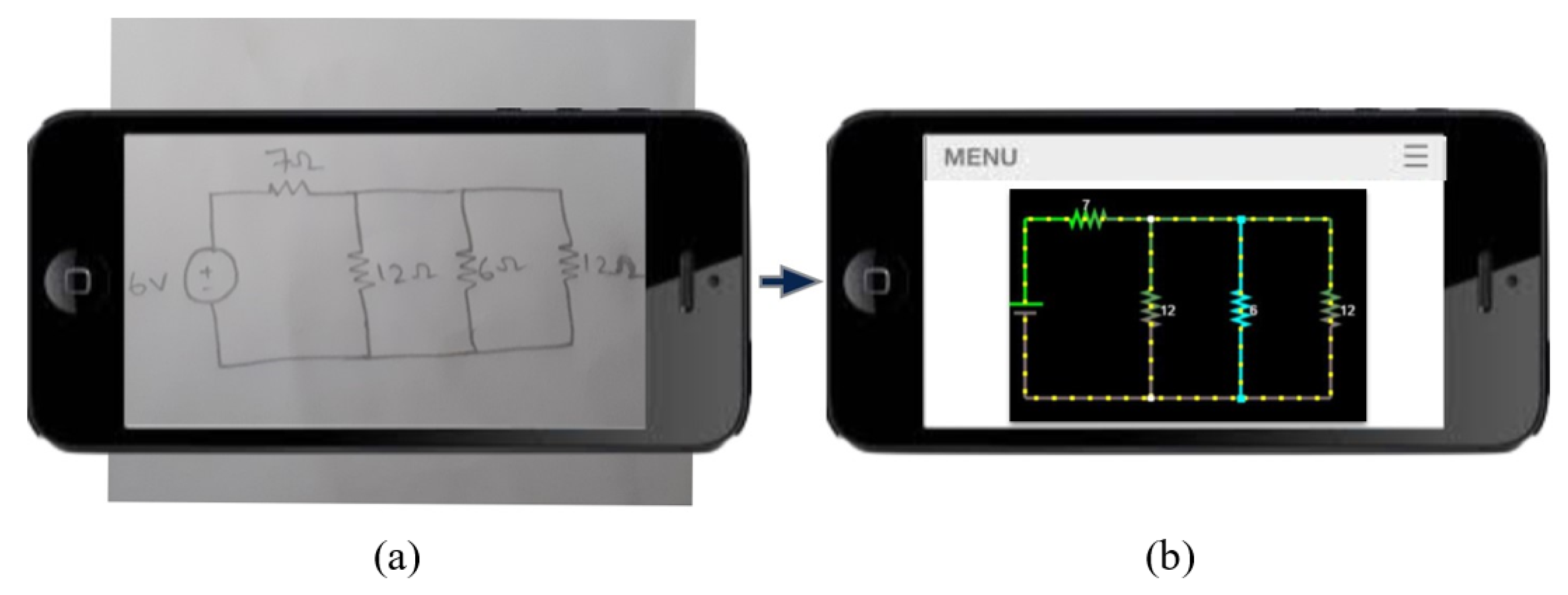
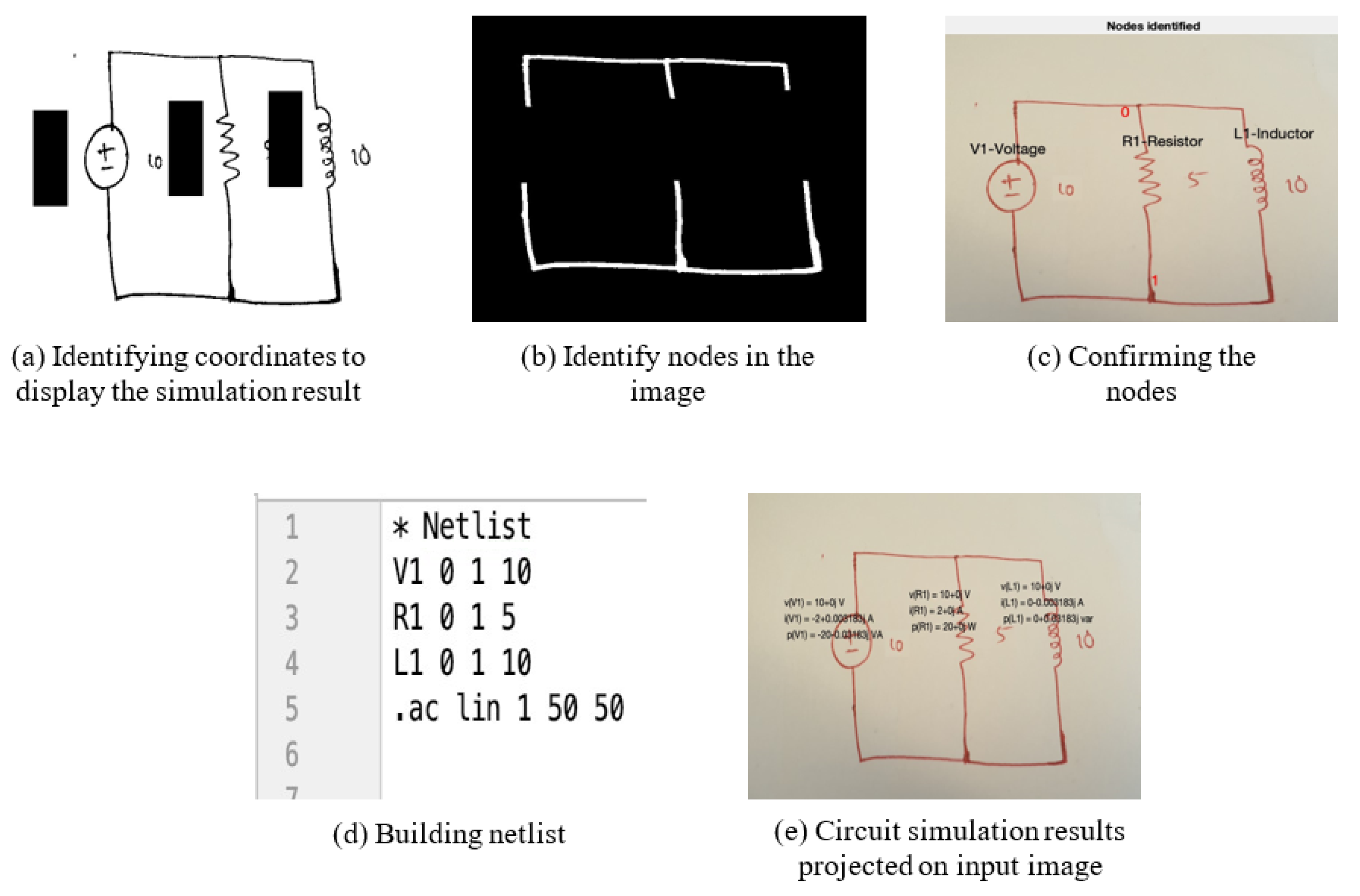
- Identify coordinates to display the final circuit simulation result shown in Figure 13a.
- Node detection is shown in Figure 13c.
- The netlist is automatically built based on the previous detection results and user input for the component values, as shown in Figure 13d. The netlist is then passed to the circuit simulator tool to obtain results.
- Results are overlaid on the input circuit image shown in Figure 13e.
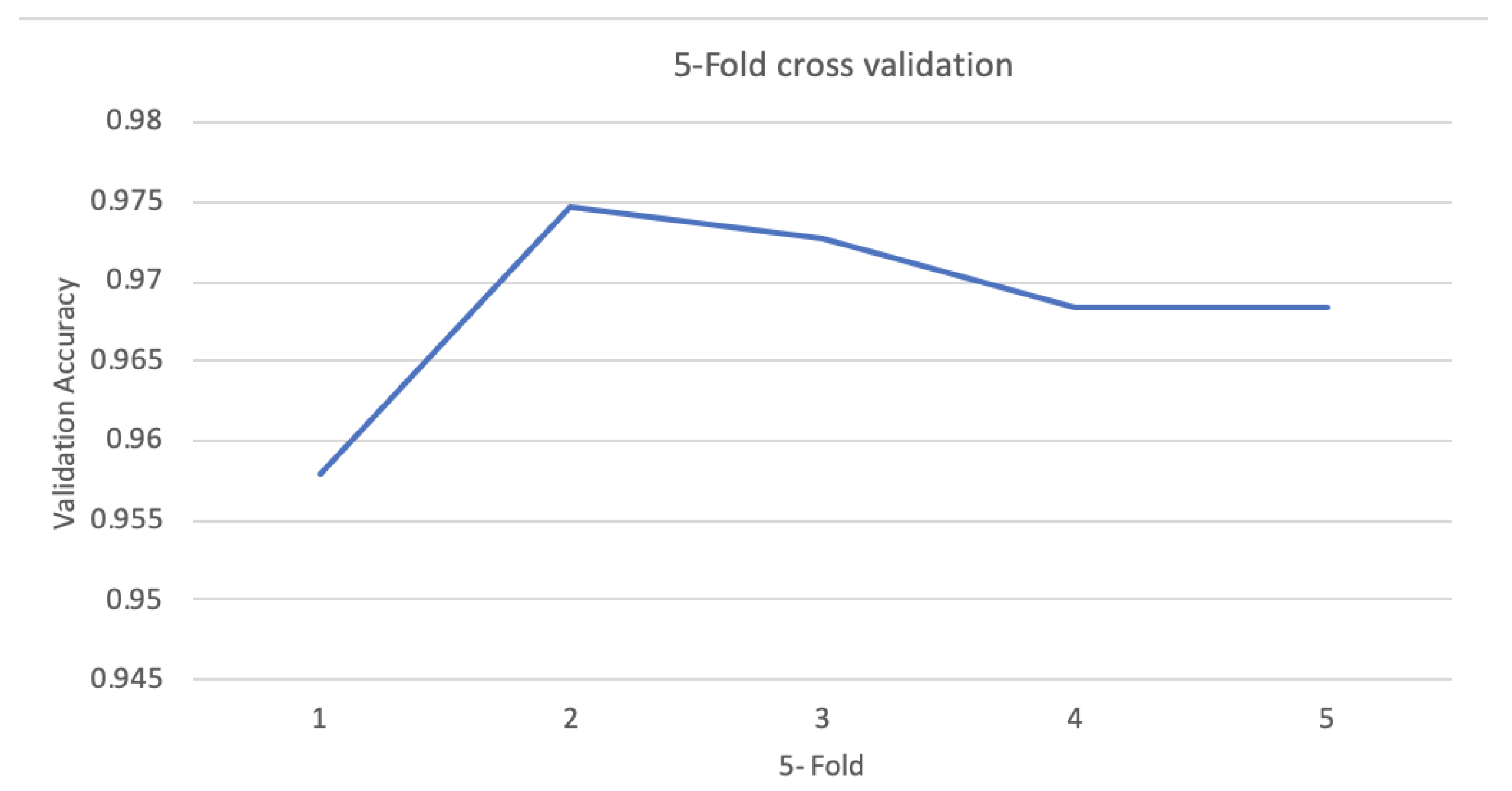
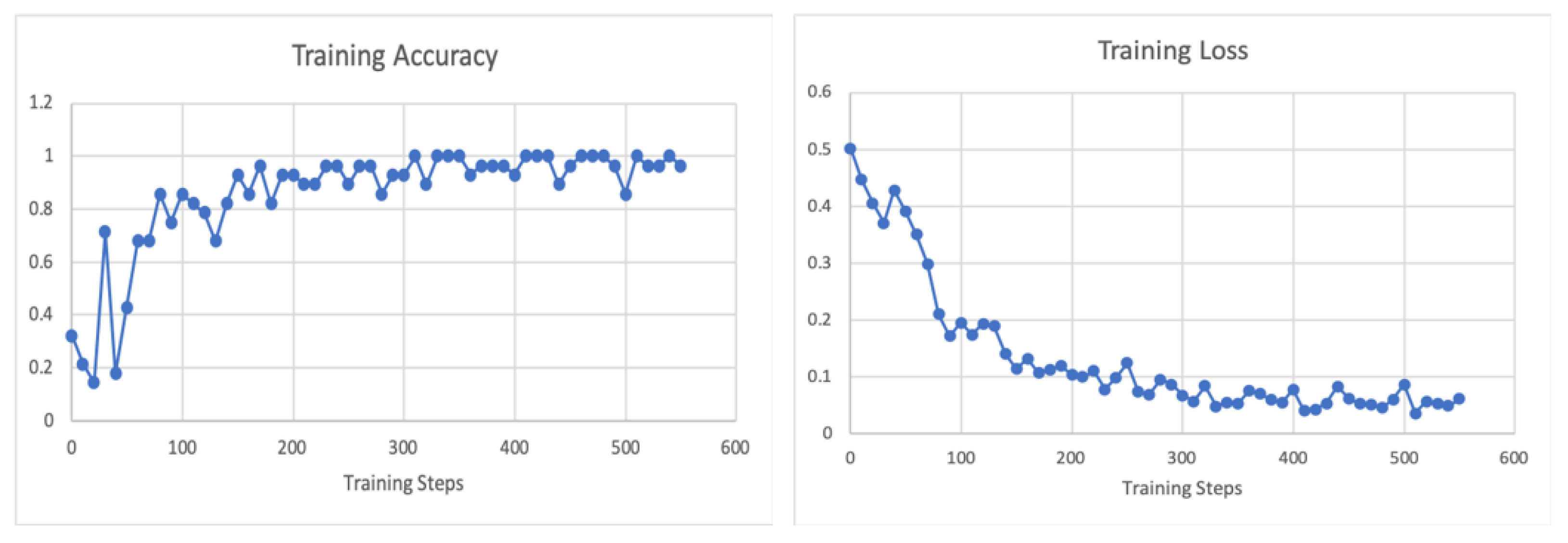
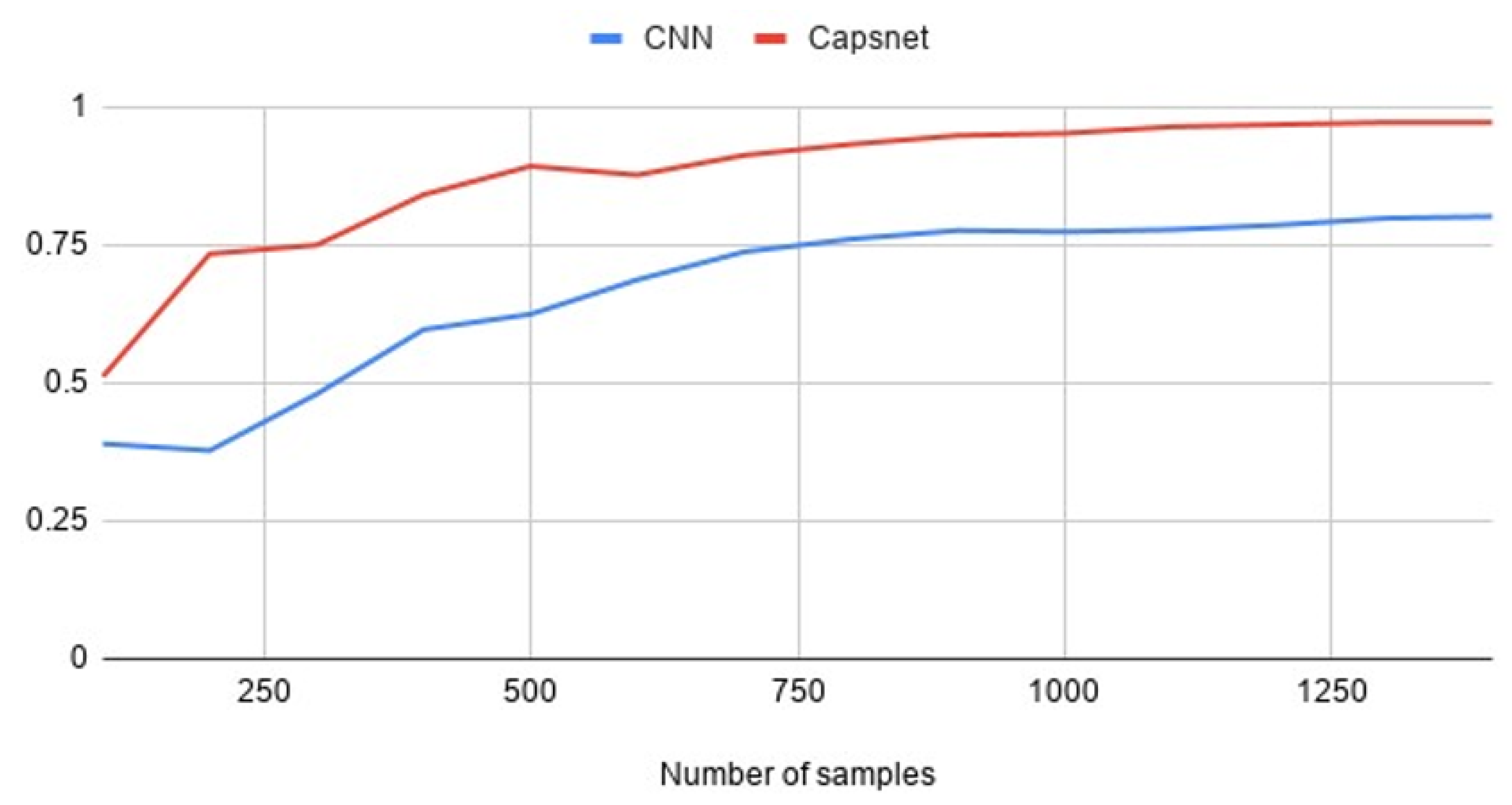
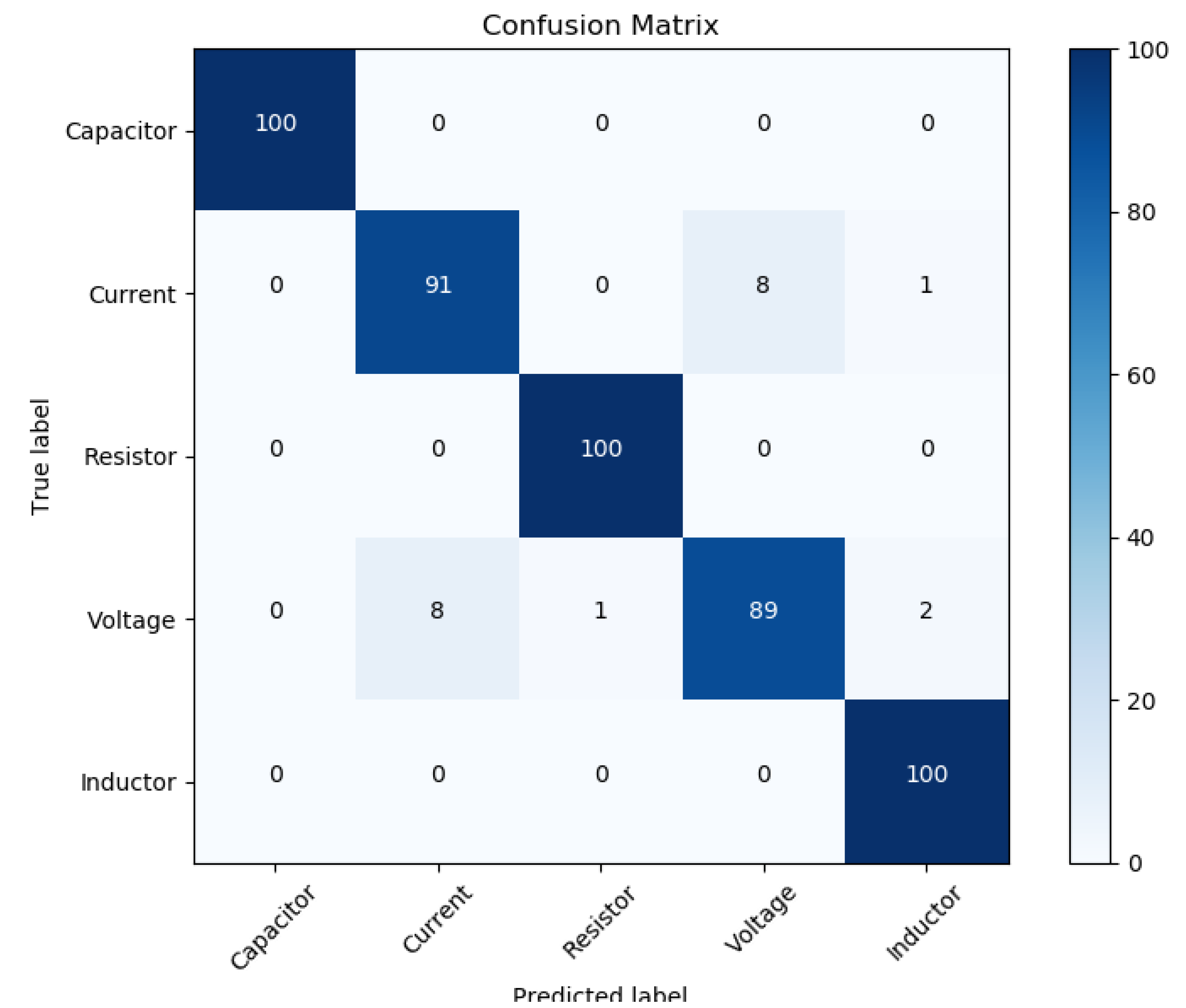
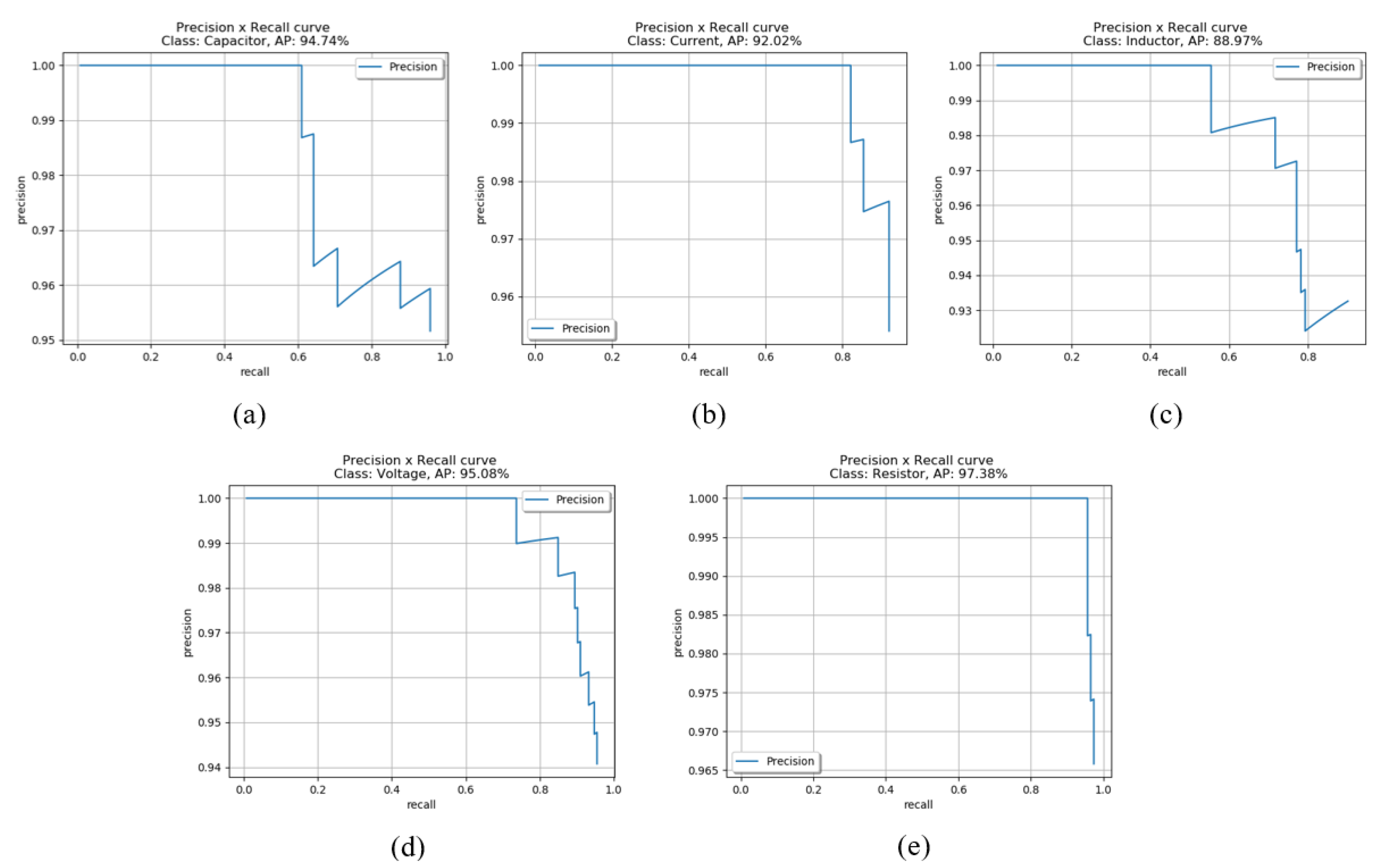
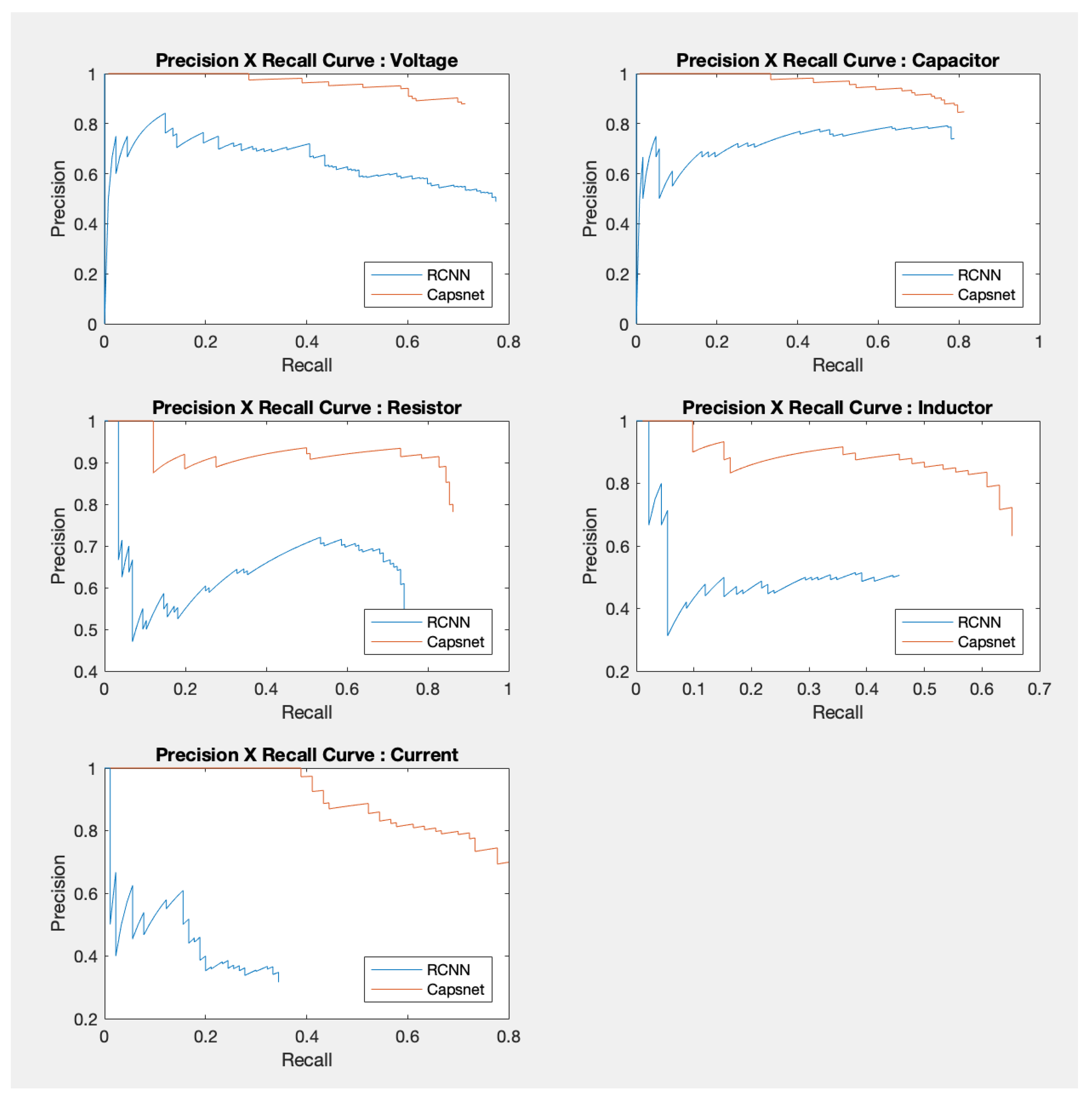
4.2. Validation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Rehmat, A.; Hartley, K. Building Engineering Awareness: Problem Based Learning Approach for STEM Integration. Interdiscip. J. Probl.-Based Learn. 2020, 14, n1. [Google Scholar] [CrossRef]
- Ullah, A.; Anwar, S. The Effective Use of Information Technology and Interactive Activities to Improve Learner Engagement. Educ. Sci. 2020, 10, 349. [Google Scholar] [CrossRef]
- Oliveira, D.; Pedro, L.; Santos, C. The Use of Mobile Applications in Higher Education Classrooms: An Exploratory Measuring Approach in the University of Aveiro. Educ. Sci. 2021, 11, 484. [Google Scholar] [CrossRef]
- CoSN Tech Driving. Cosn.org. 2019. Available online: Https://www.cosn.org/ (accessed on 27 September 2021).
- Mella-Norambuena, J.; Cobo-Rendon, R.; Lobos, K.; Sáez-Delgado, F.; Maldonado-Trapp, A. Smartphone Use among Undergraduate STEM Students during COVID-19: An Opportunity for Higher Education? Educ. Sci. 2021, 11, 417. [Google Scholar] [CrossRef]
- Iqbal, S.; Bhatti, Z. A qualitative exploration of teachers’ perspective on smartphones usage in higher education in developing countries. Int. J. Educ. Technol. High. Educ. 2020, 17, 29. [Google Scholar] [CrossRef]
- Gómez-García, G.; Hinojo-Lucena, F.; Alonso-García, S.; Romero-Rodríguez, J. Mobile Learning in Pre-Service Teacher Education: Perceived Usefulness of AR Technology in Primary Education. Educ. Sci. 2021, 11, 275. [Google Scholar] [CrossRef]
- Ilić, M.; Păun, D.; Šević, N.P.; Hadžić, A.; Jianu, A. Needs and Performance Analysis for Changes in Higher Education and Implementation of Artificial Intelligence, Machine Learning, and Extended Reality. Educ. Sci. 2021, 11, 568. [Google Scholar] [CrossRef]
- Hartley, K.; Bendixen, L.; Olafson, L.; Gianoutsos, D.; Shreve, E. Development of the smartphone and learning inventory: Measuring self-regulated use. Educ. Inf. Technol. 2020, 25, 4381–4395. [Google Scholar] [CrossRef]
- Hartley, K.; Bendixen, L. Smartphones and self-regulated learning: Opportunities and challenges. In Proceedings of the 15th International Conference on Mobile Learning 2019, Utrecht, The Netherlands, 11–13 April 2019. [Google Scholar] [CrossRef]
- Andujar, A.; Salaberri-Ramiro, M.; Martínez, M. Integrating Flipped Foreign Language Learning through Mobile Devices: Technology Acceptance and Flipped Learning Experience. Sustainability 2020, 12, 1110. [Google Scholar] [CrossRef]
- Alberola-Mulet, I.; Iglesias-Martínez, M.; Lozano-Cabezas, I. Teachers’ Beliefs about the Role of Digital Educational Resources in Educational Practice: A Qualitative Study. Educ. Sci. 2021, 11, 239. [Google Scholar] [CrossRef]
- Tavares, R.; Vieira, R.M.; Pedro, L. Mobile App for Science Education: Designing the Learning Approach. Educ. Sci. 2021, 11, 79. [Google Scholar] [CrossRef]
- Boraie, M.T.; Balghonaim, A.S. Optical recognition of electrical circuit drawings. In Proceedings of the 1997 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, PACRIM, 10 Years Networking the Pacific Rim, 1987–1997, Victoria, BC, Canada, 20–22 August 1997; Volume 2, pp. 843–846. [Google Scholar] [CrossRef]
- Edwards, B.; Chandran, V. Machine recognition of hand-drawn circuit diagrams. In Proceedings of the 2000 IEEE International Conference on Acoustics, Speech, and Signal Processing, Istanbul, Turkey, 5–9 June 2000; Volume 6, pp. 3618–3621. [Google Scholar] [CrossRef]
- Liu, Y.; Xiao, Y. Circuit Sketch Recognition; Department of Electrical Engineering Stanford University: Stanford, CA, USA, 2013. [Google Scholar]
- Patare, M.D.; Joshi, M.S. Hand-drawn Digital Logic Circuit Component Recognition using SVM. Int. J. Comput. Appl. 2016, 143, 24–28. [Google Scholar] [CrossRef]
- Sabour, S.; Frosst, N.; Hinton, G.E. Dynamic Routing Between Capsules. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.v., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 3859–3869. [Google Scholar]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2001), Kauai, HI, USA, 8–14 December 2001; Volume 1, pp. I-511–I-518. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A Hybrid Vehicle Detection Method Based on Viola-Jones and HOG + SVM from UAV Images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef] [PubMed]
- Rabbani, M.; Khoshkangini, R.; Nagendraswamy, H.; Conti, M. Hand Drawn Optical Circuit Recognition. Procedia Comput. Sci. 2016, 84, 41–48. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. arXiv 2014, arXiv:1408.5882. [Google Scholar]
- Razavian, A.; Azizpour, H.; Sullivan, J.; Carlsson, S. CNN Features Off-the-Shelf: An Astounding Baseline for Recognition. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition Workshops, Columbus, OH, USA, 23–28 June 2014. [Google Scholar] [CrossRef]
- LeCun, Y.; Huang, F.J.; Bottou, L. Learning methods for generic object recognition with invariance to pose and lighting. In Proceedings of the 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR 2004), Washington, DC, USA, 27 June–2 July 2004; Volume 2, p. II-104. [Google Scholar] [CrossRef]
- Convolutional Neural Networks for Visual Recognition. Available online: http://cs231n.github.io/convolutional-networks/ (accessed on 20 December 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; Curran Associates, Inc.: New York, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Neveu, T. A Tensorflow Implementation of CapsNet(Capsules Net) Apply on German Traffic Sign Dataset. GitHub. 2017. Available online: https://github.com/thibo73800/capsnet-traffic-sign-classifier (accessed on 14 November 2020).
- Yuen, H.; Princen, J.; Illingworth, J.; Kittler, J. Comparative study of Hough Transform methods for circle finding. Image Vis. Comput. 1990, 8, 71–77. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Precision | Recall | F1-Score | Support | |
|---|---|---|---|---|
| Capacitor | 1.00 | 1.00 | 1.00 | 100 |
| Current | 0.92 | 0.91 | 0.91 | 100 |
| Resistor | 0.99 | 1.00 | 1.00 | 100 |
| Voltage | 0.92 | 0.89 | 0.90 | 100 |
| Inductor | 0.97 | 1.00 | 0.99 | 100 |
| Micro Avg. | 0.96 | 0.96 | 0.96 | 500 |
| Macro Avg. | 0.96 | 0.96 | 0.96 | 500 |
| Weighted Avg. | 0.96 | 0.96 | 0.96 | 500 |
| Class | Capsule Network (with Data Augmentation) | Capsule Network (without Data Augmentation) | RCNN (without Data Augmentation) | |||
|---|---|---|---|---|---|---|
| 0.3 IOU | 0.5 IOU | 0.3 IOU | 0.5 IOU | 0.3 IOU | 0.5 IOU | |
| Capacitor | 94.74% | 82.40% | 86.09% | 78.63% | 99.93% | 57.41% |
| Current | 92.02% | 92.02% | 73.06% | 73.06% | 54.07% | 16.58% |
| Inductor | 88.97% | 52.53% | 83.03% | 58.84% | 81.20% | 23.83% |
| Resistor | 97.38% | 82.64% | 94.61% | 80.95% | 86.55% | 48.90% |
| Voltage | 95.08% | 93.47% | 71.38% | 69.20% | 77.31% | 51.11% |
| mAP | 93.64% | 80.61% | 81.63% | 72.14% | 79.81% | 39.56% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhalabi, M.; Ghazal, M.; Haneefa, F.; Yousaf, J.; El-Baz, A. Smartphone Handwritten Circuits Solver Using Augmented Reality and Capsule Deep Networks for Engineering Education. Educ. Sci. 2021, 11, 661. https://doi.org/10.3390/educsci11110661
Alhalabi M, Ghazal M, Haneefa F, Yousaf J, El-Baz A. Smartphone Handwritten Circuits Solver Using Augmented Reality and Capsule Deep Networks for Engineering Education. Education Sciences. 2021; 11(11):661. https://doi.org/10.3390/educsci11110661
Chicago/Turabian StyleAlhalabi, Marah, Mohammed Ghazal, Fasila Haneefa, Jawad Yousaf, and Ayman El-Baz. 2021. "Smartphone Handwritten Circuits Solver Using Augmented Reality and Capsule Deep Networks for Engineering Education" Education Sciences 11, no. 11: 661. https://doi.org/10.3390/educsci11110661
APA StyleAlhalabi, M., Ghazal, M., Haneefa, F., Yousaf, J., & El-Baz, A. (2021). Smartphone Handwritten Circuits Solver Using Augmented Reality and Capsule Deep Networks for Engineering Education. Education Sciences, 11(11), 661. https://doi.org/10.3390/educsci11110661