Abstract
The Gaokao, also known as China’s national college entrance exam, is a high-stakes exam for nearly all Chinese students. English has been one of the three most important subjects for a long time, and listening plays an important role in the Gaokao English test. However, relatively little research has been conducted on local versions of Gaokao’s English listening tests. This study analyzed the linguistic features and corresponding functional dimensions of the three different text types in the Gaokao’s listening test, investigating whether the papers used in three major regions of China were differentiated in terms of the co-occurrence patterns of lexicogrammatical features and dimensions of the transcripts. A corpus consisting of 170 sets of test papers (134,913 words) covering 31 provinces and cities from 2000 to 2022 was analyzed using a multidimensional analysis wherein six exclusive dimensions were extracted. The results showed that there were meaningful differences across short conversations, long conversations, and monologues with regard to the six dimensions’ scores, and regions further had significant differences in three dimensions: Syntactic and Clausal Complexity, Oral versus Literate Discourse, and Procedural Discourse, while Time Period was not associated with any differences. Implications for language teaching and assessment are discussed.
1. Introduction
Language assessment is concerned with sampling language performances and problems that may occur in real language use domains. Corpus linguistics has emerged as an essential tool in language assessment, particularly in examining the relationship between language tests and the language needed for academic purposes [1] Specialized language corpora offer a systematic way for researchers to sample language in a rigorous way, thereby contributing to the development of more effective language assessments [2,3]. Specifically, language corpora have been universally employed to inform the assessment of writing and speaking skills [4,5,6,7]. However, a significant gap persists in corpus-based approaches when the authors turn attention to listening assessment.
Corpus-based language research allows scholars to investigate the representativeness and validity of test content by leveraging the analytical capabilities of computational linguistics [8] and pioneering methodologies such as multidimensional analysis (henceforth MDA) [9]. As a factor analysis method, MDA, the corpus-driven tool employed in this work, is used to find clusters of co-occurring linguistic variables that together make a contribution to functional aspects of language usage in a particular genre [10]. With regard to language assessment, a detailed account of the characteristics of a certain language register may offer strong evidence to support the inference of domain descriptions in assessments [11]. This is the reason why MDA has been adopted to investigate features of written or oral texts produced by test-takers [1,12,13] or to examine the overall resemblance of language used in assessments with target language use domains [14,15,16]. MDA has been widely used to provide evidence for both written and spoken tests’ validity argument through comparing the similarities and differences between test language registers and TLU domains. Thus, this study will investigate the linguistic features of the Gaokao listening test by applying MDA. Gaokao (高考) is the Chinese abbreviation for the Nationwide Unified Examination for Admissions to General Universities and Colleges (普通高等学校招生全国统一考试), an important selective examination for all qualified high school graduates or candidates with equivalent academic ability, held once a year, which determines what level of university each student can enter and is highly competitive. It seeks to shed light on the extent and manner in which these linguistic features differ across different spoken genres within the test, across regions, and over time periods. The subsequent sections will discuss the linguistic features of listening tests, MDA, and the Gaokao listening test, followed by the presentation of the study’s research questions.
2. Literature Review
2.1. The Influence of Linguistic Complexity on Listening Tests
In recent years, researchers’ interest in L2 listening difficulty has increased. Regarding the objective difficulty of listening tasks, as opposed to their perceived difficulty [17], studies have shown that factors associated with the features of the listener and the listening task can predict the difficulty level of an L2 listening test [18]. With respect to the components of a listening task, task input variable, text content, task processes, and task response features have been researched [19,20]. Task input characteristics, such as language complexity, length, and speech pace, are widely acknowledged to play a significant role in defining listening difficulties [21,22].
For example, Brunfaut and Révész [18] examined the correlation between the level of linguistic complexity in the listening assignment material and response, the explicitness of the material, and the difficulty of the task among a group of L2 English speakers. Their findings revealed a significant association between eight textual characteristics and task difficulty, which served as measures of discourse, lexical, and phonological complexity, as well as referential cohesiveness. To be more precise, increased referential cohesiveness [23] could lower the requirements of the work and diminish the level of difficulty. Task difficulty was also significantly connected with four lexical complexity features associated with multiword expressions. Common multi-word expressions in written discourse were negatively correlated with the difficulty of the task. On the contrary, listening passages in which a higher proportion of phrases rarely seen in written academic language appeared coincided with more challenging assignments.
There are several other studies that have examined the TOEFL and IELTS listening tests which also support the idea that linguistic complexity is significantly correlated with the challenge of listening tasks and can be measured by linguistic features. Nissan et al. [21] and Kostin [24], for example, found that negation in the dialogue significantly influenced the difficulty of the mini-talks in the TOEFL listening test. Aryadoust [25] explored section four of the IELTS listening test and found that the linguistic features of items such as grammar and vocabulary influenced test performance.
Synthesizing the above studies, it is found that listening texts have many linguistic features with functional orientation, such as reference function, negation, and elaboration, which affect the difficulty of the listening test. Moreover, the typical features may be different from one listening test to another, such as the TOEFL and the IELTS listening tests. The researchers are also aware of the multifaceted nature of the components that contribute to listening difficulty. Lexical complexity, sentence complexity, text length, and the presence of discourse markers in monologues and dialogues can lead to differences in difficulty [26]. Hence, it is crucial to discover a comprehensive and evidence-based method for examining listening texts, with the aim of exploring linguistic features and their corresponding functional orientations, which may provide a foundation for future investigations into the level of difficulty in listening examinations.
2.2. Gaokao English Listening Test Research
Gaokao, also known as China’s national college entrance exam, is a once-in-a-lifetime exam for nearly all Chinese students that can have a life-changing impact. All students from 32 provincial-level administrative regions in mainland China are required to compete in the Gaokao in order to be eligible to attend universities in China. With China’s large population and limited number of top universities, the competition has been extremely fierce. On this account, fairness in the Gaokao has always been one of the key concerns in the field of education, and the government is trying its best to balance the situation. According to the Chinese Ministry of Education [27,28,29], over the past two decades, the difficulty, and accordingly the linguistic features, of the test papers used in each province or municipality varied depending on their economic development and educational resources, which is one of the main methods adopted by China to improve the fairness of the Gaokao.
For many years, English has been one of the three major subjects that Chinese high school students must study [30]. While listening plays an important role in all second language (L2) English tests, the Chinese Gaokao English test is no exception. It typically constitutes 10–20% of the marks for the whole set of English questions, i.e., the listening section is worth 15 to 30 marks out of a total of 150 marks in a paper. However, relatively little research has been conducted on Gaokao English listening tests. Existing studies were conducted from limited perspectives, such as the analysis of listening theories and teaching courses [31,32], the study of listening training and scoring skills [33,34] or content validity [35], in terms of topics, readability, duration, and pace. There are few studies that used a scientific and appropriate framework to study the linguistic and generic features of the Gaokao English Listening Tests. In addition, the previous Gaokao research is limited to test papers from a particular location over a period of several years without a thorough comparison of the listening texts. For example, Zhou and Hu [35] investigated the content validity of only the 2012–2017 Gaokao listening tests in Zhejiang Province. To date, there has been no comparative study of papers from different regions or different years from any perspectives.
2.3. Multidimensional Analysis
MDA is a methodological strategy that employs exploratory factor analysis (EFA) to condense the co-occurrence models of linguistic variables, particularly lexicogrammatical characteristics, into a concise set of underlying factors, which are then evaluated in terms of their functional significance [10,36]. Linguistic co-occurrence has been underscored as a significant theoretical concept by renowned linguists such as Halliday, Firth, and Ervin-Tripp. Brown and Fraser [37] (pp. 38–39) stated that it could become “misleading to concentrate on specific, isolated [linguistic] markers without taking into account systematic variations which involve the co-occurrence of sets of markers”.
Biber [10] developed an innovative model that comprehensively explains the linguistic diversity in written and oral English across six dimensions, relying on co-occurrence patterns identified in a corpus that encompasses many domains, such as letters, news, official documents, face-to-face talks, and so on. An instance of a dimension can be observed in a pattern where a text containing a significant number of private verbs is also likely to exhibit a high frequency of “that” deletion, contractions, and a relatively low incidence of nouns.
MDA integrates register analysis, corpus linguistics, and quantitative analysis methods. Linguistic analysis, functional interpretation, and situational analysis are the three primary components of register analyses [38]. Situational characteristics encompass the physical context, like the precise time and location. Finding the linguistic elements that are distinctive or representative of the target register is the aim of the linguistic analysis, and the functional interpretation clarifies the existence of the patterns and the reasons these linguistic characteristics are particularly prevalent in this situational setting. For example, when comparing classroom instruction and textbook texts [38], it becomes clear that the pronouns are used more frequently in classroom teaching because pronouns frequently relate to entities that occur in the communication context, such as the speaker, the listener, other individuals, or things. These individuals and objects are present within the environment of classroom exchanges but are not mentioned in the textbook.
Register is a significant indicator of linguistic variation at all language levels, as cross-register studies and comparisons have repeatedly shown [39]. However, research has also revealed that significant internal linguistic variety exists within even the most solid register classifications, which is frequently unaccounted for by variations within commonly accepted register classifications (e.g., [40]) or even sub-registers, but is brought about by situational variables such as participants, mode, purpose, and physical context [41]. For example, the content of interactive discussion forums and opinion blogs is very diverse and does not follow predetermined situational norms [42]. Veirano Pinto [43] also examined linguistic variation in 640 North American films issued between 1930 and 2010, accounting for contextual factors like the films’ year of release in the US, directors, genres, duration, nominations and awards received, and the originality or adaptation of the script. Seven dimensions were revealed for this domain through MDA, then Veirano Pinto [43] used the situational factors to explain part of the variation observed in the registers across time, including awards/nominations obtained, the year of release, script type, length, and movie genres, according to the findings. Language assessment studies have likewise identified situational variables that can explain variance in registers such as speaking tasks included in the TOEFL iBT. Kyle et al. [44] found that whether a writing task was independent or integrated (i.e., task types) could lead to linguistic differences in response to the tasks.
MDA has been used extensively in research on primary school domains, university language registers, and school EFL textbooks. While the MDA results of these registers share some similarities, such as narrative versus non-narrative language, procedural versus content-focused language, the presentation of personal stance, interactiveness/involvement against informational focus, and oral versus written discourse, they also have their own unique features and unique dimensions in each piece of research that seem to be related to the situation or context, such as the place where the communication takes place, the purpose of the conversation or texts, and the language style that the participants choose (see Supplementary Material S1 for more information). To the researchers’ knowledge, however, no scholar has taken situational factors into account when studying texts used in listening tests.
Numerous studies have deployed MDA to explore the linguistic features of discourse domains, including academic classes [45], verbal and literate college domains [46], and interviews for oral competence assessing [47]. However, there is a clear dearth of studies on the use of MDA in the textual analysis of spoken language tests, especially listening tests. There are exceptions, albeit sparse. Kyle et al. [14] employed MDA to examine literate and oral domains of language used in traditional as well as technology-mediated learning contexts (T2K-SWAL and TMLE corpora) and found that there were meaningful differences regarding their linguistic features and related functional dimensions. For example, spoken TMLE texts achieved higher scores in the phrasal and lexical complexity dimension, which indicated that spoken texts in conventional classrooms may be easier to understand than oral discourse in technology-mediated learning settings.
The only very similar study, which also used MDA to analyze a Chinese English listening exam, is the work of Shi [48]. Shi collected and examined the corpus of materials of CET-4 (College English Test Band 4 of China) listening test (06–14) for their linguistic and functional characteristics. The text length, content of the dialogues, and the types of questions are very similar to those of the Gaokao. She utilized Biber’s [10] model to evaluate her corpus and discovered some meaningful facts. For example, Conversations received high scores in Dimension 1, or informational and involved discourse, while Passage received a negative score. This suggests that while the emphasis in Passage is primarily on the precise and dense conveying of information, participants and context are heavily engaged in the language used in Conversations. Short Conversations scored higher in Dimension 4, overt display of persuasion or debate, while Passage and Long Conversations scored lower, suggesting that linguistic characteristics used to support viewpoints and argue points are often employed in Short Conversations. While the insights derived from these findings can enrich the pedagogy and assessment of listening, the modest size of the corpus—which totals just 30,684 words—and the simple comparison with Biber’s [10] model are the study’s main shortcomings. To determine the distinct dimensions of the listening materials of CET-4 tests, a full MDA analysis is necessary.
2.4. The Present Study
In summary, MDA can be viewed as a valuable tool for analyzing listening tests in a variety of ways. First, MDA has been used to conduct text analysis in many different registers and situations, which demonstrates its reliability and practicability. Second, MDA can be adopted in the analysis of both written and spoken language. The texts used in listening exams are often not spontaneous dialogues or monologues in real scenarios, but are written in advance by the question writers, so they are often not only texts with spoken language features, but also contain some written language features [18,49], and according to Biber [50], there is not a single register that can accurately reflect either the written or spoken mode because both have certain linguistic traits in common. Academic oral interactive discourse incorporates elements of written discourse, as demonstrated by Biber [51] and Biber et al. [46] (e.g., more use of lengthier words and nouns). Therefore, it is appropriate to choose MDA as an analyzing tool for the listening test.
In addition, since each listening test has its own set of characteristics, as in the distinctive features of the aforementioned language tests (e.g., [21,24,25]), MDA allows for an exploratory analysis of a new corpus to distill specific linguistic features in unique contexts, which can then be used to make internal comparisons [4,52]. Finally, linguistic features that have previously been studied in the literature include referential cohesion, negation, and elaboration, which have been shown to have an impact on the difficulty of listening exams [18,21,24,25]. Characteristics of input in content validity and readability research, such as sentence length, number of new words, and grammatical complexity, are also included in the scope of MDA, allowing for a more thorough understanding of the listening test being studied.
Thus, with the help of MDA, the current study aims to investigate the Gaokao English listening tests from this novel angle: register analysis, allowing for the exploration of the linguistic variation found in listening transcripts from different text types, geographic locations, and time periods. The research questions for this research are the following:
RQ1: How does linguistic variation manifest across the major text types featured in the Gaokao English listening test?
RQ2: Are there any similarities or differences in dimension-related variations among the three text types of Gaokao English listening tests used in different geographical locations and time periods?
3. Method
3.1. Corpus
The Chinese Gaokao English Listening Test Corpus (CGELTC, see Table 1) consists of 170 sets of test papers covering nearly all provinces and cities, including Beijing, Shanghai, Guangdong, Zhejiang, Hubei, Tianjin, Chongqing, etc., spanning from 2000 to 2022. The audio scripts of 10 test sets (between 2000 and 2006) were not available online, so in this study, text analysis was conducted using the transcripts of 160 test sets (134,913 words in total).

Table 1.
Breakdown of corpus by time period, region, and text type.
There are two kinds of college entrance examination papers in China, one which is issued by the national education department, known as the national paper, and the other one which is designed by each province or municipality directly under the central government, known as the local paper. Certain regions that are particularly economically advanced can design their own tests, and usually these tests fall into the most difficult category, especially the English exams. It is worth noting that there is not just one national paper for each year, but versions of different difficulty levels are distributed to different provinces, cities, or regions. According to Ministry of Education [27,28], the purpose behind this decision was to ensure as much equity as possible among localities with uneven educational resources. As a result, relatively “easy” papers are supposedly provided for regions with limited educational resources, while regions with better resources received more challenging ones, creating a balance [29].
In addition, China carried out a reform of the Gaokao in 2014. Before 2014, the country encouraged more provinces to join the groups of independent questions [53]. However, in 2014, the restoration of “one national paper” has become a major trend [54]. The MOE has gradually increased the number of provinces using the national paper since 2014, and the right to design their own questions has been withdrawn from some provinces. Please see Figure 1 for the trends of past test papers released before and after 2014.
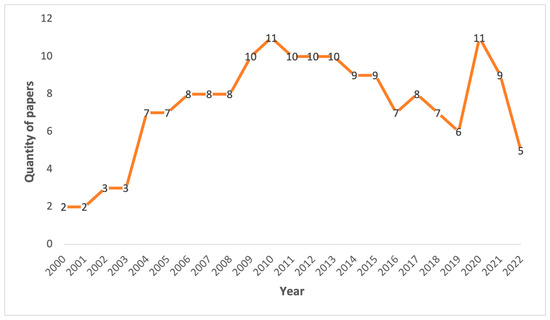
Figure 1.
Quantity of tests from different years.
Most of English listening papers in the national paper, Zhejiang paper, Tianjin paper, Shandong paper, etc. contain two sections, while others consist of three sections. There are three different kinds of text types in section A, which consist of short conversations, long conversation, and monologues. In section B and C, there may be two kinds of texts, long conversations (most common) and monologues.
3.2. Statistical Analyses
Following Kyle et al. [14,15] and Biber [10,55], the researchers conducted a multidimensional analysis to reduce the variables that were generated by the Tool for the Automatic Analysis of Syntactic Sophistication and Complexity (TAASSC; [56]) into latent factors, interpreted the factors as dimensions of language variation, and subsequently computed dimension scores and compared the scores of each dimension across different listening types and time periods. The Jamovi statistical package [57] was chosen as the tool for data processing and comparison.
Specifically, TAASSC was utilized to automatically tag each text’s pertinent linguistic elements and compute their frequencies, because it can measure a broad range of linguistic features (149, see Supplementary Material S3), comprising both established and novel complexity indices [58,59] as well as some grammatical and lexicogrammatical features [4,51], enabling the researcher to explore a wider range of fine-grained measures of syntactic sophistication and complexity compared to other current automatic analysis tools [58].
Texts and registers may be contrasted along every one of the “dimensions”, which are the co-occurrence tendencies among these language variables that are identified by exploratory factor analysis in MDA. Following Biber [10] and Kyle et al. [14], EFA was conducted, and the researchers made several crucial methodological decisions [60,61,62], such as the process for extracting factors, the number of factors to be chosen, the method for rotating factors, and the communality and cutoff loading values that are utilized to keep variables.
The first step of EFA is factor extraction. Z-scores were employed to standardize the data across all texts in the corpus [10] and principal axis factoring was chosen as the extraction approach since it is thought to be reasonably robust to the breach of the assumption of multivariate normality [60,63].
In order to decide the proper number of factors, a number of criteria were taken into account. These included total explained variance, communality, factor loadings, a scree plot showing the magnitude of eigenvalues, as well as the detailed justification for the specific factor solution [60,62,63]. Following the identification of potential factor solutions, a Promax rotation was employed to correlate the potential dimensions of language characteristics [63]. In the principal factor, linguistic characteristics with cross-loading were included just once [4,10]. The outcome of a scree plot, the percentage of explained variance, and the rotated pattern matrices were utilized to determine the final solution in this study, in accordance with earlier studies (e.g., [4,51]).
Two different methods were used to calculate the dimension scores: first, computing them through transforming language scores to z-scores and deducting the sum of the z-scores of negatively loaded metrics from that of positively loaded indices (e.g., [4,10,14,64,65]); second, calculating them by choosing Thurstone as the Estimation Method at the end of exploratory factor analysis (e.g., [66,67]). After obtaining the two sets of scores, a paired samples t-test was performed to determine if there were significant differences between the dimension scores obtained using different score estimation methods.
To address the RQ1, an ANOVA test was used to compare the dimension mean score of the three text types in the corpus [68]. To address the RQ2, the grouping of the three independent variables and their rationale need to be clarified here, while the dependent variables are the scores of each text in the six dimensions. As previously discussed, the texts will be divided into three types: short conversation, long conversations, and monologues. To examine the temporal variations in the linguistic features of Gaokao listening texts, this study divided the data into two distinct groups for comparison, using 2014 as the split point, because in 2014 China released a major reform proposal affecting listening exams. This reform, on the one hand, gradually reclaimed the regional autonomy to design their own test papers by increasing the number of provinces using the national papers, on the other hand, advocated for the implementation of multiple exams in some subjects especially English in a year, aiming to alleviate the pressure on students [54]. As for the grouping of regions, this study adhered to the Ministry of Education’s classification. In China, the level of economic development and educational resources are to relatively proportional, so in order to ensure educational equity across the country, the national test paper has three versions (National Paper 1, National Paper 2 and National Paper 3) with decreasing difficulty. Therefore, regions were divided into three groups in the present study, the first one included the four autonomous provinces and municipalities, namely Beijing, Shanghai, Zhejiang, and Tianjin; the second one consisted of all provinces and municipalities that should use National Paper 1 (the autonomous papers of each of these provinces or cities in some years are also merged into this group); and the third group contained all provinces and municipalities that use National Papers 2 and 3 (for listening tests, Papers 2 and 3 share the set of questions).
MANOVA was used to determine whether there were similarities in the dimensions that emerged in MDA among three text types of Gaokao English listening tests from different locations and time periods. Before conducting MANOVA, four assumptions of the test were examined, namely independence, multivariate normality, equality of covariance matrices, and the absence of outliers. Box’s test was used to check the covariance matrix homogeneity and tests for outliers were conducted before performing the MANOVA [69]. Meanwhile, it should be noted that MANOVA is robust to abnormality for large sample size, if this is caused by skewness rather than by outliers [69], so outliers have to be removed prior to conducting MANOVA tests.
In addition, Box’s M test is susceptible to errors when the sample size is large [70]. Thus, even if this assumption is violated, the researchers can still proceed with MANOVA and use Pillai’s trace as a statistical test [71].
4. Results
4.1. Exploratory Factory Analysis (EFA)
Overall, 99 of the initial 149 linguistic characteristics generated by TAASSC were kept after preliminary analysis. Linguistic features with extremely low frequency were dropped or combined [51]. This study maintains the 16:1 ratio between the total amount of texts and features, adhering to a strict factor analysis methodology, thus meeting the requirements for a robust factor analysis ([72], as cited in [73], p. 128). Regarding the assumptions of EFA, the adequacy of the data was demonstrated, as supported by Bartlett’s Test of Sphericity’s p < 0.001 and Kaiser–Meyer–Olkin measure of sampling adequacy [KMO] = 0.673 [74].
In addition, the scree plot showed in Figure 2 indicates that the suitable number of factors was five or six, with the amount of variance explained to be equal to 25.4% and 28.46%, respectively. The dotted line in the scree plot represents a cutoff criterion for determining the number of factors to retain in factor analysis. It often corresponds to an eigenvalue of 1.0, which is based on the Kaiser criterion. As mentioned in Biber [10], Gorsuch [72], and Farhady [75], it is generally recommended to extract the larger number of factors when facing the decision between a larger or smaller number. The pattern matrices utilizing Promax rotation were examined for detailed explanation in order to obtain a more thorough comprehension of every solution, such as the four-factor solution that correlated with the factor solution of Biber ([10,51], see also [4]). Taking into account all the aforementioned information, the six-factor solution was found to explain a reasonable percentage of variance (28.46%) in the overall data set and to be the most suitable explanation of the language dimensions, which is slightly below that in the studies by Kyle et al. [14] (31%) and Staples et al. [16] (35%), but larger than the indices reported by Santini and Jönsson [67] (22%) and Liimatta [65] (17%). The intercorrelations among the factors were relatively small (Table 2), with the largest inter-factor correlation being between Factor 4 and 5 (0.2605). Thus, the assumption of Promax that minor correlations among the factors are permitted was met [10].
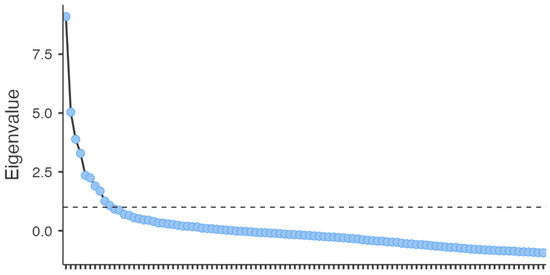
Figure 2.
Scree plot representing the optimal number of factors.
Table 2.
Inter-factor correlations for the final six-factor solution.
4.2. Interpretation and Description of the Six Dimensions
Following Biber [10,55] and Kyle et al. [14], factors derived from EFA in the previous step were functionally interpreted and identified as dimensions for double checking whether the EFA results are reasonable or applicable (please see Table 3 for six dimensions, their linguistic features, and loading coefficients). The interpretation of six dimensions drew from the research conducted by Friginal and Hardy [76], incorporating extensive comparisons and connections with their work. By comparing this study’s results with previous MDA-related works [4,10,14,15,51,55,56,77], the study identified four common dimensions (which means most of the linguistic features overlapped with previous dimensions’) as well as two new dimensions, suggesting novel linguistic characteristics not previously identified. For clarity, in Supplementary Material S1, the researchers present a summary of the dimensions from previous works.
Table 3.
Factor loadings for the six dimensions.
4.2.1. Dimension 1: Oral versus Literate Discourse
Dimension 1 aligns with earlier MDA solutions (e.g., [4,14]), highlighting the distinction between written discourse (negative characteristics) and spoken discourse (positive characteristics). The usage of finite clauses, finite independent clauses, verb phrases dependents, all clauses, and verbs, all of which are traits of spoken language, are among the best favorable characteristics. More complicated clauses, T-units, and copular be constructions are among the negative characteristics. Finite dependent clauses, such as conditional adverbial clauses, causative adverbial clauses, WH clauses, and “that” clauses, are indicative of oral discourse, according to the pioneering English MDA study [10] (pp. 104–108).
4.2.2. Dimension 2: Procedural Discourse
Procedural language is the center of dimension 2, which is similar to the third dimension proposed by Kyle et al. [14] and the second dimension proposed by Biber et al. [4] in many ways. The employment of “to” clauses, nonfinite clauses, a significant percentage of infinitive and nonfinite clauses, as well as to clauses governed by verbs are examples of positive traits. This dimension is devoid of any negative traits. The non-past tense is also an important feature of this dimension, which is in alignment with that in dimension 3 in Kyle et al. [14]. Nonfinite clauses, which are composed of verbs, inherently lack tense-marking and thus cannot express tense. Accordingly, the co-occurrence of nonfinite clauses and non-past tense is considered rational and in line with their grammatical properties.
4.2.3. Dimension 3: Informational versus Involved Production
Dimension 3’s linguistic traits coincide with Biber’s [10,55] first dimension. The positive features consist of nouns, noun phrases, and word length, while the negative features include predicative adjectives and all pronouns. Biber [55] states that the favorable characteristics of this dimension are mostly linked to a text’s dense integration of information and are related to informational goals. These characteristics are common in literary registers meant for specialized viewers, according to earlier MDA studies (see, e.g., [78,79]). Conversely, the adverse features show an emphasis on instantaneous interactions, including all pronouns and contractions [55].
This dimension was the main focus of Le Foll’s [64] study of the variation in EFL coursebooks used in schools. The author argued that this dimension represents an opposition between “informational/literate/nominal” and “involved/oral/verbal”, and this dimension has consistently shown itself to be the best and most reliable indicator of variation in full MDAs created after 1988 across a wide range of languages and registers [80].
4.2.4. Dimension 4: Elaborated Discourse—Relative Clauses
The interpretation of dimension 4, which represents elaborated discourse and relative clauses, is simple and direct, because all the linguistic features are related to the use of relative clauses without negative features, much like dimension 4 of Kyle et al. [14].
4.2.5. Dimension 5: Syntactic and Clausal Complexity
Dimension 5 represents syntactic and clausal complexity and highlights the use of finite complement clauses, clausal complements per clause, finite dependent clauses, and dependent clauses per clause, which are primarily related to syntactic and clausal complexity. To researchers’ knowledge, this dimension did not appear in previous multidimensional research, although Biber et al. [77] and Kyle et al. [14] have suggested that these four features are measures of syntactic and clausal complexity.
4.2.6. Dimension 6: Phrasal Complexity
This dimension, which represents phrasal complexity, includes both positive and negative features. The important positive features consist of adjective modifiers dependent, determiners per nominal, and attributive adjectives, which are used to measure or analyze phrasal complexity, according to Kyle et al. [14] and Kyle [56]. This dimension comprises only two negatively loading features: possessives dependent and possessives per nominal, thus aligning with the “Lexical and Phrasal Complexity” dimension identified by Kyle et al. [14], who also did not provide a specific name for the negative side. Thus, the name assigned to this dimension will be Phrasal Complexity.
The results of the sum scores methods and Thurstone’s regression scores were compared using the paired samples t-test, and the result (see Supplementary Material S4) indicated that there were no substantial disparities in dimension ratings between the two techniques. Because Thurstone can provide a more precise measure of the factor [81], it was chosen for analysis. In addition, descriptive statistics of the six dimensions’ scores (Table 4) indicate that the six dimensions’ scores are normally distributed [82,83].
Table 4.
Descriptive statistics of the six dimensions’ scores.
4.3. Answering RQ 1
To answer the first question, ANOVA tests were conducted to check whether there are any differences between the six linguistic dimensions among three different text types of Gaokao English listening tests. Table 5 demonstrates the findings of one-way ANOVA, and Table 6 presents the detailed results of Games–Howell post hoc test, please also see Figure 3 for visualized comparison results. They indicate that there are meaningful and significant differences across short conversation, long conversation, and monologue with regard to all six dimensions’ scores (p < 0.05).
Table 5.
Results of one-way ANOVA.
Table 6.
Games–Howell post hoc test.
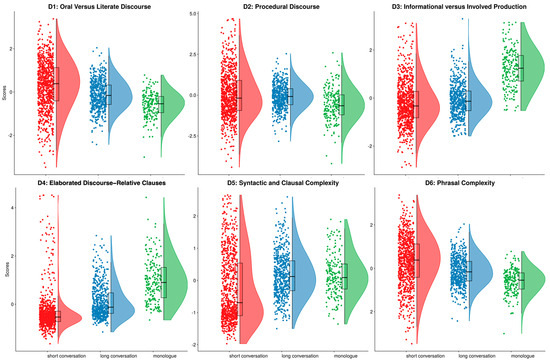
Figure 3.
Distribution of dimension scores by text types.
4.3.1. Dimension 1
As previously discussed, oral and written discourse are contrasted in dimension 1, which means texts that receive high positive scores on this dimension have more spoken features, while texts which tend to receive negative scores have more written features. Based on the means of the three text types, ANOVA, and the Games–Howell post hoc test (Table 6), it can be inferred that short conversations primarily exhibit characteristics of spoken language, while long conversations and monologues resemble written texts. Furthermore, the observed differences among these three types are statistically significant (p < 0.001). It should be noted that the Games–Howell post hoc test was used, as the assumption of equal variances among groups is violated [84].
4.3.2. Dimension 2
Dimension 2 highlights language related to procedural discourse. There are significant differences between the two kinds of conversations and monologues (both p values are smaller than 0.001). Short conversations tend to receive positive scores while monologues and long conversations tend to receive negative scores. However, the difference between short conversations and long conversations is not significant. See Supplementary Material S5 for comparison results.
4.3.3. Dimension 3
This dimension, which explains 84% variance in Biber’s dimension 1, is the most potent indicator of language variation in Biber’s English corpus [10] (pp. 126–127). From the results, it is clear that this dimension is also a strong predictor for the three text types in Gaokao English listening tests. The observed differences among these three types are statistically significant (p < 0.001). Monologues receive higher positive scores than the other two types, while both types of conversation tend to receive negative scores.
4.3.4. Dimension 4
Dimension 4 emphasizes how relative clauses are used. The results indicate that monologues and long conversations receive positive scores while short dialogues receive negative scores. Monologues’ scores on this dimension are significantly higher than long and short conversations. The difference between long conversations and short conversations is also statistically significant (p < 0.001).
4.3.5. Dimension 5
Dimension 5 scores highlight syntactic and clausal complexity. The means of long conversations and monologues are nearly the same, while short conversations’ scores are significantly lower than them (p < 0.001).
4.3.6. Dimension 6
Dimension 6 highlights phrasal complexity. In this dimension, the observed difference between short conversations and monologues is statistically significant (p = 0.034).
4.4. Answering RQ 2
To answer the second research question, the effects of time periods and locations on the scores of the three text types across the six dimensions were investigated using a MANOVA. Outliers were first removed, and the assumptions of multivariate normality and equality of covariance matrices were checked. Pillai’s trace was chosen as the statistical test because the p value of Box’s M test was smaller than 0.001 [84].
The multivariate tests revealed a significant effect for both regions (Pillai’s trace = 0.02154, F(12, 3096) = 2.82, p < 0.001) and text types (Pillai’s trace = 0.46997, F(12, 3096) = 79.248, p < 0.001). Follow-up univariate tests indicated significant effects of regions on dimension 1 (F(2) = 7.2141, p < 0.001), dimension 2 (F(2) = 4.4168, p = 0.012), and dimension 5 (F(2) = 6.165, p = 0.002). Similarly, significant effects of text types were found on dimension 1 (F(2) = 82.0631, p < 0.001), dimension 2 (F(2) = 21.5552, p < 0.001), dimension 3 (F(2) = 238.282, p < 0.001), dimension 4 (F(2) = 240.7446, p < 0.001) and dimension 5 (F(2) = 39.7784, p < 0.001).
5. Discussion
This research set out to explore whether Gaokao English listening test papers used in the three regions of China were differentiated regarding the co-occurrence trends of lexicogrammatical features of the transcripts. The study was also carried out to investigate the assumption that the MOE of China has regarding the internal structure of these tests, i.e., that the different economic development of the provinces and municipalities has resulted in students being exposed to different educational resources and receiving different levels of education, and thus the linguistic features of the examination papers used by them also vary. The study analyzed and compared three text types in the Gaokao English listening exams to determine whether the test input differed regionally as well as temporally (across time).
5.1. Analysis of RQ1-Six Dimensions and Suggestions for Gaokao Listening Exams
The first research question of the study addresses how linguistic variation manifests across the major text types featured in the Gaokao English listening test. Taking a multidimensional analysis approach, six dimensions were extracted: 1. oral versus literate discourse; 2. procedural discourse; 3. informational versus involved production; 4. elaborated discourse—relative clauses; 5. syntactic and clausal complexity; and 6. phrasal complexity. Four of these dimensions are in alignment with the dimensions extracted from previous MDA studies, including Biber [10], Biber et al. [4], Biber [55], and Kyle et al. [14,15]. The first dimension, oral versus literate discourse, aligns with Biber et al. [4] and Kyle et al. [14], represented by characteristics such as finite clause, verbs, first-person pronouns and mean length of T-unit. Dimension 2, procedural discourse, exhibits numerous similarities with the investigations conducted by Biber et al. [4] and Kyle et al. [14], such as to clauses, the nonfinite clause, and non-past tense. The linguistic features of informational versus involved production coincide with Biber et al.’s [4] and Biber’s [10], such as nouns, word length, and all pronouns. Dimension 4, elaborated discourse—relative clauses, is nearly the same as Kyle et al.’s [14] dimension 6. It contains all four linguistic features in Kyle et al.’s [14] study, which consist of relative clauses per clause, relative clauses per nominal, WH-relative clauses on subject positions, and WH-relative clauses. Adjective modifiers dependent and attributive adjectives in dimension 6, phrasal complexity, also appear in the lexical and phrasal complexity dimension of Kyle et al. [14] (please see Supplementary Material S2 for more details). To the best of the authors’ knowledge, the dimension of syntactic and clausal complexity has not been featured in prior multidimensional research.
These similarities may provide evidence supporting some kind of universality of the above dimensions, while such a pattern is less robust when dimensions like elaborated discourse, syntactic and clausal complexity, and phrasal complexity were examined. One reason for this discrepancy could be the evolving nature of language and the diverse contexts in which this and previous MDA studies were conducted. Relatedly, since the corpora analyzed in both Biber et al. [4] and Kyle et al. [14] were sampled from university language, the similarity between the dimensions extracted from the Chinese Gaokao English Listening Test Corpus and the university language domain may present some evidence in support of the content validity or authenticity [4,11] of the Gaokao English listening test. For example, the T2K-SWAL Corpus used by Biber et al. [4] comprises various university texts, including materials from office hours, labs/in-class groups, class sessions, and textbooks. The Gaokao is designed to select candidates who can continue their studies in top-ranking universities, so it is necessary to examine whether they are able to understand and utilize the English required for university studies. This helps determine whether they are able to adapt to university life and keep up with the pace of college studies. English is a compulsory subject for students in almost every major, especially for those pursuing their studies in both Chinese and English. Therefore, the similarity between the Gaokao English listening test and the corpora representing university English suggests some degree of content validity of the Gaokao English listening test.
However, it should be noted that while the concept of TLU domain pertains to the real-world contexts in which language skills are used, it is not directly referenced in the syllabus of the Chinese Gaokao English Exam [85], which only requires students to master basic phonetics, grammar, and vocabulary knowledge. In the Gaokao listening test, students must listen to and understand short monologues and conversations on familiar topics, with specific requirements that include understanding the main idea, obtaining specific factual information, making inferences, and understanding speakers’ intentions, opinions, and attitudes. While these cognitive processes are integral to listening comprehension [86], the linguistic features of the listening texts in the Gaokao listening test are neither explicitly defined nor strongly linked with actual TLU settings. It is suggested that the Chinese Gaokao English exam could benefit from a clearer delineation of the features of its listening texts and a stronger alignment with real-world TLU settings to better reflect actual listening comprehension processes.
5.2. Analysis of RQ2-Differences between Three Text Types and Regions and Instructional Implications
The second research question of this research investigates if there are any similarities or differences in dimension-related variations among the three text types of Gaokao English listening tests used in different geographical locations and time periods. Text types and regions further had significant differences in most of the dimensions’ scores while time periods did not. This indicates that the test papers did not change much before and after the reform, but the different types of texts did contain different features. Most importantly, the question papers distributed according to the different regions divided by the MOE in China were different in some dimensions. The MOE has implemented these regional differences in an attempt to support the fairness of the Gaokao. Specifically, it was found that scores on dimensions 5, 1, and 2, which are syntactic and clausal complexity, oral versus literate discourse, and procedural discourse, respectively, were significantly different across the regions.
As previously discussed, there have been relatively few studies on English listening in the Chinese Gaokao exams, and almost none from the perspective of linguistic features. The closest research to dimension 5 is the readability analysis used by some Chinese scholars (e.g., [35,87], as it evaluates ratings by integrating factors including syntactic complexity, phrase length, and the quantity of new vocabularies. According to Zhou [87], the readability of the listening test in region 2 was only slightly higher than that of region 3 in 2017, 90.0 and 89.3 respectively, which Zhou perceived as the test paper in region 3 being more difficult than that in region 2 in terms of readability—although the difference was actually negligible. This study’s conclusion is partly consistent with his, as MANOVA could only tell that the scores of region 2 and 3 in dimension 5 were different but which one was higher remained unknown. However, the limitation of Zhou’s paper is that the difference in scores between the two sets of papers was small and only two sets of papers from the same year were compared, which may not be sufficient to draw a holistic conclusion. Zhou also compared four sets of papers from 2014–2017 from region 2, where the readability was fluctuating, but all were “very easy”, suggesting that by and large nothing has changed. To the best of the authors’ knowledge, there had been no similar research on dimension 1 and dimension 2.
The differences found among different regions’ scores in several dimensions shows that the claims of the MOE are partly supported from the perspective of MDA. This suggests that some test-takers may be advantaged as the tests in their regions have a lower score on some of the universal and non-universal dimensions. In China, most students receive the same English education, but there are numerous children in remote and poor regions who have much less access to high-quality learning materials and educational resources, and even their teachers do not share the same level of education and teaching. It seems that the MOE has decided that if these children wish to go to the same universities as children from more affluent regions, leveling the playing field would involve giving them listening tests with specific lexicogrammatical features that may facilitate listening for them in the Gaokao. Otherwise, many of these students may not be able to reach the same level of proficiency as others with the initial starting trajectories being different.
In alignment with Biber [10] and Biber et al. [77], this research also found that based on Dimension 1, oral versus literate discourse, when comparing the linguistic features of spoken and written discourses, verbs are more prevalent in speech as opposed to nouns. Furthermore, oral registers commonly employ clausal subordination, whereas written language predominantly depends on phrasal modifiers, as previously investigated in MDA investigations [14,46,51]. The analysis of the three text types in dimension 1 shows that only short conversations bear more resemblance to oral discourse, while long conversations and monologues are more similar to literate discourse. Therefore, it is suggested that the materials of English listening tests should be sourced from or emulated based on the content features of dialogues or monologues in real-life scenarios, so as to encourage language teachers to pay more attention to the application of authentic, rather than scripted, oral English in real life.
Dimension 2 is related to procedural discourse which refers to spoken and written discourse that guides people in performing a task [88]. It is about a kind of “how to” communication. Oral instructions, user guides for computer software, and online help systems are all forms of procedural discourse [88]. In the study conducted by Kyle et al. [14], it was found that spoken texts in university settings generally exhibit good scores in this particular dimension, whereas literate texts are likely to display negative ratings in the university language domain. In the present research, short conversations tended to receive positive scores while monologues and long conversations tended to receive negative scores. It can be inferred that procedural discourse is more common in short conversations, which can become one of the teaching priorities in the future.
In dimension 3, which focuses on informational versus involved production, the positive attributes in this dimension pertain to the informative nature and are primarily linked to a comprehensive incorporation of information inside a text, as stated by Biber [55]. Conversely, those negative characteristics in dimension 3 pertain to a concentration on the direct exchange, including contractions and all pronouns [55]. The results of this study indicate that monologues receive higher positive scores than other two types, while both conversations tend to obtain negative scores. It can be understood that one of the purposes of monologues in the test materials under evaluation is to output dense information while that of conversations is to interact. It may be said that there is more information that students are required to process in monologues than in conversations, and therefore candidates should be more cautious when listening to monologues. It may be useful for students to practice taking notes and paying more attention to details when completing monologue listening tasks.
Dimension 4 is focused on the relative clause, which is a device of post-modification and can be used to add information [89]. From the results of MDA, with monologues and long conversations receiving positive scores while short dialogues obtain negative scores, it is suggested that high school English teachers place more emphasis on teaching relative clauses, thereby reducing the number of points that students may lose due to a low level of mastery of such clauses. Meanwhile, it is important to investigate how this particular feature of the listening tests compares with authentic listening activities in TLU domains beyond the text.
Regarding complexity, short conversations tend to receive negative scores in dimension 5 (syntactic and clausal complexity) and positive scores in dimension 6 (phrasal complexity), while long conversations and monologues are exactly the opposite. On the one hand, there is no discernible disparity between the scores of long conversations and monologues in both dimensions, so it is evident that long conversations and monologues are very similar in terms of complexity. On the other hand, in order to cope with the listening difficulties brought about by the complexity of different types of texts in different aspects, teachers could increase the input of phrases that often appear in short dialogues [90,91], as well as the explanation of complex clauses that may appear in long conversations and monologues in the daily teaching of high school English [19,92,93], so as to alleviate listening obstacles of the students, and to improve their listening ability and performance.
5.3. Limitations of the Study
This study is not without limitations. A possible limitation of the study is that conversations shorter than 200 words were excluded from analysis in Biber’s [55] study but were retained in the present analysis. Biber argued that texts of fewer than 200 words were not conducive to extracting the co-occurrence features. However, there were also some studies conducting MDA with short texts, such as Scheffler et al. [94], who used Twitter posts, and Shakir and Deuber [95], who analyzed online comments and texts from Facebook groups. In addition, it is noted that factor loadings were acceptable in this study, and the results show that they are sufficiently useful in MDA analysis.
Secondly, the number of papers in each region varies from year to year as a result of frequent changes in Gaokao policy both at the national level and at the provincial level, resulting in a less balanced number of papers in each of the groups for which comparisons were made. It would be useful to compare the findings of this study with a direct analysis of spoken registers in a TLU domain, but this would need the MOE to articulate a statement of the TLU domains to which the test extrapolates.
6. Conclusions
In this study, a multidimensional analysis of the Chinese Gaokao English Listening Test Corpus was conducted to describe the typical linguistic features and corresponding functional dimensions of the three different text types in the listening tests. The study provides evidence supporting the universality of some of the MDA dimensions and presents some recommended teaching focus for the future, such as relative clauses, phrases and procedural discourses that are usually used in short conversations, as well as complex clauses that could increase the complexity and difficulty for students’ understanding in long conversations and monologues. Familiarity with these linguistic features as well as the fact that monologues demand more information processing can help to reduce the cognitive load of the test-takers, and this, together with teaching students to use test-taking strategies such as planning, can further improve test scores [96,97], although it is important to note that higher test scores may not necessarily indicate better communication skills in non-test situations. In addition, it is suggested that test designers provide a clearer description of the language features of the test materials and tasks and include more authentic materials with a stronger link to real-world settings. Test designers likewise need to consider the importance of the diversity of domains that test-takers will encounter in their university lives and in their daily lives [98]. The scores of the functional dimensions of the test papers from three different regions of China, which were divided using different test papers, were also compared. The results show that some dimension scores were different in test papers from different regions, which may reflect the MOE’s efforts to improve the fairness of the college entrance examination. Meanwhile, the 2014 reform did not seem to significantly change the functional dimensions of the test paper input.
Future research could compare the six dimensions’ scores of the present corpus with the scores of possible TLU domains, such as a corpus consisting of real discourses Chinese college students need to deal with in their university life, or a corpus of university domains from other typical English-speaking countries, to test the content validity of the Gaokao English listening test. An attempt can also be made to apply the methodology of this study to English reading tests.
Supplementary Materials
The following supporting information can be downloaded at: https://www.mdpi.com/article/10.3390/educsci14020137/s1.
Author Contributions
Conceptualization, X.T. and V.A.; methodology, V.A. and X.T.; validation, X.T. and V.A.; formal analysis, X.T. and V.A.; investigation, X.T.; resources, X.T. and V.A.; data curation, X.T.; writing—original draft preparation, X.T.; writing—review and editing, X.T. and V.A.; visualization, X.T.; supervision, V.A. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data used in this study can be made available upon reasonable requests.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Staples, S.; Biber, D.; Reppen, R. Using Corpus-Based Register Analysis to Explore the Authenticity of High-Stakes Language Exams: A Register Comparison of TOEFL iBT and Disciplinary Writing Tasks. Mod. Lang. J. 2018, 102, 310–332. [Google Scholar] [CrossRef]
- Biber, D. Representativeness in corpus design. Lit. Linguist. Comput. 1993, 8, 243–257. [Google Scholar] [CrossRef]
- Egbert, J.; Biber, D.; Gray, B. Designing and Evaluating Language Corpora: A Practical Framework for Corpus Representativeness; Cambridge University Press: London, UK, 2022. [Google Scholar]
- Biber, D.; Conrad, S.; Reppen, R.; Byrd, P.; Helt, M.; Clark, V.; Cortes, V.; Csomay, E.; Urzua, A. Representing Language Use in the University: Analysis of the TOEFL 2000 Spoken and Written Academic Language Corpus; Test of English as a Foreign Language; Educational Testing Service: Princeton, NJ, USA, 2004. [Google Scholar]
- Callies, M.; Díez-Bedmar, M.B.; Zaytseva, E. Using learner corpora for testing and assessing L2 proficiency. In Measuring L2 Proficiency: Perspectives from SLA; Multilingual Matters: Bristol, UK, 2014; pp. 71–90. [Google Scholar] [CrossRef]
- Park, K. Corpora and language assessment: The state of the art. Lang. Assess. Q. 2014, 11, 27–44. [Google Scholar] [CrossRef]
- Weigle, S.C.; Goodwin, S. Applications of corpus linguistics in language assessment. In Contemporary Second Language Assessment: Contemporary Applied Linguistics; Bloomsbury Academic: London, UK, 2016; Volume 4, p. 209. [Google Scholar]
- Aryadoust, V.; Goh, C.C.M. Predicting Listening Item Difficulty with Language Complexity Measures: A Comparative Data Mining Study. CaMLA Working Papers 2014, 2014-01. Available online: https://michiganassessment.org/wp-content/uploads/2020/02/20.02.pdf.Res_.PredictingListeningItemDifficultywithLanguageComplexityMeasures-AComparativeDataMiningStudy.pdf (accessed on 18 January 2024).
- Biber, D. Multi-dimensional analysis: A historical synopsis. In Multi-Dimensional Analysis: Research Methods and Current Issues; Bloomsbury Academic: London, UK, 2019; pp. 11–26. [Google Scholar]
- Biber, D. Variation across Speech and Writing; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar] [CrossRef]
- Chapelle, C.A.; Enright, M.K.; Jamieson, J.M. Building a Validity Argument for the Test of English as a Foreign Language; Routledge: New York, NY, USA, 2007. [Google Scholar]
- Crosthwaite, P. A longitudinal multidimensional analysis of EAP writing: Determining EAP course effectiveness. J. Engl. Acad. Purp. 2016, 22, 166–178. [Google Scholar] [CrossRef]
- Weigle, S.C.; Friginal, E. Linguistic dimensions of impromptu test essays compared with successful student disciplinary writing: Effects of language background, topic, and L2 proficiency. J. Engl. Acad. Purp. 2015, 18, 25–39. [Google Scholar] [CrossRef]
- Kyle, K.; Choe, A.T.; Eguchi, M.; LaFlair, G.; Ziegler, N. A Comparison of Spoken and Written Language Use in Traditional and Technology-Mediated Learning Environments. ETS Res. Rep. Ser. 2021, 2021, 1–29. [Google Scholar] [CrossRef]
- Kyle, K.; Eguchi, M.; Choe, A.T.; LaFlair, G. Register variation in spoken and written language use across technology-mediated and non-technology-mediated learning environments. Lang. Test. 2022, 39, 618–648. [Google Scholar] [CrossRef]
- Staples, S.; Laflair, G.T.; Egbert, J. Comparing language use in oral proficiency interviews to target domains: Conversational, academic, and professional discourse. Mod. Lang. J. 2017, 101, 194–213. [Google Scholar] [CrossRef]
- Robinson, P. Task complexity, task difficulty, and task production: Exploring interactions in a componential framework. Appl. Linguist. 2001, 22, 27–57. [Google Scholar] [CrossRef]
- Brunfaut, T.; Revesz, A. The role of task and listener characteristics in second language listening. TESOL Q. 2015, 49, 141–168. [Google Scholar] [CrossRef]
- Bloomfield, A.; Wayland, S.C.; Rhoades, E.; Blodgett, A.; Linck, J.; Ross, S. What Makes Listening Difficult? Factors Affecting Second Language Listening Comprehension; University of Maryland Center for Advanced Study of Language: College Park, MD, USA, 2010; pp. 3–79. [Google Scholar]
- Vandergrift, L. Recent developments in second and foreign language listening comprehension research. Lang. Teach. 2007, 40, 191–210. [Google Scholar] [CrossRef]
- Nissan, S.; DeVincenzi, F.; Tang, K.L. An Analysis of Factors Affecting the Difficulty of Dialogue Items in TOEFL Listening Comprehension; TOEFL Research Report No. RR-51; Educational Testing Service: Princeton, NJ, USA, 1996. [Google Scholar] [CrossRef]
- Révész, A.; Brunfaut, T. Text characteristics of task input and difficulty in second language listening comprehension. Stud. Second. Lang. Acquis. 2013, 35, 31–65. [Google Scholar] [CrossRef]
- Dijk, T.; Kintsch, W. Cognitive Psychology and Discourse: Recalling and Summarizing Stories. In Current Trends in Textlinguistics; Dressler, W., Ed.; De Gruyter: Berlin, Germany; Boston, MA, USA, 1978; pp. 61–80. [Google Scholar] [CrossRef]
- Kostin, I. Exploring item characteristics that are related to the difficulty of TOEFL dialogue items. ETS Res. Rep. Ser. 2004, 2004, i-59. [Google Scholar] [CrossRef]
- Aryadoust, V. Differential item functioning in while-listening performance tests: The case of the International English Language Testing System (IELTS) listening module. Int. J. List. 2012, 26, 40–60. [Google Scholar] [CrossRef]
- Fox Tree, J.E. Listening in on monologues and dialogues. Discourse Process. 1999, 27, 35–53. [Google Scholar] [CrossRef]
- Ministry of Education. Response of the Ministry of Education to Proposal No. 1047 of the Fourth Session of the 12th National People’s Congress (Summary); Ministry of Education of the People’s Republic of China: Beijing, China, 2017. Available online: http://www.moe.gov.cn/jyb_xxgk/xxgk_jyta/jyta_xueshengsi/201701/t20170105_294034.html (accessed on 18 January 2024).
- Ministry of Education. About the First Session of the 13th National Committee of the Chinese People’s Political Consultative Conference Letter of Reply to Proposal No. 1046 (Education No. 121); Ministry of Education of the People’s Republic of China: Beijing, China, 2019. Available online: http://www.moe.gov.cn/jyb_xxgk/xxgk_jyta/jyta_xueshengsi/201901/t20190118_367347.html (accessed on 18 January 2024).
- Ministry of Education. Follow the Evaluation Requirements to Ensure the Fairness of the Test; Ministry of Education of the People’s Republic of China: Beijing, China, 2020. Available online: http://www.moe.gov.cn/jyb_xwfb/s5147/202007/t20200709_470963.html (accessed on 18 January 2024).
- Peng, L.; Tan, X.; Xie, F. Rethinking the Way Out for College English Teaching-After China’s Reform in National College Entrance Exam in English. J. Lang. Teach. Res. 2014, 5, 1393. [Google Scholar] [CrossRef]
- Chen, X. The teaching of high school English listening and speaking from the 2017 National College Entrance Examination listening comprehension test questions. Engl. Learn. 2017, 7, 4. Available online: https://d.wanfangdata.com.cn/periodical/yyxx201707011 (accessed on 18 January 2024).
- Pan, S. The application of context theory in high school English listening teaching: Taking the 2017–2018 Gaokao Zhejiang volume as an example. Engl. Teach. 2018, 18, 5. [Google Scholar]
- Huang, J. Training and scoring skills of high school English listening questions. Exam. Eval. 2017, 9, 159–160. Available online: https://wenku.baidu.com/view/96126941ac51f01dc281e53a580216fc710a535d?fr=xueshu&_wkts_=1702734155786 (accessed on 18 January 2024).
- Yu, X. English listening training guide and problem solving skills. New Curric. Compr. Ed. 2014, 2, 2. [Google Scholar]
- Zhou, H.; Hu, P. A study on the content validity of English listening test questions in the 2012-2017 college entrance examination in Zhejiang Province. Educ. Meas. Eval. 2017, 11, 8. [Google Scholar] [CrossRef]
- Sardinha, T.B.; Veirano Pinto, M. Multi-Dimensional Analysis, 25 Years on: A Tribute to Douglas Biber; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2014; Volume 60. [Google Scholar] [CrossRef]
- Brown, P.; Fraser, C. Speech as a marker of situation. In Social Markers in Speech; Cambridge University Press: Cambridge, UK, 1979; pp. 33–62. Available online: https://www.mpi.nl/publications/item66661/speech-marker-situation (accessed on 18 January 2024).
- Biber, D.; Conrad, S. Register, Genre, and Style; Cambridge University Press: Cambridge, UK, 2019. [Google Scholar]
- Biber, D. Register as a predictor of linguistic variation. Corpus Linguist. Linguist. Theory 2012, 8, 9–37. [Google Scholar] [CrossRef]
- Biber, D.; Egbert, J.; Keller, D. Reconceptualizing register in a continuous situational space. Corpus Linguist. Linguist. Theory 2020, 16, 581–616. [Google Scholar] [CrossRef]
- Egbert, J.; Gracheva, M. Linguistic variation within registers: Granularity in textual units and situational parameters. Corpus Linguist. Linguist. Theory 2023, 19, 115–143. [Google Scholar] [CrossRef]
- Savolainen, R. Requesting and providing information in blogs and internet discussion forums. J. Doc. 2011, 67, 863–886. [Google Scholar] [CrossRef]
- Veirano Pinto, M. Dimensions of variation in North American movies. In Multi-Dimensional Analysis, 25 Years on: A Tribute to Douglas Biber; Berber Sardinha, T., Veirano Pinto, M., Eds.; John Benjamins Publishing Company: Amsterdam, The Netherlands, 2014; pp. 109–146. [Google Scholar]
- Kyle, K.; Crossley, S.A.; McNamara, D.S. Construct validity in TOEFL iBT speaking tasks: Insights from natural language processing. Lang. Test. 2016, 33, 319–340. [Google Scholar] [CrossRef]
- Csomay, E. Linguistic variation within university classroom talk: A corpus-based perspective. Linguist. Educ. 2004, 15, 243–274. [Google Scholar] [CrossRef]
- Biber, D.; Conrad, S.; Reppen, R.; Byrd, P.; Helt, M. Speaking and writing in the university: A multidimensional comparison. TESOL Q. 2002, 36, 9–48. [Google Scholar] [CrossRef]
- Connor-Linton, J. Register validation, oral proficiency, sampling and the promise of multi dimensional analysis. In Variations in English; Biber, D., Conrad, S., Eds.; Routledge: London, UK, 2014; pp. 124–137. [Google Scholar]
- Shi, Y. A Corpus-based Analysis on Spoken Texts in CET4: By a Multidimensional Approach. In Proceedings of the 2015 Youth Academic Forum on Linguistics, Literature, Translation and Culture, Hangzhou, China, 5–6 June 2015; The American Scholars Press: Atlanta, GA, USA, 2015; p. 106. [Google Scholar]
- Rossi, O.; Brunfaut, T. Text authenticity in listening assessment: Can item writers be trained to produce authentic-sounding texts? Lang. Assess. Q. 2021, 18, 398–418. [Google Scholar] [CrossRef]
- Biber, D. What can a corpus tell us about registers and genres? In The Routledge Handbook of Corpus Linguistics; Routledge: London, UK, 2010; pp. 241–254. [Google Scholar] [CrossRef]
- Biber, D. University Language: A Corpus-Based Study of Spoken and Written Registers; John Benjamins: Amsterdam, The Netherlands, 2006. [Google Scholar]
- Wingrove, P.; Crosthwaite, P. Multi-Dimensional Exploratory Factor Analysis of TED talks. Regist. Stud. 2022, 4, 91–131. [Google Scholar] [CrossRef]
- Ministry of Education. The Historical Logic of Gaokao Test Question Design from Division to Unification; Ministry of Education of the People’s Republic of China: Beijing, China, 2015. Available online: http://www.moe.gov.cn/jyb_xwfb/xw_zt/moe_357/jyzt_2015nztzl/lianghui/pinglun/202103/t20210329_523321.html (accessed on 18 January 2024).
- Ministry of Education. The State Council on Deepening the Implementation of the Reform of the Examination and Enrollment System; Ministry of Education of the People’s Republic of China: Beijing, China, 2014. Available online: http://www.moe.gov.cn/jyb_xxgk/moe_1777/moe_1778/201409/t20140904_174543.html (accessed on 18 January 2024).
- Biber, D. Conversation text types: A multi-dimensional analysis. In DIMENSIONAL ANALYSIS, Proceedings of the 7th International Conference on Textual Data Statistical Analysis, Wallonia, Belgium, 10–12 March 2004; UCL Press: London, UK, 2004. [Google Scholar]
- Kyle, K. Measuring Syntactic Development in L2 Writing: Fine Grained Indices of Syntactic Complexity and Usage-Based Indices of Syntactic Sophistication. Ph.D. Thesis, Georgia State University, Atlanta, GA, USA, 2016. [Google Scholar] [CrossRef]
- Jamovi, Version 2.3. [Computer Software]. The Jamovi Project: Sydney, NSW, Australia, 2022. Available online: https://www.jamovi.org (accessed on 18 January 2024).
- Kyle, K.; Crossley, S.A. Measuring syntactic complexity in L2 writing using fine-grained clausal and phrasal indices. Mod. Lang. J. 2018, 102, 333–349. [Google Scholar] [CrossRef]
- Lu, X. A corpus-based evaluation of syntactic complexity measures as indices of college-level ESL writers’ language development. TESOL Q. 2011, 45, 36–62. [Google Scholar] [CrossRef]
- Brown, T.A. Confirmatory Factor Analysis for Applied Research; Guilford Publications: New York, NY, USA, 2015. [Google Scholar]
- Fabrigar, L.R.; Wegener, D.T.; MacCallum, R.C.; Strahan, E.J. Evaluating the use of exploratory factor analysis in psychological research. Psychol. Methods 1999, 4, 272. [Google Scholar] [CrossRef]
- Loewen, S.; Gonulal, T. Exploratory factor analysis and principal components analysis. In Advancing Quantitative Methods in Second Language Research; Routledge: London, UK, 2015; pp. 182–212. [Google Scholar]
- Fabrigar, L.R.; Wegener, D.T. Structural equation modeling. In Applied Multivariate Statistics for the Social Sciences; Routledge: London, UK, 2012; pp. 549–594. [Google Scholar]
- Le Foll, E. Register variation in school EFL textbooks. Regist. Stud. 2021, 3, 207–246. [Google Scholar] [CrossRef]
- Liimatta, A. Exploring register variation on Reddit: A multi-dimensional study of language use on a social media website. Regist. Stud. 2019, 1, 269–295. [Google Scholar] [CrossRef]
- Ehret, K.; Taboada, M. Are online news comments like face-to-face conversation? A multi-dimensional analysis of an emerging register. Regist. Stud. 2020, 2, 1–36. [Google Scholar] [CrossRef]
- Santini, M.; Jönsson, A. Pinning down text complexity: An Exploratory Study on the Registers of the Stockholm-Umeå Corpus (SUC). Regist. Stud. 2020, 2, 306–349. [Google Scholar] [CrossRef]
- Kim, H.Y. Analysis of variance (ANOVA) comparing means of more than two groups. Restor. Dent. Endod. 2014, 39, 74–77. [Google Scholar] [CrossRef]
- French, A.; Macedo, M.; Poulsen, J.; Waterson, T.; Yu, A. Multivariate Analysis of Variance (MANOVA). 2008. Available online: https://docplayer.net/20883992-Multivariate-analysis-of-variance-manova.html (accessed on 18 January 2024).
- Warner, R.M. Applied Statistics: From Bivariate through Multivariate Techniques; SAGE Publications: Los Angeles, CA, USA, 2008. [Google Scholar]
- Sarma, K.V.S.; Vardhan, R.V. Multivariate Statistics Made Simple: A practical Approach; Chapman and Hall/CRC Press: New York, NY, USA, 2018. [Google Scholar] [CrossRef]
- Gorsuch, R.L. Factor Analysis, 2nd ed.; Erlbaum: Hillsdale, NJ, USA, 1983. [Google Scholar] [CrossRef]
- Kanoksilapatham, B. A Corpus-Based Investigation of Scientific Research Articles: Linking Move Analysis with Multidimensional Analysis; Georgetown University: Washington, DC, USA, 2003; Available online: https://www.proquest.com/dissertations-theses/corpus-based-investigation-scientific-research/docview/305328726/se-2 (accessed on 18 January 2024).
- Kaiser, H.F. An index of factorial simplicity. Psychometrika 1974, 39, 31–36. [Google Scholar] [CrossRef]
- Farhady, H. On the plausibility of the unitary language proficiency factor. In Issues in Language Testing Research; Newbury House: Rowley, MA, USA, 1983; pp. 84–99. [Google Scholar]
- Friginal, E.; Hardy, J.A. From Factors to Dimensions: Interpreting Linguistic Co-occurrence Patterns. In Multi-Dimensional Analysis: Research Methods and Current Issues; Bloomsbury Academic: London, UK, 2019; pp. 145–164. [Google Scholar]
- Biber, D.; Gray, B.; Poonpon, K. Should we use characteristics of conversation to measure grammatical complexity in L2 writing development? TESOL Q. 2011, 45, 5–35. [Google Scholar] [CrossRef]
- Biber, D. Dimensions of Register Variation: A Cross-Linguistic Comparison; Cambridge University Press: Cambridge, UK, 1995. [Google Scholar] [CrossRef]
- Biber, D.; Finegan, E. Diachronic relations among speech-based and written registers in English. In Variation in English; Biber, D., Conrad, S., Eds.; Routledge: London, UK, 2014; pp. 66–83. [Google Scholar]
- Biber, D. Dimensions of variation among eighteenth-century speech-based and written registers. In Variation in English; Biber, D., Conrad, S., Eds.; Routledge: London, UK, 2014; pp. 200–214. [Google Scholar]
- DiStefano, C.; Zhu, M.; Mîndrilă, D. Understanding and Using Factor Scores: Considerations for the Applied Researcher. Pract. Assess. Res. Eval. 2009, 14, 20. [Google Scholar] [CrossRef]
- Bryne, B.M. Structural Equation Modelling with AMOS: Basic Concepts, Applications and Programming, 2nd ed.; Routledge: London, UK; Taylor & Francis Group: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Hair, J.F.; William, C.B.; Babin, B.J.; Anderson, R.E. Multivariate Data Analysis; Prentice Hall: Englewood Cliffs, NJ, USA, 2010. [Google Scholar]
- Field, A. Discovering Statistics Using IBM SPSS Statistics; SAGE Publication: London, UK, 2018. [Google Scholar]
- Education and Examinations Authority, Ministry of Education. Syllabus for the 2019 National Unified Examination for Admission to General Colleges and Universities (English); China Education and Examinations: Beijing, China, 2019; Available online: https://gaokao.neea.edu.cn/html1/report/19012/5951-1.htm (accessed on 18 January 2024).
- Aryadoust, V.; Luo, L. The typology of second language listening constructs: A systematic review. Lang. Test. 2023, 40, 375–409. [Google Scholar] [CrossRef]
- Zhou, W. A comparative study of English listening in the national volume college entrance examination in recent years and strategies for test preparation. Curric. Educ. Res. Study Learn. Teach. Methods 2017, 19, 1. Available online: https://wenku.baidu.com/view/e92f2f7ab6360b4c2e3f5727a5e9856a57122611?fr=xueshu&_wkts_=1702733537580 (accessed on 18 January 2024).
- Farkas, D.K. The logical and rhetorical construction of procedural discourse. Tech. Commun. 1999, 46, 42–66. [Google Scholar]
- Yamashita, J. An analysis of relative clauses in the Lancaster/IBM spoken English corpus. Engl. Stud. 1994, 75, 73–84. [Google Scholar] [CrossRef]
- Shen, W. Improving high school students’ English listening point talk. Shenzhou 2018, 21, 1. [Google Scholar]
- Xin, Y. High school English listening training and skills. China Sci. Educ. Innov. Guide 2013, 12, 1. [Google Scholar]
- Chaudron, C. Simplification of input: Topic reinstatements and their effects on L2 learners’ recognition and recall. TESOL Q. 1983, 17, 437–458. [Google Scholar] [CrossRef]
- Guo, Y. Exploring the teaching of English long sentences in the listening classroom from the perspective of syntax. J. Hubei Univ. Econ. Humanit. Soc. Sci. Ed. 2011, 8, 2. [Google Scholar]
- Scheffler, T.; Kern, L.A.; Seemann, H. The medium is not the message: Individual level register variation in blogs vs. tweets. Regist. Stud. 2022, 4, 171–201. [Google Scholar] [CrossRef]
- Shakir, M.; Deuber, D. A multidimensional study of interactive registers in Pakistani and US English. World Englishes 2018, 37, 607–623. [Google Scholar] [CrossRef]
- Aryadoust, V.; Foo, S.; Ng, L.Y. What can gaze behaviors, neuroimaging data, and test scores tell us about test method effects and cognitive load in listening assessments? Lang. Test. 2022, 39, 56–89. [Google Scholar] [CrossRef]
- Low, A.R.L.; Aryadoust, V. Investigating test-taking strategies in listening assessment: A comparative study of eye-tracking and self-report questionnaires. Int. J. List. 2023, 37, 93–112. [Google Scholar] [CrossRef]
- Aryadoust, V. Topic and accent coverage in a commercialized L2 listening test: Implications for test-takers’ identity. Appl. Linguist. 2023, amad062. [Google Scholar] [CrossRef]



Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).