Abstract
As technology continues to shape how students read and write, digital literacy practices have become increasingly multimodal and complex—posing new challenges for researchers seeking to understand these processes in authentic educational settings. This paper presents three qualitative studies that use multimodal analyses and visual modeling to examine digital reading and writing across age groups, learning contexts, and literacy activities. The first study introduces collaborative composing snapshots, a method that visually maps third graders’ digital collaborative writing processes and highlights how young learners blend spoken, written, and visual modes in real-time online collaboration. The second study uses digital reading timescapes to track the multimodal reading behaviors of fifth graders—such as highlighting, re-reading, and gaze patterns—offering insights into how these actions unfold over time to support comprehension. The third study explores multimodal composing timescapes and transmediation visualizations to analyze how bilingual high school students compose across languages and modes, including text, image, and sounds. Together, these innovative methods illustrate the power of multimodal analysis and visual modeling for capturing the complexity of digital literacy development. They offer valuable tools for designing more inclusive, equitable, and developmentally responsive digital learning environments—particularly for culturally and linguistically diverse learners.
1. Introduction
Digital reading and writing are becoming more complex as we continue to grapple with new technologies (Coiro, 2021). Technologies are available that can provide multimodal data about students’ complex digital reading and writing processes, but often-employed research methods simplify the digital literacy problem space, specifically how individuals engage with digital texts and tools to read and communicate, rather than take advantage of the complexity (Shimizu et al., 2024; Sommer, 2021). This paper shares multimodal analyses and qualitative visual models that integrate multimodal reading and writing behaviors to provide insight into how those behaviors shape digital reading, collaborative writing (CW), and multimodal composing (MMC).
The goal of this paper is to present a range of multimodal visual analyses and models that take advantage of the complex problem space related to digital literacy, rather than simplifying to a single behavior, process, or outcome. In doing so, we hope to provide avenues for researchers and educators to consider digital reading and writing processes in greater depth, fostering more nuanced understandings of how modern readers comprehend and writers compose with digital technology.
We begin by sharing a review of qualitative multimodal analysis and qualitative visual models, followed by our theoretical framing. Then, we present three studies that illustrate the use of multimodal analysis and visual models; all studies received approval from their respective institutional review boards, and informed consent was obtained from all participants and/or guardians. The first study shares models that foreground how elementary students develop ideas across multiple digital spaces, tools, and modes of communication while engaging in digital CW. In the second study, multimodal recordings and quantitative data are used to illustrate fifth-graders’ orchestration of reading and question-answering behaviors during a digital reading task. Then, we present multimodal analyses and visual models for understanding how multilingual adolescents traversed different modes (i.e., visual, textual, aural) and languages while engaging in digital MMC. For each study, we outline the setting and participants but seek to emphasize the multimodal visual models and their affordances.
These three distinct studies are brought together here to highlight the range and flexibility of qualitative multimodal analysis and visual models. While each focuses on different digital literacy practices and different populations of students, they collectively demonstrate the possibilities of these methods of analysis. As such, we conclude by discussing the similarities and limitations across the three studies, along with pedagogical implications and future directions of multimodal visual analysis and modeling.
2. Multimodal Analysis
Multimodal analysis enables researchers to consider the interplay of modes (e.g., verbal, gestural, spatial, written, etc.) in communication while also highlighting the importance of context (Jewitt, 2016; Norris, 2004). As technology evolves, researchers can more readily collect multimodal data, which requires new methodological approaches (Serafini & Reid, 2023; Sommer, 2021). Serafini and Reid (2023) introduced multimodal content analysis (MMCA), a method for examining the complex relationships among different modes in both analogue and digital multimodal ensembles (p. 629). To demonstrate MMCA, they analyzed wine labels by developing an analytic template that considered textual content, visual imagery (both narrative and classificatory), design elements, and intermodal relationships. They found, for instance, that labels strategically used text and images to signal to consumers that a wine originated from popular winery locales.
Considering multimodality in classroom discourse, Lim (2019) used Systematic Functional Multimodal Discourse Analysis (SFMDA) to consider how two teachers used language and gestures to make meaning and create a learning experience. Here, one teacher balanced authority and informality, using open gestures and inclusive language to encourage participation, while a different teacher more often used high-authority gestures and language, creating a stricter, less interactive environment.
Sommer (2021) integrated multimodal analysis into a grounded theory framework (Glaser & Strauss, 1967) to study an online discourse community. By coding communication modes separately (e.g., visual and linguistic) before analyzing their multimodal relationships, Sommer (2021) aimed to capture broad modal meanings. This iterative process of deconstructing and reassembling data enabled a multiperspective analysis, yielding richer insights.
Fazeli et al. (2023) developed the Visual-Verbal Video Analysis (VVVA) protocol, a systematic method for analyzing video data. Building on multimodal transcription (Norris, 2004), it guides researchers to examine verbalizations, gestures, sounds, writing, characters, visual elements, and content (Fazeli et al., 2023). Similarly, Mohammed et al. (2023) introduced the Four Column Analysis Structure (FoCAS), which considers time, setting, scene, and audio. These frameworks support coding across modal elements, deepening analysis. Craig et al. (2021) argues that triangulating transcripts, audio, and video enhances analytical trustworthiness and captures unarticulated elements and cultural nuances, particularly for marginalized groups. Ultimately, multimodal analysis enables richer, more comprehensive insights about interactions, contexts, and processes.
3. Qualitative Visual Models
Over 25 years ago, Radnofsky (1996) wrote about “the philosophical and practical value of creating qualitative models as a complement to traditional linguistic formulations that social science researchers use to construct meaning and represent coexisting multiple realities” (p. 385). Similar to multimodal methods of analysis, qualitative visual models provide alternative ways of knowing and understanding, while also providing easier access to complex information (Buckley & Waring, 2013; Cook, 2024; Radnofsky, 1996; Šíp & Denglerová, 2024). While visual models can support understanding and meaning-making with data, they are seemingly underutilized in qualitative research (Cook, 2024). A review of data displays across three qualitative journals over a three-year period found that only 27% of studies used any type of visual display (Verdinelli & Scagnoli, 2013). Of those displays, the most frequently used visuals were matrices, while the least frequent were metaphorical displays and decision tree models. Most visuals were used in the findings (61%), with only one single visual used in a methods section, as diagrams and visuals made during the analysis process are often kept private by the researcher (Buckley & Waring, 2013). As such, Verdinelli and Scagnoli (2013) called for an expansion of visual displays in qualitative research as an implication of their review.
Recently, ethnograms were used to visualize verbal data between students and teachers in a secondary classroom (Cook, 2024). These ethnograms provided alternative perspectives of the social interactions, captured participants’ behaviors even if they were not directly observable, and “simplif[ied] complexity through abstraction…to further subjective meaning making” (Cook, 2024, p. 160). The ethnograms were a compelling instrument for the analysis and communication of findings. Decades apart, Radnofsky (1996) and Cook (2024) both underscore that these visual methods do not replace other methods or data, but rather complement and help bring understanding to different facets of a phenomenon being studied. Here, we extend prior work by using three different studies to explore how to blend multimodal analyses and qualitative visual models, which we believe can elevate the voices and experiences of a wide range of students across a variety of digital literacy contexts.
4. New Literacies and Multimodal Social Semiotics
Digital technologies are constantly shifting and impacting how we engage as readers and writers. New literacies have been described by Lankshear and Knobel (2007) as pertaining to the technical stuff and the ethos stuff. Technical stuff is just that, the technical tools and applications available to users to create songs, texts, or multimodal compositions. They argue the conception of space has been fractured by the creation and unfolding of cyberspace, which has led to the development of a different mindset and ethos around literacies. Consider encyclopedias, which are written by specific “authorities” or “experts” and sold to inform the masses, versus wikipedia, an online encyclopedia that is composed of a collection of authors from a wide range of backgrounds. In other words, they say that “new literacies are more ‘participatory,’ ‘collaborative,’ and ‘distributed’ in nature than conventional literacies” (Lankshear & Knobel, 2007, p. 9).
That is not to say that conventional literacies are not important when considering new literacies. While the internet and digitization has shifted the nature of literacy, Leu et al. (2013) called for “a collaborative approach to theory building…because both old and new elements of literacy are layered in complex ways” (p. 1157). In other words, understanding and studying literacy requires researchers to find methods of data collection and analysis that acknowledge and integrate what one might consider traditional literacy skills with new digital competencies.
A social semiotics framework (Kress, 2010) also grounds the ideas of this paper. Here, communication and meaning-making is understood to be multimodal, which can include textual, visual, aural, gestural, and spatial modes (Kress, 2010). For effective communication, people employ a range of modes (Bezemer & Kress, 2015). Bezemer and Kress (2015) gave the example of medical students observing a surgeon while watching the surgeon’s hands that were being projected on a screen. They noted how the surgeon used multiple modes (e.g., gestures to point, verbalization to name) to teach the students. Both gesturing and verbalizing were vital for effective communication of the essential information, and without one or the other the message would have been incomplete. Simply put, people can layer and mix modes to enhance clarity and understanding. Notably, Kress (2010) emphasized that a social semiotics framework “can say which mode is foregrounded [and] which mode carries more weight” (p. 60). A social semiotics framework illuminates how individuals integrate and prioritize multiple modes of communication to convey nuanced meanings effectively across various contexts and disciplines.
At the confluence of new literacies and multimodal social semiotics, this paper considers three studies to explore multimodal analyses and visual models and build a nuanced understanding of how readers and writers engage in literacy in the digital age across the tasks of digital reading, CW, and MMC.
5. Study 1: Digital Collaborative and Multimodal Writing
Study 1 focuses on third-grade students engaged in collaborative writing (CW) within a fully online environment. This study introduces collaborative composing snapshots, a method of visually mapping how students co-develop ideas across multiple digital spaces and modes. It serves as an entry point to demonstrate how multimodal analysis and visual models can surface unseen but important contributions from participants.
5.1. Study Context
The setting for this study was a public charter school in the northeast United States, with the research conducted in a fully online instructional setting during the 2020–2021 school year. The participants, 50 third-grade students, engaged in literacy instruction through daily synchronous Zoom sessions lasting 75 min. The demographic backgrounds of the students were varied (i.e., 65.4% LatinX, 17.3% Black, and 15.4% White students). Sixty-nine percent were economically disadvantaged, and one quarter were multilingual. All students were provided with the necessary technological resources to engage in online learning.
5.2. Data Sources and Groups
Students engaged in a writer’s workshop throughout the school year. This focal unit asked students to work in groups of three to compose a tall tale inside of a shared Google Doc. Data sources for this multimodal analysis included Zoom video recordings of participants’ verbal and text-based communications, physical gestures, and virtual pointing using their mouse pointer. Groups’ Google Doc texts, which included an archive of revisions and the final product, were also collected.
Two focal groups, termed Group A and Group B, were selected as contrast cases (Stake, 2013). Group A included Mark, a LatinX multilingual male student, Kendall, a Latinx multilingual female student, and Scott, a White monolingual male student. Group B included Tim, a LatinX male student, Rita, a Black female student, and Skye, a male student who identified his ethnicity as other.
5.3. Data Analysis
DocuViz (Wang et al., 2015), a text-mining analysis tool, analyzed the archived history to provide data for each participant’s total contributions and edits, which were used to calculate proportions. Multimodal transcripts (Norris, 2004) including the off-page verbal utterances, gestural movements, chat-based statements, and the on-page virtual pointing (i.e., using the mouse to point, highlighting a portion of text to bring group member’s visual attention to a specific point, or scrolling up and reading a certain portion of text), and textual additions and revisions to the shared text from the Google Doc history, were created. From these, idea tracing (Ehret et al., 2016) was conducted to see how ideas were developed and made it to the page.
Next, excerpts of the groups’ processes, including how ideas were developed and made it onto the digital page, were mapped onto collaborative composing snapshots (Shimizu & Santos, 2022), which showed five things (Figure 1). First, they represented the three online spaces, the Zoom space (bottom portion), the Google Doc space (top portion), and the hybrid space created when a participant used Zoom’s screen share feature to display the Google Doc to others (middle portion). Second, they displayed which participants were present in which spaces (purple, yellow, red, and green stars). Third, they showed which ideas were being carried forth, indicated by different shapes (squares and circles). Fourth, they displayed which participant was developing an idea, as denoted by varying colors (green, red, purple, and yellow). Finally, they expressed which semiotic mode of interaction (Norris, 2004) was used to develop an idea, as indicated by different lines (solid, wavy, dashed, dotted, and dotted and dashed). Here, semiotic modes of interaction refer to the ways in which participants were able to negotiate their ideas including (1) verbalizations, (2) gestures, (3) text-based chats, (4) textual additions/revisions, and (5) virtual pointing.
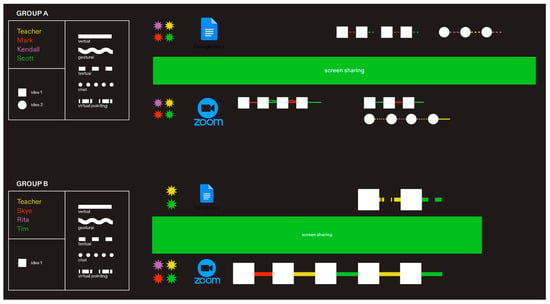
Figure 1.
Multimodal composing snapshots of Groups A and B.
5.4. DocuViz Analysis of Textual Interactions v. Multimodal Models
Table 1 shows the DocuViz analysis. Group A’s contributions were more equal across the participants, which could indicate more equitable collaboration, whereas in Group B, Tim made 70% of the total contributions and 66% of the edits, which may suggest Tim dominated over others during the process.

Table 1.
Textual contributions and edit proportions by each participant in Groups A and B.
However, it is essential to consider other modes of contribution during digital CW, such as how participants speak, chat, gesture, and virtually point. To visually model how groups developed ideas across participants, modes, and digital spaces, we consider collaborative composing snapshots.
In Group A’s collaborative composing snapshot (top of Figure 1), all participants were present in Zoom and the Google Doc (colored stars on top and bottom). As such, all participants could contribute through every available mode of interaction. This group’s full presence in the digital spaces supported the group to develop multiple ideas concurrently (square and circle). This snapshot shows how the square idea was developed through multiple verbal turns (solid lines) and textual additions/revisions (dashed lines) by Scott (green) and Mark (red). At the same time, it displays how a different idea (circle) was developed through chat-based communication (dotted lines) and textual additions (dashed lines) by the teacher (yellow) and Kendall (purple).
In Group B’s collaborative composing snapshot (bottom of Figure 1), only Tim (green) and the teacher (yellow) were inside the Google Doc space. As such, Rita (purple) and Skye (red) were limited to contributing verbally, gesturally, or through text-based chats. This group’s presence or non-presence in each digital space led students to develop and capture one idea at a time in the text. This snapshot shows how the idea (square) was developed through multiple verbal turns in the Zoom space (solid lines), before making it to the page through virtual pointing (dotted dashed lines) and textual revisions (dashed lines).
5.5. Affordances of Multimodal Analysis and Modeling of Digital Collaborative Writing
While the DocuViz analysis was helpful in understanding on-page text revisions, it did not show all possible contributions participants could make in other off-page modes of interaction. As such, relying on DocuViz alone might lead to skewed understandings of a group’s CW process. For instance, DocuViz showed that Tim (green) of Group B dominated in terms of on-page text revisions, but the multimodal analysis and model helped uncover how Tim acted as a scribe after ideas were developed off-page verbally in Zoom by the group together. Further, Group B’s snapshot (bottom of Figure 1) helped to show how although Tim (green) and the teacher (yellow) were the most active participants in that moment, it was actually an idea (square) offered by Skye (red) that was carried forth to the page after just a single off-page verbal interaction.
Additionally, these collaborative composing snapshots give voice to all forms of communication. For instance, in Figure 1, while Scott (green) and Mark (red) were more audible through their off-page verbal turns, Kendall (purple), a multilingual learner, silently developed an idea by using the chat and capturing her own idea inside the Google Doc. In a study only considering off-page verbal interactions, Kendall’s efforts would be overlooked. Furthermore, mapping students’ interactions across different spaces (i.e., Zoom, Google Doc, and the hybrid screen sharing spaces) can shed light on how students’ use of digital tools shape how groups develop ideas (multiple ideas concurrently or one idea together). However, these models only provide a “snapshot” of collaboration and must be paired with many other analyses, like DocuViz, in order to develop a clear understanding of CW processes.
6. Study 2: Static Digital Reading and Question Answering
Study 2 shifts to the individual digital reading processes of fifth-grade students. It examines how readers orchestrate physical behaviors, such as gaze, with digital behaviors, such as tracking with the mouse and highlighting while reading static digital texts. By using reading timescapes and action path diagrams, this work reveals temporal and behavioral dimensions of digital reading and illustrates how multimodal visual models can illuminate complex behaviors that can be overlooked with traditional methods of analysis.
6.1. Study Context
This analysis is part of a larger study (Goodwin et al., 2020) that collected data from 371 fifth- through eighth-grade students while they engaged in both digital and paper reading. Our goal was to move beyond the paper versus digital debate and enhance the field’s nascent understanding of digital reading by examining how readers effectively use tools, strategies, and behaviors to comprehend digital texts. For a discussion of the findings, see Shimizu et al. (2024). Here, we consider methods of analysis and modeling and the related implications.
Three rounds of analysis were used to understand the selected participants’ reading and question answering processes. First, we descriptively coded students reading and question-answering behaviors. Then, we developed action path diagrams (described below) to link these behaviors to comprehension performance. Finally, we composed reading timescapes (Smith, 2017) to illustrate how a subgroup of selected students orchestrated their digital reading behaviors.
6.2. Participants and Procedures
Thirteen fifth-grade students were the focus of this study. Purposive sampling (Patton, 1990) was used to choose students with demographic diversity and ranges of general reading ability as measured by the NWEA-MAP, the district’s standardized assessment. Based on their NWEA scores, students were grouped as displaying high, mid, or low general reading ability. Participants in this study read a 2011 eighth-grade NAEP Social Studies reading on women’s suffrage. While reading, students could digitally track with their mouse, highlight, annotate, and define words.
6.3. Data Sources
This study used video recordings captured by iMotions of students’ digital reading and question answering. The videos consisted of side-by-side videos of the students’ faces recorded by forward-facing laptop cameras and videos of the screen with which students were engaging. The video of the screen was overlaid with a gaze-tracking notation that approximated where the student was looking throughout the task. Demographic and NWEA-MAP test scores were collected from the partnering school district. Performance on the post-test was also used.
6.4. Data Analysis
6.4.1. Phase 1 Coding Quality of Digital Reading and Question-Answering Behaviors
In the present study, we analyzed the quality of the digital reading behaviors of 13 focal students. We triangulated students’ screen actions, gaze-tracking, facial expressions, audio, and general context to generate descriptive statistics about behaviors. We coded for re-reading patterns, strategic and nonstrategic digital tool use, functional and non-function scrolling, embodied tracking (i.e., mouthing words or keeping place with the mouse), off-task behaviors, and whether returns to the text during question-answering of a 15-question post-test were accurate in terms of areas of interest (AOIs), i.e., the portion of the text related to the questions.
6.4.2. Phase 2 Analysis of How Digital Reading Behaviors Link to Comprehension
To connect students’ reading behaviors to comprehension, we created action path diagrams to illustrate trends. These diagrams were informed by student reading abilities as gauged by NWEA-MAP scores, their reading behaviors, proportion of accurate returns to AOIs while answering questions, and their test performance.
6.4.3. Phase 3 Analysis of Multimodal Digital Reading Behaviors
Using the findings from the action path diagrams, the team selected six focal students for multimodal analysis of their digital reading and question answering behaviors to illustrate how students’ orchestration of behaviors supported their comprehension or not.
Time-stamped logs were created for each focal student’s reading and question answering behaviors. These consisted of five second intervals noting off-task/on-task behaviors, screen actions (highlighting, mouse tracking, defining words), readers’ eye-gaze path, and general text location for each interval. Logs were used to create visual timescapes (Smith, 2017) of how students orchestrated their screen actions and eye-gaze across time while reading digitally.
6.5. Digital Reading Multimodal Analysis
To explore the multimodal analyses and visual models, we consider the digital reading process of one mid-level reader, Student H, across our three phases of analysis.
6.5.1. Phase 1: Quality of Digital Reading and Question-Answering Behaviors
Student H was coded as an occasional re-reader. While Student H did not define any words or annotate, he tracked the text frequently with his mouse and highlighted over half (51%) of the words in the digital text. Since strategic highlighting was defined as brief highlights of central ideas or facts that could be used to assist synthesis and recall, Student H was coded as a non-strategic highlighter because of his large quantity of highlighting.
6.5.2. Phase 2: How Digital Reading Behaviors Link to Comprehension
Strategic digital tool use, functional scrolling, embodied tracking, and off-task behaviors alone did not seem to support or hinder students’ comprehension. However, readers like Student H, who engaged in occasional re-reading, more accurately returned to AOIs when answering questions and had stronger comprehension outcomes overall (Figure 2). Importantly, although Student H’s reading ability was mid-level, as measured by the NWEA assessment, he accurately returned to AOIs more often than not, and performed as well as several high-level readers on the digital portion of the post-comprehension test.
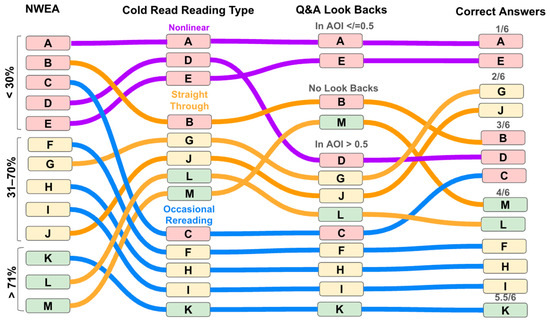
Figure 2.
Action paths of digital cold reading type, look backs, and correct answers.
6.5.3. Phase 3: Orchestration of Multimodal Digital Reading Behaviors
Student H’s timescapes (Figure 3) include his screen action at the bottom, gaze action in the middle, and text location at the top. Five second intervals run horizontally across the bottom of the figure. Highlighting was represented by a yellow bar in screen actions. On top of the highlight bar are the word(s) that were highlighted at that moment, with lengthy highlights denoted by the first and last words with an ellipse between.

Figure 3.
Student H’s cold read and question-answering timescapes.
While student H was originally coded as a non-strategic highlighter, analysis of his eye tracking and screen action showed he used the mouse and highlight tool to actively engage in reading and re-reading throughout his process, as indicated by the yellow bars and multiple backwards arrows. At 1:35, Student H highlighted “abridged” in paragraph two and tracked the text with his mouse into paragraph three, where he reread and highlighted the entire paragraph. Student H continued to consistently use his mouse for tracking, re-reading, and highlighting.
Student H’s reading process seemed to support his accurate return to AOIs during the post-comprehension assessment. For example, on question five he accurately returned to the AOI (green section in Figure 3) and answered the question correctly (checkmark). Student H shifted his gaze between his answer and the AOI to check his answer.
6.6. Affordances of Multimodal Analysis and Modeling of Digital Reading
These analyses triangulated data including recordings of readers’ faces, screen capture video data, gaze tracking, post-test assessments, and the researchers’ contextual knowledge. This supported an analysis of not only the quantity but the quality of student behaviors and how readers orchestrated multiple behaviors to support their digital reading process. Consider Student H. If we had limited the analysis to the quantity of behaviors, we would have seen he highlighted 51% of the text, leaving questions about what was highlighted and how those highlights occurred in real time. Furthermore, because of his high percentage of highlights, we originally coded him as a non-strategic highlighter. However, the multimodal analysis and models showed Student H’s high quantity of highlights occurred across the whole digital text and corresponded with many instances of re-reading (Figure 3), which likely supported accurate returns to AOIs and overall strong comprehension outcomes (Figure 2). Importantly, the timescapes helped illuminate how highlighting was important for Student H’s digital (re)reading process, even though initially his highlighting quantity suggested a lack of strategy. Student H is just one example of the importance of incorporating more than a single indicator when considering the complexity of the static digital reading process.
This method included varied sources of data, which were put in conversation with each other through a multimodal analysis, all while not interrupting students’ natural reading process. However, as student interviews were not included, we missed incorporating the readers’ perspectives. Further, the gaze trackers, integrated into laptops for minimal disruption, were less accurate than wearable devices like Tobi eyeglasses.
7. Study 3: Digital Multimodal Composing
Study 3 explores the digital multimodal composing (MMC) practices of multilingual adolescents. Through composing timescapes and transmediation models, it traces how students develop literary interpretations across languages and modes to supported their composing of academic essays. This study underscores how multimodal visual models can reveal the strategic use of language, sound, and imagery in meaning-making processes, particularly for emergent bilingual students.
7.1. Setting and Participants
This study was conducted in a 10th-grade class at an urban Title 1 charter high school in a major southeastern city in the United States. The school was situated in a community composed of Cuban exiles and families who immigrated from Central and South America.
This analysis focuses on the MMC processes of Rachel (15 years old) and Sergio (16 years old) as they collaboratively created a hypertext analysis and wrote a follow-up literary analysis essay about their poem. Both students were emergent bilingual students who had emigrated from Cuba with their families when they were young.
Students participated in a four-and-a-half-week poetry unit with a culminating project centered on students creating a hyperlinked PowerPoint that analyzed the multiple layers of meaning in a poem. Students used the interpretive skills they had developed with traditional written assignments but expanded them to a nonlinear multimodal format to have more freedom and creativity in their responses. Each hypertext analysis included a “home slide” where students presented their chosen poem. Specific words and phrases were hyperlinked from the poem to other slides, where students explored a variety of elements in greater depth, including key words and phrases, themes, literary devices, intertextual connections, questions, and personal reactions. Following the hypertext literary analysis, students were asked to write an essay expanding on their initial multimodal poetry analysis.
The class sessions followed an MMC workshop model (Dalton, 2013) intended to cultivate intentional designing for targeted purposes and audiences. The workshop followed a scaffolded sequence that involved explicit instruction, combined with opportunities for students to analyze a variety of examples, receive peer feedback, reflect on their process, and follow their own unique modal paths.
7.2. Data Collection
To allow for examination of students’ literary interpretation processes, Rachel and Sergio shared a research laptop with screen capture software that recorded their composing activities during in-class workshops. This software tracked the movements of their mice, websites visited, and all media used and edited. The accompanying audio was also recorded during the composing process, which provided insights into verbal interactions.
7.3. Data Analysis
Two multimodal analyses were developed to understand students’ processes and meaning-making across modes and languages.
7.3.1. Development of Multimodal Composing Timescapes
Multimodal composing timescapes (Smith, 2017; Smith et al., 2017) were created as an analytic tool and visualization of Rachel and Sergio’s processes for each in-class workshop. First, screen capture data was analyzed through open coding (Charmaz, 2000) to distinguish initial themes in the pair’s MMC processes. This step included creating time-stamped logs for each of their screen-capture videos. Moving sequentially through the workshops, students’ compositional actions and instances of multimodal and heritage language use were recorded. All of the screen capture videos were coded for on-screen activity and indicated the predominant mode students worked with and the duration of time (e.g., image search, image design, text type and revisions, audio search, audio remix, etc.). All instances where students spoke, wrote, or read in Spanish were coded.
Next, timescapes were created so that each bar represented the sequence and proportion of time the pair used specific modes and languages. Timescapes were color-coded to display students’ processes and compositional patterns.
7.3.2. Development of Multimodal Transmediation Models
Multimodal analysis of the screen capture and video observation data was also conducted to gain an in-depth understanding of Rachel and Sergio’s transmediation process. That is, how the ideas they developed multimodally traveled and transformed when writing their academic essay (Siegel, 1995). First, the time-stamped video logs were used again to understand students’ compositional actions, the content of their discussions as they composed, and any instances of translanguaging. Second, the content and conversations surrounding each slide of the hypertext poetry analysis were analyzed and categorized based on the main message. Third, the academic essay was divided into idea units (Smith et al., 2016)—which ranged from a single verbal clause to a couple of sentences—encompassing the boundary of an idea in the essay. Finally, to understand whether and how ideas from the hypertexts transmediated to the videos, the content and idea units across both products were compared and traced.
7.4. Affordances of Multimodal Analysis of Meaning-Making Across Modes and Languages
The development of the multimodal composing timescape for Rachel and Sergio’s hypertext poetry analysis revealed the complexity of their composing process as well as the strategic use of specific modalities and their heritage language. As depicted in the timescape (Figure 4), the pair quickly traversed different modalities (e.g., writing, visuals, sound, animations) when conducting their analysis, as well as different stages of their process, including searching the Internet, designing elements, and reviewing their work. The timescape also elucidates how they strategically translanguaged across English and Spanish in their notetaking, online informational searches, and verbally while collaboratively composing.
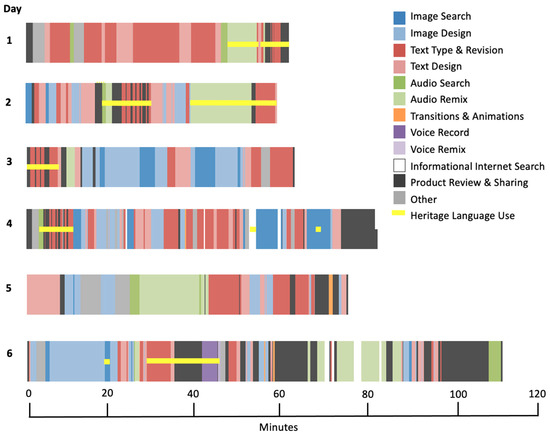
Figure 4.
Multimodal composing timescape visualizing Rachel and Sergio’s processes creating a hypertext poetry analysis.
The development of the transmediation models for Rachel revealed how she developed ideas multimodally—across visuals, text, sound, and movement—which transferred and transformed to her written analyses (Figure 5). Further, her process of transmediaton was not linear, with some multimodal ideas having a more substantial presence in the written essay than others. For example, she relied on her multimodal analysis of the symbolism of the sea and bird (6 and 7) and interpretation of “suppressing fantasies” in the poem (3) for organizing her argument in the essay, while some elements of her hypertext were not evident in her writing. This visualization points to the possibility of MMC serving as a productive means for students to develop analyses and ideas across modalities before being asked to share their understanding in more traditionally academic genres.
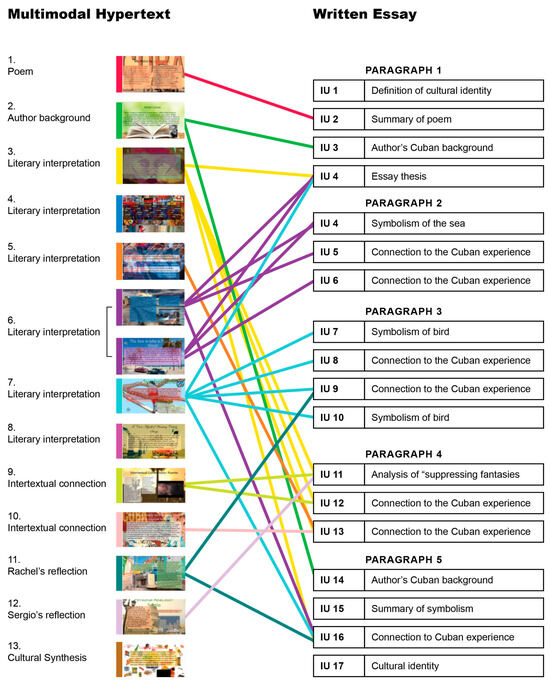
Figure 5.
Transmediation visualization shows how ideas developed and traveled across Rachel’s hypertext poetry analysis and written essay.
Both of the multimodal methods presented in this example illuminated complex meaning-making that occurred while students analyzed literature across modalities. Through these models we gain new insights into how they quickly traversed modes to develop their ideas and engage with content. While these methods afforded a window into emergent bilingual students’ MMC processes, it is important to note that they also had limitations. The timescape can be reductive in overly focusing on modal usage, whereas the transmediation visualization is narrowly focused on content in the products. For a more multidimensional understanding of youth’s MMC processes, these models need to be triangulated with analysis of students’ perspectives and interactions while collaboratively composing.
8. Discussion
The three sections discussed the use of multimodal analysis (Jewitt, 2016) and visual models to explore complex digital reading and writing processes. All three of the studies utilized systems to code and analyze the interplay of modes across the different literacy activities (Fazeli et al., 2023; Mohammed et al., 2023; Norris, 2004; Serafini & Reid, 2023; Sommer, 2021). Below, we discuss three methodological affordances that emerged across the analyses: the illustration of multifaceted practices in and across time; the elucidation of complex processes; and the foregrounding of implicit elements in cultural studies, particularly within marginalized communities.
Studies 2 and 3 both created timestamped logs to track and analyze students’ behaviors and actions, which was similar to Mohammed et al. (2023) who developed FoCAS to consider the dimensions of time, setting, scene, and audio. For instance, Study 2, which examined students’ digital reading processes, created detailed logs that recorded the time, off-task/on-task behaviors, screen actions (such as highlighting, mouse tracking, and defining words), readers’ eye-gaze paths, and the general text location for each reader. These logs provided insights into different behaviors individually, but were then used to create digital reading timescape models (Figure 3) that illustrated how students orchestrated multimodal behaviors to support their comprehension. For example, Student H’s rereading, indicated by his eye gaze, coincided with his screen action of digital highlighting, demonstrating that his highlighting supported his rereading and overall comprehension. Here, these logs and timescape models illuminated the temporal dimensions of students’ digital literacy practices that simple counts or static analyses often overlook.
The models in all three studies helped to make complex processes more understandable (Buckley & Waring, 2013; Cook, 2024; Radnofsky, 1996). Consider Study 3’s multimodal composing timescape model (Figure 4), which showed the complexity and strategic use of various modalities and their heritage language. Specifically, the timescape models showed how the process could be non-linear and helped to emphasize how students could effectively develop and organize literature analyses through multimodal modes (e.g., images and audio) that extended beyond written text. The models visualized in Study 2 showed how on-screen actions like highlighting could be paired with gaze patterns to better understand a student’s strategic digital reading process. Building from Lim’s (2019) SFMDA analysis, which considered language and gesture, Study 1 not only considered language and gesture but also analyzed virtual pointing, which was used by the participants to facilitate intersubjectivity in the online classroom context. Additionally, the collaborative composing snapshots illustrated how students developed ideas across overlapping digital spaces (Zoom, Google Docs, and screen sharing). Together, these models demonstrated the power of multimodal analysis and visualization to uncover layered, process-oriented insights into students’ literacy practices that may have remained unknown using traditional analytic approaches.
Finally, these multimodal analyses and models helped to bring attention to implicit elements and cultural subtleties, particularly within marginalized communities (Craig et al., 2021). For instance, Study 1’s collaborative composing snapshots helped to bring forth the interactions and contributions made by Kendall, a multilingual female student. Although she was silent throughout the entire episode, Kendall developed an idea using Zoom’s text-based chat and then captured that idea inside of the text by typing it. Unlike a typical verbal transcript, her efforts were made visible with the collaborative composing snapshots. Arguably, these multimodal analyses and models helped to suggest other modes of interaction (text-based chats and textual contributions) that may be more important for some multilingual learners who need extra time to process and respond when collaborating. Likewise, in Study 3, the multimodal composing timescapes revealed how bilingual students strategically translanguaged across English and Spanish—switching languages during notetaking, web searches, and peer discussion. Both examples highlight how multimodal analyses and visual models can surface culturally situated practices that might otherwise remain unnoticed, emphasizing the importance of using methods and models that honor diverse ways of communicating.
9. Limitations
While these methods can provide richer understandings and depictions of these digital literacy processes, it is important to note that these kinds of in-depth multimodal analyses require a significant amount of time (Cook, 2024; Craig et al., 2021; Fazeli et al., 2023), thereby limiting their feasibility for large-scale projects until technology is available to make these analyses more time efficient. Relatedly, because of the time-intensive nature of multimodal analysis, these studies involved a small number of participants in specific classroom contexts, which can limit the generalizability of findings when using these methods. In addition, even with data triangulation, these types of multimodal analyses rely on researcher interpretations, which inherently carry bias. To enhance trustworthiness, as well as deepen insights into the reason behind participants’ digital literacy processes, interviews or reflections could elevate participants’ perspectives.
10. Implications and Future Directions
The digitization of our world has opened up new ways for readers and writers to engage in literacy spaces (Leu et al., 2013). In turn, researchers need to expand their methodological tools to understand these shifting and complex reading and writing processes (Shimizu et al., 2024; Sommer, 2021). In this paper, we presented multimodal analyses and visual models that can capitalize on the multimodal complexities identified within the larger digital reading and writing literature. We argue that multimodal analysis can help researchers consider the quality of digital reading and writing behaviors and how one might coordinate multiple behaviors, modes, or languages across time to support their reading comprehension or develop a composition. These analysis methods and visual models can help the field develop a nuanced understanding of how digital tools shape foundational literacy processes like re-reading, generating ideas, or analyzing literature.
With these understandings, practitioners can tailor their instruction to accommodate all learning styles and the needs of their students, ensuring that each learner’s unique pathway to literacy is appropriately scaffolded with digital tools and resources. Collaborative composing snapshots help to show how teachers can attune to the different modes students may prefer to use for participation. In the example, Kendall, a multilingual learner, seemed to prefer textual modes of participation, as they may have given her more time to think and consider what she wanted to say. Knowing this, her teacher could provide opportunities for typed or written input during instruction, allow for flexible pacing, and invite multimodal contributions that do not rely solely on oral communication. Digital reading timescapes showed how students can use digital tools, like highlighters, in ways that may be counterintuitive to educators. For example, understanding how Student H used the digital highlighter to track his reading and re-reading process, his teacher might reframe highlighting not simply as a surface-level task, but as a strategic behavior to support comprehension, and explicitly teach students to use digital tools as part of a reflective reading process. Additionally, the transmediation models of bilingual high school students underscore the importance of educators designing instruction and assignments that invite translanguaging and multimodal composing to honor students’ full linguistic and semiotic repertoires. These multimodal analyses and visual models can provide new insights for educators to create a more inclusive literacy environment in which all students can grow.
Of course, these multimodal analyses and visual models are only a starting point that future researchers can build from (Cook, 2024; Radnofsky, 1996). For instance, these methods capitalize on qualitatively analyzing the visible behaviors of participants, which here were student readers and writers. Therefore, these methods give insight into the how but not necessarily the why. Future work might pair these methods with reflective think-aloud interviews to incorporate information about why a reader or writer exhibited a particular behavior. Additionally, these multimodal qualitative methods and models are time consuming and only offer insights into the complex behaviors of a small number of readers and writers. In the future, researchers might employ a mixed-method analysis that combines the behaviors found qualitatively with quantitative coding at scale. For example, machine learning and advanced psychometric techniques, informed by studies employing qualitative analyses like those described in this paper, could support the investigation of reading and writing behaviors at scale. Finally, future studies may consider different digital tasks in different disciplines or with different populations.
The multimodal analyses and visual models presented in this paper offer a valuable entry point for examining the complexities of digital reading and writing processes across diverse learners, tools, and contexts. As digital literacy practices increasingly span modes, languages, and platforms, these methods provide researchers and educators with tools to better understand—not simplify or flatten—these dynamic processes. By making complexity visible and analyzable, these approaches support more nuanced theoretical understandings of literacy and inform the design of digital tasks that are developmentally appropriate, inclusive, and equity-oriented. We hope that by illustrating these methods, future studies will build upon and adapt them to explore new questions and elevate the diverse literacies of students.
Author Contributions
Conceptualization, A.Y.S., M.H., B.E.S. and A.P.G. methodology, A.Y.S., M.H., B.E.S. and A.P.G.; formal analysis, A.Y.S., M.H., B.E.S. and A.P.G.; investigation, A.Y.S., M.H., B.E.S. and A.P.G.; data curation, A.Y.S., M.H., B.E.S. and A.P.G.; writing—original draft preparation, A.Y.S., M.H. and B.E.S.; writing—review and editing, A.Y.S. and M.H.; visualization, A.Y.S., M.H. and B.E.S.; project administration, A.Y.S., B.E.S. and A.P.G.; funding acquisition, A.P.G. and B.E.S. All authors have read and agreed to the published version of the manuscript.
Funding
Study 2 was funded through Vanderbilt University’s Trans-Institutional Programs and in part from the Institute of Education Sciences, U.S. Department of Education, Grant number R305A150199. Study 3 was funded by the National Academy of Education and Spencer Foundation. Study 1 received no external funding.
Institutional Review Board Statement
These studies were conducted in accordance with the Declaration of Helsinki. Study 1 was approved by the Institutional Review Board of the University of Tennessee-Knoxville (protocol code UTK IRB-24-08457-XP) on (22 November 2024). Study 2 was approved by the Institutional Review Board of Vanderbilt University (protocol code 150950) on (17 July 2015) and (protocol code 211312) on (15 October 2021). Study 3 was approved by the Institutional Review Board of the University of Miami (protocol code 20160632) on (13 July 2016).
Informed Consent Statement
Informed consent was obtained from all subjects involved in the three studies.
Data Availability Statement
The original data presented in Study 2 are openly available at https://doi-org.utk.idm.oclc.org/10.3886/E195723V1. The datasets presented in Study 1 and Study 3 are not readily available because of privacy.
Acknowledgments
We would like to thank the students, teachers, schools, and districts that participated in these research studies, as well as team members who worked on the projects.
Conflicts of Interest
There are no conflicts of interest to declare.
References
- Bezemer, J., & Kress, G. (2015). Multimodality, learning and communication: A social semiotic frame. Routledge. [Google Scholar]
- Buckley, C. A., & Waring, M. J. (2013). Using diagrams to support the research process: Examples from grounded theory. Qualitative Research, 13(2), 148–172. [Google Scholar] [CrossRef]
- Charmaz, K. (2000). Constructivist and objectivist grounded theory. In N. K. Denzin, & Y. Lincoln (Eds.), Handbook of qualitative research (2nd ed., pp. 509–535). Sage. [Google Scholar]
- Coiro, J. (2021). Toward a multifaceted heuristic of digital reading to inform assessment, research, practice, and policy. Reading Research Quarterly, 56(1), 9–31. [Google Scholar] [CrossRef]
- Cook, R. (2024). Using an “Ethnogram” to visualize talk in the classroom. International Journal of Research & Method in Education, 47(2), 156–169. [Google Scholar]
- Craig, S. L., McInroy, L. B., Goulden, A., & Eaton, A. D. (2021). Engaging the senses in qualitative research via multimodal coding: Triangulating transcript, audio, and video data in a study with sexual and gender minority youth. International Journal of Qualitative Methods, 20, 16094069211013659. [Google Scholar] [CrossRef]
- Dalton, B. (2013). Multimodal composition and the common core state standards. Reading Teacher, 66, 333–339. [Google Scholar] [CrossRef]
- Ehret, C., Hollett, T., Jocius, R., & Wood, S. (2016). Of shoes, shovels, and a digital book trailer: Feeling, power, and adolescent new media making in school. Journal of Literacy Research. [Google Scholar]
- Fazeli, S., Sabetti, J., & Ferrari, M. (2023). Performing qualitative content analysis of video data in social sciences and medicine: The visual-verbal video analysis method. International Journal of Qualitative Methods, 22, 16094069231185452. [Google Scholar] [CrossRef]
- Glaser, B. G., & Strauss, A. L. (1967). The discovery of grounded theory: Strategies for qualitative research. Aldine. [Google Scholar]
- Goodwin, A. P., Cho, S.-J., Reynolds, D., Brady, K., & Salas, J. (2020). Digital versus paper reading processes and links to comprehension for middle school students. American Educational Research Journal, 57(4), 1837–1867. [Google Scholar] [CrossRef]
- Jewitt, C. (2016). The routledge handbook of multimodal analysis. Routledge. [Google Scholar]
- Kress, G. (2010). Multimodality: A social semiotic approach to contemporary communication. Routledge. [Google Scholar]
- Lankshear, C., & Knobel, M. (Eds.). (2007). Sampling the “new” in new literacies. In A new literacies sampler (pp. 1–24). Peter Lang Publishing. [Google Scholar]
- Leu, D. J., Kinzer, C. K., Corio, J., Castek, J., & Henry, L. A. (2013). New literacies: A dual-level theory of the changing nature of literacy, instruction, and assessment. In D. E. Alvermann, N. J. Unrau, & R. B. Ruddell (Eds.), Theoretical models and processes of reading (pp. 1150–1181). International Reading Association. [Google Scholar]
- Lim, F. V. (2019). Investigating intersemiosis: A systemic functional multimodal discourse analysis of the relationship between language and gesture in classroom discourse. Visual Communication, 20(1), 34–58. [Google Scholar] [CrossRef]
- Mohammed, S. S., Knowles, L. A., & Cummings, J. A. (2023). In the eye of the transcriber: Four column analysis structure for qualitative research with audiovisual data. International Journal of Qualitative Methods, 22, 16094069231197332. [Google Scholar] [CrossRef]
- Norris, S. (2004). Analyzing multimodal interaction: A methodological framework. Routledge. [Google Scholar]
- Patton, M. Q. (1990). Qualitative evaluation and research methods (2nd ed.). Sage. [Google Scholar]
- Radnofsky, M. L. (1996). Qualitative models: Visually representing complex data in an image/text balance. Qualitative Inquiry, 2(4), 385–410. [Google Scholar] [CrossRef]
- Serafini, F., & Reid, S. F. (2023). Multimodal content analysis: Expanding analytical approaches to content analysis. Visual Communication, 22(4), 623–649. [Google Scholar] [CrossRef]
- Shimizu, A. Y., Havazelet, M., & Goodwin, A. P. (2024). More than one way: Fifth-graders’ varied digital reading behaviors and comprehension outcomes. AERA Open, 10. [Google Scholar] [CrossRef]
- Shimizu, A. Y., & Santos, J. S. (2022). Third graders collaboratively writing online: Interacting in multiple modalities across multiple spaces to build a tale and community. Language Arts, 100(1), 35–45. [Google Scholar] [CrossRef]
- Siegel, M. (1995). More than words: The generative power of transmediation for learning. Canadian Journal of Education/Revue Canadienne de L’éducation, 20(4), 455–475. [Google Scholar] [CrossRef]
- Šíp, R., & Denglerová, D. (2024). The art of seeing: From 2D to 3D visualization in situational analysis. International Journal of Qualitative Methods, 23, 16094069241272212. [Google Scholar] [CrossRef]
- Smith, B. E. (2017). Composing across modes: A comparative analysis of adolescents’ multimodal composing processes. Learning, Media and Technology, 42(3), 259–278. [Google Scholar] [CrossRef]
- Smith, B. E., Kiili, C., & Kauppinen, M. (2016). Transmediating argumentation: Students composing across written essays and digital videos in higher education. Computers & Education, 102, 138–151. [Google Scholar] [CrossRef]
- Smith, B. E., Pacheco, M. B., & de Almeida, C. R. (2017). Multimodal codemeshing: Bilingual adolescents’ processes composing across modes and languages. Journal of Second Language Writing, 36, 6–22. [Google Scholar] [CrossRef]
- Sommer, V. (2021). Multimodal analysis in qualitative research: Extending grounded theory through the lens of social semiotics. Qualitative Inquiry, 27(8–9), 1102–1113. [Google Scholar] [CrossRef]
- Stake, R. E. (2013). Multiple case study analysis. Guilford Press. [Google Scholar]
- Verdinelli, S., & Scagnoli, N. I. (2013). Data display in qualitative research. International Journal of Qualitative Methods, 12(1), 359–381. [Google Scholar] [CrossRef]
- Wang, D., Olson, J. S., Zhang, J., Nguyen, T., & Olson, G. M. (2015, April 18–23). DocuViz. 33rd Annual ACM Conference on Human Factors in Computing Systems, Seoul, Republic of Korea. [Google Scholar]





Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).