We see from
Figure 4 and
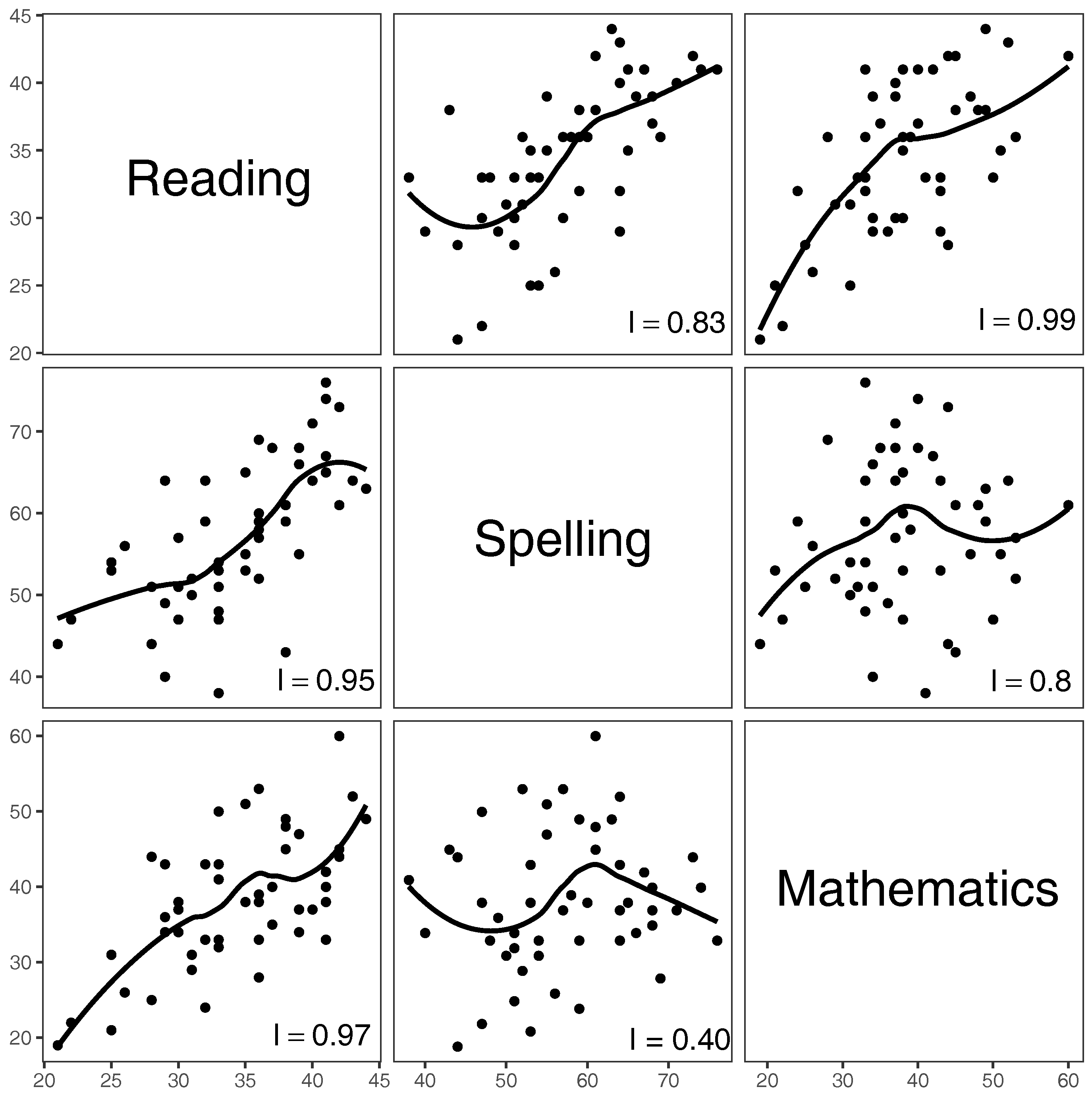
Figure 5 that trends are mostly non-monotonic. In such cases, how can we assess which of the trends are more increasing than others? We can fit linear regression lines as in
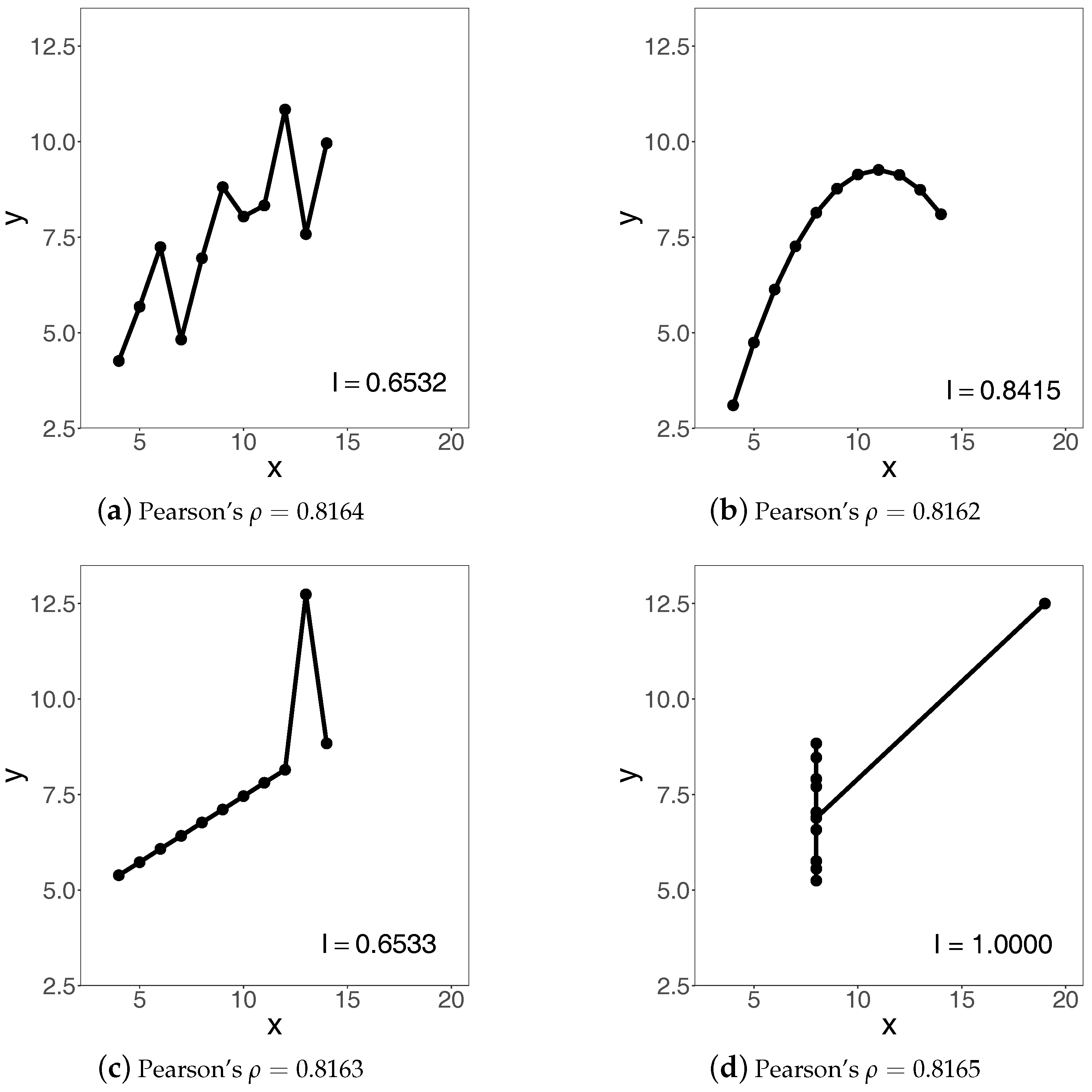
Figure 3 and rank them according to their slopes or, alternatively, on the values of the Pearson correlation coefficient. However, the non-linear and especially non-monotonic trends make such techniques inadequate (e.g., Wilcox [
26]). In this section, therefore, we put forward the idea of an index of increase, whose development has been in the works for a number of years (Davydov and Zitikis [
27,
28]; Qoyyimi and Zitikis [
29,
30]).
Obviously, neither of the two functions is monotonic on the interval, but their visual inspection suggests that sine must be closer to being increasing than cosine. Since one can argue that this assessment is subjective, we therefore employ the aforementioned index whose rigorous definition will be given in a moment. Using the computational algorithm presented in
Section 4 below, the values of the index are
for
and
for
. Keeping in mind that 3 is the normalizing constant, these values imply that sine is at the distance 2 from the set of all decreasing functions on the noted interval, whereas cosine is at the distance 1 from the same set. In other words, this implies that sine is at the distance 1 from the set of all increasing functions on the interval, whereas cosine is at the distance 2 from the set of increasing function. Inspecting the graphs of the two functions in
Figure 6, we indeed see that sine is ‘twice more increasing’ than cosine on the interval
. For those willing to experiment with their own functions on various intervals, we provide a computer code in
Appendix A.1.
The rest of the paper is devoted to a detailed description and analysis of the index.
3.1. Basic Idea
Suppose we possess
pairs
of data (all the indices to be introduced below can be calculated as long as we have at least two pairs), and let—for a moment—all the first coordinates (i.e.,
x’s) be different, as well as all the second coordinates (i.e.,
y’s) be different. Consequently, we can order all the first coordinates in the strictly increasing fashion, thus obtaining
, called order statistics, with the corresponding second coordinates
, called concomitants (e.g., David and Nagaraja [
31]; and references therein). Hence, instead of the original pairs, we are now dealing with the pairs
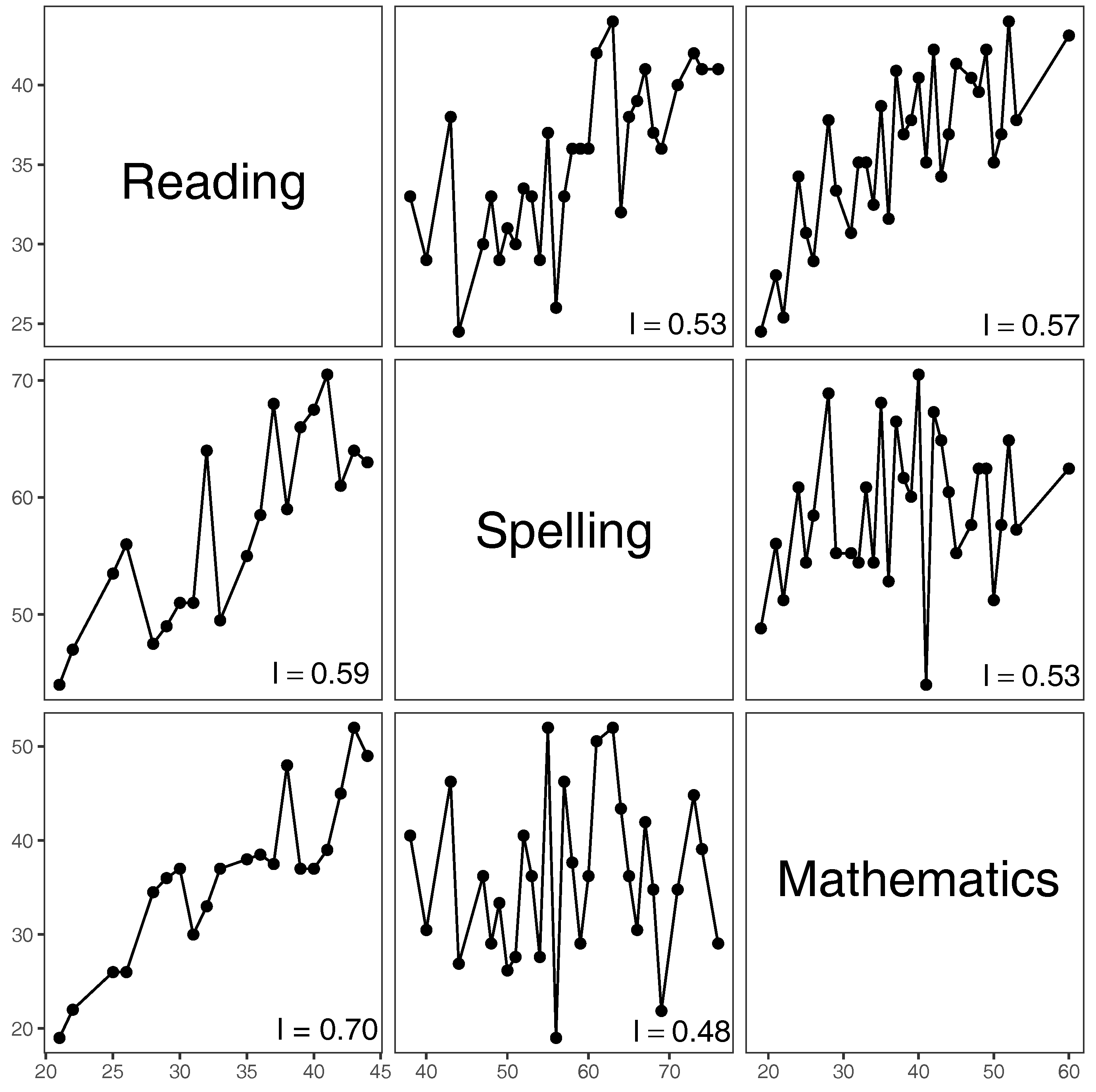
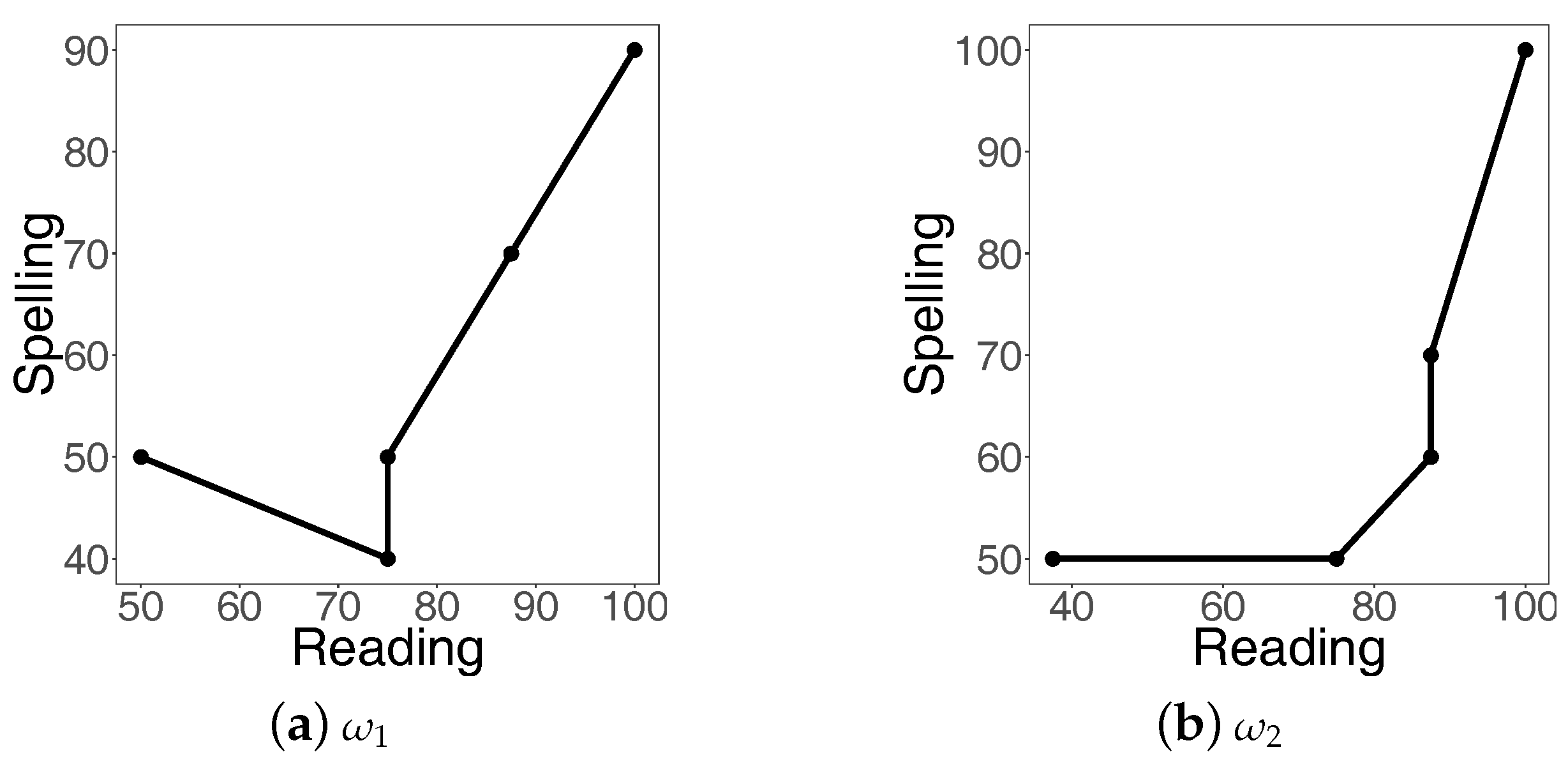
ordered according to their first coordinates. We connect these pairs, viewed as two-dimensional points, using straight lines and, unlike in regression, obtain an unaltered genuine description of the trend exhibited by the first coordinates plotted against the second ones (see
Figure 4). Having the plot, we can now think of a method for measuring its monotonicity, and for this purpose we use the index of increase
where
,
, and
denotes the positive part of real number
z, that is,
when
and
otherwise.
Obviously, the index is not symmetric, that is,
is not, in general, equal to
. This is a natural and desirable feature in the context of the present paper because student performance on different subjects is not interchangeable, and we indeed see this clearly in the figures above. The symmetry of the Pearson, ICC and Spearman correlation coefficients is one of the features that makes their uses inappropriate in a number of applications, especially when the directionality of associations is of particular concern. In general, there is a vast literature on the subject, which goes back to at least the seminal works of C. Gini a hundred years ago (e.g., Giorgi [
32,
33]) and, more generally, to the scientific rivalry between the British and Italian schools of statistical thought. For very recent and general discussions on the topic, we refer to Reimherr and Nicolae [
34]; as well as to Furman and Zitikis [
35], and references therein, where a (non-symmetric) Gini-type correlation coefficient arises naturally and plays a pivotal role in an insurance/financial context.
To work out initial understanding of the index
, we first note that the numerator on the right-hand side of Equation (
1) sums up all the upward movements, measured in terms of concomitants, whereas the denominator sums up the absolute values of all the upward and downward movements. Hence, the index
is normalized, that is, always takes values in the interval
. It measures the proportion of upward movements in the piece-wise linear plot originating from the pairs
. Later in this paper (Note 3), we give an alternative interpretation of, and thus additional insight into, the index
, which stems from a more general and abstract consideration of Davydov and Zitikis [
28]. We note in passing that the index employed by Qoyyimi and Zitikis [
30] is not normalized, and is actually difficult to meaningfully normalize, thus providing yet another argument in favour of the index that we employ in the present paper. A cautionary note is in order.
Namely, definition (
1) shows that the index
can be sensitive to outliers (i.e., very low and/or very high marks). The sensitivity can, however, be diminished by removing a few largest and/or smallest observations, which would mathematically mean replacing the sum
in both the numerator and the denominator on the right-hand side of Equation (
1) by the truncated sum
for some integers
. This approach to dealing with outliers has successfully worked in Statistics, Actuarial Science, and Econometrics, where sums of order statistics and concomitants arise frequently (e.g., Brazauskas et al. [
36,
37]; and references therein). In our current educational context, the approach of truncating the sum is also natural, because exceptionally well and/or exceptionally badly performing students have to be, and usually are, dealt with on the individual basis, instead of treating them as members of the statistically representative majority. This approach of dealing with outliers is very common and, in particular, has given rise to the very prominent area called Extreme Value Theory (e.g., de Haan and Ferreira [
38]; Reiss and Thomas [
39]; and references therein) that deals with various statistial aspects associated with exceptionally large and/or small observations.
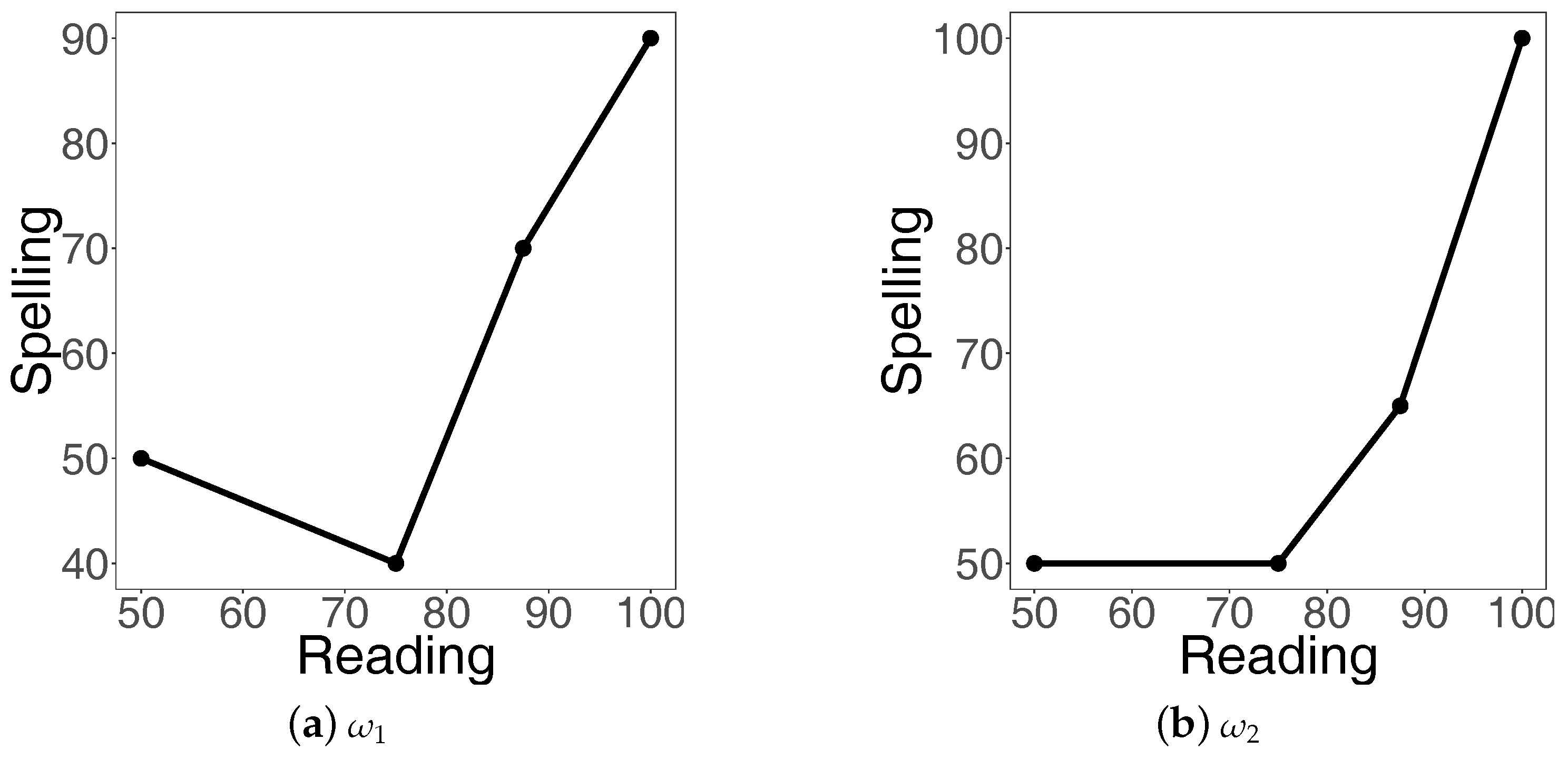
We next modify the index so that its practical implementation would become feasible for all data sets, and not just for those whose all coordinates are different.
3.2. A Practical Modification
The earlier made assumption that the first and also the second coordinates of paired data are different prevents the use of the above index on many real data sets, including that of Thorndike and Thorndike-Christ [
19] (pp. 24–25) as we see from the frequency histograms in
Figure 2. See also panel (d) in
Figure 1 for another example. Hence, a natural question arises: how can piece-wise linear plots be produced when there are several concomitants corresponding to the single value of a first coordinate? To overcome the obstacle, we suggest using the median-based approach that we describe next.
Namely, given
arbitrary pairs
, the order statistics of the first coordinates are
with the corresponding concomitants
. Let there be
m (
) distinct values among the first coordinates, and denote them by
. For each
, there is always at least one concomitant, usually more, whose median we denote by
. Hence, we have
m pairs
whose first coordinates are strictly increasing (i.e.,
) and the second coordinates are unique. We connect these
m pairs, viewed as two-dimensional points, with straight lines and obtain a piece-wise linear plot (e.g.,
Figure 4). The values of the index
reported in the right-bottom corners of the panels of
Figure 4 refer to the following modification
of the earlier defined index of increase. Note that index (
2) collapses into index (
1) when all the coordinates of the original data are different, thus implying that definition (
2) is a genuine extension of definition (
1), and it works on all data sets.
The index of increase is translation and scale invariant, which means that the equation
holds for all real ‘locations’
and
, and all positive ‘scales’
and
. A formal proof of this property is given in
Appendix B. The property is handy because it allows us to unify the scales of each subject’s scores, which are usually different. In our illustrative example, the Mathematics scores are from 0 to 65, the Reading scores are from 0 to 45, and those of Spelling are from 0 to 80. Due to property (
3), we can apply—without changing the value of
—the linear transformation
on the original scores
, thus turning them into percentages, where
is the maximal possible score for the subject under consideration, like 65 for Mathematics.
3.3. Discussion
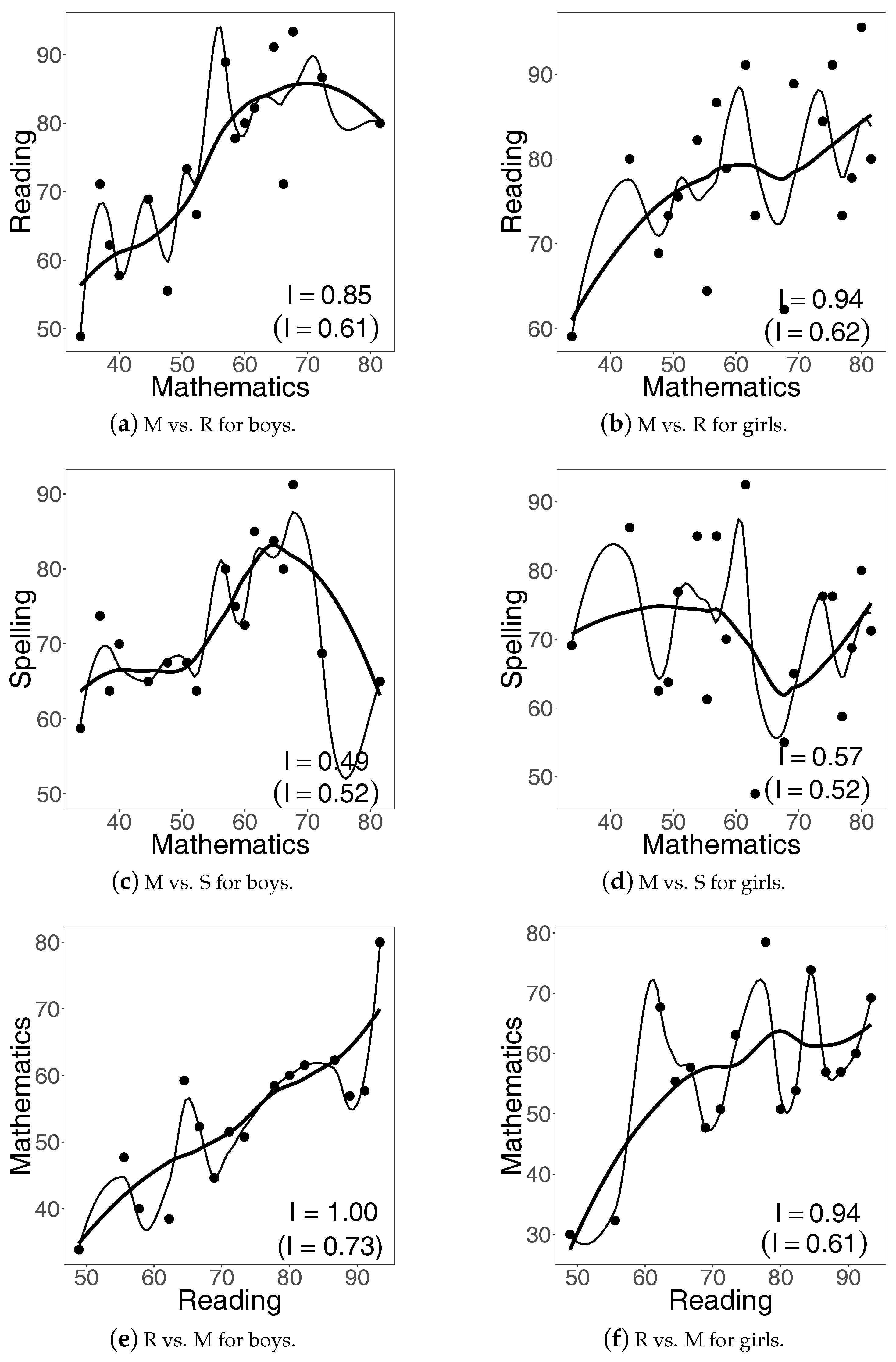
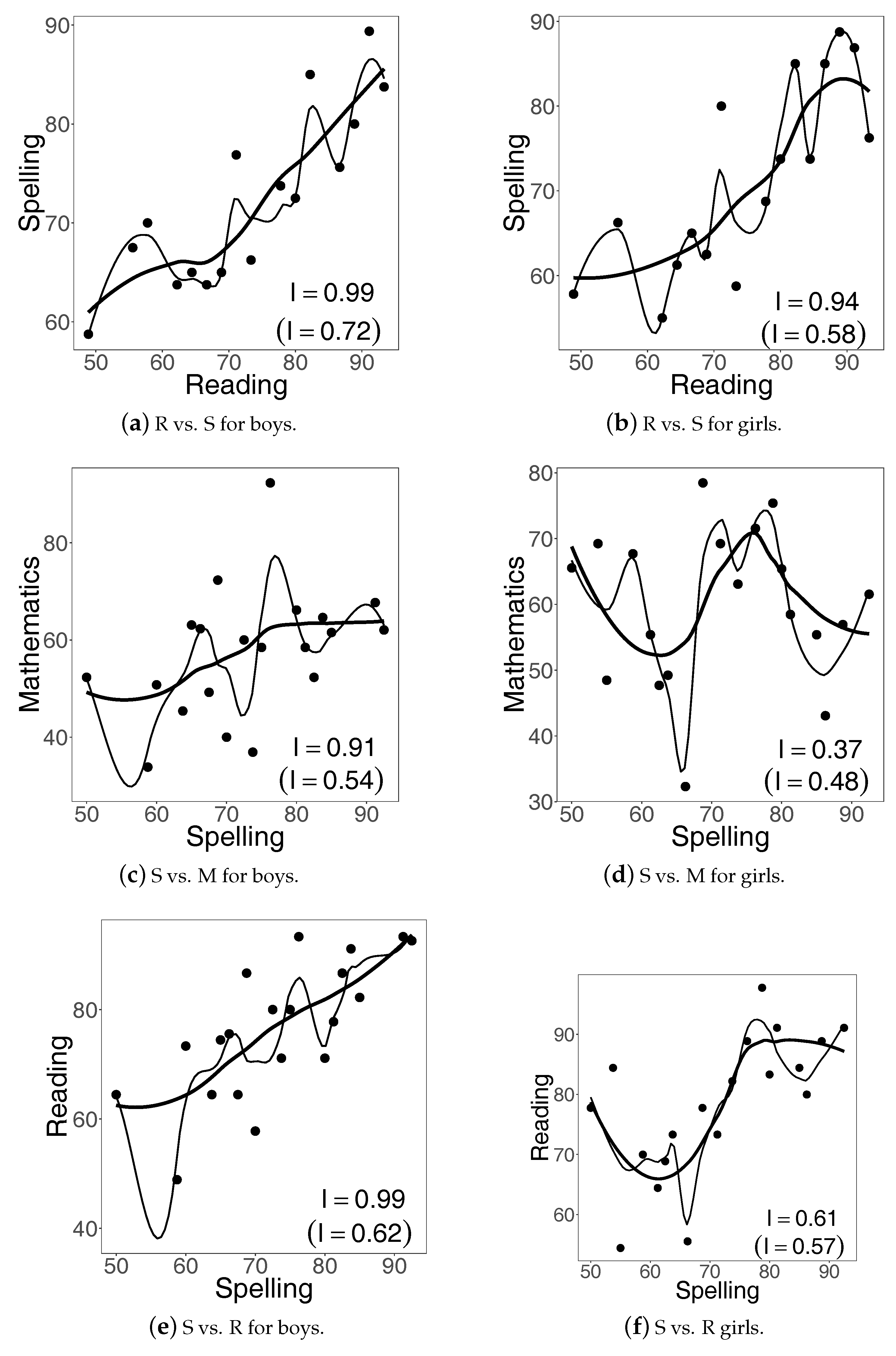
To facilitate a discussion of the values of the index
reported in the panels of
Figure 4, we organize the values in the tabular form as follows:
The value 0.70 for Reading vs. Mathematics is largest, thus implying the most increasing trend among the panels. The value suggests that there is high confidence that those performing well in Reading would also perform well in Mathematics. Note that the value 0.57 for Mathematics vs. Reading is considerably lower than 0.70, thus implying lower confidence that students with better scores in Mathematics would also perform better in Reading.
The index value of Spelling vs. Mathematics is the smallest (0.48), which suggests neither an increasing nor a decreasing pattern, and we indeed see this in the middle-bottom panel of
Figure 4: the scores in Mathematics form a kind of noise when compared to the scores in Spelling. In other words, the curve in the panel fluctuates considerably and the proportion of upward movements is almost the same as the proportion of downward movements. On the other hand, higher scores in Mathematics seem to be slightly better predictors of higher scores in Spelling, with the corresponding index value equal to 0.53.
Finally, the values of Reading vs. Spelling and Spelling vs. Reading are fairly similar, 0.59 and 0.53 respectively, even though higher Reading scores might suggest higher Spelling scores in a slightly more pronounced way than higher Spelling scores would suggest higher Reading scores.
Note 1. On a personal note, having calculated the indices of increase for the three subjects and then having looked at the graphs of
Figure 4, the authors of this article unanimously concluded that the trends do follow the patterns suggested by the respective index values. Yet, interestingly, prior to calculating the values and just having looked at the graphs, the authors were not always in agreement as to how much and in what form a given study subject influences the other ones. In summary, even though no synthetic index can truly capture every aspect of raw data, they can nevertheless be useful in forming a consensus about the meaning of data.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
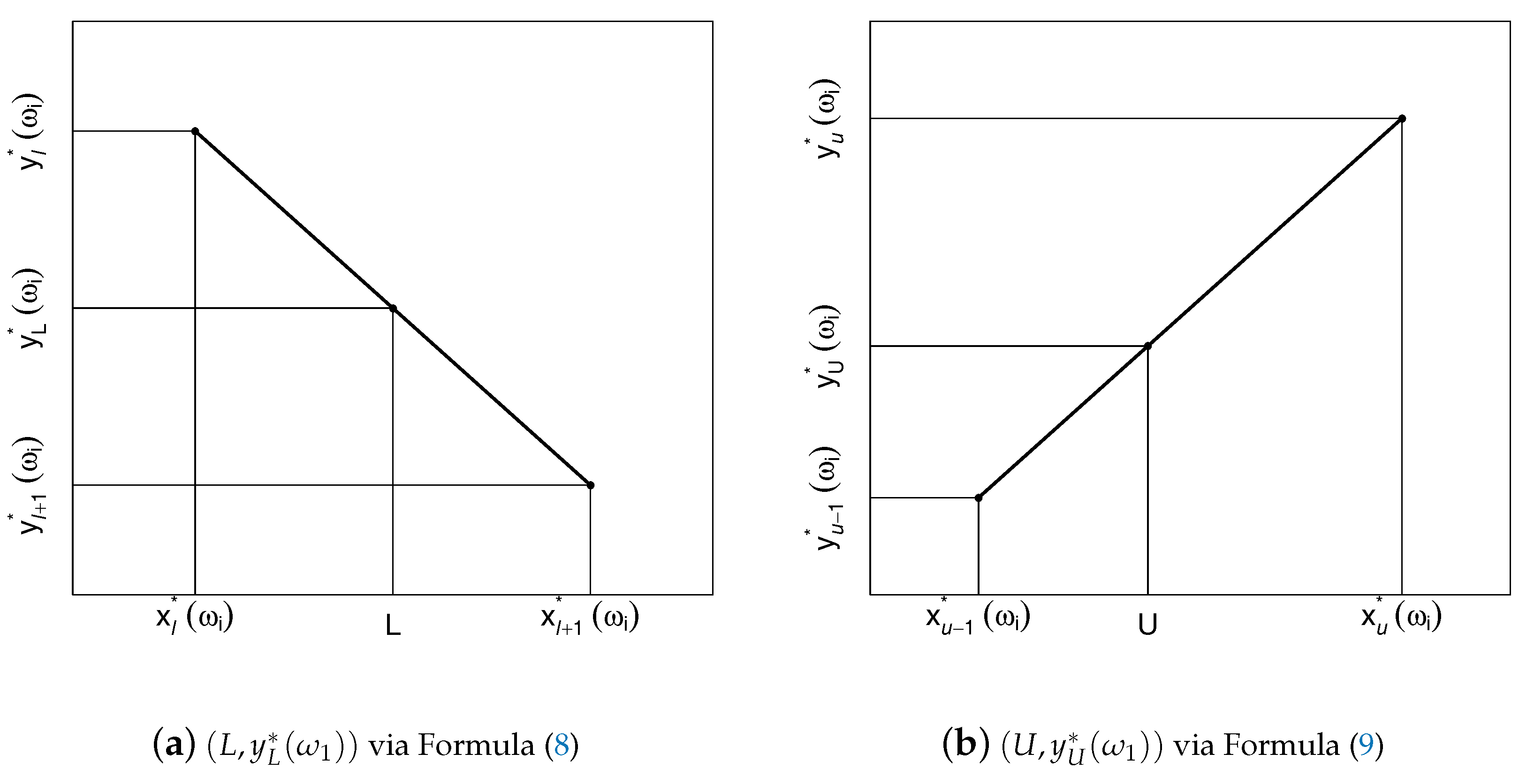{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}