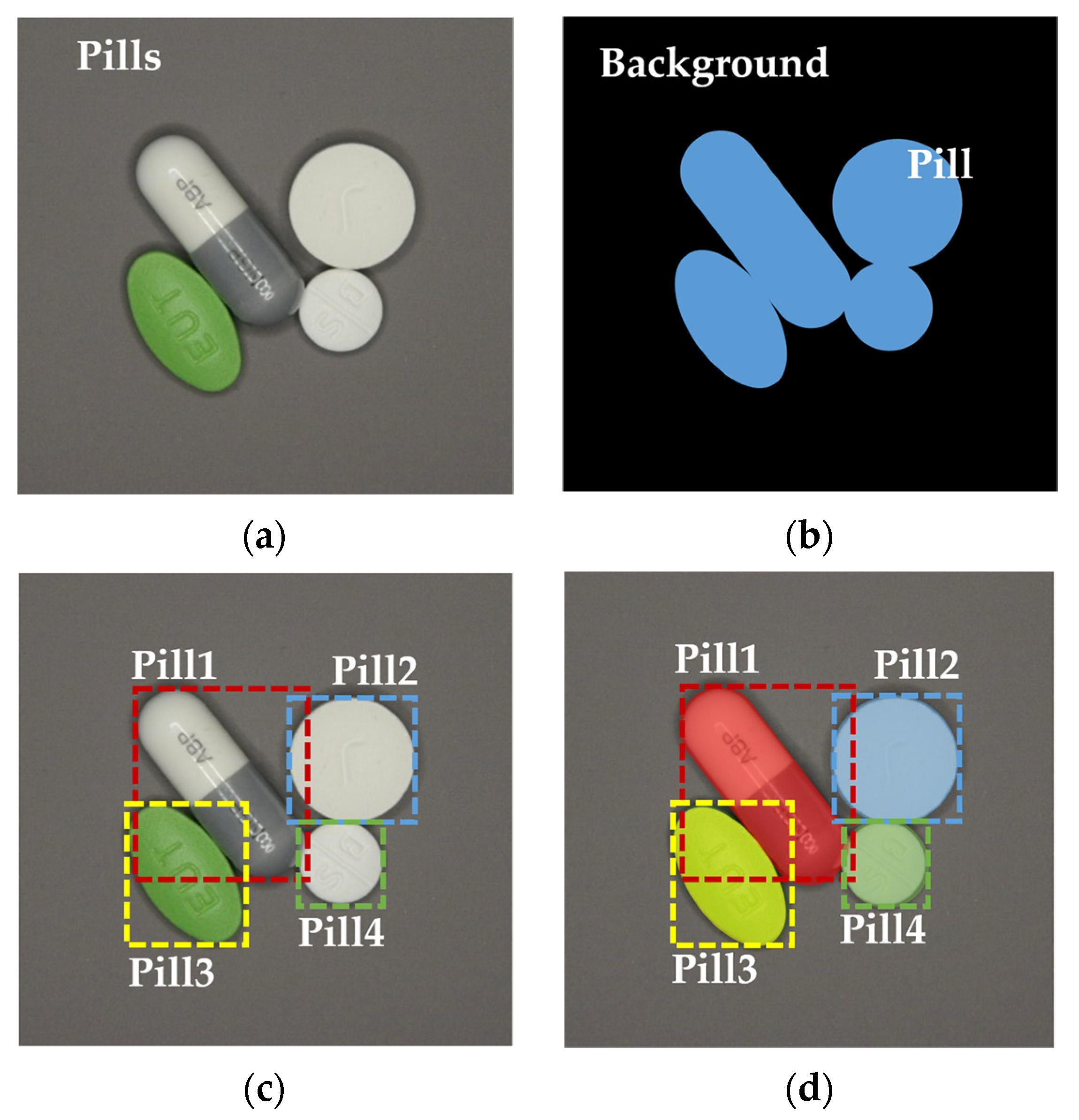
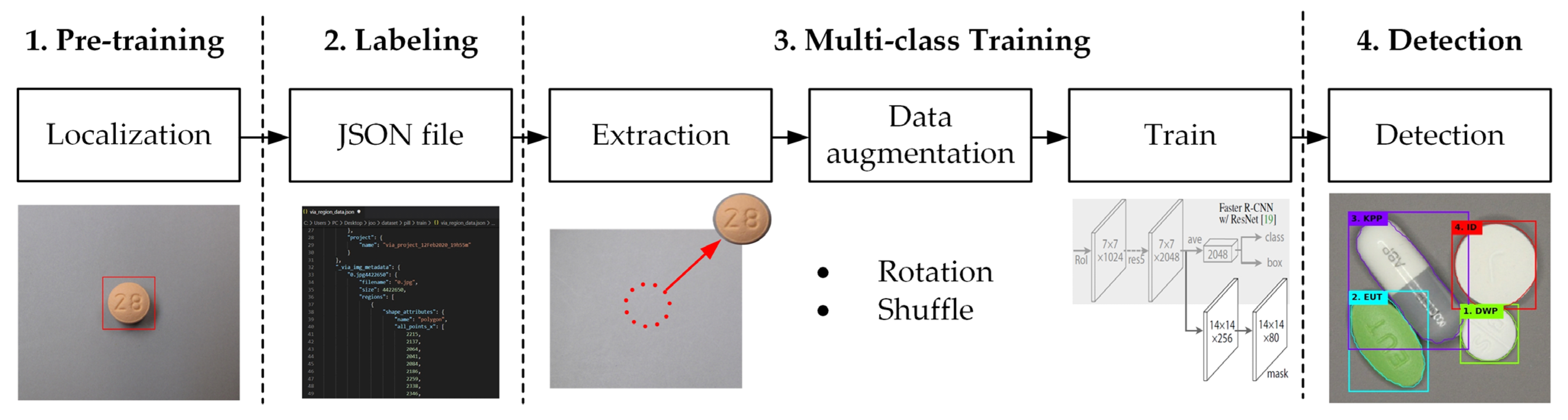
4.1. Pill Area Detection Experiment
The first stage is a model for detecting the number of pills and the area of the pills in the image regardless of the type of pills. Therefore, when learning, the parameter is set as a single “Pill” class without class classification according to the type of pill.
Figure 12 and
Figure 13 are experiments to improve the performance of the first-stage pill area detection.
Figure 12 shows an image in which only one pill was used as the training data during the first-step model training. In
Figure 12, we used six kinds of pills for the training data. Each image consists of a pill that is placed in various directions and positions. Each image was taken as two images with different exposures using the bracketing function of the camera, and 600 images were used for learning. Data augmentation was not used during training, and the epoch was fixed at 100.
Figure 12a shows the training data set, and
Figure 12b shows the result of area detection.
Figure 12b shows over-detection, that is, detecting a larger area than the area of some pills. To solve this over-detection problem, the pill area dectection model was retrained using images containing multiple pills (see
Figure 13).
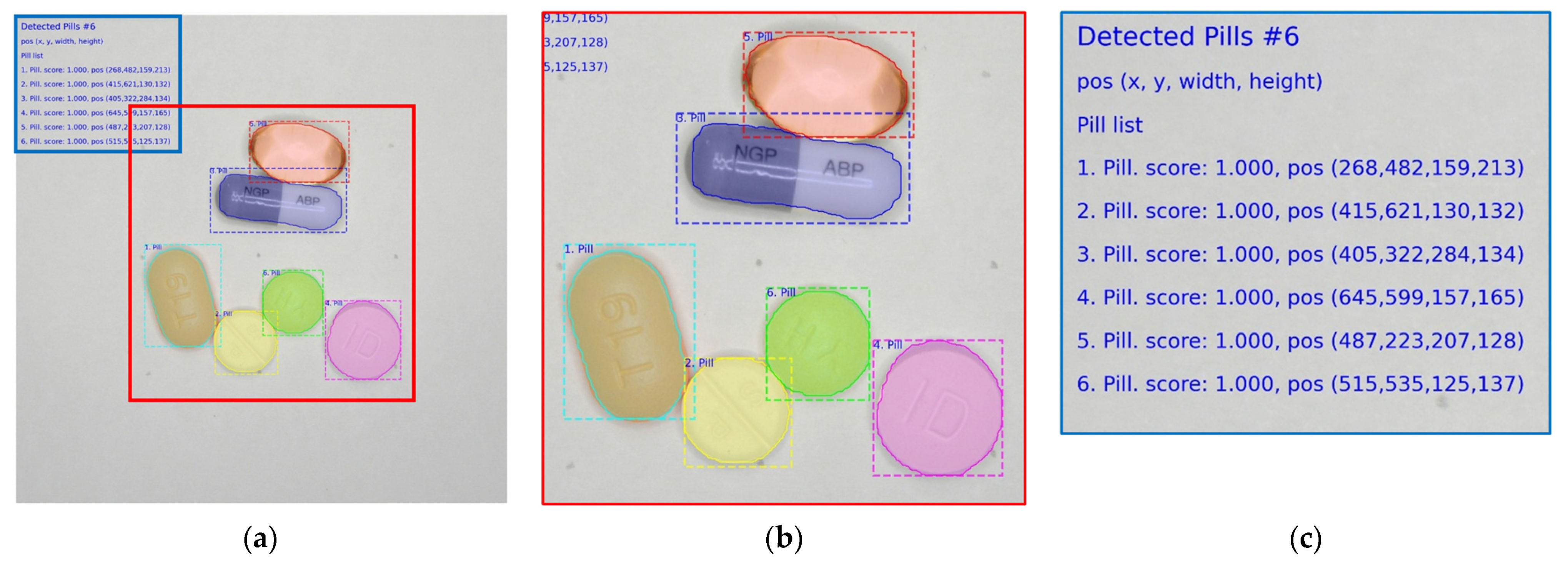
Figure 13a shows a part of the image used for training. The image includes six kinds of pills; each image contains five to six pills, and the location of the pills is variously arranged. Each image was taken as two images with different exposures using the bracketing function of the camera, and 50 images were used for training. The polygonal coordinates were manually indicated for each image. Data augmentation was not used during training, and the epoch was fixed at 20.
Figure 13b is the detection result of the pill area. In the image on the left of
Figure 13b, all the pill positions are accurately displayed. In the image on the right of
Figure 13b, the pill area is accurately displayed without over-detection or non-detection for pills not used for other backgrounds and for learning.
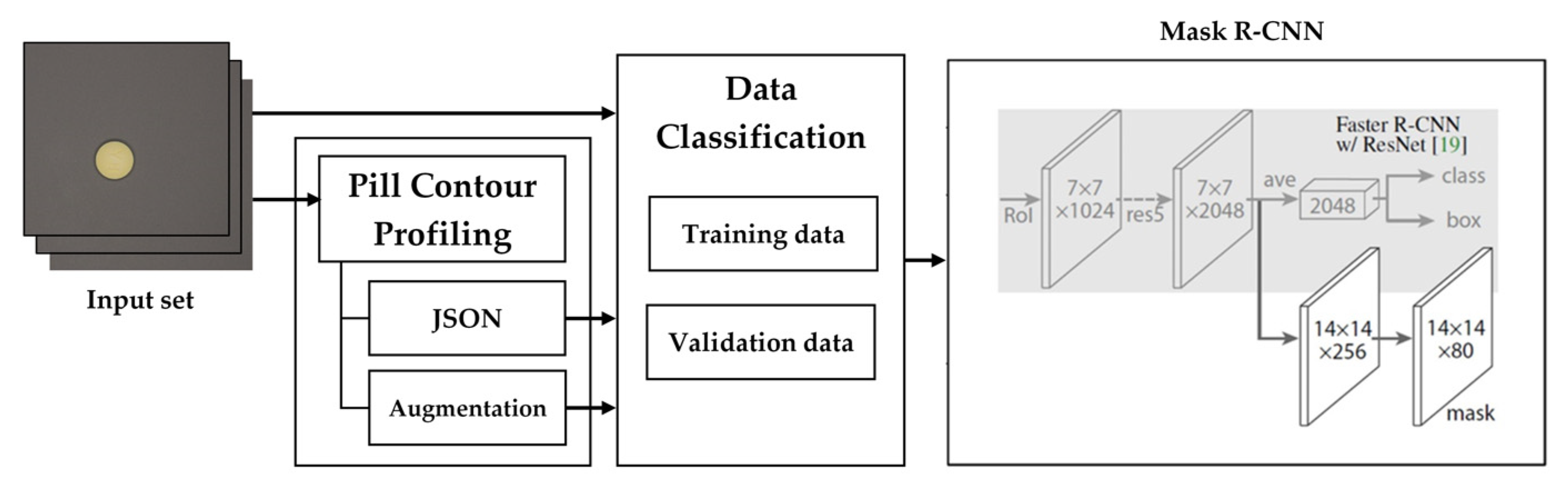
4.2. Pill Label Detection Experiment
For two-step multi-class pill detection, the training data for 27 kinds of pills (including 10 kinds of white pills) were generated. The training data consisted of a single pill image and polygonal coordinates that represented the pill area of each image. When shooting a learning video, the shutter speed of the camera was adjusted to shoot images simultaneously with different amounts of exposure, and the position of the pill was changed for each shot. The position of the pill was physically changed, such as left–right inversion, 45° unit rotation, and eight-direction movement along the up, down, left, and right diagonals. To compensate insufficient data during learning, the images were rotated at an arbitrary angle ranging from −180° to +180°, while 30% of the total data were used for validation.
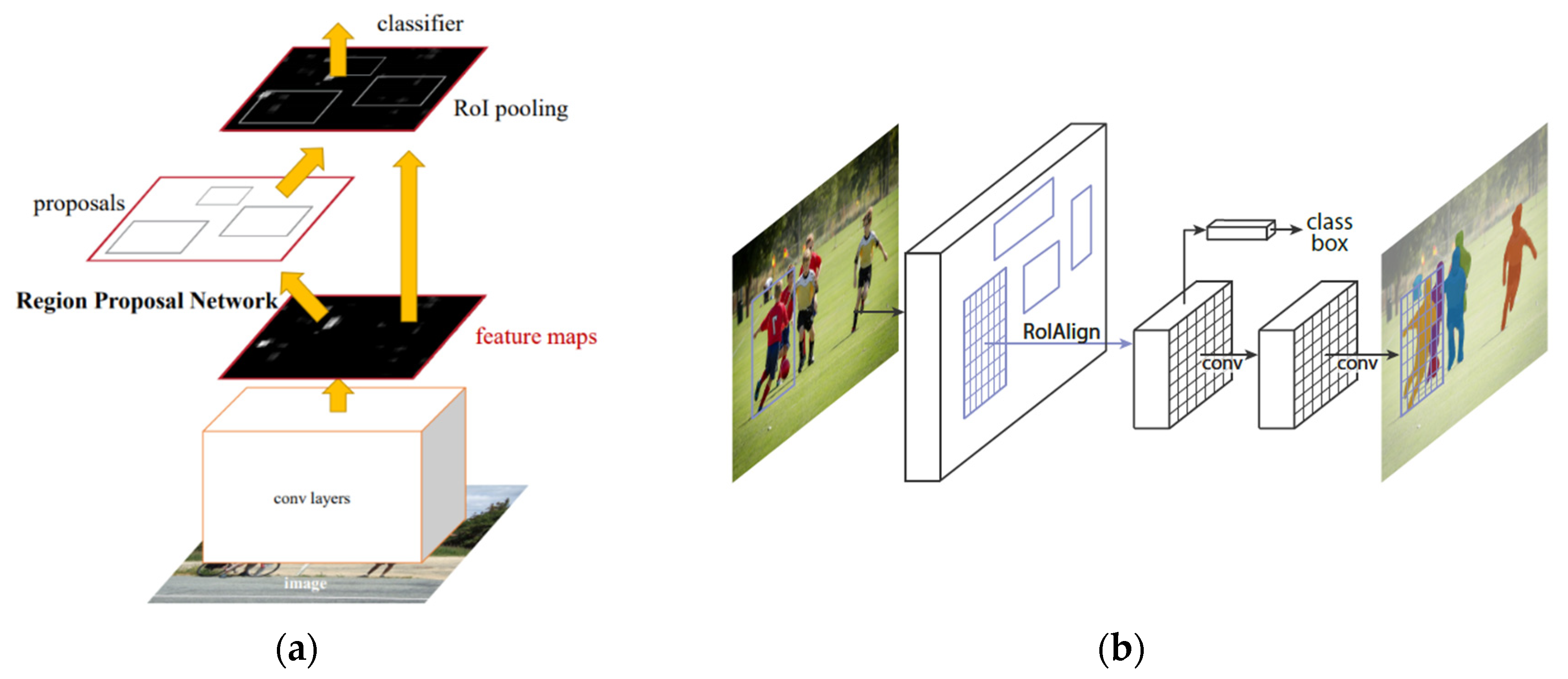
The two-step learning model is based on Mask R-CNN [
30]. The input image size was 1024 × 1024, and the color space was RGB. The batch size was 4, and the learning rate was 0.01. Backbone ResNet50 was used as the network. We also used Python 3.6, Tensorflow 1.14, and Keras 2.1.3 frameworks on the Windows 10 operating system.
Unlike the case for chromatic pills, the number of false positives for white pills increases as the class increases.
Table 1 shows false detection result. In the case of white pills photographed in the lateral direction, it is difficult to distinguish between the round and oval shapes even with the naked eye. Overfitting occurred due to relatively insufficient data. Therefore, to improve the detection performance of white pills, additional images were taken in the lateral direction when photographing white pills. In addition, the shooting direction is in four diagonal directions and a 45° angle, and the number of side training data doubled as compared with the previous case. By changing the shooting background to gray (N5) with a reflectance of 50%, the boundary between the white pills was well distinguished.
Table 2 shows the final capturing conditions as well as training and test settings.
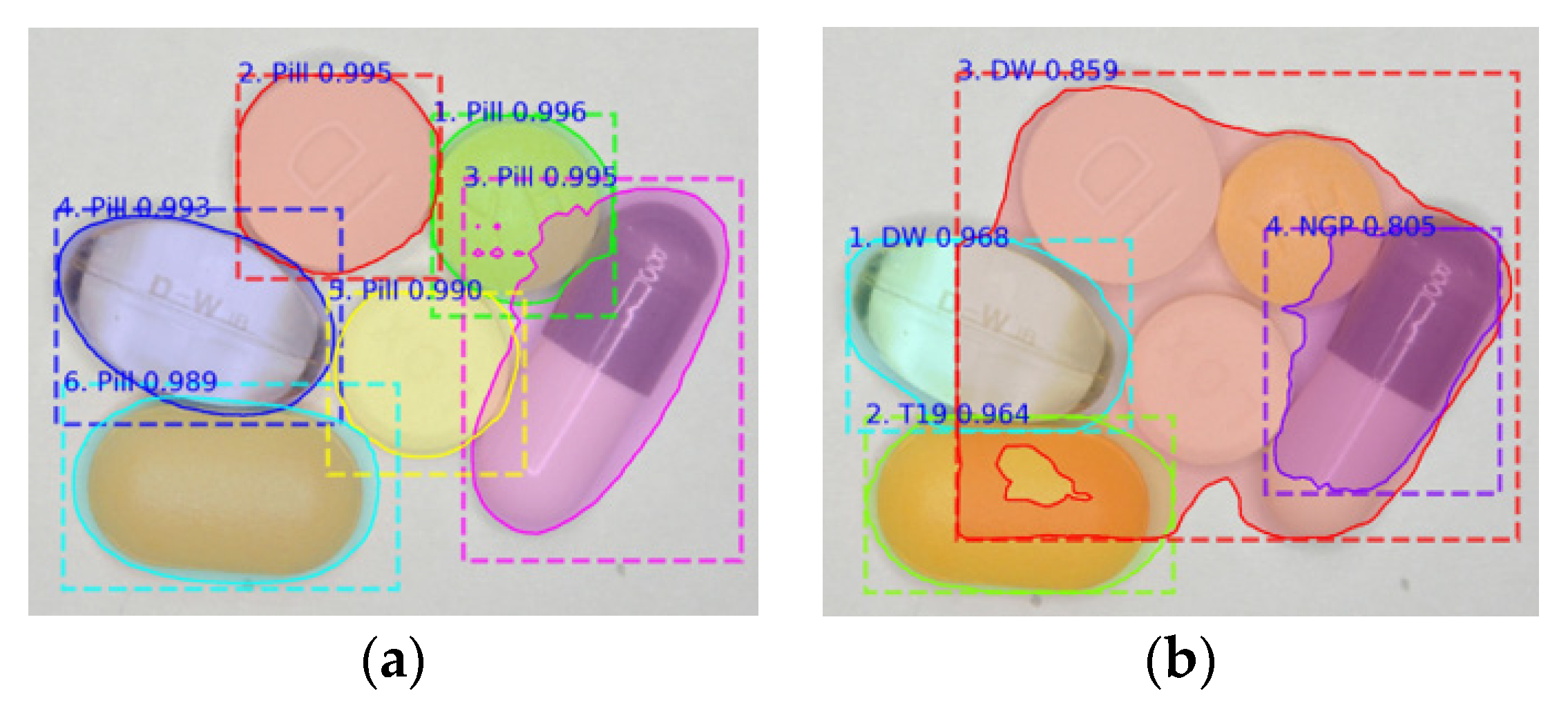
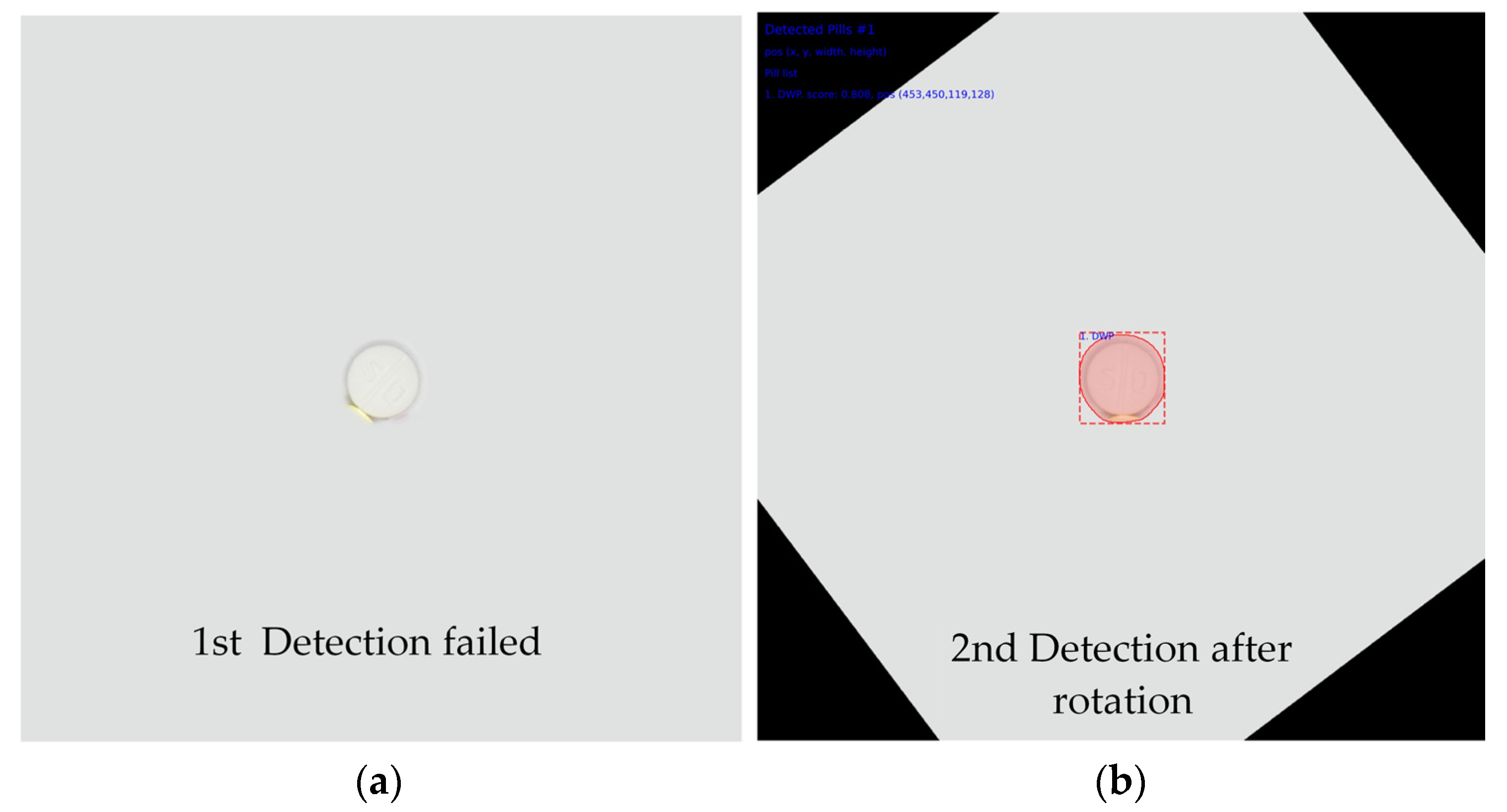
Figure 14 and
Figure 15 show the performance of the proposed two-step learning model.
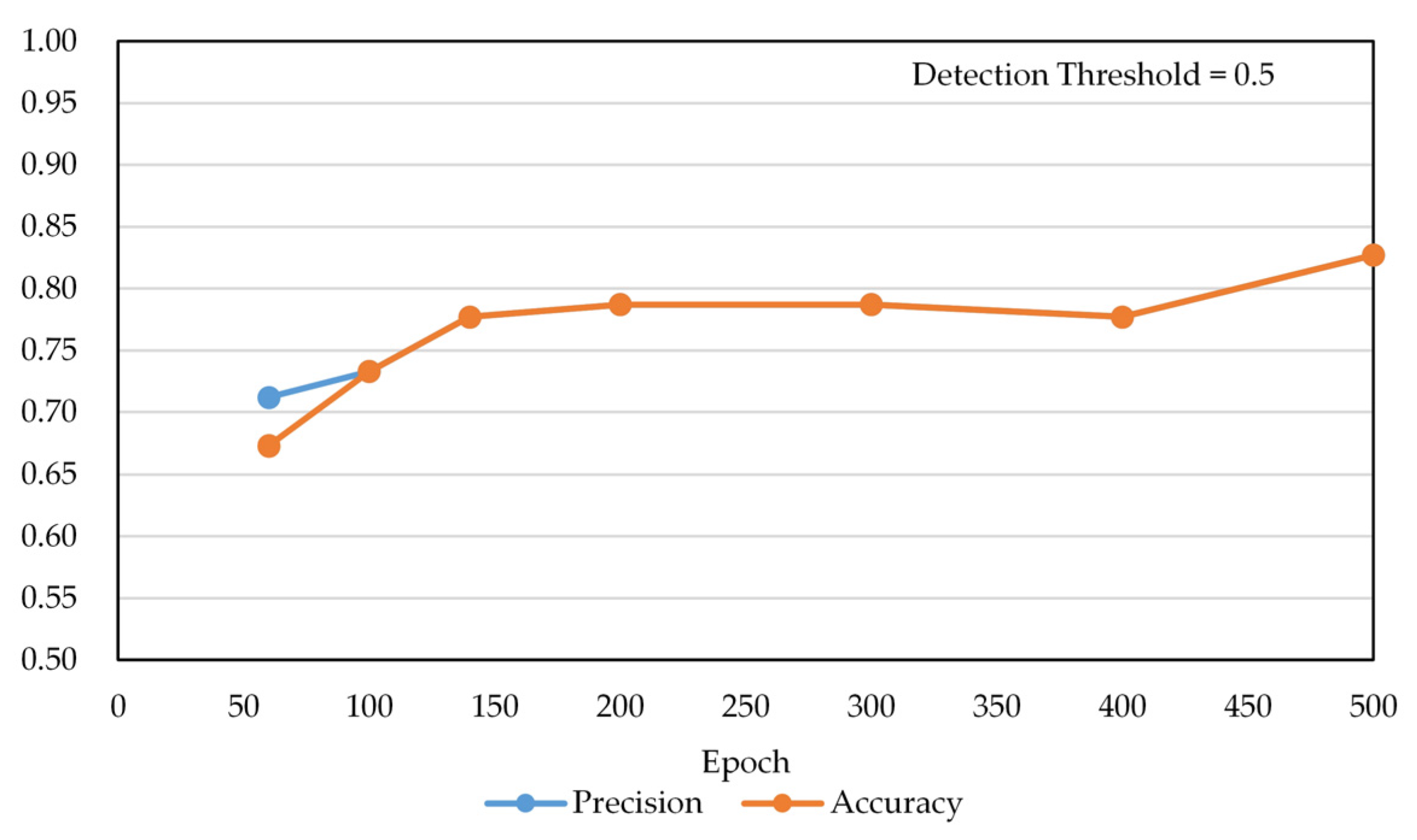
Figure 14 shows the results of not using post-processing when detecting multi-class pills, and
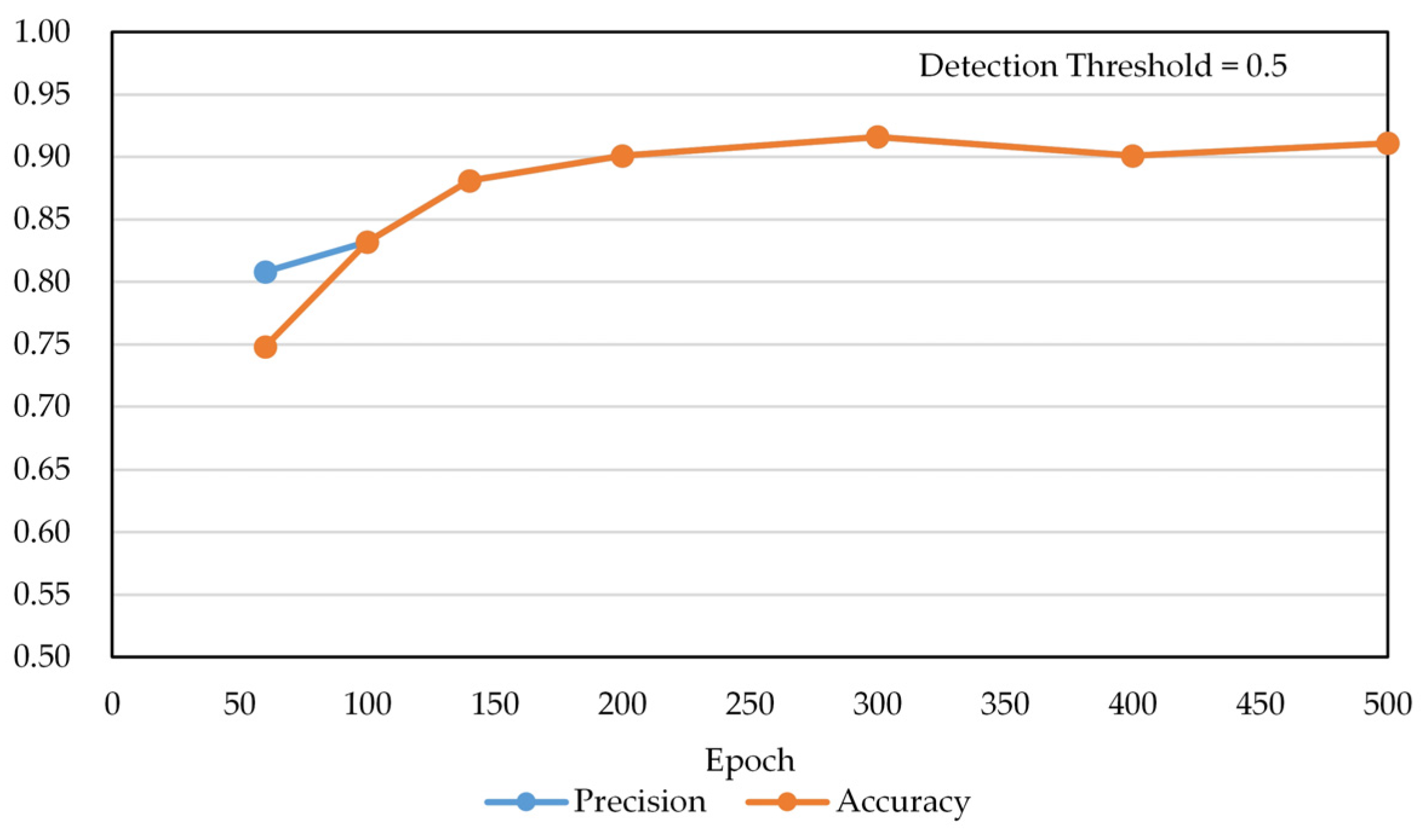
Figure 15 shows the results of applying post-processing.
Table 3 shows the numerical results of
Figure 14 and
Figure 15. The precision and accuracy values were improved by 10–16% in the learning range of less than 500 epochs depending on the area expansion and detection improvement post-processing. The post-processing model shows the best performance at 300 epochs. Accuracy is lower than precision at 60 epochs because FN cases occur, and FN cases do not happen above 100 epochs, so accuracy and precision have the same score. In
Table 3, we used two evaluation metrics, namely precision and accuracy, to compare the performance according to the epoch.
where TP, FP, and FN symbolize the true positive, false positive, and false negative, respectively.
Table 4 and
Table 5 show the detection results for the front and sideways position of the pills with and without post-processing. Overall, we can see that the detection rate for the frontal image of a pill is higher than that for the sideways image. The results of
Table 5 with post-processing show better performances than the results of
Table 4 without post-processing. Finally,
Table 6 shows the detection rate of the sideways image according to the conversion of the capturing conditions 1 and 2 (Set 1 and Set 2). By additionally taking data for the side of the white pill, we confirmed that the detection performance of Set 2 was higher than that of Set 1. The detection ratio is represented by
.
Table 7 represents the computational time of the proposed method without and with post-processing. The number of images used for the test is 50, and the number of pills is 202. The computational speed of 202 pills is 98.70 s without post-processing and 108.11 s with post-processing. The average per pill is 0.49 s without post-processing and 0.54 s with post-processing.
We compared the results of the proposed method with YOLOv3 [
31]. The training data of YOLOv3 consist of single pill images, and multi pill images are used for testing without proposed foreground-background segregation and post-processing. The images used for training and testing of YOLOv3 are the same as those of the proposed method. The input image size is 416 × 416, and the color space is RGB. The batch size is 64, and the learning rate is 0.001. Other parameters and data augmentation options use default values. The training is set to 10,000 iterations and this iteration can be calculated with approximately 880 epochs.
Table 8 shows the results of YOLOv3 and the proposed method. The precision of YOLOv3 is higher than that of the proposed method, but the accuracy of YOLOv3 is lower than that of the proposed method because the FN of the proposed method is 0. Therefore, the proposed method is better than YOLOv3 in terms of detection performance.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}












