
Process-Oriented Profiling of Speech Sound Disorders
 ,
,
Abstract
:1. Introduction
1.1. Speech Development
1.2. Current Practice in Speech Assessments and Interpretation
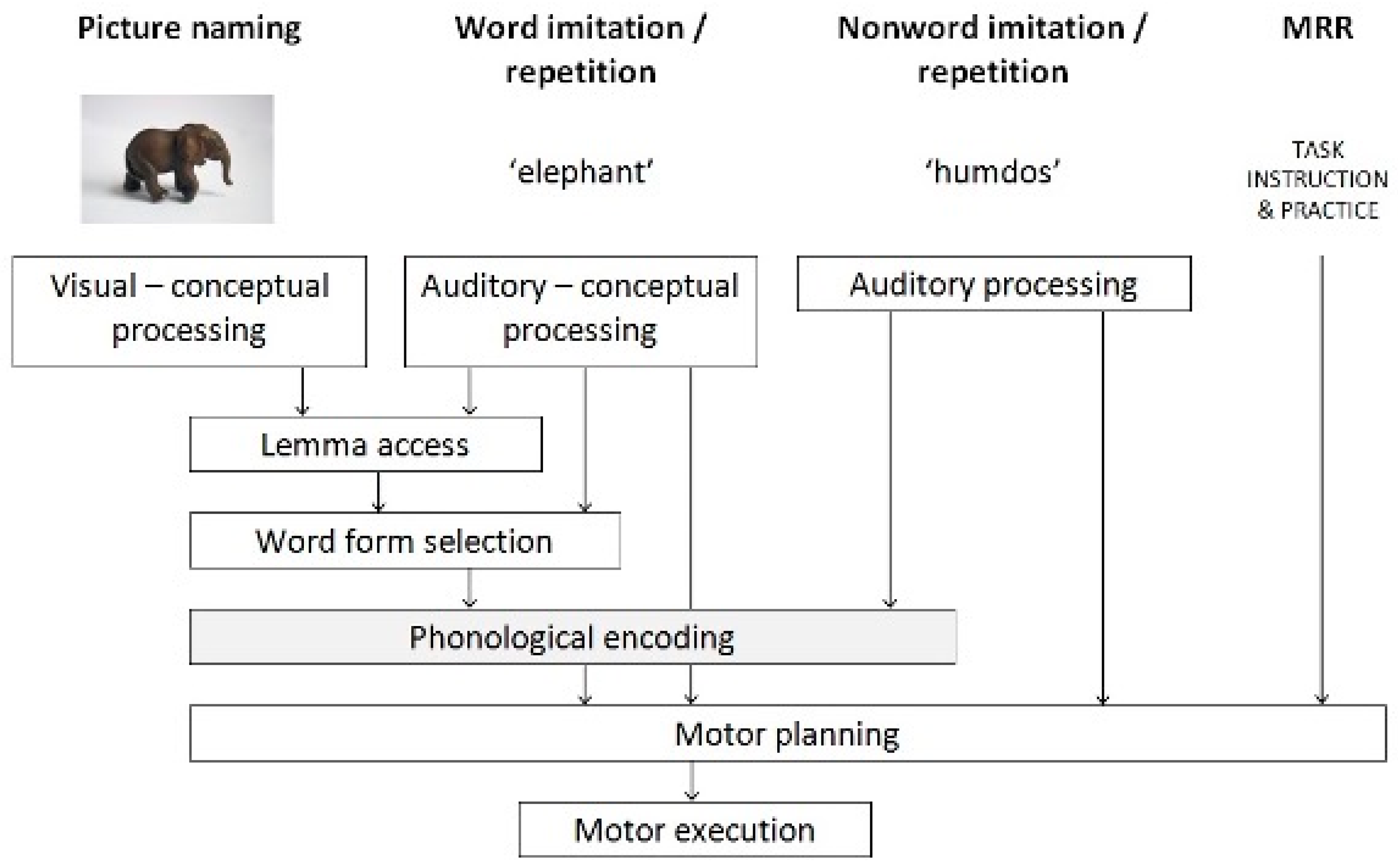
1.3. Diagnostic Profiling within the Psycholinguistic Framework
2. Materials and Methods
2.1. Participants
- Aged 4;0 to 6;11 (years;monthts);
- Dutch as the primary language as indicated by parental report;
- No history of hearing problems based on parents’ or caregivers’ information (further indicated by care givers) about the child’s hearing status;
- A speech sound disorder (SSD) diagnosed by the referring SLP.
2.2. Data Collection
2.3. Materials
2.4. Data Analysis
2.5. Statistical Analysis
3. Results
3.1. Principal Component Analysis
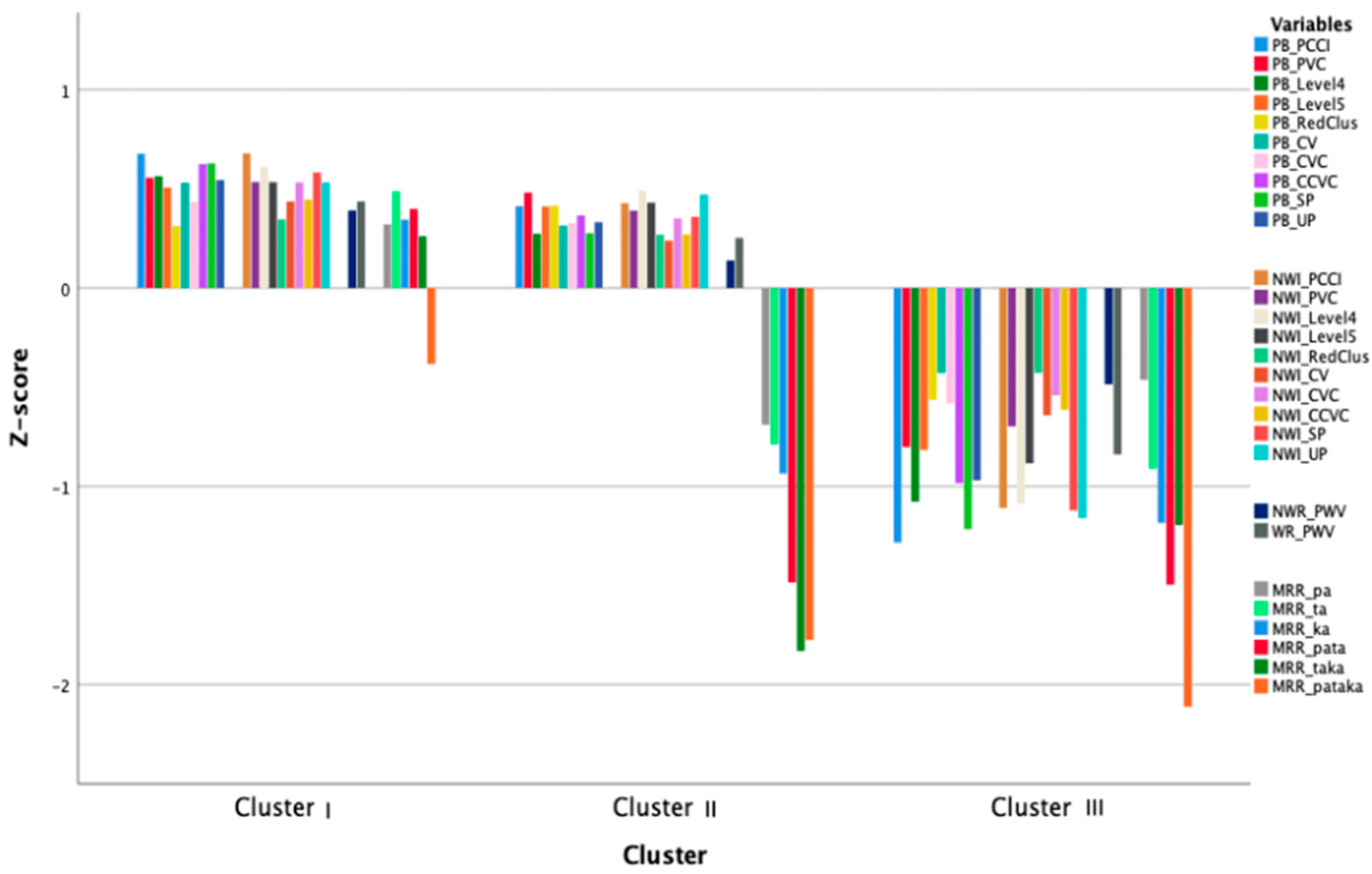
3.2. Cluster Analysis
3.3. Cluster Comparison with Non-CAI Variables
3.4. Comparison of Clusters and Components
4. Discussion
4.1. Step 1. Which Components Emerged and How Do These Compare to Norm Group Outcomes?
4.2. Which Clusters Emerged?
4.3. How Do the Different Clusters Compare to Each Other and to Norm Data?
4.4. How Do These Relate to Diagnostic Classification Systems?
4.4.1. Dodd’s Model for Differential Diagnosis (MDD)
4.4.2. Speech Disorders Classification System (SDCS)
4.5. Clinical Implications and Future Research
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Eadie, P.; Morgan, A.; Ukoumunne, O.C.; Ttofari Eecen, K.; Wake, M.; Reilly, S. Speech sound disorder at 4 years: Prevalence, comorbidities, and predictors in a community cohort of children. Dev. Med. Child Neurol. 2015, 57, 578–584. [Google Scholar] [CrossRef] [PubMed]
- Wren, Y.; Miller, L.L.; Peters, T.J.; Emond, A.; Roulstone, S. Prevalence and predictors of persistent speech sound disorder at eight years old: Findings from a population cohort study. J. Speech Lang. Hear. Res. 2016, 59, 647–673. [Google Scholar] [CrossRef] [PubMed]
- Shriberg, L.D.; Tomblin, J.B.; McSweeny, J.L. Prevalence of speech delay in 6-year-old children and comorbidity with language impairment. J. Speech. Lang. Hear. Res. 1999, 42, 1461–1481. [Google Scholar] [CrossRef]
- Association, A.S.-L.-H. Speech Sound Disorders: Articulation and Phonology (Practice Portal). Available online: www.asha.org/Practice-Portal/Clinical-Topics/Articulation-and-Phonology/ (accessed on 1 May 2022).
- Bernthal, J.E.; Bankson, N.W.; Flipsen, P. Articulation and Phonological Disorders: Speech Sound Disorders in Children; Pearson: Boston, MA, USA, 2017. [Google Scholar]
- Levelt, W.J. Spoken word production: A theory of lexical access. Proc. Natl. Acad. Sci. USA 2001, 98, 13464–13471. [Google Scholar] [CrossRef] [PubMed]
- Maassen, B. Developmental models of childhood apraxia of speech. In Routledge Handbook of Communication Disorders; Bahr, R.H., Silliman, E.R., Eds.; Routledge: New York, NY, USA, 2015; pp. 124–133. [Google Scholar]
- Namasivayam, A.K.; Coleman, D.; O’Dwyer, A.; van Lieshout, P. Speech Sound Disorders in Children: An Articulatory Phonology Perspective. Front. Psychol. 2020, 10, 2998. [Google Scholar] [CrossRef]
- Terband, H.; Maassen, B.; Maas, E. A Psycholinguistic Framework for Diagnosis and Treatment Planning of Developmental Speech Disorders. Folia Phoniatr. Et Logop. 2019, 71, 216–227. [Google Scholar] [CrossRef]
- Levelt, W.J.M. Speaking: From Intention to Articulation; MIT Press: Cambridge, MA, USA, 1989. [Google Scholar]
- Maassen, B.; Terband, H. Process-oriented diagnosis of Childhood and adult Apraxia of Speech (CAS & AOS). In Handbook of Speech Production; Redford, M.A., Ed.; Wiley-Blackwell: Malden, MA, USA, 2015. [Google Scholar]
- Stackhouse, J.; Wells, B. Children’s Speech and Literacy Difficulties: A Psycholinguistic Framework; John Wiley & Sons Incorporated: Hoboken, NJ, USA, 1997; Volume 9. [Google Scholar]
- Van Haaften, L.; Diepeveen, S.; van den Engel-Hoek, L.; Jonker, M.; de Swart, B.; Maassen, B. The psychometric evaluation of a speech production test battery for children: The reliability and validity of the Computer Articulation Instrument. J. Speech Lang. Hear. Res. 2019, 62, 2141–2170. [Google Scholar] [CrossRef]
- Vuolo, J.; Goffman, L. Language skill mediates the relationship between language load and articulatory variability in children with language and speech sound disorders. J. Speech Lang. Hear. Res. 2018, 61, 3010–3022. [Google Scholar] [CrossRef]
- Green, J.R.; Moore, C.A.; Reilly, K.J. The sequential development of jaw and lip control for speech. J. Speech Lang. Hear. Res. 2002, 45, 66–79. [Google Scholar] [CrossRef]
- Nip, I.S.; Green, J.R.; Marx, D.B. The co-emergence of cognition, language, and speech motor control in early development: A longitudinal correlation study. J. Commun. Disord. 2011, 44, 149–160. [Google Scholar] [CrossRef] [Green Version]
- Saletta, M.; Goffman, L.; Ward, C.; Oleson, J. Influence of language load on speech motor skill in children with specific language impairment. J. Speech Lang. Hear. Res. 2018, 61, 675–689. [Google Scholar] [CrossRef] [PubMed]
- Diepeveen, S.; van Haaften, L.; Terband, H.; de Swart, B.; Maassen, B. Clinical reasoning for speech sound disorders: Diagnosis and intervention in speech-language pathologists’ daily practice. Am. J. Speech-Lang. Pathol. 2020, 29, 1529–1549. [Google Scholar] [CrossRef] [PubMed]
- Joffe, V.; Pring, T. Children with phonological problems: A survey of clinical practice. Int. J. Lang. Commun. Disord. 2008, 43, 154–164. [Google Scholar] [CrossRef] [PubMed]
- Malmenholt, A.; Lohmander, A.; McAllister, A. Childhood apraxia of speech: A survey of praxis and typical speech characteristics. Logop. Phoniatr. Vocology 2017, 42, 84–92. [Google Scholar] [CrossRef] [PubMed]
- McLeod, S. Speech pathologists’ application of the ICF to children with speech impairment. Adv. Speech Lang. Pathol. 2004, 6, 75–81. [Google Scholar] [CrossRef]
- Mcleod, S.; Baker, E. Speech-language pathologists’ practices regarding assessment, analysis, target selection, intervention, and service delivery for children with speech sound disorders. Clin. Linguist. Phon. 2014, 28, 508–531. [Google Scholar] [CrossRef]
- Skahan, S.M.; Watson, M.; Lof, G.L. Speech-language pathologists’ assessment practices for children with suspected speech sound disorders: Results of a national survey. Am. J. Speech-Language Pathol. 2007, 16, 246–259. [Google Scholar] [CrossRef]
- Priester, G.H.; Post, W.J.; Goorhuis-Brouwer, S.M. Problems in speech sound production in young children. An inventory study of the opinions of speech therapists. Int. J. Pediatr. Otorhinolaryngol. 2009, 73, 1100–1104. [Google Scholar] [CrossRef]
- Waring, R.; Knight, R. How should children with speech sound disorders be classified? A review and critical evaluation of current classification systems. Int. J. Lang. Commun. Disord. 2013, 48, 25–40. [Google Scholar] [CrossRef]
- Shriberg, L.D.; Fourakis, M.; Hall, S.; Karlsson, H.K.; Lohmeier, H.L.; McSweeny, J.; Potter, N.L.; Scheer-Cohen, A.R.; Strand, E.A.; Tilkens, C.M.; et al. Extensions to the Speech Disorders Classification System (SDCS). Clin. Linguist. Phon. 2010, 24, 795–824. [Google Scholar] [CrossRef] [Green Version]
- Dodd, B. Differential Diagnosis of Pediatric Speech Sound Disorder. Curr. Dev. Disord. Rep. 2014, 1, 189–196. [Google Scholar] [CrossRef]
- Ttofari Eecen, K.; Eadie, P.; Morgan, A.T.; Reilly, S. Validation of Dodd’s Model for Differential Diagnosis of childhood speech sound disorders: A longitudinal community cohort study. Dev. Med. Child Neurol. 2019, 61, 689–696. [Google Scholar] [CrossRef] [PubMed]
- Shriberg, L.D.; Kwiatkowski, J.; Mabie, H.L. Estimates of the prevalence of motor speech disorders in children with idiopathic speech delay. Clin. Linguist. Phon. 2019, 33, 679–706. [Google Scholar] [CrossRef] [PubMed]
- Vick, J.C.; Campbell, T.F.; Shriberg, L.D.; Green, J.R.; Truemper, K.; Rusiewicz, H.L.; Moore, C.A. Data-driven subclassification of speech sound disorders in preschool children. J. Speech Lang. Hear. Res. 2014, 57, 2033–2050. [Google Scholar] [CrossRef]
- Goldman, R.; Fristoe, F.M.G. 2: Test of Articulation; American Guidance Service Inc.: Circle Pines, MN, USA, 2000. [Google Scholar]
- Dodd, B.; Hua, Z.; Crosbie, S.; Holm, A.; Ozanne, A. DEAP: Diagnostic Evaluation of Articulation and Phonology; PsychCorp of Harcourt Assessment: San Antonio, TX, USA, 2006. [Google Scholar]
- Hayden, D. PROMPT Prompts for Restructuring Oral Muscular Phonetic Targets, Introduction to Technique: A Manual; The Prompt Institute: Santa Fe, NM, USA, 2008. [Google Scholar]
- Stoeckel, R.; Caspari, S. Childhood apraxia of speech: Clinical decision making from a motor-based perspective. Perspect. ASHA Spec. Interest Groups 2020, 5, 831–842. [Google Scholar] [CrossRef]
- Baker, E.; Croot, K.; McLeod, S.; Paul, R. Psycholinguistic models of speech development and their application to clinical practice. J. Speech, Lang. Hear. Res. 2001, 44, 685–702. [Google Scholar] [CrossRef]
- Geronikou, E.; Rees, R. Psycholinguistic profiling reveals underlying impairments for Greek children with speech disorders. Child Lang. Teach. Ther. 2016, 32, 95–110. [Google Scholar] [CrossRef]
- Maassen, B.; van Haaften, L.; Diepeveen, S.; van den Engel-Hoek, L.; Veenker, T.; Terband, H.; De Swart, B. Computer Articulatie-Instrument (CAI); Boom test uitgevers: Amsterdam, The Netherlands, 2019. [Google Scholar]
- Van Doornik, A.; Gerrits, E.; McLeod, S.; Terband, H. Impact of communication partner familiarity and speech accuracy on parents’ ratings of their child for the Intelligibility in Context Scale: Dutch. Int. J. Speech-Lang. Pathol. 2018, 20, 350–360. [Google Scholar] [CrossRef]
- Schlichting, L. Peabody Picture Vocabulary Test-III-NL; Hartcourt Assessment BV: Amsterdam, The Netherlands, 2005. [Google Scholar]
- McLeod, S.; Harrison, L.; Mc Cormack, J. Schaal Voor Verstaanbaarheid in de Context [Intelligibility in Context Scale: Dutch]; van Doornik-van der Zee, J.C., Terband, H., Eds.; Charles Sturt University: Bathurst, Australia, 2013. [Google Scholar]
- Verhoeven, L.; Keuning, J.; Horsels, L.; Van Boxtel, L. Testinstrumentarium Taalontwikkelingsstoornissenvoor Kinderen van 4 Tot 10 Jaar; Cito: Arnhem, The Netherlands, 2013. [Google Scholar]
- Beers, M. The Phonology of Normally Developing and Language-Impaired Children; University of Amsterdam: Amsterdam, The Netherlands, 1995. [Google Scholar]
- Field, A. Discovering Statistics Using IBM SPSS Statistics, 5th ed.; SAGE Publications: London, UK, 2017. [Google Scholar]
- Van Haaften, L.; Diepeveen, S.; Terband, H.; Vermeij, B.; Van Den Engel-Hoek, L.; De Swart, B.; Maassen, B. Profiling speech sound disorders for clinical validation of the computer articulation instrument. Am. J. Speech-Lang. Pathol. 2019, 28, 844–856. [Google Scholar] [CrossRef]
- McLeod, S. Intelligibility in Context Scale: Cross-linguistic use, validity, and reliability. Speech Lang. Hear. 2020, 23, 9–16. [Google Scholar] [CrossRef] [Green Version]
- Roepke, E.; Brosseau-Lapré, F. Vowel errors produced by preschool-age children on a single-word test of articulation. Clin. Linguist. Phon. 2021, 35, 1161–1183. [Google Scholar] [CrossRef] [PubMed]
- Dale, E.W.; Plumb, A.M.; Sandage, M.J.; Plexico, L.W. Speech-language pathologists’ knowledge and competence regarding percentage of consonants correct. Commun. Disord. Q. 2020, 41, 222–230. [Google Scholar] [CrossRef]
- Shriberg, L.D.; Austin, D.; Lewis, B.A.; McSweeny, J.L.; Wilson, D.L. The percentage of consonants correct (PCC) metric: Extensions and reliability data. J. Speech Lang. Hear. Res. 1997, 40, 708–722. [Google Scholar] [CrossRef] [PubMed]
- van Haaften, L.; Diepeveen, S.; Terband, H.; De Swart, B.; Van Den Engel-Hoek, L.; Maassen, B. Maximum repetition rate in a large cross-sectional sample of typically developing Dutch-speaking children. Int. J. Speech-Lang. Pathol. 2021, 23, 508–518. [Google Scholar] [CrossRef] [PubMed]
- Ozanne, A. Childhood apraxia of speech. In Differential Diagnosis and Treatment of Children with Speech Disorder, 2nd ed.; Dodd, B., Ed.; Whurr: London, UK, 2005. [Google Scholar]
- Ziegler, W.; Schölderle, T.; Brendel, B.; Amsellem, J.; Staiger, A. Higher-faster-farther: Maximum performance tests in the assessment of neurogenic speech impairment. Folia Phoniatr. Et Logop. 2019, 71, 261–274. [Google Scholar] [CrossRef] [PubMed]
- Chenausky, K.V.; Brignell, A.; Morgan, A.; Gagné, D.; Norton, A.; Tager-Flusberg, H.; Schlaug, G.; Shield, A.; Green, J.R. Factor analysis of signs of childhood apraxia of speech. J. Commun. Disord. 2020, 87, 106033. [Google Scholar] [CrossRef]
- Diepeveen, S.; van Haaften, L.; Terband, H.; de Swart, B.; Maassen, B. A standardized protocol for Maximum Repetition Rate assessment in children. Folia Phoniatr. Et Logop. 2019, 71, 238–250. [Google Scholar] [CrossRef]
- Murray, E.; Mc Cabe, P.; Heard, R.; Ballard, K.J. Differential diagnosis of children with suspected Childhood Apraxia of Speech. J. Speech Lang. Hear. Res. 2015, 58, 43–60. [Google Scholar] [CrossRef]
- Shriberg, L.D.; Strand, E.A.; Fourakis, M.; Jakielski, K.J.; Hall, S.D.; Karlsson, H.B.; Mabie, H.L.; McSweeny, J.L.; Tilkens, C.M.; Wilson, D.L. A diagnostic marker to discriminate childhood apraxia of speech from speech delay: I. Development and description of the pause marker. J. Speech Lang. Hear. Res. 2017, 60, S1096–S1117. [Google Scholar] [CrossRef]
- Terband, H.; Namasivayam, A.; van Brenk, F.; Diepeveen, S.; Mailend, M.-L.; Maas, E.; Van Lieshout, P.; Maassen, B. Assessment of Childhood Apraxia of Speech: A review/tutorial of objective measurement techniques. J. Speech Lang. Hear. Res. 2019, 62, 2999–3032. [Google Scholar] [CrossRef] [Green Version]
- Williams, A.L.; McLeod, S.; Mc Cauley, R.J. Interventions for Speech Sound Disorders in Children; Paul, H., Ed.; Brookes Publishing: Baltimore MD, USA, 2010. [Google Scholar]
- Strand, E.A.; Stoeckel, R.; Baas, B. Treatment of severe childhood apraxia of speech: A treatment efficacy study. J. Med. Speech-Lang. Pathol. 2006, 14, 297–307. [Google Scholar]
- McCabe, P.; Murray, E.; Thomas, D.; Evans, P. Clinician Manual for Rapid Syllable Transition Treatment (REST); The University of Sydney: Camperdown, Australia, 2017. [Google Scholar]
- Rvachew, S.; Brosseau-Lapré, F. Developmental Phonological Disorders: Foundations of Clinical Practice; Plural Publishing: San Diego CA, USA, 2016. [Google Scholar]
- Wren, Y.; Harding, S.; Goldbart, J.; Roulstone, S. A systematic review and classification of interventions for speech-sound disorder in preschool children. Int. J. Lang. Commun. Disord. 2018, 53, 446–467. [Google Scholar] [CrossRef] [PubMed]
- Bron, A.; Groot, M.; Peters, P.; Scheper, A.; Verheugt, J.; Bouwens, N. Effectieve fonologische therapie bij kinderen: De aanhouder wint. Logopedie 2013, 85, 6–12. [Google Scholar]
- Allison, K.M.; Cordella, C.; Iuzzini-Seigel, J.; Green, J.R. Differential Diagnosis of Apraxia of Speech in Children and Adults: A Scoping Review. J. Speech Lang. Hear. Res. 2020, 63, 2952–2994. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
| Task | Parameter | n | |
|---|---|---|---|
| PN | PCCI | Percentage of consonants correct in syllable-initial position | 149 |
| PVC | Percentage of vowels correct | 149 | |
| Level 4 | Percentage of correct consonants /b/, /f/ and /ʋ/ | 149 | |
| Level 5 | Percentage of correct consonants /l/ and /R/ | 149 | |
| RedClus | Percentage of reduction of initial consonant clusters from 2 consonants to 1 | 149 | |
| CV | Percentage of correct syllable structure CV | 149 | |
| CVC | Percentage of correct syllable structure CVC | 149 | |
| CCVC | Percentage of correct syllable structure CCVC (C = consonant, V = vowel) | 149 | |
| SP | Simplification processes, total score of the processes: fronting, stopping of fricatives, voicing, devoicing and gliding | 149 | |
| UP | Unusual processes, total score of the processes: backing, unusual stopping, Hsation, nasalisation and denasalisation | 149 | |
| NWI | PCCI | Percentage of consonants correct in syllable-initial position | 146 |
| PVC | Percentage of vowels correct | 146 | |
| Level 4 | Percentage of correct consonants /b/, /f/ and /ʋ/ | 146 | |
| Level 5 | Percentage of correct consonants /l/ and /R/ | 146 | |
| RedClus | Percentage of reduction of initial consonant clusters from 2 consonants to 1 | 146 | |
| CV | Percentage of correct syllable structure CV | 146 | |
| CVC | Percentage of correct syllable structure CVC | 146 | |
| CCVC | Percentage of correct syllable structure CCVC | 146 | |
| SP | Simplification processes, total score of the processes: fronting, stopping of fricatives, voicing, devoicing and gliding | 146 | |
| UP | Unusual processes, total score of the processes: backing, unusual stopping, Hsation, nasalisation and denasalisation | 146 | |
| WR | PWV | Proportion of whole-word variability—Word repetition | 149 |
| NWR | PWV | Proportion of whole-word variability—Nonword repetition | 147 |
| MRR | pa | Number of syllables per second of sequence /pa/ | 133 |
| ta | Number of syllables per second of sequence /ta/ | 133 | |
| ka | Number of syllables per second of sequence /ka/ | 131 | |
| pata | Number of syllables per second of sequence /pata/ | 120 | |
| taka | Number of syllables per second of sequence /taka/ | 115 | |
| pataka | Number of syllables per second of sequence /pataka/ | 111 |
| Task | Parameter | Component | ||
|---|---|---|---|---|
| 1 | 2 | 3 | ||
| PN | PCCI | 0.896 | 0.262 | 0.224 |
| PVC | 0.655 | 0.430 | 0.177 | |
| RedClus | 0.817 | 0.089 | 0.163 | |
| Level 4 | 0.728 | 0.170 | 0.180 | |
| Level 5 | 0.631 | 0.237 | −0.053 | |
| CV | 0.432 | 0.249 | 0.400 | |
| CVC | 0.563 | 0.364 | 0.080 | |
| CCVC | 0.797 | 0.262 | 0.176 | |
| SP | 0.801 | 0.197 | 0.185 | |
| UP | 0.768 | 0.199 | 0.150 | |
| NWI | PCCI | 0.601 | 0.730 | 0.153 |
| PVC | 0.367 | 0.823 | 0.155 | |
| RedClus | 0.561 | 0.648 | 0.072 | |
| Level 4 | 0.508 | 0.680 | 0.053 | |
| Level 5 | 0.469 | 0.319 | 0.124 | |
| CV | 0.104 | 0.731 | 0.283 | |
| CVC | 0.349 | 0.715 | 0.257 | |
| CCVC | 0.477 | 0.481 | 0.050 | |
| SP | 0.632 | 0.532 | 0.133 | |
| UP | 0.637 | 0.542 | 0.002 | |
| WR | PWV | 0.085 | 0.730 | 0.111 |
| NWR | PWV | 0.284 | 0.566 | 0.175 |
| MRR | pa | −0.202 | 0.271 | 0.726 |
| ta | −0.004 | 0.240 | 0.786 | |
| ka | 0.202 | 0.094 | 0.667 | |
| pata | 0.230 | 0.130 | 0.708 | |
| taka | 0.198 | −0.148 | 0.720 | |
| pataka | 0.255 | 0.226 | 0.445 | |
| Eigenvalues | 12.70 | 2.64 | 1.94 | |
| % of variance | 45.37 | 9.42 | 6.93 | |
| Cronbach’s α | 0.945 | 0.909 | 0.796 | |
| Factors | PN+ | NWI/PWV | MRR |
|---|---|---|---|
| PN+ | - | 0.793 * | 0.420 * |
| NWI-/PWV | 0.793 * | - | 0.375 * |
| MRR | 0.375 * | 0.420 * | - |
| Variable | Norm Group | Cluster | ANOVA | |||||
|---|---|---|---|---|---|---|---|---|
| (n = 121) | I (n = 46) | II (n = 28) | III (n = 26) | F | p | η2 | ||
| Age (age in months (SD)) | 61.5 (1.10) | 62.1 (8.40) | 60.2 (9.09) | 61.3 (8.69) | 0.404 | 0.669 | 0.008 | |
| n and (%) boys | 66 (54.5%) | 28 (49.1%) | 18 (31.6%) | 11 (19.3%) | 3.177 | 0.204 | 0.178 | |
| PN | PCCI | 96.8 (3.7) | 90.6 (6.99) | 85.0 (11.25) | 56.2 (12.31) | 106.197 | <0.001 * I = II, I/II > III | 0.686 |
| PVC | 97.7 (3.1) | 97.7 (2.97) | 97.0 (2.59) | 87.0 (7.81) | 48.267 | <0.001 * I = II, I/II > III | 0.499 | |
| Level 4 | ~ | 90.5 (13.53) | 82.1 (20.89) | 46.6 (28.06) | 40.478 | <0.001 * I = II, I/II > III | 0.455 | |
| Level 5 | 93.6 (11.0) | 73.1 (20.87) | 69.8 (20.96) | 34.7 (24.69) | 27.78 | <0.001 * | 0.364 | |
| RedClus | 97.0 (6.2) | 89.5 (16.05) | 89.0 (14.63) | 69.3 (23.25) | 12.080 | <0.001 * I = II, I/II > III | 0.199 | |
| CV | ~ | 94.9 (6.09) | 91.5 (10.12) | 78.5 (17.22) | 18.864 | <0.001 * I = II, I/II > III | 0.280 | |
| CVC | ~ | 93.9 (5.12) | 92.3 (6.89) | 82.6 (10.30) | 21.553 | <0.001 * I = II, I/II > III | 0.308 | |
| CCVC | 94.4 (9.9) | 82.1 (20.14) | 70.7 (25.20) | 30.4 (22.81) | 45.436 | <0.001 * | 0.484 | |
| SP | 2.8 (5.2) | 13.4 (13.26) | 27.9 (27.44) | 82.8 (38.47) | 61.197 | <0.001 * I = II, I/II > III | 0.558 | |
| UP | 0.2 (0.5) | 2.8 (4.16) | 5.5 (7.28) | 19.6 (11.68) | 42.634 | <0.001 * I = II, I/II > III | 0.468 | |
| NWI | PCCI | 87.7 (6.9) | 78.3 (13.30) | 71.9 (15.61) | 39.4 (9.99) | 74.758 | <0.001 * I = II, I/II > III | 0.607 |
| PVC | 93.5 (4.8) | 91.9 (8.41) | 88.6 (11.29) | 70.5 (14.96) | 31.844 | <0.001 * I = II, I/II > III | 0.396 | |
| Level 4 | 87.8 (11.8) | 76.3 (18.63) | 72.5 (20.23) | 30.3 (18.26) | 53.376 | <0.001 * | 0.524 | |
| Level 5 | 87.2 (12.8) | 72.0 (20.70) | 68.8 (25.10) | 31.1 (17.74) | 33.562 | <0.001 * | 0.409 | |
| RedClus | 92.3 (11.8) | 86.6 (14.94) | 85.2 (18.81) | 68.4 (23.37) | 8.843 | <0.001 * I = II, I/II > III | 0.154 | |
| CV | 96.8 (7.8) | 94.8 (9.04) | 92.9 (13.15) | 74.4 (21.14) | 18.770 | <0.001 * I = II, I/II > III | 0.279 | |
| CVC | 93.3 (5.7) | 90.96 (8.18) | 87.32 (9.15) | 71.5 (18.12) | 23.551 | <0.001 * I = II, I/II > III | 0.327 | |
| CCVC | 83.0 (25.2) | 75.1 (30.40) | 67.9 (36.88) | 32.1 (35.98) | 14.043 | <0.001 * | 0.225 | |
| SP | 7.2 (7.4) | 27.5 (23.86) | 39.8 (30.29) | 105.2 (43.27) | 52.502 | <0.001 * I = II, I/II > III | 0.520 | |
| UP | 2.1 (2.2) | 9.7 (7.20) | 11.9 (8.65) | 34.1 (14.24) | 55.043 | <0.001 * I = II, I/II > III | 0.532 | |
| WR | PWV | 0.23 (0.04) | 0.30 (0.07) | 0.32 (0.11) | 0.47 (0.16) | 21.483 | <0.001 * I = II, I/II > III | 0.307 |
| NWR | PWV | 0.28 (0.08) | 0.35 (0.12) | 0.40 (0.15) | 0.51 (0.21) | 9.242 | <0.001 * I = II, I/II > III | 0.160 |
| MRR | pa | 4.64 (0.61) | 4.44 (0.51) | 3.82 (0.58) | 3.97 (0.78) | 7.092 | 0.001 * | 0.143 |
| ta | 4.44 (0.60) | 4.45 (0.44) | 3.65 (0.68) | 3.53 (0.83) | 17.092 | <0.001 * | 0.284 | |
| ka | 4.34 (0.51) | 4.01 (0.59) | 3.14 (0.80) | 2.91 (0.91) | 11.255 | <0.001 * | 0.220 | |
| pata | 4.49 (0.73) | 4.59 (0.92) | 2.81 (0.88) | 2.78 (1.01) | 23.710 | <0.001 * | 0.404 | |
| taka | 4.37 (0.75) | 4.32 (0.79) | 2.64 (0.56) | 3.15 (0.99) | 23.332 | <0.001 * | 0.418 | |
| pataka | 4.09 (0.82) | 3.47 (1.18) | 2.33 (0.57) | 2.81 (1.07) | 12.745 | <0.001 * | 0.372 | |
| Variable | Cluster | ANOVA for Continuous and χ2 for Categorical Variables | η2 for Continuous and V for Categorical Variables | ||||
|---|---|---|---|---|---|---|---|
| I (n = 46) | II (n = 28) | III (n = 26) | |||||
| PPVT-III-NL | 102.8 (14.00) $ | 101.5 (10.94) $$ | 90.8 (11.86) $$$ | 5.201 | 0.008 * | 0.152 | |
| T-TOS (ADT) | 63.4 (27.67) + | 52.9 (34.58) ++ | 34.4 (25.17) +++ | 5.959 | 0.004 * | 0.153 | |
| ICS | 4.0 (0.40) ^ | 3.8 (0.44) ^^ | 3.5 (0.51) ^^^ | 9.801 | <0.001 * | 0.201 | |
| Intelligibility affected (SLPs) (n = 73) | 28.027 | <0.001* | 0.438 | ||||
| mild | 12 (80.0%) | 3 (20.0%) | 0 (0.0%) | ||||
| moderate | 11 (42.3%) | 11 (42.3%) | 4 (15.4%) | ||||
| severe | 5 (15.6%) | 8 (25.0%) | 19 (59.4%) | ||||
| Intelligibility level (parents) (n = 78) | 22.478 | 0.001 * | 0.380 | ||||
| no speech problem | 3 (100.0%) | 0 (0.0%) | 0 (0.0%) | ||||
| mild | 16 (76.2%) | 3 (14.3%) | 2 (9.5%) | ||||
| moderate | 10 (34.5%) | 11 (37.9%) | 8 (27.6%) | ||||
| severe | 5 (20.0%) | 7 (28.0%) | 13 (52.0%) | ||||
| Diagnosis (n = 88) | 7.266 | 0.297 | 0.058 | ||||
| Phonetic disorder | 5 (62.5%) | 2 (25.0%) | 1 (12.5%) | ||||
| Phonological disorder | 27 (42.2%) | 17 (26.6%) | 20 (31.3%) | ||||
| Childhood Apraxia of Speech (CAS) | 3 (25.0%) | 6 (50.0%) | 3 (25.0%) | ||||
| Dysarthria | 0 (0.0%) | 2 (50.0%) | 2 (50.0%) | ||||
| Setting | 32.744 | <0.001 * | 0.405 | ||||
| Private practice | 22 (53.7%) | 15 (36.6%) | 4 (9.8%) | ||||
| Special education | 9 (26.5%) | 6 (17.6%) | 19 (55.9%) | ||||
| Rehabilitation centre | 4 (33.3%) | 5 (41.7%) | 3 (25.0%) | ||||
| Audiologic centre | 1 (50.0%) | 1 (50.0%) | 0 (0.0%) | ||||
| Recruited as control group | 10 (90.9%) | 1 (9.1%) | 0 (0.0%) | ||||
| Factor | ||||||
|---|---|---|---|---|---|---|
| PN+ | NWI-/PWV | MRR | ||||
| Cluster | M | SD | M | SD | M | SD |
| I | 0.72 | 0.46 | 0.64 | 0.61 | 0.87 | 0.58 |
| II | 0.49 | 0.50 | 0.41 | 0.69 | −0.76 | 0.46 |
| III | −1.25 | 0.52 | −0.96 | 0.58 | −0.72 | 0.77 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Diepeveen, S.; Terband, H.; van Haaften, L.; van de Zande, A.M.; Megens-Huigh, C.; de Swart, B.; Maassen, B. Process-Oriented Profiling of Speech Sound Disorders. Children 2022, 9, 1502. https://doi.org/10.3390/children9101502
Diepeveen S, Terband H, van Haaften L, van de Zande AM, Megens-Huigh C, de Swart B, Maassen B. Process-Oriented Profiling of Speech Sound Disorders. Children. 2022; 9(10):1502. https://doi.org/10.3390/children9101502
Chicago/Turabian StyleDiepeveen, Sanne, Hayo Terband, Leenke van Haaften, Anne Marie van de Zande, Charlotte Megens-Huigh, Bert de Swart, and Ben Maassen. 2022. "Process-Oriented Profiling of Speech Sound Disorders" Children 9, no. 10: 1502. https://doi.org/10.3390/children9101502
APA StyleDiepeveen, S., Terband, H., van Haaften, L., van de Zande, A. M., Megens-Huigh, C., de Swart, B., & Maassen, B. (2022). Process-Oriented Profiling of Speech Sound Disorders. Children, 9(10), 1502. https://doi.org/10.3390/children9101502