_Bryant.png)
A Proposed Artificial Intelligence Model for Android-Malware Detection


Abstract
:1. Introduction
- To improve the efficacy of the proposed neural networks, we present DroidMDetection, a framework for efficient and accurate malware detection and clustering that makes use of natural language processing, code static analysis, and machine learning techniques like dropout and feature selection.
- Exploration of various deep learning and machine learning methods for use in developing Android’s intrusion detection system.
- Several industry-standard Android datasets were used to test and evaluate the proposed method.
- The tested algorithms are compared to various state-of-the-art models.
- To determine the efficacy and efficiency of DroidMDetection, we conduct an exhaustive evaluation. We analyze DroidMDetection on an obfuscated dataset produced with the PRAGuard [14] dataset and the DroidChameleon [15] obfuscation tool to show the framework’s resistance to popular obfuscation methods. We conduct an empirical investigation comparing DroidMDetection to state-of-the-art systems like MaMaDroid [16], DroidMalwareDetector [17] MalDozer [7], and DroidAPIMiner [18], and find that DroidMDetection performs better.
2. Related Work
2.1. Malware Detection
2.2. Android Malware Detection Based on Deep Learning and Machine Learning
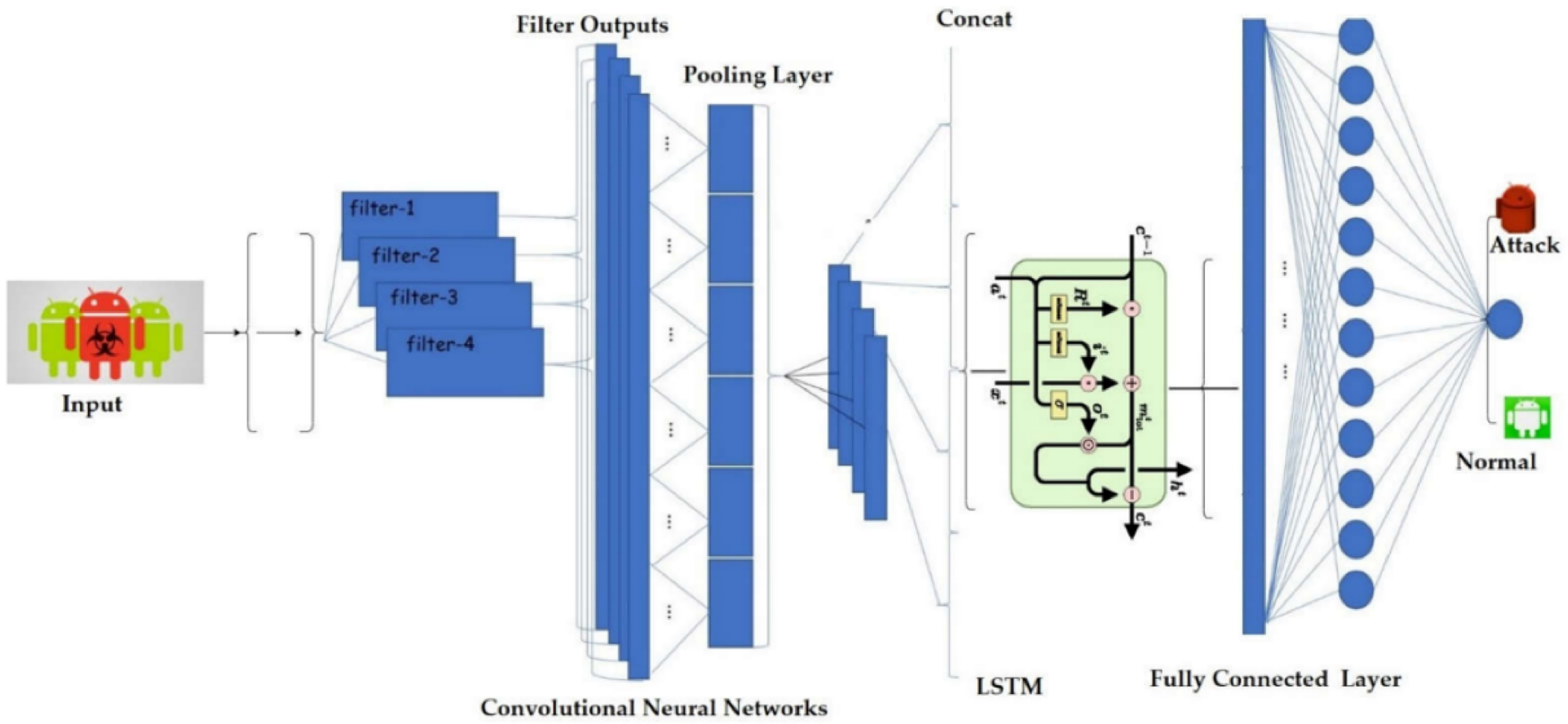
3. The Proposed DroidMDetection Approach
3.1. Feature Extraction
- Permissions: A large range of permissions, such as READ_CONTACTS, CAMERA, and CALL_PHONE, is provided as the Android Application Programming Interface (API) to determine the powers of Android apps. This means that an app’s functionality is constrained by the rights it has been granted, as specified in the AndroidManifest.xml file. Due to the availability of the open-source reverse engineering tool for Android apps known as apktool [52], apk archives could be decompiled and analyzed. The AndroidManifest.xml file for each app was then parsed for its set of permissions.
- The source code must be analyzed to do extra checks alongside these static features concerning maliciousness. By utilizing apktool, not only the AndroidManifest.xml file, but also the decompiled source code in smali format and the disassembled form of the DEX format used by Android’s Java VM implementation are extracted during the reverse engineering process [55]. Table 1 details the APIs that DroidMDetection identified as potentially malicious. To find the sensitive API calls, the decompiled code was examined recursively.
| Algorithm 1: Extracting the feature vector |
| Input: All apps and standard features. |
| Output: feature_Vec |
|
3.2. Preprocessing
Min–Max Normalization Method
3.3. Feature Selection
| Algorithm 2: Obtaining deleted features |
| Input: Linear model of regress. |
| Output: Del.Feature_Set |
|
3.4. Feature Vectorization
| Algorithm 3: Vectorization of features |
| Input: Sample feature documents S Dimension of word2vec K Feature list L of number N |
| Output: M × (K × N)- dimension vector as V |
|
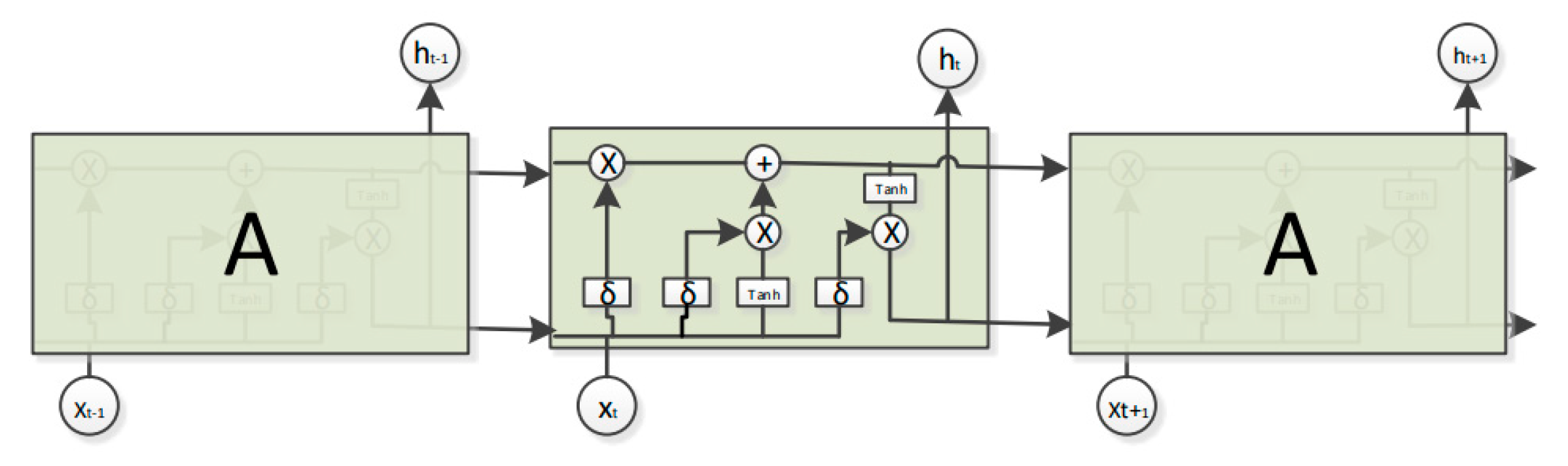
3.5. Malware Detection
3.6. Malware Clustering
3.6.1. Android App Representation for Clustering
3.6.2. Clustering Preprocessing
3.6.3. Digests Generation Using Auto-Encoder
3.6.4. Family Clustering
4. Experimental Results
4.1. Implementation Environment
4.2. Dataset
- (1)
- (2)
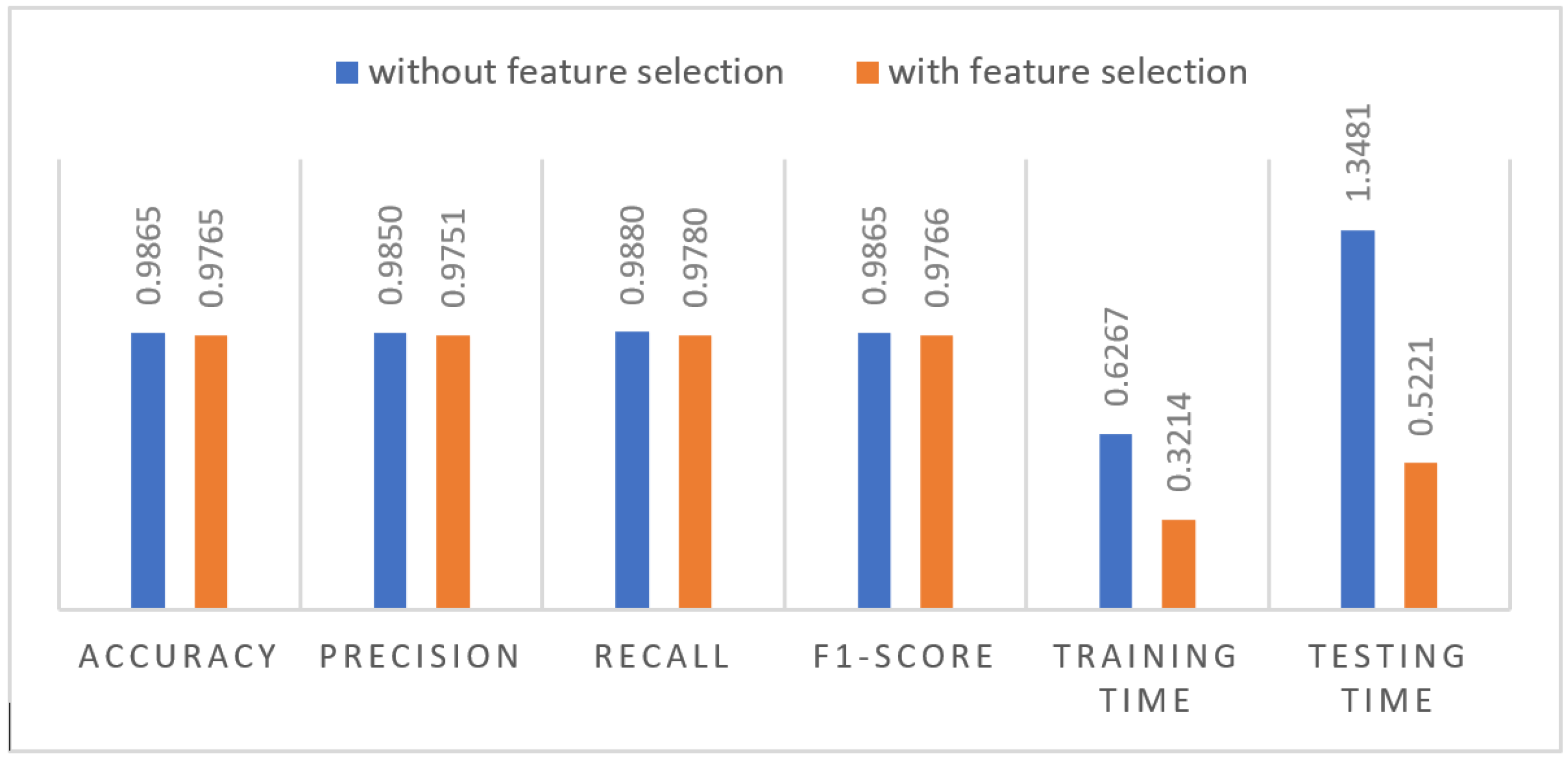
- Feature selection: We then narrowed down the features we were using by selecting fewer of them. Specifically, linear regression was the technique of choice for the feature selection phase. To generate new results, the classifiers were retrained using the smaller dataset that resulted from the feature selection process.
- (3)
- Malware detection performance: Classification results are obtained and evaluations are reviewed based on performance metrics after the most important features have been selected. The proposed model for android detection uses a large number of classifiers to guarantee its generalizability.
- (4)
- Family clustering: Once malicious apps have been identified, clustering is used to categorize them into like-minded groups.
4.3. Evaluation
4.3.1. Performance Metrics
4.3.2. Malware Detection
- (1)
- Detection Performance
- (2)
- Impact of feature selection
- (3)
- Dataset Size Effect
4.3.3. Family Clustering
4.3.4. Obfuscation Resiliency
4.3.5. Time Efficiency
4.3.6. Comparative Study
4.4. Reliability in the Face of Evolving Threats
- Understanding the Evolution of Malware and Benign Apps: We provide an overview of the dynamic nature of malware and benign apps, highlighting the rapid evolution, polymorphic behavior, and obfuscation techniques employed by malicious actors. This understanding is crucial to comprehend the challenges posed to malware detection and the potential impact on the reliability of the proposed model.
- Challenges in Maintaining Model Effectiveness: We acknowledge that the continuous evolution of malware and benign apps can introduce new variants, making it necessary to adapt the detection model to capture emerging threats effectively. We discuss the potential consequences of not addressing these challenges, such as false negatives, decreased detection accuracy, and increased vulnerability to new attack vectors.
- Adaptive and Continuous Learning Approaches: To mitigate the effects of evolving threats, we employ adaptive and continuous learning techniques within the proposed framework. These approaches allow the model to dynamically update its knowledge and adapt to changing patterns and characteristics of malware and benign apps. We explain the strategies used, such as incremental learning, ensemble methods, and regular model retraining, to ensure the model remains up to date and effective.
- Collaborative Intelligence and Threat Intelligence Integration: Recognizing the importance of collective efforts, we highlight the integration of collaborative intelligence and threat intelligence sources in the proposed approach. By leveraging real-time information on emerging threats, malware signatures, and behavioral patterns, the model can enhance its detection capabilities and adapt to the evolving threat landscape.
- Evaluation of Model Robustness: We provide insights into the evaluation of the proposed model’s robustness in the face of evolving threats. This includes benchmarking against evolving malware datasets, measuring the detection rate over time, and assessing the model’s ability to identify new malware variants and benign app changes. The evaluation demonstrates the model’s resilience and ability to adapt to the dynamic nature of the ecosystem.
4.5. Sustainability and Resilience against Evolution
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Mobile Operating System Market Share Worldwide|Statcounter Global Stats. Available online: https://gs.statcounter.com/os-market-share/mobile/worldwide (accessed on 15 July 2023).
- App Download Data (2022)—Business of Apps. Available online: https://www.businessofapps.com/data/app-statistics/ (accessed on 2 May 2023).
- Shishkova, T. IT threat evolution in Q2 2021. Mobile statistics. Securelist 2021, 26, 448. [Google Scholar]
- Alzahrani, A.J.; Ghorbani, A.A. Real-time signature-based detection approach for sms botnet. In Proceedings of the 2015 13th Annual Conference on Privacy, Security and Trust (PST), Izmir, Turkey, 21–23 July 2015; pp. 157–164. [Google Scholar]
- Girei, D.A.; Shah, M.A.; Shahid, M.B. An enhanced botnet detection technique for mobile devices using log analysis. In Proceedings of the 2016 22nd International Conference on Automation and Computing (ICAC), Colchester, UK, 7–8 September 2016; pp. 450–455. [Google Scholar]
- Milosevic, N.; Dehghantanha, A.; Choo, K.K.R. Machine learning aided Android malware classification. Comput. Electr. Eng. 2017, 61, 266–274. [Google Scholar] [CrossRef]
- Karbab, E.B.; Debbabi, M.; Derhab, A.; Mouheb, D. MalDozer: Automatic framework for android malware detection using deep learning. Digit. Investig. 2018, 24, S48–S59. [Google Scholar] [CrossRef]
- Sihag, V.; Vardhan, M.; Singh, P. A survey of android application and malware hardening. Comput. Sci. Rev. 2021, 39, 100365. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, M.; Gao, Z.; Xu, G.; Xian, H.; Li, Y.; Zhang, X. Constructing Features for Detecting Android Malicious Applications: Issues, Taxonomy and Directions. IEEE Access 2019, 7, 67602–67631. [Google Scholar] [CrossRef]
- Şahin, D.Ö.; Kural, O.E.; Akleylek, S.; Kılıç, E. A novel permission-based Android malware detection system using feature selection based on linear regression. Neural Comput. Appl. 2021, 35, 4903–4918. [Google Scholar] [CrossRef]
- Kumars, R.; Alazab, M.; Wang, W. A survey of intelligent techniques for Android malware detection. In Malware Analysis Using Artificial Intelligence and Deep Learning; Springer: Cham, Switzerland, 2021; pp. 121–162. [Google Scholar]
- Arauzo-Azofra, A.; Aznarte, J.L.; Benítez, J.M. Empirical study of feature selection methods based on individual feature evaluation for classification problems. Expert Syst. Appl. 2011, 38, 8170–8177. [Google Scholar] [CrossRef]
- Feizollah, A.; Anuar, N.B.; Salleh, R.; Wahab, A.W.A. A review on feature selection in mobile malware detection. Digit. Investig. 2015, 13, 22–37. [Google Scholar] [CrossRef]
- Maiorca, D.; Ariu, D.; Corona, I.; Aresu, M.; Giacinto, G. Stealth attacks: An extended insight into the obfuscation effects on Android malware. Comput. Secur. 2015, 51, 16–31. [Google Scholar] [CrossRef]
- VRastogi; Chen, Y.; Jiang, X. Droidchameleon: Evaluating android anti-malware against transformation attacks. In Proceedings of the 8th ACM SIGSAC Symposium on Information, Computer and Communications Security, Hangzhou, China, 8–10 May 2013; pp. 329–334. [Google Scholar]
- Mariconti, E.; Onwuzurike, L.; Andriotis, P.; De Cristofaro, E.; Ross, G.; Stringhini, G. Mamadroid: Detecting android malware by building markov chains of behavioral models. arXiv 2016, arXiv:1612.04433. [Google Scholar]
- Kabakus, A.T. DroidMalwareDetector: A novel Android malware detection framework based on convolutional neural network. In Expert Systems with Applications; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Aafer, Y.; Du, W.; Yin, H. Droidapiminer: Mining api-level features for robust malware detection in android. In Security and Privacy in Communication Networks: 9th International ICST Conference, SecureComm 2013, Sydney, NSW, Australia, 25–28 September 2013; Springer International Publishing: Berlin/Heidelberg, Germany, 2013; pp. 86–103. [Google Scholar]
- Zhu, D.; Jin, H.; Yang, Y.; Wu, D.; Chen, W. DeepFlow: Deep learning-based malware detection by mining Android application for abnormal usage of sensitive data. In Proceedings of the IEEE Symposium on Computers and Communications (ISCC), Heraklion, Greece, 3–6 July 2017; pp. 438–443. [Google Scholar]
- Nix, R.; Zhang, J. Classification of Android apps and malware using deep neural networks. In Proceedings of the 2017 International Joint Conference on Neural Networks (IJCNN), Anchorage, AK, USA, 14–19 May 2017; pp. 1871–1878. [Google Scholar]
- Zhang, Y.; Yang, Y.; Wang, X. A novel android malware detection approach based on convolutional neural network. In Proceedings of the 2nd International Conference on Cryptography, Security and Privacy, Guiyang, China, 16–19 March 2018; pp. 144–149. [Google Scholar]
- Alazab, M.; Alazab, M.; Shalaginov, A.; Mesleh, A.; Awajan, A. Intelligent mobile malware detection using permission requests and API calls. Future Gener. Comput. Syst. 2020, 107, 509–521. [Google Scholar] [CrossRef]
- Xu, K.; Li, Y.; Deng, R.H.; Chen, K. Deeprefiner: Multi-layer android malware detection system applying deep neural networks. In Proceedings of the 2018 IEEE European Symposium on Security and Privacy (EuroS&P), London, UK, 24–26 April 2018; pp. 473–487. [Google Scholar]
- Li, W.; Wang, Z.; Cai, J.; Cheng, S. An android malware detection approach using weight-adjusted deep learning. In Proceedings of the 2018 International Conference on Computing, Networking and Communications (ICNC), Maui, HI, USA, 5–8 March 2018; pp. 437–441. [Google Scholar]
- Statista, Smartphone Users Worldwide 2016–2021. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed on 19 October 2021).
- Abuthawabeh, M.K.; Mahmoud, K.W. Android malware detection and categorization based on conversation-level network traffic features. In Proceedings of the 2019 International Arab Conference on Information Technology (ACIT), Al Ain, United Arab Emirates, 3–5 December 2019; pp. 42–47. [Google Scholar]
- Sihag, V.; Vardhan, M.; Singh, P. BLADE: Robust malware detection against obfuscation in android. Forensic Sci. Int. Digit. Investig. 2021, 38, 301176. [Google Scholar] [CrossRef]
- Zhang, J.; Qin, Z.; Yin, H.; Ou, L.; Zhang, K. A feature-hybrid malware variants detection using CNN based opcode embedding and BPNN based API embedding. Comput. Secur. 2019, 84, 376–392. [Google Scholar] [CrossRef]
- Singh, A.K.; Wadhwa, G.; Ahuja, M.; Soni, K.; Sharma, K. Android malware detection using LSI-based reduced opcode feature vector. Procedia Comput. Sci. 2020, 173, 291–298. [Google Scholar] [CrossRef]
- Roy, A.; Jas, D.S.; Jaggi, G.; Sharma, K. Android malware detection based on vulnerable feature aggregation. Procedia Comput. Sci. 2020, 173, 345–353. [Google Scholar] [CrossRef]
- Cai, L.; Li, Y.; Xiong, Z. JOWMDroid: Android malware detection based on feature weighting with joint optimization of weight-mapping and classifier parameters. Comput. Secur. 2021, 100, 102086. [Google Scholar] [CrossRef]
- Aboaoja, F.A.; Zainal, A.; Ghaleb, F.A.; Al-rimy, B.A.S. Toward an Ensemble Behavioral-based Early Evasive Malware Detection Framework. In Proceedings of the 2021 International Conference on Data Science and Its Applications (ICoDSA), Bandung, Indonesia, 6–7 October 2021; pp. 181–186. [Google Scholar]
- Zhang, H.; Qin, J.; Zhang, B.; Yan, H.; Guo, J.; Gao, F. A multi-class detection system for android malicious apps based on color image features. In Security and Privacy in New Computing Environments: Third EAI International Conference, SPNCE 2020, Lyngby, Denmark, 6–7 August 2020; Springer Nature: Berlin/Heidelberg, Germany, 2020; pp. 186–206. [Google Scholar]
- Frenklach, T.; Cohen, D.; Shabtai, A.; Puzis, R. Android malware detection via an app similarity graph. Comput. Secur. 2021, 109, 102386. [Google Scholar] [CrossRef]
- Mahindru, A.; Sangal, A. FSDroid:- A feature selection technique to detect malware from Android using Machine Learning Techniques. Multimedia Tools Appl. 2021, 80, 13271–13323. [Google Scholar] [CrossRef]
- Hei, Y.; Yang, R.; Peng, H.; Wang, L.; Xu, X.; Liu, J.; Liu, H.; Xu, J.; Sun, L. Hawk: Rapid android malware detection through heterogeneous graph attention networks. IEEE Trans. Neural Networks Learn. Syst. 2021, 1–15. [Google Scholar] [CrossRef]
- Mahindru, A.; Sangal, A.L. MLDroid—Framework for Android malware detection using machine learning techniques. Neural Comput. Appl. 2021, 33, 5183–5240. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, K.; Chen, Z.; Zhang, C. MalCaps: A Capsule Network Based Model for the Malware Classification. Processes 2021, 9, 929. [Google Scholar] [CrossRef]
- de Oliveira, A.; Sassi, R.J. Chimera: An android malware detection method based on multimodal deep learning and hybrid analysis. TechRxiv 2020. [Google Scholar] [CrossRef]
- Kumar, R.; Zhang, X.; Khan, R.U.; Sharif, A. Research on Data Mining of Permission-Induced Risk for Android IoT Devices. Appl. Sci. 2019, 9, 277. [Google Scholar] [CrossRef]
- Yadav, P.; Menon, N.; Ravi, V.; Vishvanathan, S.; Pham, T.D. EfficientNet convolutional neural networks-based Android malware detection. Comput. Secur. 2022, 115, 102622. [Google Scholar] [CrossRef]
- Kinkead, M.; Millar, S.; McLaughlin, N.; O’kane, P. Towards Explainable CNNs for Android Malware Detection. Procedia Comput. Sci. 2021, 184, 959–965. [Google Scholar] [CrossRef]
- Arp, D.; Spreitzenbarth, M.; Hubner, M.; Gascon, H.; Rieck, K.; Siemens, C. Drebin: Effective and explainable detection of android malware in your pocket. Ndss 2014, 14, 23–26. [Google Scholar]
- Hosseini, S.; Nezhad, A.E.; Seilani, H. Android malware classification using convolutional neural network and LSTM. J. Comput. Virol. Hacking Tech. 2021, 17, 307–318. [Google Scholar] [CrossRef]
- Onwuzurike, L.; Mariconti, E.; Andriotis, P.; De Cristofaro, E.; Ross, G.; Stringhini, G. Mamadroid: Detecting android malware by building Markov chains of behavioral models (extended version). ACM Trans. Priv. Secur. 2019, 22, 1–34. [Google Scholar] [CrossRef]
- SImtiaz, S.I.; Rehman, S.U.; Javed, A.R.; Jalil, Z.; Liu, X.; Alnumay, W.S. DeepAMD: Detection and identification of Android malware using high-efficient Deep Artificial Neural Network. Future Gener. Comput. Syst. 2021, 115, 844–856. [Google Scholar] [CrossRef]
- Vu, L.N.; Jung, S. AdMat: A CNN-on-Matrix Approach to Android Malware Detection and Classification. IEEE Access 2021, 9, 39680–39694. [Google Scholar] [CrossRef]
- Suarez-Tangil, G.; Stringhini, G. Eight years of rider measurement in the android malware ecosystem: Evolution and lessons learned. arXiv 2018, arXiv:1801.08115. [Google Scholar]
- Cai, H. Embracing mobile app evolution via continuous ecosystem mining and characterization. In Proceedings of the IEEE/ACM 7th International Conference on Mobile Software Engineering and Systems, Seoul, Republic of Korea, 13–15 July 2020; pp. 31–35. [Google Scholar]
- Taher, F.; Elhoseny, M.; Hassan, M.K.; El-Hasnony, I.M. A Novel Tunicate Swarm Algorithm With Hybrid Deep Learning Enabled Attack Detection for Secure IoT Environment. IEEE Access 2022, 10, 127192–127204. [Google Scholar] [CrossRef]
- Apktool—A Tool for Reverse Engineering 3rd Party, Closed, Binary Android Apps. Available online: https://forum.xda-developers.com/t/util-jul-22-2023-apktool-tool-for-reverse-engineering-apk-files.1755243/ (accessed on 22 July 2023).
- Felt, A.P.; Chin, E.; Hanna, S.; Song, D.; Wagner, D. Android permissions demystified. In Proceedings of the 18th ACM Conference on Computer and Communications Security, Chicago, IL, USA, 17–21 October 2011; pp. 627–638. [Google Scholar]
- Tarute, A.; Nikou, S.; Gatautis, R. Mobile application driven consumer engagement. Telemat. Inform. 2017, 34, 145–156. [Google Scholar] [CrossRef]
- Hoffmann, J.; Ussath, M.; Holz, T.; Spreitzenbarth, M. Slicing droids: Program slicing for smali code. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1844–1851. [Google Scholar]
- El-Hasnony, I.M.; Barakat, S.I.; Elhoseny, M.; Mostafa, R.R. Improved Feature Selection Model for Big Data Analytics. IEEE Access 2020, 8, 66989–67004. [Google Scholar] [CrossRef]
- El-Hasnony, I.M.; Barakat, S.I.; Mostafa, R.R. Optimized ANFIS Model Using Hybrid Metaheuristic Algorithms for Parkinson’s Disease Prediction in IoT Environment. IEEE Access 2020, 8, 119252–119270. [Google Scholar] [CrossRef]
- Seber, G.A.F.; Lee, A.J. Linear Regression Analysis; John Wiley & Sons: Hoboken, NJ, USA, 2012. [Google Scholar]
- Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the International Conference on Machine Learning, Beijing, China, 22–24 June 2014; pp. 1188–1196. [Google Scholar]
- LeCun, Y.; Bengio, Y. Convolutional networks for images, speech, and time series. Handb. Brain Theory Neural Netw. 1995, 3361, 1995. [Google Scholar]
- Rawat, W.; Wang, Z. Deep convolutional neural networks for image classification: A comprehensive review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Aldhyani, T.H.H.; Alkahtani, H. Attacks to Automatous Vehicles: A Deep Learning Algorithm for Cybersecurity. Sensors 2022, 22, 360. [Google Scholar] [CrossRef]
- Khan, M.A.; Khan, M.A.; Jan, S.U.; Ahmad, J.; Jamal, S.S.; Shah, A.A.; Pitropakis, N.; Buchanan, W.J. A Deep Learning-Based Intrusion Detection System for MQTT Enabled IoT. Sensors 2021, 21, 7016. [Google Scholar] [CrossRef]
- Shi, Q.; Petterson, J.; Dror, G.; Langford, J.; Smola, A.; Strehl, A.; Vishwanathan, S.V.N. Hash kernels. In Proceedings of the 12th International Conference on Artificial Intelligence and Statistics (AISTATS), Clearwater, FL, USA, 16–18 April 2009. [Google Scholar]
- Hinton, G.E.; Krizhevsky, A.; Wang, S.D. Transforming auto-encoders. In Proceedings of the International Conference on Artificial Neural Networks, Espoo, Finland, 14–17 June 2011; pp. 44–51. [Google Scholar]
- Ester, M.; Kriegel, H.-P.; Sander, J.; Xu, X. A density-based algorithm for discovering clusters in large spatial databases with noise. KDD 1996, 96, 226–231. [Google Scholar]
- Abou-Assaleh, T.; Cercone, N.; Keselj, V.; Sweidan, R. N-gram-based detection of new malicious code. In Proceedings of the 28th Annual International Computer Software and Applications Conference, Hong Kong, China, 28–30 September 2004; COMPSAC 2004; Volume 2, pp. 41–42. [Google Scholar]
- Zhou, Y.; Jiang, X. Dissecting android malware: Characterization and evolution. In Proceedings of the 2012 IEEE Symposium on Security and Privacy, San Francisco, CA, USA, 20–23 May 2012; pp. 95–109. [Google Scholar]
- Allix, K.; Bissyandé, T.F.; Klein, J.; Le Traon, Y. Androzoo: Collecting millions of android apps for the research community. In Proceedings of the 13th International Conference on Mining Software Repositories, Austin, TX, USA, 14–15 May 2016. [Google Scholar]
- Rosenberg, A.; Hirschberg, J. V-measure: A conditional entropy-based external cluster evaluation measure. In Proceedings of the 2007 Joint Conference on Empirical Methods in natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 410–420. [Google Scholar]
- Morcos, M.; Gala, M.; Al Hamadi, H.; Nandyala, S.; Mcgillion, B.; Damiani, E. An ML-Based Recognizer of Exfiltration Attack over Android Platform: MLGuard. TechRxiv 2022. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| getSubscriberId | getBondedDevices |
| getDeviceId | startDiscovery |
| getSimSerialNumber | abortBroadcast |
| getLine1Number | setWifiEnabled |
| getAllCellinfo | setPreviewDisplay |
| getCallState | MediaRecorder |
| getAccounts | createFromPdu |
| getNetworkInfo | sendMultipartTextMessage |
| getExtraInfo | sendTextMessage |
| requestLocationUpdates | obtainMessage |
| getLastKnownLocation | sendDataMessage |
| getSimOperator | killProcess |
| getNetworkOperator | myPid |
| getNeighboringCellInfo | exec |
| getCellLocation | createSubprocess |
| DexClassLoader |
| Items | Configuration Value |
|---|---|
| Max pooling size | 4 |
| Kernel size | 4 |
| Fully connected layer | 32 |
| Epochs | 20 |
| Dropout | 0.50 |
| Activation function | Relu |
| Optimizer | RSMprop |
| Batch size | 20 |
| Items | Configuration Values |
|---|---|
| Max pooling size | 4 |
| Fully connected layer | 32 |
| Kernel size | 4 |
| Drop out | |
| Optimizer | RSMprop |
| Activation function | Relu |
| Epochs | 20 |
| Batch size | 150 |
| HW/SW | Settings |
|---|---|
| Clock speed | |
| Processor | Ryzen 5 3600, MAMADROID |
| GPU | NVidia RTX 3060Ti |
| RAM | |
| Python | |
| Operating system | Windows 10 |
| Sci-Kit Learn | |
| VMWare Workstation Pro |
| Name | Number of Families | Number of Samples |
|---|---|---|
| Drebin [35] | 179 | |
| MalGenome [59] | 49 | |
| MaMaDroid [37] | - | |
| MalDozer [7] | 20 | |
| AndroZoo [60] | - |
| Family | Family |
|---|---|
| GoldDream | BaseBridge |
| GinMaster | Adrd |
| Imlog | DroidKungFu |
| Iconosys | DroidDream |
| MobileTx | FakeDoc |
| Kmin | ExploitLinuxLotoor |
| Plankton | FakeRun |
| Opfake | FakeInstaller |
| SMSreg | Geinimi |
| SendPay | Gappusin |
| Actual | |||
|---|---|---|---|
| Positive | Negative | ||
| Predicted | Positive | True Positive | False Positive |
| Negative | False Negative | True Negative | |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| AE | 92.95 | 93.60 | 92.20 | 92.90 |
| LSTM | 96.95 | 96.81 | 97.10 | 96.95 |
| CNN | 97.45 | 97.12 | 97.80 | 97.46 |
| LSTM-CNN | 99.15 | 99.00 | 99.30 | 99.15 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| AE | 92.60 | 93.29 | 91.80 | 92.54 |
| LSTM | 97.05 | 96.17 | 98.00 | 97.08 |
| CNN | 97.20 | 97.39 | 97.00 | 97.17 |
| LSTM-CNN | 98.65 | 98.50 | 98.80 | 98.65 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| AE | 92.50 | 92.93 | 92.00 | 92.46 |
| LSTM | 96.35 | 96.40 | 96.30 | 96.35 |
| CNN | 97.12 | 97.07 | 97.17 | 97.12 |
| LSTM-CNN | 99.15 | 99.40 | 98.90 | 99.15 |
| Model | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| AE | 90.71 | 91.63 | 90.37 | 90.99 |
| LSTM | 95.60 | 95.78 | 95.40 | 95.59 |
| CNN | 96.45 | 96.22 | 96.70 | 96.46 |
| CNN-LSTM | 97.50 | 97.88 | 97.10 | 97.49 |
| Dataset | Accuracy | Precision | Recall | F1-Score | Training Time | Testing Time |
|---|---|---|---|---|---|---|
| Derbin | 98.65 | 98.50 | 98.80 | 98.65 | 0.6267 | 1.3481 |
| MalGenome | 99.15 | 99.00 | 99.30 | 99.19 | 0.5341 | 0.8102 |
| MalDozer | 99.15 | 99.40 | 98.90 | 99.15 | 0.7832 | 3.5542 |
| MaMaDroid | 97.50 | 97.88 | 97.10 | 97.49 | 0.9348 | 2.4531 |
| Dataset | Accuracy | Precision | Recall | F1-Score | Training Time | Testing Time |
|---|---|---|---|---|---|---|
| Derbin | 97.65 | 97.51 | 97.80 | 97.66 | 0.3214 | 0.5221 |
| MalGenome | 98.20 | 98.01 | 98.40 | 98.20 | 0.0311 | 0.1242 |
| MalDozer | 98.70 | 98.51 | 98.90 | 98.70 | 0.1432 | 0.9312 |
| MaMaDroid | 97.00 | 96.35 | 97.70 | 97.02 | 0.4102 | 1.1021 |
| Dataset | F1-Score | ||
|---|---|---|---|
| 50% | 70% | 80% | |
| Derbin | 96.45 | 97.01 | 98.49 |
| MalGenome | 96.77 | 98.01 | 99.15 |
| MalDozer | 97.28 | 98.51 | 99.25 |
| MAMADROID | 96.52 | 97.27 | 99.05 |
| Dataset | DBSCAN Clustering | After Family Matching | ||
|---|---|---|---|---|
| Coverage | Homogeneity | Coverage | Homogeneity | |
| Derbin | 51% | 93.36% | 100% | 83.91% |
| MalGenome | 44% | 91.54% | 100% | 81.32% |
| MAMADROID | 59% | 94.62% | 100% | 85.39% |
| MalDozer | 63% | 97.67% | 100% | 89.12% |
| Obfuscation Techniques | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| String Encryption | 99.45 | 99.50 | 99.40 | 99.45 |
| Trivial | 99.40 | 99.20 | 99.60 | 99.40 |
| Class Encryption | 99.60 | 99.50 | 99.70 | 99.60 |
| Reflection | 99.20 | 99.10 | 99.30 | 99.20 |
| (1) + (2) | 99.45 | 99.60 | 99.30 | 99.45 |
| (1) + (2) +(3) | 99.65 | 99.60 | 99.70 | 99.65 |
| (1) + (2) +(3) +(4) | 99.65 | 99.80 | 99.50 | 99.65 |
| Obfuscation Techniques | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Method Renaming | 99.60 | 99.70 | 99.50 | 99.60 |
| Class Renaming | 99.50 | 99.70 | 99.30 | 99.50 |
| String Encryption | 99.75 | 99.70 | 99.80 | 99.75 |
| Field Renaming | 99.75 | 99.90 | 99.60 | 99.75 |
| Call Indirection | 99.60 | 99.40 | 99.80 | 99.60 |
| Array Encryption | 99.40 | 99.40 | 99.40 | 99.40 |
| Junk Code Insertion | 99.25 | 99.30 | 99.20 | 99.25 |
| Code Reordering | 99.15 | 99.30 | 99.00 | 99.15 |
| Debug Information Removing | 99.50 | 99.30 | 99.70 | 99.50 |
| Instruction Insertion | 99.60 | 99.50 | 99.70 | 99.60 |
| Disassembling and Reassembling | 99.60 | 99.80 | 99.40 | 99.60 |
| Dataset | F1-Score | ||||
|---|---|---|---|---|---|
| Proposed | DroidAPIMiner | MaMaDroid | MalDozer | DroidMalwareDetector | |
| 2016 & newbenign | 98.52 | 36.00 | 92.00 | 91.13 | 95.22 |
| 2015 & newbenign | 97.32 | 77.00 | 95.00 | 94.31 | 96.22 |
| 2014 & newbenign | 99.04 | 92.00 | 99.00 | 93.22 | 98.43 |
| 2014 & oldbenign | 99.20 | 62.00 | 95.00 | 94.45 | 98.24 |
| 2013 & oldbenign | 98.16 | 36.00 | 97.00 | 89.23 | 96.50 |
| drebin & oldbenign | 99.05 | 32.00 | 96.00 | 91.61 | 97.14 |
| Drebin & Oldbenign | 2013 & Oldbenign | 2014 & Oldbenign | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Miner | Doser | Proposed | Miner | Dozer | Proposed | Miner | Doser | Proposed | |
| drebin & oldbenign | 32.0% | 91.2% | 99.3% | 35.0% | 92.4% | 98.3% | 34.0% | 88.4% | 99.2% |
| 2013 & oldbenign | 33.0% | 93.5% | 98.2% | 36.0% | 91.4% | 98.3% | 35.0% | 83.4% | 96.4% |
| 2014 & oldbenign | 36.0% | 90.0% | 99.1% | 39.0% | 83.4% | 89.4% | 62.0% | 66.2% | 98.5% |
| 2015 & Oldbenign | 2016 & Oldbenign | |||||
|---|---|---|---|---|---|---|
| Miner | Doser | Proposed | Miner | Dozer | Proposed | |
| drebin & oldbenign | 30.0% | 53.4% | 89.3% | 33.0% | 45.6% | 47.1% |
| 2013 & oldbenign | 31.0% | 67.4% | 90.1% | 33.0% | 88.3% | 80.2% |
| 2014 & oldbenign | 33.0% | 89.3% | 91.4% | 37.0% | 74.2% | 77.1% |
| Drebin & Newbenign | 2013 & Newbenign | 2014 & Newbenign | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Miner | Doser | Proposed | Miner | Dozer | Proposed | Miner | Doser | Proposed | |
| 2014 & newbenign | 76.0% | 88.2% | 98.6% | 75.0% | 92.4% | 99.5% | 92.0% | 90.2% | 99.3% |
| 2015 & newbenign | 68.0% | 91.4% | 99.4% | 68.0% | 87.4% | 98.1% | 69.0% | 87.1% | 95.1% |
| 2016 & newbenign | 33.0% | 90.4% | 99.6% | 35.0% | 85.1% | 98.2% | 36.0% | 67.3% | 88.4% |
| 2015 & Newbenign | 2016 & Newbenign | |||||
|---|---|---|---|---|---|---|
| Miner | Doser | Proposed | Miner | Dozer | Proposed | |
| 2014 & newbenign | 67.0% | 84.1% | 93.2% | 65.0% | 92.4% | 95.4% |
| 2015 & newbenign | 77.0% | 91.3% | 96.2% | 65.0% | 47.1% | 91.3% |
| 2016 & newbenign | 34.0% | 90.1% | 98.2% | 36.0% | 83.4% | 92.2% |
| Drebin & Oldbenign | 2013 & Oldbenign | 2014 & Oldbenign | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MaMa | MD | Proposed | MaMa | MD | Proposed | MaMa | MD | Proposed | |
| drebin & oldbenign | 96.0% | 97.3% | 99.3% | 95.0% | 95.2% | 98.3% | 72.0% | 92.1% | 99.2% |
| 2013 & oldbenign | 94.0% | 93.2% | 98.2% | 97.0% | 97.2% | 98.3% | 73.0% | 90.2% | 96.4% |
| 2014 & oldbenign | 92.0% | 94.0% | 99.1% | 93.0% | 90.2% | 89.4% | 95.0% | 97.1% | 98.5% |
| 2015 & Oldbenign | 2016 & Oldbenign | |||||
|---|---|---|---|---|---|---|
| MaMa | MD | Proposed | MaMa | MD | Proposed | |
| drebin & oldbenign | 39.0% | 88.0% | 89.3% | 42.0% | 61.2% | 47.1% |
| 2013 & oldbenign | 37.0% | 62.1% | 90.1% | 28.0% | 42.0% | 80.2% |
| 2014 & oldbenign | 78.0% | 85.1% | 91.4% | 37.0% | 55.0% | 77.1% |
| Drebin & Newbenign | 2013 & Newbenign | 2014 & Newbenign | |||||||
|---|---|---|---|---|---|---|---|---|---|
| MaMa | MD | Proposed | MaMa | MD | Proposed | MaMa | MD | Proposed | |
| 2014 & newbenign | 98.0% | 98.1% | 98.6% | 98.0% | 98.2% | 99.5% | 99.0% | 99.0% | 99.3% |
| 2015 & newbenign | 97.0% | 97.2% | 99.4% | 97.0% | 96.0% | 98.1% | 99.0% | 98.2% | 95.1% |
| 2016 & newbenign | 96.0% | 98.0% | 99.6% | 98.0% | 88.1% | 98.2% | 98.0% | 98.1% | 98.4% |
| 2015 & Newbenign | 2016 & Newbenign | |||||
|---|---|---|---|---|---|---|
| MaMa | MD | Proposed | MaMa | MD | Proposed | |
| 2014 & newbenign | 85.0% | 88.2% | 93.2% | 81.0% | 87.0% | 95.4% |
| 2015 & newbenign | 95.0% | 96.0% | 96.2% | 88.0% | 72.4% | 91.3% |
| 2016 & newbenign | 92.0% | 94.0% | 98.2% | 92.0% | 91.5% | 92.2% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Taher, F.; Al Fandi, O.; Al Kfairy, M.; Al Hamadi, H.; Alrabaee, S. A Proposed Artificial Intelligence Model for Android-Malware Detection. Informatics 2023, 10, 67. https://doi.org/10.3390/informatics10030067
Taher F, Al Fandi O, Al Kfairy M, Al Hamadi H, Alrabaee S. A Proposed Artificial Intelligence Model for Android-Malware Detection. Informatics. 2023; 10(3):67. https://doi.org/10.3390/informatics10030067
Chicago/Turabian StyleTaher, Fatma, Omar Al Fandi, Mousa Al Kfairy, Hussam Al Hamadi, and Saed Alrabaee. 2023. "A Proposed Artificial Intelligence Model for Android-Malware Detection" Informatics 10, no. 3: 67. https://doi.org/10.3390/informatics10030067
APA StyleTaher, F., Al Fandi, O., Al Kfairy, M., Al Hamadi, H., & Alrabaee, S. (2023). A Proposed Artificial Intelligence Model for Android-Malware Detection. Informatics, 10(3), 67. https://doi.org/10.3390/informatics10030067