_Bryant.png)

Genealogical Data-Driven Visits of Historical Cemeteries




Abstract
:1. Introduction
- Cultural tourism. First, the project aims to promote the Jewish Cemetery in Pisa, a cultural site presently excluded from the traditional Pisa tour, despite being located adjacent to the famous Leaning Tower;
- Innovation. The second goal involves devising a “data-driven” tour of the Jewish Cemetery, enhancing the visitor experience by providing valuable information during their physical exploration of the cemetery. IaCuP aims to complement the traditional approach of using plaques or human guides by providing a 2D interactive map with additional information layers (in this case, genealogy);
- Technology. Finally, the project aims to test different technologies to combine entity extraction, genealogical representation, and 2D map navigation. The chosen technologies could also be used in other contexts since they are free, open-source, and scalable.
2. Related Work
2.1. Projects Related to the Funerary Domain
2.2. Entity Extraction
2.3. Genealogical Tree
2.4. Map and Genealogical Visualizations
3. The Jewish Cemetery in Pisa
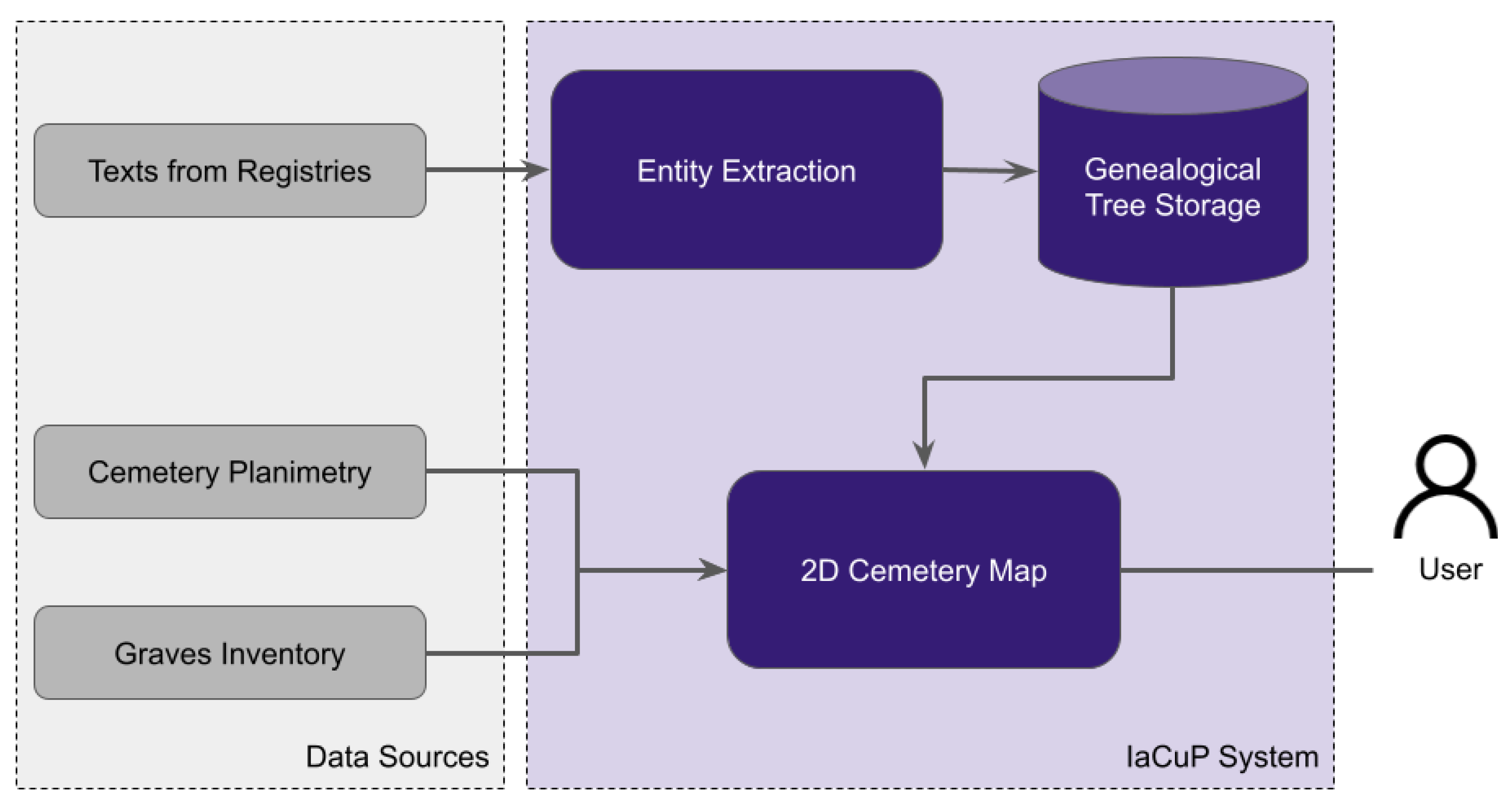
4. The Proposed Approach
- Texts from registries include the transcription of the relevant documents contained in the archive. In the specific use case described in this paper, texts contain the transcription of the Registry of Births and Deaths of the Historical Archive of the Jewish Community in Pisa;
- The cemetery planimetry includes the graphical representation of the map used as a background for the cemetery. It contains all the graves;
- The graves inventory contains the mapping between each grave and the person buried.
4.1. The Registry of Births and Deaths
4.2. The Cemetery Planimetry and the Graves Inventory
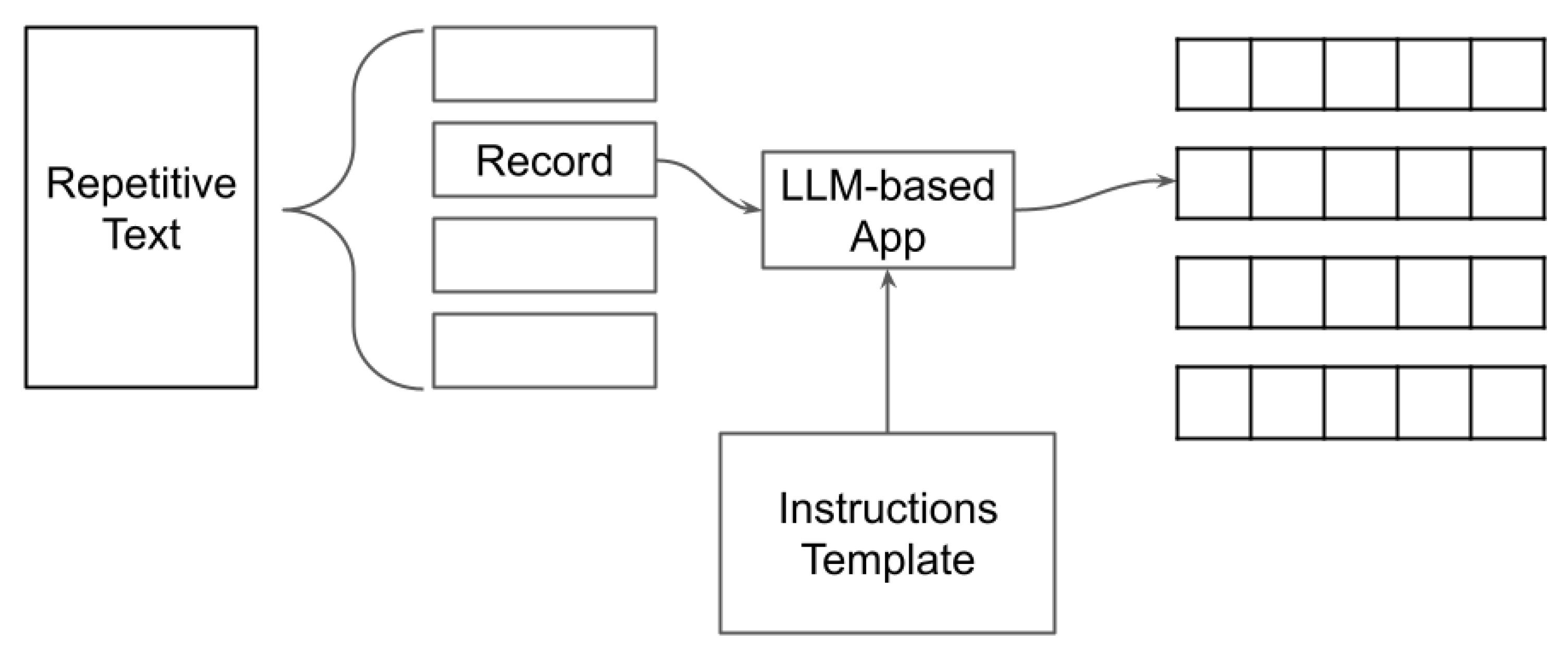
5. Entity Extraction
- For each line extract:
- - extract child name, father name, mother name, gender, date of birth and format as CSV
- Instructions:
- - If you find a son, set sex to M
- - If you find a daughter, sex is F
- - Do not include besiman tov in the child’s name
- - at the end add a new line
- Follow this example:
- Input:
- <Nel giorno di lunedì 3 Ijar (sic) 5570 relativo alli 10 maggio 1810 nacque un bambino figlio dei coniugi Signore Isac Vita Soria, e Grazia Prato nominato Raffaello besiman tov>
- Output:
- Raffaello, Isac Vita Soria, Grazia Prato, M,10/05/1810
- Answer by formatting the output in CSV format.
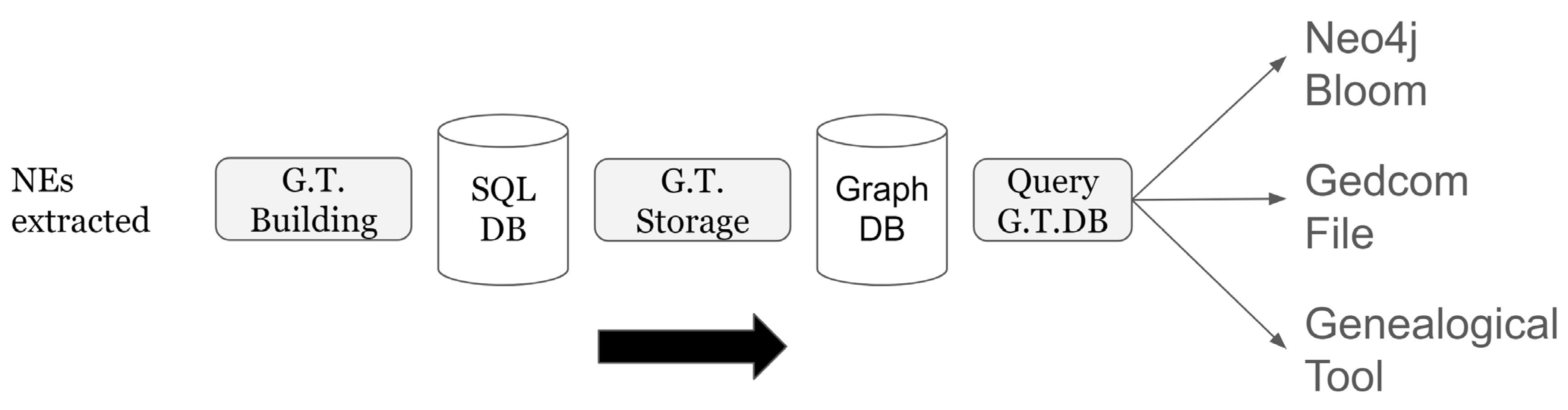
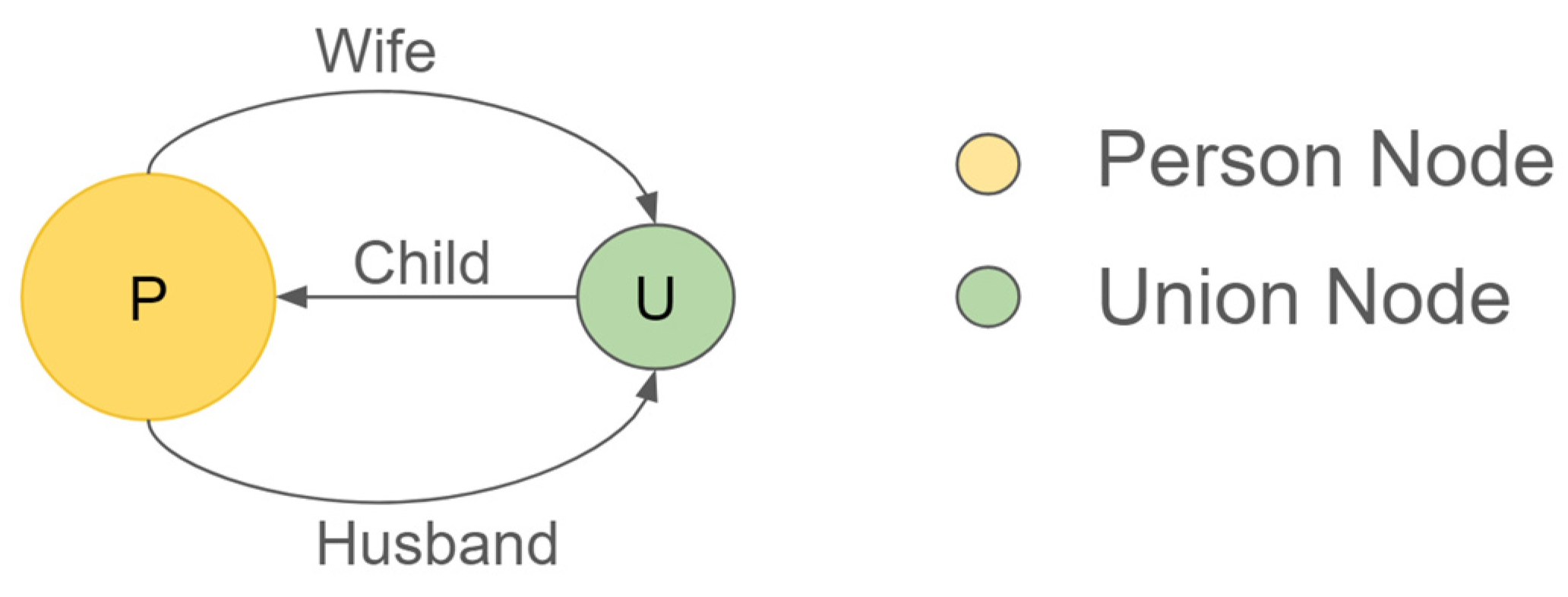
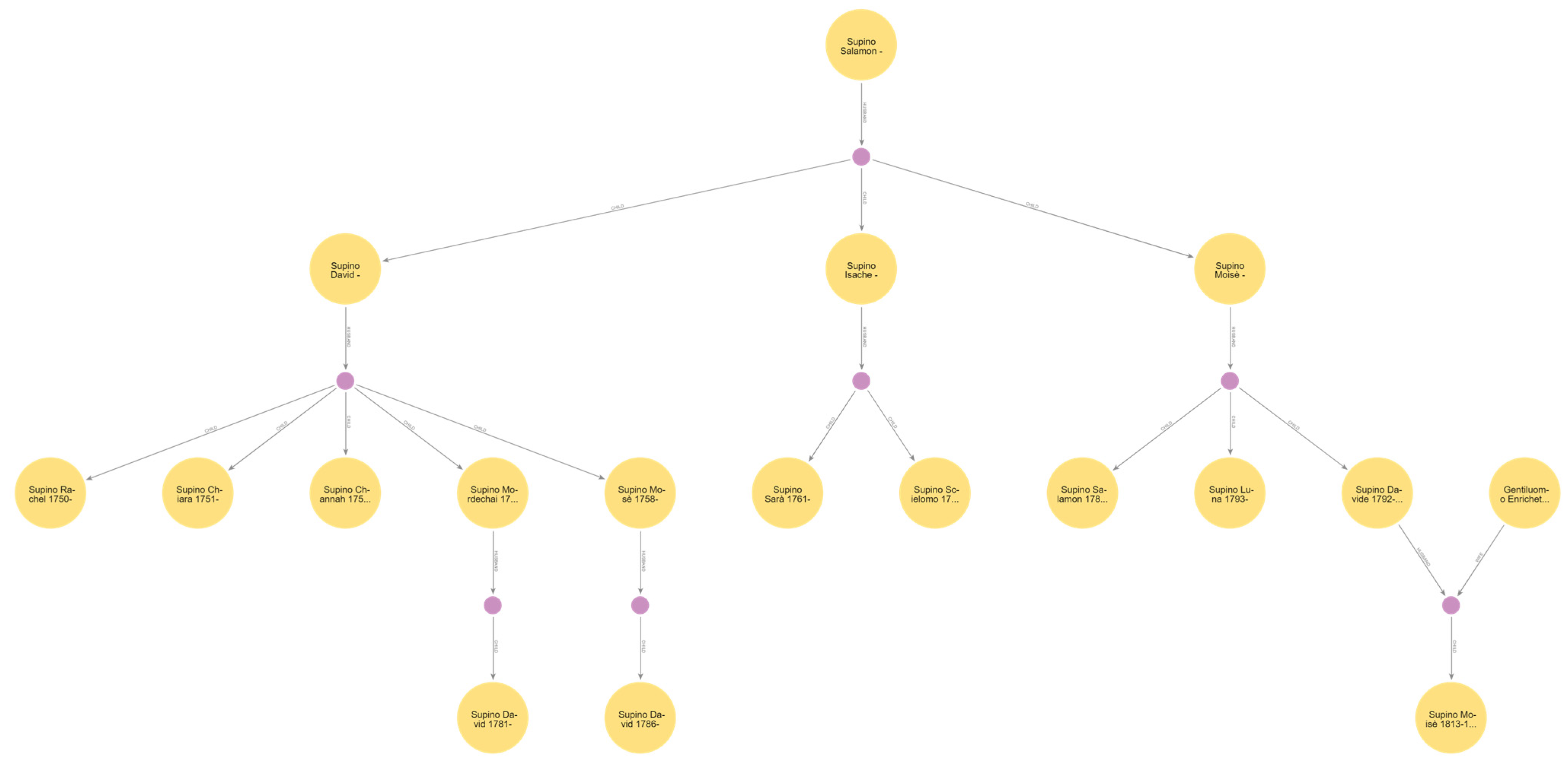
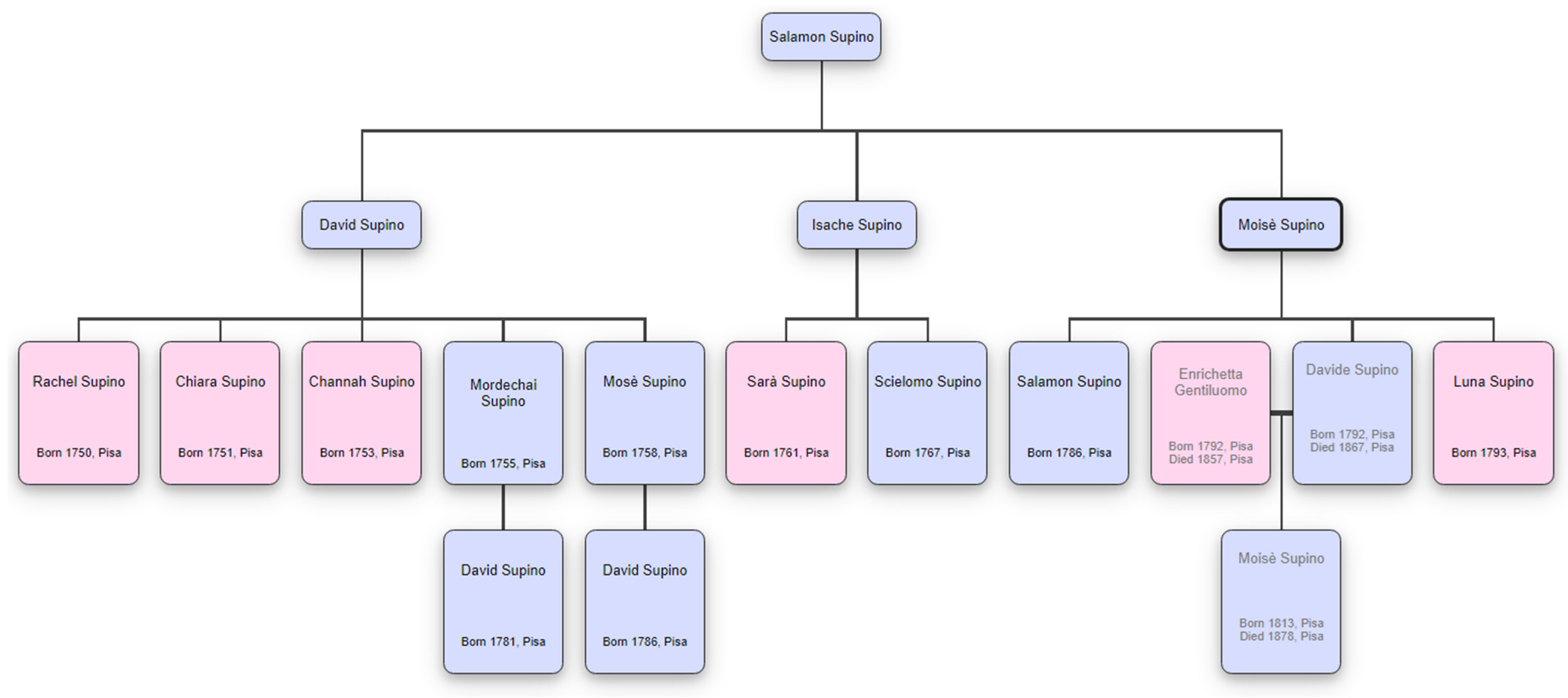
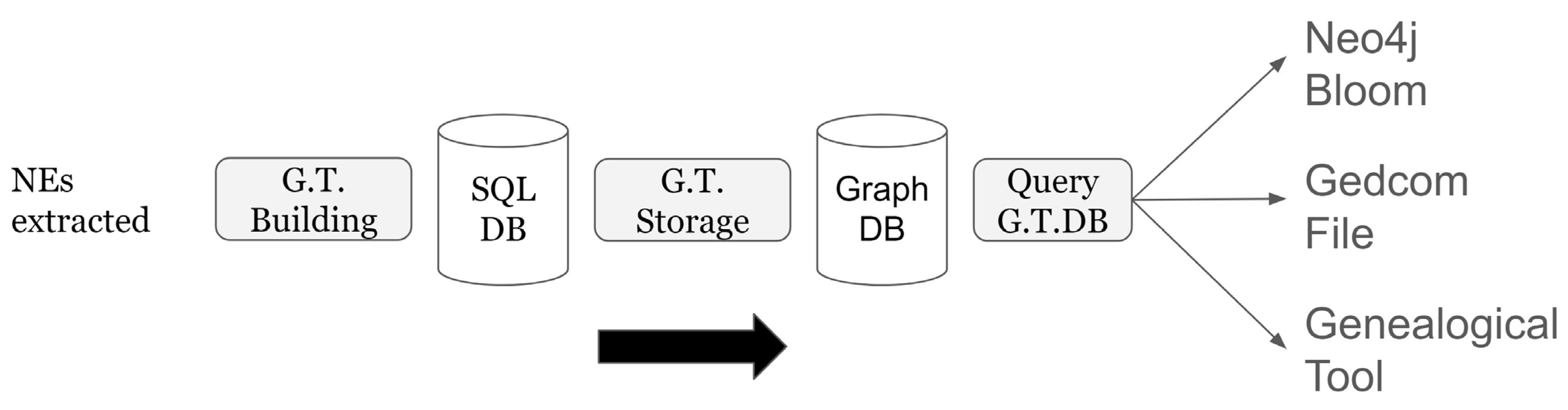
6. Genealogical Tree
- // LOAD ALL PERSON NODEs
- LOAD CSV WITH HEADERS FROM “file:///people.csv” AS r
- CREATE (p:Person {id:r.id, last:r.last, firts:r.first, sex:r.sex, father:r.father, mother:r.mother, birthDate:date(r.birthDate), birthPlace:r.birthPlace, idFamOrigin: r.idFamOrigin})
- // LOAD ALL UNION NODEs
- LOAD CSV WITH HEADERS FROM “file:///unions.csv” AS r
- CREATE (u:Union {id: r.id, wDate: r.wDate, wPlace:r.wPlace,
- idHusband:r.idHusband, husband: r.husband,
- idWife: r.idWife, wife: r.wife })
- // CREATE CHILD EDGEs
- MATCH (p:Person), (u:Union)
- WHERE p.idFamOrigine = u.id
- CREATE (p)<-[:CHILD]-(u)
- // CREATE HUSBAND EDGEs
- MATCH (u:Union), (p:Person)
- WHERE u.idHusband = p.id
- CREATE (u)<-[:HUSBAND]-(p)
- // CREATE WIFE EDGEs
- MATCH (u:Union), (p:Person)
- WHERE u.idWife = p.id
- CREATE (u)<-[:WIFE]-(p)
- // QUERY ALL PATHS STARTING FROM A PERSON NODE IDENTIFIED FROM LAST & FIRST NAME
- MATCH (root:Person {last:$last})
- WHERE root.first CONTAINS $first
- MATCH paths=(root)-[*]-(n)
- WHERE (n:Person OR n:Union)
- RETURN paths
- 0 @ISPNRCH17500626FG702IT@ INDI
- 1 NAME Rachel /Supino/
- 2 GIVN Rachel
- 2 SURN Supino
- 1 SEX F
- 1 BIRT
- 2 DATE 1750-06-26
- 2 PLAC Pisa
- 1 FAMC @FSPN?2XXXXXXXXXG702IT@
- …
7. Interactive Map and Contextual Genealogy Visualization
8. Conclusions and Future Work
- Extending the proposed strategy to incorporate marriage records and other historical documentation, such as census, religious and military records, newspapers archives, legal documents, etc., could further enrich users’ cultural context and genealogical information;
- Enhancing the proposed system’s ability to extract and interpret epigraphs (inscriptions on tombstones) could provide deeper insights into the cultural and historical significance of individual graves within a cemetery;
- Incorporating photographs of tombstones and their associated epigraphs could offer a more immersive experience for users, allowing them to explore the visual and textual aspects of cultural sites in greater detail;
- Envisioning a scaled-up, more automated version of the proposed system for bigger sites with better raw data availability and quality (e.g., readable epigraphs, complete registries, etc.).
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Lennon, J.J.; Foley, M. Dark Tourism; Cengage Learning EMEA: Andover, UK, 2000. [Google Scholar]
- Lo Duca, A.; Bacciu, C.; Marchetti, A. Chapter Fourteen—Towards a smart navigation of cemeteries as cultural sites. In Ancient Greek Art and European Funerary Art, 321; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2019; ISBN 13-978-1-5275-3930-3. [Google Scholar]
- Lo Duca, A.; Marchetti, A.; Moretti, M.; Diana, F.; Toniazzi, M.; D’Errico, A. Genealogical Data Mining from Historical Archives: The Case of the Jewish Community in Pisa. Informatics 2023, 10, 42. [Google Scholar] [CrossRef]
- Cimitero Monumentale di Milano. Percorso Generale. 2019. Available online: https://monumentale.comune.milano.it/itinerari/percorso-generale (accessed on 18 February 2024).
- Cimiteri di Roma. Cimiteri di Roma. 2020. Available online: http://www.cimiteridiroma.it/ (accessed on 18 February 2024).
- Ciolfi, L.; Petrelli, D.; Goldberg, R.; Dulake, N.; Willox, M.; Marshall, M.; Caparrelli, F. Exploring historical, social and natural heritage: Challenges for tangible interaction design at Sheffield General Cemetery. In Proceedings of the NODEM 2013: Beyond Control—The Collaborative Museum and Its Challenges, Stockholm, Sweden, 1–3 December 2013. [Google Scholar]
- Evensen, K.H.; Nordh, H.; Skaar, M. Everyday use of urban cemeteries: A Norwegian case study. Landsc. Urban Plan. 2017, 159, 76–84. [Google Scholar] [CrossRef]
- Matuszka, T.; Kiss, A. Alive cemeteries with augmented reality and Semantic Web technologies. Int. J. Comput. Inf. Sci. Eng. 2014, 8, 32–36. [Google Scholar]
- Wolgemuth, R. Cemetery Tours and Programming: A Guide; Rowman & Littlefield: Lanham, MD, USA, 2016. [Google Scholar]
- The PEACE Project. Available online: https://peace.sites.uu.nl/ (accessed on 18 February 2024).
- The FIJI Project. Available online: https://fiji.sites.uu.nl/FIJI (accessed on 18 February 2024).
- Goyal, A.; Gupta, V.; Kumar, M. Recent named entity recognition and classification techniques: A systematic review. Comput. Sci. Rev. 2018, 29, 21–43. [Google Scholar] [CrossRef]
- Humbel, M.; Nyhan, J.; Vlachidis, A.; Sloan, K.; Ortolja-Baird, A. Named-entity recognition for early modern textual documents: A review of capabilities and challenges with strategies for the future. J. Doc. 2021, 77, 1223–1247. [Google Scholar] [CrossRef]
- Wang, S.; Sun, X.; Li, X.; Ouyang, R.; Wu, F.; Zhang, T.; Li, J.; Wang, G. Gpt-ner: Named entity recognition via large language models. arXiv 2023, arXiv:2304.10428. [Google Scholar]
- Braverman, M.; Chen, X.; Kakade, S.; Narasimhan, K.; Zhang, C.; Zhang, Y. Calibration, entropy rates, and memory in language models. In Proceedings of the International Conference on Machine Learning, Vienna, Austria, 12–18 July 2020; pp. 1089–1099. [Google Scholar]
- Malmasi, S.; Fang, A.; Fetahu, B.; Kar, S.; Rokhlenko, O. Multiconer: A large-scale multilingual dataset for complex named entity recognition. arXiv 2022, arXiv:2208.14536. [Google Scholar]
- Luo, Y.; Zhao, H.; Zhan, J. Named entity recognition only from word embeddings. arXiv 2019, arXiv:1909.00164. [Google Scholar]
- Ashok, D.; Lipton, Z.C. PromptNER: Prompting For Named Entity Recognition. arXiv 2023, arXiv:2305.15444. [Google Scholar]
- Shen, T.; Long, G.; Geng, X.; Tao, C.; Zhou, T.; Jiang, D. Large Language Models are Strong Zero-Shot Retriever. arXiv 2023, arXiv:2304.14233. [Google Scholar]
- Genealogy. Wikipedia, The Free Encyclopedia. 2023. Available online: https://en.wikipedia.org/wiki/Genealogy (accessed on 1 October 2023).
- Price, J.; Buckles, K.; Van Leeuwen, J.; Riley, I. Combining Family History and Machine Learning to Link Historical Records (No. w26227); National Bureau of Economic Research: Cambridge, MA, USA, 2019. [Google Scholar]
- Pokorný, J. Graph databases: Their power and limitations. In Proceedings of the Computer Information Systems and Industrial Management: 14th IFIP TC 8 International Conference, CISIM 2015, Warsaw, Poland, 24–26 September 2015; Proceedings 14. Springer International Publishing: Cham, Switzerland, 2015; pp. 58–69. [Google Scholar]
- Van Aart, C.; Wielinga, B.; Van Hage, W.R. Mobile cultural heritage guide: Location-aware semantic search. In Proceedings of the Knowledge Engineering and Management by the Masses: 17th International Conference, EKAW 2010, Lisbon, Portugal, 11–15 October 2010; Proceedings 17. Springer: Berlin/Heidelberg, Germany, 2010; pp. 257–271. [Google Scholar]
- Shneiderman, B. The eyes have it: A task by data type taxonomy for information visualizations. In Proceedings of the Proceedings 1996 IEEE Symposium on Visual Languages, Boulder, Colorado, 3–6 September 1996; IEEE: Piscataway, NJ, USA, 1996; pp. 336–343. [Google Scholar]
- Herman, I.; Melançon, G.; Marshall, M.S. Graph visualization and navigation in information visualization: A survey. IEEE Trans. Vis. Comput. Graph. 2000, 6, 24–43. [Google Scholar] [CrossRef]
- McGuffin, M.J.; Balakrishnan, R. Interactive visualization of genealogical graphs. In Proceedings of the IEEE Symposium on Information Visualization, Minneapolis, MN, USA, 23–25 October 2005; INFOVIS 2005. IEEE: Piscataway, NJ, USA, 2005; pp. 16–23. [Google Scholar]
- Tuttle, C.; Nonato, L.G.; Silva, C. PedVis: A structured, space-efficient technique for pedigree visualization. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1063–1072. [Google Scholar] [CrossRef] [PubMed]
- Kim, N.W.; Card, S.K.; Heer, J. Tracing genealogical data with timenets. In Proceedings of the International Conference on Advanced Visual Interfaces, Roma, Italy, 26–28 May 2010; pp. 241–248. [Google Scholar]
- Mukaliyev, D. Visualizing Large Genealogies with Timelines. Master’s Thesis, Itä-Suomen Yliopisto, Kuopio, Finland, 2015. [Google Scholar]
- Bezerianos, A.; Dragicevic, P.J.; Fekete, D.; Bae, J.; Watson, B. GeneaQuilts: A System for Exploring Large Genealogies. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1073–1081. [Google Scholar] [CrossRef] [PubMed]
- Zappala, D. Using visualization and search to locate genealogy holes. In Proceedings of the 13th Annual Family History Technology Workshop, Salt Lake City, UT, USA, 21–23 March 2013. [Google Scholar]
- Mansueli, V.A.P.; Okano, M.T. Representations of Genealogies in Graph Theory: K-Graphs. In Proceedings of the IAMOT 2018 Conference—International Association for Management of Technology, Birmingham, UK, 22–26 April 2018. [Google Scholar]
- Santos, C.A.; Yan, G. Genealogical tourism: A phenomenological examination. J. Travel Res. 2010, 49, 56–67. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Child Name | Father Name | Mother Name | Sex | Date of Birth |
|---|---|---|---|---|
| Haim o Vita | Giacomo Nissim | Giaele Levi Sonsino | M | 4 February 1850 |
| Entity Type | Structure | Example | N. of Records |
|---|---|---|---|
| Father | (Multiple) Name Surname | Angelo Merisi | 9 |
| Father | (Multiple) Name Surname di/del fu Name Surname | Aron di Nissim Soria | 11 |
| Mother | (Multiple) Name Surname | Anna Usigli | 14 |
| Mother | (Multiple) Name Surname di/del fu Name | Ester del fu Josef Montefiore | 4 |
| Mother | Name | Devora | 2 |
| Grand Father | Father | Child | Child Birth of Date | Child Sex |
|---|---|---|---|---|
| Salamon | David | Rachel | 26 June 1750 | F |
| Id Person | Last | First | Sex | Father | Mother | Id Family of Origin | Birth Date | Birth Place |
|---|---|---|---|---|---|---|---|---|
| SPNSLMXXXXXXXXMG702IT | Supino | Salamon | M | Pisa | ||||
| SPNDVDXXXXXXXXMG702IT | Supino | David | M | Supino Salamon | ?F1 | SPN?F1XXXXXXXXG702IT | Pisa | |
| SPNRCH17500626FG702IT | Supino | Rachel | F | Supino David | ?F2 | SPN?F2XXXXXXXXG702IT | 26 June 1750 | Pisa |
| Id Family | Wedding Date | Wedding Place | Id Husband | Husband | Id Wife | Wife |
|---|---|---|---|---|---|---|
| SPN?F1XXXXXXXXG702IT | Pisa | SPNSLMXXXXXXXXMG702IT | Supino Salamon | ?F1 | ||
| SPN?F2XXXXXXXXG702IT | Pisa | SPNDVDXXXXXXXXMG702IT | Supino David | ?F2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo Duca, A.; Abrate, M.; Marchetti, A.; Moretti, M. Genealogical Data-Driven Visits of Historical Cemeteries. Informatics 2024, 11, 9. https://doi.org/10.3390/informatics11010009
Lo Duca A, Abrate M, Marchetti A, Moretti M. Genealogical Data-Driven Visits of Historical Cemeteries. Informatics. 2024; 11(1):9. https://doi.org/10.3390/informatics11010009
Chicago/Turabian StyleLo Duca, Angelica, Matteo Abrate, Andrea Marchetti, and Manuela Moretti. 2024. "Genealogical Data-Driven Visits of Historical Cemeteries" Informatics 11, no. 1: 9. https://doi.org/10.3390/informatics11010009
APA StyleLo Duca, A., Abrate, M., Marchetti, A., & Moretti, M. (2024). Genealogical Data-Driven Visits of Historical Cemeteries. Informatics, 11(1), 9. https://doi.org/10.3390/informatics11010009