

Detecting Structured Query Language Injections in Web Microservices Using Machine Learning


Abstract
:1. Introduction
2. Data and Materials
2.1. Characterization of SQLI Attacks
2.2. Dataset
- The dataset must come from a reliable source and be found in known repositories;
- Precise labeling and classification are necessary, with values assigned to indicate whether a query is abnormal or normal;
- Normal data should also be included for better training;
- The selected dataset must be legally permitted for use in research.
2.3. Algorithm Selection
3. Method
3.1. Machine Learning for SQLI Detection
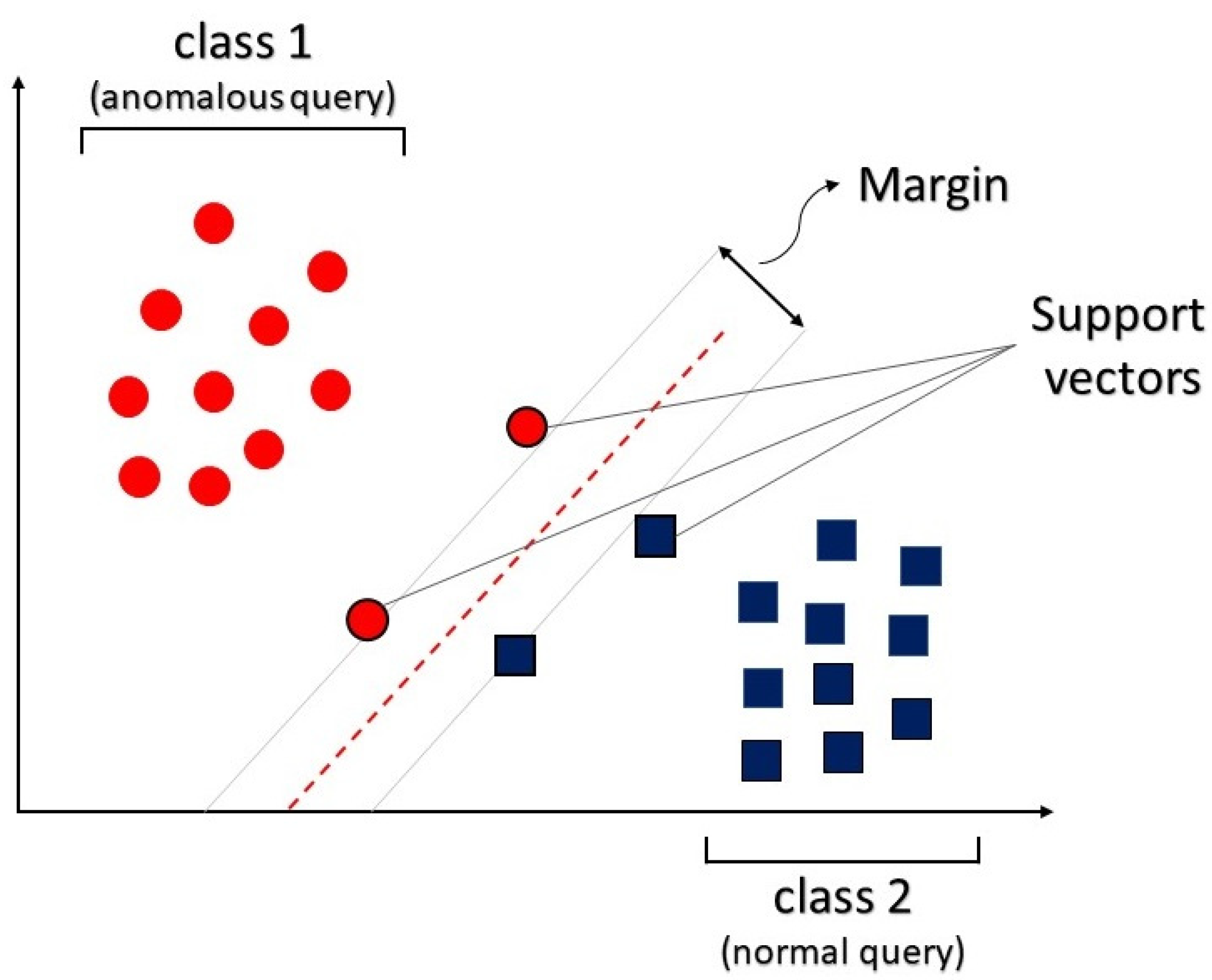
3.1.1. Support Vector Machine
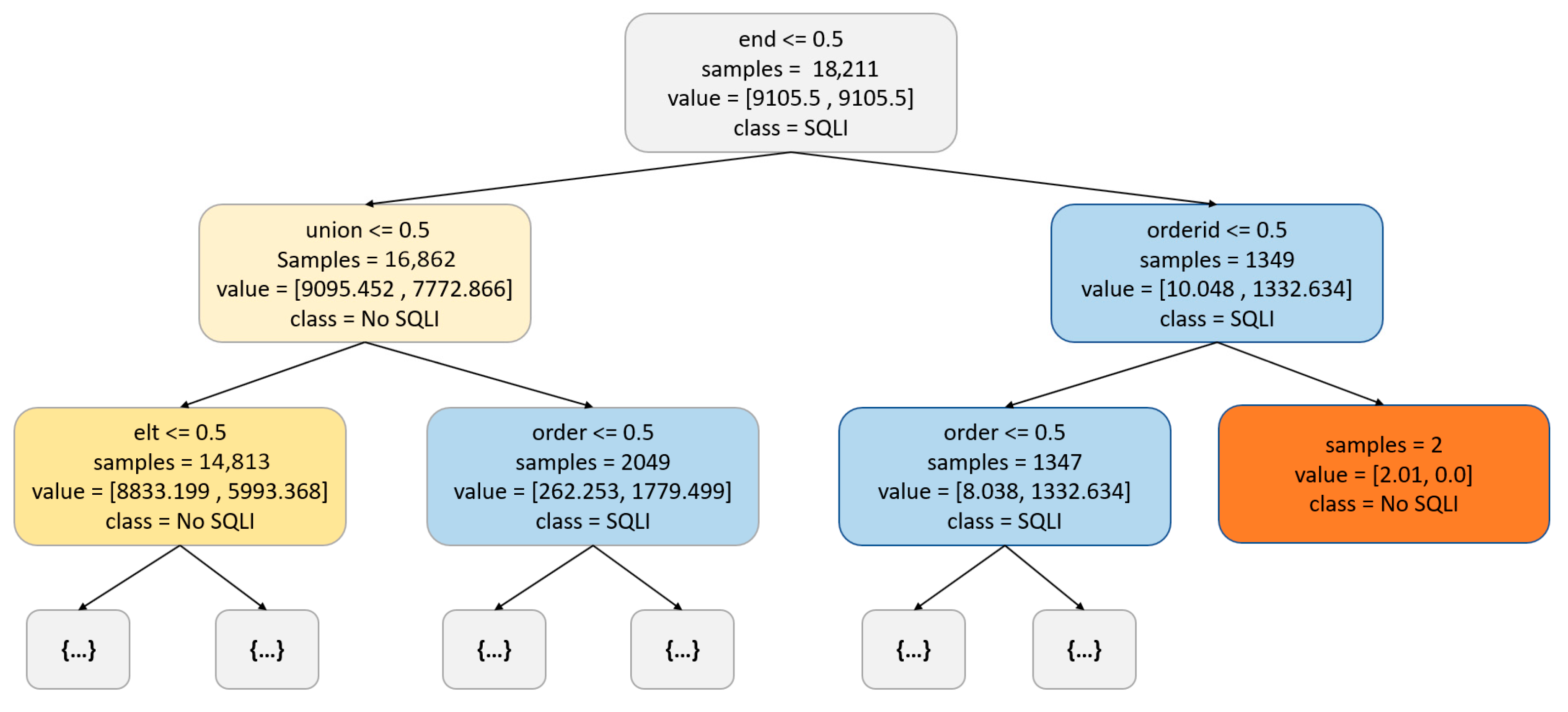
3.1.2. Decision Tree
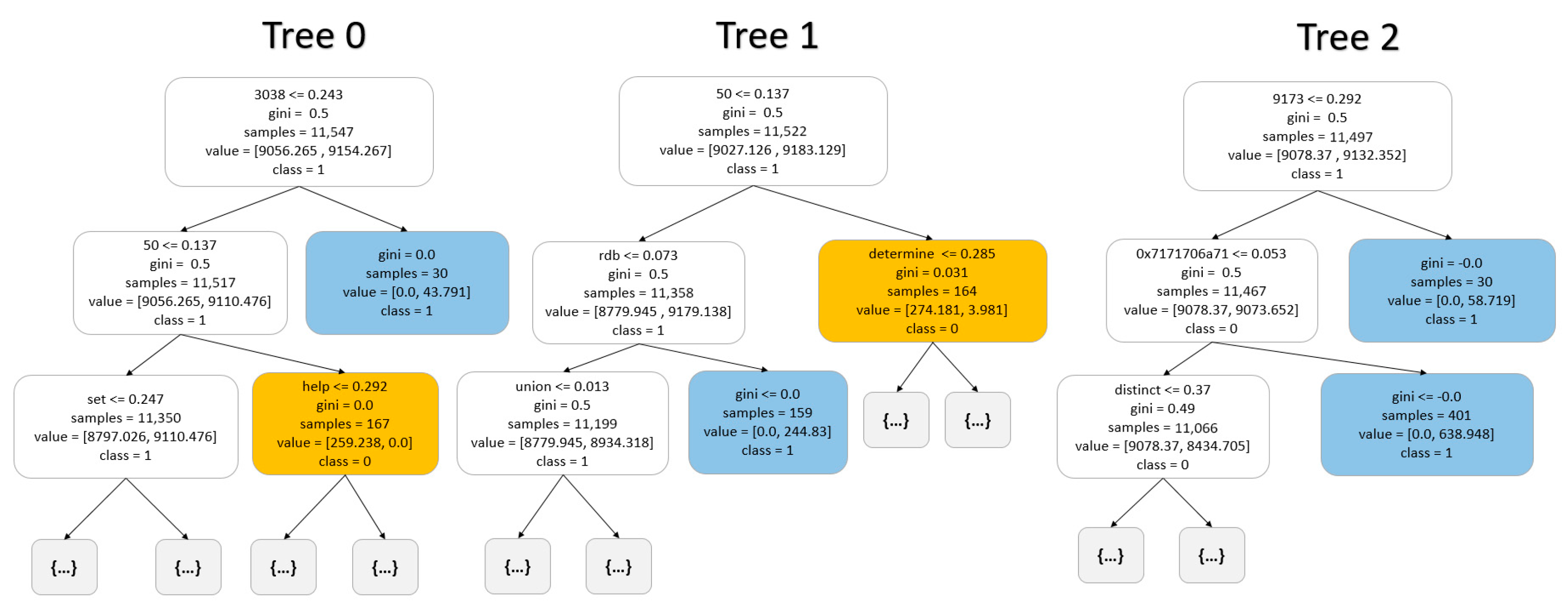
3.1.3. Random Forest
3.1.4. Performance Evaluations
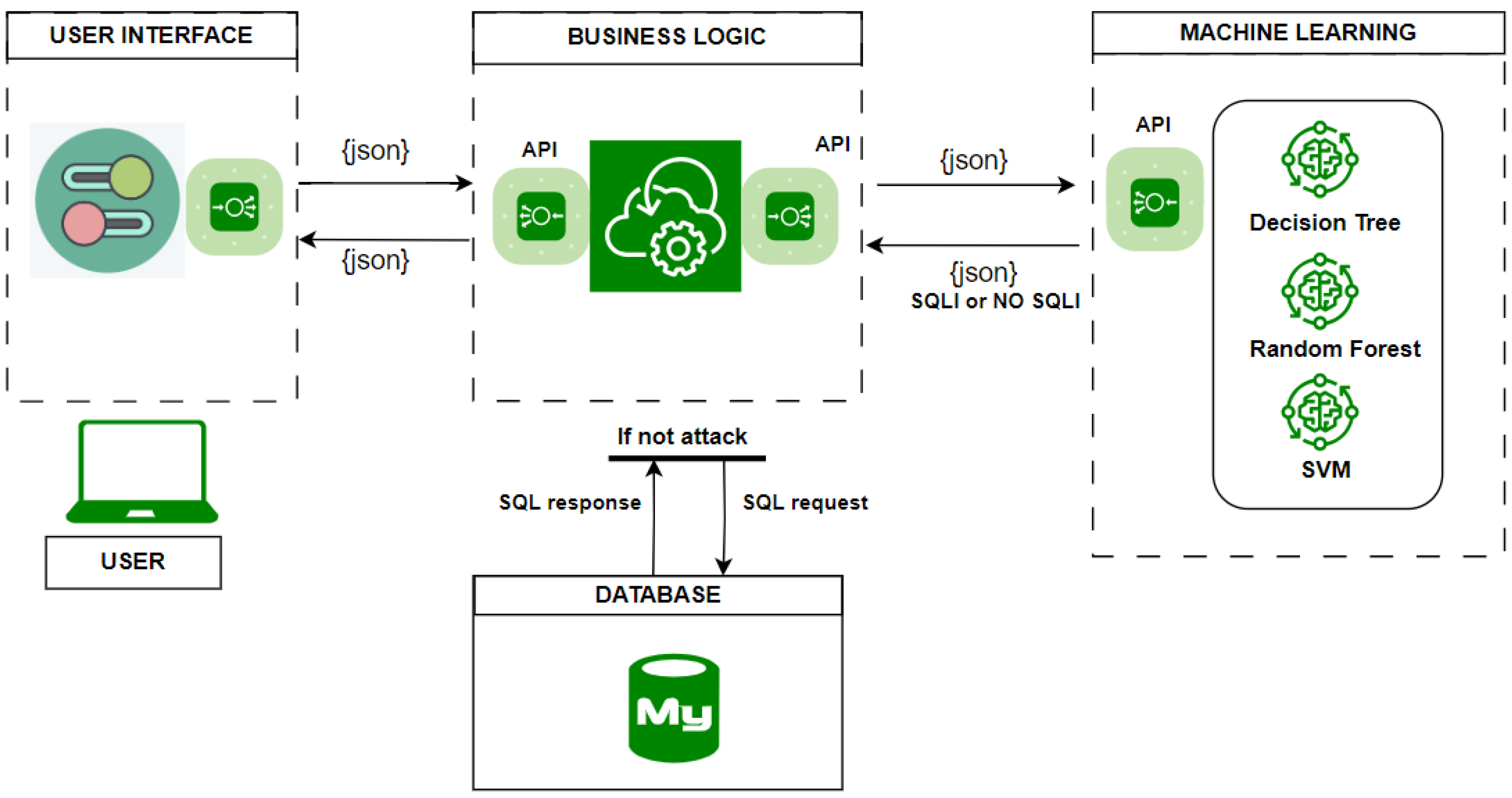
3.2. Microservices-Based Software Architecture
4. Results
4.1. Training Time
4.2. Performance
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Arcila-Diaz, J.C.; Valdivia, C. A microservice-based software architecture for improving the availability of dental health records. Int. J. Comput. 2022, 21, 475–481. [Google Scholar] [CrossRef]
- Mocean, L.; Vlad, M.-P. Database security in RDF terms. Sci. Bull. 2023, 28, 55–65. [Google Scholar] [CrossRef]
- Wang, Y.-C.; Zhang, G.-L.; Zhang, Y.-L. Analysis of SQL injection based on Petri net in wireless network. J. Inf. Sci. Eng. 2023, 39, 167–181. [Google Scholar]
- Shagari, S.M.; Gabi, D.; Dankolo, N.M.; Gana, N.N. Countermeasure to structured query language injection attack for web applications using hybrid logistic regression technique. J. Niger. Soc. Phys. Sci. 2022, 4, 832. [Google Scholar] [CrossRef]
- Furhad, M.H.; Chakrabortty, R.K.; Ryan, M.J.; Uddin, J.; Sarker, I.H. A hybrid framework for detecting structured query language injection attacks in web-based applications. Int. J. Electr. Comput. Eng. 2022, 12, 5405–5414. [Google Scholar] [CrossRef]
- Marashdih, A.W.; Zaaba, Z.F.; Suwais, K. Predicting input validation vulnerabilities based on minimal SSA features and machine learning. J. King Saud Univ. Comput. Inf. Sci. 2022, 34, 9311–9331. [Google Scholar] [CrossRef]
- Lodeiro-Santiago, M.; Caballero-Gil, C.; Caballero-Gil, P. Collaborative SQL-injections detection system with machine learning. In Proceedings of the 1st International Conference on Internet of Things and Machine Learning (IML ‘17), New York, NY, USA, 17–18 October 2017; pp. 1–5. [Google Scholar]
- Li, Y.; Zhang, B. Detection of SQL injection attacks based on improved TFIDF algorithm. J. Phys. Conf. Ser. 2019, 1395, 012013. [Google Scholar] [CrossRef]
- Tang, P.; Qiu, W.; Huang, Z.; Lian, H.; Liu, G. Detection of SQL injection based on artificial neural network. Knowl. Based Syst. 2020, 190, 105528. [Google Scholar] [CrossRef]
- Begum, A.M.; Arock, M. Efficient detection Of SQL injection attack(SQLIA) using pattern-based neural network model. In Proceedings of the IEEE 2021 International Conference on Computing, Communication, and Intelligent Systems, ICCCIS 2021, Greater Noida, India, 19–20 February 2021; pp. 343–347. [Google Scholar]
- Zhang, K. A machine learning based approach to identify SQL injection vulnerabilities. In Proceedings of the 2019 34th IEEE/ACM International Conference on Automated Software Engineering, ASE, San Diego, CA, USA, 11–15 November 2019; pp. 1286–1288. [Google Scholar]
- Tien, C.W.; Huang, T.Y.; Tien, C.W.; Huang, T.C.; Kuo, S.Y. KubAnomaly: Anomaly detection for the Docker orchestration platform with neural network approaches. Eng. Rep. 2019, 1, e12080. [Google Scholar] [CrossRef]
- Deriba, F.G.; Salau, A.O.; Mohammed, S.H.; Kassa, T.M.; Demilie, W.B. Development of a compressive framework using machine learning approaches for SQL injection attacks. Prz. Elektrotech. 2022, 98, 181–187. [Google Scholar] [CrossRef]
- Kasim, Ö. An ensemble classification-based approach to detect attack level of SQL injections. J. Inf. Secur. Appl. 2021, 59, 102852. [Google Scholar] [CrossRef]
- Padma, N.J.; Ravishankar, N.; Raju, M.B.; Ravi, N.C. Surgical striking SQL injection attacks using LSTM. Indian J. Comput. Sci. Eng. 2022, 13, 208–220. [Google Scholar] [CrossRef]
- Alkhathami, J.M.; Alzahrani, S.M. Detection of SQL injection attacks using machine learning in cloud computing platform. J. Theor. Appl. Inf. Technol. 2022, 100, 5446–5459. [Google Scholar]
- Farooq, U. Ensemble machine learning approaches for detection of SQL injection attack. Teh. Glas. 2021, 15, 112–120. [Google Scholar] [CrossRef]
- Demilie, W.B.; Deriba, F.G. Detection and prevention of SQLI attacks and developing compressive framework using machine learning and hybrid techniques. J. Big Data 2022, 9, 181–187. [Google Scholar] [CrossRef]
- Gandhi, N.; Patel, J.; Sisodiya, R.; Doshi, N.; Mishra, S. A CNN-BiLSTM based approach for detection of SQL injection attacks. In Proceedings of the 2nd IEEE International Conference on Computational Intelligence and Knowledge Economy, ICCIKE 2021, Dubai, United Arab Emirates, 17–18 March 2021; pp. 378–383. [Google Scholar]
- Sanshui. SQL Injection Detection by Machine Learning. Available online: https://www.kaggle.com/code/sanshui123/sql-injection-detection-by-machine-learning/input?select=Modified_SQL_Dataset.csv (accessed on 20 December 2023).
- Devalla, V.; Raghavan, S.S.; Maste, S.; Kotian, J.D.; Annapurna, D.D. mURLi: A tool for detection of malicious URLs and injection attacks. Procedia Comput. Sci. 2022, 215, 662–676. [Google Scholar] [CrossRef]
- Ashlam, A.A.; Badii, A.; Stahl, F. A novel approach exploiting machine learning to detect SQLi attacks. In Proceedings of the 2022 5th International Conference on Advanced Systems and Emergent Technologies, IC_ASET 2022, Hammamet, Tunisia, 22–25 March 2022; pp. 513–517. [Google Scholar]
- Fu, H.; Guo, C.; Jiang, C.; Ping, Y.; Lv, X. SDSIOT: An SQL injection attack detection and stage identification method based on outbound traffic. Electronics 2023, 12, 2472. [Google Scholar] [CrossRef]
- Zhao, C.; Si, S.; Tu, T.; Shi, Y.; Qin, S. Deep-Learning Based Injection Attacks Detection Method for HTTP. Mathematics 2022, 10, 2914. [Google Scholar] [CrossRef]
- Kecman, V. Support Vector Machines–An Introduction. In Support Vector Machines: Theory and Applications; Wang, L., Ed.; Springer: Berlin/Heidelberg, Germany, 2005; pp. 1–47. [Google Scholar] [CrossRef]
- Suthaharan, S. Decision Tree Learning. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Suthaharan, S., Ed.; Springer: Boston, MA, USA, 2016; pp. 237–269. [Google Scholar] [CrossRef]
- Altman, N.; Krzywinski, M. Ensemble methods: Bagging and random forests. Nat. Methods 2017, 14, 933. [Google Scholar] [CrossRef]
- Baškarada, S.; Nguyen, V.; Koronios, A. Architecting microservices: Practical opportunities and challenges. J. Comput. Inf. Syst. 2020, 60, 428–436. [Google Scholar] [CrossRef]
- Callens, A.; Morichon, D.; Abadie, S.; Delpey, M.; Liquet, B. Using random forest and gradient boosting trees to improve wave forecast at a specific location. Appl. Ocean Res. 2020, 104, 102339. [Google Scholar] [CrossRef]
- Crespo-Martínez, I.S.; Campazas-Vega, A.; Guerrero-Higueras, Á.M.; Riego-DelCastillo, V.; Álvarez-Aparicio, C.; Fernández-Llamas, C. SQL injection attack detection in network flow data. Comput. Secur. 2023, 127, 103093. [Google Scholar] [CrossRef]
- Lu, D.; Fei, J.; Liu, L. A semantic learning-based SQL injection attack detection technology. Electronics 2023, 12, 1344. [Google Scholar] [CrossRef]
- Alghawazi, M.; Alghazzawi, D.; Alarifi, S. Deep learning architecture for detecting SQL injection attacks based on RNN autoencoder model. Mathematics 2023, 11, 3286. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attack Type | Definition | Normal Consultation | Injectable Parameter | Abnormal Query | Description |
|---|---|---|---|---|---|
| Tautology SQLI | This type of attack attempts to use a conditional question argument to test the validity of the SQL query, this is achieved by using the WHERE clause where the attacker injects the condition and transforms it into a tautology that is always valid [13,14]. | SELECT * FROM users WHERE name = ‘user’ AND password = ‘password’; | OR ‘1’ = ‘1’; | SELECT * FROM users WHERE name = ‘user’ AND password = ‘password’ OR ‘1’ = ‘1’; | It becomes an anomalous query by adding the statement ‘OR ‘1’ = ‘1’;’ to the SQL query. This causes the table fields to always evaluate to true, resulting in data being returned from the table, regardless of the actual conditions [14,15]. |
| Ilegal/Logically incorrect query SQLI | Injection of this type occurs due to errors, lack of validations or the inputs are invalid from a logical point of view, since during the development period it helps programmers to correct their programs [16]. | SELECT * FROM products WHERE product_name = ‘name’; | ; SELECT * FROM users; --’; | SELECT * FROM products WHERE product_name = ‘; SELECT * FROM users; --’; | This injection attempts to execute two SQL queries at the same time, the first closes prematurely and the second selects all records in the users table, potentially revealing sensitive information. The “;” indicates the completion of a query in SQL. The “--” initiates a comment, which means that everything after it in the line is considered descriptive text. |
| Union query SQLI | The injection of this type consists mainly of the word UNION, which simulates a single query consisting of the SELECT clause. For this query to be applied, the tables must be related and the correct names of the tables along with their fields should be known [13,17]. | SELECT * FROM accountTable WHERE user_login = ‘user’; | UNION | SELECT * FROM accountTable WHERE user_login = ‘user’ UNION SELECT * FROM accountTable WHERE No = 10,232 | The query can point to an SQL injection from a login because it attempts to join two tables with a single query, thus attempting to return all users who have the queried username or the value 10,232 in the query column [13]. |
| Piggy-Backed Query SQLI | This type of injection executes two requests simultaneously, the first should be correct and the second should be controlled for data extraction, addition, modification, remote execution, or denial of service [16,18]. | SELECT book_name FROM booktable WHERE book_id = ‘book1’ AND book_name = 0 | ; | SELECT book_name FROM booktable WHERE book_id = ‘book1’ AND book_name = 0; DROP booktable; | This query is characterized by the fact that a real query, which is executed normally, is added with malicious queries [17]. |
| Blind SQLI | It consists of the formation of a series of true/false queries, thus collecting valuable data by inferring from the responses of the consulted website [13,18] | SELECT 5 WHERE username = :username | 1/0 ELSE SELECT 5 | ‘admin’; IF SYSTEM_USER = ‘sa’ SELECT 1/0 ELSE SELECT 5 | The query consists of two parts, before and after the semicolon, if the value is correct it will return an error message or a shortcut, but if the answer is not obtained one will arrive at ‘5’ as the answer. |
| Timing SQLI | This injection manages response times in which the attacker records the responses generated by the database, based on the incoming and outgoing data transfer technique [16]. | SELECT price FROM products WHERE id = 1; | or 1 = 1 --’; sleep (1) | SELECT price FROM products WHERE id = ‘ or 1 = 1 --’; sleep (1); | In this type of injection, the success of the attack is evaluated by entering an input, where the first statement corresponds to the ID. If the injection is successful, the response time will be observed within the period programmed in the malicious query. |
| Store Procedure SQLI | A type of database vulnerability that allows an attacker to inject malicious code into a cached SQL query. This type of attack can lead to the execution of arbitrary commands in the database, which can compromise the entire database and its records [13,14]. | SELECT * FROM accountTable WHERE user = ‘user’ AND passwd = ‘pass’; | SHUTDOWN;--; | SELECT * FROM accountTable WHERE user login = ‘user’ AND passwd = ‘pass’; SHUTDOWN;--; | The query has the last part that is considered injectable, this being a forced way of stopping or shutting down the database management system, plus the last signs indicate that everything after that is considered a query. |
| Alternate Encoding SQLI | This type of injection is applied to bypass special character validations, thus using alternative encodings such as hexadecimal, ASCII or Unicode [18]. | SELECT * FROM accountTable WHERE user = ‘user’ AND pin = ‘pass’; | 44524f5020444154414241534520 | SELECT * FROM accountTable WHERE user = ‘user’ AND pin = ‘pass’; EXEC(‘44524f5020444154414241534520’); SHUTDOWN; | This injection seeks to hide certain characters or reserved words from the databases in order to make them pass the validations and be executed, in this case there is an encryption based on HEXADECIMAL. |
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Light Gradient Boosting Machine (LGBM) [17] | 0.9933 | 0.9933 | 0.9933 | 0.9933 |
| Gradient Boosting Machine (GBM) [17] | 0.9904 | 0.9898 | 0.9903 | 0.991 |
| Artificial Neural Network (ANN) [13,18] | 0.9893 | 0.9870 | 0.9913 | 0.99 |
| AdaBoost (AB) [17,21] | 0.9808 | 0.9559 | 0.9592 | 0.9561 |
| Decision Tree (DT) [16,18,22,23] | 0.9668 | 0.9315 | 0.88955 | 0.9164 |
| Random Forest (RF) [18,22,23] | 0.9634 | 0.9247 | 0.8947 | 0.9149 |
| Support Vector Machine (SVM) [18,22,23] | 0.9546 | 0.9706 | 0.9085 | 0.9395 |
| Logistic Regression (LR) [4] | 0.9503 | 0.9737 | 0.9089 | 0.9653 |
| Naive Bayes (NB) [18,24] | 0.9074 | 0.8966 | 0.7985 | 0.9010 |
| KNN (K-Nearest Neighbors) [21] | 0.8920 | 0.9143 | 0.8931 | 0.8853 |
| Machine Learning Algorithms | Training Time (s) | RAM Memory Usage |
|---|---|---|
| Random forest | 24 | 1.5 Gi |
| SVM | 33 | 1.7 Gi |
| Decision tree | 6 | 1.4 Gi |
| Algorithm | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
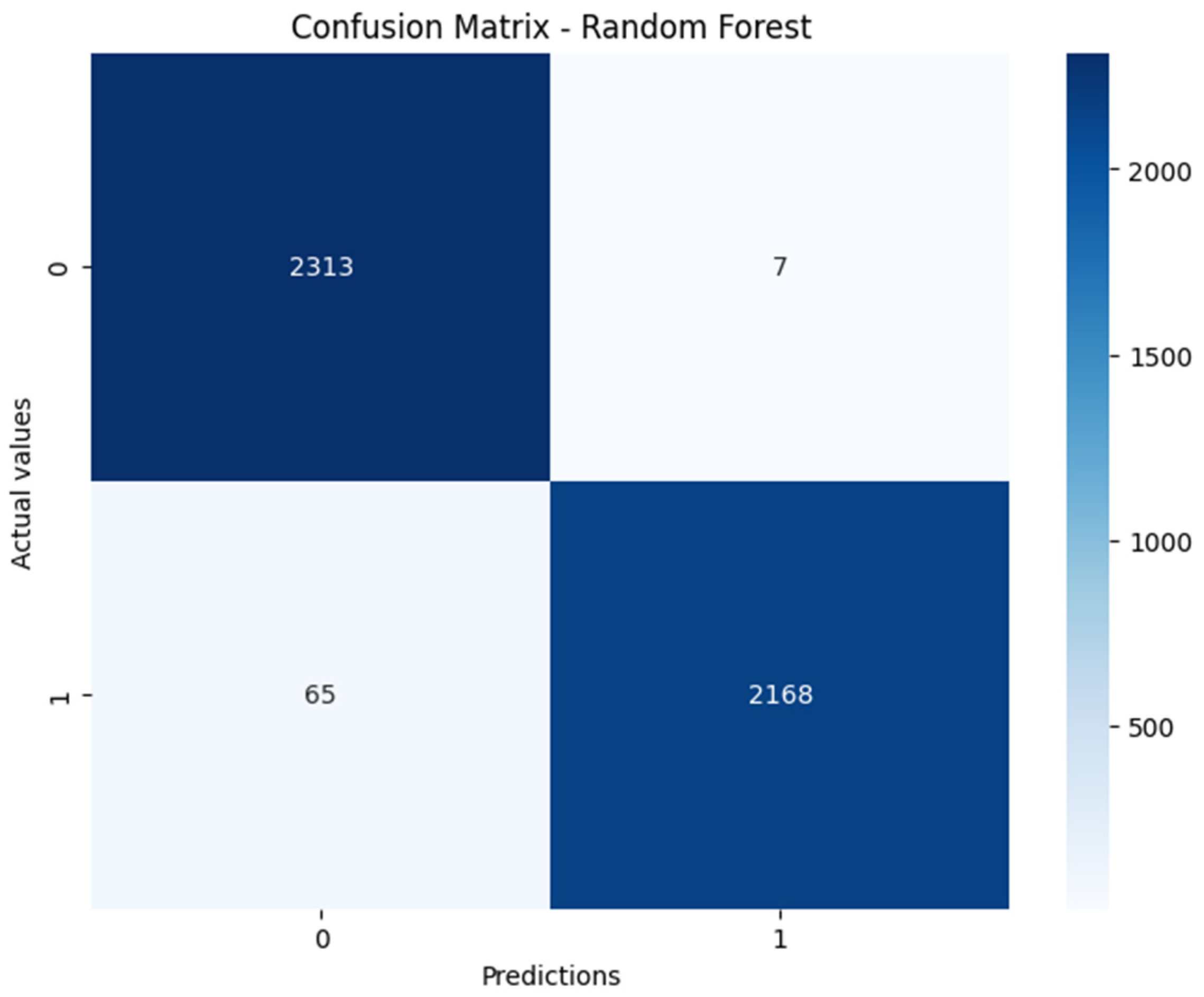
| Random Forest | 99% | 97% | 98% | 99% |
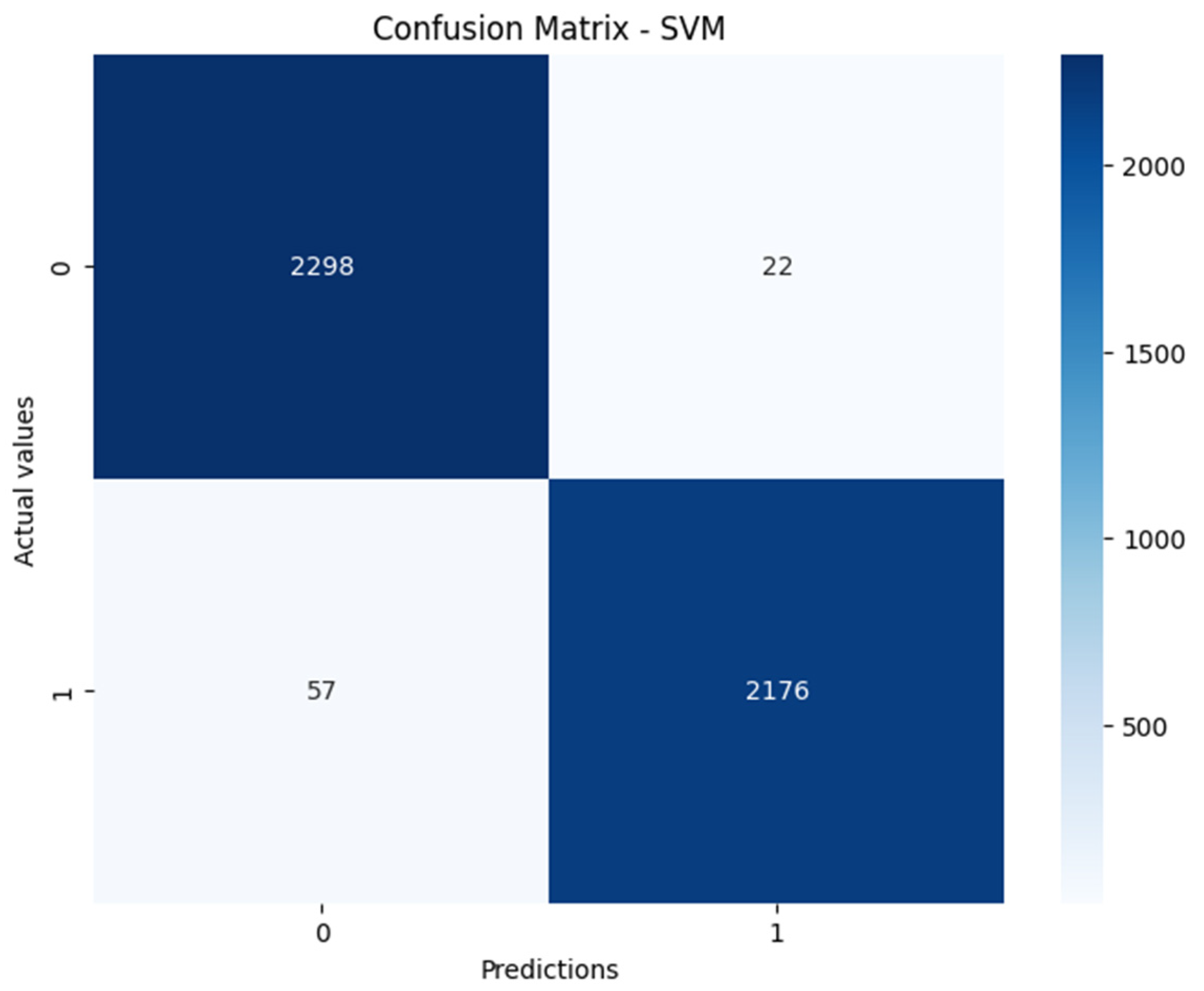
| SVM | 98% | 97% | 98% | 98% |
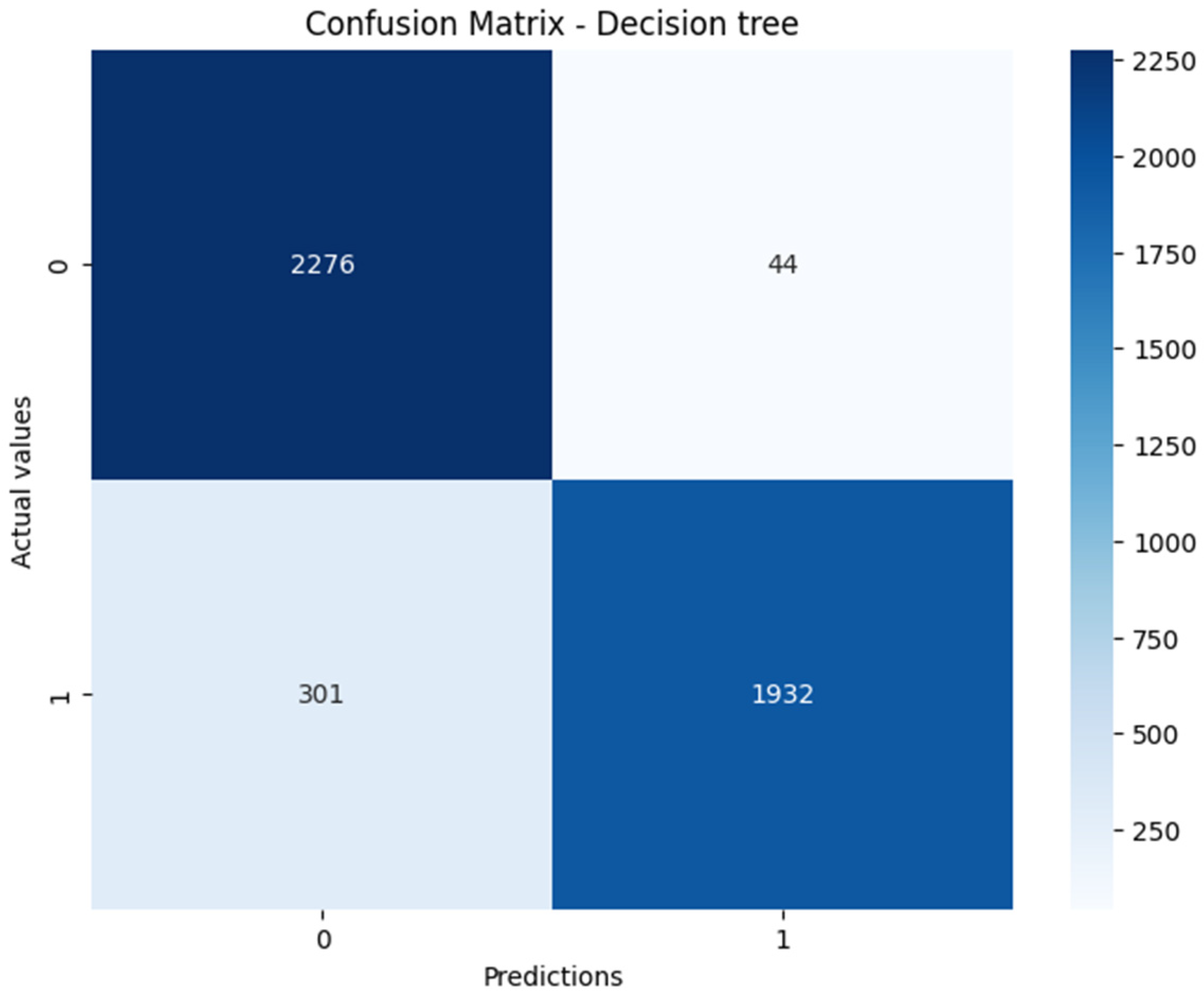
| Decision tree | 97% | 86% | 91% | 92% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peralta-Garcia, E.; Quevedo-Monsalbe, J.; Tuesta-Monteza, V.; Arcila-Diaz, J. Detecting Structured Query Language Injections in Web Microservices Using Machine Learning. Informatics 2024, 11, 15. https://doi.org/10.3390/informatics11020015
Peralta-Garcia E, Quevedo-Monsalbe J, Tuesta-Monteza V, Arcila-Diaz J. Detecting Structured Query Language Injections in Web Microservices Using Machine Learning. Informatics. 2024; 11(2):15. https://doi.org/10.3390/informatics11020015
Chicago/Turabian StylePeralta-Garcia, Edwin, Juan Quevedo-Monsalbe, Victor Tuesta-Monteza, and Juan Arcila-Diaz. 2024. "Detecting Structured Query Language Injections in Web Microservices Using Machine Learning" Informatics 11, no. 2: 15. https://doi.org/10.3390/informatics11020015
APA StylePeralta-Garcia, E., Quevedo-Monsalbe, J., Tuesta-Monteza, V., & Arcila-Diaz, J. (2024). Detecting Structured Query Language Injections in Web Microservices Using Machine Learning. Informatics, 11(2), 15. https://doi.org/10.3390/informatics11020015