Improvement in the Efficiency of a Distributed Multi-Label Text Classification Algorithm Using Infrastructure and Task-Related Data



Abstract
1. Introduction
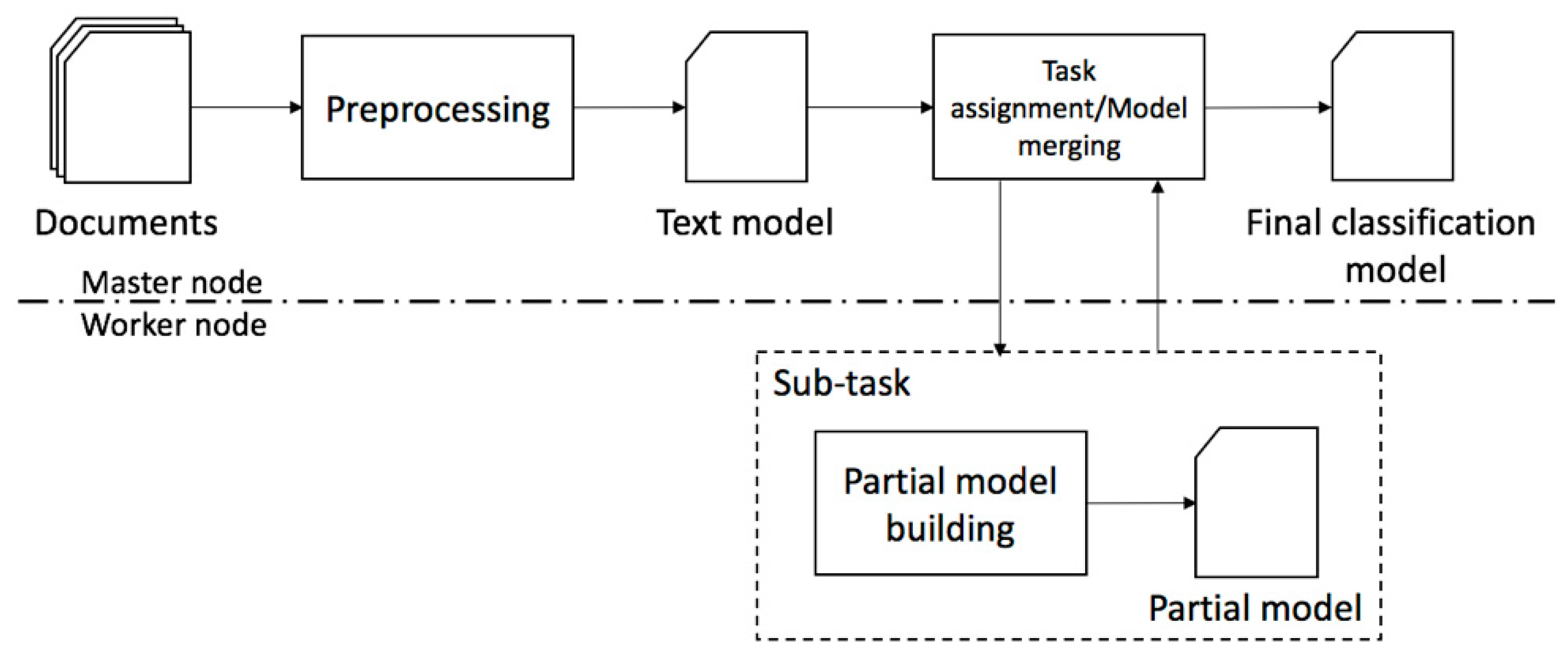
2. Distributed Classification
- Data-driven decomposition—in this case, we assume that the decomposition of the dataset is sufficient. Input dataset D is divided into n mutually disjoint subsets Dn. Each of the subsets then serves as a training set for the training of partial models. When using this approach, a merging mechanism aggregating all of the partial models has to be developed. There are several models suitable for this type of decomposition, such as k-nearest neighbors (k-NN), support vector machine classifier, or all instance-based methods in general.
- Model-driven decomposition—in this case, the input dataset remains complete and the algorithm is modified to run in a parallel or distributed way. In general, it is the decomposition of the model building itself. The nature of the decomposition is model-specific, and we can generally state that the partial subprocesses of partial model building have to be independent of each other. Various models can be decomposed in this way, such as tree-based classifiers, compound methods (boosting, bagging), or clustering algorithms based on self-organizing maps.
- Horizontal fragmentation—data are distributed in such a way that each node receives a part of the dataset, in the case that the dataset comprises n-tuples, each node receives a subset of n-tuples.
- Vertical fragmentation—in this case, partial tuples of a complete dataset are assigned to the nodes.
Distributed Multi-Label Classification
- Problem transforming methods—methods that adapt the problem itself, for example, transforming the multi-label classification problem into a set of binary classification problems.
- Algorithm adaptation—approaches that adapt the model itself to be able to handle multi-class data.
- Data preparation—a selection of textual documents, and selection of a training and testing set.
- Data preprocessing—at the beginning of the process, preprocessing of the complete dataset is performed. This includes text tokenization, lowercase transformation, and stop word removal. Then, a vector representation of the textual documents is computed using tf-idf (term frequency-inverse document frequency) weighting.
- Model building—in this step, a tree-based classifier is trained on the training set. The result is a classification model ready to be evaluated and deployed.
3. Optimization of the Classifier Building Using Dataset- and Infrastructure-Related Data
Optimization of Task Assignment in Distributed Environments
4. Design and Implementation of Optimization Mechanisms
- Task-related data
- Dataset characteristics
- ◾
- Number of documents in a dataset;
- ◾
- Number of terms in particular documents;
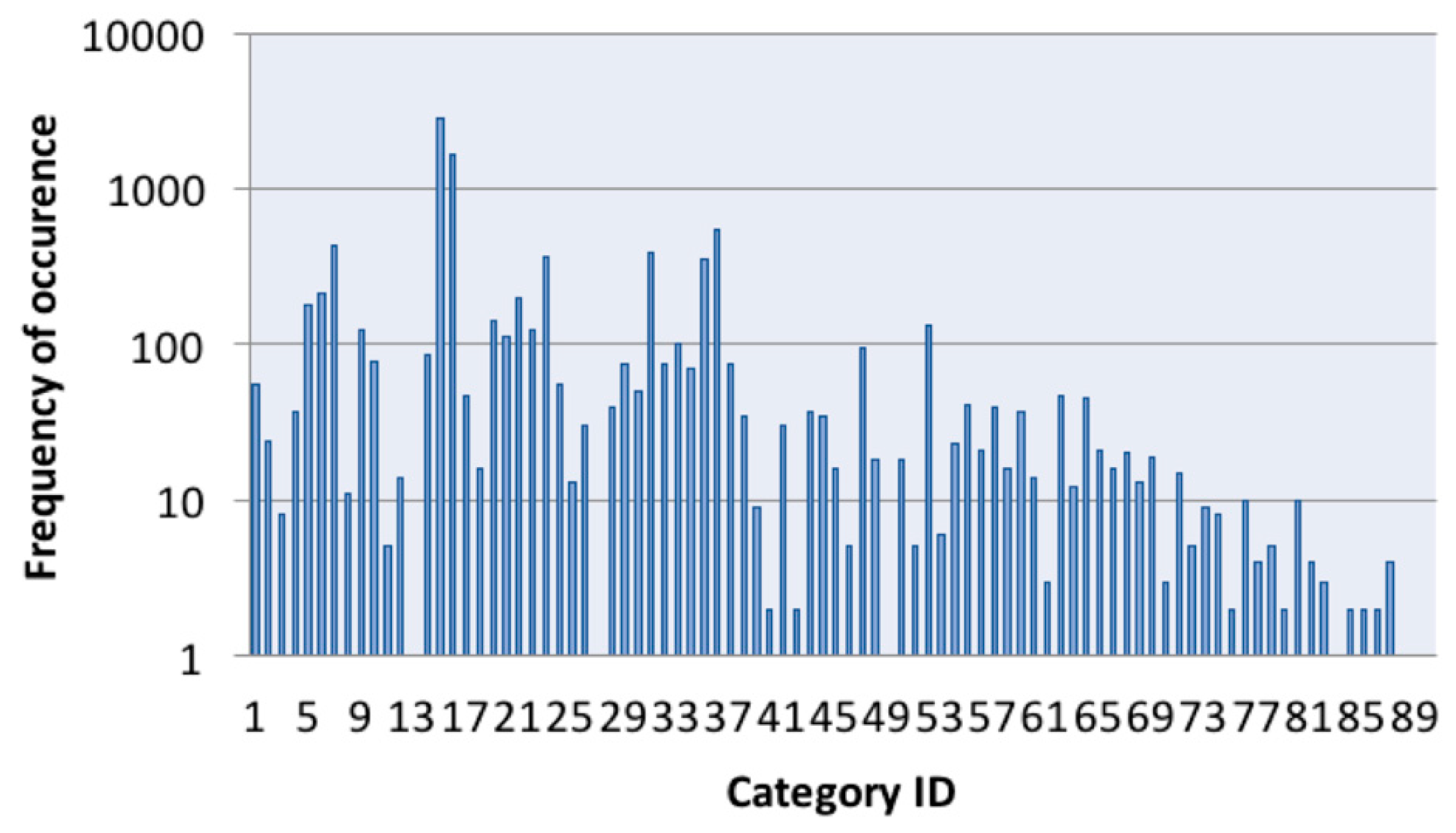
- The frequency of category occurrence (in classification tasks)—one of the most important criteria influencing the complexity of partial models (the most frequent categories result in the most complex partial models).
- Infrastructure-related data
- Number of available computing nodes;
- Node parameters
- ◾
- Number of CPU cores;
- ◾
- Available CPU;
- ◾
- Available RAM;
- ◾
- Heap space.
4.1. Tasks Assignment with No Optimization
- The first step is the initialization of the node and task parameters.
- The variable describing the overall node performance is also initialized.
- The algorithm checks the available grid nodes, and the values of the actual node parameters of all grid nodes are set.
- When the algorithm finishes checking all the available nodes, it checks the maximum value of the obtained parameter values among the grid nodes (for each parameter). Then, all node parameter values are normalized (to <0,1> interval).
- In the next step, an actual node performance parameter is computed as the sum of all parameter values. It is possible to set the weights of each parameter when a certain resource is more significant (e.g., the task is more memory- or CPU-intensive). In our case, we used equal weight values. Nodes are then ordered by the assigned performance parameters and an average node (with average performance parameters) is found.
- The next step computes the maximum number of sub-tasks assigned to a given node. A map is created storing statistics describing the sub-tasks’ complexity information extracted from the task-related data. Sub-tasks (binary classifiers) are ordered according to the frequency parameter.
- Then, the average document frequency of a binary classifier is computed. This represents the maximum number of sub-tasks that can be assigned to computational nodes with an average overall performance. For the more powerful nodes, the limit is increased, and it is decreased for the less powerful ones. The increase/decrease is computed in the same ratio as the performance parameters ratio between a particular and average node.
- Each available node is then equipped with a specific number of assigned sub-tasks in the same way as in the non-optimized distributed model. The number of assigned tasks can be exceeded in the final assignment in some cases (e.g., in a situation where all sub-tasks could not fit into the computed assignments).
4.2. Task Assignment Using Assignment Problem
5. Experiments
6. Discussion
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Feldman, R.; Feldman, R.; Dagan, I. Knowledge Discovery in Textual Databases (KDT). In Proceedings of the The First International Conference on Knowledge Discovery and Data Mining, Montreal, QC, Canada, 20–21 August 1995; pp. 112–117. [Google Scholar]
- Shearer, C.; Watson, H.J.; Grecich, D.G.; Moss, L.; Adelman, S.; Hammer, K.; Herdlein, S. The CRISP-DM model: The New Blueprint for Data Mining. J. Data Wareh. 2000, 5, 13–22. [Google Scholar]
- Shafique, U.; Qaiser, H. A Comparative Study of Data Mining Process Models (KDD, CRISP-DM and SEMMA). Innov. Space Sci. Res. 2014, 12, 217–222. [Google Scholar]
- Tsoumakas, G.; Katakis, I.; Overview, A. Multi-Label Classification: An Overview. Int. J. Data Wareh. Min. 2007, 3, 1–13. [Google Scholar] [CrossRef]
- Weinman, J.J.; Lidaka, A.; Aggarwal, S. Large-scale machine learning. In GPU Computing Gems Emerald Edition; Elsevier: Amsterdam, The Netherlands, 2011; pp. 277–291. ISBN 9780123849885. [Google Scholar]
- Caragea, D.; Silvescu, A.; Honavar, V. A Framework for Learning from Distributed Data Using Sufficient Statistics and its Application to Learning Decision Trees. Int. J. Hybrid Intell. Syst. 2004, 1, 80–89. [Google Scholar] [CrossRef] [PubMed]
- Haldankar, A.; Bhowmick, K. A MapReduce based approach for classification. In Proceedings of the 2016 Online International Conference on Green Engineering and Technologies (IC-GET), Coimbatore, India, 19 November 2016; pp. 1–5. [Google Scholar]
- Shanahan, J.; Dai, L. Large Scale Distributed Data Science from scratch using Apache Spark 2.0. In Proceedings of the 26th International Conference on World Wide Web Companion—WWW ’17 Companion, Perth, Australia, 3–7 April 2017. [Google Scholar]
- Panda, B.; Herbach, J.S.; Basu, S.; Bayardo, R.J. PLANET: Massively Parallel Learning of Tree Ensembles with MapReduce. Learning 2009, 2, 1426–1437. [Google Scholar] [CrossRef]
- Semberecki, P.; Maciejewski, H. Distributed Classification of Text Documents on Apache Spark Platform. In Artificial Intelligence and Soft Computing; Rutkowski, L., Korytkowski, M., Scherer, R., Tadeusiewicz, R., Zadeh, L.A., Zurada, J.M., Eds.; Springer International Publishing: Cham, Switzerland, 2016; Volume 9692, pp. 621–630. ISBN 978-3-319-39377-3. [Google Scholar]
- Caragea, D.; Silvescu, A.; Honavar, V. Decision Tree Induction from Distributed Heterogeneous Autonomous Data Sources. In Intelligent Systems Design and Applications; Abraham, A., Franke, K., Köppen, M., Eds.; Springer: Berlin/Heidelberg, Germany, 2003; pp. 341–350. ISBN 978-3-540-40426-2. [Google Scholar]
- Babbar, R.; Shoelkopf, B. DiSMEC—Distributed Sparse Machines for Extreme Multi-label Classification. In Proceedings of the Tenth ACM International Conference on Web Search and Data Mining-WSDM ’17, Cambridge, UK, 6–10 February 2017; pp. 721–729, ISBN 978-1-4503-4675-7. [Google Scholar]
- Babbar, R.; Schölkopf, B. Adversarial Extreme Multi-label Classification. arXiv, 2018; arXiv:1803.01570. [Google Scholar]
- Zhang, W.; Yan, J.; Wang, X.; Zha, H. Deep Extreme Multi-label Learning. In Proceedings of the 2018 ACM on International Conference on Multimedia Retrieval-ICMR ‘18, Yokohama, Japan, 11–14 June 2018; pp. 100–107, ISBN 978-1-4503-5046-4. [Google Scholar]
- Belyy, A.; Sholokhov, A. MEMOIR: Multi-class Extreme Classification with Inexact Margin. arXiv, 2018; arXiv:1811.09863. [Google Scholar]
- Sun, X.; Xu, J.; Jiang, C.; Feng, J.; Chen, S.-S.; He, F. Extreme Learning Machine for Multi-Label Classification. Entropy 2016, 18, 225. [Google Scholar] [CrossRef]
- Sarnovský, M.; Butka, P.; Bednár, P.; Babič, F.; Paralič, J. Analytical platform based on Jbowl library providing text-mining services in distributed environment. In Proceedings of the Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). In Information and Communication Technology-EurAsia Conference; Springer: Cham, Switzerland, 2015; pp. 310–319. [Google Scholar]
- Gualtieri, M. The Forrester WaveTM: In-Memory Data Grids, Q3. Available online: https://www.forrester.com/report/The+Forrester+Wave+InMemory+Data+Grids+Q3+2015/-/E-RES120420 (accessed on 2 January 2019).
- Zhang, C.; Li, F.; Jestes, J. Efficient parallel kNN joins for large data in MapReduce. In Proceedings of the Proceedings of the 15th International Conference on Extending Database Technology-EDBT ’12, Berlin, Germany, 26–30 March 2012; p. 38.
- Sarnovsky, M.; Ulbrik, Z. Cloud-based clustering of text documents using the GHSOM algorithm on the GridGain platform. In Proceedings of the SACI 2013-8th IEEE International Symposium on Applied Computational Intelligence and Informatics, Timisoara, Romania, 23–25 May 2013. [Google Scholar]
- Anchalia, P.P.; Koundinya, A.K.; Srinath , N.K. MapReduce Design of K-Means Clustering Algorithm. In Proceedings of the 2013 International Conference on Information Science and Applications (ICISA), Pattaya, Thailand, 24–26 June 2013; pp. 1–5. [Google Scholar]
- Zhao, W.; Ma, H.; He, Q. Parallel K-means clustering based on MapReduce. In Proceedings Lecture Notes in Computer Science; Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar]
- Amado, N.; Silva, O. Exploiting Parallelism in Decision Tree Induction. In Parallel and Distributed computing for Machine Learning. In Proceedings of the Conjunction 14th European Conference on Machine Learning ECML’03 7th European Conference Principles and Practice of Knowledge Discovery in Databases PKDD’03, Dublin, Ireland, 10–14 September 2018. [Google Scholar]
- Kianpisheh, S.; Charkari, N.M.; Kargahi, M. Reliability-driven scheduling of time/cost-constrained grid workflows. Futur. Gener. Comput. Syst. 2016, 55, 1–16. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, P.; Hu, B.; Moore, P. A novel approach to task assignment in a cooperative multi-agent design system. Appl. Intell. 2015, 43, 162–175. [Google Scholar] [CrossRef]
- Gruzlikov, A.M.; Kolesov, N.V.; Skorodumov, Y.M.; Tolmacheva, M.V. Graph approach to job assignment in distributed real-time systems. J. Comput. Syst. Sci. Int. 2014, 53, 702–712. [Google Scholar] [CrossRef]
- Ramírez-Velarde, R.; Tchernykh, A.; Barba-Jimenez, C.; Hirales-Carbajal, A.; Nolazco-Flores, J. Adaptive Resource Allocation with Job Runtime Uncertainty. J. Grid Comput. 2017, 15, 415–434. [Google Scholar] [CrossRef]
- Zhang, X.; Wu, Y.; Zhao, C. MrHeter: Improving MapReduce performance in heterogeneous environments. Clust. Comput. 2016, 19, 1691–1701. [Google Scholar] [CrossRef]
- Younes Hamed, A. Task Allocation for Minimizing Cost of Distributed Computing Systems Using Genetic Algorithms. Available online: https://www.semanticscholar.org/paper/Task-Allocation-for-Minimizing-Cost-of-Distributed-Hamed/1dc02df36cbd55539369def9d2eed47a90c346c4 (accessed on 2 January 2019).
- Çela, E. Assignment Problems. Handb. Appl. Optim. Part II Appl. 2002, 6, 667–678. [Google Scholar]
- Winston, W.L. Transportation, Assignment, and Transshipment Problems. Oper. Res. Appl. Algorithm. 2003, 41, 1–82. [Google Scholar]
- Kawajir, L. Waechter Introduction to IPOPT: A tutorial for downloading, installing, and using IPOPT. Available online: https://www.coin-or.org/Ipopt/documentation/ (accessed on 2 January 2019).
- Sarnovsky, M.; Kacur, T. Cloud-based classification of text documents using the Gridgain platform. In Proceedings of the SACI 2012-7th IEEE International Symposium on Applied Computational Intelligence and Informatics, Timisoara, Romania, 24–26 May 2012. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sequential | Distributed | |
|---|---|---|
| Decision tree classifier | ✓ | ✓ |
| k-Nearest neighbor classifier | ✓ | ✓ |
| Rule-based classifier | ✓ | |
| Support vector machine classifier | ✓ | |
| Boosting compound classifier | ✓ | ✓ |
| k-Means clustering | ✓ | ✓ |
| GHSOM clustering | ✓ | ✓ |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sarnovsky, M.; Olejnik, M. Improvement in the Efficiency of a Distributed Multi-Label Text Classification Algorithm Using Infrastructure and Task-Related Data. Informatics 2019, 6, 12. https://doi.org/10.3390/informatics6010012
Sarnovsky M, Olejnik M. Improvement in the Efficiency of a Distributed Multi-Label Text Classification Algorithm Using Infrastructure and Task-Related Data. Informatics. 2019; 6(1):12. https://doi.org/10.3390/informatics6010012
Chicago/Turabian StyleSarnovsky, Martin, and Marek Olejnik. 2019. "Improvement in the Efficiency of a Distributed Multi-Label Text Classification Algorithm Using Infrastructure and Task-Related Data" Informatics 6, no. 1: 12. https://doi.org/10.3390/informatics6010012
APA StyleSarnovsky, M., & Olejnik, M. (2019). Improvement in the Efficiency of a Distributed Multi-Label Text Classification Algorithm Using Infrastructure and Task-Related Data. Informatics, 6(1), 12. https://doi.org/10.3390/informatics6010012