Translation Quality and Error Recognition in Professional Neural Machine Translation Post-Editing


Abstract
:1. Background and Related Research
“translate between any pair of the 24 official EU languages, as well as Icelandic and Norwegian (Bokmål): it can handle formatted documents and plain text; it translates multiple documents into multiple languages in “one go”; it accepts diverse input formats including XML and PDF; it retains formatting; and it provides specific output formats for computer-aided translation, i.e., TMX11 and XLIFF.”([1], p. 3)
The common approach to automatic translation quality estimation is to transform the problem into a supervised regression or classification task for sentence-level scoring and word-level labelling respectively.
2. Experimental Setup and Methods
2.1. Corpus Analysis
2.2. Corpus Analysis Results
2.2.1. Automatic Error Annotation with Hjerson
- 1.
- inflectional error—a word whose full form is marked as RPER/HPER error but the base forms are the same.
- 2.
- reordering error—a word which occurs both in the reference and in the hypothesis is thus not contributing to RPER or HPER but is marked as a WER error.
- 3.
- Missing word—a word which occurs as deletion in WER errors and at the same time occurs as RPER error without sharing the base form with any hypothesis error.
- 4.
- extra word—a word which occurs as insertion in WER errors and at the same time occurs as HPER error without sharing the base form with any reference error.
- 5.
- incorrect lexical choice—a word which belongs neither to inflectional errors nor to missing or extra words is considered as lexical error [33].
2.2.2. Manual Error Annotation According to the MQM Framework
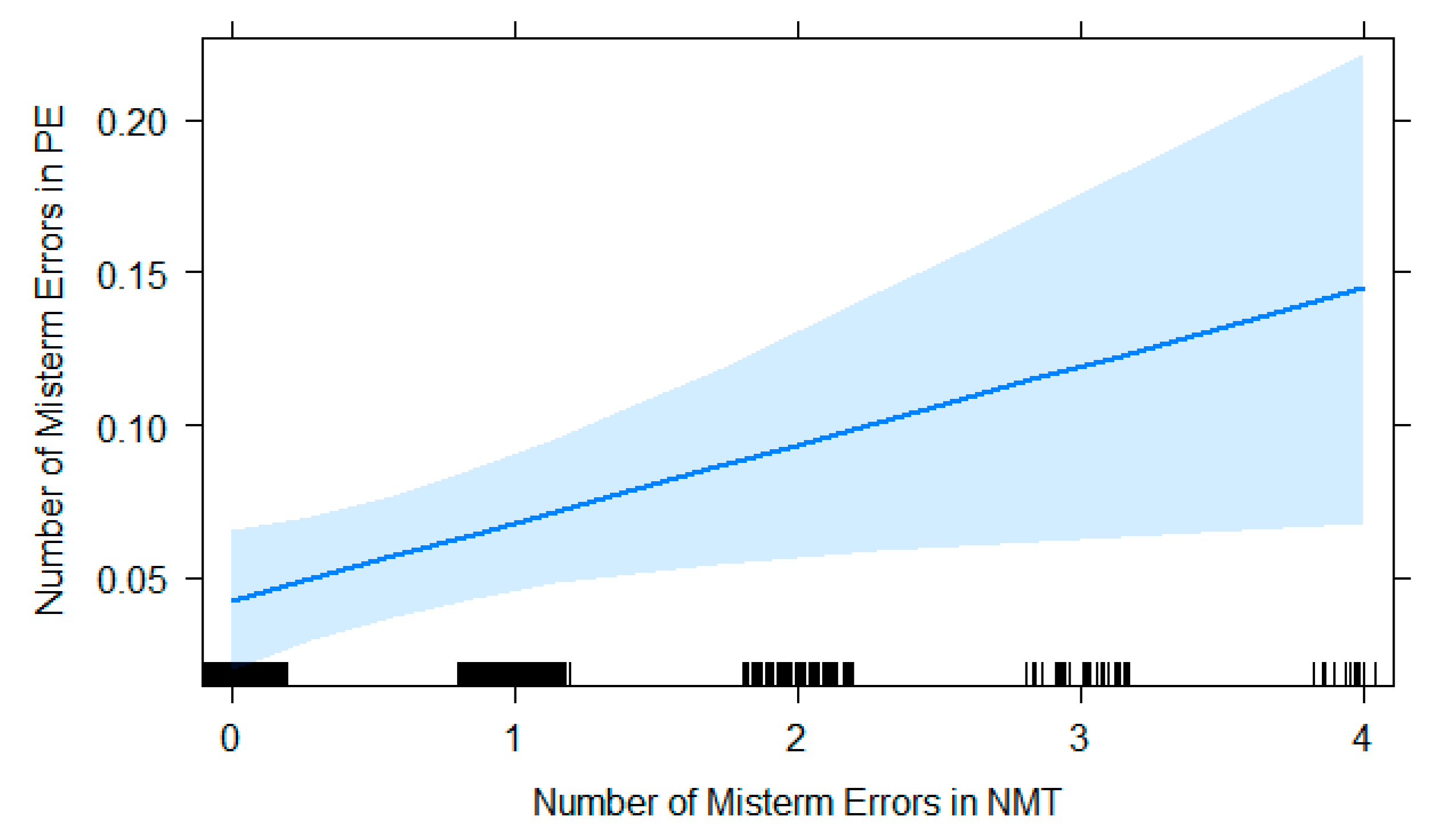
2.2.3. Effect of NMT Error Types on Errors in NMTPE
2.3. Eye-Tracking and Key-Logging Experiment
2.3.1. Participants
2.3.2. Study Design
- the user interface and functioning of the devices and tools needed for this study (see below)
- the recommended (though not obligatory) time frame (7–9 min per text) to avoid very long and very short sessions
- the engine used to produce the NMT (DGT in-house system: eTranslation)
- the fact that they would not have access to in-house or external resources to conduct research
- expected results according to the extremely high-quality standards of the in-house DGT guidelines (full post-editing, publishable quality)
3. Data Analysis
- They were presented with an error token (Err) and corrected the error.hereafter referred to as True Positives (TP)
- They were presented with an error token and did not correct the error.hereafter referred to as False Positives (FP)
- They were presented with a correct token (Corr) and did not change the token.hereafter referred to as True Negatives (TN)
- They were presented with a correct token and changed the token.hereafter referred to as False Negatives (FN)
4. Results
4.1. Errors Corrected vs. Not Corrected
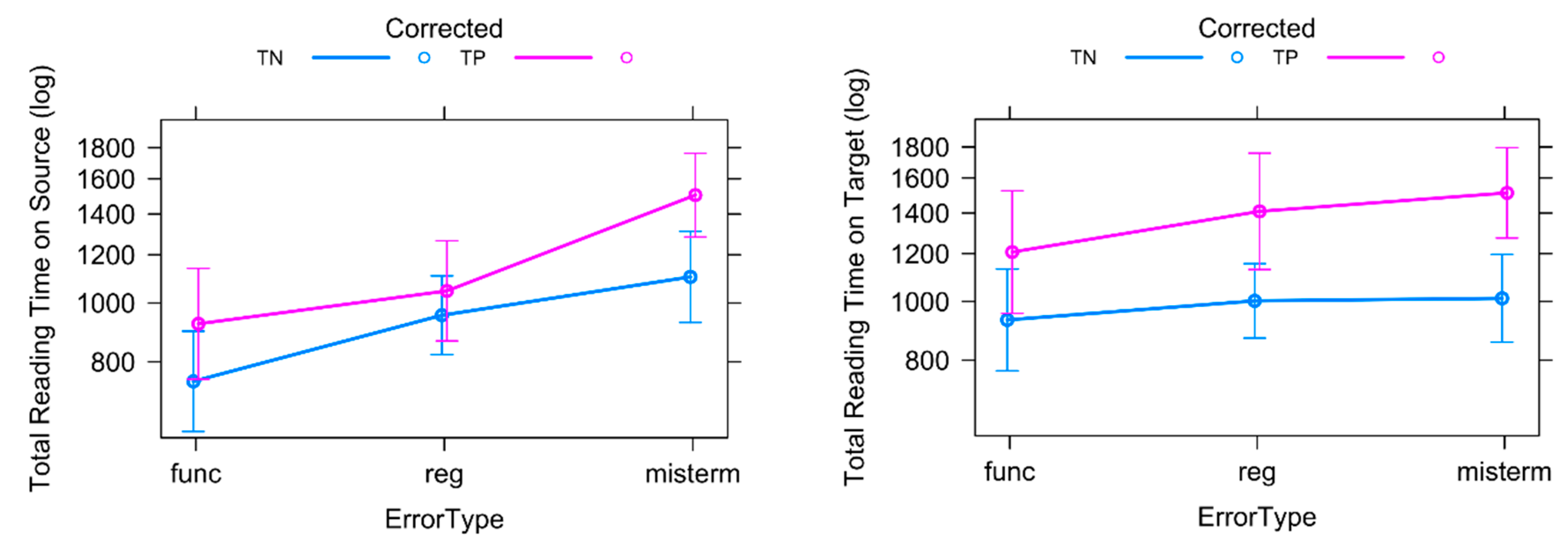
4.2. Total Reading Times of Source Text and Target Text Tokens
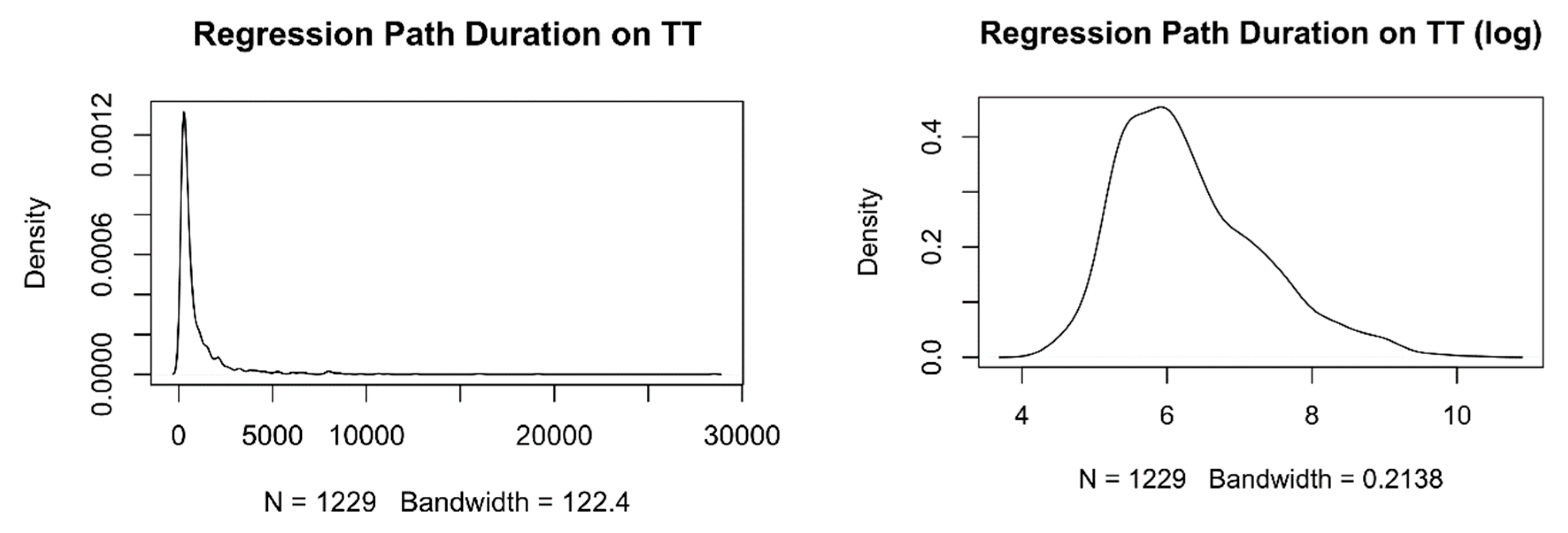
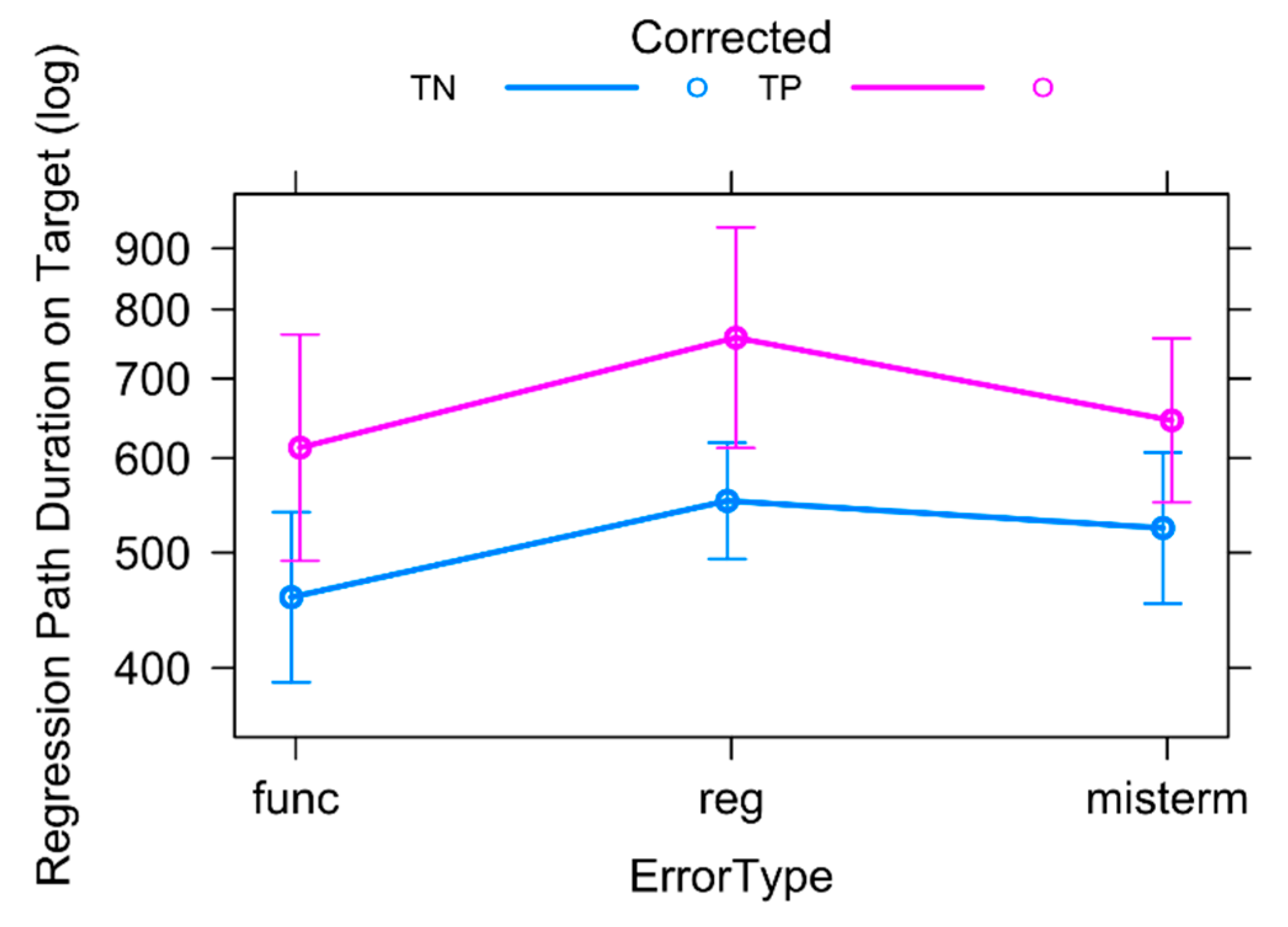
4.3. Regression Path Duration on Target Text
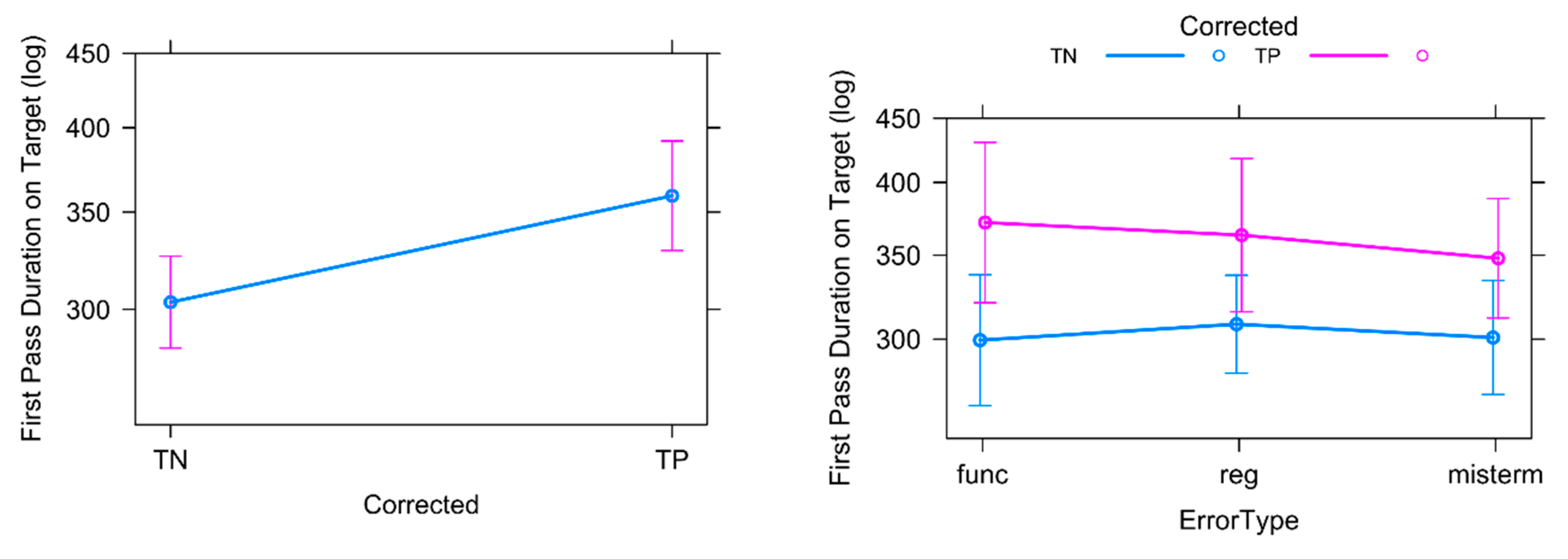
4.4. First Pass Duration (TT)
4.5. First Fixation Duration on Target Text
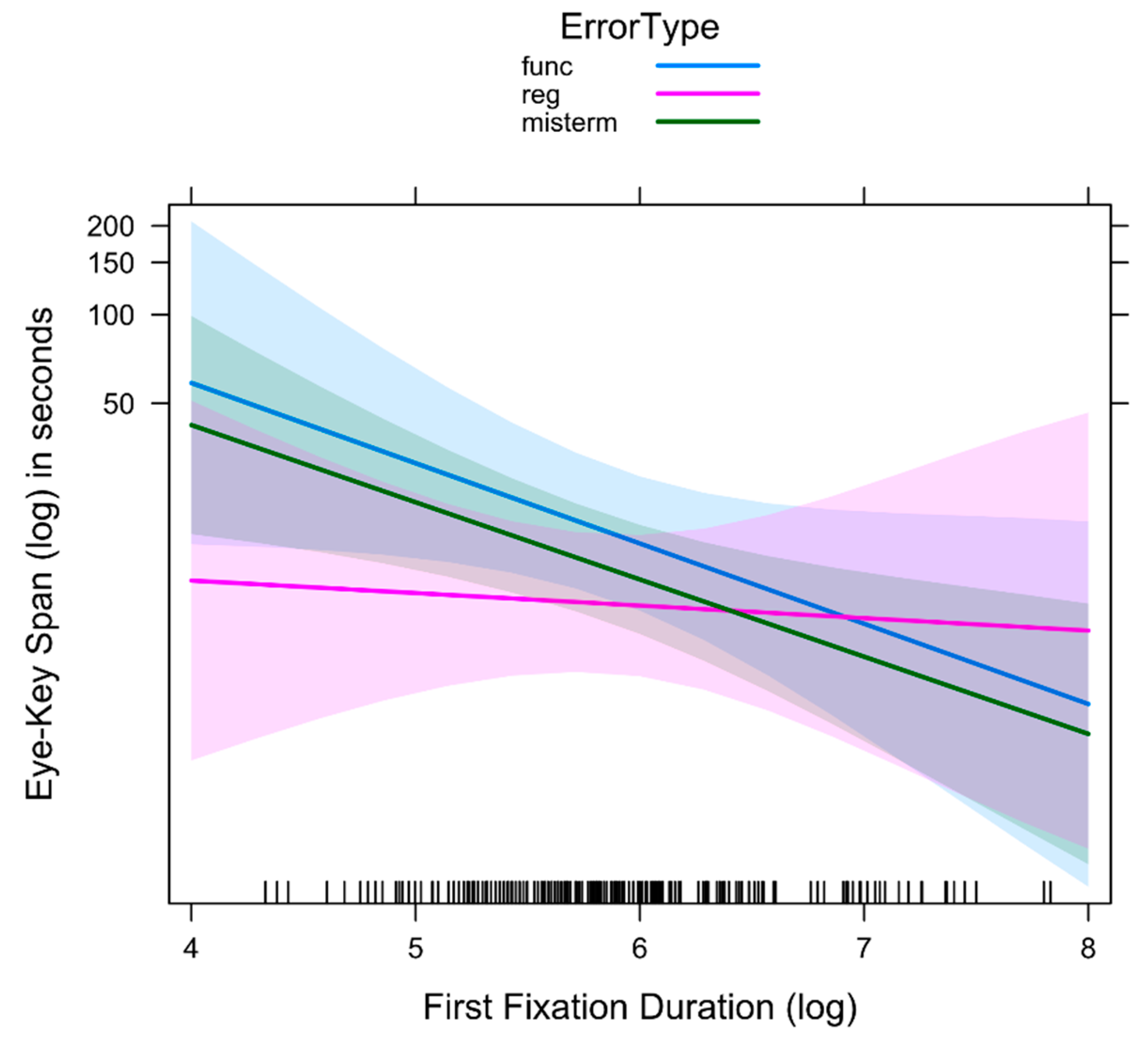
4.6. Eye–Key Span
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Chartier-Brun, P.; Mahler, K. Machine Translation and Neural Networks for a Multilingual EU. Available online: http://zerl.uni-koeln.de/chartierbrun-mahler-2018-machine-translation-eu.html (accessed on 30 April 2019).
- Drugan, J.; Strandvik, I.; Vuorinen, E. Translation Quality, Quality Management and Agency: Principles and Practice in the European Union Institutions. In Translation Quality Assessment; Moorkens, J., Ed.; Springer: New York, NY, USA, 2018; pp. 39–68. [Google Scholar]
- ISO 17100. Translation Services—Requirements for Translation Services; Technical Committee ISO/TC37: Geneva, Switzerland, 2015. [Google Scholar]
- DIN ISO 18587. Translation Services—Post-Editing of Machine Translation Output—Requirements; Technical Committee ISO/TC 37/SC 5; Beuth: Berlin, Germany, 2017. [Google Scholar]
- Biel, Ł. Quality in Institutional Eu Translation: Parameters, Policies and Practices. Qual. Asp. Inst. Transl. 2017, 8, 31. [Google Scholar]
- Svoboda, T. Translation Manuals and Style Guides as Quality Assurance Indicators: The Case of The European Commission’S Directorate-General for Translation. Qual. Asp. Inst. Transl. 2017, 8, 75. [Google Scholar]
- Wagner, E. Quality of Written Communication in a Multilingual Organisation. Termin. Et Trad. 2000, 1, 16. [Google Scholar]
- Xanthaki, H. The Problem of Quality in EU Legislation: What on Earth is Really Wrong? Common. Mark. Law Rev. 2001, 38, 651–676. [Google Scholar] [CrossRef]
- Daems, J.; Vandepitte, S.; Hartsuiker, R.; Macken, L. The Impact of Machine Translation Error Types on Post-Editing Effort Indicators. In Proceedings of the Fourth Workshop on Post-Editing Technology and Practice, Miami, FL, USA, 30 October–3 November 2015; p. 15. [Google Scholar]
- Daems, J.; Vandepitte, S.; Hartsuiker, R.J.; Macken, L. Identifying the Machine Translation Error Types with the Greatest Impact on Post-editing Effort. Front. Psychol. 2017, 8, 1282. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Daems, J.; Macken, L.; Vandepitte, S. Quality as the sum of its parts: A two-step approach for the identification of translation problems and translation quality assessment for HT and MT+PE. In Proceedings of the MT Summit XIV Workshop on Post-editing Technology and Practice, Nice, France, 2–6 September 2013; pp. 63–71. [Google Scholar]
- Lommel, A. Multidimensional Quality Metrics Definition. 2014. Available online: http://www.qt21.eu/mqm-definition/definition-2015-06-16.html. (accessed on 15 March 2019).
- Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. Neural versus phrase-based MT quality: An in-depth analysis on English–German and English–French. Comput. Speech Lang. 2018, 49, 52–70. [Google Scholar] [CrossRef]
- Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. Neural versus Phrase-Based Machine Translation Quality: A Case Study. arXiv 2016, arXiv:1608.04631. [Google Scholar]
- Daems, J. A Translation Robot for Each Translator? A Comparative Study of Manual Translation and Post-Editing of Machine Translations: Process, Quality and Translator Attitude; Ghent University: Ghent, Belgium, 2016. [Google Scholar]
- Lacruz, S. Pauses and Cognitive Effort in Post-Editing. In Post-editing of Machine Translation Processes and Applications; O’Brien, S., Winther Balling, L., Carl, M., Simard, M., Specia, L., Eds.; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2014; pp. 246–272. [Google Scholar]
- Castilho, S.; Moorkens, J.; Gaspari, F. A Comparative Quality Evaluation of PBSMT and NMT Using Professional Translators; Cambridge Scholars Publishing: Newcastle upon Tyne, UK, 2017; p. 18. [Google Scholar]
- Klubička, F.; Toral, A.; Sánchez-Cartagena, V.M. Quantitative Fine-Grained Human Evaluation of Machine Translation Systems: A Case Study on English to Croatian. Mach. Transl. 2018, 32, 195–215. [Google Scholar] [CrossRef]
- Toral, A.; Sánchez-Cartagena, V.M. A Multifaceted Evaluation of Neural versus Phrase-Based Machine Translation for 9 Language Directions. arXiv 2017, arXiv:1701.02901. [Google Scholar]
- Moorkens, J.; Walker, C.; Federici, F.M. Eye Tracking as a measure of cognitive effort for post-editing of machine translation. In Eye Tracking and Multidisciplinary Studies on Translation; John Benjamins: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Koponen, M.; Salmi, L.; Nikulin, M. A product and process analysis of post-editor corrections on neural, statistical and rule-based machine translation output. Mach. Transl. 2019, 33, 61–90. [Google Scholar] [CrossRef] [Green Version]
- Schaeffer, M.; Nitzke, J.; Tardel, A.; Oster, K.; Gutermuth, S.; Hansen-Schirra, S. Eye-tracking revision processes of translation students and professional translators. Perspectives 2019, 1–15. [Google Scholar] [CrossRef]
- Mertin, E. Prozessorientiertes Qualitätsmanagement im Dienstleistungsbereich Übersetzen; Lang: Frankfurt am Main, Germany, 2006. [Google Scholar]
- Carl, M.; Schaeffer, M.; Bangalore, S. The CRITT translation process research database. In New Directions in Empirical Translation Process Research—Exploring the CRITT TPR-DB; Carl, M., Schaeffer, M., Bangalore, S., Eds.; Springer: London, UK, 2016; pp. 13–56. [Google Scholar]
- Specia, L.; Shah, K. Machine Translation Quality Estimation: Applications and Future Perspectives. In Translation Quality Assessment; Moorkens, J., Castilho, S., Gaspari, F., Doherty, S., Eds.; Springer International Publishing: Cham, Switzerland, 2018; Volume 1, pp. 201–235. [Google Scholar]
- Wang, J.; Fan, K.; Li, B.; Zhou, F.; Chen, B.; Shi, Y.; Si, L. Alibaba Submission for WMT18 Quality Estimation Task. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Brussels, Belgium, 31 October–1 November 2018; pp. 809–815. [Google Scholar]
- Shimanaka, H.; Kajiwara, T.; Komachi, M. RUSE: Regressor Using Sentence Embeddings for Automatic Machine Translation Evaluation. In Proceedings of the Third Conference on Machine Translation: Shared Task Papers, Brussels, Belgium, 31 October–1 November 2018; pp. 751–758. [Google Scholar]
- Specia, L. Exploiting Objective Annotations for Measuring Translation Post-editing Effort. In Proceedings of the 15th conference of the European Association for Machine Translation, Leuven, Belgium, 30–31 May 2011; p. 8. [Google Scholar]
- Specia, L.; Cancedda, N.; Turchi, M.; Cristianini, N.; Dymetman, M. Estimating the sentence-level quality of machine translation systems. In Proceedings of the 13th Conference of the European Association for Machine Translation, Barcelona, Spain, 14–15 May 2009; p. 8. [Google Scholar]
- Luong, N.Q.; Besacier, L.; Lecouteux, B. LIG System for Word Level QE task at WMT14. In Proceedings of the Ninth Workshop on Statistical Machine Translation, Baltimore, MA, USA, 26–27 June 2014; pp. 335–341. [Google Scholar]
- Scarton, C.; Specia, L. Document-level translation quality estimation: Exploring discourse and pseudo-references. In Proceedings of the 17th Annual Conference of the European Association for Machine Translation, Dubrovnik, Croatia, 16–18 June 2014; pp. 101–108. [Google Scholar]
- Graham, Y.; Ma, Q.; Baldwin, T.; Liu, Q.; Parra, C.; Scarton, C. Improving Evaluation of Document-level Machine Translation Quality Estimation. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Short Papers, Valencia, Spain, 3–7 April 2017; Volume 2, pp. 356–361. [Google Scholar]
- Popović, M. Hjerson: An Open Source Tool for Automatic Error Classification of Machine Translation Output. Prague Bull. Math. Linguist. 2011, 96, 59–67. [Google Scholar] [CrossRef]
- Vilar, D.; Xu, J.; D’Haro, L.F.; Ney, H. Error Analysis of Statistical Machine Translation Output. In Proceedings of the presented at the International Conference on Language Resources and Evaluation, Genoa, Italy, 22–28 May 2006; p. 7. [Google Scholar]
- Vardaro, J.; Schaeffer, M.; Hansen-Schirra, S. Comparing the Quality of Neural Machine Translation and Professional Post-Editing. In Proceedings of the QoMEX, Berlin, Germany, 5–7 June 2019; pp. 1–3. [Google Scholar]
- Popović, M.; Ney, H. Word error rates: Decomposition over Pos classes and applications for error analysis. In Proceedings of the Second Workshop on Statistical Machine Translation—StatMT ’07, Prague, Czech Republic, 23 June 2007; pp. 48–55. [Google Scholar]
- Tezcan, A.; Hoste, V.; Macken, L. SCATE Taxonomy and Corpus of Machine Translation Errors. In Trends in E-Tools and Resources for Translators and Interpreters; Corpas Pastor, G., Durán-Muñoz, I., Eds.; Brill: Leiden, The Netherlands, 2017. [Google Scholar]
- Lommel, A. A New Framework for Translation Quality Assessment; Deutsches Forschungszentrum für Künstliche Intelligenz (DFKI): Kaiserslautern, Germany, 2014. [Google Scholar]
- Weingarten, E.; Chen, Q.; McAdams, M.; Yi, J.; Hepler, J.; Albarracín, D. From primed concepts to action: A meta-analysis of the behavioral effects of incidentally presented words. Psychol. Bull. 2016, 142, 472–497. [Google Scholar] [CrossRef] [PubMed]
- Green, S.; Heer, J.; Manning, C.D. The efficacy of human post-editing for language translation. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems—CHI ’13, Paris, France, 27 April–2 May 2013; p. 439. [Google Scholar]
- Čulo, O.; Nitzke, J. Patterns of Terminological Variation in Post-editing and of Cognate Use in Machine Translation in Contrast to Human Translation. In Proceedings of the 19th Annual Conference of the European Association for Machine Translation, Riga, Latvia, 30 May–1 June 2016; p. 9. [Google Scholar]
- Farrell, M. Machine Translation Markers in Post-Edited Machine Translation Output. In Proceedings of the 40th Conference Translating and the Computer, London, UK, 15–16 November 2018; pp. 50–59. [Google Scholar]
- Toral, A. Post-editese: An Exacerbated Translationese. arXiv 2019, arXiv:1907.00900. [Google Scholar]
- Tupper, D.E.; Cicerone, K.D. Introduction to the Neuropsychology of Everyday Life. In The Neuropsychology of Everyday Life: Assessment and Basic Competencies, Foundations of Neuropsychology; Tupper, D.E., Cicerone, K.D., Eds.; Springer: Boston, MA, USA, 1990; Volume 2. [Google Scholar]
- García, A.M.; Ibáñez, A.; Huepe, D.; Houck, A.L.; Michon, M.; Lezama, C.G.; Chadha, S.; Rivera-Rei, Á. Word reading and translation in bilinguals: The impact of formal and informal translation expertise. Front. Psychol. 2014, 5, 1302. [Google Scholar] [CrossRef] [PubMed]
- Carl, M. Translog-II: A Program for Recording User Activity Data for Empirical Translation Process Research. Int. J. Comput. Linguist. Appl. 2012, 3, 136–153. [Google Scholar]
- Germann, U. Yawat: Yet another word alignment tool. In Proceedings of the 46th Annual Meeting of the Association for Computational Linguistics on Human Language Technologies Demo Session—HLT ’08, Columbus, OH, USA, 15–20 June 2008; pp. 20–23. [Google Scholar]
- R Core Team. R: A Language for Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018. [Google Scholar]
- Bates, D.; Mächler, M.; Bolker, B.; Walker, S. Fitting Linear Mixed-Effects Models Using lme4. J. Stat. Softw. 2015, 67, 48. [Google Scholar] [CrossRef]
- Kuznetsova, A.; Brockhoff, P.B.; Christensen, R.H.B. lmerTest Package: Tests in Linear Mixed Effects Models. J. Stat. Softw. 2017, 82, 26. [Google Scholar] [CrossRef]
- Fox, J.; Weisberg, S. Visualizing Fit and Lack of Fit in Complex Regression Models with Predictor Effect Plots and Partial Residuals. J. Stat. Softw. 2018, 87, 1–27. [Google Scholar] [CrossRef]
- Walczyk, J.J. The Interplay Between Automatic and Control Processes in Reading. Read. Res. Q. 2000, 35, 554–566. [Google Scholar] [CrossRef]
- Dijkstra, T. Bilingual Visual Wod Recognition and Lexical Access. In Handbook of Bilingualism: Psycholinguistic Approaches; Kroll, J.F., De Groot, A.M.B., Eds.; Oxford University Press: Oxford, UK, 2009. [Google Scholar]
- Lenth, R. Emmeans: Estimated Marginal Means, aka Least-Squares Means; R Package Version 1.3.4; The Comprehensive R Archive Network: Vienna, Austria, 2019. [Google Scholar]
- Searle, S.R.; Speed, F.M.; Milliken, G.A. Population Marginal Means in the Linear Model: An Alternative to Least Squares Means. Am. Stat. 1980, 34, 216–221. [Google Scholar]
- Snowling, M.; Hulme, C. Editorial Part I. In the Science of Reading: A handbook; Snowling, M., Hulme, C., Eds.; Blackwell Publishing: Hoboken, NJ, USA, 2005. [Google Scholar]
- Dragsted, B.; Shreve, G.M.; Angelone, E. Coordination of reading and writing processes in translation: An eye on uncharted territory. Transl. Cogn. 2010, 15, 41. [Google Scholar]
- Schaeffer, M.; Carl, M. Shared representations and the translation process: A recursive model. Transl. Interpret. Stud. 2013, 8, 169–190. [Google Scholar]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MQM Issue | MQM Definition |
|---|---|
| Mistranslation (Mistr) | The target content does not accurately represent the source content. |
| DGT Example: | |
| • AT: Interest, scope, […] and purpose of Binding Valuation Information | |
| • NMT: Zinsen, Umfang, […] und Zweck der verbindlichen Bewertungsinformationen | |
| • NMTPE: Interesse, Umfang, […] und Zweck der verbindlichen Wertermittlungsauskünfte | |
| • REV: Relevanz, Umfang, Funktionen und Zweck verbindlicher Zollwertauskünfte | |
| Terminology (Term) | A term (domain-specific word) is translated with a term other than the one expected for the domain or otherwise specified. |
| DGT Example: | |
| • AT: Interest, scope, functions and purpose of Binding Valuation Information | |
| • NMT: Zinsen, Umfang, Aufgaben und Zweck der verbindlichen Bewertungsinformationen | |
| • NMTPE: Interesse, Umfang, Funktionen und Zweck der verbindlichen Wertermittlungsauskünfte | |
| • REV: Relevanz, Umfang, Funktionen und Zweck verbindlicher Zollwertauskünfte | |
| Unidiomatic (Phra) | The content is grammatical, but not idiomatic. |
| DGT Example: | |
| • AT: If you hire crewmembers to work on ships … | |
| • NMT: Wenn Sie Besatzungsmitglieder gemietet haben, … | |
| • NMTPE: Wenn Sie Besatzungsmitglieder eingestellt haben, … | |
| • REV: Wenn Sie Besatzungsmitglieder eingestellt haben, … | |
| Register (Reg) | The text uses a level of formality higher or lower than required by the specifications or general language conventions. |
| DGT Example: | |
| • AT: We have to […] counter the causes of climate change. | |
| • NMT: Wir müssen […] die Ursachen des Klimawandels […] bekämpfen. | |
| • NMTPE: Wir müssen […] die Auslöser des Klimawandels […] bekämpfen. | |
| • REV: Wir müssen […] die Auslöser des Klimawandels […] bekämpfen. | |
| Spelling (Spel) | Issues related to spelling of words |
| DGT Example: | |
| • AT: Informal meeting in Sibu | |
| • NMT: Informelles Treffen in Sibu | |
| • NMTPE: Informelles Treffen in Sibiu | |
| • REV: Informelles Treffen in Sibiu | |
| Function words (Func) | A function word (e.g., a preposition, “helping verb”, article, determiner) is used incorrectly. |
| DGT Example: | |
| AT: On the proposal of President Juncker, … | |
| NMT: Zum Vorschlag von Präsident Juncker … | |
| NMTPE: Auf Vorschlag von Präsident Juncker … | |
| REV: Auf Vorschlag von Präsident Juncker … | |
| Mean (SD) | Additional Information | |
|---|---|---|
| Demographic Data | ||
| Age in years | 45 (9.9) | |
| Gender (F:M) | (18:9) | |
| Language Background | ||
| L2 | English (67%), French (19%), German (7%), Spanish (4%), Italian (4%) | |
| L3 | French (63%) | |
| L4 | 81% had an L4: Spanish (27%), Italian (23%), English (18%), French (9%), Russian (9%) or either Luxembourgish, Dutch or Portuguese (5% each) | |
| L5 | 52% had an L5 (French, Italian, Lithuanian, Dutch, Portuguese, Czech, Russian, Swedish, Spanish) | |
| School subjects taught in L2 | 11% were regularly taught subjects such as biology or history in their L2 | |
| Learning environment L2 | 85% learned their L2 in a formal setting. | |
| Learning environment L3 | 81% learned L3 in a formal setting | |
| Starting age learning L2 | 10.2 (2.9) | |
| Starting age learning L3 | 14.6 (5.7) | |
| Years of study L2 | 12.1 (7.8) | |
| Language Use | ||
| Speaking L2 (setting) | 26% speak their L2 regularly with their families, or relatives 19%, most speak their L2 with their friends (74%) or colleagues (85%). | |
| Speaking L2 (amount of time) | 33% speak in their L2 between 1 and 15 h a day, 26% speak in their L2 between 1 and 15 h a week 40% speak in their L2 between 1 and 15 h a month | |
| Reading L1 (hours per week) | 16.3 (12.1) | |
| Consumption of audio-visual L1 material (hours per week) | 5.6 (5.1) | |
| Reading L2 (hours per week) | 15.6 (14.7) | |
| Consumption of audio-visual L2 material (hours per week) | 4.1 (5.6) | |
| Language Competence (self-rated) | ||
| General knowledge of L2 | 82.7 (10.7) | On a scale from 1 (very poor) to 100 (very good) |
| Active knowledge of L3 | 85.4 (8.3) | On a scale from 1 (very poor) to 100 (very good) |
| Passive knowledge of L3 | 82.5 (14.0) | On a scale from 1 (very poor) to 100 (very good) |
| Ability to translate from L2 into L1 | 92.7 (7.2) | On a scale from 1 (very poor) to 100 (very good) |
| Ability to translate from L1 into L2 | 72.5 (15.6) | On a scale from 1 (very poor) to 100 (very good) |
| Translated hours per week from L2 into L1 | 21.7 (16.2) |
| Func | Source Sentence | Martin Selmayr has been appointed today as the European Commission’s new Secretary-General on the proposal of President Juncker. |
| Test Sentence | Martin Selmayr wurde heute zum [to] Vorschlag von Präsident Juncker zum neuen Generalsekretär der Europäischen Kommission ernannt. | |
| Control Sentence | Martin Selmayr wurde heute auf [on] Vorschlag von Präsident Juncker zum neuen Generalsekretär der Europäischen Kommission ernannt. | |
| Reg | Source Sentence | Since its set up in 2007, the European Chemicals Agency (ECHA) has a key role in the implementation of all the REACH processes. |
| Test Sentence | Seit ihrer Gründung im Jahr 2007 spielt die Europäische Chemikalienagentur (ECHA) eine Schlüsselrolle bei der Umsetzung [implementation] aller REACH-Verfahren. | |
| Control Sentence | Seit ihrer Gründung im Jahr 2007 spielt die Europäische Chemikalienagentur (ECHA) eine Schlüsselrolle bei der Durchführung [implementation] aller REACH-Verfahren. | |
| Misterm | Source Sentence | (7.) There have to be breaks during the working day. |
| Test Sentence | (7.) Es muss Brüche [fractures] während des Arbeitstages geben. | |
| Control Sentence | (7.) Es muss Pausen [pauses] während des Arbeitstages geben. |
| Eye-Tracking Measure | Definition |
|---|---|
| FFDur | first fixation duration is the duration of the first fixation on the token |
| FPDurT | first pass target token reading duration is the sum of all fixation durations on the target token from the first fixation until the participants looks at a different token |
| RPDur | regression path duration is the amount of time it took from the first contact with a word until the eyes move on to the right in the text. It includes all regressions to the left. |
| TrtS | total reading time on source token is the sum of all fixations on the source token(s) aligned to a particular target token for the duration of the entire session |
| TrtT | total reading time on target token is the sum of all fixations on the target token for the duration of the entire session |
| Main Effect | Predictor in All Models | ||
|---|---|---|---|
| Random variables in all models: (1|Part) + (1|TToken) | Corrected (corrected token (TP) compared to correct token (TN)) | ||
| t | p | ||
| Dependent variables in all models: | log (TrtS) | 4.74 | 2.40 × 10−6 *** |
| log (TrtT) | 5.59 | 2.93 × 10−8 *** | |
| log (RPDur) | 3.83 | <2 × 10−16 *** | |
| log (FPDurS) | 2.09 | 0.0367 * | |
| log (FPDurT) | 4.32 | 1.74 × 10−5 *** | |
| log (FFDur) | 4.02 | 6.26 × 10−5 *** | |
| Additionally: | TrtS | TrtT | |
| In TrtS models, we included ST tokens aligned to TT tokens, which had a significant effect. | In TrtT models, we included word length in characters of the target token (LenT), which had a significant effect. | ||
| Main Effect | Predictor in All Models | ||||
|---|---|---|---|---|---|
| Random variables in all models: (1|Part) + (1|TToken) | Error Type Reference level: Func | ||||
| Misterm | Reg | ||||
| t | p | ||||
| Dependent variables in all models: | log (TrtS) | 5.39 | 1.27 × 10−7 *** | 2.11 | 0.0358 * |
| log (TrtT) | 2.08 | 0.04 * | - | Not sig. | |
| log (RPDur) | - | Not sig. | 1.81 | 0.0741. | |
| log (FPDurS) | - | Not sig. | - | Not sig. | |
| log (FPDurT) | - | Not sig. | - | Not sig. | |
| log (FFDur) | - | Not sig. | - | Not sig. | |
| Additionally: | TrtS | TrtT | |||
| In TrtS models, we included ST tokens aligned to TT tokens, which had a significant effect. | In TrtT models, we included word length in characters of the target token (LenT), which had a significant effect. | ||||
| Err | Corr | Total | |
|---|---|---|---|
| Reg | 606 (25.28%) | 604 (25.20%) | 1210 (50.48%) |
| Misterm | 311 (12.97%) | 311 (12.97%) | 622 (25.95%) |
| Func | 283 (11.81%) | 282 (11.76%) | 565 (23.57%) |
| Total | 1200 (50.06%) | 1197 (49.94%) | 2397 (100%) |
| Misterm | Reg | Func | Total | |
|---|---|---|---|---|
| TP | 230 (73.95%) | 109 (17.99%) | 123 (43.46%) | 462 (38.50%) |
| FP | 81 (26.05%) | 497 (82.01%) | 160 (56.54%) | 738 (61.50%) |
| TN | 273 (87.78%) | 493 (81.62%) | 235 (83.33%) | 1001 (83.66%) |
| FN | 38 (12.22%) | 111 (18.38%) | 47 (16.67%) | 196 (16.37%) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vardaro, J.; Schaeffer, M.; Hansen-Schirra, S. Translation Quality and Error Recognition in Professional Neural Machine Translation Post-Editing. Informatics 2019, 6, 41. https://doi.org/10.3390/informatics6030041
Vardaro J, Schaeffer M, Hansen-Schirra S. Translation Quality and Error Recognition in Professional Neural Machine Translation Post-Editing. Informatics. 2019; 6(3):41. https://doi.org/10.3390/informatics6030041
Chicago/Turabian StyleVardaro, Jennifer, Moritz Schaeffer, and Silvia Hansen-Schirra. 2019. "Translation Quality and Error Recognition in Professional Neural Machine Translation Post-Editing" Informatics 6, no. 3: 41. https://doi.org/10.3390/informatics6030041
APA StyleVardaro, J., Schaeffer, M., & Hansen-Schirra, S. (2019). Translation Quality and Error Recognition in Professional Neural Machine Translation Post-Editing. Informatics, 6(3), 41. https://doi.org/10.3390/informatics6030041