
A Graph Database Representation of Portuguese Criminal-Related Documents




Abstract
:1. Introduction
- Despite the Portuguese language is spoken and written by 250 million people (https://www.up.pt/portuguesuporto/o-portugues-no-mundo/ (accessed on 1 June 2021)), to the best of authors’ knowledge there is not a comprehensive set of tools to automatically process criminal-related documents;
- The police data repositories are populated with police reports that are manually processed by police investigators, which constitutes a time-consuming and not error-free task. Therefore, an approach that takes advantage of computational methods to automatically deal with such data is a path to be followed;
- The police reports and online newspapers are available in different formats, namely, structured, semi-structured, and unstructured data, which represents a challenge for the identification and classification of possible entities and relationships between them.
- A systematic approach that ties together the criminal investigation and the computer science domains, focused on the analysis of criminal-related documents in the Portuguese language;
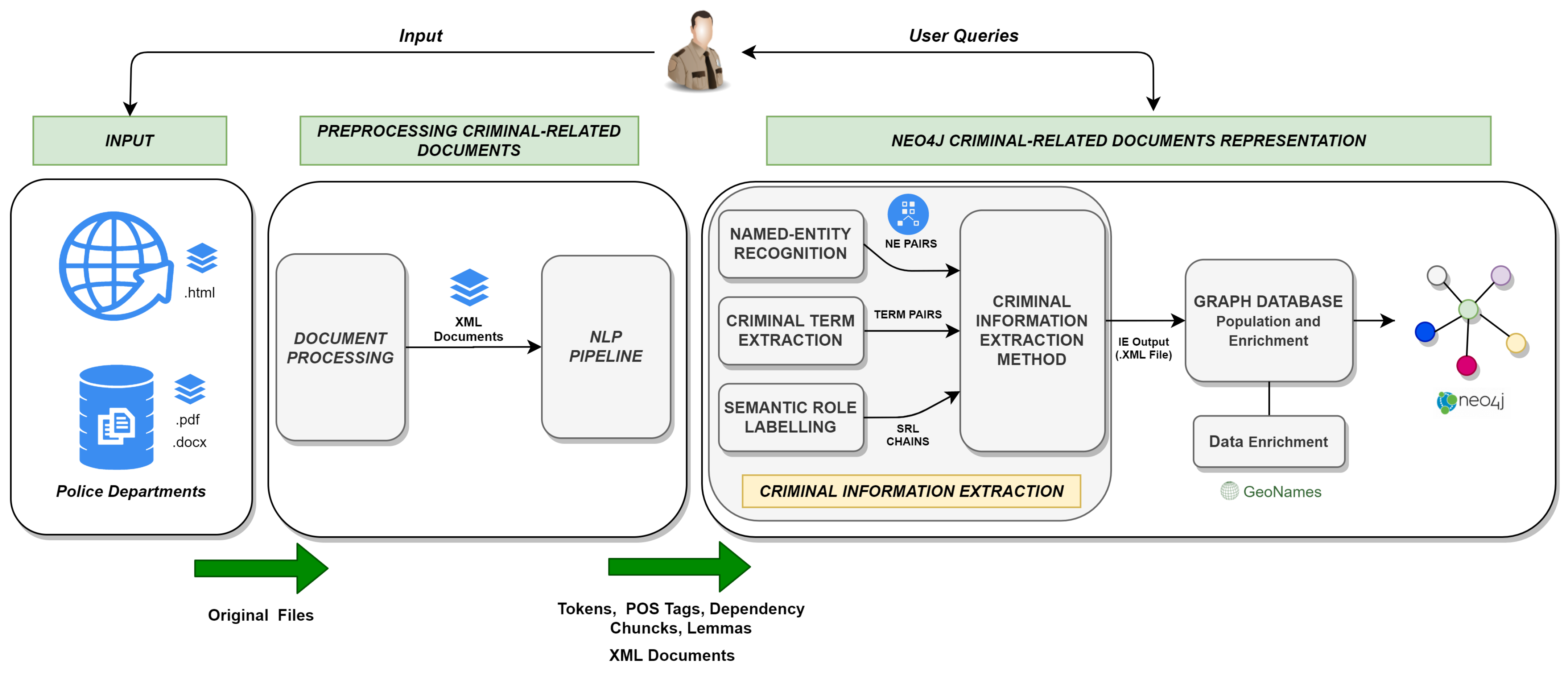
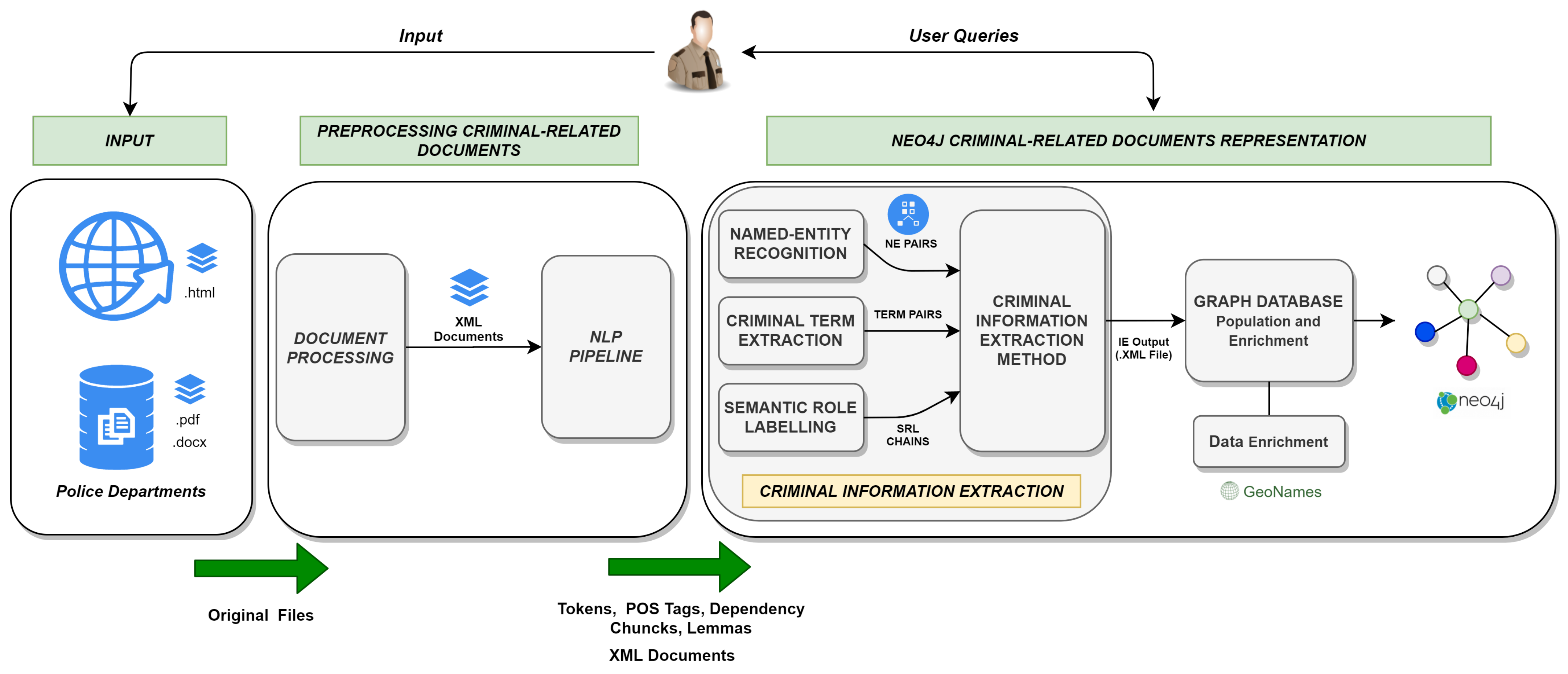
- An end-to-end framework to deal with several phases ranging from data extraction to knowledge representation into a graph database. These phases can be summarized as follows:
- -
- Input: a set of documents that are retrieved from police departments and open sources (online news about crimes), in Portable Document Format (.pdf), Microsoft Word (.doc) and HTML format;
- -
- Document preprocessing: enables a set of tasks for document processing and Natural Language Processing;
- -
- Graph database representation: enables the semantic understanding of data retrieved using Named Entity Recognition (NER), Criminal-Term Extraction, Semantic Role Labelling (SRL), and 5W1H information extraction methods. Finally, the graph database population and enrichment of data retrieved and analyzed in posterior tasks.
- An information extraction method based on an 5W1H (Who, What, Why, Where, When, and How) approach to understand the semantic relations observed in the extracted entities of the processed documents;
- A set of machine learning models to identify and classify name-entity pairs related with the criminal domain;
- An approach to identify and classify terms linked to the criminal domain that can be populated in the documents;
- A graph database implemented in Neo4j (https://www.neo4j.com/ (accessed on 1 June 2021)) to accommodate the named-entities and relations supported by modelling decisions;
- A prototype to evaluate the framework deployed and a performance assessment extract;
- A dataset built by a set of documents, such as police reports, criminal and PGdLisboa (Procuradoria-Geral Distrital de Lisboa, in English: District Attorney of Lisbon) news.
2. Literature Review
- Domain-Specific Detect Concept Space: that identifies documents related to domain-specific concepts or terms and performs a co-occurrence analysis to identify the relationships among indexed terms after filtering and indexing
- Coplink Detect Module: was designed to recommend similar cases to users and identify police officers with similar information needs.
Summary
- The partnerships that have been established between universities and other public institutions, such as police departments, allowed the access and use of classified data, originated from police investigations. Another approach followed by some authors was to combine data from distinct official and public sources;
- Several authors proposed different pipelines that were developed from scratch, or have been configured from others already available. The main purpose was to deal with data extraction, such as structured (relational databases) or unstructured data (textual data) in several file formats;
- A set of approaches resorted to relational databases or ontologies for knowledge representation. These approaches introduced two different issues: relational databases for the criminal domain fail to represent its unstructured data; ontologies are suitable for the domain but are time-consuming and difficult to build from scratch;
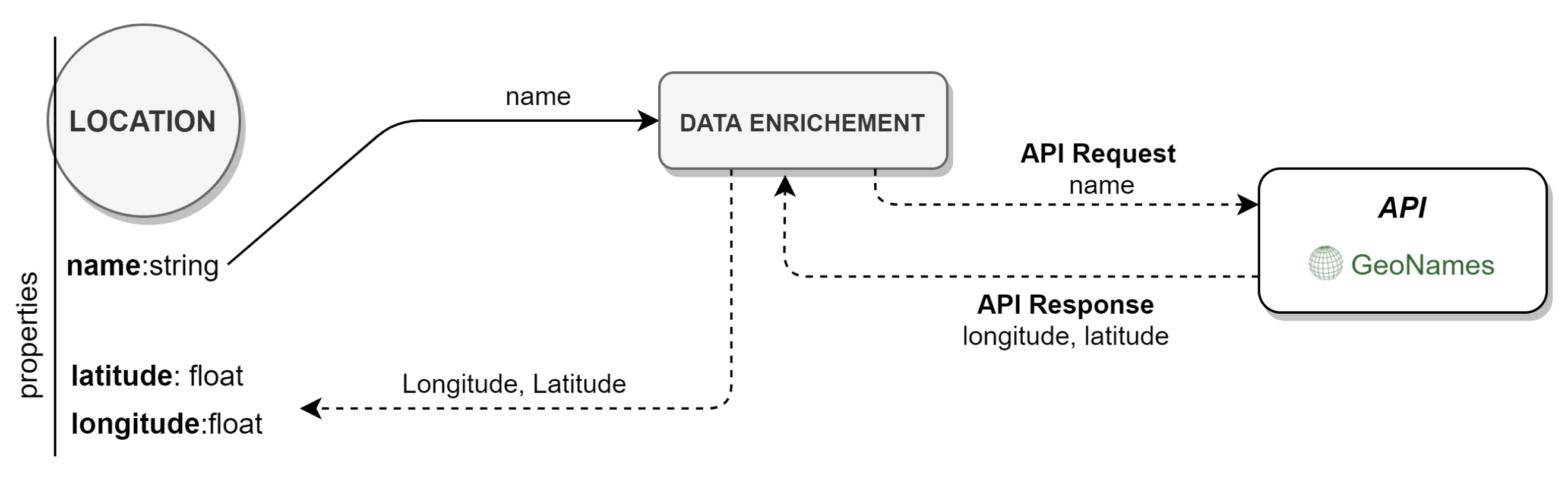
- The use of external knowledge bases for data enrichment, like the GeoNames (www.geonames.org/ (accessed on 1 June 2021)) geographical database;
- The analyzed frameworks were applied mostly to the English language, and are focused on unstructured data (textual data), such as police reports, and have used NLP tasks for different approaches.
- It is possible to confirm the lack of frameworks for criminal domain documents written in Portuguese language and variants (e.g., Brazilian-Portuguese).
3. SEMCrime Framework
“Em 18 de Abril de 2008, durante a busca ao domicilio do Pedro Silva, sita na Rua José Leite, no Bairro de Santa Apolónia, em Coimbra, foi encontrado e apreendido no interior da carteira do arguido: uma pequena lingua de haxixe, com o peso de 1.8 gramas”. (In Portuguese)
“In 18 of April 2008, during a home search in Pedro Silva home, that lives on José Leite Street, in Santa Apolónia District, in Coimbra, was found and seized inside the defendant’s wallet: a small portion of cannabis, with a weight of 1.8 grams.” (In English)
- The documents are in their original file formats, such as Microsoft™ Word, Portable Document Format (PDF), and HTML (for websites);
- After being retrieved, text may contain errors, which can cause problems with later tasks, such as tokenization or stemming;
- The text must be understood from a lexical and syntactical perspective, like tokenization or sentence splitting;
- Several entities were identified, such as persons, locations or references to dates. Entities related to the criminal domain, such as narcotics, have also been identified. The extraction of these entities is useful for the semantic analysis;
- The relations between entities need to be identified and extracted because they enable the understanding of the meaning of each sentence;
- the data retrieved must be represented in a structured form, such as a graph database, to permit end-user queries and visualization.
- Input: takes as input a set of criminal-related documents, obtained from online newspapers and police departments, in its original formats (Microsoft™ Word, Portable Document Format (PDF) or HTML file formats);
- Preprocessing Criminal-Related Documents, which is formed by the following pipeline modules:
- -
- Document Processing: this module permits the extraction, transformation and loading of criminal-related documents. Different tasks were applied, for example, a cleaning task to extract words or symbols that may cause “noise” in data. The output is a in Extensible Markup Language (XML) file, with tags to identify the documents content;
- -
- NLP Pipeline: to enable the syntactic analysis of documents. The output is a group of Tokens, POS Tags, Dependency Chunks and Lemmas identified in each sentence that belongs to documents.
- Neo4j Representation: this module was proposed to semantically understand the documents and the representation of the retrieved data into Neo4j graph database. This module is divided into the following blocks:
- -
- Criminal Information Extraction: uses a Named-Entity Recognition module to identify the named-entities relevant to the domain, a Criminal Term Extraction was introduced to extract domain-specific terms that are relevant to the criminal domain, and a Semantic Role Labelling module to identify the predicate and its semantic role that will be used in Criminal Information Extraction Method that aggregates the other two modules to deliver the identification of the 5W1H information and crime type detection in documents. This module outputs an Information Extraction XML File;
- -
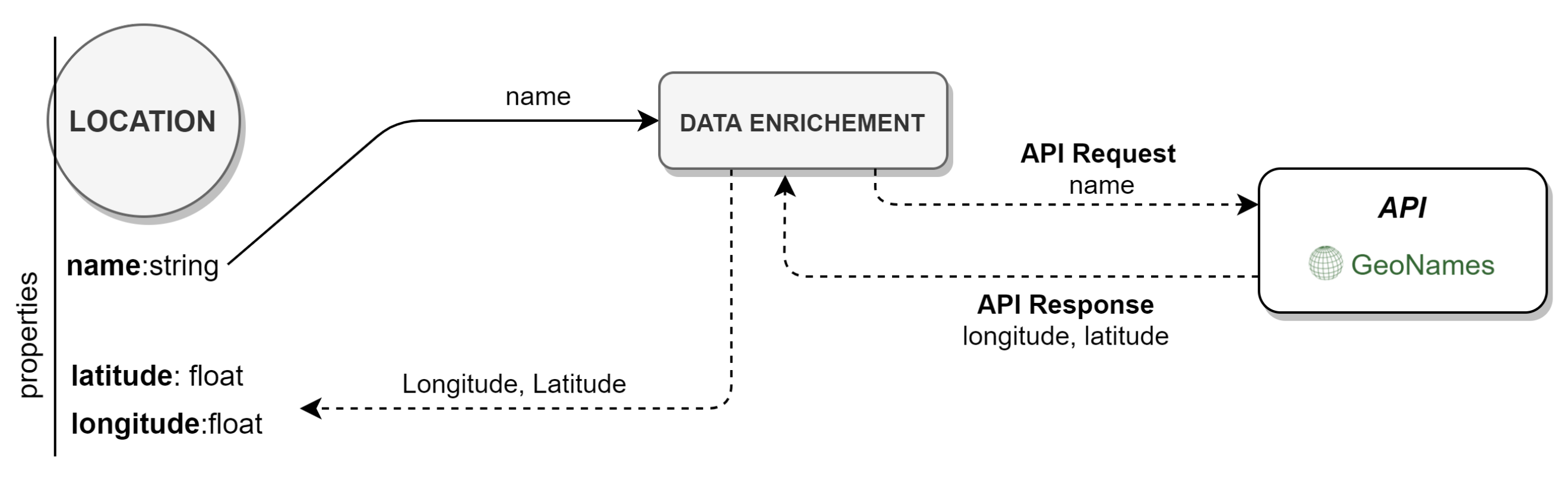
- Graph Database Population and Enrichment: this block enables the population of the Neo4j graph database, and the data enrichment using the GeoNames geographical database.
3.1. Criminal-Related Documents
- Criminal Investigation Reports: these reports synthesize in one or multiple documents the information collected during a criminal investigation by grouping the contents of an investigation, such as witnesses, suspects, police investigators, or fact descriptions;
- Criminal News: documents that are published in online newspapers [19] during criminal investigations performed by police departments, written by investigative journalists;
- PGdLisboa News: another source for criminal reports is the Procuradoria-Geral Distrital de Lisboa (https://www.pgdlisboa.pt/ (accessed on 1 June 2021)) website. The news are about cases in which there has been a final decision and are no longer subject to appeal.
3.2. Preprocessing Criminal-Related Documents

- Document Processing module focused on the adaptation of an ETL approach to identify the required mappings and transformations needed to be done automatically and perform operations that lead to a transformation of unstructured into semi-structured data (represented in an XML file);
- NLP Pipeline module enables the NLP tasks regarding lexical and syntax analysis of each document in the Portuguese language, such as sentence splitting, tokenization, or lemmatization.


3.3. Neo4j Criminal-Related Documents Representation
- Criminal Information Extraction: allows the identification and classification of named-entities (see Section 3.3.1), criminal terms (see Section 3.3.2), and semantic roles (see Section 3.3.3);
- Criminal Information Extraction Method: to enable the semantic understanding of documents, we have introduced the 5W1H Information Extraction Method (see Section 3.3.4) that identifies and classifies the 5W’s questions based on the 5W1H information, the crime type, and criminal terms;
- Graph Database Population and Enrichment: the results of 5W1H Information Extraction Method needed to be represented in the Neo4j graph database, to enable this, a Graph Database Population and Enrichment module has been introduced to populate and enrich the Neo4j graph database (see Section 3.3.5).
- this approach allow us to obtain initial results, and decrease the time-consuming associated with supervised methods. Therefore, this approach enables us to capture the language meaning by using linguistic rules, such as relationships between words;
- the built of an annotated corpus for a criminal domain is a time-consuming task and requires efforts from domain experts to produce it, therefore, approaches that used rules can help to validate applied NLP methods;
- our framework used a combined set of approaches, namely supervised (e.g., NER Classifier for Narcotics) and unsupervised (e.g., NER Classifier for Crime Types) thus allowing a combined approach to obtain results.
- restricted to the terms defined in gazetteers, for example, in the NER module the use of gazetteers to identify and classify role types could have a lack of terms, and then an identification and classification issue;
- the manual maintenance of rules can be a time-consuming task, when rules increase or need an updating task;
- the rules defined must be well-defined, because a misspelled rule will lead to an error;
- the rules are limited to a certain domain, limiting the portability of such approximations.
3.3.1. NER Module
- there is a vague definition of the criminal domain in terms of NEs, due to different contexts, such as the expression: “She is so heroine”;
- we can spot terms that are domain-dependent; however, terms used in other domains are used in this context, such as vehicle brands;
- the lack of NER tools and trained classifiers applied to the Portuguese language;
- the lack of freely available corpus for the criminal domain, with annotated criminal-related entities.
- gazetteer-based: using dictionaries with terms related to the criminal domain that needs to be detected in the documents;
- patterns rule: for example, regular expressions that enable the identification of patterns in text portions;
- supervised learning: using manually annotated corpus and learning algorithms to train classifiers to identify and classify specific NE.
- COMMON Classifier: for persons, locations, time/date and organizations;
- PATTERNS Classifier for mobile phone numbers, email addresses, license plates, and zip codes;
- NARCOTICS Classifier: for narcotics names: the narcotics names are mentioned in their current and street name (same as slang) across documents. Another motivation is that drug trafficking is one of the most reported (https://www.pordata.pt/Europa/Crimes+por+categoria-3285/ (accessed on 1 June 2021)) and typified crimes investigated by the Portuguese criminal police;
- CRIME TYPE Classifier: for crime type names: identified words or compound words in criminal-related documents that indicates crime names. For instance, in the context of of road accidents investigation we can find crimes such as homicide, drug dealing or assault;
- ROLE TYPE Classifier: for role type: the use of specific terms used to identify the persons and organizations by its roles. For example, the use of "suspect" to identify a person that is a suspect of a crime, not providing the real proper noun;
Após investigação da <organization> Policia Judiciaria </organization>, o suspeito <person> Luis Silva </person> foi indiciado pelos crimes de <crimetype> roubo </crimetype>. Os crimes foram cometidos em <location> Coimbra </location>, durante <date> Setembro </date>, com auxilio do veiculo de matricula <licenseplates> XX-XX-11 </licenseplates>. O suspeito era consumidor de <narcotics> cocaina </narcotics>.
After investigating of the <organization> Policia Judiciaria </organization>, the suspect <person> Luis Silva </person> was indicted for the crimes of <crimetype> theft </crimetype>. The crimes were committed in <location> Coimbra </location>, during <date> September </date>, with the aid of the registration vehicle <licenseplates> XX-XX-11 </licenseplates>. The suspect was a consumer of <narcotics> cocaine </narcotics>.
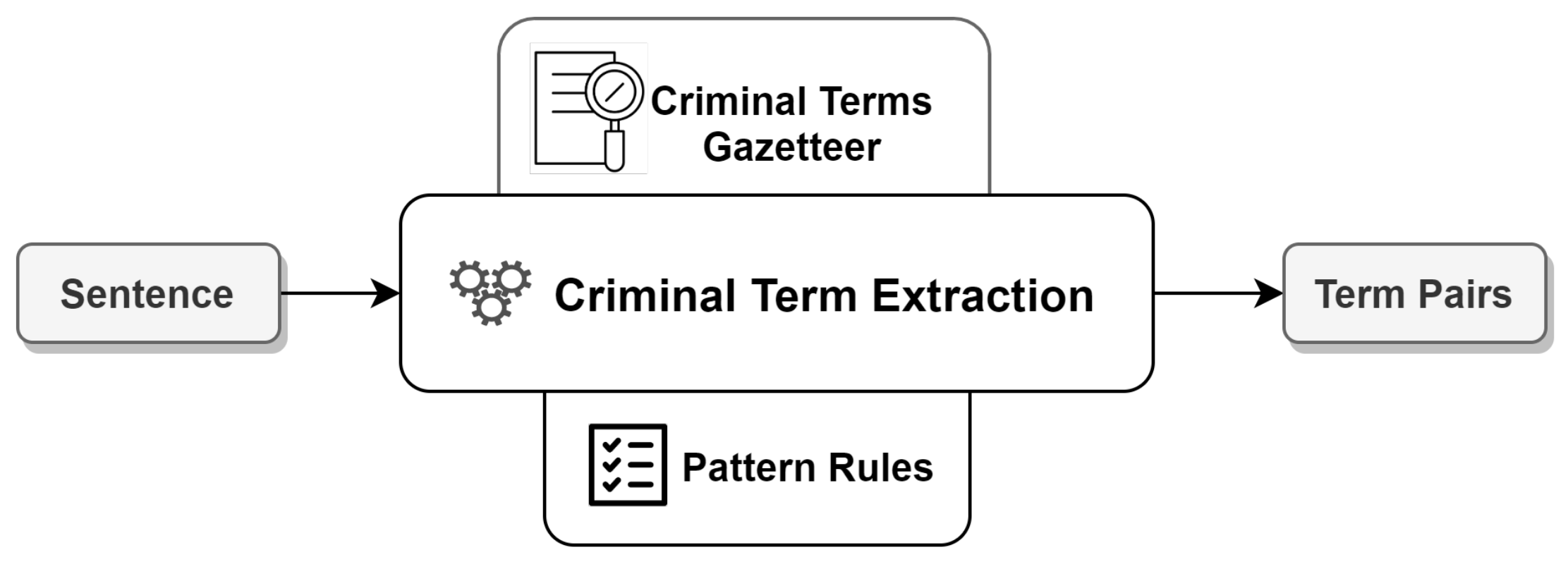
3.3.2. Criminal Term Extraction Module
Após investigação, <criminalterm> buscas domiciliárias </criminalterm> foram realizadas na casa do suspeito.
After investigation, <criminalterm> home searches </criminalterm> were made in the suspect house.
3.3.3. Semantic Role Labeling Module
O Rui Silva Arg0 assaltou V o Banco de Portugal Arg1, pelas 14 horas ArgM-TMP.
Rui Silva Arg0 robbed V the Bank of Portugal Arg1, by the 2 pm ArgM-TMP.
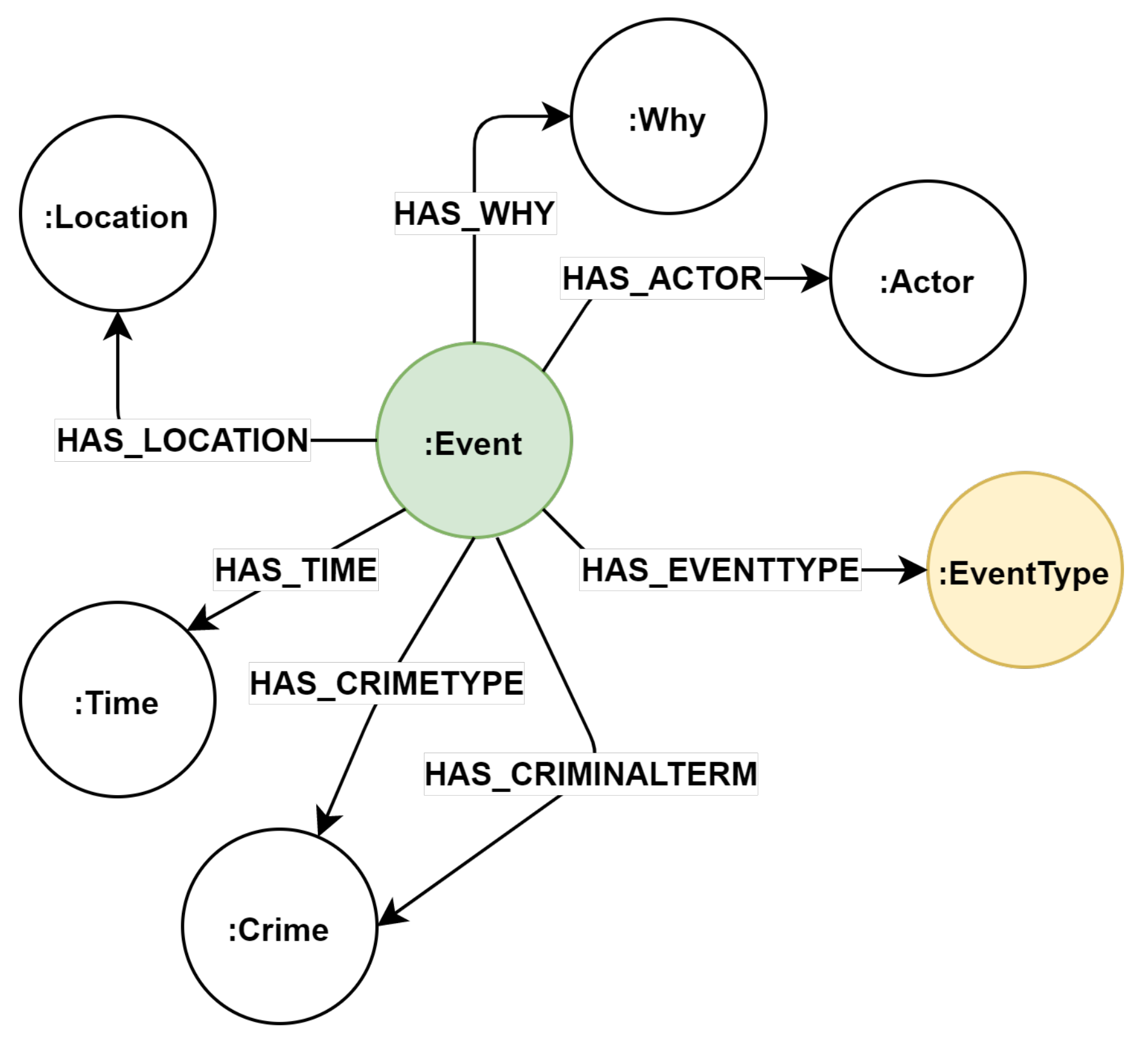
3.3.4. 5W1H Information Extraction Method
- extracting the event type and elements to answer the 5W1H information in the Portuguese language applied to the criminal domain, permitting the construction of triples that can be used in several tools or knowledge bases, such as graph databases;
- to extract the crime type and criminal terms to enable domain comprehension by adding information that is connected to the criminal domain.
O Rui Silva e o Pedro Silva WHO asssaltaram WHAT o Banco de Portugal WHOM em Coimbra WHERE pelas 14 horas WHEN.
Rui Silva and Pedro Silva WHO robbed WHAT the Bank of Portugal WHOM in Coimbra WHERE by 2 pm WHEN.


3.3.5. Graph Database Population and Enrichment
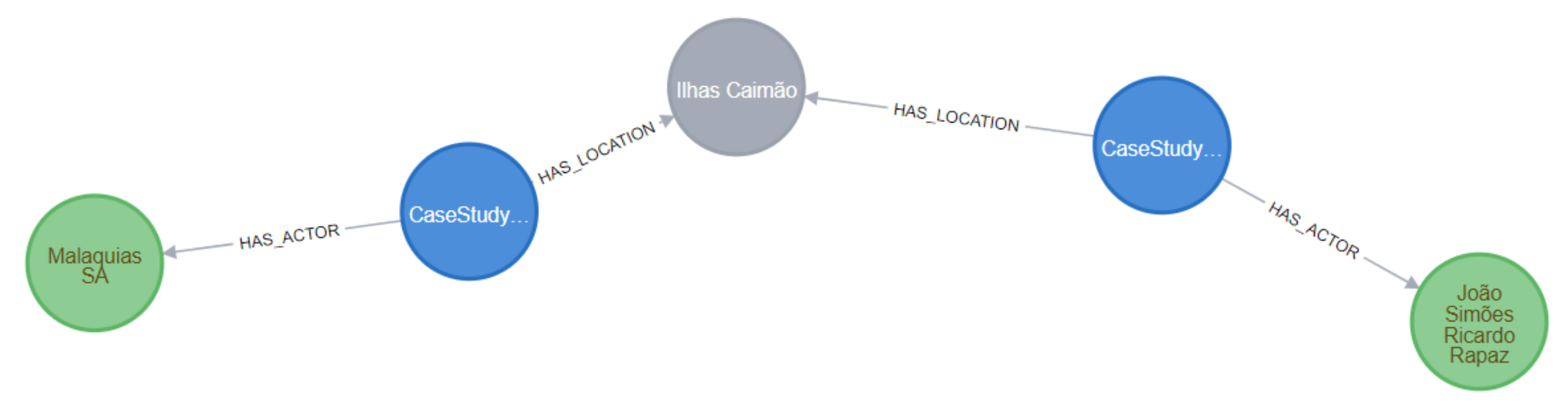
- the graph databases are specially adapted to deal with unstructured data. They represent the entities and relations into nodes, edges, and properties, without requiring a database schema. This approach is ideal for representing data that cannot be easily organized or interpreted by relational databases;
- they are suitable to calculate paths between entities, which can be useful in criminal-related applications. For example, it is possible to obtain relationships between entities not explained in the documents, and apply semantic queries adapted to the linguistic context.
“O Rui Silva e o Pedro Silva assaltaram o Banco de Portugal em Coimbra, pelas 14 horas. O Rui Silva telefonou ao Pedro Silva, com recurso ao telemóvel Nokia, com o nº 989999000”.
“Rui Silva and Pedro Silva robbed the Bank of Portugal in Coimbra, by 2 pm. Rui Silva called Pedro Silva, using a Nokia mobile phone, with the number 989999000”.
4. Implementation and Results
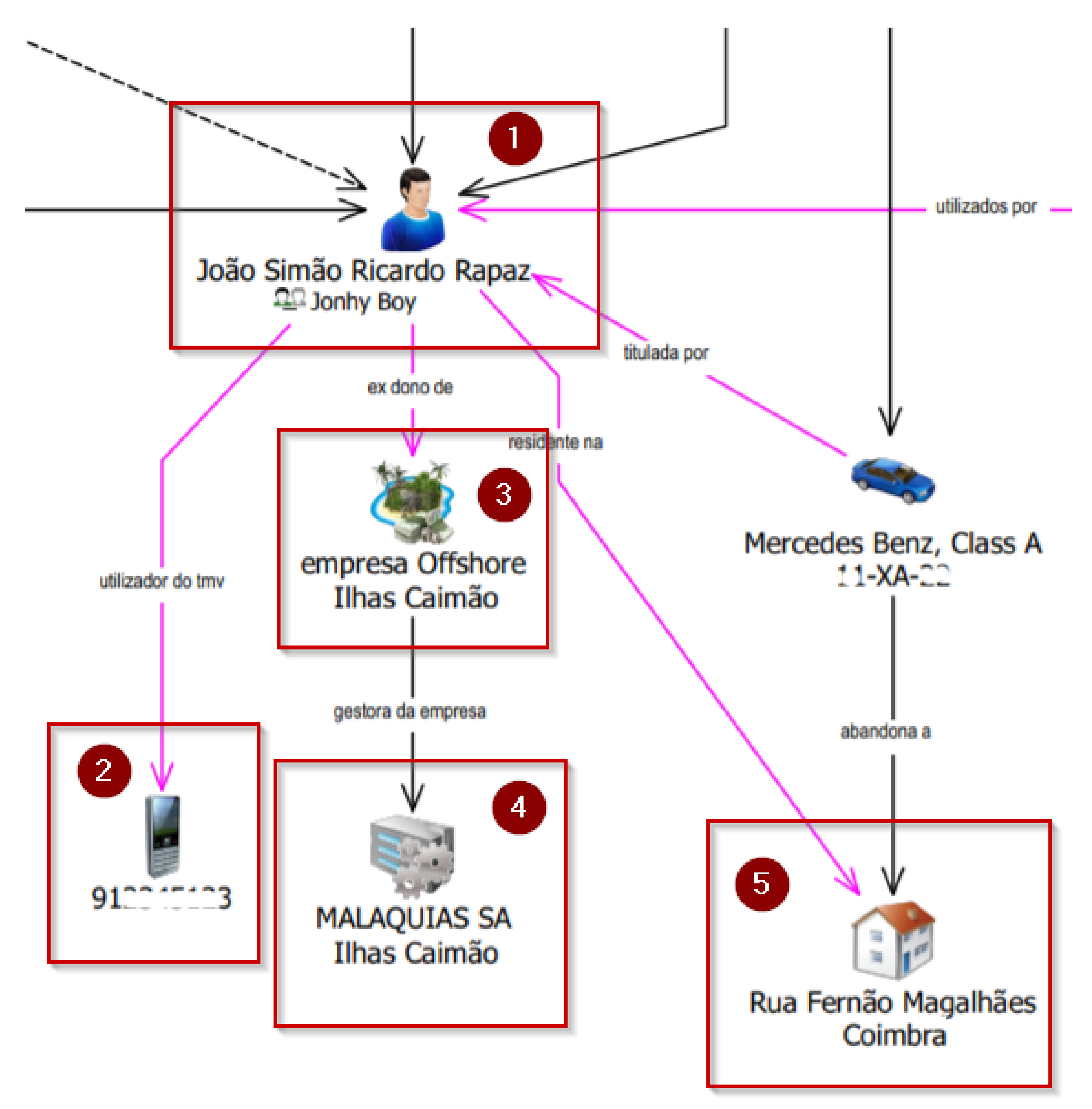
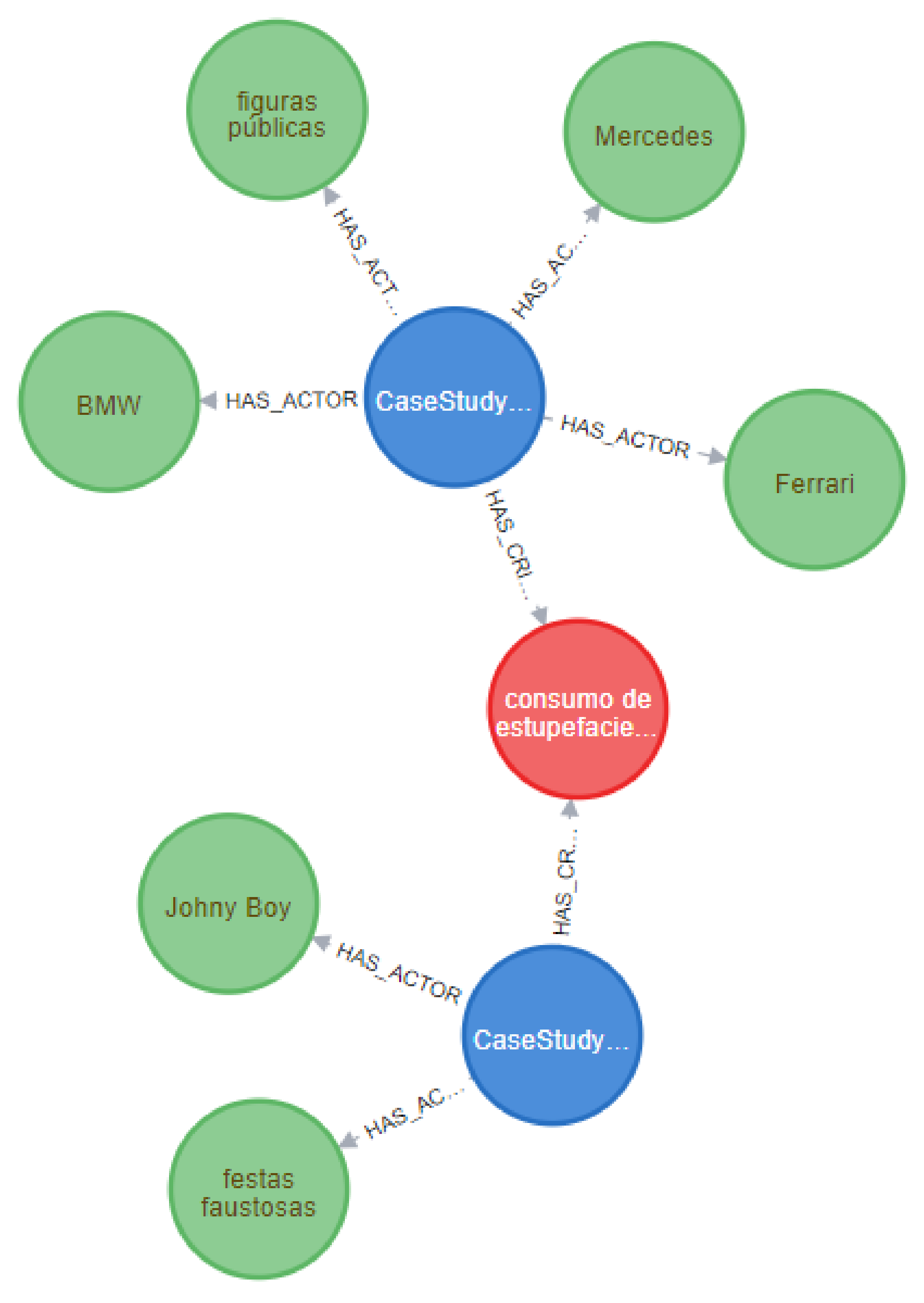
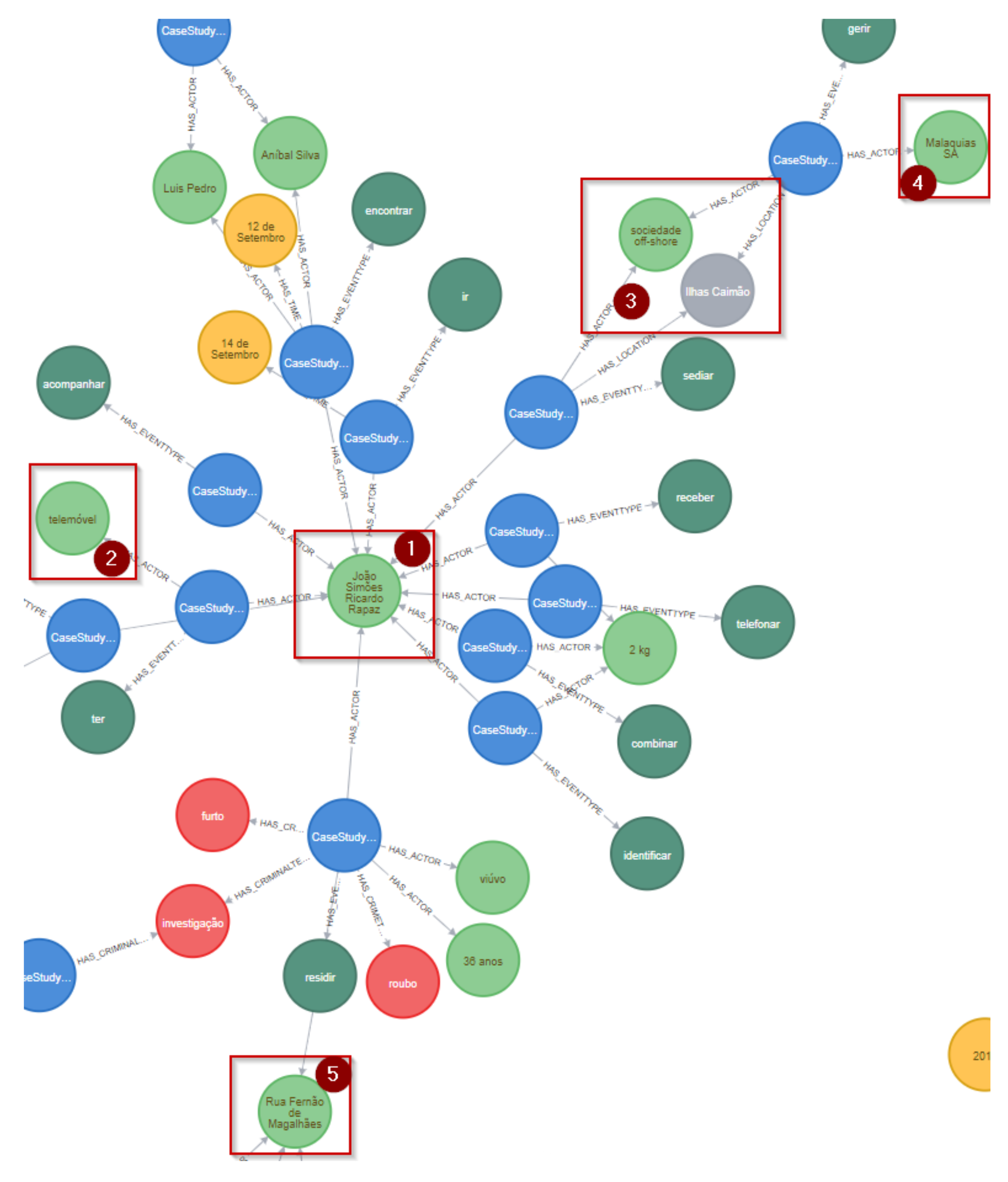
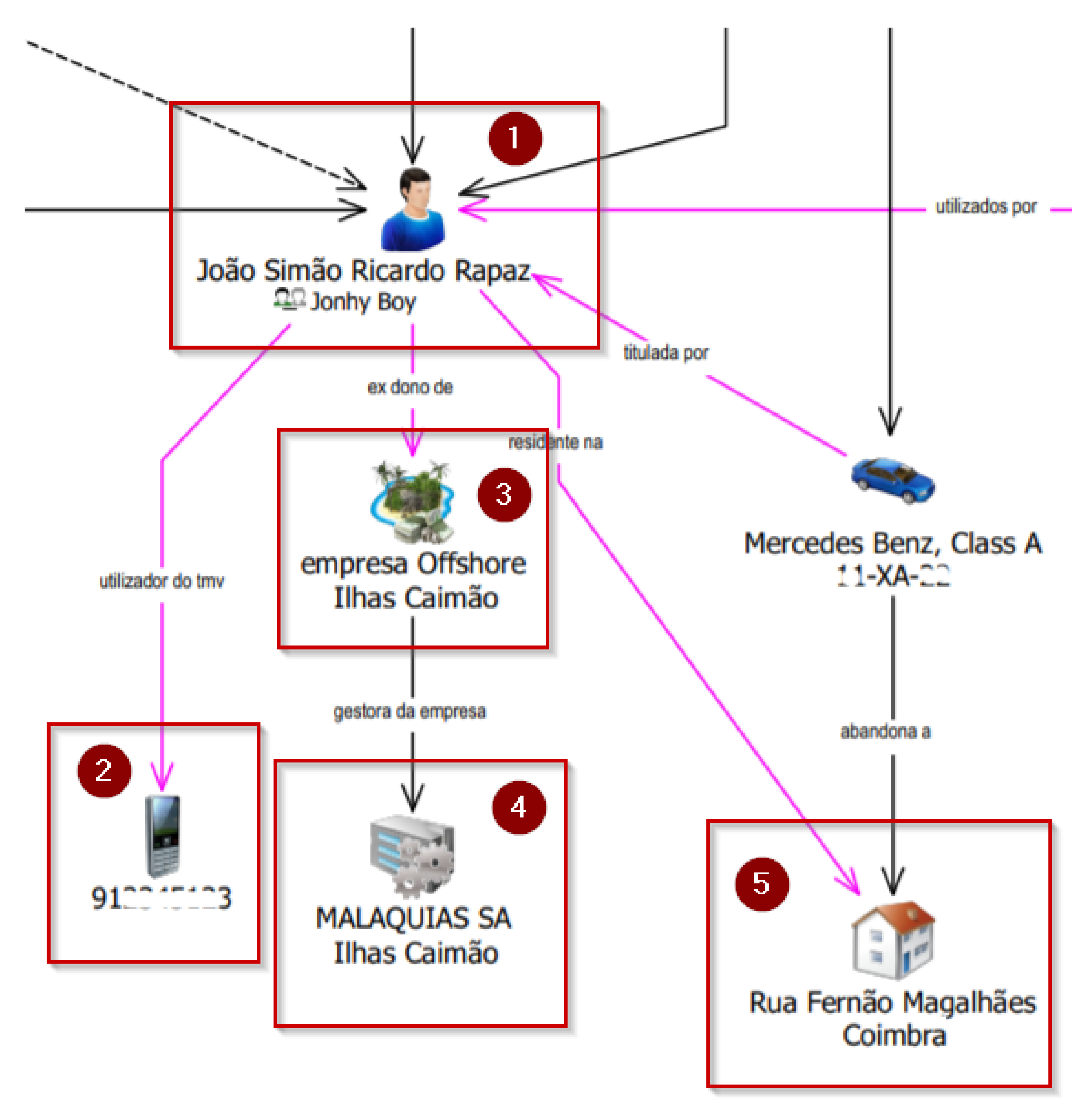
Case Study
- the analysis of the criminal investigation report, made by a domain expert, each person and location names, phone numbers, or license plates were changed or masked;
- the report was submitted into our framework;
- the domain expert analyzed the criminal investigation report using the IBM™ i2 Analyst’s Notebook tool.
5. Conclusions and Future Work
- The focus is on the Portuguese language, without discarding what has been done in other languages;
- The approaches applied to the criminal domain and related works were studied and analyzed;
- A survey of existing ETL, NLP, Graph Database approaches was made and, for each one, a list was presented, with the features that can be proposed, used or adapted;
- the criminal-related documents have different content structures and file formats; For instance, investigation reports of road accidents with fatal victims have a particular template;
- the extracted plain text may contain errors or noise identified during the extraction phase, such as double space or extra symbols;
- the existence of abbreviations and acronyms related to the domain;
- the existence of entities related to the domain that are not identified and classified by the NER approaches, such as narcotics or crime types;
- the use of domain-specific terms related to the criminal domain, such as “Pulseira Eletrónica” (in English: “ankle bracelet”);
- as in other written text, the criminal-related documents need to be semantically understood;
- the documents were analyzed, and data was retrieved, performing tasks to clean, transform, normalize and load into a semi-structured format, producing a computer-readable format (XML format);
- abbreviations and acronyms were normalized to its extended form, like the acronym “PSP” refers to “Policia de Segurança Publica”;
- a NLP pipeline was introduced, performing tasks like tokenization or sentence splitting;
- an NER module was used to identify and classify the NEs relevant to the domain. In this phase, we have proposed classifiers that identify NEs related to the domain;
- to identify and classify the domain-specific terms related to the criminal domain, we added a module to perform such task using a gazetteer of criminal terms;
- the SRL was adapted to our approach to enable the identification of the semantic roles;
- identifies and classifies the Who, What, Where, When, Why and How; using this method, we tried to find the answers to the 5Ws in each sentence, which outputs a network of entities and relations.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| 5W1H | Who, What, Where, When, Why and How |
| CRF | Conditional Random Field |
| CWTDF | CombinedWebsites and Textual Document Framework |
| ETL | Extract, Transform, Load |
| GNR | Republican National Guard |
| NE | Named Entity |
| NER | Named Entity Recognition |
| NICAV | Traffic Accident Criminal Investigation Nucleus |
| NLP | Natural Language Processing |
| OSINT | Open Source Intelligence |
| PIAF | Police Intelligence Analysis Framework |
| POS | Part-Of-Speech |
| SRL | Semantic Role Labelling |
| SVM | Support Vector Machine |
References
- Gleick, J.; Calil, A. A Informação: Uma História, Uma Teoria, Uma Enxurrada; Companhia das Letras: Sao Paulo, Brazil, 2013. [Google Scholar]
- Oussous, A.; Benjelloun, F.Z.; Lahcen, A.A.; Belfkih, S. Big Data technologies: A survey. J. King Saud Univ. Comput. Inf. Sci. 2018, 30, 431–448. [Google Scholar] [CrossRef]
- Cavanillas, J.M.; Curry, E.; Wahlster, W. New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe; Springer: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Chen, H.; Zeng, D.; Atabakhsh, H.; Wyzga, W.; Schroeder, J. COPLINK: Managing law enforcement data and knowledge. Commun. ACM 2003, 46, 28–34. [Google Scholar] [CrossRef]
- Stasko, J.; Görg, C.; Liu, Z.; Singhal, K. Jigsaw: Supporting investigative analysis through interactive visualization. In Proceedings of the VAST IEEE Symposium on Visual Analytics Science and Technology, Sacramento, CA, USA, 28 October–1 November 2007; Volume 1, pp. 131–138. [Google Scholar] [CrossRef] [Green Version]
- Stampouli, D.; Roberts, M.; Powell, G.; Lopez, T.S. Implementation of a police intelligence analysis framework. Int. J. Secur. Its Appl. 2011, 5, 13–22. [Google Scholar]
- Köpcke, H.; Rahm, E. Frameworks for entity matching: A comparison. Data Knowl. Eng. 2010, 69, 197–210. [Google Scholar] [CrossRef] [Green Version]
- Albertetti, F.; Stoffel, K. From police reports to data marts: A step towards a crime analysis framework. In Proceedings of the 5th International Workshop on Computational Forensics, Tsukuba, Japan, 11 November 2012. [Google Scholar]
- Poelmans, J.; Elzinga, P.; Neznanov, A.A.; Dedene, G.; Viaene, S.; Kuznetsov, S.O. Human-centered text mining: A new software system. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2012, 7377, 258–272. [Google Scholar] [CrossRef]
- Hosseinkhani, J.; Chaprut, S.; Taherdoost, H. Criminal network mining by web structure and content mining. In Advances in Remote Sensing, Finite Differences and Information Security. Proceedings of the 11th WSEAS International Conference on Information Security and Privacy (ISP ’12), Prague, Czech Republic, 24–26 September 2012; pp. 210–215. [Google Scholar]
- Hossain, M.S.; Butler, P.; Boedihardjo, A.P.; Ramakrishnan, N.; Tech, V. Storytelling in Entity Networks to Support Intelligence Analysts. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012. [Google Scholar]
- Adderley, R.; Seidler, P.; Badii, A.; Tiemann, M.; Neri, F.; Raffaelli, M. Semantic Mining and Analysis of Heterogeneous Data for Novel Intelligence Insights. Fourth Int. Conf. Adv. Inf. Min. Manag. 2014, 1, 36–40. [Google Scholar]
- Casanovas, P.; Arraiza, J.; Melero, F.; González-Conejero, J.; Molcho, G.; Cuadros, M. Fighting Organized Crime Through Open Source Intelligence: Regulatory Strategies of the CAPER Project. Front. Artif. Intell. Appl. 2014, 271, 189–198. [Google Scholar] [CrossRef]
- Brewster, B.; Andrews, S.; Polovina, S.; Hirsch, L.; Akhgar, B. Environmental scanning and knowledge representation for the detection of organised crime threats. Lect. Notes Comput. Sci. (Incl. Subser. Lect. Notes Artif. Intell. Lect. Notes Bioinform.) 2014, 8577, 275–280. [Google Scholar] [CrossRef]
- Sowa, J.F. Chapter 5 Conceptual Graphs. In Handbook of Knowledge Representation; Foundations of Artificial Intelligence; Van Harmelen, F., Lifschitz, V., Porter, B., Eds.; Elsevier: Amsterdam, The Netherlands, 2008; Volume 3, pp. 213–237. [Google Scholar] [CrossRef] [Green Version]
- Wijeratne, S.; Doran, D.; Sheth, A.; Dustin, J.L. Analyzing the social media footprint of street gangs. In Proceedings of the 2015 IEEE International Conference on Intelligence and Security Informatics (ISI), Baltimore, MD, USA, 27–29 May 2015; pp. 91–96. [Google Scholar] [CrossRef] [Green Version]
- Elyezjy, N.T.; Elhaless, A.M. Investigating Crimes using Text Mining and Network Analysis. Int. J. Comput. Appl. 2015, 126, 19–25. [Google Scholar]
- Mata, F.; Torres-ruiz, M.; Guzmán, G.; Quintero, R.; Zagal-flores, R.; Moreno-ibarra, M.; Loza, E. A Mobile Information System Based on Crowd-Sensed and Official Crime Data for Finding Safe Routes: A Case Study of Mexico City. Mob. Inf. Syst. 2016, 2016, 11. [Google Scholar] [CrossRef] [Green Version]
- Wiedemann, G.; Yimam, S.M.; Biemann, C. A Multilingual Information Extraction Pipeline for Investigative Journalism. arXiv 2018, arXiv:1809.00221. [Google Scholar]
- Al-Zaidy, R.; Fung, B.C.M.; Youssef, A.M. Towards Discovering Criminal Communities from Textual Data. In Proceedings of the 2011 ACM Symposium on Applied Computing, TaiChung, Taiwan, 1 January 2011; ACM: New York, NY, USA, 2011; pp. 172–177. [Google Scholar] [CrossRef]
- Pinheiro, V.; Furtado, V.; Pequeno, T.; Nogueira, D.; Aplicada, I. Natural Language Processing Based on Semantic Inferentialism for Extracting Crime Information from Text. In Proceedings of the 2010 IEEE International Conference on Intelligence and Security Informatics, Vancouver, BC, Canada, 23–26 May 2010. [Google Scholar]
- Pinheiro, V.; Pequeno, T.; Furtado, V.; Assunção, T.; Freitas, E. SIM: Um modelo semântico-inferencialista para sistemas de linguagem natural. In Proceedings of the Companion Proceedings of the XIV Brazilian Symposium on Multimedia and the Web, Vila Velha, Brazil, 26–29 October 2018; pp. 353–358. [Google Scholar]
- Furtado, V.; Ayres, L.; Oliveira, M.D.; Vasconcelos, E.; Caminha, C.; Orleans, J.D.; Belchior, M. Collective intelligence in law enforcement—The WikiCrimes system. Inf. Sci. 2010, 180, 4–17. [Google Scholar] [CrossRef]
- Camara Junior, A.T.D. Processamento de linguagem natural para indexação automática semântico-ontológica. Rev. Ibero Am. Ciência Informação 2013, 9, 569. [Google Scholar]
- Arulanandam, R.; Savarimuthu, B.T.R.; Purvis, M.A. Extracting Crime Information from Online Newspaper Articles. In Proceedings of the Second Australasian Web Conference, Auckland, New Zealand, 20–23 January 2014; Australian Computer Society, Inc.: Darlinghurst, Australia, 2014; Volume 155, pp. 31–38. [Google Scholar]
- Shabat, H.A.; Omar, N. Named Entity Recognition in Crime News Documents Using Classifiers Combination. Middle-East J. Sci. Res. 2015, 23, 1215–1221. [Google Scholar] [CrossRef]
- Ejem, R. Relation Extraction in Police Records; Univerzita Karlova, Matematicko-Fyzikální Fakulta: Chéquia, Czech Republic, 2017. [Google Scholar]
- Martin-Rodilla, P.; Hattori, M.L.; Gonzalez-Perez, C. Assisting Forensic Identification through Unsupervised Information Extraction of Free Text Autopsy Reports: The Disappearances Cases during the Brazilian Military Dictatorship. Information 2019, 10, 231. [Google Scholar] [CrossRef] [Green Version]
- Sarmento, L. SIEMÊS—A named-entity recognizer for portuguese relying on similarity rules. In Proceedings of the International Workshop on Computational Processing of the Portuguese Language, Itatiaia, Brazil, 13–17 May 2006; Springer: Berlin/Heidelberg, Germany, 2006; pp. 90–99. [Google Scholar]
- Gianola, L. Aspects Textuels de la Procédure Judiciaire Exploitée en Analyse Criminelle et Perspectives Pour son Traitement Automatique. Ph.D. Thesis, Université de Cergy-Pontoise, Cergy, France, 2020. [Google Scholar]
- Braz, J. Investigacao Criminal; Almedina: Coimbra, Portugal, 2019. [Google Scholar]
- Van Hage, W.R.; Malaisé, V.; Segers, R.; Hollink, L.; Schreiber, G. Design and use of the Simple Event Model (SEM). J. Web Semant. 2011, 9, 128–136. [Google Scholar] [CrossRef] [Green Version]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| P | R | F1 | |
|---|---|---|---|
| Criminal News | |||
| PGdLisboa News | |||
| Criminal Investigation | |||
| Reports | |||
| Avg. |
| P | R | F1 |
|---|---|---|
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Carnaz, G.; Nogueira, V.B.; Antunes, M. A Graph Database Representation of Portuguese Criminal-Related Documents. Informatics 2021, 8, 37. https://doi.org/10.3390/informatics8020037
Carnaz G, Nogueira VB, Antunes M. A Graph Database Representation of Portuguese Criminal-Related Documents. Informatics. 2021; 8(2):37. https://doi.org/10.3390/informatics8020037
Chicago/Turabian StyleCarnaz, Gonçalo, Vitor Beires Nogueira, and Mário Antunes. 2021. "A Graph Database Representation of Portuguese Criminal-Related Documents" Informatics 8, no. 2: 37. https://doi.org/10.3390/informatics8020037
APA StyleCarnaz, G., Nogueira, V. B., & Antunes, M. (2021). A Graph Database Representation of Portuguese Criminal-Related Documents. Informatics, 8(2), 37. https://doi.org/10.3390/informatics8020037