
Automatic Ethnicity Classification from Middle Part of the Face Using Convolutional Neural Networks




Abstract
:1. Introduction
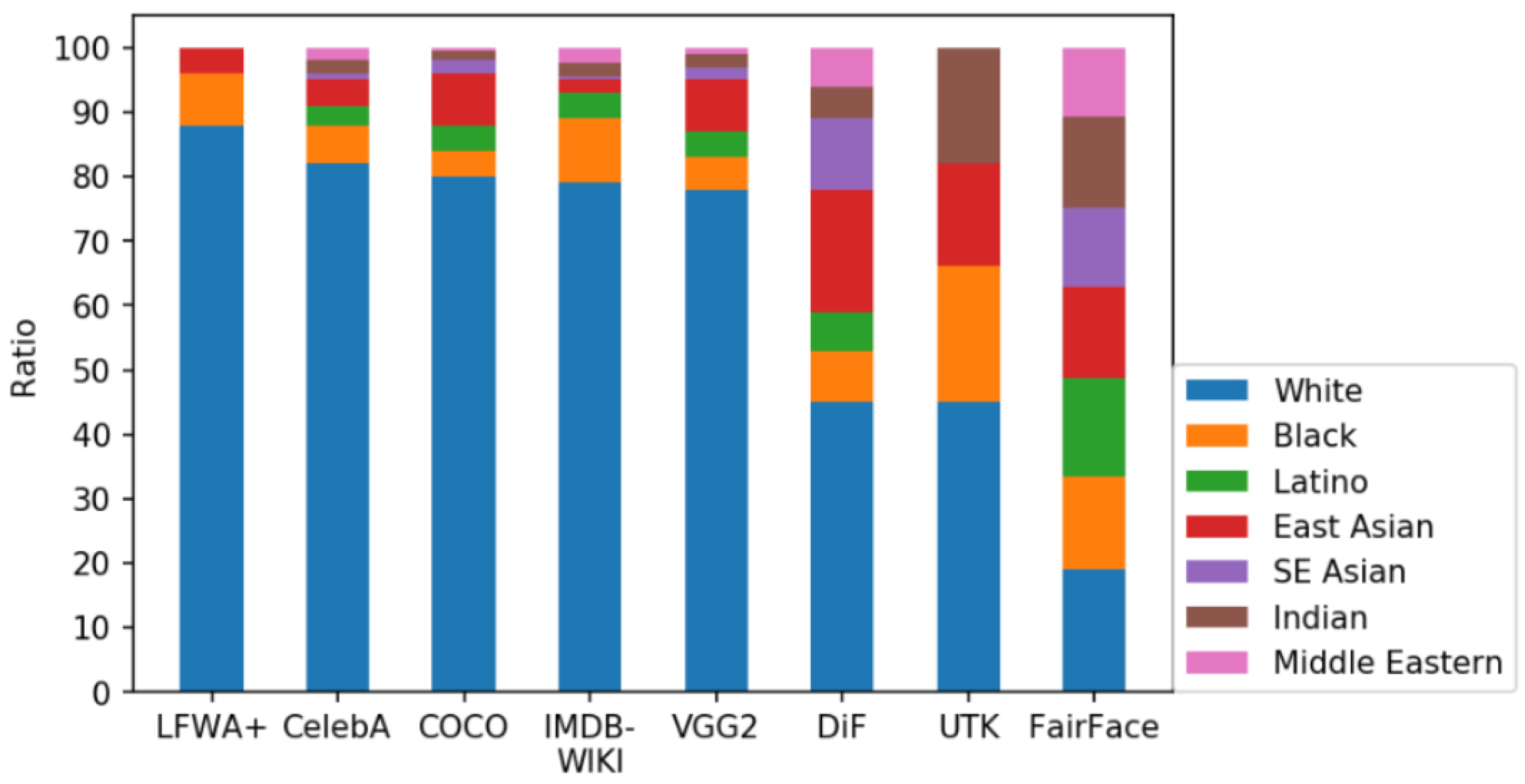
2. Related Work
3. Proposed Approach
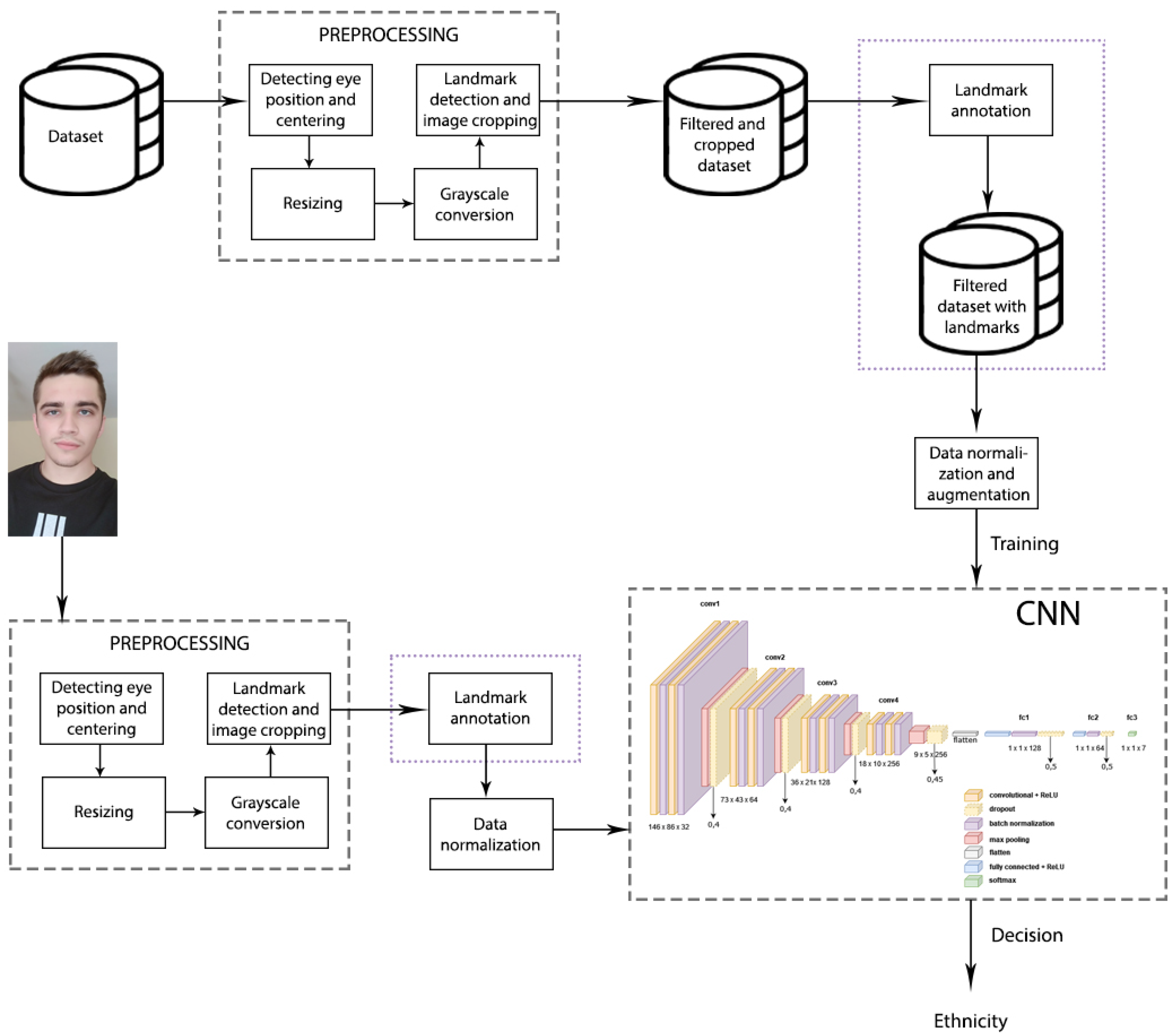
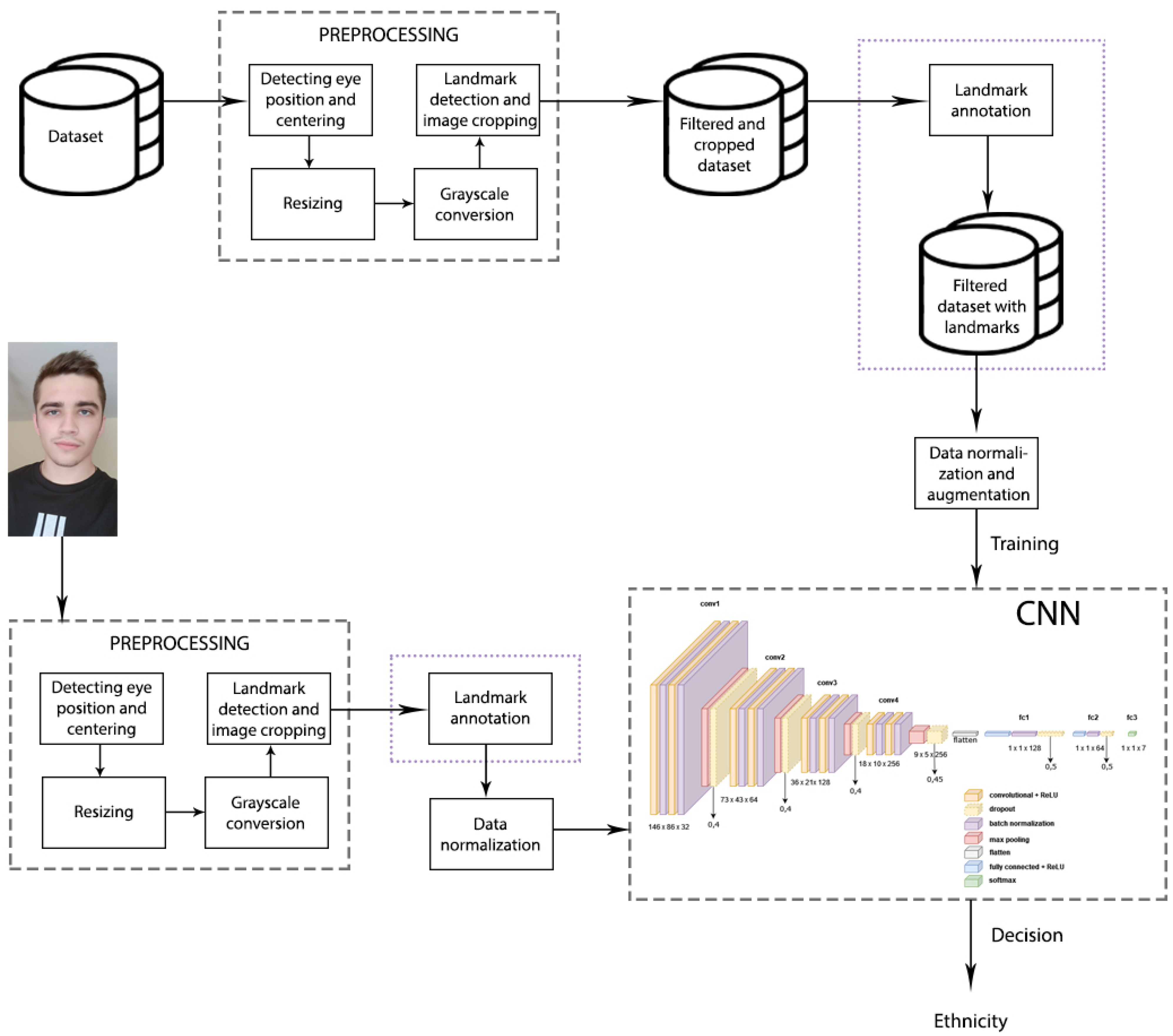
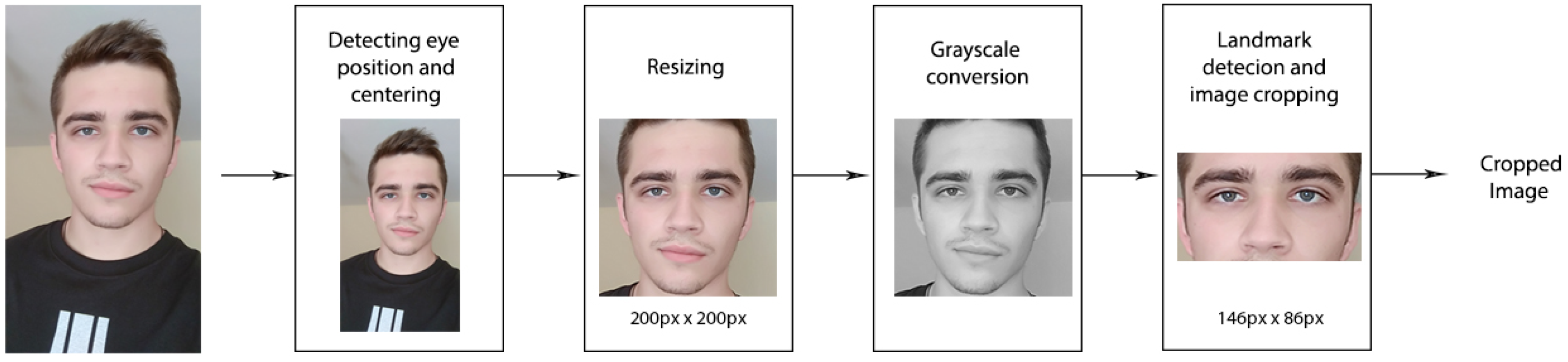
3.1. Data Preprocessing
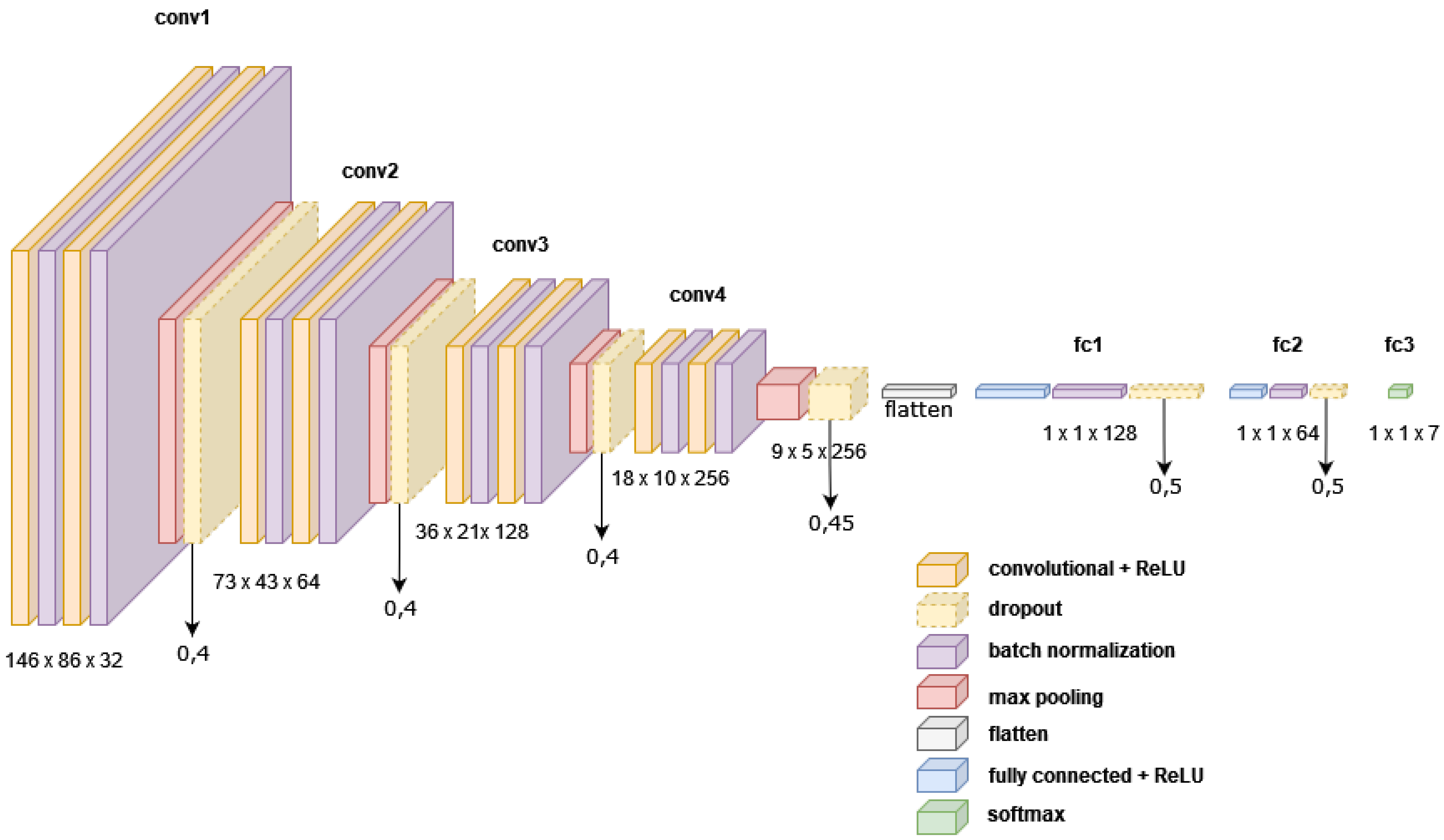
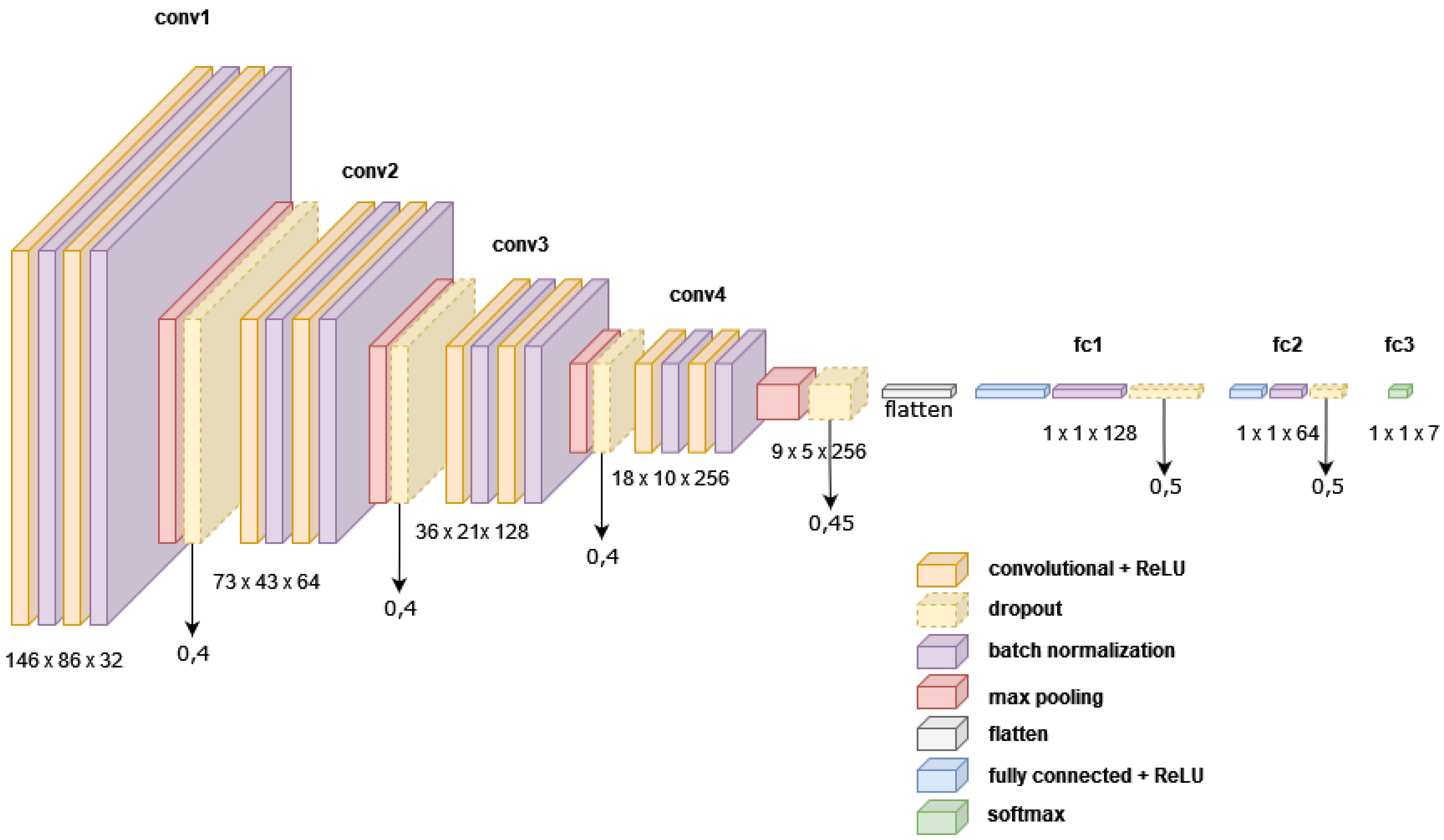
3.2. Proposed Network Architecture
4. Results and Discussion
4.1. Datasets
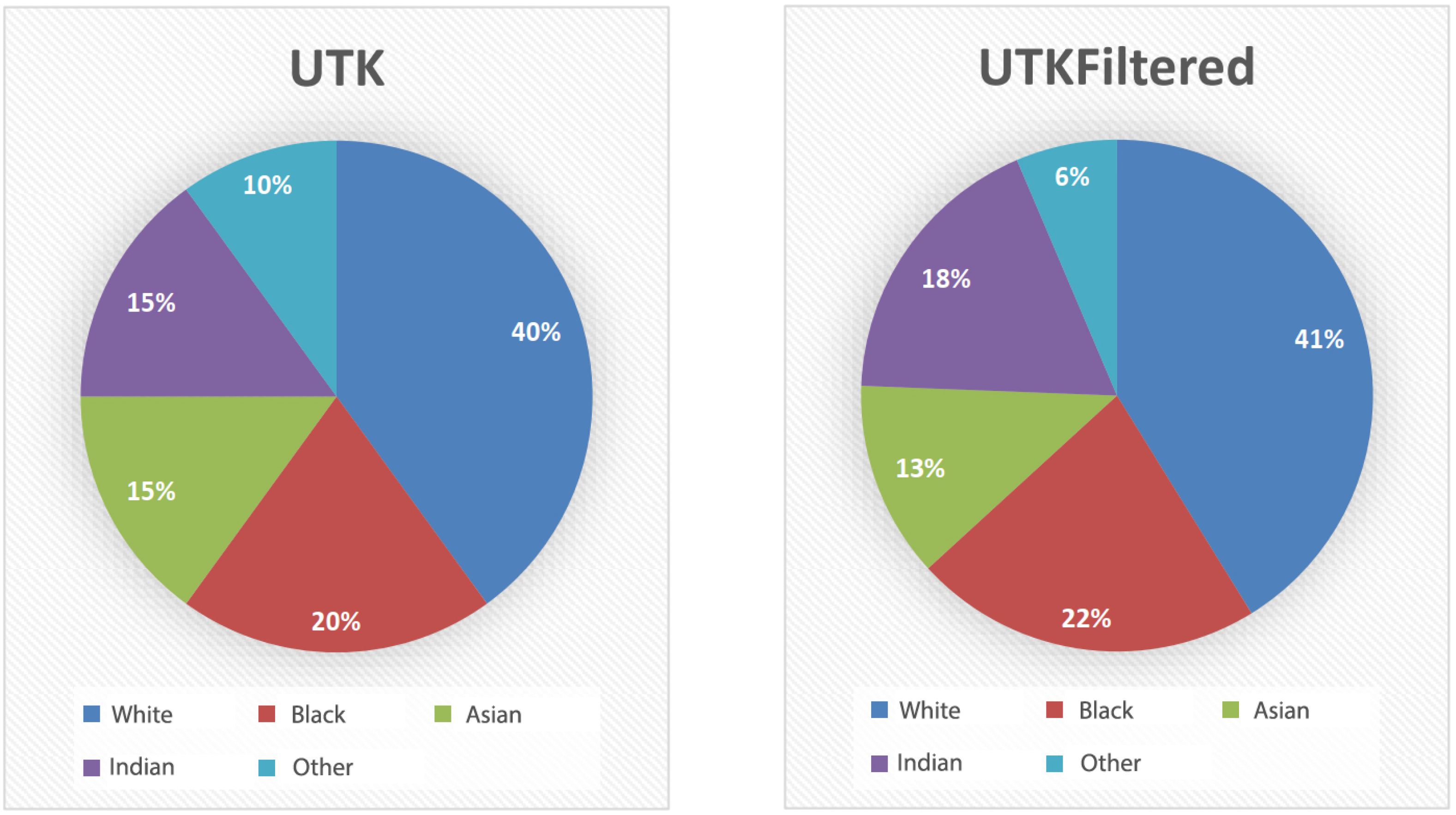
4.1.1. UTKFace Filtered
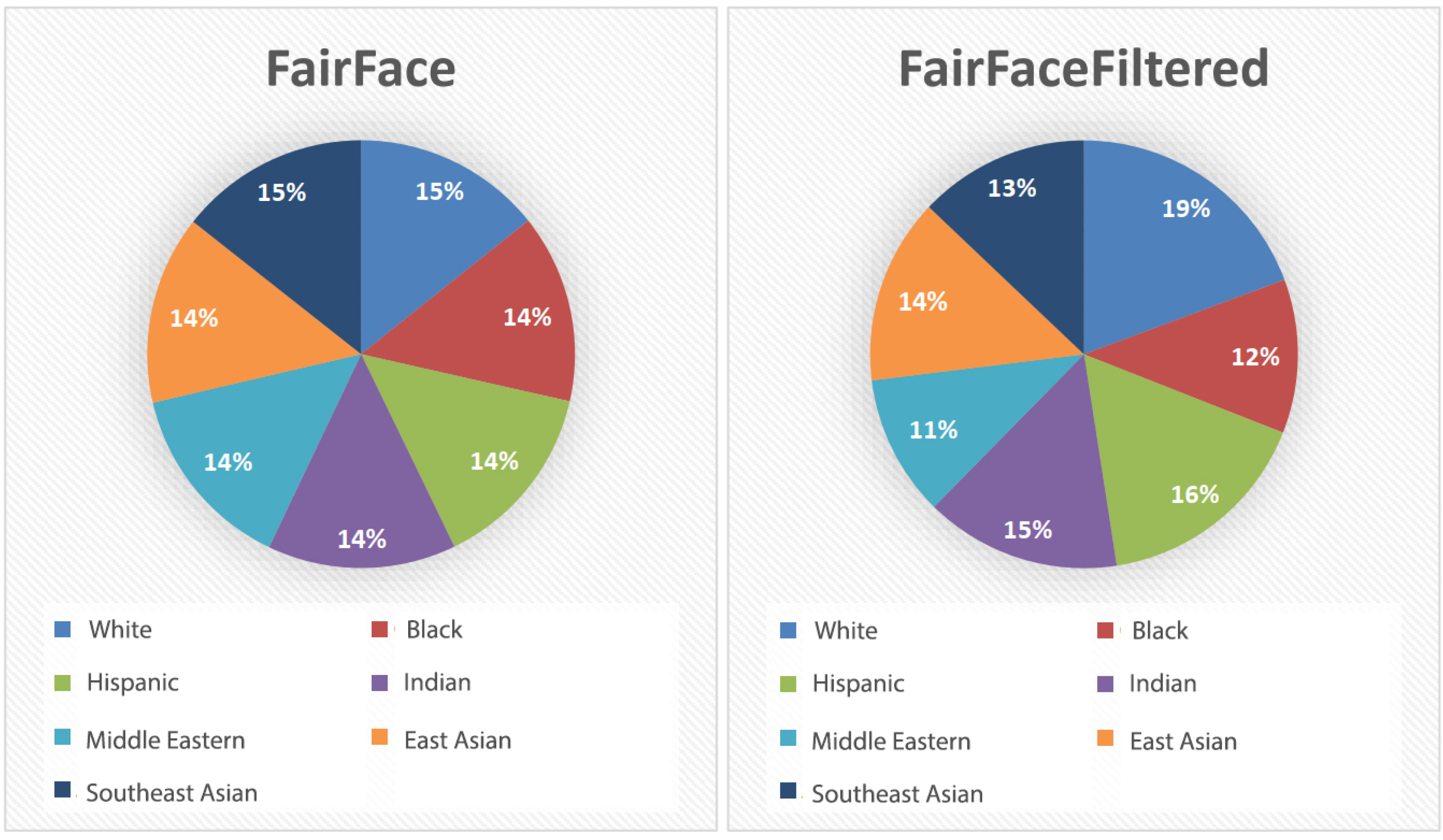
4.1.2. FairFace Filtered
4.2. Experiments
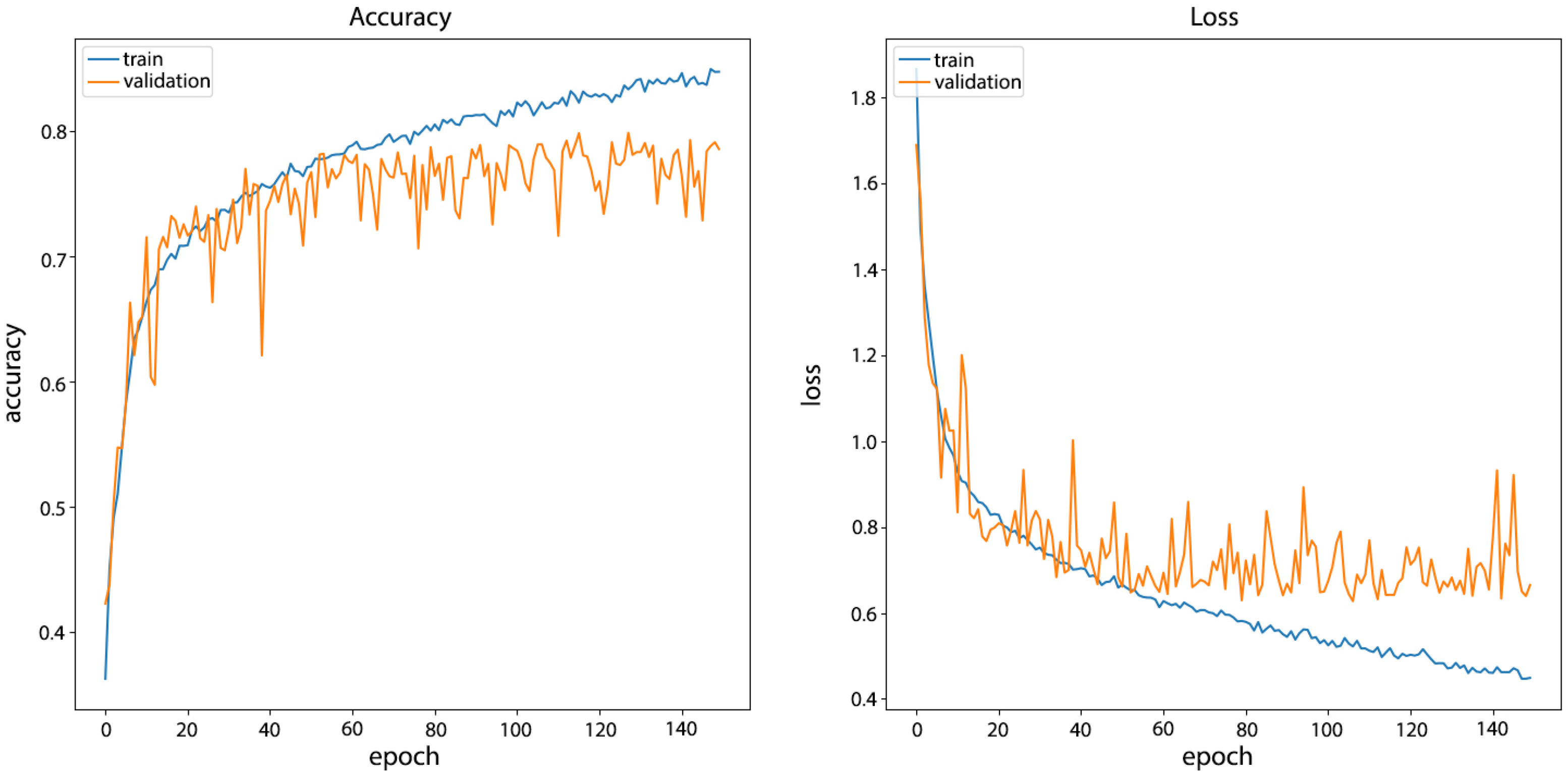
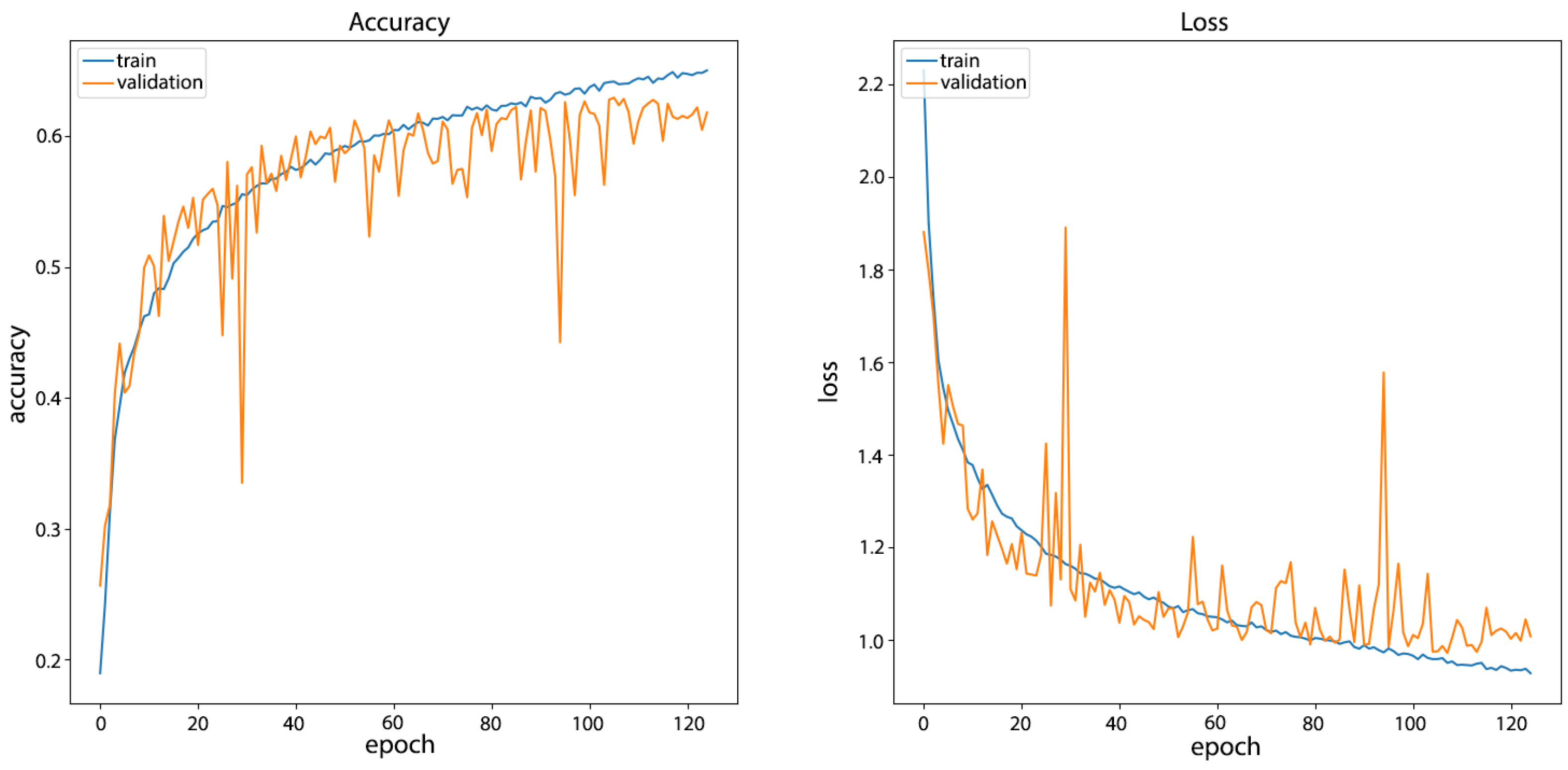
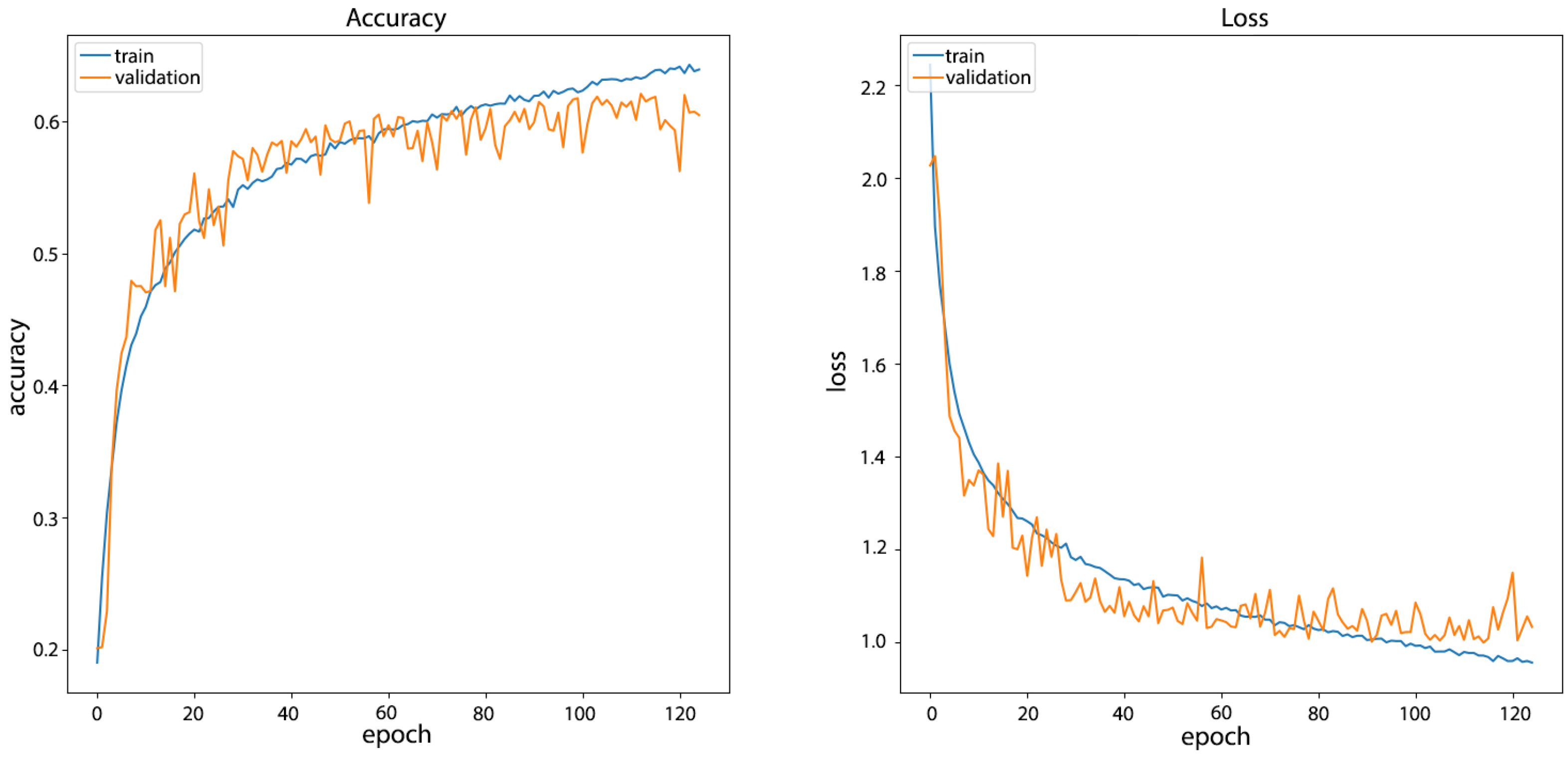
4.2.1. Training and Validation
4.2.2. Results and Discussion
4.3. Comparison of the Results with State-of-the-Art
5. Future Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tomičić, I.; Grd, P.; Bača, M. A review of soft biometrics for IoT. In Proceedings of the 2018 41st International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 21–25 May 2018; pp. 1115–1120. [Google Scholar] [CrossRef]
- Mezzoudj, S.B.A.; Seghir, R. What Else Does Your Biometric Data Reveal? A Survey on Soft Biometrics. Multimed. Tools Appl. 2016, 11, 441–467. [Google Scholar]
- Reid, D.A.; Nixon, M.S.; Stevenage, S.V. Towards large-scale face-based race classification on spark framework. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 78, 26729–26746. [Google Scholar] [CrossRef]
- Školski Rječnik Hrvatskoga Jezika. Available online: https://rjecnik.hr/search/?strict=yes&q=rasa (accessed on 14 September 2021).
- Darabant, A.S.; Borza, D.; Danescu, R. Recognizing Human Races through Machine Learning—A Multi-Network, Multi-Features Study. Mathematics 2021, 9, 195. [Google Scholar] [CrossRef]
- Becerra-Riera, F.; Llanes, N.M.; Morales-González, A.; Méndez-Vázquez, H.; Tistarelli, M. On Combining Face Local Appearance and Geometrical Features for Race Classification. In Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications; Springer International Publishing: Cham, Switzerland, 2019; pp. 567–574. [Google Scholar]
- Fu, S.; He, H.; Hou, Z.G. Learning Race from Face: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2483–2509. [Google Scholar] [CrossRef] [Green Version]
- Heng, Z.; Dipu, M.; Yap, K.H. Hybrid Supervised Deep Learning for Ethnicity Classification using Face Images. In Proceedings of the 2018 IEEE International Symposium on Circuits and Systems (ISCAS), Florence, Italy, 27–30 May 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Lu, X.; Jain, A.K. Ethnicity Identification from Face Images. In Biometric Technology for Human Identification; International Society for Optics and Photonics; SPIE: Bellingham, WA, USA, 2004; Volume 5404, pp. 114–123. [Google Scholar] [CrossRef]
- Kelly, D.J.; Quinn, P.C.; Slater, A.M.; Lee, K.; Ge, L.; Pascalis, O. The Other-Race Effect Develops During Infancy. Psychol. Sci. 2007, 18, 1084–1089. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Greco, A.; Percannella, G.; Vento, M.; Vigilante, V. Benchmarking deep network architectures for ethnicity recognition using a new large face dataset. Mach. Vis. Appl. 2020, 31, 1–31. [Google Scholar] [CrossRef]
- Anwar, I.; Islam, N.U. Learned Features are Better for Ethnicity Classification. Cybern. Inf. Technol. 2017, 17, 152–164. [Google Scholar] [CrossRef] [Green Version]
- Mohammad, A.S.; Al-Ani, J.A. Convolutional Neural Network for Ethnicity Classification using Ocular Region in Mobile Environment. In Proceedings of the 2018 10th Computer Science and Electronic Engineering (CEEC), Colchester, UK, 19–21 September 2018; pp. 293–298. [Google Scholar] [CrossRef]
- Grd, P. A Survey on Neural Networks for Face Age Estimation. In Proceedings of the 32nd Central European Conference on Information and Intelligent Systems, Varazdin, Croatia, 13–15 October 2021; pp. 219–227. [Google Scholar]
- Duan, M.; Li, K.; Yang, C.; Li, K. A hybrid deep learning CNN–ELM for age and gender classification. Neurocomputing 2018, 275, 448–461. [Google Scholar] [CrossRef]
- Wang, W.; He, F.; Zhao, Q. Facial Ethnicity Classification with Deep Convolutional Neural Networks. In Biometric Recognition; Springer International Publishing: Cham, Switzerland, 2016; pp. 176–185. [Google Scholar]
- Srinivas, N.; Atwal, H.; Rose, D.C.; Mahalingam, G.; Ricanek, K.; Bolme, D.S. Age, Gender, and Fine-Grained Ethnicity Prediction Using Convolutional Neural Networks for the East Asian Face Dataset. In Proceedings of the 2017 12th IEEE International Conference on Automatic Face Gesture Recognition (FG 2017), Washington, DC, USA, 30 May–3 June 2017; pp. 953–960. [Google Scholar] [CrossRef]
- Khan, K.; Khan, R.U.; Ali, J.; Uddin, I.; Khan, S.; Roh, B.H. Race Classification Using Deep Learning. Comput. Mater. Contin. 2021, 68, 3483–3498. [Google Scholar] [CrossRef]
- Hamdi, S.; Moussaoui, A. Comparative study between machine and deep learning methods for age, gender and ethnicity identification. In Proceedings of the 2020 4th International Symposium on Informatics and its Applications (ISIA), M’sila, Algeria, 15–16 December 2020; pp. 1–6. [Google Scholar] [CrossRef]
- Ahmed, M.A.; Choudhury, R.D.; Kashyap, K. Race estimation with deep networks. J. King Saud Univ.-Comput. Inf. Sci. 2020. [Google Scholar] [CrossRef]
- Baig, T.I.; Alam, T.M.; Anjum, T.; Naseer, S.; Wahab, A.; Imtiaz, M.; Raza, M.M. Classification of Human Face: Asian and Non-Asian People. In Proceedings of the 2019 International Conference on Innovative Computing (ICIC), Seoul, Korea, 26–29 August 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Khan, A.; Mahmoud, M. Considering Race a Problem of Transfer Learning. In Proceedings of the 2019 IEEE Winter Applications of Computer Vision Workshops (WACVW), Village, HI, USA, 7–11 January 2019; pp. 100–106. [Google Scholar]
- Talo, M.; Ay, B.; Makinist, S.; Aydin, G. Bigailab-4race-50K: Race Classification with a New Benchmark Dataset. In Proceedings of the 2018 International Conference on Artificial Intelligence and Data Processing (IDAP), Malatya, Turkey, 28–30 September 2018; pp. 1–4. [Google Scholar] [CrossRef]
- Das, A.; Dantcheva, A.; Brémond, F. Mitigating Bias in Gender, Age and Ethnicity Classification: A Multi-task Convolution Neural Network Approach. In Proceedings of the ECCV Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Han, H.; Jain, A.K.; Wang, F.; Shan, S.; Chen, X. Heterogeneous Face Attribute Estimation: A Deep Multi-Task Learning Approach. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 2597–2609. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Masood, S.; Gupta, S.; Wajid, A.; Gupta, S.; Ahmed, M. Prediction of Human Ethnicity from Facial Images Using Neural Networks. In Data Engineering and Intelligent Computing; Springer: Singapore, 2018; pp. 217–226. [Google Scholar]
- Wu, X.; Yuan, P.; Wang, T.; Gao, D.; Cai, Y. Race Classification from Face using Deep Convolutional Neural Networks. In Proceedings of the 2018 3rd International Conference on Advanced Robotics and Mechatronics (ICARM), Sigapore, 18–20 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–26 June 2005; Volume 1, pp. 886–893. [Google Scholar] [CrossRef] [Green Version]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Li, X.; Chen, S.; Hu, X.; Yang, J. Understanding the Disharmony Between Dropout and Batch Normalization by Variance Shift. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Garbin, C.; Zhu, X.; Marques, O. Dropout vs. Batch Normalization: An Empirical Study of Their Impact to Deep Learning. Multimed. Tools Appl. 2020, 79, 12777–12815. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Fu, S.Y.; Yang, G.S.; Hou, Z.G. Spiking neural networks based cortex like mechanism: A case study for facial expression recognition. In Proceedings of the 2011 International Joint Conference on Neural Networks, San Jose, CA, USA, 31 July–5 August 2011; pp. 1637–1642. [Google Scholar] [CrossRef]
- Hwang, B.W.; Roh, M.C.; Lee, S.W. Performance evaluation of face recognition algorithms on Asian face database. In Proceedings of the Sixth IEEE International Conference on Automatic Face and Gesture Recognition, Seoul, Korea, 17–19 May 2004; pp. 278–283. [Google Scholar] [CrossRef]
- Gao, W.; Cao, B.; Shan, S.; Chen, X.; Zhou, D.; Zhang, X.; Zhao, D. The CAS-PEAL Large-Scale Chinese Face Database and Baseline Evaluations. IEEE Trans. Syst. Man Cybern.-Part Syst. Hum. 2008, 38, 149–161. [Google Scholar] [CrossRef] [Green Version]
- Bastanfard, A.; Nik, M.A.; Dehshibi, M.M. Iranian Face Database with age, pose and expression. In Proceedings of the 2007 International Conference on Machine Vision, Isalambad, Pakistan, 28–29 December 2007; pp. 50–55. [Google Scholar]
- Thomaz, C.E.; Giraldi, G.A. A new ranking method for principal components analysis and its application to face image analysis. Image Vis. Comput. 2010, 28, 902–913. [Google Scholar] [CrossRef]
- Lyons, M.; Budynek, J.; Akamatsu, S. Automatic classification of single facial images. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 1357–1362. [Google Scholar] [CrossRef] [Green Version]
- Kärkkäinen, K.; Joo, J. FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age for Bias Measurement and Mitigation. In Proceedings of the 2021 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 3–8 January 2021; pp. 1547–1557. [Google Scholar] [CrossRef]
- Zhang, Z.; Song, Y.; Qi, H. Age Progression/Regression by Conditional Adversarial Autoencoder. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 4352–4360. [Google Scholar]
- Sim, T.; Baker, S.; Bsat, M. The CMU pose, illumination, and expression database. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1615–1618. [Google Scholar] [CrossRef] [Green Version]
- Riccio, D.; Tortora, G.; Marsico, M.D.; Wechsler, H. EGA—Ethnicity, gender and age, a pre-annotated face database. In Proceedings of the 2012 IEEE Workshop on Biometric Measurements and Systems for Security and Medical Applications (BIOMS), Salerno, Italy, 14 September 2012; pp. 1–8. [Google Scholar]
- Kumar, N.; Berg, A.; Belhumeur, P.N.; Nayar, S. Describable Visual Attributes for Face Verification and Image Search. IEEE Trans. Pattern Anal. Mach. Intell. 2011, 33, 1962–1977. [Google Scholar] [CrossRef] [Green Version]
- Ricanek, K.; Tesafaye, T. MORPH: A longitudinal image database of normal adult age-progression. In Proceedings of the 7th International Conference on Automatic Face and Gesture Recognition (FGR06), Southampton, UK, 10–12 April 2006; pp. 341–345. [Google Scholar] [CrossRef]
- Phillips, P.J.; Rauss, P.J.; Der, S.Z. FERET (Face Recognition Technology) Recognition Algorithm Development and Test Results; Army Research Laboratory: Adelphi, MD, USA, 1996. [Google Scholar]
- Liu, Z.; Luo, P.; Wang, X.; Tang, X. Deep Learning Face Attributes in the Wild. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 3730–3738. [Google Scholar]
- Ma, D.S.; Correll, J.; Wittenbrink, B. The Chicago face database: A free stimulus set of faces and norming data. Behav. Res. Methods 2015, 47, 1122–1135. [Google Scholar] [CrossRef] [Green Version]
- Phillips, P.J.; Flynn, P.J.; Scruggs, T.; Bowyer, K.W.; Chang, J.; Hoffman, K.; Marques, J.; Jaesik, M.; Worek, W. Overview of the face recognition grand challenge. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, CA, USA, 20–25 June 2005; Volume 1, pp. 947–954. [Google Scholar]
- Lobue, V.; Thrasher, C. The Child Affective Facial Expression (CAFE) set: Validity and reliability from untrained adults. Front. Psychol. 2015, 5, 1532. [Google Scholar] [CrossRef]
- dlib C++ Library. Available online: http://dlib.net/ (accessed on 10 October 2021).
- Opencv-Python: Wrapper Package for OpenCV Python Bindings. Available online: https://github.com/skvark/opencv-python (accessed on 10 October 2021).
- Keras Documentation: Keras API Reference. Available online: https://keras.io/api/ (accessed on 10 October 2021).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-Learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Categorical Crossentropy. Available online: https://peltarion.com/knowledge-center/documentation/modeling-view/build-an-ai-model/loss-functions/categorical-crossentropy (accessed on 12 October 2021).
- Vo, T.; Nguyen, T.; Le, C.T. Race Recognition Using Deep Convolutional Neural Networks. Symmetry 2018, 10, 564. [Google Scholar] [CrossRef] [Green Version]
- Mays, V.M.; Ponce, N.A.; Washington, D.L.; Cochran, S.D. Classification of Race and Ethnicity: Implications for Public Health. Annu. Rev. Public Health 2003, 24, 83–110. [Google Scholar] [CrossRef] [PubMed]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Year | CNN Base Model | Ethnicity | Dataset | Evaluation Protocol | Acc (%) |
|---|---|---|---|---|---|---|
| [18] | 2021 | N/A | Asian, Caucasian and African | CAS-PEAL | N/A | 99.2 |
| N/A | Asian and non-Asian | FERET | N/A | 100 | ||
| N/A | Vietnamese and Others | VNFaces | N/A | 92 | ||
| N/A | African American, Caucasian Latin, East Asian and Asian Indian | VMER | N/A | 93.2 | ||
| [11] | 2020 | VGG-Face | African American, Caucasian Latin, East Asian and Asian Indian | VMER | Holdout | 94.1 |
| MobileNet v2 | African American, Caucasian Latin, East Asian and Asian Indian | VMER | Holdout | 94 | ||
| VGG-16 | African American, Caucasian Latin, East Asian and Asian Indian | VMER | Holdout | 93.7 | ||
| ResNet-50 | African American, Caucasian Latin, East Asian and Asian Indian | VMER | Holdout | 93.1 | ||
| [19] | 2020 | VGG-16 | White, Black, Asian, Indian and Others | UTK-Face | Five-fold CV | 72.39 |
| N/A | White, Black, Asian, Indian and Others | UTK-Face | Five-fold CV | 78.88 | ||
| [20] | 2020 | R-Net | Caucasian, African, Asian, Indian | BUPT | Holdout | 97 |
| R-Net | Caucasian, African, Asian, Indian | CFD | Holdout | 85 | ||
| R-Net | Caucasian, African, Asian, Indian | UTK-Face | Holdout | 77.5 | ||
| [21] | 2019 | N/A | Asian and Non-Asian | Private | Holdout | 84.91 |
| [22] | 2019 | VGG-Face | White and Others | Part of CelebA | Holdout | 91 |
| [23] | 2018 | VGG-16 | Black, White, Indian, Asian | Bigailab-4race-50K | Holdout | 97.6 |
| [8] | 2018 | VGG-16 | Bangladeshi, Chinese, Indian | Private | Holdout | 95.2 |
| [24] | 2018 | ResNet | White, Black, Asian, Indian | UTK-Face | Holdout | 90.1 |
| ResNet | White, Black, Asian, Indian | BEFA | Holdout | 84.29 | ||
| [25] | 2018 | AlexNet | White, Black, Asian | MORPH II | Five-fold CV | 98.6 |
| AlexNet | White, Black, Asian | LFW+ | Five-fold CV | 94.9 | ||
| [13] | 2018 | N/A | Asian, Middle-East, African, Hispanic, White | FERET | Six-fold CV | 97.83 |
| [26] | 2018 | MLP | Caucasian, Mongolian and Negroid | Part of FERET | Holdout | 82.4 |
| VGGNet | Caucasian, Mongolian and Negroid | Part of FERET | Holdout | 98.6 | ||
| [27] | 2018 | VGG-16 | White, Black, Asian | Private | Holdout | 99.54 |
| VGG-16 | Asian, Non-Asian | FRGC | Holdout | 98.4 | ||
| VGG-16 | Asian, Black, Hispanic, Middle, White | Part of FERET | Holdout | 98.8 | ||
| VGG-16 | White, Black | Part of MORPH II | Holdout | 99.1 | ||
| VGG-16 | White, Black, Asian | LFW | Holdout | 98.77 | ||
| [17] | 2017 | N/A | Chinese, Filipino, Indonesian, Japanese, Korean, Malaysian and Vietnamese | WEAFD | Holdout | 33.33 |
| [12] | 2017 | VGG-Face | Asian, Black, White | FERET | Ten-fold CV | 98.91 |
| [16] | 2016 | N/A | White, Black | MORPH II | Ten-fold CV | 99.7 |
| N/A | Chinese, non-Chinese | Multiple datasets | Holdout | 99.85 | ||
| N/A | Han, Uyghur and non-Chinese | Multiple datasets | Holdout | 99.6 |
| Model | Description | Training Accuracy | Validation Accuracy |
|---|---|---|---|
| Model_20 | Norm-Augm-CL1_1+ReLU-BatchNorm-CL1_2+ReLU-BatchNorm-Pool(max)-CL2_1+ReLU-BatchNorm-CL2_2+ReLU-BatchNorm-Pool(max)-CL3_1+ReLU-BatchNorm-CL3_2+ReLU-BatchNorm-Pool(max)-CL4_1+ReLU-BatchNorm-CL4_2+ReLU-BatchNorm-Pool(max)-Flattening-FC1-BatchNorm-FC2-BatchNorm-SoftMax | 0.9881 | 0.8188 |
| Model_ 18 | Norm-Augm-CL1_1+ReLU-BatchNorm-CL1_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL2_1+ReLU-BatchNorm-CL2_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL3_1+ReLU-BatchNorm-CL3_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL4_1+ReLU-BatchNorm-CL4_2+ReLU-BatchNorm-Pool(max)-Dropout(0.45)-Flattening-FC1-BatchNorm-Dropout(0.5)-FC2-BatchNorm-Dropout(0.5)-SoftMax | 0.8955 | 0.8000 |
| Model_17 | Norm-Augm-CL1_1+ReLU-BatchNorm-CL1_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL2_1+ReLU-BatchNorm-CL2_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL3_1+ReLU-BatchNorm-CL3_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL4_1+ReLU-BatchNorm-CL4_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-Flattening-FC1-BatchNorm-Dropout(0.5)-FC2-BatchNorm-Dropout(0.5)-SoftMax | 0.8784 | 0.7742 |
| Model_9 | Norm-CL1_1+ReLU-BatchNorm-CL1_2+ReLU-BatchNorm-Pool(max)-Dropout(0.2)-CL2_1+ReLU-BatchNorm-CL2_2+ReLU-BatchNorm-Pool(max)-Dropout(0.25)-CL3_1+ReLU-BatchNorm-CL3_2+ReLU-BatchNorm-Pool(max)-Dropout(0.3)-Flattening-FC1-BatchNorm-Dropout(0.35)-FC2-BatchNorm-Dropout(0.4)-FC3-BatchNorm-SoftMax | 0.9595 | 0.7200 |
| Model_19 | Norm-Augm-CL1_1+ReLU-BatchNorm-CL1_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL2_1+ReLU-BatchNorm-CL2_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-CL3_1+ReLU-BatchNorm-CL3_2+ReLU-BatchNorm-Pool (max)-Dropout(0.4)-CL4_1+ReLU-BatchNorm-CL4_2+ReLU-BatchNorm-Pool(max)-Dropout(0.45)-CL5_1+ReLU-BatchNorm-CL5_2+ReLU-BatchNorm-Pool(max)-Dropout(0.4)-Flattening-FC1-BatchNorm-Dropout(0.5)-FC2-BatchNorm-Dropout(0.5)-SoftMax | 0.8187 | 0.7097 |
| Parameter | Value |
|---|---|
| Batch size | 64 |
| Convolution layers | 8 |
| Activation function | ReLu |
| Loss function | SoftMax categorical cross entropy |
| Optimizer | AdamOptimizer |
| Number of learnable parameters | 2,050,000 |
| Learning rate | 0.001 |
| Dropout | 40% in VGG blocks and 50% in fully connected layers |
| Dataset | No. of Images | No. of Subjects | Ethnicity Groups 1 |
|---|---|---|---|
| VMER [11] | 3,309,742 | 9129 | African American, East Asian, Caucasian Latin, Asian Indian |
| CMU-DB [41] | 1,500,000 | N/A | Caucasian, African American, Asian, Hispanic |
| BUPT [20] | 1,300,000 | N/A | Caucasian, African, Asian, Indian |
| Bigailab [23] | 300,000 | N/A | Caucasian, Black, Indian, Asian |
| CUN [33] | 112,000 | 1120 | Chinese |
| FairFace [39] | 108,192 | N/A | White, Black, East Asian, Southeast Asian, Indian, Middle Eastern, Latin |
| EGA [42] | 72,266 | 469 | African American, Asian, Caucasian, Indian, Latin |
| PubFig [43] | 58,797 | 200 | Asian, Caucasian, African American, Indian |
| MORPH II [44] | 55,134 | 13,618 | African, European, Asian, Hispanic, Others |
| KFDB [34] | 52,000 | 1000 | Korean |
| CAS-PEAL [35] | 30,900 | 1040 | Chinese |
| UTK-Face [40] | 20,000 | N/A | White, Black, Asian, Indian, Others |
| FERET [45] | 14,126 | 1199 | Caucasian, Asian, Oriental African |
| LFWA+ [46] | 13,233 | 5749 | White, Black, Asian |
| CFD [47] | N/A | 600 | Caucasian, African, Asian, Latin |
| VNFaces [11] | 6100 | N/A | Vietnamese, Others |
| FRGC [48] | 4007 | 466 | Latin, Caucasian, Asian, Indian, African American |
| IFDB [36] | 3600 | 616 | Iranian |
| FEI [37] | 2800 | 200 | Brazilian |
| WEAFD [17] | 2500 | N/A | Chinese, Japanese, Korean, (Filipino, Indonesian, Malaysian), (Vietnamese, Burmese, Thai) |
| JAFFE [38] | 2130 | 10 | Japanese |
| CAFE [49] | 1192 | 154 | Caucasian, East Asian, Pacific Region |
| Gender | White | Black | Asian | Indian | Other | Total |
|---|---|---|---|---|---|---|
| Male | 4257 | 2072 | 956 | 1939 | 569 | 9793 |
| Female | 3256 | 1946 | 1306 | 1347 | 598 | 8453 |
| Total | 7513 | 4018 | 2262 | 3286 | 1167 | 18,246 |
| Gender | White | Black | Latin | Indian | Middle Eastern | East Asian | Southeast Asian | Total |
|---|---|---|---|---|---|---|---|---|
| Male | 5397 | 2735 | 4373 | 3941 | 3989 | 3459 | 3459 | 27,353 |
| Female | 5295 | 3718 | 4813 | 4264 | 1930 | 4311 | 3700 | 28,031 |
| Total | 10,692 | 6453 | 9186 | 8205 | 5920 | 7770 | 7159 | 55,384 |
| Model | Dataset | Landmarks | Training Accuracy | Training Loss | Validation Accuracy | Validation Loss |
|---|---|---|---|---|---|---|
| Model_F1 | UTKFace filtered | without | 0.8978 | 0.2927 | 0.7860 | 0.6652 |
| Model_F2 | FairFace filtered | without | 0.7072 | 0.7655 | 0.6183 | 1.0087 |
| Model_F3 | UTKFace filtered | with | 0.8866 | 0.3179 | 0.7871 | 0.6778 |
| Model_F4 | FairFace filtered | with | 0.7024 | 0.7894 | 0.6046 | 1.0330 |
| White | Black | Asian | Indian | Other | Total | |
|---|---|---|---|---|---|---|
| No. of images | 1879 | 1004 | 566 | 822 | 292 | 4563 |
| White | Black | Latin | Indian | Middle Eastern | East Asian | Southeast Asian | Total | |
|---|---|---|---|---|---|---|---|---|
| No. of images | 2672 | 1613 | 2297 | 2051 | 1480 | 1943 | 1790 | 13,846 |
| White | Black | Asian | Indian | Other | |
|---|---|---|---|---|---|
| White | 1659 | 63 | 17 | 99 | 41 |
| Black | 49 | 835 | 12 | 95 | 13 |
| Asian | 33 | 20 | 492 | 12 | 9 |
| Indian | 112 | 59 | 7 | 627 | 17 |
| Other | 134 | 25 | 13 | 67 | 53 |
| Ethnicity | Precision | Recall | F1-Score |
|---|---|---|---|
| White | 0.8349 | 0.8829 | 0.8583 |
| Black | 0.8333 | 0.8317 | 0.8325 |
| Asian | 0.9094 | 0.8693 | 0.8889 |
| Indian | 0.6967 | 0.7628 | 0.7282 |
| Other | 0.3985 | 0.1815 | 0.2494 |
| White | Black | Latin | Indian | Middle Eastern | East Asian | Southeast Asian | |
|---|---|---|---|---|---|---|---|
| White | 1764 | 15 | 380 | 135 | 319 | 34 | 25 |
| Black | 19 | 1107 | 128 | 300 | 12 | 3 | 44 |
| Latin | 329 | 86 | 1019 | 468 | 240 | 27 | 128 |
| Indian | 58 | 85 | 182 | 1575 | 102 | 5 | 44 |
| Middle Eastern | 316 | 7 | 221 | 208 | 712 | 5 | 11 |
| East Asian | 44 | 16 | 76 | 33 | 24 | 1312 | 438 |
| Southeast Asian | 35 | 47 | 162 | 116 | 16 | 354 | 1060 |
| Ethnicity | Precision | Recall | F1-Score |
|---|---|---|---|
| White | 0.6877 | 0.66018 | 0.6737 |
| Black | 0.8122 | 0.6863 | 0.7440 |
| Latin | 0.47005 | 0.4436 | 0.4564 |
| Indian | 0.5556 | 0.7679 | 0.6447 |
| Middle Eastern | 0.4996 | 0.4811 | 0.4902 |
| East Asian | 0.7540 | 0.6752 | 0.7125 |
| Southeast Asian | 0.6057 | 0.5922 | 0.5989 |
| White | Black | Asian | Indian | Other | |
|---|---|---|---|---|---|
| White | 1699 | 62 | 16 | 86 | 16 |
| Black | 61 | 867 | 9 | 59 | 8 |
| Asian | 53 | 18 | 477 | 11 | 7 |
| Indian | 148 | 81 | 5 | 575 | 13 |
| Other | 185 | 26 | 7 | 43 | 31 |
| Ethnicity | Precision | Recall | F1-Score |
|---|---|---|---|
| White | 0.7917 | 0.9042 | 0.8442 |
| Black | 0.8226 | 0.8635 | 0.8426 |
| Asian | 0.9280 | 0.8428 | 0.8833 |
| Indian | 0.7429 | 0.6995 | 0.7206 |
| Other | 0.4133 | 0.1062 | 0.1689 |
| White | Black | Latin | Indian | Middle Eastern | East Asian | Southeast Asian | |
|---|---|---|---|---|---|---|---|
| White | 1801 | 21 | 439 | 127 | 223 | 37 | 24 |
| Black | 23 | 1176 | 131 | 215 | 6 | 9 | 53 |
| Latin | 414 | 109 | 1043 | 390 | 165 | 48 | 128 |
| Indian | 77 | 144 | 225 | 1458 | 87 | 16 | 44 |
| Middle Eastern | 401 | 15 | 279 | 180 | 579 | 16 | 10 |
| East Asian | 84 | 23 | 91 | 19 | 9 | 1341 | 376 |
| Southeast Asian | 49 | 61 | 163 | 91 | 14 | 431 | 981 |
| Ethnicity | Precision | Recall | F1-Score |
|---|---|---|---|
| White | 0.6322 | 0.6740 | 0.6524 |
| Black | 0.7592 | 0.7291 | 0.7438 |
| Latin | 0.4399 | 0.4541 | 0.4469 |
| Indian | 0.5879 | 0.7109 | 0.6436 |
| Middle Eastern | 0.5346 | 0.3912 | 0.4518 |
| East Asian | 0.7065 | 0.6902 | 0.6982 |
| Southeast Asian | 0.6071 | 0.5480 | 0.5760 |
| Model | Dataset | Landmarks | Accuracy | Weighted F1 |
|---|---|---|---|---|
| Model_F1 | UTKFace filtered | without | 0.8034 | 0.7940 |
| Model_F2 | FairFace filtered | without | 0.6174 | 0.6177 |
| Model_F3 | UTKFace filtered | with | 0.7997 | 0.7832 |
| Model_F4 | FairFace filtered | with | 0.6052 | 0.6028 |
| Paper | Ethnicity | Dataset | Accuracy (%) |
|---|---|---|---|
| [18] | Asian, Caucasian and African | CAS-PEAL | 99.2 |
| Asian and Non-Asian | FERET | 100 | |
| Vietnamese and Others | VNFaces | 92 | |
| African American, Caucasian Latin, East Asian and Asian Indian | VMER | 93.2 | |
| [11] | African American, Caucasian Latin, East Asian and Asian Indian | VMER | 94.1 |
| African American, Caucasian Latin, East Asian and Asian Indian | VMER | 94 | |
| African American, Caucasian Latin, East Asian and Asian Indian | VMER | 93.7 | |
| African American, Caucasian Latin, East Asian and Asian Indian | VMER | 93.1 | |
| [19] | White, Black, Asian, Indian and Others | UTK-Face | 72.39 |
| White, Black, Asian, Indian and Others | UTK-Face | 78.88 | |
| [20] | Caucasian, African, Asian, Indian | BUPT | 97 |
| Caucasian, African, Asian, Indian | CFD | 85 | |
| Caucasian, African, Asian, Indian | UTK-Face | 77.5 | |
| [21] | Asian and Non-Asian | Private | 84.91 |
| [22] | White and Others | Part of CelebA | 91 |
| [23] | Black, White, Indian, Asian | Bigailab-4race-50K | 97.6 |
| [8] | Bangladeshi, Chinese, Indian | Private | 95.2 |
| [24] | White, Black, Asian, Indian | UTK-Face | 90.1 |
| White, Black, Asian, Indian | BEFA | 84.29 | |
| [25] | White, Black, Asian | MORPH II | 98.6 |
| White, Black, Asian | LFW+ | 94.9 | |
| [13] | Asian, Middle-East, African, Hispanic, White | FERET | 97.83 |
| [26] | Caucasian, Mongolian and Negroid | Part of FERET | 82.4 |
| Caucasian, Mongolian and Negroid | Part of FERET | 98.6 | |
| [27] | White, Black, Asian | Private | 99.54 |
| Asian, Non-Asian | FRGC | 98.4 | |
| Asian, Black, Hispanic, Middle, White | Part of FERET | 98.8 | |
| White, Black | Part of MORPH II | 99.1 | |
| White, Black, Asian | LFW | 98.77 | |
| [17] | Chinese, Filipino, Indonesian, Japanese, Korean, Malaysian and Vietnamese | WEAFD | 33.33 |
| [12] | Asian, Black, White | FERET | 98.91 |
| [16] | White, Black | MORPH II | 99.7 |
| Chinese, non-Chinese | Multiple datasets | 99.85 | |
| Han, Uyghur and non-Chinese | Multiple datasets | 99.6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Belcar, D.; Grd, P.; Tomičić, I. Automatic Ethnicity Classification from Middle Part of the Face Using Convolutional Neural Networks. Informatics 2022, 9, 18. https://doi.org/10.3390/informatics9010018
Belcar D, Grd P, Tomičić I. Automatic Ethnicity Classification from Middle Part of the Face Using Convolutional Neural Networks. Informatics. 2022; 9(1):18. https://doi.org/10.3390/informatics9010018
Chicago/Turabian StyleBelcar, David, Petra Grd, and Igor Tomičić. 2022. "Automatic Ethnicity Classification from Middle Part of the Face Using Convolutional Neural Networks" Informatics 9, no. 1: 18. https://doi.org/10.3390/informatics9010018
APA StyleBelcar, D., Grd, P., & Tomičić, I. (2022). Automatic Ethnicity Classification from Middle Part of the Face Using Convolutional Neural Networks. Informatics, 9(1), 18. https://doi.org/10.3390/informatics9010018