
A Visual Data Storytelling Framework

 ,
,
Abstract
:1. Introduction
- RQ1—What is the appropriate coding strategy to compose data into an entertaining story composition which maintains the communication quality of key information in an environment with increased complexity and redundancy?
- RQ2—How to apply data storytelling with technologies emerging from digital media to develop novel visual data storytelling content beyond conventional textual and chart-based styles?
2. Related Works
2.1. Casual Visualisation and Narrative Visualisation
2.2. Our Extension of Existing Research Works
3. Design of the Visual Data Storytelling Framework
3.1. Definition of Components of the Framework
3.2. Introducing Visual Data Storytelling as a Process
3.2.1. Cognitive and Communication Aspects
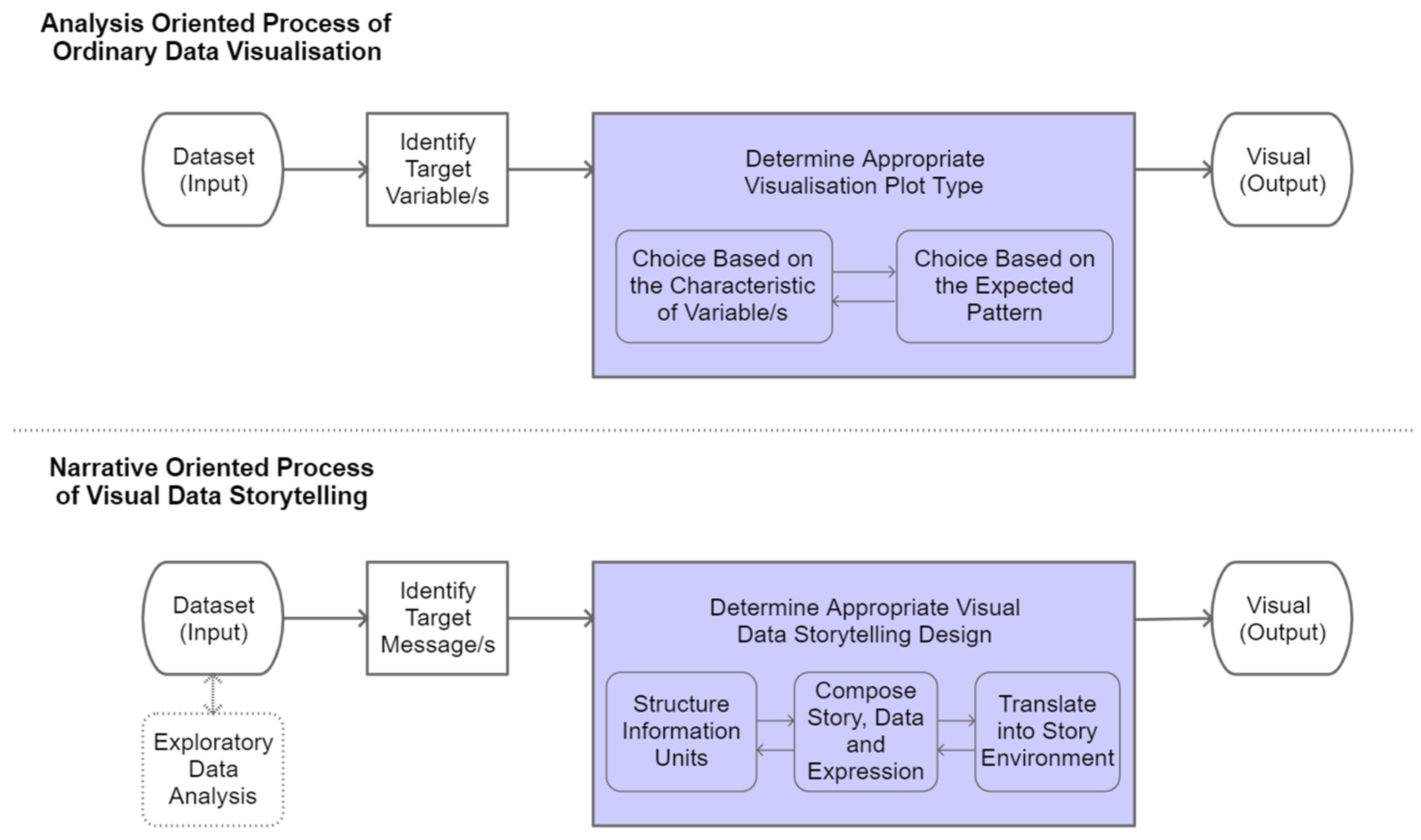
3.2.2. Comparing Visual Data Storytelling and Regular Data Visualisation
3.2.3. Analysis-Oriented Process
3.2.4. Narrative-Oriented Process
3.2.5. Data Processing Procedures from Analysis to Storytelling
3.3. Our Visual Data Storytelling Framework
3.3.1. Communication Quality
- The information is encoded into a spatial story environment.
- The story environment includes the four basic story components: character, background, action, and effect.
- The story environment design aims to make interconnections between the story components/visual elements.
- The design of the visual elements that represent key information units is creative or unordinary. The design of the other context elements is familiar and logical.
3.3.2. Visual Channels within a Story Environment
3.3.3. Composition of Information Units into a Story
- Very basic meaning/information that is communicated in a human visual communication context.
- A single unit/element that is processed and encoded throughout the visual data storytelling process.
- A loose equivalent of an information bit (which is commonly referred to in the telecommunication relevant domain) in a human visual communication context.
3.4. Measurements for the Framework
4. Demonstrate the Framework through a Prototype
4.1. Prototype Implementation
4.2. Platform and Tools
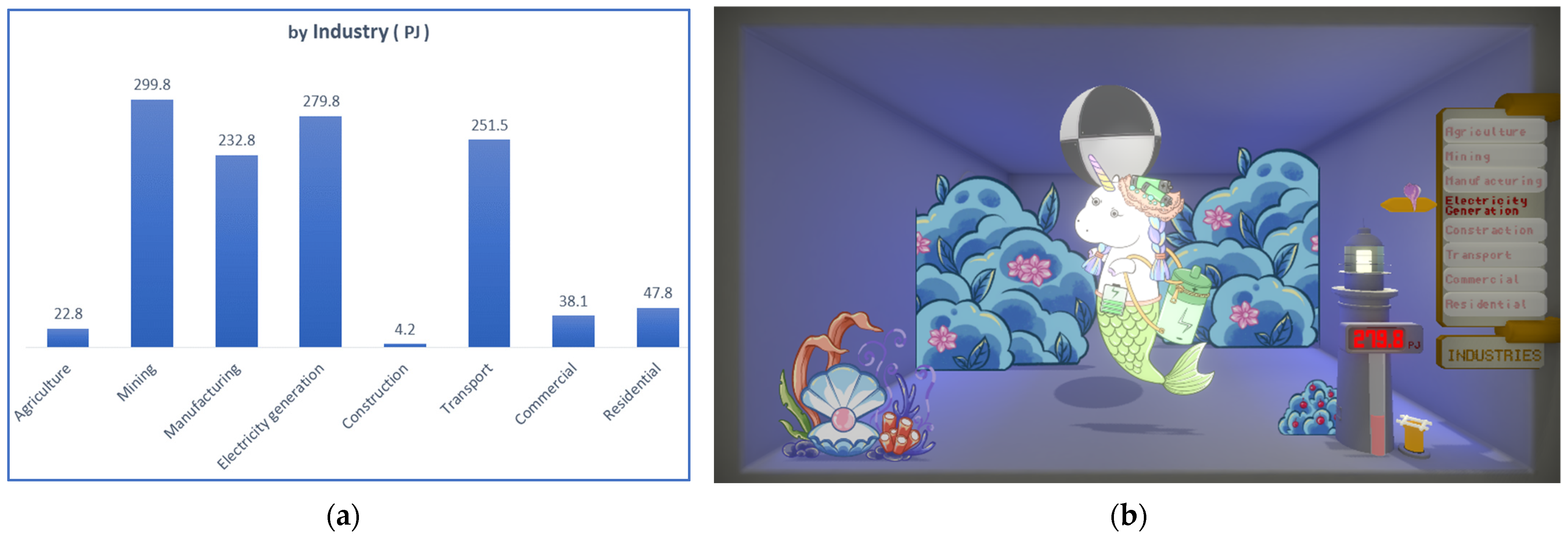
4.3. Test-Dataset: Australian Energy Consumption
4.4. Proof of Concept Prototype Information Mapping
4.5. Translation of Data Storytelling Components
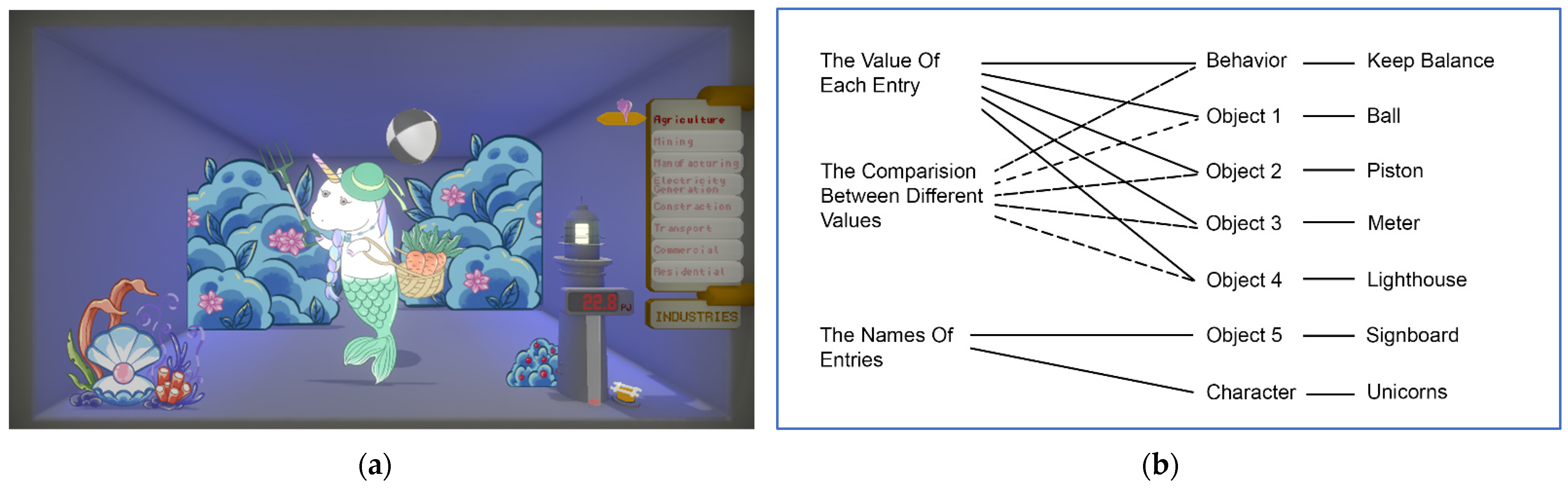
4.5.1. Structuring
- Data Message 1: names of the industries (creating awareness about what energy-consuming industries exist).
- Data Message 2: values of consumption numbers (how much energy each industry consumes).
- Data Message 3: differences in the value of numbers (creating awareness about which industries used more energy and which used less).
- First Priority: Data Message 1.
- Second Priority: Data Message 2 and Data Message 3.
- Story Component 1~8: characters (eight unicorns).
- Story Component 9~13: environment props (lighthouse, meter, piston, ball, and signboard).
- Story Component 14~15: actions/movements (ball playing, piston movement).
- Expression Attachment 1~3: cute, fun, and lively.
4.5.2. Composing
- Information Composition = Story Component + Data Message + Expression Attachment.
- Information Composition 1~8: Story Component 1~8 + Data Message 1 + Expression Attachment 1.
- Information Composition 9~13: Story Component 9~13 + Data Message 2 + Expression Attachment 2.
- Information Composition 14~15: Story Component 14~15 + Data Message 3 + Expression Attachment 3.
4.5.3. Translating
- First priority-related visual elements: Position at major center position and first right-side front position. Allocate with direct interaction and character animation.
- Second priority-related visual elements: Position at minor center position and second right-side front position. Allocate with indirect interaction and simple animation.
5. Conclusions
5.1. Key Contributions
- Description of the story structure strategy in the visual data storytelling context balancing desirable uncertainty and communication accuracy.
- Definition of the concept of information units as a conceptual basic element in the visual data storytelling communication process to support framework building.
- Introduction of a modular approach to customising messages for visual data story-telling at a basic information level.
- Demonstration of a potential way to create visual data storytelling content that presents information within a visual story environment instead of the conventional ‘narrative text plus data chart’ model.
- Introduction of a prototype development with the game engine Unity that applies the approach of composing a dataset with story elements to communicate it as a visual composition in a casual context.
5.2. Limitations and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
References
- Kosara, R.; Mackinlay, J. Storytelling: The Next Step for Visualization. Computer 2013, 46, 44–50. [Google Scholar] [CrossRef]
- Börner, K.; Polley, D.E. Visual Insights: A Practical Guide to Making Sense of Data; The MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Wickham, H.; Grolemund, G. R for Data Science: Import, Tidy, Transform, Visualize, and Model Data; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2017. [Google Scholar]
- Segel, E.; Heer, J. Narrative Visualization: Telling Stories with Data. IEEE Trans. Vis. Comput. Graph. 2010, 16, 1139–1148. [Google Scholar] [CrossRef]
- Pousman, Z.; Stasko, J.; Mateas, M. Casual Information Visualization: Depictions of Data in Everyday Life. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1145–1152. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y. Converging Data Storytelling and Visualization. In Proceedings of the International Conference on Entertainment Computation, Poznan, Poland, 17–20 September 2018. [Google Scholar]
- Zhang, Y.; Lugmayr, A. Designing a User-Centered Interactive Data-Storytelling Framework. In Proceedings of the 31st Australian Conference on Human-Computer-Interaction, Fremantle, WA, Australia, 2–5 December 2019; Association for Computing Machinery: New York, NY, USA, 2019; pp. 428–432. [Google Scholar]
- Börner, K. Atlas of Knowledge: Anyone Can Map; The MIT Press: Cambridge, MA, USA, 2015. [Google Scholar]
- Ware, C. Information Visualization: Perception for Design; Elsevier: Amsterdam, The Netherlands; Morgan Kaufman: Boston, MA, USA, 2013. [Google Scholar]
- Wilkinson, L. The Grammar of Graphics; Springer: New York, NY, USA, 1999. [Google Scholar]
- Knaflic, C.N. Storytelling with Data: A Data Visualization Guide for Business Professionals; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Ma, K.; Liao, I.; Frazier, J.; Hauser, H.; Kostis, H. Scientific Storytelling Using Visualization. IEEE Comput. Graph. Appl. 2012, 32, 12–19. [Google Scholar] [PubMed]
- Tufte, E.R. The Visual Display of Quantitative Information; Graphics Press: Cheshire, CT, USA, 1983. [Google Scholar]
- Lee, B.; Riche, N.H.; Isenberg, P.; Carpendale, S. More Than Telling a Story: Transforming Data into Visually Shared Stories. IEEE Comput. Graph. Appl. 2015, 35, 84–90. [Google Scholar] [CrossRef]
- Lee, B.; Choe, E.K.; Isenberg, P.; Marriott, K.; Stasko, J.; Rhyne, T.-M. Reaching Broader Audiences with Data Visualization. IEEE Comput. Graph. Appl. 2020, 40, 82–90. [Google Scholar] [CrossRef]
- Lugmayr, A.; Sutinen, E.; Suhonen, J.; Sedano, C.; Hlavacs, H.; Montero, C. Serious storytelling—A first definition and review. Multimed. Tools Appl. 2017, 76, 15707–15733. [Google Scholar] [CrossRef]
- Lugmayr, A.; Stockleben, B.; Scheib, C.; Mailaparampil, M. Cognitive big data: Survey and review on big data research and its implications. What is really ‘new’ in big data? J. Knowl. Manag. 2017, 21, 197–212. [Google Scholar] [CrossRef]
- Trajkova, M.; Alhakamy, A.; Cafaro, F.; Vedak, S.; Mallappa, R.; Kankara, S.R. Exploring Casual COVID-19 Data Visualizations on Twitter: Topics and Challenges. Informatics 2020, 7, 35. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Heer, J. Authoring Narrative Visualizations with Ellipsis. Comput. Graph. Forum 2014, 33, 361–370. [Google Scholar] [CrossRef]
- Amini, F.; Riche, N.H.; Lee, B.; Hurter, C.; Irani, P. Understanding Data Videos: Looking at Narrative Visualization through the Cinematography Lens. In Proceedings of the 33rd Annual ACM Conference on human factors in computing systems, ACM, Seoul, Korea, 18–23 April 2015; pp. 1459–1468. [Google Scholar]
- Hullman, J.; Diakopoulos, N. Visualization Rhetoric: Framing Effects in Narrative Visualization. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2231–2240. [Google Scholar] [CrossRef] [PubMed]
- Figueiras, A. Narrative Visualization: A Case Study of How to Incorporate Narrative Elements in Existing Visualizations. In Proceedings of the 2014 18th International Conference on Information Visualisation, Paris, France, 16–18 July 2014; pp. 46–52. [Google Scholar]
- McQueen, M. How to Prepare Now for What’s Next: A Guide to Thriving in an Age of Disruption.; John Wiley & Sons, Incorporated: Newark, NJ, USA, 2018. [Google Scholar]
- Baldick, C. The Oxford Dictionary of Literary Terms; Oxford University Press, Incorporated: Oxford, UK, 2015. [Google Scholar]
- Fishelov, D. The Poetics of Six-Word Stories. Narrative 2019, 27, 30–46. [Google Scholar] [CrossRef]
- Lugmayr, A.; Zou, Y.; Stockleben, B.; Lindfors, K.; Melakoski, C. Categorization of ambient media projects on their business models, innovativeness, and characteristics—Evaluation of Nokia Ubimedia MindTrek Award Projects of 2010. Multimed. Tools Appl. 2012, 66, 33–57. [Google Scholar] [CrossRef]
- McLuhan, M. Understanding Media: The Extensions of Man; Routledge & Kegan Paul Limited: London, UK, 1964. [Google Scholar]
- Shannon, C.E.; Weaver, W. Mathematical Theory of Communication; University of Illinois Press: Urbana, IL, USA, 1964. [Google Scholar]
- Iser, W. The Act of Reading: A Theory of Aesthetic Response; Johns Hopkins University Press: Baltimore, MD, USA, 1978. [Google Scholar]
- Roediger, H.L. The effectiveness of four mnemonics in ordering recall. J. Exp. Psychol. Hum. Learn. Mem. 1980, 6, 558–567. [Google Scholar] [CrossRef]
- Ghosh, V.E.; Gilboa, A. What is a memory schema? A historical perspective on current neuroscience literature. Neuropsychologia 2014, 53, 104–114. [Google Scholar] [CrossRef]
- Thorndyke, P.W.; Yekovich, F.R. A critique of schema-based theories of human story memory. Poetics 1980, 9, 23–49. [Google Scholar] [CrossRef]
- Maguire, E.A.; Valentine, E.R.; Wilding, J.M.; Kapur, N. Routes to remembering: The brains behind superior memory. Nat. Neurosci. 2002, 6, 90–95. [Google Scholar] [CrossRef]
- Upala, M.A.; Gonce, L.O.; Tweney, R.D.; Slone, D.J. Contextualizing Counterintuitiveness: How Context Affects Comprehension and Memorability of Counterintuitive Concepts. Cogn. Sci. 2007, 31, 415–439. [Google Scholar] [CrossRef]
- Van Kesteren, M.T.R.; Ruiter, D.J.; Fernández, G.; Henson, R.N. How schema and novelty augment memory formation. Trends Neurosci. 2012, 35, 211–219. [Google Scholar] [CrossRef]
- Chatman, S.B. Story and Discourse: Narrative Structure in Fiction and Film; Cornell University Press: Ithaca, NY, USA, 1978. [Google Scholar]
- Bateman, S.; Mandryk, R.L.; Gutwin, C.; Genest, A.; McDine, D.; Brooks, C. Useful junk? The effects of visual embellishment on comprehension and memorability of charts. In Proceedings of the 28th International Conference on Human Factors in Computing Systems—CHI Textquotesingle10, Atlanta, GA, USA, 10–15 April 2010; ACM Press: Times Square, NY, USA, 2010. [Google Scholar]
- Borkin, M.A.; Bylinskii, Z.; Kim, N.W.; Bainbridge, C.M.; Yeh, C.S.; Borkin, D.; Pfister, H.; Oliva, A. Beyond Memorability: Visualization Recognition and Recall. IEEE Trans. Vis. Comput. Graph. 2016, 22, 519–528. [Google Scholar] [CrossRef]
- Wang, Z.; Wang, S.; Farinella, M.; Murray-Rust, D.; Riche, N.H.; Bach, B. Comparing Effectiveness and Engagement of Data Comics and Infographics. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; Association for Computing Machinery: Glasgow, Scotland, 2019; pp. 1–12. [Google Scholar]
- Leppink, J.; Paas, F.; van der Vleuten, C.P.M.; van Gog, T.; van Merriënboer, J.J.G. Development of an instrument for measuring different types of cognitive load. Behav. Res. Methods 2013, 45, 1058–1072. [Google Scholar] [CrossRef] [PubMed]
- Benedek, J.; Miner, T. Measuring Desirability: New methods for evaluating desirability in a usability lab setting. In Proceedings of the Usability Professionals Association Conference, Orlando, FL, USA, 8–12 July 2002. [Google Scholar]
- Lugmayr, A. Brief introduction into information systems & management research in media industries. In Proceedings of the 2013 IEEE International Conference on Multimedia and Expo Workshops (ICMEW), San Jose, CA, USA, 15–19 July 2013; IEEE: New York, NY, USA, 2013; pp. 1–6. [Google Scholar]
- Lugmayr, A.; Reymann, S.; Kemper, S.; Dorsch, T.; Roman, P. Bits of Personality Everywhere: Implicit User-Generated Content in the Age of Ambient Media. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing with Applications, Sydney, Australia, 10–12 December; IEEE: New York, NY, USA, 2008; pp. 516–521. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Key Concepts | Our Contribution | Reference |
|---|---|---|
| Graphic variables and design elements for data visualization. | We design a new modular and customizable framework to reflect the changes from a static lecture environment to a dynamic story environment, and support the visual data storytelling content development. | [8,9,10,11] |
| Narrative visualization components and layers. | We identified an extended range of visual channels which cover the essential components and editorial spaces of narrative visualisation content. | [4,19,21] |
| Design process and phases of narrative visualization. | By integrating existing narrative visualisation studies with the communication model, we introduced three phases of information processing for visual data storytelling: structuring, composing and translating. | [19,20] |
| Analysis Oriented Process of Ordinary Data Visualisation | Narrative Oriented Process of Visual Data Storytelling | |
|---|---|---|
| Analysis oriented | Orientation | Narrative oriented |
| Professionals | Audience | Non-professionals |
| Variables | Basic Unit | Information Units |
| Simple message | Information Feature | Story-like information composition |
| Thin | Entertainment | Rich |
| 2D static visual space | Visual Space | 3D dynamic visual space |
| Straightforward | Visual Complexity | Relatively complex |
| Information Composition | Visual Element | Visual Channel | Transformation |
|---|---|---|---|
| Information Composition No. 1~No. 8 | Unicorn No. 1~No. 8 (Figure) | Colour Clothes/Accessories Design Style | Story Component ↦ Character (Unicorn) Expression Attachment ↦ Design (Unicorn) Data Massage ↦ Hue (Body, Accessory): Body, Accessory ∈ Unicorn Data Massage ↦ Assortment (Accessory): Accessory ∈ Unicorn |
| Information Composition No. 9 | Lighthouse (Figure) | Shade/Lighting Design Style | Story Component ↦ Property (Lighthouse) Expression Attachment ↦ Design (Lighthouse) Data Massage ↦ Luminance (Beacon): Beacon ∈ Lighthouse |
| Information Composition No. 10 | Meter (Figure) | Text Size/Length Design Style | Story Component ↦ Property (Meter) Expression Attachment ↦ Design (Meter) Data Massage ↦ Text (Number): Number ∈ Meter Data Massage ↦ Length (Bar): Bar ∈ Meter |
| Information Composition No. 11 | Piston (Figure) | Design Style | Story Component ↦ Property (Piston) Expression Attachment ↦ Design (Piston) |
| Information Composition No. 12 | Ball (Figure) | Size/Length Design Style | Story Component ↦ Property (Ball) Expression Attachment ↦ Design (Ball) Data Massage ↦ Size (Ball) |
| Information Composition No. 13 | Signboard (Figure) | Text Design Style | Story Component ↦ Property (Signboard) Expression Attachment ↦ Design (Signboard) Data Massage ↦ Text (Word): Word ∈ Signboard |
| Information Composition No. 14 | Ball Playing (Animation) | Movement Pattern | Story Component ↦ Action (Unicorn, Ball) Expression Attachment ↦ Design (Movement Pattern): Movement Pattern ∈ Unicorn, Ball Data Massage ↦ Movement Pattern (Unicorn, Ball) |
| Information Composition No. 15 | Piston Movement (Animation) | Movement Frequency | Story Component ↦ Action (Piston) Expression Attachment ↦ Design (Movement Frequency): Movement Frequency ∈ Piston Data Massage ↦ Movement Frequency (Piston) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.; Reynolds, M.; Lugmayr, A.; Damjanov, K.; Hassan, G.M. A Visual Data Storytelling Framework. Informatics 2022, 9, 73. https://doi.org/10.3390/informatics9040073
Zhang Y, Reynolds M, Lugmayr A, Damjanov K, Hassan GM. A Visual Data Storytelling Framework. Informatics. 2022; 9(4):73. https://doi.org/10.3390/informatics9040073
Chicago/Turabian StyleZhang, Yangjinbo, Mark Reynolds, Artur Lugmayr, Katarina Damjanov, and Ghulam Mubashar Hassan. 2022. "A Visual Data Storytelling Framework" Informatics 9, no. 4: 73. https://doi.org/10.3390/informatics9040073
APA StyleZhang, Y., Reynolds, M., Lugmayr, A., Damjanov, K., & Hassan, G. M. (2022). A Visual Data Storytelling Framework. Informatics, 9(4), 73. https://doi.org/10.3390/informatics9040073