Data-Driven Bayesian Network Learning: A Bi-Objective Approach to Address the Bias-Variance Decomposition




Abstract
:1. Introduction
2. Related Work
3. Background
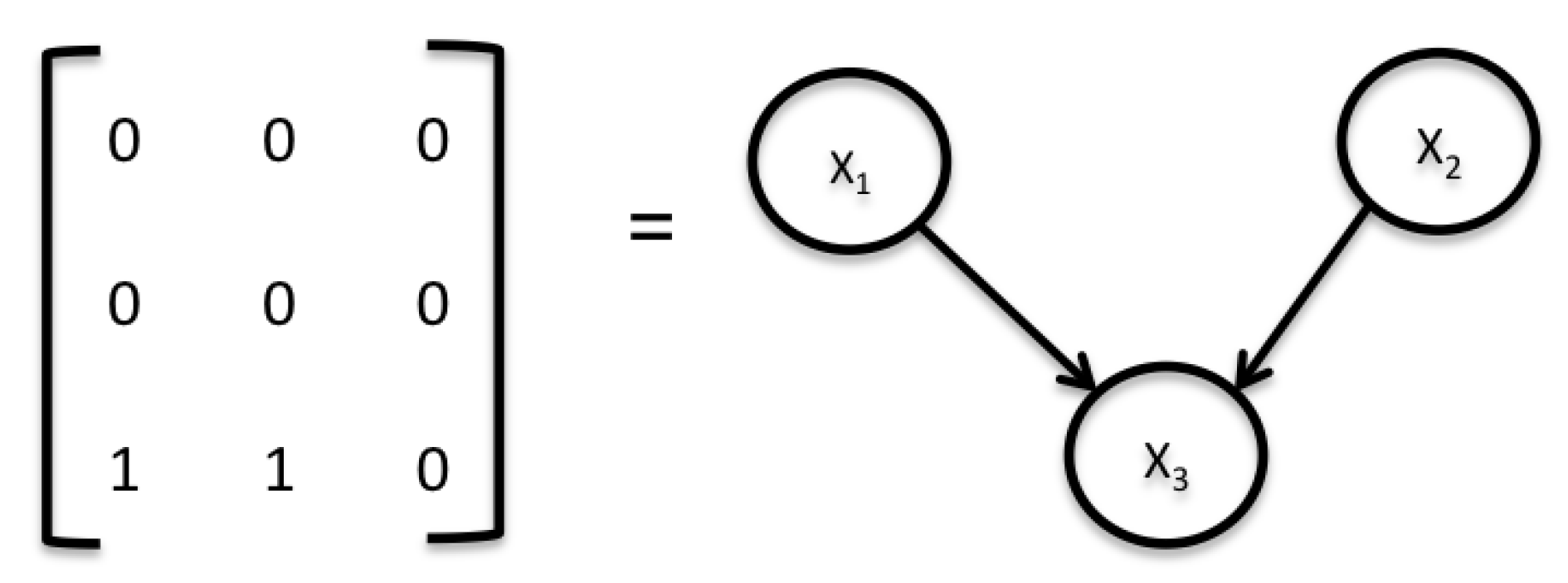
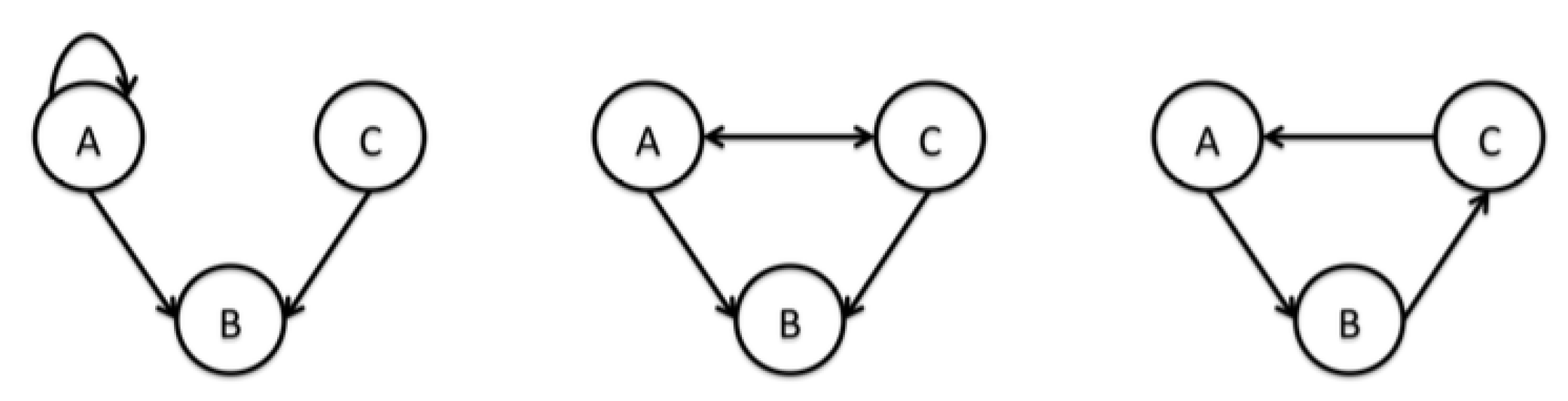
3.1. Bayesian Networks
3.2. Minimum Description Length
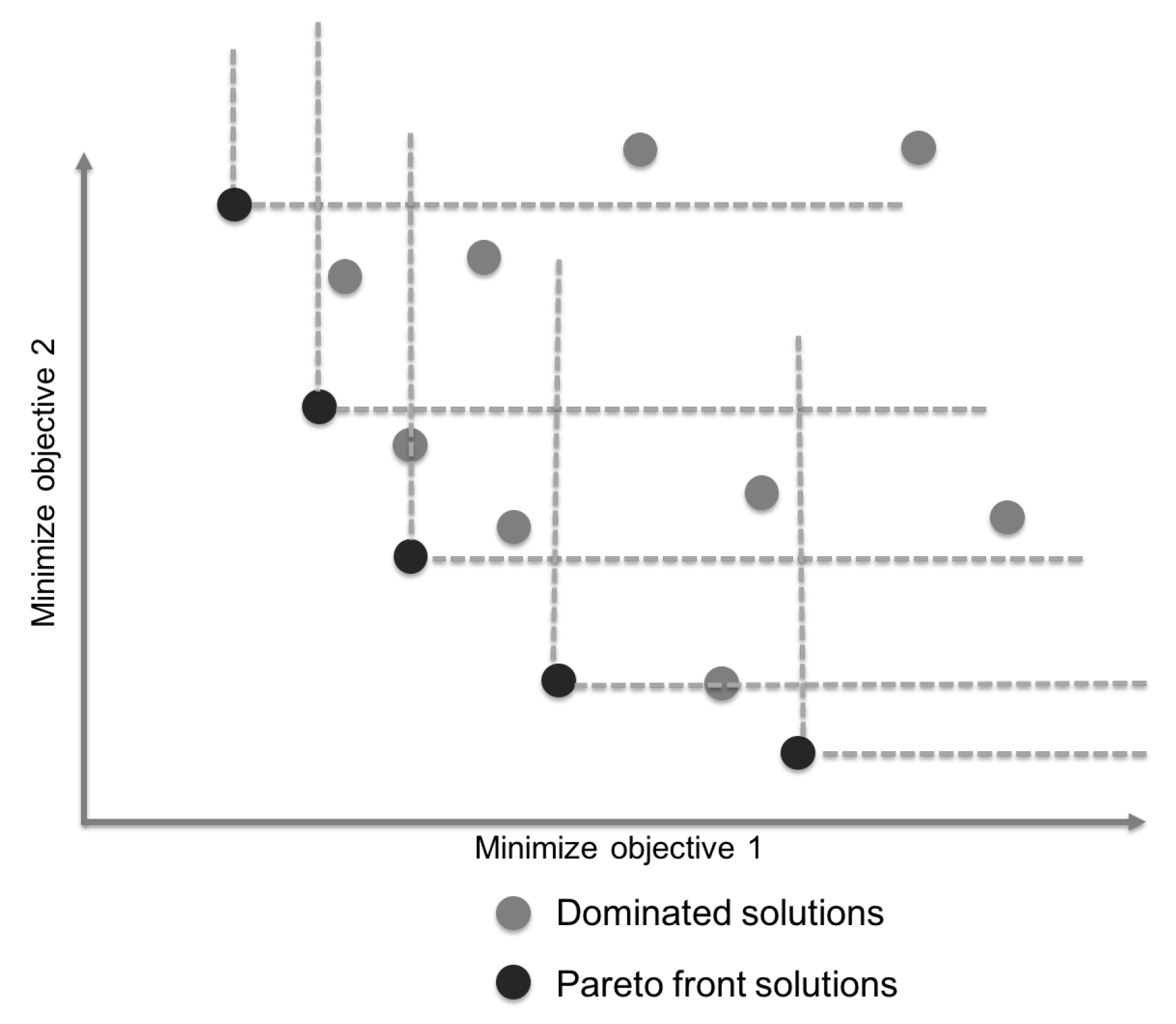
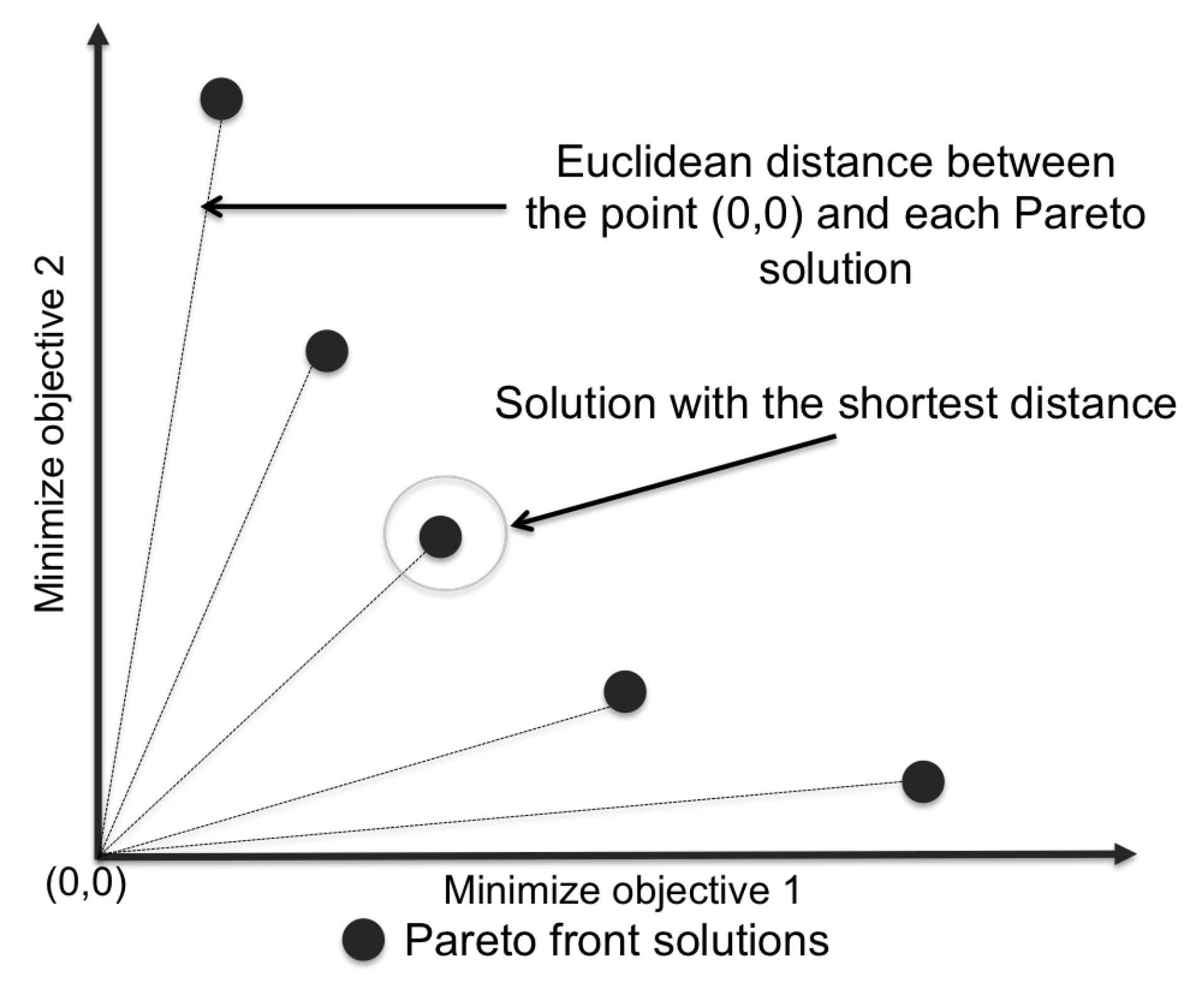
3.3. Multi-Objective Optimization Problem
4. Nondominated Sorting Genetic Algorithm for Learning Bayesian Networks (NS2BN)
| Algorithm 1: NS2BN |
| 1: G = 0 {Generation} |
| 2: Generate a population P of random solutions |
| 3: Repair cycles of each |
| 4: Evaluate the fitness functions using the first and the second term of the Equation (2) of each |
| 5: while do |
| 6: Create an offspring population Q using: binary tournament selection, one-point crossover and bit inversion mutation. |
| 7: Repair cycles |
| 8: Evaluate the fitness functions using the first and the second term of the Equation (2) of each |
| 9: Combine parents and offspring populations |
| 10: Sort using non-dominated criterio |
| 11: Replacement |
| 12: |
| 13: end while |
5. Experimental Setup
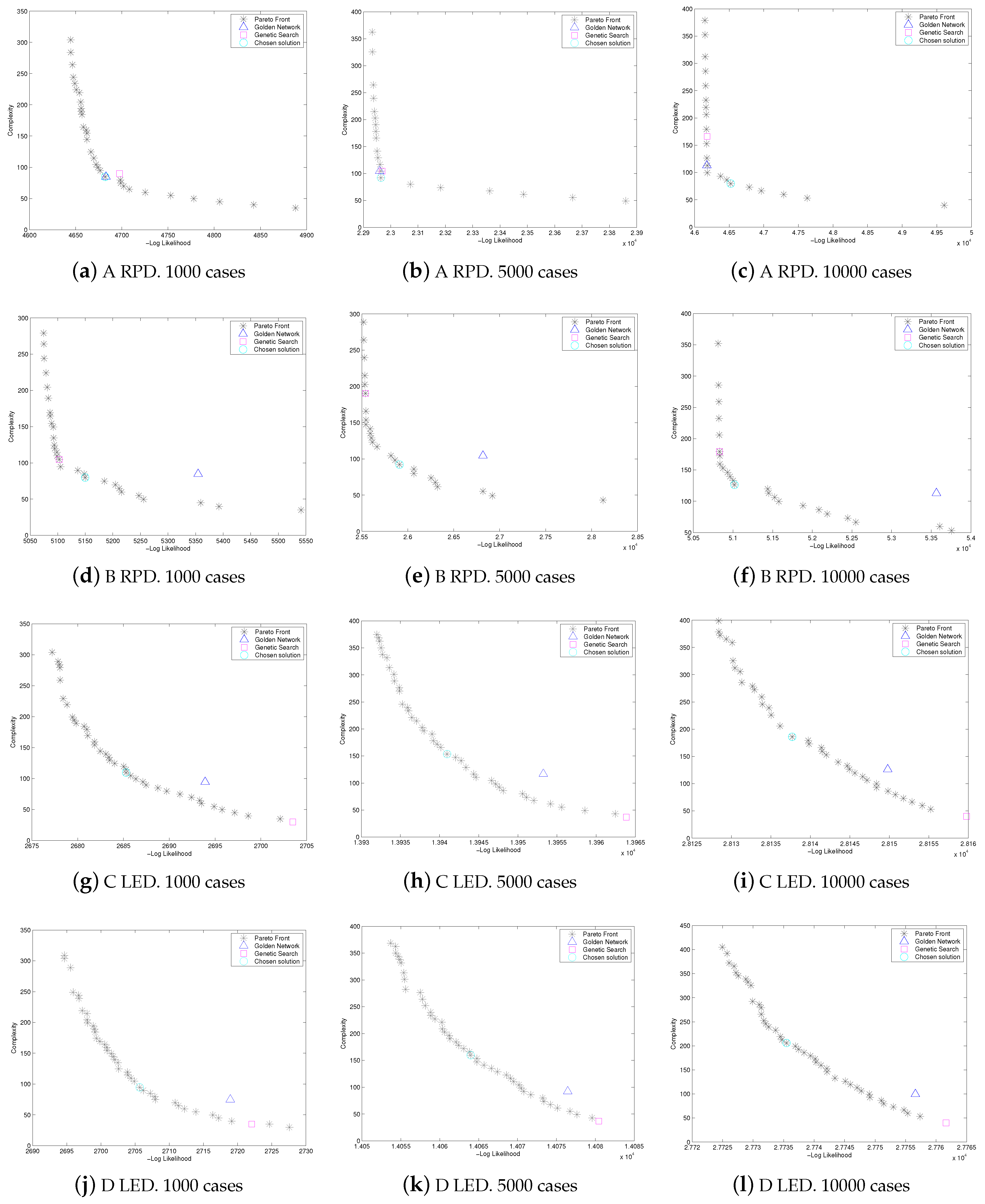
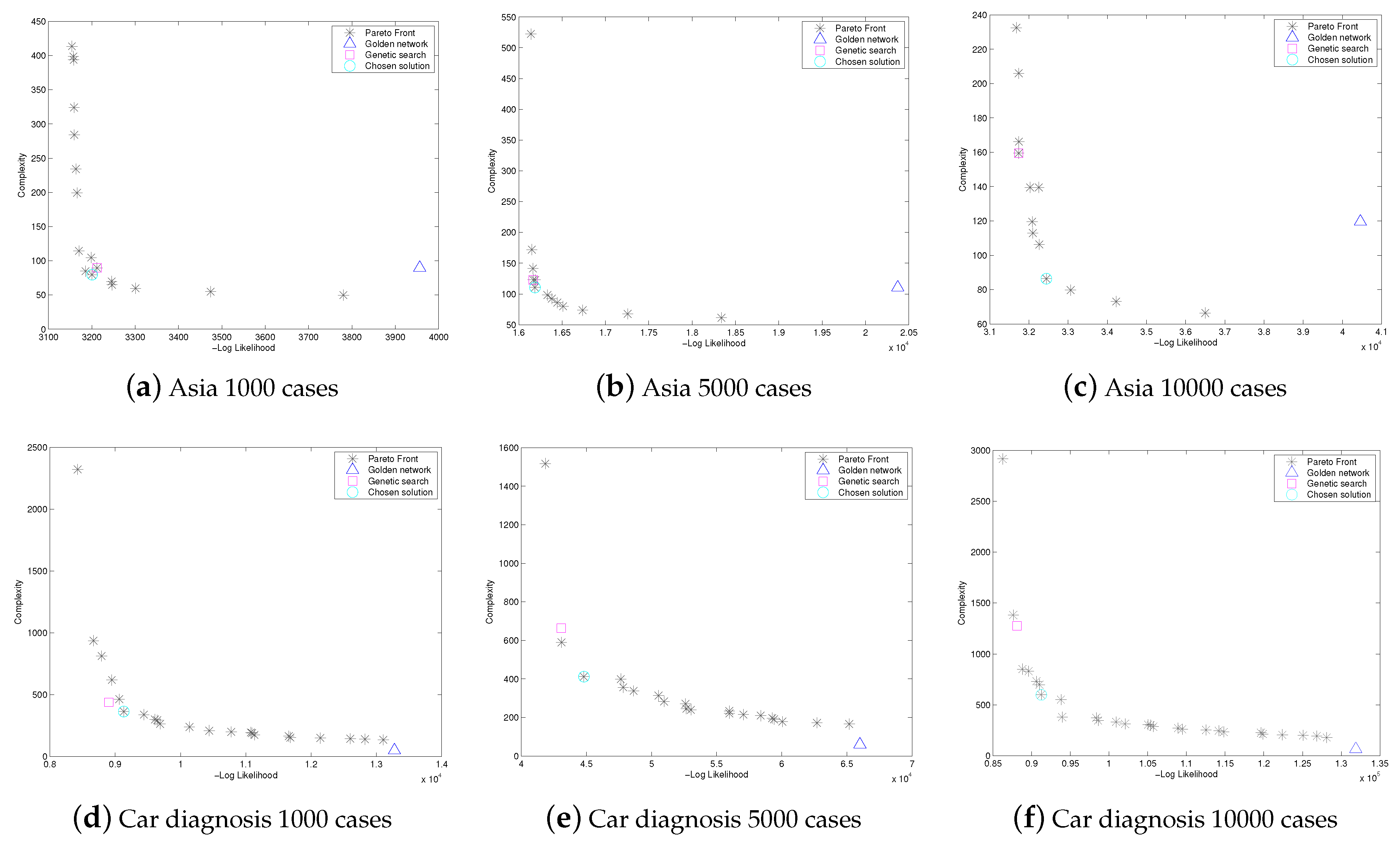
6. Results
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Pearl, J. Bayesian networks: A model of self-activated memory for evidential reasoning. In Proceedings of the 7th Conference of the Cognitive Science Society, Irvine, CA, USA, 15–17 August 1985; pp. 329–334. [Google Scholar]
- Buntine, W. A Guide to the Literature on Learning Probabilistic Networks from Data. IEEE Trans. Knowl. Data Eng. 1996, 8, 195–210. [Google Scholar] [CrossRef] [Green Version]
- Rónán, D.; Qiang, D.; Stuart, A. Learning Bayesian networks: Approaches and issues. Knowl. Eng. Rev. 2011, 26, 99–157. [Google Scholar]
- Heckerman, D. A Tutorial on Learning with Bayesian Networks. In Learning in Graphical Models; Jordan, M.I., Ed.; MIT Press: Cambridge, MA, USA, 1999; pp. 301–354. [Google Scholar]
- Neapolitan, R.E. Learning Bayesian Networks; Prentice-Hall, Inc.: Upper Saddle River, NJ, USA, 2003. [Google Scholar]
- Domingos, P. Bayesian Averaging of Classifiers and the Overfitting Problem. In Proceedings of the 17th International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 223–230. [Google Scholar]
- Liu, Z.; Malone, B.; Yuan, C. Empirical Evaluation of Scoring Functions for Bayesian Network Model Selection. In Proceedings of the Ninth Annual MCBIOS Conference, Oxford, MS, USA, 17–18 February 2012; pp. 1–16. [Google Scholar]
- Geman, S.; Bienenstock, E.L.; Doursat, R. Neural Networks and the Bias/Variance Dilemma. Neural Comput. 1992, 4, 1–58. [Google Scholar] [CrossRef]
- Friedman, J.H. On Bias, Variance, 0’/1 Loss, and the Curse-of-Dimensionality. Data Min. Knowl. Discov. 1997, 1, 55–77. [Google Scholar] [CrossRef]
- Myung, I.J. The Importance of Complexity in Model Selection. J. Math. Psychol. 2000, 44, 190–204. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hastie, T.; Tibshirani, R.; Friedman, J. Model Assessment and Selection. In The Elements of Statistical Learning; Springer New York Inc.: New York, NY, USA, 2001; pp. 219–227. [Google Scholar]
- Akaike, H. Information Theory and an Extension of the Maximum Likelihood Principle. In Selected Papers of Hirotugu Akaike; Springer: New York, NY, USA, 1998; pp. 199–213. [Google Scholar] [CrossRef]
- Cooper, G.F.; Herskovits, E. A Bayesian Method for the Induction of Probabilistic Networks from Data. Mach. Learn. 1992, 9, 309–347. [Google Scholar] [CrossRef]
- Silander, T.; Roos, T.; Myllymäki, P. Learning locally minimax optimal Bayesian networks. Int. J. Approx. Reason. 2010, 51, 544–557. [Google Scholar] [CrossRef] [Green Version]
- Grünwald, P.D. The Minimum Description Length Principle. Adaptive Computation and Machine Learning. In The Minimum Description Length Principle. Adaptive Computation and Machine Learning; The MIT Press: Cambridge, MA, USA, 2007; p. 703. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J. Unsupervised Learning. In The Elements of Statistical Learning; Springer: New York, NY, USA, 2001; p. 533. [Google Scholar]
- Ye, S.; Cai, H.; Sun, R. An Algorithm for Bayesian Networks Structure Learning Based on Simulated Annealing with MDL Restriction. In Proceedings of the 2008 Fourth International Conference on Natural Computation, Jinan, China, 18–20 October 2008; Volume 3, pp. 72–76. [Google Scholar]
- Kuo, S.; Wang, H.; Wei, H.; Chen, C.; Li, S. Applying MDL in PSO for learning Bayesian networks. In Proceedings of the 2011 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE 2011), Taipei, Taiwan, 27–30 June 2011; pp. 1587–1592. [Google Scholar]
- Suzuki, J. Bayesian Network Structure Estimation Based on the Bayesian/MDL Criteria When Both Discrete and Continuous Variables Are Present. In Proceedings of the 2012 Data Compression Conference, Snowbird, UT, USA, 10–12 April 2012; pp. 307–316. [Google Scholar]
- Zhong, X.; You, W. Combining MDL and BIC to Build BNs for System Reliability Modeling. In Proceedings of the 2015 2nd International Conference on Information Science and Security (ICISS), Seoul, Korea, 14–16 December 2015; pp. 1–4. [Google Scholar]
- Chen, C.; Yuan, C. Learning Diverse Bayesian Networks. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7793–7800. [Google Scholar]
- Grünwald, P.D. Model Selection Based on Minimum Description Length. J. Math. Psychol. 2000, 44, 133–152. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Kadirkamanathan, V. Learning with multi-objective criteria. In Proceedings of the Fourth International Conference on Artificial Neural Networks, Cambridge, UK, 26–28 June 1995; pp. 53–58. [Google Scholar]
- Braga, A.P.; Takahashi, R.H.C.; Costa, M.A.; Teixeira, R.d.A. Multi-Objective Algorithms for Neural Networks Learning. In Multi-Objective Machine Learning; Springer: Berlin/Heidelberg, Germany, 2006; pp. 151–171. [Google Scholar] [CrossRef]
- Gräning, L.; Jin, Y.; Sendhoff, B. Generalization improvement in multi-objective learning. In Proceedings of the International Joint Conference on Neural Networks, Vancouver, BC, Canada, 16–21 July 2006; pp. 9893–9900. [Google Scholar]
- Yaman, S.; Lee, C.H. A Comparison of Single- and Multi-Objective Programming Approaches to Problems with Multiple Design Objectives. J. Signal Process. Syst. 2010, 61, 39–50. [Google Scholar] [CrossRef]
- Rosales, A.; Escalante, H.J.; Gonzalez, J.A.; Reyes, C.A.; Coello, C.A. Bias and Variance Optimization for SVMs Model Selection. In Proceedings of the Iberian Conference on Pattern Recognition and Image Analysis, Madeira, Portugal, 5–7 June 2013; pp. 108–116. [Google Scholar]
- Bouckaert, R.R. Probabilistic Network Construction Using the Minimum Description Length Principle. In Proceedings of the European Conference on Symbolic and Quantitative Approaches to Reasoning and Uncertainty, Granada, Spain, 8–10 November 1993. [Google Scholar]
- Lam, W.; Bacchus, F. Learning Bayesian Belief Networks: An Approach Based on the MDL Principle. Comput. Intell. 1994, 10, 269–293. [Google Scholar] [CrossRef] [Green Version]
- Suzuki, J. Learning Bayesian Belief Networks Based on the Minimum Description Length Principle: An Efficient Algorithm Using the B & B Technique. In Proceedings of the Thirteenth International Conference on International Conference on Machine Learning, Bari, Italy, 3–6 July 1996; pp. 462–470. [Google Scholar]
- Suzuki, J. Learning Bayesian Belief Networks Based on the Minimum. Description Length Principle: Basic Properties. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 1999, E82-A, 2237–2245. [Google Scholar]
- Grünwald, P.D. A Tutorial Introduction to the Minimum Description Length Principle. In Advances in Minimum Description Length: Theory and Applications; The MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Zou, Y.; Roos, T.; Ueno, M. On Model Selection, Bayesian Networks, and the Fisher Information Integral. In Advanced Methodologies for Bayesian Networks; Springer International Publishing: Cham, Switzerland, 2015; pp. 122–135. [Google Scholar] [CrossRef]
- Cruz-Ramírez, N.; Acosta-Mesa, H.G.; Mezura-Montes, E.; Guerra-Hernández, A.; Hoyos-Rivera, G.d.J.; Barrientos-Martínez, R.E.; Gutiérrez-Fragoso, K.; Nava-Fernández, L.A.; González-Gaspar, P.; Novoa-del Toro, E.M.; et al. How good is crude MDL for solving the bias-variance dilemma? An empirical investigation based on Bayesian networks. PLoS ONE 2014, 9. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cotta, C.; Muruzábal, J. Towards a More Efficient Evolutionary Induction of Bayesian Networks; Springer: London, UK, 2002; pp. 730–739. [Google Scholar]
- Blanco, R.; Inza, I.; Larrañaga, P. Learning Bayesian networks in the space of structures by estimation of distribution algorithms. Int. J. Intell. Syst. 2003, 18, 205–220. [Google Scholar] [CrossRef]
- Wong, M.L.; Lam, W.; Leung, K.S. Using Evolutionary Programming and Minimum Description Length Principle for Data Mining of Bayesian Networks. IEEE Trans. Pattern Anal. Mach. Intell. 1999, 21, 174–178. [Google Scholar] [CrossRef]
- Wong, M.L.; Lee, S.Y.; Leung, K.S. Data Mining of Bayesian Networks Using Cooperative Coevolution. Decis. Support Syst. 2004, 38, 451–472. [Google Scholar] [CrossRef]
- Li, X.L.; He, X.D.; Chen, C.M. A Method for Learning Bayesian Networks by Using Immune Binary Particle Swarm Optimization. In Database Theory and Application; Slezak, D., Kim, T.H., Zhang, Y., Ma, J., Chung, K.I., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 64, pp. 115–121. [Google Scholar] [CrossRef]
- Li, G.; Xing, L.; Chen, Y. A New BN Structure Learning Mechanism Based on Decomposability of Scoring Functions. In Bio-Inspired Computing—Theories and Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 212–224. [Google Scholar] [CrossRef]
- Ross, B.J.; Zuviria, E. Evolving dynamic Bayesian networks with Multi-objective genetic algorithms. Appl. Intell. 2007, 26, 13–23. [Google Scholar] [CrossRef] [Green Version]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A Fast Elitist Multi-Objective Genetic Algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2000, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Keller, A. Multi-Objective Optimization in Theory and Practice II: Metaheuristic Algorithms; Bentham Science Publishers: Sharjah, UAE, 2019. [Google Scholar]
- Cowie, J.; Oteniya, L.; Coles, R. Particle Swarm Optimisation for Learning Bayesian Networks. Available online: https://core.ac.uk/reader/9050000 (accessed on 19 June 2020).
- Allen, T.V.; Greiner, R. Model Selection Criteria for Learning Belief Nets: An Empirical Comparison. In Proceedings of the Seventeenth International Conference on Machine Learning, Stanford, CA, USA, 29 June–2 July 2000; pp. 1047–1054. [Google Scholar]
- Ramsey, J. Tetrad IV. Available online: http://www.phil.cmu.edu/tetrad (accessed on 19 June 2020).
- Scutari, M. Learning Bayesian Networks with the bnlearn R Package. J. Stat. Softw. 2010, 35, 1–22. [Google Scholar] [CrossRef] [Green Version]
- Dua, D.; Graff, C. UCI Machine Learning Repository. 2019. Available online: http://archive.ics.uci.edu/ml/index.php (accessed on 19 June 2020).
- Holland, J. Adaptation in Natural and Artificial Systems; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Jing, R.; Wang, M.; Zhang, Z.; Liu, J.; Liang, H.; Meng, C.; Shah, N.; Li, N.; Zhao, Y. Comparative study of posteriori decision-making methods when designing building integrated energy systems with multi-objectives. Energy Build. 2019, 194, 123–139. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| No. | Name | Attributes | Instances | Arcs |
|---|---|---|---|---|
| 1. | A6 Nodes-random probability distribution | 6 | 1000, 5000, 10000 | 8 |
| 2. | B6 Nodes-random probability distribution | 6 | 1000, 5000, 10000 | 8 |
| 3. | C6 Nodes-low entropy probability distribution | 6 | 1000, 5000, 10000 | 9 |
| 4. | D6 Nodes-low entropy probability distribution | 6 | 1000, 5000, 10000 | 7 |
| 5. | Asia | 8 | 1000, 5000, 10000 | 8 |
| 6. | Car Diagnosis | 18 | 1000, 5000, 10000 | 20 |
| 7. | Child | 20 | 1000, 3000 | Unknown |
| 8. | German Credit | 21 | 1000 | Unknown |
| 9. | Hepatitis | 20 | 80 | Unknown |
| 10. | Glass | 10 | 270 | Unknown |
| 11. | Heart Disease. Cleveland | 14 | 298 | Unknown |
| 12. | Credit Approval | 16 | 654 | Unknown |
| Model | Trade-off | MDL | CV | |
|---|---|---|---|---|
| −Log Likelihood | Complexity | |||
| A6-Nodes random probability distribution. 1000 cases | ||||
| Chosen solution | 4682.057654 | 84.70916642 | 4766.76682 | 71.25(±3.25) |
| Genetic solution | 4697.44594 | 89.69205856 | 4787.137998 | 72.10(±2.86) |
| A6-Nodes random probability distribution. 5000 cases | ||||
| Chosen solution | 22964.2851 | 92.15784285 | 23056.44294 | 72.42(±1.55) |
| Genetic solution | 22968.59399 | 104.4455552 | 23073.03954 | 71.88(±1.93) |
| A6-Nodes random probability distribution. 10000 cases | ||||
| Chosen solution | 46522.66474 | 79.72627428 | 46602.39101 | 70.37(±0.76) |
| Genetic solution | 46181.77888 | 166.0964047 | 46347.87529 | 70.29(±0.81) |
| B6-Nodes random probability distribution. 1000 cases | ||||
| Chosen solution | 5149.786108 | 79.72627428 | 5229.512382 | 85.59(±3.32) |
| Genetic solution | 5102.720574 | 104.640735 | 5207.361309 | 85.75(±3.34) |
| B6-Nodes random probability distribution. 5000 cases | ||||
| Chosen solution | 25909.78695 | 92.15784285 | 26001.94479 | 83.58(±1.45) |
| Genetic solution | 25540.93739 | 190.4595419 | 25731.39693 | 84.23(±1.41) |
| B6-Nodes random probability distribution. 10000 cases | ||||
| Chosen solution | 51018.73479 | 126.2332676 | 51144.96806 | 84.62(±0.96) |
| Genetic solution | 50830.79577 | 179.3841171 | 51010.17989 | 84.71(±0.98) |
| C6-Nodes low-entropy probability distribution. 1000 cases | ||||
| Chosen solution | 2685.283382 | 109.6236271 | 2794.907009 | 89.70(±0.54) |
| Genetic solution | 2703.478277 | 29.89735285 | 2733.37563 | 89.60(±0.49) |
| C6-Nodes low-entropy probability distribution. 5000 cases | ||||
| Chosen solution | 13940.96186 | 153.5964047 | 14094.55826 | 90.22(±0.09) |
| Genetic solution | 13963.84415 | 36.86313714 | 14000.70728 | 90.24(±0.08) |
| C6-Nodes low-entropy probability distribution. 10000 cases | ||||
| Chosen solution | 28137.70083 | 186.0279733 | 28323.7288 | 90.21(±0.03) |
| Genetic solution | 28159.77242 | 39.86313714 | 28199.63556 | 90.21(±0.03) |
| D6-Nodes low-entropy probability distribution. 1000 cases | ||||
| Chosen solution | 2705.676276 | 94.6749507 | 2800.351227 | 91.40(±0.49) |
| Genetic solution | 2722.059767 | 34.880245 | 2756.940012 | 91.40(±0.49) |
| D6-Nodes low-entropy probability distribution. 5000 cases | ||||
| Chosen solution | 14063.96978 | 159.7402609 | 14223.71004 | 90.76(±0.08) |
| Genetic solution | 14080.43878 | 36.86313714 | 14117.30192 | 90.76(±0.08) |
| D6-Nodes low-entropy probability distribution. 10000 cases | ||||
| Chosen solution | 27735.47963 | 205.9595419 | 27941.43917 | 90.27(±0.05) |
| Genetic solution | 27761.63739 | 39.86313714 | 27801.50053 | 90.27(±0.05) |
| Asia. 1000 cases | ||||
| Chosen solution | 3200.726031 | 79.72627428 | 3280.452306 | 94.30(±1.87) |
| Genetic solution | 3211.984813 | 89.69205856 | 3301.676872 | 94.30(±1.87) |
| Asia. 5000 cases | ||||
| Chosen solution | 16188.02485 | 110.5894114 | 16298.61427 | 94.10(±0.81) |
| Genetic solution | 16167.19634 | 122.8771238 | 16290.07347 | 94.10(±0.81) |
| Asia. 10000 cases | ||||
| Chosen solution | 32444.35458 | 86.37013047 | 32530.72471 | 94.12(±0.52) |
| Genetic solution | 31738.67533 | 159.4525486 | 31898.12788 | 94.12(±0.52) |
| Car diagnosis. 1000 cases | ||||
| Chosen solution | 9130.727267 | 363.7511264 | 9494.478394 | 71.10(±0.30) |
| Genetic solution | 8903.130665 | 438.4945085 | 9341.625174 | 69.33(±1.52) |
| Car diagnosis. 5000 cases | ||||
| Chosen solution | 44811.82111 | 411.6383647 | 45223.45948 | 75.10(±1.64) |
| Genetic solution | 43066.63622 | 663.5364685 | 43730.17269 | 76.12(±1.86) |
| Car diagnosis. 10000 cases | ||||
| Chosen solution | 91244.39425 | 597.9470571 | 91842.34131 | 76.76(±1.34) |
| Genetic solution | 88106.54485 | 1275.620388 | 89382.16524 | 72.44(±1.46) |
| German Credit | ||||
| Chosen solution | 775.3134767 | 358.7682342 | 1134.081711 | 70.00(±0.00) |
| Genetic solution | 795.3572652 | 308.9393128 | 1104.296578 | 70.00(±0.00) |
| Hepatitis | ||||
| Chosen solution | 843.1819384 | 88.50699333 | 931.6889318 | 83.75(±5.76) |
| Genetic solution | 843.1298695 | 101.1508495 | 944.280719 | 83.75(±5.76) |
| Glass | ||||
| Chosen solution | 1809.775474 | 7335.03997 | 9144.815443 | 76.58(±7.29) |
| Genetic solution | 2174.033877 | 170.3122737 | 2344.346151 | 35.51(±2.08) |
| Heart Disease. Cleveland | ||||
| Chosen solution | 3743.020428 | 250.5367332 | 3993.557162 | 56.89(±5.06) |
| Genetic solution | 3752.086989 | 151.9649037 | 3904.051893 | 53.89(±0.85) |
| Credit Approval | ||||
| Chosen solution | 8037.915455 | 233.7734795 | 8271.688934 | 72.90(±5.29) |
| Genetic solution | 8052.242078 | 201.0451924 | 8253.287271 | 60.49(±5.03) |
| Golden-Network | GABN | NS2BN |
|---|---|---|
| A RPD. 1000 cases | 0.006256036 | 0.000412874 |
| A RPD. 5000 cases | 0.000735484 | 0.000166667 |
| A RPD. 10000 cases | 0.000622825 | 0.010558429 |
| B RPD. 1000 cases | 0.5008542 | 0.512832286 |
| B RPD. 5000 cases | 0.50817743 | 0.527715617 |
| B RPD. 10000 cases | 0.501635069 | 0.506660672 |
| C LED. 1000 cases | 0.006859061 | 0.000558415 |
| C LED. 5000 cases | 0.001254388 | 8.84927E-06 |
| C LED. 10000 cases | 0.000630321 | 0.000231126 |
| D LED. 1000 cases | 0.005505678 | 0.001674059 |
| D LED. 5000 cases | 0.001196043 | 0.0007695 |
| D LED. 10000 cases | 0.000561088 | 0.000529102 |
| Asia 1000 cases | 0.184669176 | 0.183903387 |
| Asia 5000 cases | 0.279944777 | 0.277977466 |
| Asia 10000 cases | 0.272191288 | 0.262362486 |
| Car diagnosis 1000 cases | 0.161505741 | 0.278079726 |
| Car diagnosis 5000 cases | 0.160725004 | 0.192815203 |
| Car diagnosis 10000 cases | 0.200548739 | 0.223971025 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aguilera-Rueda, V.-J.; Cruz-Ramírez, N.; Mezura-Montes, E. Data-Driven Bayesian Network Learning: A Bi-Objective Approach to Address the Bias-Variance Decomposition. Math. Comput. Appl. 2020, 25, 37. https://doi.org/10.3390/mca25020037
Aguilera-Rueda V-J, Cruz-Ramírez N, Mezura-Montes E. Data-Driven Bayesian Network Learning: A Bi-Objective Approach to Address the Bias-Variance Decomposition. Mathematical and Computational Applications. 2020; 25(2):37. https://doi.org/10.3390/mca25020037
Chicago/Turabian StyleAguilera-Rueda, Vicente-Josué, Nicandro Cruz-Ramírez, and Efrén Mezura-Montes. 2020. "Data-Driven Bayesian Network Learning: A Bi-Objective Approach to Address the Bias-Variance Decomposition" Mathematical and Computational Applications 25, no. 2: 37. https://doi.org/10.3390/mca25020037
APA StyleAguilera-Rueda, V.-J., Cruz-Ramírez, N., & Mezura-Montes, E. (2020). Data-Driven Bayesian Network Learning: A Bi-Objective Approach to Address the Bias-Variance Decomposition. Mathematical and Computational Applications, 25(2), 37. https://doi.org/10.3390/mca25020037