
Variational Bayesian Learning of SMoGs: Modelling and Their Application to Synthetic Aperture Radar

Abstract
:1. Introduction
2. Variational Bayesian Learning of SMoGs
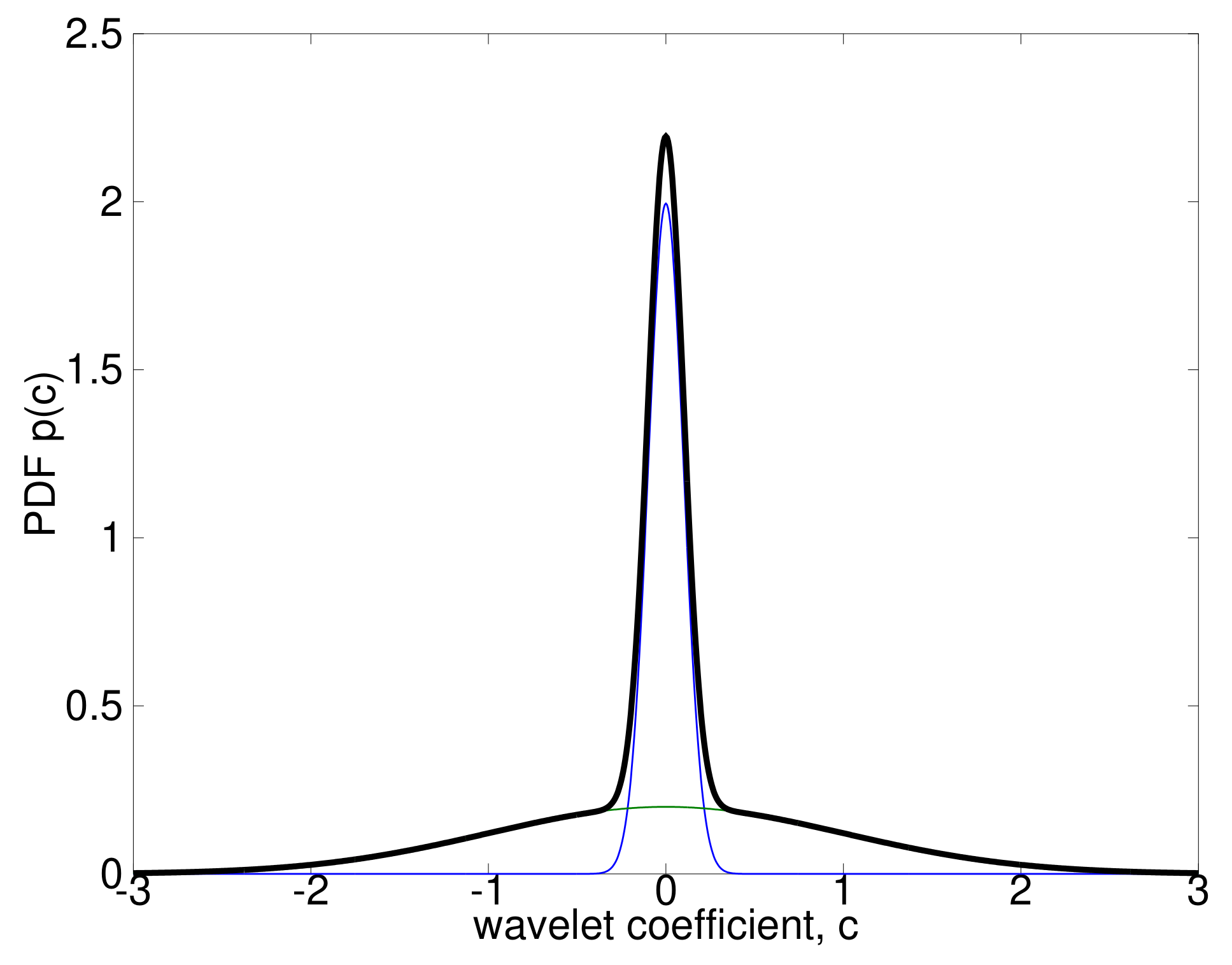
2.1. Bayesian Modelling of Sparse Wavelet Coefficients
2.1.1. The Bayesian SMoG Model
Introducing Hidden Variables
Probability Assignments
- The prior over the mixing proportions vector, , is a Dirichlet distribution with concentration hyperparameters , with :where and are the Gamma and multivariate Beta functions, respectively. The Dirichlet is sometimes called a ‘distribution over distributions’, since it is a probability distribution on the simplex of sets of non-negative numbers that sum to one [6]. In other words, each draw from a Dirichlet is itself a distribution. It is the conjugate prior of the Categorical distribution [3]. Note that in the SMoG model, in contrast to the general MoG, it is more logical to assign different hyperparameters for the different components, and , in the binary case, i.e., have an asymmetric prior because, for sparse data, we expect that most of the bases should be inactive (‘off’). Therefore, we assign a much larger a-priori concentration parameter, , corresponding to the peak of the distribution at zero, than . This means that the a-priori probability of drawing an inactive coefficient from the model is significantly higher than drawing an active one.
- The prior over each component mean, , is a Gaussian, with hyperparameters such that the hyperparameter of the prior is , implying , while we let the algorithm learn the posterior hyperparameters of . That is, we do not fix the means themselves to 0 but only the prior hyperparameters and let the algorithm learn the actual value of the corresponding posterior hyperparameters itself using an empirical Bayes approach. The above expresses our prior belief that the centres of the distribution of the are drawn from a hyperprior with mean zero and a small width, . This reflects the empirical observation that, for sparse signals, it is highly probable that most wavelet coefficients will be zero:
- The prior over each component precision, , of the jth dyadic scale is a Gamma distribution with hyperparameters . While in general we would often express our lack of prior information in the scales of the parameters by selecting a vague (‘uninformative’) prior [7], in this case we want to express our expectation that, for sparse signals, again, only a few wavelet coefficients will be significantly different from zero. Therefore, we will select the prior hyperparameters such that the non-active coefficients , which will form the majority of the representation, will be neatly concentrated around 0, i.e., assign a high precision to that state, while the few ‘large’ ones will be drawn from a component with a small precision (high variance), to allow “wiggle space”:where we have used the scale-shape parameterization of the Gamma distribution.
2.1.2. SMoG Bayesian Network
2.2. Variational Bayesian Inference
- Take the log-joint probability, , expand it into the various terms that correspond to the unkowns , , and, for each , keep only its ‘relevant’ terms, i.e., the terms that contain expressions containing the variable . These are none other than the nodes in the Markov blanket of the node .
- Take the posterior averages, , of the various terms. If the model is constructed such that the node conditional PDFs (i.e., given their parents) are in the conjugate-exponential family of distributions, these averages will be analytically computable.
- Rearrange and combine the various sub-terms so that we end up with expression patterns that correspond to known distributions, such as those in the exponential family, to finally find the expression of the update equation for each .
2.3. Applying VB Learning to the SMoG Model
2.3.1. Update Equations for the Unknowns of the Model
Responsibility-Weighted Statistics
Update Schedule
2.3.2. Evaluating and Interpreting the Negative Free Energy
3. Variational Bayesian SMoG for Signal Denoising
A One-Dimensional Example: Wavelet Analysis of Geodetic Signals
4. Speckle Reduction in Synthetic Aperture Radar
4.1. Established Speckle Reduction Filters
4.1.1. The Median Filter
4.1.2. The Lee Filter
4.1.3. The Kuan Filter
4.1.4. The Frost Filter
4.1.5. The Gamma Filter
4.2. Evaluation Indices
- The Pearson correlation coefficient (corrcoef), ,where is a model estimate of a (known, in this case) quantity, .
- The signal-to-noise ratio (SNR), measured in dB,where is the error committed by the estimator at hand, leading to the mean squared error (MSE), where .
- The peak signal-to-noise ratio (PSNR), measured in dB,where is the maximum grayscale value an image can take, e.g., for an 8–bit encoded image.
- The Equivalent Number of Looks (ENL). ENL, which is a measure of noise level, is one of the most common indices used in SAR images. It is defined asENL refers to one image, and can be used both on the original, observed image and the reconstructed image. In multilook processing, the number of looks, L, of a SAR image is the number of independent images of a scene that have been averaged to produce a smoother image, and, as mentioned before, speckle noise drops by the square root of L. In the case of a single image, the equivalent number of looks, , is a good measure of the speckle noise level. To compute the ENL, one selects a large uniform image region, or a number of such regions, and computes the empirical statistics of speckle there.
- The Edge Preserving Index (EPI), as the name implies, is a measure of the edge and linear feature preserving capability of despeckling algorithms. Since any form of denoising inevitably leads to some degradation of high-frequency features, this is an important quality index in SAR. EPI therefore compares the edges of the original with those of the restored image, and is computed as the ratio of highpass versions of the original and despeckled images. A simple definition iswhere the pixel indices were used here to highlight the row-wise and column-wise operations, respectively. In practice, smoother forms of edge detection may be used, for example using a higher-order Laplacian filter, implementing the operatorFrom its functional form it is easy to see that EPI is analogous to an edge correlation index. A value of one indicates perfect edge preservation. The SNR and corrcoef are measures that use global image properties. On the contrary, oftentimes we want to focus on specific features, such as edges. EPI complements those measures.
- The Radiation Accuracy Error (RAE) is a measure of radiometric loss due to filtering between the original image and the filtered image. It therefore operates on the pair of original and filtered images and is defined as the ratio of the average grayscale values of the estimated SAR image to that of the measured one:A value close to zero indicates an unbiased estimator.
5. Experiments and Analysis
5.1. Experiments with Simulated SAR Images
5.2. Despeckling of Real SAR Images
6. Conclusions
Funding
Acknowledgments
Conflicts of Interest
References
- Olshausen, B.A.; Millman, K.J. Learning Sparse Codes with a Mixture-of-Gaussians Prior. In Advances in Neural Information Processing Systems 12; Solla, S.A., Leen, T.K., Müller, K., Eds.; MIT Press: Cambridge, MA, USA, 2000; pp. 841–847. [Google Scholar]
- Roussos, E.; Roberts, S.; Daubechies, I. Variational Bayesian Learning for Wavelet Independent Component Analysis. In Proceedings of the 25th International Workshop on Bayesian Inference and Maximum Entropy Methods in Science and Engineering, San Jose, CA, USA, 7–12 August 2005; AIP: New York, NY, USA, 2005. [Google Scholar]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; Wiley: Hoboken, NJ, USA, 2000; p. 610. [Google Scholar]
- Attias, H. A Variational Bayesian Framework for Graphical Models. In Advances in Neural Information Processing Systems 12; MIT Press: Cambridge, MA, USA, 2000; pp. 209–215. [Google Scholar]
- Beal, M.J.; Ghahramani, Z. Variational Bayesian learning of directed graphical models with hidden variables. Bayesian Anal. 2006, 1, 793–831. [Google Scholar] [CrossRef]
- Frigyik, B.A.; Kapila, A.; Gupta, M.R. Introduction to the Dirichlet Distribution and Related Processes; Technical Report UWEETR-2010-0006; Department of Electrical Engineering, University of Washington: Seattle, WA, USA, 2010. [Google Scholar]
- Gelman, A. Prior distributions for variance parameters in hierarchical models. Bayesian Anal. 2006, 1, 515–534. [Google Scholar] [CrossRef]
- Gelfand, I.M.; Fomin, S.V. Calculus of Variations; Prentice Hall: Englewood Cliffs, NJ, USA, 1963; p. 240. [Google Scholar]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press Inc.: New York, NY, USA, 1995; p. 482. [Google Scholar]
- Penny, W.; Roberts, S. Variational Bayes for 1-Dimensional Mixture Models; Technical Report PARG–00–2; Department of Engineering Science, University of Oxford: Oxford, UK, 2000. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. Ser. B (Methodol.) 1977, 39, 1–38. [Google Scholar]
- Coggeshall, F. The Arithmetic, Geometric, and Harmonic Means. Q. J. Econ. 1886, 1, 83–86. [Google Scholar] [CrossRef]
- Choudrey, R. Variational Methods for Bayesian Independent Component Analysis. Ph.D. Thesis, Department of Engineering Science, University of Oxford, Oxford, UK, 2003. [Google Scholar]
- Mallat, S. A Wavelet Tour of Signal Processing, 3rd ed.; Academic Press: Cambridge, MA, USA, 2008. [Google Scholar]
- Huang, S.Q.; Liu, D.Z. Some uncertain factor analysis and improvement in spaceborne synthetic aperture radar imaging. Signal Process. 2007, 87, 3202–3217. [Google Scholar] [CrossRef]
- Argenti, F.; Lapini, A.; Bianchi, T.; Alparone, L. A Tutorial on Speckle Reduction in Synthetic Aperture Radar Images. IEEE Geosci. Remote Sens. Mag. 2013, 1, 6–35. [Google Scholar] [CrossRef] [Green Version]
- Lee, J.S. Digital image enhancement and noise filtering by use oflocal statistics. IEEE Trans. Pattern Anal. Mach. Intell. 1980, 2, 165–168. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kuan, D.T.; Sawchuk, A.A.; Strand, T.C.; Chavel, P. Adaptive noise smoothing filter for images with signal-dependent noise. IEEE Trans. Pattern Anal. Mach. Intell. 1985, 7, 165–177. [Google Scholar] [CrossRef] [PubMed]
- Frost, V.S.; Stiles, J.A.; Shanmugan, K.S.; Holtzman, J.C. A Model for Radar Images and Its Application to Adaptive Digital Filtering of Multiplicative Noise. IEEE Trans. Pattern Anal. Mach. Intell. 1982, 4, 157–166. [Google Scholar] [CrossRef] [PubMed]
- Lopes, A.; Nezry, E.; Touzi, R.; Laur, H. Structure detection and statistical adaptive speckle filtering in SAR images. Int. J. Remote Sens. 1993, 14, 1735–1758. [Google Scholar] [CrossRef]
- Bernardo, J.M.; Smith, A.F.M. Bayesian Theory; John Wiley & Sons: New York, NY, USA, 1994. [Google Scholar]
- Sun, B.; Chen, J.; Tovar, E.J.; Qiao, Z.G. Unbiased-average minimum biased diffusion speckle denoising approach for synthetic aperture radar images. J. Appl. Remote Sens. 2015, 9, 1–13. [Google Scholar] [CrossRef] [Green Version]
- ESA Earth Online, Radar Course. Available online: https://earth.esa.int/web/guest/missions/esa-operational-eo-missions/ers/instruments/sar/applications/radar-courses/course-3 (accessed on 30 May 2021).
- Image Interpretation. Available online: https://earth.esa.int/web/guest/missions/esa-operational-eo-missions/ers/instruments/sar/applications/radar-courses/content-3/-/asset_publisher/mQ9R7ZVkKg5P/content/radar-course-3-image-interpretation-tone (accessed on 20 November 2019).
- Argenti, F.; Alparone, L. Speckle Removal from SAR Images in the Undecimated Wavelet Domain. IEEE Trans. Geosci. Remote Sens. 2002, 40, 2363–2374. [Google Scholar] [CrossRef]
- Kseneman, M.; Gleich, D. Information Extraction and Despeckling of SAR Images with Second Generation of Wavelet Transform; Advances in Wavelet Theory and Their Applications in Engineering, Physics and Technology; IntechOpen: Rijeka, Croatia, 2012. [Google Scholar] [CrossRef] [Green Version]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corr. Coef. | SNR (dB) | PSNR (dB) | ENL | EPI | RAE | |
|---|---|---|---|---|---|---|
| Median filter | 0.9950 | 12.171 | 28.907 | 57.565 | 0.7500 | −0.013079 |
| Lee filter | 0.8734 | 5.1333 | 14.831 | 84.751 | 0.3985 | −0.2191 |
| Kuan filter | 0.9935 | 11.593 | 27.750 | 50.878 | 0.5680 | −0.025053 |
| Frost filter | 0.9974 | 13.566 | 31.696 | 157.22 | 0.9427 | −7.8217 |
| GMAP filter | 0.9911 | 10.856 | 26.277 | 63.864 | 0.7497 | −0.051018 |
| VB Wavelets | 0.9990 | 15.384 | 35.332 | 633.14 | 0.9720 | 1.3528 |
| Corr. Coef. | SNR (dB) | PSNR (dB) | ENL | EPI | RAE | |
|---|---|---|---|---|---|---|
| Median filter | 0.9890 | 10.431 | 25.427 | 31.717 | 0.5621 | −0.023736 |
| Lee filter | 0.8723 | 5.1149 | 14.794 | 57.672 | 0.3222 | −0.2188 |
| Kuan filter | 0.9898 | 10.625 | 25.814 | 34.399 | 0.4656 | −0.027765 |
| Frost filter | 0.9960 | 12.643 | 29.850 | 85.742 | 0.9225 | −8.1316 |
| GMAP filter | 0.9899 | 10.598 | 25.760 | 46.723 | 0.6776 | −0.049878 |
| VB Wavelets | 0.9980 | 13.753 | 32.071 | 276.57 | 0.9560 | 5.8928 |
| ENL | EPI | RAE | |
|---|---|---|---|
| Median filter | 14.280 | 0.6333 | 0.029565 |
| Lee filter | 32.158 | 0.5156 | −0.073089 |
| Kuan filter | 17.112 | 0.6340 | −0.011139 |
| Frost filter | 27.402 | 0.5144 | −5.0381 |
| Gamma MAP filter | 28.623 | 0.6197 | −0.020175 |
| Enhanced Gamma MAP | 47.294 | 0.5561 | 0.1333 |
| VB Wavelet Method | 55.696 | 0.6648 | 6.7503 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roussos, E. Variational Bayesian Learning of SMoGs: Modelling and Their Application to Synthetic Aperture Radar. Math. Comput. Appl. 2021, 26, 45. https://doi.org/10.3390/mca26020045
Roussos E. Variational Bayesian Learning of SMoGs: Modelling and Their Application to Synthetic Aperture Radar. Mathematical and Computational Applications. 2021; 26(2):45. https://doi.org/10.3390/mca26020045
Chicago/Turabian StyleRoussos, Evangelos. 2021. "Variational Bayesian Learning of SMoGs: Modelling and Their Application to Synthetic Aperture Radar" Mathematical and Computational Applications 26, no. 2: 45. https://doi.org/10.3390/mca26020045
APA StyleRoussos, E. (2021). Variational Bayesian Learning of SMoGs: Modelling and Their Application to Synthetic Aperture Radar. Mathematical and Computational Applications, 26(2), 45. https://doi.org/10.3390/mca26020045