CTESN surrogates are created for three problems. First, Robertson’s equations are solved, parametrizing the rates of reaction and initial condition separately. Then, the Sliding Basepoint system is modeled, comparing explicitly the difference due to the projection method and parametrizing the initial conditions of the problem. Finally, the POLLU system is solved, again parametrizing the initial conditions of the problem and comparing the results obtained using differing projection methods. Unless mentioned otherwise, the training data were sampled from the DoE space randomly.
In all results in this section, the MAE is computed as
where
is the number of test cases;
and
are the prediction and true solution, respectively, for the
ith timestep of the
jth test case.
3.1. Robertson’s Equations
The first demonstrated application is the surrogate modeling of the Robertson Equations [
19]. They are written as:
where
, and
represent the concentration of the reactant species and
, and
represent the fixed rates of reaction. The system is usually subject to initial conditions of
.
They are a system of ODEs that describe a standard rate process and are often used to benchmark numerical ODE solvers due to the stiffness of the system. More specifically, the long-time integration of Robertson’s equations is known to be a challenging problem for numerical ODE solvers, and the system hence serves as a good test for surrogate models. In this work, models are created by parametrizing the system in two ways; first, the rates of reaction are parametrized. This has been the focus of several other papers written on CTESNs [
21,
27]. Second, the initial conditions of the system are parametrized.
3.1.1. Parametrizing Rates of Reaction
In this section, the Design of Experiment (DoE) space for the rates is given as:
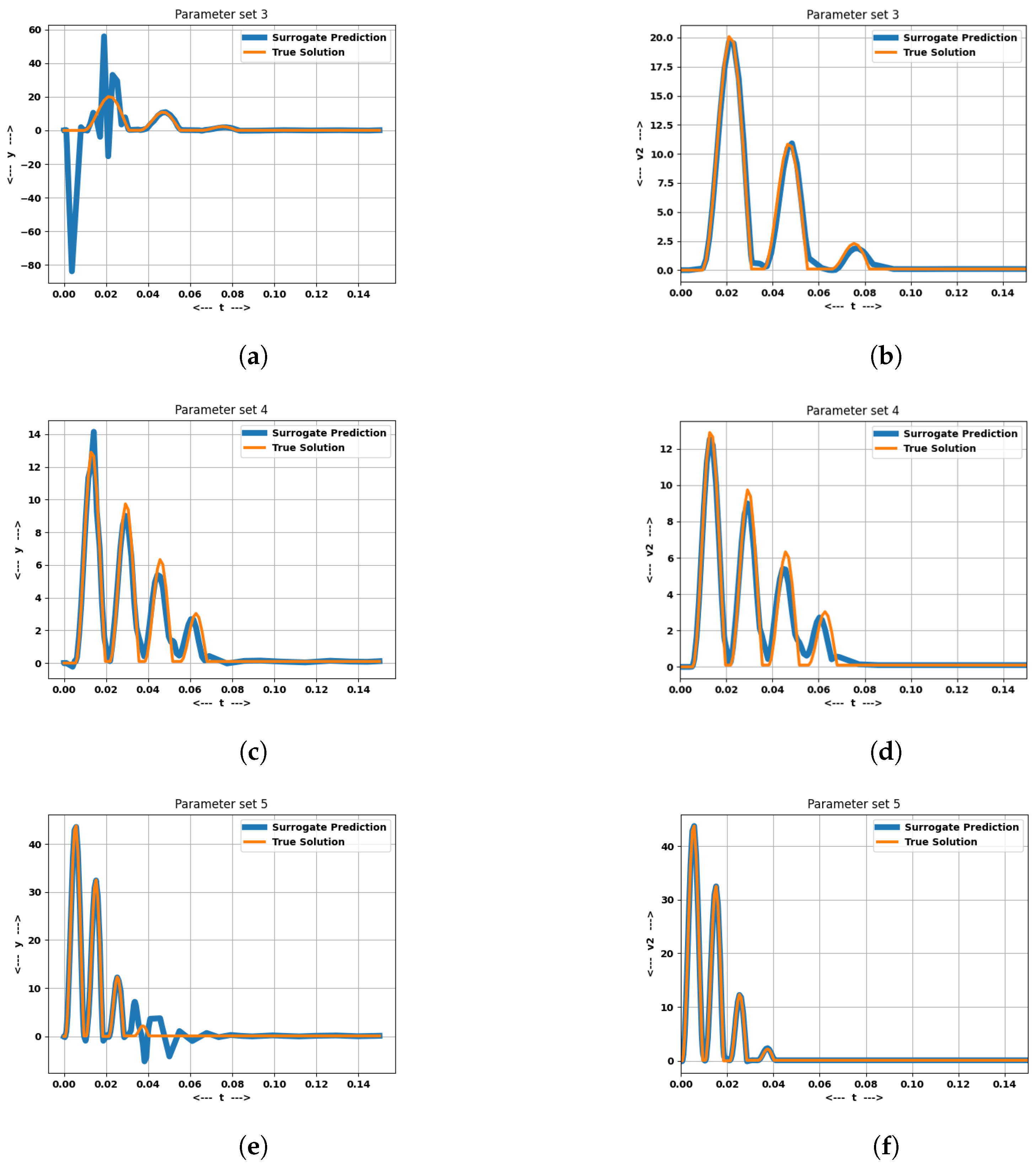
The focus is limited to presenting the results of the prediction of the variable . This variable has a sharp transient that occurs at a time scale much smaller than the other two, and hence causes the system to be stiff.
The average MAE for
, averaged across several test cases listed in
Table 1, is shown in
Table 2 sorted in descending order of generalization MAE. Predictions for
for a particular test parameter are shown in
Figure 2. For the same hyper-parameters, it can be observed that the absence of either the augmenting polynomial or the k-NN interpolation (i.e., using all collocation points to predict the solution in the RBF) significantly increases the error of prediction. It can also be seen that the nonlinear projection performs better on average than the linear projection.
In the next section, the initial condition of Robertson’s ODE is parametrized, and a similar error analysis is performed.
3.1.2. Parametrizing Initial Conditions
The initial condition of the system is parametrized. This problem can be challenging for lower initial values of
(0) as it leads to a smaller and sharper transient in
, which becomes more difficult to capture accurately by the surrogate. The DoE space of the initial condition is given as
The condition for is decided on the basis that the sum of all quantities should always equal to 1. Once more, the focus is on comparing the predicted results in .
Table 3 tabulates the average MAE across all test cases for the problem, listed in
Table 4, sorted in descending order.
Figure 3 shows the comparison for a test parameter, across five different configurations of the CTESN surrogate model. A similar trend of hyper-parameter performance as seen in
Table 2 is noted, in that the absence of the k-NN interpolation increases the error of the prediction. For the same hyper-parameters, the nonlinear projection once again achieves lower generalization MAE than the linear projection.
3.2. Sliding Basepoint Model
Finally, the discussed methods are applied to the surrogate modeling of a realistic crash safety design problem. A system of ODEs proposed by Horváth et al. [
28] that approximately models an automobile collision is solved via a created surrogate model. This system, called the Sliding Basepoint model, has parameters that were fitted on realistic crash data and are assumed to accurately model a collision problem.
Figure 4 depicts the system at its initial state and at a later time. The system is given as:
where
refer to the masses, total forces on, positions, and velocities of the bodies, respectively.
in reality reflects the mass of the chassis of the car;
behaves similarly to the deformation of the bumper.
represents the spring force:
between the two masses and
P represents the power of dissipation
Finally, the forces are computed based on best-fit models described in the paper:
The values of the fixed parameters are given in
Table 5, and the parameter values changed while testing the surrogate are listed in
Table 6. The reader is referred to the paper [
28] for further details. The system is subject to initial conditions
.
The mechanics of crash and impact problems are known to have sharp transients and highly oscillatory behaviors associated with them, making their numerical solutions slow and costly to compute for a wide range of parameters. Hence, CTESNs will be a good surrogate modeling tool for the problem.
In this work, the initial conditions of the problem ( and ) are parametrized to simulate different impact velocities and directions (the spring constant of the bumper can be assumed to be different in different directions). The state space for the problem is the vector .
The DoE space is the range:
chosen to represent a wide range of speeds and stiffness constants. The DoE space was sampled using a space-filling sampling strategy [
29] and the surrogate models were trained on 100 data points, and data were generated using a stiff ODE solver using solver parameters given in [
28].
Table 7 shows the average MAE for the state variable
for the linear and nonlinear projection methods, all other hyper-parameters being kept the same, for test parameters listed in
Table 5.
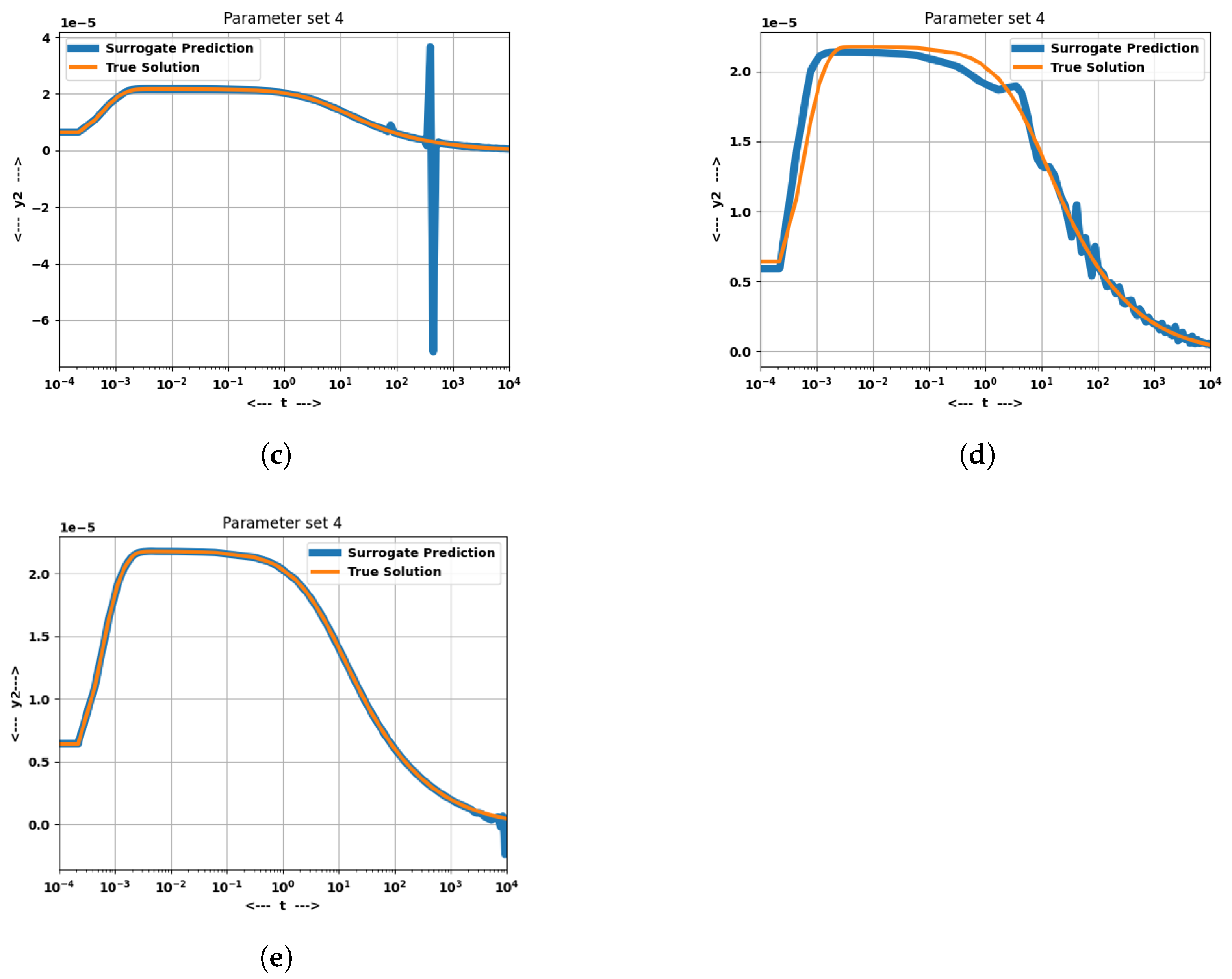
was chosen to demonstrate the accuracy of the surrogates because, as is visible in
Figure 5, it has sharp nonlinear oscillatory transients starting from the moment of collision, which is difficult to capture for surrogate models. It can be seen from
Table 7 and
Figure 5 that the LPCTESN has a poorer performance on test cases compared to the NLPCTESN.
Of particular interest is the speedup obtained by using the surrogate; this leads to up to a 200× speedup in the prediction of the solution, the ODE solver taking roughly 0.02 s per solve of the ODE system. This is important because the transients in
Figure 5 occur at the same time scale
. With a 200× speedup, if the surrogate is deployed on board a vehicle, it can judge the severity of the collision much more quickly by computing impact forces from the result of the system, and closed-loop control and safety measures can be deployed. In this case, it would effectively function as a digital twin for collision monitoring.
3.3. The POLLU Model
The CTESN approach is used to model the POLLU air pollution model developed at the Dutch National Institute of Public Health and Environmental Protection [
20]. It consists of 20 species and 25 reactions, modeled by nonlinear ODEs of the form
where
y is the concentration vector (in ppm) of the reacting species,
P is the production term, and
L is a diagonal matrix representing the loss term for every species in the system.
Table 8 shows the production and loss rates for each species of the system. The values of the rate constants
r are given in
Table A1. The reader is referred to the paper [
20] for a complete description of the reaction system.
The system is a common benchmark for stiff ODE solvers and represents a difficult problem to solve due to the large number of species and ODEs involved. When such systems have to be solved at many grid points, say, in a computational mesh, they represent a very expensive computation and hence this example is an ideal application for testing surrogates of stiff ODEs. In this work, the initial conditions of the system are simultaneously parametrized, according to the following:
Here,
,
, and
refer to the initial concentration of the respective species. The initial conditions for the rest of the species are default as per the paper [
20].
The training data were sampled using 100 data points within this DoE space, selected randomly. The reservoir size
was set to 100, and the number of queried neighbors
by the k-NN RBF was set to 10.
Table 9 shows the mean absolute errors computed across several test cases (listed in
Table 10) for a few species in the reaction, for the linear and nonlinear projection methods. It can be observed that the nonlinear projection CTESN outperforms the linear projection CTESN when all other hyper-parameters are kept the same.
Figure 6 shows the comparison of the prediction graphically; the LPCTESN prediction is much noisier than the NLPCTESN prediction at later times. This was also observed with Robertson’s equations, where the predictions at larger time scales by the LPCTESN tended to become noisier.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}







