
FutureCite: Predicting Research Articles’ Impact Using Machine Learning and Text and Graph Mining Techniques


Abstract

1. Introduction
2. Materials
- First, the research paper data we utilized to extract text and metadata features in our dataset consists of 11,941 papers. However, after applying different filters to the dataset (described in the cleaning and preprocessing phase), we obtained 6560 research papers. Thus, the size of our dataset is moderate.
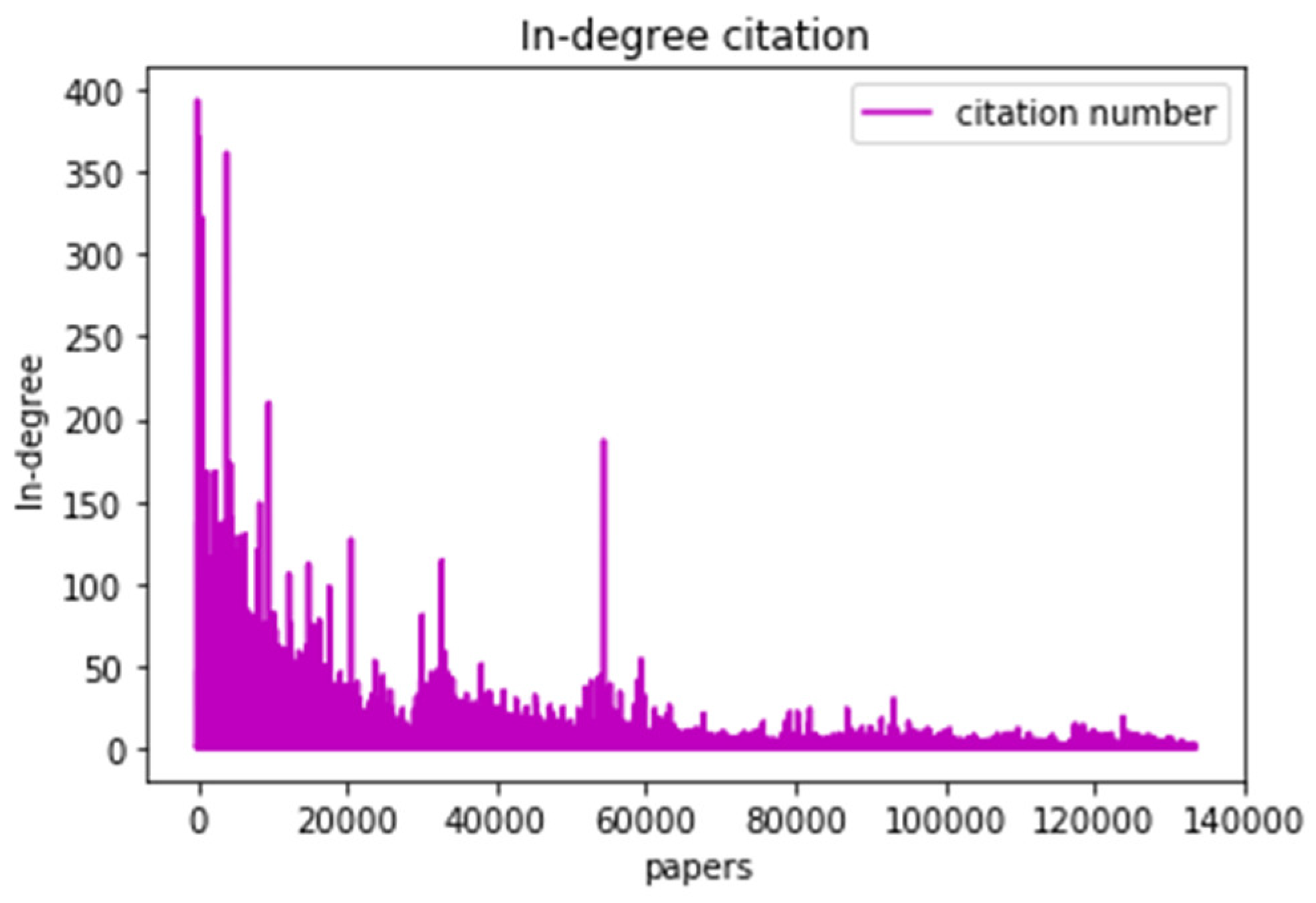
- Second, the citation graph data, where all papers and their corresponding references are provided, formulate citation edge lists consisting of 133,482 papers and 335,531 relationships (i.e., citations). This citation graph is utilized to define the class labels using different thresholds for each label. These thresholds were selected based on the distribution of citation counts in the dataset, as will be explained later.
- The third type is the Author–Coauthor Graph, comprising 10,270 authors and 26,963 author–coauthor relationships.
- The fourth and last data type, the Author–Research graph, consists of 10,270 authors and 6560 publications and the relations between them.
3. Methods
3.1. Problem Formulation
3.2. FutureCite Model Workflow
- Data preparation and preprocessing;
- Feature extraction and integration. These features are grouped based on three categories: graph-based, text-based, and metadata-based.
- Data normalization and sampling;
- Class label preparation;
- ML classification, where several classifiers are built for class prediction.
3.3. Class Label Creation
3.4. Data Preprocessing and Feature Extraction
3.4.1. Metadata-Based Features
3.4.2. Text-Based Features
3.4.3. Graph-Based Features
- Node Degree—CD(v) [38]: represents the sum of all edges connected to a node v. In a directed graph, the degree can be divided into two categories: in-degree and out-degree.
- Page Rank [39], equivalent to the eigenvector centrality CE of node v, measures the node’s importance based on its neighboring nodes’ importance.
- Betweenness Centrality CB [40] of a node v counts the shortest paths that pass through the node. It is calculated using the following equation:
3.4.4. Features Integration
3.5. FutureCite Predictive Model
3.5.1. Sampling Techniques for Imbalanced Data
3.5.2. Multilabel Classification Model
- Python 3.3 [47] is used for implementing all project phases, including preprocessing, feature extraction, training and validation, and classification. We utilized several supported packages, including scikit-learn for ML algorithms, NetworkX for graph mining [48], imblearn package [49] to handle imbalanced class labels, Matplotlib to plot different figures, and Pandas data frame to deal with the data preparation and preprocessing [50].
- Gephi 0.9.2. [51]: Gephi is used to visualize and analyze graph data, including the author–coauthor and citation graphs. The data are preprocessed and prepared to be in a suitable shape for this tool. Gephi allows us to explore the structure of the citation network and gain valuable insights into the relationships between different research papers, authors, and venues. These tools are essential for developing a comprehensive method for predicting the future citation level of research papers.
4. Results and Discussion
4.1. Evaluation Metrics and Protocols
4.2. FutureCite Prediction Performance Evaluation
5. Conclusions, Remarks, and Recommendations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alamro, H.; Thafar, M.A.; Albaradei, S.; Gojobori, T.; Essack, M.; Gao, X. Exploiting machine learning models to identify novel Alzheimer’s disease biomarkers and potential targets. Sci. Rep. 2023, 13, 4979. [Google Scholar] [CrossRef] [PubMed]
- Dong, Y.; Chawla, N.V.; Swami, A. Metapath2Vec: Scalable Representation Learning for Heterogeneous Networks. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 135–144. [Google Scholar]
- Thafar, M.A.; Albaradie, S.; Olayan, R.S.; Ashoor, H.; Essack, M.; Bajic, V.B. Computational Drug-target Interaction Prediction based on Graph Embedding and Graph Mining. In Proceedings of the 2020 10th International Conference on Bioscience, Biochemistry and Bioinformatics, Kyoto, Japan, 19–22 January 2020; pp. 14–21. [Google Scholar]
- Thafar, M.A.; Alshahrani, M.; Albaradei, S.; Gojobori, T.; Essack, M.; Gao, X. Affinity2Vec: Drug-target binding affinity prediction through representation learning, graph mining, and machine learning. Sci. Rep. 2022, 12, 4751. [Google Scholar] [CrossRef] [PubMed]
- Thafar, M.A.; Olayan, R.S.; Ashoor, H.; Albaradei, S.; Bajic, V.B.; Gao, X.; Gojobori, T.; Essack, M. DTiGEMS+: Drug–target interaction prediction using graph embedding, graph mining, and similarity-based techniques. J. Cheminformatics 2020, 12, 44. [Google Scholar] [CrossRef] [PubMed]
- Frenken, K.; Hoekman, J.; Ding, Y.; Rousseau, R.; Wolfram, D. Measuring Scholarly Impact: Methods and Practice; Springer: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Butun, E.; Kaya, M. Predicting Citation Count of Scientists as a Link Prediction Problem. IEEE Trans. Cybern. 2020, 50, 4518–4529. [Google Scholar] [CrossRef] [PubMed]
- Ali, Z.; Kefalas, P.; Muhammad, K.; Ali, B.; Imran, M. Deep learning in citation recommendation models survey. Expert Syst. Appl. 2020, 162, 113790. [Google Scholar] [CrossRef]
- Alshahrani, M.; Almansour, A.; Alkhaldi, A.; Thafar, M.A.; Uludag, M.; Essack, M.; Hoehndorf, R. Combining biomedical knowledge graphs and text to improve predictions for drug-target interactions and drug-indications. PeerJ 2022, 10, e13061. [Google Scholar] [CrossRef] [PubMed]
- Gupta, A.; Dengre, V.; Kheruwala, H.A.; Shah, M. Comprehensive review of text-mining applications in finance. Financ. Innov. 2020, 6, 39. [Google Scholar] [CrossRef]
- Thafar, M.A.; Albaradei, S.; Uludag, M.; Alshahrani, M.; Gojobori, T.; Essack, M.; Gao, X. OncoRTT: Predicting novel oncology-related therapeutic targets using BERT embeddings and omics features. Front. Genet. 2023, 14, 1139626. [Google Scholar] [CrossRef] [PubMed]
- Akujuobi, U.; Sun, K.; Zhang, X. Mining top-k Popular Datasets via a Deep Generative Model. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 584–593. [Google Scholar]
- Castano, S.; Ferrara, A.; Montanelli, S. Topic summary views for exploration of large scholarly datasets. J. Data Semant. 2018, 7, 155–170. [Google Scholar] [CrossRef]
- West, J.D.; Wesley-Smith, I.; Bergstrom, C.T. A Recommendation System Based on Hierarchical Clustering of an Article-Level Citation Network. IEEE Trans. Big Data 2016, 2, 113–123. [Google Scholar] [CrossRef]
- Weis, J.W.; Jacobson, J.M. Learning on knowledge graph dynamics provides an early warning of impactful research. Nat. Biotechnol. 2021, 39, 1300–1307. [Google Scholar] [CrossRef] [PubMed]
- Xia, W.; Li, T.; Li, C. A review of scientific impact prediction: Tasks, features and methods. Scientometrics 2023, 128, 543–585. [Google Scholar] [CrossRef]
- Heimerl, F.; Han, Q.; Koch, S.; Ertl, T. CiteRivers: Visual Analytics of Citation Patterns. IEEE Trans. Vis. Comput. Graph. 2016, 22, 190–199. [Google Scholar] [CrossRef]
- Lu, M.; Qu, Z.; Wang, M.; Qin, Z. Recommending authors and papers based on ACTTM community and bilayer citation network. China Commun. 2018, 15, 111–130. [Google Scholar] [CrossRef]
- Pobiedina, N.; Ichise, R. Citation count prediction as a link prediction problem. Appl. Intell. 2016, 44, 252–268. [Google Scholar] [CrossRef]
- Samad, A.; Islam, M.A.; Iqbal, M.A.; Aleem, M. Centrality-Based Paper Citation Recommender System. EAI Endorsed Trans. Ind. Netw. Intell. Syst. 2019, 6, e2. [Google Scholar] [CrossRef]
- Kanellos, I.; Vergoulis, T.; Sacharidis, D.; Dalamagas, T.; Vassiliou, Y. Impact-based ranking of scientific publications: A survey and experimental evaluation. IEEE Trans. Knowl. Data Eng. 2019, 33, 1567–1584. [Google Scholar] [CrossRef]
- Sterling, J.A.; Montemore, M.M. Combining Citation Network Information and Text Similarity for Research Article Recommender Systems. IEEE Access 2022, 10, 16–23. [Google Scholar] [CrossRef]
- Jiang, S.; Koch, B.; Sun, Y. HINTS: Citation Time Series Prediction for New Publications via Dynamic Heterogeneous Information Network Embedding. In Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 3158–3167. [Google Scholar]
- Thafar, M.A.; Olayan, R.S.; Albaradei, S.; Bajic, V.B.; Gojobori, T.; Essack, M.; Gao, X. DTi2Vec: Drug-target interaction prediction using network embedding and ensemble learning. J. Cheminformatics 2021, 13, 71. [Google Scholar] [CrossRef]
- Alshahrani, M.; Thafar, M.A.; Essack, M. Application and evaluation of knowledge graph embeddings in biomedical data. PeerJ Comput. Sci. 2021, 7, e341. [Google Scholar] [CrossRef]
- Ganguly, S.; Pudi, V. Paper2vec: Combining Graph and Text Information for Scientific Paper Representation. In Advances in Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2017; pp. 383–395. [Google Scholar]
- Akujuobi, U.; Zhang, X. Delve: A Dataset-Driven Scholarly Search and Analysis System. SIGKDD Explor. Newsl. 2017, 19, 36–46. [Google Scholar] [CrossRef]
- Mingers, J.; Macri, F.; Petrovici, D. Using the h-index to measure the quality of journals in the field of business and management. Inf. Process. Manag. 2012, 48, 234–241. [Google Scholar] [CrossRef]
- Zhang, W.; Yoshida, T.; Tang, X. A comparative study of TF*IDF, LSI and multi-words for text classification. Expert Syst. Appl. 2011, 38, 2758–2765. [Google Scholar] [CrossRef]
- Aljehane, S.; Alshahrani, R.; Thafar, M. Visualizing the Top 400 Universities. 2015. Available online: https://www.researchgate.net/profile/Maha-Thafar/publication/285927843_Visualizing_the_Top_400_Universities/links/5664c6cd08ae192bbf90aa9c/Visualizing-the-Top-400-Universities.pdf (accessed on 1 July 2023).
- Shakeel, H.M.; Iram, S.; Al-Aqrabi, H.; Alsboui, T.; Hill, R. A Comprehensive State-of-the-Art Survey on Data Visualization Tools: Research Developments, Challenges and Future Domain Specific Visualization Framework. IEEE Access 2022, 10, 96581–96601. [Google Scholar] [CrossRef]
- Opsahl, T.; Agneessens, F.; Skvoretz, J. Node centrality in weighted networks: Generalizing degree and shortest paths. Soc. Netw. 2010, 32, 245–251. [Google Scholar] [CrossRef]
- Albaradei, S.; Napolitano, F.; Thafar, M.A.; Gojobori, T.; Essack, M.; Gao, X. MetaCancer: A deep learning-based pan-cancer metastasis prediction model developed using multi-omics data. Comput. Struct. Biotechnol. J. 2021, 19, 4404–4411. [Google Scholar] [CrossRef]
- Albaradei, S.; Alganmi, N.; Albaradie, A.; Alharbi, E.; Motwalli, O.; Thafar, M.A.; Gojobori, T.; Essack, M.; Gao, X. A deep learning model predicts the presence of diverse cancer types using circulating tumor cells. Sci. Rep. 2023, 13, 21114. [Google Scholar] [CrossRef]
- De, S.S.; Dehuri, S.; Cho, S.-B. Research contributions published on betweenness centrality algorithm: Modelling to analysis in the context of social networking. Int. J. Soc. Netw. Min. 2020, 3, 1–34. [Google Scholar] [CrossRef]
- Salavati, C.; Abdollahpouri, A.; Manbari, Z. Ranking nodes in complex networks based on local structure and improving closeness centrality. Neurocomputing 2019, 336, 36–45. [Google Scholar] [CrossRef]
- Albaradei, S.; Uludag, M.; Thafar, M.A.; Gojobori, T.; Essack, M.; Gao, X. Predicting bone metastasis using gene expression-based machine learning models. Front. Genet. 2021, 12, 771092. [Google Scholar] [CrossRef]
- Evans, T.S.; Chen, B. Linking the network centrality measures closeness and degree. Commun. Phys. 2022, 5, 172. [Google Scholar] [CrossRef]
- Zhang, P.; Wang, T.; Yan, J. PageRank centrality and algorithms for weighted, directed networks. Phys. A Stat. Mech. Its Appl. 2022, 586, 126438. [Google Scholar] [CrossRef]
- Prountzos, D.; Pingali, K. Betweenness centrality: Algorithms and implementations. In Proceedings of the 18th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Shenzhen, China, 23–27 February 2013; pp. 35–46. [Google Scholar]
- Liu, A.; Ghosh, J.; Martin, C.E. Generative Oversampling for Mining Imbalanced Datasets. DMIN 2007, 7, 66–72. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A python toolbox to tackle the curse of imbalanced datasets in machine learning. J. Mach. Learn. Res. JMLR 2017, 18, 559–563. [Google Scholar]
- Suthaharan, S. Support Vector Machine. In Machine Learning Models and Algorithms for Big Data Classification: Thinking with Examples for Effective Learning; Suthaharan, S., Ed.; Springer: New York, NY, USA, 2016; pp. 207–235. [Google Scholar]
- Ting, S.L.; Ip, W.H.; Tsang, A.H.C. Is Naive Bayes a good classifier for document classification. Int. J. Softw. Eng. Appl. 2011, 5, 37–46. [Google Scholar]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Chen, T.; Guestrin, C. XGBoost: A Scalable Tree Boosting System. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Van Rossum, G. Python Programming Language. USENIX Annual Technical. 2007. Available online: http://kelas-karyawan-bali.kurikulum.org/IT/en/2420-2301/Python_3721_kelas-karyawan-bali-kurikulumngetesumum.html (accessed on 25 March 2024).
- Platt, E.L. Network Science with Python and NetworkX Quick Start Guide: Explore and Visualize Network Data Effectively; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- He, H.; Ma, Y. Imbalanced Learning: Foundations, Algorithms, and Applications; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Nelli, F. Python Data Analytics: Data Analysis and Science Using Pandas, Matplotlib and the Python Programming Language; Apress: New York, NY, USA, 2015. [Google Scholar]
- Yang, J.; Cheng, C.; Shen, S.; Yang, S. Comparison of complex network analysis software: Citespace, SCI 2 and Gephi. In Proceedings of the 2017 IEEE 2nd International Conference on Big Data Analysis (ICBDA), Beijing, China, 10–12 March 2017; pp. 169–172. [Google Scholar]
- Maria Navin, J.R.; Pankaja, R. Performance analysis of text classification algorithms using confusion matrix. Int. J. Eng. Tech. Res. IJETR 2016, 6, 75–78. [Google Scholar]
- Powers, D.M. Evaluation: From Precision, Recall and F-Measure to ROC, Informedness, Markedness and Correlation. 2011. Available online: https://arxiv.org/abs/2010.16061 (accessed on 25 March 2024).
- Jeh, G.; Widom, J. SimRank: A measure of structural-context similarity. In Proceedings of the Eighth ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Edmonton, AB, Canada, 23–26 July 2002; pp. 538–543. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper ID | In-Degree |
|---|---|
| 085B9585 | 394 |
| 812313D9 | 371 |
| 70128864 | 362 |
| 641D5808 | 337 |
| 59C818AC | 327 |
| Rule | Class Label | Label Description | Number of Research Papers in This Class |
|---|---|---|---|
| In-degree > 50 | 1 | Highly cited | 44 |
| In-degree > 20 | 2 | Well cited | 180 |
| In-degree > 5 | 3 | Above/ average cited | 1118 |
| In-degree ≤ 5 | 4 | Below average cited | 5218 |
| Author Name | Degree | PageRank | Betweenness Centrality |
|---|---|---|---|
| PHLIP YU | 165 | 0.002163 | 0.068579 |
| CHRISTOS FALOUTSOS | 182 | 0.002010 | 0.066565 |
| JIAWEI HAN | 224 | 0.002468 | 0.063534 |
| HEIKKI MANNILA | 57 | 0.000814 | 0.020424 |
| QIANG YANG | 88 | 0.001045 | 0.019324 |
| Classifier | Precision | Recall | F1-Score |
|---|---|---|---|
| SVM | 77.9% | 75.6% | 76.73% |
| NB | 74.2% | 64.6% | 69.08% |
| RF | 81.5% | 78.8% | 80.13% |
| XGBoost | 82.4% | 80.3% | 81.30% |
| Features Category | Classifier | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Text-based features | RF | 79.7% | 77.2% | 78.43 % |
| XGBoost | 81.3% | 78.7% | 80.00% | |
| Integrated features: text-based, graph-based, and metadata-based | RF | 81.5% | 78.8% | 80.13% |
| XGBoost | 82.4% | 80.3% | 81.30% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thafar, M.A.; Alsulami, M.M.; Albaradei, S. FutureCite: Predicting Research Articles’ Impact Using Machine Learning and Text and Graph Mining Techniques. Math. Comput. Appl. 2024, 29, 59. https://doi.org/10.3390/mca29040059
Thafar MA, Alsulami MM, Albaradei S. FutureCite: Predicting Research Articles’ Impact Using Machine Learning and Text and Graph Mining Techniques. Mathematical and Computational Applications. 2024; 29(4):59. https://doi.org/10.3390/mca29040059
Chicago/Turabian StyleThafar, Maha A., Mashael M. Alsulami, and Somayah Albaradei. 2024. "FutureCite: Predicting Research Articles’ Impact Using Machine Learning and Text and Graph Mining Techniques" Mathematical and Computational Applications 29, no. 4: 59. https://doi.org/10.3390/mca29040059
APA StyleThafar, M. A., Alsulami, M. M., & Albaradei, S. (2024). FutureCite: Predicting Research Articles’ Impact Using Machine Learning and Text and Graph Mining Techniques. Mathematical and Computational Applications, 29(4), 59. https://doi.org/10.3390/mca29040059