Time-of-Flight Camera Intensity Image Reconstruction Based on an Untrained Convolutional Neural Network

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Basic Theories and Principles
2.1. Ranging Principle of ToF Cameras
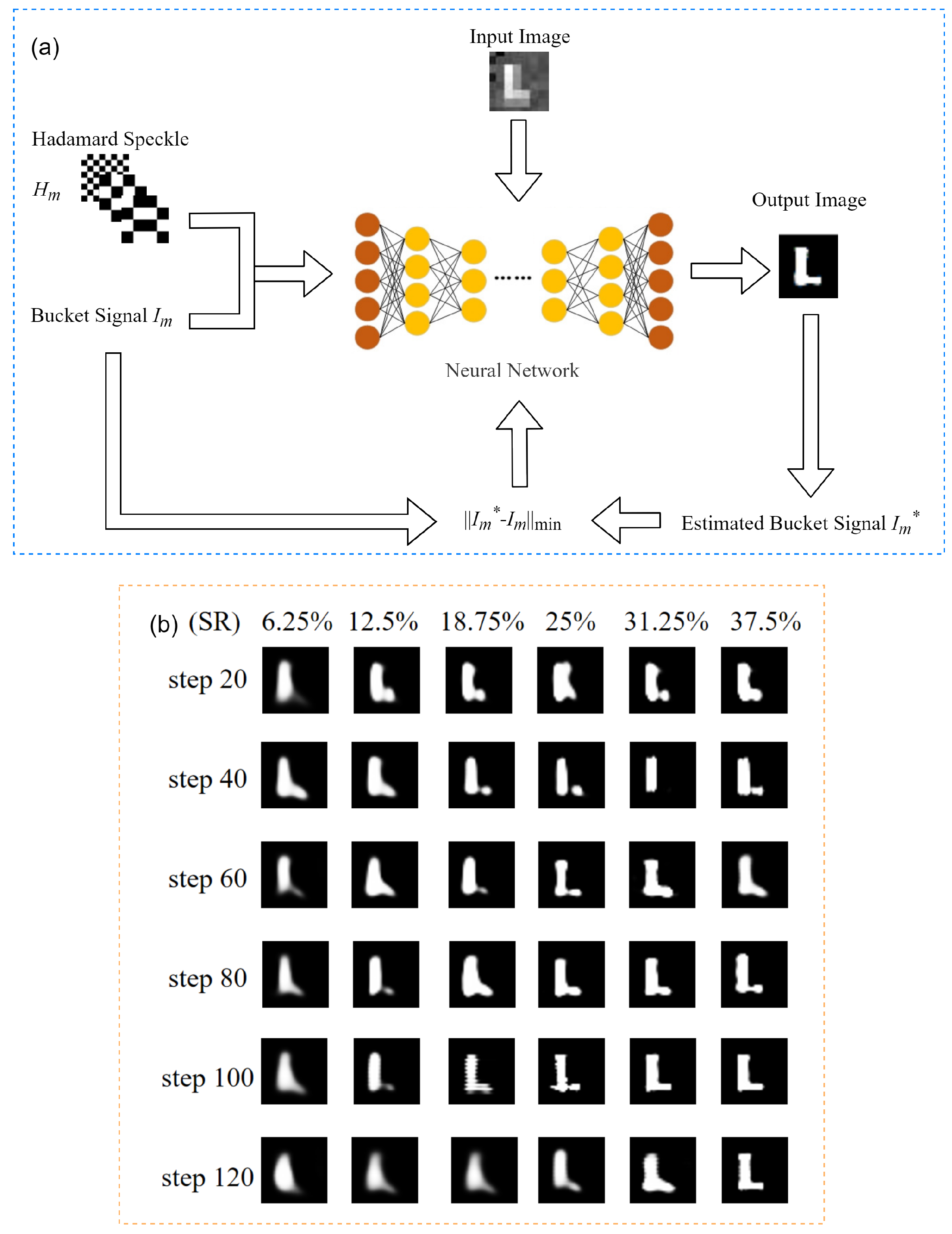
2.2. Untrained Neural Network Architecture
3. Experimental Scheme and Analysis of Results
3.1. Introduction to the Experimental Setup and Experimental Principles
3.2. Experimental Results and Cause Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Liu, Y.; Pears, N.; Rosin, P.L.; Huber, P. 3D Imaging, Analysis and Applications; Springer: London, UK, 2020. [Google Scholar]
- Foix, S.; Alenya, G.; Torras, C. Lock-in Time-of-Flight (ToF) Cameras: A Survey. IEEE Sens. J. 2011, 11, 1917–1926. [Google Scholar] [CrossRef]
- Oggier, T.; Lehmann, M.; Kaufmann, R.; Schweizer, M.; Richter, M.; Metzler, P.; Lang, G.; Lustenberger, F.; Blanc, N. An all-solid-state optical range camera for 3D real-time imaging with sub-centimeter depth resolution (SwissRanger). In Proceedings of the Optical Design and Engineering, St. Etienne, France, 30 September–3 October 2003; SPIE: Bellingham, WA, USA, 2004; Volume 5249, pp. 534–545. [Google Scholar] [CrossRef]
- Plagemann, C.; Ganapathi, V.; Koller, D.; Thrun, S. Real-time identification and localization of body parts from depth images. In Proceedings of the 2010 IEEE International Conference on Robotics and Automation, Anchorage, AK, USA, 3–7 May 2010; pp. 3108–3113. [Google Scholar]
- Velten, A.; Wu, D.; Jarabo, A.; Masia, B.; Barsi, C.; Joshi, C.; Lawson, E.; Bawendi, M.; Gutierrez, D.; Raskar, R. Femto-photography: Capturing and visualizing the propagation of light. ACM Trans. Graph. (ToG) 2013, 32, 1–8. [Google Scholar] [CrossRef]
- Heide, F.; Hullin, M.B.; Gregson, J.; Heidrich, W. Low-budget transient imaging using photonic mixer devices. ACM Trans. Graph. (ToG) 2013, 32, 1–10. [Google Scholar] [CrossRef]
- Kim, Y.; Theobalt, C.; Diebel, J.; Kosecka, J.; Micusík, B.; Thrun, S. Multi-view image and ToF sensor fusion for dense 3D reconstruction. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, 27 September–4 October 2009; pp. 1542–1549. [Google Scholar] [CrossRef]
- Heide, F.; Heidrich, W.; Hullin, M.; Wetzstein, G. Doppler time-of-flight imaging. ACM Trans. Graph. (ToG) 2015, 34, 1–11. [Google Scholar] [CrossRef]
- Kadambi, A.; Whyte, R.; Bhandari, A.; Streeter, L.; Barsi, C.; Dorrington, A.; Raskar, R. Coded time of flight cameras: Sparse deconvolution to address multipath interference and recover time profiles. ACM Trans. Graph. (ToG) 2013, 32, 1–10. [Google Scholar] [CrossRef]
- Ponec, A.J. Single Pixel Amplitude-Modulated Time-of-Flight Camera. In Proceedings of the Physics. 2017. Available online: https://api.semanticscholar.org/CorpusID:18636940 (accessed on 1 August 2024).
- Edgar, M.P.; Sun, M.J.; Gibson, G.M.; Spalding, G.C.; Phillips, D.B.; Padgett, M.J. Real-time 3D video utilizing a compressed sensing time-of-flight single-pixel camera. In Proceedings of the Optical Trapping and Optical Micromanipulation XIII, San Diego, CA, USA, 28 August–1 September 2016; SPIE: Bellingham, WA, USA, 2016; Volume 9922, pp. 171–178. [Google Scholar] [CrossRef]
- Sun, M.J.; Edgar, M.P.; Gibson, G.M.; Sun, B.; Radwell, N.; Lamb, R.; Padgett, M.J. Single-pixel three-dimensional imaging with time-based depth resolution. Nat. Commun. 2016, 7, 12010. [Google Scholar] [CrossRef]
- Gupta, M.; Agrawal, A.; Veeraraghavan, A.; Narasimhan, S.G. A practical approach to 3D scanning in the presence of interreflections, subsurface scattering and defocus. Int. J. Comput. Vis. 2013, 102, 33–55. [Google Scholar] [CrossRef]
- Charbon, E.; Fishburn, M.; Walker, R.; Henderson, R.K.; Niclass, C. SPAD-based sensors. In TOF Range-Imaging Cameras; Springer: Berlin/Heidelberg, Germany, 2013; pp. 11–38. [Google Scholar] [CrossRef]
- Lange, R.; Seitz, P. Solid-state time-of-flight range camera. IEEE J. Quantum Electron. 2001, 37, 390–397. [Google Scholar] [CrossRef]
- Jeremias, R.; Brockherde, W.; Doemens, G.; Hosticka, B.; Listl, L.; Mengel, P. A CMOS photosensor array for 3D imaging using pulsed laser. In Proceedings of the 2001 IEEE International Solid-State Circuits Conference. Digest of Technical Papers. ISSCC (Cat. No. 01CH37177), San Francisco, CA, USA, 7 February 2001; pp. 252–253. [Google Scholar] [CrossRef]
- Buttgen, B.; Seitz, P. Robust optical time-of-flight range imaging based on smart pixel structures. IEEE Trans. Circuits Syst. Regul. Pap. 2008, 55, 1512–1525. [Google Scholar] [CrossRef]
- Albota, M.A.; Aull, B.F.; Fouche, D.G.; Heinrichs, R.M.; Kocher, D.G.; Marino, R.M.; Mooney, J.G.; Newbury, N.R.; O’Brien, M.E.; Player, B.E.; et al. Three-dimensional imaging laser radars with Geiger-mode avalanche photodiode arrays. Linc. Lab. J. 2002, 13, 351–370. [Google Scholar]
- Niclass, C.; Rochas, A.; Besse, P.A.; Charbon, E. Design and characterization of a CMOS 3-D image sensor based on single photon avalanche diodes. IEEE J.-Solid-State Circuits 2005, 40, 1847–1854. [Google Scholar] [CrossRef]
- Walker, R.J.; Richardson, J.A.; Henderson, R.K. A 128×96 pixel event-driven phase-domain ΔΣ-based fully digital 3D camera in 0.13 μm CMOS imaging technology. In Proceedings of the 2011 IEEE International Solid-State Circuits Conference, San Francisco, CA, USA, 20–24 February 2011; pp. 410–412. [Google Scholar] [CrossRef]
- Richardson, J.; Walker, R.; Grant, L.; Stoppa, D.; Borghetti, F.; Charbon, E.; Gersbach, M.; Henderson, R.K. A 32 × 32 50 ps resolution 10 bit time to digital converter array in 130nm CMOS for time correlated imaging. In Proceedings of the 2009 IEEE Custom Integrated Circuits Conference, San Jose, CA, USA, 13–16 September 2009; pp. 77–80. [Google Scholar] [CrossRef]
- Itzler, M.A.; Entwistle, M.; Owens, M.; Patel, K.; Jiang, X.; Slomkowski, K.; Rangwala, S.; Zalud, P.F.; Senko, T.; Tower, J.; et al. Geiger-mode avalanche photodiode focal plane arrays for three-dimensional imaging LADAR. In Proceedings of the Infrared Remote Sensing and Instrumentation XVIII, San Diego, CA, USA, 1–5 August 2010; SPIE: Bellingham, WA, USA, 2010; Volume 7808, pp. 75–88. [Google Scholar] [CrossRef]
- Meadows, D.; Johnson, W.; Allen, J. Generation of surface contours by moiré patterns. Appl. Opt. 1970, 9, 942–947. [Google Scholar] [CrossRef] [PubMed]
- Takeda, M.; Mutoh, K. Fourier transform profilometry for the automatic measurement of 3-D object shapes. Appl. Opt. 1983, 22, 3977–3982. [Google Scholar] [CrossRef] [PubMed]
- Srinivasan, V.; Liu, H.C.; Halioua, M. Automated phase-measuring profilometry of 3-D diffuse objects. Appl. Opt. 1984, 23, 3105–3108. [Google Scholar] [CrossRef] [PubMed]
- Su, X.; Su, L.; Li, W.; Xiang, L. New 3D profilometry based on modulation measurement. In Proceedings of the Automated Optical Inspection for Industry: Theory, Technology, and Applications II, Beijing, China, 16–19 September 1998; SPIE: Bellingham, WA, USA, 1998; Volume 3558, pp. 1–7. [Google Scholar] [CrossRef]
- Dai, H.; Su, X. Shape measurement by digital speckle temporal sequence correlation with digital light projector. Opt. Eng. 2001, 40, 793–800. [Google Scholar] [CrossRef]
- Wada, N.; Bannai, T. A Compact binocular 3D camera-recorder. SMPTE Motion Imaging J. 2011, 120, 54–59. [Google Scholar] [CrossRef]
- Cui, Y.; Schuon, S.; Chan, D.; Thrun, S.; Theobalt, C. 3D shape scanning with a time-of-flight camera. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010; pp. 1173–1180. [Google Scholar] [CrossRef]
- Tamas, L.; Cozma, A. Embedded real-time people detection and tracking with time-of-flight camera. In Proceedings of the Real-Time Image Processing and Deep Learning 2021, Online Only, FL, USA, 12–17 April 2021; SPIE: Bellingham, WA, USA, 2021; Volume 11736, pp. 65–70. [Google Scholar] [CrossRef]
- Takhar, D.; Laska, J.N.; Wakin, M.B.; Duarte, M.F.; Baron, D.; Sarvotham, S.; Kelly, K.F.; Baraniuk, R.G. A new compressive imaging camera architecture using optical-domain compression. In Proceedings of the Computational Imaging IV, San Jose, CA, USA, 15–19 January 2006; SPIE: Bellingham, WA, USA, 2006; Volume 6065, pp. 43–52. [Google Scholar] [CrossRef]
- Xie, J.; Feris, R.S.; Sun, M.T. Edge-guided single depth image super resolution. IEEE Trans. Image Process. 2015, 25, 428–438. [Google Scholar] [CrossRef]
- Song, X.; Dai, Y.; Qin, X. Deep depth super-resolution: Learning depth super-resolution using deep convolutional neural network. In Proceedings of the 13th Asian Conference on Computer Vision, Taipei, Taiwan, 20–24 November 2016; pp. 360–376. [Google Scholar] [CrossRef]
- Kahlmann, T.; Oggier, T.; Lustenberger, F.; Blanc, N.; Ingensand, H. 3D-ToF sensors in the automobile. In Proceedings of the Photonics in the Automobile, Geneva, Switzerland, 29 November–1 December 2004; SPIE: Bellingham, WA, USA, 2005; Volume 5663, pp. 216–224. [Google Scholar] [CrossRef]
- Heide, F.; Xiao, L.; Kolb, A.; Hullin, M.B.; Heidrich, W. Imaging in scattering media using correlation image sensors and sparse convolutional coding. Opt. Express 2014, 22, 26338–26350. [Google Scholar] [CrossRef]
- Shapiro, J.H. Computational ghost imaging. Phys. Rev. A 2008, 78, 061802. [Google Scholar] [CrossRef]
- Pittman, T.B.; Shih, Y.; Strekalov, D.; Sergienko, A.V. Optical imaging by means of two-photon quantum entanglement. Phys. Rev. A 1995, 52, R3429. [Google Scholar] [CrossRef]
- Ferri, F.; Magatti, D.; Gatti, A.; Bache, M.; Brambilla, E.; Lugiato, L.A. High-resolution ghost image and ghost diffraction experiments with thermal light. Phys. Rev. Lett. 2005, 94, 183602. [Google Scholar] [CrossRef]
- Cheng, J. Ghost imaging through turbulent atmosphere. Opt. Express 2009, 17, 7916–7921. [Google Scholar] [CrossRef] [PubMed]
- Yongbo, W.; Zhihui, Y.; Zhilie, T. Experimental study on anti-disturbance ability of underwater ghost imaging. Laser Optoelectron. Prog. 2021, 58, 0611002. [Google Scholar] [CrossRef]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Duarte, M.F.; Davenport, M.A.; Takhar, D.; Laska, J.N.; Sun, T.; Kelly, K.F.; Baraniuk, R.G. Single-pixel imaging via compressive sampling. IEEE Signal Process. Mag. 2008, 25, 83–91. [Google Scholar] [CrossRef]
- Katz, O.; Bromberg, Y.; Silberberg, Y. Compressive ghost imaging. Appl. Phys. Lett. 2009, 95, 131110. [Google Scholar] [CrossRef]
- Shapiro, J.H.; Boyd, R.W. The physics of ghost imaging. Quantum Inf. Process. 2012, 11, 949–993. [Google Scholar] [CrossRef]
- Erkmen, B.I.; Shapiro, J.H. Ghost imaging: From quantum to classical to computational. Adv. Opt. Photonics 2010, 2, 405–450. [Google Scholar] [CrossRef]
- Bennink, R.S.; Bentley, S.J.; Boyd, R.W. “Two-photon” coincidence imaging with a classical source. Phys. Rev. Lett. 2002, 89, 113601. [Google Scholar] [CrossRef]
- D’Angelo, M.; Shih, Y. Can quantum imaging be classically simulated? arXiv 2003, arXiv:quant-ph/0302146. [Google Scholar] [CrossRef]
- Gatti, A.; Brambilla, E.; Lugiato, L. Entangled imaging and wave-particle duality: From the microscopic to the macroscopic realm. Phys. Rev. Lett. 2003, 90, 133603. [Google Scholar] [CrossRef] [PubMed]
- Bennink, R.S.; Bentley, S.J.; Boyd, R.W.; Howell, J.C. Quantum and classical coincidence imaging. Phys. Rev. Lett. 2004, 92, 033601. [Google Scholar] [CrossRef]
- Valencia, A.; Scarcelli, G.; D’Angelo, M.; Shih, Y. Two-photon imaging with thermal light. Phys. Rev. Lett. 2005, 94, 063601. [Google Scholar] [CrossRef] [PubMed]
- Zhang, D.; Zhai, Y.H.; Wu, L.A.; Chen, X.H. Correlated two-photon imaging with true thermal light. Opt. Lett. 2005, 30, 2354–2356. [Google Scholar] [CrossRef]
- Katkovnik, V.; Astola, J. Compressive sensing computational ghost imaging. J. Opt. Soc. Am. A 2012, 29, 1556–1567. [Google Scholar] [CrossRef]
- Yu, W.K.; Li, M.F.; Yao, X.R.; Liu, X.F.; Wu, L.A.; Zhai, G.J. Adaptive compressive ghost imaging based on wavelet trees and sparse representation. Opt. Express 2014, 22, 7133–7144. [Google Scholar] [CrossRef] [PubMed]
- Chen, Z.; Shi, J.; Zeng, G. Object authentication based on compressive ghost imaging. Appl. Opt. 2016, 55, 8644–8650. [Google Scholar] [CrossRef]
- Hinton, G.E.; Osindero, S.; Teh, Y.W. A fast learning algorithm for deep belief nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef]
- Ranzato, M.; Boureau, Y.L.; Cun, Y. Sparse feature learning for deep belief networks. In Proceedings of the 20th International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 3–6 December 2007. [Google Scholar]
- Tao, Q.; Li, L.; Huang, X.; Xi, X.; Wang, S.; Suykens, J.A. Piecewise linear neural networks and deep learning. Nat. Rev. Methods Prim. 2022, 2, 42. [Google Scholar] [CrossRef]
- Lyu, M.; Wang, W.; Wang, H.; Wang, H.; Li, G.; Chen, N.; Situ, G. Deep-learning-based ghost imaging. Sci. Rep. 2017, 7, 17865. [Google Scholar] [CrossRef]
- He, Y.; Wang, G.; Dong, G.; Zhu, S.; Chen, H.; Zhang, A.; Xu, Z. Ghost imaging based on deep learning. Sci. Rep. 2018, 8, 6469. [Google Scholar] [CrossRef] [PubMed]
- Shimobaba, T.; Endo, Y.; Nishitsuji, T.; Takahashi, T.; Nagahama, Y.; Hasegawa, S.; Sano, M.; Hirayama, R.; Kakue, T.; Shiraki, A.; et al. Computational ghost imaging using deep learning. Opt. Commun. 2018, 413, 147–151. [Google Scholar] [CrossRef]
- Barbastathis, G.; Ozcan, A.; Situ, G. On the use of deep learning for computational imaging. Optica 2019, 6, 921–943. [Google Scholar] [CrossRef]
- Nah, S.; Hyun Kim, T.; Mu Lee, K. Deep multi-scale convolutional neural network for dynamic scene deblurring. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3883–3891. [Google Scholar] [CrossRef]
- Kirmani, A.; Colaço, A.; Wong, F.N.; Goyal, V.K. Exploiting sparsity in time-of-flight range acquisition using a single time-resolved sensor. Opt. Express 2011, 19, 21485–21507. [Google Scholar] [CrossRef]
- Sun, B.; Edgar, M.P.; Bowman, R.; Vittert, L.E.; Welsh, S.; Bowman, A.; Padgett, M.J. 3D computational imaging with single-pixel detectors. Science 2013, 340, 844–847. [Google Scholar] [CrossRef] [PubMed]
- Wang, C.; Mei, X.; Pan, L.; Wang, P.; Li, W.; Gao, X.; Bo, Z.; Chen, M.; Gong, W.; Han, S. Airborne near infrared three-dimensional ghost imaging lidar via sparsity constraint. Remote. Sens. 2018, 10, 732. [Google Scholar] [CrossRef]
- Mei, X.; Wang, C.; Pan, L.; Wang, P.; Gong, W.; Han, S. Experimental demonstration of Vehicle-borne Near Infrared Three-Dimensional Ghost Imaging LiDAR. In Proceedings of the 2019 Conference on Lasers and Electro-Optics (CLEO), San Jose, CA, USA, 5–10 May 2019; pp. 1–2. [Google Scholar] [CrossRef]
- Li, Z.P.; Ye, J.T.; Huang, X.; Jiang, P.Y.; Cao, Y.; Hong, Y.; Yu, C.; Zhang, J.; Zhang, Q.; Peng, C.Z.; et al. Single-photon imaging over 200 km. Optica 2021, 8, 344–349. [Google Scholar] [CrossRef]
- Li, Z.P.; Huang, X.; Jiang, P.Y.; Hong, Y.; Yu, C.; Cao, Y.; Zhang, J.; Xu, F.; Pan, J.W. Super-resolution single-photon imaging at 8.2 kilometers. Opt. Express 2020, 28, 4076–4087. [Google Scholar] [CrossRef]
- Wang, T.L.; Ao, L.; Zheng, J.; Sun, Z.B. Reconstructing depth images for time-of-flight cameras based on second-order correlation functions. Photonics 2023, 10, 1223. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, T.-L.; Ao, L.; Han, N.; Zheng, F.; Wang, Y.-Q.; Sun, Z.-B. Time-of-Flight Camera Intensity Image Reconstruction Based on an Untrained Convolutional Neural Network. Photonics 2024, 11, 821. https://doi.org/10.3390/photonics11090821
Wang T-L, Ao L, Han N, Zheng F, Wang Y-Q, Sun Z-B. Time-of-Flight Camera Intensity Image Reconstruction Based on an Untrained Convolutional Neural Network. Photonics. 2024; 11(9):821. https://doi.org/10.3390/photonics11090821
Chicago/Turabian StyleWang, Tian-Long, Lin Ao, Na Han, Fu Zheng, Yan-Qiu Wang, and Zhi-Bin Sun. 2024. "Time-of-Flight Camera Intensity Image Reconstruction Based on an Untrained Convolutional Neural Network" Photonics 11, no. 9: 821. https://doi.org/10.3390/photonics11090821
APA StyleWang, T.-L., Ao, L., Han, N., Zheng, F., Wang, Y.-Q., & Sun, Z.-B. (2024). Time-of-Flight Camera Intensity Image Reconstruction Based on an Untrained Convolutional Neural Network. Photonics, 11(9), 821. https://doi.org/10.3390/photonics11090821