A Semi-Supervised Method for PatchMatch Multi-View Stereo with Sparse Points

Abstract
1. Introduction
- Active sensors should be used for the acquisition of accurate and complete surface information, but the process usually takes several hours, for instance, when acquiring data on moving dynamic objects in a field of view [7]. The existing mature technique COLMAP [8] can accurately estimate the camera’s pose and thus obtain complete surface information but requires precise and non-overlapping camera coordinate positions; therefore, the application of this operational technique is limited.
- Assuming that only the depth information of sparse 3D point construction is involved in the test, the SGT-PatchMatch problem is solved by studying its basic features. However, the relatively sparse depth information will inevitably reduce the quality of the overall 3D reconstruction, so it is necessary to ensure the effectiveness of the test in addition to improving the training speed.
- The learning-based PatchMatch method is able to solve these difficulties by using the contextual information of the non-occluded part of the neighborhood (for occluded pixels) and the high-resolution features of the edge pixels (for edge pixels), and the actual depth value on the occluded region or edge can be obtained through the matching points. However, with a small amount of information for supervision, the model using the learning-based PatchMatch method will be insensitive to occluded pixels and edge pixels.
2. Related Work
2.1. Learning-Based Multi-View Stereo (MVS) and PatchMatch
2.2. Learning-Based Unsupervised and Semi-Supervised Models
2.3. Datasets
3. Method
3.1. Refinement of Network Issues
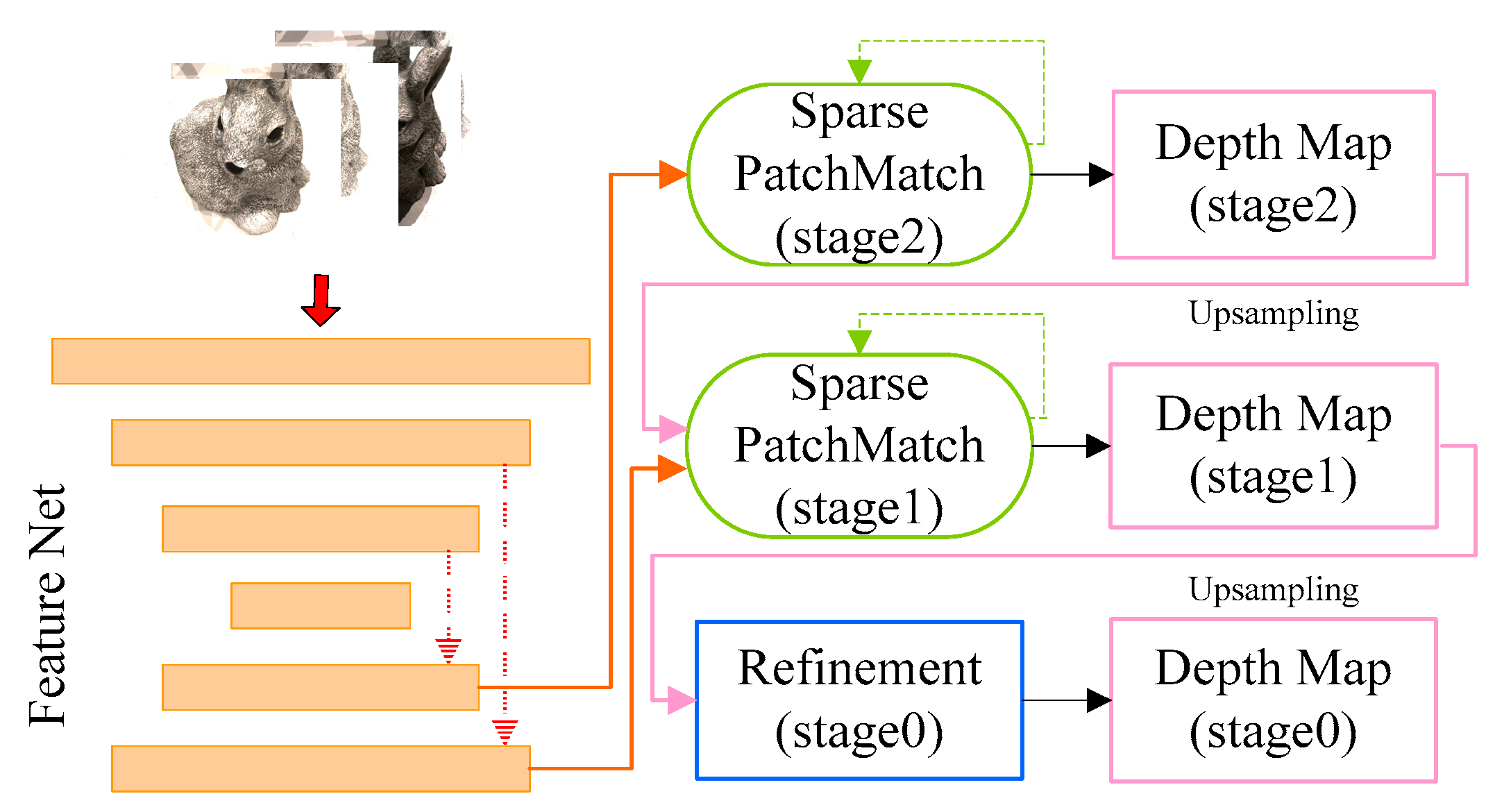
3.2. Network Structure Design
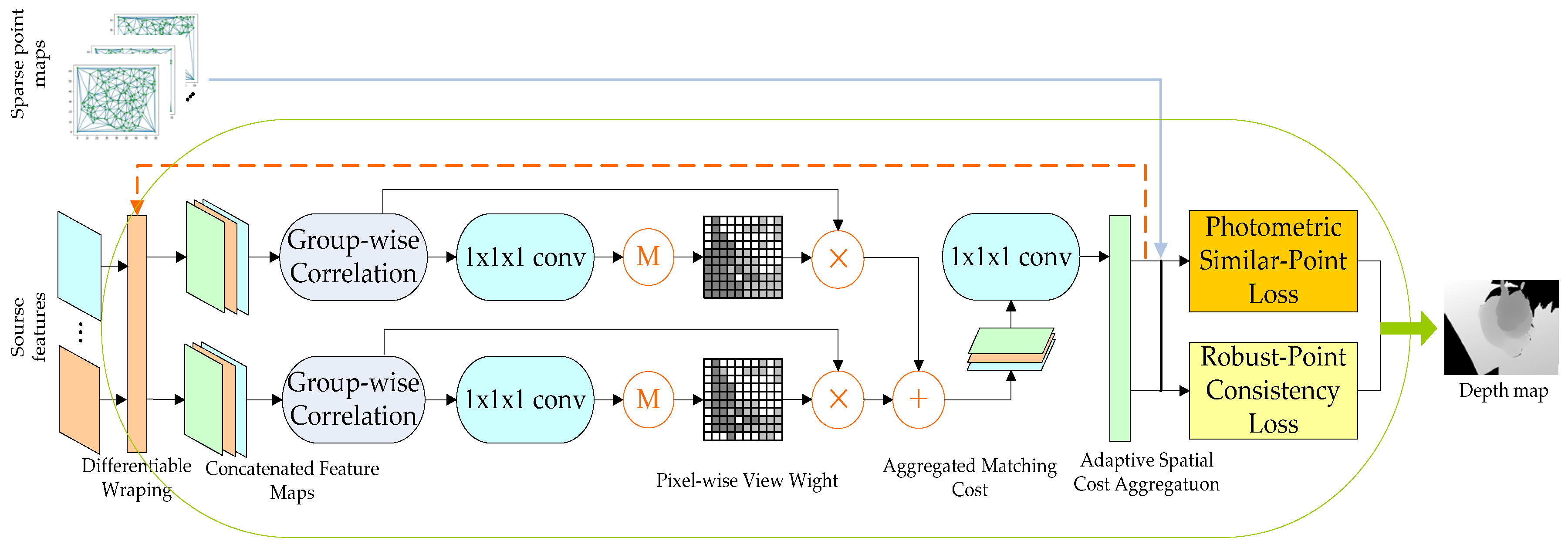
3.3. Refinement of Network Structure
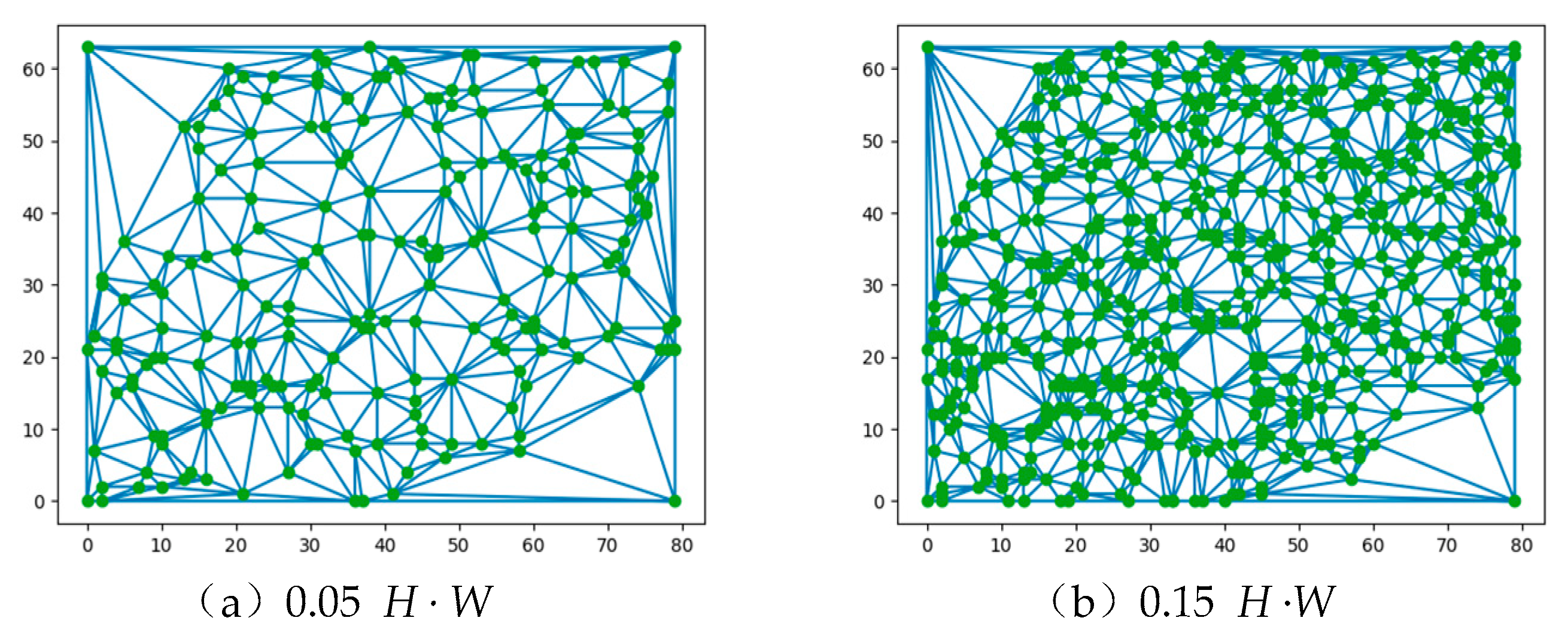
3.3.1. Sparse Point Acquisition
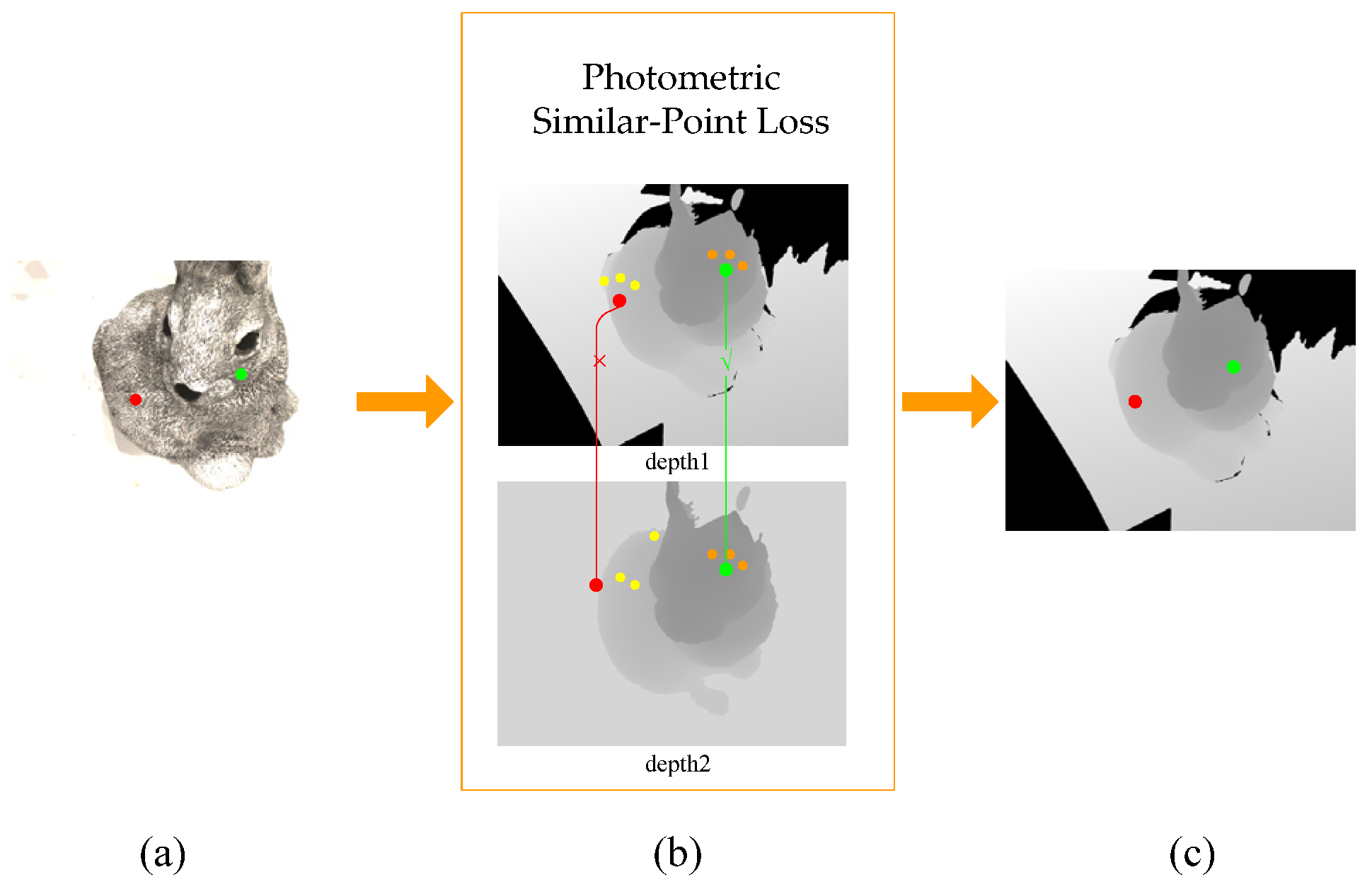
3.3.2. Photometric Similar-Point Loss
3.3.3. Robust-Point Consistency Loss
4. Experiments and Analyses
4.1. Experiment Setup
4.2. Comparative Experiment on DTU
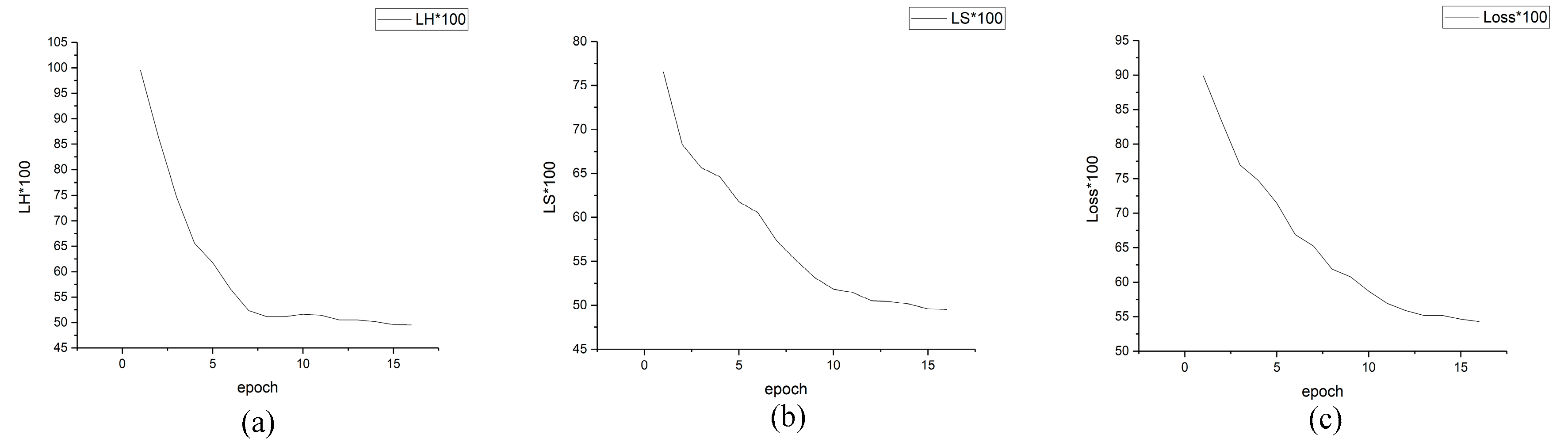
4.3. Ablation Studies
4.4. Generalization
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Cernea, D. OpenMVS: Multi-view stereo reconstruction library. City 2020, 5, 7. [Google Scholar]
- Orsingher, M.; Zani, P.; Medici, P.; Bertozzi, M. Revisiting PatchMatch Multi-View Stereo for Urban 3D Reconstruction. In Proceedings of the 2022 IEEE Intelligent Vehicles Symposium (IV), Aachen, Germany, 4–9 June 2022; pp. 190–196. [Google Scholar]
- Ding, Y.; Zhu, Q.; Liu, X.; Yuan, W.; Zhang, H.; Zhang, C. KD-MVS: Knowledge Distillation Based Self-supervised Learning for Multi-view Stereo. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 630–646. [Google Scholar]
- Cheng, X.; Zhao, Y.; Raj, R.S.; Hu, Z.; Yu, X.; Yang, W. Local PatchMatch Based on Superpixel Cut for Efficient High-resolution Stereo Matching. Braz. Arch. Biol. Technol. 2022, 65. [Google Scholar] [CrossRef]
- Li, J.; Lu, Z.; Wang, Y.; Wang, Y.; Xiao, J. DS-MVSNet: Unsupervised Multi-view Stereo via Depth Synthesis. In Proceedings of the 30th ACM International Conference on Multimedia, New York, NY, USA, 10–14 October 2022; pp. 5593–5601. [Google Scholar]
- Zhai, X.; Oliver, A.; Kolesnikov, A.; Beyer, L. S4l: Self-supervised semi-supervised learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1476–1485. [Google Scholar]
- Hasnain, M.; Pasha, M.F.; Ghani, I.; Jeong, S.R. Simulated dataset collection method of dynamic quality of services (QoS) metrics. Int. J. Inf. Technol. 2021, 13, 889–895. [Google Scholar] [CrossRef]
- Liu, S.; Bonelli, W.; Pietrzyk, P.; Bucksch, A. Comparison of Open-Source Three-Dimensional Reconstruction Pipelines for Maize-Root Phenotyping. ESS Open Arch. 2022. [Google Scholar] [CrossRef]
- Shen, T.; Luo, Z.; Zhou, L.; Deng, H.; Zhang, R.; Fang, T.; Quan, L. Beyond Photometric Loss for Self-Supervised Ego-Motion Estimation. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019. [Google Scholar] [CrossRef]
- Duchi, J.; Hashimoto, T.; Namkoong, H. Distributionally robust losses for latent covariate mixtures. Oper. Res. 2022. [Google Scholar] [CrossRef]
- Wang, F.; Galliani, S.; Vogel, C.; Speciale, P.; Pollefeys, M. Patchmatchnet: Learned multi-view patchmatch stereo. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14194–14203. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Fang, T.; Quan, L. Mvsnet: Depth inference for unstructured multi-view stereo. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 767–783. [Google Scholar]
- Yao, Y.; Luo, Z.; Li, S.; Shen, T.; Fang, T.; Quan, L. Recurrent mvsnet for high-resolution multi-view stereo depth inference. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5525–5534. [Google Scholar]
- Gu, X.; Fan, Z.; Zhu, S.; Dai, Z.; Tan, F.; Tan, P. Cascade cost volume for high-resolution multi-view stereo and stereo matching. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2495–2504. [Google Scholar]
- Yu, Z.; Gao, S. Fast-mvsnet: Sparse-to-dense multi-view stereo with learned propagation and gauss-newton refinement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1949–1958. [Google Scholar]
- Luo, K.; Guan, T.; Ju, L.; Huang, H.; Luo, Y. P-mvsnet: Learning patch-wise matching confidence aggregation for multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 10452–10461. [Google Scholar]
- Khot, T.; Agrawal, S.; Tulsiani, S.; Mertz, C.; Lucey, S.; Hebert, M. Learning unsupervised multi-view stereopsis via robust photometric consistency. arXiv 2019, arXiv:1905.02706. [Google Scholar]
- Dai, Y.; Zhu, Z.; Rao, Z.; Li, B. MVS2: Deep Unsupervised Multi-View Stereo with Multi-View Symmetry. In Proceedings of the 2019 International Conference on 3D Vision (3DV), Quebec City, QC, Canada, 16–19 September 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Huang, B.; Yi, H.; Huang, C.; He, Y.; Liu, J.; Liu, X. M3VSNET: Unsupervised Multi-Metric Multi-View Stereo Network. In Proceedings of the 2021 IEEE International Conference on Image Processing (ICIP), Anchorage, AK, USA, 19–22 September 2021; pp. 3163–3167. [Google Scholar] [CrossRef]
- Xu, H.; Zhou, Z.; Qiao, Y.; Kang, W.; Wu, Q. Self-supervised Multi-view Stereo via Effective Co-Segmentation and Data-Augmentation. Proc Conf AAAI Artif Intell 2021, 35, 3030–3038. [Google Scholar] [CrossRef]
- Kim, T.; Choi, J.; Choi, S.; Jung, D.; Kim, C. Just a Few Points are All You Need for Multi-view Stereo: A Novel Semi-supervised Learning Method for Multi-view Stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6158–6166. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yang, J.; An, W.; Guo, Y. Flickr1024: A Large-Scale Dataset for Stereo Image Super-Resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 7–28 October 2019; pp. 3852–3857. [Google Scholar] [CrossRef]
- Aanæs, H.; Jensen, R.R.; Vogiatzis, G.; Tola, E.; Dahl, A.B. Large-Scale Data for Multiple-View Stereopsis. Int. J. Comput. Vis. 2016, 120, 153–168. [Google Scholar] [CrossRef]
- Knapitsch, A.; Park, J.; Zhou, Q.Y.; Koltun, V. Tanks and temples: Benchmarking large-scale scene reconstruction. ACM Trans. Graph. (ToG) 2017, 36, 1–13. [Google Scholar] [CrossRef]
- Kaneda, A.; Nakagawa, T.; Tamura, K.; Noshita, K.; Nakao, H. A proposal of a new automated method for SfM/MVS 3D reconstruction through comparisons of 3D data by SfM/MVS and handheld laser scanners. PLoS ONE 2022, 17, e0270660. [Google Scholar] [CrossRef] [PubMed]
- Ding, Y.; Yuan, W.; Zhu, Q.; Zhang, H.; Liu, X.; Wang, Y.; Liu, X. Transmvsnet: Global context-aware multi-view stereo network with transformers. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 8585–8594. [Google Scholar]
- Mallick, A.; Stückler, J.; Lensch, H. Learning to adapt multi-view stereo by self-supervision. arXiv 2020, arXiv:2009.13278. [Google Scholar]
- Xu, H.; Zhou, Z.; Wang, Y.; Kang, W.; Sun, B.; Li, H.; Qiao, Y. Digging into uncertainty in self-supervised multi-view stereo. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 6078–6087. [Google Scholar]
- Kaya, B.; Kumar, S.; Oliveira, C.; Ferrari, V.; Van Gool, L. Uncalibrated neural inverse rendering for photometric stereo of general surfaces. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3804–3814. [Google Scholar]
- Ju, Y.; Shi, B.; Jian, M.; Qi, L.; Dong, J.; Lam, K.M. NormAttention-PSN: A High-frequency Region Enhanced Photometric Stereo Network with Normalized Attention. Int. J. Comput. Vis. 2022, 130, 3014–3034. [Google Scholar] [CrossRef]
- Honzátko, D.; Türetken, E.; Fua, P.; Dunbar, L.A. Leveraging Spatial and Photometric Context for Calibrated Non-Lambertian Photometric Stereo. In Proceedings of the International Conference on 3D Vision (3DV), London, UK, 1–3 December 2021; pp. 394–402. [Google Scholar]
- Jian, M.; Dong, J.; Gong, M.; Yu, H.; Nie, L.; Yin, Y.; Lam, K.-M. Learning the Traditional Art of Chinese Calligraphy via Three-Dimensional Reconstruction and Assessment. IEEE Trans. Multimed. 2019, 22, 970–979. [Google Scholar] [CrossRef]
- Karami, A.; Menna, F.; Remondino, F. Combining Photogrammetry and Photometric Stereo to Achieve Precise and Complete 3D Reconstruction. Sensors 2022, 22, 8172. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
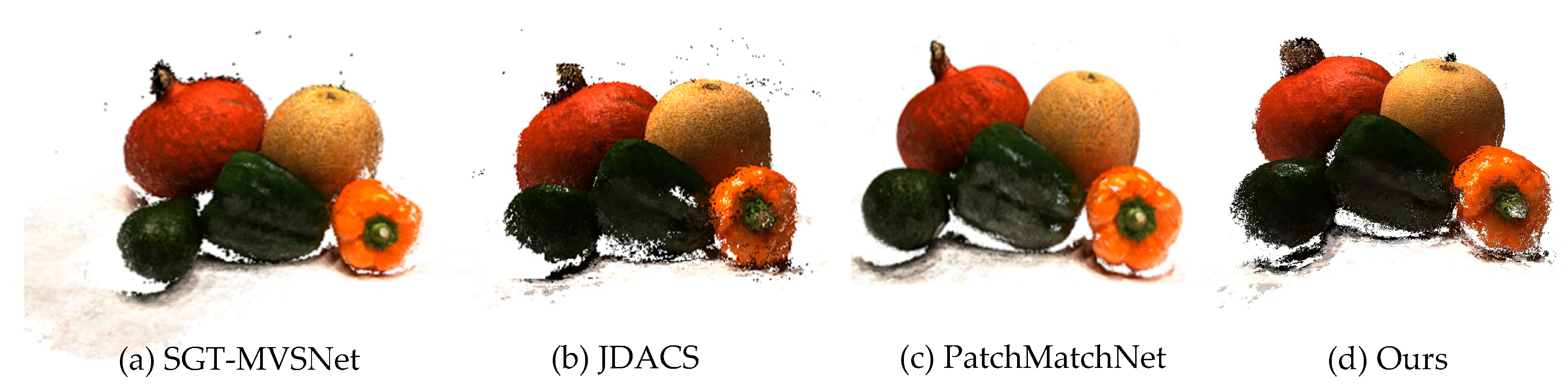{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Supervised | Testing Speed (n/s) | Acc (mm) | Comp (mm) | Overall (mm) |
|---|---|---|---|---|---|
| COLMAP [8] | - | - | 0.400 | 0.664 | 0.532 |
| MVS2 [18] | ✗ | 521,98 | 0.760 | 0.515 | 0.637 |
| Meta-MVSNet [27] | ✗ | 503.26 | 0.594 | 0.779 | 0.687 |
| M3VSNet [19] | ✗ | 492.76 | 0.636 | 0.531 | 0.583 |
| JDACS [20] | ✗ | 485.78 | 0.571 | 0.515 | 0.543 |
| U-MVSNet [28] | ✗ | 481.31 | 0.470 | 0.430 | 0.450 |
| SGT-MVSNet [21] | ☑ | 454.67 | 0.441 | 0.381 | 0.411 |
| PatchMatchNet [11] | ✓ | 492.52 | 0.427 | 0.277 | 0.352 |
| Ours | ☑ | 418.35 | 0.445 | 0.267 | 0.356 |
| Method | Acc (mm) | Comp (mm) | Overall (mm) |
|---|---|---|---|
| BaseNet+SP+LH | 0.482 | 0.324 | 0.403 |
| BaseNet+SP+LS | 0.478 | 0.311 | 0.395 |
| BaseNet+SP+LH+LS (ours) | 0.445 | 0.267 | 0.356 |
| Method | Ground Truth | Testing Speed (n/s) | Acc (mm) | Comp (mm) | Overall (mm) |
|---|---|---|---|---|---|
| SGT- PatchMatchNet | Sparse1 | 418.35 | 0.445 | 0.267 | 0.356 |
| Sparse2 | 438.87 | 0.433 | 0.259 | 0.346 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhan, W.; Cao, K.; Jiang, Y.; Chen, Y.; Wang, J.; Hong, Y. A Semi-Supervised Method for PatchMatch Multi-View Stereo with Sparse Points. Photonics 2022, 9, 983. https://doi.org/10.3390/photonics9120983
Zhan W, Cao K, Jiang Y, Chen Y, Wang J, Hong Y. A Semi-Supervised Method for PatchMatch Multi-View Stereo with Sparse Points. Photonics. 2022; 9(12):983. https://doi.org/10.3390/photonics9120983
Chicago/Turabian StyleZhan, Weida, Keliang Cao, Yichun Jiang, Yu Chen, Jiale Wang, and Yang Hong. 2022. "A Semi-Supervised Method for PatchMatch Multi-View Stereo with Sparse Points" Photonics 9, no. 12: 983. https://doi.org/10.3390/photonics9120983
APA StyleZhan, W., Cao, K., Jiang, Y., Chen, Y., Wang, J., & Hong, Y. (2022). A Semi-Supervised Method for PatchMatch Multi-View Stereo with Sparse Points. Photonics, 9(12), 983. https://doi.org/10.3390/photonics9120983