Neural Network-Based Transceiver Design for VLC System over ISI Channel


{kind=link}
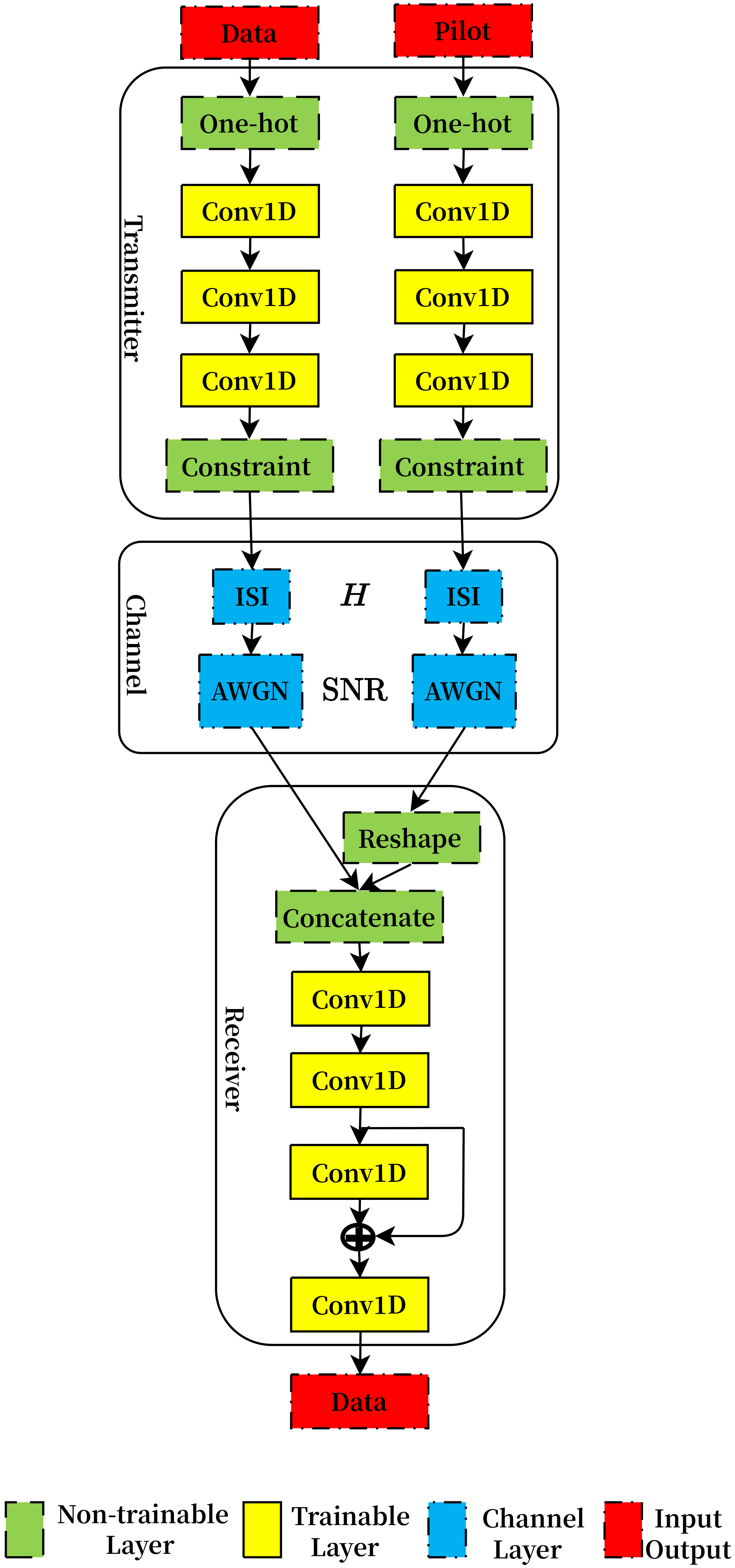{kind=link}
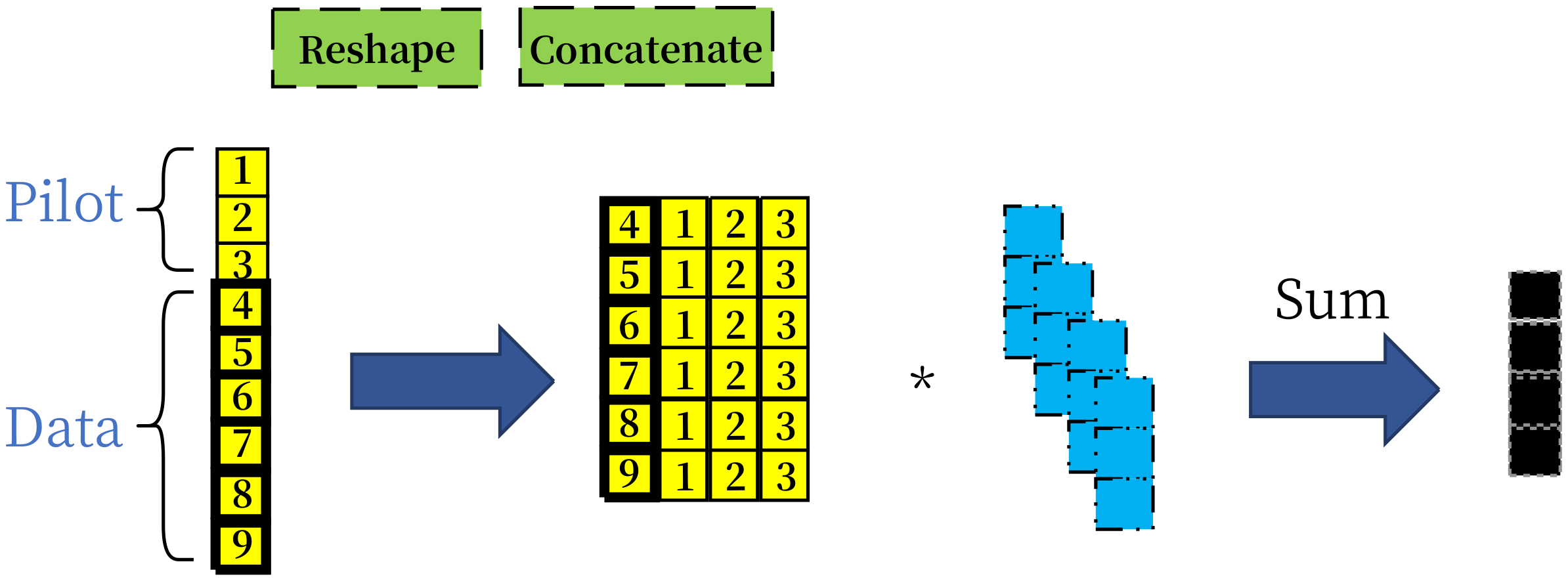{kind=link}
{kind=link}
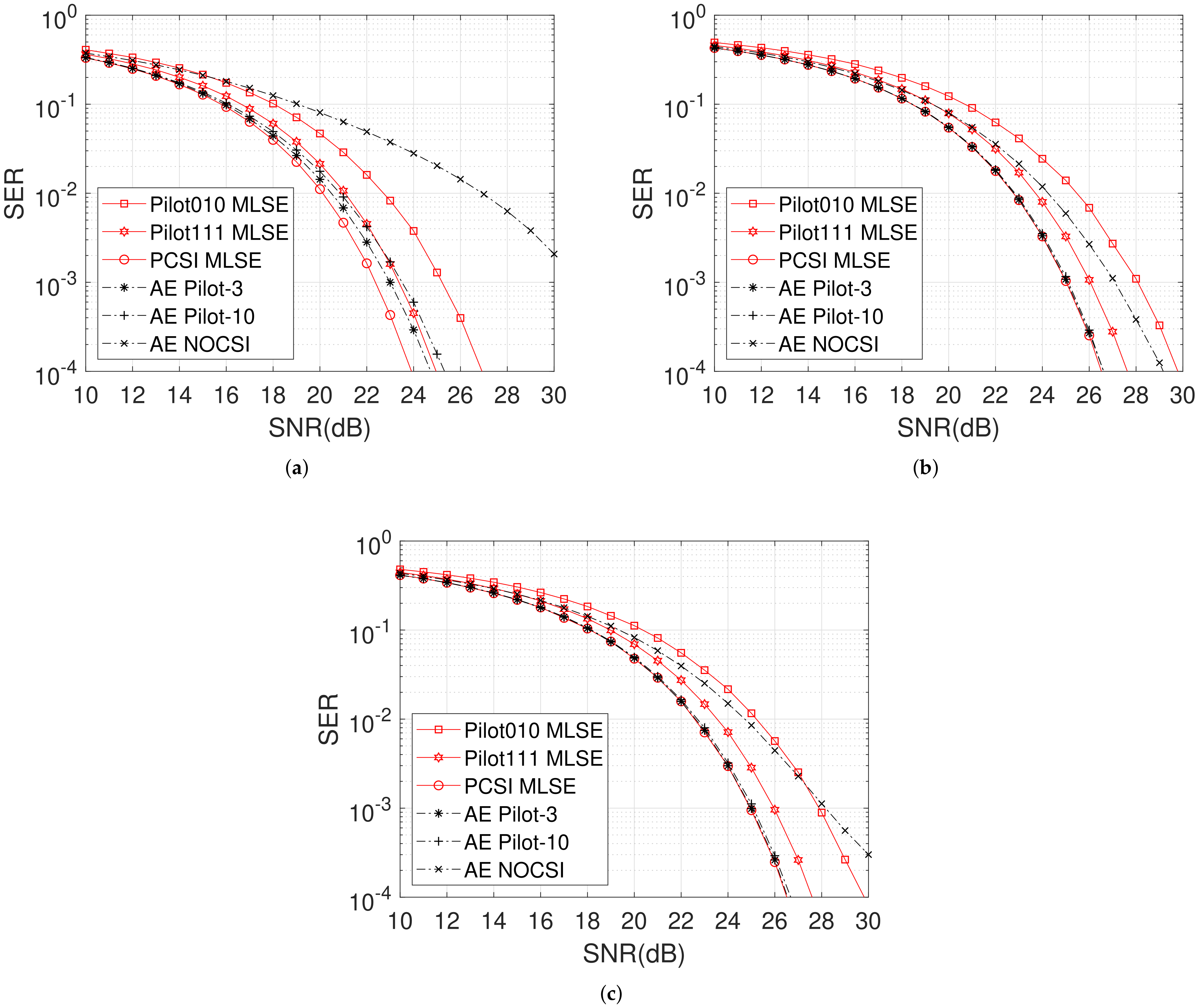{kind=link}
Abstract
Share and Cite
Li, L.; Zhu, Z.; Zhang, J. Neural Network-Based Transceiver Design for VLC System over ISI Channel. Photonics 2022, 9, 190. https://doi.org/10.3390/photonics9030190
Li L, Zhu Z, Zhang J. Neural Network-Based Transceiver Design for VLC System over ISI Channel. Photonics. 2022; 9(3):190. https://doi.org/10.3390/photonics9030190
Chicago/Turabian StyleLi, Lin, Zhaorui Zhu, and Jian Zhang. 2022. "Neural Network-Based Transceiver Design for VLC System over ISI Channel" Photonics 9, no. 3: 190. https://doi.org/10.3390/photonics9030190
APA StyleLi, L., Zhu, Z., & Zhang, J. (2022). Neural Network-Based Transceiver Design for VLC System over ISI Channel. Photonics, 9(3), 190. https://doi.org/10.3390/photonics9030190