
RecSys Pertaining to Research Information with Collaborative Filtering Methods: Characteristics and Challenges



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
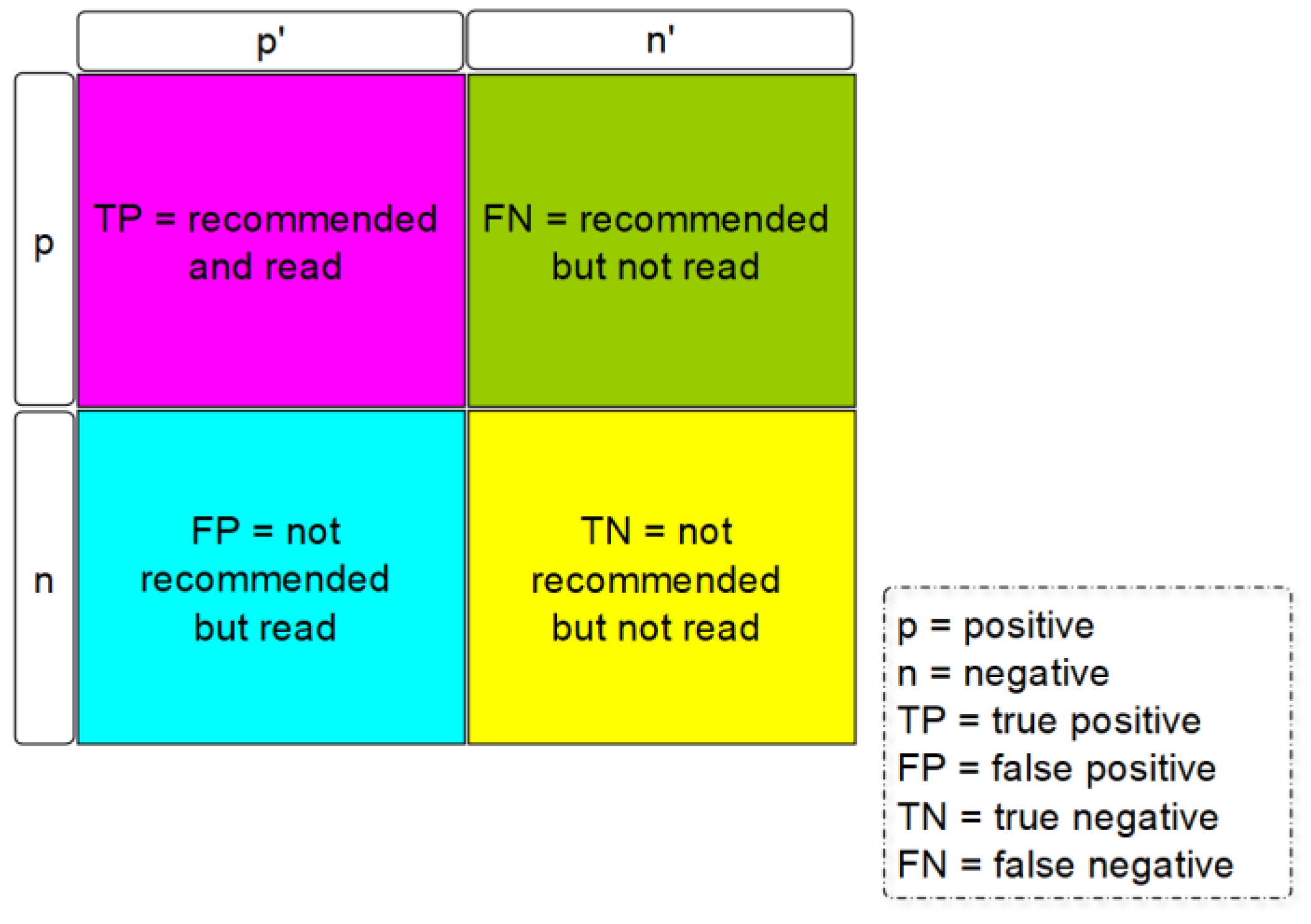
- To what extent is making a recommendation possible if it is based on a collaborative filtering approach directed to research information—in particular, publication data?
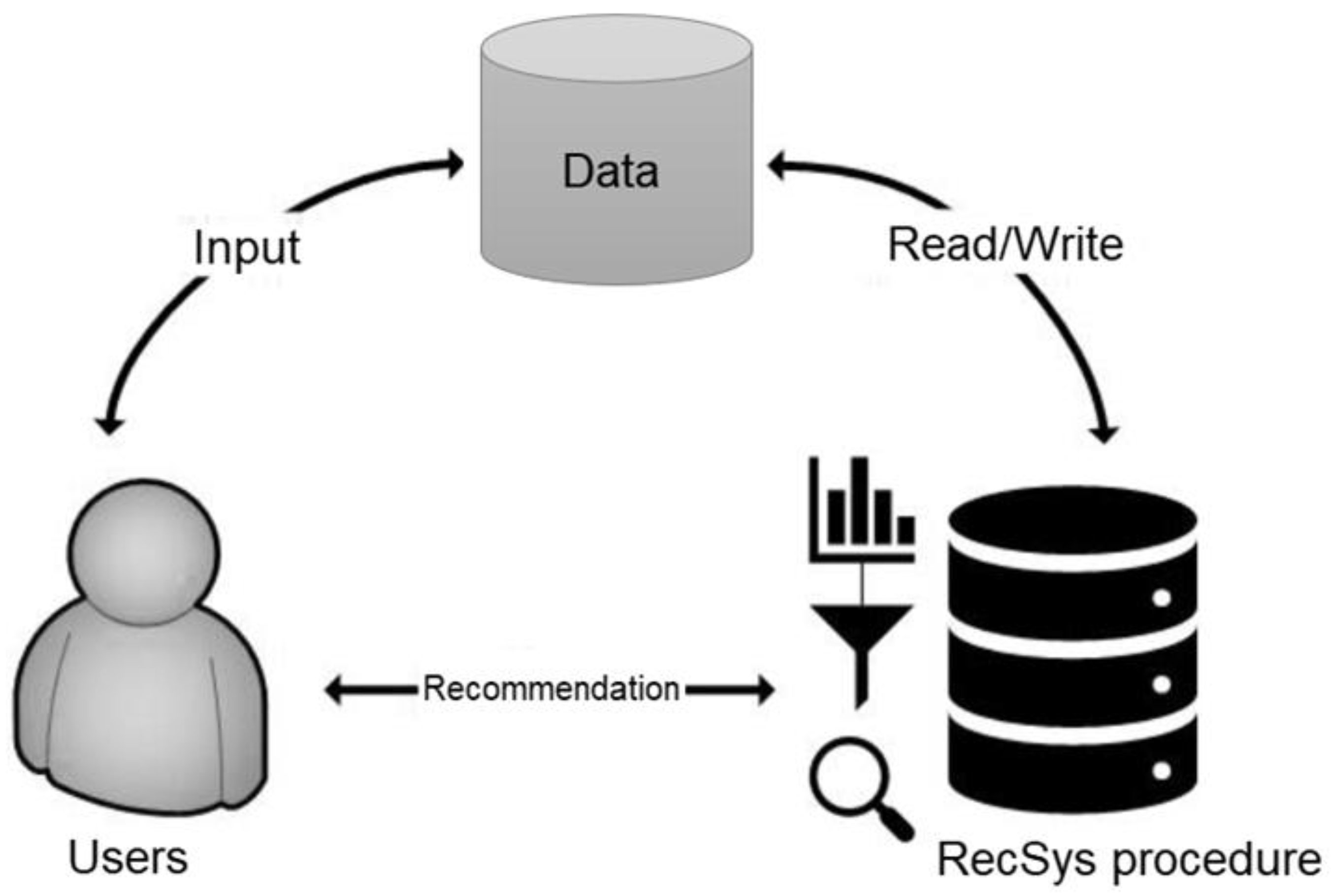
2. State of the Art: RecSys and Collaborative Filtering Processes
- Non-personalized filtering: The recommendations are the same for all customers. This type of filtering materializes, for example, in systems, where the most popular products are recommended.
- Advantages: Non-personalized filtering is easy to implement, since the recommendations consist of popular or highly rated articles and the data required for these recommendations can therefore be easily captured [17].
- Disadvantages: As filtering is not personalized, every user receives the same recommendation; therefore, such recommendations may not apply to all users [17].
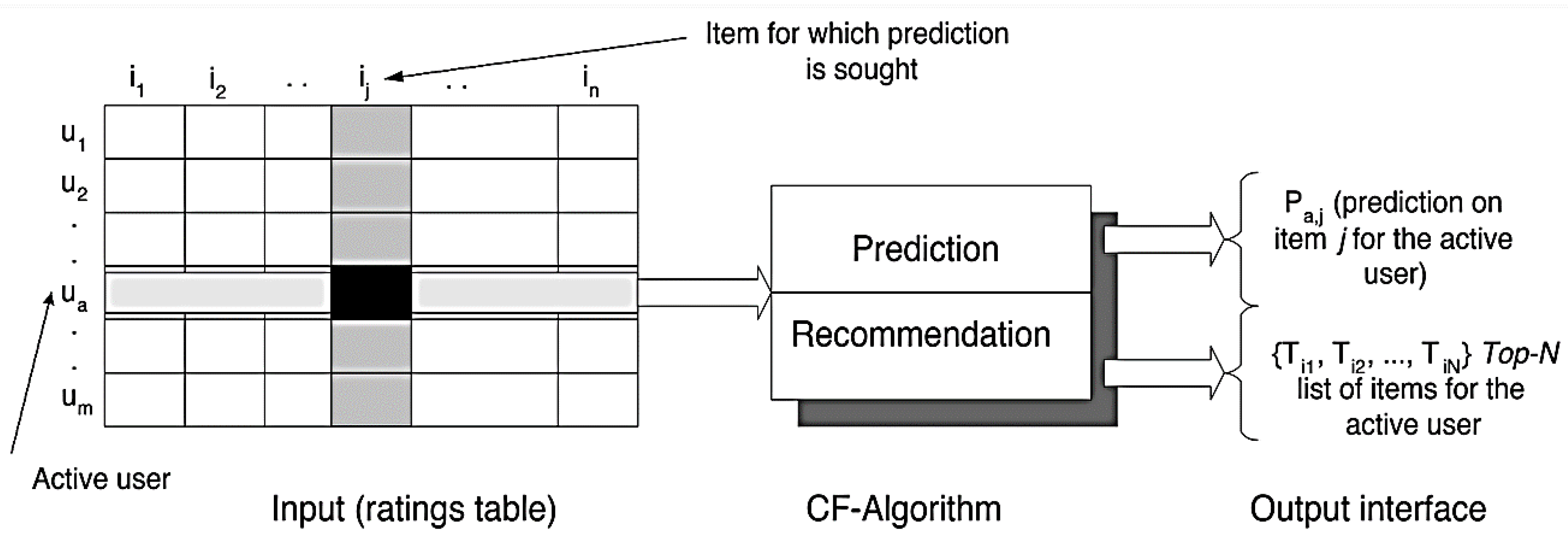
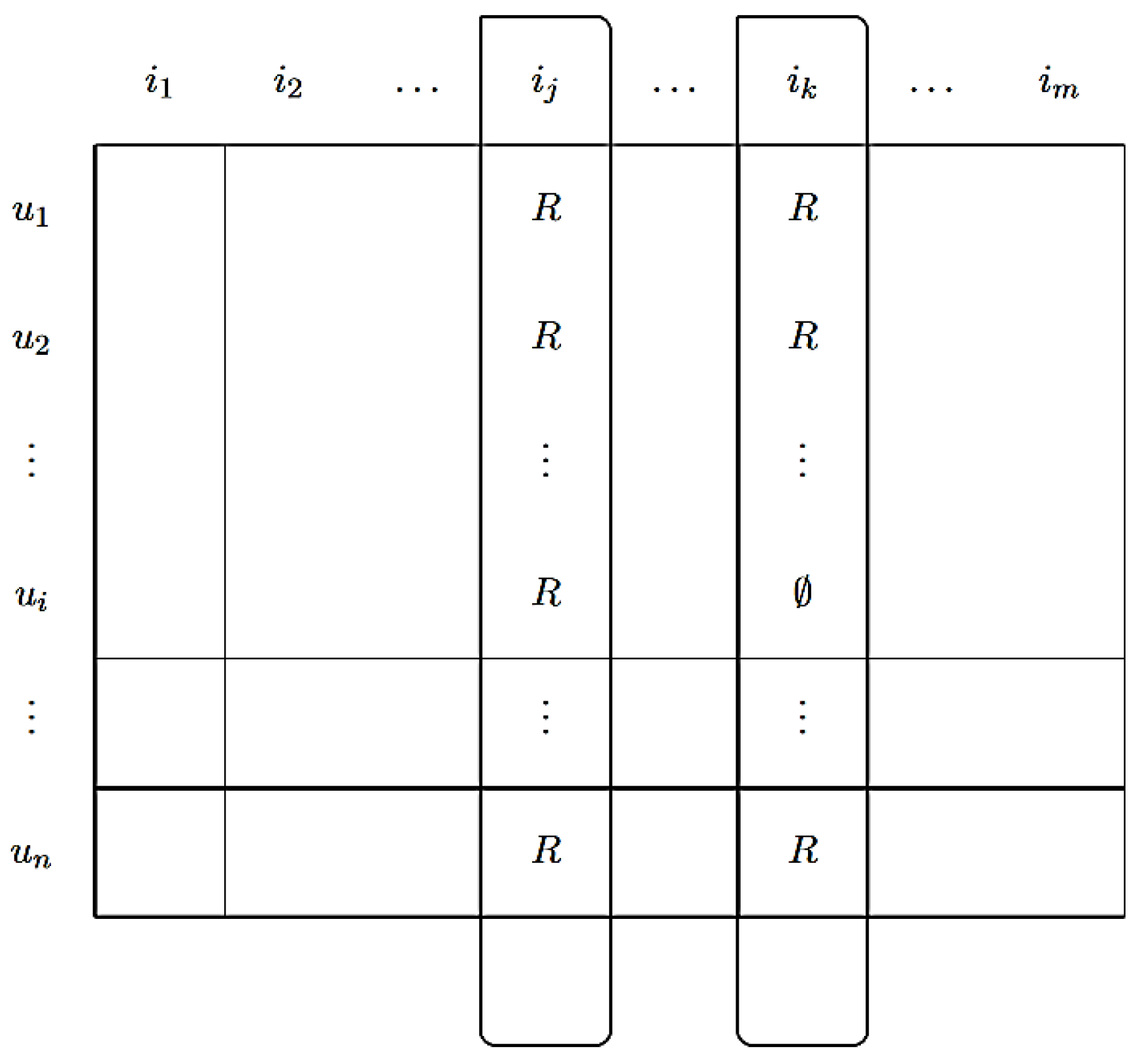
- Collaborative filtering: Recommendations are based on historical reviews of users or data. Traditionally, either items rated highly by similar users or articles that are similar to already highly rated items are recommended.
- Advantages: The greatest advantage of collaborative filtering systems is that they do not need any reference to the content of the article. This means that they are completely independent of any kind of information involved and the item descriptions. All that is required to recommend the item is a name and the associated rating.
- Disadvantages: Collaborative filtering is basically based on statistical methods and requires a certain degree of consistency in user ratings. As a result, a very high density of ratings is required in order for this to function properly.
- Content-based filtering: Recommendations are based on the content or properties of articles. Articles that are similar in content to preferred articles are recommended.
- Advantages: Content-based filtering uses article-to-article correlation [18]. The user is offered articles that would be suitable according to their user profile. This knowledge is derived from the profiles of the individual user. With this method, the cold start problem is minimized, and since there is no new item problem only the new user problem remains. There are no privacy problems because one’s own ratings and preferences are not visible to other users. Additionally, the detailed preferences of users can be taken into account.
- Disadvantages: Content-based filtering and its systems are limited by the content-descriptive characteristics of the items needing to be evaluated. For example, a content-based recommendation system for publications can only be based on article descriptions, such as the author’s name, publication title, journal, volume, issue, year, etc., because the publication itself cannot be interpreted by the system. This means that only fully described publications (namely, all publications that are included in the calculation) can lead to a successful recommendation. One also needs to have enough descriptors to avoid meta-evaluations such as those seen in collaborative filtering. There is also the problem that not all aspects of an article can be formally described.
- Knowledge-based filtering: Recommendations are made based on specialist knowledge of how certain properties of an item influence the satisfaction of user needs. For this purpose, similarity functions or knowledge databases with explicit rules are used.
- Advantages: With this method, users have the advantage of finding articles based on the restrictions with which they are familiar or articles that are similar and those that meet the criteria set [18].
- Disadvantages: The system must have access to a knowledge database that the information can be easily identified or derived from. In addition, there is the challenge of making a good recommendation to investigate which article properties are decisive for the user [18].
- Demographic filtering: Recommendations are based on sociodemographic data. This method only uses information about the user, such as their gender, age, and employment status. The system thus generates recommendations based on demographic similarities.
- Advantages: In contrast to other filtering methods, this method does not require historical data [19].
- Disadvantages: Collecting all of the demographic information can conflict with the requirements of data protection, as it is sensitive and personal data. In addition, this is one of the traditional techniques used to create the profiles of users and no advanced data mining techniques are used [10].
- Hybrid filtering: A combination of the filters already presented are used to generate recommendations. Recommendations consist of combinations of several filter methods, such as collaborative filtering and content-based filtering.
- Advantages: The aim of hybrid filtering is to bring different models together in order to increase performance and minimize the system-specific and inherent problems of recommendation systems.
- Disadvantages: With hybrid filtering, the quality of the description of the items and their quality depends on the number of ratings.
- Memory-based, where a user rating of an item is predicted on the basis of all previous ratings of the other users.
- Model-based with the help of stochastic procedures and a training data set, attempting to find patterns in the evaluations of the various users and to create a model based on them. The learned model is then used to propose new articles. In the case of model-based methods, methods from the field of machine learning and data mining are used as a forecasting model. Examples of such methods are decision trees, rule-based models, Bayesian methods, and latent factor models.
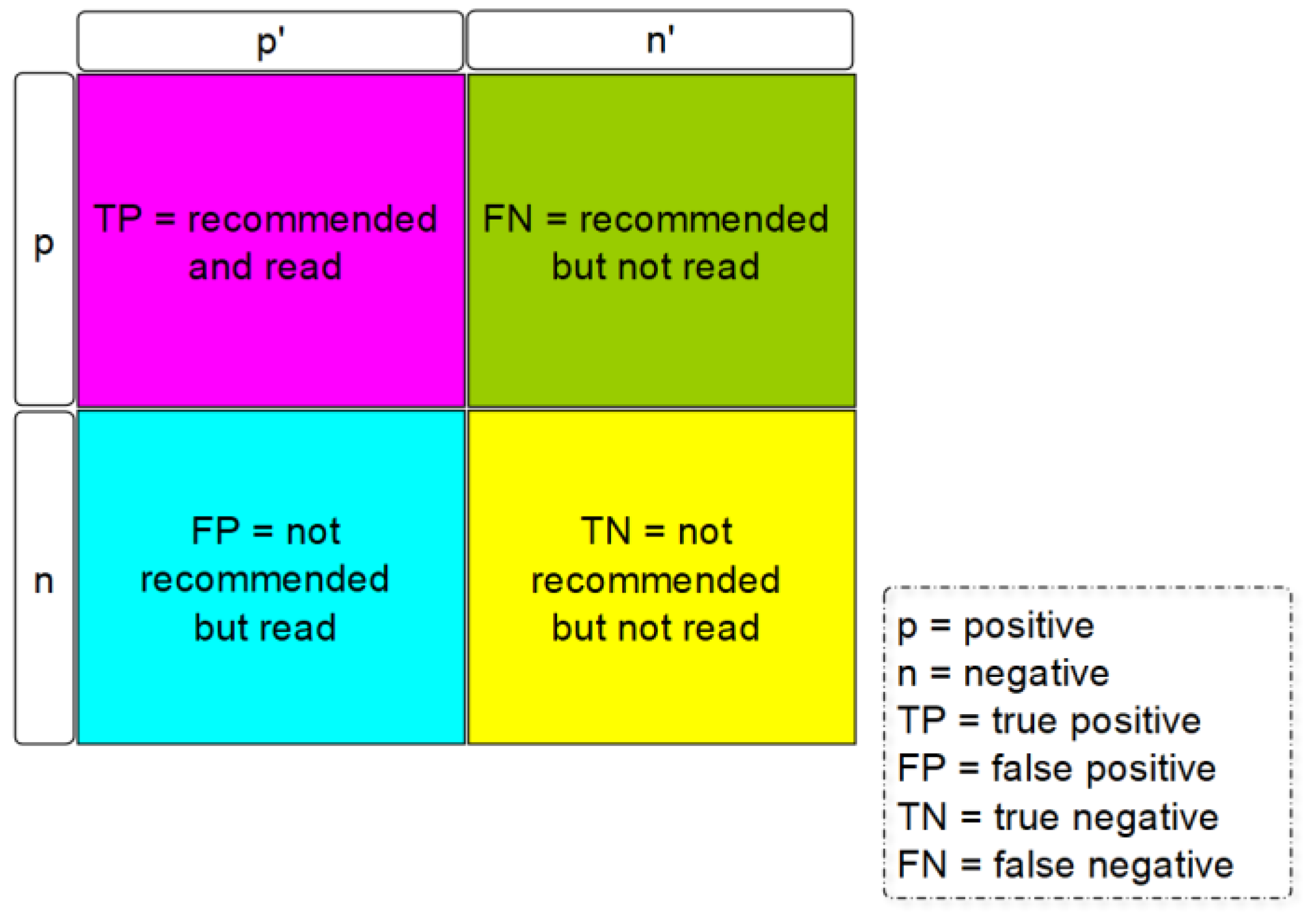
3. Challenges When Using RecSys
- Relevance: The filtered set of all articles should be relevant to the user.
- Novelty: The recommendations determined should be novel to the user—i.e., after a certain contact frequency without user interaction, the recommendation should be replaced by a new one.
- Discovery: Recommendation systems should deliver results that are unknown and surprising to the user, but at the same time interesting.
- Diversity: The recommendations from the recommendation system should have a certain diversity, i.e., even if the user has only looked at publications from the IT area so far, they should not only see publications from the IT area as recommendations.
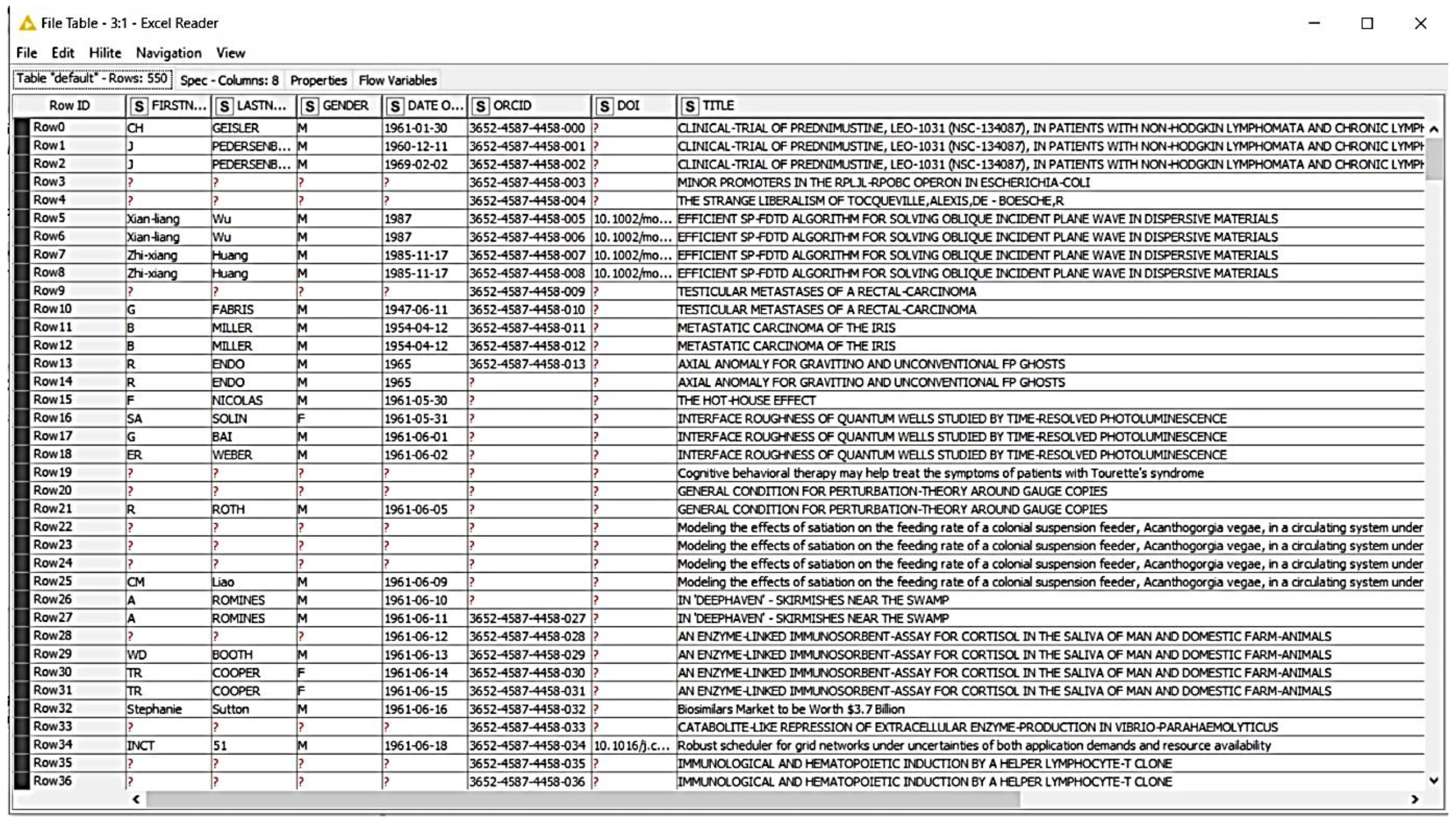
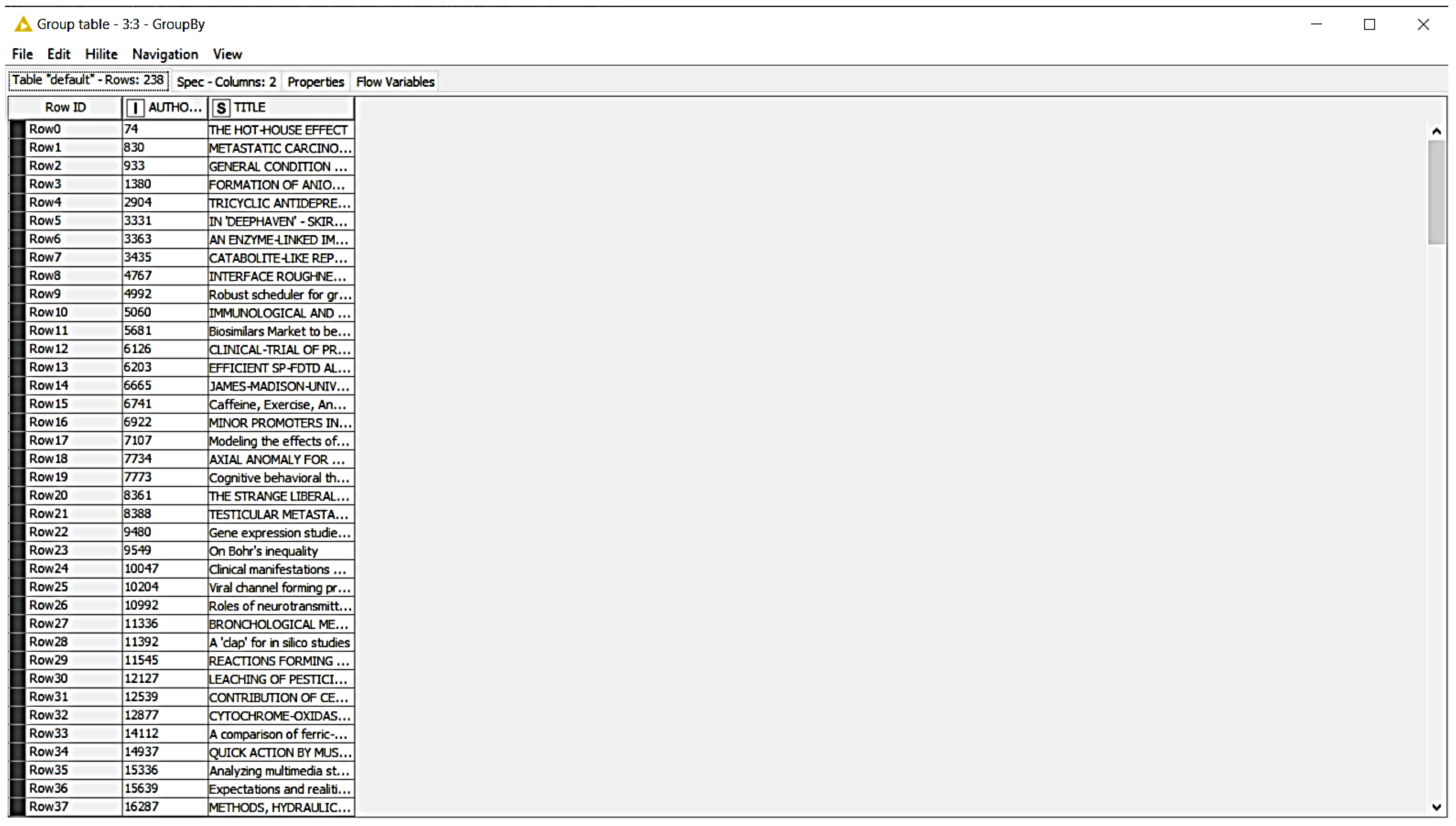
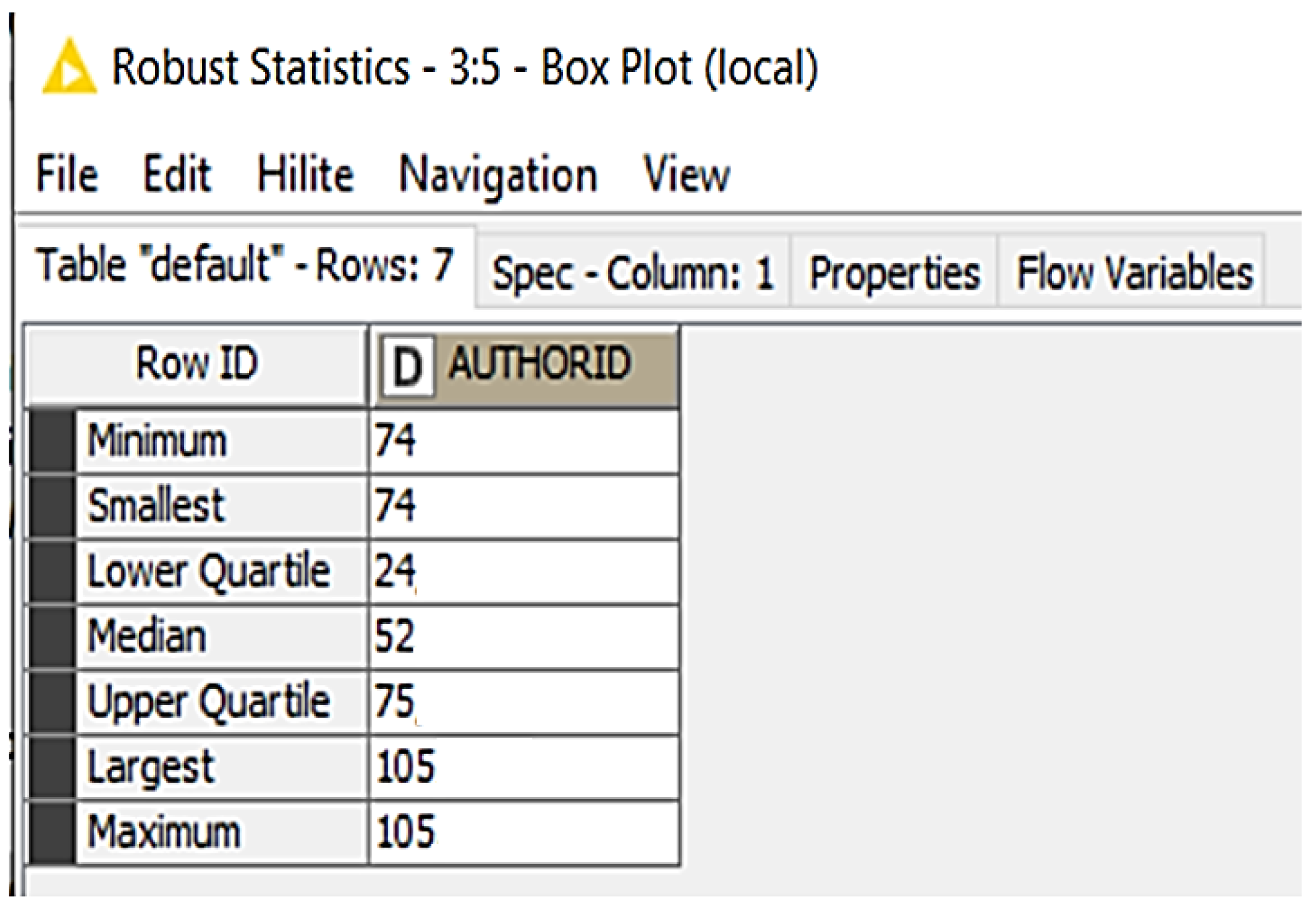
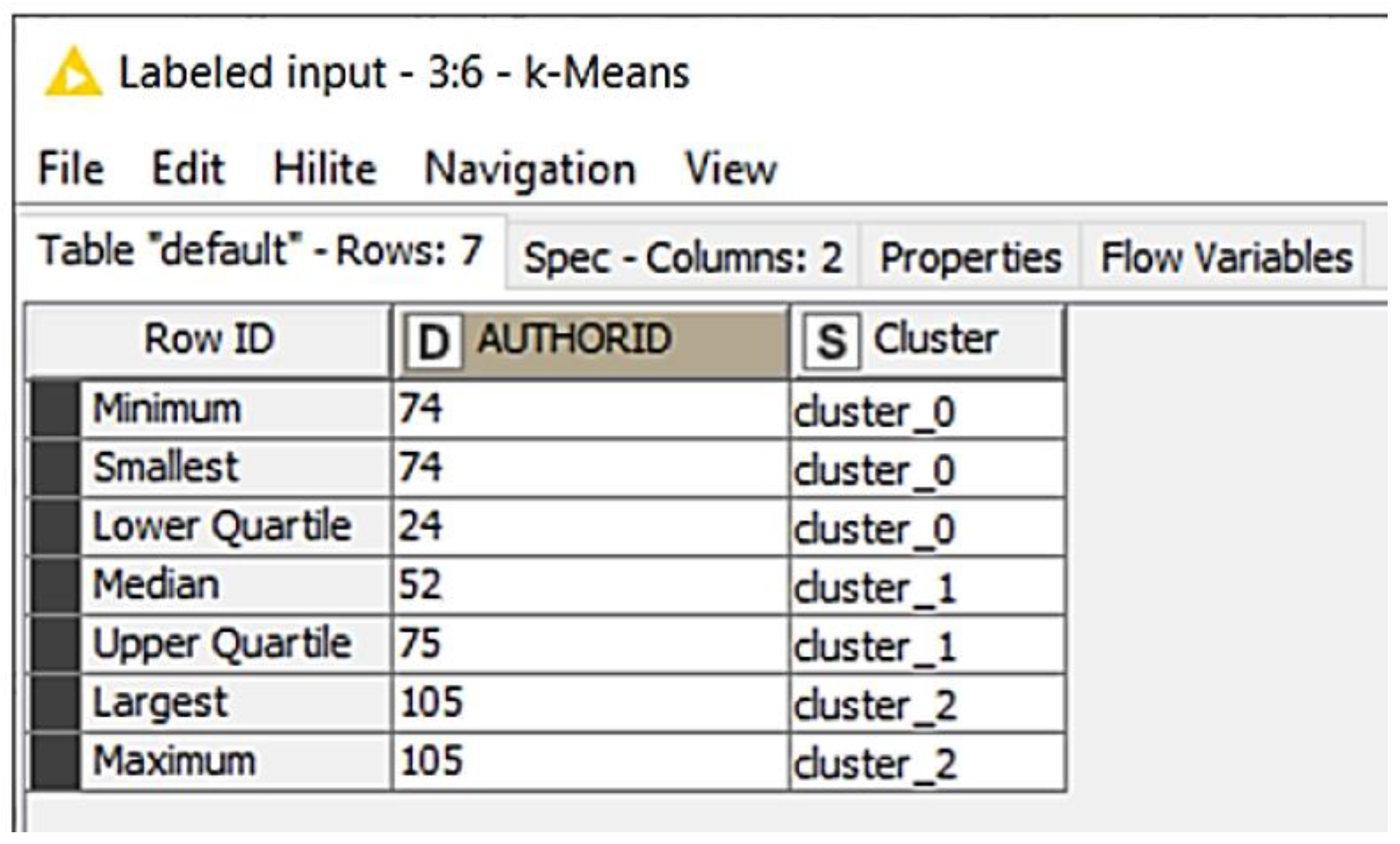
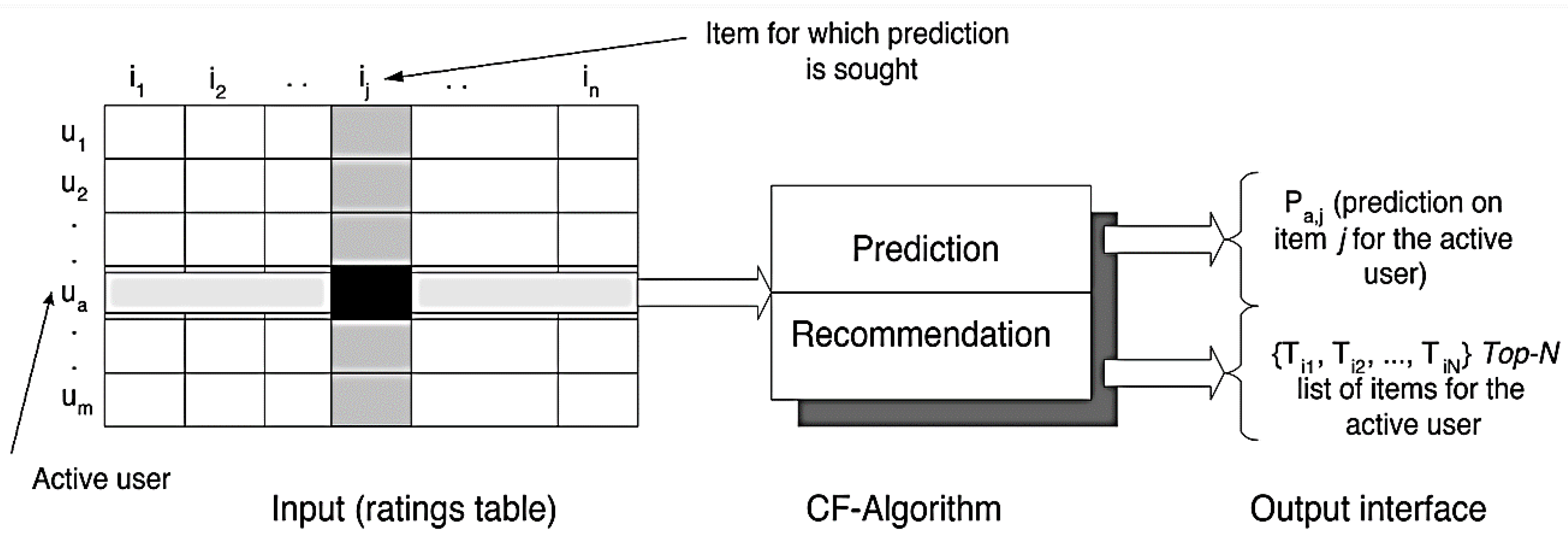
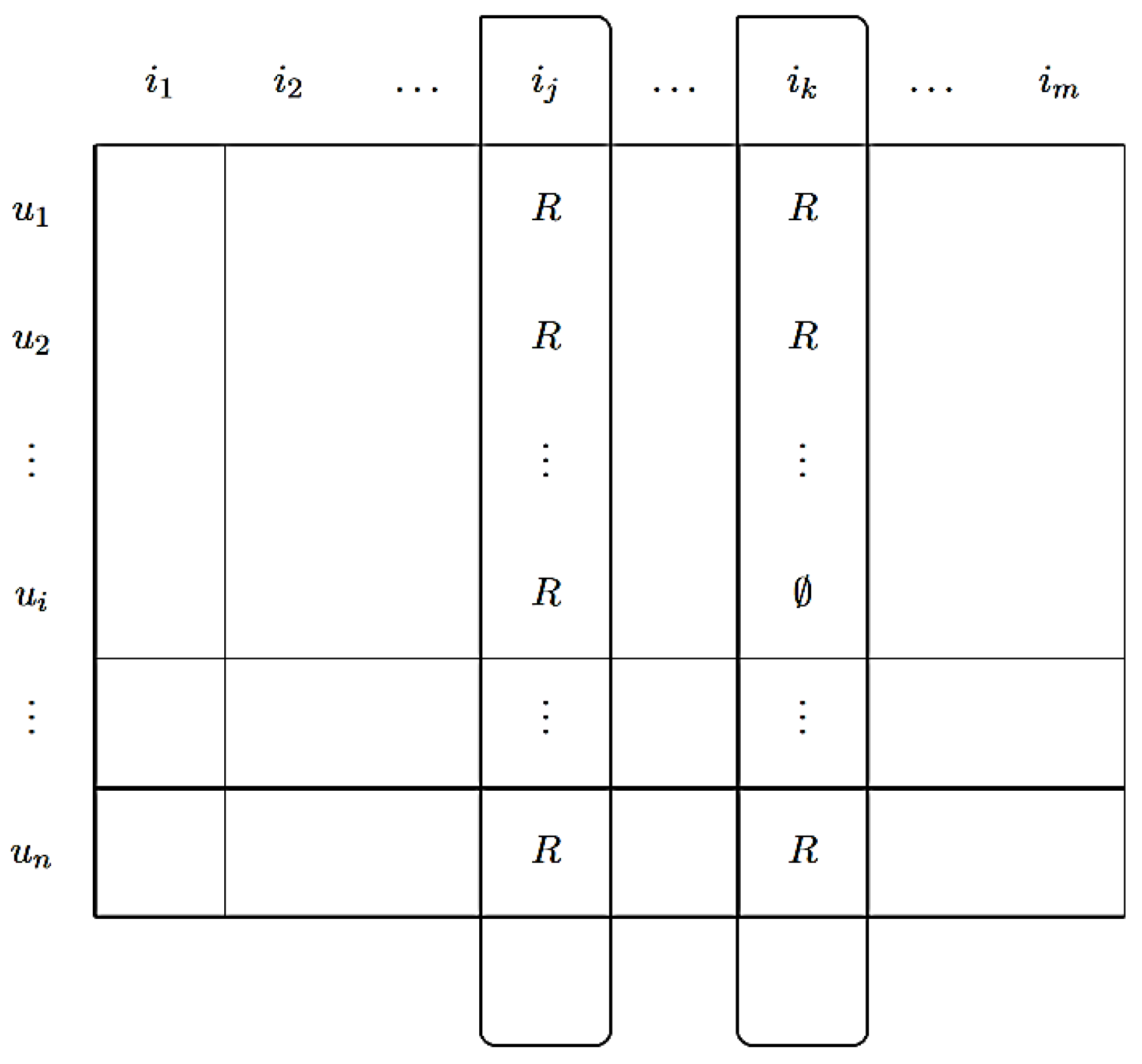
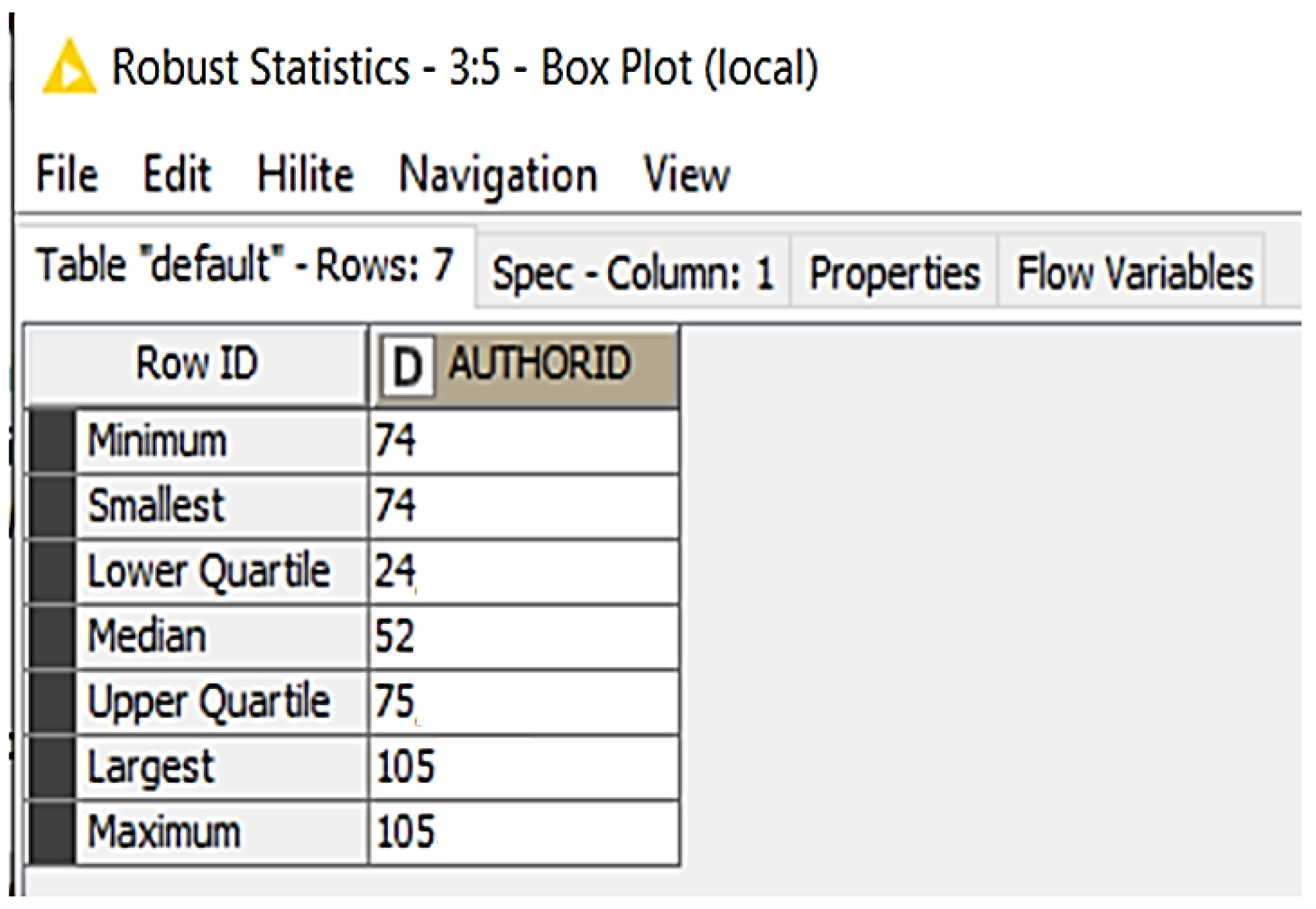
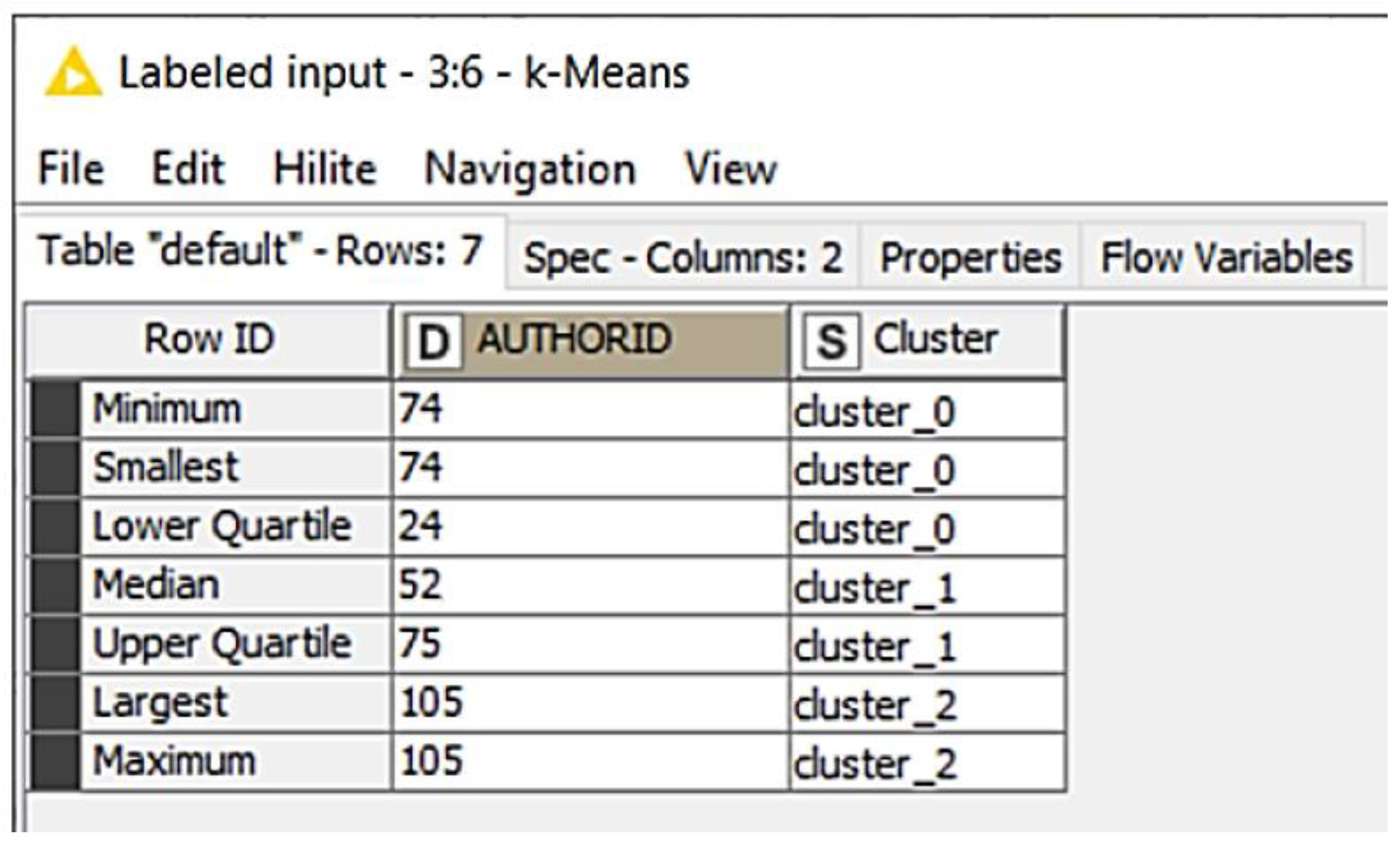
4. Materials and Methods
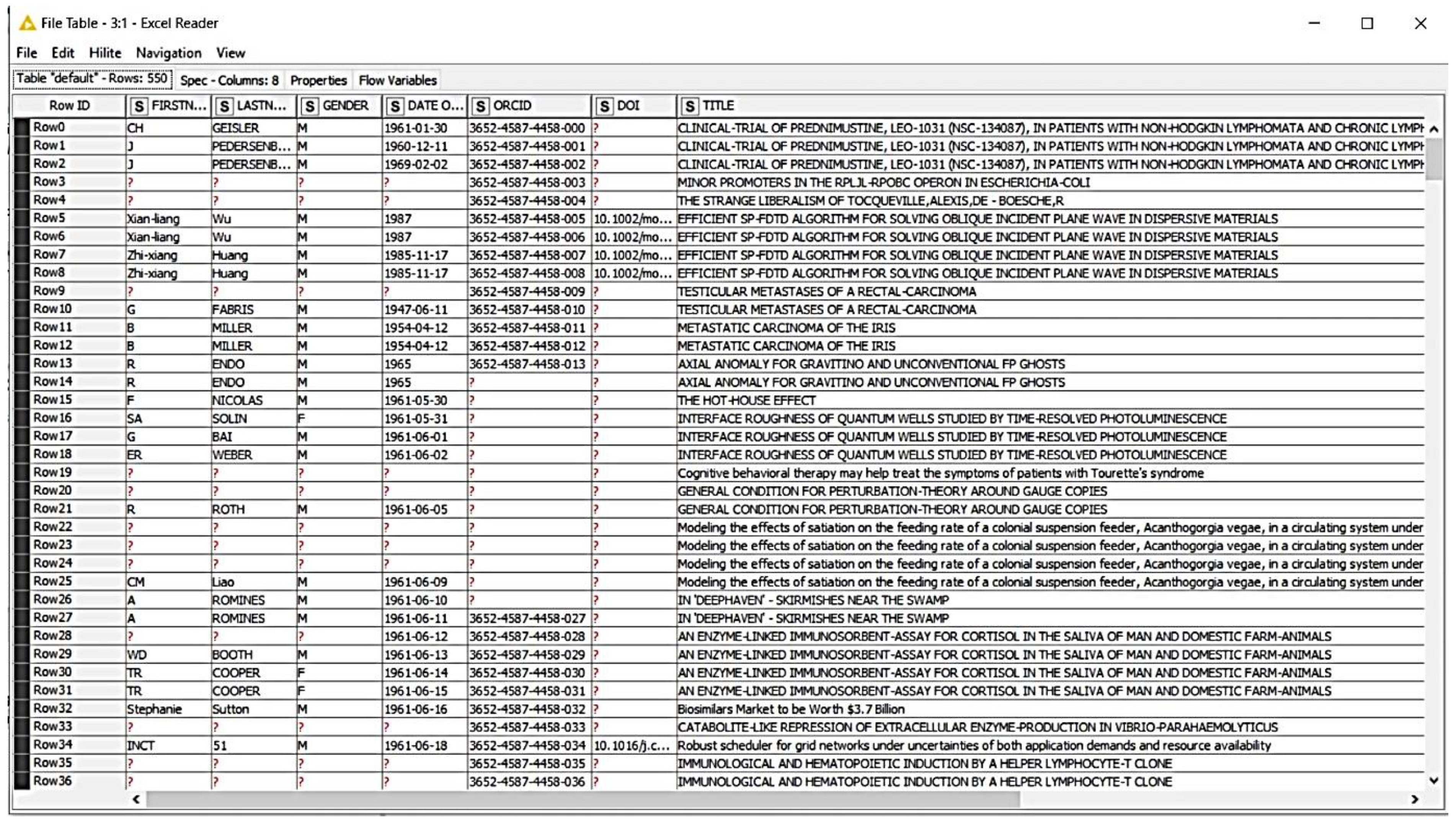
5. Results
- ▪
- First name;
- ▪
- Last name;
- ▪
- Gender;
- ▪
- Date of birth;
- ▪
- ORCID;
- ▪
- DOI;
- ▪
- Title.
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Beel, J.; Langer, S.; Genzmehr, M.; Gipp, B.; Breitinger, C.; Nürnberger, A. Research paper recommender system evaluation: A quantitative literature survey. In Proceedings of the International Workshop on Reproducibility and Replication in Recommender Systems Evaluation, Hong Kong, China, 12 October 2013; pp. 15–22. [Google Scholar] [CrossRef] [Green Version]
- Salton, G. Associative document retrieval techniques using bibliographic information. J. ACM 1963, 10, 440–457. [Google Scholar] [CrossRef]
- Yang, Q.; Li, Z.; Liu, A.; Liu, G.; Zhao, L.; Zhang, X.; Zhang, M.; Zhou, X. A novel hybrid publication recommendation system using compound information. World Wide Web 2019, 22, 2499–2517. [Google Scholar] [CrossRef]
- Ricci, F.; Rokach, L.; Shapira, B. Introduction to Recommender Systems Handbook. In Recommender Systems Handbook; Ricci, F., Rokach, L., Shapira, B., Kantor, P., Eds.; Springer: Boston, MA, USA, 2011. [Google Scholar] [CrossRef]
- Wang, D.; Liang, Y.; Xu, D.; Feng, X.; Guan, R. A content-based recommender system for computer science publications. Knowl.-Based Syst. 2018, 157, 1–9. [Google Scholar] [CrossRef]
- Pariser, E. The Filter Bubble: What the Internet Is Hiding from You; Penguin UK Books: London, UK, 2012. [Google Scholar]
- Sunstein, C.R. Republic.com 2.0; Princeton University Press: Princeton, NJ, USA, 2009. [Google Scholar]
- Claes, A.; Philippette, T. Defining critical data literacy for recommender systems: A media-grounded approach. J. Media Lit. Educ. 2020, 12, 17–29. [Google Scholar] [CrossRef]
- Bawden, D.; Robinson, L. Information Overload: An introduction. In Oxford Encyclopedia of Political Decision Making; Oxford University Press: Oxford, UK, 2020. [Google Scholar] [CrossRef]
- Adomavicius, G.; Tuzhilin, A. Toward the next generation of recommender systems: A survey of the state-of-the-art and possible extensions. IEEE Trans. Knowl. Data Eng. 2005, 17, 734–749. [Google Scholar] [CrossRef]
- Bogers, T.; van den Bosch, A. Recommending scientific articles using citeulike. In Proceedings of the 2008 ACM Conference on Recommender Systems (RecSys ’08), Lausanne, Switzerland, 23–25 October 2008; Association for Computing Machinery: New York, NY, USA, 2008; pp. 287–290. [Google Scholar] [CrossRef]
- Pera, M.S.; Ng, Y.K. A personalized recommendation system on scholarly publications. In Proceedings of the 20th ACM International Conference on Information and Knowledge Management (CIKM ’11), Glasgow, UK, 24–28 October 2011; Association for Computing Machinery: New York, NY, USA, 2011; pp. 2133–2136. [Google Scholar] [CrossRef]
- Raamkumar, A.S.; Foo, S. Multi-method Evaluation in Scientific Paper Recommender Systems. In Adjunct Publication of the 26th Conference on User Modeling, Adaptation and Personalization (UMAP ’18); Association for Computing Machinery: New York, NY, USA, 2018; pp. 179–182. [Google Scholar] [CrossRef]
- Francesco Ricci, F.; Rokach, L.; Shapira, B. Recommender Systems Handbook; Springer: Boston, MA, USA, 2015. [Google Scholar] [CrossRef] [Green Version]
- Aggarwal, C.C. Recommender Systems: The Textbook; Springer International Publishing AG: Cham, Switzerland, 2016. [Google Scholar] [CrossRef] [Green Version]
- Hohfeld, S.; Kwiatkowski, M. Empfehlungssysteme aus informationswissenschaftlicher Sicht-State of the Art. Inf. Wiss. Und Prax. 2007, 58, 265–276. [Google Scholar]
- Fan, Y.; Shen, Y.; Mai, J. Study of the Model of E-commerce Personalized Recommendation System Based on Data Mining. In Proceedings of the International Symposium on Electronic Commerce and Security, Guangzhou, China, 3–5 August 2008; pp. 647–651. [Google Scholar] [CrossRef]
- Burke, R. Integrating knowledge-based and collaborative-filtering recommender systems. In Proceedings of the Workshop on AI and Electronic Commerce; 1999; pp. 69–72. Available online: https://aaaipress.org/Papers/Workshops/1999/WS-99-01/WS99-01-011.pdf (accessed on 25 December 2021).
- Burke, R. Hybrid recommender systems: Survey and experiments. User Modeling User-Adapt. Interact. J. Pers. Res. 2002, 12, 331–370. [Google Scholar] [CrossRef]
- Javed, U.; Shaukat, K.; Hameed, I.A.; Iqbal, F.; Alam, T.M.; Luo, S. A Review of Content-Based and Context-Based Recommendation Systems. Int. J. Emerg. Technol. Learn. 2021, 16, 274–306. Available online: https://online-journals.org/index.php/i-jet/article/view/18851 (accessed on 25 December 2021). [CrossRef]
- Isinkaye, F.O.; Folajimi, Y.O.; Ojokoh, B.A. Recommendation systems: Principles, methods and evaluation. Egypt. Inform. J. 2015, 16, 261–273. [Google Scholar] [CrossRef] [Green Version]
- Sarwar, B.; Karypis, G.; Konstan, J.; Reidl, J. Item-based collaborative filtering recommendation algorithms. In Proceedings of the 10th International World Wide Web Conference; 2001; pp. 285–295. Available online: https://dl.acm.org/doi/10.1145/371920.372071 (accessed on 25 December 2021).
- Breese, J.S.; Heckerman, D.; Kadie, C. Empirical analysis of predictive algorithms for collaborative filtering. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, UAI’98, Madison, WI, USA, 24–26 July 1998; Morgan Kaufmann Publishers Inc: San Francisco, CA, USA; pp. 43–52. Available online: http://dl.acm.org/citation.cfm?id=2074094.2074100 (accessed on 25 December 2021).
- Lika, B.; Kolomvatsos, K.; Hadjiefthymiades, S. Facing the cold start problem in recommender systems. Expert Syst. Appl. 2014, 41, 2065–2073. [Google Scholar] [CrossRef]
- Sarwar, B.; Karypis, G.; Konstan, J.; Riedl, J. Incremental SVD-Based Algorithms for Highly Scalable Recommender Systems. In Proceedings of the 5th International Conference on Computer and Information Technology (ICCIT ’02); 2002. Available online: http://glaros.dtc.umn.edu/gkhome/node/129 (accessed on 9 January 2022).
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by latent semantic analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar] [CrossRef]
- Miyahara, K.; Pazzani, M.J. Collaborative Filtering with the Simple Bayesian Classifier. In PRICAI 2000 Topics in Artificial Intelligence. PRICAI 2000; Lecture Notes in Computer Science; Mizoguchi, R., Slaney, J., Eds.; Springer: Berlin/Heidelberg, Germany, 2000; Volume 1886. [Google Scholar] [CrossRef] [Green Version]
- Miyahara, K.; Pazzani, M.J. Improvement of collaborative filtering with the simple Bayesian classifier. Inf. Process. Soc. Jpn. 2002, 43, 3429–3437. [Google Scholar]
- Chee, S.H.S.; Han, J.; Wang, K. RecTree: An Efficient Collaborative Filtering Method. In Data Warehousing and Knowledge Discovery. DaWaK 2001; Kambayashi, Y., Winiwarter, W., Arikawa, M., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2114, pp. 141–151. [Google Scholar] [CrossRef] [Green Version]
- Claypool, M.; Gokhale, A.; Miranda, T.; Murnikov, P.; Netes, D.; Sartin, M. Combining Content-Based and Collaborative Filters in an Online Newspaper. In Proceedings of the ACM SIGIR ’99 Workshop on Recommender Systems: Algorithms and Evaluation, ACM, Berkeley, CA, USA, 19 August 1999. [Google Scholar]
- Resnick, P.; Varian, H.R. Recommender systems. Commun. ACM 1997, 40, 56–58. [Google Scholar] [CrossRef]
- Bell, R.; Koren, Y. Improved neighborhood-based collaborative filtering. In Proceedings of the KDD Cup and Workshop, San Jose, CA, USA, 12 August 2007; pp. 7–14. [Google Scholar]
- Kanungo, A.; Kamath, S.; Gosai, S.; Mishra, R. Cross Platform Recommendation System. In ICDSMLA 2019. Lecture Notes in Electrical Engineering; Kumar, A., Paprzycki, M., Gunjan, V., Eds.; Springer: Singapore, 2020; Volume 601. [Google Scholar] [CrossRef]
- Azeroual, O. Text and Data Quality Mining in CRIS. Information 2019, 10, 374. [Google Scholar] [CrossRef] [Green Version]
- Kristol, D.M. HTTP Cookies: Standards, privacy, and politics. ACM Trans. Internet Technol. 2001, 1, 151–198. [Google Scholar] [CrossRef]
- Feltrin, L. KNIME an Open Source Solution for Predictive Analytics in the Geosciences [Software and Data Sets]. IEEE Geosci. Remote Sens. Mag. 2015, 3, 28–38. [Google Scholar] [CrossRef]
- Nawrocka, A.; Kot, A.; Nawrocki, M. Application of machine learning in recommendation systems. In Proceedings of the 19th International Carpathian Control Conference (ICCC), Szilvasvarad, Hungary, 28–31 May 2018; pp. 328–331. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Azeroual, O.; Koltay, T. RecSys Pertaining to Research Information with Collaborative Filtering Methods: Characteristics and Challenges. Publications 2022, 10, 17. https://doi.org/10.3390/publications10020017
Azeroual O, Koltay T. RecSys Pertaining to Research Information with Collaborative Filtering Methods: Characteristics and Challenges. Publications. 2022; 10(2):17. https://doi.org/10.3390/publications10020017
Chicago/Turabian StyleAzeroual, Otmane, and Tibor Koltay. 2022. "RecSys Pertaining to Research Information with Collaborative Filtering Methods: Characteristics and Challenges" Publications 10, no. 2: 17. https://doi.org/10.3390/publications10020017
APA StyleAzeroual, O., & Koltay, T. (2022). RecSys Pertaining to Research Information with Collaborative Filtering Methods: Characteristics and Challenges. Publications, 10(2), 17. https://doi.org/10.3390/publications10020017