
Systematic Design and Evaluation of a Citation Function Classification Scheme in Indonesian Journals


Abstract
1. Introduction
1.1. Background
1.2. Related Works
1.2.1. Citation Function Categories: Development and Utilization
1.2.2. Classification Scheme Evaluation Methods
1.2.3. Automatic Classification Evaluation
2. Materials and Methods
2.1. Data Collection
2.2. Proposing a New Scheme
2.3. Annotation Process
2.4. Evaluation of the Scheme
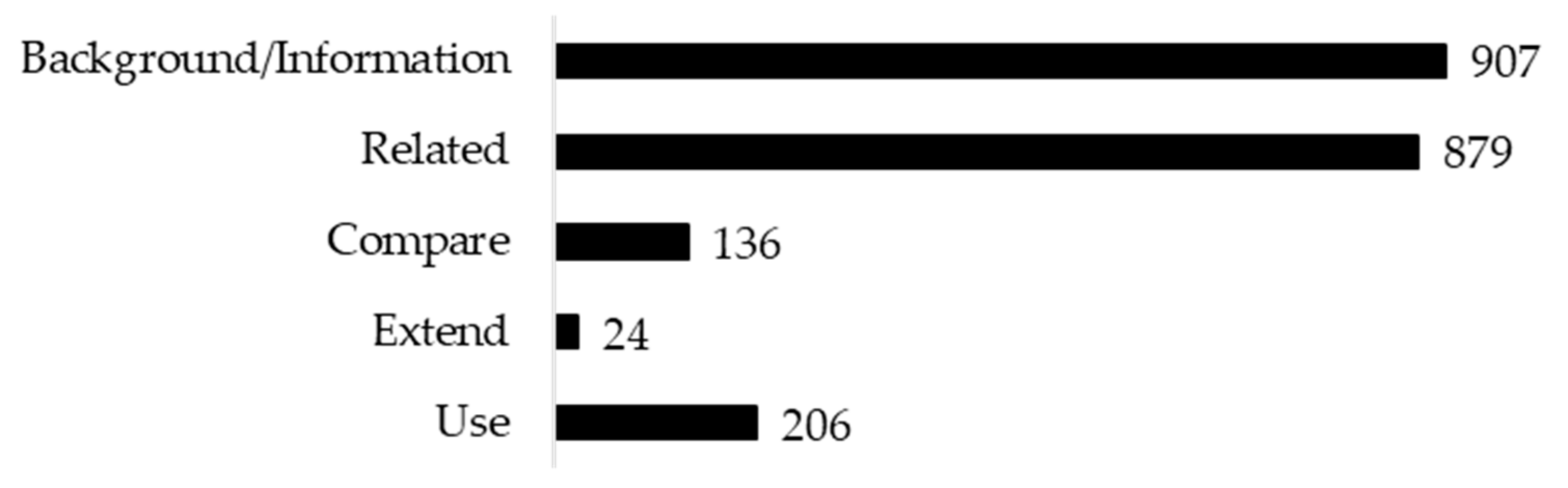
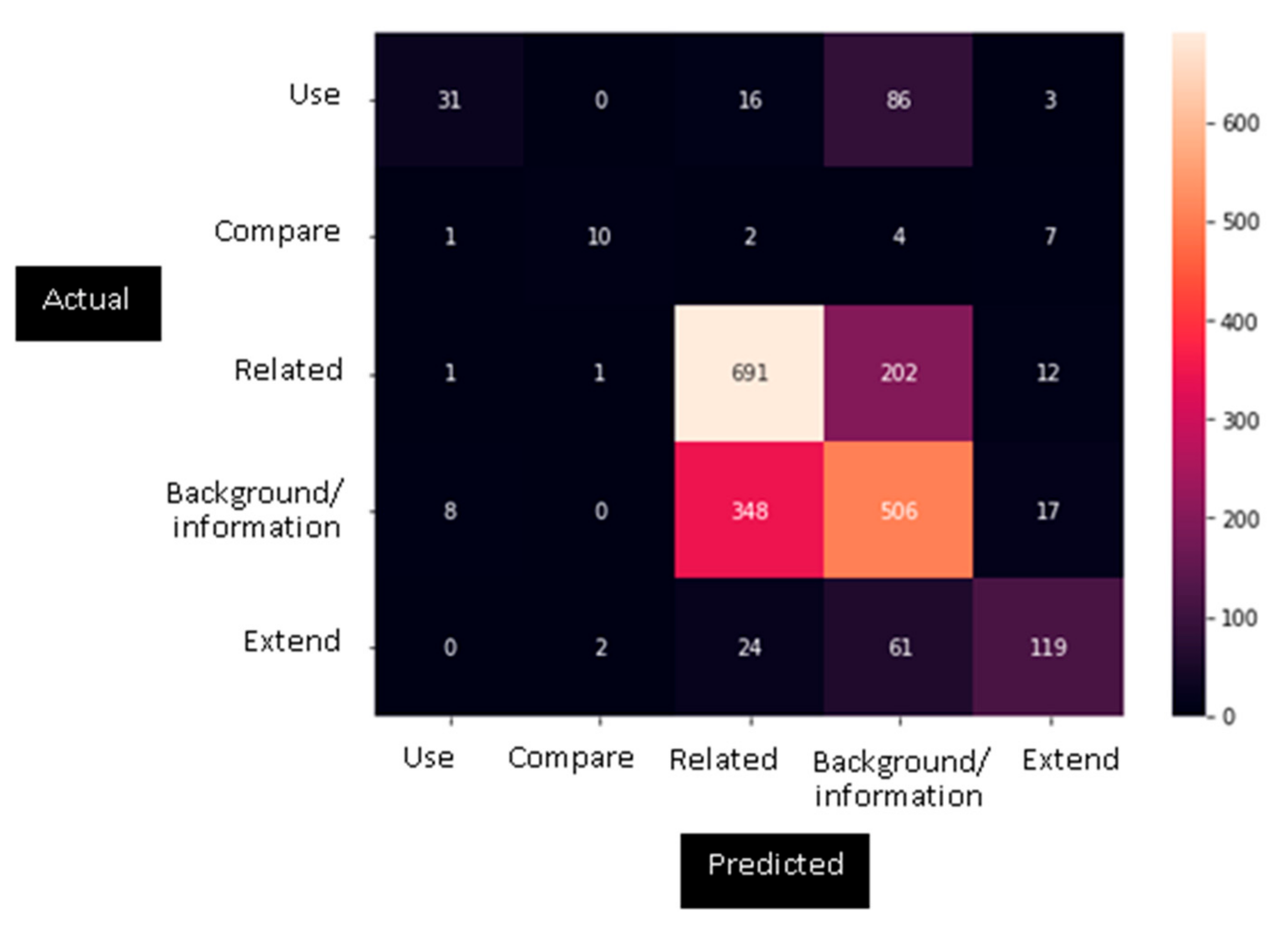
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
| No. | Acronym | Explanation |
| 1 | ACL | The Association For Computational Linguistics |
| 2 | BCN | Biattentive Classification Network |
| 3 | BERT | Bidirectional Encoder Representations From Transformers |
| 4 | CATA | Computer-Aided Text Analysis |
| 5 | CNN | Convolutional Neural Networks |
| 6 | DL | Deep Learning |
| 7 | ELMo | Embeddings From Language Models |
| 8 | IMRAD | Introduction Method Result and Discussion |
| 9 | LR | Logistic Regression |
| 10 | LSTM | Long Short-Term Memory |
| 11 | ML | Machine Learning |
| 12 | NB | Naïve Bayes Binomial |
| 13 | RF | Random Forest |
| 14 | RNN | Recurrent Neural Networks |
| 15 | SVM | Support Vector Machine |
| 16 | TF-IDF | Weighted Term Frequency-Inverse Document Frequency |
References
- Abu-jbara, A.; Ezra, J.; Radev, D. Purpose and Polarity of Citation: Towards NLP-Based Bibliometrics. In Proceedings of the NAACL-HLT, Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Stroudsburg, PA, USA, 2013; pp. 596–606. [Google Scholar]
- Neuendorf, K.A. The Content Analysis Guidebook, 2nd ed.; SAGE Publications: Thousand Oaks, CA, USA, 2017. [Google Scholar]
- Hussain, S.J.; Maqsood, S.; Jhanjhi, N.; Khan, A.; Supramaniam, M.; Ahmed, U. A Comprehensive Evaluation of Cue-Word- Based Features and In-Text-Citation-Based Features for Citation Classification. Int. J. Adv. Comput. Sci. Appl. 2019, 10, 209–218. [Google Scholar] [CrossRef]
- Hassan, S.U.; Safder, I.; Akram, A.; Faisal, K. A Novel Machine-Learning Approach to Measuring Scientific Knowledge Fows. Scientometrics 2018, 116, 973–996. [Google Scholar] [CrossRef]
- Ferrod, R.; Schifanella, C.; Caro, L.D.; Cataldi, M. Disclosing Citation Meanings for Augmented Research Retrieval and Exploration. Lect. Notes Comput. Sci. 2019, 11503, 101–105. [Google Scholar]
- Rachman, G.H.; Khodra, M.L.; Widyantoro, D.H. Classification of Citation Sentence for Filtering Scientific References. In Proceedings of the 4th International Conference on Information Technology, ICITISEE, Yogyakarta, Indonesia, 20–21 November 2019; Department of Electrical Engineering and Information Technology, Universitas Gadjah Mada (DTETI UGM): Yogyakarta, Indonesia, 2019; pp. 347–352. [Google Scholar] [CrossRef]
- Yousif, A.; Niu, Z.; Chambua, J.; Khan, Z.Y. Multi-Task Learning Model Based on Recurrent Convolutional Neural Networks for Citation Sentiment and Purpose Classification. Neurocomputing 2019, 335, 195–205. [Google Scholar] [CrossRef]
- Zhao, H.; Luo, Z.; Feng, C.; Zheng, A.; Liu, X. A Context-Based Framework for Modeling the Role and Function of On-Line Resource Citations in Scientific Literature. In Proceedings of the EMNLP-IJCNLP, Hong Kong, China, 3–7 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 5206–5215. [Google Scholar]
- Teufel, S.; Siddharthan, A.; Tidhar, D. An Annotation Scheme for Citation Function. In Proceedings of the 7th SIGdial Workshop on Discourse and Dialogue, Sydney, Australia, 15–16 July 2006; Association for Computational Linguistics: Stroudsburg, PA, USA, 2006; pp. 80–87. [Google Scholar]
- Perier-Camby, J.; Bertin, M.; Atanassova, I.; Armetta, F. A Preliminary Study to Compare Deep Learning with Rule-Based Approaches for Citation Classification. In Proceedings of the 8th International Workshop on Bibliometric-enhanced Information Retrieval (BIR 2019), Cologne, Germany, 14 April 2019; Sun SITE Central Europe (CEUR) Technical University of Aachen (RWTH): Aachen, Germany, 2019; pp. 125–131. [Google Scholar]
- Su, X.; Prasad, A.; Kan, M.; Sugiyama, K. Neural Multi-Task Learning for Citation Function and Provenance. In Proceedings of the ACM/IEEE Joint Conference on Digital Libraries (JCDL), Champaign, IL, USA, 2–6 June 2019; IEEE Press: New York, USA, 2019; pp. 394–395. [Google Scholar]
- Moravcsik, M.J.; Murugesan, P. Some Results on the Function and Quality of Citations. Soc. Stud. Sci. 1975, 5, 86–92. [Google Scholar] [CrossRef]
- Chubin, D.E.; Moitra, S.D. Content Analysis of References: Adjunct or Alternative to Citation Counting? Soc. Stud. Sci. 1975, 4, 423–441. [Google Scholar] [CrossRef]
- Cohan, A.; Ammar, W.; Van Zuylen, M.; Cady, F. Structural Scaffolds for Citation Intent Classification in Scientific Publications. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019; pp. 3586–3596. [Google Scholar]
- Bakhti, K.; Niu, Z.; Nyamawe, A.S. Semi-Automatic Annotation for Citation Function Classification. In Proceedings of the 2018 International Conference on Control, Artificial Intelligence, Robotics & Optimization (ICCAIRO), Prague, Czech Republic, 19–21 May 2018; IEEE Press: New York, USA, 2019; pp. 43–47. [Google Scholar]
- Séaghdha, D.Ó. Designing and Evaluating a Semantic Annotation Scheme for Compound Nouns. In Proceedings of the 4th Corpus Linguistics Conference (CL-07), Birmingham, UK, 27–30 July 2007; University of Birmingham: Birmingham, UK, 2007; pp. 1–17. [Google Scholar]
- Boldrini, E.; Balahur, A.; Martínez-Barco, P.; Montoyo, A. EmotiBlog: An Annotation Scheme for Emotion Detection and Analysis in Non-Traditional Textual Genres. In Proceedings of the International Conference on Data Mining, IEEE, Las Vegas, NV, USA, 13–16 July 2009; IEEE Press: New York, NY, USA, 2009; pp. 491–497. [Google Scholar]
- Ritz, J.; Dipper, S.; Michael, G. Annotation of Information Structure: An Evaluation across Different Types of Texts. In Proceedings of the Sixth International Conference on Language Resources and Evaluation (LREC’08), Marrakech, Morocco, 28–30 May 2008; European Language Resources Association (ELRA): Luxemburg, 2008; pp. 2137–2142. [Google Scholar]
- Palmer, A.; Carr, C.; Robinson, M.; Sanders, J. COLD: Annotation Scheme and Evaluation Data Set for Complex Offensive Language in English. J. Lang. Technol. Comput. Linguist. 2020, 34, 1–28. [Google Scholar]
- Øvrelid, L. Empirical Evaluations of Animacy Annotation. In Proceedings of the 12th Conference of the European Chapter of the ACL (EACL 2009), Athens, Greece, 30 March–3 April 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; pp. 630–638. [Google Scholar]
- Ibanez, M.P.V.; Ohtani, A. Annotating Article Errors in Spanish Learner Texts: Design and Evaluation of an Annotation Scheme. In Proceedings of the 28th Pacific Asia Conference on Language, Information and Computation, Phuket, Thailand, 12–14 December 2014; Chulalongkorn University: Bangkok, Thailand, 2014; pp. 234–243. [Google Scholar]
- Taskin, Z.; Al, U. A Content-Based Citation Analysis Study Based on Text Categorization. Scientometrics 2017, 114, 335–357. [Google Scholar] [CrossRef]
- Zhao, H.; Feng, C.; Luo, Z.; Ye, Y. A Context-Based Framework for Resource Citation Classification in Scientific Literatures. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; Association for Computing Machinery: New York, NY, USA; pp. 1041–1044. [Google Scholar]
- Lukman, L.; Lukman, L.; Dimyati, M.; Rianto, Y.; Subroto, I.M.; Sutikno, T.; Hidayat, D.S.; Nadhiroh, I.M.; Stiawan, D.; Haviana, S.F.; et al. Proposal of the S-Score for Measuring the Performance of Researchers, Institutions, and Journals in Indonesia. Sci. Ed. 2018, 5, 135–141. [Google Scholar] [CrossRef]
- Lopez, P. GROBID: Combining Automatic Bibliographic Data Recognition and Term Extraction for Scholarship Publications. In Research and Advanced Technology for Digital Libraries; ECDL 2009. Lecture Notes in Computer Science; Agosti, M., Borbinha, J., Kapidakis, S., Papatheodorou, C., Tsakonas, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2009; Volume 5714, pp. 473–474. [Google Scholar]
- Ahmad, R.; Afzal, M.T.; Qadir, M.A. Pattern Analysis of Citation Anchors in Citing Documents for Accurate Identification of In-Text Citations. IEEE Access 2017, 5, 5819–5828. [Google Scholar] [CrossRef]
- Jurgens, D.; Hoover, R.; Mcfarland, D. Citation Classification for Behavioral Analysis of a Scientific Field. arXiv 2016, arXiv:1609.00435. [Google Scholar]
- Alvarez, M.H.; Martinez-barco, P. Citation Function, Polarity and Influence Classification. Natl. Lang. Eng. 2017, 23, 561–588. [Google Scholar] [CrossRef]
- Nanba, H.; Kando, N.; Okumura, M. Classification of Research Papers Using Citation Links and Citation Types: Towards Automatic Review Article Generation. In Proceedings of the 11th ASIS SIG/CR Classification Research Workshop, Chicago, IL, USA, 12–16 November 2000; American Society for Information Science and Technology: Maryland, USA, 2000; pp. 117–134. [Google Scholar]
- Krippendorff, K. Content Analysis: An Introduction to Its Methodology, 2nd ed; SAGE Publications, Inc.: Thousand Oaks, CA, USA, 2004. [Google Scholar]
- Landis, J.R.; Koch, G.G. The Measurement of Observer Agreement for Categorical Data. Biometrics 1977, 33, 159–174. [Google Scholar] [CrossRef] [PubMed]
- Lane, H.; Howard, C.; Hapke, H. Natural Language Processing in Action; Manning Publication Co.: New York, NY, USA, 2019. [Google Scholar]
- Bertin, M.; Atanassova, I.; Gingras, Y. The Invariant Distribution of References in Scientific Articles. J. Assoc. Inf. Sci. Technol. 2016, 67, 164–177. [Google Scholar] [CrossRef]
- Bertin, M.; Atanassova, I. A Study of Lexical Distribution in Citation Contexts through the IMRaD Standard. In Proceedings of the 1st Workshop on Bibliometric-Enhanced Information Retrieval Co-located with 36th European Conference on Information Retrieval (ECIR 2014), Amsterdam, The Netherlands, 13–16 April 2014; Sun SITE Central Europe (CEUR) Technical University of Aachen (RWTH): Aachen, Germany, 2014; Volume 1567, pp. 14–25. [Google Scholar]
- Ramyachitra, D.; Manikandan, P. Imbalanced Dataset Classification and Solutions: A Review. Int. J. Comput. Bus. Res. 2014, 5, 4. [Google Scholar]
- Maricic, S.; Spaventi, J.; Pavicic, L.; Pifat-mrzljak, G. Citation Context versus the Frequency Counts of Citation History. J. Am. Soc. Inf. Sci. 1998, 49, 530–540. [Google Scholar]
- Khan, A.M.; Shahid, A.; Afzal, M.T.; Nazar, F.; Alotaibi, F.S.; Alyoubi, K.H. SwICS: Section-Wise In-Text Citation Score. IEEE Access 2019, 7, 137090–137102. [Google Scholar] [CrossRef]


| No. | Journal Title | Indexing Category | Number of Articles | Number of Citation Sentences |
|---|---|---|---|---|
| 1 | Jurnal Gizi dan Pangan | S2 | 21 | 473 |
| 2 | Jurnal Teknologi dan Industri Pangan | S2 | 21 | 476 |
| 3 | Jurnal Aplikasi Teknologi Pangan | S2 | 24 | 432 |
| 4 | Jurnal Penelitian Pascapanen Pertanian | S2 | 12 | 217 |
| 5 | Jurnal Teknologi & Industri Hasil Pertanian | S2 | 11 | 131 |
| 6 | Advances in Food Science, Sustainable Agriculture and Agroindustrial Engineering | S2 | 10 | 178 |
| 7 | Warta Industri Hasil Pertanian | S2 | 14 | 245 |
| Total | 113 | 2.153 | ||
| No. | Category Name | Article Sources and Dataset Scope | Group | Proposed Category |
|---|---|---|---|---|
| 1 | background | [10] 5338 sentences about computational linguistics indexed in The Association for Computational Linguistics (ACL); [14] 52,705 sentences about computational linguistics, biomedical, and life sciences indexed in ACL and Pubmed; [26] 548 sentences from 26 articles about computational linguistics indexed in CmpLg (Computation and Language archive); [27] 1969 sentences from 185 articles about computational linguistics indexed in ACL | background/information | background/information |
| 2 | based on/supply | [28] 1432 sentences about computational linguistics indexed in ACL | ||
| 3 | basis | [9] 9159 sentences about computer science and medical indexed in Semantic scholar; [29] 2000 sentences from 80 articles about computational linguistics indexed in ACL | ||
| 4 | introduce | [12] | ||
| 5 | present | [4] 1562 sentences about computational linguistics indexed in ACL | ||
| 6 | idea | [6] | ||
| 7 | problem | [5] 1153 sentences from 50 articles about computational linguistics indexed in ACL | ||
| 8 | hedges | [24] 384 sentences about computational linguistics indexed in ACL | ||
| 9 | report | [4] | ||
| 10 | support | [9] | ||
| 11 | cocogm | [9] | compare | compare |
| 12 | cocor0 | [9] | ||
| 13 | cocoxy | [9] | ||
| 14 | compare | [7] | ||
| 15 | compare and contrast (coco) | [8,11] | ||
| 16 | comparison | [6,14,23] 134,127 sentences from 20,000 article about natural language processing; [29] 395 articles (science field and indexing information are not available) | ||
| 17 | comparison or contrast | [9] | ||
| 18 | result comparison | [14] | ||
| 19 | contrast | [24] | criticism | |
| 20 | criticism | [6] | ||
| 21 | weak/weakness | [9,28] | ||
| 22 | correct | [10] | confirm | |
| 23 | positive | [12] | ||
| 24 | similar | [9] | ||
| 25 | continuation | [27] | extend | extend |
| 26 | extend | [7] | ||
| 27 | extension | [10,27] | ||
| 28 | follow | [4] | ||
| 29 | motivation | [10,27] | ||
| 30 | modification | [9] | ||
| 31 | proposed-by | [4] | ||
| 32 | approach | [4] | use | use |
| 33 | data | [22] 101,019 sentences from 423 articles in library and information science literature in Turkish journals | ||
| 34 | data validation | [22] | ||
| 35 | definition | [22] | ||
| 36 | mathematical | [10] | ||
| 37 | method | [4,14,22] | ||
| 38 | use | [4,7,8,10] | ||
| 39 | useful | [10] | ||
| 40 | substantiation | [6] | ||
| 41 | literature | [22] | related | related |
| 42 | see-for detail | [4] | ||
| 43 | related | [6] | ||
| 44 | acknowledge | [28] | ||
| 45 | produce | [7] | other | − |
| 46 | future | [10] | ||
| 47 | other | [7] | ||
| 48 | neutral | [9] |
| No. | Category | Definition |
|---|---|---|
| 1 | Use | Articles that are cited are used directly in research, such as concepts, methods, data, formulas, and algorithms. Generally indicated by the words use, used, based, and so forth. |
| 2 | Extend | The cited article is used as a basis and is added to in the research. Characterized by the words continue, develop, follow, adopt, modify, be motivated, and so on. |
| 3 | Compare | The articles cited are used as a comparison (especially the results) to the current information. The citations are characterized by the words compared, appropriate, similar, similarity, confirmation, different, weaknesses, advantages, contrast, inline, contradicting, higher, lower, similar, and so forth |
| 4 | Related | Articles that are cited have links or discuss the materials, methods, processes, or results specifically/in detail. Words that identify these citations include research (-previous, -other), related, whereas, have been done, reported, defined, according to, literature, and so on. |
| 5 | Background/ Information | Articles cited provide general information or theory (not specific to the field of science) to introduce, exemplify, provide background on, and explain the context, problems, objectives, and so forth. |
| Evaluation | Total | Category | ||||
|---|---|---|---|---|---|---|
| Use | Extend | Compare | Related | Information | ||
| Fleiss’ Kappa | 0.65 | 0.86 | 0.88 | 0.81 | 0.57 | 0.59 |
| Z | 47.11 | 68.94 | 70.86 | 65.25 | 45.49 | 48.03 |
| p-value | 0 | 0 | 0 | 0 | 0 | 0 |
| Lower α (0.05) | 0.62 | 0.83 | 0.86 | 0.79 | 0.54 | 0.57 |
| Upper α (0.05) | 23.38 | 135.12 | 138.90 | 127.90 | 89.18 | 94.15 |
| Classifier | Accuracy | Precision | Recall | F1-Score |
|---|---|---|---|---|
| Multinomial Naïve Bayes (NB) | 0.61 | 0.62 | 0.61 | 0.61 |
| Logistic Regression (LR) | 0.65 | 0.66 | 0.65 | 0.65 |
| Support Vector Machines (SVM) | 0.63 | 0.63 | 0.63 | 0.63 |
| Random Forest (RF) | 0.66 | 0.67 | 0.66 | 0.65 |
| Convolutional Neural Network (CNN) | 0.66 | 0.66 | 0.66 | 0.66 |
| Long Short-Term Memory (LSTM) | 0.93 | 0.93 | 0.93 | 0.93 |
| Categories | Random Forest | LSTM | ||||
|---|---|---|---|---|---|---|
| Precision | Recall | F1-score | Precision | Recall | F1-Score | |
| Use | 0.76 | 0.23 | 0.35 | 0.86 | 0.85 | 0.90 |
| Extend | 0.75 | 0.58 | 0.65 | 1.00 | 1.00 | 1.00 |
| Compare | 0.77 | 0.42 | 0.54 | 1.00 | 0.50 | 0.67 |
| Related | 0.64 | 0.76 | 0.70 | 0.95 | 0.96 | 0.96 |
| Background/information | 0.59 | 0.58 | 0.58 | 0.97 | 0.94 | 0.95 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yaniasih, Y.; Budi, I. Systematic Design and Evaluation of a Citation Function Classification Scheme in Indonesian Journals. Publications 2021, 9, 27. https://doi.org/10.3390/publications9030027
Yaniasih Y, Budi I. Systematic Design and Evaluation of a Citation Function Classification Scheme in Indonesian Journals. Publications. 2021; 9(3):27. https://doi.org/10.3390/publications9030027
Chicago/Turabian StyleYaniasih, Yaniasih, and Indra Budi. 2021. "Systematic Design and Evaluation of a Citation Function Classification Scheme in Indonesian Journals" Publications 9, no. 3: 27. https://doi.org/10.3390/publications9030027
APA StyleYaniasih, Y., & Budi, I. (2021). Systematic Design and Evaluation of a Citation Function Classification Scheme in Indonesian Journals. Publications, 9(3), 27. https://doi.org/10.3390/publications9030027